Practical Enhancement of User Experience in NVMe SSDs



Abstract
:1. Introduction
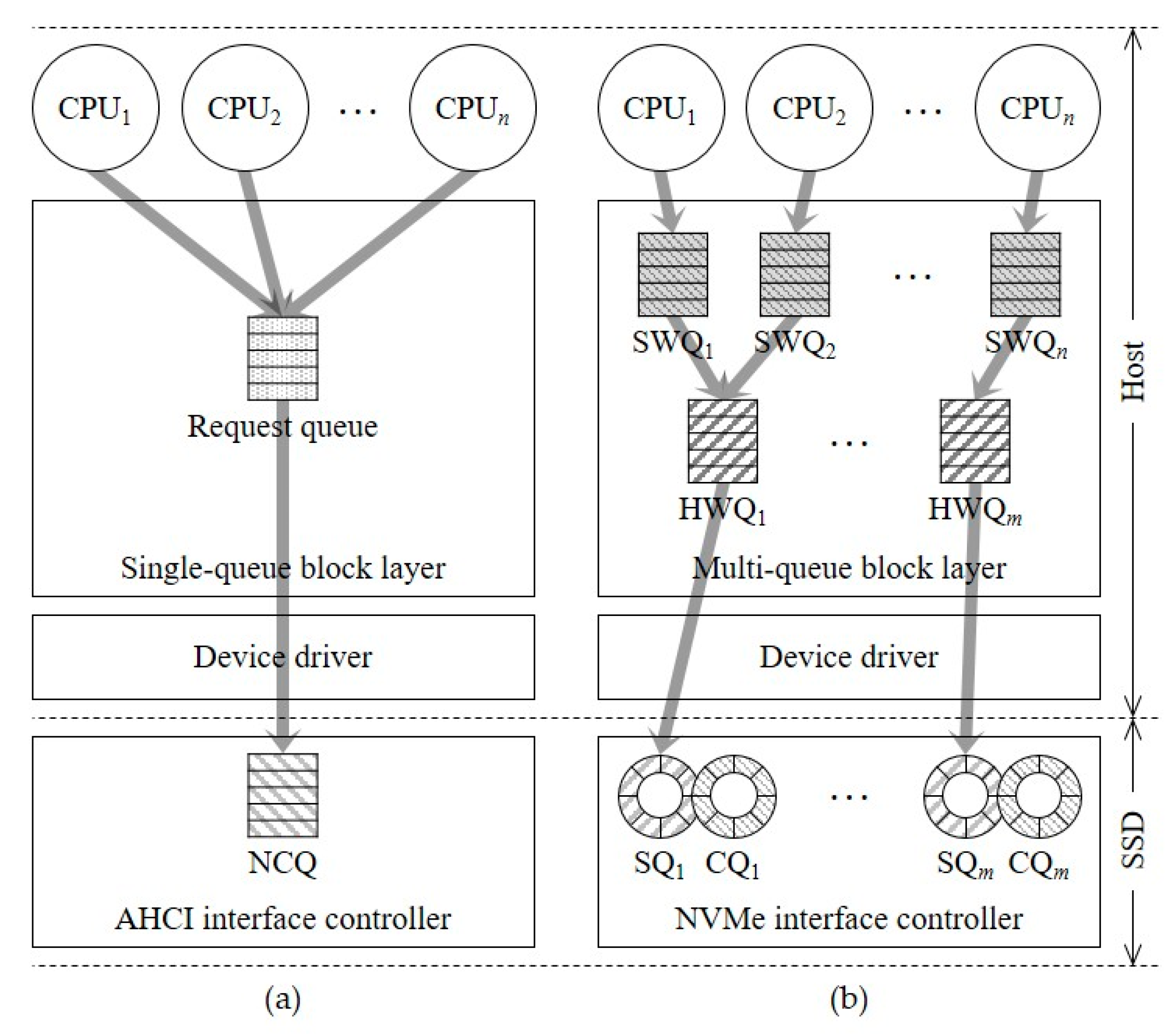
2. Related Works
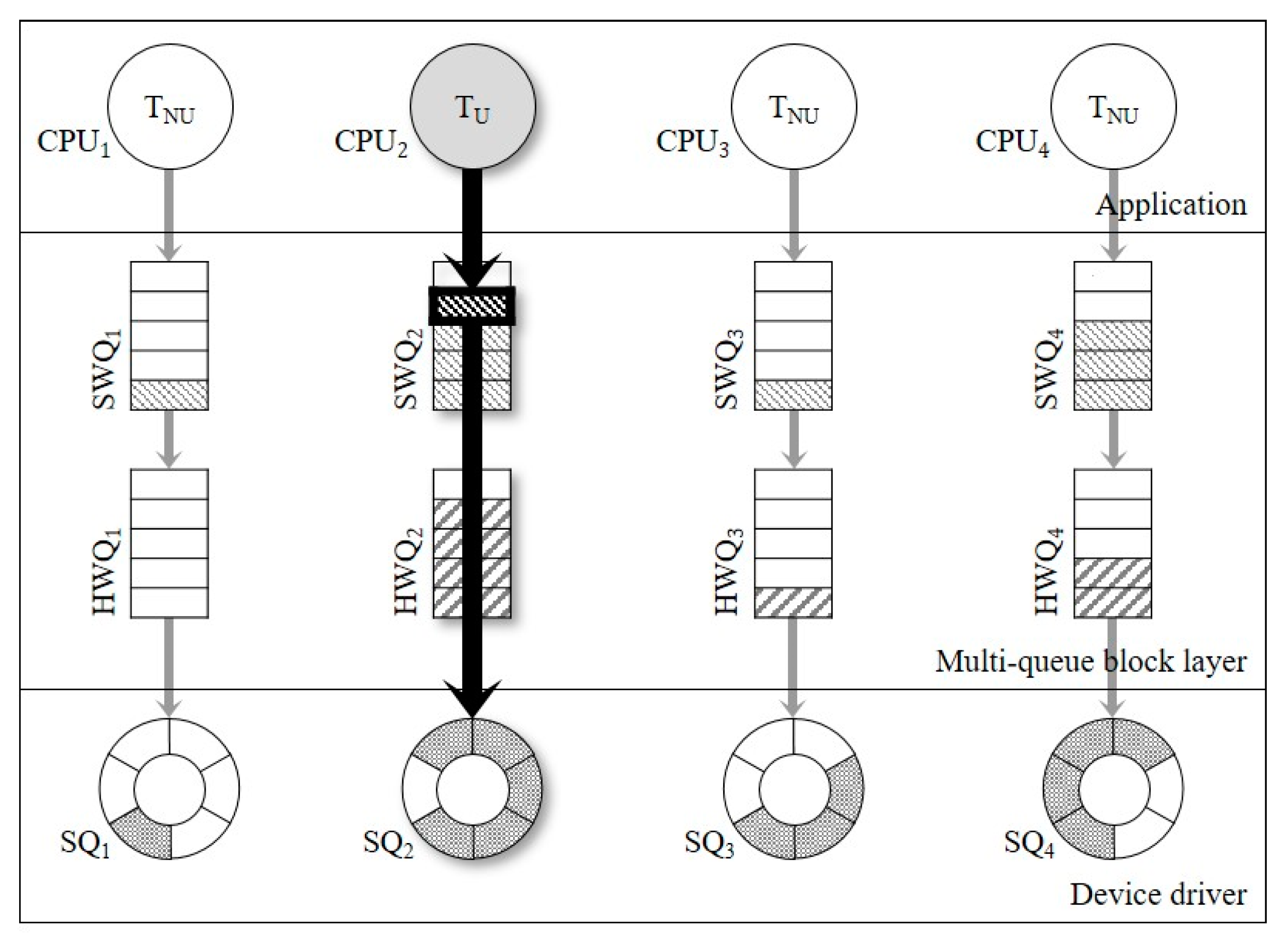
