1. Introduction
Land-use planning in snow avalanche terrain involves consideration of safe zones for placement of occupied or non-occupied structures and placement/design of avalanche defenses in the runout zone. The associated hazard mapping provides safe locations for settlements, transportation routes, and infrastructure in mountainous areas. It is usually the safest and most cost-effective way of responding to the hazard [
1]. An important consideration is the estimation of how far snow avalanches are expected to run at a location and how often. Estimating the runout distance is a vital feature of zoning schemes for the alpine countries of Europe (France, Switzerland, Austria, Italy) as well as Spain, Iceland, Norway, Canada, and the USA.
The methods of estimating runout distances are mostly in two general classes: (1) physical models (e.g., avalanche dynamics), which normally require the solution of the equation of conservation of momentum combined with the conservation of mass.to calculate speeds along the path with runout distances defined when the speed drops to zero. The formulation in [
2] was one of the earliest models, and this model still forms the basis of some model applications today; (2) empirical or statistical models, which are based on data from avalanche events, which normally yield a probabilistic or statistical estimate of runout for locations along the path. In addition to these broad classes, there are hybrid methods combining dynamics and statistical calculations.
The two general methods of estimating runout distances (dynamics and empirical methods) are independent. In this paper, avalanche dynamics is beyond the scope, and only the empirical method is considered.
The method of runout prediction here involves the collection of extreme runout positions for a set of avalanche paths in a mountain range, which was first carried out in [
3]. For this paper, extreme runout means the extreme position reached by avalanches on a path. The measured runout estimates are then fit to a statistical or probabilistic model to yield calculations of the exceedance probability as a function of position in the runout zone. The advantage of this method is that it is entirely based on data; however, it does imply some assumptions that are plausible. Uncertainty can then be quantified by standard statistical error calculations, such as the uncertainty in the estimation of quantiles. In addition, the method yields probabilistic estimates that fit into modern risk-based consulting methods [
4,
5,
6,
7,
8,
9,
10,
11]. Precision modern mapping techniques, including GIS [
12,
13] and machine learning [
14], are available to aid the analysis. The disadvantage of the empirical method is that it is normally only 1D, whereas 2D and 3D maps may be needed. Another disadvantage is that, normally, one must compile a substantial database of extreme runouts to apply the method. In some cases, where the terrain is all in the alpine and devoid of forest cover, or vegetation in the runout zone, and records of occurrences do not exist, it may not be possible to apply the method with a reasonable degree of accuracy.
The analysis here includes data from 738 extreme runouts with nine different databases from North America and Europe. The objective is to provide a rigorous probabilistic formalism to explain and compare the differences between the datasets that have been collected over more than 40 years. The analysis was carried out by fitting each of the nine datasets to 65 different probability distributions using five goodness-of-fit tests for each. The analysis gave two distributions, which are highlighted due to calculated goodness-of-fit statistics: the generalized logistic (GLO, also called the shifted log logistic) and the generalized extreme value (GEV).
Calculations are given for the datasets to show the differences between them in terms of median runout distance, scaled runout, and exceedance probability on the tails of the distributions. In [
15], scaled runout estimates from five databases were compared using only truncated Gumbel distributions.
One of the assumptions in using the method is stationarity of the distribution with respect to climate change. The possible effects of climate change are discussed in the online
Supplementary Material based on fairly extensive studies of the problem thus far. It was concluded that, to date, there is a lack of information in relation to climate change affecting the extreme avalanche runout data here, which applies to return periods of about 100 years on average.
The structure of the paper is as follows:
Section 2. Method of Runout Prediction;
Section 3: Results including descriptive statistics and runout distances;
Section 4. Probabilistic results;
Section 5. Details of the highlighted distributions (GLO; GEV);
Section 6. Results of the extremal behavior of the highlighted distributions (GLO, GEV);
Section 7. Conclusions and discussion. A list of abbreviations used is presented in a table at the end of the paper.
