
A Review of You Only Look Once Algorithms in Animal Phenotyping Applications


Simple Summary
Abstract
1. Introduction
2. Materials and Methods
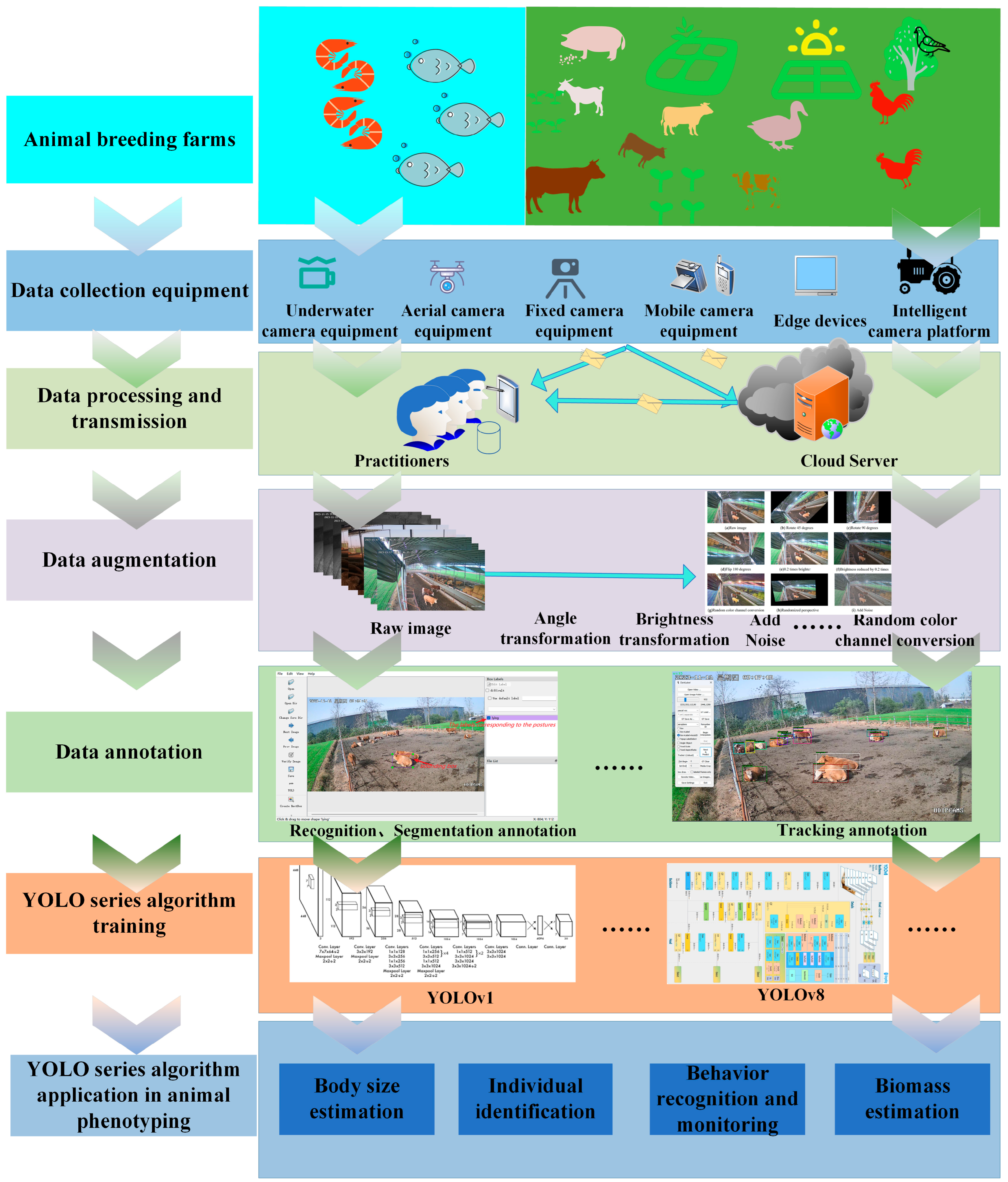
2.1. Development of the Target Detection of YOLO Family Algorithms
- (1)
- Data Collection: Data collection is conducted in livestock farms using flexible equipment selection based on environmental conditions, including underwater cameras, fixed cameras, handheld devices, drones, and edge devices.
