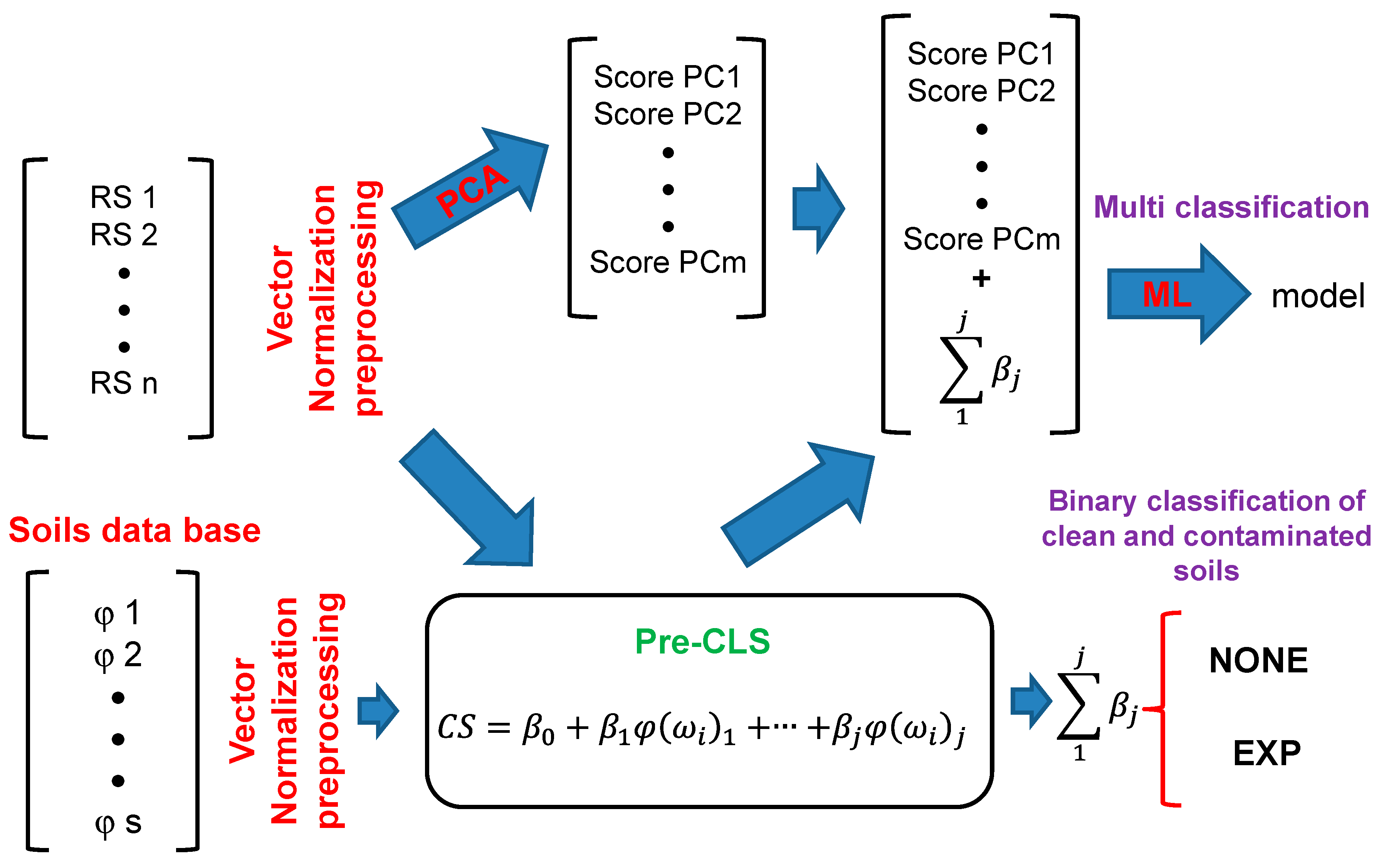
All spectra were converted to the Kubelka–Munk function [
63] because the reflectance values for all samples were very low. This transformation is appropriate for the diffuse reflectance spectra of powders [
64] with R values <60% [
65]. The models were generated using this transformation. The graphs plotting the predicted versus true values for the samples used in CV and testing are shown in
