The Weak Spots in Contemporary Science (and How to Fix Them)


{kind=link}
{kind=link}
Simple Summary
Abstract
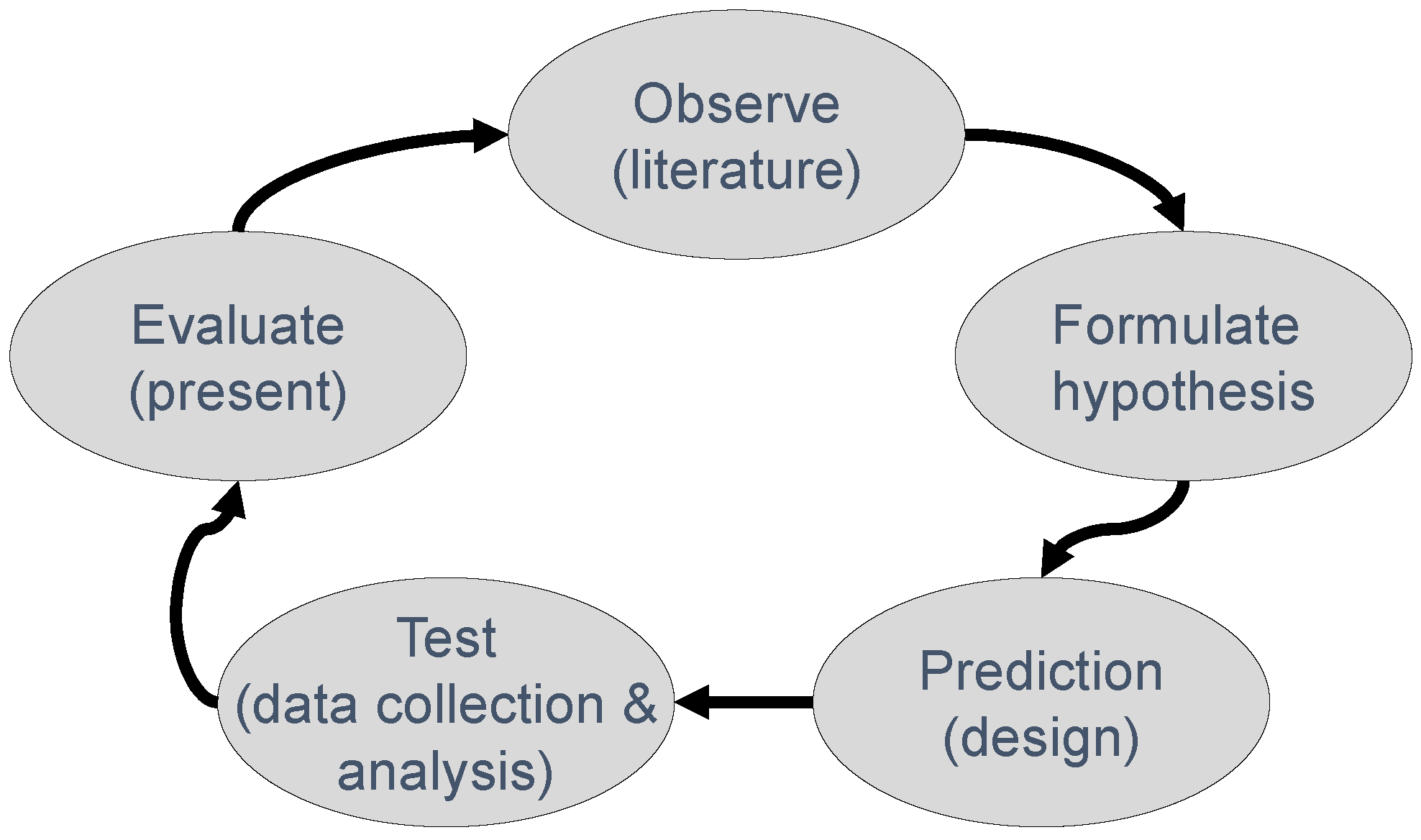
1. Introduction
2. Misconduct and Other Ways of Cutting Corners
O me! what eyes hath Love put in my head,Which have no correspondence with true sight;Or, if they have, where is my judgment fled,That censures falsely what they see aright?If that be fair whereon my false eyes dote,What means the world to say it is not so?Source: The 148th Sonnet by William Shakespeare (from https://en.wikisource.org/wiki/Sonnet_148_(Shakespeare)).
3. Theoretical Bloopers and Selective Reading
4. Improper Blinding and other Design Failures
5. Analyzing the Data
6. Reporting (or Failing to Report) the Evidence
7. Researchers are Only Human
We started out with an elegant hypothesis that could improve the world.Surely there must be something wrong with that first analysis.That second analysis could have been the first analysis, so why wouldn’t we report that second one?