- (2)
- Data Transmission: Collected data are stored locally or in cloud platforms to facilitate data retrieval and processing.
- (3)
- Data Augmentation: Data enhancement techniques such as rotation, flipping, brightness adjustment, random color channel permutations, random perspective transformations, and noise addition are applied to expand dataset diversity.
- (4)
- Data Labeling: Data are labeled according to specific application scenarios.
- (5)
- Model Training: Labeled datasets are input into appropriate YOLO-series algorithms for model training, optimizing detection accuracy and generalization capabilities.
- (6)
- YOLO-Based Phenotyping Applications: The trained YOLO models are deployed for animal body size estimation, individual identification, behavioral recognition and monitoring, and biomass estimation, enabling intelligent livestock management and sustainable farming practices.
2.1.1. YOLOv1
2.1.2. YOLOv2
- (1)
- Batch normalization: Integrated after convolutional layers to accelerate training, improve stability, and enhance generalization.
- (2)
- Resolution scaling: Fixed input resolution at 448 × 448 pixels to preserve spatial details for higher accuracy.
- (3)
- Anchor box mechanism: Borrowed from Faster R-CNN, this approach employs predefined anchor boxes to optimize prediction speed and accuracy.
- (4)
- K-Means clustering [25]: Applied to cluster training data bounding boxes, ensuring anchor box dimensions align with target sizes.
2.1.3. YOLOv3
- (1)
- Network architecture enhancement: Upgraded from DarkNet-19 to DarkNet-53, deepening the network depth and improving performance. This strengthened the model’s feature extraction capabilities, enhancing detection accuracy.
- (2)
- Introduction of FPN structure: Integrated the Feature Pyramid Network (FPN) to fuse multi-scale feature information, bolstering the model’s ability to detect objects of varying sizes. Through multi-scale predictions, it demonstrated particularly enhanced detection sensitivity for small objects. Based on this improvement, the YOLO-series network is divided into four components: input network, backbone network, neck, and detection head.
2.1.4. YOLOv4
- (1)
- Input Enhancements: Implemented Mosaic data augmentation, Cross Mini-Batch Normalization (CMBN), and Self-Adversarial Training (SAT) to enhance dataset diversity and model robustness.
- (2)
- Backbone Optimization: Replaced Darknet-53 with CSPDarknet53, improving learning capacity while reducing computational bottlenecks and memory costs.
- (3)
- Neck Structure: Incorporated Spatial Pyramid Pooling (SPP) and FPN + PAN architectures to better fuse multi-scale features and expand the receptive field, boosting detection performance.
2.1.5. YOLOv5
2.1.6. YOLOX
2.1.7. YOLOv6
2.1.8. YOLOv7
- (1)
- Network architecture optimization: Introduced more efficient convolutional layers, attention mechanisms, and path aggregation networks to enhance performance and speed.
- (2)
- Transformer module integration: Deployed Transformer-based attention mechanisms to improve the model’s understanding of image features, boosting recognition accuracy in complex scenarios.
- (3)
- Feature extractor refinement: Utilized deeper and more complex network structures to extract advanced features, enabling better image content interpretation and detection precision.
- (4)
- Input/output optimization: Implemented various optimization techniques in input and output network components to achieve a balanced trade-off between detection speed and accuracy, providing a robust foundation for diverse applications.
2.1.9. YOLOv8
2.1.10. YOLOv9
2.2. Evaluation Metrics
2.3. Datasets and Preprocessing
2.3.1. Public and Custom Datasets
- (1)
- Sample Focus: Animal phenotyping self-built datasets are tailored to address specific production challenges, such as sheep individual identification, through dedicated facial datasets [37].
- (2)
- Small Data Volume: These datasets are designed for single-task optimization, resulting in compact data size, low resource consumption, and ease of deployment.
- (3)
- Convenient Data Collection: Their focused scope and limited scale enable straightforward collection using cameras in real-world farming environments.
- (1)
- Poor Scalability: The closed nature of animal phenotyping data restricts sample diversification, limiting their applicability to related problems.
- (2)
- Low Reproducibility Assurance: Insufficient documentation and transparency in dataset construction hinder researchers’ ability to reproduce or improve upon them for algorithmic advancements.
