How Do Continuous High-Resolution Models of Patchy Seabed Habitats Enhance Classification Schemes?


Abstract
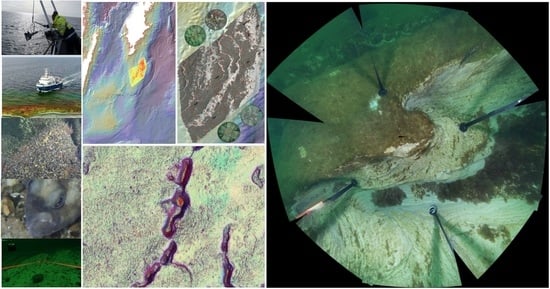
1. Introduction
2. Materials and Methods
2.1. Acquisition and Processing
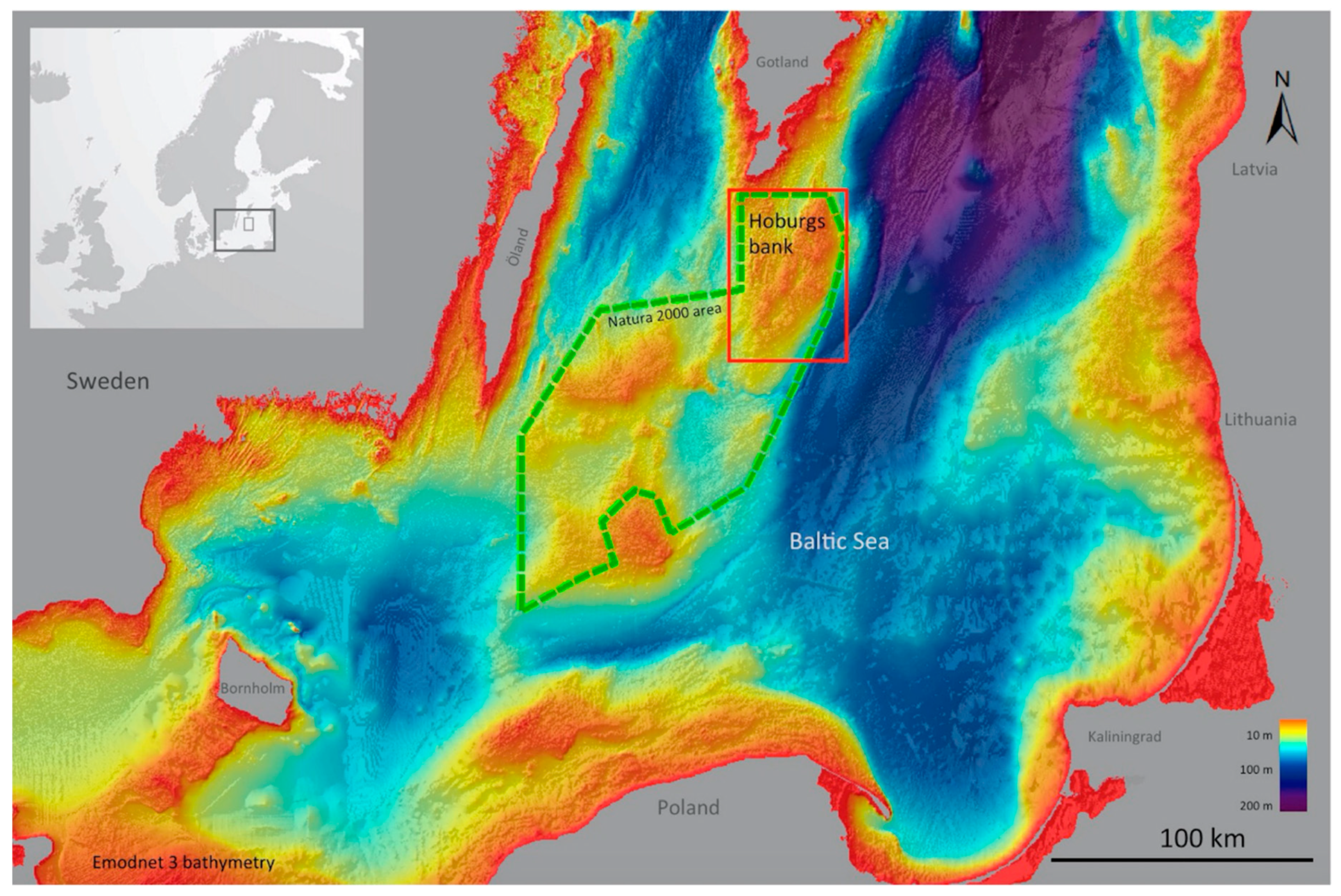
2.1.1. Study Area
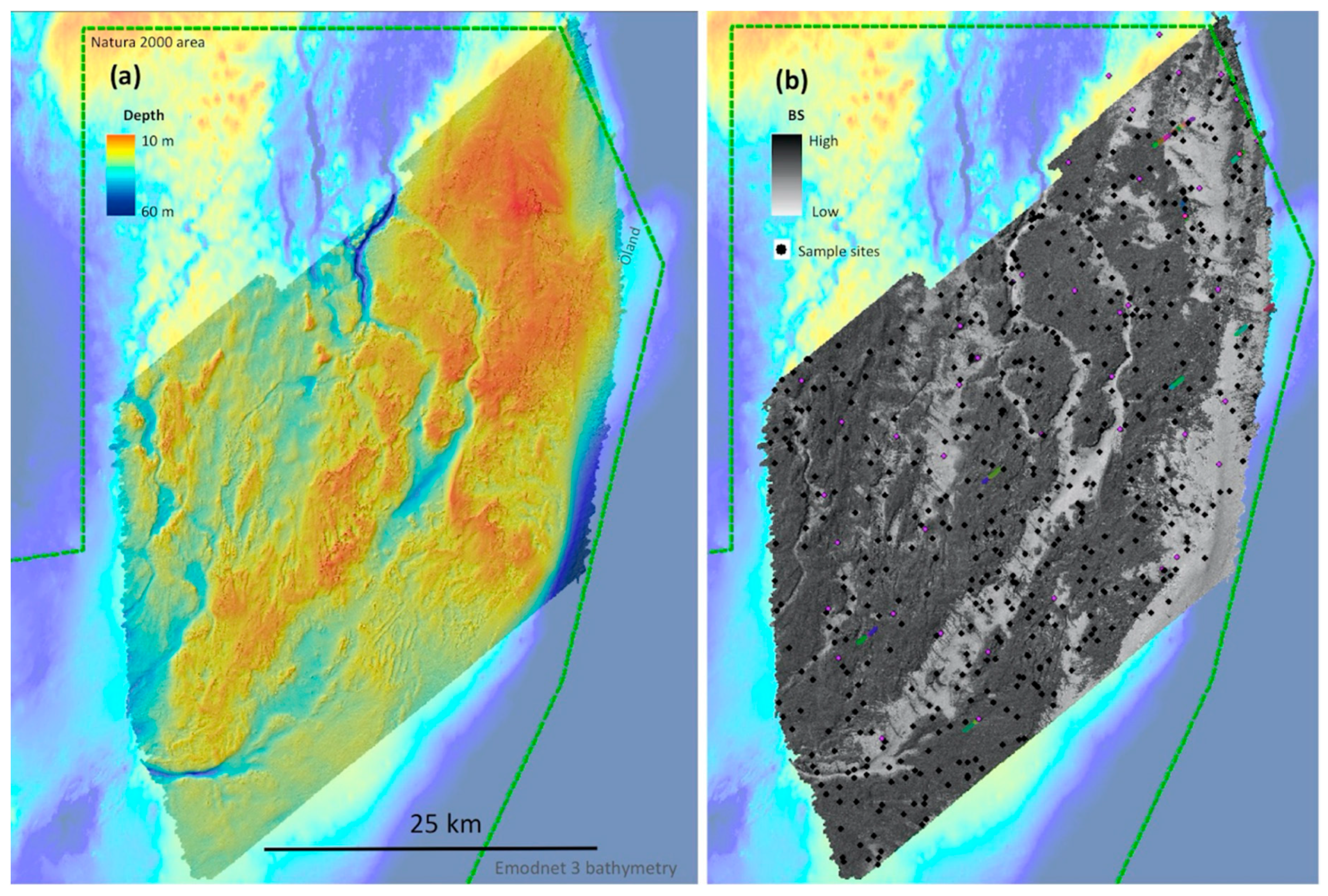
2.1.2. Hydrographic Survey
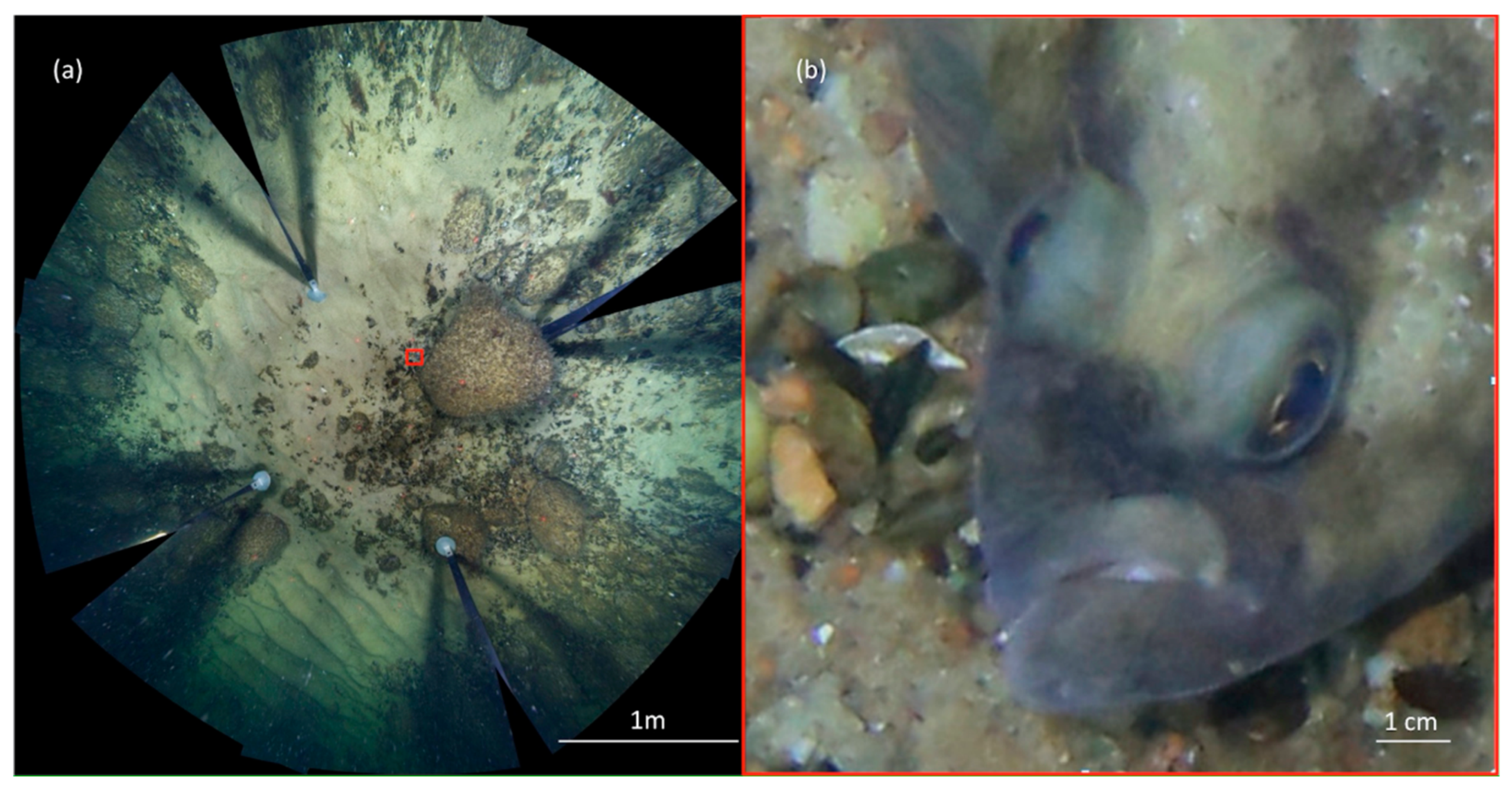
2.1.3. Sampling and Underwater Observations
2.1.4. Legacy Data and Expert Annotations
2.2. Environmental Setting
2.3. Thematic and Continuous Models
2.4. Combining Models into Classified Maps
2.5. Accuracy Assessment
3. Results
3.1. Thematic vs. Reclassified
3.2. Predictors and Training Data
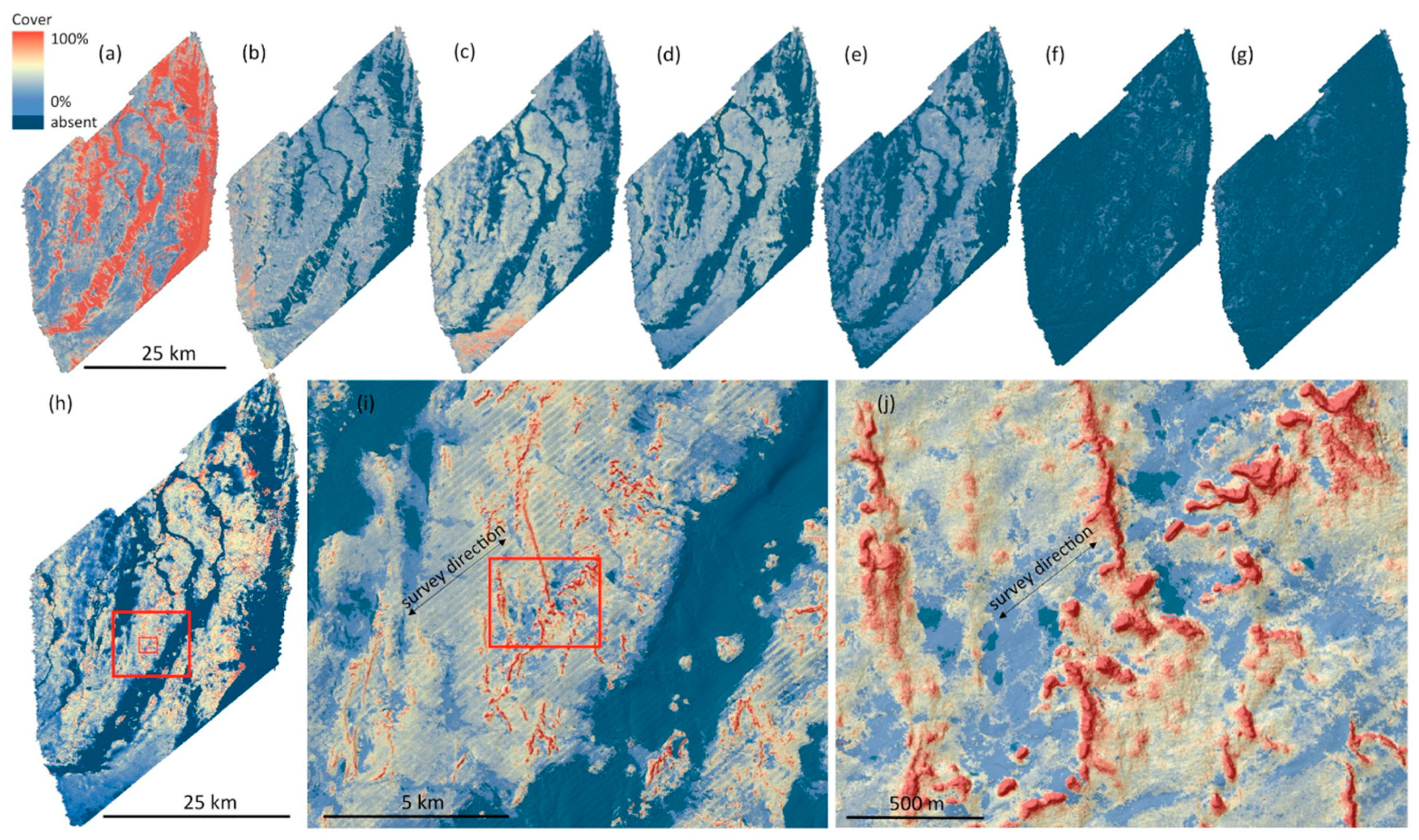
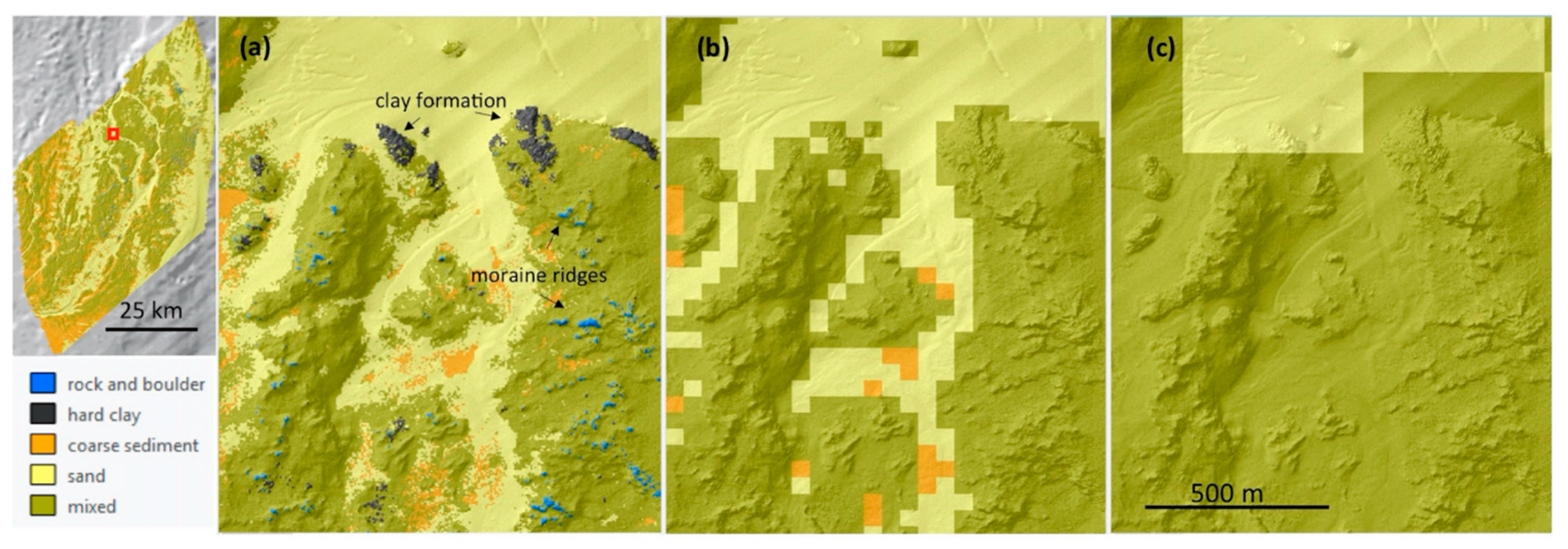
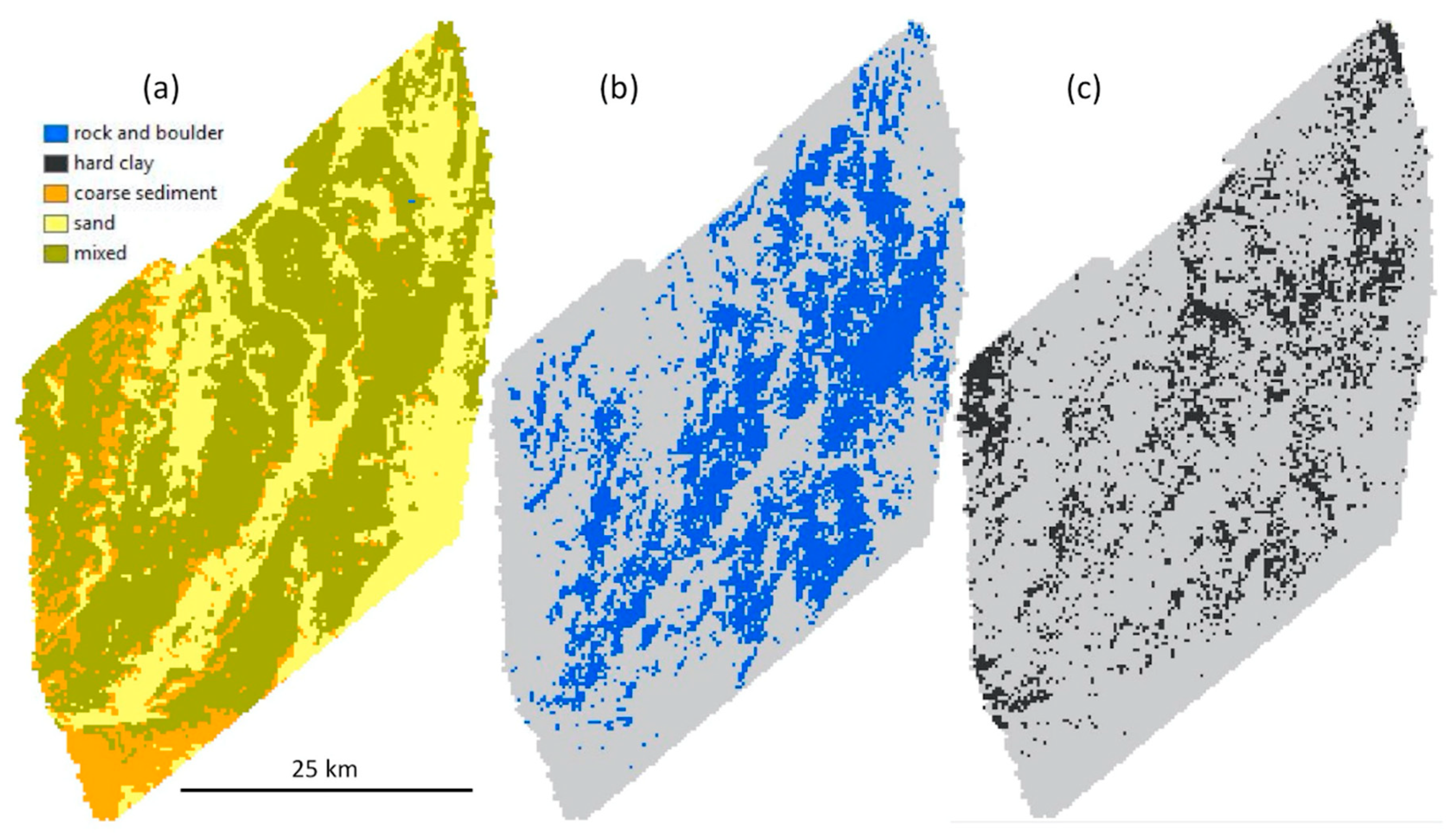
3.3. Continuous Percent Coverage Models
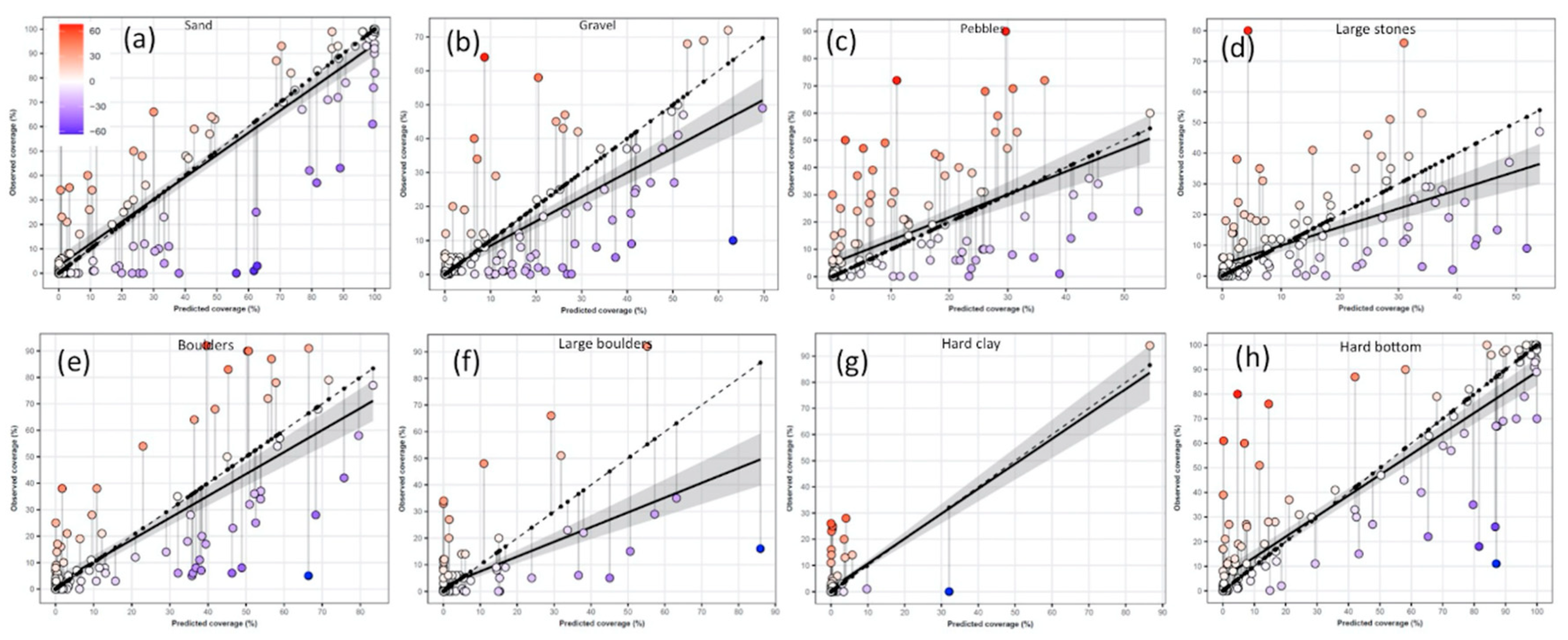
3.3.1. Substrate Components
3.3.2. Substrate Fine Fractions
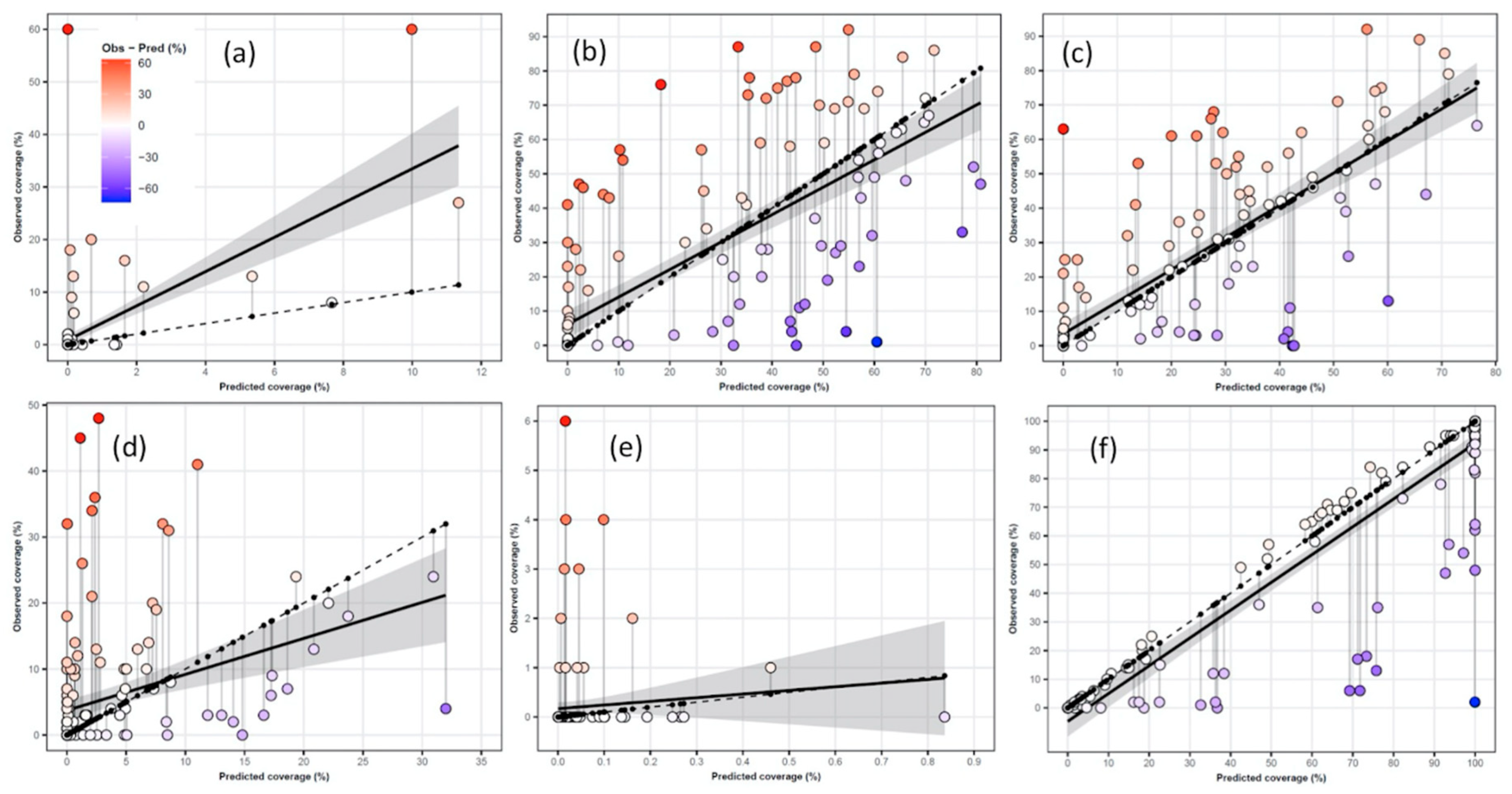
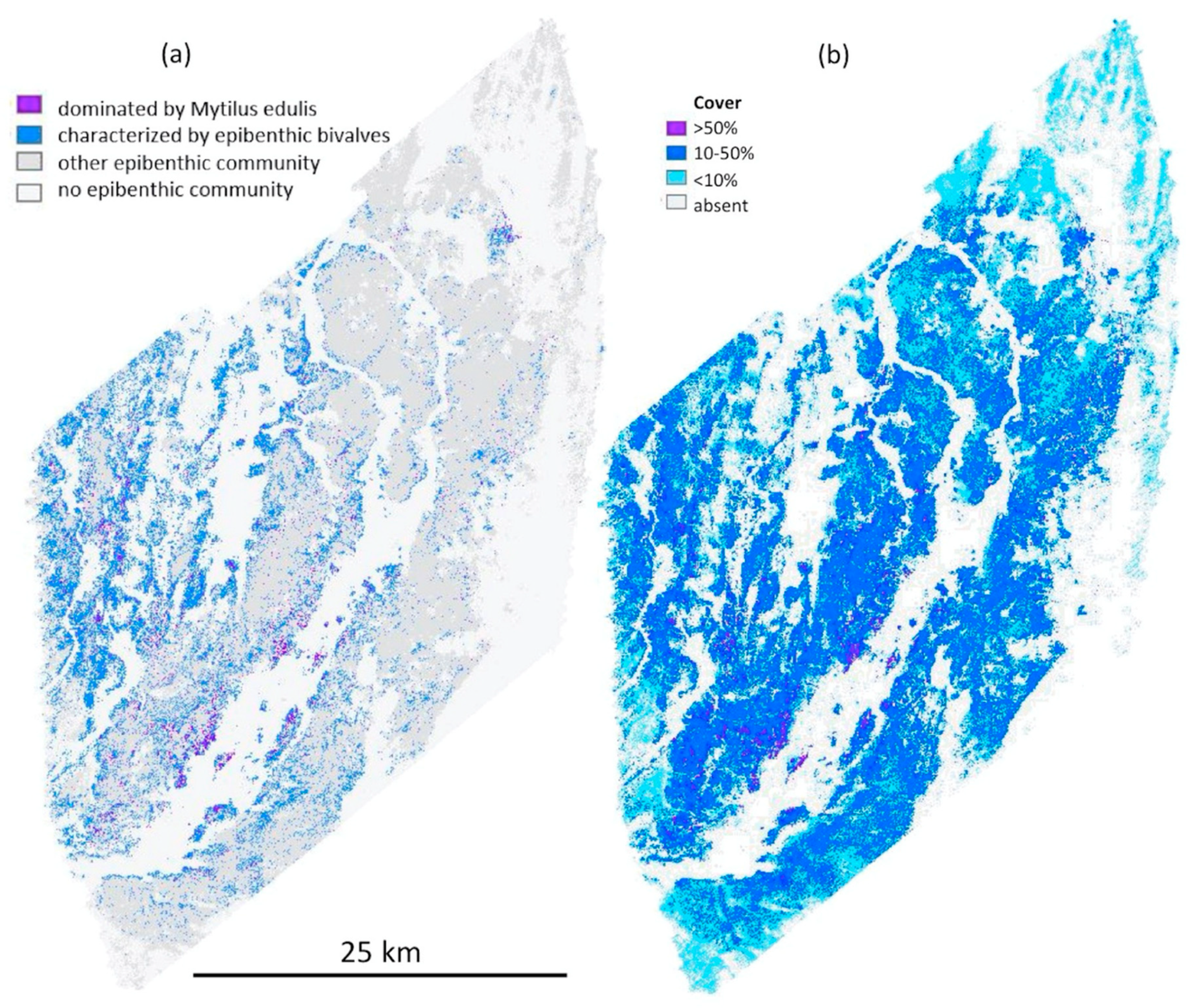
3.3.3. Biological Components
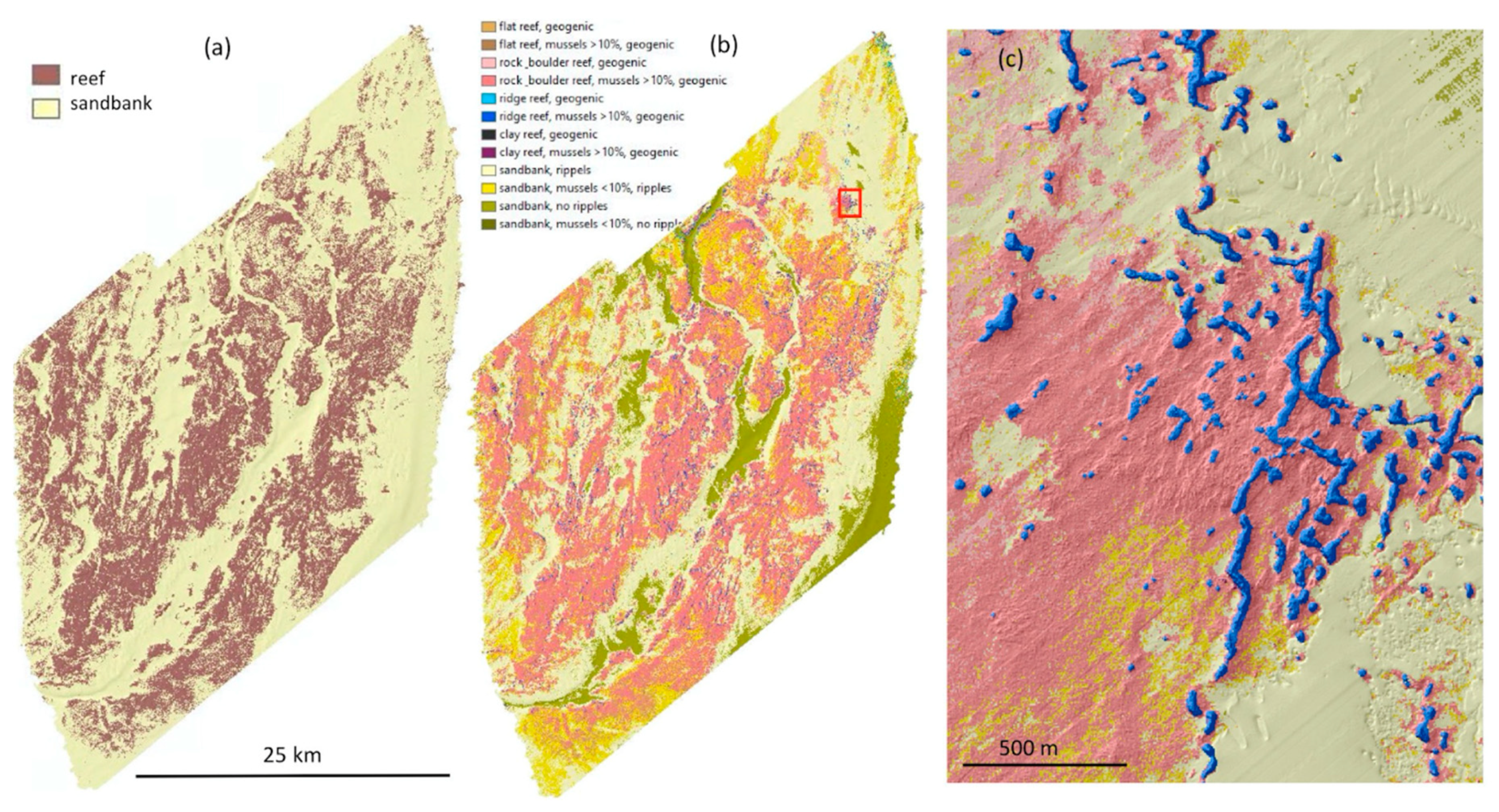
3.4. Thematic Maps
3.5. End-User Applications
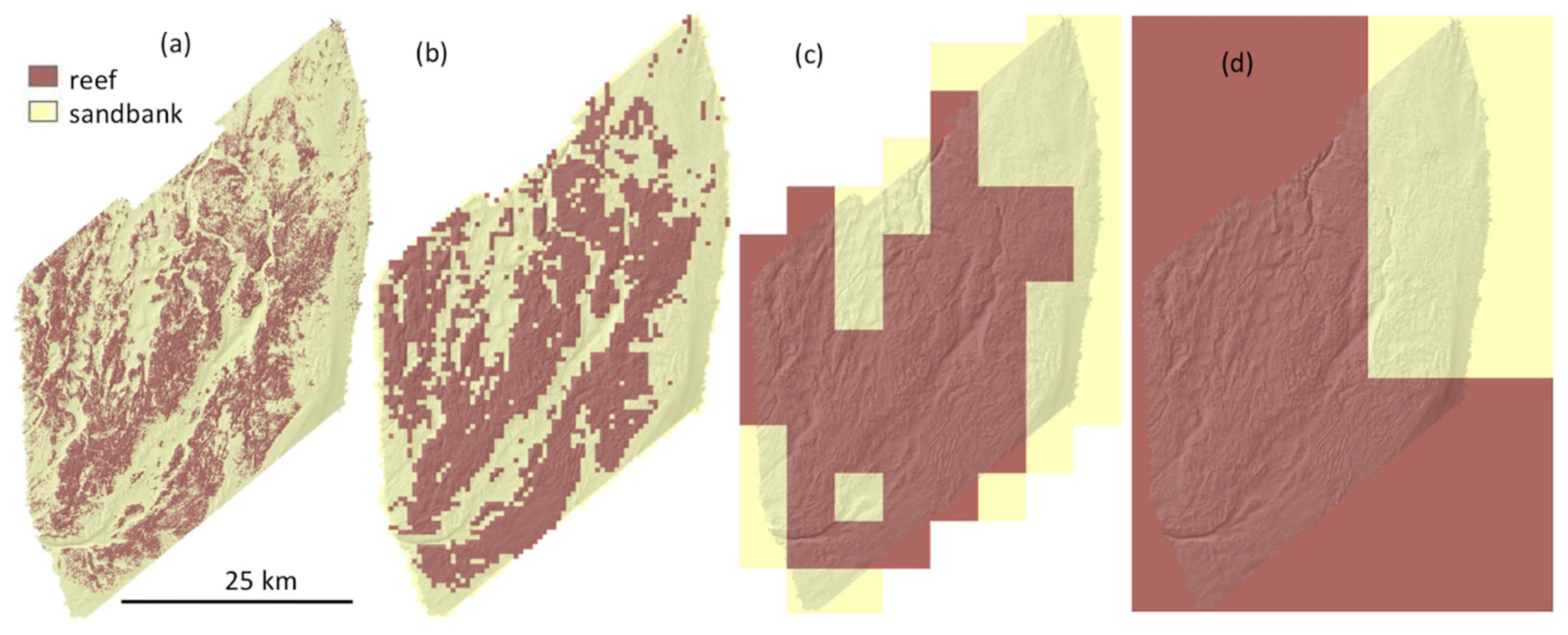
3.5.1. Impact of Scale
3.5.2. Effect of Predefined Thresholds in HUB
4. Discussion
4.1. User Applications
4.2. Technical Applications
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predictor Group | HUB3 % contr. | HUB4–6 no sub % contr. | HUB4–6 with sub % contr. | Mytilus no sub % contr. | Mytilus with sub % contr. | Average no sub% contr. | Average with sub % contr. |
|---|---|---|---|---|---|---|---|
| BS mosaic metrics 0.5 m–1 m | 3.1 | 4.3 | 3.0 | 3.3 | 1.2 | 3.5 | 2.1 |
| BS mosaic metrics 5 m | 10.0 | 4.6 | 2.0 | 3.8 | 0.7 | 6.1 | 1.3 |
| BS ARA | 2.8 | 4.9 | 1.4 | 3.1 | 0.6 | 3.6 | 1.0 |
