A Decision-Making Tool Based on Exploratory Visualization for the Automotive Industry



Abstract
1. Introduction
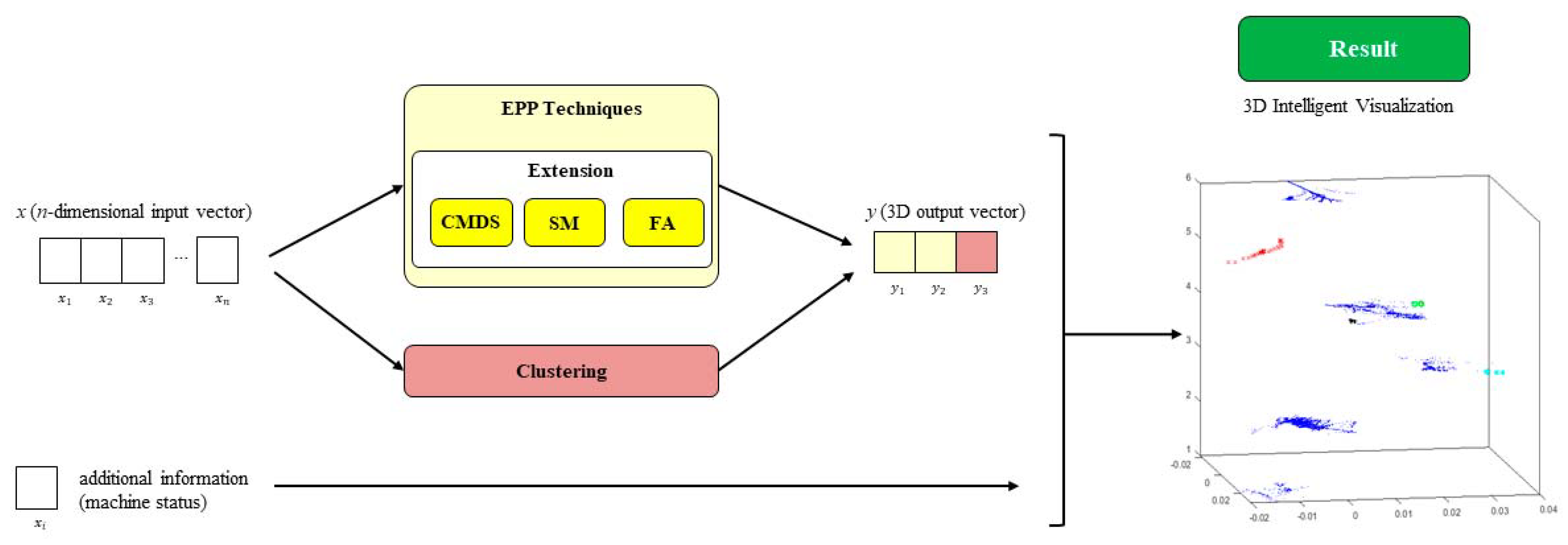
2. Hybrid Unsupervised Exploratory Plots
2.1. Classical Multidimensional Scaling
- Euclidean;
- Squared Euclidean;
- Standardized Euclidean (seuclidean): each coordinate difference between observations is scaled by dividing by the corresponding element of the standard deviation;
- Cityblock;
- Minkowski;
- Chebyshev: maximum coordinate difference;
- Cosine: one minus the cosine of the included angle between points;
- Correlation: one minus the sample correlation between points;
- Hamming, which is the percentage of coordinates that differ;
- Jaccard: one minus the Jaccard coefficient, which is the percentage of non-zero coordinates that differ;
- Spearman: one minus the sample Spearman’s rank correlation between observations.
2.2. Sammon Mapping
2.3. Factor Analysis (FA)
3. A Real Case Study: Waterjet Cutting
- Intensifier: the waterjet pumps or intensifiers [51], which supply water at extremely high pressure to waterjet machines;
- Cyclone: the vacuum cyclone unit located in a waterjet machine, used for suctioning the waste generated towards a chute. It also holds the pieces during the cut.
3.1. Intensifier
- Water leaks: the intensifier will stop working if there is a severe water leak. This is a critical failure with high associated costs, as it stops production;
- High temperature in a cylinder: if high temperature lasts a long time, it could lead to a break in the header;
- Detected SH malfunction; this means that it is necessary to repair the SH, or otherwise it will crash and stop the production. This malfunction/problem is perceived by the maintenance staff.
3.2. Cyclone
- The suction circuit is blocked: the waste absorbing system does not work properly. This is a critical failure as it stops production;
- Vacuum malfunctioning: the vacuum does not work properly. It is an infrequent failure that does not stop production, but could lead to defective parts.
4. Results
- PCA: Number of output dimensions—2/3;
- MLHL: Number of output dimensions—2/3; number of iterations—1000/2000/3000; learning rate—0.01/0.005/0.001; p—0.1/0.5;
- CMLHL: Number of output dimensions—2/3; number of iterations—1000/2000/3000; learning rate—0.01/0.005/0.001; p—0.1/0.5; τ—0.05;
- CMDS: Number of output dimensions—2/3; distance metrics—Euclidean/Squared Euclidean/Standardized Euclidean/Cityblock/Minkowski/Chebyshev/Cosine/Correlation/Jaccard/Spearman;
- SM: Number of output dimensions—2/3; number of iterations—100/200/500;
- FA: Number of output dimensions—2/3; 200 iterations maximum;
- k-means: Distances—Squared Euclidean/Cityblock/Cosine/Correlation; k—3/4/6/8;
- Agglomerative clustering: Distances—Euclidean/Chebyshev/Minkowski/Correlation/Seuclidean/Squared Euclidean/Cityblock/Mahalanobis/Cosine/Spearman/Hamming/Jaccard; linkages—average/centroid/complete/median/single/ward/weighted; a cutoff value adjusted to obtain the same number of clusters as in the case of k-means (3/4/6/8).
