
Factor Structure of Almutairi’s Critical Cultural Competence Scale

Abstract
:1. Introduction
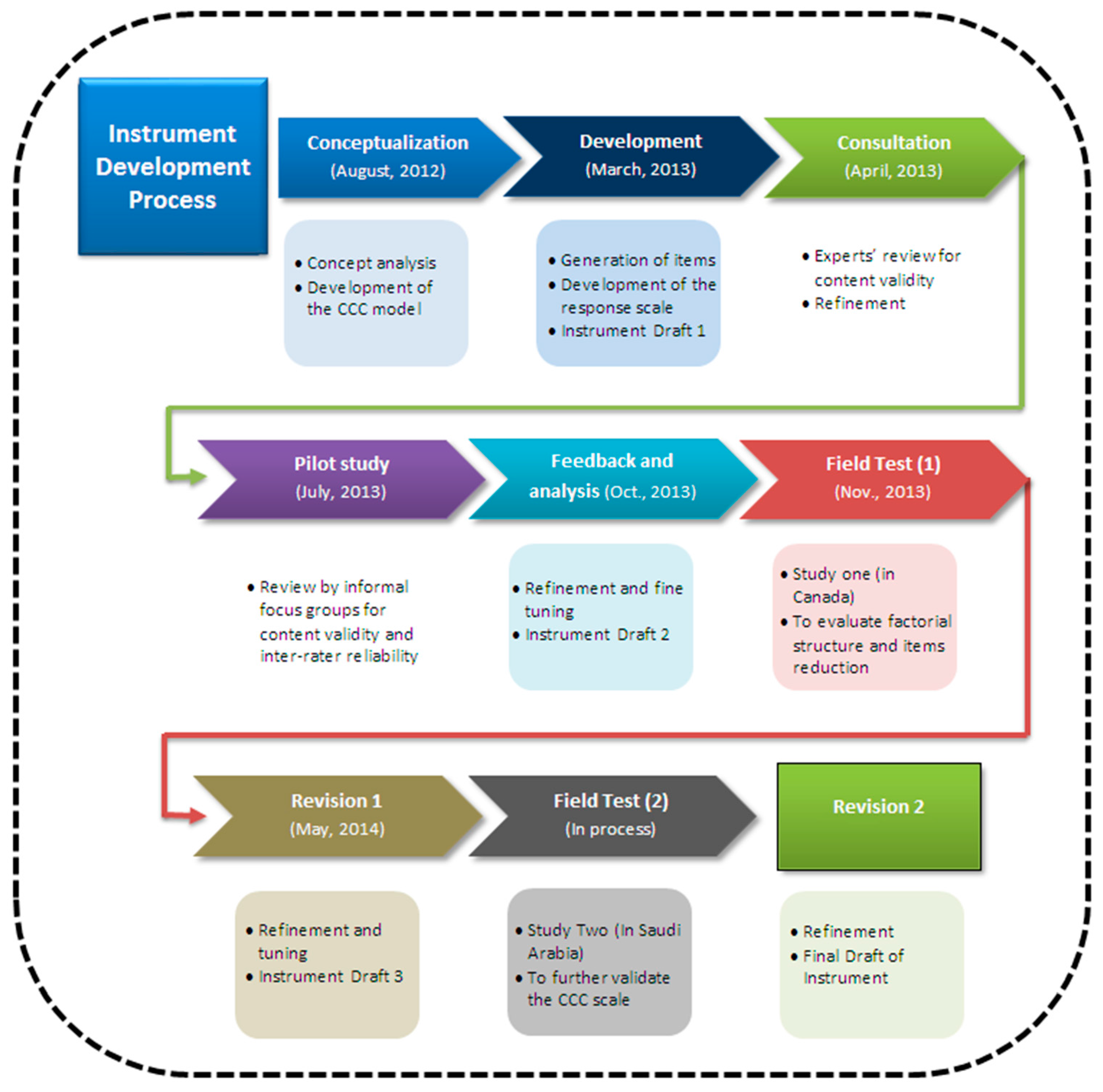
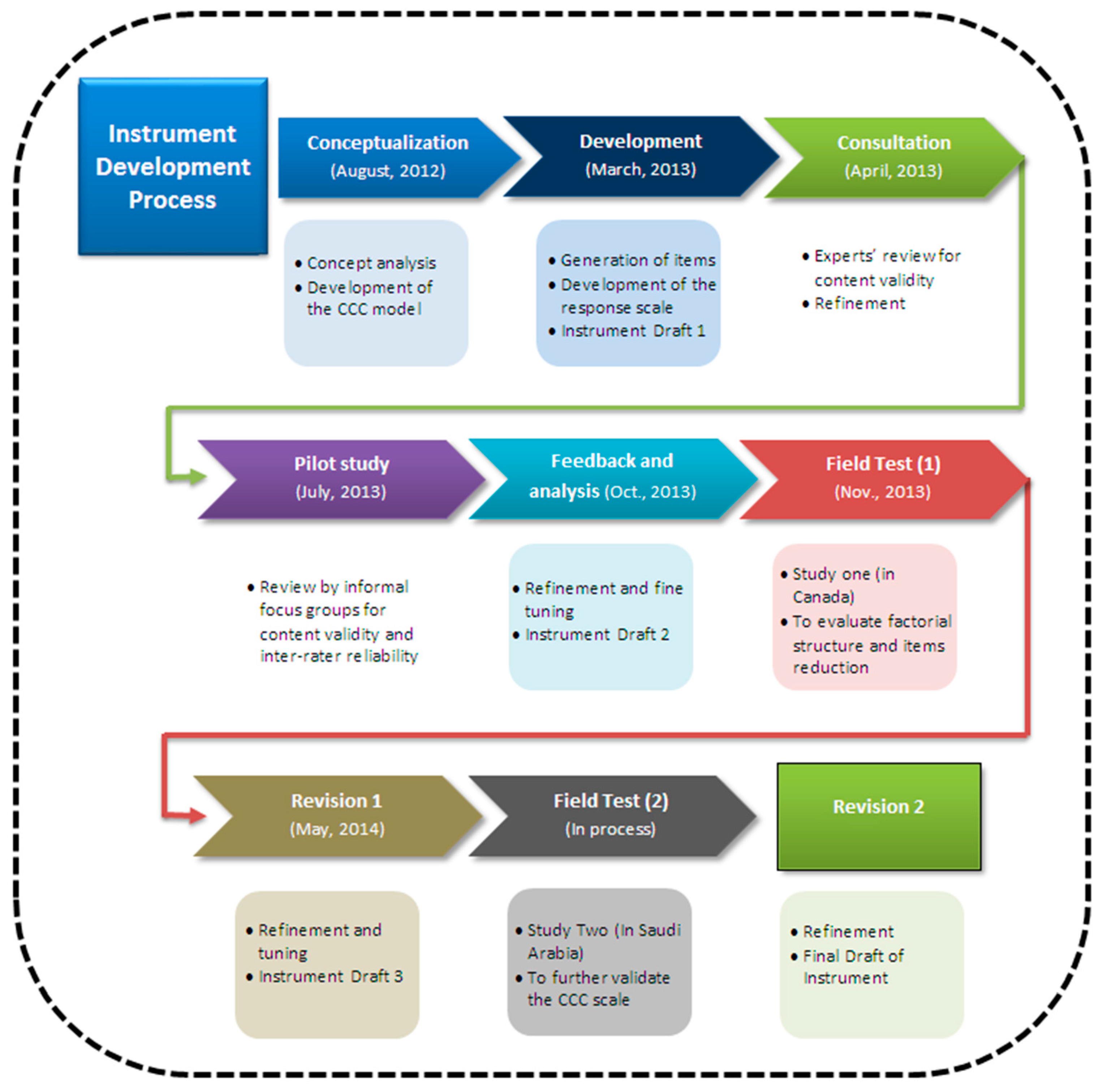
2. Methods
2.1. Study Participants and Recruitment and Data Collection Procedures
2.2. Data Analysis
3. Results
3.1. Respondent Characteristics
3.2. Principal Component Analysis Results
3.3. Internal Consistency
4. Discussion and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bernal, H., and R. Froman. 1987. The confidence of community health nurses in caring for ethnically diverse populations. J. Nurs. Scholarsh. 19: 201–203. [Google Scholar] [CrossRef]
- Bernal, H. 1993. A model for delivering culture-relevant care in the community. Publ. Heal. Nurs. 10: 228–232. [Google Scholar] [CrossRef]
- Rooda, L.A. 1993. Knowledge and attitudes of nurses toward culturally different patients: Implications for nursing education. J. Nurs. Educ. 32: 209–213. [Google Scholar] [PubMed]
- Motwani, J., J. Hodge, and S. Crampton. 1995. Managing diversity in health care industry: A conceptual model and an empirical investigation. Heal. Care Superv. 13: 16–23. [Google Scholar]
- Jabaya-Rusth, M.L., J. Kingery, D. Holcomb, W.P. Bruckner, and R.E. Pruitt. 1994. Development of a multicultural sensitivity scale. J. Heal. Educ. 25: 350–357. [Google Scholar] [CrossRef]
- Pope-Davis, D.B., A.L. Reynolds, J.G. Dings, and T.M. Ottavi. 1994. Multicultural competencies of doctoral interns at university counseling centers: An exploratory investigation. Prof. Psychol. Res. Pract. 25: 466–470. [Google Scholar] [CrossRef]
- Carpenter-Song, E.A., M.N. Schwallie, and J. Longhofer. 2007. Cultural competence reexamined: Critique and directions for the future psychiatric services. Psychiatr. Serv. 58: 1362–1365. [Google Scholar] [CrossRef] [PubMed]
- Kumagai, A.K., and M.L. Lypson. 2009. Beyond cultural competence: Critical consciousness, social justice, and multicultural education. Acad. Med. 84: 82–87. [Google Scholar] [CrossRef] [PubMed]
- Almutairi, A.F., and P. Rodney. 2013. Critical cultural competence for culturally diverse workforces: Toward equitable and peaceful health care. Adv. Nurs. Sci. 36: 200–212. [Google Scholar] [CrossRef] [PubMed]
- Anderson, J., J. Perry, C. Blue, A. Browne, A. Henderson, K.B. Khan, S.R. Kirkham, J. Lynam, P. Semeniuk, and V. Smye. 2003. “Rewriting” cultural safety within the postcolonial and postnational feminist project: Toward new epistemologies of healing. Adv. Nurs. Sci. 26: 196–214. [Google Scholar] [CrossRef]
