Robust Speech Hashing for Digital Audio Forensics


Abstract
1. Introduction
2. Basic Concepts
2.1. Collatz Conjecture
2.2. MFCC
2.3. RSA
- Select two different prime numbers, named p and q.
- Calculate .
- Calculate the function .
- Randomly select an integer e, where and e is coprime with .
- Calculate a private exponent d, where .
- Apply module operation: .
- Finally, public keys are e and n, and the private key is d.
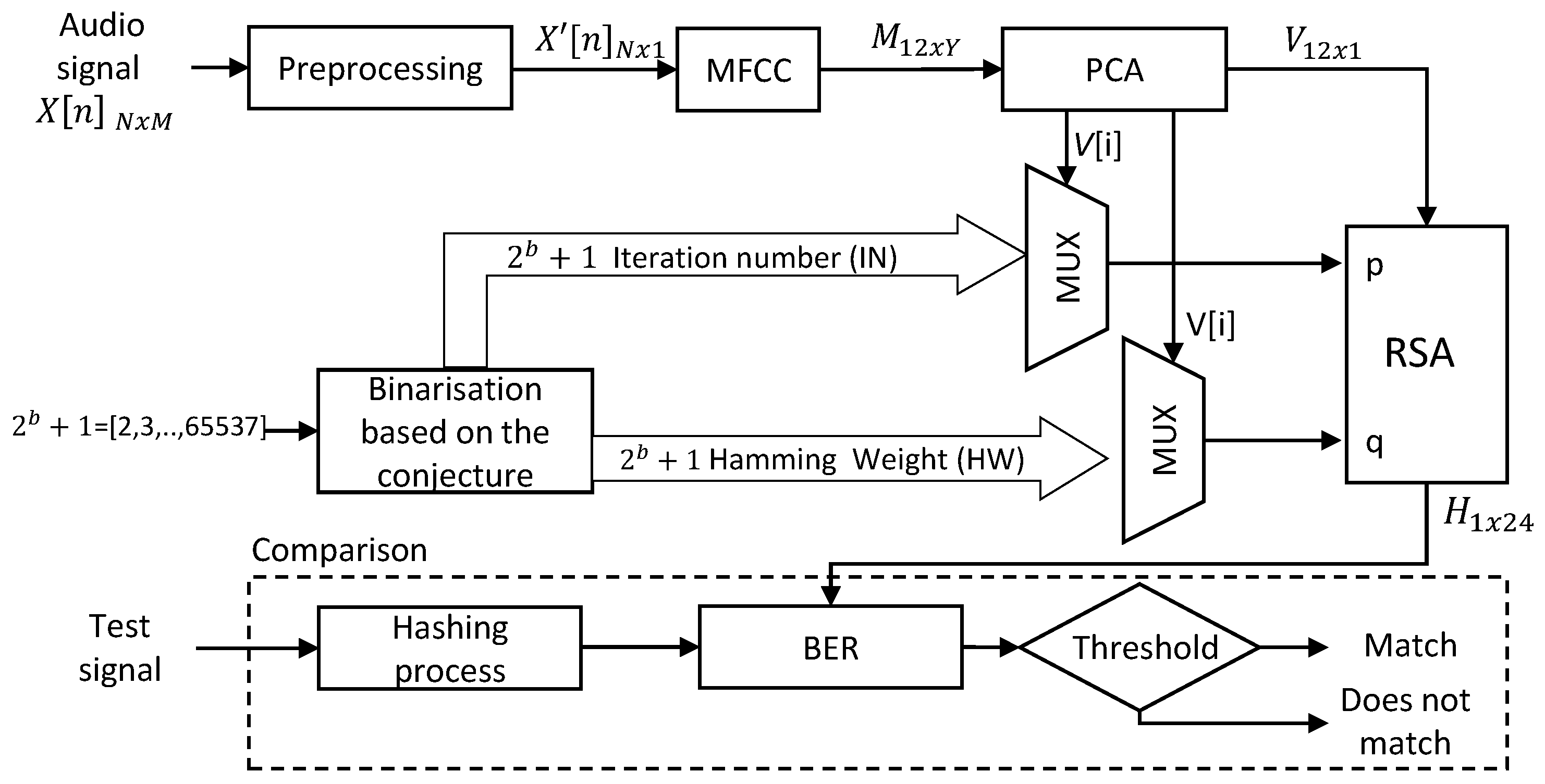
3. Proposed Method
3.1. Step 1. Pre-Processing
3.2. Step 2. MFCC
3.3. Step 3. PCA
- In time series data, the closer the vectors are (in time), the greater the dependency, and vice versa [36]. Since the columns in matrix M correspond to 250 ms window frames (FD–FS), the time separation of these frames is greater than the corresponding separation of the samples in the original signal ().
- The main purpose of the proposed hash function is descriptive, not inferential, i.e., to summarize the data. Therefore, non-independence does not seriously affect the application of the PCA [36].