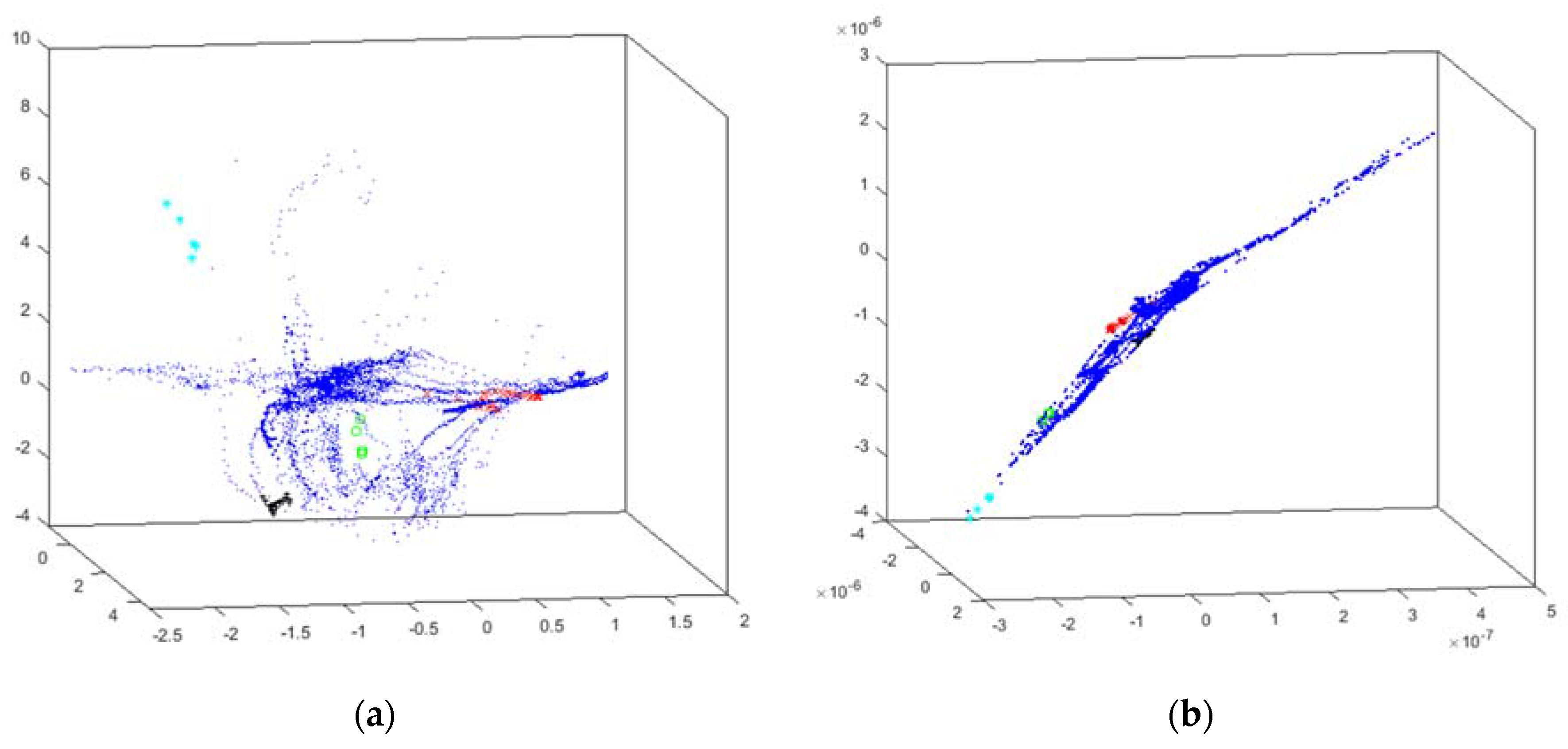
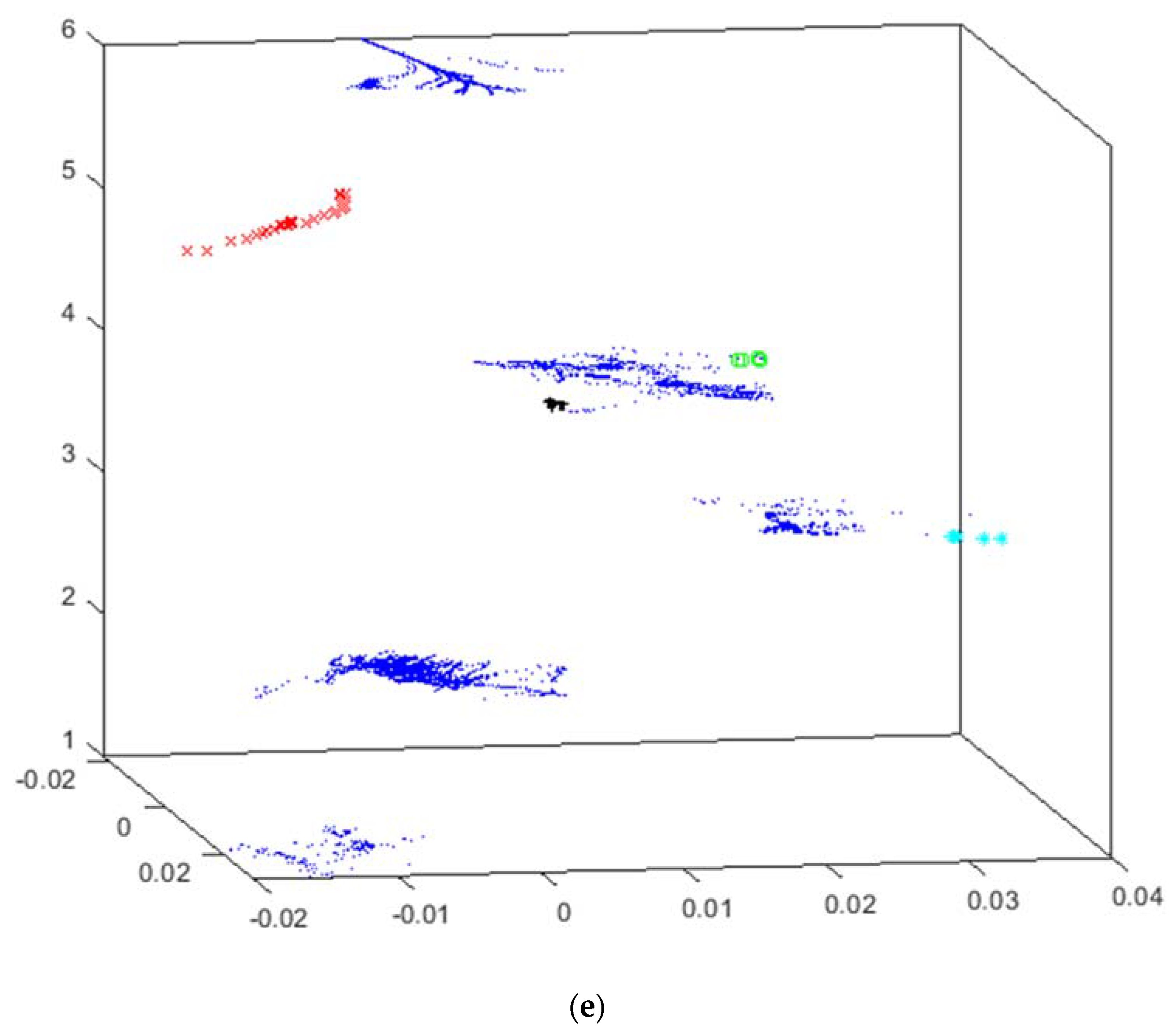
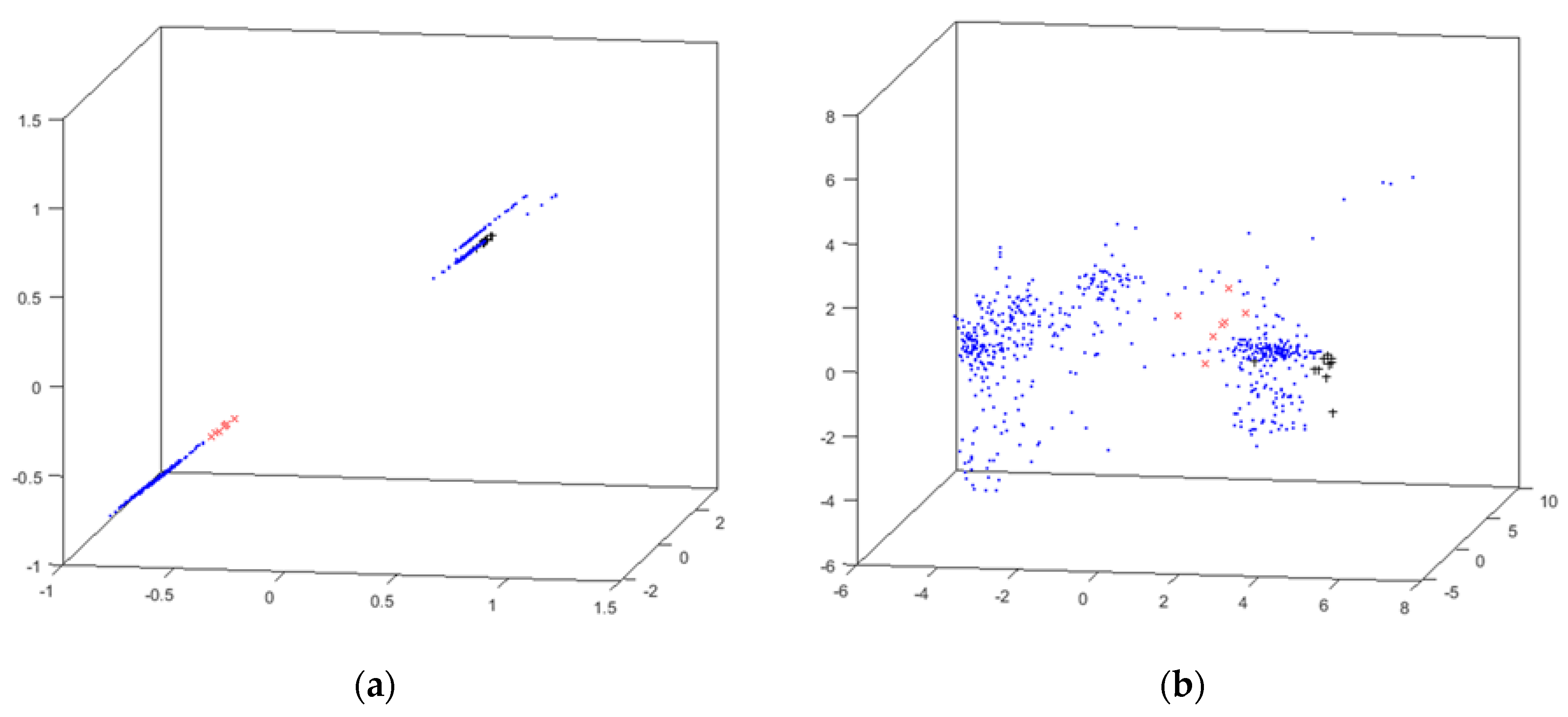
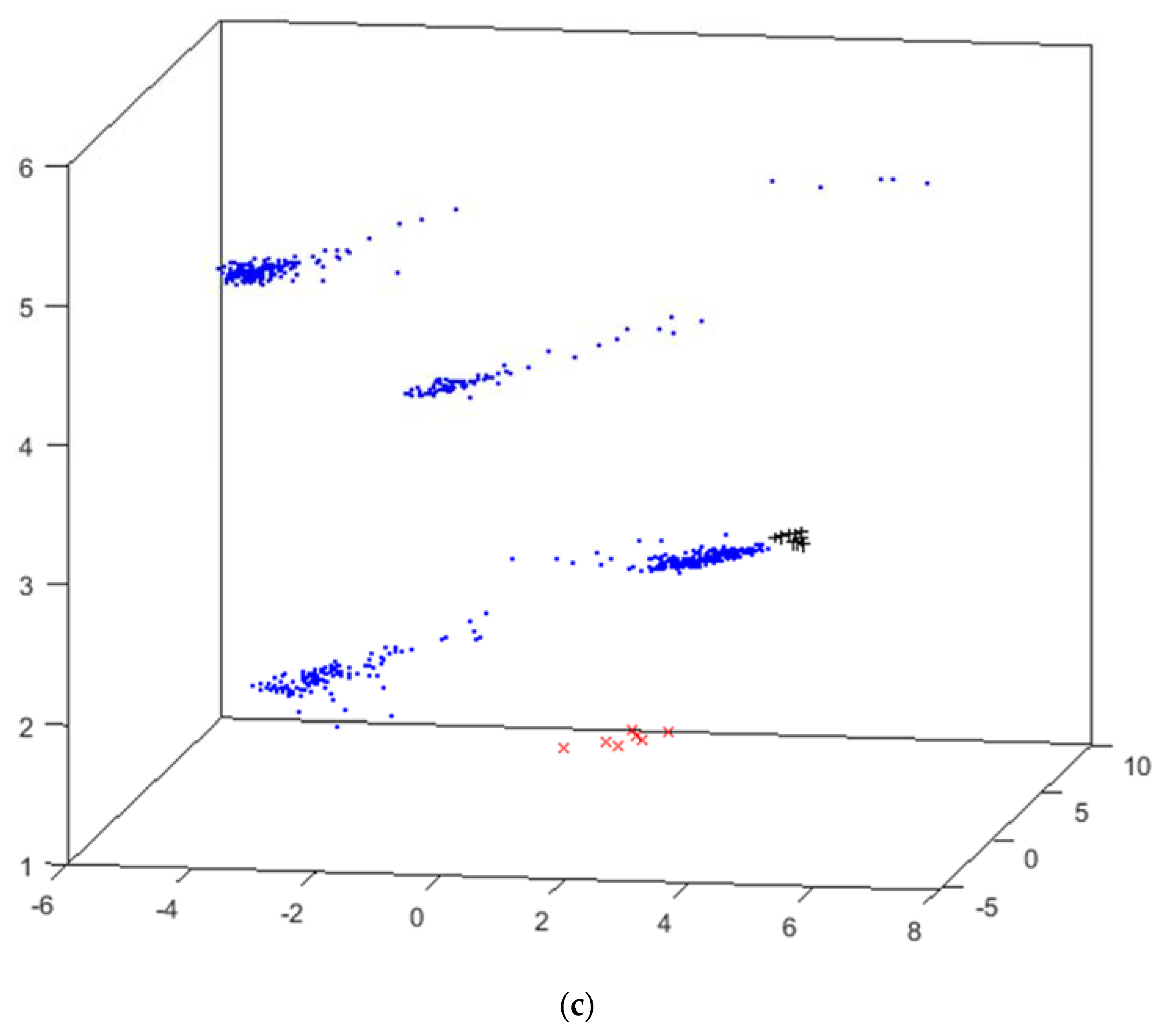
4.1. Intensifiers Results
- x (red x): water leak;
- + (black +): high temperature in cylinder #1;
- * (cyan *): high temperature in cylinder #2;
- o (green o): detected SH malfunctioning;
- · (blue point): no problem reported (i.e., intensifier properly working).