2.3.2. Annotation Methods
3. Results
3.1. Analysis of YOLO Algorithms in Animal Phenotyping Applications
3.1.1. Body Size Estimation
3.1.2. Individual Recognition
3.1.3. Behavior Recognition and Monitoring
3.1.4. Biomass Estimation
3.1.5. Analysis of Phenotypic Application Differences in Animals
- (1)
- Non-invasive identification: Achieved through non-contact image or video analysis and avoiding physical interference with animals (e.g., stress-induced responses from radio-frequency tagging), thereby ensuring animal welfare and health.
- (2)
- Cross-species generalization: Enabled by multi-scale feature fusion and adaptive data augmentation, YOLO algorithms adapt to diverse phenotyping needs across aquatic animals (e.g., fish), terrestrial livestock (e.g., cattle, sheep), and avian species (e.g., chickens, ducks).
- (3)
- High robustness in complex scenarios: Enhanced through attention mechanisms, Feature Pyramid Networks, and dynamic data augmentation, YOLO maintains superior detection accuracy under challenging conditions such as low illumination, dense occlusion, and small-target detection.
- (1)
- Comparative Analysis of Cattle Posture Recognition Algorithms. As shown in Table 8, the literature [40] demonstrates that YOLO-based algorithms exhibit superior performance compared to two-stage frameworks like Faster R-CNN in cattle posture recognition, achieving significant improvements in accuracy, recall rate, mAP50, and mAP50:95. This further validates the feasibility of YOLO-based solutions for cattle posture recognition. Notably, among YOLO variants—including YOLOX, YOLOv7, YOLOv8, and YOLOv8n_BiF_DSC—performance metrics such as accuracy, recall rate, mAP50, and mAP50:95 show gradual increments. While subtle differences exist across YOLO family algorithms under identical scenarios, their overall recognition rates remain consistently high. Specifically, YOLOv8n_BiF_DSC achieves an mAP50 of 96.5%, meeting practical requirements for intelligent cattle health monitoring and sustainable farming.
- (2)
- Comparative Analysis of YOLO-Series Algorithms in Complex Scenarios. The literature [40] compared the performance of YOLO-based algorithms under varying lighting conditions (Figure 5a) and crowd densities (Figure 5b) for cattle posture recognition. Under normal lighting and low-density scenarios, both YOLOv8n and the improved YOLOv8n_BiF_DSC algorithm demonstrated excellent recognition accuracy, exhibiting minimal false detections and omissions. However, in complex environments such as low-light, high-light, or densely packed scenes, image noise increased, and critical features were severely degraded. While YOLOv8n could still identify most cattle postures, minor errors in detection and omission persisted. In contrast, the enhanced YOLOv8n_BiF_DSC algorithm maintained excellent recognition accuracy under these challenging conditions, proving the robustness of YOLO-series algorithms in adverse environments. For instance, in extremely dark conditions, attention mechanisms and convolutional optimizations within YOLO frameworks enable reliable animal phenotyping recognition, providing technical support for intelligent animal identification and management.
