1. Introduction
Global challenges that environmental applied research is facing in the last years are related to minimizing the climate change impacts while increasing environmental resilience (from agricultural production to human wellbeing, natural resource conservation, etc.). Tuscany, Italy and the whole Mediterranean Basin constitute one of the “hot spots” highlighted by the last IPCC report [
1], which mainly is experiencing the effects of climate change. Moreover, the particular geography and the millennial overexploitation of natural resources have made Tuscan territory particularly vulnerable to natural hazards.
The analysis of temperature and precipitation trends in the last decades shows an increase of the extreme events’ frequency, intensity, extent and duration. Heat waves and droughts have important and increasing repercussions on physical, chemical and biological systems, and on some socioeconomical aspects such as health, agriculture, natural ecosystems and tourism [
2].
The drought event that started in 2016 and was still in progress at the end of 2017 is only the last of a series of dramatic and costly examples of prolonged droughts in Tuscany that have been systematically recurring every 4–5 years in this century. The last two episodes (2011–2012 and 2016–2017) cost the Tuscan agricultural industry over 500 million euro of losses in crop production and livestock (estimates from Coldiretti, the National Confederation of Farmers), and water resources experienced a significant decrease of surface and groundwater availability. Drought is the second most important natural disaster (after flooding) that affects population [
3]. Moreover, with respect to other natural extreme events, drought is a creeping phenomenon [
4], characterized by a slow and often difficult-to-define onset and a long-lasting evolution; its intensity and spatial extent are extremely variable and its impact on the environment and human activities can show up late and persist even after the end of the drought event [
5].
One of the main issues to cope with drought is the temporal gap existing between the onset and development of a dry period, and the response in managing drought-related emergencies. Although these extreme events require effective actions, policymakers and water users often show low preparedness because of the lack of a proactive approach consisting of monitoring and forecasting activities, mitigation measures and public education. In this context, it is crucial to be providing scientifically based technical support able to deliver simple, timely and reliable information in order to increase readiness, response and recovery capabilities [
2,
6,
7].
Advances in information and communication technology (ICT), as high-performance computing, processing and storing, new coding standards, the availability of open and costless data, and the strong impulse of the geoinformation technology foster the development of self-sustained monitoring and forecasting systems. All these new technological improvements in the ICT infrastructure, coupled with scientific advances, allow a timely, ready-to-use and user-specific upgrading of the early-warning communication. In addition, sharing effective and reliable information, describing the complexity of the phenomenon, implies that most efforts must be addressed to the implementation of a comprehensive framework [
8,
9,
10] based on a coherent workflow, from data acquisition to information delivering [
11]. It should be based on the interoperability [
12] and open-data concepts, and on the integration of different data sources, both climate-based and satellite-derived.
Several monitoring and forecasting systems have been developed at different spatial scales, from global to sub-national, even if few of them are still operational. At continental level there are the European Drought Observatory (EDO) [
13], developed by the Joint Research Centre (JRC), and the African [
14] and Latin American and Caribbean Flood and Drought Monitors, both developed by Princeton University. The US Drought Monitor [
15] is one of the most well-known examples of national systems, and another example is the Australian service (
http://www.bom.gov.au/climate/drought/), run by the Australian Government Bureau of Meteorology. In Italy, the Hydro–Meteo–Climate Service of the Regional Environmental Agency (ARPA) of Emilia Romagna is probably the most comprehensive drought observatory (
https://www.arpae.it/index.asp?idlivello=991), together with the Tuscan one.
Starting from these examples, even though climate change is a global phenomenon, its impacts can be detected at a local level; and from the needs of the Tuscany region and the Tuscan Water Authority to identify areas with the highest impact risk in order to take earlier decisions, the LaMMA Consortium (Environmental Modelling and Monitoring Laboratory for Sustainable Development), in collaboration with the Institute of Biometeorology of the National Research Council (IBIMET–CNR), implemented a system prototype for the identification of drought occurrences and trends [
16]. This system is based on a monitoring component and on a forecasting one, and is based on two types of indices: direct climate-based and indirect vegetation-based indices.
Over the years of testing, the framework has evolved from the point of view both of the enrichment of the set of indices, and the improvement in the spatial resolution; but the main bottleneck has remained the non-automation of the operational chain and the lack of a unique working environment, which limits the resource optimization.
For these reasons, looking forward the development of a permanent Tuscan drought observatory (DO), our research studies are actually concentrated on the implementation of a spatial data infrastructure (SDI) that follows the service-oriented architecture (SOA) paradigm [
17], based on the Open Geospatial Consortium (OGC) (
http://www.opengeospatial.org/) standards. The framework has been conceived as a database-centred architecture, using the open-source PostgreSQL (
https://www.postgresql.org/) database management system (DBMS).
The main innovation of this approach consists in integrating the geographic data flows (from the downloading of remote sensing data to the storage of final indices) and all the related geoprocessing functions in a single environment.
Moreover, efforts and the breakthroughs of the community that works on open-source systems are allowing an ever-closer and more effective interaction between different languages and software. In fact, the integration of the PL/R (R procedural language) wrapper [
18] into the procedural language of PostgreSQL (PL/pgSQL) has allowed the creation of advanced statistical procedures using the R engine (
https://cran.r-project.org/). The application of this approach actually focused on the implementation of the monitoring part of the operational chain, and allows working with datasets with different spatio–temporal dimensions, ensuring a versatility and a flexibility, so as to effectively respond to the needs of actual users and also to future demands.
The overall aim of this paper is to present a comprehensive operational monitoring and forecasting system based on open and interoperable technological solutions, implemented to facilitate the communication of scientific knowledge on drought assessment for decision-making processes.
2. Study Area and Data
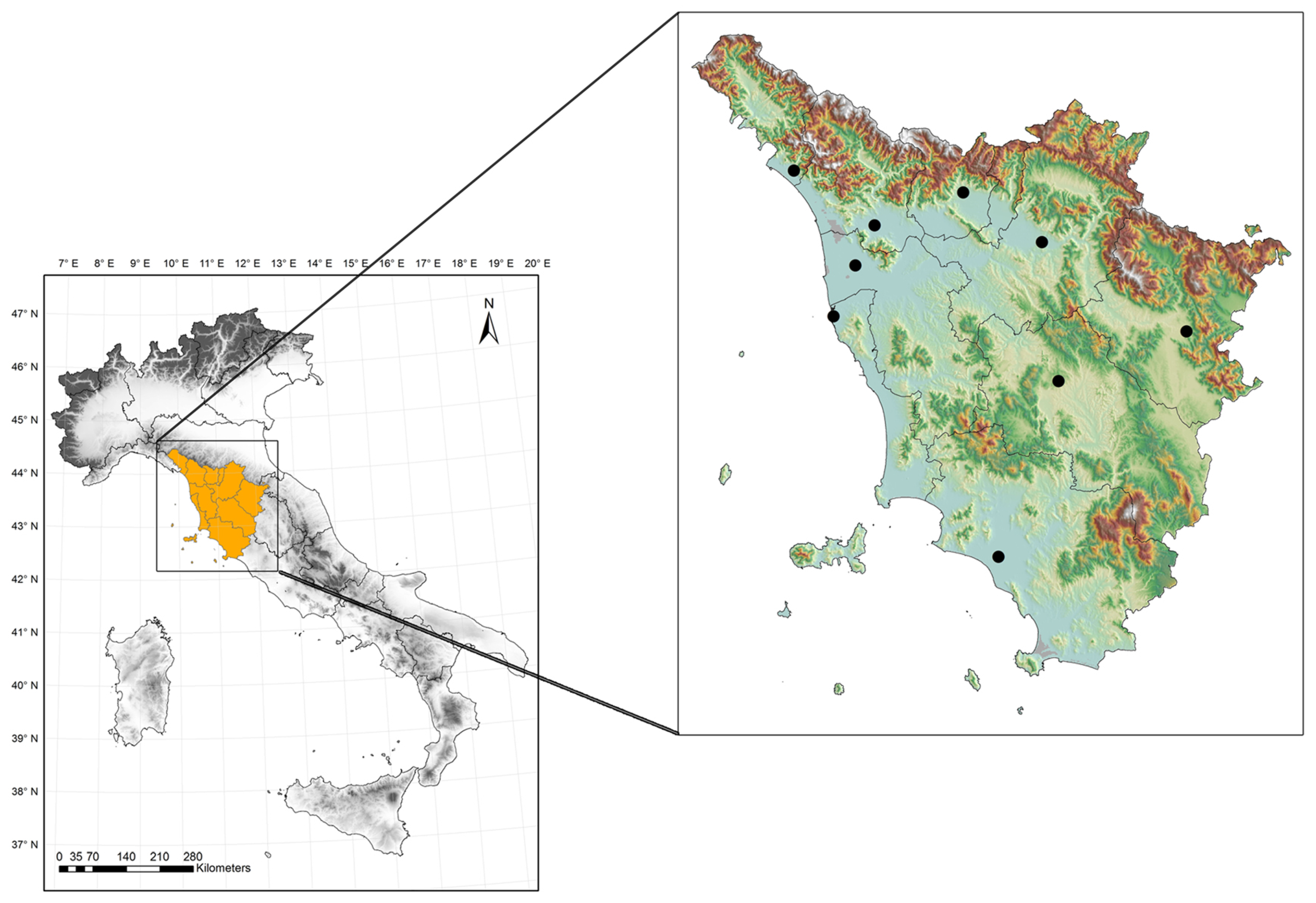
The drought observatory is focused on monitoring and forecasting conditions over Tuscany, even if datasets refer to larger areas based on the image size (for satellite products) or other needs for climatological purposes. Tuscany is a geographically complex region of central Italy (
Figure 1), with half of its territory covered by forests, and characterized by a rainfall regime influenced by latitude, distance from the sea and orography, and ranging from about 600 mm in the southern coastal area, to 2700–2800 mm in the northern part of the Apennines (reaching a height of almost 2000 m a.s.l.).