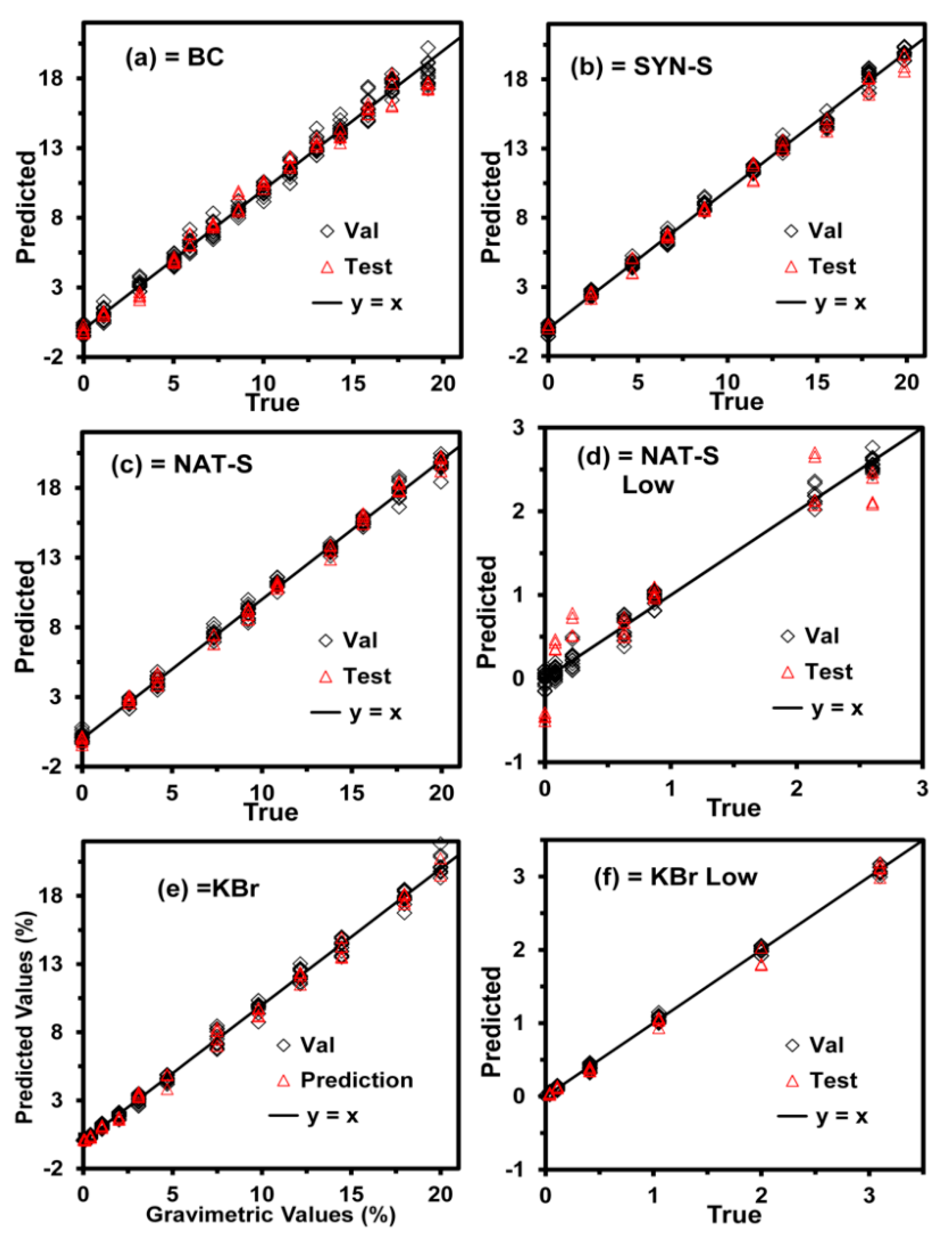
Figure 2, where the CV data are represented with open diamonds. In contrast, the test data are represented with open triangles. The solid black line represents the ideal case or perfect model (y = x), where the predicted values are equal to the true values throughout the entire data range.