4. Discussion
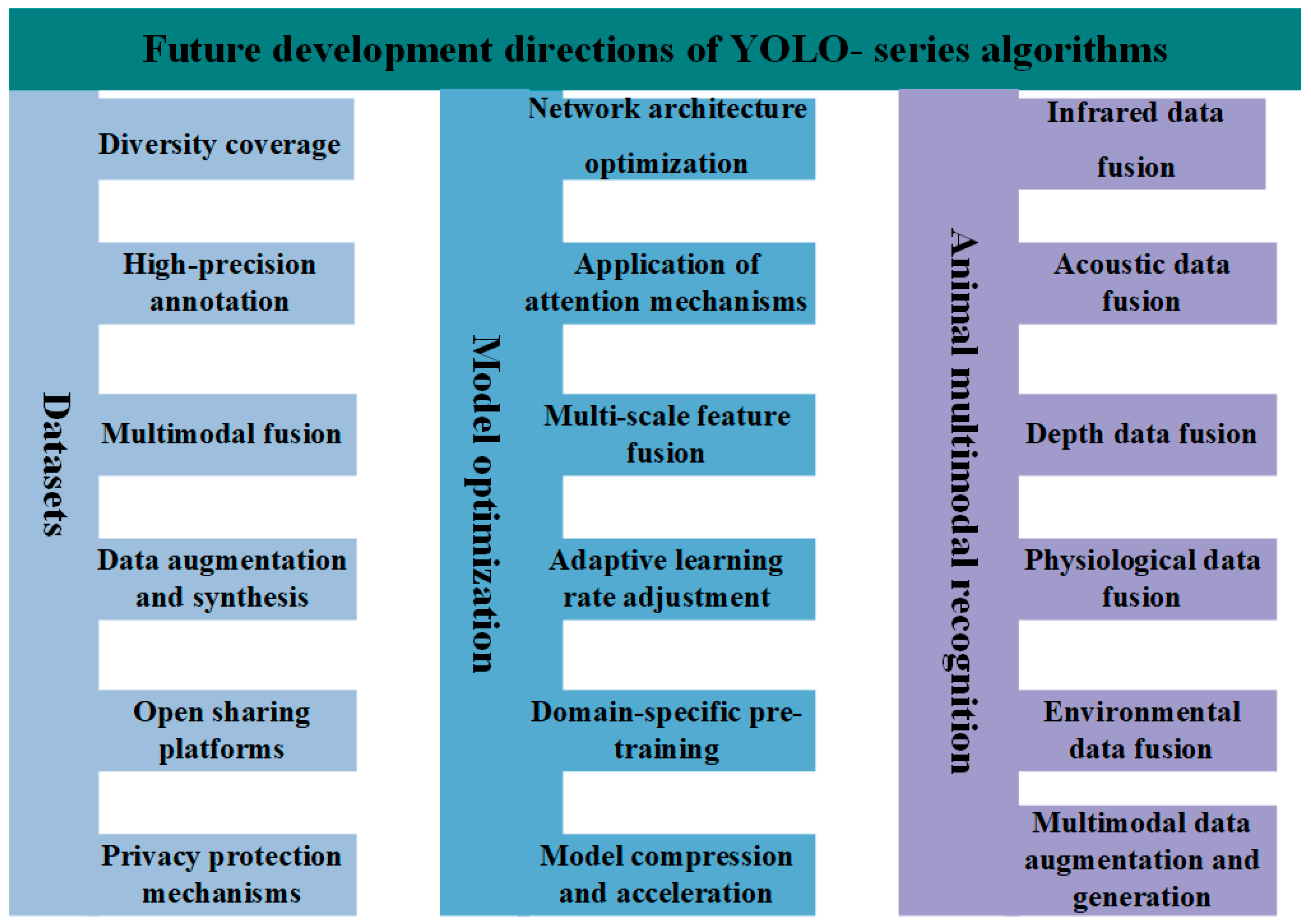
4.1. Future Development Directions
4.1.1. Datasets
4.1.2. Model Optimization
4.1.3. Animal Multimodal Recognition
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Correction Statement
References
- Seyfarth, R.M.; Cheney, D.L. The evolution of concepts about agents: Or, what do animals recognize when they recognize an individual. In The Conceptual Mind: New Directions in the Study of Concepts; MIT Press: Cambridge, MA, USA, 2015; pp. 57–76. [Google Scholar]
- Van Heel, M.; Harauz, G.; Orlova, E.V.; Schmidt, R.; Schatz, M. A new generation of the IMAGIC image processing system. J. Struct. Biol. 1996, 116, 17–24. [Google Scholar] [CrossRef]
- Al-Amri, S.S.; Kalyankar, N.V. Image segmentation by using threshold techniques. arXiv 2010, arXiv:1005.4020. [Google Scholar]
- Ziou, D.; Tabbone, S. Edge detection techniques-an overview. In Распoзнавание Образoв и Анализ Изoбражен/Pattern Recognition and Image Analysis: Advances in Mathematical Theory and Applications; HAL: Milwaukee, WI, USA, 1998; Volume 8, pp. 537–559. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Wei, X. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao HY, M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Kühl, H.S.; Burghardt, T. Animal biometrics: Quantifying and detecting phenotypic appearance. Trends Ecol. Evol. 2013, 28, 432–441. [Google Scholar] [CrossRef]
- Voulodimos, A.S.; Patrikakis, C.Z.; Sideridis, A.B.; Ntafis, V.A.; Xylouri, E.M. A complete farm management system based on animal identification using RFID technology. Comput. Electron. Agric. 2010, 70, 380–388. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Huang, X.; Huang, F.; Hu, J.; Zheng, H.; Liu, M.; Dou, Z.; Jiang, Q. Automatic Face Detection of Farm Images Based on an Enhanced Lightweight Deep Learning Model. Int. J. Pattern Recognit. Artif. Intell. 2024, 38, 2456009. [Google Scholar] [CrossRef]
- Li, M.; Su, L.; Zhang, Y.; Zhang, Y.; Zong, Z.; Zhang, S. An Automatic Body Measurement Method for Mongolian Horses Based on Improved YOLOv8n-pose and 3D Point Cloud Analysis. Smart Agric. Chin. Engl. Ed. 2024, 6, 91–102. [Google Scholar]
- Ocholla, I.A.; Pellikka, P.; Karanja, F.; Vuorinne, I.; Väisänen, T.; Boitt, M.; Heiskanen, J. Livestock Detection and Counting in Kenyan Rangelands Using Aerial Imagery and Deep Learning Techniques. Remote Sens. 2024, 16, 2929. [Google Scholar] [CrossRef]
- Wang, L.; Bai, J.; li, W.; Jiang, J. Research Progress on YOLO Series Object Detection Algorithms. Comput. Eng. Appl. 2023, 59, 15–29. [Google Scholar]
- Mi, Z.; Lian, Z. Survey of YOLO Methods for General Object Detection. Comput. Eng. Appl. 2024, 1–19. Available online: http://kns.cnki.net/kcms/detail/11.2127.tp.20240705.1328.006.html (accessed on 9 October 2024).
- Xu, Y.; Li, J.; Dong, Y.; Zhang, X. Survey of Development of YOLO Object Detection Algorithms. J. Comput. Sci. Explor. 2024, 18, 2221–2238. [Google Scholar]