| BS mosaic multiscale 20 m–2 km | 4.0 | 4.1 | 2.6 | 3.2 | 1.1 | 3.8 | 1.9 |
| Pg.s sediment thickness | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 |
| Depth 5 m | 4.4 | 3.8 | 3.7 | 2.1 | 0.8 | 3.4 | 2.3 |
| Terrain metrics 0.5 m–1 m | 8.5 | 9.4 | 5.6 | 10.1 | 2.7 | 9.3 | 4.1 |
| Terrain metrics 5 m | 5.4 | 7.7 | 5.3 | 6.7 | 2.4 | 6.6 | 3.9 |
| Terrain metrics multiscale 20 m–2 km | 16.3 | 20.6 | 15.5 | 14.7 | 7.3 | 17.2 | 11.4 |
| Distance to reefs and sand | 9.6 | 7.4 | 3.2 | 4.9 | 1.4 | 7.3 | 2.3 |
| OBIA based on terrain metrics and BS 2.5 m | 25.9 | 19.7 | 7.3 | 40.0 | 3.0 | 28.5 | 5.1 |
| Oceanography | 2.4 | 2.5 | 2.2 | 1.3 | 0.6 | 2.1 | 1.4 |
| Uncertainty (depth, backscatter) | 2.0 | 3.1 | 2.3 | 2.0 | 1.3 | 2.4 | 1.8 |
| Northing/easting | 4.3 | 3.5 | 3.1 | 1.7 | 0.9 | 3.1 | 2.0 |
| Substrate models | - | - | 40.2 | - | 75.2 | - | 57.7 |
| R2 | RMSE | MAE | Bias | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ind | i.adj | comp | comb | ind | i.adj | comp | comb | Ind | i.adj | comp | comb | ind | i.adj | comp | comb | |
| Sand | 0.80 | 0.83 | 0.81 | 0.81 | 20.4 | 17.9 | 19.2 | 19.3 | 11.8 | 10.1 | 10.0 | 10.0 | 5.7 | −1.4 | 0.9 | 0.9 |
| Gravel | 0.46 | 0.53 | 0.49 | 0.49 | 12.6 | 12.6 | 12.6 | 12.7 | 6.9 | 7.4 | 7.1 | 7.1 | 2.8 | −2.3 | 0.4 | 0.3 |
| Pebbles | 0.23 | 0.34 | 0.28 | 0.28 | 17.7 | 15.7 | 18.2 | 18.2 | 10.1 | 9.3 | 10.6 | 10.5 | 6.0 | 3.4 | −0.6 | −0.6 |
| L stones | 0.25 | 0.32 | 0.32 | 0.33 | 13.5 | 13.4 | 16.4 | 16.2 | 7.3 | 7.4 | 9.4 | 9.4 | 4.1 | −0.2 | −3.6 | −3.5 |
| Boulders | 0.44 | 0.61 | 0.55 | 0.56 | 18.8 | 15.4 | 16.8 | 16.7 | 9.8 | 8.7 | 8.7 | 8.5 | 5.6 | −0.4 | 0.4 | 0.6 |
| L boulders | 0.44 | 0.36 | 0.62 | 0.64 | 9.7 | 11.5 | 7.8 | 7.6 | 4.0 | 4.7 | 3.2 | 3.1 | 1.1 | −0.2 | 1.5 | 1.6 |