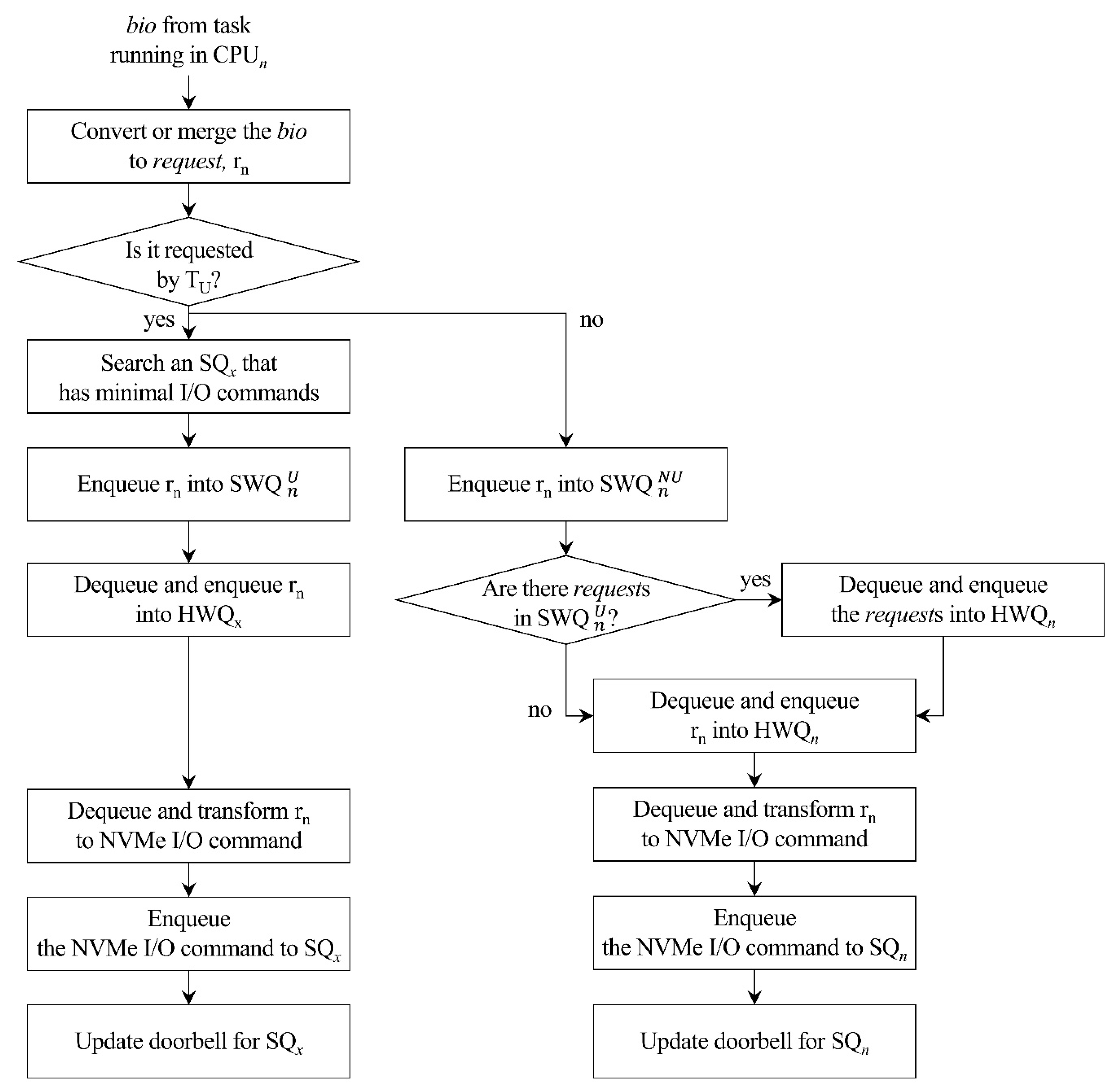
3. Redesign of the Multi-Queue Block I/O Layer to Improve User Experience
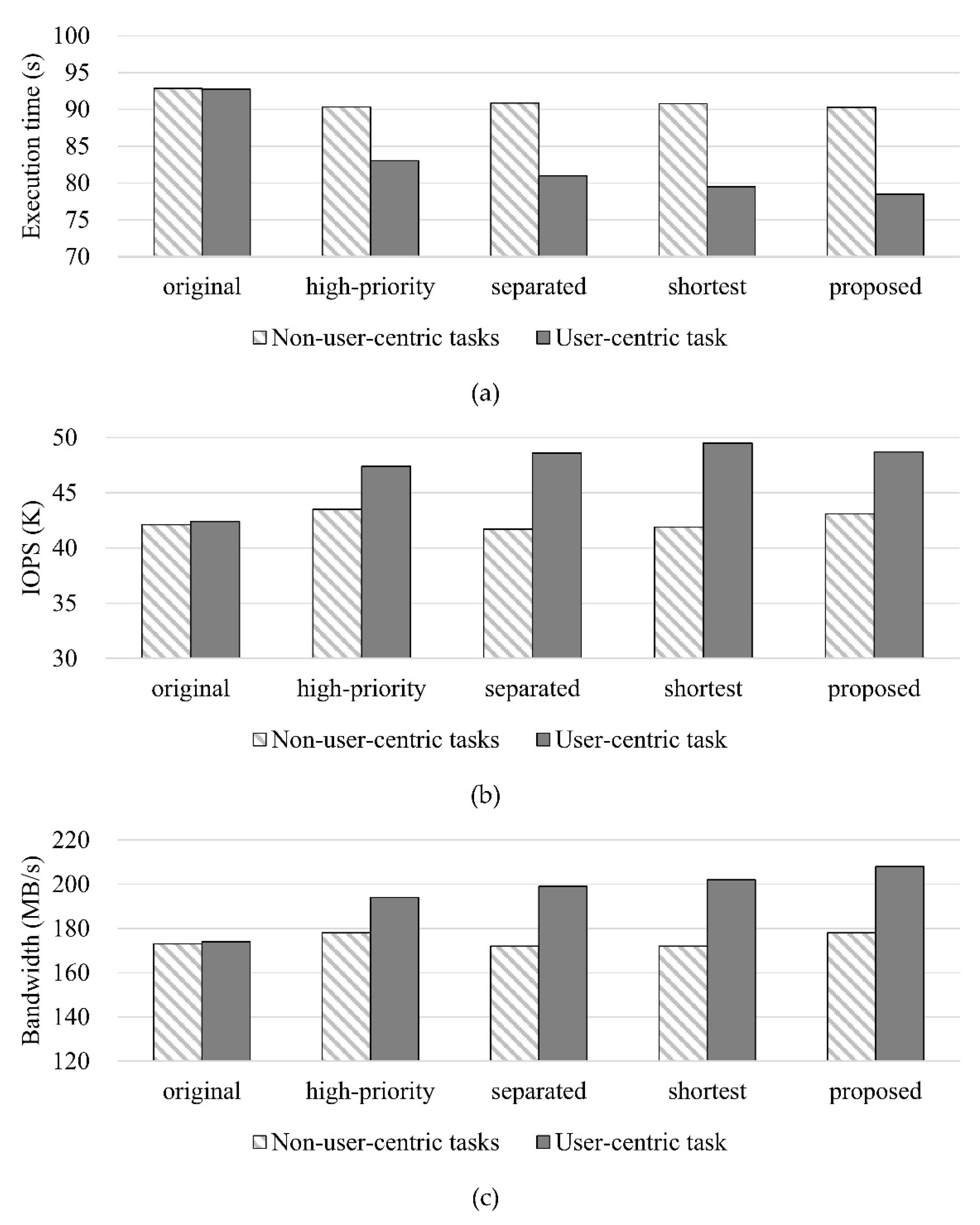
4. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Eshghi, K.; Micheloni, R. SSD architecture and PCI express interface. In Inside Solid State Drives (SSDs); Springer Series in Advanced Microelectronics; Springer: Dordrecht, The Netherlands, 2013; Volume 37, pp. 19–45. ISBN 978-94-007-5146-0. [Google Scholar]
- NVM Express: NVM Express Overview. Available online: https://nvmexpress.org/wp-content/uploads/NVMe_Overview.pdf (accessed on 5 March 2020).