- Abrams, L.S., and J.A. Moio. 2009. Critical race theory and the cultural competence dilemma in social work education. J. Soc. Work Educ. 45: 245–261. [Google Scholar] [CrossRef]
- Campinha-Bacote, J. 1999. A model and instrument for addressing cultural competence in health care. J. Nurs. Educ. 38: 203–207. [Google Scholar] [PubMed]
- Doorenbos, A.Z., S.M. Schim, R. Benkert, and N.N. Borse. 2005. Psychometric evaluation of the cultural competence assessment instrument among healthcare providers. Nurs. Res. 54: 324–331. [Google Scholar] [CrossRef] [PubMed]
- Almutairi, A.F. 2012. A Case Study Examination of the Influence of Cultural Diversity in the Multicultural Nursing Workforce on the Quality of Care and Patient Safety in Saudi Arabian Hospital. Ph.D. Thesis, Queensland University of Technology, Brisbane, Australia. [Google Scholar]
- Campinha-Bacote, J. 2002. The Process of cultural competence in the delivery of healthcare services: A model of care. J. Transcult. Nurs. 13: 181–184. [Google Scholar] [CrossRef] [PubMed]
- Anderson, J.M. 2004. Lessons from a postcolonial-feminist perspective: Suffering and a path to healing. Nurs. Inq. 11: 238–246. [Google Scholar] [CrossRef] [PubMed]
- Reimer-Kirkham, S., J.L. Baumbusch, A. Schultz, and J.M. Anderson. 2007. Knowledge development and evidence-based practice: Insights and opportunities from a postcolonial feminist perspective for Transformative Nursing Practice. Adv. Nurs. Sci. 30: 26–40. [Google Scholar] [CrossRef]
- Tang, S.Y., and A.J. Browne. 2008. ‘Race’ matters: Racialization and egalitarian discourses involving Aboriginal people in the Canadian health care context. Ethn. Heal. 13: 109–127. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.H. 2005. History and identity: A systems of checks and balances for Aotearoa/New Zealand. In New Zealand Identities: Departures and Destinations. Edited by J.H. Liu, T. McCreanor, T. McIntosh and T. Teaiwa. Wellington, New Zealand: Victoria University Press. [Google Scholar]
- Ramsden, I.M. 2002. Cultural Safety and Nursing Education in Aotearoa and Te Waipounamu. Wellington, New Zealand: Victoria University of Wellington. [Google Scholar]
- MacKenzie, S.B., P.M. Podsakoff, and N.P. Podsakoff. 2011. Construct measurement and validation procedures in MIS and behavior research: Integrating new and existing techniques. Manag. Inf. Syst. Q. 35: 293–334. [Google Scholar]
- Almutairi, A.F., S. Dahinten, and P. Rodney. 2015. Almutairi’s critical cultural competence model for a multicultural healthcare environment. Nurs. Inq. 22: 317–325. [Google Scholar] [CrossRef] [PubMed]
