
Can Natural Speech Prosody Distinguish Autism Spectrum Disorders? A Meta-Analysis

Abstract
1. Introduction
2. Literature Review
3. The Present Study
4. Materials and Methods
4.1. Search Strategy
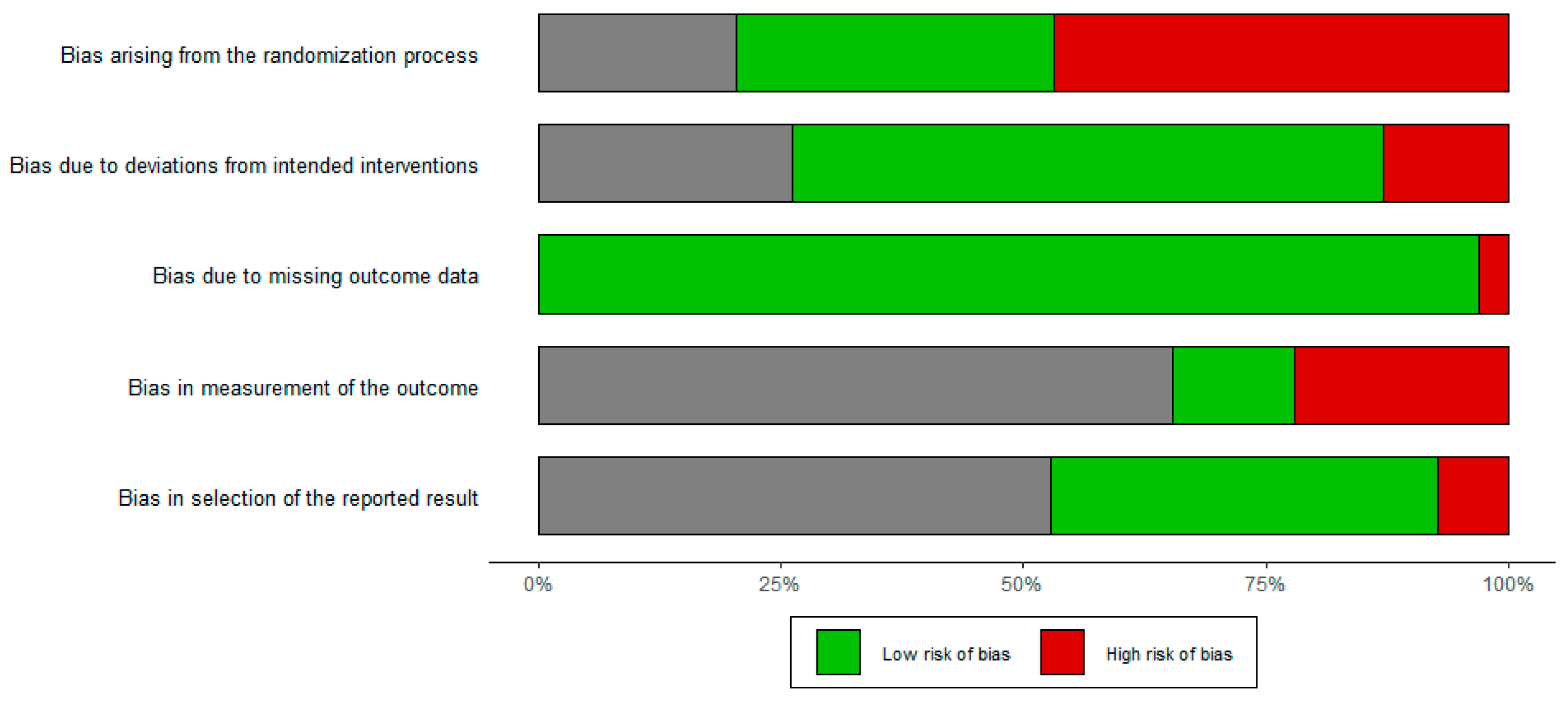
4.2. Risk of Bias Assessment
4.3. Data Extraction
4.4. Statistical Analysis
5. Results
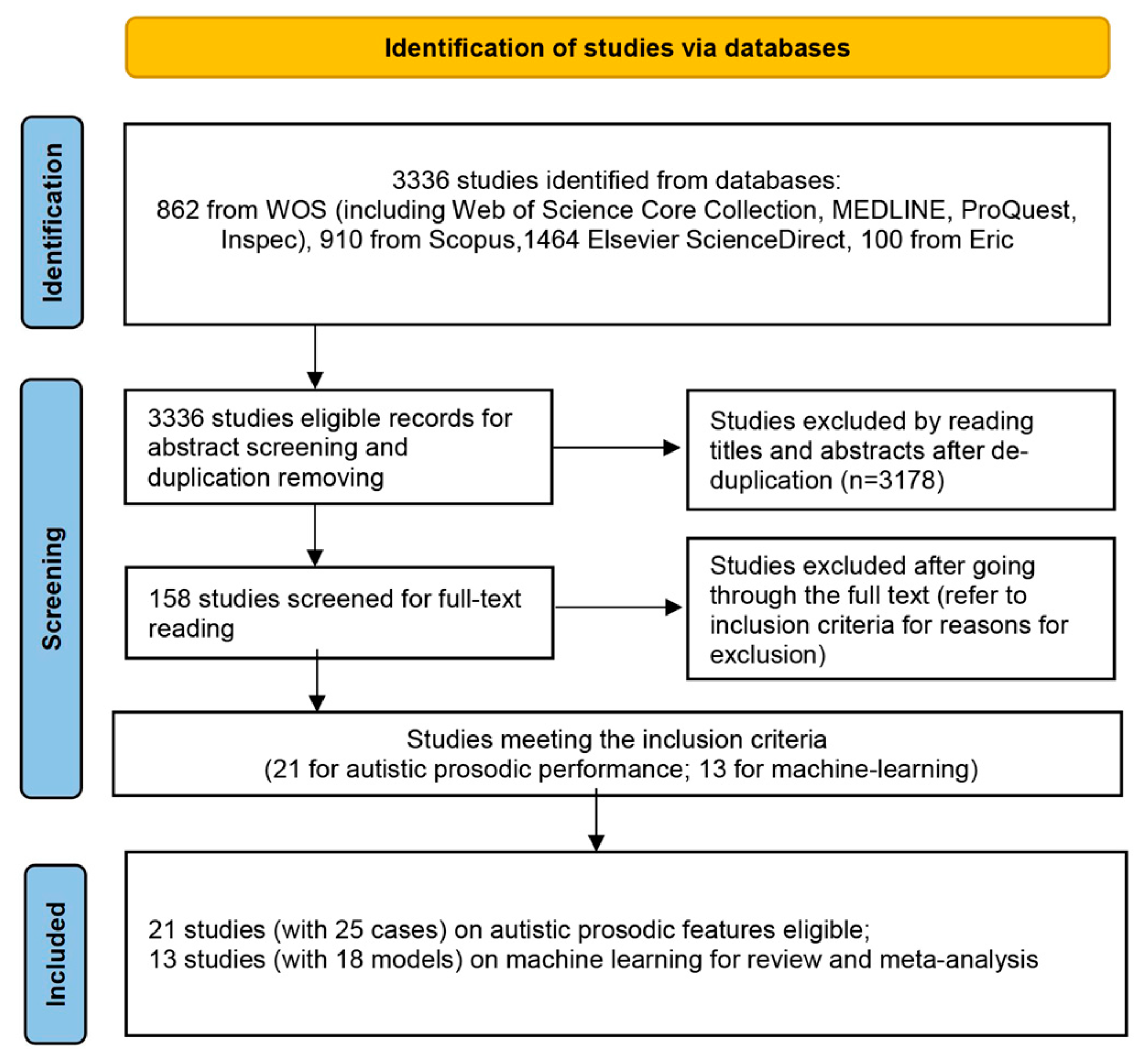
5.1. Study Selection Overview
5.2. Results of Prosodic Differences between ASD and TD Groups
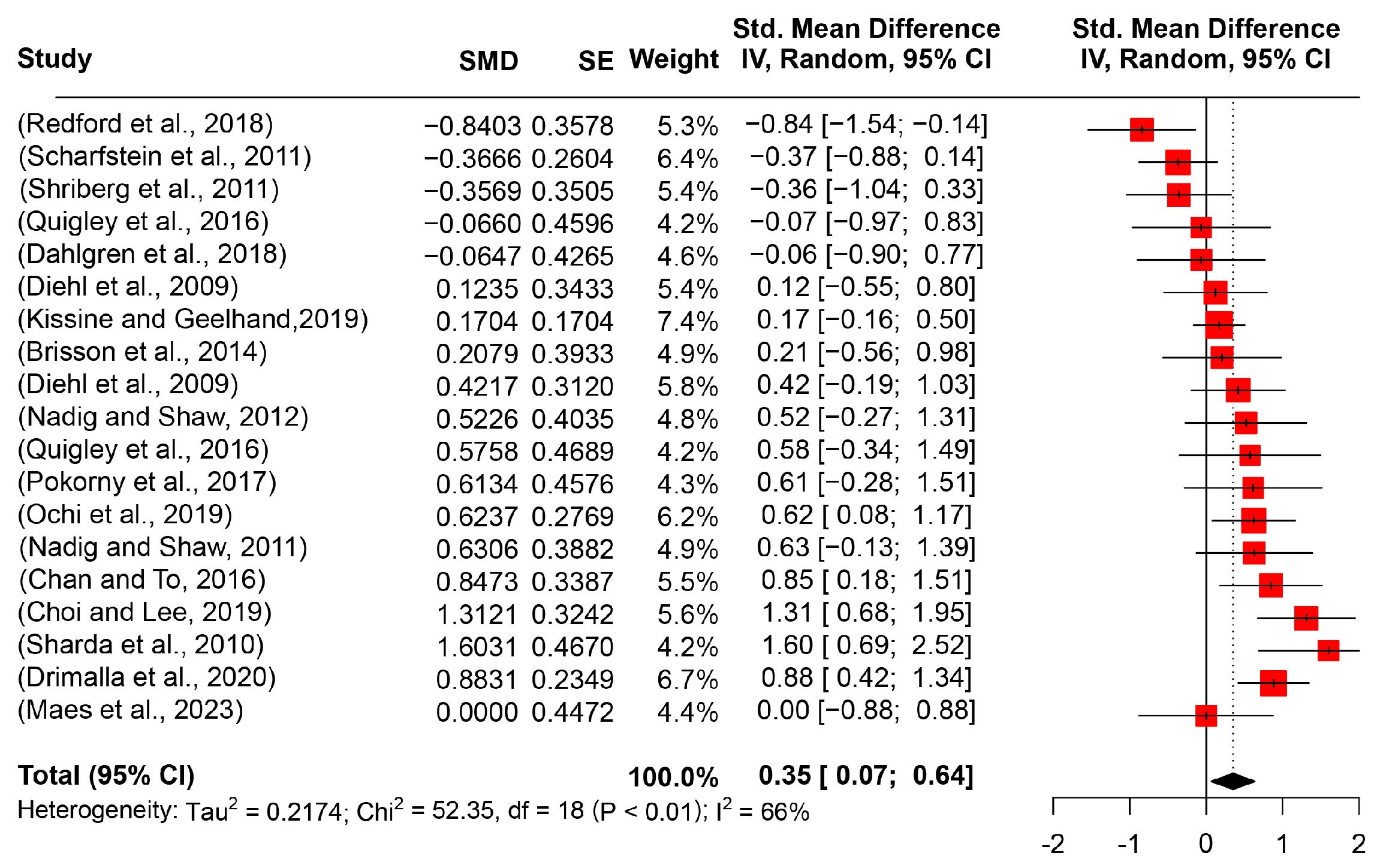
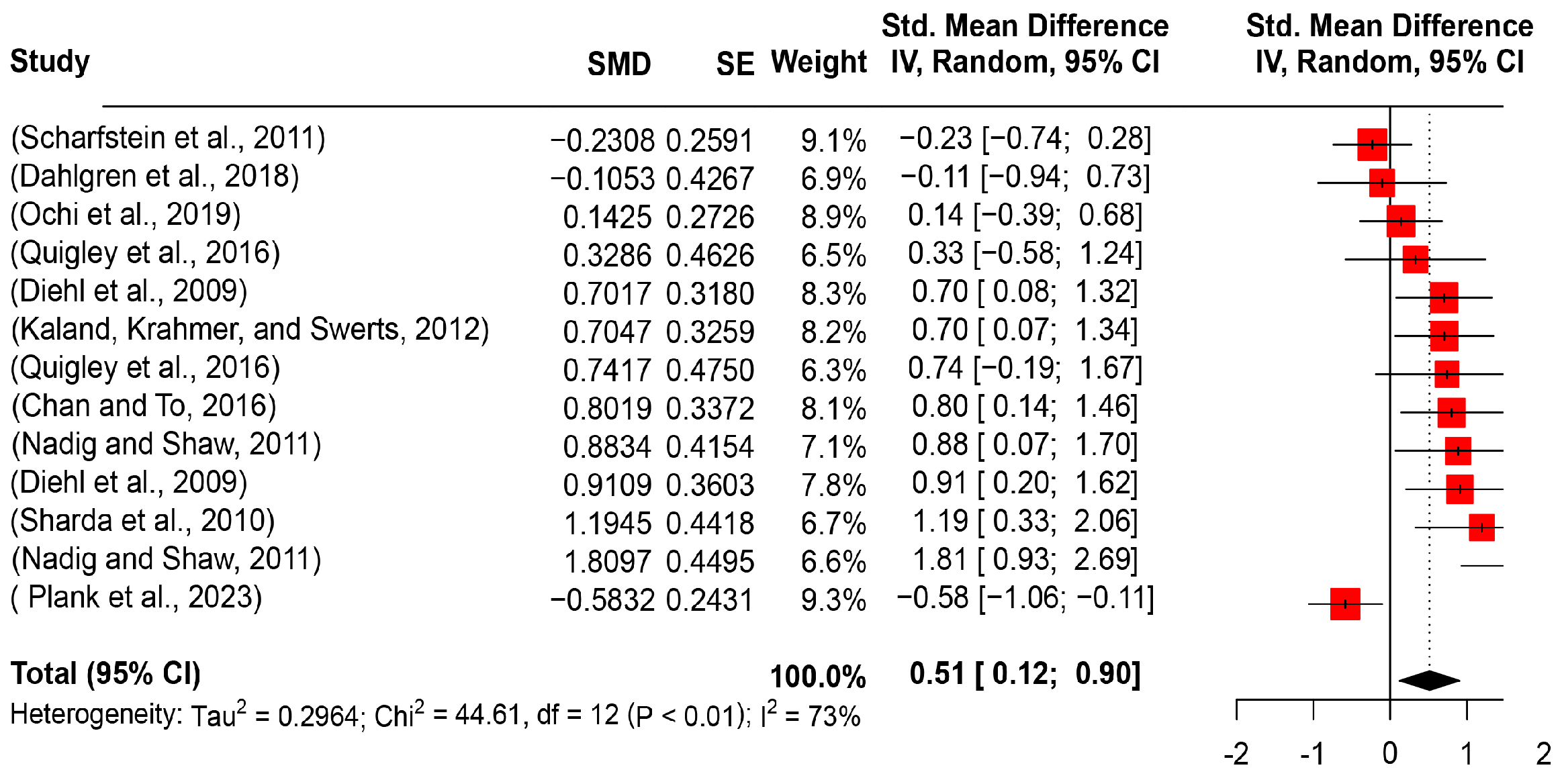
5.2.1. Pitch Mean
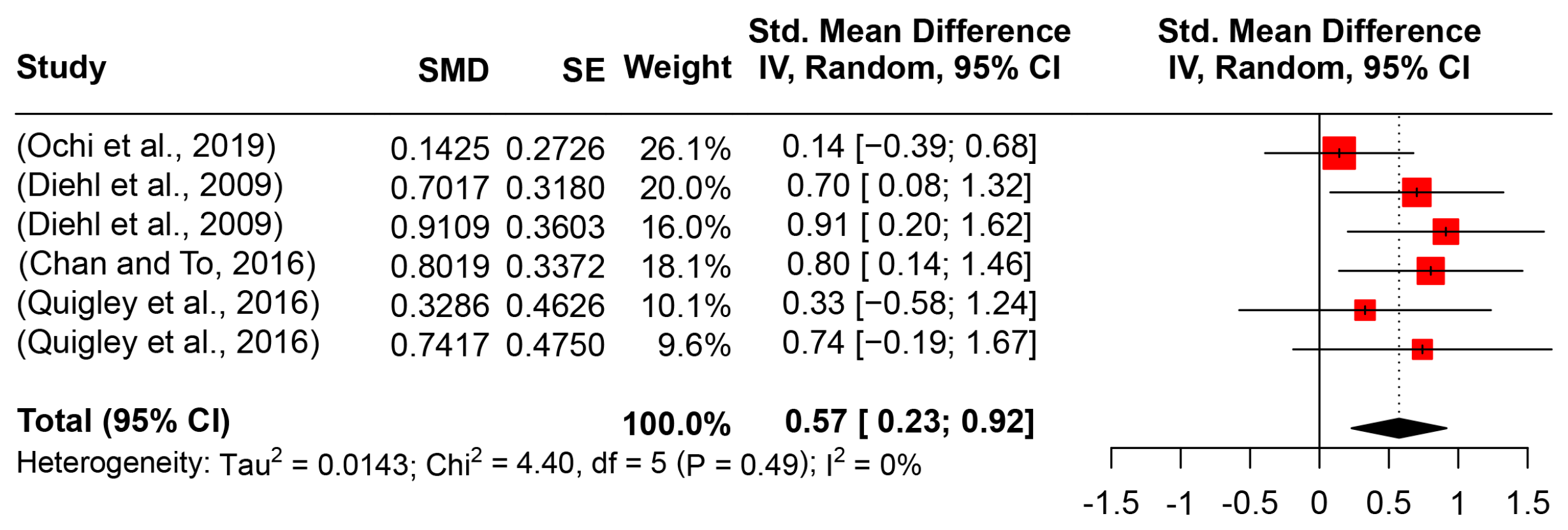
5.2.2. Pitch Range
5.2.3. Pitch Standard Deviation
5.2.4. Pitch Variability
5.2.5. Utterance Duration
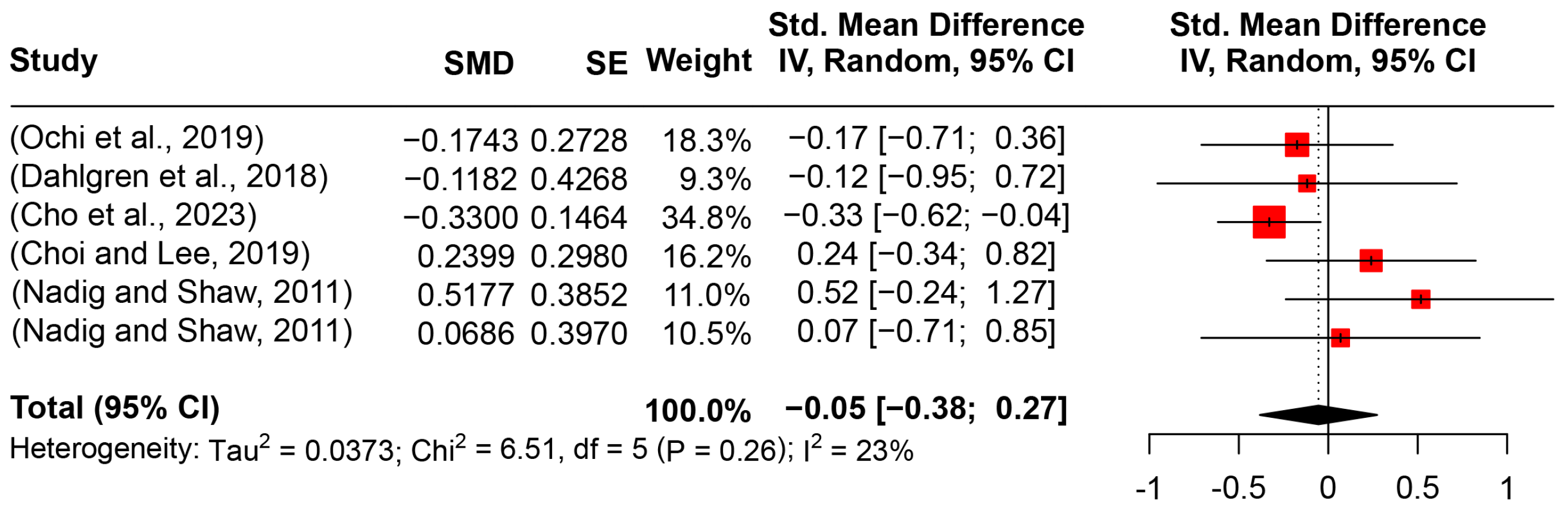
5.2.6. Speaking Rate
5.2.7. Intensity Mean and Variation
5.3. Results from Machine Learning for ASD Diagnosis
5.4. Publication Bias and Risk of Bias
6. Discussion
6.1. Prosodic Performance of ASD
6.2. Moderator and Heterogeneity Analysis
6.3. Predictive Value of Machine Learning
6.4. Implications and Limitations
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Patel, S.P.; Nayar, K.; Martin, G.E.; Franich, K.; Crawford, S.; Diehl, J.J.; Losh, M. An Acoustic Characterization of Prosodic Differences in Autism Spectrum Disorder and First-Degree Relatives. J. Autism Dev. Disord. 2020, 50, 3032–3045. [Google Scholar] [CrossRef]
- Redford, M.A.; Kapatsinski, V.; Cornell-Fabiano, J. Lay Listener Classification and Evaluation of Typical and Atypical Children’s Speech. Lang. Speech 2018, 61, 277–302. [Google Scholar] [CrossRef] [PubMed]
- Nadig, A.; Shaw, H. Acoustic and perceptual measurement of expressive prosody in high-functioning autism: Increased pitch range and what it means to listeners. J. Autism Dev. Disord. 2012, 42, 499–511. [Google Scholar] [CrossRef] [PubMed]
- Bone, D.; Lee, C.-C.; Black, M.P.; Williams, M.E.; Lee, S.; Levitt, P.; Narayanan, S. The psychologist as an interlocutor in autism spectrum disorder assessment: Insights from a study of spontaneous prosody. J. Speech Hear. Res. 2014, 57, 1162–1177. [Google Scholar] [CrossRef] [PubMed]
- Lau, J.C.Y.; Patel, S.; Kang, X.; Nayar, K.; Martin, G.E.; Choy, J.; Wong, P.C.M.; Losh, M. Cross-linguistic patterns of speech prosodic differences in autism: A machine learning study. PLoS ONE 2022, 17, e0269637. [Google Scholar] [CrossRef]
- Loveall, S.J.; Hawthorne, K.; Gaines, M. A meta-analysis of prosody in autism, williams syndrome, and down syndrome. J. Commun. Disord. 2021, 89, 106055. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Xiong, J.; Chen, B.; Zhang, C.; Deng, X.; He, F.; Yang, L.; Chen, C.; Peng, J.; Yin, F. Autism spectrum disorder and comorbid neurodevelopmental disorders (ASD-NDDs): Clinical and genetic profile of a pediatric cohort. Clin. Chim. Acta 2022, 524, 179–186. [Google Scholar] [CrossRef]