| Hard clay | 0.66 | 0.61 | 0.23 | 0.36 | 5.7 | 5.8 | 9.2 | 8.8 | 1.8 | 1.8 | 2.3 | 2.0 | 1.5 | 1.1 | 1.1 | 0.7 |
| Mean | 0.44 | 0.51 | 0.51 | 0.52 | 15.4 | 13.2 | 15.2 | 15.1 | 8.3 | 7.1 | 8.2 | 8.1 | 4.2 | 0 | −0.2 | −0.1 |
| SD | 0.20 | 0.19 | 0.21 | 0.19 | 5.3 | 3.9 | 4.5 | 4.6 | 3.6 | 1.8 | 3.3 | 3.4 | 2.1 | 1.8 | 1.7 | 1.7 |
| Coarse Substrate | Hard Clay | Mixed | Rock & Boulder | Sand | Sum (n) | User Accuracy % | |
|---|---|---|---|---|---|---|---|
| Coarse substrate | 12 | 0 | 10 | 0 | 0 | 22 | 54.55 |
| Hard clay | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Mixed | 3 | 1 | 42 | 3 | 0 | 49 | 85.71 |
| Rock & boulder | 0 | 0 | 3 | 16 | 0 | 19 | 84.21 |
| Sand | 3 | 0 | 7 | 0 | 54 | 64 | 84.38 |
| Sum (n) | 18 | 1 | 62 | 19 | 54 | 154 | 0 |
| Producer accuracy % | 66.67 | 0 | 67.74 | 84.21 | 100 | 0 | 80.52 |
| HUB 3 | UV obs. 1 | Legacy 2 | Expert 3 | Total |
|---|---|---|---|---|
| Rock and boulder | 67 | 34 | 16 | 117 |
| Hard clay | 5 | 0 | 83 | 88 |
| Coarse sediment | 72 | 89 | 138 | 299 |
| Sand | 195 | 159 | 252 | 606 |
| Mixed | 220 | 167 | 61 | 448 |
| Total | 559 | 449 | 550 | 1558 |
| HUB Level 4–6 | UV obs. 1 |
|---|---|
| Characterised by perennial algae | 73 |
| Dominated by perennial filamentous algae | 94 |
| Characterised by epibenthic bivalves | 42 |
| Dominated by Mytilus spp. | 59 |
| Characterised by cnidarians | 25 |
| Characterised by annual algae | 2 |
| Mixed epibenthic community | 16 |
| Sparse epibenthic community | 79 |
| No epibenthic community | 169 |
| Total | 559 |
References
- Galparsoro, I.; Connor, D.W.; Borja, A.; Aish, A.; Amorim, P.; Bajjouk, T.; Chambers, C.; Coggan, R.; Dirberg, G.; Ellwood, H.; et al. Using EUNIS habitat classification for benthic mapping in European seas: Present concerns and future needs. Mar. Pollut. Bull. 2012, 64, 2630–2638. [Google Scholar] [CrossRef] [PubMed]