- Marcoulides, G.A. 2013. Modern Methods for Business Research. New York, NY, USA: Psychology Press. [Google Scholar]
- Sternberg, R.J., and S. Rayner. 2012. Handbook of Intellectual Styles: Preferences in Cognition, Learning, and Thinking. New York, NY, USA: Springer Publishing Company. [Google Scholar]
- Franzen, M.D. 2000. Reliability and Validity in Neuropsychological Assessment. New York, NY, USA: Springer Science & Business Media. [Google Scholar]
- Yang, K., and G. Miller. 2007. Handbook of Research Methods in Public Administration. Boca Raton, FL, USA: CRC Press. [Google Scholar]
- Williams, B., T. Brown, and A. Onsman. 2010. Exploratory factor analysis: A five-step guide for novices. Australas. J. Paramed. 8: 1–13. [Google Scholar]
- Costello, A.B., and J.W. Osborne. 2005. Best practices in exploratory factor analysis: Four recommendations for getting the most from your analysis. Pract. Assess. Res. Eval. 10: 1–9. [Google Scholar]
- Polit, D.F., and C.T. Beck. 2012. Nursing Research: Generating and Assessing Evidence for Nursing Practice, 9th ed. Philadelphia, PA, USA: Wolters Kuwer Health. [Google Scholar]
- Field, A. 2013. Discovering Statistics Using IBM SPSS Statistics, 4th ed. Los Angeles, CA, USA: Sage. [Google Scholar]
- Guadagnoli, E., and W.F. Velicer. 1988. Relation to sample size to the stability of component patterns. Psychol. Bull. 103: 265–275. [Google Scholar] [CrossRef] [PubMed]
- MacCallum, R.C., K.F. Widaman, S. Zhang, and S. Hong. 1999. Sample size in factor analysis. Psychol. Methods 4: 84–99. [Google Scholar] [CrossRef]
- Conway, J.M., and A.I. Huffcutt. 2013. A Review and Evaluation of Exploratory Factor Analysis Practices in Organizational Research. Organ. Res. Methods 6: 147–168. [Google Scholar] [CrossRef]
- Ford, J.K., R.C. MacCallum, and M. Tait. 1986. The application of exploratory factor analysis in applied psychology: Acritical review and analysis. Pers. Psychol. 39: 291–314. [Google Scholar] [CrossRef]
- D'agostino, Sr., R.B., and H.K. Russell. 2005. Encyclopedia of Biostatistics. Oxford, UK: John Wiley & Sons. [Google Scholar]
- Pallant, J. 2007. SPSS Survival Manual: A Step-by-Step Guide to Data Analysis Using SPSS for Windows, 3rd ed. Sydney, Australia: Allen & Unwin. [Google Scholar]
- Glorfeld, L.W. 1995. An improvement on Horn’s parallel analysis methodology for selecting the correct number of factors to retain. Educ. Psychol. Meas. 55: 377–393. [Google Scholar] [CrossRef]
- Clarke, L.A., and D. Watson. 2016. Constructing Validity: Basic Issues in Objective Scale Development. In Methodological Issues and Strategies in Clinical Research, 4th ed. Edited by A.E. Kazdin. Washington, DC, USA: American Psychological Association, pp. 187–203. [Google Scholar]