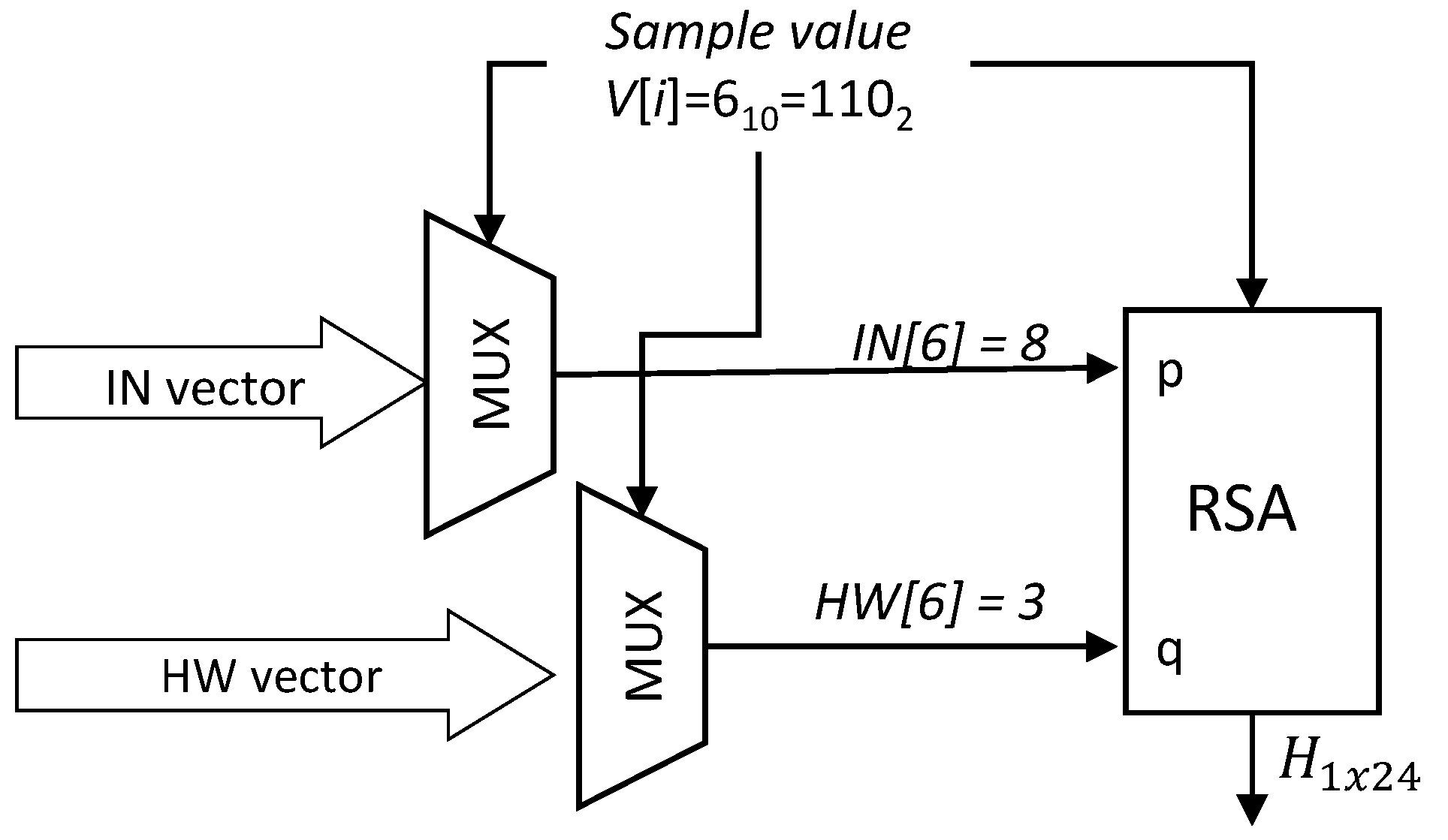
3.4. Step 4. Binarization Based on the Collatz Conjecture
| Algorithm 1 Collatz-Based Binarization. |
|
3.5. Step 5. RSA Encryption
3.6. Step 6. Comparison
4. Experimental Results And Analysis
4.1. Experimental Dataset
4.2. Performance Analysis
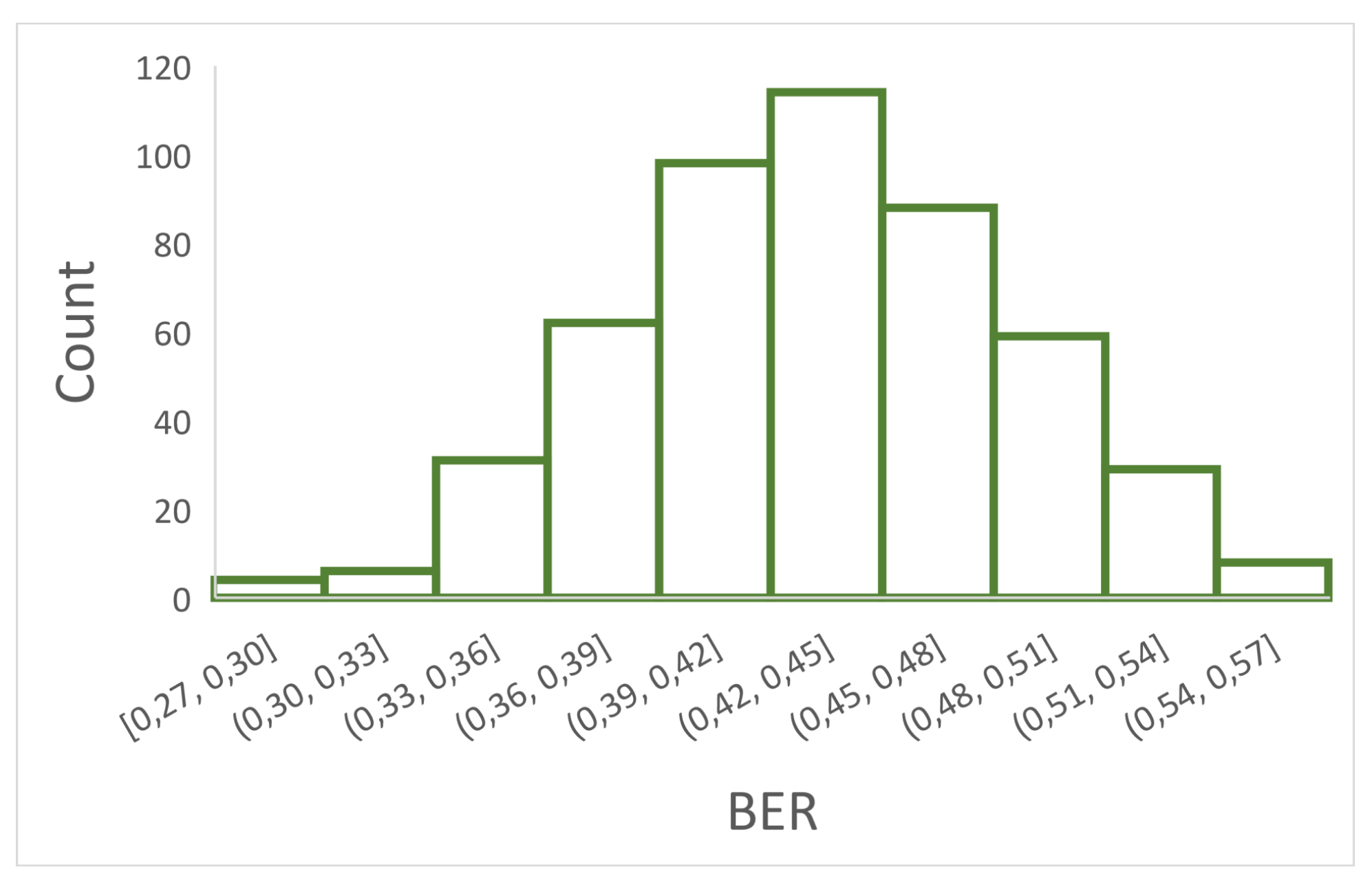
- Bit Error Rate (BER): One of the widely used parameters for comparing a pair of hash codes is the BER. It is equal to the number of bits that differ between two hash codes, divided by the length of the hash sequence. The maximum value of BER is 1 and the minimum is 0. In the first case the two hash codes are completely different, while in the second case the codes are the same.The formula for obtaining the BER is:where and are the hash codes of two different recordings, L is the length of the hash value, and ⊕ is the XOR operator.In this study, with 500 different recordings (a), the number of BER values obtained with all available pairs is calculated using the binomial coefficient:for , . Then, our result is . Having many BER values, they should follow a Gaussian distribution with and [37]. Since , , the expected standard deviation value will be . As a result, Figure 3 shows the histogram of 499 BER values obtained by the comparison between a sample recording and the rest of the remaining 499 recordings.Table 3 shows the expected values and experimental values obtained from the 124,750 BER values. As can be seen in this Table, with the proposed hash function, the data distribution approximates the Gaussian distribution. This function facilitates resistance to collisions since both the mean and the dispersion of bits that differ between two hash codes of different recordings are close to the theoretical value.