- Pittman, S.; Connor, D.W.; Radke, L.; Wright, D. Application of Estuarine and Coastal Classifications in Marine Spatial Management. Treatise Estuar. Coast. Sci. 2011, 1, 163–205. [Google Scholar]
- Strong, J.A.; Clements, A.; Lillis, H.; Galparsoro, I.; Bildstein, T.; Pesch, R. A review of the influence of marine habitat classification schemes on mapping studies: Inherent assumptions, influence on end products, and suggestions for future developments. ICES J. Mar. Sci. 2019, 76, 10–22. [Google Scholar] [CrossRef]
- Wedding, L.M.; Lepczyk, C.A.; Pittman, S.J.; Friedlander, A.M.; Jorgensen, S. Quantifying seascape structure: Extending terrestrial spatial pattern metrics to the marine realm. Mar. Ecol. Prog. Ser. 2011, 427, 219–232. [Google Scholar] [CrossRef]
- Davies, C.E.; Moss, D. EUNIS Habitat Classification Marine Habitat Types: Revised Classification and Criteria; C02492NEW; Centre for Ecology and Hydrology: Dorset, UK, 2004. [Google Scholar]
- HELCOM. Technical Report on the HELCOM Underwater Biotope and Habitat Classification; 139; Helsinki Commission: Helsinki, Finland, 2013; p. 96. [Google Scholar]
- European Commission. Natura 2000. Available online: http://ec.europa.eu/environment/nature/natura2000/index_en.htm (accessed on 23 March 2019).
- European Parliament Council. Directive 2008/56/EC of the European Parliament and of the Council of 17 June 2008 establishing a framework for community action in the field of marine environmental policy (Marine Strategy Framework Directive). Off. J. Eur. Commun. 2008, 164, 19–40. [Google Scholar]
- Council of the European Union. Council Directive 92/43/EEC of 21 May 1992 on the conservation of natural habitats and of wild fauna and flora. Off. J. Eur. Commun. 1992, 206, 7–50. [Google Scholar]