- Hinton, P.R., C. Brownlow, I. McMurray, and B. Cozens. 2004. SPSS Explained. East Sussex, UK: Routledge. [Google Scholar]
- George, D., and P. Mallery. 2003. SPSS for Windows Step by Step: A Simple Guide and Reference, 4th ed. Boston, MA, USA: Allyn & Bacon. [Google Scholar]
- Basilevsky, A.T. 2009. Statistical Factor Analysis and Related Methods: Theory and Applications. New York, NY, USA: John Wiley & Sons. [Google Scholar]
- Schim, S.M., A.Z. Doorenbos, J. Miller, and R. Benkert. 2003. Development of a cultural competence assessment instrument. J. Nurs. Meas. 11: 29–40. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.-W., M.M. Davidson, O.F. Yakushko, H.B. Savoy, J.A. Tan, and J.K. Bleier. 2003. The scale of ethnocultural empathy: Development, validation, and reliability. J. Couns. Psychol. 50: 221–234. [Google Scholar] [CrossRef]
- Earley, P.C., and S. Ang. 2003. Cultural Intelligence: Individual Interactions Across Cultures. Stanford, CA, USA: Stanford University Press. [Google Scholar]
- Preston, C.C., and A.M. Colman. 2000. Optimal Number of Response Categories in Rating Scales: Reliability, Validity, Discriminating Power, and Respondent Preferences. Acta Psychol. 104: 1–15. [Google Scholar] [CrossRef]
- Goodwin, C.J. 2009. Research in Psychology: Methods and Design. Danvers, MA, USA: John Wiley & Sons. [Google Scholar]
- Lissitz, R.W., and S.B. Green. 1975. The effect of the number of scale points on reliability: A Monte Carlo approach. J. Appl. Psychol. 60: 10–13. [Google Scholar] [CrossRef]
- Canadian Institute for Health Information. 2014. Regulated Nurses, 2013: Data Tables. Available online: https://www.cihi.ca/en/access-data-reports (accessed on 7 May 2017).
- Almutairi, A., A. McCarthy, and G. Gardner. 2014. Understanding cultural competence in a multicultural nursing workforce: Registered nurses’ experience in Saudi Arabia. J. Transcult. Nurs. 26: 16–23. [Google Scholar] [CrossRef] [PubMed]
- Almutairi, A., G. Gardner, and A. McCarthy. 2012. Perceptions of clinical safety climate of the multicultural nursing workforce in Saudi Arabia: A cross- sectional survey. Coll. J. Aust. J. Nurs. Pract. Scholarsh. Res. 20: 187–194. [Google Scholar] [CrossRef]

{kind=link}
| Variable | Frequency | % | Mean (SD) |
|---|---|---|---|
| (N = 170) | |||
| Age (years) | 43.6 ± 11.7 | ||
| Experience in the profession (years) | 16.6 ± 12.1 | ||
| Experience in the organization (years) | 11.1 ± 9.4 | ||
| Gender | |||
| Male | 14 | 8.8 | |
| Female | 146 | 91.3 | |