This complexity makes particularly important the availability of a system as comprehensive and integrated as possible to respond to the different user requests.
Input datasets include both in-situ and remote-sensing parameters, in order to implement and validate geoprocessing procedures and model runs (
Table 1).
One of the two sources of rainfall data for the monitoring system is the Climate Hazards Group InfraRed Precipitation with Station data (CHIRPS) precipitation dataset [
19,
20], that has the double advantage of being one of the global daily datasets with the highest spatial resolution (0.05°), and coming from the combination of satellite and ground-based data.
Ten meteorological stations, representing the provincial capitals, were also selected both to validate the CHIRPS dataset for the Tuscany area and to calculate one of the two climate-based indices.
For the analysis of vegetation response to temperature and moisture stresses, a set of remote-sensing products from the Moderate-Resolution Imaging Spectroradiometer (MODIS) was selected: the Normalized Difference Vegetation Index (NDVI) [
21], the Enhanced Vegetation Index (EVI) [
21] and the Land Surface Temperature (LST) [
22].
For the forecasting system, gridded monthly precipitation data from the CRU (Climate Research Unit) TS v.4.00 dataset [
23] is used to calculate SPI 3, together with a series of atmospheric predictors.
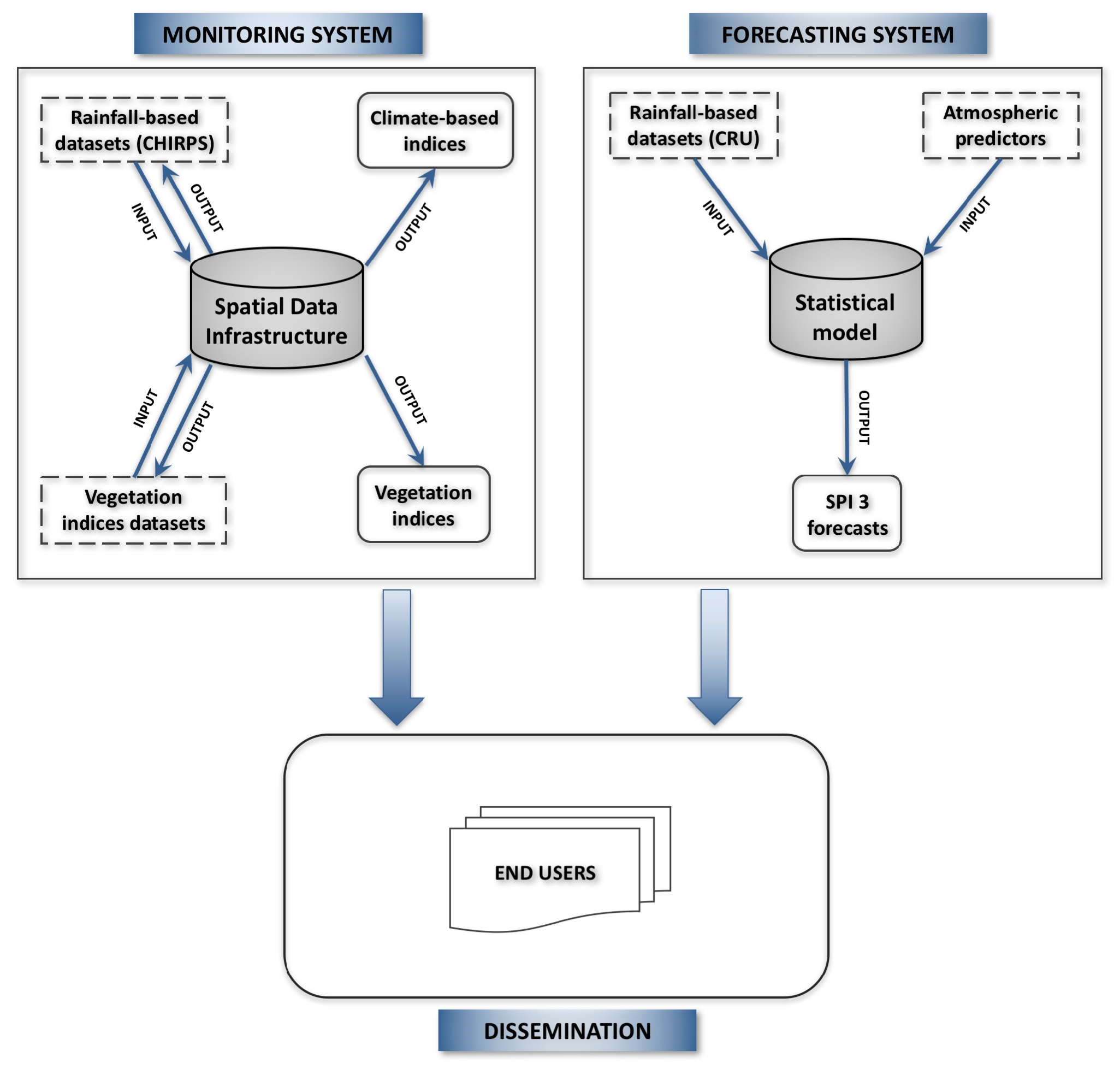
4. Monitoring System
The monitoring system is developed integrating state-of-the-art science and advances in technologies, and selecting a set of coupled rainfall-based and satellite-derived indices (
Table 2), taking into account: (1) types of drought; (2) availability and consistency of data; (3) geographical characteristics; (4) time and spatial variability; and (5) main final users.
Precipitation, as the first and main parameter pointing out drought occurrence, is used in many indices, among which the most widespread Standardized Precipitation Index (SPI) [
24] and the less-known Effective Drought Index (EDI) [
25] are considered better than others [
26], providing different timescales of drought occurrence, and detecting its variation and duration.
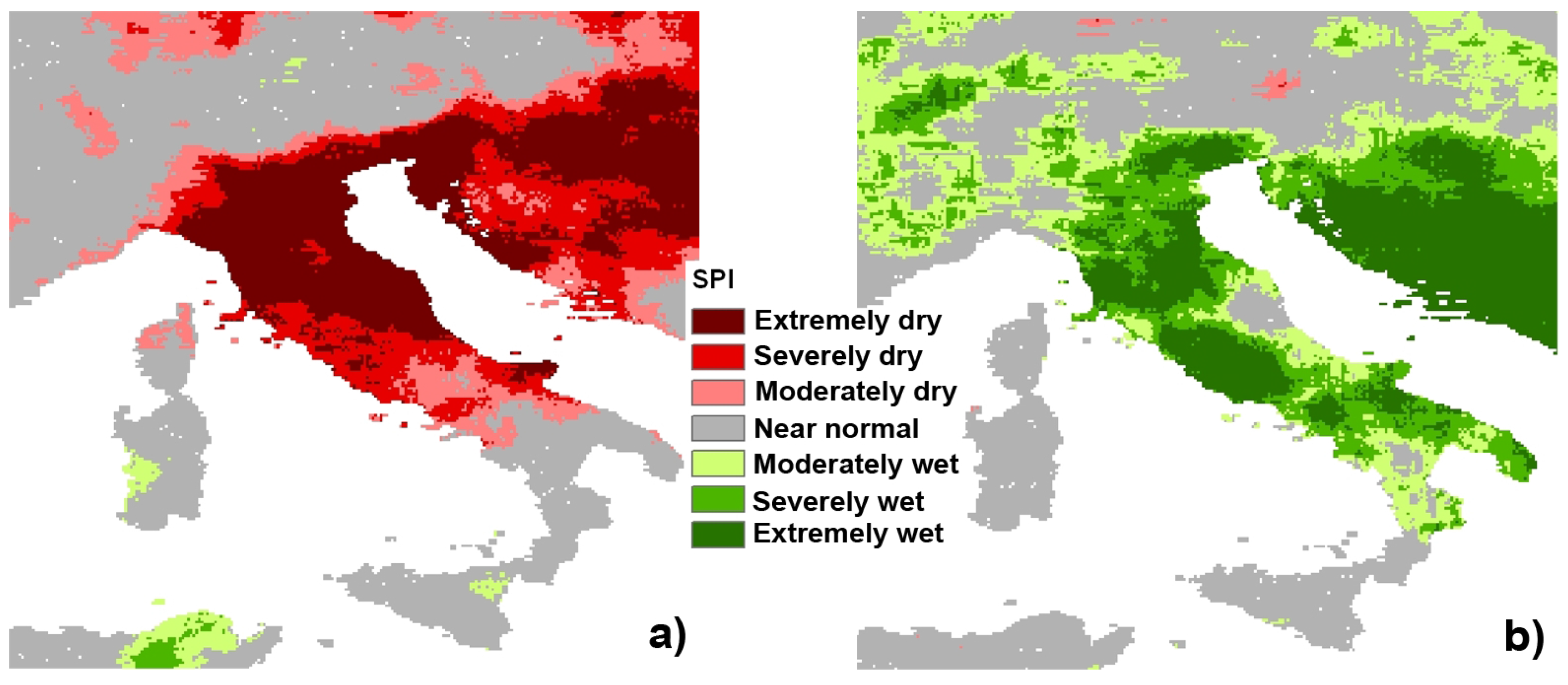
The SPI, widely considered a robust and reliable index [
27,
28], allows multiple timescale tracking (usually 3, 6, 12, 24 months) of dry/wet periods, detects drought variation and duration, and provides a comparison between geographically different locations thanks to its standardization (
Figure 3).