8. Solutions
8.1. Transparency and Post-Publication Peer Review
8.2. Pre-Registration and Registered Reports
8.3. Improved Training and Reporting Guidelines
8.4. Replication and Dealing with Publication Bias
8.5. Inferential Techniques, Power, and other Statistical Tools
9. Discussion
10. Conclusions
Acknowledgments
Conflicts of Interest
References
- De Groot, A.D. Methodologie Grondslagen van Onderzoek en Denken in de Gedragswetenschappen; Mouton: Gravenhage, The Netherlands, 1961. [Google Scholar]
- Popper, K.R. The Logic of Scientific Discovery; Basic Books: New York, NY, USA, 1959. [Google Scholar]
- Fanelli, D. “Positive” results increase down the hierarchy of the sciences. PLoS ONE 2010, 5, e10068. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P.A. Why most published research findings are false. PLoS Med. 2005, 2, e124. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P.A. Why most discovered true associations are inflated. Epidemiology 2008, 19, 640–648. [Google Scholar] [CrossRef] [PubMed]
- Munafò, M.R.; Nosek, B.A.; Bishop, D.V.M.; Button, K.S.; Chambers, C.D.; Percie du Sert, N.; Simonsohn, U.; Wagenmakers, E.-J.; Ware, J.J.; Ioannidis, J.P.A. A manifesto for reproducible science. Nat. Hum. Behav. 2017, 1, 21. [Google Scholar] [CrossRef]
- Levelt Committee; Noort Committee; Drenth Committee. Flawed Science: The Fraudulent Research Practices of Social Psychologist Diederik Stapel; Tilburg University: Tilburg, The Netherlands, 2012. [Google Scholar]
- Fanelli, D. How many scientists fabricate and falsify research? A systematic review and meta-analysis of survey data. PLoS ONE 2009, 4, e5738. [Google Scholar] [CrossRef] [PubMed]
- Hartgerink, C.H.J.; Wicherts, J.M.; van Assen, M.A.L.M. The value of statistical tools to detect data fabrication. Res. Ideas Outcomes 2016, 2, e8860. [Google Scholar] [CrossRef]
- Kerr, N.L. Harking: Hypothesizing after the results are known. Personal. Soc. Psychol. Rev. 1998, 2, 196–217. [Google Scholar] [CrossRef] [PubMed]
- Tukey, J.W. Exploratory Data Analysis; Addison-Wesley: Reading, MA, USA, 1977. [Google Scholar]
- Bem, D.J. Writing an empirical article. In Guide to Publishing in Psychology Journals; Sternberg, R.J., Ed.; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Rosenthal, R. Science and ethics in conducting, analyzing, and reporting psychological research. Psychol. Sci. 1994, 5, 127–134. [Google Scholar] [CrossRef] [PubMed]
- John, L.K.; Loewenstein, G.; Prelec, D. Measuring the prevalence of questionable research practices with incentives for truth-telling. Psychol. Sci. 2012, 23, 524–532. [Google Scholar] [CrossRef] [PubMed]
- Agnoli, F.; Wicherts, J.M.; Veldkamp, C.L.; Albiero, P.; Cubelli, R. Questionable research practices among italian research psychologists. PLoS ONE 2017, 12, e0172792. [Google Scholar] [CrossRef] [PubMed]
- Bourgeois, F.T.; Murthy, S.; Mandl, K.D. Outcome reporting among drug trials registered in ClinicalTrials.gov. Ann. Intern. Med. 2010, 153, 158–166. [Google Scholar] [CrossRef] [PubMed]
- Chan, A.-W.; Hrobjartsson, A.; Haahr, M.T.; Gotzsche, P.C.; Altman, D.G. Empirical evidence for selective reporting of outcomes in randomized trials—Comparison of protocols to published articles. JAMA 2004, 291, 2457–2465. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P.; Caplan, A.L.; Dal-Re, R. Outcome reporting bias in clinical trials: Why monitoring matters. BMJ 2017, 356, j408. [Google Scholar] [CrossRef] [PubMed]
- Jones, C.W.; Keil, L.G.; Holland, W.C.; Caughey, M.C.; Platts-Mills, T.F. Comparison of registered and published outcomes in randomized controlled trials: A systematic review. BMC Med. 2015, 13, 282. [Google Scholar] [CrossRef] [PubMed]
- Jones, P.M.; Chow, J.T.Y.; Arango, M.F.; Fridfinnson, J.A.; Gai, N.; Lam, K.; Turkstra, T.P. Comparison of registered and reported outcomes in randomized clinical trials published in anesthesiology journals. Anesth. Analg. 2017, 125, 1292–1300. [Google Scholar] [CrossRef] [PubMed]