- Havs- och Vattenmyndigheten. Symphony. Integrerat Planeringsstöd för Stalig Havsplanering Utifrån en Ekosystemsansats; Havs- och Vattenmyndigheten: Göteborg, Sweden, 2018; p. 72. [Google Scholar]
- Schiele, K.S.; Darr, A.; Zettler, M.L.; Friedland, R.; Tauber, F.; von Weber, M.; Voss, J. Biotope map of the German Baltic Sea. Mar. Pollut. Bull. 2015, 96, 127–135. [Google Scholar] [CrossRef]
- Cameron, A.; Askew, N. EUSeaMap-Preparatory Action for Development and Assessment of a European Broad-Scale Seabed Habitat Map Final Report; 2011. Available online: http://jncc.gov.uk/euseamap (accessed on 23 March 2019).
- Pecl, G.T.; Araujo, M.B.; Bell, J.D.; Blanchard, J.; Bonebrake, T.C.; Chen, I.C.; Clark, T.D.; Colwell, R.K.; Danielsen, F.; Evengard, B.; et al. Biodiversity redistribution under climate change: Impacts on ecosystems and human well-being. Science 2017, 355. [Google Scholar] [CrossRef]
- Fiorentino, D.; Lecours, V.; Brey, T. On the Art of Classification in Spatial Ecology: Fuzziness as an Alternative for Mapping Uncertainty. Front. Ecol. Evol. 2018, 6. [Google Scholar] [CrossRef]
- Herkül, K.; Peterson, A.; Paekivi, S. Applying multibeam sonar and mathematical modeling for mapping seabed substrate and biota of offshore shallows. Estuar. Coast. Shelf Sci. 2017, 192, 57–71. [Google Scholar] [CrossRef]
- Carlén, I.; Thomas, L.; Carlström, J.; Amundin, M.; Teilmann, J.; Tregenza, N.; Tougaard, J.; Koblitz, J.C.; Sveegaard, S.; Wennerberg, D.; et al. Basin-scale distribution of harbour porpoises in the Baltic Sea provides basis for effective conservation actions. Biol. Conserv. 2018, 226, 42–53. [Google Scholar] [CrossRef]
- Calder, B.R.; Mayer, L.A. Automatic processing of high-rate, high-density multibeam echosounder data. Geochem. Geophys. Geosyst. 2003, 4, 1048. [Google Scholar] [CrossRef]
