Time to Renovate the Humor Styles Questionnaire? An Item Response Theory Analysis of the HSQ


Abstract
1. Introduction
1.1. The Humor Styles Questionnaire
1.2. The Present Research
2. Materials and Methods
2.1. Participants
2.2. Analytic Approach
3. Results and Discussions
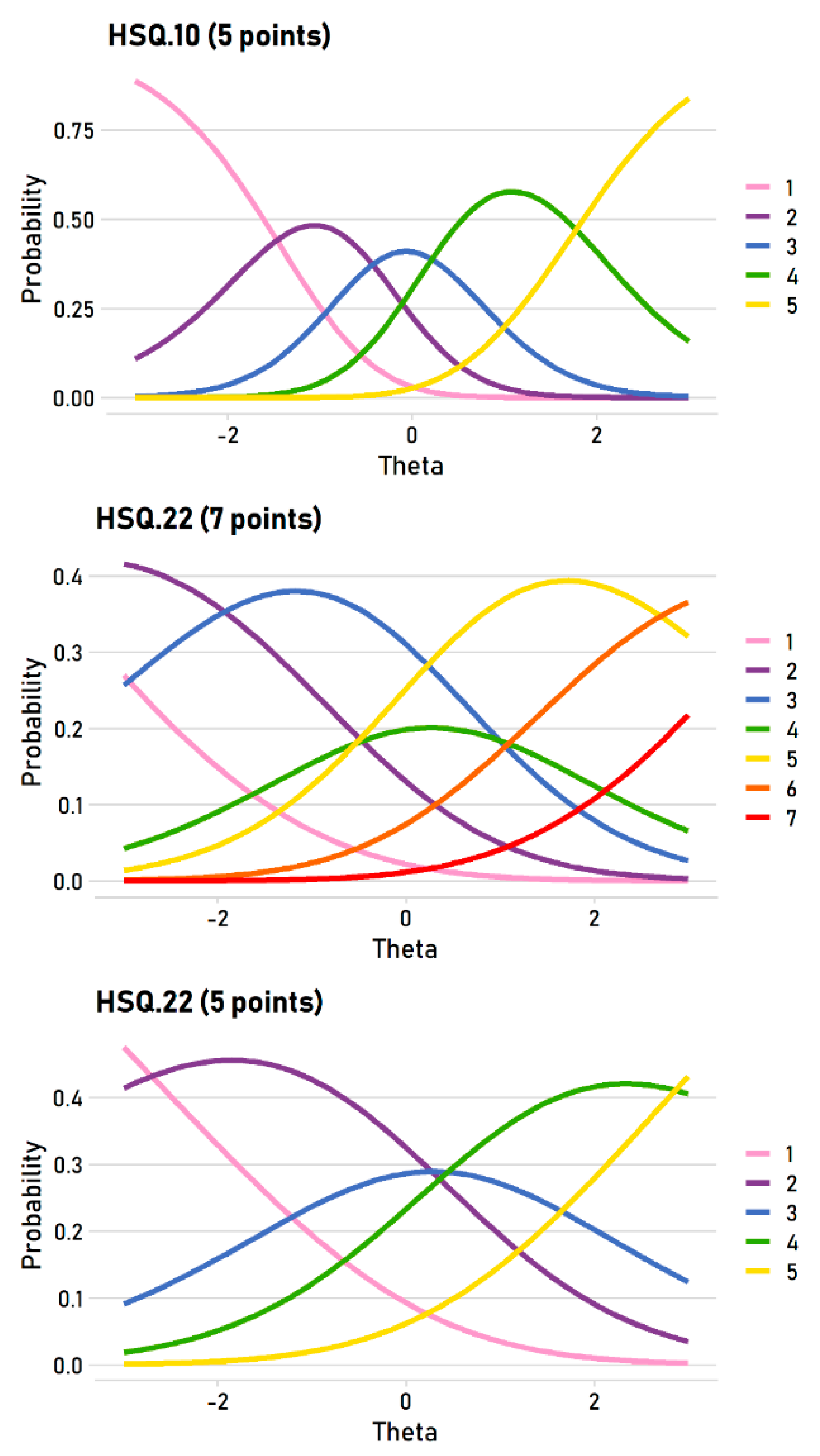
3.1. Rating Scale Analysis: Is Seven Points Too Many?
3.2. Reliability, Dimensionality, and Local Dependence
3.2.1. Reliability
3.2.2. Dimensionality
3.2.3. Local Dependence
3.3. Item Difficulty, Item Discrimination, and Test Information
3.3.1. Difficulty
3.3.2. Discrimination
3.3.3. Test Information
3.3.4. Summary
3.4. Gender Bias and Differential Item Functioning
3.5. Readability and Item Polarity
4. Conclusions
- The HSQ’s subscales are essentially unidimensional and yield scores with good reliability relative to their length.
- The items have essentially no gender-based differential item functioning, which is a striking finding for a scale with prominent gender differences. We see this as a major strength of the HSQ.
- Except for the affiliative subscale, all the subscales provide most of their information around the center of the trait, which is apt for measures of normal individual differences.
- The rating scale analysis indicates that seven points is probably too many. The five-point items were more consistently ordered, and a five-point scale is a sensible alternative. The behavior of a rating scale is an empirical question, so we would encourage future development of the scale to explore the behavior of alternative rating scales, such as four or six points.
- The affiliative subscale is simply too “easy” for the intended population, and it is much easier than the other subscales. We see the disparity in overall difficulty as a problem for the HSQ because overall subscale scores are not comparable. The varying difficulty levels are almost certainly an unintended consequence of the scale development process and something that should be targeted in future revisions. There is no ideal difficulty level, but scales that measure normal individual differences usually seek to distribute their items across the difficulty spectrum, thus allowing them to gain insight into a wide range of the trait.
- The items’ readability should be adjusted and harmonized. The subscales vary in sentence length and readability, which introduces unwanted variance.