- Kirkham, J.J.; Dwan, K.M.; Altman, D.G.; Gamble, C.; Dodd, S.; Smyth, R.; Williamson, P.R. The impact of outcome reporting bias in randomised controlled trials on a cohort of systematic reviews. BMJ 2010, 340, c365. [Google Scholar] [CrossRef] [PubMed]
- Lancee, M.; Lemmens, C.M.C.; Kahn, R.S.; Vinkers, C.H.; Luykx, J.J. Outcome reporting bias in randomized-controlled trials investigating antipsychotic drugs. Transl. Psychiatry 2017, 7, e1232. [Google Scholar] [CrossRef] [PubMed]
- Perlmutter, A.S.; Tran, V.T.; Dechartres, A.; Ravaud, P. Statistical controversies in clinical research: Comparison of primary outcomes in protocols, public clinical-trial registries and publications: The example of oncology trials. Ann. Oncol. 2017, 28, 688–695. [Google Scholar] [PubMed]
- Rankin, J.; Ross, A.; Baker, J.; O’Brien, M.; Scheckel, C.; Vassar, M. Selective outcome reporting in obesity clinical trials: A cross-sectional review. Clin. Obes. 2017, 7, 245–254. [Google Scholar] [CrossRef] [PubMed]
- van Lent, M.; IntHout, J.; Out, H.J. Differences between information in registries and articles did not influence publication acceptance. J. Clin. Epidemiol. 2015, 68, 1059–1067. [Google Scholar] [CrossRef] [PubMed]
- Wayant, C.; Scheckel, C.; Hicks, C.; Nissen, T.; Leduc, L.; Som, M.; Vassar, M. Evidence of selective reporting bias in hematology journals: A systematic review. PLoS ONE 2017, 12, e0178379. [Google Scholar] [CrossRef] [PubMed]
- Chalmers, I.; Bracken, M.B.; Djulbegovic, B.; Garattini, S.; Grant, J.; Gülmezoglu, A.M.; Howells, D.W.; Ioannidis, J.P.A.; Oliver, S. How to increase value and reduce waste when research priorities are set. Lancet 2014, 383, 156–165. [Google Scholar] [CrossRef]
- Liberati, A.; Altman, D.G.; Tetzlaff, J.; Mulrow, C.; Gotzsche, P.C.; Ioannidis, J.P.; Clarke, M.; Devereaux, P.J.; Kleijnen, J.; Moher, D. The prisma statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: Explanation and elaboration. PLoS Med. 2009, 6, e1000100. [Google Scholar] [CrossRef] [PubMed]
- Callaham, M.; Wears, R.L.; Weber, E. Journal prestige, publication bias, and other characteristics associated with citation of published studies in peer-reviewed journals. JAMA 2002, 287, 2847–2850. [Google Scholar] [CrossRef] [PubMed]
- De Vries, Y.A.; Roest, A.M.; Franzen, M.; Munafo, M.R.; Bastiaansen, J.A. Citation bias and selective focus on positive findings in the literature on the serotonin transporter gene (5-httlpr), life stress and depression. Psychol. Med. 2016, 46, 2971–2979. [Google Scholar] [CrossRef] [PubMed]
- Fanelli, D. Positive results receive more citations, but only in some disciplines. Scientometrics 2012, 94, 701–709. [Google Scholar] [CrossRef]
- Giuffrida, M.A.; Brown, D.C. Association between article citation rate and level of evidence in the companion animal literature. J. Vet. Intern. Med. 2012, 26, 252–258. [Google Scholar] [CrossRef] [PubMed]
- Greenberg, S.A. How citation distortions create unfounded authority: Analysis of a citation network. BMJ 2009, 339, b2680. [Google Scholar] [CrossRef] [PubMed]
- Jannot, A.S.; Agoritsas, T.; Gayet-Ageron, A.; Perneger, T.V. Citation bias favoring statistically significant studies was present in medical research. J. Clin. Epidemiol. 2013, 66, 296–301. [Google Scholar] [CrossRef] [PubMed]
- Kivimaki, M.; Batty, G.D.; Kawachi, I.; Virtanen, M.; Singh-Manoux, A.; Brunner, E.J. Don’t let the truth get in the way of a good story: An illustration of citation bias in epidemiologic research. Am. J. Epidemiol. 2014, 180, 446–448. [Google Scholar] [CrossRef] [PubMed]
- Pfungst, O. Clever Hans (The Horse of Mr. Von Osten): A Contribution to Experimental, Animal, and Human Psychology; Henry Holt & Company: New York, NY, USA, 1911. [Google Scholar]
- Tuyttens, F.A.M.; de Graaf, S.; Heerkens, J.L.T.; Jacobs, L.; Nalon, E.; Ott, S.; Stadig, L.; van Laer, E.; Ampe, B. Observer bias in animal behaviour research: Can we believe what we score, if we score what we believe? Anim. Behav. 2014, 90, 273–280. [Google Scholar] [CrossRef]
