1. Introduction
Synthesizers are parametric systems able to generate audio signals ranging from musical instruments to entirely unheard-of sound textures. Since their commercial beginnings more than 50 years ago, synthesizers have revolutionized music production, while becoming increasingly accessible, even to neophytes with no background in signal processing.
While there exists a variety of sound synthesis types [
1], all of these techniques require an extensive a priori knowledge to make the most out of a synthesizer possibilities. Hence, the main appeal of these systems (namely their versatility provided by large sets of parameters) also entails their major drawback. Indeed, the sheer combinatorics of parameter settings makes exploring all possibilities to find an adequate sound a daunting and time-consuming task. Furthermore, there exist highly non-linear relationships between the parameters and the resulting audio. Unfortunately, no synthesizer provides intuitive controls related to perceptual and semantic properties of the generated audio. Hence, a method allowing an intuitive and creative exploration of sound synthesizers has become a crucial need, especially for non-expert users.
A potential direction taken by synth manufacturers is to propose programmable
macro-controls that allow to efficiently manipulate the generated sound qualities by controlling multiple parameters through a single knob. However, these need to be programmed manually, which still requires expert knowledge. Furthermore, no method has ever tried to tackle this
macro-control learning task, as this objective appears unclear and depends on a variety of unknown factors. An alternative to manual parameters setting would be to infer the set of parameters that could best reproduce a given
target sound. This task of
parameters inference has been studied in the past years using various techniques, such as iterative relevance feedback on audio descriptors [
2], Genetic Programming to directly grow modular synthesizers [
3], or bi-directional LSTM with highway layers [
4] to produce parameters approximation. Although these approaches might be appealing, they all share the same fundamental flaws that (i) though it is unlikely that a synthesizer can generate exactly any audio target, none explicitly model these limitations, (ii) they do not account for the non-linear relationships that exist between parameters and the corresponding synthesized audio, and (iii) none of these approaches allow for higher-level controls or interaction with audio synthesizers. Hence, no approach has succeeded in unveiling the true relationships between these
auditory and
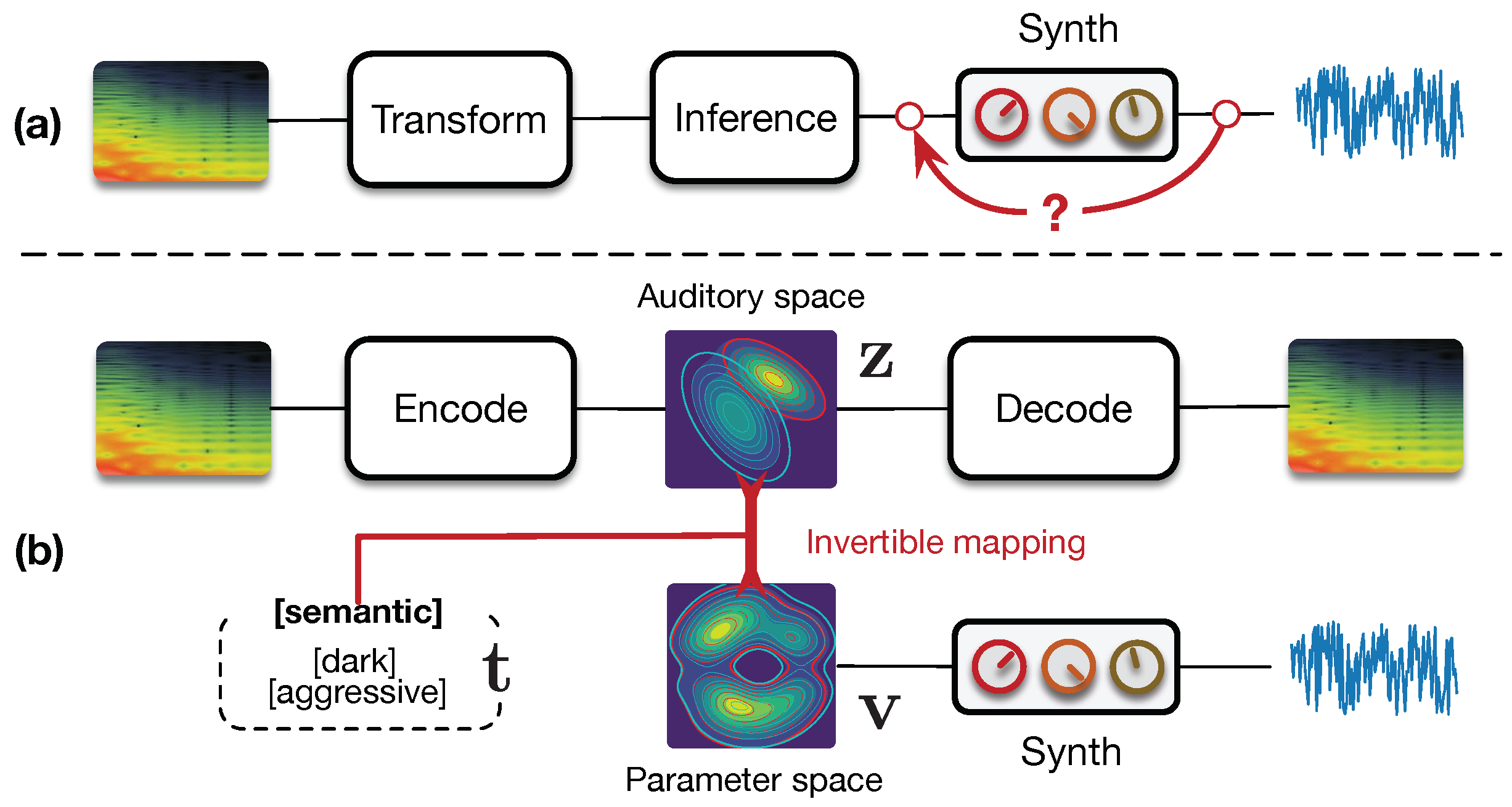
parameters spaces. Hence, it appears mandatory to organize the parameters and audio capabilities of a given synthesizer in their respective spaces, while constructing an invertible mapping between these spaces in order to access a range of high-level interactions. This idea is depicted in
Figure 1.