- Fonseca, L.; Calder, B. Geocoder: An Efficient Backscatter Map Constructor. In Proceedings of the US Hydrographic Conference, San Diego, CA, USA, 29–31 March 2005. [Google Scholar]
- Freire, F.; Kågesten, G.; Baumgartner, F.; Dahlgren, A. Bio-Geophysical Survey Methods for Habitat Mapping of Hoburgs Bank 2019; Geological Survey of Sweden: Uppsala, Sweden, 2019; p. 43.
- Buja, K. Sampling Design Tool for ArcGIS. Available online: https://coastalscience.noaa.gov/project/sampling-design-tool-arcgis/ (accessed on 23 March 2019).
- Naturvårdsverket. Inventering av Marina Naturtyper på Utsjöbankar. Rapport 5566; Naturvårdsverket: Stockholm, Sweden, 2006; p. 79. [Google Scholar]
- Hengl, T.; Nussbaum, M.; Wright, M.N.; Heuvelink, G.B.; Gräler, B. Random forest as a generic framework for predictive modeling of spatial and spatio-temporal variables. PeerJ 2018, 6, e5518. [Google Scholar] [CrossRef] [PubMed]
- Pittman, S.J.; Costa, B.M.; Battista, T.A. Using Lidar Bathymetry and Boosted Regression Trees to Predict the Diversity and Abundance of Fish and Corals. J. Coast. Res. 2009, 2009, 27–38. [Google Scholar] [CrossRef]
- Costa, B.; Battista, T. The semi-automated classification of acoustic imagery for characterizing coral reef ecosystems. Int. J. Remote Sens. 2013, 34, 6389–6422. [Google Scholar] [CrossRef]
- Kågesten, G.; Sautter, W.; Edwards, K.A.; Costa, B.M.; Kracker, L.M.; Battista, T.A. Shallow-Water Benthic Habitats of Northeast Puerto Rico and Culebra Island; NOAA: Silver Spring, MD, USA, 2015.
- ENVI. Feature Extraction Module Version 4.6. User’s Guide. 2008. Available online: http://www.harrisgeospatial.com/portals/0/pdfs/envi/feature_extraction_module.pdf (accessed on 23 March 2019).
