A Vision-Based Approach for Ensuring Proper Use of Personal Protective Equipment (PPE) in Decommissioning of Fukushima Daiichi Nuclear Power Station


Abstract
1. Introduction
- G Zone: general work uniforms are required, e.g., disposable dust masks.
- Y Zone: coveralls are required, e.g., full-face dust masks or half-face masks.
- R Zone: anorak and full-face masks are required.
2. Related Works
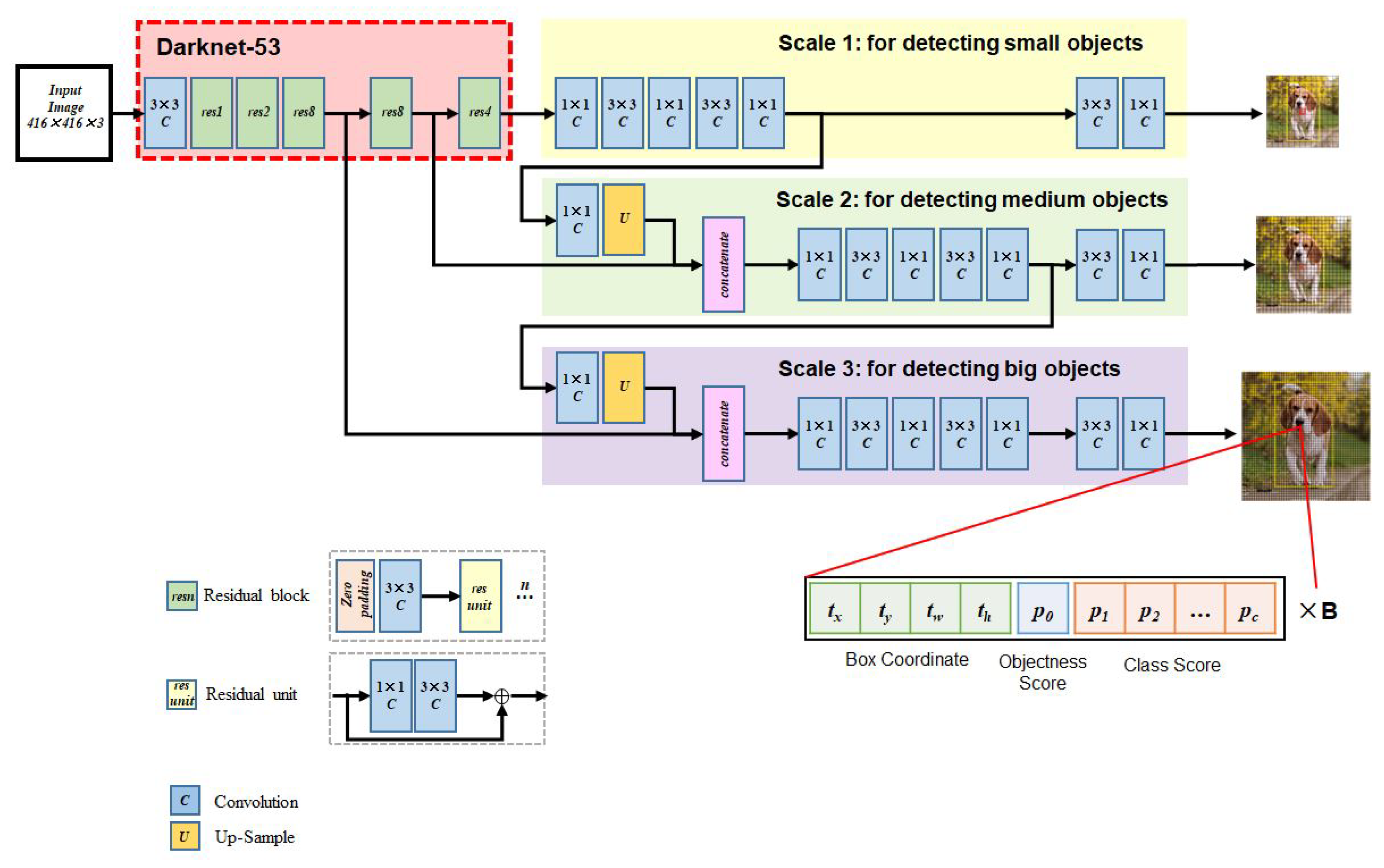
3. Methodology
- For each image captured by an on-site surveillance camera, individual(s) are detected, together with their keypoints coordinates, using an individual detection model.