The recent rise of
generative models might provide an elegant solution to these questions. Indeed, amongst these models, the
Variational Auto-Encoder (VAE) [
5] aims to uncover the underlying structure of the data, by explicitly learning a
latent space [
5]. This space can be seen as a high-level representation, which aims to disentangle underlying variation factors and reveal interesting structural properties of the data [
5,
6]. VAEs address the limitations of control and analysis through this latent space, while being able to learn on small sets of examples. Furthermore, the recently proposed
Normalizing Flows (NF) [
7] also allow to model highly complex distributions in this latent space. Although the use of VAEs for audio applications has only been scarcely investigated, Esling et al. [
8] recently proposed a perceptually regularized VAE that learns a space of audio signals aligned with perceptual ratings via a regularization loss. The resulting space exhibits an organization that is well aligned with perception. Hence, this model appears as a valid candidate to learn an organized audio space.
Recently, we introduced a radically novel formulation of audio synthesizer control [
9] by formalizing it as the general question of finding an invertible mapping between organized latent spaces, linking the audio space of a synthesizer’s capabilities to the space of its parameters. We provided a generic probabilistic formalization and showed that it allows to address simultaneously the tasks of
parameter inference,
macro-control learning, and
audio-based preset exploration within a single model. To solve this new formulation, we proposed
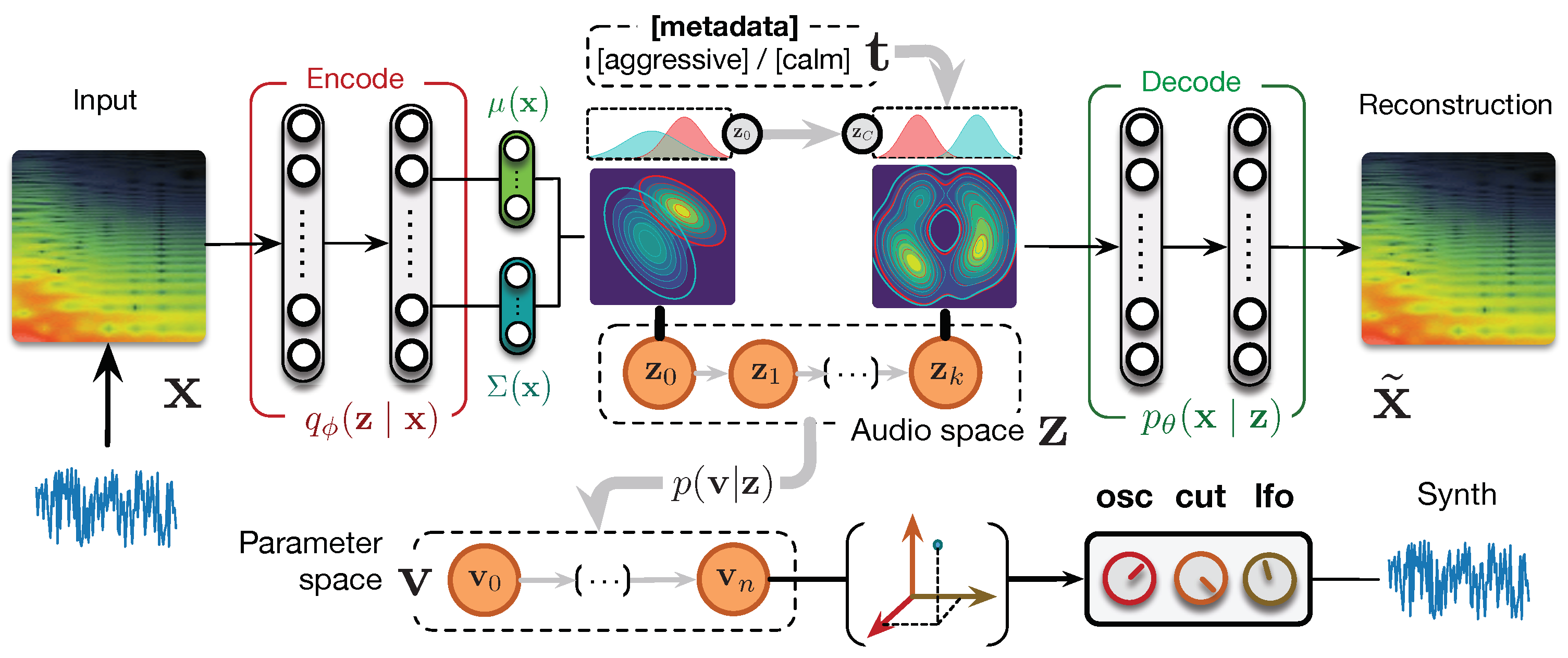
conditional regression flows, which map a latent space to any given target space, as depicted in
Figure 2. Based on this formulation,
parameter inference simply consisted of encoding the audio target to the latent audio space that is mapped to the parameter space. Interestingly, this bypasses the well-known blurriness issue in VAEs as we can generate directly with the synthesizer instead of the decoder. In this paper, we extend the evaluation of our proposal on larger sets of parameters against various baseline models and show its superiority in parameter inference and audio reconstruction. Furthermore, we discuss how our model is able to address the task of automatic
macro-control learning that we introduced in Ref. [
9] with this increased complexity. As the latent dimensions are continuous and map to the parameter space, they provide a natural way to learn the perceptually most significant macro-parameters. We show that these controls map to smooth, yet non-linear parameters evolution, while remaining perceptually continuous. Hence, this provides a way to learn the compressed and principal dimensions of macro-control in a synthesizer. Furthermore, as our mapping is invertible, we can map synthesis parameters back to the audio space. This allows intuitive
audio-based preset exploration, where exploring the neighborhood of a preset encoded in the audio space yields similarly sounding patches, yet with largely different parameters. In this paper, we further propose
disentangling flows to steer the organization of some of the latent dimensions to match given target distributions. We evaluate the ability of our model to learn these
semantic controls by explicitly targeting disentanglement in the latent space of the semantic tags associated to synthesizer presets. We show that, although the model learns to separate the semantic distributions, the corresponding controls are not easily interpretable. Finally, we introduce a real-time implementation of our model in
Ableton Live and discuss its potential use in creative applications (All code, supplementary figures, results, and the real-time Max4Live plugin are available as open-source packages on a supporting webpage:
https://acids-ircam.github.io/flow_synthesizer/).