For these reasons, and to have the possibility of expanding the geographical area of analysis as necessary, the CHIRPS dataset was considered suitable. Indeed, working over larger territory or different climatic zones–since the spatial distribution of weather stations is often inadequate–encourages the employment of a dataset that merges precipitation detected both by satellites and rain gauges.
In order to validate the CHIRPS dataset for the Tuscany region, a comparison of monthly precipitation timeseries from 10 rain gauges and the corresponding values of the CHIRPS grid cells for the period 1981–2010 has been done. an overall underestimation of CHIRPS monthly rainfall emerges from the analysis (R correlation = 0.69; mean bias = −8 mm; RMSE = 10.4 mm), which is acceptable for gridded datasets and our purposes.
Instead, the EDI index, calculated with a daily timestep, is more sensitive to each single rainfall event and shows a more detailed influence of precipitation on the recovery from an accumulated deficit.
where
EP is the effective precipitation;
is rainfall of
m days before; and
i represents the number of days (usually equal to 365 days) along which rainfall is summed in order to calculate the drought intensity.
MEP is the mean climatological effective precipitation (calculated over a 30-year period);
DEP is the deviation of the effective precipitation from the MEP indicating a water deficit/surplus for a specific day.
EDI is the standardized value of DEP, where
ST(DEP) is the standard deviation of each daily DEP.
Additionally, EDI is effective to spatially recognize the onset of a drought episode [
26], and consequently can be used at the punctual level for further specific information.
The second group of indices, focused on vegetation health monitoring, represents an indirect drought-responsive way to analyze the phenomenon, and satellite-derived indices are widely used due to their spatio–temporal characteristics of full ground cover and quasi-continuous time observations. The vegetation performance, usually used for agricultural drought monitoring, is also useful to have an indication of the intensity of a drought event; woody plants, in fact, with their deep root systems, have evolved mechanisms to cope with dehydration conditions stronger than those of herbaceous plants [
29], and therefore a decrease in the forest productivity can indicate a prolonged lack of water availability.
The vegetation indices selected for the DO are related to temperature and moisture stresses throughout a combination of NDVI or EVI, and LST parameters. They are [
30] the Vegetation Condition Index (VCI) and the Temperature Condition Index (TCI).
where
NDVIi,
NDVImin, and
NDVImax are respectively the last NDVI image available and the absolute minimum and maximum values along the timeseries, related to the same period.
where
LSTi,
LSTmin, and
LSTmax are respectively the last LST image available and the absolute minimum and maximum values along the timeseries, related to the same period. In accordance with the study of Sun and Kafatos [
31], we use daytime LST instead of brightness temperature for calculating TCI.
We are actually evaluating the possibility to use EVI instead of NDVI due to its characteristics of being less influenced by scattering related to aerosols [
32] and less susceptible to saturation [
33] in forests with high vegetation cover (
Figure 4). However, the evaluation of the performance of the former with respect to the latter is still a work in progress.
The 8-days TCI images are averaged to be compatible with the 16-days time resolution of VCI.
The combination of VCI and TCI originates the comprehensive Vegetation Health Index (VHI) [
30,
34].
where
a and
b are coefficients that quantify the VCI and TCI contributions to the vegetation response, respectively. Since our environment is complex and characterized by different vegetation types (from Mediterranean evergreen coniferous and broad-leaf forests to temperate coniferous and deciduous broad-leaf ones) responding differently to temperature and water availability, we assigned the same weight (0.5) to the coefficients to simplify the computation of the index.
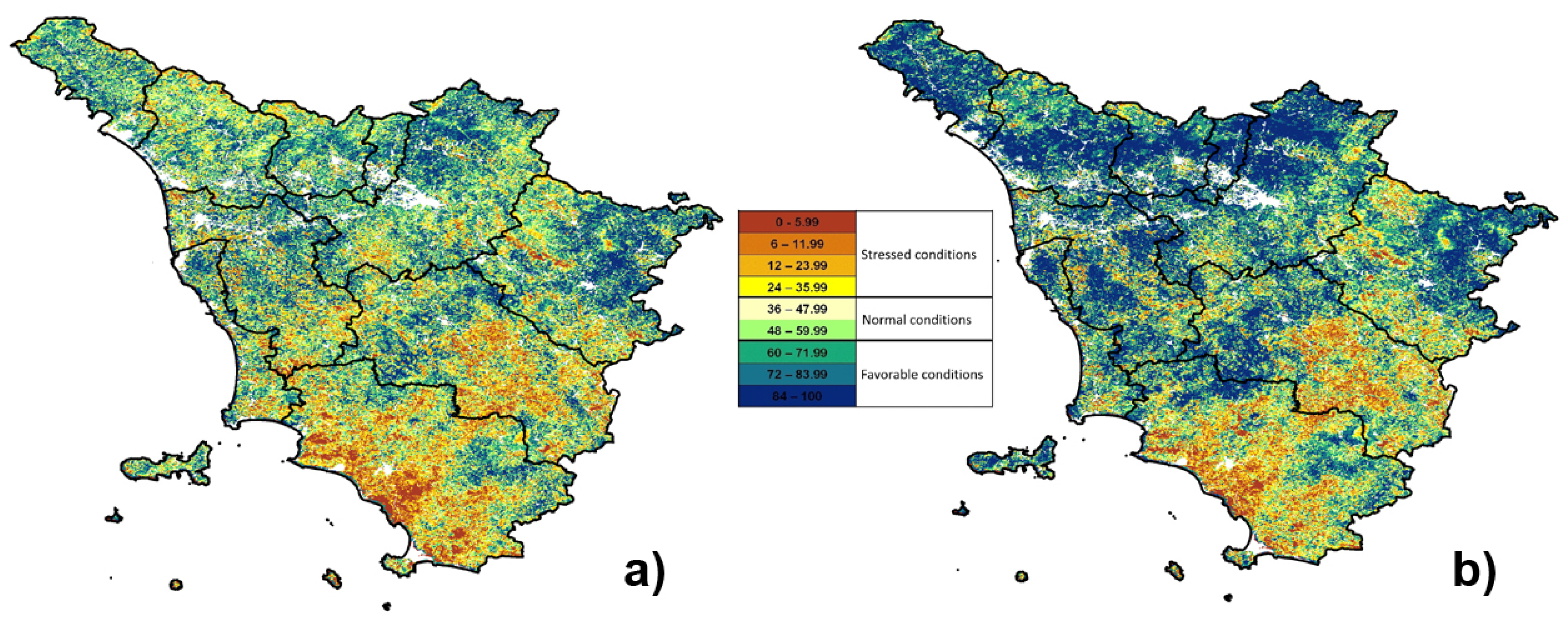
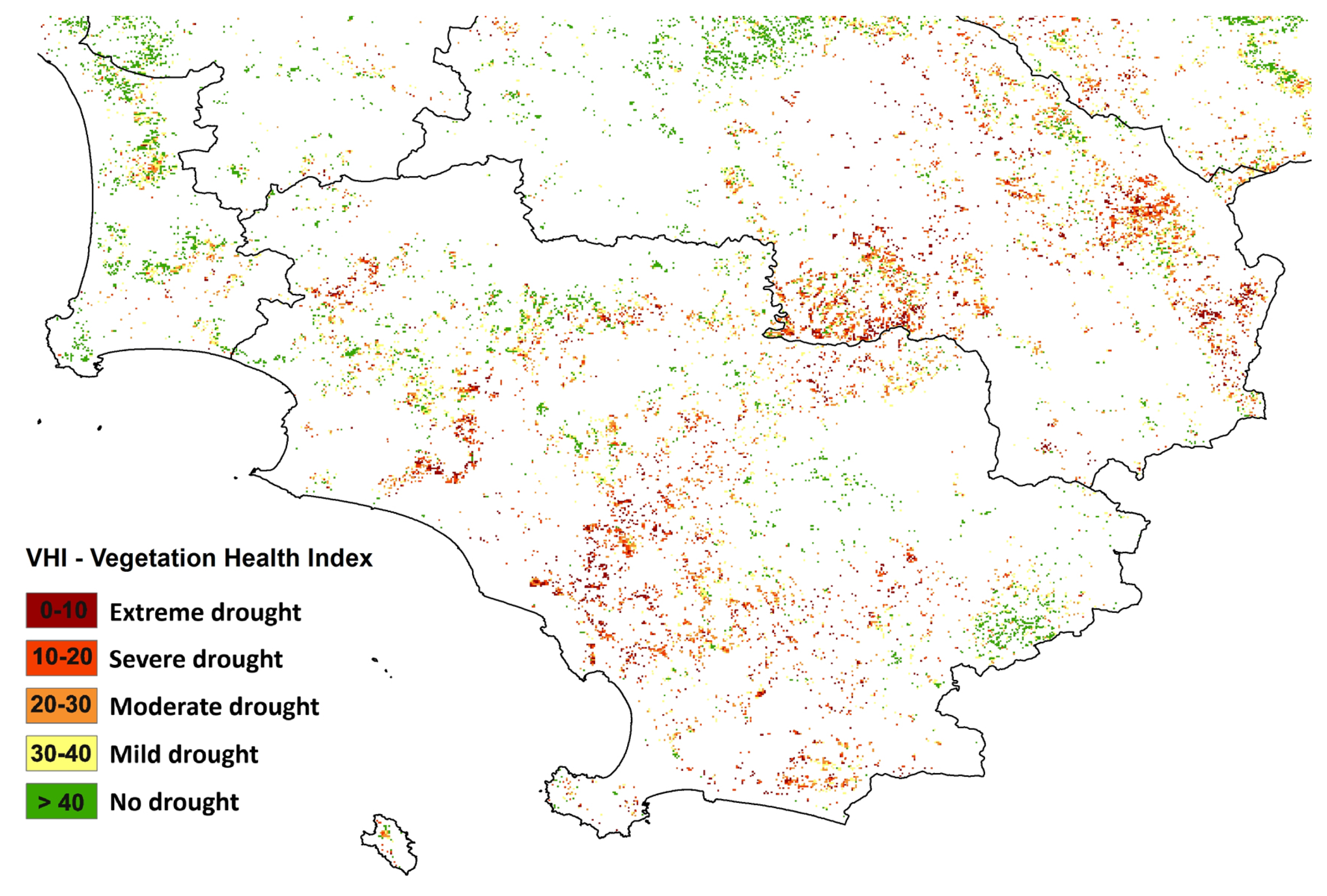
Concerning the vegetation indices, due to the different spatial resolutions of TCI (1 km) and VCI (250 m), the calculation of the comprehensive VHI index has been combined with resampling functions in order to obtain a final map with higher details (250 m) (
Figure 5).