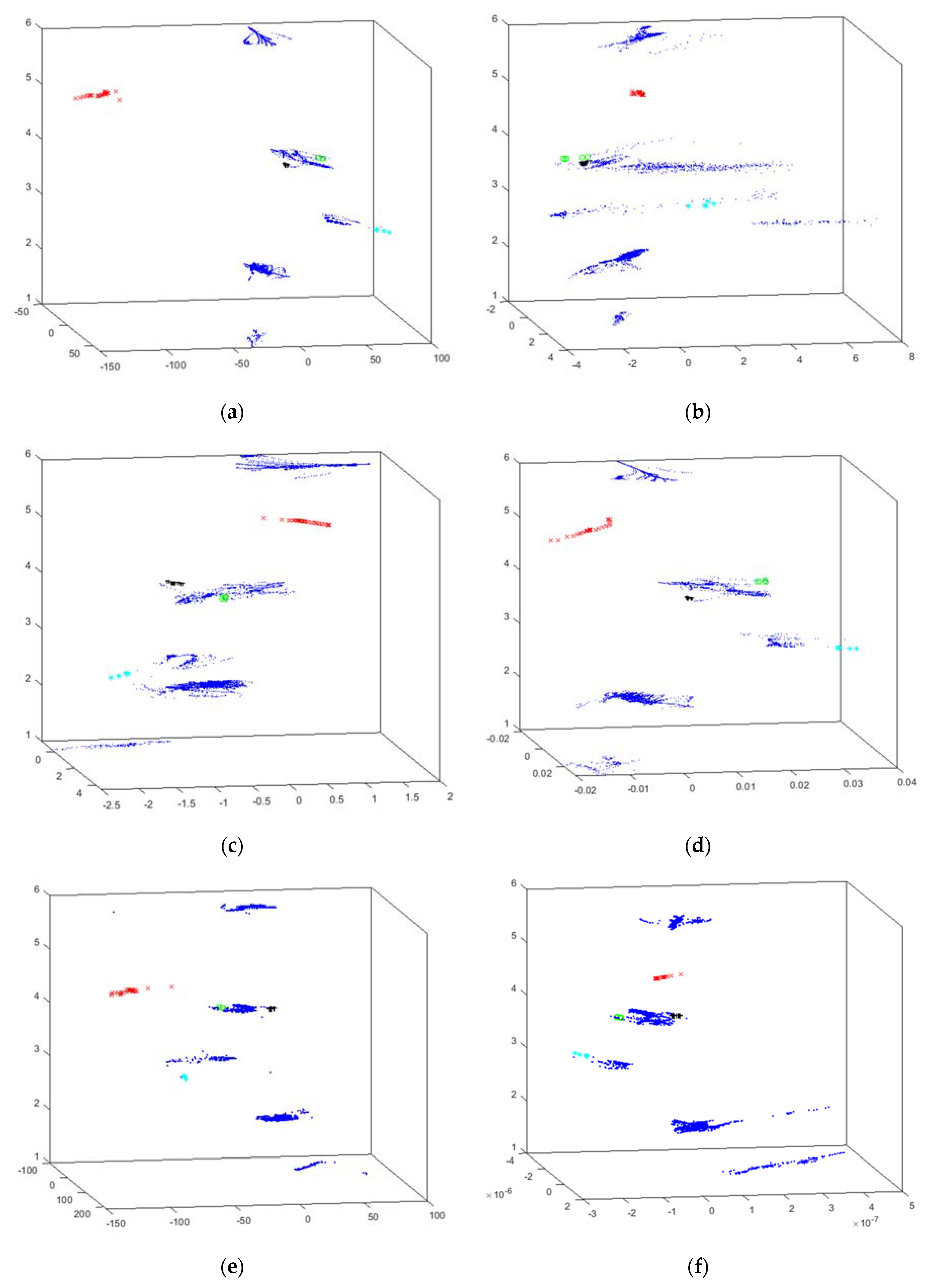
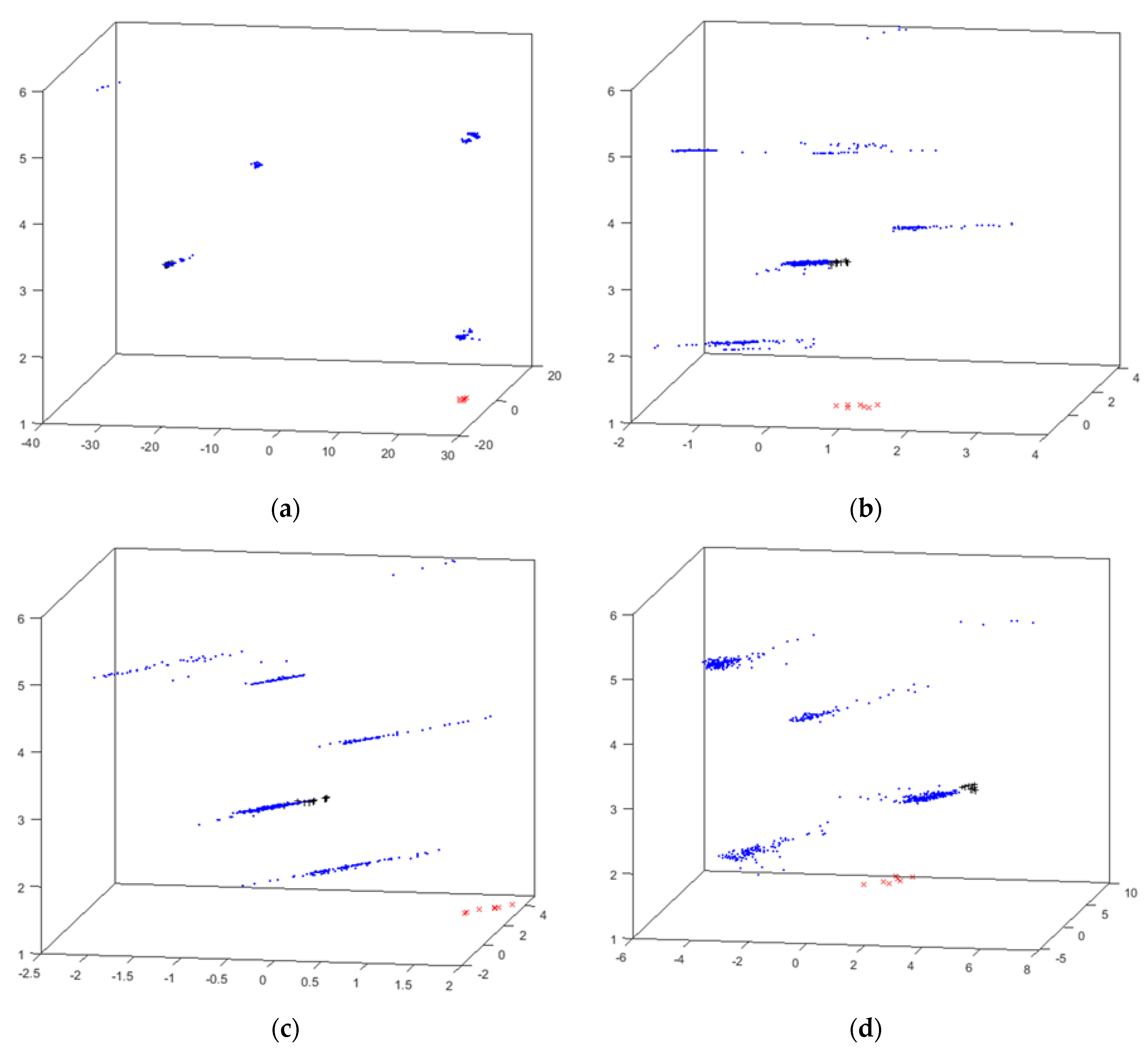
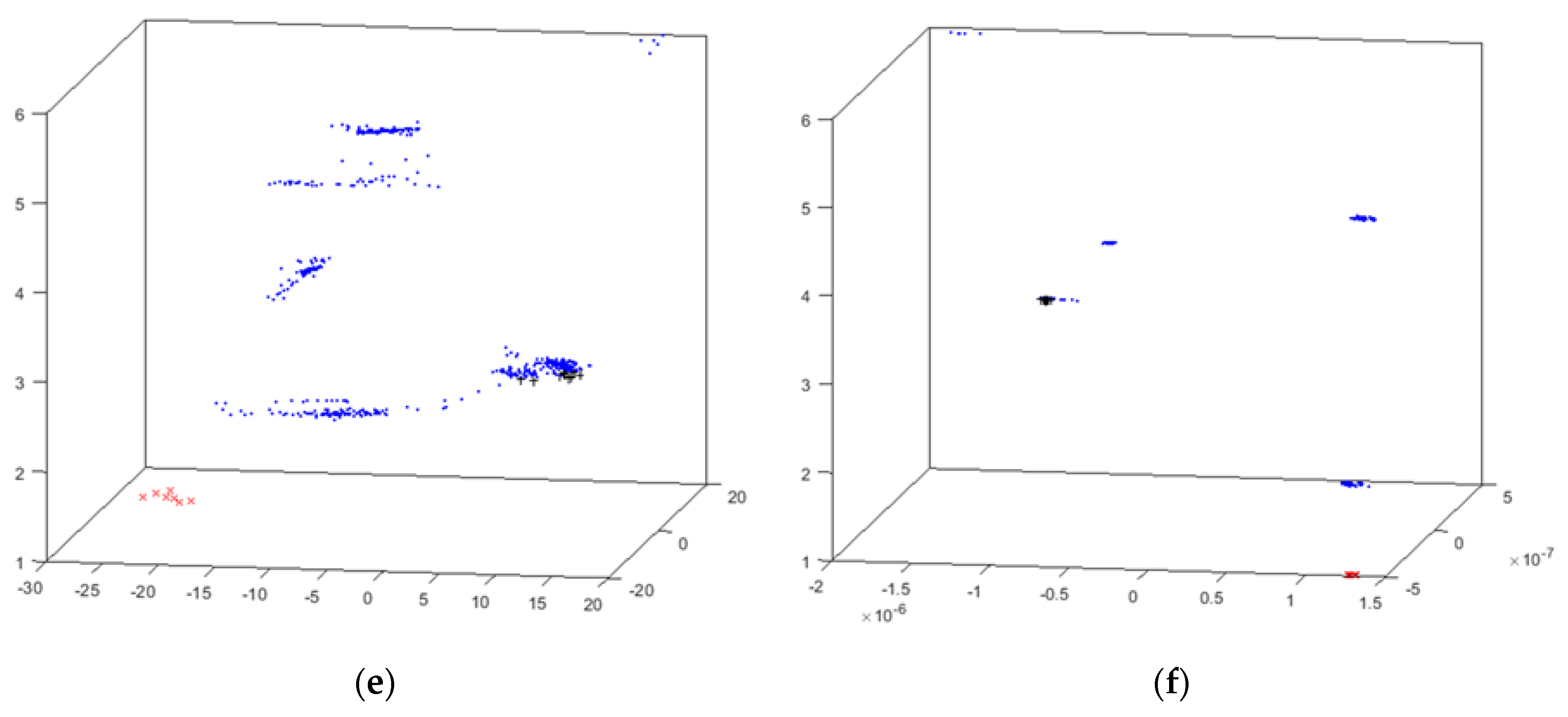
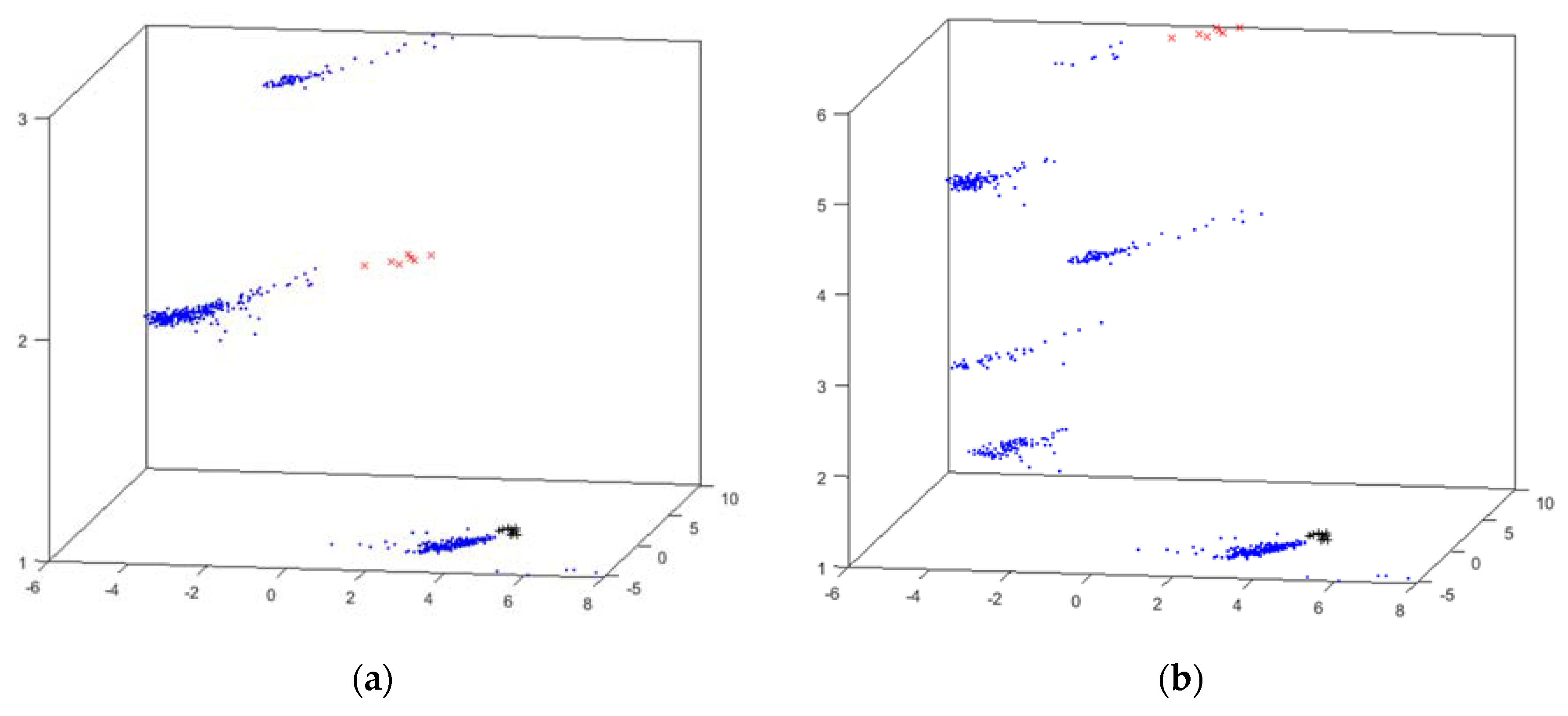
4.2. Cyclone Results
- x (red x): suction circuit is blocked;
- + (black +): vacuum malfunctioning;
- · (blue point): no problem reported (i.e., cyclone properly working).
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Networks |
| CMDS | Classical Multidimensional Scaling |
| CMLHL | Cooperative Maximum-Likelihood Hebbian Learning |
| EPP | Exploratory Projection Pursuit |
| FA | Factor Analysis |
| FD | Failure Detection |
| HP | Hydraulic Piston |
| HUEP | Hybrid Unsupervised Exploratory Plot |
| IoT | Internet of Things |
| KNN | k-Nearest Neighbour |
| MDS | Multidimensional scaling |
| ML | Machine Learning |
| MLHL | Maximum-Likelihood Hebbian Learning |
| PCA | Principal Component Analysis |
| PdM | Predictive Maintenance |
| SH | Seal Head |
| SM | Sammon Mapping |
References