- Bjørling, M.; Gonzalez, J.; Bonnet, P. LightNVM: The Linux Open-Channel SSD Subsystem. In Proceedings of the 15th USENIX Conference on File and Storage Technologies (FAST 17), Santa Clara, CA, USA, 27 February–2 March 2017; pp. 359–374. [Google Scholar]
- Zhang, J.; Donofrio, D.; Shalf, J.; Kandemir, M.T.; Jung, M. NVMMU: A Non-Volatile Memory Management Unit for Heterogeneous GPU-SSD Architectures. In Proceedings of the International Conference on Parallel Architecture and Compilation (PACT), San Francisco, CA, USA, 18–22 October 2015; pp. 13–24. [Google Scholar] [CrossRef]
- Zhang, J.; Kwon, M.; Gouk, D.; Koh, S.; Lee, C.; Alian, M.; Chun, M.; Kandemir, M.T.; Kim, N.S.; Kim, J.; et al. FlashShare: Punching Through Server Storage Stack from Kernel to Firmware for Ultra-Low Latency SSDs. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018; pp. 477–492. [Google Scholar]
- NVM Express Base Specification Revision 1.3c. Available online: https://nvmexpress.org/wp-content/uploads/NVM-Express-1_3c-2018.05.24-Ratified.pdf (accessed on 5 March 2020).
- Peng, B.; Zhang, H.; Yao, J.; Dong, Y.; Xu, Y.; Guan, H. MDev-NVMe: A NVMe Storage Virtualization Solution with Mediated Pass-Through. In Proceedings of the USENIX Annual Technical Conference (USENIX ATC 18), Boston, MA, USA, 11–13 July 2018; pp. 665–676. [Google Scholar]
- Kim, S.; Yang, J.S. Optimized I/O Determinism for Emerging NVM-based NVMe SSD in an Enterprise System. In Proceedings of the 55th Annual Design Automation Conference, San Francisco, CA, USA, 24–28 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Kim, H.J.; Lee, Y.S.; Kim, J.S. NVMeDirect: A User-space I/O Framework for Application-Specific Optimization on NVMe SSDs. In Proceedings of the 8th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 16), Denver, CO, USA, 20–21 June 2016. [Google Scholar]
- Xu, Q.; Siyamwala, H.; Ghosh, M.; Awasthi, M.; Suri, T.; Guz, Z.; Shayesteh, A.; Balakrishnan, V. Performance Characterization of Hyperscale Applicationson on NVMe SSDs. In Proceedings of the ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, New York, NY, USA, 15–19 June 2015; pp. 473–474. [Google Scholar] [CrossRef]
- Awad, A.; Kettering, B.; Solihin, Y. Non-Volatile Memory Host Controller Interface Performance Analysis in High-Performance I/O Systems. In Proceedings of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Philadelphia, PA, USA, 29–31 March 2015; pp. 145–154. [Google Scholar] [CrossRef]
- Qian, J.; Jiang, H.; Srisa-An, W.; Seth, S.; Skelton, S.; Moore, J. Energy-Efficient I/O Thread Schedulers for NVMe SSDs on NUMA. In Proceedings of the 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), Madrid, Spain, 14–17 May 2017; pp. 569–578. [Google Scholar] [CrossRef]
- Jun, B.; Shin, D. Workload-Aware Budget Compensation Scheduling for NVMe Solid State Drives. In Proceedings of the IEEE Non-Volatile Memory System and Applications Symposium (NVMSA), Hong Kong, China, 19–21 August 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, Z.; Hoseinzadeh, M.; Wong, P.; Artoux, J.; Mayers, C.; Evans, D.T.; Bolt, R.T.; Bhimani, J.; Mi, N.; Swanson, S. H-NVMe: A Hybrid Framework of NVMe-Based Storage System in Cloud Computing Environment. In Proceedings of the IEEE 36th International Performance Computing and Communications Conference (IPCCC), San Diego, CA, USA, 10–12 December 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Kim, J.; Ahn, S.; La, K.; Chang, W. Improving I/O Performance of NVMe SSD on Virtual Machines. In Proceedings of the 31st Annual ACM Symposium on Applied Computing, Pisa, Italy, 4–8 April 2016; pp. 1852–1857. [Google Scholar] [CrossRef]
