Multiclass Non-Randomized Spectral–Spatial Active Learning for Hyperspectral Image Classification

 ,
,  ,
, 
 ,
,
Abstract
1. Introduction
2. Methodology
2.1. Hyperspectral Data Formulation
2.2. Multinomial Logistic Regression via Splitting and Augmented Lagrangian (MLR-LORSAL)
- iff is a crisp set.
- is maximum if .
- If then where and
| Algorithm 1: Pipeline of Proposed Algorithm. |
 |
3. Experimental Process
- Mutual Information (MI): Selects the samples by maximizing the mutual information between the classifier and class labels and can obtain samples from the complicated region [39].
- Breaking Ties (BT): Selects the samples by minimizing the distance of the two classes having the highest posterior probabilities, and can choose samples from the boundary regions [46]. In the multiclass scenario, BT can be utilized by finding the difference between the first two most probable classes.
- Modified Breaking Ties (MBT): Adds more diverse samples as compared to MI and BT. The MBT algorithm follows two important steps: first, it selects samples from the unlabeled pool with the same maximum a posteriori (MAP) estimation; and then choose the samples from the most complicated region [46].
4. Experimental Datasets and Results
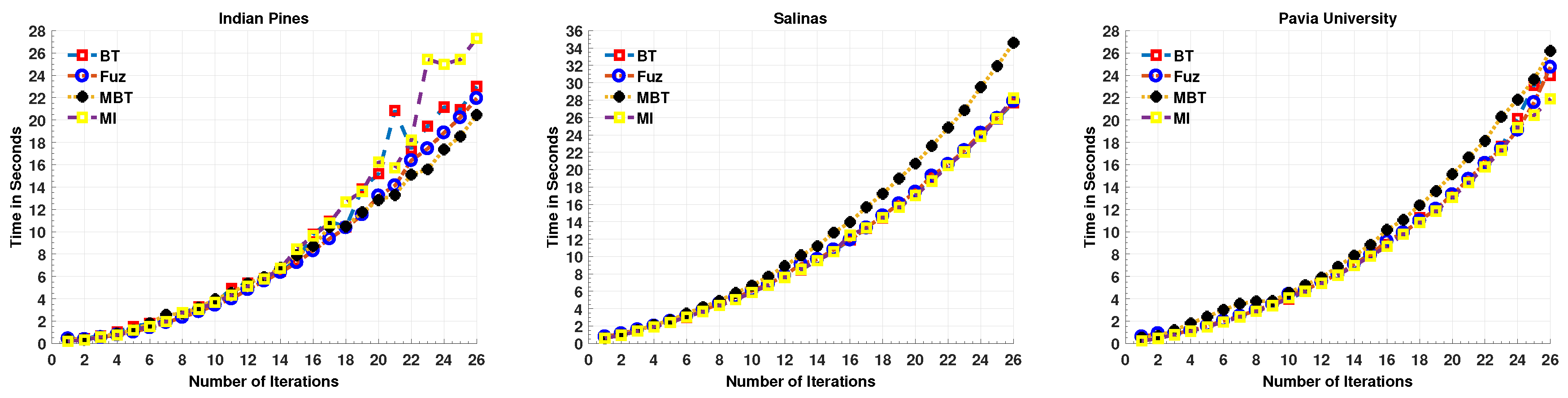
4.1. Computational Cost
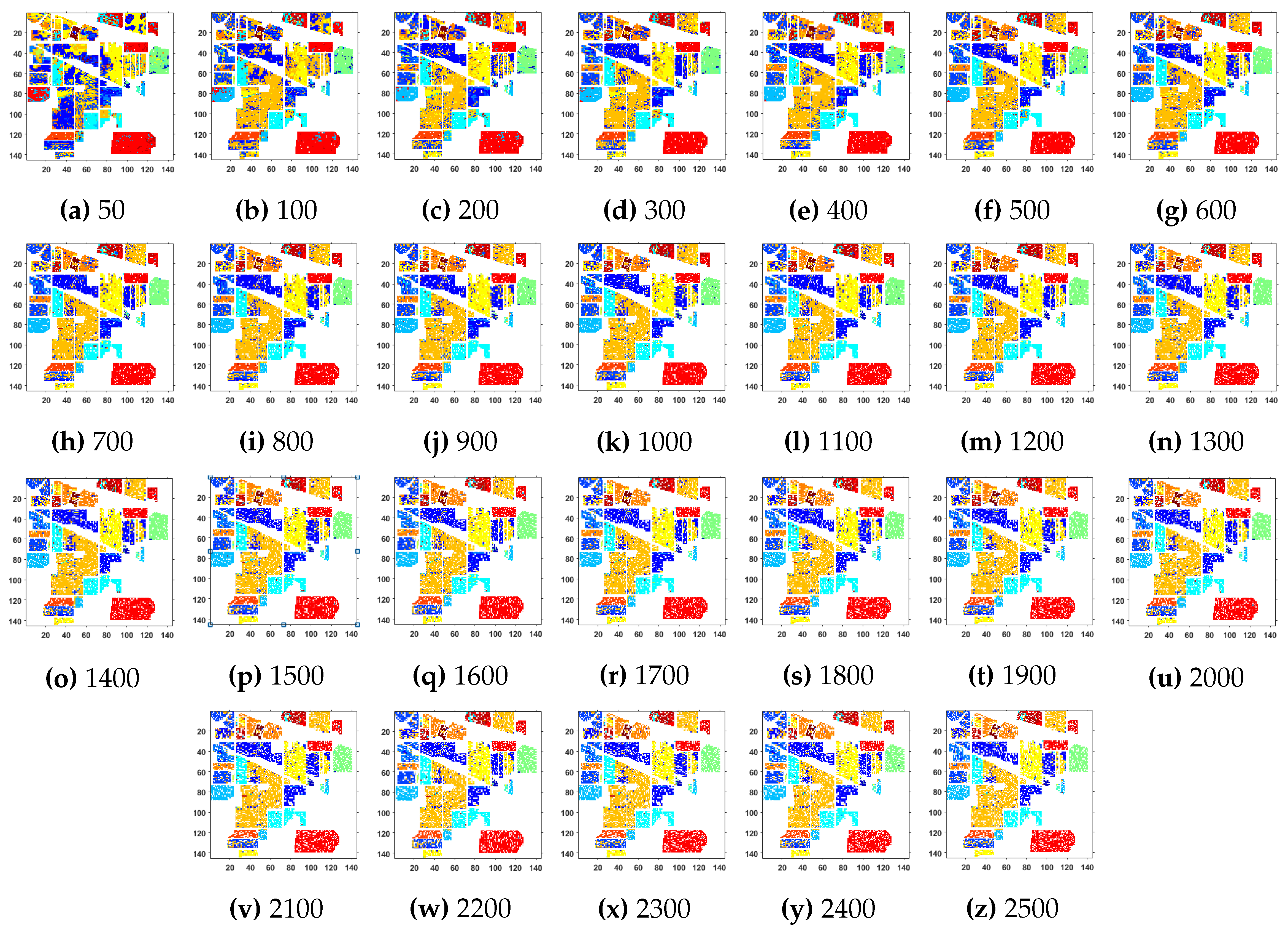
4.2. Experimental Results on Indian Pines Dataset
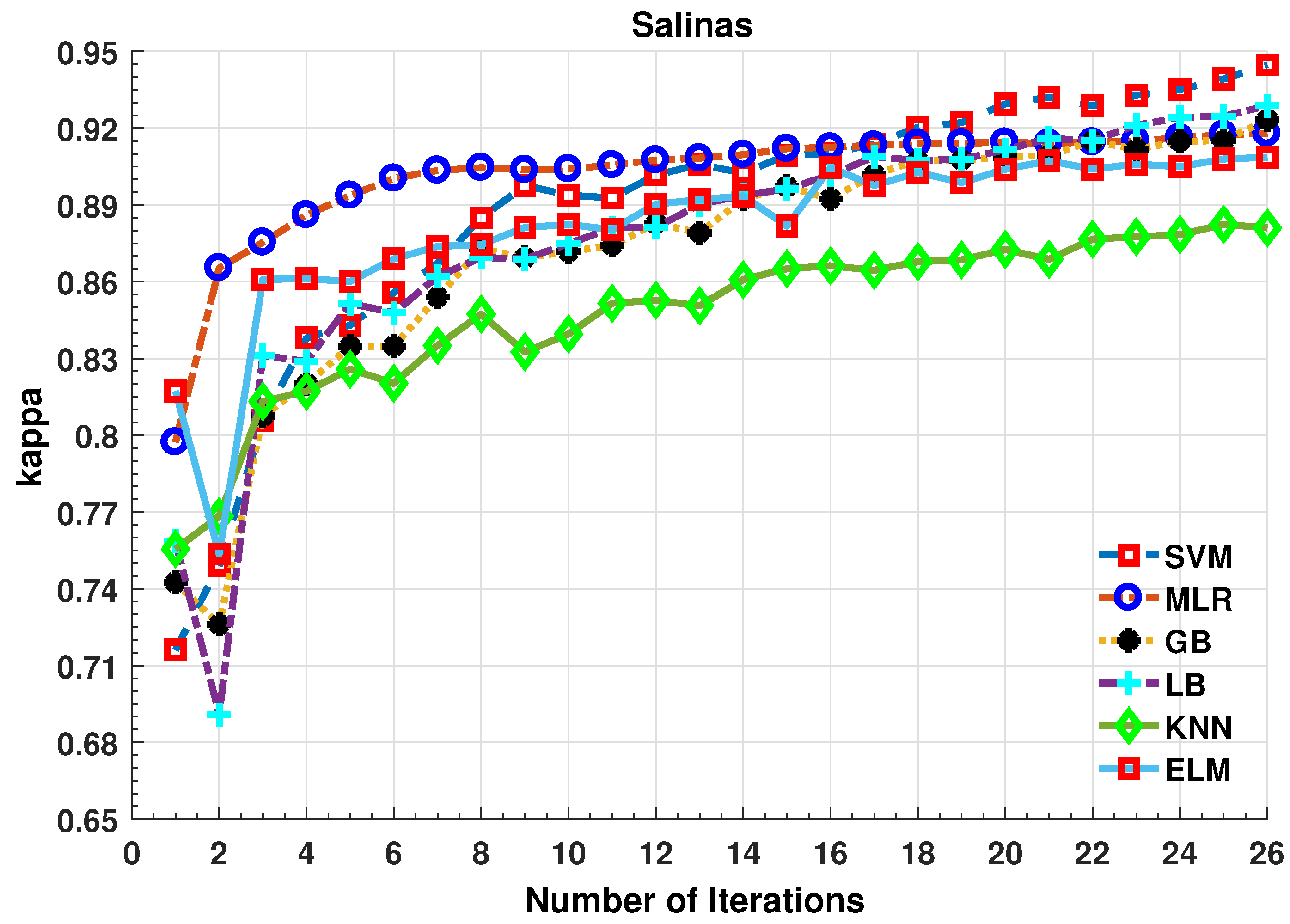
4.3. Experimental Results on Salinas
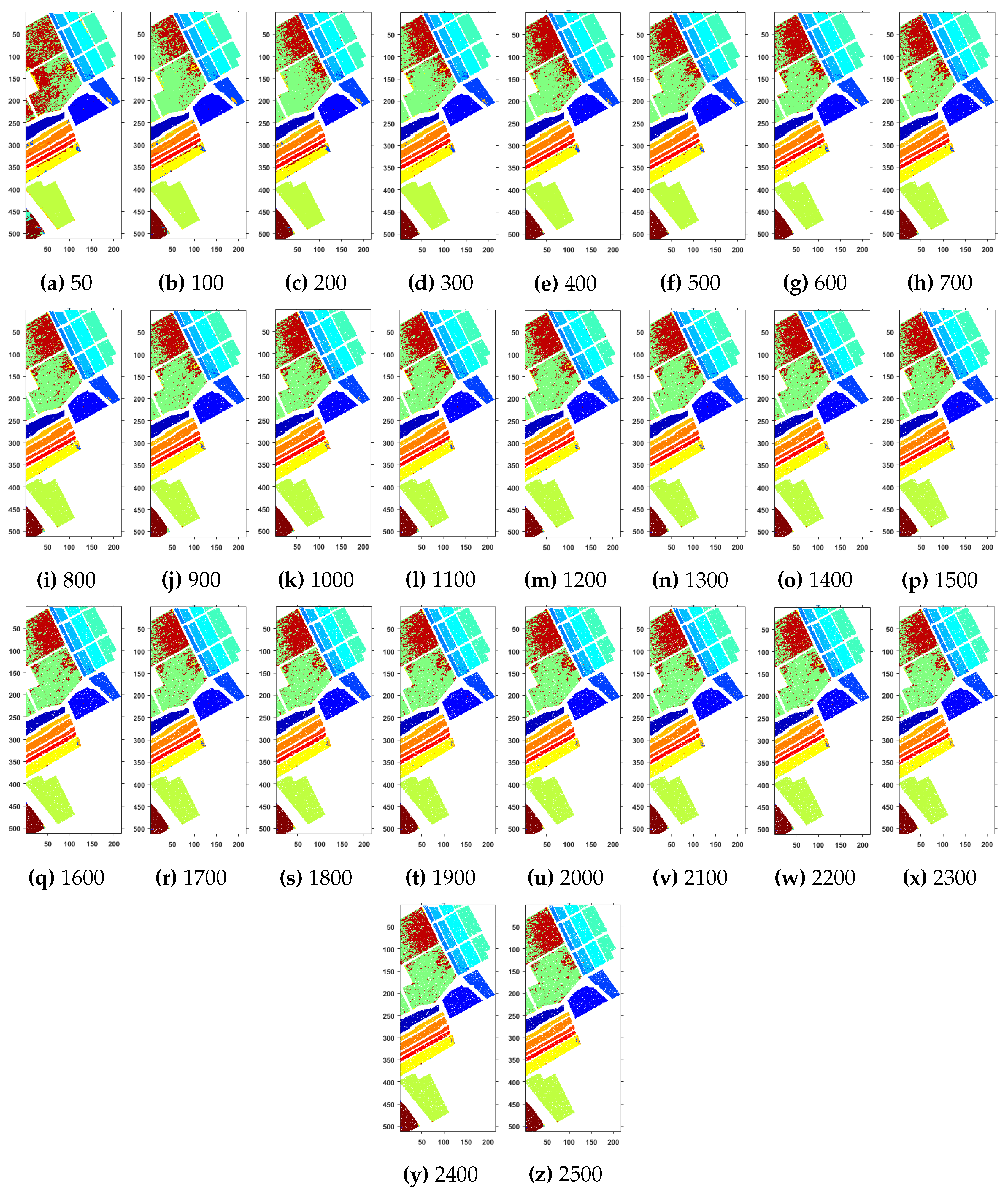
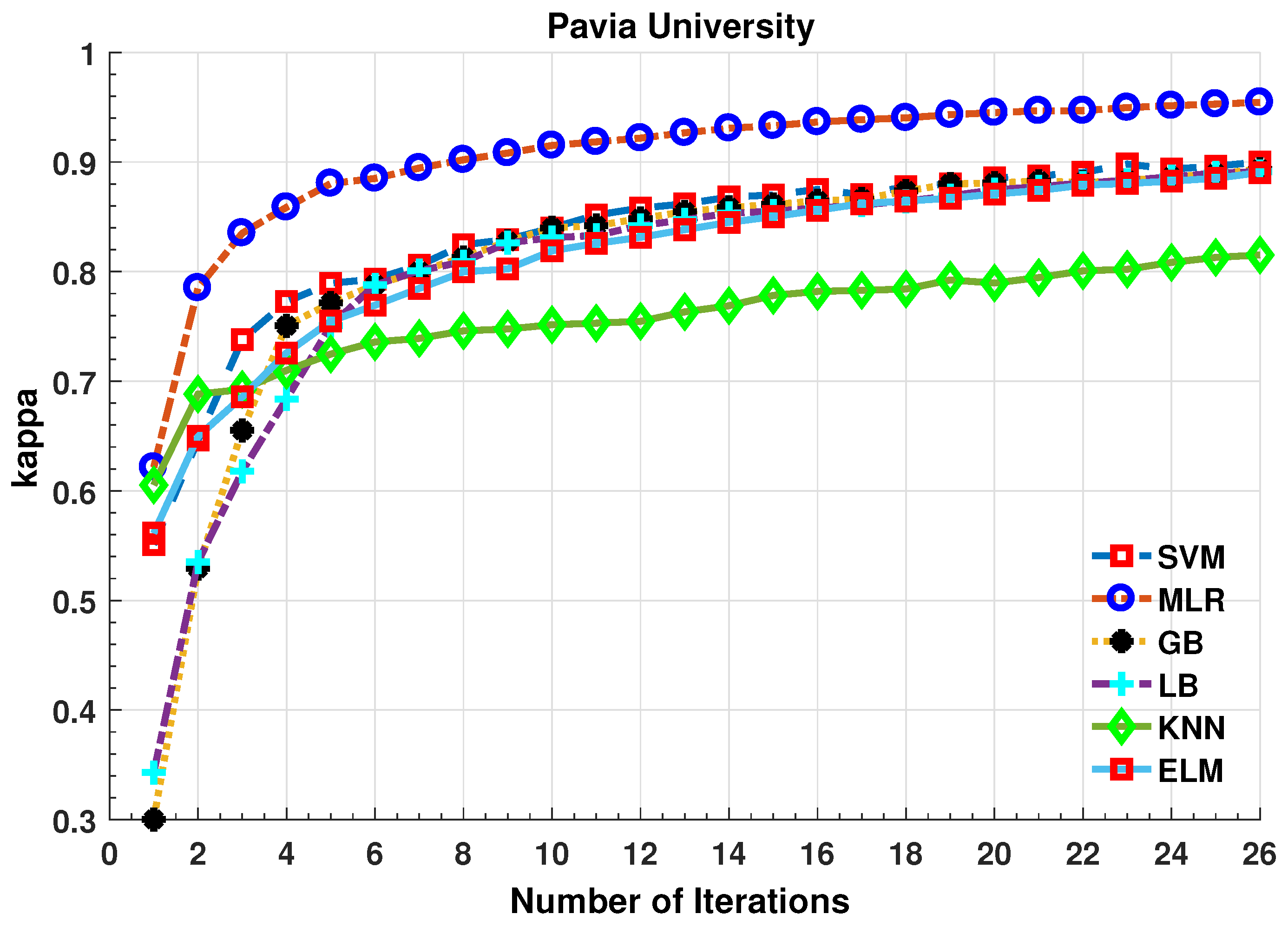
4.4. Experimental Results on Pavia University
4.5. Results Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ahmad, M.; Shabbir, S.; Oliva, D.; Mazzara, M.; Distefano, S. Spatial-prior Generalized Fuzziness Extreme Learning Machine Autoencoder-based Active Learning for Hyperspectral Image Classification. Optik-Int. J. Light Electron Opt. 2020, 206, 163712. [Google Scholar] [CrossRef]