- Chen, J.; Wu, Y.; Yuan, Y. Advances in YOLO Series Algorithms for UAV-based Object Detection. J. Beijing Univ. Aeronaut. Astronaut. 2024, 1–33. [Google Scholar] [CrossRef]
- Jiang, Y.; Jiang, Z.; Zhu, R.; Nian, Y. Lightweight Strawberry Maturity Detection Method in Complex Environments Based on PCIA-YOLO. J. Nanjing Agric. Univ. 2024, 1–15. Available online: http://kns.cnki.net/kcms/detail/32.1148.S.20240930.1738.008.html (accessed on 9 October 2024).
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef]
- Park, J.-H.; Kang, C. A study on enhancement of fish recognition using cumulative mean of YOLO network in underwater video images. J. Mar. Sci. Eng. 2020, 8, 952. [Google Scholar] [CrossRef]
- Guo, S.S.; Lee, K.H.; Chang, L.; Tseng, C.D.; Sie, S.J.; Lin, G.Z.; Lee, T.F. Development of an automated body temperature detection platform for face recognition in cattle with YOLO V3-tiny deep learning and infrared thermal imaging. Appl. Sci. 2022, 12, 4036. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, S.; Cui, X.; Wang, X.; Cao, W.; Yu, H.; Pan, X. Goat-face recognition in natural environments using the improved YOLOv4 algorithm. Agriculture 2022, 12, 1668. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, G.; Seng, X.; Zheng, H.; Zhang, H.; Liu, T. Deep learning method for rapidly estimating pig body size. Anim. Prod. Sci. 2023, 63, 909–923. [Google Scholar] [CrossRef]
- Li, Y.W.; Li, J.X.; Na, T.X.; Zhi, Q.; Duan, L.; Zhang, P. Recognizing attack behavior of herd pigs using improved YOLOX. Trans. Chin. Soc. Agric. Eng. 2023, 39, 177–184. [Google Scholar]
- Xu, S.; Zheng, H.; Tao, S.; Chai, Y.; He, Q.; Chen, H. A Lightweight Pig Face Recognition Method Based on Efficient Mobile Network and Horizontal Vertical Attention Mechanism. IEEE Trans. Instrum. Meas. 2024, 73, 3513914. [Google Scholar] [CrossRef]
- Xiao, D.; Wang, H.; Liu, Y.; Li, W.; Li, H. DHSW-YOLO: A duck flock daily behavior recognition model adaptable to bright and dark conditions. Comput. Electron. Agric. 2024, 225, 109281. [Google Scholar] [CrossRef]
- Yu, H.; Xu, Y.; Zhang, J.; Zhao, W.; Guan, Z.; Tao, D. Ap-10k: A benchmark for animal pose estimation in the wild. arXiv 2021, arXiv:2108.12617. [Google Scholar]
- Yang, X.; de Castro, B.J.; Sánchez-González, L.; Lera, F.J.R. Dataset for herding and predator detection with the use of robots. Data Brief 2024, 55, 110691. [Google Scholar] [CrossRef]
- Huang, X.; Dou, Z.; Huang, F.; Zheng, H.; Hou, X.; Wang, C.; Feng, T.; Rao, Y. A Dataset of Target Detection for Dairy Cow Body Condition Scores; China Scientific Data: Beijing, China, 2025. [Google Scholar] [CrossRef]
- Banno, K.; Gonçalves, F.M.F.; Sauphar, C.; Anichini, M.; Hazelaar, A.; Sperre, L.H.; da Silva Torres, R. Identifying losers: Automatic identification of growth-stunted salmon in aquaculture using computer vision. Mach. Learn. Appl. 2024, 16, 100562. [Google Scholar] [CrossRef]