2. Method and Theory for Extreme Empirical Runout Prediction
The empirical method of extreme snow avalanche runout was pioneered in [
3]. The extreme runout is defined by the
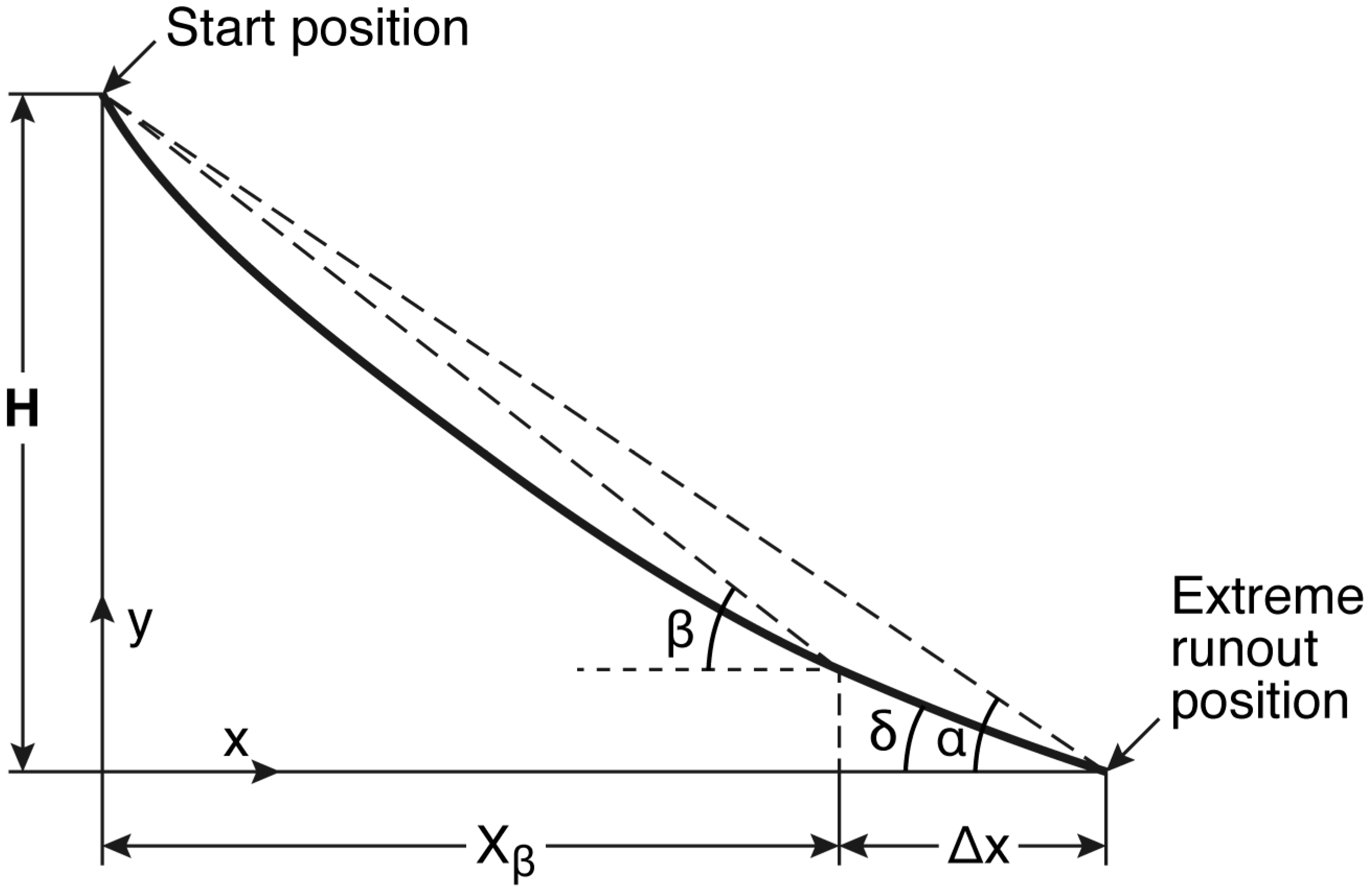
angle, by sighting to the top of the start zone from the extreme runout position. The
angle was introduced [
16] for use in landslides. Later, [
17] the
angle was applied to the runout of rock avalanche masses, and in [
18], it was also applied to snow avalanche runout. In this paper, the position of the extreme runout is that reached by avalanches for each avalanche path, which is the position where
is located and measured from.
In [
3], a reference position was defined in the runout zone known as the
point from which to calculate runout. The
point is the point where the avalanche path terrain profile first attains a slope angle of
proceeding downslope into the runout zone. In some cases, a bench may occur higher up in the path with a slope angle of
or less. In such a case, the bench is ignored and the
point is chosen lower on the path in the runout zone. Experience is required to locate valid
and
points. Linear regression was first applied in [
3] to estimate
for a set of more than 100 avalanche paths from western Norway. The authors’ analysis included other topographic parameters such as start zone slope angle, path confinement, and path shape. The calculations were later repeated [
19] with 206 avalanche paths from Norway, with 3 predictor variables, and their results showed that the only significant predictor was
. The Lied–Bakkehøi [
3] linear regression method became known as the
model. The
model was reviewed for a number of databases in Jamieson [
20]; however, it is beyond the scope of this paper.
