NN-Based Prediction of Sentinel-1 SAR Image Filtering Efficiency



Abstract
1. Introduction
- Human vision and respective visual quality metrics are more strictly connected with preservation of edges, details and texture than conventional metrics [28,29]; then, keeping in mind that object and edge detection performance as well as probability of image correct classification in their neighborhoods are strongly connected with edge/detail sharpness, the use of visual quality metrics is well motivated.
- noise type and, at least, some of its parameters are a priori known or pre-estimated with an appropriate accuracy (for the corresponding methods see [39]);
- there is one or several input parameters that can be quickly calculated for an analyzed image (subject to filtering or its skipping) and that are able to properly characterize image and noise properties that determine filtering efficiency;
- there is a strict dependence between a predicted metric and aforementioned parameters that can be determined a priori and approximated in different ways, e.g., analytically or by a neural network approximator.
2. Image/Noise Model, Filter and Quality Metrics
- metrics determined for original (noisy) images using available , where denotes the true noise-free image, defines the speckle in the -th pixel that has mean equal to unity and variance , define image size;
- metrics that characterize quality of despeckled images using available ;
- “improvements” of metric values due to despeckling where and are metric values for despeckled and original images, respectively.
- Many metrics have a “nonlinear” behavior; for example, for the metric FSIM most images have values over 0.8 even if images have a low visual quality. This property complicates analysis;
- Improvement of metric values does not always guarantee that image visual quality has improved; for example, improvement of PSNR by 3…5 dB does not show that image visual quality has improved due to filtering if input PSNR () determined for original (noisy) image is low (e.g., about 20 dB); similarly, improvement of FSIM by 0.01 corresponds to sufficient improvement of visual quality if input value of FSIM calculated for original image but the same improvement can correspond to negligible improvement of visual quality if .
- PSNR and its modification, PSNR-HVS-M [47], that takes into account peculiarities of human vision system (HVS). Both metrics are expressed in dB; larger values correspond to better quality, metric values are positive;
- Visual quality metric WSNR [53] that is expressed in dB; it has positive values and larger ones relate to better visual quality;
- The recently proposed metric HaarPSI [54] varies from 0 to 1, having larger values for better quality images;