- Guo, Y.; Hong, W.; Ding, Y.; Huang, X. Goat Face Detection Method Based on Coordinate Attention Mechanism and YOLO v5s Model. Trans. Chin. Soc. Agric. Mach. 2023, 54, 313–321. [Google Scholar]
- Huang, X.; Feng, T.; Guo, Y.; Liang, D. Lightweight Dairy Cow Body Condition Scoring Method Based on Improved YOLO v5s. Trans. Chin. Soc. Agric. Mach. 2023, 54, 287–296. [Google Scholar]
- Guo, J.; He, G.; Xu, L.; Liu, T.; Feng, D.; Liu, S. Pigeon Behavior Detection Model Based on Improved YOLO v4. Trans. Chin. Soc. Agric. Mach. 2023, 54, 347–355. [Google Scholar]
- Li, G.; Shi, G.; Zhu, C. Dynamic Serpentine Convolution with Attention Mechanism Enhancement for Beef Cattle Behavior Recognition. Animals 2024, 14, 466. [Google Scholar] [CrossRef]
- Li, G.; Sun, J.; Guan, M.; Sun, S.; Shi, G.; Zhu, C. A New Method for Non-Destructive Identification and Tracking of Multi-Object Behaviors in Beef Cattle Based on Deep Learning. Animals 2024, 14, 2464. [Google Scholar] [CrossRef] [PubMed]
- Bakhshayeshi, I.; Erfani, E.; Taghikhah, F.R.; Elbourn, S.; Beheshti, A.; Asadnia, M. An Intelligence Cattle Reidentification System over Transport by Siamese Neural Networks and YOLO. IEEE Internet Things J. 2023, 11, 2351–2363. [Google Scholar] [CrossRef]
- Weng, Z.; Ke, L.; Zheng, Z. Cattle face detection method based on channel pruning YOLOv5 network and mobile deployment. J. Intell. Fuzzy Syst. Prepr. 2023, 45, 10003–10020. [Google Scholar] [CrossRef]
- Shao, D.; He, Z.; Fan, H.; Sun, K. Detection of cattle key parts based on the improved Yolov5 algorithm. Agriculture 2023, 13, 1110. [Google Scholar] [CrossRef]
- Lee, J.; Park, S.; Nam, G.; Jang, J.; Lee, S. Pig Image Learning for Improving Weight Measurement Accuracy. J. Korea Soc. Comput. Inf. 2024, 29, 33–40. [Google Scholar]
- Gonzalez, B.; Garcia, G.; Velastin, S.A.; GholamHosseini, H.; Tejeda, L.; Farias, G. Automated Food Weight and Content Estimation Using Computer Vision and AI Algorithms. Sensors 2024, 24, 7660. [Google Scholar] [CrossRef]
- Peng, Y.; Peng, Z.; Zou, H.; Liu, M.; Hu, R.; Xiao, J.; Wang, Z. A dynamic individual yak heifer live body weight estimation method using the YOLOv8 network and body parameter detection algorithm. J. Dairy Sci. 2024, 107, 6178–6191. [Google Scholar] [CrossRef]
- Jiang, B.; Wu, Q.; Yin, X.; Wu, D.; Song, H.; He, D. FLYOLOv3 deep learning for key parts of dairy cow body detection. Comput. Electron. Agric. 2019, 166, 104982. [Google Scholar] [CrossRef]
- Dai, Y. Target Recognition and Body Length Measurement of Small Tailed Han Sheep. In Proceedings of the 2024 International Conference on Mechanics, Electronics Engineering and Automation (ICMEEA 2024), Singapore, 26–28 July 2024; Atlantis Press: Dordrecht, The Netherlands, 2024; pp. 629–636. [Google Scholar]