5. Results
5.1. Parameters Inference
First, we compare the accuracy of all models on the
parameters inference task by computing the magnitude-normalized
Mean Square Error (
) between predicted and original parameters values. We average these results across folds and report variance. We also evaluate the distance between the audio synthesized from the inferred parameters and the original audio with the
Spectral Convergence (SC) distance (magnitude-normalized Frobenius norm) and
MSE (it should be noted that these measures only provide a global evaluation of spectrogram similarity, and that perceptual aspects of the results should be evaluated in human listening experiments that are left for future work). We provide evaluation results for 16, 32, and 64 parameters on the test set in
Table 1.
In low parameters settings, baseline models seem to perform an accurate approximation of parameters, with the providing the best inference. Based on this criterion solely, our formulation would appear to provide only a marginal improvement, with s even outperformed by baseline models and best results obtained by the . However, analysis of the corresponding audio accuracy tells an entirely different story. Indeed, AEs approaches strongly outperform baseline models in audio accuracy, with the best results obtained by our proposed (1-way ANOVA , ). These results show that, even though AE models do not provide an exact parameters approximation, they are able to account for the importance of these different parameters on the synthesized audio. This supports our original hypothesis that learning the latent space of synthesizer audio capabilities is a crucial component to understand its behavior. Finally, it appears that adding disentangling flows () slightly impairs the audio accuracy. However, the model still outperform most approaches, while providing the huge benefit of explicit semantic macro-controls.
5.2. Increasing Parameters Complexity
We evaluate the robustness of different models by increasing the number of parameters from 16 to 32 and finally 64 (
Table 1). As we can see, the accuracy of baseline models is highly degraded, notably on audio reconstruction. Interestingly, the gap between parameter and audio accuracies is strongly increased. This seems logical as the relative importance of parameters in larger sets provoke stronger impacts on the resulting audio. Also, it should be noted that
models now outperform baselines even on parameters accuracy. Although our proposal also suffers from larger sets of parameters, it appears as the most resilient and can still cope with this higher complexity. While the gap between AE variants is more pronounced, the
flows strongly outperform all methods (
,
).
5.3. Reconstructions and Latent Space
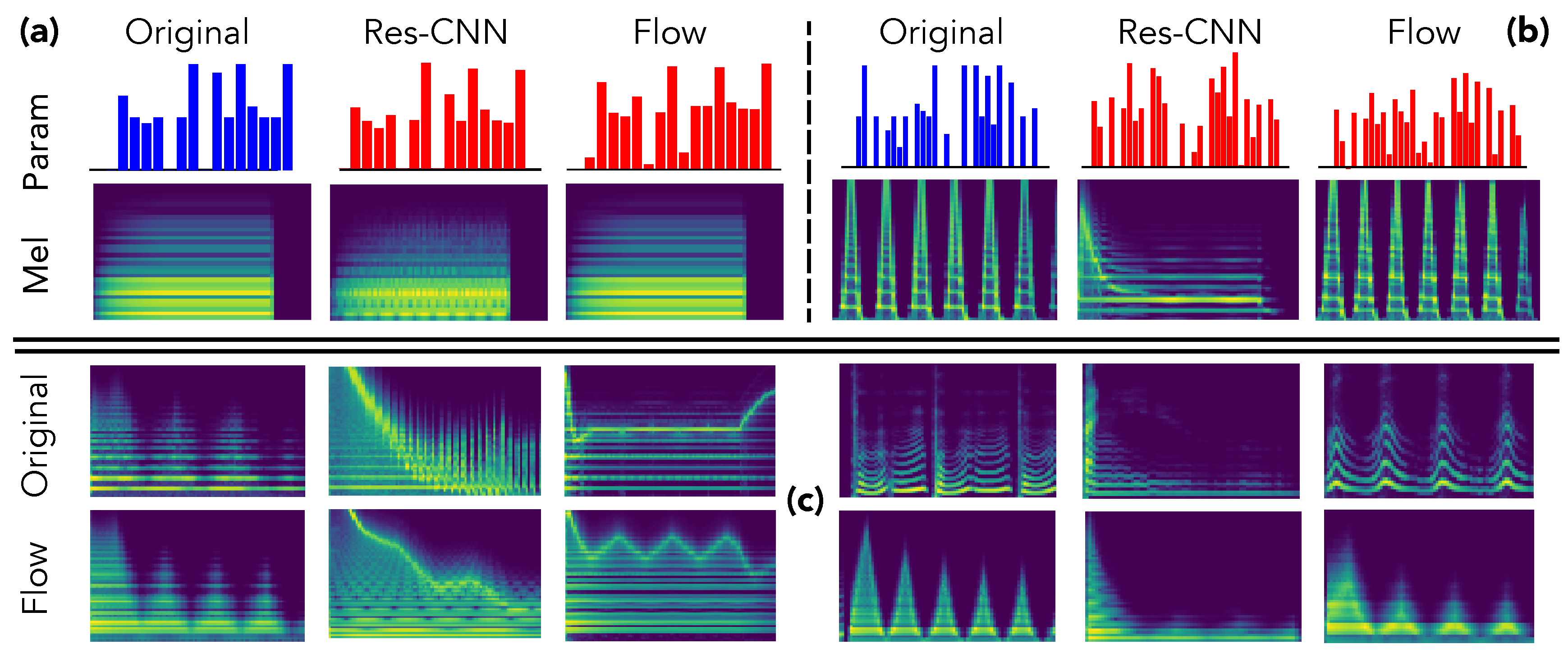
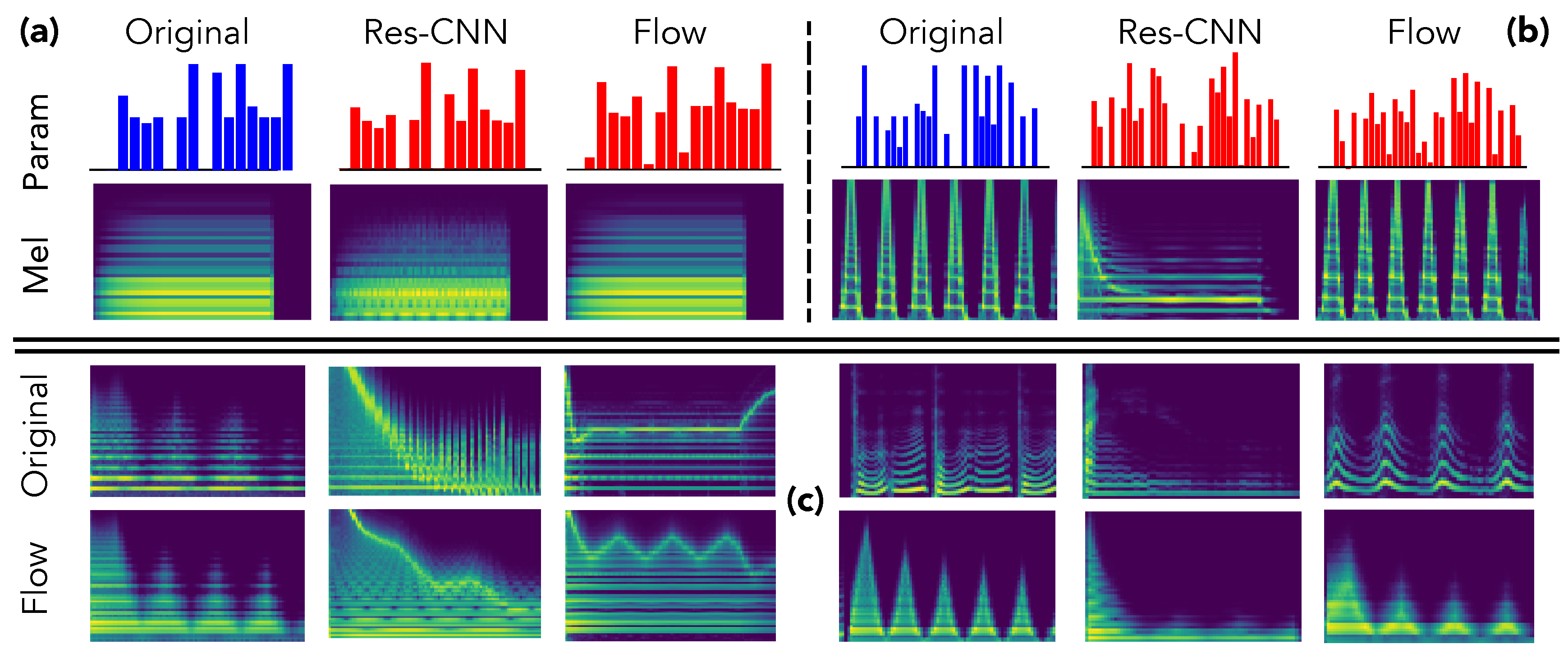
We provide an in-depth analysis of the relations between inferred parameters and corresponding synthesized audio to support our previous claims. First, we selected two samples from the test set and compare the inferred parameters and synthesized audio in
Figure 3.