- The proportion of reverse-scored items should be more similar across the subscales, and reversing with simple negation should be avoided.
- Some items are relatively low in discrimination and thus offer relatively little information. These are good candidates for item revision or deletion.
- According to local dependence statistics, a handful of items impair unidimensionality and are thus easy targets for item revision or deletion.
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Turner, M.J.; Hesford, J.W. The Impact of Renovation Capital Expenditure on Hotel Property Performance. Cornell Hosp. Q. 2019, 60, 25–39. [Google Scholar] [CrossRef]
- Martin, R.A.; Puhlik-Doris, P.; Larsen, G.; Gray, J.; Weir, K. Individual Differences in Uses of Humor and Their Relation to Psychological Well-Being: Development of the Humor Styles Questionnaire. J. Res. Personal. 2003, 37, 48–75. [Google Scholar] [CrossRef]
- Kuiper, N.A. Model of humor styles. In Encyclopedia of Personality and Individual Differences; Zeigler-Hill, V., Shackelford, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Bond, T.G.; Yan, Z.; Heine, M. Applying the Rasch Model: Fundamental Measurement in the Human Sciences, 4th ed.; Routledge: Abingdon, UK, 2020. [Google Scholar]
- DeMars, C. Item Response Theory; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Kuiper, N.A. Humor Styles Questionnaire. In Encyclopedia of Personality and Individual Differences; Zeigler-Hill, V., Shackelford, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Martin, R.A.; Ford, T. The Psychology of Humor: An Integrative Approach, 2nd ed.; Academic Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Schermer, J.A.; Rogoza, R.; Kwiatkowska, M.M.; Kowalski, C.M.; Aquino, S.; Ardi, R.; Bolló, H.; Branković, M.; Chegeni, R.; Crusius, J.; et al. Humor Styles across 28 Countries. Curr. Psychol. 2019. [Google Scholar] [CrossRef]
- Scheel, T.; Gerdenitsch, C.; Korunka, C. Humor at Work: Validation of the Short Work-Related Humor Styles Questionnaire (SwHSQ). Humor 2016, 29, 439–465. [Google Scholar] [CrossRef]
- Anlı, G. Reliability and validity studies of the turkish version of humor styles questionnaire for children. Curr. Psychol. 2019. [Google Scholar] [CrossRef]
- Fox, C.L.; Dean, S.; Lyford, K. Development of a humor styles questionnaire for children. Humor 2013, 26, 295–319. [Google Scholar] [CrossRef]