- Ahmad, M.; Haq, I.U. Linear Unmixing and Target Detection of Hyperspectral Imagery Using OSP. In Proceedings of the International Conference on Modeling, Simulation and Control, Singapore, 25–27 January 2011; pp. 179–183. [Google Scholar]
- Banerjee, B.P.; Raval, S.; Cullen, P.J. UAV-hyperspectral imaging of spectrally complex environments. Int. J. Remote Sens. 2020, 41, 4136–4159. [Google Scholar] [CrossRef]
- Jia, B.; Wang, W.; Ni, X.; Lawrence, K.C.; Zhuang, H.; Yoon, S.C.; Gao, Z. Essential processing methods of hyperspectral images of agricultural and food products. Chemom. Intell. Lab. Syst. 2020, 198, 103936. [Google Scholar] [CrossRef]
- Koz, A. Ground-Based Hyperspectral Image Surveillance Systems for Explosive Detection: Part II—Radiance to Reflectance Conversions. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4754–4765. [Google Scholar] [CrossRef]
- Ahmad, M.; Khan, A.; Khan, A.M.; Mazzara, M.; Distefano, S.; Sohaib, A.; Nibouche, O. Spatial Prior Fuzziness Pool-Based Interactive Classification of Hyperspectral Images. Remote Sens. 2019, 11, 1136. [Google Scholar] [CrossRef]
- Erickson, Z.; Luskey, N.; Chernova, S.; Kemp, C.C. Classification of Household Materials via Spectroscopy. IEEE Robot. Autom. Lett. 2019, 4, 700–707. [Google Scholar] [CrossRef]
- Jiang, Y.; Snider, J.L.; Li, C.; Rains, G.C.; Paterson, A.H. Ground Based Hyperspectral Imaging to Characterize Canopy-Level Photosynthetic Activities. Remote Sens. 2020, 12, 315. [Google Scholar] [CrossRef]