- Zhou, K.; Liu, T.; Zhou, L. Industry 4.0: Towards Future Industrial Opportunities and Challenges. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 2147–2152. [Google Scholar] [CrossRef]
- Khan, M.; Xiaotong, W.; Xiaolong, X.; Wanchun, D. Big Data Challenges and Opportunities in the Hype of Industry 4.0. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017. [Google Scholar] [CrossRef]
- Del Campo, G.; Calatrava, S.; Canada, G.; Olloqui, J.; Martinez, R.; Santamaria, A. IoT Solution for Energy Optimization in Industry 4.0: Issues of a Real-Life Implementation. In Proceedings of the 2018 Global Internet of Things Summit (GIoTS), Bilbao, Spain, 4–7 June 2018. [Google Scholar] [CrossRef]
- Vathoopan, M.; Johny, M.; Zoitl, A.; Knoll, A. Modular Fault Ascription and Corrective Maintenance Using a Digital Twin. In Proceedings of the 16th IFAC Symposium on Information Control Problems in Manufacturing INCOM 2018, Bergamo, Italy, 11–13 June 2018; pp. 1041–1046. [Google Scholar] [CrossRef]
- Shafiq, S.I.; Szczerbicki, E.; Sanin, C. Manufacturing Data Analysis in Internet of Things/Internet of Data (IoT/IoD) Scenario. Cybern. Syst. 2018, 49, 280–295. [Google Scholar] [CrossRef]
- Qu, Y.J.; Ming, X.G.; Liu, Z.W.; Zhang, X.Y.; Hou, Z.T. Smart Manufacturing Systems: State of the Art and Future Trends. Int. J. Adv. Manuf. Technol. 2019, 103, 3751–3768. [Google Scholar] [CrossRef]
- Herrero, Á.; Jiménez, A.; Bayraktar, S. Hybrid Unsupervised Exploratory Plots: A Case Study of Analysing Foreign Direct Investment. Complexity 2019, 2019. [Google Scholar] [CrossRef]
- Friedman, J.H. Exploratory Projection Pursuit. J. Am. Stat. Assoc. 1987, 82, 249–266. [Google Scholar] [CrossRef]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data Clustering: A Review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Grupo Antolin. Available online: https://www.grupoantolin.com/ (accessed on 14 May 2020).