- Hofmann, J.; Platt, T.; Lau, C.; Torres-Marín, J. Gender Differences in Humor-Related Traits, Humor Appreciation, Production, Comprehension, (Neural) Responses, Use, and Correlates: A Systematic Review. Curr. Psychol. 2020. [Google Scholar] [CrossRef]
- Mendiburo-Seguel, A.; Páez, D.; Martínez-Sánchez, F. Humor Styles and Personality: A Meta-analysis of the Relation between Humor Styles and the Big Five Personality Traits. Scand. J. Psychol. 2015, 56, 335–340. [Google Scholar] [CrossRef]
- Plessen, C.Y.; Franken, F.R.; Ster, C.; Schmid, R.R.; Wolfmayr, C.; Mayer, A.M.; Maierwieser, R.J. Humor Styles and Personality: A Systematic Review and Meta-Analysis on the Relations between Humor Styles and the Big Five Personality Traits. Personal. Individ. Differ. 2020, 154, 109676. [Google Scholar] [CrossRef]
- Schneider, M.; Voracek, M.; Tran, U.S. “A Joke a Day Keeps the Doctor Away?” Meta-Analytical Evidence of Differential Associations of Habitual Humor Styles with Mental Health. Scand. J. Psychol. 2018, 59, 289–300. [Google Scholar] [CrossRef]
- Greengross, G.; Silvia, P.J.; Nusbaum, E.C. Sex Differences in Humor Production Ability: A Meta-Analysis. J. Res. Personal. 2020, 84, 103886. [Google Scholar] [CrossRef]
- Greengross, G. Sex and Gender Differences in Humor: Introduction and Overview. Humor 2020, 33. [Google Scholar] [CrossRef]
- Yaprak, P.; Güçlü, M.; Ayyildiz Durhan, T. The Happiness, Hardiness, and Humor Styles of Students with a Bachelor’s Degree in Sport Sciences. Behav. Sci. 2018, 8, 82. [Google Scholar] [CrossRef] [PubMed]
- Markos, A.; D’Enza, A.I.; van de Velden, M. Beyond Tandem Analysis: Joint Dimension Reduction and Clustering in R. J. Stat. Softw. 2019, 91, 1–24. [Google Scholar] [CrossRef]
- Yentes, R.D.; Wilhelm, F. Careless: Procedures for Computing Indices of Careless Responding, R Package, Version 1.1.3. 2018. Available online: https://cran.r-project.org/package=careless (accessed on 12 November 2020).
- R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, version 4.0.3. R Core Team: Vienna, Austria, 2020. Available online: https://www.R-project.org (accessed on 12 November 2020).
- Revelle, W. Psych: Procedures for Psychological, Psychometric, and Personality Research, R Package Version 2.0.9. 2020. Available online: https://CRAN.R-project.org/package=psych (accessed on 12 November 2020).
- Robitzsch, A.; Kiefer, T.; Wu, M. TAM: Test Analysis Modules, R Package Version 3.6-8. 2020. Available online: https://CRAN.R-project.org/package=TAM (accessed on 12 November 2020).