- Tuyttens, F.A.M.; Stadig, L.; Heerkens, J.L.T.; Van laer, E.; Buijs, S.; Ampe, B. Opinion of applied ethologists on expectation bias, blinding observers and other debiasing techniques. Appl. Anim. Behav. Sci. 2016, 181, 27–33. [Google Scholar] [CrossRef]
- Bello, S.; Krogsboll, L.T.; Gruber, J.; Zhao, Z.J.; Fischer, D.; Hrobjartsson, A. Lack of blinding of outcome assessors in animal model experiments implies risk of observer bias. J. Clin. Epidemiol. 2014, 67, 973–983. [Google Scholar] [CrossRef] [PubMed]
- Holman, L.; Head, M.L.; Lanfear, R.; Jennions, M.D. Evidence of experimental bias in the life sciences: Why we need blind data recording. PLoS Biol. 2015, 13, e1002190. [Google Scholar] [CrossRef] [PubMed]
- Hirst, J.A.; Howick, J.; Aronson, J.K.; Roberts, N.; Perera, R.; Koshiaris, C.; Heneghan, C. The need for randomization in animal trials: An overview of systematic reviews. PLoS ONE 2014, 9, e98856. [Google Scholar] [CrossRef] [PubMed]
- Bailoo, J.D.; Reichlin, T.S.; Wurbel, H. Refinement of experimental design and conduct in laboratory animal research. ILAR J. 2014, 55, 383–391. [Google Scholar] [CrossRef] [PubMed]
- Bara, M.; Joffe, A.R. The methodological quality of animal research in critical care: The public face of science. Ann. Intensive Care 2014, 4, 26. [Google Scholar] [CrossRef] [PubMed]
- Macleod, M.R.; Lawson McLean, A.; Kyriakopoulou, A.; Serghiou, S.; de Wilde, A.; Sherratt, N.; Hirst, T.; Hemblade, R.; Bahor, Z.; Nunes-Fonseca, C.; et al. Risk of bias in reports of in vivo research: A focus for improvement. PLoS Biol. 2015, 13, e1002273. [Google Scholar] [CrossRef] [PubMed]
- Tuyttens, F.A.M.; Sprenger, M.; Van Nuffel, A.; Maertens, W.; Van Dongen, S. Reliability of categorical versus continuous scoring of welfare indicators: Lameness in cows as a case study. Anim. Welf. 2009, 18, 399–405. [Google Scholar]
- Boissy, A.; Manteuffel, G.; Jensen, M.B.; Moe, R.O.; Spruijt, B.; Keeling, L.J.; Winckler, C.; Forkman, B.; Dimitrov, I.; Langbein, J.; et al. Assessment of positive emotions in animals to improve their welfare. Physiol. Behav. 2007, 92, 375–397. [Google Scholar] [CrossRef] [PubMed]
- Vogt, A.; Aditia, E.L.; Schlechter, I.; Schütze, S.; Geburt, K.; Gauly, M.; König von Borstel, U. Inter- and intra-observer reliability of different methods for recording temperament in beef and dairy calves. Appl. Anim. Behav. Sci. 2017, 195, 15–23. [Google Scholar] [CrossRef]
- Wicherts, J.M.; Veldkamp, C.L.; Augusteijn, H.E.; Bakker, M.; van Aert, R.C.; van Assen, M.A. Degrees of freedom in planning, running, analyzing, and reporting psychological studies: A checklist to avoid p-hacking. Front. Psychol. 2016, 7, 1832. [Google Scholar] [CrossRef] [PubMed]
- Steegen, S.; Tuerlinckx, F.; Gelman, A.; Vanpaemel, W. Increasing transparency through a multiverse analysis. Perspect. Psychol. Sci. 2016, 11, 702–712. [Google Scholar] [CrossRef] [PubMed]
- Sala I Martin, X.X. I just ran two million regressions. Am. Econ. Rev. 1997, 87, 178–183. [Google Scholar]
- Simonsohn, U.; Simmons, J.P.; Nelson, L.D. Better p-curves: Making p-curve analysis more robust to errors, fraud, and ambitious p-hacking, a reply to ulrich and miller (2015). J. Exp. Psychol. Gen. 2015, 144, 1146–1152. [Google Scholar] [CrossRef] [PubMed]
- Simmons, J.P.; Nelson, L.D.; Simonsohn, U. False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychol. Sci. 2011, 22, 1359–1366. [Google Scholar] [CrossRef] [PubMed]
- Bakker, M.; van Dijk, A.; Wicherts, J.M. The rules of the game called psychological science. Perspect. Psychol. Sci. 2012, 7, 543–554. [Google Scholar] [CrossRef] [PubMed]
- Hartgerink, C.H.J.; van Aert, R.C.; Nuijten, M.B.; Wicherts, J.M.; van Assen, M.A. Distributions of p-values smaller than .05 in psychology: What is going on? PeerJ 2016, 4, e1935. [Google Scholar] [CrossRef] [PubMed]
- Van Aert, R.C.M.; Wicherts, J.M.; van Assen, M.A.L.M. Conducting meta-analyses based on p-values: Reservations and recommendations for applying p-uniform and p-curve. Perspect. Psychol. Sci. 2016, 11, 713–729. [Google Scholar] [CrossRef] [PubMed]