4.1. Monitoring SDI Architecture
To implement a reliable and science-based local operational monitoring system, a well-structured SDI is an essential prerequisite to produce effective spatial information, and to support the whole operational chain, from the data acquisition, to its management, processing and dissemination. An SDI is defined as ”sources, systems, network linkages, standards, and institutional issues involved in delivering spatially-related data from many different sources”, and information for purposes other than those it was created for “to the widest possible group of potential users at affordable costs” [
35].
Based on this general concept, an SDI can create an environment able to facilitate the discovery, accessibility, sharing and reuse of research data, contributing to support decision-making processes related to the impact of drought occurrences at the local level. In the last decades, the SDI conceptual model has evolved, from the oldest [
35,
36,
37] more product-based, to the most recent process-based ones [
38]. The first considers only standardized data production, access and delivering, linking different spatial databases; the latter, more comprehensive and widely used, includes databases also hosting metadata and tools that allow an active, flexible and responsive input/output visualization, data processing and downloading in order to obtain information useful for decision makers, technicians or researchers [
39].
Williamson [
40] considers the SDI development a more complex concept and in constant evolution “because of the social, political, cultural and technological context to which such development must respond”.
In the research context and in our perspective, an SDI built to support a DO should respond to some fundamental requirements: research data openness, interoperability, flexibility, scalability, responsiveness and specific user needs. For this reason, our user-oriented and process-based DO SDI is focused on the best use of climate data for drought assessment and their translation in information, in opposition to simple data sharing.
Even if the top-down SDI implementation approach required for global and national SDIs emphasizes the need of a full standardization and uniformity [
41], in practice its implementation in a local bottom-up approach requires a compromise between the application of OGC/ISO standards and the system optimization that has to respond to different actual and future user needs and their available resources [
41,
42]. Indeed, standard implementation, if strictly applied, could make more complex and heavier the services’ development and usage.
Starting from these concepts, the DO SDI technological components are organized in typical client–server architecture, and interact from the data provider’s download data process to the result representation to end-users, following general OGC guidelines [
39,
43,
44]. OGC standards are used in several elements developed into the DO SDI, starting from the data model, designed using Unified Modeling Language (UML) (ISO TC/211), to PostGIS open-source software that “provide[s] the most complete implementation of OGC simple feature specifications (SFS) of any free and open-source software (FOSS) database management systems (DBMSs)” [
45], and follows the OGC Structured Query Language (SQL) standards [
46,
47]. The data model is developed following a participative approach among the researchers involved in data collection and analysis for the application schema implementation. Moreover, to ensure the platform interoperability between geospatial data and services, three main services are considered in the general SDI architecture: catalog service, data service and processing service [
48,
49]. This release of the DO SDI includes OGC Catalogue Service for the Web (CSW) and Web Map Service (WMS) [
50]. Concerning the Web Processing Service (WPS), some constraints have been still overcome with further developments [
51].
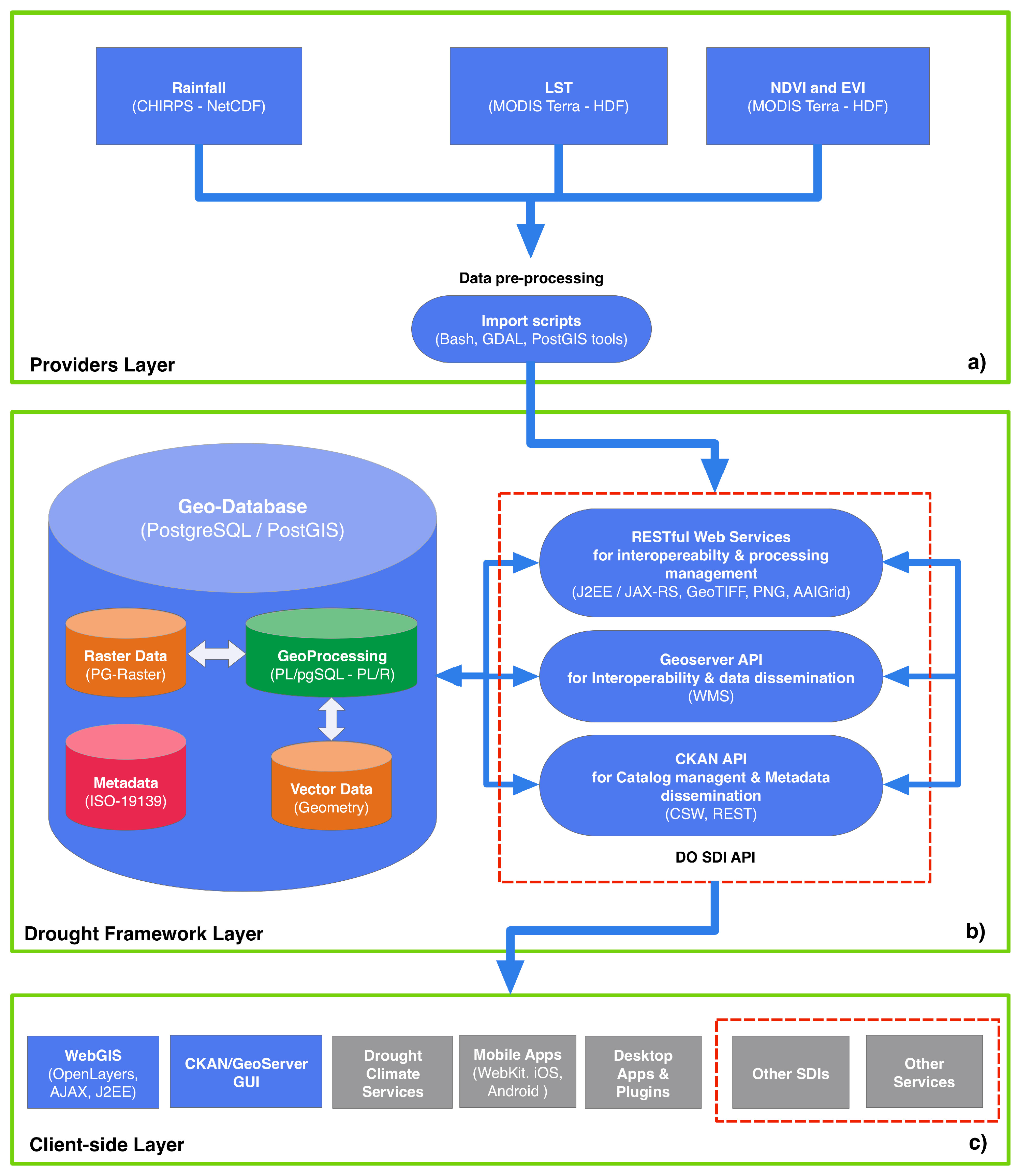
The design of the DO SDI is built using the most spread open-source software, according to the required functionalities. The architecture, designed for the DO monitoring framework optimization, is composed of three layers (
Figure 6a–c): (1) providers layer for retrieving input data; (2) drought framework layer for managing metadata and processing stored data; and (3) client-side layer for result dissemination. All the three layers communicate through specific representational state transfer (REST) web services following the SOA paradigm. Even if the REST paradigm is only marginally considered in the OGC’s standard implementation (i.e., for the WMTS [
52]), we preferred it to the Simple Object Access Protocol (SOAP) ones because it is lightweight and has less client-side complexity to manage by the users [
53]. Furthermore, RESTful web services provide functions of data extraction and downloading in an effective and highly flexible way.