- Ahmad, M.; Khan, A.M.; Mazzara, M.; Distefano, S. Multi-layer Extreme Learning Machine-based Autoencoder for Hyperspectral Image Classification. In Proceedings of the 14th International Conference on Computer Vision Theory and Applications (VISAPP’19), Prague, Czech Republic, 25–27 February 2019; pp. 25–27. [Google Scholar]
- Alcolea, A.; Paoletti, M.E.; Haut, J.M.; Resano, J.; Plaza, A. Inference in Supervised Spectral Classifiers for On-Board Hyperspectral Imaging: An Overview. Remote Sens. 2020, 12, 534. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, W.; Fang, Z. Multiple Kernel-Based SVM Classification of Hyperspectral Images by Combining Spectral, Spatial, and Semantic Information. Remote Sens. 2020, 12, 120. [Google Scholar] [CrossRef]
- Vincent, F.; Besson, O. One-Step Generalized Likelihood Ratio Test for Subpixel Target Detection in Hyperspectral Imaging. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4479–4489. [Google Scholar] [CrossRef]
- Su, H.; Yu, Y.; Du, Q.; Du, P. Ensemble Learning for Hyperspectral Image Classification Using Tangent Collaborative Representation. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3778–3790. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; Xu, X. Hierarchical guidance filtering-based ensemble classification for hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4177–4189. [Google Scholar] [CrossRef]
- Alshurafa, N.I.; Katsaggelos, A.K.; Cossairt, O.S. Hyperspectral Imaging Sensor. U.S. Patent App. 16/492,214, 1 February 2020. [Google Scholar]
- Xia, J.; Du, P.; He, X.; Chanussot, J. Hyperspectral remote sensing image classification based on rotation forest. IEEE Geosci. Remote Sens. Lett. 2013, 11, 239–243. [Google Scholar] [CrossRef]