- The visual quality metric GMSD [48] is positive and smaller is better;
- The metric MAD [28] varies in wide limits, is positive and smaller is better;
- The metric GSM [55] varies in narrow limits, is smaller than unity and the larger the better;
- The metric DSS [56] varies in the limits from 0 to 1 and the larger the better.
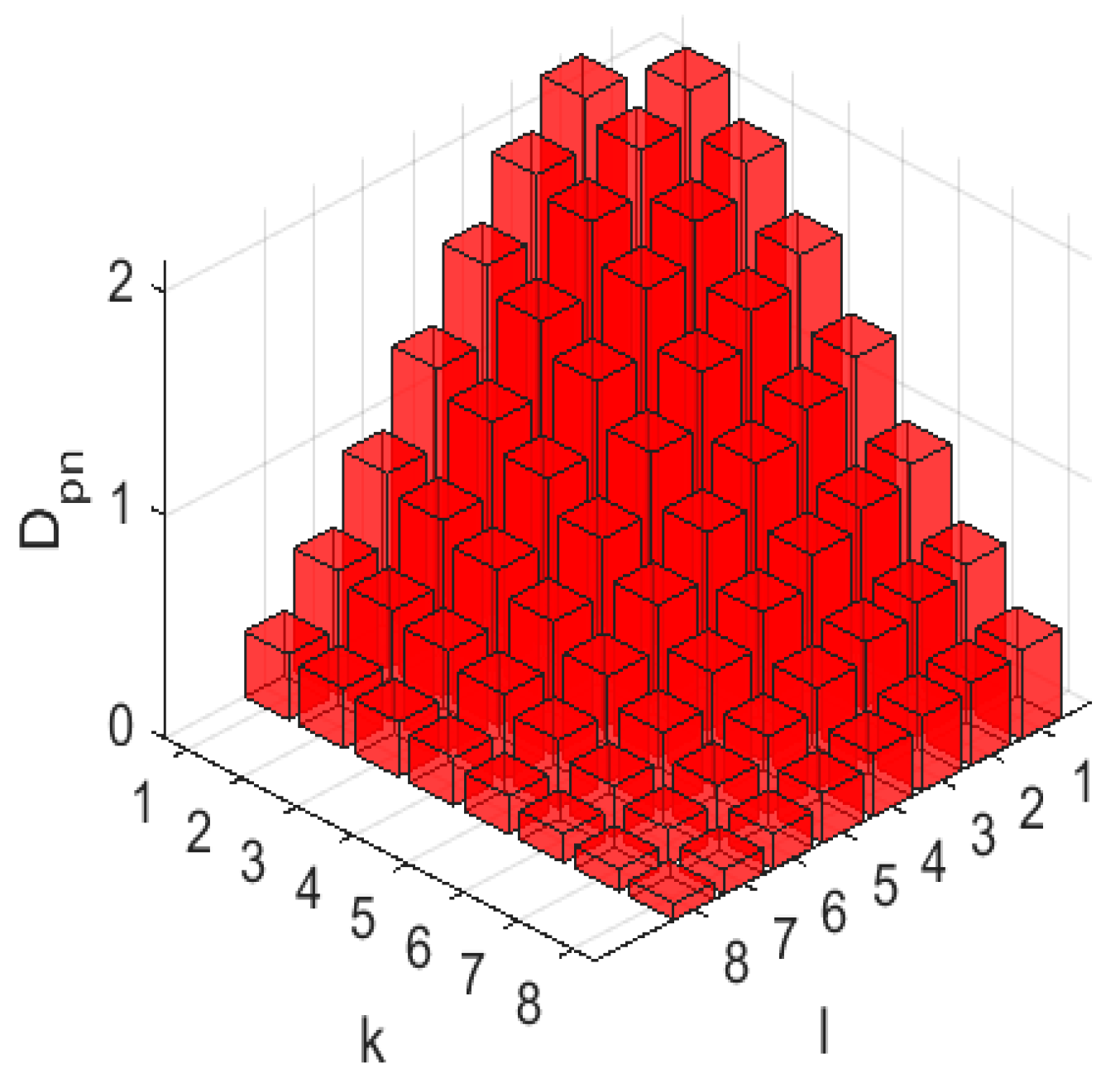
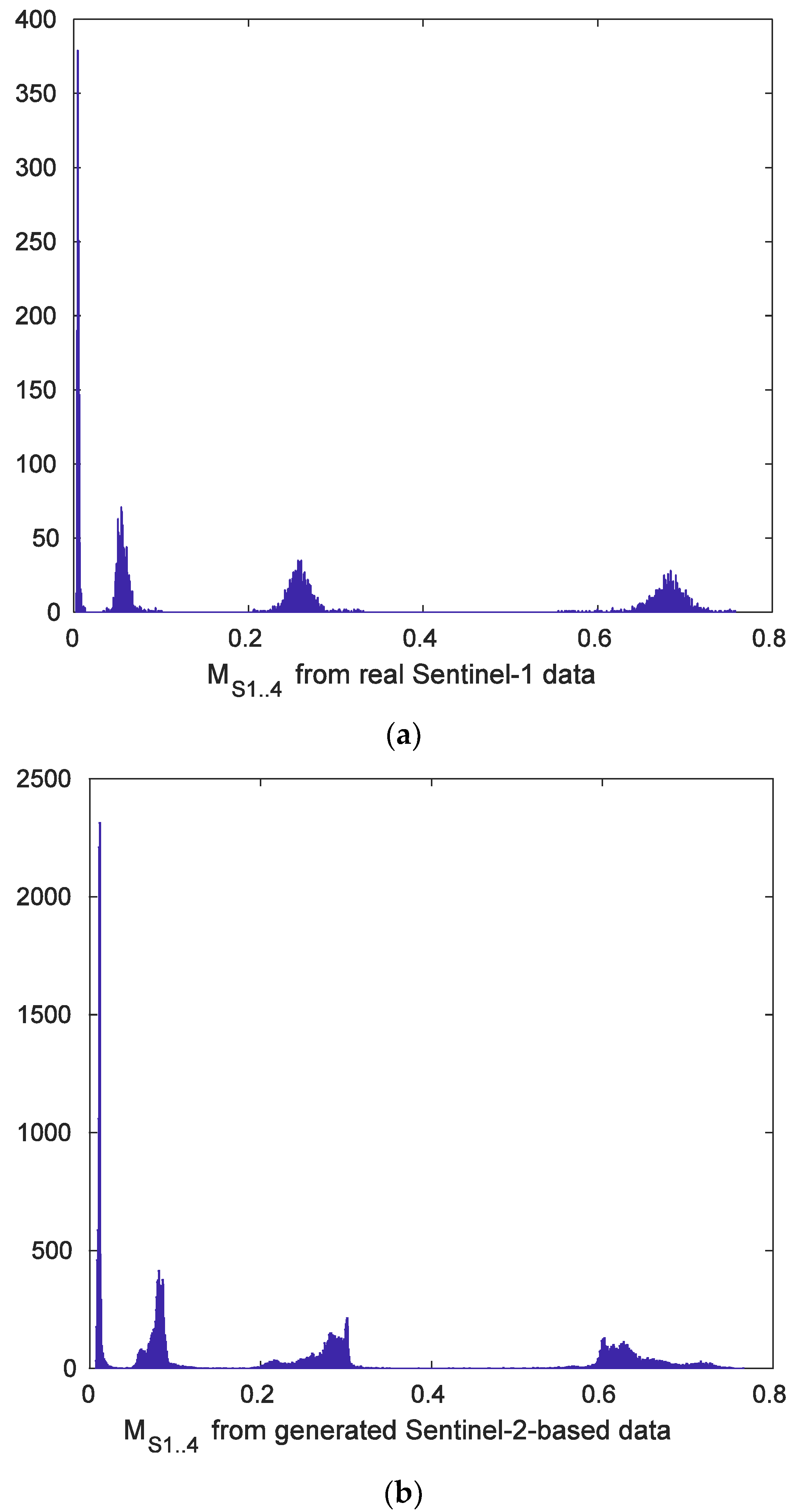
3. Simulated Images and Estimated Parameters
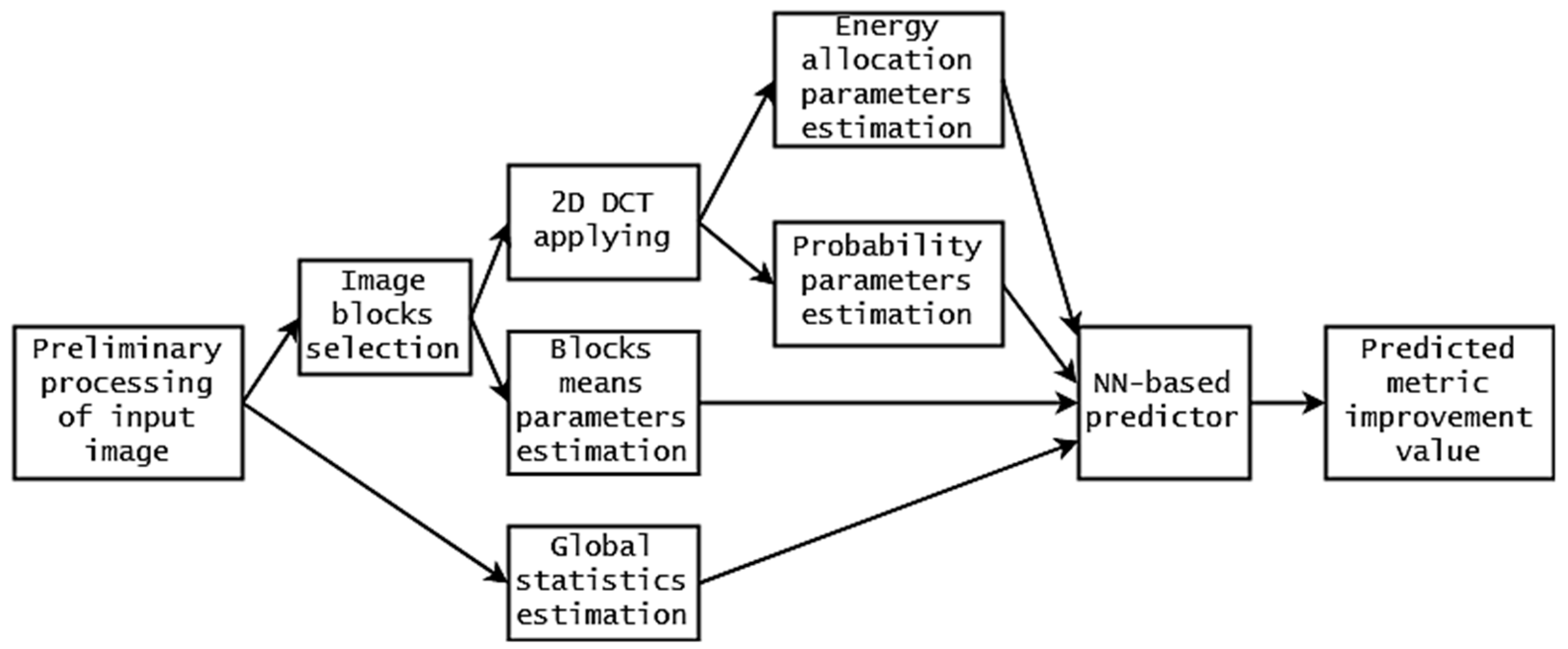
4. Peculiarities of NN Training
5. Training Results and Verification
- combination # 19 that uses only six input parameters (different means that can be easily calculated) produces RMSE = 0.574 and Adjusted equal to 0.958, i.e., accuracy criteria much better than mentioned above;
- combination # 24 that employs ten input parameters (image statistics and probability parameters) and produces RMSE = 0.322 and Adjusted equal to 0.986, i.e., very good accuracy criteria;
- combination # 33 that involves 13 input parameters that belong to different groups; it provides RMSE = 0.251 and Adjusted equal to 0.992, i.e., the same accuracy as the combination of all 28 input parameters (combination # 36); thus one can choose combination # 33 for practical application if prediction of improvement of PSNR is required.