All models were generated using the complete spectral window (1000–1600 cm
−1). In this study, VN was used as a preprocessing step as it proved to be better than the other tested preprocessing steps except for KBr. Other preprocessing steps were tested, such as mean centering (MC), linear offset subtraction, straight-line subtraction, minimum and maximum normalization, multiplicative scatter correction, first derivative, second derivative, and no preprocessing step. When applying VN, the average intensity is calculated first, and then this value is subtracted from the spectrum. Next, the sum of the squared intensities is calculated, and the spectrum is divided by the square root of this sum. Models for DNT in KBr were generated to evaluate the detection in the absence of interferences: one at high concentrations (0–20%) and another at low concentrations (0–3%). The errors for these models are listed in
Table 1. The most effective preprocessing method for the KBr models was MC. This result suggests that VN is a suitable preprocessing step only when interferences from the matrix are present. In a model free from the interfering matrix (KBr), applying VN for generating samples with low concentrations had the same signal intensity as samples with high concentrations. This is reflected in the lousy prediction and high uncertainty for samples with low concentrations (see
Supplementary Materials: Figure S3).
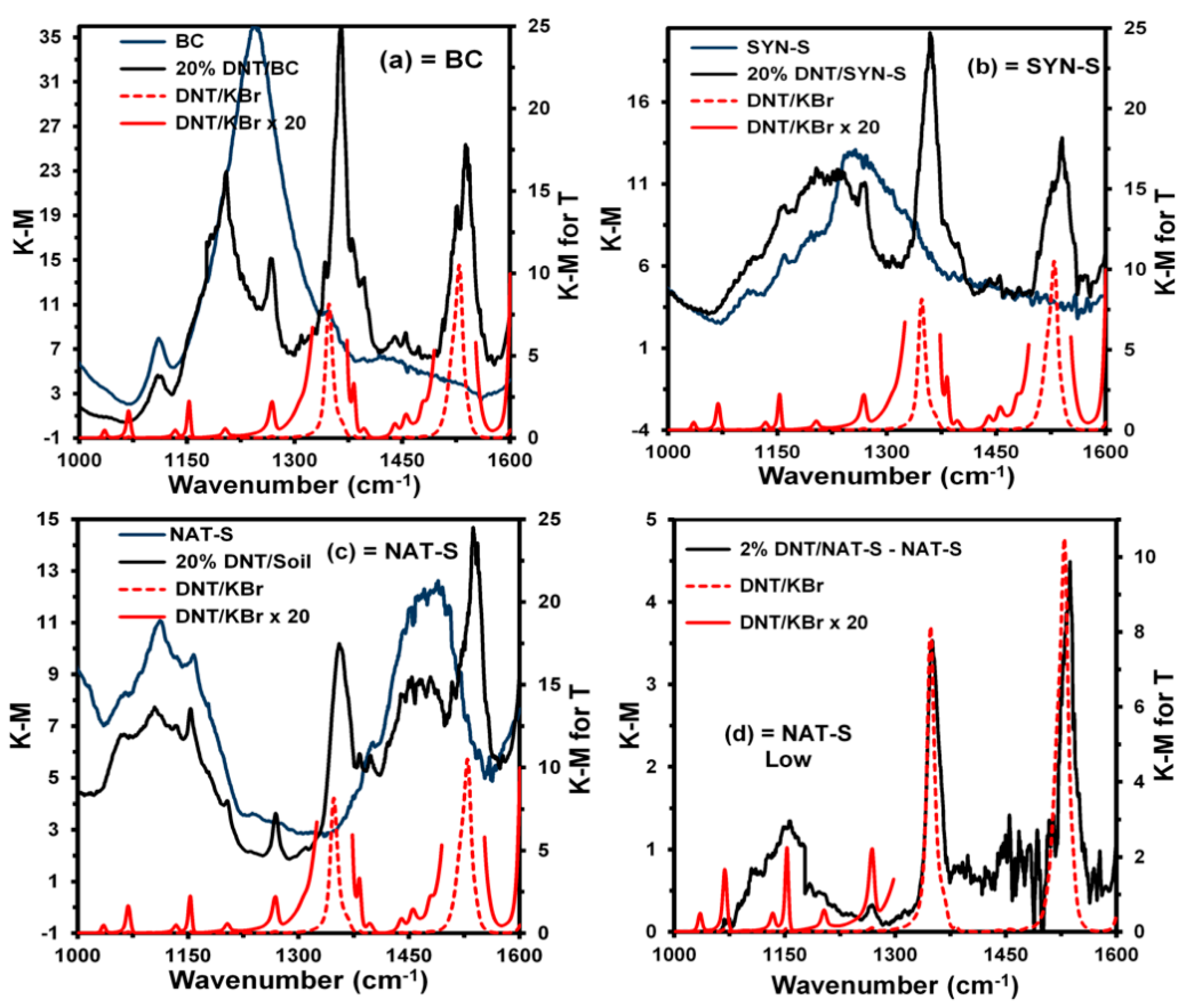
The spectra of the neat matrices, matrices with 20% DNT, and the corresponding standard reference spectra of DNT in KBr for transmittance are shown in
Figure 3a–c, respectively.
Figure 3d shows the resulting spectrum for the matrix with 2% DNT in NAT-S minus the spectrum of the neat matrix and corresponding standard reference spectra of DNT in KBr for transmittance. For clarity, DNT reference spectra are represented with the red, dotted lines. From these graphs, it is evident that DNT signals are observed on the background matrix signals in all cases, including 2% DNT in NAT-S.
Figures of Merit (FM)