- Safari, K.; Prasad, S.; Labate, D. A Multiscale Deep Learning Approach for High-Resolution Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Song, A.; Kim, Y. Deep learning-based hyperspectral image classification with application to environmental geographic information systems. Korean J. Remote Sens. 2017, 33, 1061–1073. [Google Scholar]
- Ahmad, M. A Fast 3D CNN for Hyperspectral Image Classification. arXiv 2020, arXiv:2004.14152. [Google Scholar]
- Liu, B.; Yu, X.; Yu, A.; Wan, G. Deep convolutional recurrent neural network with transfer learning for hyperspectral image classification. J. Appl. Remote Sens. 2018, 12, 1–17. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.; Chan, J.C. Learning and Transferring Deep Joint Spectral–Spatial Features for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4729–4742. [Google Scholar] [CrossRef]
- Ma, J.; Xiao, B.; Deng, C. Graph based semi-supervised classification with probabilistic nearest neighbors. Pattern Recognit. Lett. 2020, 133, 94–101. [Google Scholar] [CrossRef]
- Ahmad, M. Fuzziness-based Spatial-Spectral Class Discriminant Information Preserving Active Learning for Hyperspectral Image Classification. arXiv 2020, arXiv:2005.14236. [Google Scholar]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Ahmad, M.; Protasov, S.; Khan, A.M.; Hussain, R.; Khattak, A.M.; Khan, W.A. Fuzziness-based active learning framework to enhance hyperspectral image classification performance for discriminative and generative classifiers. PLoS ONE 2018, 13, e0188996. [Google Scholar] [CrossRef] [PubMed]
- Bovolo, F.; Bruzzone, L.; Carlin, L. A novel technique for subpixel image classification based on support vector machine. IEEE Trans. Image Process. 2010, 19, 2983–2999. [Google Scholar] [CrossRef] [PubMed]
- Persello, C.; Bruzzone, L. Active and semisupervised learning for the classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6937–6956. [Google Scholar] [CrossRef]