An important aspect of the
model is that both the response
and the predictor
contain no length scale explicitly, whereas the probabilistic methods here show scale effects in extreme runout distances; therefore, the scale effects are automatically included. The scale effects have been shown in [
15,
21], but a detailed discussion of such is beyond the scope of this paper. The choice of the
point as a reference to estimate extreme runout is very important for two reasons. First, the good correlations with
for all databases show that extreme avalanches tend to reach runout at slope angles close to
. For the data in this paper, nearly all extreme avalanches ran beyond the
point, which makes it a good reference to gauge runout. Second, the choice of such a reference reduces the variance in calculating the runout position compared to the use of
alone [
22]. Accordingly, in the present paper, the
reference point is retained from the pioneering work in [
3]. Since
has a positive correlation with
, one might be led to the conclusion that steeper paths have shorter runout since both are measures of steepness. However, that is not plausible physically. The correct interpretation of the fairly high positive correlation between
and
is that extreme avalanches tend to have runout close to the
point, making
and
correlated to each other [
21].
The original dataset from Norway also contained
angles defined by a sighting from the
point (extreme runout position) to the
point. In [
23], a runout ratio
was defined from the three angles as follows:
where
is the horizontal reach (m) from the
point to the extreme runout position, which I term the runout distance (m), and
is the horizontal reach (m) from the start position to the
point. The values of
or
may take positive or negative values depending on whether the extreme runout position is below or above the
point, respectively. If the extreme runout position is at the
point,
. In Equation (1), the values of
take positive values for runout proceeding downslope and negative values for runout on adverse slopes proceeding upslope.
Figure 1 contains the geometry with
as the total vertical drop (m) and definitions of all data used in the paper.
The proper collection of field data and application to this problem implies some assumptions. In addition, the selection of a suitable probability distribution to represent the data herein implies some assumptions. The basic assumptions of the method are included in the online
Supplementary Material.
3. Results: Description of Data and Descriptive Statistics
Descriptive statistics for the individual datasets reveal important characteristics defining the differences between the datasets. All nine datasets were collected in the field by locating the extreme position recorded for avalanche reach or from vegetative damage assessed in the field. All data have been reported and described in previous publications and in the
Supplementary Material. The data descriptions, including recent revisions to the databases and comments on data accuracy, are summarized in the online
Supplementary Material.
Table 1 contains the basic data on the median values of
,
, and the following scale parameters
.
For all the values in
Table 1, median values are given since they account for the skewness in the data. In [
15], the average values were listed for five ranges; however, median values are superior if there is skewness in the data, as is the case here.
In
Table 1, the first seven datasets were collected without restriction on scale variables:
. The avalanches had an average return period of about 100 years. The SHORT SLOPE database was restricted to paths with
and had an estimated average return period of about 50 years [
8]. The FOREST dataset contained paths where mature forest cover was penetrated by large avalanches with no estimated average return period assigned [
24]. All nine databases have been previously published. An updated description of all the databases is given in the online
Supplementary Material.
All the calculated median values concerning distance in
Table 1 were rounded to the nearest 5 m distance. Similarly, the
angles used in calculations were considered to be accurate to the nearest degree. Even without modeling, the median runout distances are of use. A median value would typically apply to an exceedance probability of 0.5, meaning about 50% of extreme avalanches in a database would be expected to run further.
Exploratory data analysis of the individual databases showed that the data skewness (
) gave a very good explanation of the differences, and it is related to the shape factors of the distributions. We show below (
Figure 2 and
Figure 3) that either the data sample skewness or the population skewness is an important parameter to explain the differences between
in the datasets. The data skewness (or sample skewness) is defined as follows:
where
is the sample size and
is the mean value of the data. The population or distribution skewness is defined as follows:
where
is the expectation operator,
is a random variable, and
is the distribution mean. In this paper, the random variable is the runout ratio
with sample values
.
Figure 2 shows the median runout distance,
, plotted against
for eight databases. The data from NORWAY did not include runout distances.
A 95% confidence ellipse is shown. A confidence ellipse is a visual display of the correlation between the variables. The 95% confidence ellipse represents a 95% chance of the next datum falling within the ellipse.
The equation of the regression line is , with . The regression line illustrates a very good fit in spite of eight diverse datasets. The data from Norway did not include values of ; therefore, they are not included in the calculations.
Figure 2 is important since it is independent of any probability distribution, and it suggests that any attempt to fit all the databases with a single distribution, as in this study, should include a consideration of data skewness, which is normally related to a distribution shape factor. Since the sample skewness values
take positive and negative values, so too should the shape factor. Some of the 65 distributions we tested in the next sections had shape factors that took only values (such as the three-parameter gamma distribution); however, they gave poor fits to our databases with low or negative skewness.
