Exploiting a Deep Neural Network for Efficient Transmit Power Minimization in a Wireless Powered Communication Network



Abstract
1. Introduction
1.1. Deep Learning
1.2. Wireless Powered Communication Network
1.3. Related Work
1.4. Main Contribution
- First, we propose a sequential parametric convex approximation (SPCA)-based iterative solution for the transmit power minimization problem in a WPCN. The proposed solution can determine the optimal values for minimum transmit power and allocation of downlink/uplink time for energy and information transmission. We generated a data set for deep learning using this solution.
- Secondly, we propose a learning-based DNN scheme exploiting the training data from the SPCA-based approach. The DNN architecture accepts the channel coefficient as input and gives an optimized solution as output. The proposed DNN is fairly accurate at learning the relationships between the input and output of the WPCN system. The proposed scheme gives fast and fairly accurate results compared to the SPCA-based iterative algorithm.
- The performance of our scheme is verified through simulations and experiments. It is proven that the proposed scheme gives an accurate approximation of a conventional iterative algorithm scheme while managing the time complexity well. Our scheme gives a much faster solution than the conventional iterative algorithm.
2. System Model and Problem Formulation
2.1. Downlink Wireless Energy Transfer
2.2. Uplink Wireless Information Transfer
3. SPCA-Based Iterative Solution
3.1. Single User
| Algorithm 1 Sequential parametric convex approximation (SPCA)-based iterative algorithm to generate data for a single user. |
|
3.2. Multiuser
| Algorithm 2 SPCA-based iterative algorithm to generate data for multiple users. |
|
4. Proposed Learning-Based Optimization Scheme
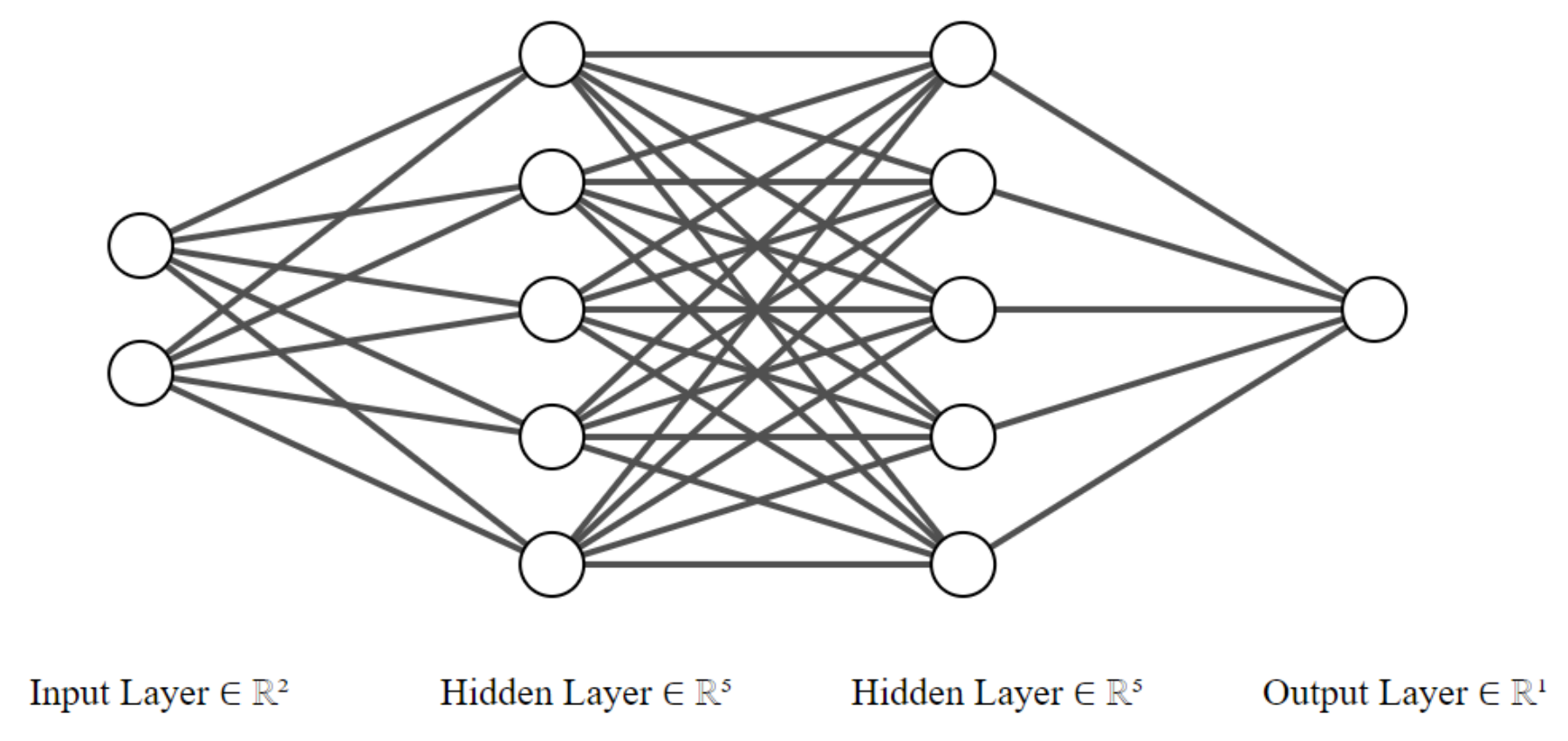
4.1. DNN Architecture
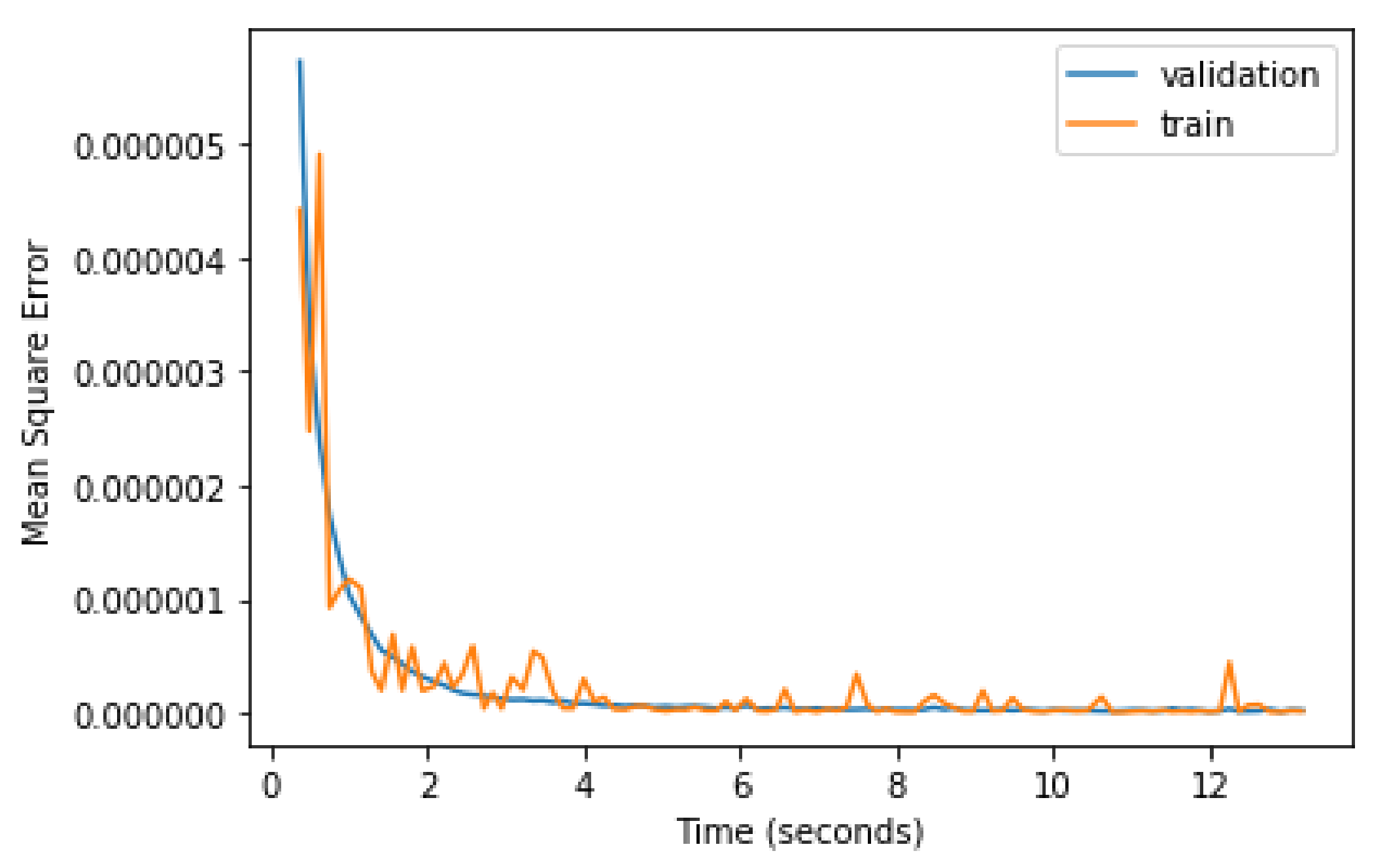
4.2. Training the Neural Network
5. Performance Evaluation
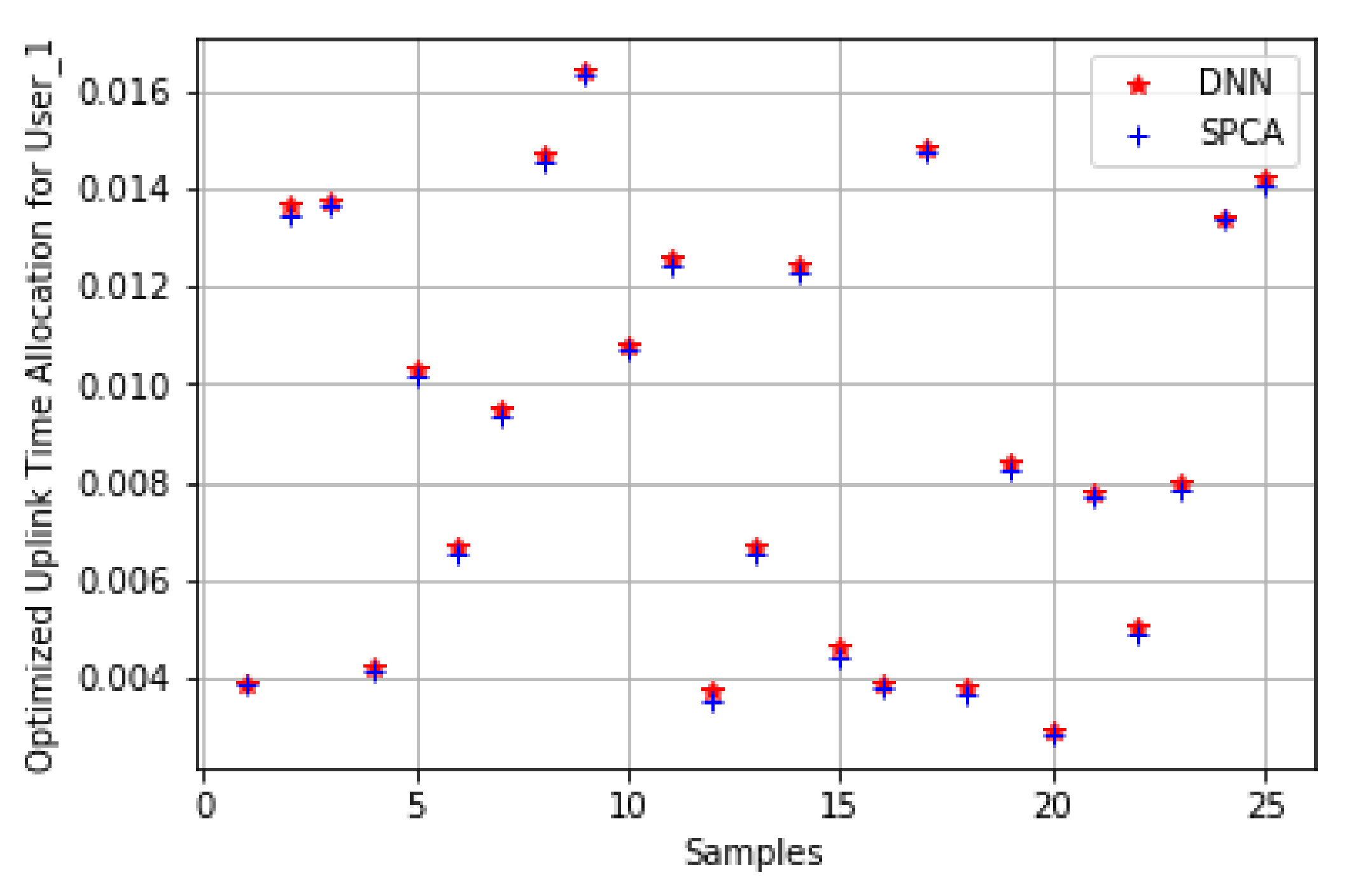
5.1. Single User
5.2. Multi-User
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Samuel, N.; Diskin, T.; Wiesel, A. Learning to Detect. IEEE Trans. Signal Process. 2019, 67, 2554–2564. [Google Scholar] [CrossRef]
- Wang, T.; Wen, C.; Wang, H.; Gao, F.; Jiang, T.; Jin, S. Deep learning for wireless physical layer: Opportunities and challenges. China Commun. 2017, 14, 92–111. [Google Scholar] [CrossRef]
- Farsad, N.; Goldsmith, A. Neural Network Detection of Data Sequences in Communication Systems. IEEE Trans. Signal Process. 2018, 66, 5663–5678. [Google Scholar] [CrossRef]
- Farsad, N.; Goldsmith, A.J. Detection Algorithms for Communication Systems Using Deep Learning. arXiv 2017, arXiv:1705.08044. [Google Scholar]
- Ju, H.; Zhang, R. Throughput Maximization in Wireless Powered Communication Networks. IEEE Trans. Wirel. Commun. 2014, 13, 418–428. [Google Scholar] [CrossRef]