- American Psychiatric Association (APA). Diagnostic and Statistical Manual of Mental Disorders, 5th ed.; American Psychiatric Association: Washington, DC, USA, 2013. [Google Scholar]
- Robledo, J.; Donnellan, A.M. Supportive Relationships in Autism Spectrum Disorder: Perspectives of Individuals with ASD and Supporters. Behav. Sci. 2016, 6, 23. [Google Scholar] [CrossRef]
- Paul, R.; Augustyn, A.; Klin, A.; Volkmar, F.R. Perception and production of prosody by speakers with autism spectrum disorders. J. Autism Dev. Disord. 2005, 35, 205–220. [Google Scholar] [CrossRef]
- Shriberg, L.D.; Paul, R.; Black, L.M.; van Santen, J.P. The hypothesis of apraxia of speech in children with autism spectrum disorder. J. Autism Dev. Disord. 2011, 41, 405–426. [Google Scholar] [CrossRef]
- McCann, J.; Peppé, S.; Gibbon, F.; O’hare, A.; Rutherford, M. Prosody and its relationship to language in school-aged children with high-functioning autism. Int. J. Lang. Commun. Disord. 2007, 42, 682–702. [Google Scholar] [CrossRef]
- Chi, N.A.; Washington, P.; Kline, A.; Husic, A.; Hou, C.; He, C.; Dunlap, K.; Wall, D.P. Classifying Autism from Crowdsourced Semistructured Speech Recordings: Machine Learning Model Comparison Study. JPP 2022, 5, e35406. [Google Scholar] [CrossRef] [PubMed]
- Tager-Flusberg, H. Understanding the language and communicative impairments in autism. Int. Rev. Res. Ment. Retard. 2001, 23, 185–205. [Google Scholar] [CrossRef]
- Cho, S.; Cola, M.; Knox, A.; Pelella, M.R.; Russell, A.; Hauptmann, A.; Covello, M.; Cieri, C.; Liberman, M.; Schultz, R.T.; et al. Sex differences in the temporal dynamics of autistic children’s natural conversations. Mol. Autism 2023, 14, 13. [Google Scholar] [CrossRef] [PubMed]
- Diehl, J.J.; Watson, D.; Bennetto, L.; Mcdonough, J.; Gunlogson, C. An acoustic analysis of prosody in high-functioning autism. Appl. Psycholinguist. 2009, 30, 385–404. [Google Scholar] [CrossRef]
- Drimalla, H.; Scheffer, T.; Landwehr, N.; Baskow, I.; Roepke, S.; Behnia, B.; Dziobek, I. Towards the automatic detection of social biomarkers in autism spectrum disorder: Introducing the simulated interaction task (SIT). NPJ Digit. Med. 2020, 3, 25. [Google Scholar] [CrossRef] [PubMed]
- Cho, S.; Liberman, M.; Ryant, N.; Cola, M.; Schultz, R.T.; Parish-Morris, J. Automatic Detection of Autism Spectrum Disorder in Children Using Acoustic and Text Features from Brief Natural Conversations. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019. [Google Scholar] [CrossRef]
