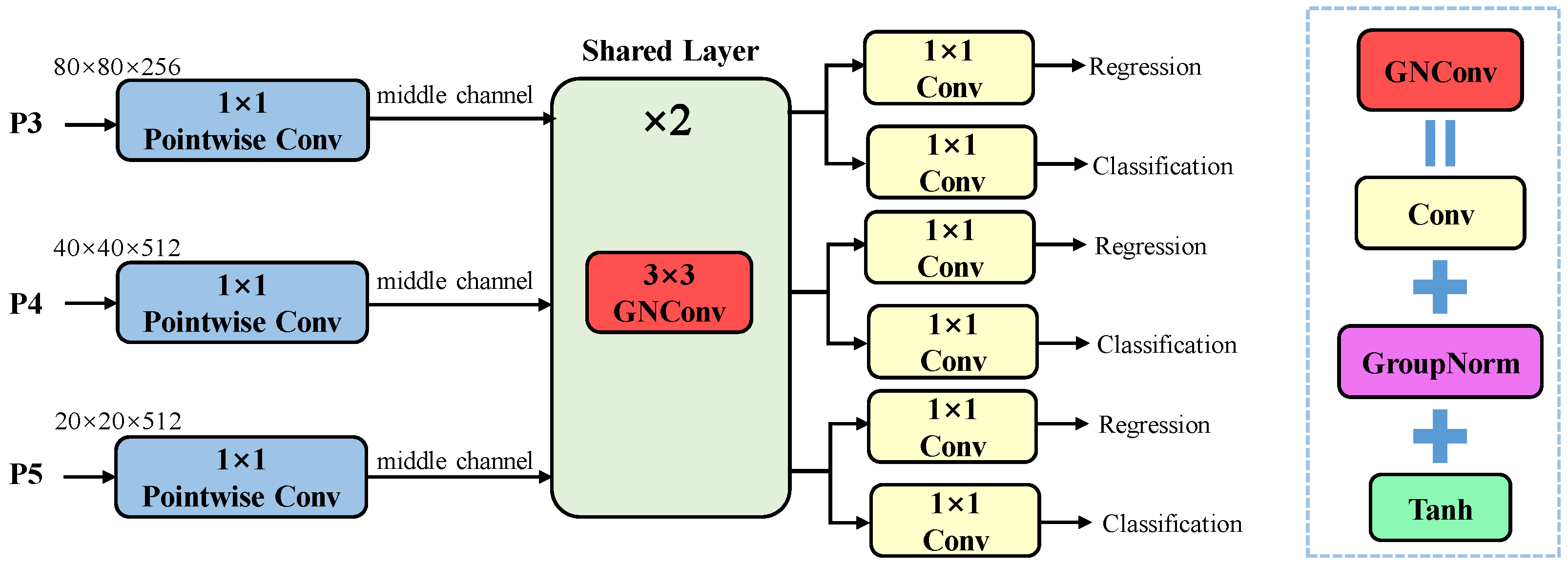
1. Introduction
With the rapid development of modern livestock farming, computer vision technology has become an essential tool for enhancing livestock management, playing a crucial role in animal health management and production monitoring [
1,
2]. While both single-species and multi-species livestock farming have their respective advantages, single-species systems are often preferred in intensive production settings due to their relatively streamlined management and reduced risk of cross-species disease transmission, particularly in high-density environments [
3,
4]. In such systems, single-class object detection technology has significant advantages, enabling efficient and accurate identification, counting, and tracking of specific species. As the scale of farming continues to expand, the application of single-class object detection technology is increasingly widespread in single-species farming scenarios, such as poultry and domestic animals [
5,
6,
7]. By integration with automated monitoring technology, it not only improves production efficiency and reduces resource waste but also brings significant economic benefits to the livestock industry. Additionally, this approach effectively reduces stress response in animals during management processes, providing crucial technical support for improving animal welfare.
