Reliability-Enhanced Camera Lens Module Classification Using Semi-Supervised Regression Method



Abstract
1. Introduction
2. Related Work
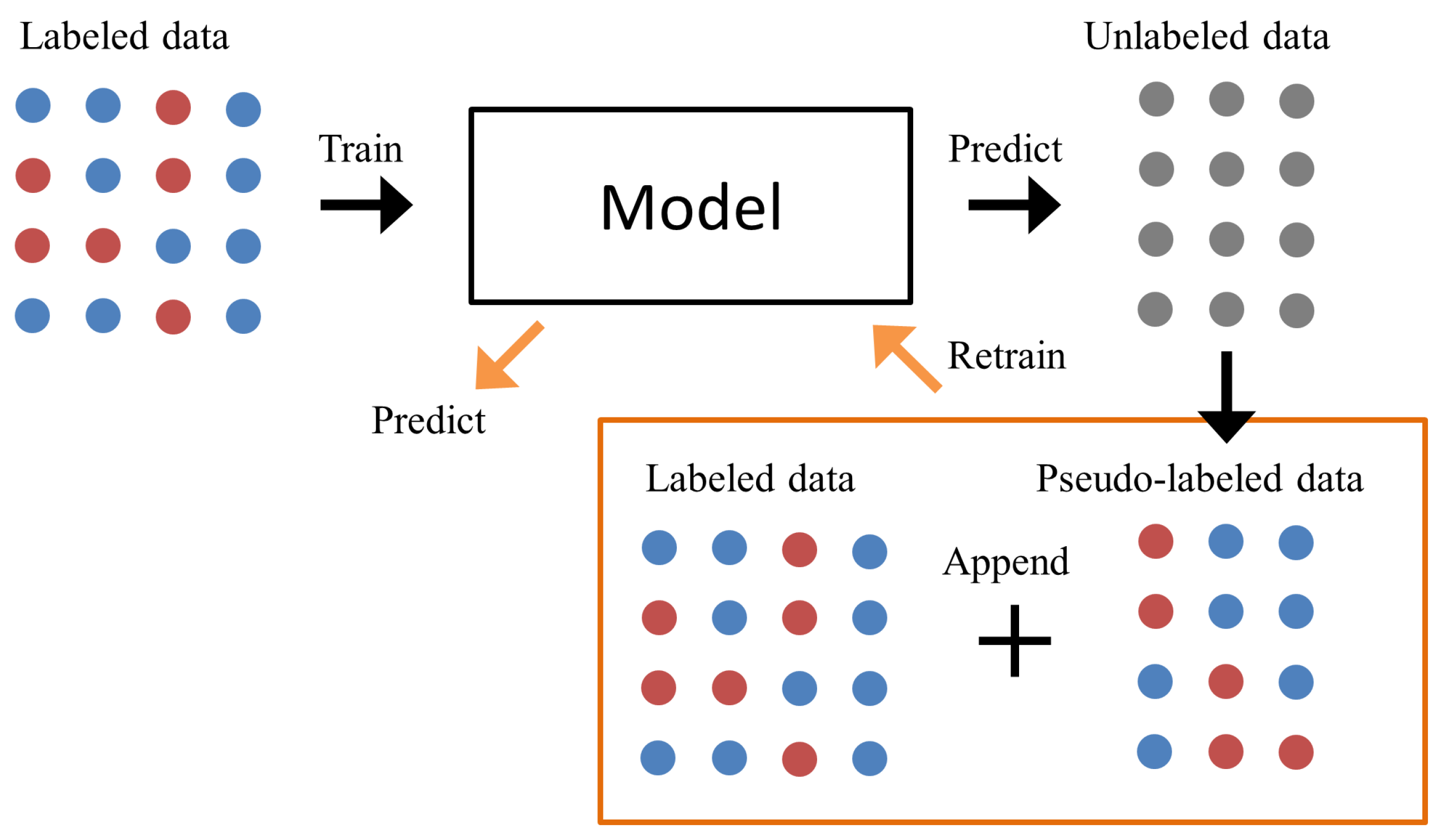
2.1. Semi-Supervised Learning
2.2. Machine Learning Algorithms
- XGBoostXGBoost [34] is a type of ensemble as well as a boosting algorithm that combines multiple decision trees. It is a scalable version of Gradient Boosting introduced by Friedman et al. [35]. It adjusts the weights of the next observation based on the previous one. The algorithm generally shows strong predictive performance and it has earned much popularity at the Kaggle competitions by achieving high marks in numerous machine learning tasks.
- Random ForestRandom Forest [36] is a bagging algorithm that uses an ensemble of decision trees. It effectively decreases the variance in the prediction by generating various combinations of training data. Its major advantage lies in the diversity of decision trees as variables are randomly selected. It is frequently used for both classification and regression tasks in machine learning.
