1. Introduction
In our increasingly globalized world, second language (L2) acquisition has become an essential skill, with Mandarin Chinese emerging as one of the most strategically important languages to learn (
Guo, 2024;
Wu, 2024). Given the growing global demand for second-language learning, understanding cognitive mechanisms that enable learners to progress from novice to advanced proficiency is an increasingly important focus for research. A key theoretical debate in psycholinguistic research currently centers on whether advanced L2 readers employ the same cognitive strategies as native speakers or rely on distinct mechanisms for sentence processing and ambiguity resolution (
Hopp, 2022).
With the present research, we focus on an important challenge in learning to read Chinese as a second language that is unique to its writing system. Unlike other writing systems used worldwide, Chinese employs a character-based writing system that does not use spaces or other visual cues to demarcate word boundaries (
X. Li et al., 2015;
Zang et al., 2011). This creates frequent temporary segmental ambiguities, where character sequences can be parsed to create alternative possible word analyses with distinct meanings (
W. Zhou et al., 2020). For skilled L1 Chinese readers, this segmental processing ambiguity does not appear to be a significant cause of reading difficulty. Instead, readers appear able to efficiently and accurately segment continuous unspaced character strings into words with ease (
Bai et al., 2008;
X. Li & Shen, 2013;
X. Li et al., 2009;
X. Li & Pollatsek, 2020;
Zang et al., 2013), reading at approximately 250 words per minute, comparable to reading speeds for spaced alphabetic scripts like English (
Liversedge et al., 2016). However, segmental ambiguities seem likely to challenge L2 Chinese readers, especially those who do not encounter similar segmental ambiguities in their native language (
Aziz & Jayaputri, 2022). Understanding how L2 Chinese readers process and ultimately overcome segmental ambiguity is therefore crucial for developing effective pedagogical approaches that support the progression from novice to advanced L2 reading proficiency.
1.1. The Role of Visual Cues to Word Boundaries
Many writing systems, including alphabetic scripts like English, use interword spaces to visually mark word boundaries. A wealth of research shows that this low-spatial frequency cue plays an important role in alphabetic reading, helping readers to unambiguously identify words and guide their eye movements (
Rayner, 1979,
2009;
X. Li & Pollatsek, 2020). Moreover, reading is disrupted when the spaces between words are removed in such scripts, indicating that interword spaces play an important role in efficient reading performance (
McConkie & Rayner, 1975;
Pollatsek & Rayner, 1982;
Rayner et al., 1998;
Perea & Acha, 2009;
Winskel et al., 2009;
Pinna & Deiana, 2014;
Perea et al., 2015). This raises the question of whether using spaces to mark word boundaries might improve reading efficiency in Chinese? For native Chinese readers, current research suggests that including interword spacing that correctly cue word boundaries can reduce processing time for ambiguous or complex sentences (
Hsu & Huang, 2000a,
2000b). However, for more simple sentences, including interword spaces does not appear to significantly impact reading speed or comprehension accuracy, suggesting that interword spaces provide only limited benefits for skilled Chinese readers (
Bai et al., 2008;
Hsu & Huang, 2000a,
2000b;
X. Li & Pollatsek, 2020;
Zang et al., 2013; see also
Huang et al., 2024, and see
Wang et al., 2025, for studies investigating effects in Javanese—an unspaced syllabic script).
Fewer studies have investigated the potential benefits of interword spaces for L2 Chinese readers. Those studies that have addressed this issue nevertheless suggest that L2 readers can use these visual cues to guide segmentation decisions while also experiencing difficulty when interword spaces are used to incorrectly cue word segmentation (
D. Shen et al., 2012;
Cui, 2023). Interword spaces are also widely employed in Chinese language textbooks aimed at L2 beginner Chinese learners (
J. Yang, 2006;
X. Q. Li et al., 2013), suggesting that they may be useful in supporting L2 beginners. However, as visual boundary cues are absent in everyday Chinese text, L2 beginner Chinese learners may also experience difficulty when transitioning to authentic reading. Finally, some studies suggest that inserting spaces between words in Chinese text may disrupt normal reading efficiency by causing upcoming characters to be perceived at more eccentric visual locations than normal, thereby altering normal text layout and reducing acuity for upcoming characters (
Rayner, 2009;
Bai et al., 2011;
Perea et al., 2015).
Such observations have led researchers to explore alternative methods for marking word boundaries without altering standard text layout. One promising approach uses color to perceptually group characters belonging to the same word, thereby cueing word boundaries without introducing additional physical space (see
Pinna & Deiana, 2014;
Häikiö et al., 2016;
Perea et al., 2015 for research in alphabetic scripts;
Perea & Wang, 2017;
W. Zhou et al., 2018,
2019;
Pan et al., 2020,
2025 for research in Chinese; and
Wang et al., 2025, for research in Javanese—an unspaced syllabic script). Studies in alphabetic reading suggest that alternating word color can compensate for the removal of spaces in scripts like Spanish that normally employ interword spaces, allowing readers to maintain native-like reading speeds and processing efficiency relative to normally spaced text (
Perea et al., 2015;
Pinna & Deiana, 2014). Benefits are also observed in morphologically complex alphabetic languages like Finnish, where using text color to demarcate morphemes appears to better support the segmentation of long, multisyllabic words compared to more conventional hyphenation methods (
Häikiö et al., 2016).
Research in Chinese additionally suggests that skilled L1 reading can benefits from use of alternating text color to group characters into words. Several studies report that L1 reading is faster, with fewer and shorter fixations, when alternating text color marks word boundaries, taken as evidence that color cues are effective for helping skilled readers to recognize words (
Perea & Wang, 2017;
W. Zhou et al., 2018;
Pan et al., 2020,
2025). However, less attention has been paid to the possible benefits for L2 Chinese readers. To our knowledge, only
W. Zhou et al. (
2020) has investigated this issue to date, showing that L2 reading is faster when alternating text color correctly cues word boundaries. At the same time, using text color to incorrectly cue word boundaries has been shown to increase reading times by both L1 and L2 readers (
W. Zhou et al., 2018,
2020). This suggests that both groups use color cues to process word boundaries even when these conflict with correct word segmentation. Studies to date have focused on relatively simple texts and have not directly investigated the influence of color cues on the processing of segmental ambiguities. Such effects may nevertheless be important for beginning readers, however, by helping them to more rapidly resolve segmental ambiguities. Given this absence of relevant research, we therefore addressed this question, by comparing the effects of color cues on the processing of temporary segmental ambiguities by high-proficiency L2 readers and skilled L1 readers.