- Dijkstra, P.; Barelds, D.; Ronner, S.; Nauta, A. Humor Styles and Their Relationship to Well-Being among the Gifted. Gift. Talent. Int. 2011, 26, 89–98. [Google Scholar] [CrossRef]
- Markey, P.M.; Suzuki, T.; Marino, D.P. The Interpersonal Meaning of Humor Styles. Humor 2014, 27, 47–64. [Google Scholar] [CrossRef]
- MacDonald, K.B.; Kumar, A.; Schermer, J.A. No Laughing Matter: How Humor Styles Relate to Feelings of Loneliness and Not Mattering. Behav. Sci. 2020, 10, 165. [Google Scholar] [CrossRef]
- Sirigatti, S.; Penzo, I.; Giannetti, E.; Stefanile, C. The Humor Styles Questionnaire in Italy: Psychometric Properties and Relationships with Psychological Well-Being. Eur. J. Psychol. 2014, 10, 429–450. [Google Scholar] [CrossRef]
- Linacre, J.M. Optimizing Rating Scale Category Effectiveness. J. Appl. Meas. 2002, 3, 85–106. [Google Scholar]
- Slocum-Gori, S.L.; Zumbo, B.D. Assessing the Unidimensionality of Psychological Scales: Using Multiple Criteria from Factor Analysis. Soc. Indic. Res. 2011, 102, 443–461. [Google Scholar] [CrossRef]
- Hayton, J.C.; Allen, D.G.; Scarpello, V. Factor Retention Decisions in Exploratory Factor Analysis: A Tutorial on Parallel Analysis. Organ. Res. Methods 2004, 7, 191–205. [Google Scholar] [CrossRef]
- Velicer, W. Determining the Number of Components from the Matrix of Partial Correlations. Psychometrika 1976, 41, 321–327. [Google Scholar] [CrossRef]
- Marais, I. Local Dependence. In Rasch Models in Health; Christensen, K.B., Kreiner, S., Mesbah, M., Eds.; John Wiley & Sons: Hoboken, NJ, USA, 2013; pp. 111–130. [Google Scholar]
- Christensen, K.B.; Makransky, G.; Horton, M. Critical Values for Yen’s Q3: Identification of Local Dependence in the Rasch Model Using Residual Correlations. Appl. Psychol. Meas. 2017, 41, 178–194. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.H.; Thissen, D. Local Dependence Indices for Item Pairs Using Item Response Theory. J. Educ. Behav. Stat. 1997, 22, 265–289. [Google Scholar] [CrossRef]
- Heintz, S.; Ruch, W. Can Self-Defeating Humor Make You Happy? Cognitive Interviews Reveal the Adaptive Side of the Self-Defeating Humor Style. Humor 2018, 31, 451–472. [Google Scholar] [CrossRef]
- Tsukawaki, R.; Imura, T. The Light and Dark Side of Self-Directed Humor: The Development and Initial Validation of the Dual Self-Directed Humor Scale (DSDHS). Personal. Individ. Differ. 2020, 157, 109835. [Google Scholar] [CrossRef]
- Köhler, C.; Robitzsch, A.; Hartig, J. A Bias-Corrected RMSD Item Fit Statistic: An Evaluation and Comparison to Alternatives. J. Educ. Behav. Stat. 2020, 45, 251–273. [Google Scholar] [CrossRef]
- Buchholz, J.; Hartig, J. Comparing Attitudes across Groups: An IRT-Based Item-Fit Statistic for the Analysis of Measurement Invariance. Appl. Psychol. Meas. 2019, 43, 241–250. [Google Scholar] [CrossRef]
- Ostini, R.; Nering, M.L. Polytomous Item Response Theory Models; SAGE: Thousand Oaks, CA, USA, 2006. [Google Scholar]
- Choi, S.W.; Gibbons, L.E.; Crane, P.K. Lordif: An R Package for Detecting Differential Item Functioning Using Iterative Hybrid Ordinal Logistic Regression/Item Response Theory and Monte Carlo Simulations. J. Stat. Softw. 2011, 39, 1–30. [Google Scholar] [CrossRef]
- Choi, S.W.; Gibbons, L.E.; Crane, P.K. Lordif: Logistic Ordinal regression Differential Item Functioning Using IRT, R package version 0.3.3. 2016. Available online: https://cran.r-project.org/package=lordif (accessed on 12 November 2020).