- Cao, X.; Yao, J.; Xu, Z.; Meng, D. Hyperspectral Image Classification With Convolutional Neural Network and Active Learning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4604–4616. [Google Scholar] [CrossRef]
- Shahshahani, B.M.; Landgrebe, D.A. The effect of unlabeled samples in reducing the small sample size problem and mitigating the Hughes phenomenon. IEEE Trans. Geosci. Remote Sens. 1994, 32, 1087–1095. [Google Scholar] [CrossRef]
- Yang, L.; Yang, S.; Jin, P.; Zhang, R. Semi-supervised hyperspectral image classification using spatio-spectral Laplacian support vector machine. IEEE Geosci. Remote Sens. Lett. 2013, 11, 651–655. [Google Scholar] [CrossRef]
- Fang, L.; Zhao, W.; He, N.; Zhu, J. Multiscale CNNs Ensemble Based Self-Learning for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Melville, P.; Mooney, R.J. Diverse ensembles for active learning. In Proceedings of the Twenty-First International Conference on Machine Learning; ACM: New York, NY, USA, 2004; p. 74. [Google Scholar]
- Jamshidpour, N.; Safari, A.; Homayouni, S. A GA-Based Multi-View, Multi-Learner Active Learning Framework for Hyperspectral Image Classification. Remote Sens. 2020, 12, 297. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Li, M. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef]
- Ahmad, M.; Khan, A.M.; Hussain, R. Graph-based spatial–spectral feature learning for hyperspectral image classification. IET Image Process. 2017, 11, 1310–1316. [Google Scholar] [CrossRef]
- Yu, H.; Yang, X.; Zheng, S.; Sun, C. Active learning from imbalanced data: A solution of online weighted extreme learning machine. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1088–1103. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral–spatial classification of hyperspectral data using loopy belief propagation and active learning. IEEE Trans. Geosci. Remote Sens. 2012, 51, 844–856. [Google Scholar] [CrossRef]