1.2. Segmental Ambiguity in Chinese Reading
The present research focused on incremental segmental ambiguities, which are common in Chinese reading, occurring when a multi-character word contains an embedded shorter word. For instance, the three-character “incremental” word 体育馆 (meaning “stadium”) incorporates the two-character word 体育 (meaning “sport”) as its first two characters, creating temporary ambiguity between whole-word and embedded-word analyses of these characters. Current theoretical accounts diverge in their predictions about how this ambiguity is processed. Serial accounts (
Perfetti & Tan, 1999) propose that readers initially segment text based on their knowledge that Chinese predominantly employs one- and two-character words. According to this approach, readers should initially identify a two-character embedded word within a longer “incremental” word before experiencing processing difficulty on encountering the residual third character. Readers should then attempt to revise this misanalysis by adopting a whole-word analysis of the ambiguity, with this reanalysis incurring a further processing cost.
By comparison, parallel accounts, including the Chinese Reading Model (CRM;
X. Li & Pollatsek, 2020), propose that the alternative possible lexical analyses are considered in parallel (
Inhoff & Wu, 2005;
X. Li et al., 2009). Within the CRM, it is assumed that on each fixation the reader attempts to segment a small set of characters within their perceptual span. While the perceptual span encompasses about one character to the left and two or three characters to the right of the fixated character for skilled college-aged L1 readers (
Inhoff & Liu, 1998), it is likely to be smaller for L2 readers (see
Fernandez et al., 2023;
Jordan et al., 2014). All possible character groupings within this region are assumed to become activated in parallel, with alternative segmental analyses competing for selection via mechanisms inspired by competition-based models of word recognition (e.g.,
McClelland & Rumelhart, 1981). Following this approach, when processing a multi-character sequence like 体育馆, lexical entries for both the whole word (体育馆) and its embedded word (体育) become activated and compete for selection. According to the CRM, the whole-word analysis usually wins this competition, as it receives greater bottom–up activation because it has more component characters. Parallel accounts of Chinese word segmentation therefore predict that skilled L1 Chinese readers prefer to adopt a whole-word analysis of an incremental segmental ambiguity.
J. Zhou and Li (
2021) compared these contrasting accounts of word segmentation in two eye movement experiments with skilled college-aged L1 Chinese readers. In Experiment 1, participants read sentences containing either an incremental target word (e.g., 酒精灯) or a control target word that was identical to the increment target’s embedded word (e.g., 酒精). The verb immediately preceding the target word differed across versions of the sentences so that it could combine either plausibly or implausibly with the target word in the control sentences (点燃酒精灯/酒精 [lit the alcohol lamp/alcohol] are both plausible, but 清洗酒精灯 [washed the alcohol lamp] is plausible, while 清洗酒精 [washed the alcohol] is implausible), and so also the embedded word in the incremental word sentences. However, in this experiment, the verbs always combined plausibly with the whole-word analysis of the segmental ambiguity.
Zhou and Li observed plausibility effects for the control target words but not the embedded words in the incremental sentences, which they took to show that readers initially adopted a whole-word analysis of the ambiguity without activating the embedded-word analysis. Experiment 2 independently manipulated the plausibility of the incremental words and their embedded words across different verb contexts. Plausibility effects were observed only for incremental target words and not the embedded words, which was taken as further evidence that readers preferentially adopted a whole-word analysis of the ambiguity. Findings from both experiments therefore were consistent with a parallel account exemplified by the CRM. These findings were subsequently replicated by
L. Li et al. (
2024) for skilled college-aged L1 readers and older L1 readers, suggesting that segmental ambiguity processing is preserved in older age. What remains unclear, however, is whether L2 Chinese readers employ the same processing strategy as L1 readers.
Research on L2 ambiguity resolution has to date relied on offline methods to assess learners’ accuracy in identifying word boundaries (
H. H. Shen & Jiang, 2013;
H. H. Shen & Dai, 2024;
S. Yang, 2021), showing that L2 learners frequently make segmentation errors, adversely affecting their comprehension. However, L2 research has not investigated how these ambiguities are processed during reading in real time. The present research therefore addressed this issue, using eye movement measures to assess real-time ambiguity processing by skilled L1 readers and high-proficiency L2 readers, while also investigating the effects of visual boundary cues on this processing.
1.3. The Present Experiment
Similarly to
J. Zhou and Li (
2021), the present research measured eye movements for sentences containing temporarily ambiguous three-character incremental words (e.g., “音乐剧” [musical]), where the initial two characters (“音乐” [music]) could also form a valid word. The embedded word was either plausible or implausible in the context of the immediately preceding verb, while the whole-word analysis was plausible regardless of the verb context. This enabled us to investigate whether L1 or L2 groups process the embedded word’s plausibility during reading. If both groups adopt a whole-word analysis of the ambiguity, in line with parallel processing accounts, no effects of embedded word ambiguity should be observed. However, if either the L1 or L2 group identify the embedded word, we would expect to observe a plausibility effect. Moreover, if this effect is observed in measures of initial ambiguity processing, this would suggest that they first selected this analysis of the ambiguity, potentially in line with a serial processing account.
We also examined the effects of color coding word boundaries. We did so by presenting the sentence stimuli under different color conditions: either in a standard mono-color format or with alternating text color used to demarcate word boundaries. Under one alternating text color condition, characters belonging to the whole-word analysis of an ambiguity were displayed in the same text color; under the other condition, the two characters belonging to the embedded word were displayed in the same text color while the third character was displayed in a different text color. This enabled us to test whether using alternating text color to mark word boundaries would influence decisions about how to segment the ambiguity. Presenting all three characters in the same color might aid selection of whole-word analysis, potentially facilitating processing of the ambiguity relative to the mono-color condition. Alternatively, presenting the embedded word’s characters in the same color, distinct from that of the third character, might encourage selection of the embedded-word analysis. In this case, we might observe a larger embedded word plausibility effect relative to the other two conditions. The manipulation would therefore reveal whether using alternating text color to mark word boundaries influences segmental ambiguity processing by L1 and L2 readers.
Following
J. Zhou and Li (
2021), we additionally analyzed eye movements for the pre-target verbs that immediately preceded the target word. This allowed us to investigate parafoveal processing dynamics for the two groups of readers. Parafoveal processing refers to the acquisition of linguistic information from an upcoming word in the text (see
Cutter et al., 2015;
Schotter et al., 2012). This is seen as a hallmark of skilled reading, allowing readers to begin processing the following word before it is fixated. It was therefore of interest to establish whether skilled L1 and high-proficiency L2 readers exhibit similar parafoveal processing capabilities. A key question was whether either group could acquire parafoveal semantic information while fixating the pre-target verb. This question is highly controversial in research on alphabetic reading (
Antúnez et al., 2022;
Hohenstein et al., 2010;
López-Peréz et al., 2016;
Rayner et al., 1986,
2014), where it has generally been assumed that only lower-level orthographic and phonological information can be processed parafoveally, and not semantic information. However, there is growing evidence that such effects can be obtained in Chinese reading, potentially because of its more compact script (
Yan et al., 2009;
J. Yang et al., 2012;
Pan et al., 2016). Moreover, this research suggests that Chinese readers can pre-process the contextual plausibility of parafoveal words. A key further question we therefore address in the present research is whether readers can process the plausibility of the embedded-word analysis of the segmental ambiguity while fixating the pre-target verb in our sentence stimuli, and whether such effects differ for L1 compared to L2 readers.