The accuracies of the models were determined from the values of the RMSEE, RMSECV, and RMSEP. The results for each model (labeled by matrix) are listed in
Table 1. The precision was inferred through the values of the relative standard deviation (RSD). The RSD values for the prediction of the same sample in the same site were calculated for different concentrations and their average to measure the repeatability (RSDr). The RSD values for the prediction of the same sample in various locations on the sample surfaces were calculated for different concentrations and their average to measure the mixture homogeneities (RSDh). The RSD values for different samples at the same concentration were calculated for different concentrations and their average to measure the reproducibility (RSDrd). From these values, which are listed in
Table 2, it can be concluded that the technique has excellent repeatability, while the samples have excellent homogeneity. However, only good reproducibility was determined for the models.
Another FM used for measuring precision was the RPD. As previously mentioned, the RPD is the ratio of the variation in the validation samples and the size of probable errors occurring during predictions. The RPD values are also listed in
Table 2.
The best models were the ones with the lowest RMSEP values and the highest RPD values. The values obtained for the RPD were excellent. It has been suggested that models with RPD values greater than 5 can be considered suitable for quality control. On the other hand, models with RPD values greater than 6.5 can be used for process monitoring. Moreover, models with RPD values greater than 8 can be used in any application [
66]. All the models tested in this study had RPD values higher than 8. This result indicates that the proposed technique can be used for the direct analysis of HE in soils. At the same time, the detection of explosives and their respective effects over different soil types have not been studied in detail so far. We plan to expand the present study to include reliable models over various types of soils as part of our future work.