- Ulrich, R.; Miller, J. P-hacking by post hoc selection with multiple opportunities: Detectability by skewness test?: Comment on Simonsohn, Nelson, and Simmons (2014). J. Exp. Psychol. Gen. 2015, 144, 1137–1145. [Google Scholar] [CrossRef] [PubMed]
- Patel, C.J.; Burford, B.; Ioannidis, J.P.A. Assessment of vibration of effects due to model specification can demonstrate the instability of observational associations. J. Clin. Epidemiol. 2015, 68, 1046–1058. [Google Scholar] [CrossRef] [PubMed]
- Wicherts, J.M.; Bakker, M.; Molenaar, D. Willingness to share research data is related to the strength of the evidence and the quality of reporting of statistical results. PLoS ONE 2011, 6, e26828. [Google Scholar] [CrossRef] [PubMed]
- Franco, A.; Malhotra, N.; Simonovits, G. Underreporting in psychology experiments: Evidence from a study registry. Soc. Psychol. Personal. Sci. 2016, 7, 8–12. [Google Scholar] [CrossRef]
- Chiu, K.; Grundy, Q.; Bero, L. ‘Spin’ in published biomedical literature: A methodological systematic review. PLoS Biol. 2017, 15, e2002173. [Google Scholar] [CrossRef] [PubMed]
- Bakker, M.; Wicherts, J.M. The (mis)reporting of statistical results in psychology journals. Behav. Res. Methods 2011, 43, 666–678. [Google Scholar] [CrossRef] [PubMed]
- Nuijten, M.B.; Hartgerink, C.H.J.; van Assen, M.A.L.M.; Epskamp, S.; Wicherts, J.M. The prevalence of statistical reporting errors in psychology (1985–2013). Behav. Res. Methods 2016, 48, 1205–1226. [Google Scholar] [CrossRef] [PubMed]
- Berle, D.; Starcevic, V. Inconsistencies between reported test statistics and p-values in two psychiatry journals. Int. J. Methods Psychiatr. Res. 2007, 16, 202–207. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Berthou, E.; Alcaraz, C. Incongruence between test statistics and p values in medical papers. BMC Med. Res. Methodol. 2004, 4, 13. [Google Scholar] [CrossRef] [PubMed]
- Kilkenny, C.; Parsons, N.; Kadyszewski, E.; Festing, M.F.; Cuthill, I.C.; Fry, D.; Hutton, J.; Altman, D.G. Survey of the quality of experimental design, statistical analysis and reporting of research using animals. PLoS ONE 2009, 4, e7824. [Google Scholar] [CrossRef] [PubMed]
- Vines, T.H.; Albert, A.Y.K.; Andrew, R.L.; Debarre, F.; Bock, D.G.; Franklin, M.T.; Gilbert, K.J.; Moore, J.-S.; Renaut, S.; Rennison, D.J. The availability of research data declines rapidly with article age. Curr. Biol. 2014, 24, 94–97. [Google Scholar] [CrossRef] [PubMed]
- Wicherts, J.M.; Borsboom, D.; Kats, J.; Molenaar, D. The poor availability of psychological research data for reanalysis. Am. Psychol. 2006, 61, 726–728. [Google Scholar] [CrossRef] [PubMed]
- Bouter, L.M.; Tijdink, J.; Axelsen, N.; Martinson, B.C.; ter Riet, G. Ranking major and minor research misbehaviors: Results from a survey among participants of four world conferences on research integrity. Res. Integr. Peer Rev. 2016, 1, 17. [Google Scholar] [CrossRef]
- Van der Schot, A.A.; Phillips, C. Publication bias in animal welfare scientific literature. J. Agric. Environ. Ethics 2012, 26, 945–958. [Google Scholar] [CrossRef]
- Franco, A.; Malhotra, N.; Simonovits, G. Publication bias in the social sciences: Unlocking the file drawer. Science 2014, 345, 1502–1505. [Google Scholar] [CrossRef] [PubMed]
- Cooper, H.; DeNeve, K.; Charlton, K. Finding the missing science: The fate of studies submitted for review by a human subjects committee. Psychol. Methods 1997, 2, 447–452. [Google Scholar] [CrossRef]
- Gall, T.; Ioannidis, J.P.A.; Maniadis, Z. The credibility crisis in research: Can economics tools help? PLoS Biol. 2017, 15, e2001846. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P. How to make more published research true. PLoS Med. 2014, 11, e1001747. [Google Scholar] [CrossRef] [PubMed]
