1. Introduction
Landslide refers to the movement of debris, rocks, and soil under the influence of gravity [
1]. It is a common phenomenon in mountainous areas [
2] and accounts for 9% of the world’s disasters [
3]. Landslide causes damage to infrastructure, human fatalities, and economic losses [
4]. Two types of factors, predisposing and triggering ones, affect the occurrence of landslides. Predisposing factors create suitable conditions for landslides, whereas triggering factors initiate the landslides [
5]. The predisposing factors of landslides include slope, elevation, aspect, curvature, geology, and land use/land cover [
6]. Landslides can be triggered naturally by rapid snow melting, volcanic activity, groundwater pressure, seismic activities, wildfire, and intensive or prolonged rainfall [
7,
8,
9,
10]. Landslides can also be triggered by human activities, such as excavation, deforestation, hillslope cutting, road construction, traffic vibration, and agricultural cultivation [
11]. Landslide susceptibility assessment, which shows the probability of landslides over an area, is critical to minimize the losses and deaths caused by the landslide [
12,
13]. A landslide susceptibility map can answer where future landslide would occur over an area but cannot answer when and the intensity. For landslide risk mapping, generally, both spatial probability, time component (when), and intensity (dimension of landslides) are considered [
14]
Landslide susceptibility can be investigated using quantitative and qualitative methods. Quantitative methods determine the mathematical relationship between landslides’ occurrences and their associated predisposing factors [
11]. Quantitative methods can be categorized as deterministic and probabilistic methods. In a deterministic approach, a slope safety factor, defined as the ratio of shear strength to shear stress, is commonly used to determine an area’s landslide susceptibility [
7]. This approach is suitable for small areas due to the challenge of measuring the safety factor over a large area [
15]. Probabilistic methods use different statistical algorithms, such as logistic regression, multiple linear regression, support vector machines, frequency ratio, and certainty factor, to determine the relationship between the presence or absence of landslides and landslide predisposing factors. Probabilistic methods can be either bivariate or multivariate [
16]. Bivariate methods conduct a paired comparison of landslide occurrence with each predisposing factor. These methods usually divide each factor into a set of classes and determine the relationship between landslide occurrence and these classes [
11]. The commonly used bivariate methods include the frequency ratio, the weight of evidence, fuzzy logic, evidential belief function, and statistical index [
7,
13]. Multivariate methods determine the relationship between landslide occurrence and multiple predisposing factors. Some commonly used multivariate methods include logistic regression, adaptive regression spline, general additive models, and decision tree. These methods can have a better performance than bivariate methods [
17].
Qualitative methods depend on expert knowledge and judgment. Qualitative methods include field geomorphological analysis and index-based approaches, namely, the Analytical Hierarchy Process (AHP) and Weighted Linear Combination (WLC) [
17,
18]. In field geomorphological analysis, investigators carry out field investigations based on geomorphology and slope stability, and they classify the study area into several susceptibility classes [
18]. Susceptibility maps produced using this method are not comparable since the judgment of the investigators may vary. Simultaneously, it is applicable for a comparatively small area and it is a time-consuming process [
19,
20]. In index-based approaches, investigators usually assign a weight for each predisposing factor based on their knowledge and then sum all factors based on their weights to determine the landslide susceptibility [
17,
18,
19]. Index-based approaches are subjective but are very useful with enough landslide locations and when other data are not available. This is because quantitative methods require enough landslide locations and good quality landslide predisposing factors for susceptibility mapping [
20].
The method selection for landslide susceptibility mapping depends on the scale of analysis, cost, the timeline of the project, and the inventory data [
19]. Bivariate methods require an inventory covering the whole area to reduce the produced susceptibility maps’ bias towards known landslide locations [
21,
22]. Studies have compared different models to determine a suitable method for a specific area [
15]. Machine learning methods, such as support vector machines, random forest, and gradient boosting give satisfactory accuracy for landslide susceptibility maps. However, geomorphic processes such as landslides are very complex in nature, and in recent days, vast amounts of data have become available [
14]. These things bring uncertainty in the machine learning models [
15]. Therefore, in recent years, hybrid models for integrating bivariate methods with multivariate, machine learning, and qualitative methods have been developed to increase the prediction capability [
17,
23,
24,
25,
26]. The main aim hybrid models is to integrate a couple of weak models and improve the accuracy and reduce the uncertainty of the susceptibility map [
14,
15]. Some examples were shown by Althuwaynee et al. [
11], who integrated a bivariate model of evidential belief function (EBF) with AHP and logistic regression to assess landslide susceptibility in Pohen and Gyeongju, South Korea. This integrated approach reduced subjectivity and increased prediction capability. Xu et al. [
27] compared the integrations of the index of entropy with the logistic regression and with a support vector machine to produce landslide susceptibility maps of the Shaanxi Province of China. Their results indicated that the integration with logistic regression provided a better prediction than the integration with support vector machines. Some studies suggested that integrating bivariate and multivariate models produces better results than the integration of bivariate and machine learning models [
11]. Althuwaynee et al. [
12] combined the chi-squared automatic interaction detection with AHP and suggested that this integrated approach outperforms the AHP method [
15].