The overall objective in developing a local DO SDI is to provide an appropriate environment in which both users and producers of spatial information can cooperate in a cost-efficient and cost-effective way to better achieve their targets.
4.1.1. Providers Layer
The providers layer (
Figure 6a) is in charge of managing input data coming from different sources (CHIRPS rainfall, and MODIS LST, NDVI, EVI) and storing them in the geodatabase (GeoDB) implemented into the framework layer (
Figure 6b).
The OGC data formats actually supported by the DO SDI are the NetCDF [
54,
55] for input CHIRPS rainfall dataset, and the Well-Known Text (WKT) [
56] for vectors used for the extraction and processing functions. MODIS data are in Hierarchical Data Format–Earth Observing Systems (HDF–EOS) format, approved standard recommended for use in NASA Earth science data systems.
Specific Bash scripts have been developed in order to download and prepare input data before saving them into the GeoDB. Geospatial Data Abstraction Library (GDAL) and PostGIS reprojection, tiling and storing functions have been used in order to improve the GeoDB performance and to harmonize the datasets with the data model. All datasets have been reprojected into a common and widely used reference system: the EPSG:4326 (i.e., Latlong, WGS84). The same Bash scripts call RESTful Web Services supplied by the framework layer to store the datasets in the GeoDB. Moreover, a cron daemon (crontab file) has been enabled to start the scripts automatically for a continuous input-data updating.
4.1.2. Drought Framework Layer
The drought framework layer (
Figure 6b) is the main component of the DO SDI architecture, in which the PostgreSQL database represents the only environment for data storage and geoprocessing. At this implementation stage, geoprocessing queries do not completely follow OGC WPS specifications [
57], working with REST Web Services instead of SOAP. All the services allow the storage of new data while their retrieving and processing are developed locally using the REST paradigm, and called through simply HTTP GET and POST operation requests [
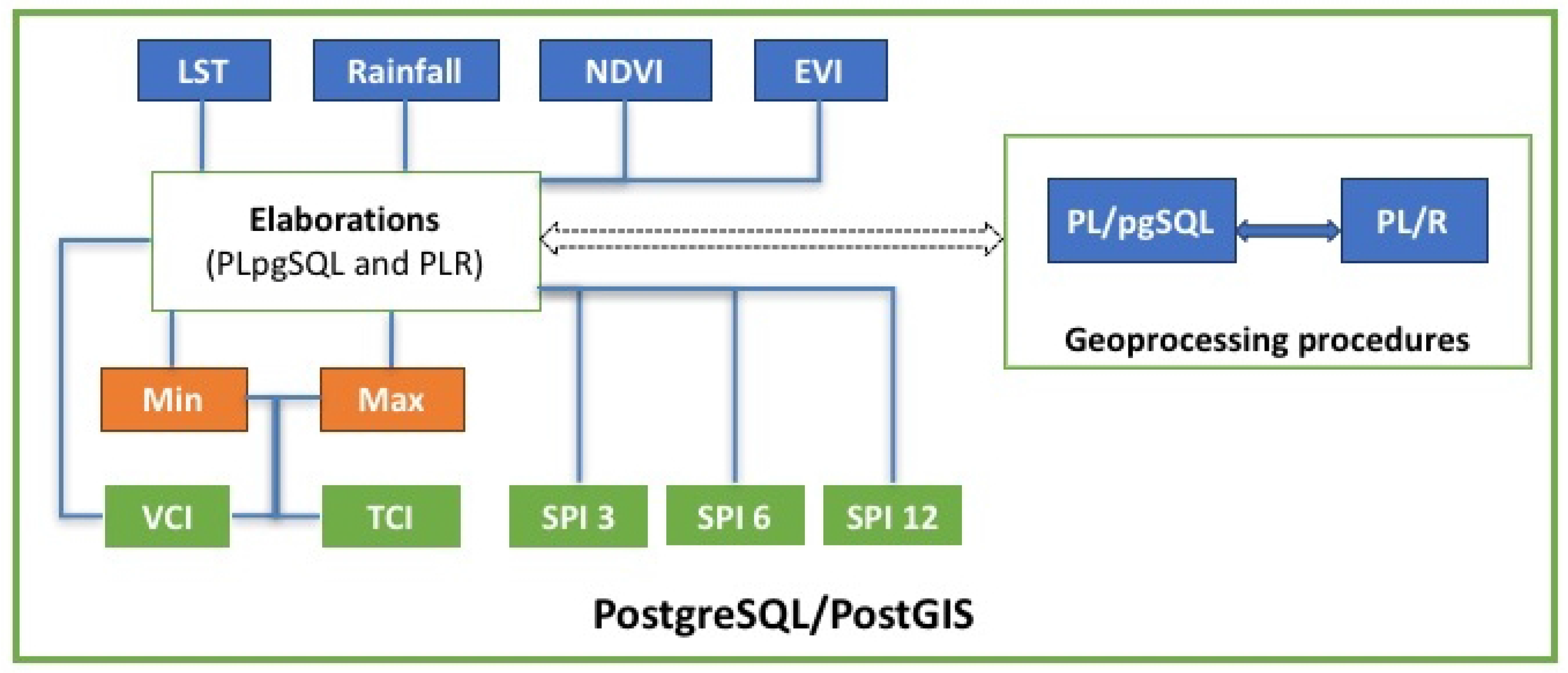
44]. PostgreSQL is used to store input data (rainfall, LST, NDVI, EVI), to perform all geoprocessing procedures (queries, indices elaborations, statistical operations, etc.), and to generate intermediate data (LST
min, LST
max, NDVI
min, NDVI
max, EVI
min, EVI
max) and output images (SPI, TCI, VCI, E-VCI, VHI, E-VHI) with different formats, that is, GeoTIFF, PNG, ASCII Grid (
Figure 7).
Though all the indices are calculated inside PostgreSQL, the different complexities of vegetation and rainfall index computation has forced us to use different libraries. TCI and VCI, in fact, result from simple arithmetic operations that can be done directly in PL/pgSQL using the PostGIS library, successfully taking advantage of its features. The SPI index, instead, is obtained with more complex statistical functions (fitting of a gamma probability distribution, transformed into a standard Gaussian variable). For this reason, SPI elaboration has been implemented with the integration of a specific R library [
58] with the PostGIS library. The integration between the R engine and PostGIS is made possible by PL/R, the R wrapper for PostgreSQL.
For the implementation of the SPI processing, different approaches are possible in order to maximize the performance. In the first approach, currently employed, the SPI procedure is managed by a Java 2 Enterprise Edition (J2EE) service that creates time-saving parallel threads, each one working simultaneously on specific subregions of rainfall grids and calling iteratively the PL/R function. The PL/R function performs a pixel-by-pixel SPI calculation over time vectors. This approach consumes more CPU resources but saves RAM consumption. The number of parallel treads influences the total time needed to calculate the SPI (the higher the number, the lesser the time consumption). The second approach consists of a PL/R routine that works over a single vector of matrix of a tiled subregion. This approach consumes less CPU resources, but is more RAM-consuming. The comparison of the two approaches will show which of them performs better to further reduce the time consumption.
The framework layer also supplies a suite of RESTful Web Services (
Figure 6b), developed using JAX-RS (Java API for RESTful Web Services), for retrieving stored data (inputs, intermediate and outputs) and handling the geospatial operations developed with PL/pgSQL (i.e., the extraction of raster portions from a given polygon, basic statistics, and model runs).
A key component of an interoperable SDI is the catalog of metadata, useful for data and resource discovery and evaluation using space, time and thematic attributes before accessing them [
59,
60]. Catalogs also require web interfaces for metadata and data publishing, based on open standards, and the WMS is one of the OGC standards, used for graphical representation (images) of geospatial data [
50].