In the context of determining HEs, sensitivity refers to the ability of a method or instrument to detect an analyte at a specified concentration. In contrast, the sensitivity of an analytical approach as defined in this study, is the capability of the method to discriminate between small differences in concentrations or masses of a target analyte. The sensitivity of each method studied was calculated according to Equations (1) and (2), and the results of these calculations are presented in
Table 3. The SEN value calculated for a model with VN preprocessing should be interpreted differently from the one without preprocessing or employing other preprocessing steps. Thus, the sensitivity values were derived from two types of models: models with VN as the preprocessing step and models without preprocessing steps. When using VN preprocessing, the spectra were normalized such that the sum of squares of intensity is equal to one. In other words, the spectra are converted to unit vectors. The SEN parameters were calculated from the magnitude of the vector calibration functions
b, which, in turn, were derived from the spectra and their respective concentrations of standards. VN directly affects the magnitude ‖
b‖ and value of SEN as a consequence. However, a better parameter for sensitivity can be obtained by calculating γ because this parameter is only affected by instrumental noises. The noise level was measured by collecting 20 spectra of a blank (target) and calculating an average of the standard deviations for all wavenumbers. The resulting noise for the models was different when considering 20 normalized spectra with VN (see
Table 3). Otherwise, the γ-values calculated from the two types of models were very similar, which is an indication that γ is not affected by VN preprocessing or any other types of preprocessing.
The inverse of γ (denoted as γ
−1) provides an estimation of the minimum concentration difference (resultant) discernible by the model considering the instrumental noise as the only source of error. In the case of NAT-S Low, γ was 0.003% for the model with VN preprocessing and 0.002% for the model without preprocessing, with the difference being statistically insignificant. It is not possible to make a comparison of the sensitivities between the modes with matrix and without matrix because the magnitude of ‖
b‖ depends on the number of signals and number of latent variables (LV) (see
Supplementary Materials: Figure S5). For the models of spectra with many signals (BC, SYN-S, and NAT-S), the magnitude of ‖