- Extra TreesExtra trees [37] is a variant of random forest which is a popular bagging algorithm based on the max-voting scheme. extra trees are made up of several decision trees in which there are multiple root nodes, internal nodes, and leaf nodes. For each decision tree, a different bootstrapped data set is used. It should also be noted that for bootstrapping, all samples are eventually used because they are selected without replacement. At each step in building a tree and forming a node, a random subset of variables is considered resulting in a wide variety of trees. At the same time, a random value is selected for each variable under consideration leading to more diversified trees and fewer splitters to evaluate. The diversity and smaller tree depths are what make extra trees more effective than Random Forest as well as individual decision trees. Once various decision trees are established, a test sample would run down each decision tree to deliver outputs. The most frequent output will be provided as the final label to the test sample as the result of the max-voting scheme.
- Multilayer PerceptronMultilayer perceptron [38] is a feed-forward neural network composed of multiple layers of perceptron. It is usually differentiated from DNN by the number of hidden layers. It utilizes a non-linear activation function to learn the non-linearity of input features.
3. Methodology
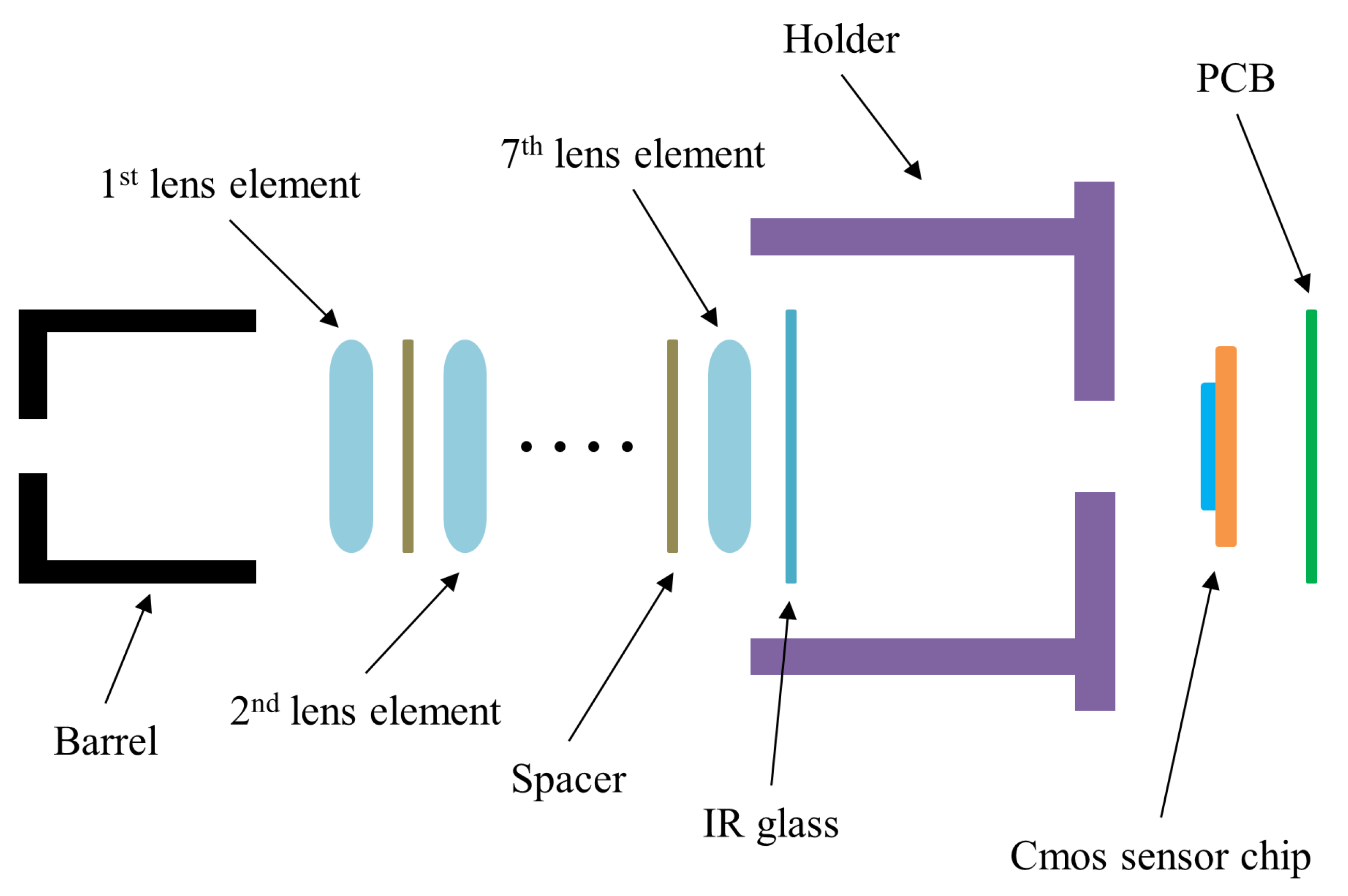
3.1. Dataset Preprocessing
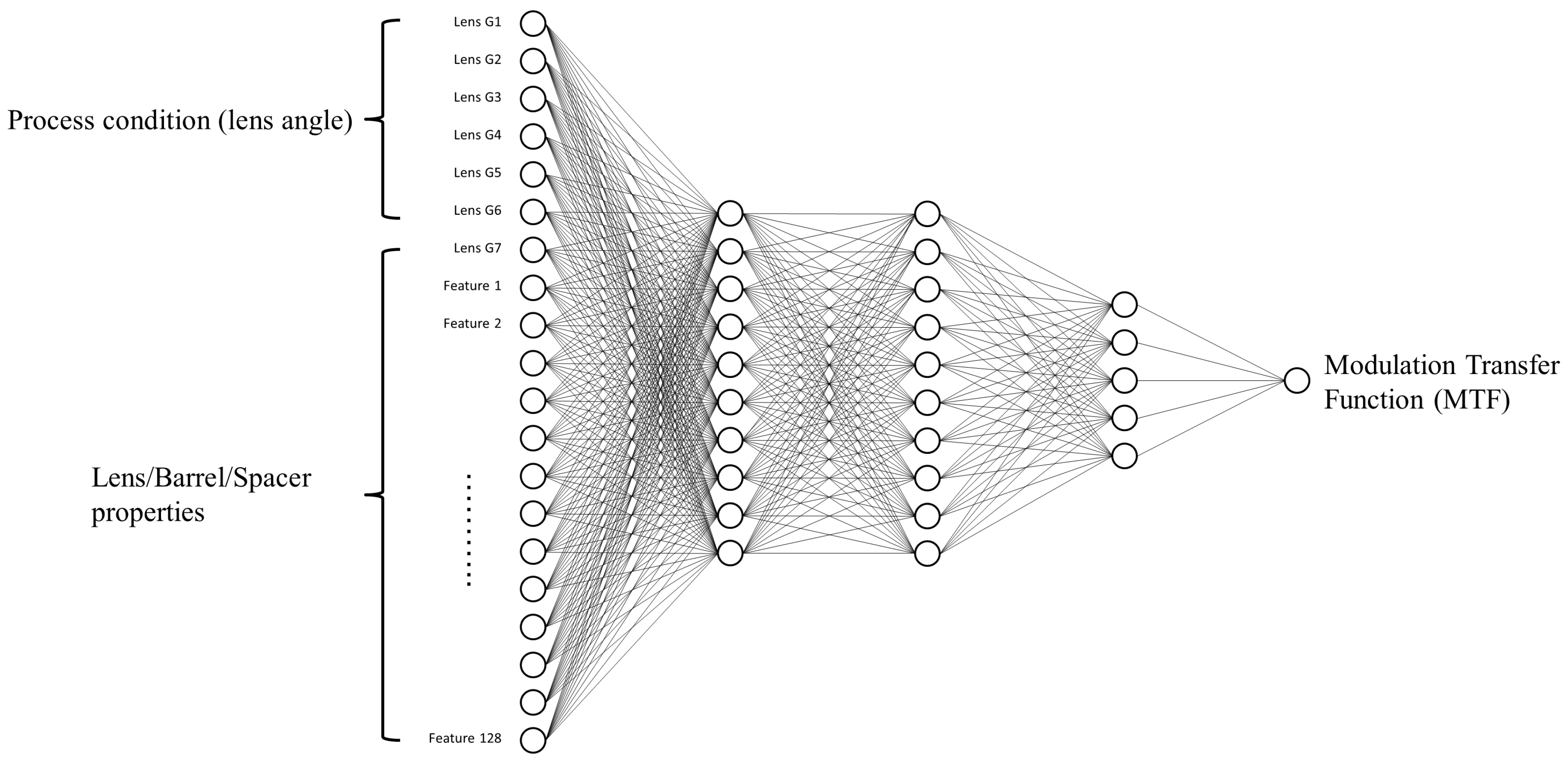
3.2. Deep Learning Architecture
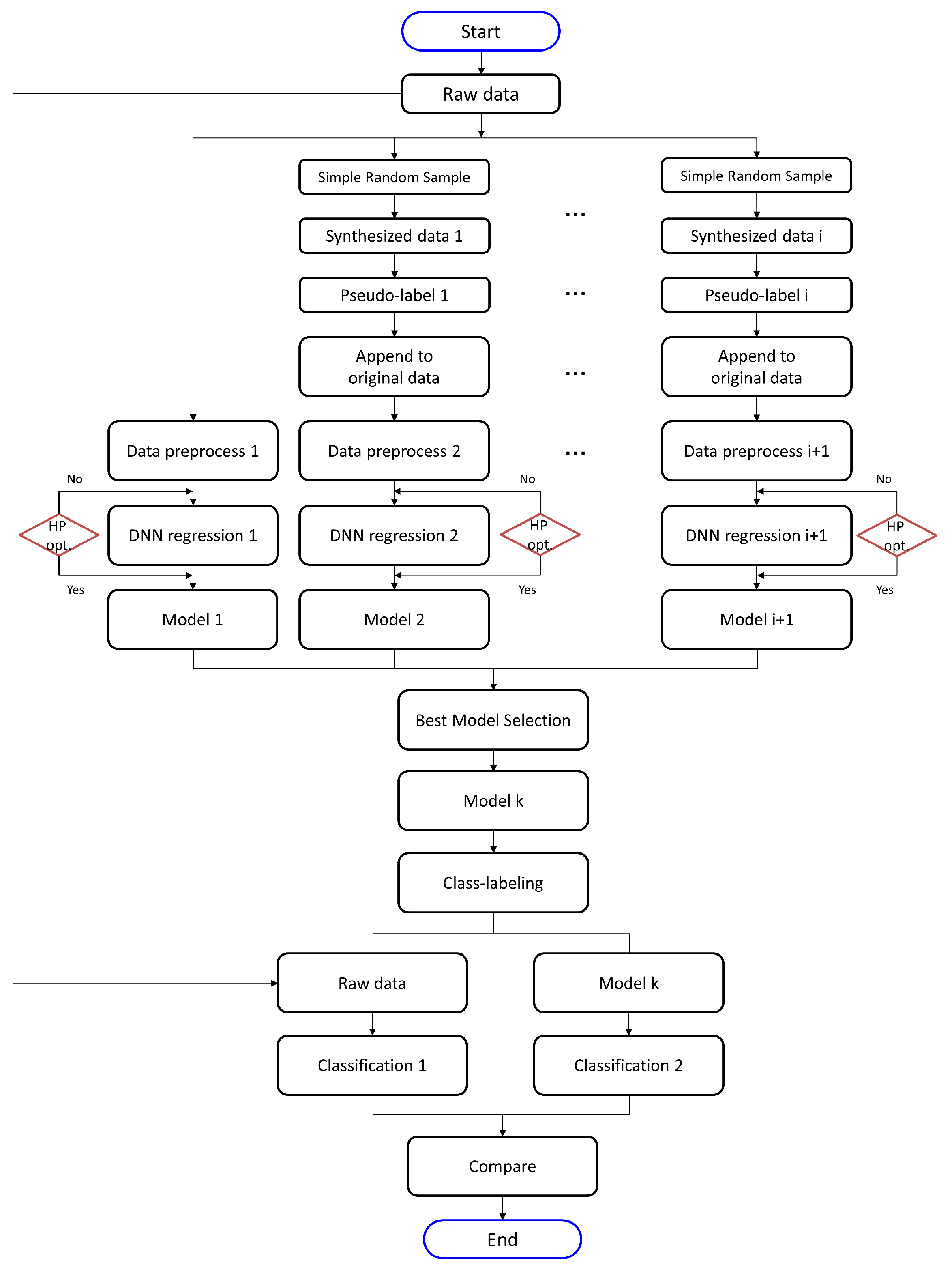
3.3. Experimental Workflow
4. Result and Discussion
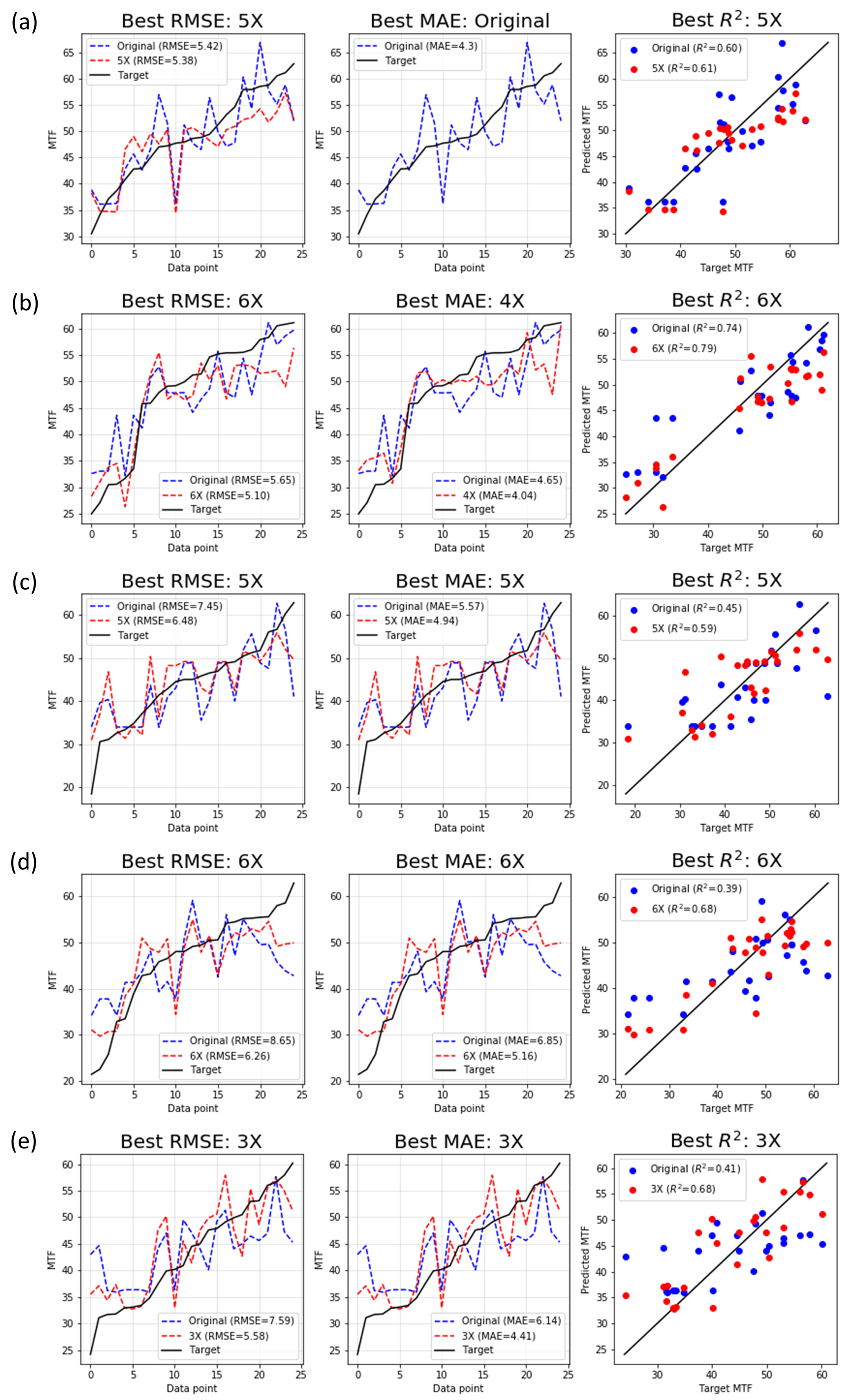
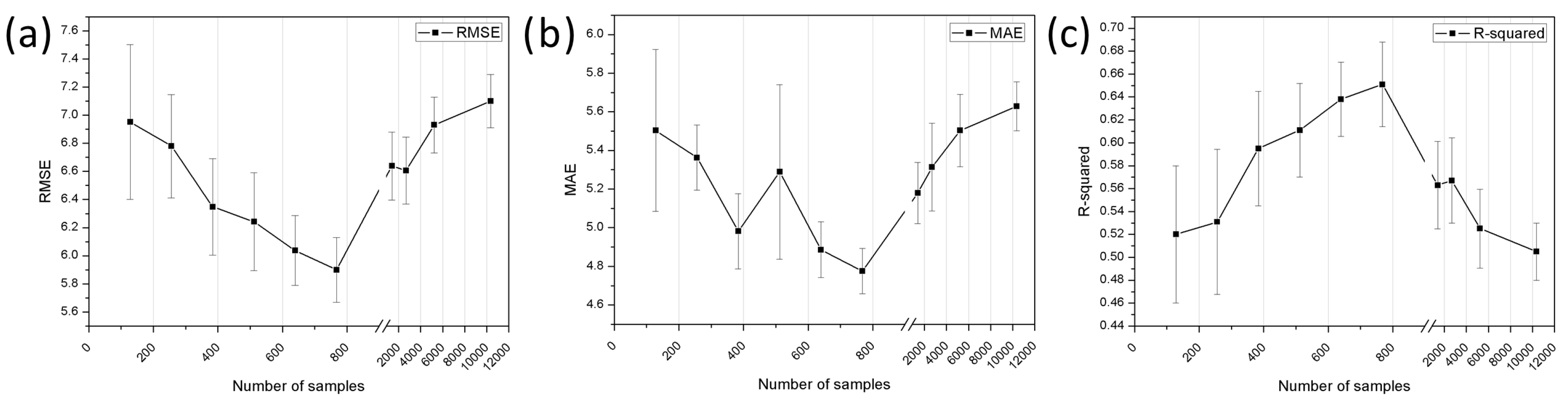
4.1. Regression Performance
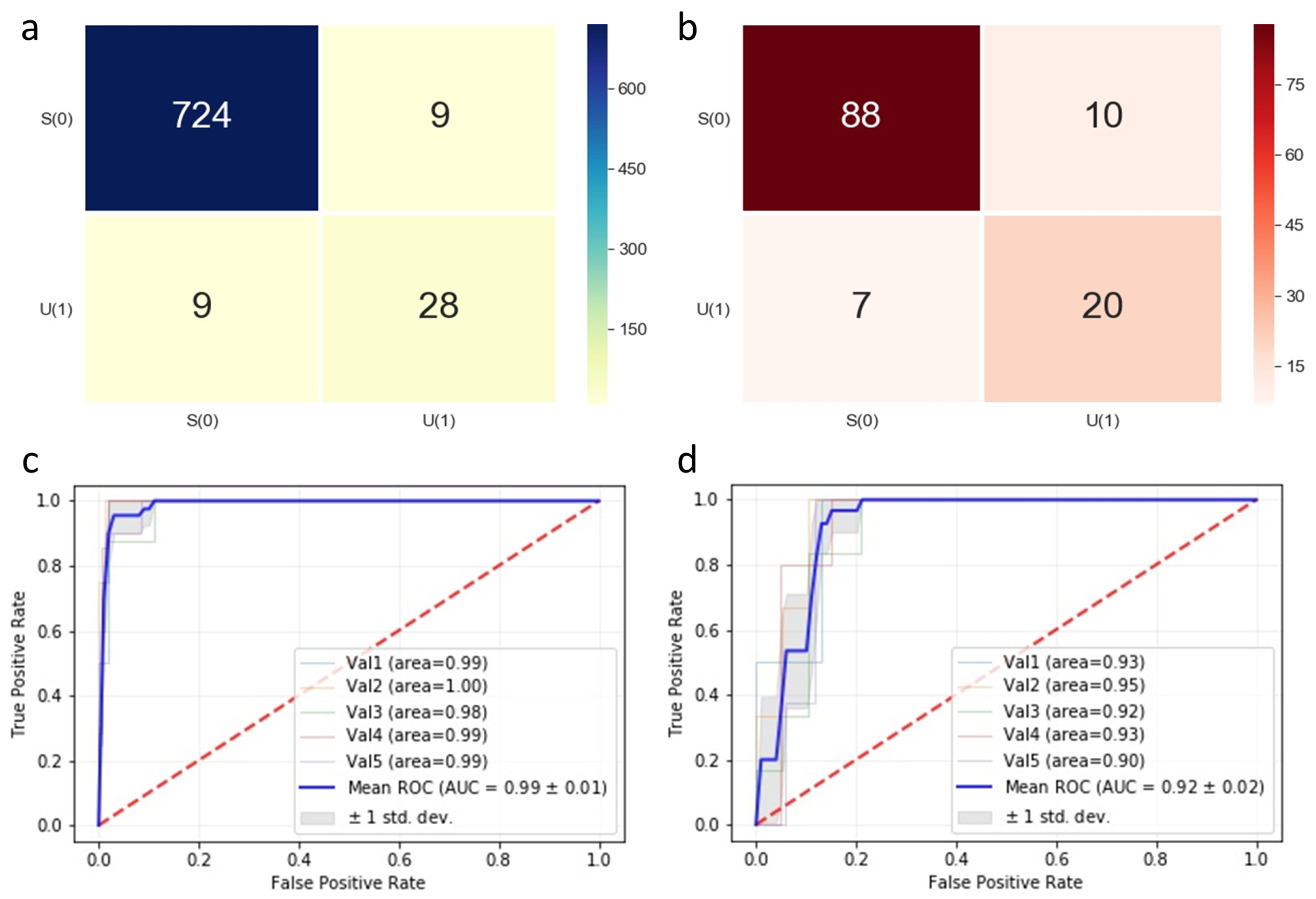
4.2. Classification Performance