Demonstrating such effects would support the view that upcoming words can be segmented and lexically identified before being directly fixated (although note that
J. Zhou and Li (
2021) observed no such effects in their study). Moreover, this analysis may also shed light on the parafoveal processing capabilities of high-proficiency L2 readers, and whether these differ from those of skilled L1 readers. Very little research to date has investigated L2 parafoveal processing, despite the importance of parafoveal processing in skilled readers. Existing research suggests that L2 readers exhibit parafoveal processing competence in alphabetic reading (
Tiffin-Richards, 2024). However, Chinese-specific studies that have been conducted to date suggest that L2 parafoveal processing is limited in this script (
Cong & Chen, 2022;
Xiao et al., 2021). We therefore conducted exploratory analyses comparing L1 and L2 parafoveal processing of segmental ambiguities, and whether this might be influenced by parafoveal visual boundary cues.
1.4. Summary
In summary, the present research investigates how color cues influence word segmentation in Chinese by both L1 (native) and L2 (non-native) readers. Specifically, it aims to directly test:
Whether L1 and L2 readers use similar or different strategies to resolve segmental ambiguity during Chinese reading; and
Whether highlighting word boundaries using alternating text colors can support ambiguity resolution for either group.
In addressing these questions, the research also offers broader insights into differences in L1 and L2 sentence processing. First, it contributes to understanding of eye movement patterns in L1 and L2 readers during Chinese reading, building on a relatively limited body of research. Second, it sheds light on the more general impact on eye movement behavior on using text color cues to mark word boundaries in text for both groups of readers. Finally, by analyzing eye movements just before readers encounter an ambiguous segment, the study offers new insights into the parafoveal processing abilities of L1 and L2 readers, and the role of parafoveal information in resolving segmental ambiguity.
3. Results
Accuracy answering comprehension questions was high for all participants (>85%, L1, M = 92%, SD = 0.04; L2, M = 86%, SD = 0.07, p < 0.001), indicating that both groups understood the sentences well.
Following standard procedures, fixations shorter than 80 ms and longer than 1200 ms were removed (affecting 5.6% of fixations for L1 participants and 3.4% of fixations for L2 participants). The remaining data were analyzed by linear mixed-effects models (LMEMs;
Baayen et al., 2008) using R (version 4.3.2;
R Core Team, 2024) and the lme4 package (
Bates et al., 2011).
p-values were estimated using the lmerTest package (
Kuznetsova et al., 2017). For binomial variables, generalized LMEMs were conducted with the Laplace approximation. Continuous variables were log-transformed (
Wagenmakers et al., 2012). A maximal random-effects structure was used (
Barr et al., 2013). For sentence-level measures, participant group and text color were treated as fixed factors; in target word analyses, participant group, embedded word plausibility, text color, and their interaction served as fixed factors while participants and stimuli constituted crossed random effects. If model convergence issues arose, the random-effects structure was simplified by initially trimming it for stimuli—beginning with the removal of random effect correlations followed by random slopes (
Matuschek et al., 2017). Contrasts were defined using sliding contrasts (the contr. sdif function) in the MASS package (
Venables & Ripley, 2002). Following convention, t/z values > 1.96 were considered significant.
We analyzed eye movements across the full sentence and at the word level for the two-character pre-target verbs and three-character incremental target words. The sentence-level analyses provided general insights into L1 versus L2 differences in eye movement behavior in reading, as well as the overall impact of text color coding segmental ambiguity (See
Figure 2). For these analyses, we report sentence reading time (SRT, the time from the onset of a sentence display until the participant pressed a response key to indicate that they had finished reading the sentence), average fixation duration (AFD, the mean length of fixations), the overall number of fixations (NF), the number of regressions (NR, backward eye movements in the sentences), and average forward saccade amplitude (AFS, the mean length of forward-directed eye movements, which are reported as the number of characters traversed by a saccade).
Word-level analyses allowed us to directly examine L1–L2 differences in how text color cues influence the processing of the segmental ambiguity. The effects observed at the target region provided insight into how these factors impact foveal (fixational) processing of the ambiguous segment. By comparison, effects at the pre-target region revealed how parafoveal processing contributes to resolving segmental ambiguity before the ambiguous segment is directly fixated.
For the word-level analyses, we report measures informative about first-pass reading; that is, the initial processing of a word prior to a fixation to its right or a regression from that word. These measures comprised first-fixation duration (FFD; duration of the first progressive fixation on a word), single-fixation duration (SFD; first-pass fixation duration for words receiving only one first-pass fixation), and gaze duration (GD; sum of all first-pass fixations on a word). We also report word-level measures that are informative about later processing; namely, total reading time (TRT; sum of all fixations on a word) and regression-in (RI; probability of a regression to a word).
The word-level analyses enabled us to test hypotheses regarding the processing of segmental ambiguity and the effects of color coding for both participant groups.
Von der Malsburg and Angele (
2017) cautioned that using multiple dependent measures in eye movement research increases the risk of false positives, particularly through practices such as ‘cherry picking’ statistically significant results from individual measures. To mitigate this risk, we distinguished between hypothesis-driven analyses, grounded in prior research, and exploratory analyses that offer a broader descriptive account of the observed effects. Specifically, when examining plausibility effects related to the processing of the segmental ambiguity, we focused our hypothesis-driven analyses on the gaze duration and total reading time for the target word for both participant groups, as this measure would be sensitive to segmental processing during either the first-pass or later processing of the target region—noting that
J. Zhou and Li (
2021) observed effects only in total reading time in their study. In addition to these hypothesis-driven analyses, we report exploratory analyses using a broader range of eye movement measures to investigate potential differences in how L1 and L2 readers process segmental ambiguities.
As noted above, effects at the pre-target region offered potential insights into the effects of color on parafoveal processing of the segmental ambiguity by L1 and L2 readers. If such effects were present, they were most likely to emerge in first-pass processing measures, such as gaze duration. We therefore focused hypothesis-driven analyses on gaze duration, while incorporating other eye movement measures in exploratory analyses to provide a more comprehensive account of potential L1–L2 differences. Additionally,
W. Zhou et al. (
2020) reported L1–L2 differences in the effects of using alternating text color to mark word boundaries, with influences observed in both first-pass (gaze duration) and later (total reading time) measures. Accordingly, we focused our hypothesis-driven analyses on these two measures when assessing group differences in the effects of color coding. To date, no studies have directly examined the impact of text color coding on the processing of segmental ambiguity. Therefore, in the present experiment, we also analyzed gaze duration and total reading time to investigate whether marking word boundaries with color influences the resolution of segmental ambiguity.