- Yang, G.; Ho, C.K.; Zhang, R.; Guan, Y.L. Throughput Optimization for Massive MIMO Systems Powered by Wireless Energy Transfer. IEEE J. Sel. Areas Commun. 2015, 33, 1640–1650. [Google Scholar] [CrossRef]
- Li, Q.; Wang, L.; Xu, D. Resource Allocation in Cognitive Wireless Powered Communication Networks under Outage Constraint. In Proceedings of the 2018 IEEE 4th International Conference on Computer and Communications (ICCC), Chengdu, China, 7–10 December 2018; pp. 683–687. [Google Scholar] [CrossRef]
- Tuan, P.V.; Koo, I. Simultaneous Wireless Information and Power Transfer Solutions for Energy-Harvesting Fairness in Cognitive Multicast Systems. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2018, 101, 1988–1992. [Google Scholar] [CrossRef]
- Tuan, P.V.; Koo, I. Optimizing Efficient Energy Transmission on a SWIPT Interference Channel Under Linear/Nonlinear EH Models. IEEE Syst. J. 2019, 14, 457468. [Google Scholar] [CrossRef]
- Sun, H.; Chen, X.; Shi, Q.; Hong, M.; Fu, X.; Sidiropoulos, N.D. Learning to Optimize: Training Deep Neural Networks for Interference Management. IEEE Trans. Signal Process. 2018, 66, 5438–5453. [Google Scholar] [CrossRef]
- Gron, A. Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, 1st ed.; O’Reilly Media, Inc.: Newton, MA, USA, 2017. [Google Scholar]