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Steinich, T.; Blahnik, V. Optical design of camera optics for mobile phones. Adv. Opt. Technol. 2012, 1, 51–58. [Google Scholar] [CrossRef]
- Hatcher, W.G.; Yu, W. A survey of deep learning: Platforms, applications and emerging research trends. IEEE Access 2018, 6, 24411–24432. [Google Scholar] [CrossRef]
- Gheisari, M.; Wang, G.; Bhuiyan, M.Z.A. A survey on deep learning in big data. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; IEEE: New York, NY, USA, 2017; Volume 2, pp. 173–180. [Google Scholar]
- Zhang, X.; Yin, J.; Zhang, X. A semi-supervised learning algorithm for predicting four types MiRNA-disease associations by mutual information in a heterogeneous network. Genes 2018, 9, 139. [Google Scholar] [CrossRef] [PubMed]
- Chandna, P.; Deswal, S.; Pal, M. Semi-supervised learning based prediction of musculoskeletal disorder risk. J. Ind. Syst. Eng. JISE 2010, 3, 291–295. [Google Scholar]
- Wu, H.; Prasad, S. Semi-supervised deep learning using pseudo labels for hyperspectral image classification. IEEE Trans. Image Process. 2017, 27, 1259–1270. [Google Scholar] [CrossRef] [PubMed]
- Kostopoulos, G.; Karlos, S.; Kotsiantis, S.; Ragos, O. Semi-supervised regression: A recent review. J. Intell. Fuzzy Syst. 2018, 35, 1483–1500. [Google Scholar] [CrossRef]
- Wang, X.; Fu, L.; Ma, L. Semi-supervised support vector regression model for remote sensing water quality retrieving. Chin. Geogr. Sci. 2011, 21, 57–64. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Li, M. Semi-Supervised Regression with Co-Training. IJCAI 2005, 5, 908–913. [Google Scholar]
- Hady, M.F.A.; Schwenker, F.; Palm, G. Semi-supervised Learning for Regression with Co-training by Committee. In International Conference on Artificial Neural Networks; Springer: Berlin, Germany, 2009; pp. 121–130. [Google Scholar]