- ER (entropy rate). The ER value allows you to compare the performance of hash functions and, unlike other evaluation parameters, does not depend on the length of the hash code. The higher the ER value, the better the performance. The ER is obtained by taking into account the probability of transition between two hash sequences, p, using the following equation:where . For our case, , and therefore . These values are discussed in Section 4.5.
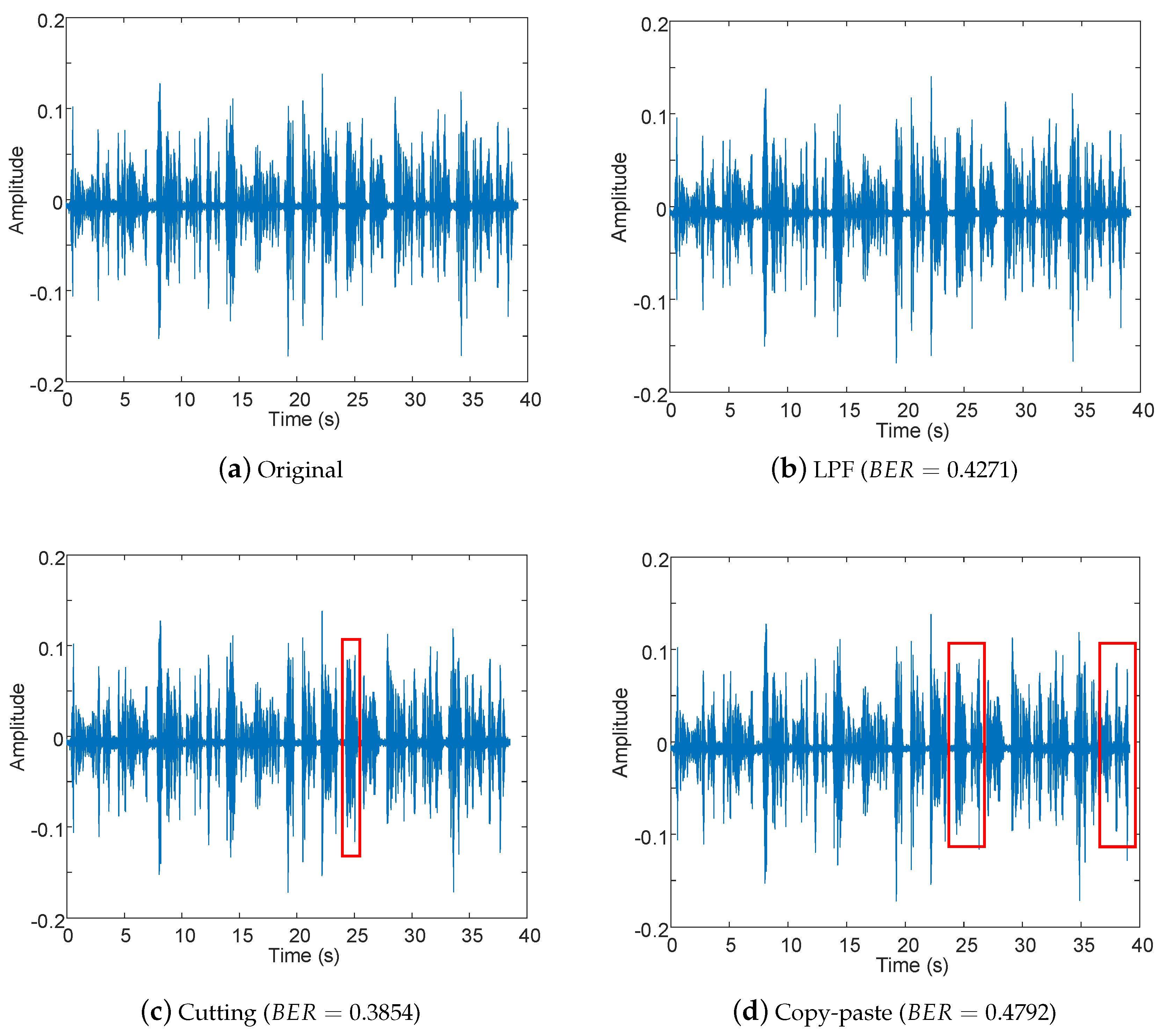
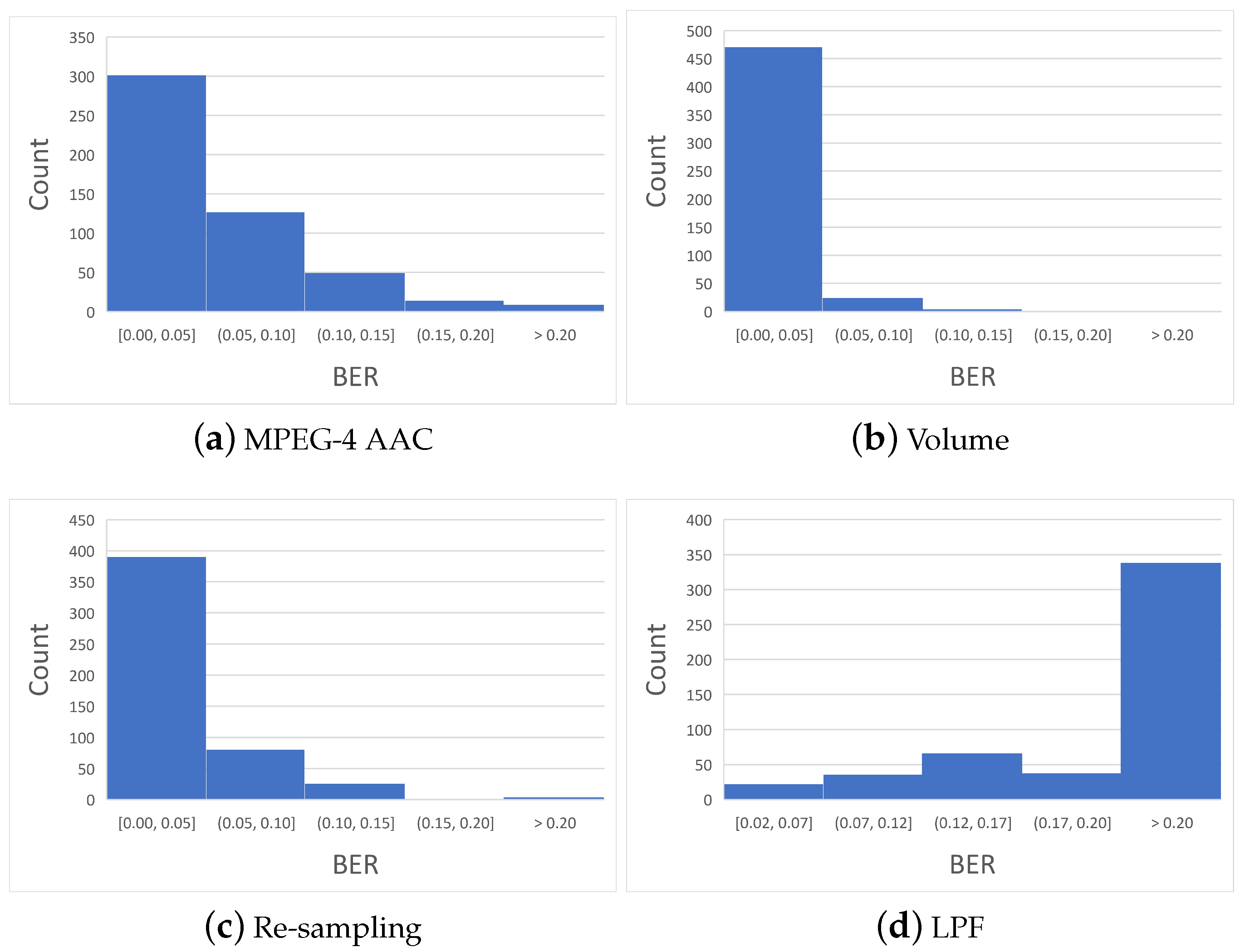
4.3. Analysis with Perceptual and Non-Perceptual Manipulations
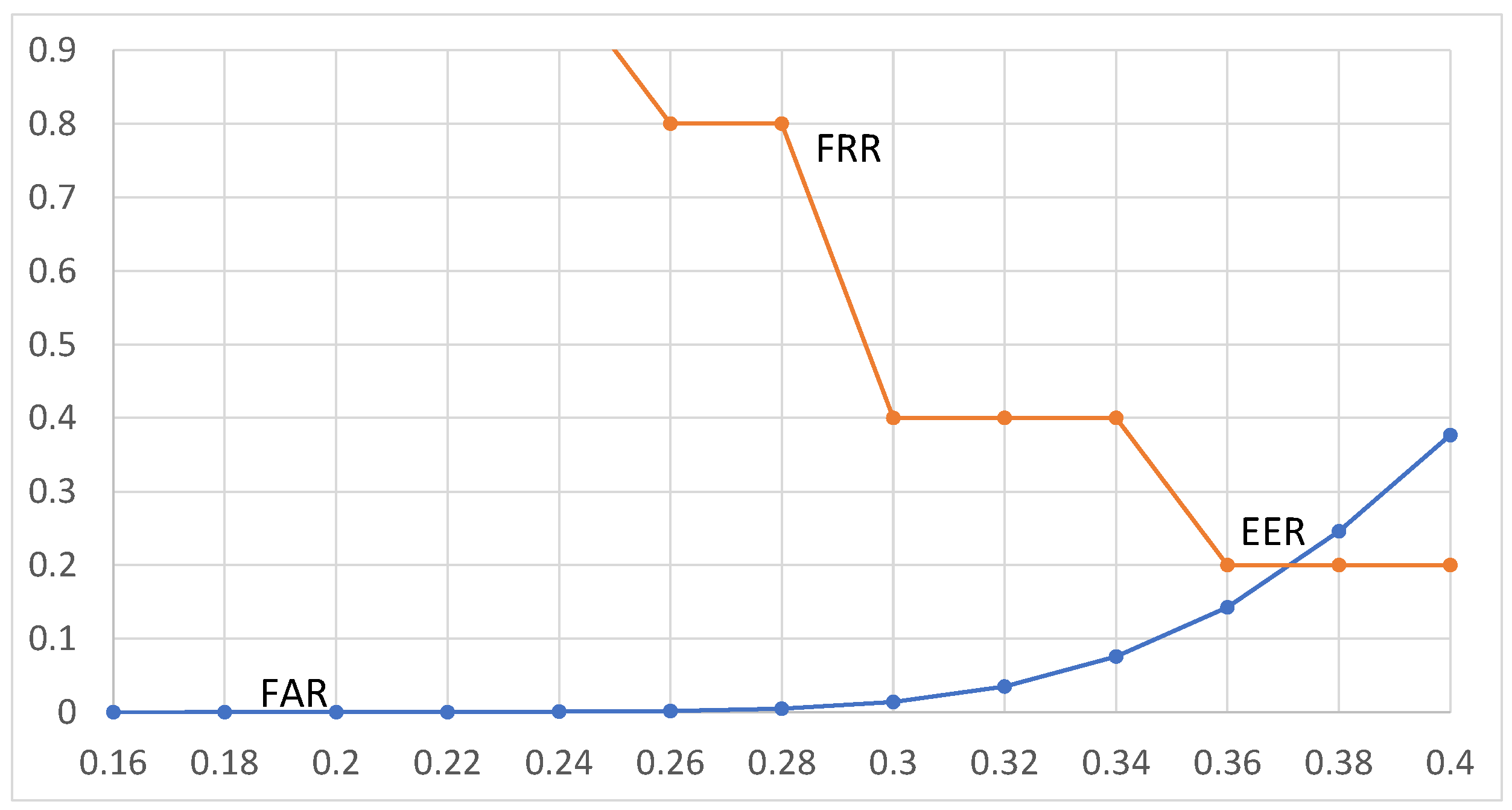
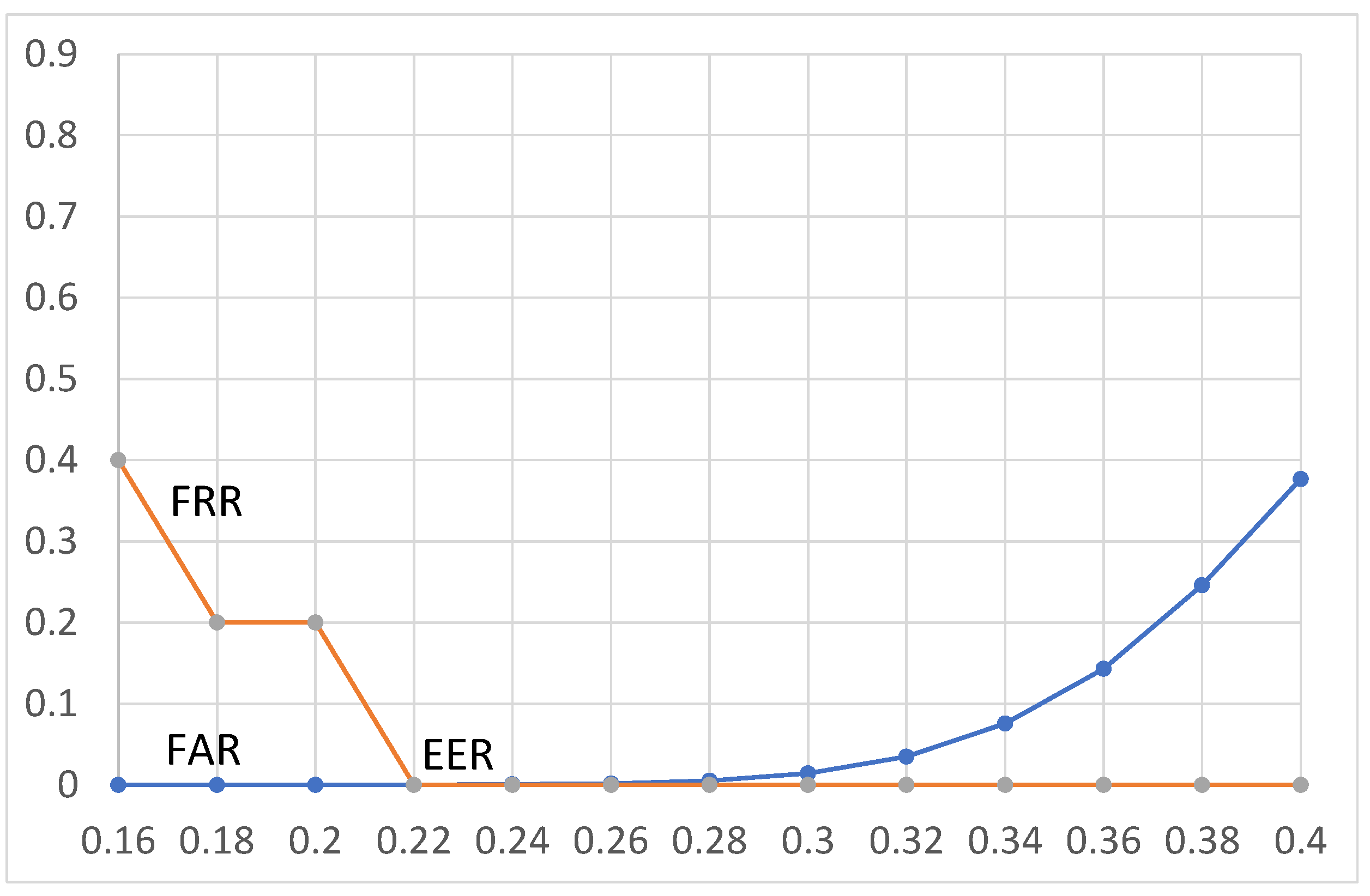
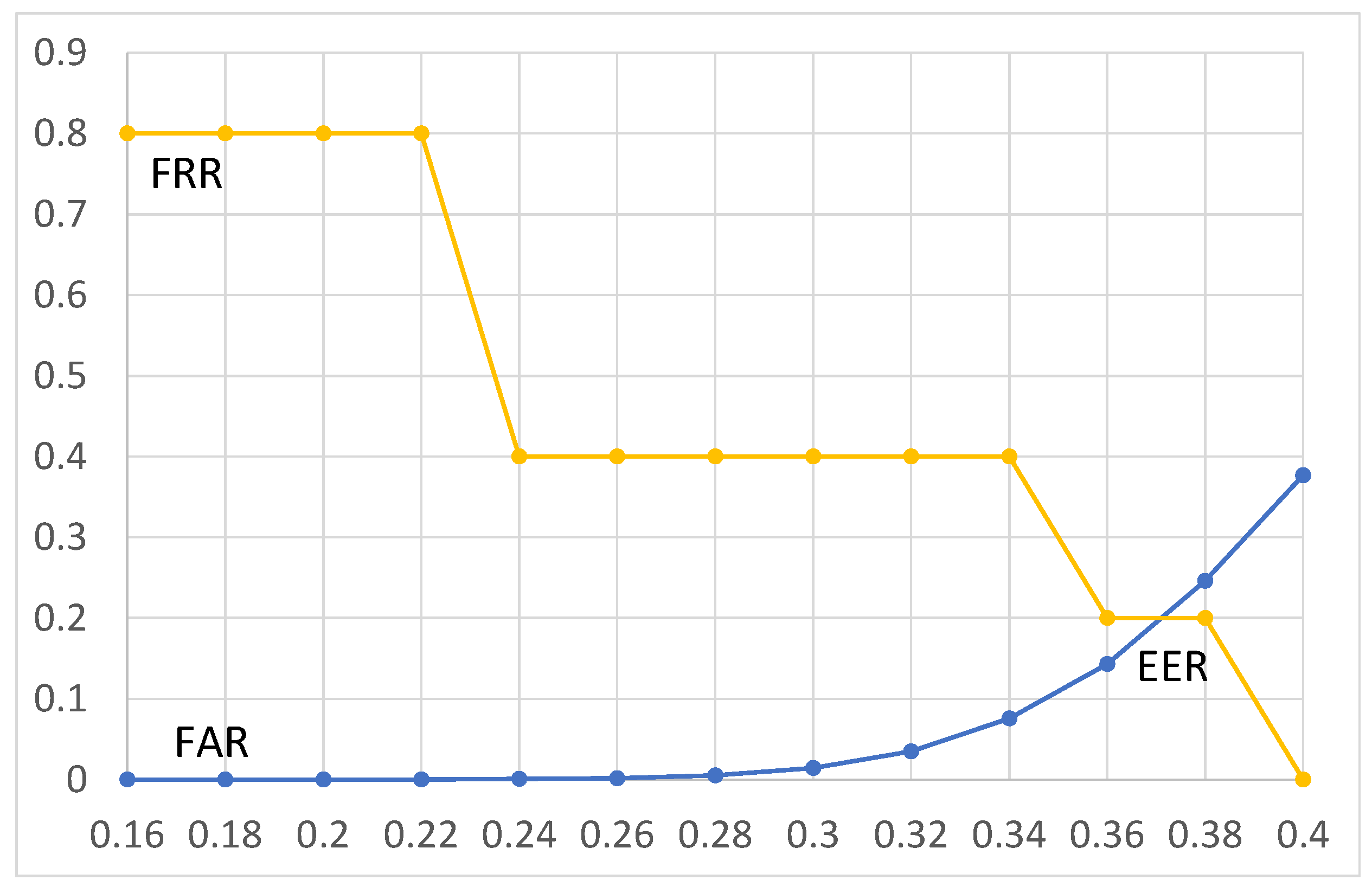
4.4. EER (Equal Error Rate) and the Threshold (th)
4.5. Comparison with Related Works
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Renza, D.; Ballesteros, D.; Lemus, C. Authenticity verification of audio signals based on fragile watermarking for audio forensics. Expert Syst. Appl. 2018, 91, 211–222. [Google Scholar] [CrossRef]
- Zhang, Q.; Qiao, S.; Huang, Y.; Zhang, T. A high-performance speech perceptual hashing authentication algorithm based on discrete wavelet transform and measurement matrix. Multimed. Tools Appl. 2018, 77, 21653–21669. [Google Scholar] [CrossRef]
- Fallahpour, M.; Megias, D. Audio Watermarking Based on Fibonacci Numbers. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 1273–1282. [Google Scholar] [CrossRef]
- Renza, D.; Ballesteros, D.M.; Ortiz, H.D. Text Hiding in Images Based on QIM and OVSF. IEEE Lat. Am. Trans. 2016, 14, 1206–1212. [Google Scholar] [CrossRef]
- Gonzalez, F.P.; Alfaro, P.C.; Freire, L.P.; Vieites, D.P. Method and System for Robust Audio Hashing. U.S. Patent 9,286,909, 15 March 2016. [Google Scholar]
- Meyers, M.; Rogers, M. Computer forensics: The need for standardization and certification. Int. J. Digit. Evid. 2004, 3, 1–11. [Google Scholar]