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Schowengerdt, R.A. Remote Sensing: Models and Methods for Image Processing, 3rd ed.; Academic Press: San Diego, CA, USA, 2007. [Google Scholar]
- Lee, J.S.; Pottier, E. Polarimetric Radar Imaging: From Basics to Applications; CRC Press: Boca Raton, FL, USA, 2009; p. 422. [Google Scholar]
- Kussul, N.; Skakun, S.; Shelestov, A.; Kussul, O. The use of satellite SAR imagery to crop classification in Ukraine within JECAM project. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Quebec, QC, Canada, 13–18 July 2014; pp. 1497–1500. [Google Scholar] [CrossRef]
- Roth, A.; Marschalk, U.; Winkler, K.; Schättler, B.; Huber, M.; Georg, I.; Künzer, C.; Dech, S. Ten Years of Experience with Scientific TerraSAR-X Data Utilization. Remote Sens. 2018, 10, 1170. [Google Scholar] [CrossRef]
- Mullissa, A.G.; Persello, C.; Tolpekin, V. Fully Convolutional Networks for Multi-Temporal SAR Image Classification. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 6635–6638. [Google Scholar] [CrossRef]
- Oliver, C.; Quegan, S. Understanding Synthetic Aperture Radar Images; SciTech Publishing: Raleigh, NC, USA, 2004. [Google Scholar]
- Touzi, R. Review of Speckle Filtering in the Context of Estimation Theory. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2392–2404. [Google Scholar] [CrossRef]
- Kupidura, P. Comparison of Filters Dedicated to Speckle Suppression in SAR Images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI–B7, 269–276. [Google Scholar] [CrossRef]
- Vasile, G.; Trouvé, E.; Lee, J.S.; Buzuloiu, V. Intensity-driven adaptive-neighborhood technique for polarimetric and interferometric SAR parameters estimation. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1609–1621. [Google Scholar] [CrossRef]
- Anfinsen, S.N.; Doulgeris, A.P.; Eltoft, T. Estimation of the Equivalent Number of Looks in Polarimetric SAR Imagery. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008; pp. 487–490. [Google Scholar] [CrossRef]
- Deledalle, C.; Denis, L.; Tabti, S.; Tupin, F. MuLoG, or how to apply Gaussian denoisers to multi-channel SAR speckle reduction? IEEE Trans. Image Process. 2017, 26, 4389–4403. [Google Scholar] [CrossRef] [PubMed]
- Solbo, S.; Eltoft, T. A stationary wavelet domain Wiener filter for correlated speckle. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1219–1230. [Google Scholar] [CrossRef]
- Lee, J.S.; Wen, J.H.; Ainsworth, T.; Chen, K.S.; Chen, A. Improved Sigma Filter for Speckle Filtering of SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2009, 47, 202–213. [Google Scholar] [CrossRef]
- Parrilli, S.; Poderico, M.; Angelino, C.; Verdoliva, L. A nonlocal SAR image denoising algorithm based on LLMMSE wavelet shrinkage. IEEE Trans. Geosci. Remote Sens. 2012, 50, 606–616. [Google Scholar] [CrossRef]
- Yun, S.; Woo, H. A new multiplicative denoising variational model based on mth root transformation. IEEE Trans. Image Process. 2012, 21, 2523–2533. [Google Scholar] [CrossRef]
- Makitalo, M.; Foi, A.; Fevralev, D.; Lukin, V. Denoising of single-look SAR images based on variance stabilization and non-local filters. In Proceedings of the International Conference on Mathematical Methods in Electromagnetic Theory (MMET), Kiev, Ukraine, 6–8 September 2010; pp. 1–4. [Google Scholar] [CrossRef]
- Tsymbal, O.; Lukin, V.; Ponomarenko, N.; Zelensky, A.; Egiazarian, K.; Astola, J. Three-state locally adaptive texture preserving filter for radar and optical image processing. EURASIP J. Appl. Signal Process. 2005, 2005, 1185–1204. [Google Scholar] [CrossRef]
- Deledalle, C.; Tupin, F.; Denis, L. Patch similarity under non Gaussian noise. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 1885–1888. [Google Scholar] [CrossRef]
- Rubel, O.; Lukin, V.; Egiazarian, K. Additive Spatially Correlated Noise Suppression by Robust Block Matching and Adaptive 3D Filtering. J. Imaging Sci. Technol. 2018, 62, 6040-1–6040-11. [Google Scholar] [CrossRef]
- Fevralev, D.; Lukin, V.; Ponomarenko, N.; Abramov, S.; Egiazarian, K.; Astola, J. Efficiency analysis of color image filtering. EURASIP J. Adv. Signal Process. 2011, 2011, 1–19. [Google Scholar] [CrossRef]
- Chatterjee, P.; Milanfar, P. Is Denoising Dead? IEEE Trans. Image Process. 2010, 19, 895–911. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, P.; Milanfar, P. Practical Bounds on Image Denoising: From Estimation to Information. IEEE Trans. Image Process. 2011, 20, 1221–1233. [Google Scholar] [CrossRef] [PubMed]
- Rubel, O.; Lukin, V.; de Medeiros, F. Prediction of Despeckling Efficiency of DCT-based filters Applied to SAR Images. In Proceedings of the International Conference on Distributed Computing in Sensor Systems, Fortaleza, Brazil, 10–12 June 2015; pp. 159–168. [Google Scholar] [CrossRef]
- Rubel, O.; Abramov, S.; Lukin, V.; Egiazarian, K.; Vozel, B.; Pogrebnyak, A. Is Texture Denoising Efficiency Predictable? Int. J. Pattern Recognit. Artif. Intell. 2018, 32, 1860005. [Google Scholar] [CrossRef]
- Singh, P.; Shree, R. A new SAR image despeckling using directional smoothing filter and method noise thresholding. Eng. Sci. Technol. Int. J. 2018, 21, 589–610. [Google Scholar] [CrossRef]
- Wang, P.; Patel, V. Generating high quality visible images from SAR images using CNNs. In Proceedings of the IEEE Radar Conference (RadarConf18), Oklahoma City, OK, USA, 23–27 April 2018; pp. 570–575. [Google Scholar] [CrossRef]
- Gomez, L.; Ospina, R.; Frery, A.C. Statistical Properties of an Unassisted Image Quality Index for SAR Imagery. Remote Sens. 2019, 11, 385. [Google Scholar] [CrossRef]
- Larson, E.; Chandler, D. Most apparent distortion: Full-reference image quality assessment and the role of strategy. J. Electron. Imaging 2010, 19, 011006:1–011006:21. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef]
- SENTINEL-1 SAR User Guide Introduction. Available online: https://sentinel.esa.int/web/sentinel/user-guides/sentinel-1-sar (accessed on 4 April 2019).