- PPE(s) are recognized and localized using an object detection model.
- The proper use of PPE identification is performed by analyzing the geometric relationships of the individual’s keypoints and the detected PPE(s).
3.1. Individual Detection
3.2. PPE Detection
3.3. Identification of Proper PPE Use
4. Experimental Procedure
4.1. Experimental Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
5. Results and Discussion
5.1. Impact of Distance
5.2. Impact of Individual Posture
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| PPE | Personal Protective Equipment |
| NPS | Nuclear Power Station |
| TEPCO | Tokyo Electric Power Company |
| RFID | radio frequency identification |
| NHU | non-hardhat-use |
| HOG | histogram of oriented gradients |
| AEC | architecture, engineering and construction |
| WOI | worker-of-interest |
| SSD | Shot Multibox Detector |
| RPA | reverse progressive attention |
| CNN | convolutional neural network |
| PAF | part affinity fields |
References
- Safety Assessment for Decommissioning; Number 77 in Safety Reports Series; INTERNATIONAL ATOMIC ENERGY AGENCY: Vienna, Austria, 2013.
- Efforts to Improve Working Environment and Reduce Radiation Exposure at Fukushima Daiichi Nuclear Power Station; Technical Report; Tokyo Electric Power Company: Tokyo, Japan, 2016.
- Mori, K.; Tateishi, S.; Hiraoka, K. Health issues of workers engaged in operations related to the accident at the Fukushima Daiichi Nuclear Power Plant. In Psychosocial Factors at Work in the Asia Pacific; Springer: Cham, Switzerland, 2016; pp. 307–324. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using Part Affinity Fields. arXiv 2018, arXiv:1812.08008. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Kelm, A.; Laußat, L.; Meins-Becker, A.; Platz, D.; Khazaee, M.J.; Costin, A.M.; Helmus, M.; Teizer, J. Mobile passive Radio Frequency Identification (RFID) portal for automated and rapid control of Personal Protective Equipment (PPE) on construction sites. Autom. Constr. 2013, 36, 38–52. [Google Scholar] [CrossRef]
- Dong, S.; He, Q.; Li, H.; Yin, Q. Automated PPE misuse identification and assessment for safety performance enhancement. In Proceedings of the ICCREM 2015, Lulea, Sweden, 11–12 August 2015; pp. 204–214. [Google Scholar]
- Shrestha, K.; Shrestha, P.P.; Bajracharya, D.; Yfantis, E.A. Hard-hat detection for construction safety visualization. J. Constr. Eng. 2015, 2015, 1–8. [Google Scholar] [CrossRef]
- Park, M.W.; Elsafty, N.; Zhu, Z. Hardhat-wearing detection for enhancing on-site safety of construction workers. J. Constr. Eng. Manag. 2015, 141, 04015024. [Google Scholar] [CrossRef]
- Fang, Q.; Li, H.; Luo, X.; Ding, L.; Luo, H.; Rose, T.M.; An, W. Detecting non-hardhat-use by a deep learning method from far-field surveillance videos. Autom. Constr. 2018, 85, 1–9. [Google Scholar] [CrossRef]