As we can see, although the provides a close inference of the parameters, the synthesized approximation completely misses important structural aspects, even in simpler instances as the simple harmonic structure in the first example (a). This confirms our hypothesis that direct inference models are unable to assess the relative impact of parameters on the audio. Indeed, the errors in all parameters are considered equivalently, even though the same error magnitude on two different parameters can lead to dramatic differences in the synthesized audio. Oppositely, even though the parameters inferred by our proposal are quite far from the original preset, the corresponding audio is largely more similar. This indicates that the latent space provides knowledge on the audio-based neighborhoods of the synthesizer. Therefore, this allows to understand the impact of different parameters in a given region of the latent audio space.
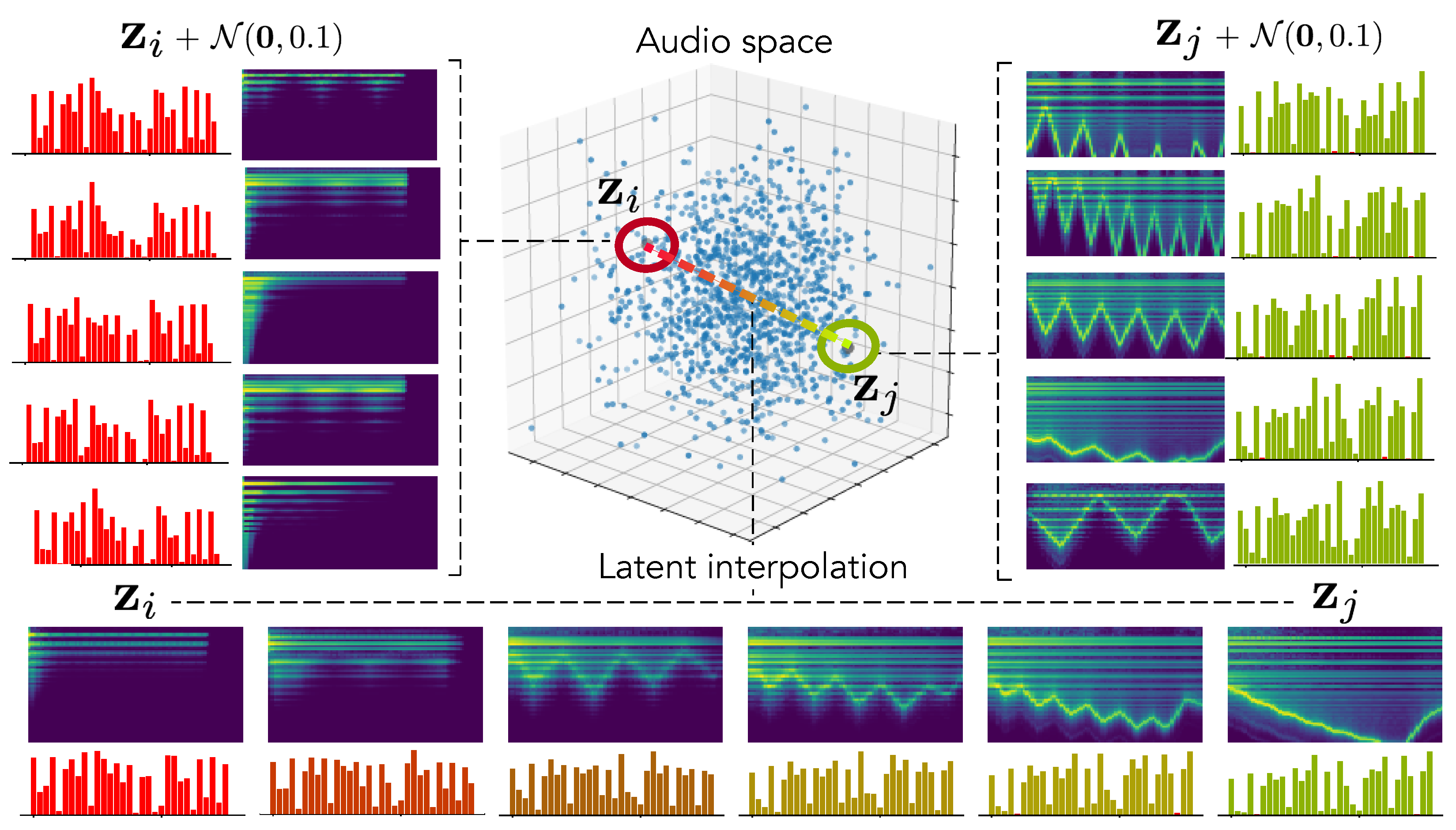
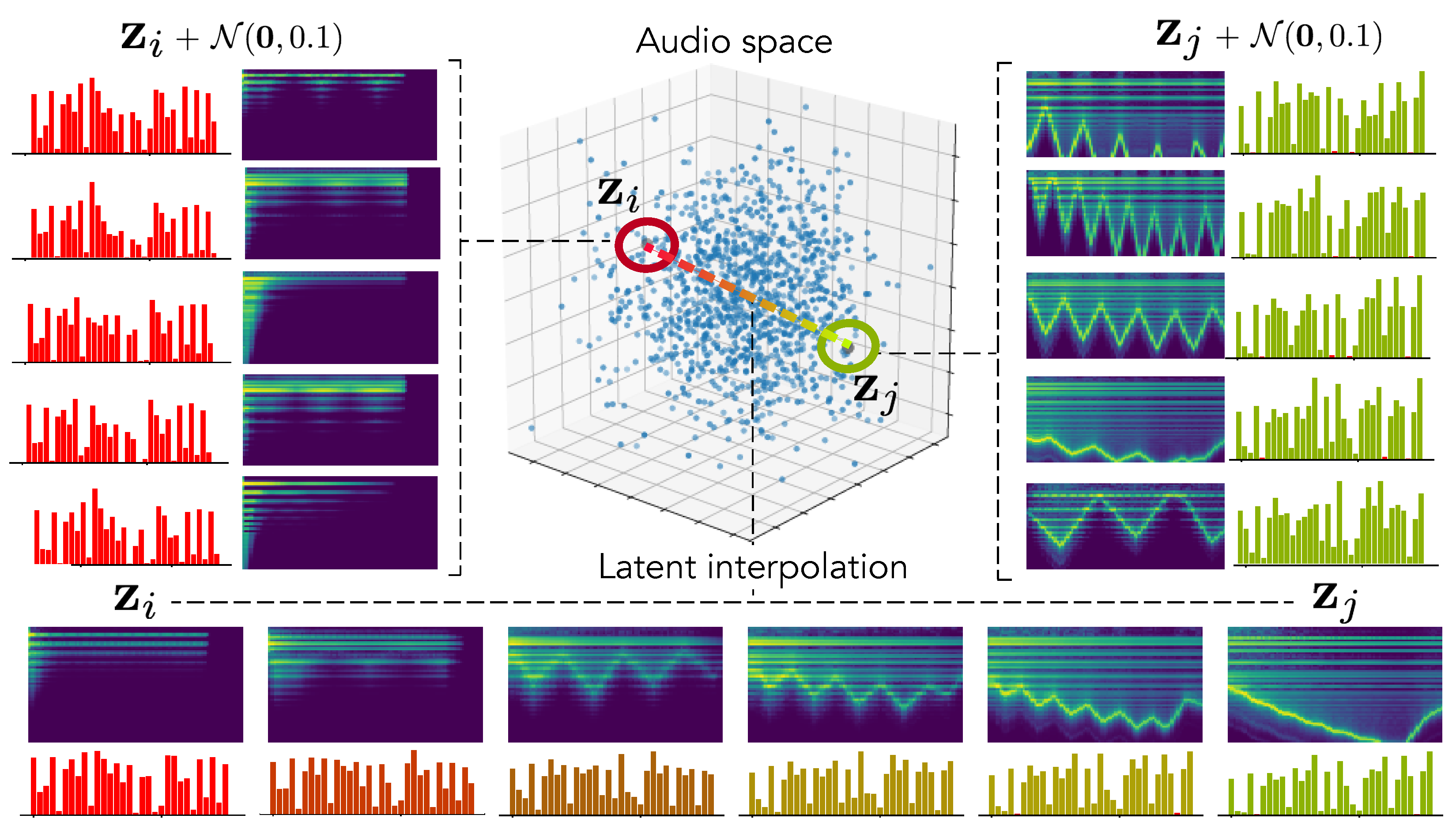
To confirm this hypothesis, we encode two random distant examples from the test set in the latent audio space and perform random sampling around these points to evaluate how local neighborhoods are organized. We also analyze the latent interpolation between those examples. The results are displayed in
Figure 4. As we can see, our hypothesis seems to be confirmed by the fact that neighborhoods are highly similar in terms of audio but have a larger variance in terms of parameters. Interestingly, this leads to complex but smooth non-linear dynamics in the parameters interpolation.