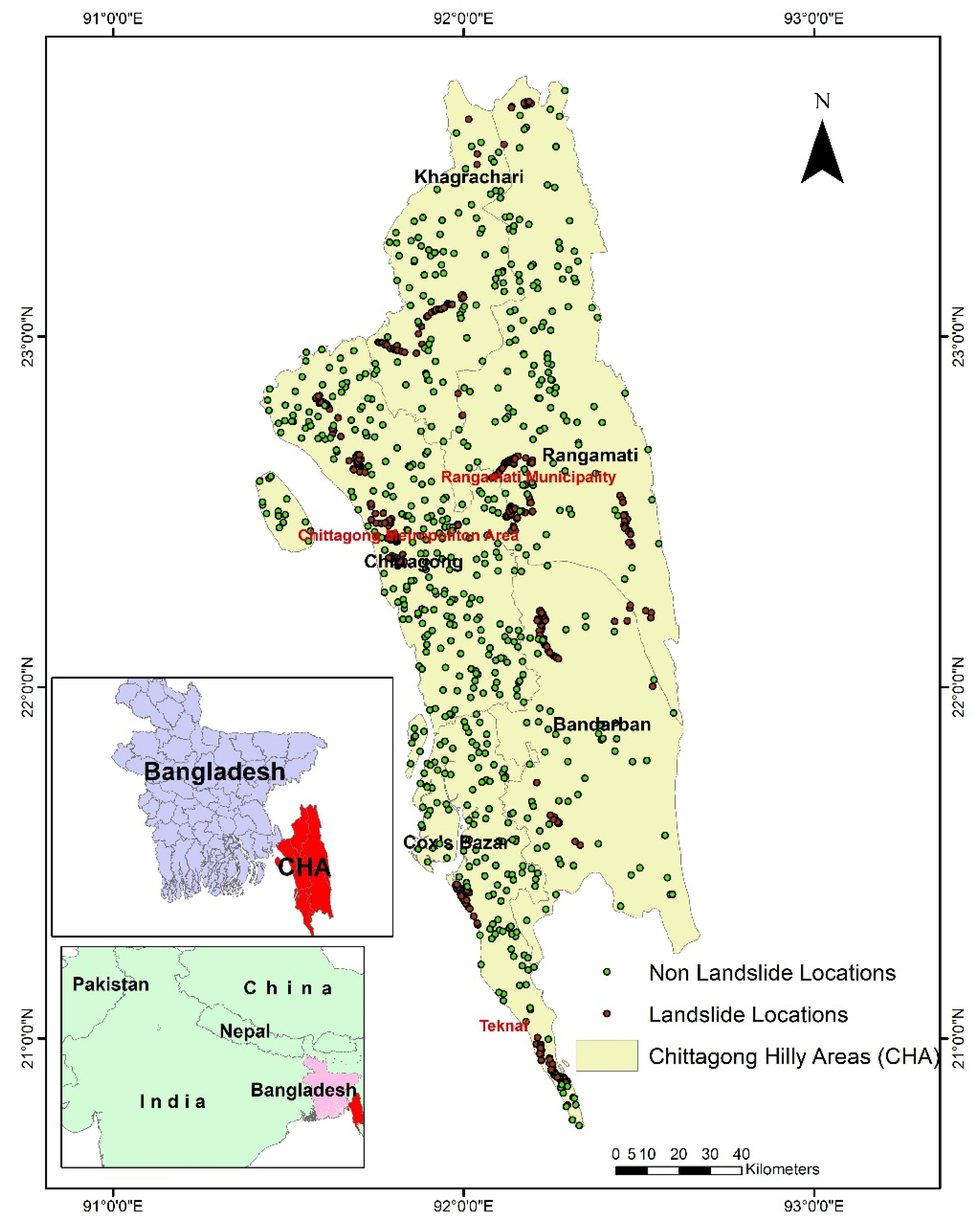
The Chittagong Hilly Areas (CHA) is situated in the hilly region of Bangladesh (
Figure 1) [
28]. In the last two decades, 320 people died because of landslides in this area [
29,
30,
31]. A significant portion of tribal people lives in this area, and their use of slash and burning methods to cultivate crops results in land degradation that may trigger additional landslides [
32]. A landslide susceptibility map of the whole area would provide useful guidance for land use and regional planning in this area, specifically in urban areas and areas where cultivation agriculture is practiced.
Most landslide susceptibility maps in the CHA have been produced for cities such as the Chittagong Metropolitan Area (CMA), Cox’s Bazar, and Teknaf and Rangamati municipalities [
33,
34,
35,
36]. These cities only cover a small portion of the area. No study has been conducted to assess the landslide susceptibility of the whole region [
30]. Existing studies have used qualitative methods, such as AHP and WLC, bivariate methods, such as WoE, multivariate statistical methods, such as logistic regression, and machine learning methods, such as support vector machines, to study landslide susceptibility [
37,
38]. No study has applied the hybrid methods to map landslide susceptibility in the CHA.