- Wang, M.; Hua, X.S.; Song, Y.; Dai, L.R.; Zhang, H.J. Semi-supervised kernel regression. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; IEEE: New York, NY, USA, 2006; pp. 1130–1135. [Google Scholar]
- Cai, D. Spectral Regression: A Regression Framework for Efficient Regularized Subspace Learning. Ph.D. Thesis, University of Illinois at Urbana-Champaign, Urbana, IL, USA, 2009. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on Challenges in Representation Learning; ICML: Atlanta, GA, USA, 2013; Volume 3, p. 2. [Google Scholar]
- Zhou, Z.H.; Li, M. Semisupervised regression with cotraining-style algorithms. IEEE Trans. Knowl. Data Eng. 2007, 19, 1479–1493. [Google Scholar] [CrossRef]
- Sun, X.; Gong, D.; Zhang, W. Interactive genetic algorithms with large population and semi-supervised learning. Appl. Soft Comput. 2012, 12, 3004–3013. [Google Scholar] [CrossRef]
- Ng, M.K.; Chan, E.Y.; So, M.M.; Ching, W.K. A semi-supervised regression model for mixed numerical and categorical variables. Pattern Recognit. 2007, 40, 1745–1752. [Google Scholar] [CrossRef]
- Li, Y.F.; Zha, H.W.; Zhou, Z.H. Learning safe prediction for semi-supervised regression. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; AAAI: San Francisco, CA, USA, 2017. [Google Scholar]
- Kang, P.; Kim, D.; Cho, S. Semi-supervised support vector regression based on self-training with label uncertainty: An application to virtual metrology in semiconductor manufacturing. Expert Syst. Appl. 2016, 51, 85–106. [Google Scholar] [CrossRef]
- Ji, J.; Wang, H.; Chen, K.; Liu, Y.; Zhang, N.; Yan, J. Recursive weighted kernel regression for semi-supervised soft-sensing modeling of fed-batch processes. J. Taiwan Inst. Chem. Eng. 2012, 43, 67–76. [Google Scholar] [CrossRef]
