1. Introduction
Nowadays, early warning systems in flood forecasting have become an important feature of any national hydrological service that faces the threat of flooding [
1,
2,
3]. There are many highly developed and developing national flood warning systems that serve end users on a national scale [
4]. Such systems contribute to a high extent to hydrological service delivery systems, as in the result of such warning systems’ operations there are many products generated: from flood alerts to more comprehensive hydrological conditions products, e.g., flood extent calculation. The power of such systems is that they cover a wide range of actions—from data collection and processing to hydrological modeling, analysis, and dissemination to clients.
Due to large areas and very different climatic and natural conditions and thus flood formation processes, there is no single early warning system in flood forecasting; thus, river basin approaches are taken. This paper describes such an approach for a selected river basin in the Far East of Russia, the Amur River, which is the main river of that area and one of the largest rivers in the world. It is 2800 km long (from the confluence of the Shilka and Argun rivers, Russia) and has a catchment area of 1.85 million km2. The average annual water discharge of the Amur River at Khabarovsk is 8300 m³/s and at Komsomolsk-on-Amur is 9600 m³/s. The Amur River is a transboundary river. Its basin is located in three states: Russia (995,000 km2, about 54% of the catchment area), China (44% of the catchment area), and Mongolia (2% of the catchment area). The Amur River is the longest transboundary river in Russia. The Argun, Amur, and Ussuri rivers form the state border between Russia and China, which is more than 3500 km long. Hydrologic regime features in brief are as follows: spring flood (20–30 days), intensive summer flood due to monsoon circulation, and low flow during winter.
In July–September 2013, catastrophic flooding occurred in the Amur River basin, affecting vast areas of Far East Russia and Northern China due to extreme sums of precipitations [
5]. It had become one of the largest natural disasters of recent decades in terms of duration, extent, and economic losses. According to the Ministry of Emergency Situations of Russia (EMERCOM, Moscow, Russia), the consequences of the 2013 flooding in the Amur River basin were as follows: Over 200 settlements with populations of about 80,000 people and about 600,000 ha of agricultural land were flooded, and about 1500 km of roads and about 1000 km of power transmission lines were damaged. Large cities (Khabarovsk and Komsomolsk-on-Amur, Russia) suffered major flooding. Thousands of houses were flooded—many of them beyond repair. Tens of thousands of people were evacuated; many of them lost their homes and property. Fortunately, there was no loss of life in the 2013 flooding in Russia. Unfortunately, loss of life was reported in China. It was calculated that peak flow of the flood was as high as 464,00 m
3/s with an estimated 200–250-year recurrence interval generated near the major city of Khabarovsk, in the Far East of Russia [
6].
At the time of this catastrophic flood, an old flood forecast system was in operation and included partially manual data processing and thus had forecast issuance routines, an absence of qualitative and quantitative forecasts, and analytical products (first of all in format of maps) to serve end users in the region. Main user requirements in the Amur River basin are flood warnings on the Amur River and its main tributary (the Zeya River, Russia), calculation and short-term forecast of the Zeya reservoir inflow, flood inundation maps (real-time), and real-time data of different hydrometeorological elements in map, graph, and table format. This information should be available online. It was apparent that, to fill this gap, a new early warning system needed to be developed in the basin. A basin approach was developed to serve all major water-related users in a large river system, the Amur River basin. The main goal of the study was to develop the infrastructure for fully automated flood forecasting and a warning service in a large river system—beginning from data processing and finishing with forecasting product visualization and their further dissemination using GIS web technologies. The latter has become a popular practice all over the world [
7,
8,
9,
10,
11,
12,
13]. Emphasis was put on water-level and reservoir-inflow forecasting, as the river is well known for its flood potential. The whole flood forecasting and early warning system design was developed based on the principle that an incorporated database management subsystem, hydrologic modeling and forecasting components, and web-GIS dissemination procedures provide end-users with better and more efficient access to observations, forecast products, and services.
2. Materials and Methods
Flood forecasting in the Amur River system must include forecasts of the water level along the main river reach and its main tributary—the Zeya River, as there are a number of large cities located right on the river banks, including Khabarovsk (the capital of the Far Eastern Federal District of the Russian Federation), and Komsomolsk-on-Amur (second largest city with a number of heavy industrial areas). Thus, water level forecasts on the Amur River are of great value and importance. The second largest issue is forecasting of the water inflow into the Zeya reservoir. This reservoir is located in the mountainous area of the Amur River basin and has a relatively harsh regime of its tributaries, especially during the monsoon period (late summer-autumn). The Zeya reservoir was constructed as a flood reduction measure in the region, as the most tremendous floods come from the Zeya River.
Water level forecasting was planned for 20 forecasting points along the river system. These points cover the most important cities and towns along the river reach and its main tributary. The forecasting technique selection was limited to the fact that only long-term water level data were available for these points, as the border between the Russian Federation and the People’s Republic of China goes along the river and no discharge calculations were historically available. With such limited data availability, a simple approach, based on the gauge-to-gauge correlation using different lead times that depend on flood wave height, was taken [
14,
15,
16]. The Amur River is a large river with slow-developing processes, so such a simplified technique appeared to be sufficient to estimate flood wave transformation and thus reasonable in terms of forecast quality. The view of the forecast techniques is reflected with the following formula:
where
HL and
HU are the water stages (cm) of the gauges in the lower and upper reach of the river, respectively;
t is the day of the forecast issue,
τ is the lead time of the forecast (days);
a0,
a1,
a2 are the coefficients computed with least squares method. To make the technique operational, only actual water level data from the upstream gauges are required. The lead time of the technique reached up to 6 days with the daily time step.
Operational water level forecast quality was estimated for 2015–2017 warm periods (May–September) for 1- to 6-day lead times and 20 forecast points (
Table 1). Standard deviation, root mean squared error, and Nash–Sutcliffe efficiency for each forecast gauge are shown in the table to give an idea of forecast quality, which proved to be good for the majority of lead times and forecast points, especially for lead times of 1–4 days.