- Para, J.; Del Ser, J.; Nebro, A.J.; Zurutuza, U.; Herrera, F. Analyze, Sense, Preprocess, Predict, Implement, and Deploy (ASPPID): An Incremental Methodology Based on Data Analytics for Cost-Efficiently Monitoring the Industry 4.0. Eng. Appl. Artif. Intell. 2019, 82, 30–43. [Google Scholar] [CrossRef]
- Skiena, S.S. Visualizing Data. In The Data Science Design Manual; Texts in Computer Science; Springer: Cham, Switzerland, 2017; pp. 155–200. [Google Scholar] [CrossRef]
- Posada, J.; Toro, C.; Barandiaran, I.; Oyarzun, D.; Stricker, D.; De Amicis, R.; Pinto, E.B.; Eisert, P.; Döllner, J.; Vallarino, I. Visual Computing as a Key Enabling Technology for Industrie 4.0 and Industrial Internet. IEEE Comput. Graph. Appl. 2015, 35, 26–40. [Google Scholar] [CrossRef]
- Segura, Á.; Diez, H.V.; Barandiaran, I.; Arbelaiz, A.; Álvarez, H.; Simões, B.; Posada, J.; García-Alonso, A.; Ugarte, R. Visual Computing Technologies to Support the Operator 4.0. Comput. Ind. Eng. 2020, 139, 105550. [Google Scholar] [CrossRef]
- Posada, J.; Zorrilla, M.; Dominguez, A.; Simões, B.; Eisert, P.; Stricker, D.; Rambach, J.; Dollner, J.; Guevara, M. Graphics and Media Technologies for Operators in Industry 4.0. IEEE Comput. Graph. Appl. 2018, 38, 119–132. [Google Scholar] [CrossRef]
- Jimenez-Cortadi, A.; Irigoien, I.; Boto, F.; Sierra, B.; Rodriguez, G. Predictive Maintenance on the Machining Process and Machine Tool. Appl. Sci. 2020, 10, 224. [Google Scholar] [CrossRef]
- Uhlmann, E.; Pontes, R.P.; Geisert, C.; Hohwieler, E. Cluster Identification of Sensor Data for Predictive Maintenance in a Selective Laser Melting Machine Tool. In Proceedings of the 4th International Conference on System-Integrated Intelligence: Intelligent, Flexible and Connected Systems in Products and Production, Hannover, Germany, 19–20 June 2018; pp. 60–65. [Google Scholar] [CrossRef]
- Diez-Olivan, A.; Pagán, J.A.; Sanz, R.; Sierra, B. Data-Driven Prognostics Using a Combination of Constrained K-Means Clustering, Fuzzy Modeling and LOF-Based Score. Neurocomputing 2017, 241, 97–107. [Google Scholar] [CrossRef]
- Yoo, Y.; Park, S.H.; Baek, J.-G. A Clustering-Based Equipment Condition Model of Chemical Vapor Deposition Process. Int. J. Precis. Eng. Manuf. 2019, 1677–1689. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Guo, L.; Lin, J.; Xing, S. A Neural Network Constructed by Deep Learning Technique and Its Application to Intelligent Fault Diagnosis of Machines. Neurocomputing 2018, 272, 619–628. [Google Scholar] [CrossRef]
- Lei, Y.; Jia, F.; Lin, J.; Xing, S.; Ding, S.X. An Intelligent Fault Diagnosis Method Using Unsupervised Feature Learning Towards Mechanical Big Data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Delgado-Prieto, M.; Cirrincione, G.; Espinosa, A.G.; Ortega, J.A.; Henao, H. Bearing Fault Detection by a Novel Condition-Monitoring Scheme Based on Statistical-Time Features and Neural Networks. IEEE Trans. Ind. Electron. 2013, 60, 3398–3407. [Google Scholar] [CrossRef]
- Pacheco, F.; De Oliveira, J.V.; Sánchez, R.-V.; Cerrada, M.; Cabrera, D.; Li, C.; Zurita, G.; Artés, M. A Statistical Comparison of Neuroclassifiers and Feature Selection Methods for Gearbox Fault Diagnosis under Realistic Conditions. Neurocomputing 2016, 194, 192–206. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lin, J.; Zhou, X.; Lu, N. Deep Neural Networks: A Promising Tool for Fault Characteristic Mining and Intelligent Diagnosis of Rotating Machinery with Massive Data. Mech. Syst. Signal Process. 2016, 72–73, 303–315. [Google Scholar] [CrossRef]
- Yang, Y.-H.; Pan, Y.-K.; Zhang, L.-P.; Liu, X.-Z. Incipient Fault Detection Method Based on Stream Data Projection Transformation Analysis. IEEE Access 2019, 7, 93062–93075. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q. A Robust Intelligent Fault Diagnosis Method for Rolling Element Bearings Based on Deep Distance Metric Learning. Neurocomputing 2018, 310, 77–95. [Google Scholar] [CrossRef]
- Lei, Y.; He, Z.; Zi, Y.; Chen, X. New Clustering Algorithm-Based Fault Diagnosis Using Compensation Distance Evaluation Technique. Mech. Syst. Signal Process. 2008, 22, 419–435. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, J.; Xu, Y.; Zheng, Y.; Peng, X.; Jiang, W. Unsupervised Fault Diagnosis of Rolling Bearings Using a Deep Neural Network Based on Generative Adversarial Networks. Neurocomputing 2018, 315, 412–424. [Google Scholar] [CrossRef]
- Jianbo, Y. Local and Nonlocal Preserving Projection for Bearing Defect Classification and Performance Assessment. IEEE Trans. Ind. Electron. 2012, 59, 2363–2376. [Google Scholar] [CrossRef]
- Li, W.; Zhang, S.; Rakheja, S. Feature Denoising and Nearest–Farthest Distance Preserving Projection for Machine Fault Diagnosis. IEEE Trans. Ind. Inform. 2016, 12, 393–404. [Google Scholar] [CrossRef]
- Chen, X.-L.; Wang, P.-H.; Hao, Y.-S.; Zhao, M. Evidential KNN-Based Condition Monitoring and Early Warning Method with Applications in Power Plant. Neurocomputing 2018, 315, 18–32. [Google Scholar] [CrossRef]
- Wang, D. K-Nearest Neighbors Based Methods for Identification of Different Gear Crack Levels under Different Motor Speeds and Loads: Revisited. Mech. Syst. Signal Process. 2016, 70–71, 201–208. [Google Scholar] [CrossRef]
- Luwei, K.C.; Yunusa-Kaltungo, A.; Sha’Aban, Y. Integrated Fault Detection Framework for Classifying Rotating Machine Faults Using Frequency Domain Data Fusion and Artificial Neural Networks. Machines 2018, 6, 59. [Google Scholar] [CrossRef]
- You, D.; Gao, X.; Katayama, S. WPD-PCA-Based Laser Welding Process Monitoring and Defects Diagnosis by Using FNN and SVM. IEEE Trans. Ind. Electron. 2015, 62, 628–636. [Google Scholar] [CrossRef]
- Zhao, C.; Gao, F. Fault-Relevant Principal Component Analysis (FPCA) Method for Multivariate Statistical Modeling and Process Monitoring. Chemom. Intell. Lab. Syst. 2014, 133, 1–16. [Google Scholar] [CrossRef]