- Lopez-Martinez, C.; Lopez-Sanchez, J.M. Special Issue on Polarimetric SAR Techniques and Applications. Appl. Sci. 2017, 7, 768. [Google Scholar] [CrossRef]
- Abdikan, S.; Sanli, F.; Ustuner, M.; Calò, F. Land Cover Mapping Using Sentinel-1 SAR Data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI–B7, 757–761. [Google Scholar] [CrossRef]
- Whelen, T.; Siqueira, P. Time-series classification of Sentinel-1 agricultural data over North Dakota. Remote Sens. Lett. 2018, 9, 411–420. [Google Scholar] [CrossRef]
- Abramov, S.; Krivenko, S.; Roenko, A.; Lukin, V.; Djurovic, I.; Chobanu, M. Prediction of Filtering Efficiency for DCT-based Image Denoising. In Proceedings of the Mediterranean Conference on Embedded Computing (MECO), Budva, Serbia, 15–20 June 2013; pp. 97–100. [Google Scholar] [CrossRef]
- Lukin, V.; Abramov, S.; Kozhemiakin, R.; Rubel, A.; Uss, M.; Ponomarenko, N.; Abramova, V.; Vozel, B.; Chehdi, K.; Egiazarian, K.; et al. DCT-Based Color Image Denoising: Efficiency Analysis and Prediction. In Color Image and Video Enhancement; Emre Celebi, M., Lecca, M., Smolka, B., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 55–80. [Google Scholar]
- Rubel, A.; Lukin, V.; Egiazarian, K. A method for predicting DCT-based denoising efficiency for grayscale images corrupted by AWGN and additive spatially correlated noise. In Proceedings of the SPIE Conference Image Processing: Algorithms and Systems XIII, San Francisco, CA, USA, 10–11 February 2015; Volume 9399. [Google Scholar] [CrossRef]
- Rubel, A.; Rubel, O.; Lukin, V. On Prediction of Image Denoising Expedience Using Neural Networks. In Proceedings of the International Scientific-Practical Conference Problems of Infocommunications. Science and Technology (PIC S&T), Kharkiv, Ukraine, 9–12 October 2018; pp. 629–634. [Google Scholar] [CrossRef]
- Rubel, O.; Rubel, A.; Lukin, V.; Egiazarian, K. Blind DCT-based prediction of image denoising efficiency using neural networks. In Proceedings of the 7th European Workshop on Visual Information Processing (EUVIP), Tampere, Finland, 23–25 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Colom, M.; Lebrun, M.; Buades, A.; Morel, J.M. Nonparametric multiscale blind estimation of intensity-frequency-dependent noise. IEEE Trans. Image Process. 2015, 24, 3162–3175. [Google Scholar] [CrossRef] [PubMed]
- Pogrebnyak, O.; Lukin, V. Wiener discrete cosine transform-based image filtering. J. Electron. Imaging 2012, 21, 043020-1–043020-15. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Rubel, A.; Rubel, O.; Lukin, V. Neural Network-based Prediction of Visual Quality for Noisy Images. In Proceedings of the 15th International Conference the Experience of Designing and Application of CAD Systems in Microelectronics (CADSM), Polyana, Svalyava, Ukraine, 26–28 February 2019; p. 6. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Abramova, V.; Lukin, V.; Abramov, S.; Rubel, O.; Vozel, B.; Chehdi, K.; Egiazarian, K.; Astola, J. On Requirements to Accuracy of Noise Variance Estimation in Prediction of DCT-based Filter Efficiency. Telecommun. Radio Eng. 2016, 75, 139–154. [Google Scholar] [CrossRef]
- Abramova, V.; Abramov, S.; Lukin, V.; Egiazarian, K. Blind Estimation of Speckle Characteristics for Sentinel Polarimetric Radar Images. In Proceedings of the IEEE Microwaves, Radar and Remote Sensing Symposium (MRRS), Kiev, Ukraine, 29–31 August 2017; pp. 263–266. [Google Scholar] [CrossRef]