- Santos, J.F.; Brosh, N.; Falk, T.H.; Zwaigenbaum, L.; Bryson, S.E.; Roberts, W.; Smith, I.M.; Szatmari, P.; Brian, J.A. Very early detection of Autism Spectrum Disorders based on acoustic analysis of pre-verbal vocalizations of 18-month old toddlers. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar] [CrossRef]
- Tanaka, H.; Sakti, S.; Neubig, G.; Toda, T.; Nakamura, S. Linguistic and Acoustic Features for Automatic Identification of Autism Spectrum Disorders in Children’s Narrative. In Proceedings of the Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, Baltimore, MD, USA, 27 June 2014; pp. 88–96. [Google Scholar] [CrossRef]
- Asghari, S.Z.; Farashi, S.; Bashirian, S.; Jenabi, E. Distinctive prosodic features of people with autism spectrum disorder: A systematic review and meta-analysis study. Sci. Rep. 2021, 11, 23093. [Google Scholar] [CrossRef]
- Fusaroli, R.; Lambrechts, A.; Bang, D.; Bowler, D.M.; Gaigg, S.B. Is voice a marker for Autism spectrum disorder? A systematic review and meta-analysis. Autism Res. 2017, 10, 384–407. [Google Scholar] [CrossRef]
- Li, M.; Tang, D.; Zeng, J.; Zhou, T.; Zhu, H.; Chen, B.; Zou, X. An automated assessment framework for atypical prosody and stereotyped idiosyncratic phrases related to autism spectrum disorder. Comput. Speech Lang. 2019, 56, 80–94. [Google Scholar] [CrossRef]
- Baron-Cohen, S. Mind Blindness: An Essay on Autism and Theory of Mind; MIT Press: Cambridge, UK, 1995. [Google Scholar]
- Ding, H.; Zhang, Y. Speech Prosody in Mental Disorders. Annu. Rev. Linguist. 2023, 9, 335–355. [Google Scholar] [CrossRef]
- Arciuli, J. Prosody and autism. In Communication in Autism; Arciuli, J., Brock, J., Eds.; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2014; pp. 103–122. [Google Scholar] [CrossRef]
- Shriberg, L.D.; Paul, R.; McSweeny, J.L.; Klin, A.M.; Cohen, D.J.; Volkmar, F.R. Speech and prosody characteristics of adolescents and adults with high-functioning autism and Asperger syndrome. J. Speech Lang. Hear. R. 2001, 44, 1097–1115. [Google Scholar] [CrossRef]
- Guo, C.; Chen, F.; Yan, J.; Gao, X.; Zhu, M. Atypical prosodic realization by Mandarin-speaking autistic children: Evidence from tone sandhi and neutral tone. J. Commun. Disord. 2022, 100, 106280. [Google Scholar] [CrossRef] [PubMed]
- Dahlgren, S.; Sandberg, A.D.; Strömbergsson, S.; Wenhov, L.; Råstam, M.; Nettelbladt, U. Prosodic traits in speech produced by children with autism spectrum disorders—Perceptual and acoustic measurements. Autism Dev. Lang. Impair. 2018, 3, 2396941518764527. [Google Scholar] [CrossRef]
- Hubbard, D.J.; Faso, D.J.; Assmann, P.F.; Sasson, N.J. Production and perception of emotional prosody by adults with autism spectrum disorder. Autism Res. 2017, 10, 1991–2001. [Google Scholar] [CrossRef] [PubMed]