b‖ is higher than that for the models with low-intensity signals (KBr models). A better FM for this comparison is the LOD. For the models with the matrix (BC, SYN-S, and NAT-S), the LOD values are close to that of the model without the matrix (KBr models). Curves for the samples of low concentrations of DNT in NAT-S were generated to determine whether the employed concentration range influenced the LOD values of the curves. In these cases, the LOD decreased from 0.8% to 0.3%. DNT concentrations between 0.3% and 0.8% in the NAT-S Low model can be quantified with higher uncertainties and higher probabilities of false positives and missed detections because RSD should be between 10% and 33%.
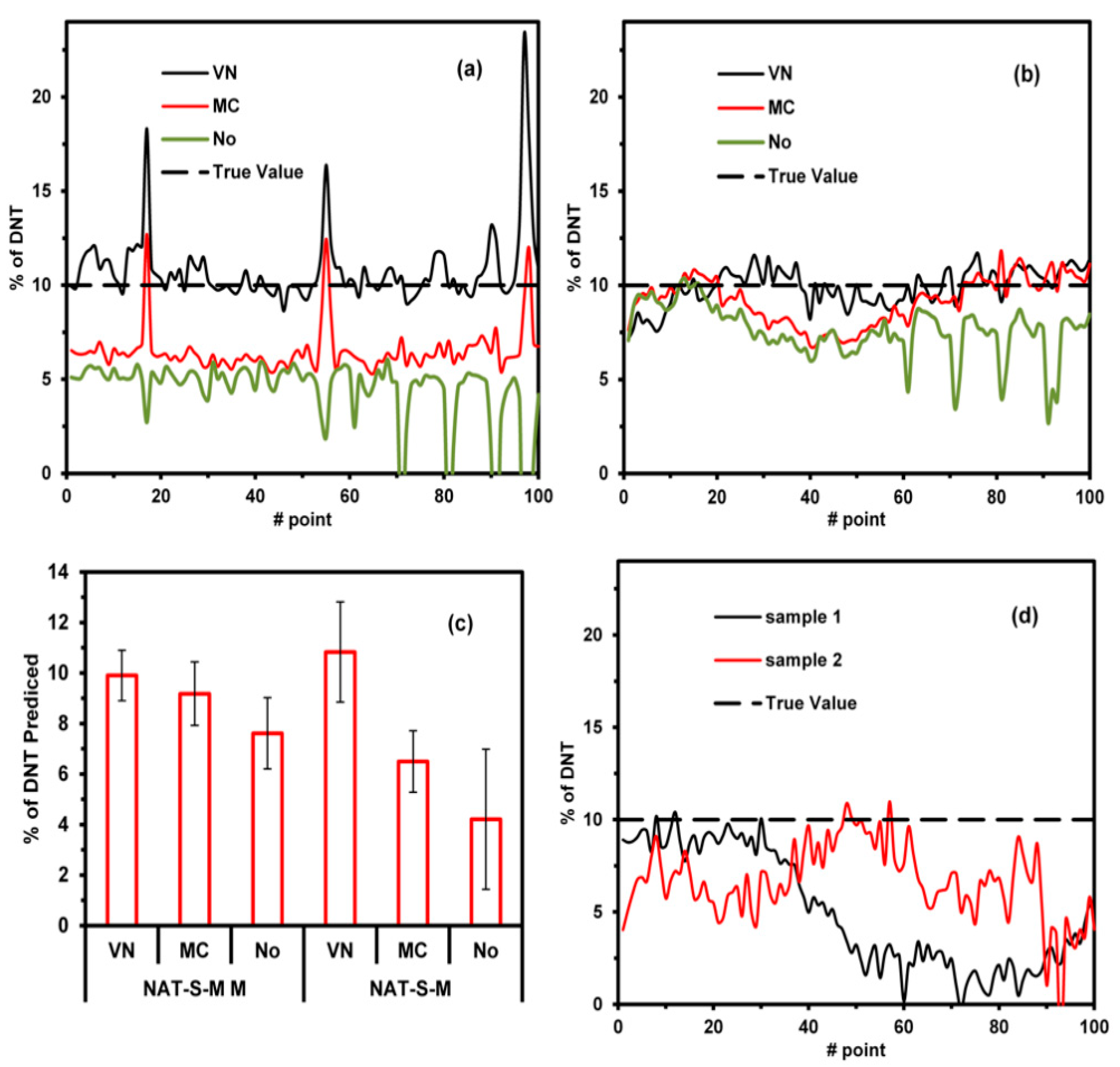
To test the NAT-S model, a map of three new types of samples was analyzed, and a map of 10 × 10 mm
2 (100 points) for each sample was generated. Two samples comprised the same soil as that used in the NAT-S models and were contaminated with 10% of DNT. The first sample consisted of a simple mixture (NAT-S-M). The second sample involved mixing and macerating the components (NAT-S-MM). The concentrations were predicted using the NAT-S model with three preprocessing methods: VN, MC, and no preprocessing. The map for the NAT-S model with VN is included in
Supplementary Materials: Figures S6–S9, while the predictions for the 100 points for each map using different preprocessing methods are shown in
Figure 4a,b. VN preprocessing applied to both samples (NAT-S-M and NAT-S-MM) resulted in better results, with the predicted values being close to the true value on average (10% DNT, see
Figure 4c). MC preprocessing worked better in NAT-S-MM than NAT-S-M. This indicates that while the macerated process homogenized the size of the particles, MC was not able to compensate for the difference in the particle size. In contrast, the VN preprocessing method was able to compensate for these differences. The prediction of DNT in NAT-S-M shows peaks of high DNT concentrations (>10% DNT). This is because the particles of DNT were not homogenized. The models with no preprocessing provided bad predictions due to the difference in the baseline of the spectra. The above discussion demonstrates that VN preprocessing corrects the spectral variation due to changes in the particle size. To demonstrate the change in spectrum with the particle size, the tested soil was sieving for three particle sizes (
d):
d > 0.85 mm, 0.85 mm >
d > 0.25 mm, and
d < 0.25 mm. One hundred spectra were acquired at various locations on the sample surface for each value of
d, and the average and standard deviation of the spectra were determined (see
Supplementary Materials: Figures S10 and S11). The background offset spectral decreases with
d, whereas the standard deviation increases with
d; however, this pattern is not consistent throughout the spectra. It is higher in the 1000–1200-cm
−1 and 1400–1600-cm
−1 regions. This can be explained by the fact that MC is not able to correct the background offset spectral completely in contrast to VN; VN is better because it scales the spectrum to unit vectors, whereas MC only changes the baseline.