The Zeya reservoir daily inflow estimation (calculation) and forecasting were one of the most important issues within the overall task. The water balance method was used to calculate daily inflow into the reservoir before, which is much more appropriate for water inflow amounts of at least 10 days or even monthly values. The method is very sensitive to mean water level estimation, and for reservoirs of such shape and volume curve even a small error in the water level estimation can lead to significant volume errors [
17]. For this reason, a hydrometric technique of the water inflow estimation was used [
16], which is commonly represented by the following formula:
where
Qin is the daily water inflow into a water river reservoir,
Qi(t) is the daily discharge (m
3/s) from the
i-th subbasin, and
Ki is the adjustment factor for ungauged area of the
i-th subbasin, which is calculated according to following equation:
where
Fi is the area of
i-th subbasin (km
2), and
FGi is the gauged area of the
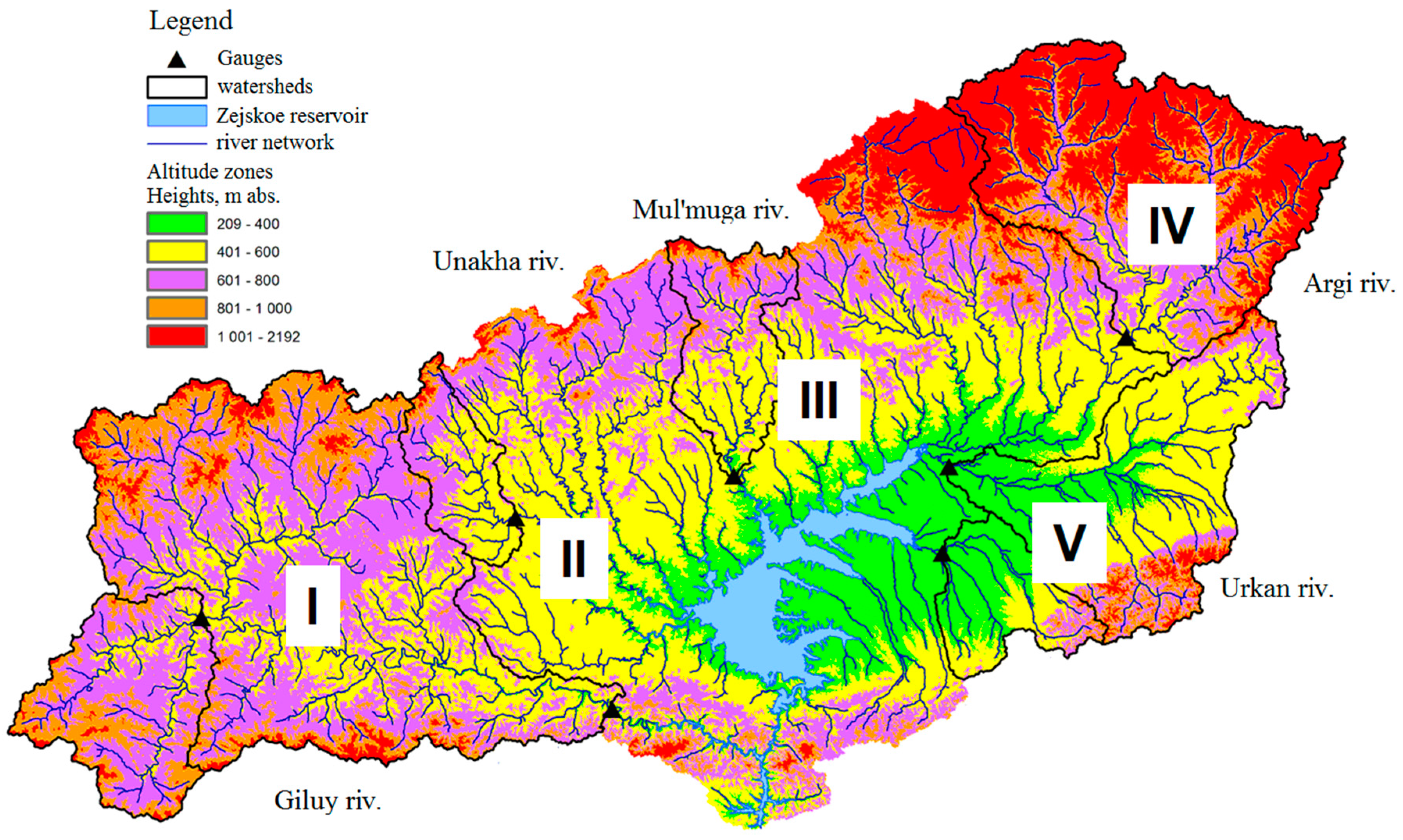
i-th subbasin. The whole Zeya reservoir basin was divided into 5 subbasins (
Figure 1, Roman numerals). Each subbasin has gauged (there are five significant rivers with hydrometric gauges at their outlets—
Figure 1) and ungauged areas, so adjustment factor Ki was calculated for each subbasin. Equation (2) was adjusted accounting for the lag time of the discharge from the outlet gauge of each of the five subbasins to the reservoir. Charts of the river network (channel) travel time were used to estimate the temporal adjustments. As a result, the following formula was produced to estimate the inflow into the reservoir:
where
QI, …,
QV are the discharges (m
3/s) at the river hydrometric gauges of each of the five subbasins. To derive coefficients of the equation, the size of the river watersheds, their configuration, and the river channel lag time were taken into account. Evaluation of such technique was done via comparison with the water-balance inflow technique based on the 10-day time scale. The results of the comparison showed that the derived technique was reliable.
Forecasting of the inflow into the Zeya reservoir is based on the use of the conceptual model of the reservoir basin. Forecast of the water river discharge in the gauges is the basis for the inflow forecast estimation in the reservoir. The conceptual model used for this purpose is widely used in Russia for different catchments [
18]. The model description is comprehensively presented in [
18,
19]; major concepts of the model are presented below. The model is based on a parametric description of the main runoff formation processes.
The structure of the model of the homogeneous landscape-hydrologic region includes a description of the following processes:
snow accumulation;
snow melt and snow cover;
melt and rain water yield of the basin with account for water infiltration and retention;
dynamic water supply on the slopes and watershed routing;
river channel routing.
In addition to regionalization (5 regions were delineated), elevations were divided into zones. All calculations were performed for each elevation zone of each region. The model consists of submodels that define the above-listed processes of the runoff formation for every elevation zone of each of the regions. Model input data include water level observations on 7 stream gauges as well as precipitation and temperature averaged for the calculation area (the elevation zones of the regions).
Calculations of the total melt water yield during the melt period are done according to the following equation, which takes into account capacity of soil infiltration and empty storage:
where
Yi is the melt water yield (mm) from the
i-th elevation zone,
wi is a portion of permanent impervious area (a fraction of 1) of the
i-th elevation zone;
P0 is the water retention capacity (mm) of the watershed under conditions of minimal autumn soil moistening;
th is the hyperbolic tangent;
Hi(t) is the integral layer of water (mm) from the beginning of the snowmelt period
t0 until time
t (days), which is computed according to the following scheme:
where
Ui is the state of the watershed water retention capacity (mm);
hci,
xi,
zi are the layers of melt water, rain water, and evaporation (all in mm) for time
j (days) in the
i-th elevation zone;
I is the water (mm) that infiltrated the deeper soil layers (outside of the soil retention capacity). Detailed description of the members of these formulas is given in [
18]. Equation (5) is used in the model to compute water yield from each elevation zone;
ui(t), e.g., is the runoff that is generated on slopes during the calculation time step (1 day):
Runoff from slopes into the river channel
qi(t) (mm) is determined based on its connections with gravitational water supply on slopes
Wi (mm):
where
ai(t) is the coefficient related to hydraulic properties of the runoff from slopes. By continuously solving Equation (8), it is possible to perform continuous calculations of the water that flows into the river network during the snowmelt period.
Total slope runoff into the river network
qi(t) (mm/day) is computed separately for each elevation zone. Further calculation of the average basin inflow is performed according to the following equation:
where
φi is the fraction of the
i-th elevation zone within the river basin (fraction of 1), and
n is the number of elevation zones. River discharge forecast is calculated according to the superposing principle using the following formula:
where
Q(t + ∆t) is the discharge in the river basin outlet (m
3/s);
t is the forecast issue date;
∆t is the forecast lead time (days);
fn(τ) is the slope runoff travel time curve (unitless);
Qw(t + ∆t) is the component of the river discharge (m
3/s), induced by the recession of the initial (by the time
t) water storage in the river network;
Qmin is the base flow (m
3/s). Detailed description of the derivation of the each member of Equation (10) is given in [
18].
With a forecast of the discharges at the forecast points (outlets of the reservoir tributaries), it is possible to use the data as input in the inflow-calculation Equation (2) and thus have inflow into reservoir forecast. Such a technique allows for a forecast lead time of up to 7 days [
20]. However, in operational forecasting, only a 5-day lead time is used as a maximal lead time, taking into account the reliability of meteorological forecasts in complex terrain areas. An ensemble prediction system has not been developed yet for this region. Thus, several meteorological inputs of temperature and precipitation from four numerical weather prediction models are used for daily operational reservoir inflow forecasting: COSMO (Hydrometcentre of Moscow, Russia [
21]), UKMO (U.K. MetOffice, Exeter, UK), NCEP (U.S. National Center for Environmental Prediction, College Park, MD, USA), and JMA (Japan Meteorological Agency, Tokyo, Japan). These 4 inputs allow a hydrological forecaster to some extent to take any uncertainty in a meteorological forecast into account until an ensemble prediction system is developed and implemented for the area.