In this study, the frequency ratio (FR) method was integrated with the knowledge-based AHP (FR_AHP) and with multivariate logistic regression (LR) (FR_LR) to assess landslide susceptibility for the whole CHA. Then, the landslide susceptibility maps produced by FR, FR_AHP, and FR_LR were compared to evaluate their performances at the regional scale.
2. Study Area
The CHA include five districts: Chittagong, Cox’s Bazar, Rangamati, Bandarban, and Khagrachari, covering 20,957 km
2 (
Figure 1). The western part of the region, mainly in the Chittagong and Cox’s Bazar districts, is characterized by lower elevations (<50 m above sea level). The southeastern part, primarily in the Bandarban, Rangamati, and Khagrachari districts, is relatively high (>500 m above sea level) [
28].
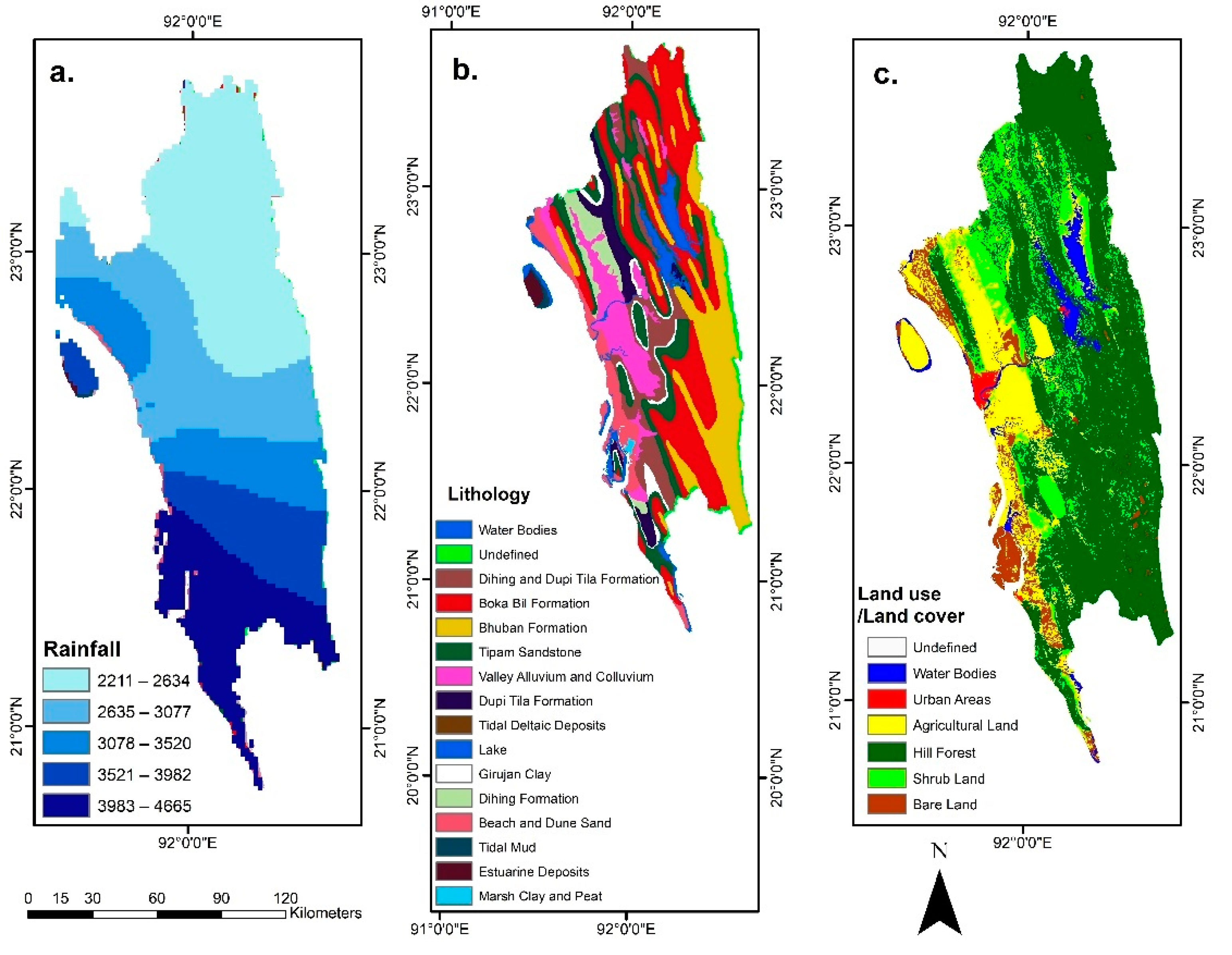
This area consists of 15 lithological formations. From these formations, the Dihing formation is the youngest tertiary sediment of loose sandstone, alternating with siltstone and shale. The Dupi Tila formation consists of sandstone, sandy clay, and siltstone [
28,
34,
38,
39]. The Boka Bil formation consists of silt shale, siltstone, sandstone, sandstone, and altered siltstone. Silt shale, siltstone, sandstone, and altered siltstone are the main components of the Boka Bil formation. Girujan Clay consists of shale and silty shale [
34]. The hilly part of the study area, mainly in the western region, consists of the Tipam, Boka Bil, and Bhuban formations [
28]. The Eastern part of the study is comparatively flat and contains Beach and Dune Sands, Tidal Mud, Estuarine Deposits, and Marsh Clay and Peats [
34].