Figure 2 and
Figure 3 show the relationship between median runout distance
and
(distribution shape factor) for the GLO distribution as an example.
Figure 2 is entirely based on data, independent of any distribution, whereas
Figure 3 is based on modelling.
Figure 2 and
Figure 3 show that the median runout distance depends strongly on data skewness or shape factor. The more the data are skewed to the right, the longer the median runout distance, since more cases are running past the
reference point.
Figure 3 represents 611 extreme runout distances, and the regression line has
. The equation of the regression line in
Figure 2 is
. A 95% confidence ellipse is shown.
The data skewness (
) is a function of the shape parameter only for the GLO. Linear regression for the relation between
and k gave
;
. The constant in the regression equation was not statistically significant. The combined results of
Figure 2 and
Figure 3, along with the
relation, suggest that the shape parameter
of the GLO distribution fitted to the avalanche data is an index of the data skewness and population skewness, and it is importantly related to
. For the GEV distribution, calculations gave
, where
is the shape parameter for the GEV distribution.
4. Application of the Method and Results
In this paper, the
method is used. Here, the dimensionless
parameter was fit to 65 different distributions using several large statistics packages. The goal was to assess commonality among the diverse set of databases in this study by seeking single distributions that provided a good fit to all the datasets. The list of distributions, along with the number of parameters for each, is given in the online
Supplementary Material. Descriptions and definitions of the distributions may be found in textbooks.
In practice, compiling the databases requires field experience with avalanches. One must be confident that for a path in question the extreme position reached by avalanches can be located either from published reports or in the field and for rough return periods of 100 years or more. Otherwise, the path in question should not be used. Typically, in field work, about 1–2 paths might be included in a full day in the field. In the field, the uncertainty in locating the extreme position by vegetation damage or other evidence at the site is no better than . The map scale should be 1:10,000 or better, which applies to the data here.
Methods to estimate return periods, including information from this paper, are given in [
10,
11,
25] and in combination with avalanche dynamics in [
4,
5,
6,
7,
8,
26]. The determination of return periods is beyond the scope of this paper, which is exclusively concerned with the empirical, probabilistic prediction of extreme runout of flowing avalanches, meaning those with a dense core of material at the base. The prediction of low-density powder snow avalanche cloud reach is not included in this paper.
We made calculations for 65 distributions for each dataset, but our data include
with positive and negative values. Therefore, distributions that apply only to positive values of
were eliminated since no fit could be found for our databases with negative values. In addition, distributions without a shape factor to account for varying data skewness, as in
Figure 2, were eliminated. Since the data were collected as extreme cases, one might logically expect to consider extreme value distributions. Gumbel [
27] gave three extreme value distributions for which distributions converge to on the tails: Gumbel, Fréchet, and Weibull. Of these, the Fréchet and Weibull apply to positive data values only, and the Gumbel has constant distribution skewness; therefore, all three could be eliminated for application to all nine of our databases.
Previous studies, e.g., [
15,
20,
28] have used only one goodness-of-fit criterion to gauge suitability for comparing datasets: the coefficient of variation
of probability plots and, mainly, the Gumbel distribution. In this study, we used five goodness-of-fit tests and, in addition, we considered behavior on the tail since the latter is important in engineering decisions. Even though the goodness of fit for distributions may be comparable, engineering decisions normally require the use of a distribution with a heavier tail such that computed runout distances are not too short.
The goodness-of-fit tests used were the Kolmogorov–Smirnov (K-S) test, the chi-squared (C-S) test, both described in [
29] (pp. 533–538), and the Anderson–Darling (A-D) test [
30]. For the chi-squared test, 4–7 degrees of freedom and equal probabilities for bins were used. In addition, probability (PP) and quantile (QQ) plots were made to assess the distribution fits overall. A PP plot is used to compare an empirical CDF with the theoretical CDF of the distribution. A QQ plot is used to compare quantiles of the data with the quantiles of the theoretical distribution.
For the (K-S) and (C-S) tests, the statistical significance level was used to gauge goodness of fit. It represents the probability of rejecting a fitted distribution when the data fit the distribution well. The quantity is similar to a confidence level. The lower the value of , the more stringent the goodness-of-fit requirement and the lower the critical value of the goodness-of-fit statistic. The most commonly used values for are typically 0.1 and 0.05; however, here, the more stringent value of 0.2 has been used. For all distributions, the critical value was determined for , and the calculated value of the statistic was compared with the critical value for hypothesis testing against the null hypothesis that the distribution considered was a good fit. The null hypothesis was that the distribution was not rejected if the calculated value from the data was less than the critical value.