5.4. Out-Of-Domain Generalization
We evaluate
out-of-domain generalization by applying parameters inference and re-synthesis on two sets of audio samples either produced by other synthesizers, or with vocal imitations. We rely on the same evaluation method as previously described and provide results for the audio similarity in
Table 2 (Right). Here, the overall distribution of scores remains consistent with previous observations. However, it seems that the average error is quite high, indicating a potentially distant reconstruction of some examples. This might be explained by the limited number of parameters used for training our models. Therefore, they cannot account for complex sounds with various types of modulations. Interestingly, while the addition of more parameters to perform the optimization allows to reduce the global approximation error in AE models, it seems to worsen the feed-forward estimation. This seems to further confirm our original hypothesis that feed-forward approaches are not able to handle advanced interactions in the parameters.
In order to better understand the results and limits of our proposal, we display in
Figure 3 the resynthesis of random examples taken from the synthesizer (left) and vocal imitations (right) datasets. As we can see, in all cases, our proposal accurately reproduces the temporal spectral shape of target sounds, even if the timbre is somewhat distant. Upon closer listening, it seems that the models fail to reproduce the local timbre of voices but performs quite well with sounds from other synthesizers. However, the evolution of the spectral shape is still reproduced. Interestingly, this provides a form of
vocal sketching control where the user inputs vocal imitations of the sound that he is looking for. This allows to quickly produce an approximation of the intended sound and, then, exploring the audio neighborhood of the sketch for intuitive refinement.
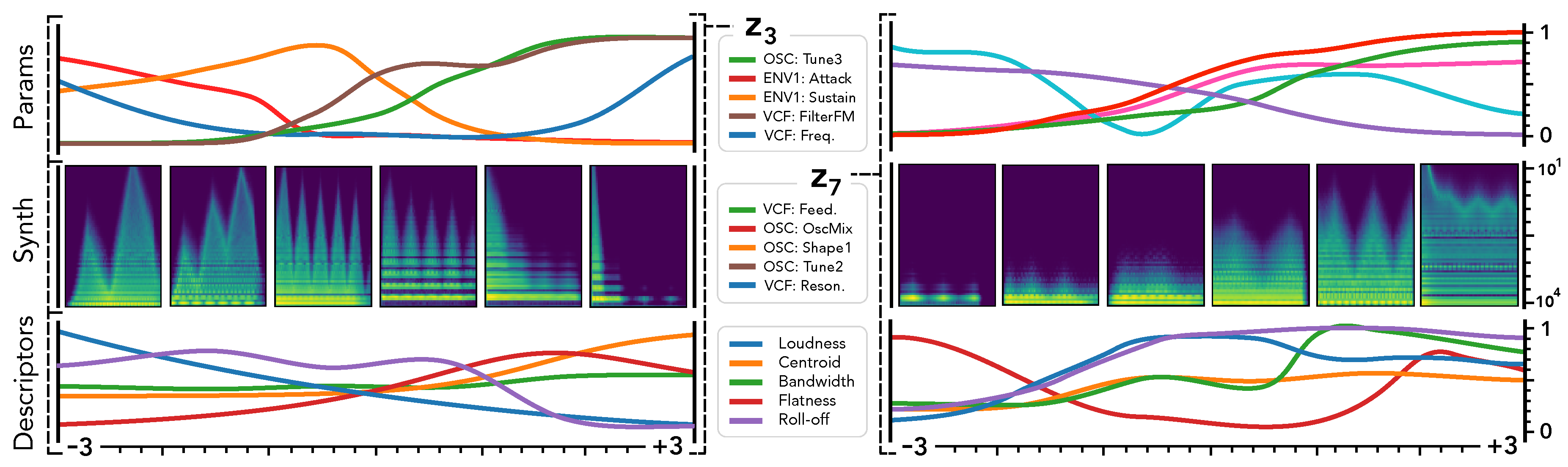
5.5. Macro-Parameters Learning
Our formulation is the first to provide a continuous mapping between the audio
and parameter
spaces of a synthesizer. As latent VAE dimensions has been shown to disentangle major data variations, we hypothesized that we could directly use
as
macro-parameters defining the principal dimensions of audio variations in a given synthesizer. Hence, we introduce the new task of
macro-parameters learning by mapping latent audio dimensions to parameters through
, which provides simplified control of the major audio variations for a given synthesizer. This is depicted in
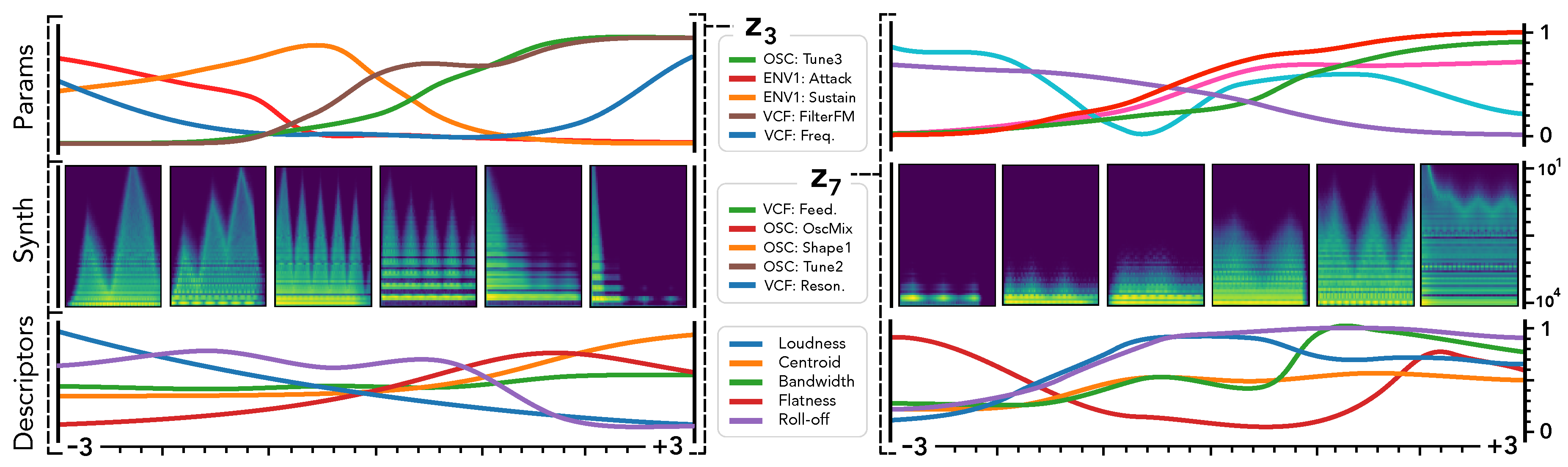
Figure 5.