In the third sample, another type of natural soil (NAT2-S) was used to evaluate the NAT-S model. Two samples of NAT2-S were contaminated with 10% of DNT and mixed. Mappings of 10 × 10 mm
2 (100 points) were generated with the %DNT predicted from the NAT-S model using VN preprocessing. The mappings are present in
Supplementary Materials: Figure S12, while predictions for each point are illustrated in
Figure 4d. It can be noticed from the figure that the predictions were lower than the true values. This indicates that the NAT-S model quantifies below the true value of 10% DNT; however, it is capable of predicting the existence of an explosive in a soil. This indicates that the technique should be used in known soil to have good quantification.
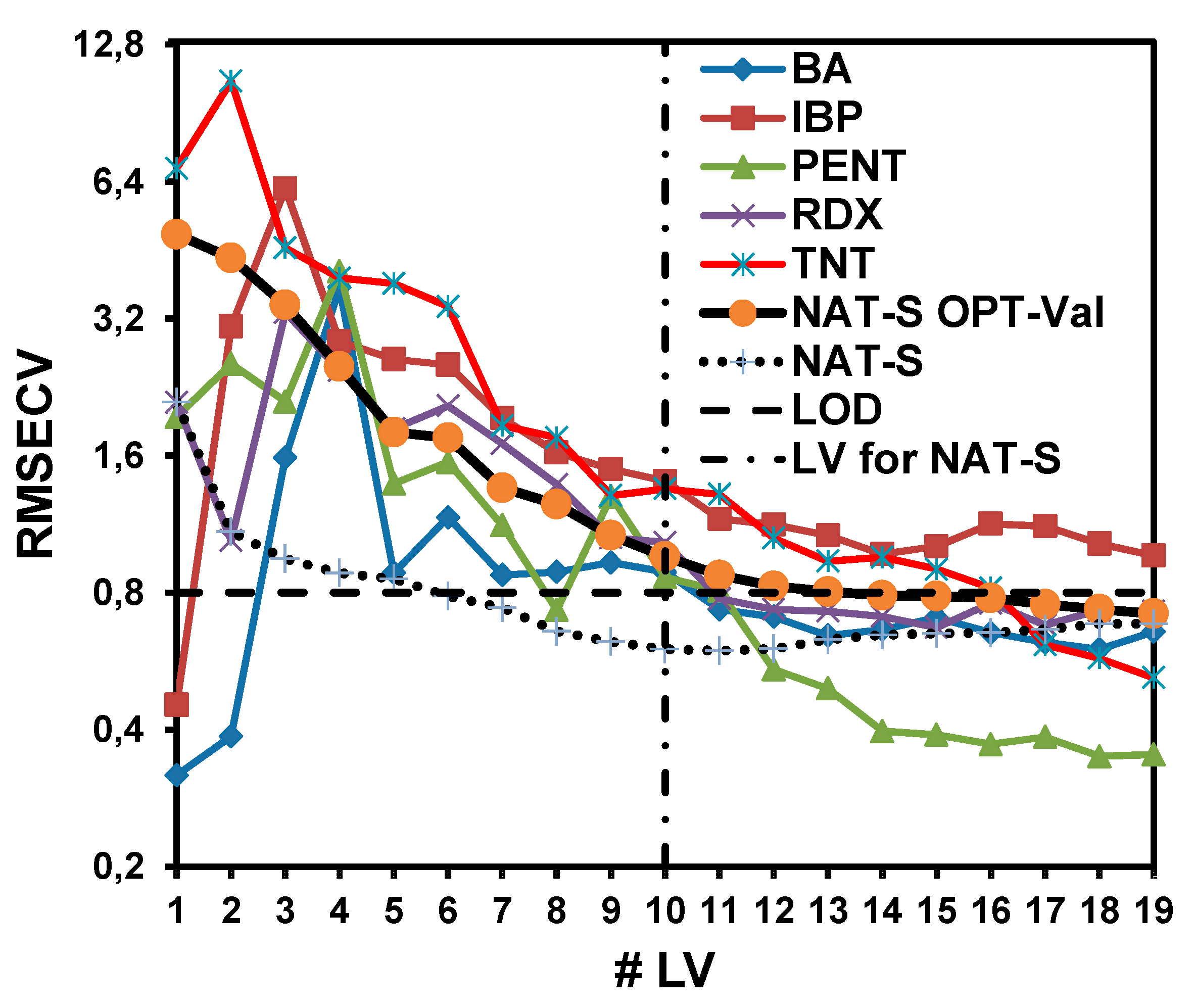
To challenge the NAT-S model with other interferences, mixtures of other analytes in soil were prepared with a concentration of 10% (median of the model). The analytes used as interferences were BA, IBP, PETN, RDX, and TNT. BA and IBP do not have nitro groups but have aromatic rings and thus many common signals with DNT in the range of 1000–1600 cm
−1. PETN and RDX are nitro aliphatic explosives. TNT is very similar to DNT but considered to be a more challenging interference. Predictions for these samples were generated using the calibration curves for DNT/NAT-S. While the predicted values should have been zero or close to zero because the samples did not contain DNT, the average predicted concentrations were 8.8% (BA), 3.1% (IBP), -8.0% (PETN), 2.3% (RDX), and 25.8% (TNT) (see
Table 4). The objective was to measure the model’s capability of discriminating against these interferences.
To improve the model with respect to the recognition of interferences, an optimization procedure was applied. This procedure involved implementing the optimization of the most significant regions of the spectra after using various preprocessing steps. During optimization, the spectral region was divided into equal spectral sub-regions. Then, the optimum combination of sub-regions was determined by starting with 10 sub-regions and successively excluding one