The efficiency of the developed technique of reservoir inflow forecasting was estimated using long-term data [
20].
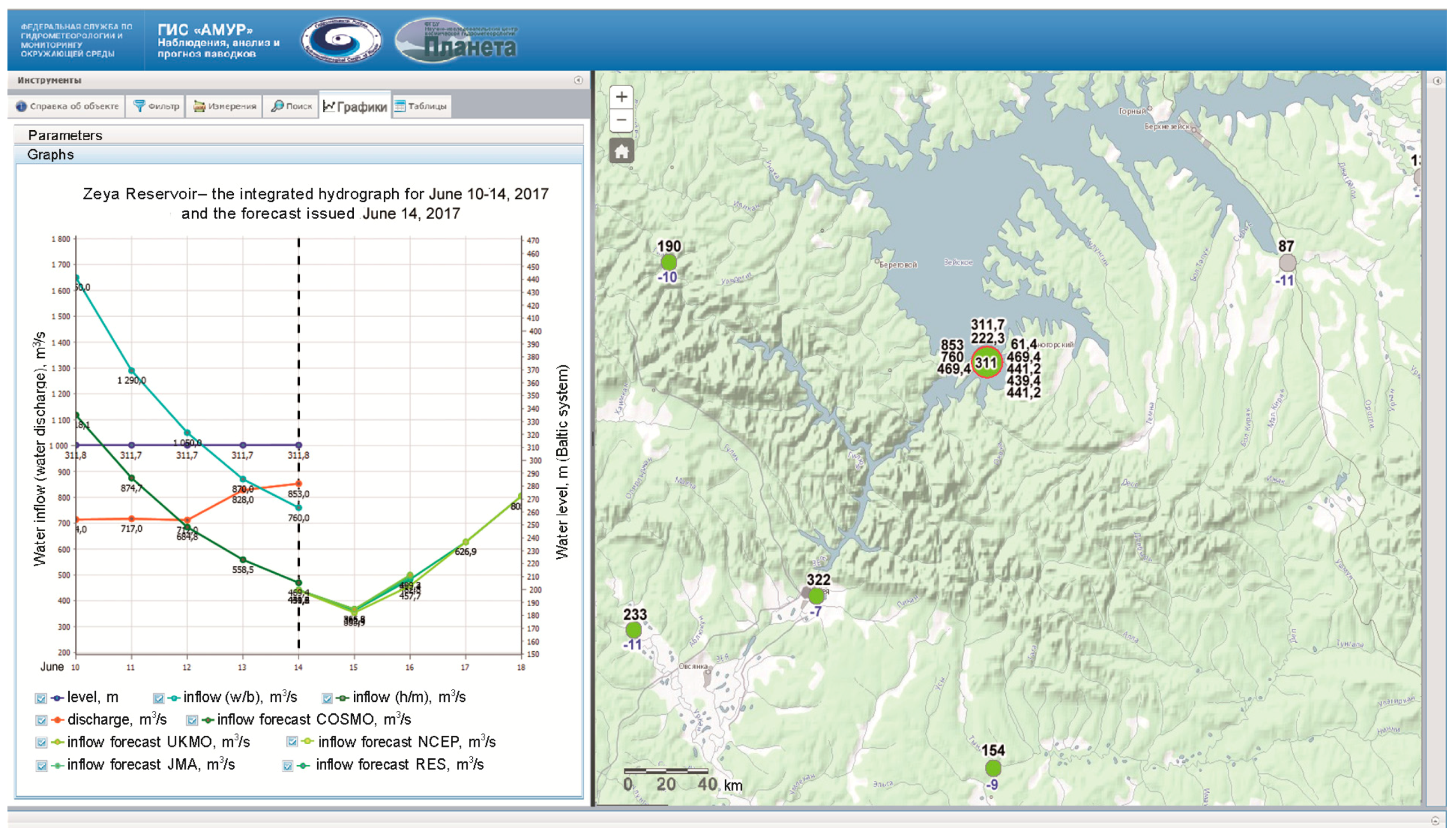
Operational reservoir inflow forecast quality was estimated for 2015–2017 warm periods (May –September) for 1- to 3-day lead times and 4 numerical weather prediction inputs (