- Bhimani, J.; Yang, J.; Yang, Z.; Mi, N.; Xu, Q.; Awasthi, M.; Pandurangan, R.; Balakrishnan, V. Understanding Performance of I/O Intensive Containerized Applications for NVMe SSDs. In Proceedings of the IEEE 35th International Performance Computing and Communications Conference (IPCCC), Las Vegas, NV, USA, 9–11 December 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Joshi, K.; Yadav, K.; Choudhary, P. Enabling NVMe WRR Support in Linux Block Layer. In Proceedings of the 9th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 17), Santa Clara, CA, USA, 10–11 July 2017. [Google Scholar]
- Bjørling, M.; Axboe, J.; Nellans, D.; Bonnet, P. Linux block IO: Introducing Multi-Queue SSD Access on Multi-Core Systems. In Proceedings of the 6th International Systems and Storage Conference, Haifa, Israel, 30 June–2 July 2013; pp. 1–10. [Google Scholar] [CrossRef]
- Tavakkol, A.; Gómez-Luna, J.; Sadrosadati, M.; Ghose, S.; Mutlu, O. MQSim: A Framework for Enabling Realistic Studies of Modern Multi-Queue SSD Devices. In Proceedings of the 16th USENIX Conference on File and Storage Technologies (FAST 18), Oakland, CA, USA, 12–15 February 2018; pp. 49–66. [Google Scholar]
- Kim, T.Y.; Kang, D.H.; Lee, D.; Eom, Y.I. Improving Performance by Bridging the Semantic Gap Between Multi-Queue SSD and I/O Virtualization Framework. In Proceedings of the 31st Symposium on Mass Storage Systems and Technologies (MSST), Santa Clara, CA, USA, 30 May–5 June 2015; pp. 1–11. [Google Scholar] [CrossRef]
- Lee, M.; Kang, D.H.; Lee, M.; Eom, Y.I. Improving Read Performance by Isolating Multiple Queues in NVMe SSDs. In Proceedings of the 11th International Conference on Ubiquitous Information Management and Communication, Beppu, Japan, 5–7 January 2017; pp. 1–6. [Google Scholar]
- Yang, T.; Huang, P.; Zhang, W.; Wu, H.; Lin, L. CARS: A Multi-layer Conflict-Aware Request Scheduler for NVMe SSDs. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 25–29 March 2019; pp. 1293–1296. [Google Scholar] [CrossRef]
- Gugnani, S.; Lu, X.; Panda, D.K. Analyzing, Modeling, and Provisioning QoS for NVMe SSDs. In Proceedings of the IEEE/ACM 11th International Conference on Utility and Cloud Computing (UCC), Zurich, Switzerland, 17–20 December 2018; pp. 247–256. [Google Scholar] [CrossRef]
- Huang, S.M.; Chang, L.P. Providing SLO compliance on NVMe SSDs through parallelism reservation. ACM Transact. Des. Autom. Electron. Syst. 2018, 23, 1–26. [Google Scholar] [CrossRef]
- Hahn, S.S.; Lee, S.; Yee, I.; Ryu, D.; Kim, J. Improving User Experience of Android Smartphones Using Foreground App-Aware I/O Management. In Proceedings of the 8th Asia-Pacific Workshop on Systems, Mumbai, India, 2–3 September 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Ahn, S.; La, K.; Kim, J. Improving I/O Resource Sharing of Linux Cgroup for NVMe SSDs on Multi-core Systems. In Proceedings of the 8th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 16), Denver, CO, USA, 20–21 June 2016. [Google Scholar]