sub-region. This procedure continued until the values of the cross-validation errors did not improve further. The RMSECV values were calculated for each combination of the preprocessing steps, and the models with the lowest values of errors were selected. Twenty spectra of each interference were introduced together with the validation spectra set off with 0% of DNT true value. Then, optimization was performed by minimizing the RMSECV value. This was labeled as an optimization of the validation set (OPT-Val).
In OPT-Val, all interferences were stabilized with the correct rejections. The parameters for the NAT-S OPT-Val model were approximately similar to those of the NAT-S model except for the LV. In particular, nine LV were added to the NAT-S OPT-Val model to stabilize the interferences (
Table 5). In the optimization process, the entire region was selected, and the best pretreatment was found to be VN. Therefore, the only difference between the two models was that the optimized model had more LVs. This procedure was optimum for the elimination of the interferences; however, it assumed that the interferences do not interact with the analyte or the matrix. As part of our future work, samples of DNT in soil with interferences interacting with DNT can be added to the model to remove these potential errors.
For the NAT-S OPT-Val model, 19 LV were required to obtain a good RMSECV value.
Figure 5 shows the dependence of the RMSECV values for the prediction of each interference as a function of the LV. The NAT-S OPT-Val and NAT-S models were generated to determine how the RMSECV values decrease with the LV and compare the two models. The NAT-S model showed the minimum RMSECV at L = 10. Adding more LV resulted in worse RMSECV values. For the NAT-S OPT-Val model, the minimum RMSECV was achieved with 19 LV. Nevertheless, at 10 LV, the RMSECV values for other interferences were also sufficiently close to the RMSECV value for the model. For that reason, TNT and IBP interferences did not allow the RMSECV value of the NAT-S OPT-Val model to approach the RMSECV value of the NAT-S model.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}