- Menard, S. Coefficients of Determination for Multiple Logistic Regression Analysis. Am. Stat. 2000, 54, 17–24. [Google Scholar]
- Meade, A.W. A Taxonomy of Effect Size Measures for the Differential Functioning of Items and Scales. J. Appl. Psychol. 2010, 95, 728–743. [Google Scholar] [CrossRef] [PubMed]
- DuBay, W.H. The Principles of Readability; Impact Information: Costa Mesa, CA, USA, 2004. [Google Scholar]
- Conrad, K.J.; Wright, B.D.; McKnight, P.; McFall, M.; Fontana, A.; Rosenheck, R. Comparing Traditional and Rasch Analyses of the Mississippi PTSD Scale: Revealing Limitations of Reverse-Scored Items. J. Appl. Meas. 2004, 5, 15–30. [Google Scholar] [PubMed]
- Netemeyer, R.G.; Bearden, W.O.; Sharma, S. Scaling Procedures: Issues and Applications; SAGE: Thousand Oaks, CA, USA, 2003. [Google Scholar]
- Primi, R.; De Fruyt, F.; Santos, D.; Antonoplis, S.; John, O.P. True or False? Keying Direction and Acquiescence Influence the Validity of Socio-Emotional Skills Items in Predicting High School Achievement. Int. J. Test. 2020, 20, 97–121. [Google Scholar] [CrossRef]
- Suárez-Alvarez, J.; Pedrosa, I.; Lozano Fernández, L.M.; García-Cueto, E.; Cuesta, M.; Muñiz, J. Using Reversed Items in Likert Scales: A Questionable Practice. Psicothema 2018, 30, 149–158. [Google Scholar] [PubMed]
- Woods, C.M. Careless Responding to Reverse-Worded Items: Implications for Confirmatory Factor Analysis. J. Psychopathol. Behav. Assess. 2006, 28, 186. [Google Scholar] [CrossRef]
- Jiang, T.; Li, H.; Hou, Y. Cultural Differences in Humor Perception, Usage, and Implications. Front. Psychol. 2019, 10, 123. [Google Scholar] [CrossRef]
- Heintz, S.; Ruch, W. An Examination of the Convergence between the Conceptualization and the Measurement of Humor Styles: A Study of the Construct Validity of the Humor Styles Questionnaire. Humor 2015, 28, 611–633. [Google Scholar] [CrossRef]
- Ruch, W.; Heintz, S. Experimentally Manipulating Items Informs on the (Limited) Construct and Criterion Validity of the Humor Styles Questionnaire. Front. Psychol. 2017, 8, 616. [Google Scholar] [CrossRef]
- Martin, R.A. On the Challenges of Measuring Humor Styles: Response to Heintz and Ruch. Humor 2015, 28, 635–639. [Google Scholar] [CrossRef]
- Messick, S. Validity of Psychological Assessment: Validation of Inferences from Persons’ Responses and Performances as Scientific Inquiry into Score Meaning. Am. Psychol. 1995, 50, 741–749. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Difficulty (b) | Slope (a) | Tau 1 | Tau 2 | Tau 3 | Tau 4 | Infit | Outfit | RMSD | Disordered | Local Dependence |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Affiliative Style | |||||||||||
| 1. usually don’t laugh or joke around with others | −1.033 | 1.452 | −1.204 | −0.324 | 0.020 | 1.508 | 1.01 | 1.06 | 0.028 | ||