- Liu, L.; Zhang, R.; Chua, K. Wireless information transfer with opportunistic energy harvesting. In Proceedings of the 2012 IEEE International Symposium on Information Theory Proceedings, Cambridge, MA, USA, 1–6 July 2012; pp. 950–954. [Google Scholar] [CrossRef]
- Cheng, Y.; Fu, P.; Chang, Y.; Li, B.; Yuan, X. Joint Power and Time Allocation in Full-Duplex Wireless Powered Communication Networks. Mob. Inf. Syst. 2016, 2016. [Google Scholar] [CrossRef]
- Kang, J.; Chun, C.; Kim, I. Deep-Learning-Based Channel Estimation for Wireless Energy Transfer. IEEE Commun. Lett. 2018, 22, 2310–2313. [Google Scholar] [CrossRef]
- He, D.; Liu, C.; Wang, H.; Quek, T.Q.S. Learning-Based Wireless Powered Secure Transmission. IEEE Wirel. Commun. Lett. 2019, 8, 600–603. [Google Scholar] [CrossRef]
- Lee, W.; Kim, M.; Cho, D. Transmit Power Control Using Deep Neural Network for Underlay Device-to-Device Communication. IEEE Wirel. Commun. Lett. 2019, 8, 141–144. [Google Scholar] [CrossRef]
- Beck, A.; Ben-Tal, A.; Tetruashvili, L. A sequential parametric convex approximation method with applications to nonconvex truss topology design problems. J. Glob. Optim. 2010, 47, 29–51. [Google Scholar] [CrossRef]
- Grant, M.; Boyd, S. CVX: Matlab Software for Disciplined Convex Programming, Version 2.1. 2014. Available online: http://cvxr.com/cvx (accessed on 2 July 2020).