We show the two most informative latent dimensions based on their variance. We study the traversal of these dimensions by keeping all other fixed at to assess how defines smooth macro-parameters through the mapping . We report the evolution of the 5 parameters with highest variance (top), the corresponding synthesis (middle) and audio descriptors (bottom).
First, we can see that latent dimension corresponds to very smooth evolutions in terms of synthesized audio and descriptors. This is coherent with previous studies on the disentangling abilities of VAEs [
6]. However, a very interesting property appear when we map to the parameter space. Although the parameters evolution is still smooth, it exhibits more non-linear relationships between different parameters. This correlates with the intuition that there are lots of complex interplays in parameters of a synthesizer. Our formulation allows to alleviate this complexity by automatically providing
macro-parameters that are the most relevant to the audio variations of a given synthesizer. Here, we can see that the
latent dimension (left) seems to provide a
percussivity parameter, where low values produce a very slow attack, while moving along this dimension, the attack becomes sharper and the amount of noise increases. Similarily,
seems to define an
harmonic densification parameter, starting from a single peak frequency and increasingly adding harmonics and noise. Although the unsupervised macro-parameters provide some clear effects on the synthesis, it appears that they do not act on a single aspect of the timbre. This seems to indicate that the macro-parameters still relate to some entangled properties of the audio. Furthermore, as these dimensions are unsupervised, we still need to define their effects through direct exploration. Additional macro-parameters are discussed on the supporting webpage of this paper.
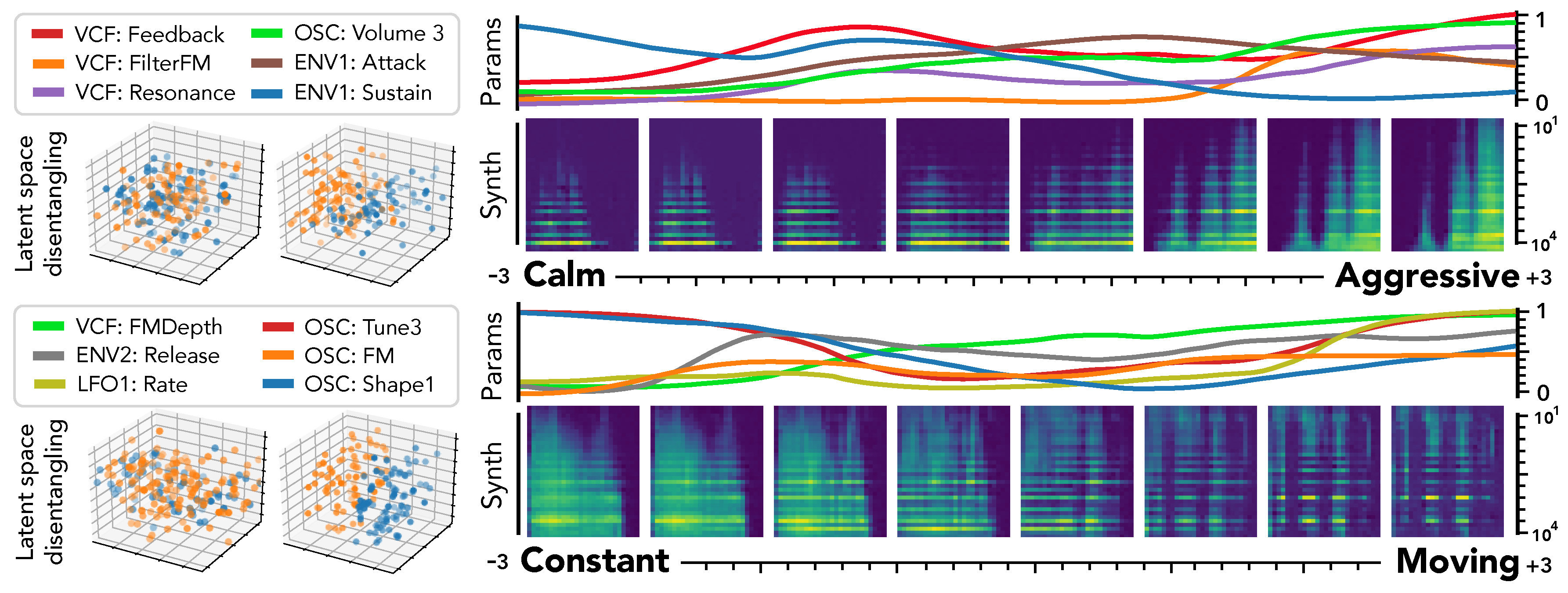
5.6. Semantic Parameter Discovery
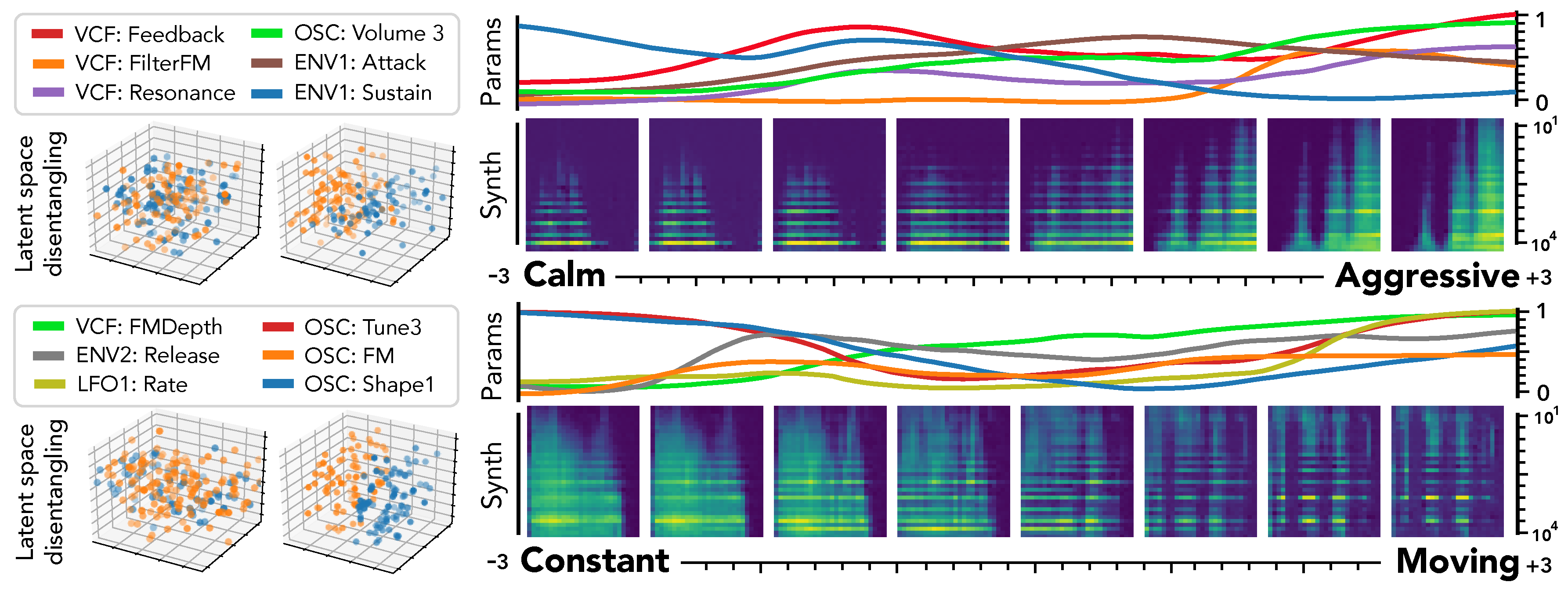
Our proposed
disentangling flows can steer the organization of selected latent dimensions so that they provide a separation of given tags. As this audio space is mapped to parameters through
, this turns the selected dimensions into
macro-parameters with a defined semantic meaning. To evaluate this, we analyze the behavior of corresponding latent dimensions, as depicted in
Figure 6.
First, we can see the effect of disentangling flows on the latent space (left), which provide a separation of semantic pairs. We study the traversal of semantic dimensions while keeping all other fixed at and infer parameters through . We display the 6 parameters with highest variance and the resulting synthesized audio. As previously observed for unsupervised dimensions, the semantic latent dimensions also seem to provide a very smooth evolution in terms of both parameters and synthesized audio. Regarding the precise effect of different semantic dimensions, it appears that the [‘Constant’, ‘Moving’] pair provides a very intuitive result. Indeed, the synthesized sounds are mostly stationary in extreme negative values, but gradually incorporate clearly marked temporal modulations. Hence, our proposal appears successful to uncover semantic macro-parameters for a given synthesizer. However, the corresponding parameters are quite harder to interpret. The [‘Calm’, ‘Aggressive’] dimension also provides an intuitive control starting from a sparse sound and increasingly adding modulation, resonance and noise. However, we note that the notion of ‘Aggressive’ is highly subjective and requires finer analyses to be conclusive.