However, in real-world farming scenarios, particularly in production systems characterized by intensive practices for poultry, the high similarity in farmed animals’ appearance, their dense clustering, and severe occlusion significantly impair the accuracy of detection models [
8,
9]. Additionally, environmental factors such as variations in lighting, complex backgrounds, and motion blur further exacerbate the challenges of target detection. Early methods, such as Histogram of Oriented Gradients (HOG) [
10], relied on hand-crafted features and achieved limited success in simple scenarios, but their feature representation capabilities were constrained under complex backgrounds or occlusion conditions, making them poorly adaptable to diverse scenes and target variations [
11].
In recent years, deep learning models such as Regions with Convolutional Neural Network features (R-CNN) [
12], Single Shot MultiBox Detector (SSD) [
13], and You Only Look Once (YOLO) [
14] have seen remarkable progress, driving significant advancements in livestock detection technology. For instance, Tu et al. [
15] employed R-CNN for pig detection and segmentation, yielding reliable results in controlled environments, though its computational complexity limits real-time applications. Song et al. [
16] applied YOLOv3 to sparsely distributed sheep, achieving a mean Average Precision (mAP) of 97.2%. Yu et al. [
17] enhanced YOLOv5 by incorporating a small object detection head to improve individual cow behavior recognition, but the model’s generalization across varying lighting conditions was constrained by training data primarily collected in well-lit environments. Cao et al. [
18] developed DenseFCN with point supervision, achieving a 97% counting accuracy for chickens in complex video settings. Lai et al. [
19] proposed IO-YOLOv5 for pig detection under dense occlusion and diverse lighting, integrating feature fusion modules to attain a 92.6% mAP. Despite these achievements, convolutional neural networks (CNNs) rely on local convolution operations, struggling to model global contextual information effectively, which reduces target discriminability in dense occlusion and complex backgrounds. Furthermore, during post-processing, detection models are highly sensitive to non-maximum suppression (NMS) thresholds, where setting an appropriate threshold is critical yet challenging. Although improved variants like Soft-NMS [
20] enhance overlapping target selection, they still fail to fully address dense scene issues, as valid bounding boxes may be suppressed, impacting overall performance.
To address livestock detection in dense occlusion scenarios, current optimization strategies can be broadly categorized into three types. The first strategy focuses on improving detection precision through loss function optimization. For instance, Hao et al. [
21] utilized Focal Loss to dynamically adjust loss weights, significantly reducing missed detections in pig populations. Similarly, Yang et al. [
22] employed Repulsion Loss to enhance target separation, effectively improving the detection of deceased chickens. Additionally, Sun et al. [
23] introduced SIoU loss to refine bounding box regression accuracy. However, while these improvements excel in specific tasks, they often lack sufficient generalization to handle the diverse complexities of dense occlusion environments. The second category emphasizes enhancing feature representation. For example, the feature fusion technique has been shown to improve chicken detection performance [
24], while bilinear feature fusion has proven effective in boosting sheep detection accuracy [
25]. While these methods improve multi-scale object detection, they may not capture the fine-grained local features necessary for accurately distinguishing objects in dense occlusion environments. The third category employs attention mechanisms to emphasize critical regions, with methods like channel attention [
26,
27], spatial attention [
28], and Convolutional Block Attention Module (CBAM) [
29,
30] being widely applied in livestock detection. However, these mechanisms may easily result in a significant increase in the number of parameters and computational load. Additionally, they fail to fully leverage the relationship between low-level detailed features and high-level semantic features, which is crucial for resolving occlusion in densely packed scenarios.