- Delp, E.; Memon, N.; Wu, M. Digital forensics [From the Guest Editors]. IEEE Signal Process. Mag. 2009, 26, 14–15. [Google Scholar] [CrossRef]
- Choo, M.J.; Huh, J.H. Digital Forensics System Using PLC for Inter-Floor Noise Measurement: Detailing PLC-Based Android Solution Replacing CCTV-based Solution. Electronics 2019, 8, 1091. [Google Scholar] [CrossRef]
- Maher, R.C. Audio forensic examination. IEEE Signal Process. Mag. 2009, 26, 84–94. [Google Scholar] [CrossRef]
- Maher, R.C. Overview of Audio Forensics. In Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2010; pp. 127–144. [Google Scholar] [CrossRef]
- Malik, H. Acoustic Environment Identification and Its Applications to Audio Forensics. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1827–1837. [Google Scholar] [CrossRef]
- Zakariah, M.; Khan, M.K.; Malik, H. Digital multimedia audio forensics: Past, present and future. Multimed. Tools Appl. 2017, 77, 1009–1040. [Google Scholar] [CrossRef]
- Ho, A.T.S.; Li, S. Handbook of Digital Forensics of Multimedia Data and Devices, 1st ed.; Wiley-IEEE Press: Chichester, UK, 2015. [Google Scholar]
- Renza, D.; Arango, J.; Ballesteros, D. A mobile-oriented system for integrity preserving in audio forensics. Appl. Sci. 2019, 9, 3097. [Google Scholar] [CrossRef]
- SWGIT. Best Practices for Maintaining the Integrity of Digital Images and Digital Video, SWGIT Document Section 13; Version 1.1; Technical Report; Scientific Working Group on Imaging Technology: Washington, DC, USA, 2012. [Google Scholar]
- Ozer, H.; Sankur, B.; Memon, N.; Anarım, E. Perceptual Audio Hashing Functions. EURASIP J. Adv. Signal Process. 2005, 2005, 658950. [Google Scholar] [CrossRef]
- Yiqing Lin, W.H.A. Audio Watermark; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Wang, A.L.C.; Wong, C.; Symons, J. Method and System for Identification of Distributed Broadcast Content. U.S. Patent 8,086,171, 27 December 2011. [Google Scholar]