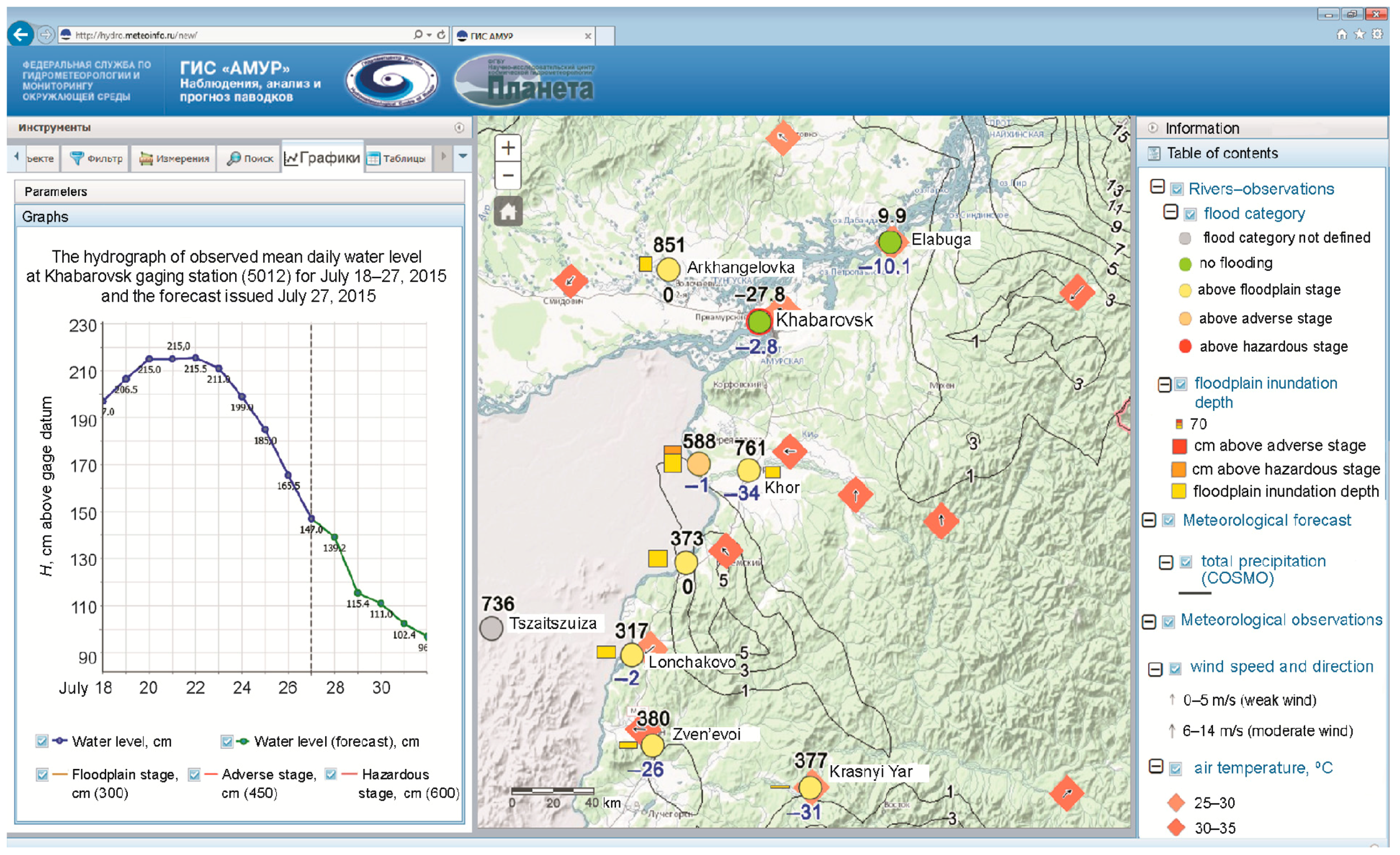
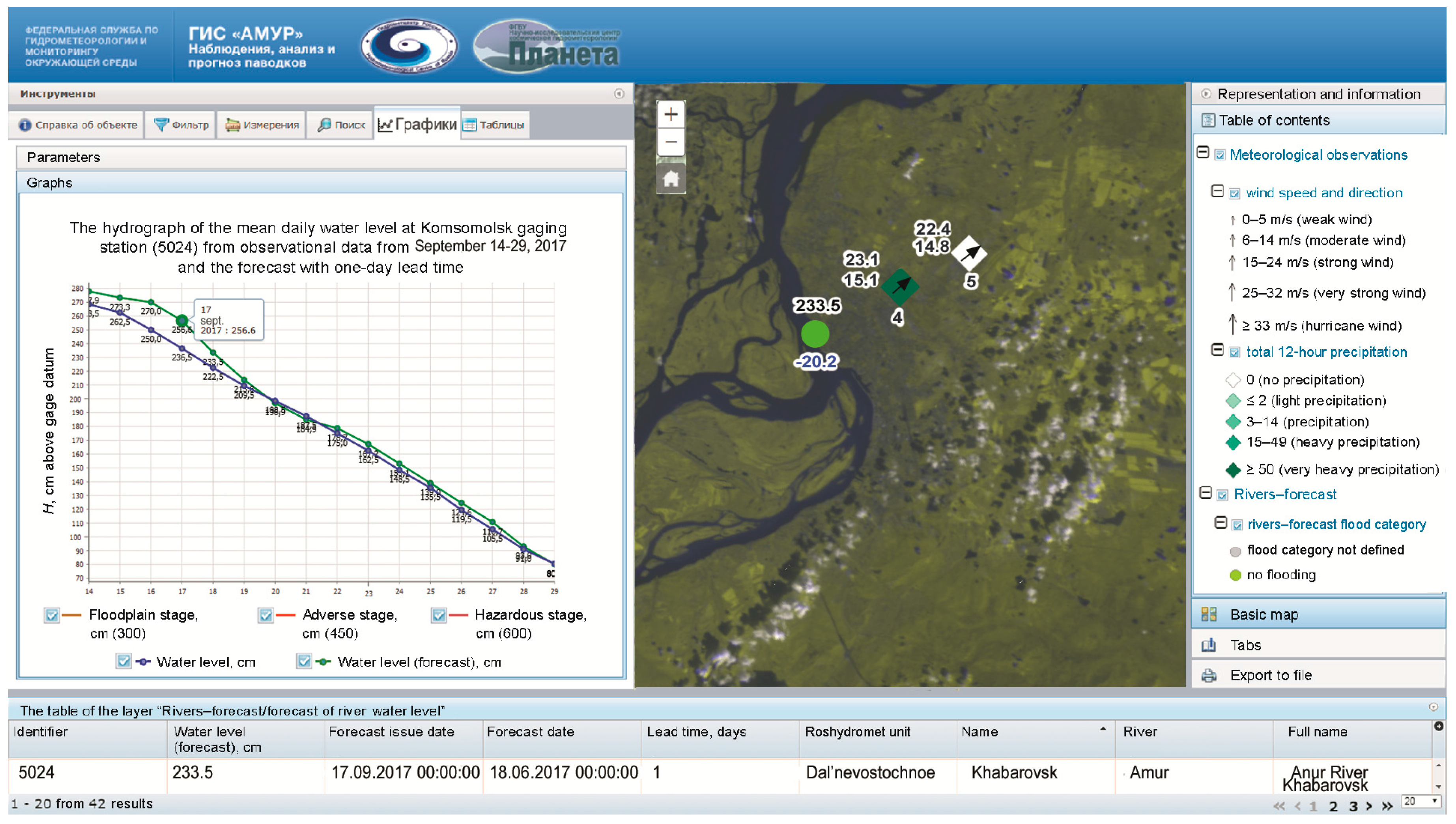
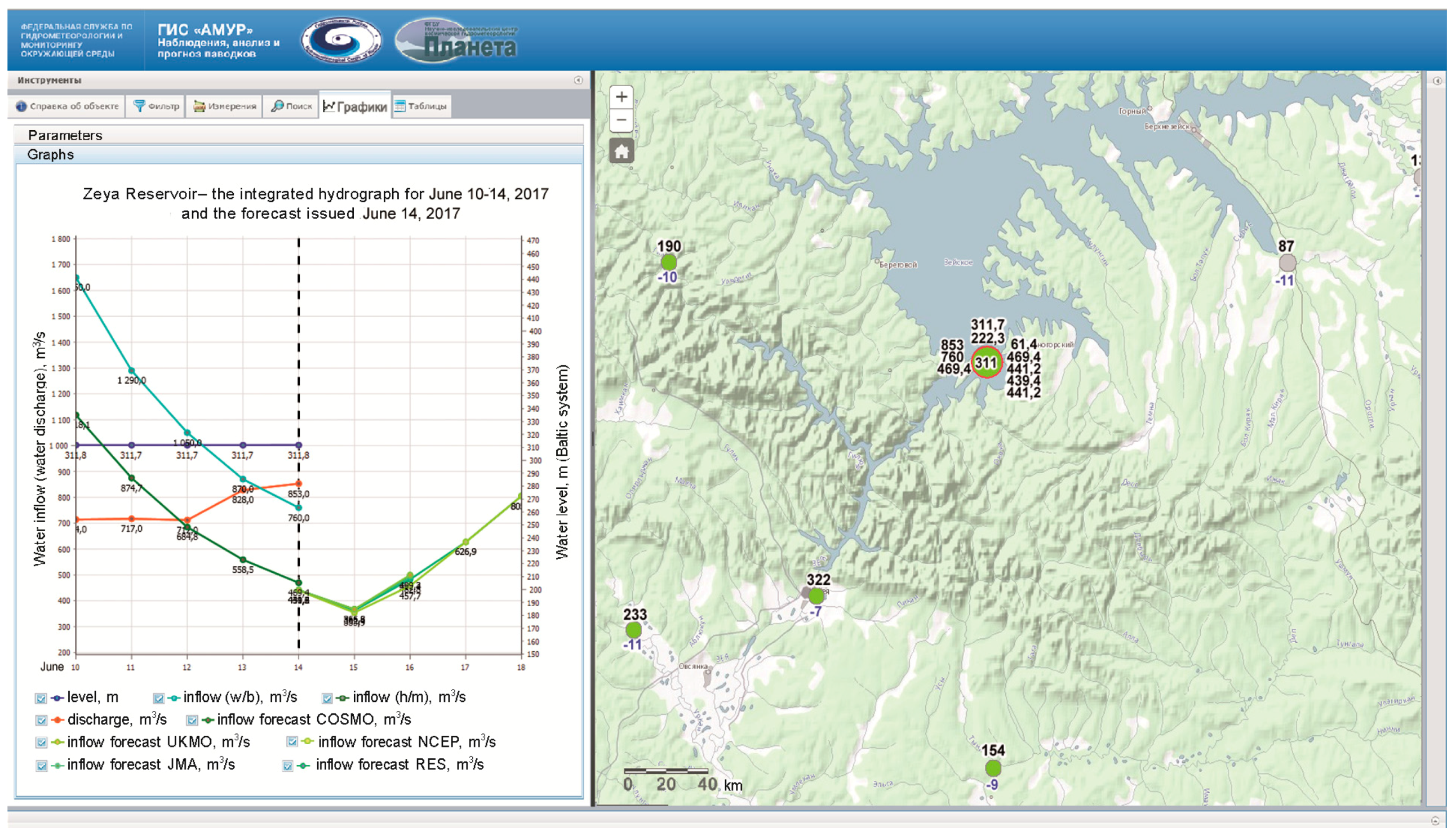
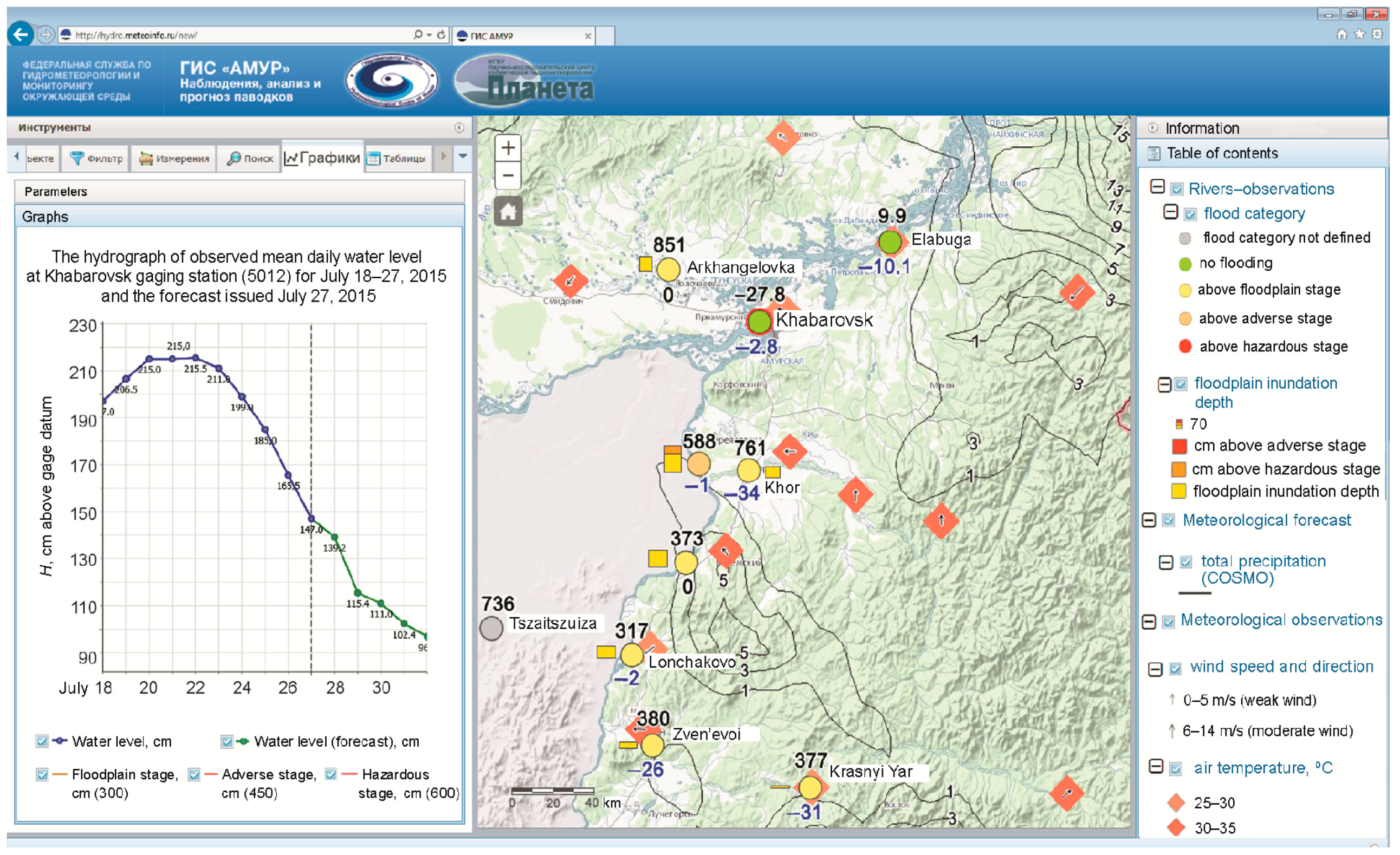
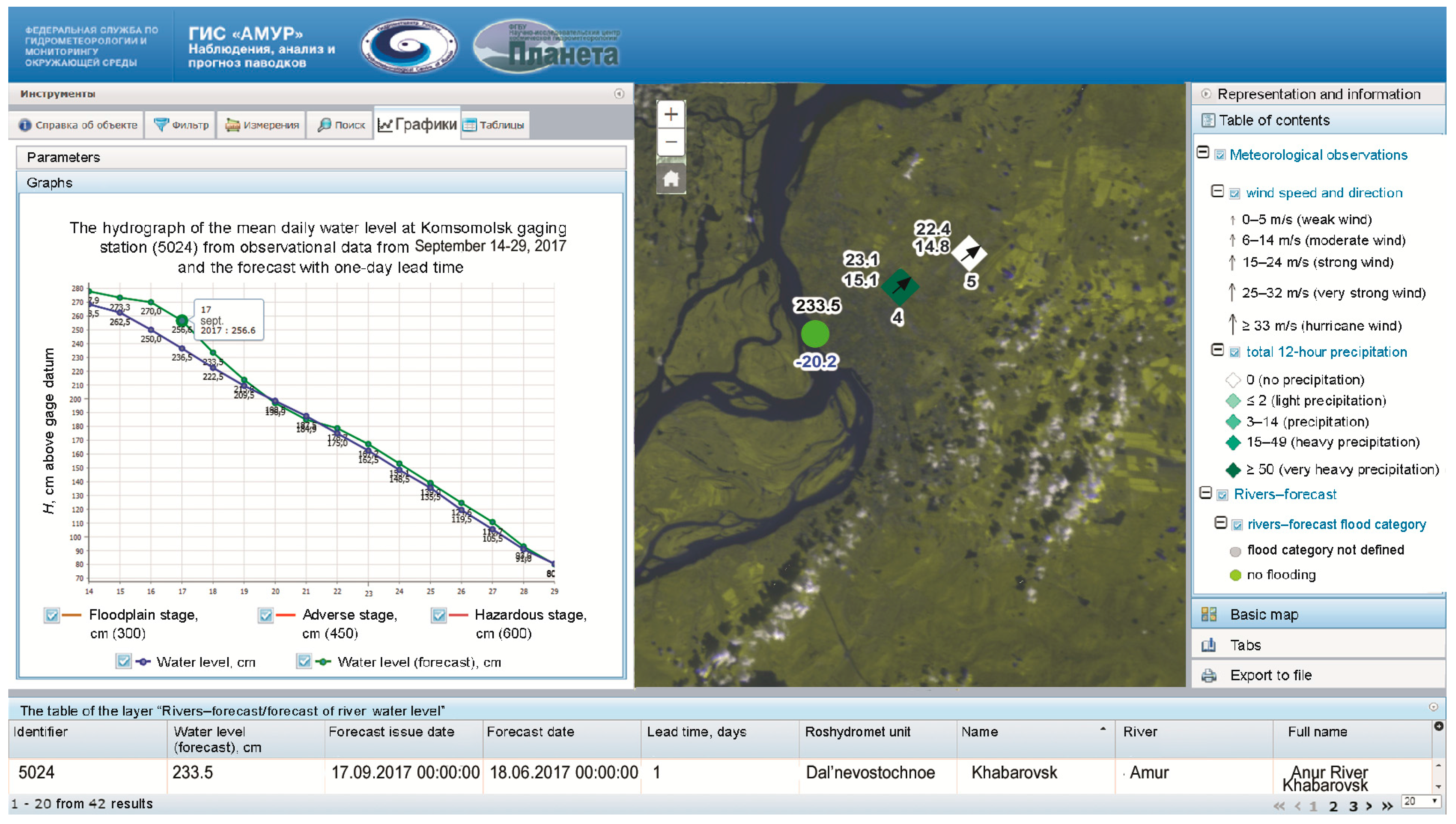
Table 2). The Nash–Sutcliffe (NS) efficiency criterion was used. Generally, the forecasts prove to be quite good, as the values of NS are higher than 0.65 for presented lead times. Visualization and dissemination of the inflow forecast information is presented in
Figure 2. Main end-users can observe the forecast in graphical format (the left side of
Figure 2) and in map format (the right side of
Figure 2).