For the (A-D) test, goodness-of-fit was partly assessed by ensuring that the test statistic had a low value in comparison with the other distributions. The (A-D) statistic was calculated for all the fitted distributions with ranks provided. For the (A-D) statistic, the critical values depend on the distribution, the sample size, and the shape parameter. The critical values as a function of
are not known for many of the distributions. Multiple regression analyses were provided in [
31] for extreme value distributions including the GLO and GEV distributions as a function of
, sample size, and shape parameter. In
Table 2, the (A-D) calculated is provided along with the value of
by which the test passed from the critical values provided in [
31]. In
Table 2, the values of (K-S) and (C-S) represent comparison with critical values for
. For a given dataset, the decision about which distribution has a better fit was based primarily on a comparison of the critical values, with the calculated values of the A-Ds. For example, if the critical value for
was the same, we would consider the fit equivalent; however, if it was higher for a distribution over another, we would say the former would be the better fit. The A-D is very powerful, since it compares cumulative distribution functions over the entire distribution, not just the tail. It is the only one of the goodness-of-fit tests that can discriminate among the distributions to determine the shape of the best-fitting one.
Our considerations for the most important distributions included all five goodness- of-fit tests, plus the behavior on the tails, since the latter is important in engineering decisions. A distribution with a heavier tail is normally favored in engineering applications since others would yield shorter runout distances for the same exceedance probability or return period. The A-D was given the most weight, along with the prediction of a heavier tail.
Below, we have presented detailed calculations on the two best choices (GLO; GEV) to fit all of our databases. Both have shape parameters (positive or negative) to account for data skewness, a location, and a scale parameter.
Table 2 contains the goodness-of-fit results and distribution parameters.
Table 2 contains goodness-of-fit statistics and parameters for the nine datasets fit to the GLO and GEV distributions using either Maximum Likelihood Estimates (MLEs) or Method of Moments (MMs) to determine the distribution constants. For the calculations of all 65 distributions, MM was used for distributions where moment estimates are available for all possible parameter values and do not involve iterative numerical methods. Examples include Normal, Log-Normal, Gumbel, Pearson type 3, Log Pearson type 3, and Weibull. The MLE was used for the other distributions requiring numerical methods. The maximum number of MLE iterations used for all calculations was 100, with accuracy
. For example, the shape parameter k for COLORADO was calculated as 0.29275; however, the value presented was 0.29 (
Table 2 below).
The data from AUSTRIA included ; therefore, it was possible to perform the calculations from the ratio directly as well as using the angles. The ratio calculations gave for comparison with the values above.
In
Table 2, entries with * failed the test for the specified values of
The C-S entries for COLORADO passed at
. The A-D entry for the GLO for Iceland (**) passed the critical value of the A-D for 0.01. From [
31], the critical value for A-D is actually 0.77; however, the calculated value (0.78) is essentially the same, given the uncertainty from the regression expressions. The entry N/F ** for the GEV (FOREST), C-S, signifies that no fit was found for the calculations.
If the critical value of the A-D is chosen as , and all databases pass for the GLO, whereas the GEV fails for two. If the critical value of A-D is chosen as , then the GLO fails for three databases, and the GEV for three.
Of the 65 distributions tested, only five had a shape factor that could take positive and negative values: the GEV and GLO, which have three parameters (shape, scale, location), and three four-parameter distributions, as follows: generalized gamma, Johnson SB, and Johnson SU. No fit was obtained for seven databases for the Johnson SU. For Johnson SB, three databases failed both the A-D and C-S tests, and for the generalized gamma, three databases failed both the A-D and C-S, with another failing the C-S.
It was stated above that the three classical extreme value distributions will not provide fits for all the databases. Two other extreme value distributions were considered: the three-parameter Weibull distribution and the three-parameter Fréchet distribution. Both have a shape factor, a scale, and a location parameter so that negative values may be accepted. The three-parameter Fréchet distribution gave erroneous, unrealistic results on the tail of the distribution for six of the nine databases. The Weibull three-parameter distribution had a lighter tail than either of the two distributions in
Table 2. Both are restricted to positive shape factors, as with the three-parameter gamma distribution.