5.7. Creative Applications
Our proposal allows to perform a direct exploration of presets based on audio similarity. Indeed, as the flow is
invertible, we can map parameters to the audio space for exploration, and then back to parameters to obtain a new preset. Furthermore, this can be combined with
vocal sketch control where the user inputs vocal imitations of the sound that he is looking for. In order to allow creative experiments, we implemented all the models and interactions detailed in this paper in an experimental Max4Live interface that is displayed in
Figure 7. We embedded our models inside
MaxMSP by using an
OSC communication server with the
Python implementation. We further integrate it into
Ableton Live by using the
Max4Live interface. This interface wraps the Diva VST and allows to provide control based on all of the proposed models. Hence, this interface allows to input a wave file or direct vocal recording to perform
parameter inference. The model can provide the VST parameters for the approximation in less than 30 ms on a CPU. The interface also provides a representations of the projected latent audio space, onto which is plotted the preset library. This allows to perform audio-based preset exploration, but also to draw paths between different presets or simply across the audio space. By freely exploring the dimensions, the user can also experiment the
unsupervised macro-control and also explore
supervised semantic dimensions. Finally, we implemented an interaction with the
Leap Motion controller, which allows to directly control the synthesized sound with one’s hand.
6. Conclusions
In this paper, we discussed several novel ideas based on our recent novel formulation of the problem of synthesizer control as matching the two latent spaces defined as the audio perception space and the synthesizer parameter space. To solve this new formulation, we relied on VAEs and Normalizing Flows to organize and map the auditory and parameter spaces of a given synthesizer. We introduced the disentangling flows, which allow to obtain an invertible mapping between two separate latent spaces, while steering the organization of some latent dimensions to match target variation factors by splitting the objective as partial density evaluation.
We showed that our approach outperforms all previous proposals on the seminal problem of parameters inference, and that it is able to provide an interesting approximation to any type of sound in almost real-time, even on a CPU. We showed that for sounds that are not produced by synthesizers, our model is able to match the evolution of the spectral shape quite well, even though the local timbre is not well approximated. We further showed that our formulation also naturally introduces various original and first-of-kind tasks of macro-control learning, audio-based preset exploration, and semantic parameters discovery. Hence, our proposal is the first to be able to simultaneously address most synthesizer control issues at once, while providing higher-level understanding and controls. In order to allow for usable and creative exploration of our proposed methods, we implemented a Max4Live interface that is available freely along with the source code of all approaches on the supporting webpage of this paper.
Altogether, we hope that this work will provide new means of exploring audio synthesis, sparking the development of new leaps in musical creativity.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}