- Muthulakshmi, M.; Akashvarma, M.; Yashaswini, G.; Keerthana, E.; Siddharth, S.; Saipooja, K.; Selvaraj, P. Body Weight Prediction of Goats: A Computer Vision Approach. In Proceedings of the 2023 4th International Conference on Intelligent Technologies (CONIT), Hubballi, India, 21–23 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Bery, S.; Brown-Brandl, T.M.; Jones, B.T.; Rohrer, G.A.; Sharma, S.R. Determining the presence and size of shoulder lesions in sows using computer vision. Animals 2023, 14, 131. [Google Scholar] [CrossRef]
- Zhao, K.; Duan, Y.; Chen, J.; Li, Q.; Hong, X.; Zhang, R.; Wang, M. Detection of respiratory rate of dairy cows based on infrared thermography and deep learning. Agriculture 2023, 13, 1939. [Google Scholar] [CrossRef]
- Li, G.; Shi, G.; Jiao, J. YOLOv5-KCB: A new method for individual pig detection using optimized K-means, CA attention mechanism and a bi-directional feature pyramid network. Sensors 2023, 23, 5242. [Google Scholar] [CrossRef]
- Zhong, C.; Wu, H.; Jiang, J.; Zheng, C.; Song, H. YOLO-DLHS-P: A lightweight behavior recognition algorithm for captive pigs. IEEE Access 2024, 12, 104445–104462. [Google Scholar] [CrossRef]
- Zhang, X.; Xuan, C.; Xue, J.; Chen, B.; Ma, Y. LSR-YOLO: A high-precision, lightweight model for sheep face recognition on the mobile end. Animals 2023, 13, 1824. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Zhu, K.; Wang, F.; Jiang, F. Deep neural network-based real time fish detection method in the scene of marine fishing supervision. J. Intell. Fuzzy Syst. 2021, 41, 4527–4532. [Google Scholar] [CrossRef]
- Zhou, S.; Cai, K.; Feng, Y.; Tang, X.; Pang, H.; He, J.; Shi, X. An accurate detection model of Takifugu rubripes using an improved YOLO-V7 network. J. Mar. Sci. Eng. 2023, 11, 1051. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Z.; Dai, B.; Zhao, K.; Shen, W.; Yin, Y.; Li, Y. Cow-YOLO: Automatic cow mounting detection based on non-local CSPDarknet53 and multiscale neck. Int. J. Agric. Biol. Eng. 2024, 17, 193–202. [Google Scholar]
- Zheng, Z.; Li, J.; Qin, L. YOLO-BYTE: An efficient multi-object tracking algorithm for automatic monitoring of dairy cows. Comput. Electron. Agric. 2023, 209, 107857. [Google Scholar] [CrossRef]
- Du, L.; Lu, Z.; Li, D. A novel automatic detection method for breeding behavior of broodstock based on improved YOLOv5. Comput. Electron. Agric. 2023, 206, 107639. [Google Scholar] [CrossRef]
- Sun, S.; Wei, L.; Chen, Z.; Chai, Y.; Wang, S.; Sun, R. Nondestructive estimation method of live chicken leg weight based on deep learning. Poult. Sci. 2024, 103, 103477. [Google Scholar] [CrossRef]
- Bist, R.B.; Yang, X.; Subedi, S.; Chai, L. Automatic detection of bumblefoot in cage-free hens using computer vision technologies. Poult. Sci. 2024, 103, 103780. [Google Scholar] [CrossRef]
- Bist, R.B.; Yang, X.; Subedi, S.; Chai, L. Mislaying behavior detection in cage-free hens with deep learning technologies. Poult. Sci. 2023, 102, 102729. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; He, G.; Deng, H.; Fan, W.; Xu, L.; Cao, L.; Hassan, S.G. Pigeon cleaning behavior detection algorithm based on light-weight network. Comput. Electron. Agric. 2022, 199, 107032. [Google Scholar] [CrossRef]