- Wang, A.L.c.; Culbert, D. Robust and Invariant Audio Pattern Matching. U.S. Patent 7,627,477, 1 December 2009. [Google Scholar]
- Baluja, S.; Covell, M. Approximate Hashing Functions for Finding Similar Content. U.S. Patent 7,831,531, 20 September 2010. [Google Scholar]
- Chen, N.; Wan, W.; Xiao, H.D. Robust audio hashing based on discrete-wavelet-transform and non-negative matrix factorization. IET Commun. 2010, 4, 1722. [Google Scholar] [CrossRef]
- Nouri, M.; Zeinolabedini, Z.; Farhangian, N.; Fekri, N. Analysis of a novel audio hash function based upon stationary wavelet transform. In Proceedings of the 2012 6th International Conference on Application of Information and Communication Technologies (AICT), Tbilisi, GA, USA, 17–19 October 2012; pp. 1–6. [Google Scholar]
- Zhang, Q.; Qiao, S.; Zhang, T.; Huang, Y. A fast speech feature extraction method based on perceptual hashing. In Proceedings of the 2017 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Guilin, China, 29–31 July 2017; pp. 1295–1300. [Google Scholar]
- Li, J.; Wu, T. Perceptual Audio Hashing Using RT and DCT in Wavelet Domain. In Proceedings of the 2015 11th International Conference on Computational Intelligence and Security (CIS), Shenzhen, China, 19–20 December 2015; pp. 363–366. [Google Scholar]
- Chen, N.; Xiao, H.D.; Wan, W. Audio hash function based on non-negative matrix factorization of Mel-frequency cepstral coefficients. IET Inf. Secur. 2011, 5, 19–25. [Google Scholar] [CrossRef]
- Silva, T.O.E. Maximum excursion and stopping time record-holders for the problem: Computational results. Math. Comput. 1999, 68, 371–385. [Google Scholar] [CrossRef]
- Garner, L.E. On the Collatz 3n + 1 Algorithm. Proc. Am. Math. Soc. 1981, 82, 19. [Google Scholar]