- Stephens, D.; Diesing, M. Towards Quantitative Spatial Models of Seabed Sediment Composition. PLoS ONE 2015, 10, e0142502. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- De’th, G. Boosted Trees for Ecological Modeling and Prediction. Ecology 2007, 88, 243–251. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA; Heidelberg, Germany; Dordrecht, The Netherlands; London, UK, 2013; p. 574. [Google Scholar]
- Pittman, S.J.; Brown, K.A. Multi-Scale Approach for Predicting Fish Species Distributions across Coral Reef Seascapes. PLoS ONE 2011, 6, e20583. [Google Scholar] [CrossRef] [PubMed]
- Leathwick, J.; Moilanen, A.; Francis, M.; Elith, J.; Taylor, P.; Julian, K.; Hastie, T.; Duffy, C. Novel methods for the design and evaluation of marine protected areas in offshore waters. Conserv. Lett. 2008, 1, 91–102. [Google Scholar] [CrossRef]
- Stamoulis, K.; Delevaux, J.; Williams, I.; Poti, M.; Lecky, J.; Costa, B.; Kendall, M.; Pittman, S.; Donovan, M.; Wedding, L.; et al. Seascape Models Reveal Places to Focus Coastal Fisheries Management. Ecol. Appl. 2018, 28, 910–925. [Google Scholar] [CrossRef]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we Need Hundreds of Classifiers to Solve Real World Classification Problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Zaki, M.; Meira, W., Jr. Data Mining and Analysis: Fundamental Concepts and Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar] [CrossRef]
- Hallberg, O.; Nyberg, J.; Elhammer, A.; Erlandsson, C. Ytsubstratklassning av Maringeologisk Information; Sveriges Geologiska Undersökning: Uppsala, Sweden, 2010. [Google Scholar]
- Piñeiro, G.; Perelman, S.; Guerschman, J.P.; Paruelo, J.M. How to evaluate models: Observed vs. predicted or predicted vs. observed? Ecol. Model. 2008, 216, 316–322. [Google Scholar] [CrossRef]
- Ma, Z.; Redmond, R.L. Tau coefficients for accuracy assessment of classification of remote sensing data. Photogramm. Eng. Remote Sens. 1995, 61, 435–439. [Google Scholar]
- Lecours, V.; Devillers, R.; Schneider, D.C.; Lucieer, V.L.; Brown, C.J.; Edinger, E.N. Spatial scale and geographic context in benthic habitat mapping: Review and future directions. Mar. Ecol. Prog. Ser. 2015, 535, 259–284. [Google Scholar] [CrossRef]
- Kendall, M.; Miller, T. The Influence of Thematic and Spatial Resolution on Maps of a Coral Reef Ecosystem. Mar. Geod. 2008, 31, 75–102. [Google Scholar] [CrossRef]
- Sheehan, E.; Cousens, S.; Nancollas, S.; Stauss, C.; Royle, J.; Attrill, M. Drawing lines at the sand: Evidence for functional vs. visual reef boundaries in temperate Marine Protected Areas. Mar. Pollut. Bull. 2013, 76, 194–202. [Google Scholar] [CrossRef]
- Beisiegel, K.; Tauber, F.; Gogina, M.; Zettler, M.L.; Darr, A. The potential exceptional role of a small Baltic boulder reef as a solitary habitat in a sea of mud. Aquat. Conserv. Mar. Freshw. Ecosyst. 2019, 29, 321–328. [Google Scholar] [CrossRef]
- Rönnbäck, P.; Kautsky, N.; Pihl, L.; Troell, M.; Söderqvist, T.; Wennhage, H. Ecosystem Goods and Services from Swedish Coastal Habitats: Identification, Valuation, and Implications of Ecosystem Shifts. AMBI 2007, 36, 534–544. [Google Scholar] [CrossRef]
- Rengstorf, A.; Grehan, A.; Yesson, C.; Brown, C. Towards High-Resolution Habitat Suitability Modeling of Vulnerable Marine Ecosystems in the Deep-Sea: Resolving Terrain Attribute Dependencies. Mar. Geod. 2012, 35, 343–361. [Google Scholar] [CrossRef]
- Sandman, A.; Wikström, S.; Blomqvist, M.; Kautsky, H.; Isaeus, M. Scale-dependent influence of environmental variables on species distribution: A case study on five coastal benthic species in the Baltic Sea. Ecography 2012, 35, 001–010. [Google Scholar]
- Peters, D.; Okin, G. A toolkit for ecosystem ecologists in the time of Big Science. Ecosystems 2016, 20, 259–266. [Google Scholar] [CrossRef]
- Kågesten, G. Geological Seafloor Mapping with Backscatter Data from a Multibeam Echo Sounder. Master’s Thesis, Department of Earth Sciences Uppsala University, Uppsala, Sweden, 2008; p. 32. [Google Scholar]
- Kostylev, V.; Todd, B.; Fader, B.; Courtney, R.; Cameron, G.; Pickrill, R. Benthic habitat mapping on the Scotian Shelf based on multibeam bathymetry, surficial geology and sea floor photographs. Mar. Ecol. Prog. Ser. 2001, 219, 121–137. [Google Scholar] [CrossRef]
- Brown, C.J.; Blondel, P. Developments in the application of multibeam sonar backscatter for seafloor habitat mapping. Appl. Acoust. 2009, 70, 1242–1247. [Google Scholar] [CrossRef]
- Beijbom, O.; Edmunds, P.J.; Kline, D.I.; Mitchell, B.G.; Kriegman, D. Automated annotation of coral reef survey images. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1170–1177. [Google Scholar]
- González-Rivero, M.; Beijbom, O.; Rodriguez-Ramirez, A.; Holtrop, T.; González-Marrero, Y.; Ganase, A.; Roelfsema, C.; Phinn, S.; Hoegh-Guldberg, O. Scaling up Ecological Measurements of Coral Reefs Using Semi-Automated Field Image Collection and Analysis. Remote Sens. 2016, 8, 30. [Google Scholar] [CrossRef]
- Dumke, I.; Purser, A.; Marcon, Y.; Nornes, S.M.; Johnsen, G.; Ludvigsen, M.; Søreide, F. Underwater hyperspectral imaging as an in situ taxonomic tool for deep-sea megafauna. Sci. Rep. 2018, 8, 12860. [Google Scholar] [CrossRef]
- Berthold, T.; Leichter, A.; Rosenhahn, B.; Berkhahn, V.; Valerius, J. Seabed sediment classification of side-scan sonar data using convolutional neural networks. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017. [Google Scholar]
- Rocchini, D.; Hortal, J.; Lengyel, S.; Lobo, J.M.; Jiménez-Valverde, A.; Ricotta, C.; Bacaro, G.; Chiarucci, A. Accounting for uncertainty when mapping species distributions: The need for maps of ignorance. Prog. Phys. Geogr. 2011, 35, 211–226. [Google Scholar] [CrossRef]
















| Level | Description |
|---|---|
| 1 Baltic (Letter) | Baltic |
| 2 Vertical Zone (Letter) | Photic Aphotic |
| 3 Substrate (Letter) | Coverage of a specified substrate type ≥90% Coverage <90%, Mixed |
| 4 Community Structure (Number) | Coverage of Macroscopic vegetation or sessile macroscopic epifauna ≥10% Coverage > 0% < 10%, Sparse Coverage = 0%, No vegetation or macro fauna present |
| 5 Characteristic Community (Letter) | Coverage of a specified taxonomic group ≥10% Coverage ≥ 10% but not of a specified taxonomic group, Mixed community Coverage = 0%, No macroscopic community |
| 6 Dominating Taxa (Number) | Biomass/bio volume of some specified taxa ≥50% |
| Size Range (mm) | Hard/Soft | Substrate | Grab-Sampler | Drop-Camera |
|---|---|---|---|---|
| Bedrock 1 | Point intercept | |||
| >600 | Hard bottom | Large boulders | Point intercept | |
| 200–600 | Boulders | Point intercept | ||
| 60–200 | Large stones | Point intercept | ||
| 20–60 | Pebbles & stones | Point intercept | ||
| 2–20 | Gravel | Point intercept | ||
| 0.6–2 | Soft bottom | Coarse sand | Sieve analysis | Point intercept 2 |
| 0.2–0.6 | Medium sand | Sieve analysis | ||
| 0.006–0.2 | Fine sand | Sieve analysis | ||
| 0.002–0.06 | Silt | Sieve analysis | Point intercept 2 | |
| <0.002 | Soft clay | Sieve analysis | Point intercept 2 | |
| <0.002 | Hard bottom | Hard clay | Point intercept |
| Data Source | N | Method | Target |
|---|---|---|---|
| Drop camera samples (2016–2017) 1 | 559 | Point intercept | Percent coverage of benthic organisms. |