- Lukin, V.; Ponomarenko, N.; Egiazarian, K.; Astola, J. Analysis of HVS-Metrics’ Properties Using Color Image Database TID2013. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems (ACIVS), Catania, Italy, 26–29 October 2015; pp. 613–624. [Google Scholar] [CrossRef]
- Ponomarenko, N.; Silvestri, F.; Egiazarian, K.; Carli, M.; Astola, J.; Lukin, V. On between-coefficient contrast masking of DCT basis functions. In Proceedings of the Third International Workshop on Video Processing and Quality Metrics for Consumer Electronics (VPQM), Scottsdale, AZ, USA, 25–26 January 2007; p. 4. [Google Scholar]
- Xue, W.; Zhang, L.; Mou, X.; Bovik, A. Gradient magnitude similarity deviation: A highly efficient perceptual image quality index. IEEE Trans. Image Process. 2014, 23, 684–695. [Google Scholar] [CrossRef]
- Ponomarenko, M.; Egiazarian, K.; Lukin, V.; Abramova, V. Structural Similarity Index with Predictability of Image Blocks. In Proceedings of the 17th International Conference on Mathematical Methods in Electromagnetic Theory (MMET), Kiev, Ukraine, 2–5 July 2018; pp. 115–118. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.; Bovik, A. Multiscale structural similarity for image quality assessment. In Proceedings of the The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; pp. 1398–1402. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Q. Information content weighting for perceptual image quality assessment. IEEE Trans. Image Process. 2011, 20, 1185–1198. [Google Scholar] [CrossRef]
- Gu, K.; Wang, S.; Zhai, G.; Lin, W.; Yang, X.; Zhang, W. Analysis of Distortion Distribution for Pooling in Image Quality Prediction. IEEE Trans. Broadcast. 2016, 62, 446–456. [Google Scholar] [CrossRef]
- Mitsa, T.; Varkur, K. Evaluation of contrast sensitivity functions for the formulation of quality measures incorporated in halftoning algorithms. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, MN, USA, 27–30 April 1993; pp. 301–304. [Google Scholar] [CrossRef]
- Reisenhofer, R.; Bosse, S.; Kutyniok, G.; Wiegand, T. A Haar Wavelet-Based Perceptual Similarity Index for Image Quality Assessment. Signal Process. Image Commun. 2018, 61, 33–43. [Google Scholar] [CrossRef]
- Liu, A.; Lin, W.; Narwaria, M. Image quality assessment based on gradient similarity. IEEE Trans. Image Process. 2012, 21, 1500–1512. [Google Scholar] [CrossRef] [PubMed]
- Balanov, A.; Schwartz, A.; Moshe, Y.; Peleg, N. Image quality assessment based on DCT subband similarity. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 2105–2109. [Google Scholar] [CrossRef]
- Abramov, S.; Uss, M.; Lukin, V.; Vozel, B.; Chehdi, K.; Egiazarian, K. Enhancement of Component Images of Multispectral Data by Denoising with Reference. Remote Sens. 2019, 11, 611. [Google Scholar] [CrossRef]
- Cameron, C.; Windmeijer, A. An R-squared measure of goodness of fit for some common nonlinear regression models. J. Econom. 1997, 77, 329–342. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Combination Number | Input Parameters | RMSE | |
|---|---|---|---|
| 1 | 1.148 | 0.827 | |
| 2 | , | 0.939 | 0.888 |
| 3 | , , | 0.891 | 0.900 |
| 4 | , , , | 0.882 | 0.902 |
| 5 | , | 0.907 | 0.897 |
| 6 | , , | 0.791 | 0.921 |