- Andrei, Ş.; Masalagiu, C. About the Collatz conjecture. Acta Inform. 1998, 35, 167–179. [Google Scholar] [CrossRef]
- Han, W.; Chan, C.F.; Choy, C.S.; Pun, K.P. An efficient MFCC extraction method in speech recognition. In Proceedings of the 2006 IEEE International Symposium on Circuits and Systems, Island of Kos, Greece, 21–24 May 2006; p. 4. [Google Scholar]
- Morrison, G.S.; Sahito, F.H.; Jardine, G.; Djokic, D.; Clavet, S.; Berghs, S.; Dorny, C.G. INTERPOL survey of the use of speaker identification by law enforcement agencies. Forensic Sci. Int. 2016, 263, 92–100. [Google Scholar] [CrossRef]
- Kinnunen, T.; Saeidi, R.; Sedlak, F.; Lee, K.A.; Sandberg, J.; Hansson-Sandsten, M.; Li, H. Low-Variance Multitaper MFCC Features: A Case Study in Robust Speaker Verification. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 1990–2001. [Google Scholar] [CrossRef]
- Ai, O.C.; Hariharan, M.; Yaacob, S.; Chee, L.S. Classification of speech dysfluencies with MFCC and LPCC features. Expert Syst. Appl. 2012, 39, 2157–2165. [Google Scholar]
- Rivest, R.L.; Shamir, A.; Adleman, L.M. Cryptographic Communications System and Method. U.S. Patent 4,405,829, 20 September 1983. [Google Scholar]
- Hansen, J.H.; Hasan, T. Speaker Recognition by Machines and Humans: A tutorial review. IEEE Signal Process. Mag. 2015, 32, 74–99. [Google Scholar] [CrossRef]
- Dhillon, I.S.; Sra, S. Generalized Nonnegative Matrix Approximations with Bregman Divergences. In Proceedings of the Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 5–8 December 2005; pp. 283–290. [Google Scholar]
- Jolliffe, I. Principal component analysis for time series and other non-independent data. In Principal Component Analysis; Springer: New York, NY, USA, 2002; pp. 299–337. [Google Scholar]