This area can be divided into a low hill (<300 m) and high hill ranges (>300 m) [
38]. The low hill ranges consists of the Tipam, Boka Bil, and Bhuban Formations [
28]. It consists of both consolidated and unconsolidated sediments. The interbedding of shale, sandstone, and siltstone is one of the characteristics of these ranges’ rock structure [
39]. The high hill ranges contain Tipam Sandstone, Girujan Clay, and Bhuban Formation [
34]. Landslides occur in both low and high hill ranges [
27,
38]. Loss of human life and infrastructural damages mainly occurred in Chittagong, Cox’s Bazar, and Rangamati districts [
30,
35]. The three largest cities, Chittagong Metropolitan Area (CMA), Cox’s Bazar, and Rangamati municipalities, are situated in these three districts. Due to the high population density and anthropogenic activities compared to other parts of the study area, the rate of causalities is high [
30,
31,
35]. However, landslides also occur in the other two districts: Khagrachari and Bandarban of the study area [
35].
According to the Koppen classification, CHA’s climate is characterized by a tropical monsoon climate with an annual rainfall from 2540–3777 mm [
35,
36]. About 80% of the landslides occur during the monsoon season (June–September) due to excessive monthly rain (about 480 mm) [
38]. Fifteen percent of the rainfall occurs during the pre-monsoon (March–May) and post-monsoon (October–November) seasons. The winter season (December–February) is the driest in the study area.
5. Discussion
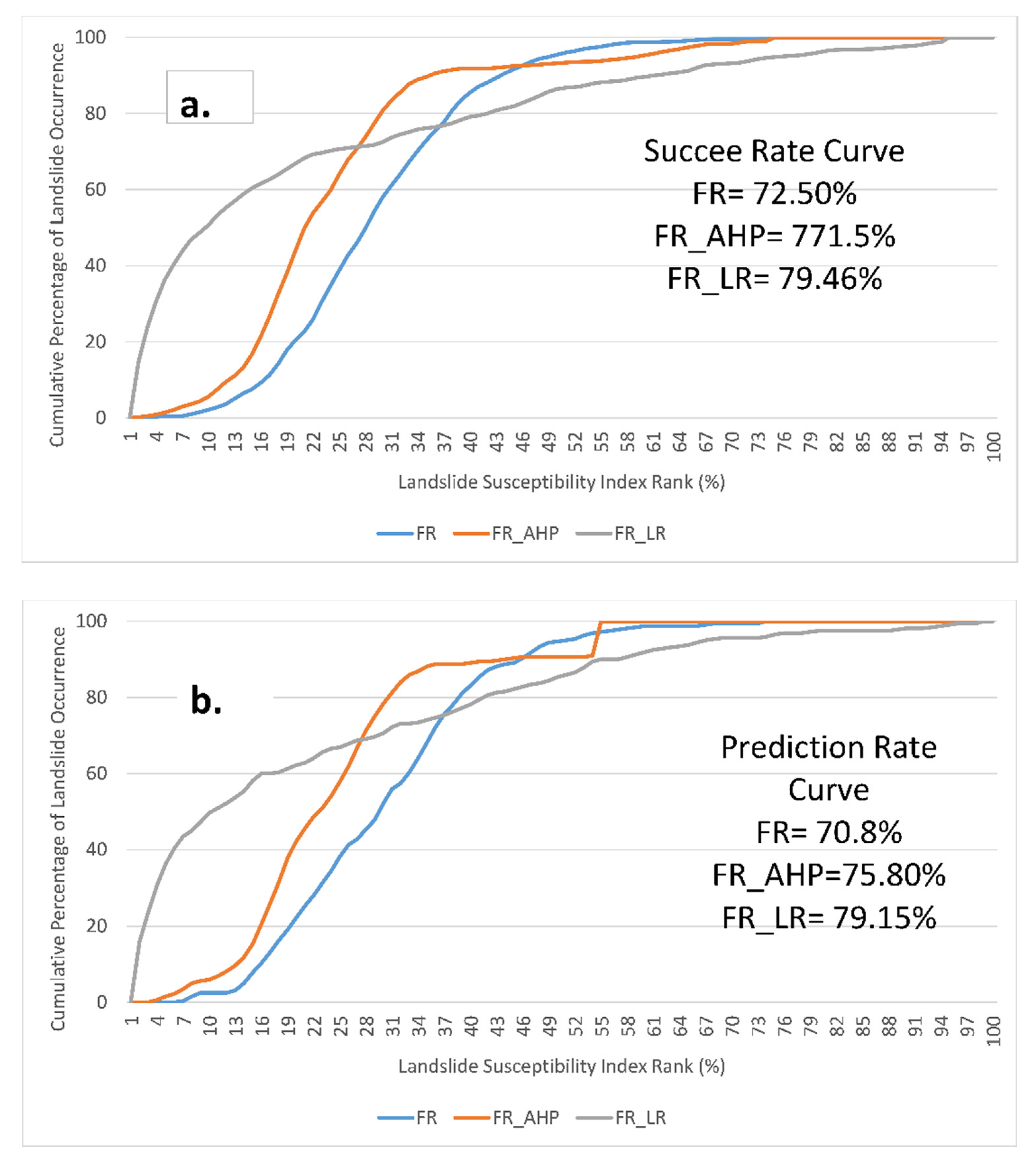
The objective of this study was to produce landslide susceptibility maps of the CHA, Bangladesh. The integration of FR with LR gave the highest prediction rate (79.15%). This study’s findings are consistent with previous studies, suggesting that the integration of bivariate models such as FR or evidential belief function with knowledge-based AHP and multivariate logistic regression increased the accuracy of bivariate models [
10,
11].