| Nursing Education | |||
| Diploma | 55 | 3.4 | |
| BSN | 96 | 60 | |
| MSN | 9 | 5.6 | |
| Job Position | |||
| Staff nurse | 141 | 88.1 | |
| Clinical nurse specialist | 4 | 2.5 | |
| Nurse educator | 2 | 1.3 | |
| Nurse leader | 6 | 3.8 | |
| Nurse manager | 1 | 0.6 | |
| Other | 6 | 3.8 | |
| Nursing Specialty | |||
| Medical unit | 45 | 28.1 | |
| Emergency department | 30 | 18.8 | |
| Outpatient clinic | 29 | 18.1 | |
| Surgical unit | 26 | 16.3 | |
| Intensive care units | 12 | 7.5 | |
| Oncology units | 4 | 2.5 | |
| Pediatric unit | 3 | 1.9 | |
| Other | 11 | 6.9 | |
| Ethnicity | |||
| Caucasian | 118 | 74.2 | |
| South Asian | 20 | 12.6 | |
| Chinese | 9 | 5.7 | |
| Far East Asian | 3 | 1.9 | |
| Other Asian | 2 | 1.3 | |
| First nation | 1 | 0.6 | |
| Other | 6 | 3.8 | |
| Cultural Training | |||
| Yes | 64 | 40.5 | |
| No | 94 | 59.5 |
| Item | Rotated Factor Loadings | Communalities | |||||
|---|---|---|---|---|---|---|---|
| 1 Critical Empowerment | 2 Critical Awareness | 3 Critical Skills | 4 Critical Knowledge | ||||
| 1. | CCC 49: I feel disrespected because of my culture. [R] | 0.796 | 0.715 | ||||
| 2. | CCC48: I face biased remarks and racism. [R] | 0.776 | 0.628 | ||||
| 3. | CCC 51: I feel alienated in my workplace because of my cultural background. [R] | 0.761 | 0.608 | ||||
| 4. | CCC 56: I am treated differently to my counterparts by management because of my cultural background. [R] | 0.700 | 0.561 | ||||
| 5. | CCC50: I feel disrespected because of my gender. | 0.689 | 0.500 | ||||
| 6. | CCC 61: In this organization, people are treated differently according to their country of origin. [R] | 0.684 | 0.520 | ||||
| 7. | CCC 60: I have an equal opportunity in terms of professional development compared to colleagues in my organization. | 0.643 | 0.439 | ||||
| 8. | CCC 83: My colleagues from other cultures look down on me. [R] | 0.643 | 0.492 | ||||
| 9. | CCC 64: I feel that my colleagues from other cultures are more powerful. [R] | 0.626 | 0.513 | ||||
| 10. | CCC47: I feel that my skin colour determines how people relate to me in this context. [R] | 0.622 | 0.411 | ||||
| 11. | CCC 59: I have an equal opportunity in terms of promotion compared to colleagues in my organization. | 0.606 | 0.417 | ||||
| 12. | CCC 62: I worry about losing my job if I speak out about my concerns of discrimination.. [R] | 0.606 | 0.450 | ||||
| 13. | CCC44: I feel reluctant to speak out about my conditions of work0. [R] | 0.587 | 0.372 | ||||
| 14. | CCC46: My nursing competence is frequently challenged by my colleagues compared to that of my counterparts. [R] | 0.536 | 0.421 | ||||