- Haitsma, J.; Kalker, T.; Oostveen, J. Robust audio hashing for content identification. In Proceedings of the International Workshop on Content-Based Multimedia Indexing, Madrid, Spain, 13–15 June 2011; Volume 4, pp. 117–124. [Google Scholar]
- Mıhçak, M.K.; Venkatesan, R. A Perceptual Audio Hashing Algorithm: A Tool for Robust Audio Identification and Information Hiding. In Information Hiding; Springer: Berlin/Heidelberg, Germany, 2001; pp. 51–65. [Google Scholar]
- Li, J.; Jing, Y.; Wang, H. Audio Perceptual Hashing Based on NMF and MDCT Coefficients. Chin. J. Electron. 2015, 24, 579–588. [Google Scholar] [CrossRef]
- Zhang, Q.Y.; Xing, P.F.; Huang, Y.B.; Dong, R.H.; Yang, Z.P. An efficient speech perceptual hashing authentication algorithm based on wavelet packet decomposition. J. Inf. Hiding Multimed. Signal Process. 2015, 6, 311–322. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Frame duration (ms) | 500 |
| Frame shift (ms) | 250 |
| Preemphasis coefficient | 0.97 |
| Number of filterbank channels | 20 |
| Number of cepstral coefficients | 12 |
| Cepstral sine lifter parameter | 22 |
| Lower frequency limit (Hz) | 300 |
| Upper frequency limit (Hz) | 3900 |
| Operation | Binary Vector | |
|---|---|---|
| 6 | 0 | |
| 3 | 1 | |
| 10 | 0 | |
| 5 | 1 | |
| 16 | 0 | |
| 8 | 0 | |
| 4 | 0 | |
| 2 | 0 | |
| 1 | 1 (MSB) |
| Type | Theoretical Values | Experimental Values | ||
|---|---|---|---|---|
| Parameter | ||||
| Value | 0.5 | 0.05103 | 0.4175 | 0.05439 |
| Perceptual Manipulation | Description | Parameters |
|---|---|---|
| Format conversion: FLAC | Conversion to FLAC and returned to wav | Sample rate: 8 kHz Bits per sample: 24 |
| Format conversion: MPEG-4 AAC | Conversion to MPEG-4 AAC and returned to wav | Sample rate: 44.1 kHz BitRate: 192 kbps |
| Decrease Volume | The amplitude of the recording is attenuated by a scale of 2 | Gain: −6 dB |