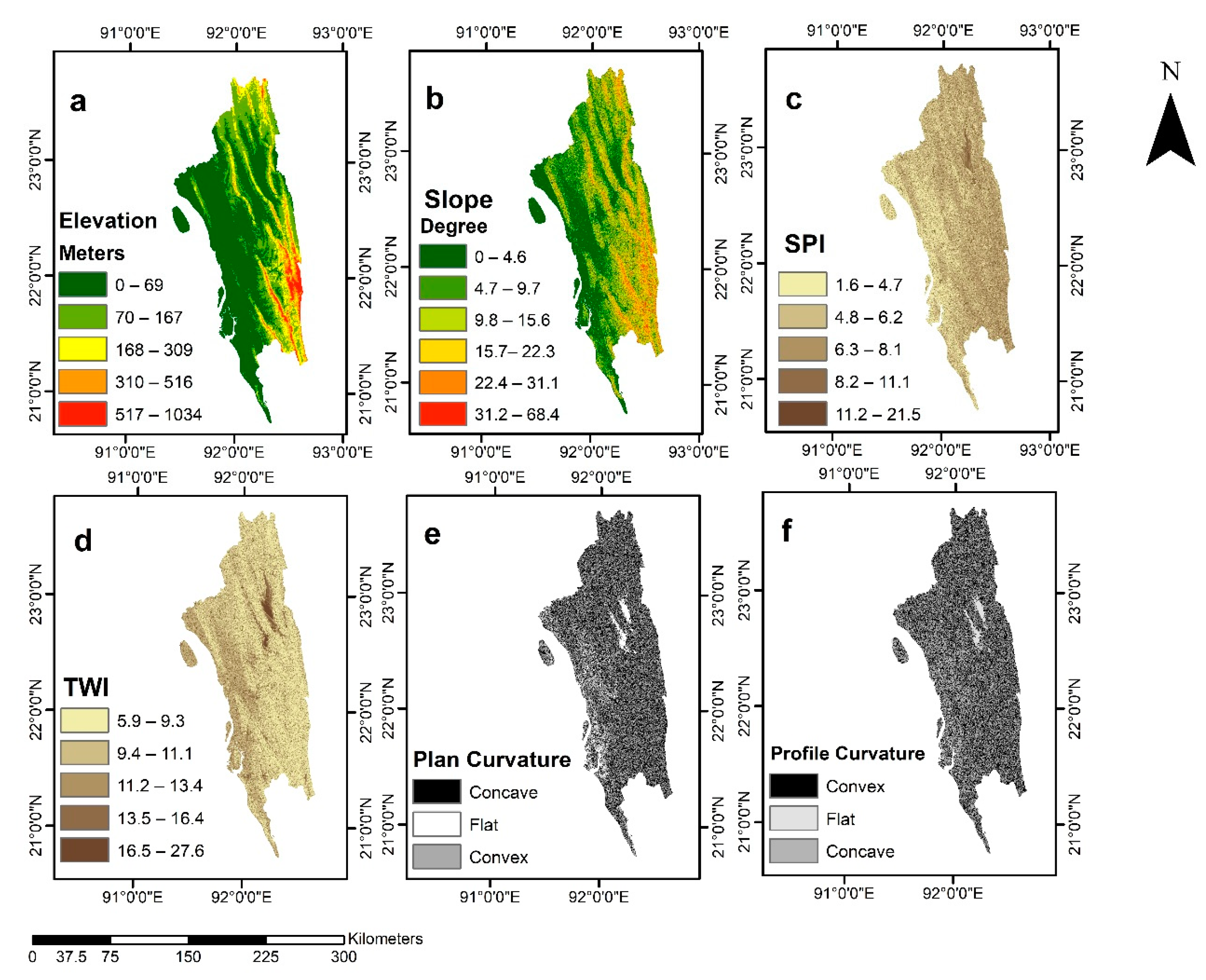
In this research, FR values (in FR model), integer weights (in FR_AHP model), and coefficients (in FR_LR) model) of significant predisposing factors were derived to quantify the effects of the predisposing factors. The FR values were > 1, where the slope was above 4.6°, and it is >1.5 above the 15.7° slope. In other studies, conducted in different regions of the world, the FR value exceeded 1.5 at around a 20° slope [
51]. It indicates that other factors were responsible for the landslides at comparatively gentle slopes (<15°). For example, urban areas have the highest FR value, and cities and towns were formed in areas where the slope <20° [
29,
34]. In the study area, at high elevations (517–1034 m), the FR value was <1 (
Table 1). In these areas, the probability of a landslide is low, and the city has similarities with other studies [
18]. At higher elevations, the strength of rocks is comparatively higher than the areas with low elevation. Moreover, at high elevations, the rate of anthropogenic activities is low. Therefore, in these areas, the probability of a landslide is comparatively low [
7]. The probability of a landslide was high in areas where the NDVI ranged between 0.05–0.26 (
Table 1). This NDVI range indicates that areas with low vegetation density, mainly urban areas and shrublands, and areas with low vegetation are always prone to landslides [
11]. Two types of land use/land cover, urban areas (FR = 15.20) and shrubland (FR = 3.15), had comparatively higher FR values than other land use/land cover types. This indicates that anthropogenic activities have an impact on the occurrence of landslides. Rahman et al. [
33] found a similar relationship, where the landslide rate is higher in areas where hill-cutting occured in Chittagong Metropolitan Areas. The FR model does not deal with the interaction of the predisposing factors and does not require non-landslide locations, as it is based on landslide locations [