- Brisson, J.; Martel, K.; Serres, J.; Sirois, S.; Adrien, J.L. Acoustic analysis of oral productions of infants later diagnosed with autism and their mother. Infant Ment. Health J. 2014, 35, 285–295. [Google Scholar] [CrossRef] [PubMed]
- Asgari, M.; Chen, L.; Fombonne, E. Quantifying voice characteristics for detecting autism. Front. Psychol. 2021, 12, 665096. [Google Scholar] [CrossRef]
- Pepp’e, S.; McCann, J.; Gibbon, F.; O’Hare, A.; Rutherford, M. Receptive and expressive prosodic ability in children with high-functioning autism. J. Speech Hear. Res. 2007, 50, 1015–1028. [Google Scholar] [CrossRef] [PubMed]
- Ochi, K.; Ono, N.; Owada, K.; Kojima, M.; Kuroda, M.; Sagayama, S.; Yamasue, H. Quantification of speech and synchrony in the conversation of adults with autism spectrum disorder. PLoS ONE 2019, 14, e0225377. [Google Scholar] [CrossRef]
- McCarty, P.; Frye, R.E. Early Detection and Diagnosis of Autism Spectrum Disorder: Why Is It So Difficult? Semin. Pediatr. Neurol. 2020, 35, 100831. [Google Scholar] [CrossRef]
- Kissine, M.; Geelhand, P. Brief Report: Acoustic Evidence for Increased Articulatory Stability in the Speech of Adults with Autism Spectrum Disorder. J. Autism Dev. Disord. 2019, 49, 2572–2580. [Google Scholar] [CrossRef]
- Bone, D.; Black, M.P.; Lee, C.C.; Williams, M.E.; Levitt, P.; Lee, S.; Narayanan, S. Spontaneous-speech acoustic-prosodic features of children with autism and the interacting psychologist. In Proceedings of the Interspeech, Portland, OR, USA, 9–13 September 2012. [Google Scholar] [CrossRef]
- Bone, D.; Black, M.P.; Ramakrishna, A.; Grossman, R.B.; Narayanan, S.S. Acoustic-prosodic correlates of ‘awkward’ prosody in story retellings from adolescents with autism. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015. [Google Scholar] [CrossRef]
- MacFarlane, H.; Salem, A.C.; Chen, L.; Asgari, M.; Fombonne, E. Combining voice and language features improves automated autism detection. Autism Res. 2022, 15, 1288–1300. [Google Scholar] [CrossRef]
- Leightley, D.; Williamson, V.; Darby, J.; Fear, N.T. Identifying probable post-traumatic stress disorder: Applying supervised machine learning to data from a UK military cohort. J. Ment. Health 2018, 28, 34–41. [Google Scholar] [CrossRef]
- Beccaria, F.; Gagliardi, G.; Kokkinakis, D. Extraction and Classification of Acoustic Features from Italian Speaking Children with Autism Spectrum Disorders. In Proceedings of the RaPID Workshop-Resources and Processing of Linguistic, Para-Linguistic and Extra-Linguistic Data from People with Various Forms of Cognitive/Psychiatric/Developmental Impairments-within the 13th Language Resources and Evaluation Conference, Marseille, France, 20 June 2022; Available online: https://aclanthology.org/2022.rapid-1.4 (accessed on 23 May 2023).