- Wu, J.; Cai, N.; Chen, W.; Wang, H.; Wang, G. Automatic detection of hardhats worn by construction personnel: A deep learning approach and benchmark dataset. Autom. Constr. 2019, 106, 102894. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Kinect for Windows. Available online: https://developer.microsoft.com/en-us/windows/kinect/ (accessed on 22 July 2020).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX symposium on operating systems design and implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Microsoft Azure IoT. Available online: https://azure.microsoft.com/en-us/overview/iot/ (accessed on 6 June 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of the Internet Images | Number of the Real-World Images | Total | |
|---|---|---|---|
| ine Hard hat | 933 | 1209 | 2142 |
| Full-face mask | 642 | 1021 | 1666 |
| Impacts | No. | Value | Images | Hard Hat | Full-Face Mask | ||
|---|---|---|---|---|---|---|---|
| Positive Samples | Negative Samples | Positive Samples | Negative Samples | ||||
| Distance | 1 | 3 m | 500 | 684 | 816 | 500 | 1000 |
| 2 | 5 m | 500 | 770 | 730 | 500 | 1000 | |
| 3 | 7 m | 500 | 818 | 682 | 500 | 1000 | |
| Individual posture | 1 | Standing | 500 | 1582 | 1813 | 972 | 2417 |
| 2 | Bending | 500 | 277 | 168 | 180 | 284 | |
| 3 | Squatting | 500 | 413 | 247 | 348 | 299 | |
| Predicted | Ground Truth | |
|---|---|---|
| TP | Proper use | Proper use |
| FP | Proper use | Improper use |
| FN | Improper use | Proper use |
| Categories | Distance | TP | FP | FN | Precision (%) | Recall (%) |
|---|---|---|---|---|---|---|
| Hard hat | 3 m | 666 | 27 | 18 | 96.10 | 97.37 |
| 5 m | 695 | 36 | 75 | 95.08 | 90.26 | |
| 7 m | 665 | 15 | 153 | 97.79 | 81.30 | |
| Full-face mask | 3 m | 499 | 0 | 1 | 100 | 99.80 |
| 5 m | 500 | 7 | 0 | 98.62 | 100 | |
| 7 m | 487 | 0 | 13 | 100 | 97.40 |
| Categories | Individual’s Posture | TP | FP | FN | Precision (%) | Recall (%) |
|---|---|---|---|---|---|---|
| Hard hat | Standing | 1435 | 78 | 147 | 94.84 | 90.71 |
| Bending | 247 | 0 | 30 | 100 | 89.17 | |
| Squatting | 344 | 0 | 69 | 100 | 81.29 | |
| Full-face mask | Standing | 968 | 7 | 4 | 99.28 | 99.59 |
| Bending | 179 | 0 | 1 | 100 | 99.44 | |
| Squatting | 339 | 8 | 9 | 97.69 | 97.41 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Demachi, K. A Vision-Based Approach for Ensuring Proper Use of Personal Protective Equipment (PPE) in Decommissioning of Fukushima Daiichi Nuclear Power Station. Appl. Sci. 2020, 10, 5129. https://doi.org/10.3390/app10155129
Chen S, Demachi K. A Vision-Based Approach for Ensuring Proper Use of Personal Protective Equipment (PPE) in Decommissioning of Fukushima Daiichi Nuclear Power Station. Applied Sciences. 2020; 10(15):5129. https://doi.org/10.3390/app10155129
Chicago/Turabian StyleChen, Shi, and Kazuyuki Demachi. 2020. "A Vision-Based Approach for Ensuring Proper Use of Personal Protective Equipment (PPE) in Decommissioning of Fukushima Daiichi Nuclear Power Station" Applied Sciences 10, no. 15: 5129. https://doi.org/10.3390/app10155129
APA StyleChen, S., & Demachi, K. (2020). A Vision-Based Approach for Ensuring Proper Use of Personal Protective Equipment (PPE) in Decommissioning of Fukushima Daiichi Nuclear Power Station. Applied Sciences, 10(15), 5129. https://doi.org/10.3390/app10155129