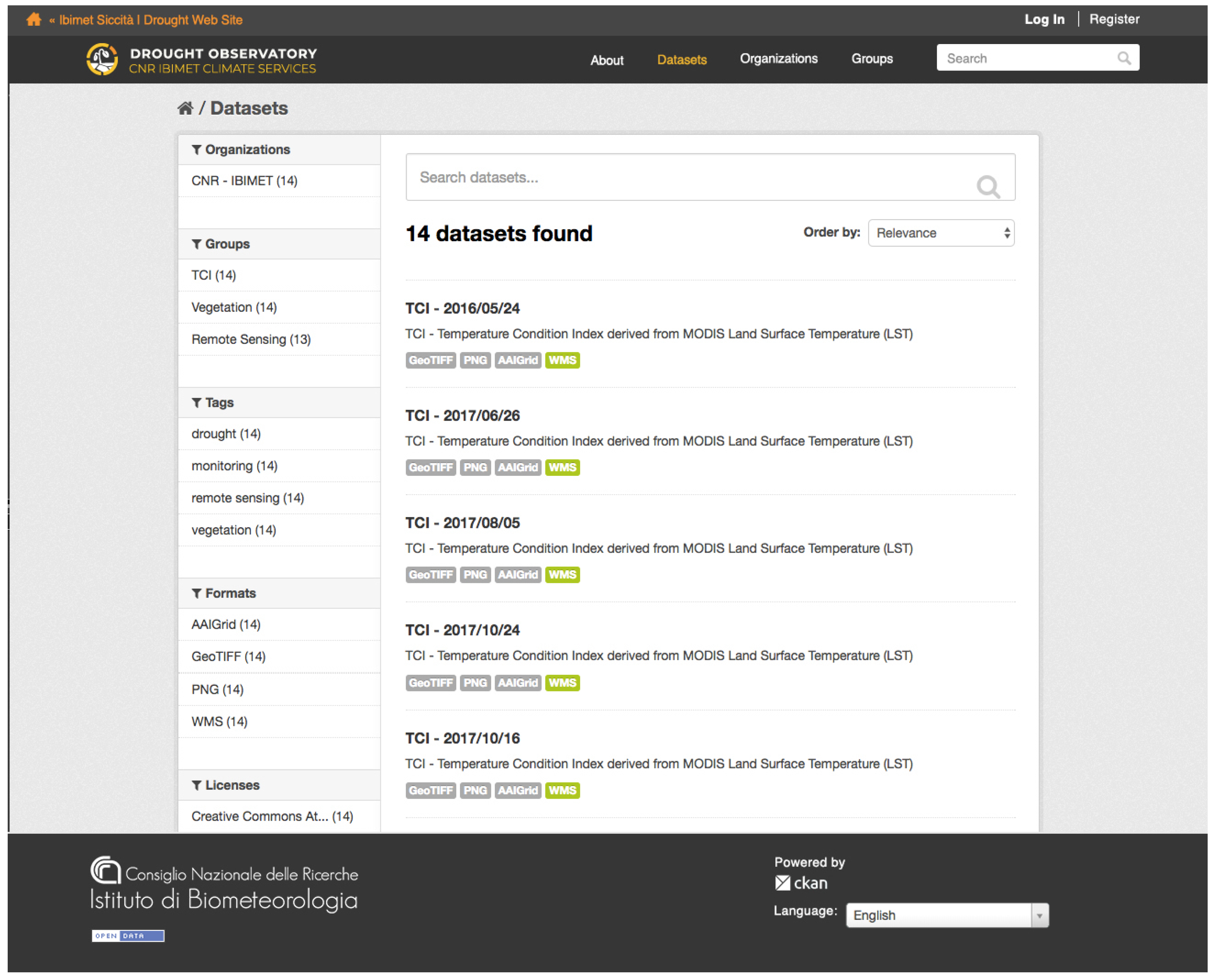
The drought framework layer includes the open-source Comprehensive Knowledge Archive Network (CKAN) data-management platform (
http://ckan.org/) and GeoServer data-publishing web server (
http://geoserver.org/), respectively used to harvest the catalog and to publish data and metadata. CKAN supports ISO 19139 (geographic information—metadata—XML schema implementation) encoding for metadata description, and it is also able to manage the OGC CSW and WMS standards.
Through the supplied API (application programming interface) functions composed of RESTful Web Services, GeoServer API and CKAN Services, spatial data are discovered and ready to be reused by any third-party client applications, guaranteeing the integration of this climate data with other information types and therefore the interoperability of the whole system.
Figure 8 shows the first release of the data catalog implemented for the Drought Climate Service.
4.1.3. Client-Side Layer
A process-based SDI should stress information communication in order to reach a wide range of users and facilitate effective decision planning [
38].
The web services implemented in the client-side layer (
Figure 6c) support the development of customized applications for result dissemination and service handling.
Different customized client applications are developed following the specific users’ needs (researchers, practitioners, public authorities and community), taking advantage of interoperable services supplied by the drought framework layer.
Through the supplied RESTful API functions of the drought framework layer, it is also possible:
to create WebGIS applications, customized websites, and services that require DO SDI data;
to develop a plugin for other desktop GIS applications such as QGIS or ArcGIS;
to share and to integrate DO data with other interoperable SDIs.
Moreover, a complete catalog is supplied through CKAN and GeoServer GUI implementation, and data are visualized in several formats and standard protocols: WMS, GeoTIFF—considered an important de facto standard—PNG, and AAIGrid.
5. Forecasting System
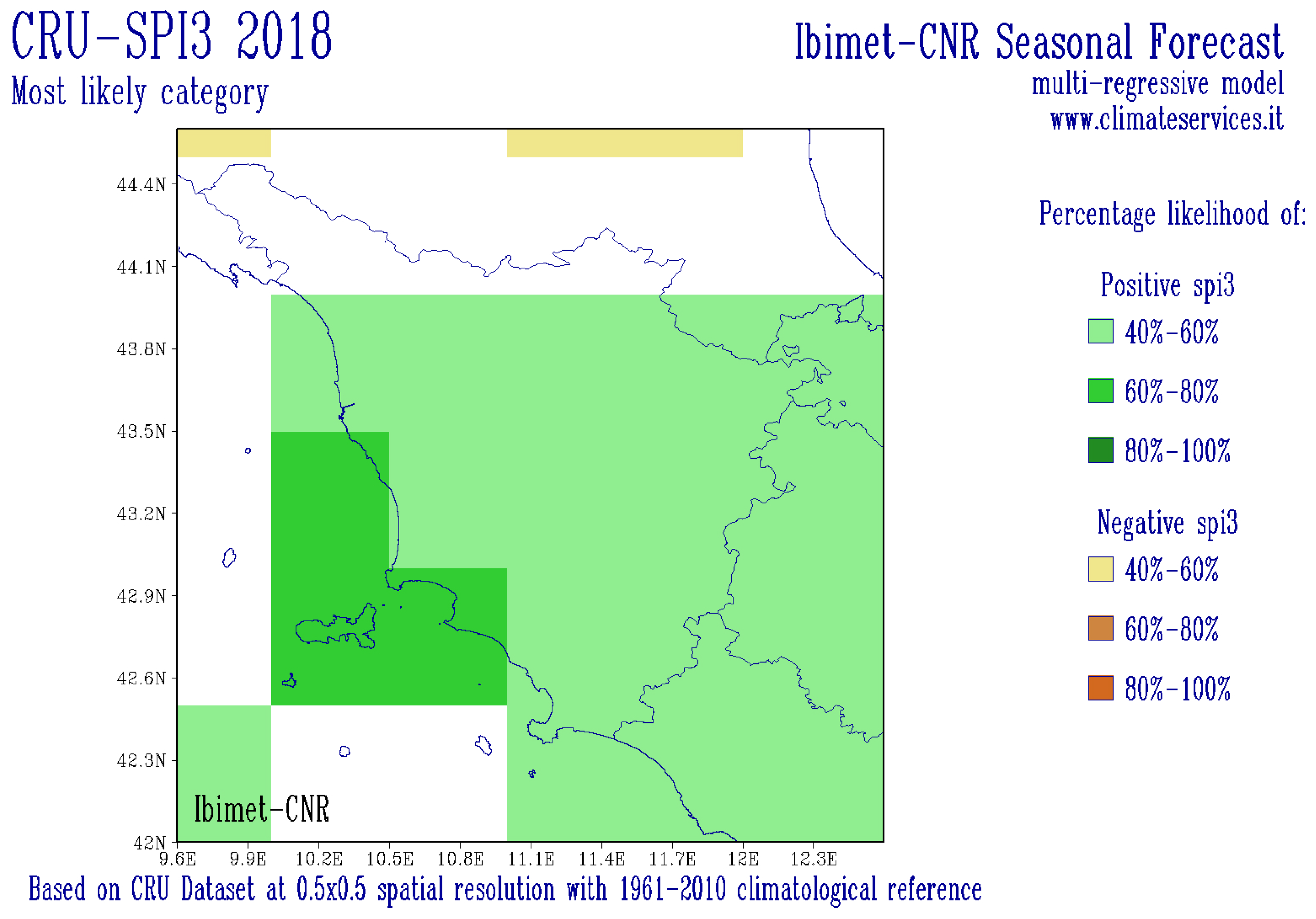
The forecasting system is based on an empirical approach to predict meteorological drought using the SPI 3, a few months in advance (
Figure 9) from large-scale observed climate indices. The forecast’s window (25°–65° N; 20° W–45° E) has a spatial resolution of 0.5°.
This seasonal forecast empirical system adopts a physically based statistical approach which uses a multivariate regression (MR) model to estimate future anomalies [
16].
The SPI-3 dependent variable of the MR model is calculated using the CRU rainfall dataset, more suitable than CHIRPS for this analysis because of its long timeseries. For the SPI computation, which is done by using the SPEI R package (
https://CRAN.R-project.org/package=SPEI), the Pearson III distribution and the period 1961–2010 are used for standardizing the variable to a Gaussian distribution with zero mean and standard deviation of one. Predictors are selected among observed atmospheric and oceanic climatic indices according to the list in
Table 3, then they are centered and standardized by using the overall mean and standard deviation, respectively. The de-trending procedure is applied by monthly subsetting each timeseries, since an MR model is built for each forecast month.