| 15. | CCC 57: I feel safe in expressing my concerns to management. | 0.528 | 0.322 | ||||
| 16. | CCC45: My nursing competence is frequently challenged by my patients compared to that of my counterparts. [R] | 0.524 | 0.393 | ||||
| 17. | CCC 66: Social norms limit my ability to advocate for my patients. [R] | 0.502 | 0.351 | ||||
| 18. | CCC15: Gender can determine the way people relate to others. | 0.729 | 0.581 | ||||
| 19. | CCC14: Social class is an important factor in determining the way people relate to others. | 0.713 | 0.509 | ||||
| 20. | CCC 16: Gender roles, positions or activities can empower some people over others. | 0.667 | 0.481 | ||||
| 21. | CCC23: Cultural differences between people can generate conflicts and tensions during interactions. | 0.608 | 0.404 | ||||
| 22. | CCC 24: Cultural differences influence how we interact and relate to others from other cultures. | 0.564 | 0.387 | ||||
| 23. | CCC 19: An interpersonal power imbalance could compromise a healthcare provider’s well-being. | 0.530 | 0.327 | ||||
| 24. | CCC 73: When I interact with people from other cultures, I feel my cultural values and norms are better. | −0.503 | 0.285 | ||||
| 25. | CCC 74: I find it annoying when time is not important for some people from other cultures. | −0.502 | 0.295 | ||||
| 26. | CCC 75: The large number of visitors for patients from other cultures is a nuisance. | −0.490 | 0.259 | ||||
| 27. | CCC 18: Cultural and linguistic differences could compromise healthcare provider’s well-being. | 0.470 | 0.275 | ||||
| 28. | CCC13: In a multicultural environment, ‘race’ can determine the way people relate to others. | 0.463 | 0.279 | ||||
| 29. | CCC 20: Cultural and linguistic differences between the healthcare provider and patient could compromise patient’s safety. | 0.447 | 0.288 | ||||
| 30. | CCC 34: There are no cultural variations between different cultural groups. [R] | 0.763 | 0.619 | ||||
| 31. | CCC33: There are no cultural variations within a cultural group of people. [R] | 0.705 | 0.509 | ||||
| 32. | CCC 36: It is not important to assess a patient’s preferences in terms of healthcare services if I am knowledgeable about their culture. [R] | 0.550 | 0.361 | ||||
| 33. | CCC 9: People from the same culture have the same religion. | 0.533 | 0.291 | ||||
| 34. | CCC37: Western biomedicine is always attentive to diverse cultural meanings. | 0.521 | 0.309 | ||||
| 35. | CCC31: Cultural norms that people adhere to are largely fixed and unvarying. [R] | 0.505 | 0.324 | ||||