| Drop camera samples (2016–2017) 1 | 559 | Point intercept | Percent coverage of substrate fractions (i.e., sand, gravel, pebbles, stones, boulders, large boulders and hard clay) |
| Legacy data (drop camera, video transects and sediment samples from 2005) 2 | 449 | Estimated coverage | Percent coverage of substrate fractions. |
| Expert annotation (depth, backscatter) 2 | 550 | Estimated coverage | Percent coverage of substrate fractions. |
| Grab samples (2016–2017) 2 | 117 | Sieve analysis | Percent coverage of fine substrate fractions (i.e., soft clay, silt, fine - coarse sand) |
| Grab samples (2016–2017) 2 | 434 | Expert | Thematic substrate classes (i.e., silty gravelly sand) |
| HUB Level 5 and 6 | Species included in Group |
|---|---|
| Characterized by annual algae | Ceramium tenuicorne, Ceramium sp., Chorda filum, Dictyosiphon/Stict\yosiphon (complex), Ectocarpus/Pylaiella (complex), Filamentous Phaeophyceae, Haliosiphon tomentosus |
| Characterized by perennial algae | Battersia arctica, Coccotylus/Phyllophora (complex), Delesseria sanguinea, Filamentous Rhodophyceae, Furcellaria lumbricalis, Polysiphonia/Rhodomela (complex), Unidentified Rhodophyceae. |
| Dominated by perennial filamentous algae | Battersia arctica, Filamentous Rhodophyceae, Polysiphonia/Rhodomela (complex). |
| Characterized by epibenthic bivalves | Mytilus spp. |
| Dominated by Mytilidae | Mytilus spp. |
| Characterized by cnidarians | Hydrozoa (Cordylophora caspia) |
| Characterized by moss animals | Electra sp. |
| Overall Accuracy (%) | Tau | |||
|---|---|---|---|---|
| Thematic | Reclassified | Thematic | Reclassified | |
| HUB 3 | 77.9 | 80.5 | 0.72 | 0.76 |
| HUB 4 | 79.9 | 81.8 | 0.70 | 0.72 |
| HUB 4–5 | 63.0 | 62.3 | 0.55 | 0.55 |
| HUB 4–6 | 55.8 | 53.2 | 0.49 | 0.47 |
| Natura 2000 | 87.7 | 87.7 | 0.75 | 0.75 |
| Mean | 72.9 | 73.1 | 0.64 | 0.65 |
| HUB 3 | HUB 4 | HUB 4–5 | HUB 4–6 | HUB 1–6 | N2000 | N2000 Subtypes | |
|---|---|---|---|---|---|---|---|
| Thematic maps | 5 | 3 | 7 | 9 | 29 | 2 | - |
| Reclassified maps | 5 | 3 | 8 | 12 | 59 (8) | 2 | 12 |
| Predictors | Training Data | Bootstrap (Training Data) | Validation (Testing Data) |
|---|---|---|---|
| 1) All | Survey, legacy, expert | OA 77%, kappa 0.68 | OA 77,9%, Tau 0.72 |
| 2) Reduced | Survey, legacy, expert | OA 76%, kappa 0.66 | OA 77.2%, Tau 0.71 |
| 3) Reduced | Survey, legacy, expert | OA 70%, kappa 0.58 | OA 73.4%, Tau 0.67 |
| 4) Reduced | Survey, legacy, expert | OA 68%, kappa 0.55 | OA 64.3%, Tau 0.55 |
| 5) Reduced | Survey, legacy, expert | OA 64% kappa 0.49 | OA 61.0%, Tau 0.51 |
| 6) Reduced | Survey, legacy, expert | OA 63% kappa 0.47 | OA 55.2%, Tau 0.44 |
| 1) All | Survey | OA 73% kappa 0.60 | OA 58.9%, Tau 0.49 |
| Predictors | R2 | RMSE | MAE | ME | OA Classes | OA Abs-pres. | Cover (Mean) |
|---|---|---|---|---|---|---|---|
| 1) All | 0.62 | 15.53 | 9.10 | 2.30 | 75 % | 89 % | 10.7 % |
| 2) No substrate | 0.60 | 16.69 | 9.84 | 5.61 | 69 % | 88 % | 8.0 % |
| 3) No backscatter | 0.49 | 19.60 | 11.83 | 7.96 | 60 % | 75 % | 4.4 % |
| R2 | RMSE | MAE | ME | OA Classes | OA Abs-pres. | |
|---|---|---|---|---|---|---|
| Sand | 0.83 | 17.9 | 10.1 | −1.4 | 72.1 | 84.4 |
| Gravel | 0.53 | 12.6 | 7.4 | −2.3 | 74.0 | 77.9 |
| Pebbles | 0.34 | 15.7 | 9.3 | 3.4 | 75.3 | 81.2 |
| Large stones | 0.32 | 13.4 | 7.4 | −0.2 | 77.9 | 80.5 |
| Boulders | 0.61 | 15.4 | 8.7 | −0.4 | 74.7 | 85.1 |
| Large boulders | 0.36 | 11.5 | 4.7 | −0.2 | 83.1 | 87.7 |
| Hard clay | 0.61 | 5.8 | 1.8 | 1.1 | 91.6 | 92.2 |
| Hard bottom | 0.79 | 18.2 | 9.4 | 0.3 | 75.3 | 92.9 |
| 0–10% | 10–50% | 50–90% | 90–100% | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | ME | SD | n | ME | SD | n | ME | SD | n | ME | SD | |
| Sand | 53 | 5.6 | 15.3 | 33 | −2.1 | 20.8 | 20 | −15.5 | 27.3 | 48 | −2.7 | 7.2 |
| Gravel | 95 | 1.9 | 7.8 | 50 | −9.1 | 14.2 | 9 | −8.5 | 21.6 | 0 | - | - |
| Pebbles | 100 | 4.2 | 10.0 | 52 | 2.3 | 22.2 | 2 | −11.4 | 24.0 | 0 | - | - |
| Large stones | 102 | 3.0 | 9.9 | 50 | −5.7 | 16.4 | 2 | −24.9 | 25.3 | 0 | - | - |
| Boulders | 105 | 2.0 | 5.9 | 29 | −6.3 | 24.6 | 20 | −4.6 | 27.2 | 0 | - | - |
| Large boulders | 134 | 1.3 | 5.5 | 15 | −5.2 | 21.8 | 5 | −25.1 | 38.6 | 0 | - | - |
| Hard clay | 152 | 1.3 | 5.0 | 1 | −32.1 | - | 1 | 7.5 | - | 0 | - | - |
| Hard bottom | 86 | 4.8 | 13.3 | 21 | 3.6 | 22.4 | 24 | −14.7 | 26.6 | 23 | −4.4 | 8.9 |
| R2 | RMSE | MAE | |
|---|---|---|---|
| Clay | 0.03 | 2.02 | 0.92 |
| Clay-silt | 0.27 | 0.71 | 0.54 |
| Silt | 0.32 | 0.66 | 0.53 |
| Fine sand | 0.76 | 1.07 | 0.85 |
| Medium sand | 0.79 | 0.76 | 0.59 |
| Coarse sand | 0.58 | 1.41 | 1.02 |
| R2 | RMSE | MAE | ME | OA Classes | OA Abs-pres. | |
|---|---|---|---|---|---|---|
| Annual algae | 0.37 | 7.1 | 1.5 | 1.5 | 94.8 | 91.6 |
| Perennial algae | 0.52 | 20.4 | 13.0 | 1.8 | 68.2 | 91.6 |
| Mytilus spp. | 0.62 | 15.5 | 9.1 | 2.3 | 75.3 | 89.0 |
| Cnidarians | 0.12 | 9.7 | 4.7 | 2.4 | 77.3 | 79.9 |
| Moss animals | 0.01 | 0.8 | 0.2 | −0.2 | 100 | 90.3 |
| Colonized substrate | 0.84 | 17.9 | 8.0 | −6.7 | 80.5 | 97.4 |
| 0–10% | 10–50% | 50–90% | 90–100% | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | ME | SD | n | ME | SD | n | ME | SD | n | ME | SD | |
| Annual algae | 153 | 1.4 | 6.9 | 1 | 15.7 | - | 0 | - | - | 0 | - | - |
| Perennial algae | 84 | 4.3 | 10.9 | 39 | 5.0 | 29.5 | 31 | −8.8 | 23.0 | 0 | - | - |
| Mytilus spp. | 80 | 2.6 | 8.4 | 56 | 2.5 | 20.7 | 18 | 0.6 | 20.5 | 0 | - | - |
| Cnidarian | 139 | 3.4 | 8.5 | 15 | −7.1 | 12.4 | 0 | - | - | 0 | - | - |
| Moss animals | 154 | 0.2 | 0.8 | 0 | - | - | 0 | - | - | 0 | - | - |
| Colonized | 27 | −0.8 | 1.8 | 22 | −9.8 | 14.2 | 23 | −13.7 | 27.6 | 82 | −5.9 | 15.3 |
| 5 m | 10 m | 25 m | 50 m | 250 m | |
|---|---|---|---|---|---|
| Sand | 36.4%, 469 km2 | 35.2%, 472 km2 | 35%, 465 km2 | 33.9%, 456 km2 | 31.3%, 420 km2 |
| Coarse | 16.2%, 217 km2 | 14.3%, 192 km2 | 13%, 179 km2 | 12,4%, 167 km2 | 10,0%, 133 km2 |
| Mixed | 46.4%, 623 km2 | 50,0%, 672 km2 | 51.8%, 696 km2 | 53.5%, 719 km2 | 58.7%, 789 km2 |
| Rock and boulder | 0.74%, 10 km2 | 0.56%, 7.5 km2 | 0.32% 4.3 km2 | 0.10%, 1.4 km2 | 0.01%, 0.12 km2 |
| Hard clay | 0.06%, 0.81 km2 | 0.02%, 0.22 km2 | 0.003%, 0.04 km2 | 0 | 0 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kågesten, G.; Fiorentino, D.; Baumgartner, F.; Zillén, L. How Do Continuous High-Resolution Models of Patchy Seabed Habitats Enhance Classification Schemes? Geosciences 2019, 9, 237. https://doi.org/10.3390/geosciences9050237
Kågesten G, Fiorentino D, Baumgartner F, Zillén L. How Do Continuous High-Resolution Models of Patchy Seabed Habitats Enhance Classification Schemes? Geosciences. 2019; 9(5):237. https://doi.org/10.3390/geosciences9050237
Chicago/Turabian StyleKågesten, Gustav, Dario Fiorentino, Finn Baumgartner, and Lovisa Zillén. 2019. "How Do Continuous High-Resolution Models of Patchy Seabed Habitats Enhance Classification Schemes?" Geosciences 9, no. 5: 237. https://doi.org/10.3390/geosciences9050237
APA StyleKågesten, G., Fiorentino, D., Baumgartner, F., & Zillén, L. (2019). How Do Continuous High-Resolution Models of Patchy Seabed Habitats Enhance Classification Schemes? Geosciences, 9(5), 237. https://doi.org/10.3390/geosciences9050237