Furthermore, a maximum of five months leading up to the forecast SPI-3 are set for each predictor to be included in the design matrix, that is, the matrix of the regressors. For example, the design matrix of the SPI-3 model of May is composed of the predictors’ timeseries from October to February, since the SPI-3 of May is computed by using the precipitation of March, April and May. The de-trending procedure is based on a local nonparametric regression and is applied to the dependent variable as well. Finally, 12 design matrices with 43 observations, that is, monthly values of the 1974–2015 timeseries, and
predictors, are set, being 13 indices and five leading timesteps. Then, a procedure of deletion has been applied in order to address the well-known issue of multi-collinearity in MR models by eliminating linear combinations as well as high correlation between explanatory variables. From this filtered design matrix, a double-steps procedure is applied to select the best model in terms of predictive performance: (1) Find the eight best models for each group of one up to 12 predictors according to the adjusted
index; (2) find the best model among those identified at (1) by means of 10-fold cross-validation criterion and RMSE index. More in-detail, the procedure at (1) is performed by means of the “leaps” R library [
68], that uses an efficient algorithm to return the best model: in practice, it iteratively computes the adjusted
index, which is calculated from the classical
taking into account a penalization for models with numerous predictors (
, where
n and
p are the number of samples and parameters, respectively), for all the possible combinations of predictors. The algorithm output is basically the ranking of the models with different number of predictors. From this ranking, the selection of the best model is done by applying a 10-fold cross-validation procedure, that iteratively divides the data samples in a training and control set, using the training for estimating the linear regression coefficients, and the control for evaluating the predictive performance of each model. Finally, the model with the minimum RMSE value is chosen. The entire procedure has been carried out at each grid cell of the spatial domain. Thus, an evaluation of the predictive performance of the best model for each SPI-3 can be done, summarizing the results obtained in each grid cell, and such an evaluation is reported in
Table 4. In particular, the columns
signif 0.05 and
signif 0.10 represent the percentage of predictors in the best model that are individually significant at level
and
of the t-test, respectively. The value of these indices are quite high, attesting to the robustness of the chosen models. On the other hand, the range of the
, which is composed of the minimum and maximum values obtained throughout the spatial domain, shows criticality for some individual cell grids and a few months; nevertheless, the great number of values above
reveals generally a good model definition. This behavior is more pronounced during the winter season, when drought can be more critical. The predictive performance of the selected models is generally good (see the minimum values in the column
range RMSE with respect to the corresponding observed SPI values). Lower performance was identified in the summer period, when dryness events are common and thus have weaker impacts.
6. Dissemination
A stable, well-structured and interoperable SDI allows one to have a wide database of drought indices, constantly fed by input data, that guarantees the analysis of different drought aspects at high spatial resolution. Firstly, climate-based indices give information about the extension, intensity and duration of a drought event, whereas vegetation-based indices inform on its impacts. Secondly, with the availability of a long timeseries of these indices, it is possible to conduct trend analysis, useful not only for scientific purposes but also for decision makers for adaptation planning.
Vegetation index maps can be also cross-checked with other types of layers, such as Tuscan boundaries and land cover, to mask urban areas and water bodies, and for a more detailed analysis of results. During a drought occurrence, in fact, the Tuscan land cover is used in order to classify and localize which forest type or tree crops are more affected (
Figure 10).
All the final results are analyzed and compared to have a coherent overview of the signal during a drought event and to prepare effective information for end-users. The final information is actually provided through different communication channels in order to reach different targets.
6.1. Web Page
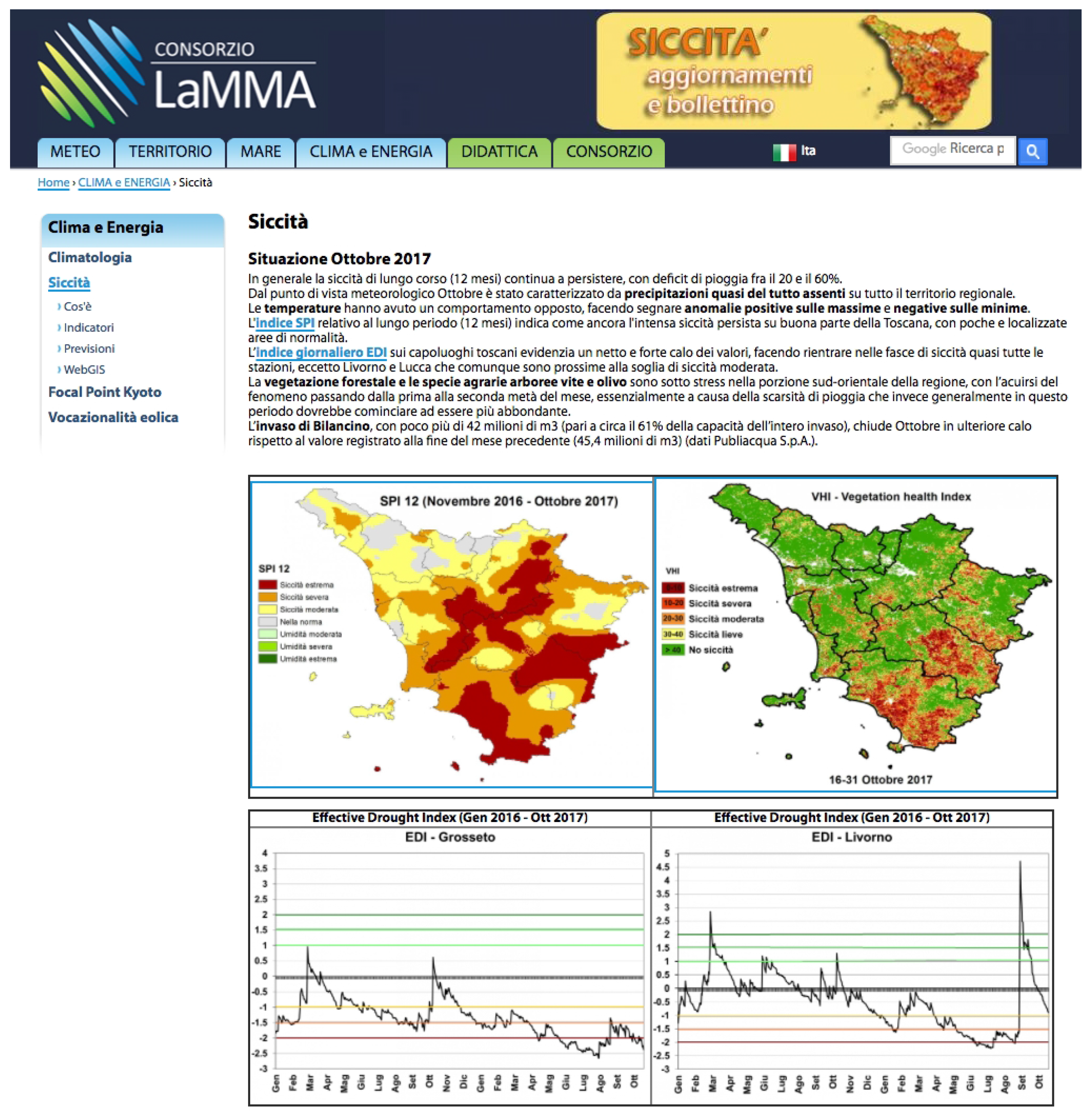
A first synthetic information suite suitable for the generic public and media is provided on a specific web page (
Figure 11) of the LaMMA Consortium website. News on the current conditions are monthly updated and local impacts from media are also reported (
http://www.lamma.rete.toscana.it/siccita-situazione-corrente). From the web page, it is also possible to access the monthly bulletins.
6.2. Monthly Bulletins
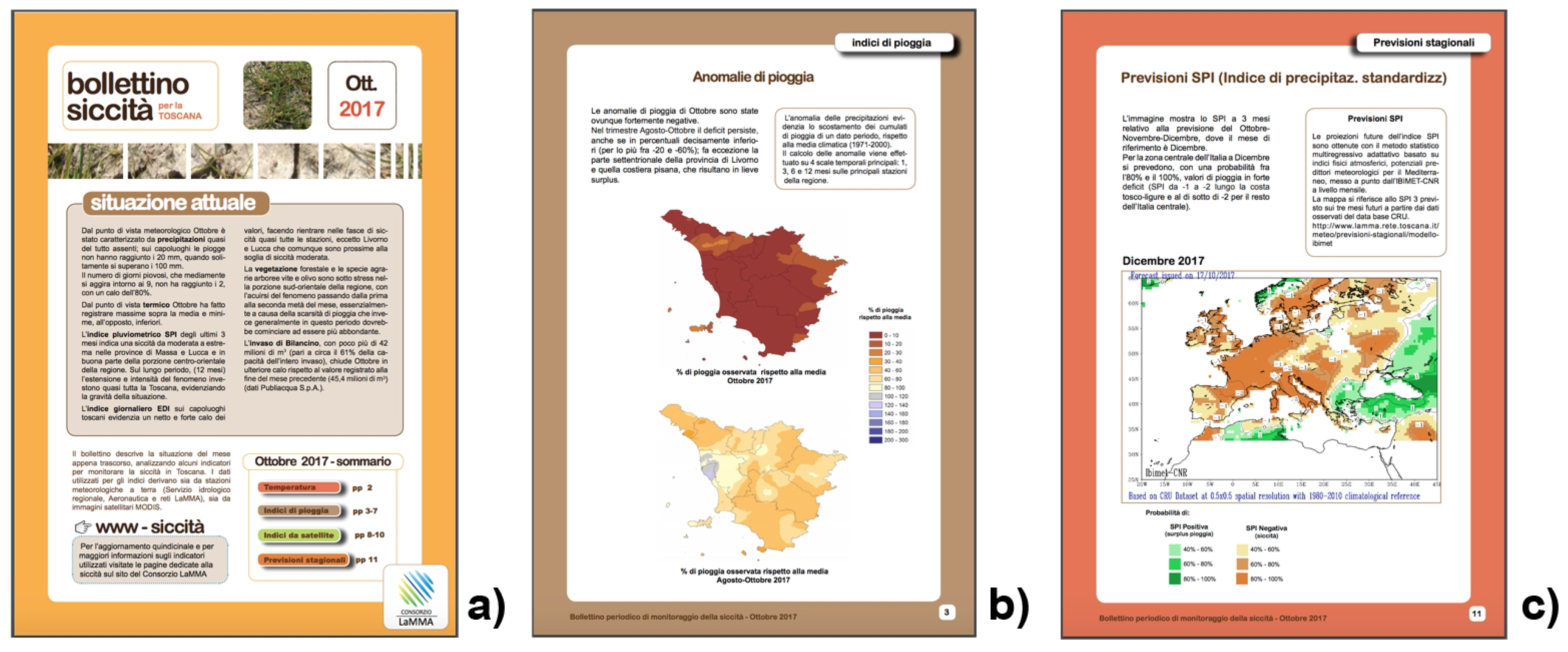
Monthly bulletins are published both on the web page of the LaMMA Consortium and through the ISSUU web platform (
http://issuu.com/consorziolamma), describing more detailed analysis on both current and future conditions (
Figure 12) useful for decision makers in the agricultural and environmental departments of the Tuscany region, and regional or local water authorities.