- Zhu, X.; Goldberg, A.B. Kernel regression with order preferences. In Proceedings of the National Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 1989; MIT Press: Cambridge, MA, USA, 1932; Volume 22, p. 681. [Google Scholar]
- Camps-Valls, G.; Munoz-Mari, J.; Gómez-Chova, L.; Calpe-Maravilla, J. Semi-supervised support vector biophysical parameter estimation. In Proceedings of the IGARSS 2008—2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008; IEEE: New York, NY, USA, 2008; Volume 3, p. III-1131. [Google Scholar]
- Xu, S.; An, X.; Qiao, X.; Zhu, L.; Li, L. Semi-supervised least-squares support vector regression machines. J. Inf. Comput. Sci. 2011, 8, 885–892. [Google Scholar]
- Cortes, C.; Mohri, M. On transductive regression. In Advances in Neural Information Processing Systems; NeurIPS: San Diego, CA, USA, 2007; pp. 305–312. [Google Scholar]
- Angelini, L.; Marinazzo, D.; Pellicoro, M.; Stramaglia, S. Semi-supervised learning by search of optimal target vector. Pattern Recognit. Lett. 2008, 29, 34–39. [Google Scholar] [CrossRef]
- Chapelle, O.; Vapnik, V.; Weston, J. Transductive inference for estimating values of functions. In Advances in Neural Information Processing Systems; NeurIPS: San Diego, CA, USA, 2000; pp. 421–427. [Google Scholar]
- Brouard, C.; D’Alché-Buc, F.; Szafranski, M. Semi-supervised Penalized Output Kernel Regression for Link Prediction. In Proceedings of the 28th International Conference on Machine Learning (ICML 2011), Bellevue, WA, USA, 28 June–2 July 2011; ICML: Atlanta, GA, USA, 2011; pp. 593–600. [Google Scholar]
- Xie, L.; Newsam, S. IM2MAP: Deriving maps from georeferenced community contributed photo collections. In Proceedings of the 3rd ACM SIGMM International Workshop on Social Media, Scottsdale, AZ, USA, 30 November 2011; ACM: New York, NY, USA, 2011; pp. 29–34. [Google Scholar]