- Kiss, G.; van Santen, J.P.H.; Prud’hommeaux, E.; Black, L.M. Quantitative analysis of pitch in speech of children with neurodevelopmental disorders. In Proceedings of the Interspeech, Portland, OR, USA, 9–13 September 2012. [Google Scholar] [CrossRef]
- Kallay, J.E.; Dilley, L.; Redford, M.A. Prosodic Development During the Early School-Age Years. J. Speech Lang. Hear. Res. 2022, 65, 4025–4046. [Google Scholar] [CrossRef]
- Engstrand, O. Systematicity of phonetic variation in natural discourse. Speech Commun. 1992, 11, 337–346. [Google Scholar] [CrossRef]
- Furui, S.; Nakamura, M.; Ichiba, T.; Iwano, K. Analysis and recognition of spontaneous speech using Corpus of Spontaneous Japanese. Speech Commun. 2005, 47, 208–219. [Google Scholar] [CrossRef]
- Rischel, J. Formal linguistics and real speech. Speech Commun. 1992, 11, 379–392. [Google Scholar] [CrossRef]
- Jasmin, K.; Gotts, S.J.; Xu, Y.; Liu, S.; Riddell, C.D.; Ingeholm, J.E.; Kenworthy, L.; Wallace, G.L.; Braun, A.R.; Martin, A. Overt social interaction and resting state in young adult males with autism: Core and contextual neural features. Brain 2019, 142, 808–822. [Google Scholar] [CrossRef]
- Hedges, L.V. Distribution Theory for Glass’s Estimator of Effect Size and Related Estimators. J. Educ. Behav. Stat. 1981, 6, 107–128. [Google Scholar] [CrossRef]
- Higgins, J.P.; Thompson, S.G. Quantifying heterogeneity in a meta-analysis. Stat. Med. 2002, 21, 1539–1558. [Google Scholar] [CrossRef] [PubMed]
- Doleman, B.; Freeman, S.; Lund, J.; Williams, J.; Sutton, A. Identifying Publication Bias in Meta-Analyses of Continuous Outcomes in the Presence of Baseline Risk; Cochrane Database of Systematic Reviews (Online): Hoboken, NJ, USA, 2020. [Google Scholar]
- Scharfstein, L.A.; Beidel, D.C.; Sims, V.K.; Rendon Finnell, L. Social skills deficits and vocal characteristics of children with social phobia or Asperger’s disorder: A comparative study. J. Abnorm. Child Psychol. 2011, 39, 865–875. [Google Scholar] [CrossRef]
- Quigley, J.; McNally, S.; Lawson, S. Prosodic Patterns in Interaction of Low-Risk and at-Risk-of-Autism Spectrum Disorders Infants and Their Mothers at 12 and 18 Months. Lang. Learn. Dev. 2016, 12, 295–310. [Google Scholar] [CrossRef]
- Pokorny, F.B.; Schuller, B.; Marschik, P.B.; Brueckner, R.; Nyström, P.; Cummins, N.; Bölte, S.; Einspieler, C.; Falck-Ytter, T. Earlier Identification of Children with Autism Spectrum Disorder: An Automatic Vocalisation-Based Approach. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar] [CrossRef]
- Chan, K.K.; To, C.K.S. Do Individuals with High-Functioning Autism Who Speak a Tone Language Show Intonation Deficits? J. Autism Dev. Disord. 2016, 46, 1784–1792. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.; Lee, Y. Conversational Factors Discriminating between High-Functioning Autism Spectrum Disorders and Typical Development: Perceptual Rating Scale. Commun. Sci. Disord. 2019, 24, 343–353. [Google Scholar] [CrossRef]
- Sharda, M.; Subhadra, T.P.; Sahay, S.; Nagaraja, C.; Singh, L.; Mishra, R.; Sen, A.; Singhal, N.; Erickson, D.; Singh, N.C. Sounds of melody-pitch patterns of speech in autism. Neurosci. Lett. 2010, 478, 42–45. [Google Scholar] [CrossRef] [PubMed]
- Maes, P.; Weyland, M.; Kissine, M. Structure and acoustics of the speech of verbal autistic preschoolers. J. Child Lang. 2023, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Kaland, C.; Krahmer, E.J.; Swerts, M. Contrastive intonation in autism: The effect of speaker- and listener-perspective. In Proceedings of the Interspeech, Portland, OR, USA, 9–13 September 2012. [Google Scholar] [CrossRef]
- Lehnert-LeHouillier, H.; Terrazas, S.; Sandoval, S. Prosodic Entrainment in Conversations of Verbal Children and Teens on the Autism Spectrum. Front. Psychol. 2020, 11, 582221. [Google Scholar] [CrossRef] [PubMed]
- Plank, I.; Koehler, J.; Nelson, A.; Koutsouleris, N.; Falter-Wagner, C. Automated extraction of speech and turn-taking parameters in autism allows for diagnostic classification using a multivariable prediction model. Front. Psychiatry 2023, 14, 1257569. [Google Scholar] [CrossRef] [PubMed]
- Morett, L.M.; O’Hearn, K.; Luna, B.; Ghuman, A.S. Altered Gesture and Speech Production in ASD Detract from In-Person Communicative Quality. J. Autism Dev. Disord. 2016, 46, 998–1012. [Google Scholar] [CrossRef] [PubMed]
- Oller, D.K.; Niyogi, P.; Gray, S.; Richards, J.A.; Gilkerson, J.; Xu, D.; Yapanel, U.; Warren, S.F. Automated vocal analysis of naturalistic recordings from children with autism, language delay, and typical development. Proc. Natl. Acad. Sci. USA 2010, 107, 13354–13359. [Google Scholar] [CrossRef]
- Fusaroli, R.; Bang, D.; Weed, E. Non-Linear Analyses of Speech and Prosody in Asperger’s Syndrome. In Proceedings of the IMFAR 2013, San Sebastian, Spain, 3 May 2013. [Google Scholar]
- Fusaroli, R.; Grossman, R.B.; Cantio, C.; Bilenberg, N.; Weed, E. The temporal structure of the autistic voice: A cross-linguistic examination. In Proceedings of the IMFAR 2015, Salt Lake, UT, USA, 13–16 May 2015. [Google Scholar]
- Fusaroli, R.; Lambrechts, A.; Yarrow, K.; Maras, K.; Gaigg, S. Voice patterns in adult English speakers with Autism Spectrum Disorder. In Proceedings of the IMFAR 2015, Salt Lake, UT, USA, 13–16 May 2015. [Google Scholar]