- Tuia, D.; Ratle, F.; Pacifici, F.; Kanevski, M.F.; Emery, W.J. Active learning methods for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2218–2232. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Hyperspectral image segmentation using a new Bayesian approach with active learning. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3947–3960. [Google Scholar] [CrossRef]
- Yu, H.; Sun, C.; Yang, W.; Yang, X.; Zuo, X. AL-ELM: One uncertainty-based active learning algorithm using extreme learning machine. Neurocomputing 2015, 166, 140–150. [Google Scholar] [CrossRef]
- Böhning, D. Multinomial logistic regression algorithm. Ann. Inst. Stat. Math. 1992, 44, 197–200. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Bruzzone, L. Kernel-based methods for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1351–1362. [Google Scholar] [CrossRef]
- De Luca, A.; Termini, S. A definition of a nonprobabilistic entropy in the setting of fuzzy sets theory. Inf. Control 1972, 20, 301–312. [Google Scholar] [CrossRef]
- Hyperspectral Datasets Description. 2020. Available online: http://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes (accessed on 12 January 2020).
- Yang, J.; Yu, H.; Yang, X.; Zuo, X. Imbalanced extreme learning machine based on probability density estimation. In International Workshop on Multi-Disciplinary Trends in Artificial Intelligence; Springer: Fuzhou, China, 2015; pp. 160–167. [Google Scholar]
- Liu, W.; Yang, J.; Li, P.; Han, Y.; Zhao, J.; Shi, H. A novel object-based supervised classification method with active learning and random forest for PolSAR imagery. Remote Sens. 2018, 10, 1092. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Explanations |