- Smaldino, P.E.; McElreath, R. The natural selection of bad science. R. Soc. Open Sci. 2016, 3, 160384. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P.A.; Greenland, S.; Hlatky, M.A.; Khoury, M.J.; Macleod, M.R.; Moher, D.; Schulz, K.F.; Tibshirani, R. Increasing value and reducing waste in research design, conduct, and analysis. Lancet 2014, 383, 166–175. [Google Scholar] [CrossRef]
- Young, N.S.; Ioannidis, J.P.A.; Al-Ubaydi, O. Why current publication practices may distort science. PLoS Med. 2008, 5, 1418–1422. [Google Scholar] [CrossRef] [PubMed]
- Tversky, A.; Kahneman, D. Belief in the law of small numbers. Psychol. Bull. 1971, 76, 105–110. [Google Scholar] [CrossRef]
- Bakker, M.; Hartgerink, C.H.; Wicherts, J.M.; van der Maas, H.L. Researchers’ intuitions about power in psychological research. Psychol. Sci. 2016, 27, 1069–1077. [Google Scholar] [CrossRef] [PubMed]
- Fugelsang, J.A.; Stein, C.B.; Green, A.E.; Dunbar, K.N. Theory and data interactions of the scientific mind: Evidence from the molecular and the cognitive laboratory. Can. J. Exp. Psychol. 2004, 58, 86–95. [Google Scholar] [CrossRef] [PubMed]
- Marsh, D.M.; Hanlon, T.J. Seeing what we want to see: Confirmation bias in animal behavior research. Ethology 2007, 113, 1089–1098. [Google Scholar] [CrossRef]
- Mynatt, C.R.; Doherty, M.E.; Tweney, R.D. Confirmation bias in a simulated research environment—Experimental-study of scientific inference. Q. J. Exp. Psychol. 1977, 29, 85–95. [Google Scholar] [CrossRef]
- Nickerson, R.S. Confirmation bias: A ubiquitous phenomenon in many guises. Rev. Gen. Psychol. 1998, 2, 175–220. [Google Scholar] [CrossRef]
- Christensen-Szalanski, J.J.J.; Willham, C.F. The hindsight bias: A meta-analysis. Organ. Behav. Hum. Decis. Process. 1991, 48, 147–168. [Google Scholar] [CrossRef]
- Anderson, M.S.; Martinson, B.C.; de Vries, R. Normative dissonance in science: Results from a national survey of US scientists. J. Empir. Res. Hum. Res. Ethics 2007, 2, 3–14. [Google Scholar] [CrossRef] [PubMed]
- Nosek, B.A.; Spies, J.; Motyl, M. Scientific utopia: Ii—Restructuring incentives and practices to promote truth over publishability. Perspect. Psychol. Sci. 2012, 7, 615–631. [Google Scholar] [CrossRef] [PubMed]
- Mazar, N.; Amir, O.; Ariely, D. The dishonesty of honest people: A theory of self-concept maintenance. J. Mark. Res. 2008, 45, 633–644. [Google Scholar] [CrossRef]
- Shalvi, S.; Dana, J.; Handgraaf, M.J.; de Dreu, C.K. Justified ethicality: Observing desired counterfactuals modifies ethical perceptions and behavior. Organ. Behav. Hum. Decis. Processes 2011, 115, 181–190. [Google Scholar] [CrossRef]
- Shalvi, S.; Gino, F.; Barkan, R.; Ayal, S. Self-serving justifications. Curr. Dir. Psychol. Sci. 2015, 24, 125–130. [Google Scholar] [CrossRef]
- Nosek, B.A.; Bar-Anan, Y. Scientific utopia: I. Opening scientific communication. Psychol. Inq. 2012, 23, 217–243. [Google Scholar] [CrossRef]
- Asendorpf, J.B.; Conner, M.; Fruyt, F.D.; Houwer, J.D.; Denissen, J.J.A.; Fiedler, K.; Fiedler, S.; Funder, D.C.; Kliegl, R.; Nosek, B.A.; et al. Recommendations for increasing replicability in psychology. Eur. J. Personal. 2013, 27, 108–119. [Google Scholar] [CrossRef]
- Wicherts, J.M. Psychology must learn a lesson from fraud case. Nature 2011, 480, 7. [Google Scholar] [CrossRef] [PubMed]
- Alsheikh-Ali, A.A.; Qureshi, W.; Al-Mallah, M.H.; Ioannidis, J.P.A. Public availability of published research data in high-impact journals. PLoS ONE 2011, 6, e24357. [Google Scholar] [CrossRef] [PubMed]
- Nosek, B.A.; Alter, G.; Banks, G.; Borsboom, D.; Bowman, S.; Breckler, S.; Buck, S.; Chambers, C.; Chin, G.; Christensen, G. Promoting an open research culture: Author guidelines for journals could help to promote transparency, openness, and reproducibility. Science 2015, 348, 1422. [Google Scholar] [CrossRef] [PubMed]
- Kidwell, M.C.; Lazarevic, L.B.; Baranski, E.; Hardwicke, T.E.; Piechowski, S.; Falkenberg, L.S.; Kennett, C.; Slowik, A.; Sonnleitner, C.; Hess-Holden, C.; et al. Badges to acknowledge open practices: A simple, low-cost, effective method for increasing transparency. PLoS Biol 2016, 14, e1002456. [Google Scholar] [CrossRef] [PubMed]