We tested all 65 of the distributions (
Supplementary Material), and the two highlighted distributions were the best concerning our considerations, which were extreme behavior on the tail and goodness of fit. The four, five, and six-parameter distributions (Beta, Burr, Dagum, generalized gamma, JohnsonSB, JohnsonSU, Pearson6, Phased Bi-Exponential4, Wakeby 5, Phase Bi-Weibull 6) all had either light tails compared to, e.g., the GLO (
Table 3), very high A-D statistics combined with two-shape parameters, or wildly varying distribution parameters (up to
). The other three-parameter distributions (Erlang3, Error3, Log-Pearson 3, Log Logistic 3, Power Function 3, Triangular) had either very high A-D statistics, wildly varying distribution parameters (up
), and wildly varying results on the tails. In [
28], the Generalized Pareto distribution was fit to two truncated datasets. The Generalized Pareto failed the goodness-of-fit tests for all our distributions since it only applies to truncated datasets. The truncation of a dataset changes the exceedance probability for events on the tail of the distribution.
We cannot rule out that some other distribution other than the 65 analyzed might be found, which matches our criteria better than the two highlighted (GLO and GEV). However, we believe the two highlighted sets give a very good picture of the meaning of our nine databases.
5. Description of the GLO and GEV Distributions
The pdf (probability density function) of the GLO distribution is given in Equation (2).
where
are the shape factor, scale factor (
> 0), and location parameter, respectively. The shape factor
lies between
when the pdf is bounded, and for the data here, it is in the range [−0.20, 0.29]. Reversing the sign of
reflects the pdf function about
: the median value. This is a very important property for the datasets here since