- Doquire, G.; Verleysen, M. A graph Laplacian based approach to semi-supervised feature selection for regression problems. Neurocomputing 2013, 121, 5–13. [Google Scholar] [CrossRef]
- Kim, K.I.; Steinke, F.; Hein, M. Semi-supervised regression using Hessian energy with an application to semi-supervised dimensionality reduction. In Advances in Neural Information Processing Systems; NeurIPS: San Diego, CA, USA, 2009; pp. 979–987. [Google Scholar]
- Lin, B.; Zhang, C.; He, X. Semi-supervised regression via parallel field regularization. In Advances in Neural Information Processing Systems; NeurIPS: San Diego, CA, USA, 2011; pp. 433–441. [Google Scholar]
- Cai, D.; He, X.; Han, J. Semi-Supervised Regression Using Spectral Techniques; Technical Report UIUCDCS-R-2006-2749; Computer Science Department, University of Illinois at Urbana-Champaign: Urbana, IL, USA, 2006. [Google Scholar]
- Rwebangira, M.R.; Lafferty, J. Local Linear Semi-Supervised Regression; School of Computer Science Carnegie Mellon University: Pittsburgh, PA, USA, 2009; Volume 15213. [Google Scholar]
- Zhang, Y.; Yeung, D.Y. Semi-supervised multi-task regression. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin, Germany, 2009; pp. 617–631. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Murtagh, F. Multilayer perceptrons for classification and regression. Neurocomputing 1991, 2, 183–197. [Google Scholar] [CrossRef]
- Olken, F.; Rotem, D. Simple random sampling from relational databases. In Proceedings of the 12th International Conference on Very Large Databases, Kyoto, Japan, 25–28 August 1986; Springer: Berlin, Germany, 1986; pp. 1–10. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | SSR Method | Algorithm | Real-World Applications | Publications |
|---|---|---|---|---|
| Non-parametric | Semi-supervised co-regression | COREG | Real world dataset (UCI, StatLib), Sunglasses lens | [14,15] |