- Wicherts, J.M. Data re-analysis and open data. In Toward a More Perfect Psychology: Improving Trust, Accuracy, and Transparency in Research; Plucker, J., Makel, M., Eds.; American Psychological Association: Wahington, DC, USA, 2017. [Google Scholar]
- Wicherts, J.M.; Bakker, M. Publish (your data) or (let the data) perish! Why not publish your data too? Intelligence 2012, 40, 73–76. [Google Scholar] [CrossRef]
- Bisol, G.D.; Anagnostou, P.; Capocasa, M.; Bencivelli, S.; Cerroni, A.; Contreras, J.; Enke, N.; Fantini, B.; Greco, P.; Heeney, C. Perspectives on open science and scientific data sharing: An interdisciplinary workshop. J. Anthropol. Sci. 2014, 92, 1–22. [Google Scholar]
- Godlee, F.; Gale, C.R.; Martyn, C.N. Effect on the quality of peer review of blinding reviewers and asking them to sign their reports a randomized controlled trial. JAMA 1998, 280, 237–240. [Google Scholar] [CrossRef] [PubMed]
- De Groot, A.D. The meaning of “significance” for different types of research [translated and annotated by Eric-Jan Wagenmakers, Denny Borsboom, Josine Verhagen, Rogier Kievit, Marjan Bakker, Angelique Cramer, Dora Matzke, Don Mellenbergh, and Han L. J. van der Maas]. Acta Psychol. 2014, 148, 188–194. [Google Scholar] [CrossRef] [PubMed]
- Bakker, M.; Wicherts, J.M. Outlier removal, sum scores, and the inflation of the type I error rate in independent samples t tests. The power of alternatives and recommendations. Psychol. Methods 2014, 19, 409–427. [Google Scholar] [CrossRef] [PubMed]
- Chambers, C.D. Registered reports: A new publishing initiative at cortex. Cortex 2013, 49, 609–610. [Google Scholar] [CrossRef] [PubMed]
- Munafo, M.R. Improving the efficiency of grant and journal peer review: Registered reports funding. Nicotine Tob. Res. 2017, 19, 773. [Google Scholar] [CrossRef] [PubMed]
- Kilkenny, C.; Browne, W.J.; Cuthill, I.C.; Emerson, M.; Altman, D.G. Improving bioscience research reporting: The arrive guidelines for reporting animal research. PLoS Biol. 2010, 8, e1000412. [Google Scholar] [CrossRef] [PubMed]
- Vandenbroucke, J.P.; von Elm, E.; Altman, D.G.; Gotzsche, P.C.; Mulrow, C.D.; Pocock, S.J.; Poole, C.; Schlesselman, J.J.; Egger, M.; Initiative, S. Strengthening the reporting of observational studies in epidemiology (strobe): Explanation and elaboration. Int. J. Surg. 2014, 12, 1500–1524. [Google Scholar] [CrossRef] [PubMed]
- Moher, D.; Schulz, K.F.; Altman, D.G. The consort statement: Revised recommendations for improving the quality of reports of parallel-group randomised trials. Lancet 2001, 357, 1191–1194. [Google Scholar] [CrossRef]
- Schulz, K.F.; Altman, D.G.; Moher, D.; Group, C. Consort 2010 statement: Updated guidelines for reporting parallel group randomised trials. BMC Med. 2010, 8, 18. [Google Scholar] [CrossRef] [PubMed]
- Baker, D.; Lidster, K.; Sottomayor, A.; Amor, S. Two years later: Journals are not yet enforcing the arrive guidelines on reporting standards for pre-clinical animal studies. PLoS Biol. 2014, 12, e1001756. [Google Scholar] [CrossRef] [PubMed]
- Turner, L.; Shamseer, L.; Altman, D.G.; Schulz, K.F.; Moher, D. Does use of the consort statement impact the completeness of reporting of randomised controlled trials published in medical journals? A cochrane review. Syst. Rev. 2012, 1, 60. [Google Scholar] [CrossRef] [PubMed]
- Ghimire, S.; Kyung, E.; Kang, W.; Kim, E. Assessment of adherence to the consort statement for quality of reports on randomized controlled trial abstracts from four high-impact general medical journals. Trials 2012, 13, 77. [Google Scholar] [CrossRef] [PubMed]
- Van Assen, M.A.L.M.; van Aert, R.C.; Nuijten, M.B.; Wicherts, J.M. Why publishing everything is more effective than selective publishing of statistically significant results. PLoS ONE 2014, 9, e84896. [Google Scholar] [CrossRef] [PubMed]
- Malicki, M.; Marusic, A.; Consortium, O. Is there a solution to publication bias? Researchers call for changes in dissemination of clinical research results. J. Clin. Epidemiol. 2014, 67, 1103–1110. [Google Scholar] [CrossRef] [PubMed]