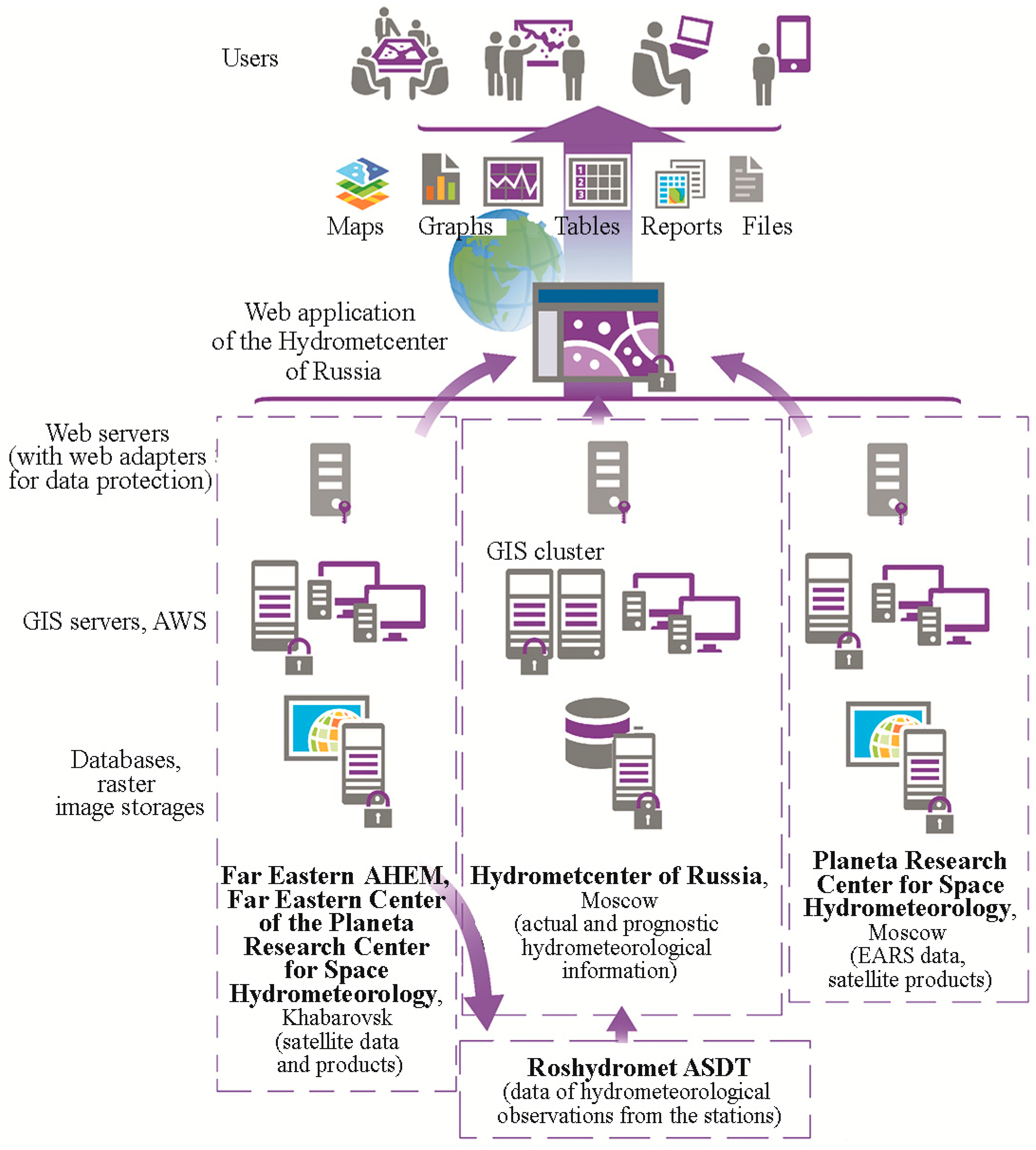
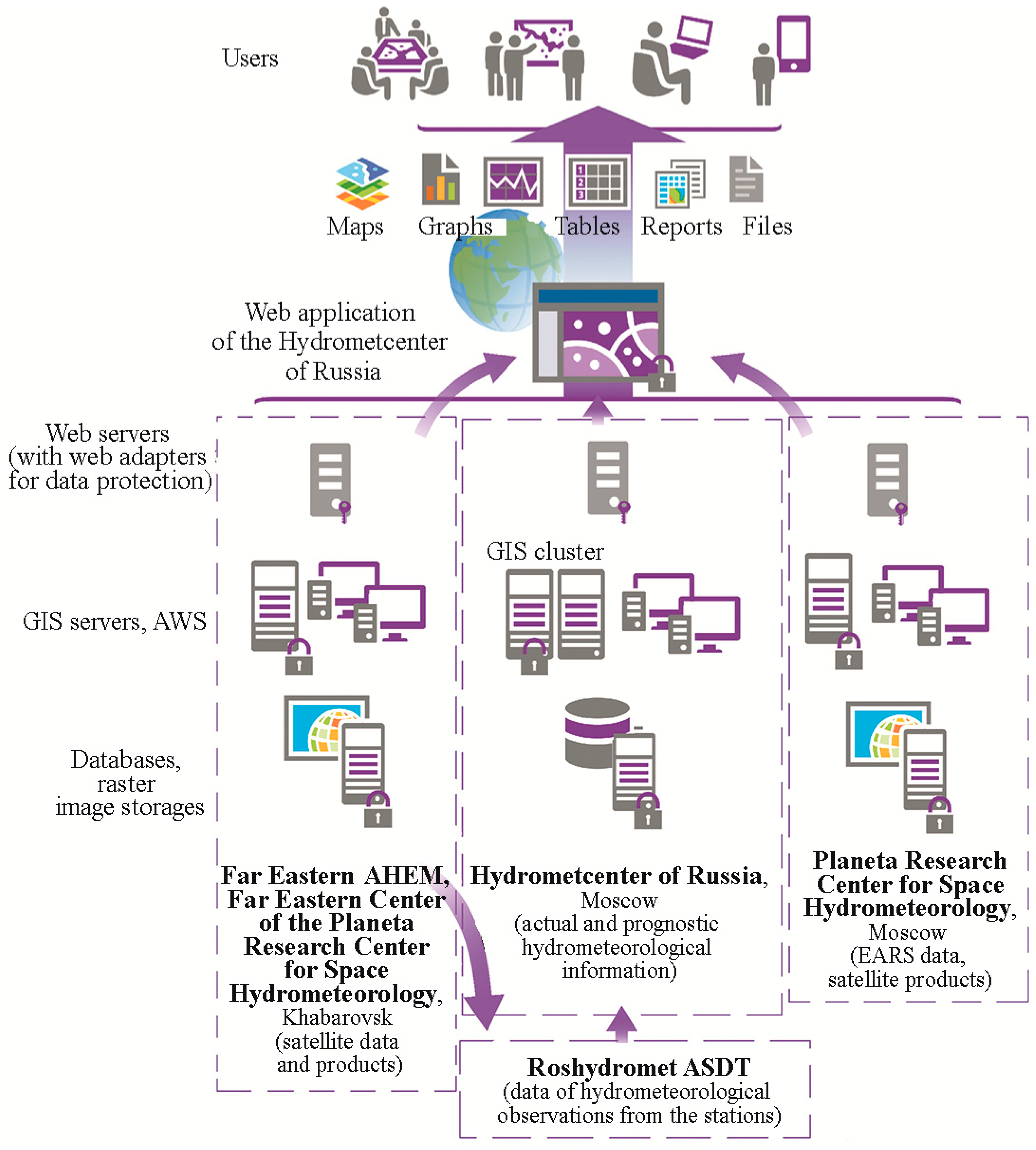
To support all processes within the flood forecasting system and to specifically provide the dissemination subsystem with data, a database (DB) subsystem was developed. The DB subsystem contains three databases: the main database with the operational hydrometeorological information from the observational network and with meteorological forecasts as well as two DBs with satellite data. Enterprise DBMS MS SQL Server-2012 software was used as the database management system (DBMS). This DBMS model was chosen due to its broad potential of operation with the large size of information in GIS and web systems based on the ArcGIS platform. One of these three databases (the main database) is located in the Hydrometcentre of Russia and includes the following operationally updated information: the observational data from gauging stations (water level, water temperature, air temperature, and the amount of precipitation measured twice a day); observational data from weather stations (basic meteorological parameters measured at standard synoptic time steps); observations and calculations of the Zeya hydropower plant (HPP) reservoir parameters; the water level forecast at gauging stations; reservoir inflow forecast; weather forecasts; reference information on gauging and weather stations, rivers, reservoirs, and subbasins of the Amur River basin. This database also contains observational data from the gauging station network in the Amur River basin including observational data on the water levels of the Songhua River that comes from China within the framework of the Roshydromet—Ministry of the Water Recourses of the People’s Republic of China. Two other databases contain satellite data, and they are located in the Far Eastern and European centers of the SRC “Planeta.” The DBs in these centers include the satellite data received by its own receivers in the radio acquisition range. They include the data of “Meteor-M No. 1,” “Meteor-M No. 2,” “Kanopus-V No. 1,” “Resurs-P” Nos. 1 and 2, “Landsat 8,” and “Terra/Aqua” as well as flood extent maps and snow cover maps of the Amur River basin. The DB of the European SRC “Planeta” includes DEM as well as satellite data received from the “Sentinel 1” radar sounding space vehicle and the satellite products received via the EARS system of international exchange: maps of relative soil humidity and surface wind plotted from the ASCAT/MetOp data. The separate file storage was created in the DB subsystem for the satellite data. This storage contains the raster format data. The DB contains only metadata and links to information. The abovementioned DBs are updated automatically. For this purpose, the Python-based software was developed and implemented. The overall subsystem scheme is presented in
Figure 3.
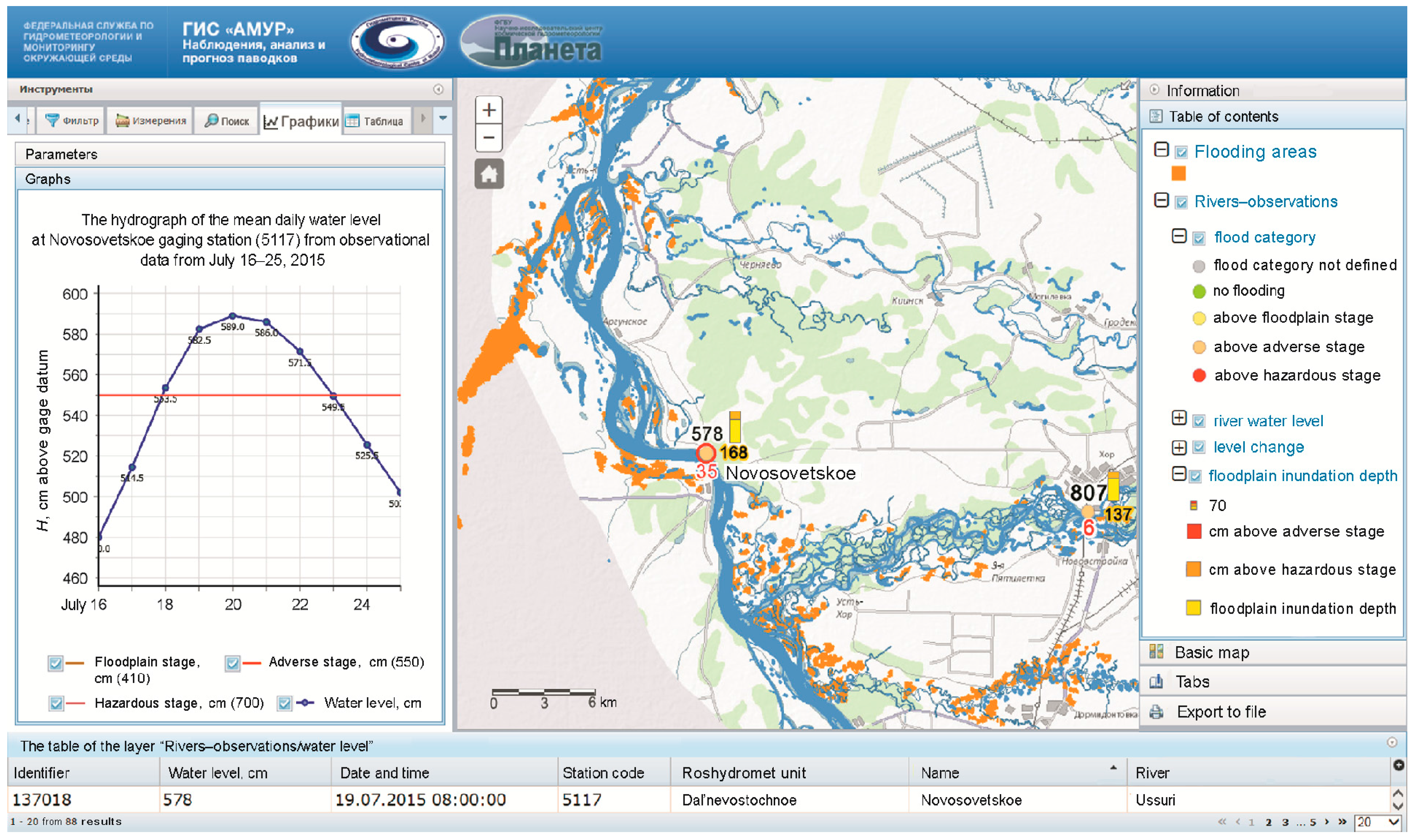
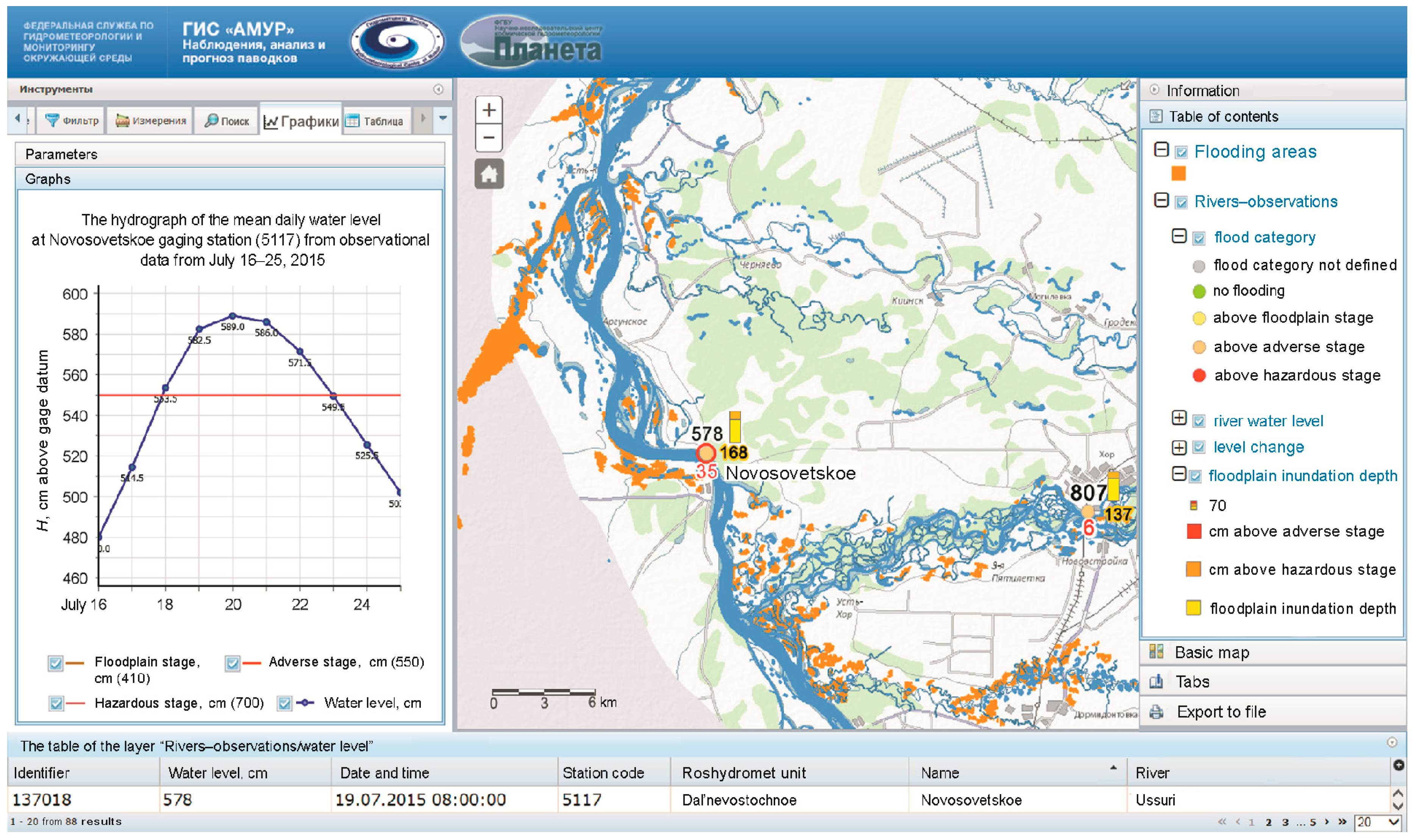