| 36. | CCC 35: It is easy to anticipate behaviors and practices of people if I know their culture. [R] | 0.457 | 0.274 | ||||
| 37. | CCC 80: I use some of my patients’ languages during my care if I know a little. | 0.733 | 0.555 | ||||
| 38. | CCC 81: I use culturally congruent body language when interacting with people from other cultures. | 0.730 | 0.536 | ||||
| 39. | CCC 79: I am able to change healthcare practices to meet my patients’ cultural and religious needs and expectations. | 720 | 0.529 | ||||
| 40. | CCC 76: I discuss the different cultural meanings in terms of health and illness with my patients from other cultures in order to provide them with optimal care0. | 0.621 | 0.460 | ||||
| 41. | CCC 82: I use simple language when I speak with people from other cultures and I consider their potential language limitations. | 0.568 | 0.332 | ||||
| 42. | CCC 78: I discuss ethically sensitive issues with my patients/families. | 0.515 | 0.299 | ||||
| 43. | CCC 39: Assessing the linguistic needs of my patients and their family during care delivery is important | 0.440 | 0.330 | ||||
| Eigenvalues | 8.25 | 4.29 | 3.03 | 2.60 | |||
| % of variance explained | 19.19 | 9.98 | 7.06 | 6.10 | |||
| Components | Corresponding Items |
|---|---|
| Critical Empowerment | The individual’s experience of racialization:
The individual’s assessment of their organization
The individual’s confidence
|
| Critical Awareness | Self-awareness of own attitudes and values
Awareness of the consequences of cultural and power differences
|
| Critical Knowledge |
|
| Critical Skills |
|
| Scale | No. of Items | Cronbach’s Alpha |
|---|---|---|
| Critical Awareness | 12 | 0.60 |
| Critical Knowledge | 7 | 0.70 |
| Critical Skills | 7 | 0.77 |
| Critical Empowerment | 17 | 0.92 |
| Overall score of CCC | 43 | 0.86 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almutairi, A.F.; Dahinten, V.S. Factor Structure of Almutairi’s Critical Cultural Competence Scale. Adm. Sci. 2017, 7, 13. https://doi.org/10.3390/admsci7020013
Almutairi AF, Dahinten VS. Factor Structure of Almutairi’s Critical Cultural Competence Scale. Administrative Sciences. 2017; 7(2):13. https://doi.org/10.3390/admsci7020013
Chicago/Turabian StyleAlmutairi, Adel F., and V. Susan Dahinten. 2017. "Factor Structure of Almutairi’s Critical Cultural Competence Scale" Administrative Sciences 7, no. 2: 13. https://doi.org/10.3390/admsci7020013
APA StyleAlmutairi, A. F., & Dahinten, V. S. (2017). Factor Structure of Almutairi’s Critical Cultural Competence Scale. Administrative Sciences, 7(2), 13. https://doi.org/10.3390/admsci7020013