| CoBCReg | N/A | [16] | ||
| SAFER | Real world dataset (NTU) | [17] | ||
| Semi-supervised kernel regression | SS-SVR | Semiconductor manufacturing, | [18,19,20,21,22] | |
| Soft-sensing process, | ||||
| Benchmark (Boston, Abalone, etc.), | ||||
| Hyperspectral satellite images, | ||||
| MERIS, | ||||
| Corn, | ||||
| Real world dataset (Delve, TSDL, StatLib) | ||||
| KRR | Real world dataset (Boston housing, California housing, etc.), | [23,24,25] | ||
| IRIS, Colon cancer, Leukemia, | ||||
| Real world dataset (Boston, kin32fh) | ||||
| POKR | Real world dataset | [26] | ||
| SSR via graph regularization | GLR | Geographical photo collections, | [27,28] | |
| Delve Census, Orange juice | ||||
| Hessian Regularization | Real world dataset | [29] | ||
| Parallel Field Regularization | Temperature, Moving hands | [30] | ||
| Spectral Regression | MNIST, Spoken letter | [31] | ||
| Local linear SSR | LLSR | Real world dataset | [32] | |
| Semi-supervised Gaussian process regression | SSMTR | N/A | [33] | |
| Parametric | Semi-supervised linear regression | SSRM | German | [16] |
| Input Variables | |||||||
|---|---|---|---|---|---|---|---|
| Process condition | Lens properties | Barrel | Spacer | ||||
| Lens angle | Outer diameter | Inner diameter | Roundness | Thickness | Concentricity | Inner diameter | Thickness |
| Sampling Method | Training Data Set | Number of Sampled Data |
|---|---|---|
| Simple Random Sample (SRS) | 1 | 128 |
| 2 | 256 (multiples, 2×) | |
| 3 | 384 (multiples, 3×) | |
| 4 | 512 (multiples, 4×) | |
| 5 | 640 (multiples, 5×) | |
| 6 | 768 (multiples, 6×) | |
| 7 | 1280 (multiples, 10×) | |
| 8 | 2560 (multiples, 20×) | |
| 9 | 5120 (multiples, 40×) | |
| 10 | 10,240 (multiples, 80×) |