- Rybner, A.; Jessen, E.T.; Mortensen, M.D.; Larsen, S.N.; Grossman, R.; Bilenberg, N.; Cantio, C.; Jepsen, J.R.M.; Weed, E.; Simonsen, A.; et al. Vocal markers of autism: Assessing the generalizability of machine learning models. Autism Res. 2022, 15, 1018–1030. [Google Scholar] [CrossRef]
- Chowdhury, T.; Romero, V.; Stent, A. Parameter Selection for Analyzing Conversations with Autism Spectrum Disorder. In Proceedings of the INTERSPEECH, Dublin, Ireland, 20–24 August 2023. [Google Scholar] [CrossRef]
- Marchi, E.; Schuller, B.; Baron-Cohen, S.; Golan, O.; Bölte, S.; Arora, P.; Häb-Umbach, R. Typicality and emotion in the voice of children with autism spectrum condition: Evidence across three languages. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015. [Google Scholar] [CrossRef]
- Yarkoni, T.; Westfall, J. Choosing prediction over explanation in psychology: Lessons from machine learning. Perspect. Psychol. Sci. 2017, 12, 1100–1122. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Arroabarren, I.; Carlosena, A. Modelling of vibrato production. In Proceedings of the 2004 12th European Signal Processing Conference, Vienna, Australia, 6–10 September 2004. [Google Scholar] [CrossRef]
- Lee, J.; Kim, G.W.; Kim, S. Laryngeal height and voice characteristics in children with autism spectrum disorders. Phon. Speech Sci. 2021, 13, 91–101. [Google Scholar] [CrossRef]
- Huttunen, K.H.; Keränen, H.I.; Pääkkönen, R.J.; Päivikki Eskelinen-Rönkä, R.; Leino, T.K. Effect of cognitive load on articulation rate and formant frequencies during simulator flights. J. Acoust. Soc. Am. 2011, 129, 1580–1593. [Google Scholar] [CrossRef]
- Thurber, C.; Tager-Flusberg, H. Pauses in the narratives produced by autistic, mentally retarded, and normal children as an index of cognitive demand. J. Autism Dev. Disord. 1993, 23, 309–322. [Google Scholar] [CrossRef]
- Arvaniti, A. The usefulness of metrics in the quantification of speech rhythm. J. Phon. 2012, 40, 351–373. [Google Scholar] [CrossRef]
- Grossman, R.B.; Bemis, R.H.; Plesa Skwerer, D.; Tager-Flusberg, H. Lexical and affective prosody in children with high-functioning autism. J. Speech Lang. Hear. Res. 2010, 53, 778–793. [Google Scholar] [CrossRef] [PubMed]
- Kanner, L. Autistic disturbances of affective contact. Nerv. Child 1943, 2, 217–250. [Google Scholar]
- Van Santen, J.P.H.; Prud’hommeaux, E.T.; Black, L.M.; Mitchell, M. Computational prosodic markers for autism. Autism 2010, 14, 215–236. [Google Scholar] [CrossRef]
- Ye, J. Rhythm theory. In Proceedings of the Fifth National Conference on Modern Phonetics, Tsinghua University, Beijing, China, 13–14 October 2001. [Google Scholar]
- Fine, J.; Bartolucci, G.; Ginsberg, G.; Szatmari, P. The use of intonation to communicate in pervasive developmental disorders. J. Child Psychol. Psychiatry 1991, 32, 771–782. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | N_ASD | N_TD | Age_ASD | Age_TD | Group | Language | Task | PitchMeanASDvsTD |
|---|---|---|---|---|---|---|---|---|
| (Redford et al., 2018) [2] | 17 | 17 | M: 9 (Yr.) SD: 18 (mon.) | M: 8.9 (Yr.) SD: 15 (mon.) | Children | English | Conversation | −0.8403 (0.3578) |
| (Scharfstein et al., 2011) [51] | 30 | 30 | M: 0.57 (mon.) | M: 10.60 (mon.) | Children | English | Interaction | −0.3666 (0.2604) |
| (Shriberg et al., 2011) [11] | 46 | 10 | M: 69.9 (mon.) SD: 14.4 (mon.) | Range: 4–7 (Yr.) | Children | English | Conversation | −0.3569 (0.3505) |
| (Quigley et al., 2016) [52] | 10 | 9 | M: 12.12 (mon.) SD: 0.89 (mon.) | M: 11.95 (mon.) SD: 0.84 (mon.) | Infant | English | Interaction | −0.066 (0.4596) |
| (Dahlgren et al., 2018) [29] | 11 | 11 | M: 11.1 (Yr.) SD: 1.10 (Yr.) | M: 11.1 (Yr.) SD: 0.47 (Yr.) | Children | Swedish | Narration | −0.0647 (0.4265) |
| (Diehl et al., 2009) [16] | 17 | 17 | M: 8.81 (Yr.) SD: 2.13 (Yr.) | M: 9.49 (Yr.) SD: 2.22 (Yr.) | Children | English | Narration | 0.1235 (0.3433) |
| (Kissine and Geelhand, 2019) [36] | 38 | 38 | M: 28.1 (Yr.) SD: 11.48 (Yr.) | M: 27.9 (Yr.) SD: 11.53 (Yr.) | NA | French | NA | 0.1704 (0.1704) |
| (Brisson et al., 2014) [31] | 13 | 13 | M: 4.38 (mon.) SD: 0.88 (mon.) | M: 3.71 (mon.) SD: 1.39 (mon.) | Infant | French | Interaction | 0.2079 (0.3933) |
| (Diehl et al., 2009) [16] | 21 | 21 | M: 13.58 (Yr.) SD: 2.10 (Yr.) | M: 13.24 (Yr.) SD: 2.09 (Yr.) | Children | English | Narration | 0.4217 (0.312) |
| (Nadig and Shaw, 2012) [3] | 15 | 11 | M: 10.6 (Yr.) SD: 17 (mon.) | M: 10.8 (Yr.) SD: 23 (mon.) | Children | English | Interaction | 0.5226 (0.4035) |
| (Quigley et al., 2016) [52] | 10 | 9 | M: 18.27 (mon.) SD: 0.85 (mon.) | M: 18.13 (mon.) SD: 0.88 (mon.) | Infant | English | Interaction | 0.5758 (0.4689) |
| (Pokorny et al., 2017) [53] | 10 | 10 | NA | NA | Infant | Swedish | Interaction | 0.6134 (0.4576) |
| (Ochi et al., 2019) [34] | 62 | 17 | M: 26.9 (Yr.) SD: 7.0 (Yr.) | M: 29.6 (Yr.) SD: 7.0 (Yr.) | Adult | Japanese | Interaction | 0.6237 (0.2769) |
| (Nadig and Shaw, 2012) [3] | 15 | 13 | M: 11.0 (Yr.) SD: 19 (mon.) | M: 11.0 (Yr.) SD: 24 (mon.) | Children | English | Conversation | 0.6306 (0.3882) |
| (Chan and To, 2016) [54] | 19 | 19 | M: 25.72 (Yr.) SD: 3.63 (Yr.) | M: 25.50 (Yr.) SD: 3.21 (Yr.) | Adult | Chinese | Narration | 0.8473 (0.3387) |