3.1. Sentence-Level Analyses
Main effects of group: main effects of group were informative about general L1–L2 differences in eye movement behavior during reading. L2 readers exhibited longer sentence reading times compared to L1 readers (SRT, 7823 vs. 3126 ms), made more and longer fixations (NF, 27.93 vs. 12.37; AFD, 243 vs. 208 ms), shorter forward saccades (AFS, 0.55 vs. 3.47 chars), and more regressions (NR, 5.33 vs. 3.32). These effects indicated that the L2 group read about twice as slowly, making more than twice as many fixations that were around 20% longer. L2 readers also made more regressions to reread text, while making short forward saccades, characteristic of a cautious character-by-character reading strategy. By comparison, L1 readers appeared to process multiple characters on each fixation, traversing about 3–4 characters on each saccade, consistent with the perceptual span reported for skilled readers in previous research (
Inhoff & Liu, 1998).
These sentence-level findings provided clear evidence of differences in the overall eye movement patterns of L1 and L2 readers during sentence reading. The findings were consistent with L2 readers adopting a more cautious, character-by-character reading strategy.
Table 4 shows the mean eye movements for sentence-level measures, while
Table 5 summarizes the statistical effects.
Effects of Color Coding on Sentence Processing
Sentence-level analyses also provided valuable insights into the overall effects of color coding for both L1 and L2 readers. In these analyses, we focused on total sentence reading time, as it offered the most comprehensive measure of how text color coding influences overall reading performance. This approach also helped to minimize the risk of false positives that can arise from selectively reporting results across multiple dependent variables (
Von der Malsburg & Angele, 2017). Numerically, the mono-color displays produced shorter reading times than either of the two color-coded displays for L1 readers but longer reading times compared to the color-coded displays for L2 readers.
This was not entirely borne out statistically, however. Statistically, we observed shorter reading times for mono-color compared to both embedded word segmentation (4857 vs. 4926 ms) and incremental word segmentation (4857 vs. 4815 ms) conditions, with an interaction for L1 vs. L2 groups only for the contrast between mono-color and incremental word segmentation (L1 effect = 122 ms, L2 effect = 321 ms). The absence of other interaction effects likely reflected high variance in sentence reading time for the L2 group, suggesting variability in the effects of color coding for these readers. The lack of an interaction for the contrast between incremental and embedded word segmentation suggested using text color to cue alternative analyses of the ambiguity did not differentially affect sentence reading time for the two groups.
Exploratory analyses of other sentence-level eye movement measures provided more detail about effects for L1 and L2 readers. These showed that, compared to the mono-color display, text color coding produced a small reduction in average fixation duration for both groups, as well as a small reduction in the number of fixations for the L1 group only. Statistically, these effects were characterized by slightly more and longer fixations for mono-color compared with the embedded word segmentation condition (AFD, 223 vs. 221; NF, 17.85 vs. 18.41) and a similar number of fixations that were longer on average for mono-color versus the incremental word segmentation condition (AFD, 223 vs. 220 ms). These were qualified by interaction effects (L1 vs. L2) for mono-color versus incremental word segmentation (AFD, L1 effect = 2 ms, L2 effect = 5 ms; NF, L1 effect = 0.58, L2 effect = 0.19). The absence of an interaction for the contrast between incremental and embedded word segmentation suggested that using text color to cue an alternative analysis of the ambiguity did not differentially affect the number or average duration of fixation by the two groups. Overall, the effects in these measures were small, suggesting that color coding the text had only weak effects in these variables.
Numerically, L2 readers made more regressions than L1 readers, with little variation across display conditions. Statistically, we observed fewer regressions for mono-color displays compared with either embedded word segmentation (3.92 vs. 4.19) or incremental word segmentation (3.92 vs. 4.13) displays. These effects were qualified by interaction (i.e., L1 vs. L2) effects. However, differences in regression rates were small across conditions, revealing a negligible effect of color-coding for either group.
Forward saccade length showed marked differences between L1 and L2 readers but little variation across the different display conditions. These were a little longer in mono-color vs. embedded word segmentation conditions (2.44 vs. 2.35 char) and mono-color vs. incremental word segmentation conditions (2.44 vs. 2.38 char), with no difference for embedded word vs. incremental word segmentation conditions (2.44 vs. 2.35 char). While these effects were qualified by interactions (i.e., L1 vs. L2) for mono-color vs. embedded word and embedded word vs. incremental word conditions, the variation in saccade length across display conditions was small, suggesting that text color coding had little influence on saccade-targeting.
Overall, we observed little effects of color coding on sentence-level eye movement behavior for L1 and L2 readers.
3.2. Word-Level Analyses
As already noted, the word-level analyses allowed us to directly test hypotheses concerning the effects of color coding on ambiguity processing by L1 and L2 readers. The analyses were also informative about the overall effects of text color coding on processes of word identification.
In this context, we focused on reporting the interaction effects associated with participant groups in the current findings, while other main effects and interactions are detailed in the
Supplementary Online Materials.
3.2.1. Target Region
Table 6 shows the mean eye movements for the target region, while
Table 7 summarizes the statistical effects.