Satellite data and products are used in the system for monitoring the current hydrological conditions, obtaining the areal characteristics of the zones of flooding, and tracking the spatial-temporal changes. The effectiveness of satellite data for the solution of these tasks is well known and has been shown in several papers [
22,
23,
24,
25].
In order to disseminate operational forecast information to end users (e.g., Emergency Agency, regional administration, water transport industry), the subsystem of visualization, analysis, and dissemination of the abovementioned forecasts in the Amur River basin was developed. The subsystem is closely connected with the DB subsystem (see above), which serves as the informational basis for dissemination. Hydrological and meteorological observations, satellite data, and topographic features of the basin are also included in the subsystem together with hydrological forecasts to form a comprehensive understanding of the hydrometeorological conditions of the basin. The use of web GIS technologies enables visualizing and integrating geographic, hydrological, meteorological, synoptic, and satellite geospatial data in the uniform environment (Internet). The developed subsystem (the permanent operation site is the Roshydromet Main Computing Center) is spatially distributed. The preparation of hydrometeorological products including computations and forecasts is carried out at the Hydrometcentre of Russia. The reception and processing of satellite data are carried out at the SRC “Planeta” (described in the section above). The acquisition and processing of satellite data received from EARS (EUMETSAT Advanced Retransmission Service) are conducted in the European Center of the Planeta Research Center for Space Hydrometeorology [
26].
The subsystem of preparation and delivery of output products to the end users has broad operational potential in the systematization of information product types, in the automatic support of electronic database catalogs, in the metadata maintenance with the detailed description of catalogs, etc. It has a high degree of safety implemented at three levels (passwording at the levels of the database, web services, and web applications). The additional data protection is provided through the web server adapter. The subsystem includes two basic components: a GIS component for the management of GIS servers and automated workstations (AWSs), intended for computing and forecasting hydrometeorological parameters and for preparing the actual and forecast information (server and corporate GIS), and a web component for interaction with users (the web server with web application).