- Deng, X.; Tian, X.; Chen, S.; Harris, C.J. Fault Discriminant Enhanced Kernel Principal Component Analysis Incorporating Prior Fault Information for Monitoring Nonlinear Processes. Chemom. Intell. Lab. Syst. 2017, 162, 21–34. [Google Scholar] [CrossRef]
- Yang, Y.-H.; Chen, X.; Zhang, Y.; Liu, X. A Novel Decentralized Weighted ReliefF-PCA Method for Fault Detection. IEEE Access 2019, 7, 140478–140487. [Google Scholar] [CrossRef]
- MacQueen, J.B. Some Methods for Classification and Analysis of Multivariate Observations; Western Management Science International University of California: Los Angeles, CA, USA, 1966. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis; (Springer Series in Statistics); Springer-Verlag: New York, NY, USA, 2002. [Google Scholar] [CrossRef]
- Corchado, E.; Macdonald, D.; Fyfe, C. Maximum and Minimum Likelihood Hebbian Learning for Exploratory Projection Pursuit. Data Min. Knowl. Discov. 2004, 8, 203–225. [Google Scholar] [CrossRef]
- Corchado, E.; Fyfe, C. Connectionist Techniques for the Identification and Suppression of Interfering Underlying Factors. Int. J. Pattern Recognit. Artif. Intell. 2003, 17, 1447–1466. [Google Scholar] [CrossRef]
- Torgerson, W.S. Multidimensional Scaling: I. Theory and Method. Psychometrika 1952, 17, 401–419. [Google Scholar] [CrossRef]
- Wang, J. Classical Multidimensional Scaling. Geom. Struct. High-Dimens. Data Dimens. Reduct. 2012, 115–129. [Google Scholar] [CrossRef]
- Gower, J.C. Principal Coordinates Analysis. In Wiley StatsRef: Statistics Reference Online; American Cancer Society: Atlanta, GA, USA, 2015; pp. 1–7. [Google Scholar] [CrossRef]
- Sammon, J.W. A Nonlinear Mapping for Data Structure Analysis. IEEE Trans. Comput. 1969, C–18, 401–409. [Google Scholar] [CrossRef]
- Henderson, P. Sammon mapping. Pattern Recognit. Lett. 1997, 18, 1307–1316. [Google Scholar]
- Lerner, B.; Guterman, H.; Aladjem, M.; Dinstein, I. On the Initialisation of Sammon’s Nonlinear Mapping. Pattern Anal. Appl. 2000, 3, 61–68. [Google Scholar] [CrossRef]
- Härdle, W.K.; Simar, L. Factor Analysis. Appl. Multivar. Stat. Anal. 2015, 359–384. [Google Scholar] [CrossRef]
- Cleff, T. Factor Analysis. Appl. Stat. Multivar. Data Anal. Bus. Econ. 2019, 433–446. [Google Scholar] [CrossRef]
- Kong, C. Water-Jet Cutting. CIRP Encycl. Prod. Eng. 2019, 1803–1807. [Google Scholar] [CrossRef]
- KMT Streamline SL-V Pumps Catalog.Pdf. Available online: https://www.kmtwaterjet.com/KMT%20Streamline%20SL-V%20Pumps%20Catalog.pdf (accessed on 14 May 2020).
- Cleophas, T.J.; Zwinderman, A.H. Density-Based Clustering to Identify Outlier Groups in Otherwise Homogeneous Data (50 Patients). Mach. Learn. Med. Cookb. 2014, 9–11. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Description | Unit |
|---|---|---|
| HPXXTemp_oC_avg | HP average temperature | °C |
| HPXXTemp_oC_max | HP maximum temperature | °C |
| HPXXTemp_oC_min | HP minimum temperature | °C |
| HPXXTemp_oC_std | HP standard deviation temperature | °C |
| SHXXTemp_oC_avg | SH average temperature | °C |
| SHXXTemp_oC_max | SH maximum temperature | °C |
| SHXXTemp_oC_min | SH minimum temperature | °C |
| SHXXTemp_oC_std | SH standard deviation temperature | °C |
| SHXXLeak_mLm | SH increase leak of water since last period | 1.5 mL/increase |
| Feature Name | Description | Unit |
|---|---|---|
| AccPeak_g_avg | Engine vibration average | G |
| AccPeak_g_max | Engine vibration maximum | G |
| AccPeak_g_min | Engine vibration minimum | G |
| AccPeak_g_std | Engine vibration standard deviation | G |
| CmdDutyEngineSpeed_Hz | Fan RPM setpoint | Hz |
| CmdRestEngineSpeed_percent | % RPM idle setpoint | % |
| CmdVacuumPressure_mBar | Vacuum pressure setpoint | mBar |
| EngineTemp_oC_avg | Engine temperature average | °C |
| EngineTemp_oC_max | Engine temperature maximum | °C |
| EngineTemp_oC_min | Engine temperature minimum | °C |
| EngineTemp_oC_std | Engine temperature standard deviation | °C |
| FanSpeed_Hz_avg | Fan speed average | Hz |
| FanSpeed_Hz_max | Fan speed maximum | Hz |
| FanSpeed_Hz_min | Fan speed minimum | Hz |
| FanSpeed_Hz_std | Fan speed standard deviation | Hz |
| VacuumPressure1_mBar_avg | Vacuum pressure sensor1 average | mBar |
| VacuumPressure1_mBar_max | Vacuum pressure sensor1 maximum | mBar |
| VacuumPressure1_mBar_min | Vacuum pressure sensor1 minimum | mBar |
| VacuumPressure1_mBar_std | Vacuum pressure sensor1 standard deviation | mBar |
| VacuumPressure2_mBar_avg | Vacuum pressure sensor2 average | mBar |
| VacuumPressure2_mBar_max | Vacuum pressure sensor2 maximum | mBar |
| VacuumPressure2_mBar_min | Vacuum pressure sensor2 minimum | mBar |
| VacuumPressure2_mBar_std | Vacuum pressure sensor2 standard deviation | mBar |
| Duration | Cycle time for part production | ms |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Redondo, R.; Herrero, Á.; Corchado, E.; Sedano, J. A Decision-Making Tool Based on Exploratory Visualization for the Automotive Industry. Appl. Sci. 2020, 10, 4355. https://doi.org/10.3390/app10124355
Redondo R, Herrero Á, Corchado E, Sedano J. A Decision-Making Tool Based on Exploratory Visualization for the Automotive Industry. Applied Sciences. 2020; 10(12):4355. https://doi.org/10.3390/app10124355
Chicago/Turabian StyleRedondo, Raquel, Álvaro Herrero, Emilio Corchado, and Javier Sedano. 2020. "A Decision-Making Tool Based on Exploratory Visualization for the Automotive Industry" Applied Sciences 10, no. 12: 4355. https://doi.org/10.3390/app10124355
APA StyleRedondo, R., Herrero, Á., Corchado, E., & Sedano, J. (2020). A Decision-Making Tool Based on Exploratory Visualization for the Automotive Industry. Applied Sciences, 10(12), 4355. https://doi.org/10.3390/app10124355