| (Choi and Lee, 2019) [55] | 17 | 34 | M: 98.8 (mon.) SD: 18.6 (mon.) | M: 99.3 (mon.) SD: 20.7 (mon.) | Children | Korean | Conversation | 1.3121 (0.3242) |
| (Sharda et al., 2010) [56] | 15 | 10 | M: 6.25 (Yr.) SD: 1.5 (Yr.) | M: 7.3 (Yr.) SD: 2.0 (Yr.) | Children | English-Hindi bilingual | Interaction | 1.6031 (0.4670) |
| (Drimalla et al., 2020) [17] | 37 | 43 | M: 36.89 (Yr.) | M: 33.14 (Yr.) | Adult | German | Interaction | 0.8831 (0.2349) |
| (Maes et al., 2023) [57] | 10 | 10 | M: 4 (Yr.); 06.9 (mon.) SD: 1 (Yr); 00.23 (mon) | M: 4 (Yr); 06.54 (mon.) SD: 0 (Yr); 09.82 (mon.) | Children | French | Interaction | 0 (0.4472) |
| Name | N_ASD | N_TD | Age_ASD | Age_TD | Group | Language | Task | PitchRangeASDvsTD |
| (Dahlgren et al., 2018) [29] | 11 | 11 | M: 11.1 (Yr.) SD: 1.10 (Yr.) | M: 11.1 (Yr.) SD: 0.47 (Yr.) | Children | Swedish | Narration | −0.0957 (0.4266) |
| (Quigley et al., 2016) [52] | 10 | 9 | M: 2.12 (mon.) SD: 0.89 (mon.) | M: 1.95 (mon.) SD: 0.84 (mon.) | Infant | English | Interaction | 0.1271 (0.4599) |
| (Quigley et al. 2016) [52] | 10 | 9 | M: 8.27 (mon.) SD: 0.85 (mon.) | M: 8.13 (mon.) SD: 0.88 (mon.) | Infant | English | Interaction | 0.3682 (0.4633) |
| (Kaland, Krahmer, and Swerts, 2012) [58] | 20 | 20 | M: 28.9 (Yr.) | NA | Adult | Dutch | Interaction | 0.7047 (0.3259) |
| (Chan and To, 2016) [54] | 19 | 19 | M: 25.72 (Yr.) SD: 3.63 (Yr.) | M: 25.50 (Yr.) SD: 3.21 (Yr.) | Adult | Chinese | Narration | 0.8019 (0.3372) |
| (Lehnert-LeHouillier et al., 2020) [59] | 12 | 12 | M: 12.14 (Yr.) SD: 1.84 (Yr.) | M: 12.23 (Yr.) SD: 1.89 (Yr.) | Children | English | Conversation | 0.88 (0.4335) |
| (Nadig and Shaw, 2012) [3] | 15 | 11 | M: 10.6 (Yr.) SD: 17 (mon.) | M: 10.8 (Yr.) SD: 23 (mon.) | Children | NA | Interaction | 0.8834 (0.4154) |
| (Shardaet al., 2010) [56] | 15 | 10 | M: 6.25 (Yr.) SD: 1.5 (Yr.) | M: 7.3 (Yr.) SD: 2.0 (Yr.) | Children | English-Hindi bilingual | Interaction | 1.1945 (0.4418) |
| (Nadig and Shaw, 2012) [3] | 15 | 13 | M: 11.0 (Yr.) SD: 19 (mon.) | M: 11.0 (Yr.) SD: 24 (mon.) | Children | NA | Conversation | 1.8097 (0.4495) |
| (Maes et al., 2023) [57] | 10 | 10 | M: 4; 06.9 (Yr.) SD: 1; 00.23 (Yr.) | M: 4; 06.54 (Yr.) SD: 0; 09.82 (Yr.) | Children | French | Interaction | −0.003 (0.4472) |
| Name | N_ASD | N_TD | Age_ASD | Age_TD | Group | Language | Task | PitchSDASDvsTD |
| (Ochi et al., 2019) [34] | 65 | 17 | M: 26.9 (Yr.) SD: 7.0 (Yr.) | M: 29.6 (Yr.) SD: 7.0 (Yr.) | Adult | NA | Interaction | 0.1425 (0.2726) |
| (Diehl et al., 2009) [16] | 21 | 21 | M: 13.58 (Yr.) SD: 2.10 (Yr.) | M: 13.24 (Yr.) SD: 2.09 (Yr.) | Children | English | Narration | 0.7017 (0.318) |
| (Diehl et al., 2009) [16] | 17 | 17 | M: 8.81 (Yr.) SD: 2.13 (Yr.) | M: 9.49 (Yr.) SD: 2.22 (Yr.) | Children | English | Narration | 0.9109 (0.3603) |
| (Chan and To, 2016) [54] | 19 | 19 | M: 25.72 (Yr.) SD: 3.63 (Yr.) | M: 25.50 (Yr.) SD: 3.21 (Yr.) | Adult | Chinese | Narration | 0.8019 (0.3372) |
| (Quigley et al., 2016) [52] | 10 | 9 | M: 2.12 (mon.) SD: 0.89 (mon.) | M: 1.95 (mon.) SD: 0.84,mon.) | Infant | English | Interaction | 0.3286 (0.4626) |
| (Quigley et al., 2016) [52] | 10 | 9 | M: 8.27 (mon.) SD: 0.85 (mon.) | M: 8.13 (mon.) SD: 0.88 (mon.) | Infant | English | Interaction | 0.7417 (0.475) |
| Name | N_ASD | N_TD | Age_ASD | Age_TD | Group | Language | Task | PitchVarASDvsTD |
| (Scharfstein et al., 2011) [51] | 30 | 30 | M: 10.57 (Yr.) | M: 10.60 (Yr.) | Children | English | Interaction | −0.2308 (0.2591) |
| (Dahlgren et al., 2018) [29] | 11 | 11 | M: 11.1 (Yr.) SD: 1.10 (Yr.) | M: 11.1 (Yr.) SD: 0.47 (Yr.) | Children | Swedish | Narration | −0.1053 (0.4267) |
| (Ochi et al., 2019) [34] | 65 | 17 | M: 26.9 (Yr.) SD: 7.0 (Yr.) | M: 29.6 (Yr.) SD: 7.0 (Yr.) | Adult | NA | Interaction | 0.1425 (0.2726) |
| (Quigley et al., 2016) [52] | 10 | 9 | M: 2.12 (mon.) SD: 0.89 (mon.) | M: 1.95 (mon.) SD: 0.84 (mon.) | Infant | English | Interaction | 0.3286 (0.4626) |
| (Diehl et al., 2009) [16] | 21 | 21 | M: 13.58 (Yr.) SD: 2.10 (Yr.) | M: 13.24 (Yr.) SD: 2.09 (Yr.) | Children | English | Narration | 0.7017 (0.318) |
| (Kaland, Krahmer, and Swerts, 2012) [58] | 20 | 20 | M: 28.9 (Yr.) | NA | Adult | NA | Interaction | 0.7047 (0.3259) |
| (Quigley et al., 2016) [52] | 10 | 9 | M: 8.27 (mon.), SD: 85 (mon.) | M: 8.13 (mon.) SD: 8 (mon.) | Infant | English | Interaction | 0.7417 (0.475) |
| (Chan and To, 2016) [54] | 19 | 19 | M: 25.72 (Yr.) SD: 3.63 (Yr.) | M: 25.50 (Yr.) SD: 3.21 (Yr.) | Adult | Chinese | Narration | 0.8019 (0.3372) |
| (Nadig and Shaw, 2012) [3] | 15 | 11 | M: 10.6 (Yr.) SD: 17 (mon.) | M: 10.8 (Yr.) SD: 23 (mon.) | Children | NA | Interaction | 0.8834 (0.4154) |
| (Diehl et al., 2009) [16] | 17 | 17 | M: 8.81 (Yr.) SD: 2.13 (Yr.) | M: 9.49 (Yr.) SD: 2.22 (Yr.) | Children | English | Narration | 0.9109 (0.3603) |
| (Sharda et al., 2010) [56] | 15 | 10 | M: 6.25 (Yr.) SD: 1.5 (Yr.) | M: 7.3 (Yr.) SD: 2.0 (Yr.) | Children | English-Hindi bilingual | Conversation | 1.1945 (0.4418) |
| (Nadig and Shaw, 2012) [3] | 15 | 13 | M: 11.0 (Yr.) SD: 19 (mon.) | M: 11.0 (Yr.) SD: 2 (mon.) | Children | NA | Conversation | 1.8097 (0.4495) |
| (Plank et al., 2023) [60] | 26 | 54 | M: 34.85 (Yr.) SD: 12.01 (Yr.) | M: 30.80 (Yr.) SD: 10.42 (Yr.) | Adult | German | Conversation | −0.5832 (0.2431) |
| Name | N_ASD | N_TD | Age_ASD | Age_TD | Group | Language | Task | DurationASDvsTD |