50]. Therefore, the produced landslide susceptibility maps are often biased towards known landslide locations, and the accuracy is usually lower than the multivariate models [
17]. In this study, as mentioned before, a significant number of mapped landslides were in urban areas, near roads and settlements. The FR_AHP model uses a pairwise comparison to assign weights for different factors, which increased accuracy [
10]. It is based on landslide locations and does not also require non-landslide locations. The FR_AHP model also shows that predisposing factors, such as land use/land cover, TWI, NDVI, lithology, and distance from the fault lines, have high impacts on the occurrence of landslides. However, the higher integer weight of land use/land cover can be attributed to the biases that exist in the landslide inventory. In contrast, the FR_LR model considers the interaction of predisposing factors and trains the model using both landslide and non-landslide locations. The maximum likelihood estimation is used to determine the best fit model. The coefficients (
Table 5) of significant predisposing factors show that some predisposing factors with very high integer weights in the FR_AHP model, such as land use/land cover, did not have a very high coefficient. It shows that the interaction of predisposing factors in a model can give different results than a model that does not consider this interaction [
19]. Landslides are generally the outcome of a series of events, such as excessive rainfall and hill cutting, that involve the interaction of different factors. Therefore, the FR_LR model is more practical than the FR and FR_AHP models. Simultaneously, the FR_LR model outperforms the other two models; however, the difference between the prediction rate of FR_AHP and FR_LR is only 4.40%. All three models fall under the “fair category” [
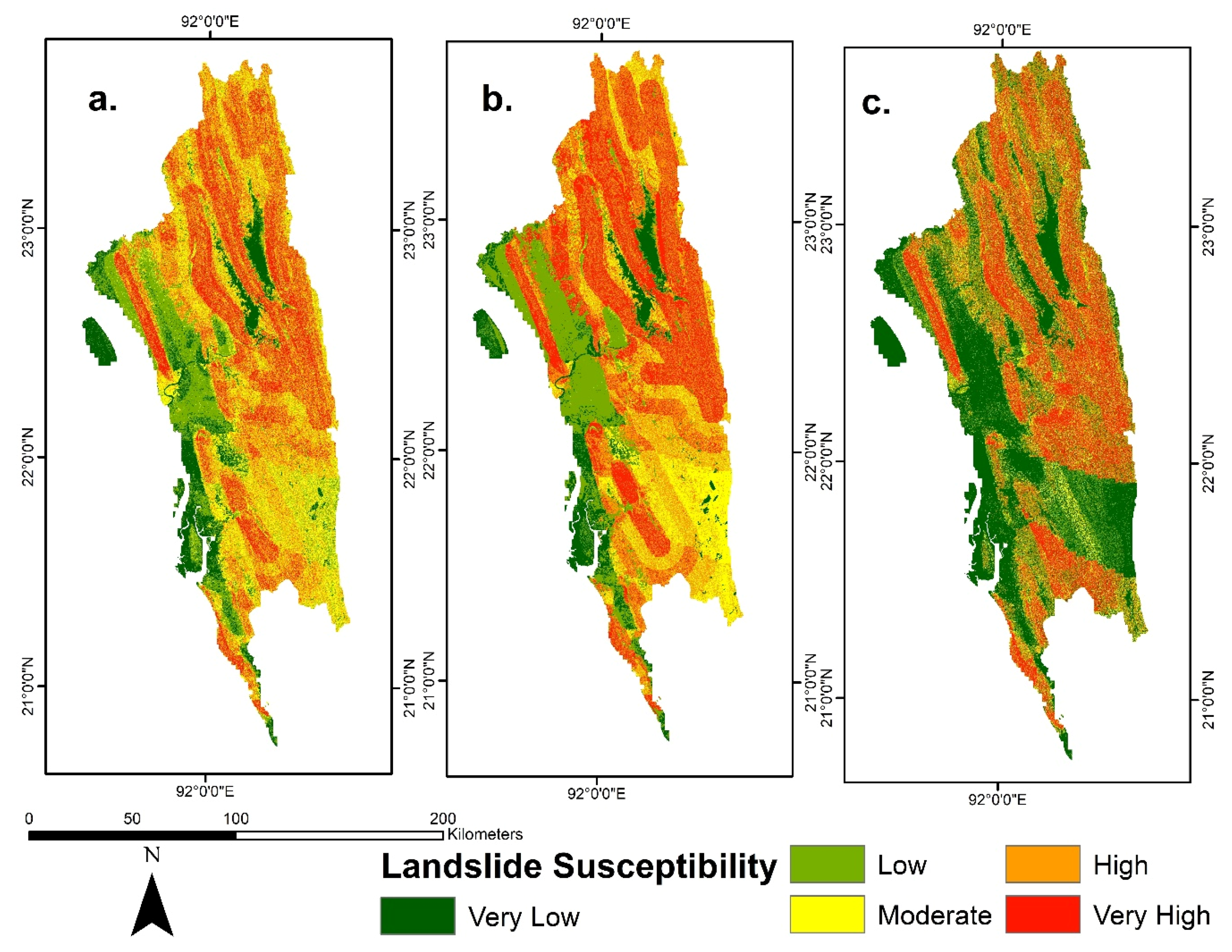
55], and FR and FR_AHP models are more straightforward than the FR_LR model. Therefore, while these three models have some practical values in urban planning and disaster management, FR_LR is a better model in terms of its practicality and performance.