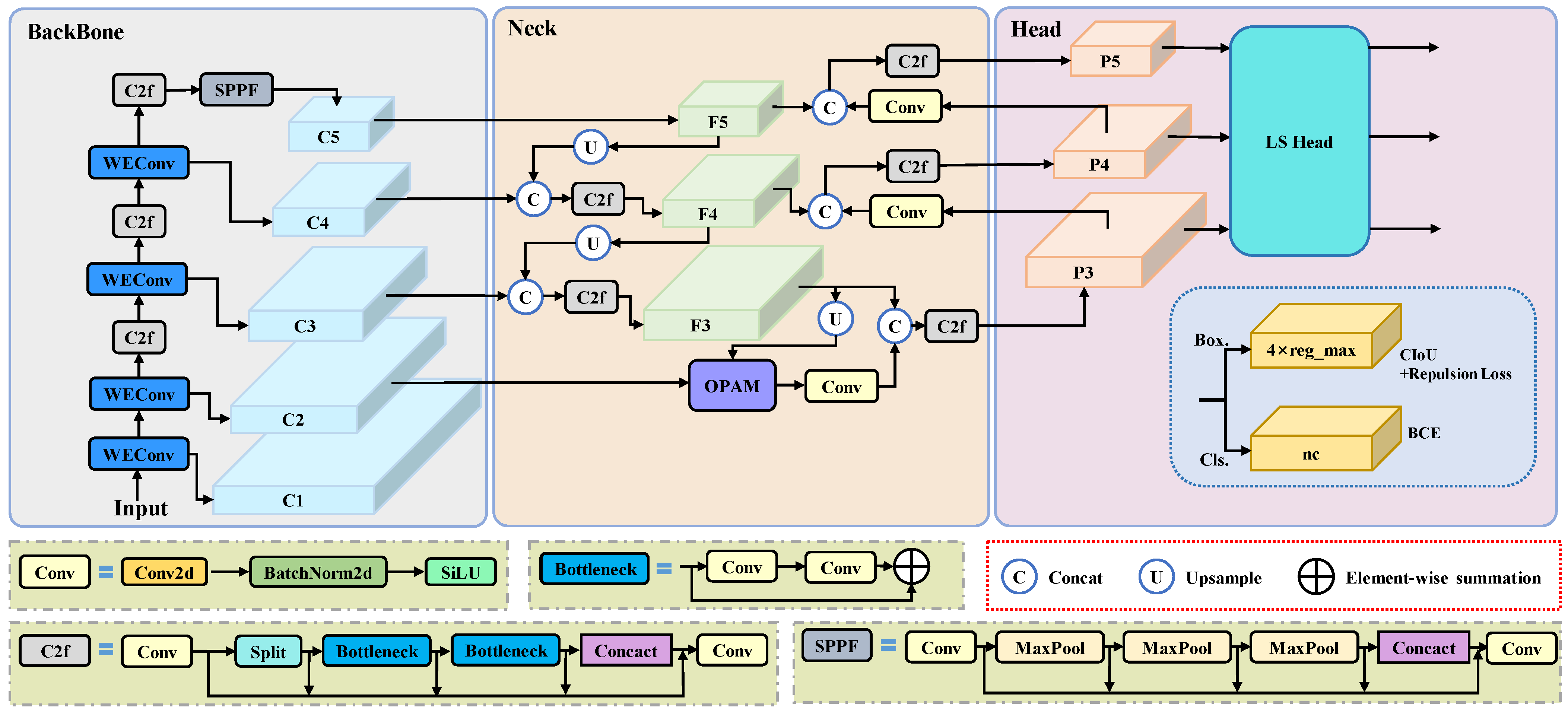
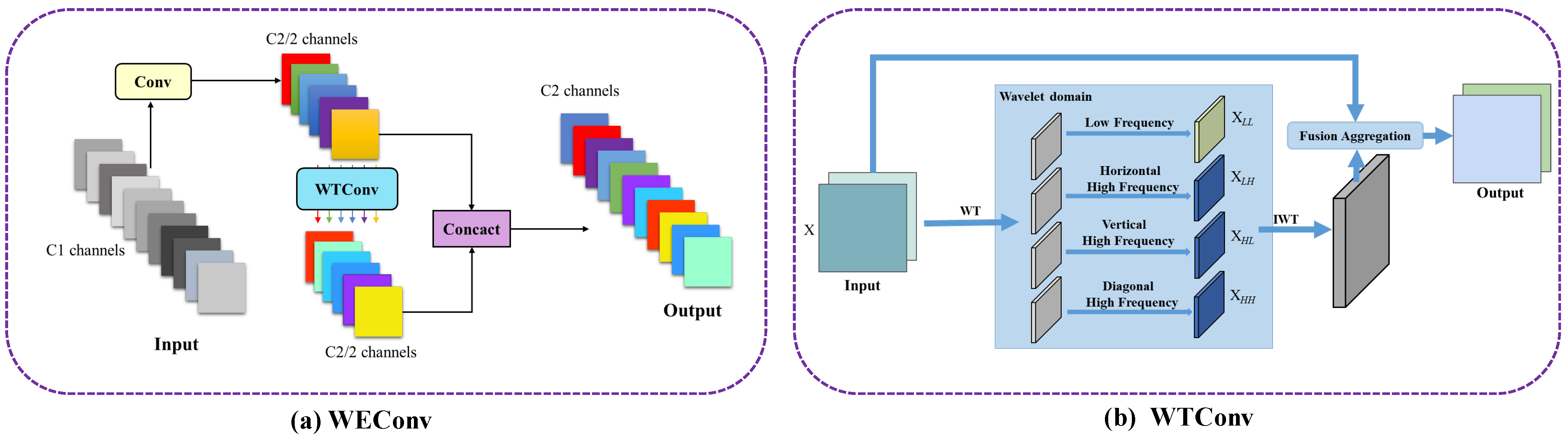
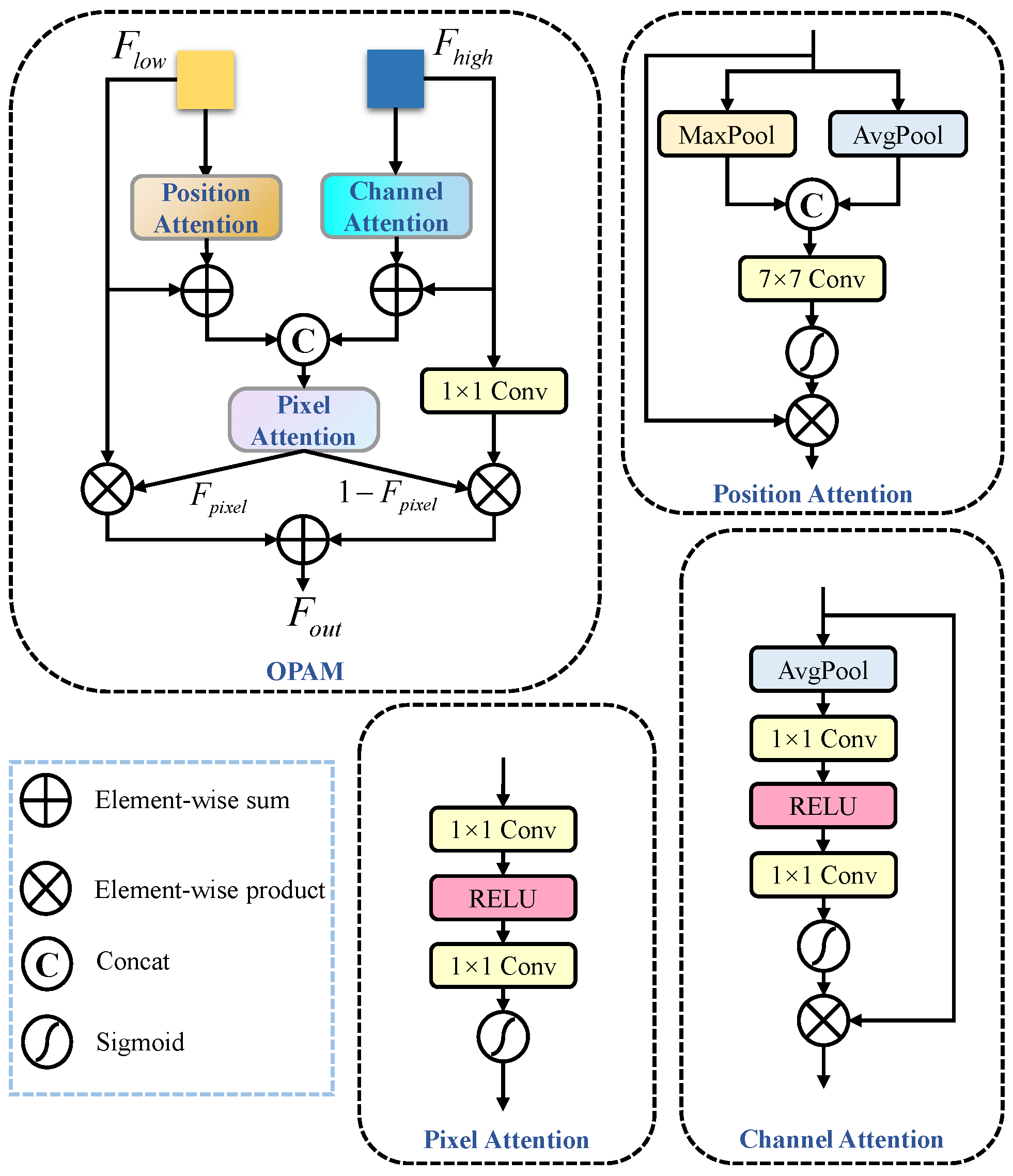
While object detection in dense environments has experienced some progress, significant challenges still exist, especially when dealing with frequent occlusions where limited features can be extracted. Additionally, existing methods often improve performance by simply superimposing more complex modules and consequently increasing computational complexity and the number of parameters. To address the aforementioned challenges, we propose YOLO-SDD, a network designed for single-class dense detection. First, we introduce Wavelet-Enhanced Convolution (WEConv) to capture spatial information across various scales and frequencies, thereby improving the model’s feature extraction ability for dense and edge targets. Next, to further enhance the model’s robustness in occluded environments, we design the Occlusion Perceptual