- Open Science Collaboration. Estimating the reproducibility of psychological science. Science 2015, 349, aac4716. [Google Scholar]
- Anderson, C.J.; Bahnik, S.; Barnett-Cowan, M.; Bosco, F.A.; Chandler, J.; Chartier, C.R.; Cheung, F.; Christopherson, C.D.; Cordes, A.; Cremata, E.J.; et al. Response to comment on “estimating the reproducibility of psychological science”. Science 2016, 351, 1037. [Google Scholar] [CrossRef] [PubMed]
- Gilbert, D.T.; King, G.; Pettigrew, S.; Wilson, T.D. Comment on “estimating the reproducibility of psychological science”. Science 2016, 351, 1037. [Google Scholar] [CrossRef] [PubMed]
- Van Aert, R.C.; van Assen, M.A. Bayesian evaluation of effect size after replicating an original study. PLoS ONE 2017, 12, e0175302. [Google Scholar] [CrossRef] [PubMed]
- Maxwell, S.E.; Lau, M.Y.; Howard, G.S. Is psychology suffering from a replication crisis? What does “failure to replicate” really mean? Am. Psychol. 2015, 70, 487–498. [Google Scholar] [CrossRef] [PubMed]
- Nickerson, R.S. Null hypothesis significance testing: A review of an old and continuing controversy. Psychol. Methods 2000, 5, 241–301. [Google Scholar] [CrossRef] [PubMed]
- Wagenmakers, E.J. A practical solution to the pervasive problems of p values. Psychon. Bull. Rev. 2007, 14, 779–804. [Google Scholar] [CrossRef]
- Cumming, G. The new statistics: Why and how. Psychol. Sci. 2014, 25, 7–29. [Google Scholar] [CrossRef] [PubMed]
- Benjamin, D.J.; Berger, J.O.; Johannesson, M.; Nosek, B.A.; Wagenmakers, E.J.; Berk, R.; Bollen, K.A.; Brembs, B.; Brown, L.; Camerer, C.; et al. Redefine statistical significance. Nat. Hum. Behav. 2017. [Google Scholar] [CrossRef]
- Cohen, J. The earth is round (p less-than.05). Am. Psychol. 1994, 49, 997–1003. [Google Scholar] [CrossRef]
- Cohen, J. Things i have learned (thus far). Am. Psychol. 1990, 45, 1304–1312. [Google Scholar] [CrossRef]
- Button, K.S.; Ioannidis, J.P.A.; Mokrysz, C.; Nosek, B.A.; Flint, J.; Robinson, E.S.J.; Munafo, M.R. Power failure: Why small sample size undermines the reliability of neuroscience. Nat. Rev. Neurosci. 2013, 14, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Van Smeden, M.; Hessen, D.J. Testing for two-way interactions in the multigroup common factor model. Struct. Equ. Model.: A Multidiscip. J. 2013, 20, 98–107. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R. Improvements on cross-validation: The 632+ bootstrap method. J. Am. Stat. Assoc. 1997, 92, 548–560. [Google Scholar]
- Dwork, C.; Feldman, V.; Hardt, M.; Pitassi, T.; Reingold, O.; Roth, A. Statistics. The reusable holdout: Preserving validity in adaptive data analysis. Science 2015, 349, 636–638. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P.; Fanelli, D.; Dunne, D.D.; Goodman, S.N. Meta-research: Evaluation and improvement of research methods and practices. PLoS Biol. 2015, 13, e1002264. [Google Scholar] [CrossRef] [PubMed]
- Hubbard, R. Corrupt Research: The Case for Reconceptualizing Empirical Management and Social Science; SAGE Publications: Thousand Oaks, CA, USA, 2015. [Google Scholar]
- Haig, B.D. An abductive theory of scientific method. Psychol. Methods 2005, 10, 371–388. [Google Scholar] [CrossRef] [PubMed]
- Baker, M. 1500 scientists lift the lid on reproducibility. Nature 2016, 533, 452–454. [Google Scholar] [CrossRef] [PubMed]


© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wicherts, J.M. The Weak Spots in Contemporary Science (and How to Fix Them). Animals 2017, 7, 90. https://doi.org/10.3390/ani7120090
Wicherts JM. The Weak Spots in Contemporary Science (and How to Fix Them). Animals. 2017; 7(12):90. https://doi.org/10.3390/ani7120090
Chicago/Turabian StyleWicherts, Jelte M. 2017. "The Weak Spots in Contemporary Science (and How to Fix Them)" Animals 7, no. 12: 90. https://doi.org/10.3390/ani7120090
APA StyleWicherts, J. M. (2017). The Weak Spots in Contemporary Science (and How to Fix Them). Animals, 7(12), 90. https://doi.org/10.3390/ani7120090