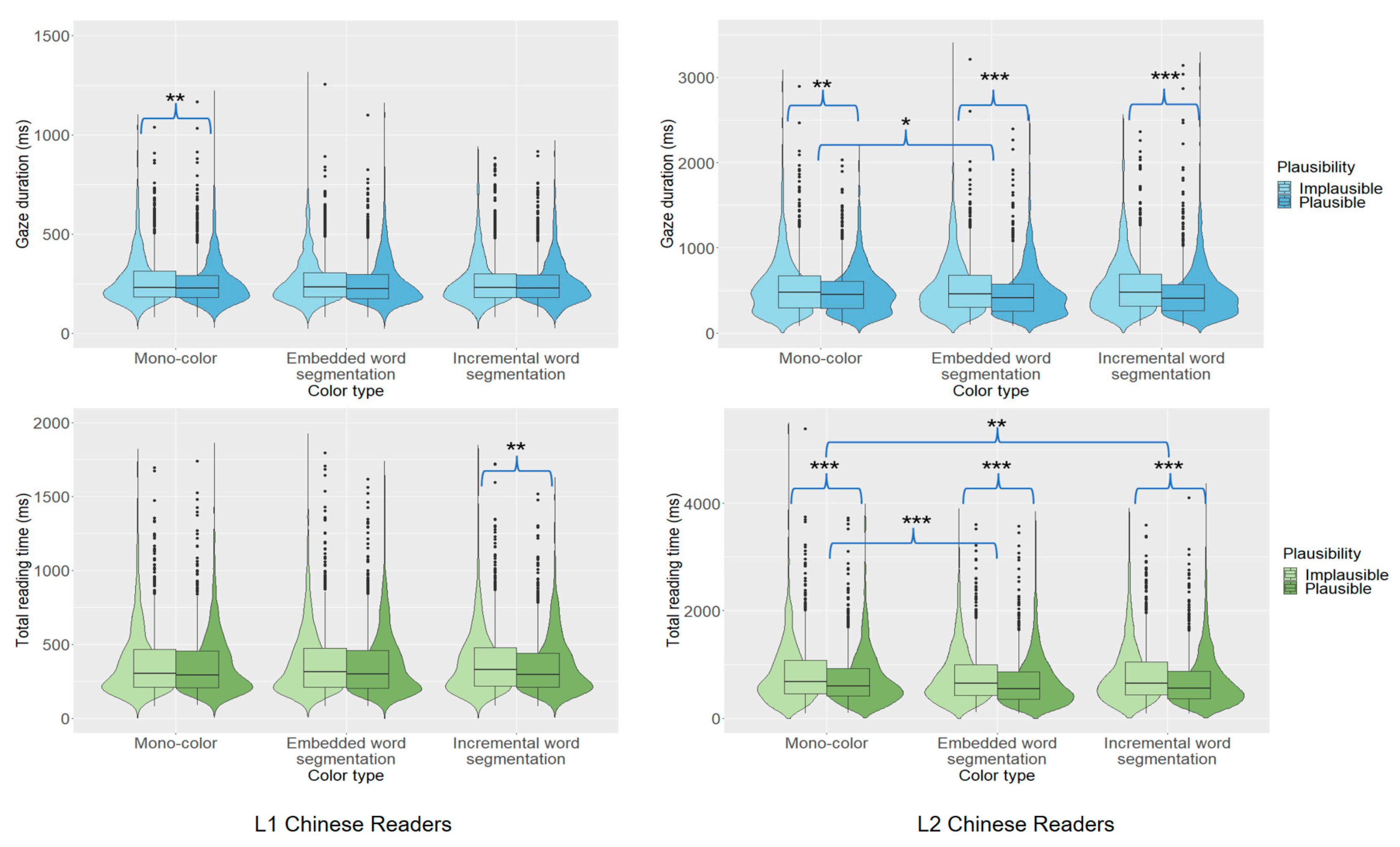
We first examined the group effects on target word processing. These were informative about overall L1–L2 differences in the processing of words during reading. Both first-pass fixation time (GD) and total reading time were overall much longer for L2 than L1 readers, with no difference in regression rates. Gaze duration and total reading time were both more than twice as long for L2 readers, suggesting that L2 readers experienced greater difficulty processing this region of text.
We next examined the overall effects of color coding on L1–L2 processing. For L1 readers, we observed increased gaze duration and total reading time for target words when color coding cued an embedded-word analysis compared to the mono-color condition, and longer gaze duration and total reading time for target words when color coding cued an embedded-word analysis rather than a whole-word analysis. This suggested that using color to cue a dispreferred segmental analysis disrupted target word processing by L1 readers, in line with prior research (
D. Shen et al., 2012;
Cui, 2023;
W. Zhou et al., 2020).
By comparison, for L2 readers, we observed no overall effects of color coding on first-pass or later fixation time measures. This seemed likely to be a consequence of L2 readers having generally long fixation times for the target words regardless of text color coding (i.e., a ceiling effect).
Effects of target word plausibility at the target region allowed us to directly assess L1–L2 differences in segmental ambiguity processing across different color conditions. As a reminder, the embedded-word analysis of the ambiguous segment was either plausible or implausible depending on the preceding verb context, whereas the whole-word analysis was always plausible. Thus, observing a plausibility effect at the target word would indicate that readers had processed the embedded word’s interpretation. Crucially, if such an effect emerged during first-pass processing, it would suggest that readers initially selected an embedded-word analysis upon fixating the target word.
Our analysis revealed that L1 readers produced a plausibility effect in total reading time (444 vs. 455 ms), while L2 readers produced one in gaze duration (740 vs. 757 ms). These effects indicated that both groups showed sensitivity to target word plausibility and had processed the embedded-word analysis of the ambiguity. While this effect appeared in first-pass reading for L2 but not L1 readers, this seemed likely to be attributable to L2 readers spending much longer on the first-pass processing of this word compared to L1 readers, rather than them producing the effect earlier during processing.
Further analyses examined effects for each group for the different sentence displays. The L1 group produced plausibility effects in total reading time and regression-in for target words in mono-color displays, indicating that they were more likely to re-read these words when the embedded-word analysis was implausible rather than plausible. No such effects were observed when text color cued either an embedded or incremental word analysis of the ambiguity.
The L2 group showed no effect of plausibility in mono-color displays. However, they produced an effect in gaze duration for target words when text color cued an embedded-word analysis (734 vs. 776 ms). This suggested that the color coding prioritized an embedded-word analysis of the ambiguity. Crucially, however, the effect was due to longer fixation times for plausible than implausible embedded words. Note that this was opposite to the predicted effect and so would benefit from being replicated. One explanation may be that L2 readers experienced greater competition between embedded- and whole-word analyses during ambiguity processing when both were plausible as compared to when only the whole-word analysis was plausible.
The absence of a corresponding effect when text color cued a whole-word analysis (759 vs. 743 ms) suggested that L2 readers did not initially consider an embedded-word analysis when processing the target word in these sentences. For these sentences, we instead observed a plausibility effect in regressions back to the target word due to elevated regression rates when the embedded word analysis was plausible (28 vs. 32). One possibility is that L2 readers preferentially adopt a whole-word analysis of the ambiguity but were more likely to re-inspect the target word when an embedded-word analysis also was plausible. Effects of target word plausibility are illustrated in
Figure 3.
3.2.2. Pre-Target Region
Table 8 presents the mean eye movements data for the pre-target region, while
Table 9 summarizes the statistical effects.
We next considered the effects at the pre-target word region, which were informative about L1–L2 parafoveal processing of the segmental ambiguity.
We first examined group effects, which were informative about overall L1–L2 processing differences. As with findings for the target region, first-pass fixation time (FFD, GD) and total reading time were overall longer for L2 than L1 readers, with no group difference in regression rates. Similar to target region findings, gaze duration and total reading time were both more than twice as long for L2 readers, further indicating that they experienced considerable processing difficulty.
We next examined overall effects of text color coding on L1 and L2 processing at the pre-target region. No effects of text color were observed at the pre-target region for L1 readers. By comparison, L2 readers produced longer total reading times for color-coded displays relative to mono-color displays, suggesting that L2 readers spent overall longer on this region when text color was used to cue word segmentation. We also observed a first-pass effect (in GD) for L2 readers when text color cued an embedded-word analysis of the ambiguity relative to the mono-color conditions. This suggested that L2 readers could process text color coding parafoveally and that this affected pre-target word processing when it cued a dispreferred analysis of the ambiguity.