|---|---|
| X | Hyperspectral Data Cube, where |
| L | Number of Bands in Hyperspectral Image Cube. |
| Number of Samples in each Band of Hyperspectral cube. | |
| C | Total Number of Classes in Hyperspectral Cube. |
| n | Total Number of Initial Training Samples. |
| m | Total Number of Initial Test Samples. |
| h | Total Number of Queried Sample |
| Number of Samples Selected in each Iteration where also | |
| Index of Selected Samples. | |
| ith Spectral Sample and . | |
| Class label of ith Spectral Sample, where | |
| Training Set consist of n Samples. | |
| Initial Test Set consist of m Samples, where and | |
| Membership Matrix, i.e., output of classifier | |
| Membership of ith sample for jth class | |
| Fuzziness computed through | |
| Selected Reference Training Samples | |
| Spectral Angular Distance among the New and Existing Training Samples | |
| Overall Accuracy | |
| Kappa metric | |
| TP | True Positive |
| FP | False Positive |
| TN | True Negative |
| FN | False Negative |
| MI | Mutual Information |
| BT | Breaking Ties |
| MBT | Modified Breaking Ties |
| Metric | MI | BT | MBT | Fuzziness |
|---|---|---|---|---|
| Overall Accuracy | 0.80 ± 0.17 | 0.81 ± 0.17 | 0.77 ± 0.14 | 0.81 ± 0.14 |
| 0.78 ± 0.19 | 0.79 ± 0.19 | 0.74 ± 0.16 | 0.80 ± 0.16 | |
| Recall | 0.92 ± 0.01 | 0.81 ± 0.02 | 0.69 ± 0.03 | 0.93 ± 0.02 |
| Precision | 0.95 ± 0.01 | 0.80 ± 0.02 | 0.63 ± 0.03 | 0.92 ± 0.02 |
| F1-Score | 0.94 ± 0.01 | 0.79 ± 0.01 | 0.66 ± 0.03 | 0.92 ± 0.02 |
| Metric | MI | BT | MBT | Fuzziness |
|---|---|---|---|---|
| Overall Accuracy | 0.90 ± 0.06 | 0.91 ± 0.06 | 0.88 ± 0.05 | 0.90 ± 0.05 |
| 0.88 ± 0.06 | 0.90 ± 0.06 | 0.87 ± 0.05 | 0.88 ± 0.05 | |