The GIS component of the management of GIS servers and automated workstations is implemented on the ArcGIS 10.5 (ESRI, Redlands, CA, USA) Enterprise platform for desktops and servers. The GIS component of hydrometeorological data consists of two GIS servers and three automated workstations (AWS) for a hydrologist. The hydrologist’s AWSs are intended for the development and maintenance of DBs with actual data on the water level and water discharge at gauging stations and for preliminary computations and forecasts of the water level at gauging stations. The hydrologist’s AWSs are equipped with ArcGIS for Desktop Advanced (ArcInfo) software and with the following supplementary modules, among others: Spatial Analyst, Geostatistical Analyst, and 3DAnalyst. They are united into the corporate network and are controlled from the GIS server. The main function of the GIS server is the creation of web services of observed and forecasted hydrological, meteorological, and synoptic information based on the data stored in DB as well as the optimization and management of these services. Moreover, GIS servers provide differentiated access to the data among the hydrologists who are responsible for different zones. GIS servers are equipped with ArcGIS for Server Advanced software. GIS servers were united into the cluster in order to provide the uniform load distribution among GIS servers in the case of multiple simultaneous user queries and to maintain the uninterrupted operation of the subsystem in case of server failure.
To optimize the subsystem and to increase its operation speed, an unusual solution was used. The precreated vector layers containing the objects of the observed area were recorded to the DB (e.g., for the ground-based data, the location and symbolic presentation of gauging and weather stations as well as the attributive information containing general information about an object; for the satellite data, the symbolic presentation of parameters in the regular grid points bound to the map). The vector layers of objects are related to the tables containing constantly updated information on observed and forecasted hydrological and other parameters. Such a DB structure allowed for the indication of the ready-made objects of the vector layer and the needed actual or forecasted information, so that the time taken for the creation and tuning of object representation is spared. The objects situated outside the limits of the screen are not involved. The proposed solution considerably reduces the time of data visualization on the display in case of fragment size or map scale changes.
GIS components of satellite data are located in the Far Eastern and European centers of the SRC “Planeta.” Each of these centers contains one GIS server and automated workstations. These GIS components provide ready-made satellite web-mapping services for the subsystem. It is noteworthy that ArcGIS technologies almost instantly visualize large-size satellite images (more than 500 Mb for one image) organized in the form of services; this is because the information’s image, rather than the information itself, is displayed. These services support Open Geospatial Consortium standards (WMS, WFS, etc.) and, if needed, can be connected to any web information system via Internet and to any desktop GIS system via the corporate network.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}