Effects of target word plausibility at the pre-target region allowed us to directly assess L1–L2 differences in parafoveal processing segmental ambiguity across different color conditions. As already noted, the embedded-word analysis of the ambiguous segment was either plausible or implausible depending on the preceding verb context, whereas the whole-word analysis was always plausible. Thus, observing a plausibility effect at the pre-target region would indicate that readers had processed the embedded word’s interpretation of the ambiguity while fixating this earlier region. Crucially, if this effect emerged during first-pass processing, it would suggest that readers had accessed the embedded-word analysis of the ambiguity parafoveally.
For L1 readers, we observed first-pass (GD) and total reading time effects of embedded word plausibility (GD, 263 vs. 254 ms; TRT, 377 vs. 362 ms). The effect in GD indicated that L1 readers could parafoveally process the embedded word’s plausibility. For L2 readers, we observed embedded word plausibility effects in first-pass reading time (FFD, GD) as well as total reading time. These first-pass effects showed that L2 readers also could parafoveally process the embedded word’s plausibility (FFD, 269 vs. 261 ms; GD, 543 vs. 483 ms; TRT, 813 vs. 704 ms). The effect appeared to emerge earlier in processing for the L2 than L1 group, first appearing for the L2 group in the first fixation duration. However, this might have been a consequence of the L2 group having generally longer first fixation duration, so that effects emerged in this measure rather than in gaze duration.
Further analyses examined effects for each type of color display. For L1 readers, there was little effect of embedded word plausibility on processing at the pre-target region. Under the mono-color condition, we observed a plausibility effect in gaze duration (266 vs. 254 ms), suggesting that L1 readers processed the embedded word’s plausibility parafoveally. A similar effect in total reading time when text color cued an incremental analysis (379 vs. 357 ms) suggested that L1 readers engaged in greater re-reading of the pre-target region when the embedded word was implausible.
For L2 readers, we observed more interesting effects. For all three sentence types, we observed effects of embedded word plausibility in first-pass reading (gaze duration), due to longer fixation times at the pre-target region when this was followed by an implausible than plausible embedded word (mono-color, 544 vs. 492 ms; embedded word, 537 vs. 477 ms; incremental word, 547 vs. 480 ms). This indicated that L2 readers processed the embedded word’s plausibility parafoveally regardless of text color coding.
A similar effect was observed in total reading time (mono-color, 841 vs. 739 ms; embedded word segmentation, 788 vs. 679 ms; incremental word segmentation, 811 vs. 695 ms). This indicated that L2 readers engaged in re-reading of the pre-target region when the embedded word was implausible. Under the mono-color and embedded word conditions, the effects in regression-in provided further evidence for this effect of embedded word plausibility on the re-reading behavior of the L2 group (mono-color, 0.30 vs. 0.23; embedded word segmentation, 0.26 vs. 0.22).
L2 readers may have shown more extensive parafoveal processing effects at the pre-target region compared to L1 readers because of their much longer first-pass processing times at this region. Their longer processing time may have enabled them to engage in greater parafoveal processing compared to L1 readers. The effects of target word plausibility at the pre-target region are illustrated in
Figure 4.
4. Discussion
The present research used eye movement measures to investigate the influence of visual boundary cues on segmental ambiguity processing by skilled native (L1) Chinese readers and high-proficiency second language (L2) readers. In total, 102 skilled L1 and 60 L2 readers read sentences containing a temporarily ambiguous three-character incremental words (e.g., “音乐剧” [musical]), where the initial two characters (“音乐” [music]) could also form a valid word. The embedded word was either plausible or implausible in the context of the immediately preceding verb (e.g., 观看/欣赏 [音乐]剧, watch/enjoy [music] musical), while the whole-word analysis was plausible regardless of the verb context. This enabled us to investigate whether both groups would access the plausibility of the embedded word while processing this ambiguity. This was important, as it would imply that readers processed the ambiguity in line with a serial-based account of segmental processing (
Perfetti & Tan, 1999) rather than a parallel-based account like the Chinese Reading Model (CRM;
X. Li & Pollatsek, 2020).
Sentence stimuli were presented using either a neutral mono-color display providing no word segmentation cues or color-coded displays marking word boundaries. Color-coded displays employed either (a) uniform coloring to promote a whole-word analysis of the segmental ambiguity or (b) contrasting colors for the two-character embedded word versus final character to promote an embedded-word analysis of the ambiguity and so induce a segmental misanalysis. This approach allowed us to test specific hypotheses concerning (1) L1–L2 processing segmental ambiguities during Chinese reading and (2) the use of color cues to support this ambiguity processing.
Additionally, the sentence- and word-level findings provide broader insights into L1–L2 reading behaviors. Moreover, by analyzing eye movements before readers fixated an ambiguous segment, the study provides new insights into the parafoveal processing abilities of L1 and L2 readers and its role in segmental ambiguity processing.
4.1. Sentence-Level Eye Movement Behavior
We began by examining overall sentence-level differences in eye movement patterns for the two groups. The L2 group read significantly more slowly than the L1 group—over twice as slow—by making more frequent and longer fixations, as well as more regressions. They also produced much shorter forward saccades, suggesting a cautious, word-by-word reading strategy. By contrast, the L1 group made forward eye movements that spanned 3–4 characters per saccade, consistent with processing approximately 4–5 characters per fixation. This aligns with estimates of the perceptual span for skilled readers (
Inhoff & Liu, 1998). These patterns held across all sentence display types, indicating that L2 participants experienced greater reading difficulty, and adopted a more conservative reading strategy, even when word boundaries were clearly marked through text color coding. Despite these differences, both groups demonstrated high comprehension accuracy on follow-up questions presented after a subset of the sentence stimuli, suggesting that each group’s distinct reading strategy was effective in supporting sentence comprehension.
Next, we examined effects of using color cues to mark word boundaries on sentence-level eye movement behavior in both the L1 and L2 groups. Prior research suggested that color coding word boundaries can enhance reading efficiency for both L1 and L2 readers (
Pan et al., 2025;
W. Zhou et al., 2018,
2020), with similar findings reported for older adults and developing child readers (
Pan et al., 2020,
2025).