| Recall | 0.94 ± 0.01 | 0.95 ± 0.01 | 0.94 ± 0.01 | 0.94 ± 0.01 |
| Precision | 0.94 ± 0.01 | 0.94 ± 0.01 | 0.94 ± 0.01 | 0.93 ± 0.01 |
| F1-Score | 0.94 ± 0.01 | 0.94 ± 0.01 | 0.94 ± 0.01 | 0.93 ± 0.01 |
| Metric | MI | BT | MBT | Fuzziness |
|---|---|---|---|---|
| Overall Accuracy | 0.85 ± 0.13 | 0.88 ± 0.13 | 0.86 ± 0.12 | 0.87 ± 0.13 |
| 0.81 ± 0.16 | 0.84 ± 0.16 | 0.82 ± 0.14 | 0.84 ± 0.15 | |
| Recall | 0.86 ± 0.02 | 0.88 ± 0.02 | 0.88 ± 0.02 | 0.87 ± 0.02 |
| Precision | 0.85 ± 0.03 | 0.88 ± 0.02 | 0.86 ± 0.03 | 0.87 ± 0.03 |
| F1-Score | 0.85 ± 0.02 | 0.87 ± 0.02 | 0.86 ± 0.02 | 0.86 ± 0.02 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, M.; Mazzara, M.; Raza, R.A.; Distefano, S.; Asif, M.; Sarfraz, M.S.; Khan, A.M.; Sohaib, A. Multiclass Non-Randomized Spectral–Spatial Active Learning for Hyperspectral Image Classification. Appl. Sci. 2020, 10, 4739. https://doi.org/10.3390/app10144739
Ahmad M, Mazzara M, Raza RA, Distefano S, Asif M, Sarfraz MS, Khan AM, Sohaib A. Multiclass Non-Randomized Spectral–Spatial Active Learning for Hyperspectral Image Classification. Applied Sciences. 2020; 10(14):4739. https://doi.org/10.3390/app10144739
Chicago/Turabian StyleAhmad, Muhammad, Manuel Mazzara, Rana Aamir Raza, Salvatore Distefano, Muhammad Asif, Muhammad Shahzad Sarfraz, Adil Mehmood Khan, and Ahmed Sohaib. 2020. "Multiclass Non-Randomized Spectral–Spatial Active Learning for Hyperspectral Image Classification" Applied Sciences 10, no. 14: 4739. https://doi.org/10.3390/app10144739
APA StyleAhmad, M., Mazzara, M., Raza, R. A., Distefano, S., Asif, M., Sarfraz, M. S., Khan, A. M., & Sohaib, A. (2020). Multiclass Non-Randomized Spectral–Spatial Active Learning for Hyperspectral Image Classification. Applied Sciences, 10(14), 4739. https://doi.org/10.3390/app10144739