3.1. Overview of the Proposed MIL Network
We first briefly introduces the definition of MIL. In MIL, a set of bags are given:
. Each bag contains various instances, and can be conveniently expressed in
, where
. The numbers of bags and instances in bag
are designated as
N and
, respectively. Recall that only bag-level labels are available in training. Let
be the label for bag
, where 1 means
is positive and 0 otherwise. On the contrary, no labels are available for instances. Relations between bag labels and instance labels can be formally expressed as follows:
Having the above preliminary knowledge, we now discuss instance-embedding learning for MIL. As a weakly supervised classification problem, MIL methods usually have two kinds of predictive targets [
7]: bag- and instance-level prediction.
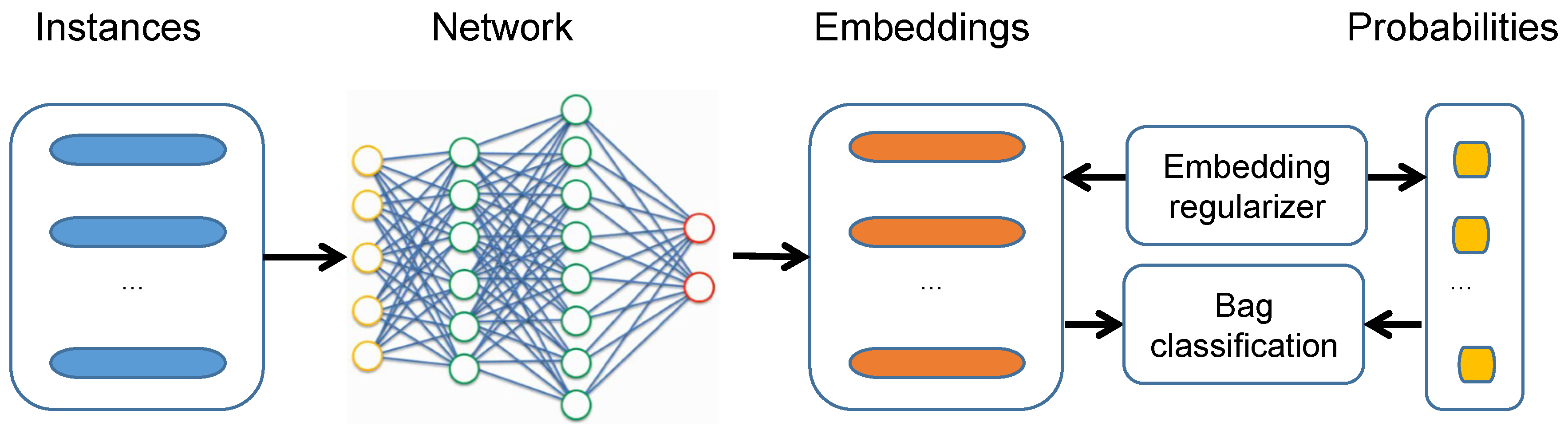
The overall multi-instance neural network is illustrated in
Figure 1. The instances were first fed into three fully connected (FC) layers for instance-embedding generation with 256, 128, and 64 neurons, respectively. Each FC layer was followed by a Rectified Linear Unit (ReLU) layer [
46] for nonlinearity, and a dropout layer [
47] (0.5 dropout ratio) to avoid overfitting. Then, learned instance embedding was fed into three streams: instance-level predictor network, bag-level predictor network, and embedding regularizer network, as described in
Section 3 and
Figure 1. For instance-level prediction, an FC layer with one neuron was used to predict its probability of belonging to the positive class of each instance, and a max-pooling layer was used to aggregate instance scores (i.e., positiveness) into the bag scores. For bag-level prediction, a MIL pooling function, as described in
Section 3.3, was used to aggregate instance representations (i.e., instance embedding) into bag representations (i.e., bag embedding), and an FC layer with one neuron was used to obtain the bag scores. Since regularized instance embedding (RIE) is the novelty in the proposed MIL network, we call the proposed method RIE in the rest of the paper.
3.3. Instance-Embedding Learning
Different from fully supervised learning, instance labels in MIL are unknown. Thus, performing instance-level embedding/representation learning is a very challenging task. However, instance-level learning is very important in many applications since it reveals more detailed information and makes MIL approaches more interpretable. As a result, we attempt to solve this challenging problem in this paper.