| 5. don’t have to work hard at making other people laugh | −0.628 | 1.186 | −1.447 | −0.820 | 0.296 | 1.971 | 1.00 | 0.99 | 0.016 | 29 | |
| 9. rarely make other people laugh by telling funny stories | −0.509 | 0.691 | −1.198 | −0.593 | −0.446 | 2.237 | 1.01 | 1.06 | 0.038 | ||
| 13. laugh and joke a lot with friends | −1.494 | 1.605 | −1.052 | −0.190 | 0.004 | 1.238 | 1.03 | 0.99 | 0.017 | 25 | |
| 17. don’t like to tell jokes | −0.994 | 1.682 | −1.014 | −0.266 | 0.059 | 1.221 | 1.03 | 1.01 | 0.027 | ||
| 21. enjoy making people laugh | −1.531 | 1.767 | −0.784 | −0.583 | −0.069 | 1.436 | 1.02 | 0.99 | 0.015 | ||
| 25. don’t often joke around with friends | −1.356 | 1.852 | −0.863 | −0.118 | −0.164 | 1.144 | 1.07 | 1.01 | 0.024 | Yes | 13 |
| 29. can’t think of witty things to say with people | −0.690 | 0.809 | −1.066 | −0.472 | −0.199 | 1.738 | 1.02 | 1.05 | 0.032 | 5 | |
| Self-Enhancing Style | |||||||||||
| 2. if feeling depressed, can cheer up with humor | −0.310 | 1.194 | −1.764 | −0.528 | 0.284 | 2.008 | 1.00 | 1.00 | 0.023 | ||
| 6. when by myself, I’m amused by absurdities of life | −1.783 | 0.624 | −1.704 | −0.410 | −0.006 | 2.120 | 1.01 | 0.99 | 0.032 | 30 | |
| 10. if feeling upset I usually try to think of something funny to feel better | 0.025 | 1.367 | −1.490 | −0.452 | 0.189 | 1.753 | 1.01 | 1.01 | 0.018 | ||
| 14. my humorous outlook keeps me from getting overly upset | −0.300 | 1.156 | −1.498 | −0.330 | 0.246 | 1.583 | 1.01 | 1.02 | 0.021 | ||
| 18. if by myself and unhappy, I think of something funny to cheer up | 0.197 | 1.371 | −1.601 | −0.407 | 0.224 | 1.784 | 1.01 | 1.01 | 0.023 | ||
| 22. if feeling sad, I lose my sense of humor | 0.220 | 0.462 | −2.921 | 0.055 | 0.223 | 2.643 | 1.00 | 1.02 | 0.037 | ||
| 26. thinking about some amusing aspect of a situation is effective way of coping | −0.746 | 1.078 | −1.376 | −0.697 | 0.204 | 1.870 | 1.01 | 1.00 | 0.024 | ||
| 30. can usually find things to laugh about when by myself | −1.586 | 0.527 | −1.706 | −0.432 | −0.065 | 2.203 | 1.01 | 0.99 | 0.035 | 6 | |
| Aggressive Style | |||||||||||
| 3. if someone makes a mistake I will tease them | 0.137 | 0.828 | −1.801 | −0.518 | 0.392 | 1.927 | 1.01 | 1.01 | 0.022 | ||
| 7. people are never offended by my sense of humor | 0.371 | 0.671 | −2.602 | −0.371 | 0.966 | 2.007 | 1.00 | 1.02 | 0.021 | ||
| 11. when telling jokes I am not concerned about how other people are taking it | 0.557 | 0.582 | −2.333 | 0.433 | −0.368 | 2.269 | 1.00 | 1.02 | 0.025 | Yes | |
| 15. do not like when people use humor for putting someone down | 0.598 | 0.939 | −1.108 | −0.220 | 0.013 | 1.315 | 1.01 | 1.01 | 0.016 | ||
| 19. sometimes I think of something funny that I can’t stop myself from saying it, even if not appropriate | −0.140 | 0.584 | −1.942 | −0.143 | −0.245 | 2.330 | 1.01 | 1.01 | 0.024 | Yes | |
| 23. never participate in laughing at others | −0.237 | 0.655 | −1.918 | −0.612 | 0.317 | 2.213 | 1.00 | 1.01 | 0.026 | ||