takes positive and negative values, which imply positive and negative skewness for the distribution and sample values. We showed above that the data skewness, which is related to
, is the key to understanding the differences in the median runout distance.
The GLO distribution has previously been used in flood frequency/stream flow analysis [
32,
33,
34] and rainfall analysis [
31].
The cumulative distribution function (CDF) for the GLO distribution is as follows:
For
, the domain is
and for
, it is
. After considerable algebra, it can be shown from [
35] that for
,
converges to a Weibull distribution on the left tail (smallest values) and a Gumbel distribution on the right tail (largest values). When
, it becomes the logistic distribution. Similarly, for
,
converges to a Gumbel distribution on the left tail (smallest values) and a Weibull distribution on the right tail. When
, the GLO (shifted log-logistic) distribution reduces to the log-logistic distribution; however, the latter applies only to positive values of RR.
The exceedance probability is given by .
The pdf of the GEV distribution is given by the following:
where
. The CDF is given by the following:
The shape factor () may take positive and negative values. The value of governs the behavior of the tail. If = 0, the behavior is for the Gumbel distribution; if > 0, it is the Fréchet, and if < 0, it is the Weibull.
Both the GLO and GEV may be considered as extreme value distributions. The original work on extreme values [
27] considered only the Gumbel, Fréchet, and Weibull for convergence on the tails. However, there are a number of distributions [
35] that may be considered extreme value distributions.
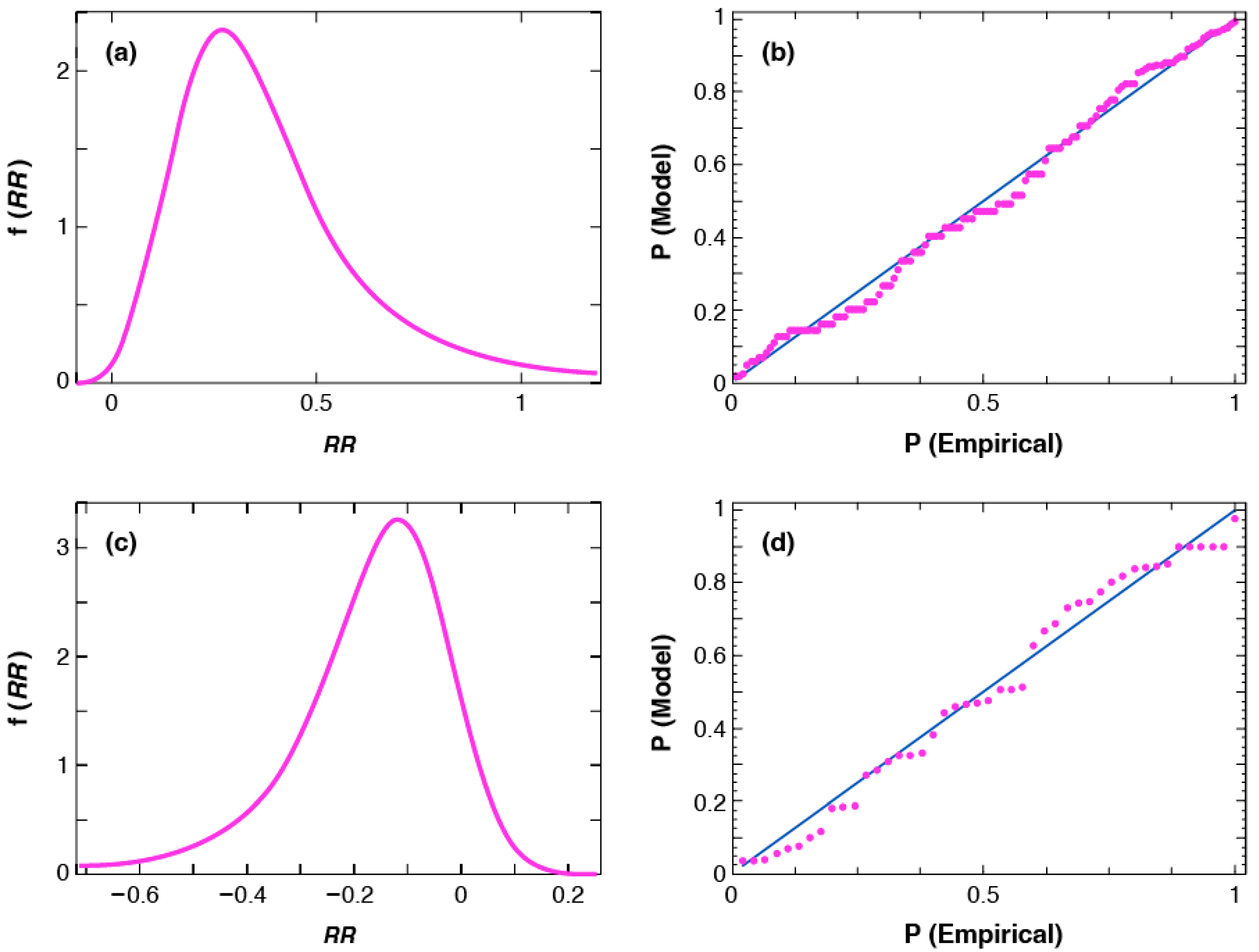
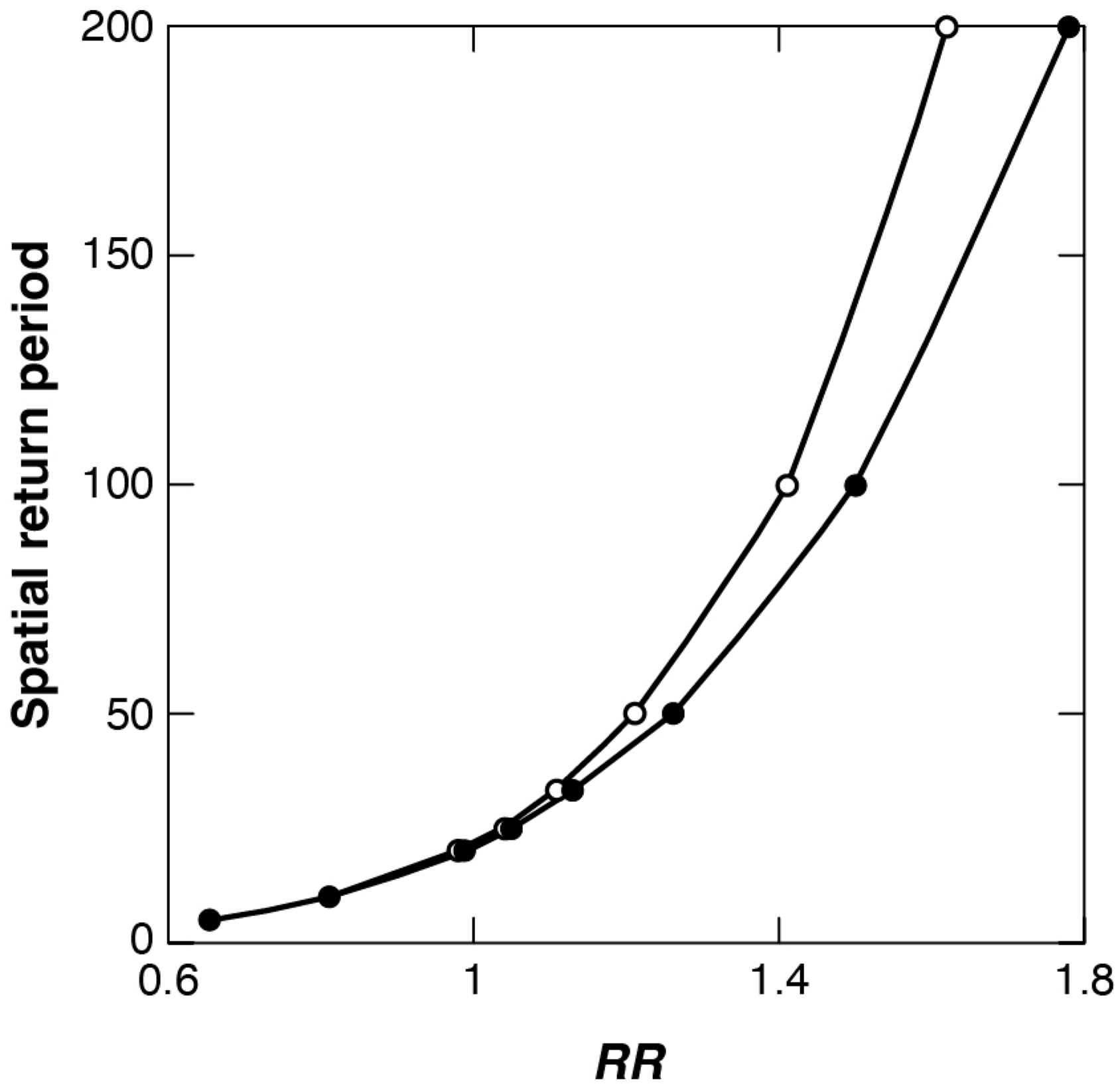
Table 3 and
Figure 4 (below) show that, for the extreme avalanche data, the GLO is more extreme compared to the GEV.