The FR_LR model classified the highest percentage of areas as low or very low susceptibility zones among the three models. All three models showed the western part in the Cox’s Bazar and Chittagong district as low or very low susceptibility zones. These areas are mainly flatland near the coast, and therefore, it is evident that these areas will fall in lower susceptibility zones. However, some areas in the flatlands were erroneously classified as moderate to high susceptible zones by the LR_FR model. This type of error was reported in other studies where the logistic regression was used [
32], indicating that the logistic regression model can classify the high and very high susceptible zones correctly, but some errors can be seen in the low susceptible zones [
55]. Unlike FR and FR_AHP, FR_LR classified the southeastern part of the study area as either low or moderate susceptibility zones. In FR and FR_AHP models, these areas were classified as moderate susceptibility zones with some spots of low susceptibility zones. These areas can be used for development activities.
In this study, FR and FR_AHP had very high correlations. The same number of factors (13) were used for the FR and FR_AHP models, and the only difference is that FR was employed to determine the weight for each factor in the FR-AHP model, whereas all factors were treated as the same weight in the FR model. The use of different weights for factors may increase the accuracy of the landslide susceptibility map, but they are the same in principle; therefore, they produce very similar results. Compared to the correlation between FR and FR_AHP, the associations of FR to FR_LR and FR_AHP to FR_LR are lower but still statistically significant. In the FR_LR model, 12 factors (slope was excluded) were used, and the model only identified seven factors as statistically significant. In other words, only these eight factors were used to define the presence of landslides, making the FR_LR results different from the results of FR and FR-AHP. Integration of two methods can bring the problems of the two methods in the integrated one or remove one model’s problem [
10]. In this study, FR and FR_AHP produced a similar type of map. However, the FR_AHP model has a higher accuracy, which it achieved by increasing the percentage of areas under high and very high susceptibility zones. The FR model has an overestimation problem since the TNR was comparatively low. Overestimation of the landslide susceptibility reduces the practical applicability of the landslide susceptibility map. A practically viable and consistent susceptibility map would classify the least percentage of area as high or very high susceptibility zones, where most of the landslides will occur [
49]. The integration of FR_LR reduced the overestimation issues. It increased the accuracy and also gave a consistent and practically viable map. This is because it removed the overestimation of the susceptibility to landslides in the southeastern part of the study area. On the other hand, the integration of FR_AHP increased the TPR and therefore the overall accuracy increased, but it failed to improve TNR and was relatively low compared to FR_LR.