| 7 | , , , | 0.754 | 0.928 |
| 8 | , , , , | 0.748 | 0.929 |
| 9 | , | 1.527 | 0.703 |
| 10 | , , | 1.469 | 0.727 |
| 11 | , , , | 1.474 | 0.720 |
| 12 | , | 1.014 | 0.861 |
| 13 | , , | 0.929 | 0.891 |
| 14 | , , , | 0.932 | 0.885 |
| 15 | , | 1.340 | 0.769 |
| 16 | , , | 1.296 | 0.782 |
| 17 | , , , | 1.284 | 0.787 |
| 18 | , | 0.927 | 0.886 |
| 19 | , , | 0.574 | 0.958 |
| 20 | , , , | 0.558 | 0.961 |
| 21 | , , , , | 1.390 | 0.757 |
| 22 | , , , , , , , | 0.555 | 0.960 |
| 23 | , , , , , , , , | 0.527 | 0.965 |
| 24 | , , , , , , , , , | 0.322 | 0.986 |
| 25 | , , , , , , , , , , | 0.303 | 0.988 |
| 26 | , , , , , , , , , , , | 0.320 | 0.987 |
| 27 | , , , , , , , , , | 0.288 | 0.989 |
| 28 | , , , , , , , , , , | 0.246 | 0.992 |
| 29 | , , , , , , , , , , , | 0.249 | 0.992 |
| 30 | , , , , , , , , , , , , | 0.259 | 0.991 |
| 31 | , , , , , , , , , , , , | 0.277 | 0.990 |
| 32 | , , , , , , , , , | 0.288 | 0.989 |
| 33 | , , , , , , , , , | 0.251 | 0.992 |
| 34 | , , , , , , , , , , | 0.248 | 0.992 |
| 35 | , , , , , , , , , , , | 0.250 | 0.992 |
| 36 | , , , , , , , , , , , , , , , | 0.250 | 0.992 |
| Combination Number | Input Parameters | RMSE | |
|---|---|---|---|
| 1 | 0.944 | 0.871 | |
| 2 | , | 0.793 | 0.908 |
| 3 | , , | 0.751 | 0.918 |
| 4 | , , , | 0.748 | 0.919 |
| 5 | , | 0.816 | 0.898 |
| 6 | , , | 0.656 | 0.937 |
| 7 | , , , | 0.633 | 0.942 |
| 8 | , , , , | 0.626 | 0.943 |
| 9 | , | 1.370 | 0.729 |
| 10 | , , | 1.364 | 0.721 |
| 11 | , , , | 1.342 | 0.732 |
| 12 | , | 1.205 | 0.790 |
| 13 | , , | 1.180 | 0.791 |
| 14 | , , , | 1.117 | 0.814 |
| 15 | , | 1.207 | 0.786 |
| 16 | , , | 1.175 | 0.797 |
| 17 | , , | 1.183 | 0.790 |
| 18 | , | 0.786 | 0.911 |
| 19 | , , | 0.575 | 0.952 |
| 20 | , , , | 0.570 | 0.953 |
| 21 | , , , , | 1.266 | 0.767 |
| 22 | , , , , , , , | 0.688 | 0.931 |
| 23 | , , , , , , , , | 0.666 | 0.935 |
| 24 | , , , , , , , , , | 0.370 | 0.980 |
| 25 | , , , , , , , , , , | 0.357 | 0.981 |
| 26 | , , , , , , , , , , , | 0.375 | 0.979 |
| 27 | , , , , , , , , , | 0.302 | 0.987 |
| 28 | 0.264 | 0.990 | |
| 29 | 0.263 | 0.990 | |
| 30 | 0.264 | 0.990 | |
| 31 | , , , , , , , , , , , | 0.290 | 0.988 |
| 32 | , , , , , , , , , | 0.300 | 0.987 |
| 33 | , , , , , , , , , | 0.272 | 0.989 |
| 34 | , , , , , , , , , , | 0.268 | 0.989 |
| 35 | , , , , , , , , , , , | 0.262 | 0.990 |
| 36 | , , , , , , , , , , , , , , , | 0.263 | 0.990 |
| Combination Number | Input Parameters | RMSE | |
|---|---|---|---|
| 1 | 0.081 | 0.846 | |
| 2 | , | 0.067 | 0.898 |
| 3 | , , | 0.063 | 0.910 |
| 4 | , , , | 0.063 | 0.911 |
| 5 | , | 0.055 | 0.921 |
| 6 | , , | 0.043 | 0.958 |
| 7 | , , , | 0.043 | 0.958 |
| 8 | , , , , | 0.042 | 0.960 |
| 9 | , | 0.109 | 0.730 |
| 10 | , , | 0.104 | 0.754 |
| 11 | , , | 0.101 | 0.768 |
| 12 | , | 0.103 | 0.753 |
| 13 | , , | 0.097 | 0.777 |
| 14 | , , , | 0.092 | 0.808 |
| 15 | , | 0.093 | 0.805 |
| 16 | , , | 0.089 | 0.815 |
| 17 | , , , | 0.091 | 0.800 |
| 18 | , | 0.052 | 0.937 |
| 19 | , , | 0.036 | 0.964 |
| 20 | , , , | 0.034 | 0.975 |
| 21 | , , , , | 0.098 | 0.786 |
| 22 | , , , , , , , | 0.057 | 0.926 |
| 23 | , , , , , , , , | 0.056 | 0.924 |
| 24 | , , , , , , , , , | 0.029 | 0.980 |
| 25 | , , , , , , , , , , | 0.028 | 0.981 |
| 26 | , , , , , , , , , , , | 0.030 | 0.979 |
| 27 | , , , , , , , , , | 0.020 | 0.991 |