At first glance, our findings appear to contrast with these claims. Our sentence-level results showed minimal impact of alternating text color (used to indicate word boundaries) compared to mono-color presentations for both L1 and L2 readers. While some statistical effects emerged from the eye movement data, the mean differences were small and unlikely to reflect meaningful improvements in reading efficiency. However, a closer look at prior sentence-level findings in the literature suggests that there may be broader similarities between our results and prior research. Previous studies reported that using alternating colors to incorrectly mark word boundaries disrupted reading fluency for both L1 and L2 readers. By contrast, correctly coding word boundaries using alternating text color yielded only modest, and often minimal, facilitative effects. Thus, consistent with our findings, prior research suggests that color coding word boundaries offers limited benefit for skilled L1 readers or even for high-proficiency L2 readers. This is notable given that the L2 group in our study showed greater reading difficulty overall and relied on a conservative reading strategy to support adequate comprehension.
4.2. Target-Word Eye Movement Behavior
The specific focus of the present research was on investigating effects of text color cues on the processing of temporary segmental ambiguity. These ambiguities occur frequently in Chinese reading because of the absence of interword spaces or other visual cues to word boundaries. They are characterized by situations in which a sequence of characters is ambiguous between alternative lexical analyses, often where this ambiguity is subsequently resolved, and so disambiguated, by later text. We focused specifically on the processing of “incremental” segmental ambiguities that occur when a multi-character word contains an embedded shorter word. We gave as an example the three-character word 体育馆 (meaning “stadium”), which begins with the two-character word 体育 (meaning “sport”). During reading, this creates temporary ambiguity between a whole-word and an embedded-word analysis of these characters. We noted that current theoretical accounts diverge in their predictions about how this ambiguity is processed. Serial accounts (e.g.,
Perfetti & Tan, 1999) propose that readers initially segment the embedded word in strings before subsequently reanalyzing this misanalysis, which incurs an additional processing cost. By comparison, parallel accounts, like the Chinese Reading Model (CRM;
X. Li & Pollatsek, 2020), propose that alternative analyses compete for selection, with the longer word usually winning. Crucially, we also noted that prior research has not investigated effects for L2 readers or the influence of text color cues on the processing of temporary segmental ambiguities. However, it seems that L2 readers, in particular, may benefit from visual cues that correctly identify word boundaries in ambiguous strings. This was therefore the focus of our study.
We first examined the effects of ambiguity by analyzing a target region containing the ambiguous segment. Within this region, characters were either presented in a neutral mono-color format or color-coded to cue either the embedded word or whole word’s interpretation of the ambiguity. Consistent with the sentence-level findings, L2 readers exhibited greater processing difficulty, as reflected in longer fixation times during both initial and later stages of processing. This highlighted that even high-proficiency L2 readers continued to face challenges in word-level processing.
A further notable finding was that L1 readers showed no difference in fixation time between the mono-color condition and the condition using incremental segmentation color coding. However, they exhibited a processing cost when the color coding cued an embedded-word segmentation, with longer gaze duration (GD) and total reading time compared to the mono-color condition. By contrast, no such effects were observed for L2 readers. These findings suggest that, at the word level, color coding that cues an incorrect interpretation of an ambiguity can disrupt processing for L1 readers. However, L2 readers did not show the same sensitivity to these segmentation cues.
Following the approach of
J. Zhou and Li (
2021), we investigated the processing of the segmental ambiguity using verb contexts in which the embedded word’s interpretation was either contextually plausible or implausible, while the whole word’s interpretation remained consistently plausible. This allowed us to use plausibility effects in eye movement measures as an index of whether readers lexically accessed the embedded word during the processing of the ambiguity.
For the L1 group, the results revealed an embedded-word plausibility effect in total reading time on the target words, as well as in regressions back to those words, but only under the mono-color condition. Because these effects emerged in later processing measures, it suggested that L1 readers did not encounter segmental processing difficulty during first-pass reading of the target region. Furthermore, the absence of plausibility effects under the color-coded conditions indicated that alternating text color, whether supporting or miscuing segmentation, did not disrupt L1 readers’ processing of the ambiguity at the target word. Overall, the findings from the target region provide no evidence that color coding designed to miscue the segmentation of a segmental ambiguity adversely affected skilled L1 readers’ ambiguity processing.
For the L2 group, no embedded-word plausibility effects were observed under either the mono-color condition or when color coding cued a whole-word analysis of the ambiguity. This pattern suggested that, like L1 readers, L2 readers did not initially identify the embedded word in these contexts and thus may have employed a similar segmentation strategy. However, when color coding explicitly cued the embedded word’s interpretation, L2 readers exhibited a reversed plausibility effect: showing longer gaze duration for plausible embedded words than for implausible ones. This unexpected pattern may indicate that text color cues highlighting a plausible embedded word created a viable alternative to the incremental analysis, increasing competition between the two segmentation options and thereby extending the processing time for target words. By contrast, when the embedded word was implausible, it may have been more readily rejected, generating less competition and shorter gaze duration. Although these L2 findings are intriguing, they offer only limited evidence that color cues significantly influenced their processing of segmental ambiguities, while no such influence was observed for L1 readers.
4.3. Pre-Target Word Eye Movement Behavior
Following
J. Zhou and Li (
2021), we also examined the effects at the pre-target verb to explore the possibility of parafoveal pre-processing of the ambiguity. One potential mechanism is that while fixating the verb, readers may access semantic information about the upcoming target word. This early access could enable them to begin evaluating the plausibility of different interpretations of the ambiguous segment before directly fixating on it. Importantly, such a process would constitute parafoveal processing, where linguistic information is extracted from a word in the peripheral vision and partially processed prior to direct fixation (for reviews, see
Cutter et al., 2015;
Schotter et al., 2012).
L1 readers showed an embedded-word plausibility effect in gaze duration under the mono-color condition and in total reading time under the incremental word color-coding condition. The effects in early measures such as gaze duration were particularly informative, as they reflected first-pass processing and may provide evidence for parafoveal processing of upcoming words. This finding suggested that, under the mono-color condition, L1 readers were able to parafoveally access the identity of the upcoming embedded word and evaluate its plausibility. This is a notable result, as it indicates that skilled L1 readers can extract semantic information from upcoming characters in the parafovea. We return to its implications shortly. By contrast, the plausibility effect observed in total reading time in the incremental word condition was less informative about parafoveal processing. Instead, it likely reflected later-stage re-reading behavior, whereby L1 readers spent more time revisiting the target word when the embedded word as plausible. Given our assumption that L1 readers initially adopt a whole-word analysis of the ambiguity, this may represent a post-hoc “sense check” to verify the initial interpretation. Nonetheless, the finding is still valuable, as it suggests L1 readers remain aware of alternative interpretations of the ambiguity, even if they do not act on them during initial processing.
L2 readers exhibited a broader pattern of effects at the pre-target verb. Across all three color conditions, they showed an embedded-word plausibility effect in gaze duration, indicating that they had processed the upcoming embedded word’s plausibility parafoveally. Notably, this effect was not modulated by the text color manipulation, suggesting that L2 readers could extract semantic information parafoveally from the upcoming embedded word regardless of the presence or type of segmentation cues. A parallel plausibility effect was observed in total reading time across all sentence conditions, with longer reading times at the pre-target verb when the embedded-word analysis was implausible. This further supports the conclusion that L2 readers actively evaluated the plausibility of potential segmentations while still fixating the verb, and that this evaluation influenced both early and later stages of their reading behavior.