- Kim, K.; Hong, S.; Kim, T. Supporting the Priorities in the Multi-queue Block I/O Layer for NVMe SSDs. J. Semicond. Technol. Sci. 2020, 20, 55–62. [Google Scholar] [CrossRef]
- Zhuravlev, S.; Saez, J.C.; Blagodurov, S.; Fedorova, A.; Prieto, M. Survey of scheduling techniques for addressing shared resources in multicore processors. ACM Comput. Surv. 2012, 45, 1–28. [Google Scholar] [CrossRef]
- Wong, C.S.; Tan, I.K.T.; Kumari, R.D.; Lam, J.W.; Fun, W. Fairness and Interactive Performance of O (1) and CFS Linux Kernel Schedulers. In Proceedings of the International Symposium on Information Technology, Kuala Lumpur, Malaysia, 26–28 August 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Flexible I/O Tester. Available online: https://github.com/axboe/fio (accessed on 5 March 2020).
- Son, Y.; Kang, H.; Han, H.; Yeom, H.Y. An Empirical Evaluation of NVM Express SSD. In Proceedings of the International Conference on Cloud and Autonomic Computing, Boston, MA, USA, 21–25 September 2015; pp. 275–282. [Google Scholar] [CrossRef]
- Firefox. Available online: https://www.mozilla.org/en-US/firefox/ (accessed on 5 March 2020).
- App/Videos—GNOME Wiki. Available online: https://wiki.gnome.org/Apps/Videos (accessed on 5 March 2020).
- LibreOffice—Free Office Suite. Available online: https://www.libreoffice.org/ (accessed on 5 March 2020).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CPU | Intel i7-8700K CPU @ 3.70 GHz (6 cores) | |
| Storage | Samsung SSD 970 PRO | |
| - Interface: PCIe 3.0 x 4, NVMe 1.3 | - Capacity: 512GB | |
| Operating system | Ubuntu 14.04 LTS 64-bit (Linux 4.13.10) | |
| Shell | Bash 4.4.18 | |
| I/O workload | fio 3.6 | |
| - I/O engine: libaio | - LBA range: 15GiB | |
| - I/O pattern: random read | - Number of threads: 512 | |
| Notation | Description |
|---|---|
| original | Evaluates with an unmodified kernel and shell program |
| high-priority | Raises the process priority of the user-centric tasks through the modified shell program |
| separated | Provides a separated software queue for user-centric tasks based on high-priority |
| shortest | Delivers I/O requests from user-centric tasks to the shortest-sized SQ based on high-priority |
| proposed | Includes all ideas: high-priority, separated, and shortest |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; Kim, K.; Shin, H.; Kim, T. Practical Enhancement of User Experience in NVMe SSDs. Appl. Sci. 2020, 10, 4765. https://doi.org/10.3390/app10144765
Kim S, Kim K, Shin H, Kim T. Practical Enhancement of User Experience in NVMe SSDs. Applied Sciences. 2020; 10(14):4765. https://doi.org/10.3390/app10144765
Chicago/Turabian StyleKim, Seongmin, Kyusik Kim, Heeyoung Shin, and Taeseok Kim. 2020. "Practical Enhancement of User Experience in NVMe SSDs" Applied Sciences 10, no. 14: 4765. https://doi.org/10.3390/app10144765
APA StyleKim, S., Kim, K., Shin, H., & Kim, T. (2020). Practical Enhancement of User Experience in NVMe SSDs. Applied Sciences, 10(14), 4765. https://doi.org/10.3390/app10144765