| 27. if I don’t like someone, I use humor to put them down | 1.114 | 0.671 | −1.300 | 0.274 | −2.01 | 1.227 | 1.01 | 1.01 | 0.025 | Yes | |
| 31. if something is funny, I will not laugh if someone will be offended | −0.138 | 0.977 | −1.572 | −0.052 | 0.369 | 1.256 | 1.01 | 1.01 | 0.023 | ||
| Self-Defeating Style | |||||||||||
| 4. let people make fun at my expense | 0.272 | 0.859 | −2.076 | −0.300 | 0.421 | 1.955 | 1.01 | 1.02 | 0.032 | 24 | |
| 8. get carried away in putting myself down | 0.455 | 1.859 | −1.342 | −0.235 | 0.186 | 1.392 | 1.01 | 1.00 | 0.016 | ||
| 12. try to make people accept me by saying something funny about my faults | 0.036 | 0.934 | −1.699 | −0.481 | 0.059 | 2.122 | 1.01 | 1.02 | 0.034 | ||
| 16. don’t say funny things to put myself down | 0.113 | 0.771 | −1.933 | −0.321 | 0.089 | 2.165 | 1.00 | 1.04 | 0.040 | ||
| 20. go overboard in putting myself down when trying to be funny | 0.785 | 1.973 | −1.320 | −0.225 | 0.174 | 1.371 | 1.02 | 0.97 | 0.015 | ||
| 24. seem to be the one that other people joke about | 1.016 | 0.536 | −2.767 | −0.128 | 0.290 | 2.605 | 1.01 | 1.02 | 0.033 | 4, 32 | |
| 28. if unhappy, I cover it up by joking | −0.251 | 0.381 | −1.747 | −0.366 | −0.472 | 2.584 | 1.00 | 1.01 | 0.029 | Yes | |
| 32. letting others laugh at me keeps my friends in good spirits | 0.098 | 0.989 | −1.402 | −0.674 | 0.172 | 1.905 | 1.01 | 0.99 | 0.033 | 24 |
| Subscale | Cronbach’s α | Omega (ωH) | EAP Reliability | Gender Difference (d) | Reversed Items | Flesch Reading Ease | Gunning Fog Index | Sentence Length (Words) |
|---|---|---|---|---|---|---|---|---|
| Affiliative | 0.86 | 0.77 | 0.85 | −0.19 [−0.31, −0.08] | 5 | 71.0 | 6.7 | 11.13 |
| Self-enhancing | 0.82 | 0.68 | 0.84 | −0.09 [−0.20, 0.02] | 1 | 57.5 | 11.7 | 18.38 |
| Aggressive | 0.79 | 0.68 | 0.80 | −0.48 [−0.60, −0.36] | 4 | 67.3 | 9.2 | 17.25 |
| Self-defeating | 0.82 | 0.71 | 0.86 | −0.18 [−0.30, −0.07] | 1 | 70.1 | 10.2 | 19.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silvia, P.J.; Rodriguez, R.M. Time to Renovate the Humor Styles Questionnaire? An Item Response Theory Analysis of the HSQ. Behav. Sci. 2020, 10, 173. https://doi.org/10.3390/bs10110173
Silvia PJ, Rodriguez RM. Time to Renovate the Humor Styles Questionnaire? An Item Response Theory Analysis of the HSQ. Behavioral Sciences. 2020; 10(11):173. https://doi.org/10.3390/bs10110173
Chicago/Turabian StyleSilvia, Paul J., and Rebekah M. Rodriguez. 2020. "Time to Renovate the Humor Styles Questionnaire? An Item Response Theory Analysis of the HSQ" Behavioral Sciences 10, no. 11: 173. https://doi.org/10.3390/bs10110173
APA StyleSilvia, P. J., & Rodriguez, R. M. (2020). Time to Renovate the Humor Styles Questionnaire? An Item Response Theory Analysis of the HSQ. Behavioral Sciences, 10(11), 173. https://doi.org/10.3390/bs10110173