| 28 | , , , , , , , , , , | 0.019 | 0.992 |
| 29 | , , , , , , , , , , , | 0.019 | 0.992 |
| 30 | , , , , , , , , , , , , | 0.019 | 0.992 |
| 31 | , , , , , , , , , , , , | 0.018 | 0.993 |
| 32 | , , , , , , , , , | 0.020 | 0.991 |
| 33 | , , , , , , , , , | 0.019 | 0.992 |
| 34 | , , , , , , , , , , | 0.019 | 0.992 |
| 35 | , , , , , , , , , , , | 0.019 | 0.992 |
| 36 | , , , , , , , , , , , , , , , | 0.019 | 0.992 |
| Output Parameters | RMSE | STD of RMSE | ||
|---|---|---|---|---|
| I-PSNR | 0.251 | 0.027 | 0.992 | 0.002 |
| I-PSNRHVSM | 0.264 | 0.024 | 0.990 | 0.002 |
| I-FSIM | 0.018 | 0.001 | 0.982 | 0.003 |
| I-MSSSIM | 0.010 | 0.001 | 0.994 | 0.001 |
| I-GMSD | 0.011 | 0.001 | 0.953 | 0.007 |
| I-HaarPSI | 0.020 | 0.001 | 0.972 | 0.004 |
| I-GSM | 0.002 | 0.000 | 0.991 | 0.001 |
| I-SSIM4 | 0.019 | 0.002 | 0.992 | 0.002 |
| I-MAD | 3.620 | 0.252 | 0.894 | 0.014 |
| I-IWSSIM | 0.015 | 0.001 | 0.979 | 0.003 |
| I-ADDSSIM | 0.001 | 0.000 | 0.962 | 0.005 |
| I-ADDGSIM | 0.001 | 0.000 | 0.956 | 0.007 |
| I-DSS | 0.034 | 0.002 | 0.945 | 0.007 |
| I-WSNR | 0.198 | 0.017 | 0.988 | 0.002 |
| Output Parameters | RMSE | STD of RMSE | ||
|---|---|---|---|---|
| I-PSNR | 0.271 | 0.036 | 0.990 | 0.003 |
| I-PSNRHVSM | 0.285 | 0.042 | 0.987 | 0.006 |
| I-FSIM | 0.019 | 0.002 | 0.978 | 0.007 |
| I-MSSSIM | 0.011 | 0.002 | 0.993 | 0.003 |
| I-GMSD | 0.012 | 0.002 | 0.939 | 0.037 |
| I-HaarPSI | 0.022 | 0.004 | 0.964 | 0.032 |
| I-GSM | 0.002 | 0.000 | 0.989 | 0.004 |
| I-SSIM4 | 0.021 | 0.002 | 0.990 | 0.003 |
| I-MAD | 3.999 | 0.844 | 0.865 | 0.046 |
| I-IWSSIM | 0.016 | 0.002 | 0.973 | 0.009 |
| I-ADDSSIM | 0.001 | 0.000 | 0.952 | 0.016 |
| I-ADDGSIM | 0.002 | 0.000 | 0.944 | 0.023 |
| I-DSS | 0.037 | 0.004 | 0.932 | 0.017 |
| I-WSNR | 0.214 | 0.026 | 0.986 | 0.004 |
| Output Parameters | RMSE | STD of RMSE | ||
|---|---|---|---|---|
| I-PSNR | 0.417 | 0.070 | 0.965 | 0.016 |
| I-PSNRHVSM | 0.429 | 0.071 | 0.962 | 0.015 |
| I-FSIM | 0.023 | 0.002 | 0.958 | 0.016 |
| I-MSSSIM | 0.014 | 0.002 | 0.986 | 0.005 |
| I-GMSD | 0.018 | 0.002 | 0.868 | 0.043 |
| I-HaarPSI | 0.031 | 0.004 | 0.921 | 0.024 |
| I-GSM | 0.003 | 0.001 | 0.975 | 0.032 |
| I-SSIM4 | 0.030 | 0.003 | 0.975 | 0.008 |
| I-MAD | 4.764 | 0.799 | 0.744 | 0.085 |
| I-IWSSIM | 0.019 | 0.002 | 0.957 | 0.013 |
| I-ADDSSIM | 0.002 | 0.000 | 0.882 | 0.043 |
| I-ADDGSIM | 0.002 | 0.000 | 0.812 | 0.083 |
| I-DSS | 0.050 | 0.006 | 0.873 | 0.039 |
| I-WSNR | 0.311 | 0.049 | 0.963 | 0.013 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rubel, O.; Lukin, V.; Rubel, A.; Egiazarian, K. NN-Based Prediction of Sentinel-1 SAR Image Filtering Efficiency. Geosciences 2019, 9, 290. https://doi.org/10.3390/geosciences9070290
Rubel O, Lukin V, Rubel A, Egiazarian K. NN-Based Prediction of Sentinel-1 SAR Image Filtering Efficiency. Geosciences. 2019; 9(7):290. https://doi.org/10.3390/geosciences9070290
Chicago/Turabian StyleRubel, Oleksii, Vladimir Lukin, Andrii Rubel, and Karen Egiazarian. 2019. "NN-Based Prediction of Sentinel-1 SAR Image Filtering Efficiency" Geosciences 9, no. 7: 290. https://doi.org/10.3390/geosciences9070290
APA StyleRubel, O., Lukin, V., Rubel, A., & Egiazarian, K. (2019). NN-Based Prediction of Sentinel-1 SAR Image Filtering Efficiency. Geosciences, 9(7), 290. https://doi.org/10.3390/geosciences9070290