|---|---|---|---|---|---|---|---|---|
| (Morett et al. 2015) [61] | 18 | 21 | M: 15.17 SD: 2.75 | M: 15.81 SD: 2.42 | Children | English | Narration | −0.8087 (0.334) |
| (Ochi et al., 2019) [34] | 65 | 17 | M: 26.9 (Yr.) SD: 7.0 (Yr.) | M: 29.6 (Yr.) SD: 7.0 (Yr.) | Adult | Japanese | Interaction | −0.212 (0.2729) |
| (Sharda, et al., 2010) [56] | 15 | 10 | M: 6.25 (Yr.) SD: 1.5 (Yr.) | M: 7.3 (Yr.) SD: 2.0 (Yr.) | Children | English-Hindi bilingual | Interaction | −0.0046 (0.4082) |
| (Brisson et al., 2014) [31] | 13 | 13 | M: 4.38 SD: 0.88 | M: 3.71 SD: 1.39 | Infant | French | Interaction | −0.0031 (0.3922) |
| (Kissine and Geelhand, 2019) [36] | 38 | 38 | M: 28.1 SD: 11.48 | M: 27.9 SD: 11.5 | NA | French | NA | 0.0032 (0.2294) |
| (Cho et al., 2023) [15] | 45 | 47 | M: 25.7 (mon.) SD: 3.63 (mon.) | M: 25.5 (mon.) SD: 3.21 (mon.) | Children | Chinese | Conversation | 0.44 (0.1566) |
| (Quigley et al. 2016) [52] | 10 | 9 | M: 2.12 (mon.) SD: 0.89 (mon) | M: 1.95 (mon.) SD: 0.84 (mon.) | Infant | English | Interaction | 0.4903 (0.4903) |
| (Quigley et al. 2016) [52] | 10 | 9 | M: 8.27 (mon.) SD: 0.85 (mon.) | M: 8.13 (mon.) SD: 0.88 (mon.) | Infant | English | Interaction | 0.8738 (0.4808) |
| (Maes et al., 2023) [57] | 10 | 10 | M: 4 (Yr.); 06.9 (mon.) SD: 1 (Yr.); 00.23 (mon.) | M: 4 (Yr.); 06.54 (mon.) SD: 0 (Yr.); 09.8 (mon.) | Children | French | Interaction | 0.1603 (0.4479) |
| Name | N_ASD | N_TD | Age_ASD | Age_TD | Group | Language | Task | RateASDvsTD |
| (Ochi et al., 2019) [34] | 65 | 17 | M: 26.9 (Yr.) SD: 7.0 (Yr.) | M: 29.6 (Yr.) SD: 7.0 (Yr.) | Adult | Japanese | Interaction | −0.1743 (0.2728) |
| (Dahlgren et al., 2018) [29] | 11 | 11 | M: 11.1 (Yr.) SD: 1.10 (Yr.) | M: 11.1 (Yr.) SD: 0.47 (Yr.) | Children | NA | Narration | −0.1182 (0.4268) |
| (Cho et al., 2023) [15] | 45 | 47 | M: 25.7 (mon.) SD: 3.63 (mon.) | M: 25.5 (mon.) SD: 3.21 (mon.) | Chidlren | Chinese | Conversation | −0.33 (0.1464) |
| (Choi and Lee, 2019) [55] | 17 | 34 | M: 98.8 (mon.) SD: 18.6 (mon.) | M: 99.3 (mon.) SD: 20.7 (mon.) | Children | Korean | Conversation | 0.2399 (0.298) |
| (Nadig and Shaw, 2012) [3] | 15 | 13 | M: 11.0 (Yr.) SD: 19 (mon.) | M: 11.0 (Yr.) SD: 24 (mon.) | Children | English | Conversation | 0.5177 (0.3852) |
| (Nadig and Shaw, 2012) [3] | 15 | 11 | M: 10.6 (Yr.) SD: 17 (mon.) | M: 10.8 (Yr.) SD: 23 (mon.) | Children | English | Interaction | 0.0686 (0.397) |
| Authos | Sample Size | Task | Performance |
|---|---|---|---|
| (Oller et al., 2010) [62] | ASD: 77; TD: 106 | Interaction | ACC: 0.86; SENS: 0.75; SPEC: 0.98 |
| (Kiss et al., 2012) [42] | ASD: 14; TD: 28 | Interaction | AUC: 0.75; ACC: 0.74; SPEC: 0.57 |
| (Fusaroli et al., 2013) [63] | ASD: 10; TD: 13 | Narration | ACC: 0.86; SENS: 0.884; SPEC: 0.854 |
| (Fusaroli, Grossman, et al., 2015) [64] | ASD: 52; TD: 34 | Narration | ACC: 0.7165; SENS: 0.5832; SPEC: 0.8442 |
| (Fusaroli, Grossman, et al., 2015) [64] | ASD: 26; TD: 34 | Narration | ACC: 0.8201; SENS: 0.848; SPEC: 0.8139 |
| (Fusaroli, Lambrechts, et al., 2015) [65] | ASD: 17; TD: 17 | Narration | ACC: 0.819; SENS: 0.8483; SPEC: 0.822 |
| (Asgari et al., 2021) [32] | ASD: 90; TD: 28 | Conversation | AUC: 0.82; ACC: 0.733; SENS: 0.6967; SEPC: 0.7683 |
| (Santos et al., 2013) [19] | ASD: 23; TD: 20 | Conversation | AUC: 0.66; ACC: 0.628; SPEC: 0.55 |
| (Santos et al., 2013) [19] | ASD: 23; TD: 20 | Conversation | AUC: 0.97; ACC: 0.977; SPEC: 1 |
| (MacFarlane et al., 2022) [39] | ASD: 88; TD: 70 | Interaction | AUC: 0.78; ACC: 0.7215; SENS: 0.75; SPEC: 0.6857 |
| (MacFarlane et al., 2022) [39] | ASD: 88; TD: 70 | Interaction | AUC: 0.8748; ACC: 0.7975; SENS: 0.7727; SPEC: 0.8286 |
| (MacFarlane et al., 2022) [39] | ASD: 88; TD: 70 | Interaction | AUC: 0.9205; ACC: 0.8671; SENS: 0.8977; SPEC: 0.8266 |
| (Lau et al., 2022) [5] | ASD: 83; TD: 63 | Narration | AUC: 0.886; ACC: 0.835; SENS: 0.79; SPEC: 0.877 |
| (Lau et al., 2022) [5] | ASD: 83; TD: 63 | Narration | AUC: 0.559; ACC: 0.566; SENS: 0.632; SPEC: 0.509 |
| (Rybner et al., 2022) [66] | ASD: 10; TD: 8 | Narration | ACC: 0.89; SENS: 0.75; SPEC: 1; PREC: 1 |
| (Rybner et al., 2022) [66] | ASD: 28; TD: 32 | Narration | ACC: 0.68; SENS: 0.5; SPEC: 0.76; PREC: 0.82 |
| (Plank et al., 2023) [60] | ASD: 26; TD: 54 | Conversation | ACC: 0.762; SENS: 0.738; SPEC: 0.76; PREC: 0.63 |
| (Chowdhury et al., 2023) [67] | ASD: 14; TD: 15 | Conversation | ACC: 0.76; SENS: 0.64; SPEC: 0.87; PREC: 0.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, W.; Xu, L.; Zhang, H.; Zhang, S. Can Natural Speech Prosody Distinguish Autism Spectrum Disorders? A Meta-Analysis. Behav. Sci. 2024, 14, 90. https://doi.org/10.3390/bs14020090
Ma W, Xu L, Zhang H, Zhang S. Can Natural Speech Prosody Distinguish Autism Spectrum Disorders? A Meta-Analysis. Behavioral Sciences. 2024; 14(2):90. https://doi.org/10.3390/bs14020090
Chicago/Turabian StyleMa, Wen, Lele Xu, Hao Zhang, and Shurui Zhang. 2024. "Can Natural Speech Prosody Distinguish Autism Spectrum Disorders? A Meta-Analysis" Behavioral Sciences 14, no. 2: 90. https://doi.org/10.3390/bs14020090
APA StyleMa, W., Xu, L., Zhang, H., & Zhang, S. (2024). Can Natural Speech Prosody Distinguish Autism Spectrum Disorders? A Meta-Analysis. Behavioral Sciences, 14(2), 90. https://doi.org/10.3390/bs14020090