| Re-sampling | Sampling frequency is set to 16 kHz and returned to 8 kHz | 8 kHz → 16 kHz → 8 kHz (using anti-aliasing FIR filter) |
| Re-quantization | Each sample is quantized to 32 bits/sample, and returned to 16 bits/sample | 16 bits → 32 bits → 16 bits |
| Low-pass filtering | Butterworth low pass filter (LPF) | 3 kHz, fifth order |
| Noise | Gaussian Additive noise | |
| Cutting | Delete samples from the original signal | 5000 samples are deleted |
| Copy-move | Copy and move samples in the original signal | 10,000 samples are exchanged |
| Signal | RMS Value |
|---|---|
| Original | |
| Original − Flac | 0 |
| Original − MPEG-4 AAC | |
| Original − Volume | |
| Original − Re-sampling | |
| Original − Re-quantization | 0 |
| Signal | BER |
|---|---|
| Original | 0% |
| Flac | 0% |
| MPEG-4 AAC | 10.42% |
| Volume | 4.17% |
| Re-sampling | 1.04% |
| Re-quantization | 0% |
| Manipulation | Average of BER Values |
|---|---|
| FLAC | 0.00% |
| MPEG-4 AAC | 4.79% |
| Volume | 0.99% |
| Re-sampling | 2.75% |
| Re-quantization | 0.00% |
| LPF | 26.44% |
| Noise | 41.62% |
| Cutting | 33.45% |
| Copy-move | 33.05% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Renza, D.; Vargas, J.; Ballesteros, D.M. Robust Speech Hashing for Digital Audio Forensics. Appl. Sci. 2020, 10, 249. https://doi.org/10.3390/app10010249
Renza D, Vargas J, Ballesteros DM. Robust Speech Hashing for Digital Audio Forensics. Applied Sciences. 2020; 10(1):249. https://doi.org/10.3390/app10010249
Chicago/Turabian StyleRenza, Diego, Jaisson Vargas, and Dora M. Ballesteros. 2020. "Robust Speech Hashing for Digital Audio Forensics" Applied Sciences 10, no. 1: 249. https://doi.org/10.3390/app10010249
APA StyleRenza, D., Vargas, J., & Ballesteros, D. M. (2020). Robust Speech Hashing for Digital Audio Forensics. Applied Sciences, 10(1), 249. https://doi.org/10.3390/app10010249