Attention Module (OPAM), which effectively integrates low-level detailed features with high-level semantic features to improve the model’s discriminative ability. Furthermore, we propose Lightweight Shared Head (LS Head), which not only allows the detection head to learn common spatial features across multiple detection layers through a shared convolutional structure but also significantly reduces computational overhead and model parameters. The main contributions of this paper are listed as follows:
We propose a single-class object detection framework called YOLO-SDD, specifically designed for the detection of poultry (e.g., chickens and geese) and sheep. To enhance the model’s detection performance and efficiency in complex occlusion scenarios, we introduce WEConv, LS Head, and OPAM.
We establish a dataset named ChickenFlow, focusing on scenarios with dense occlusion among flocks of chickens. This dataset enriches existing resources for object detection and provides crucial data support for research in occluded object detection in dense environments.
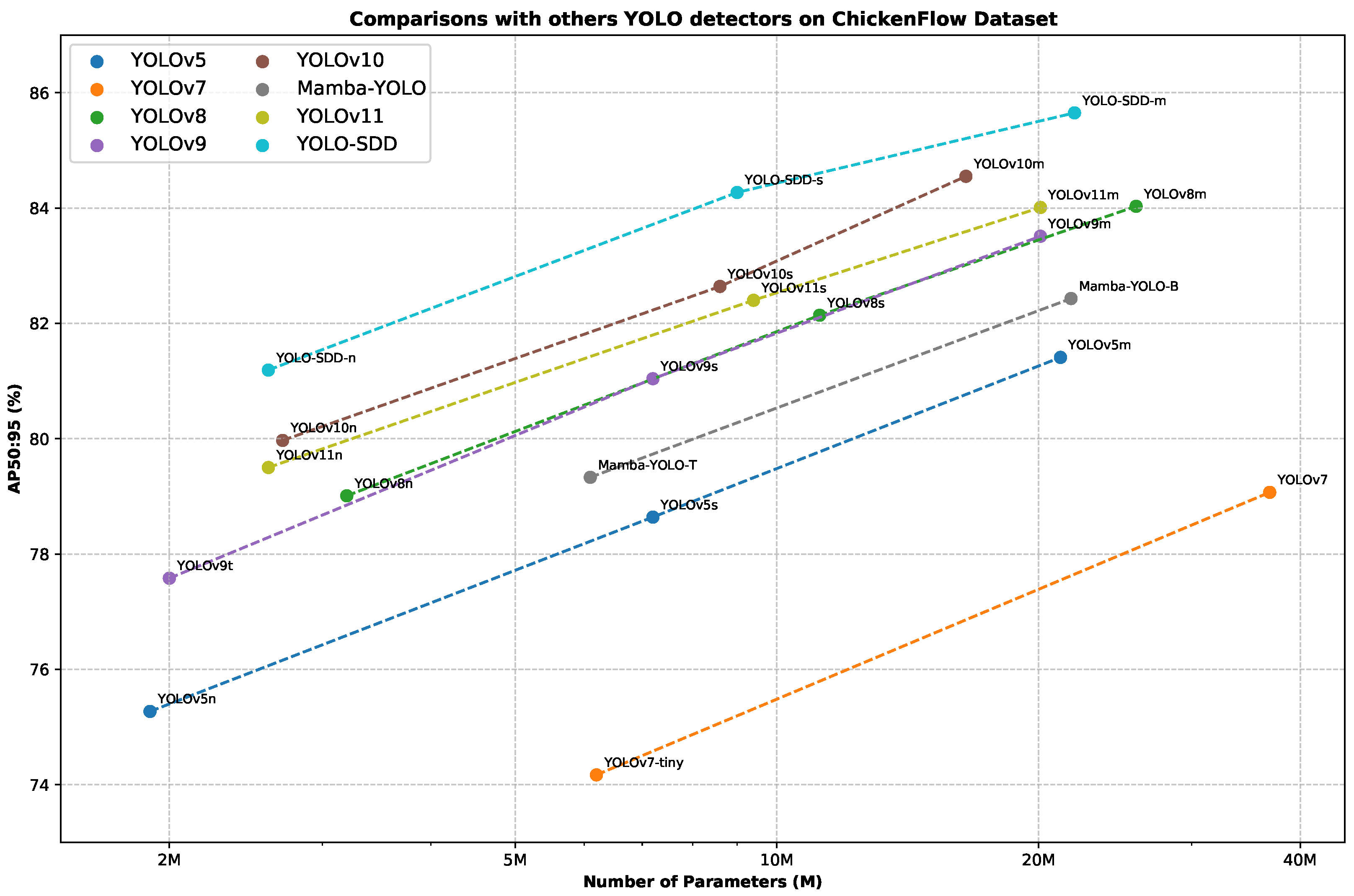
Extensive experiments are conducted on three livestock farming datasets involving chickens, geese, and sheep, comparing YOLO-SDD with seven of the most popular object detectors. The results demonstrate that YOLO-SDD excels in both accuracy and robustness. Additionally, ablation studies validate the contributions of each module to the improved performance and efficiency in detecting objects.
4. Conclusions
In this paper, we propose YOLO-SDD, a network specifically designed for single-class dense object detection with occlusion awareness. The model incorporates three key innovations: the WEConv for improved feature extraction under dense occlusion, the OPAM to enhance feature discrimination in complex occlusion scenarios, and the LS Head optimized for single-class detection tasks. Extensive experiments on the ChickenFlow, GooseDetect, and SheepCounter datasets demonstrated that YOLO-SDD outperforms the state-of-the-art detectors, especially in challenging, densely occluded environments. The ablation studies further validate the contribution of each module to the overall performance.
Our future work will focus on extending the model’s applicability to different livestock scenarios and species to enhance its practical utility. Although YOLO-SDD reduces computational complexity compared to the baseline YOLOv8, deployment on resource-constrained devices remains challenging. Techniques such as model pruning and knowledge distillation could be explored to further alleviate computational burden. Additionally, integrating YOLO-SDD with multi-object tracking technologies could improve real-time monitoring accuracy and stability in dynamic scenes.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}