Figure 4 shows the pdfs and probability (PP) plots for COLORADO (positive skewness) and FOREST (negative skewness) for the data fit to a GLO distribution.
7. Conclusions and Discussion Summary
1. We presented a rigorous analysis of the world’s largest collection of extreme snow avalanche runout distances (611) and (738). The analysis showed that the data skewness or the distribution shape factors of two highlighted extreme value distributions (GLO and GEV) are key to explaining the differences in either the median runout distance or median for the different datasets.
2. The two highlighted distributions were selected based on an analysis of 65 distributions listed in the
Supplementary Material. Using five goodness-of-fit tests, we tested all nine of our databases against each distribution to explore commonality among the datasets. Data characteristics required, including needing both positive and negative values of
and positive and negative values of
implying both positive and negative distribution shape factors
for the datasets that eliminated many distributions.
3. The descriptive statistics in
Table 1 and the distribution constants in
Table 2 are immediately useful in comparing our results to other datasets or future datasets. For the six datasets collected without restrictions on total vertical drop (CO, AK, SI, AU, IL, CA), the median runout distance ranges from 140 m to 295 m, representing positions for which about 50% of extreme avalanches would be expected to run further. The distribution constants (
Table 2) for the GLO and GEV and the distribution scale factors (
) in
Table 1 may be used to compare our results with other datasets collected.
4. Probabilistic engineering decisions depend not only on the goodness of fit but also on the heaviness of the tail of a chosen distribution. Our analysis showed that of the two highlighted distributions, the GLO has the heavier tail. For our data, the GEV predicts shorter runout for the same exceedance probability or spatial return period. The
method is important in engineering an assessment of the extreme avalanche runout distance since it is completely independent of the other method for runout prediction, which is based on avalanche dynamics. The
method feeds directly into return period determination [
10,
11] since return period determination also implies probabilistic methods for the long return periods of an order of 100 years, typically used in planning.
5. Previous results, e.g., [
8,
9,
15,
20,
36] originate from databases tested against the Gumbel or Generalized Pareto [
28] distributions, only with one goodness-of-fit test. The application of the rigorous procedure in this study for the Gumbel distribution showed that five of our nine databases (CO, IL, CA, SS, FR) failed the A-D test with values higher than the critical value at 0.01. All of our databases failed for the Generalized Pareto distribution since it applies to truncated distributions. Truncation changes the exceedance probabilities for events on the tail of a distribution.
6. In regard to climate change, the review in the
Supplementary Material suggests that there is no evidence at this time for climate change affecting extreme, rare avalanche events. Extreme avalanches are normally thought to occur by deep weak layers in the snowpack being overloaded, and there is no evidence of that for events occurring on the time scale of on the order of 100 years, which most of the data here apply to. Extreme avalanches are rare, discrete, and independent events with no memory of past events and, as such, may be thought of as Poisson events. The encounter probability
for Poisson events [
37] represents the probability of at least one event reaching or exceeding a position with a return period
over the time period of observation
:
. For the return period
years and observation period
years, the encounter probability ranges from 39 to 63% for observation of at least one of these extreme events. The effects of climate change on average avalanche activity were noticed to begin about 50 years ago [
38,
39]. We suggest that the most likely adjustments for climate change will be in regard to the exceedance probability used, not the lack of stationarity for extreme databases.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}