The bulletin contains a deep analysis of each index, even if during colder seasons the elaboration of vegetation indices is not performed; only the period between April and October is considered, due to the minor influence of cloud cover on satellite-based data. Following a specific request of the Tuscan Water Authority, starting from June 2017 the number of indices was increased, including maps of minimum and maximum temperature of the last month, and rainfall anomalies of three specific periods: the last month, the last three months and the cumulative period starting from the 1st of October, considered the beginning of the hydrological year.
The number of accesses to the main page and bulletins from 1 January 2016 to 30 November 2017 was 17,225, most of which (13,000) were linked to the actual long-lasting drought period 2016–2017 (from 1 October 2016 to 30 November 2017); the peak of accesses was obviously centered during the hottest months, June–September (about 2000 accesses/month), when the water demand is typically higher.
6.3. WebGIS Application
A WebGIS application (
http://www.lamma.rete.toscana.it/webgis-siccita) based on open-source solutions has been customized for the LaMMA Consortium’s drought web page in order to integrate different datasets and share maps of drought indices with researchers, decision makers and other stakeholders [
69].
Thanks to the advances in open-source technologies, further developments are foreseen to improve spatial data visualization and analysis functions. The new DO WebGIS version will be developed in J2EE as a single-view application. It will supply a control panel to select and view all stored images, and a toolbar for simple geospatial operations (raster extraction, queries over a subarea or a single pixel, raster overlay, etc.). To visualize geographical data, a GeoMap component will be implemented using OpenLayers, the open-source library for WebGIS applications.
6.4. Climate Services
In the framework of the European Research and Innovation Roadmap for Climate Services [
70], the research community is called upon to respond to a new challenge to produce raw data and processed usable information to provide European Climate Services (ECS) with high-quality and scientifically proven data, in order to answer a complex query or support a decision [
51]. The implementation of CS, in fact, is actually considered at the international level one of the best ways to provide science-based climate information and specific support to decision makers with different needs, as stated in the Paris Agreement (
http://unfccc.int/paris_agreement/items/9485.php), Article 7, Paragraph 7, and by the World Meteorological Organization (WMO) [
71].
Some different types of CS have been developed in the last years [
72], including climate change scenario platforms and web portals where physical data and climate-related products (e.g., maps, charts, reports, guidelines, advice and bulletins) are available.
The aim of DO is to turn scientific information from drought-monitoring and forecasting into operational information and services, as also recommended by the World Meteorological Organization (WMO) in the Priority Needs for the Operationalization of the Global Framework for Climate Services (2016–2018) paper (
http://www.wmo.int/gfcs/implementation-plan). Also suggested by Giuliani [
73], the availability of open-source tools and standardized interoperable SDI web services ensures the sustainability in the development of web applications with geo-referenced data and customized territorial analysis that could be connected to other climate services. This approach facilitates the creation of value-added products and services by researchers involved in climate investigations.
Actually, the DO information products will also be shared through the IBIMET-CNR Climate Services platform (
https://climateservices.it/), developed in collaboration with the LaMMA Consortium (
Figure 13) in the context of national and international research projects, and tailored to the needs of end-users involved in the related activities. Moreover, through the Drought Climate Service (DCS) interface under development, researchers and other skilled users will be able to directly elaborate or download any drought index dataset using RESTful API web services.
provide better accessibility and usability of climate information by users,
ensure operational and continuously updated services,
encourage global, free and open exchange of climate-relevant data,
facilitate and strengthen—not duplicate,
be built through partnerships.
7. Future Perspectives
Several drought-monitoring systems have been developed, especially at the international and national levels, but due to the complexity of the phenomenon, only few of them are still operational and comprehensive, and therefore able to explore all the aspects of the problem. In Italy, in addition to the Tuscan DO, the only example at the regional level is the operational service of the Emilia Romagna Environmental Agency.
The need for creating a Tuscan DO has arisen in response both to the deep, negative effects of the 2011–2012 drought event on water resources, human activities and the environment in general, and to the delayed action of decision makers. The regional operational service implemented by applying emerging ICTs and following the interoperability, open-data and open-source concepts, provides the decision makers with useful, effective and timely data and information dissemination, where the internet is the perfect vehicle, and the monthly bulletin represents the comprehensive communication instrument that anybody can use as a first decision support.
Compared to the initial drought-monitoring prototype based on manual procedures (and local ground-based rainfall datasets), the actual DO, built on a robust SDI, standard web services and semi-automatic geoprocessing procedures, has several advantages.
The presented DO SDI architecture is a process-based, multipurpose and multi-user operational service that does not necessarily need strong technical capacities to retrieve and use data and information; it is interoperable, open, expandable and customizable, thus also allowing one to respond to one of the GFCS principles, asserting that the “framework will address needs at three spatial scales: global, regional and national”, including climate-vulnerable developing countries. Furthermore, the development of a local SDI can also contribute to increase effectiveness of higher SDI hierarchies (national, regional, global), thanks both to the involvement of local users to identify their needs and priorities, and to the availability of information specifically produced.
Moreover, Giuliani et al. [
73] assert that GFCS should address future efforts towards the adoption of interoperable geospatial solutions and web-based services.
Once the basic architecture is defined, several implementations are possible: input datasets and outputs can be increased or replaced with more detailed or locally suitable new data/models; new procedures of analysis can be easily integrated (also thanks to PL/R libraries) with a relatively low development workload.
RESTful Web Services allow high interoperability, as they may be integrated into any client application needing data from the DO SDI (e.g., to use rainfall data in hydrological models, or vegetation indices for agroecological studies as crop models and yield estimates). Furthermore, following the open-source concept, all the RESTful APIs developed are made available on the GitHub platform (
https://github.com/n3tmaster/DroughtGWS).
The drought framework implemented can be used as the core of the IBIMET-CNR DCS (Drought Climate Service), enhancing the value chain of scientific climate knowledge, providing an adaptive, efficient and responsive environment able to communicate science-based, effective, comprehensive and timely climate information, ready to use and customized for different levels of users, within, between and outside scientific communities. This approach seems to converge on the most recent advancements in geospatial technologies to support CS [
73], adopted at higher geographical levels (national and global). Indeed, the different information tools developed guarantee a continuous and on-demand service to several local users, from the Tuscany region or the Tuscan Water Authority (AIT), who can ask at any time updated information related to a specific index or periods more useful for their assessments, to researchers that need data for their further investigations, and even in other geographical areas covered by the available datasets.
Thanks to technological evolutions, new satellite products and scientific research, the DO SDI is a continuous work in progress.
In fact, from an interoperability point of view, the natural evolution of the DO is the integration of the forecast system into the SDI, even if this task has some constraints linked to the amount of data required (rainfall and predictor datasets) and to the complexity of the statistical computations, for which a deep performance evaluation is needed.
Moreover, due to the importance of water resources for agriculture, which is the main sector affected by drought events, the challenge for the next period is to push the DO SDI potentialities for local applications that need more detailed information. In the coming year, in fact, is planned the evaluation of new user-tailored drought indices (including the possible use of the E-VCI instead of the classical VCI), and the implementation and validation of a model for the actual evapotranspiration (AET) estimates in a farm with an annual crop rotation system alternating tomatoes, wheat and chickpeas. The model provides an estimate of AET with a high spatio–temporal resolution, based on ground and remote-sensing data [
74], combining estimates of potential evapotranspiration (ET
0) and of fractional vegetation cover derived from NDVI, in order to simulate both transpiration and evaporation processes. The NDVI will come from Sentinel 2-MSI (MultiSpectral Instrument) satellite images with a high resolution of 10 m. NDVI images will be also used to monitor the crop growth in relation to the irrigation system, in order to study a satellite-based model for crop water requirements and irrigation optimization.
As a consequence, in order to improve the overall performance of the whole SDI, new sophisticated tuning procedures will be implemented into the PostgreSQL DB (e.g., the creation of new spatial indices, the optimization of PL/R processes, etc.). Moreover, the increase of climate data volume and the introduction of agrometeorological models could require new approaches for processing data. Distributed computing and the use of cluster, grid or cloud infrastructure seems to be a promising way [
73] towards an efficient processing solution for generating information on climate change impacts at different scales.

 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}