In previous MIL methods, instance-embedding learning was usually ignored, while bag embedding was extensively studied. We formulated an instance-embedding-learning framework and propose novel regularized instance embedding as follows.
Let be an embedding of instance , where . Usually, f is a differential neural network with parameters . contains all the parameters in the multiple layers of the network f. On the basis of instance embedding, there are two styles of prediction functions: instance- and bag-level prediction.
Instance-level prediction: Let
be an instance classifier, where
is a binary classifier that predicts the positiveness
of instance
, denoted as follows:
Then, instance-level probabilities
are aggregated into bag-level probability using a max operator, denoted as
where
is the total number of instances in the
ith bag, and
denotes the probability of the
ith bag being positive. Here, max is chosen rather than
for the max function, as it is more suitable with the MIL definition.
Bag-level prediction: This generates bag-level embedding/representation and directly makes bag-level predictions without considering instance-level probabilities. Given an instance-embedding set from the same bag
, we generated the bag embedding using a function denoted as
F. There are at least two ways to define
F, i.e., using a
or
pooling function, which are given as follows:
and
Here, max and
are both elementwise pooling functions that operate on
D-dimensional instance-embedding vectors. After that, a bag predictor is applied to generate bag probability, denoted as follows:
where
H is a linear classifier for bag classification. In neural networks,
H can be implemented as a fully connected layer, and its parameters can be optimized together with instance- and bag-level feature-extraction networks in an end-to-end manner.
The loss function for bag
is
. In this paper, we use cross-entropy loss
Other loss functions, e.g., Euclidean or softmax loss, can also be utilized. We chose cross-entropy loss following the setting in [
5] and the same loss function provides fair comparison in the experiments. For instance- and bag-level predictors, the MIL loss functions of
are given, respectively, as follows:
3.4. Regularized Instance Embedding
The above loss function learns instance embedding on the basis of max- and mean-pooling functions, which fail to consider pairwise information between instances within the same bag, since max- or min-pooling functions deal with each instance individually. Here, we propose to use pairwise information to regularize instance embedding. As a result, we could obtain more accurate instance embedding for better instance and bag classification.
In machine learning, as a common assumption, instances belonging to the same category tend to be more similar, while instances from different categories are dissimilar. However, we cannot directly judge whether instances are from the same category or not because instance labels are unavailable. To solve this problem, instance probabilities were used as latent variables to assist in distinguishing instances categories. For learning better instance embedding, we designed a regularizer to maximize the similarity between instances from the same category and minimize similarity between instances from different categories.
Given a batch of bags
, supposing there are
n instances in
, we denote a pair of instances
; no matter if they are from the same bag or not, the regularization objective can be formulated as Equation (
11).
where
is the total number of instance pairs, and
n means the total number of instances in batch
.
calculates instance similarity;
calculates instance relationship. If
and
belong to the same category,
is positive; otherwise,
is negative, which is denoted as follows.
where
is the probability threshold to classify whether an instance is positive or negative. Further, a weighted version of
is given as follows.
Since
,
. Equation (
11) can be easily optimized and has a larger penalty if instance predictors have higher confidence. The similarity measure for two embedding vectors has many choices. Here, we used the simple cosine similarity described in Equation (
14).
The regularizer in Equation (
11) uniformly embraces three cases. The first case is two instances belonging to two different bags that are essentially different in terms of embedding and prediction. This leads to a negative value with a large magnitude. The second case is two instances coming from the same bag but different categories.
3.5. Optimization Using Stochastic Gradient Descent
In the above formulations, learned instance embedding
f, instance-level predictor
h, and bag-level predictor
H could all be implemented using fully connected layers in a neural network, and optimized in an end-to-end manner. The overall loss function of the neural network is given as follows:
where
, and
are loss weight parameters. In the experiments, the weight parameters can simply be set by cross-validation on the training data.
After calculating the loss of the whole network, we minimized the loss function by employing back propagation with stochastic gradient descent (SGD). We used the PyTorch [
48] framework to implement the whole network. SGD with automatic differentiation can be directly invoked in PyTorch.




{kind=link}