| Learning Rate | Iteration | Batch Size | Layer | Number of Samples | Validation Set | RMSE | MAE | |
|---|---|---|---|---|---|---|---|---|
| 3 × | 3,125,550 | 32 | [10, 10, 5] | 384 | Val 5 | 5.584 | 5.582 | 0.678 |
| 4 × | 119,400 | 16 | [10, 10, 5] | 128 | Val 2 | 5.705 | 5.000 | 0.738 |
| 3 × | 3,349,350 | 64 | [10, 10, 5] | 768 | Val 5 | 5.861 | 5.170 | 0.645 |
| 2 × | 4,336,650 | 256 | [10, 10, 5] | 1280 | Val 2 | 5.880 | 5.630 | 0.720 |
| 2 × | 4,282,800 | 256 | [10, 10, 5] | 768 | Val 2 | 6.120 | 5.420 | 0.698 |
| Metric | SVM | Random Forest | Gradient Boosting | XGBoost | Proposed Method |
|---|---|---|---|---|---|
| RMSE | 9.83 | 6.19 | 6.19 | 5.98 | 5.89 |
| MAE | 6.84 | 4.53 | 4.59 | 4.34 | 4.78 |
| 0.25 | 0.58 | 0.58 | 0.61 | 0.65 |
| Data Type | Accuracy | Recall | Specificity | F1-Score |
|---|---|---|---|---|
| Augmented | 97.7% | 98.8% | 75.7% | 98.8% |
| Raw | 86.4% | 89.8% | 74.1% | 91.2% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.W.; Lee, Y.G.; Tama, B.A.; Lee, S. Reliability-Enhanced Camera Lens Module Classification Using Semi-Supervised Regression Method. Appl. Sci. 2020, 10, 3832. https://doi.org/10.3390/app10113832
Kim SW, Lee YG, Tama BA, Lee S. Reliability-Enhanced Camera Lens Module Classification Using Semi-Supervised Regression Method. Applied Sciences. 2020; 10(11):3832. https://doi.org/10.3390/app10113832
Chicago/Turabian StyleKim, Sung Wook, Young Gon Lee, Bayu Adhi Tama, and Seungchul Lee. 2020. "Reliability-Enhanced Camera Lens Module Classification Using Semi-Supervised Regression Method" Applied Sciences 10, no. 11: 3832. https://doi.org/10.3390/app10113832
APA StyleKim, S. W., Lee, Y. G., Tama, B. A., & Lee, S. (2020). Reliability-Enhanced Camera Lens Module Classification Using Semi-Supervised Regression Method. Applied Sciences, 10(11), 3832. https://doi.org/10.3390/app10113832