- Boyd, S.; Boyd, S.; Vandenberghe, L.; Press, C.U. Convex Optimization; Berichte über Verteilte Messysteme; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Hanin, B.; Rolnick, D. How to start training: The effect of initialization and architecture. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Montréal, QC, Canada, 2018; pp. 571–581. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Single User | Multiple Users | |
|---|---|---|
| DNN execution time per sample | s | s |
| SPCA execution time per sample | s | s |
| MSE for optimal power | ||
| MSE for time allocation |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hameed, I.; Tuan, P.-V.; Koo, I. Exploiting a Deep Neural Network for Efficient Transmit Power Minimization in a Wireless Powered Communication Network. Appl. Sci. 2020, 10, 4622. https://doi.org/10.3390/app10134622
Hameed I, Tuan P-V, Koo I. Exploiting a Deep Neural Network for Efficient Transmit Power Minimization in a Wireless Powered Communication Network. Applied Sciences. 2020; 10(13):4622. https://doi.org/10.3390/app10134622
Chicago/Turabian StyleHameed, Iqra, Pham-Viet Tuan, and Insoo Koo. 2020. "Exploiting a Deep Neural Network for Efficient Transmit Power Minimization in a Wireless Powered Communication Network" Applied Sciences 10, no. 13: 4622. https://doi.org/10.3390/app10134622
APA StyleHameed, I., Tuan, P.-V., & Koo, I. (2020). Exploiting a Deep Neural Network for Efficient Transmit Power Minimization in a Wireless Powered Communication Network. Applied Sciences, 10(13), 4622. https://doi.org/10.3390/app10134622