Effects observed at the pre-target region provide evidence for parafoveal processing of word plausibility by both L1 and L2 readers; in this case, the plausibility of the embedded word analysis of the ambiguity. These findings suggest that both groups could extract complex semantic information regarding the contextual fit of an upcoming word in the parafovea. Such parafoveal semantic processing remains highly controversial in alphabetic reading (e.g.,
Antúnez et al., 2022;
Hohenstein et al., 2010;
López-Peréz et al., 2016;
Rayner et al., 1986,
2014). However, there is growing evidence for its occurrence in Chinese reading (e.g.,
Yan et al., 2009;
J. Yang et al., 2012;
Pan et al., 2016). The parafoveal effects observed in the present study may therefore have important theoretical implications. First, they provide evidence that segmental processing of ambiguous words can begin at an early stage, prior to direct fixation on these words, during parafoveal preview. This suggests a level of semantic processing that precedes full lexical access during fixation. However, this interpretation must be considered alongside ongoing debates about whether parafoveal word segmentation in L1 Chinese reading also influences saccade-targeting behavior (see
X. Li et al., 2011;
Yan et al., 2010).
Notably,
J. Zhou and Li (
2021) did not report similar parafoveal processing effects in their study with L1 skilled readers. This discrepancy may be explained in one of two ways. First, the parafoveal effects we observed for L1 readers were relatively weak compared to those seen in L2 readers. We attributed this to L2 participants spending more time fixating the pre-target verb, allowing for more opportunity for parafoveal processing of upcoming words. It is possible that similar effects in Zhou and Li’s study were simply too subtle to be reliably detected. Second, the present study had substantially greater statistical power than Zhou and Li’s study, due to a larger participant sample and a larger stimulus set. This increased sensitivity may have led to detection of previously overlooked effects.
It is worth noting that the Chinese Reading Model (CRM) does not currently incorporate a mechanism for parafoveal word segmentation. However, the model could plausibly be extended to account for such processing. According to the CRM, word segmentation occurs within the perceptual span, which is generally assumed to apply to the currently fixated word. Yet it is reasonable to suggest that efficient reading may also involve segmentation of upcoming words within the parafovea. Our findings support this possibility, particularly for L2 readers, who appeared capable of evaluating the plausibility of the upcoming embedded word before direct fixation. One interpretation is that the L2 readers initiated word segmentation during parafoveal processing, with the result that the embedded word temporarily emerged as the preferred candidate in the competition for lexical selection during this early stage of processing.
These findings have important implications for ongoing debates about the development of parafoveal processing in L2 readers. While some studies suggest both beginning and proficient L2 readers are capable of sophisticated parafoveal processing (
Tiffin-Richards, 2024), prior research in Chinese has generally reported more limited parafoveal processing among L2 readers (
Cong & Chen, 2022;
Xiao et al., 2021). The present results contribute to this debate by providing evidence that high-proficiency L2 Chinese readers can engage in parafoveal processing, acquiring complex semantic preview information, such as the plausibility of upcoming words.
Finally, the present findings contribute to our understanding of the role of text color cues in supporting L2 word segmentation during reading. Previous research has suggested that color cues can facilitate word segmentation for both L1 and L2 Chinese readers (
W. Zhou et al., 2020), although such studies have not specifically examined their effects on the processing of segmental ambiguities. By contrast, the current findings indicate minimal benefit of text color cues for resolving segmental ambiguities. In fact, there was some evidence that color coding word boundaries may even slow reading for L1 readers.
This raises important questions about how the current results relate to prior research. One key difference lies in the design: previous studies manipulated color coding to cue correct or incorrect segmentation for all words in a sentence, whereas in the present study, all words except the segmental ambiguity were shown with correct segmentation, and only the ambiguous word was manipulated across conditions. Another important distinction is that prior studies typically reported only modest benefits of color coding when it cued correct segmentation, with larger effects observed when segmentation was miscued. Taken together, these observations suggest that the facilitative effects of text color may be more limited than previously claimed. Rather than broadly enhancing word segmentation, text color may exert its strongest influence when it disrupts segmentation, highlighting its potential to interfere more than to assist under certain conditions.
Clearly, further research is needed to deepen our understanding of these issues. Such studies could investigate a broader range of segmental ambiguities, including the overlapping word ambiguity examined by
Chen et al. (
2025), where character sequences such as 客运营 can be parsed either as a word formed by the first two characters (“passenger transport”) or by the last two characters (“operation”).
An important limitation of the present study is that we focused on high-proficiency L2 readers. Although this group demonstrated a cautious reading strategy, they may also have developed relatively strong word segmentation skills. It is possible that clearer effects of text color coding would emerge in less-skilled L2 readers, particularly those in the early stages of acquiring word segmentation strategies. Moreover, our L2 participant group was heterogeneous, comprising individuals with a broad range of first languages, including some that employ interword spacing (e.g., English) and others that do not (e.g., Thai or Japanese). This linguistic diversity may have introduced variability in segmentation strategies. Future research could explore L1-to-L2 transfer effects more directly by examining more homogeneous groups of L2 readers, specifically those whose first languages are either consistently spaced or unspaced. Such comparisons may help clarify how native language structures influence the acquisition and deployment of word segmentation strategies in L2 Chinese reading.
5. Conclusions
To conclude, our results, while complex, support several five key conclusions:
First, L2 readers adopted a slower, more effortful reading strategy than L1 readers yet achieved comparable comprehension, indicating that both groups used different but effective strategies for processing Chinese sentences.
Second, L1 readers processed segmental ambiguities efficiently and were only affected by misleading segmentation cues. By contrast, L2 readers showed slower, more effortful processing and may be more affected by lexical competition, indicating less automatic ambiguity resolution.
Third, L1 readers were selectively sensitive to color cues, showing disrupted processing when cues misaligned with correct segmentation. By contrast, L2 readers showed limited sensitivity to color cues, with minimal facilitation or disruption, suggesting reduced reliance on visual segmentation aids in resolving ambiguity.
Fourth, both L1 and L2 readers showed evidence of parafoveal processing of the embedded word’s plausibility, with stronger and more consistent effects for L2 readers, likely due to longer fixation times allowing greater semantic preview.
Crucially, these findings suggest that segmental processing can begin prior to direct fixation for both L1 and L2 readers, highlighting the role of parafoveal preview in initiating online processing of segmental ambiguity during reading.






{kind=link}
{kind=link}
{kind=link}
{kind=link}