This study’s main limitation is that the analysis did not use some essential predisposing factors, such as soil permeability, soil depth, and types of soils, due to the unavailability of data. Landslides are mainly rainfall-triggered in the study area, and the soil permeability would help explain the landslide mechanisms. The quality of the landslide susceptibility maps depends on both the landslide inventory and predisposing factors. In this study, fieldwork covered the accessible areas, and Google Earth mapping covered the inaccessible areas. Most landslides in the fieldwork were mapped along the road or near the settlement, whereas by using Google Earth mapping, we were able to map landslides where signs of landslides can be identified in the image. Therefore, the inventory cannot be fully representative of the whole area. To get rid of this bias, we did not use predisposing factors such as the distance from the road network in the model. Generally, different types of landslides occur in various types of geology. Therefore, the preparation of separate susceptibility maps for different types of landslides gives better prediction [
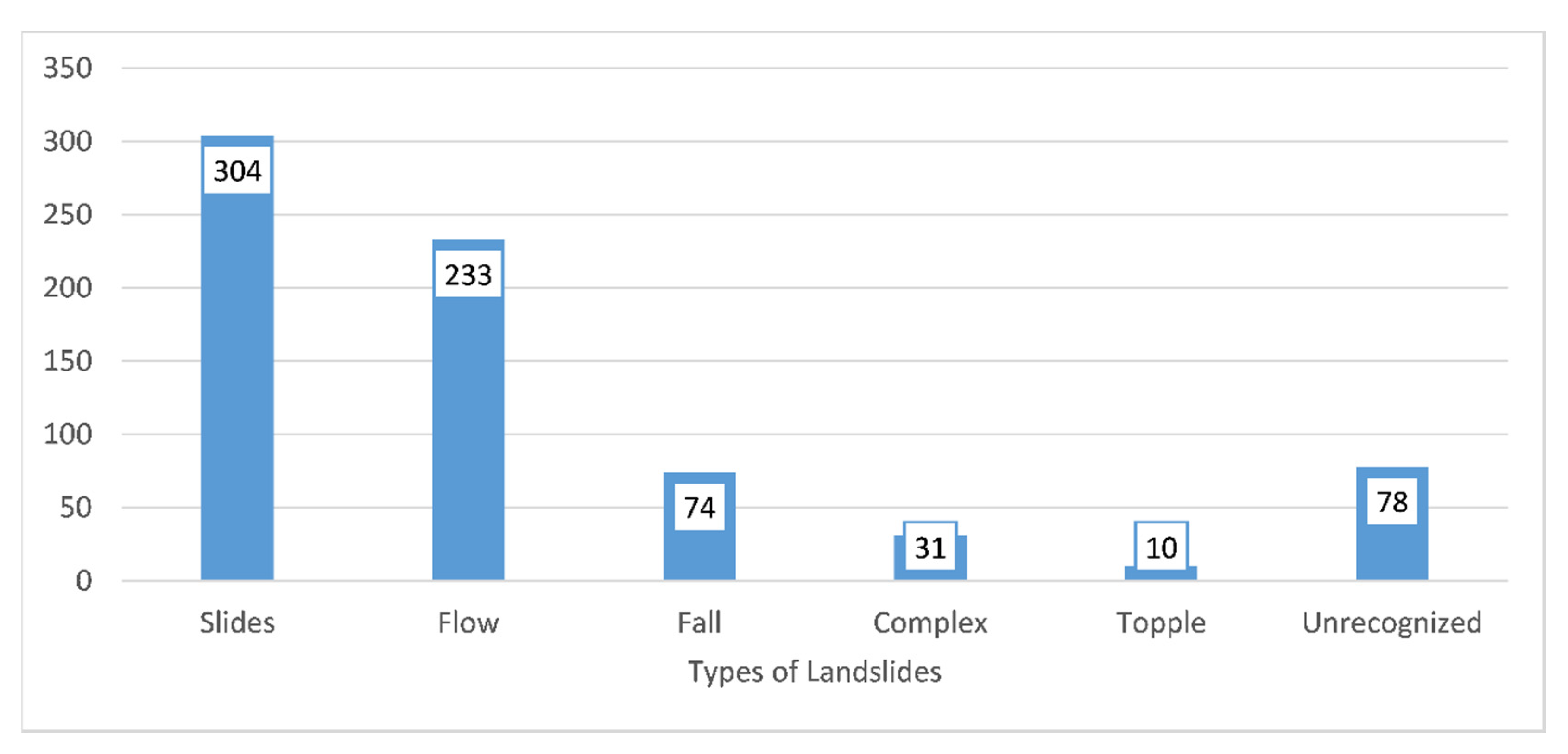
57]. In this study, we similarly analyzed all types of landslides. In the study area, slide and flow were the two dominant types of landslides, and we failed to identify the type of around 10% of the landslides. One way was to get rid of these landslides from the model, but this reduces its accuracy.
6. Conclusions
In this study, FR was integrated with AHP and LR to produce landslide susceptibility maps for the CHA. These models were compared, and they showed that the integration of FR with AHP and LR increases the prediction capability of a single model (FR). The AUC of the prediction rate curves shows that FR_LR was the best model, but the difference between the accuracy of FR_LR and FR_AHP is only 4.10%. However, when the practical applicability is concerned, FR_LR is better than FR_AHP.
This study is the first step for the landslide susceptibility mapping of the whole CHA. This study’s susceptibility maps are essential for the policymakers and can be used for regional development and land use planning of the CHA. The susceptibility maps identified most of the western region of the CHA as low susceptible zones. Some parts of the mid-west were classified as moderate susceptible zones. These areas can be utilized for regional development. Strict land-use planning should be implemented for the high and very high susceptible zones, where authorities and stakeholders should take precautionary measures for any development activities such as road construction.
A more representative landslide inventory of the whole study area is necessary to improve the landslide susceptibility mapping. In this study, it has been established that the integration of FR with multivariate statistical models increases the prediction capability and gives a practically viable map. The recommendation of this study is to integrate the bivariate and multivariate models for regional-scale landslide susceptibility mapping. Machine learning and deep learning methods often outperform classical models. Future studies can test the integration of bivariate models with machine learning methods, such as support vector machines, and deep learning methods, such as Artificial Neural Networks (ANN).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}