- Mao, R.; Shen, D.; Wang, R.; Cui, Y.; Hu, Y.; Li, M.; Wang, M. An Integrated Gather-and-Distribute Mechanism and Attention-Enhanced Deformable Convolution Model for Pig Behavior Recognition. Animals 2024, 14, 1316. [Google Scholar] [CrossRef]
- Chen, G.; Yuan, Z.; Luo, X.; Liang, J.; Wang, C. Research on Behavior Recognition and Online Monitoring System for Liaoning Cashmere Goats Based on Deep Learning. Animals 2024, 14, 3197. [Google Scholar] [CrossRef]
- Jiang, M.; Jiang, M.; Rao, Y.; Zhang, J.; Shen, Y. Automatic behavior recognition of group-housed goats using deep learning. Comput. Electron. Agric. 2020, 177, 105706. [Google Scholar] [CrossRef]
- Wang, J.; Zhai, Y.; Zhu, L.; Xu, L.; Yuan, H. PD-YOLO: A study of daily behavioural detection in housed sheep. PLoS ONE 2024, 19, e0313412. [Google Scholar] [CrossRef]
- Deng, X.; Zhang, S.; Shao, Y.; Yan, X.L. A real-time sheep counting detection system based on machine learning. INMATEH—Agric. Eng. 2022, 67, 85–94. [Google Scholar] [CrossRef]
- Xu, H.; Chen, X.; Wu, Y.; Liao, B.; Liu, L.; Zhai, Z. Using channel pruning–based YOLOv5 deep learning algorithm for accurately counting fish fry in real time. Aquac. Int. 2024, 32, 9179–9200. [Google Scholar] [CrossRef]
- Natesan, B.; Liu, C.M.; Ta, V.D.; Liao, R. Advanced robotic system with keypoint extraction and YOLOv5 object detection algorithm for precise livestock monitoring. Fishes 2023, 8, 524. [Google Scholar] [CrossRef]
- Avsar, E.; Feekings, J.P.; Krag, L.A. Edge computing based real-time Nephrops (Nephrops norvegicus) catch estimation in demersal trawls using object detection models. Sci. Rep. 2024, 14, 9481. [Google Scholar] [CrossRef]
- Zhao, C.; Liang, X.; Yu, H.; Wang, H.; Fan, S.; Li, B. Automatic Identification and Counting Method of Caged Hens and Eggs Based on Improved YOLO v7. Trans. Chin. Soc. Agric. Mach. 2023, 54, 300–312. (In Chinese) [Google Scholar]
- Jiang, K.; Xie, T.; Yan, R.; Wen, X.; Li, D.; Jiang, H.; Jiang, N.; Feng, L.; Duan, X.; Wang, J. An attention mechanism-improved YOLOv7 object detection algorithm for hemp duck count estimation. Agriculture 2022, 12, 1659. [Google Scholar] [CrossRef]
- Weng, Z.; Bai, R.; Zheng, Z. SCS-YOLOv5s: A cattle detection and counting method for complex breeding environment. J. Intell. Fuzzy Syst. 2024, JIFS-237231. [Google Scholar] [CrossRef]
- Li, B.; Fang, J.; Zhao, Y. An algorithm for cattle counting in rangeland based on multi-scale perception and image association. IET Image Process. 2024, 18, 4151–4167. [Google Scholar] [CrossRef]
- Shao, X.; Liu, C.; Zhou, Z.; Xue, W.; Zhang, G.; Liu, J.; Yan, H. Research on Dynamic Pig Counting Method Based on Improved YOLOv7 Combined with DeepSORT. Animals 2024, 14, 1227. [Google Scholar] [CrossRef]
- Schütz, A.K.; Louton, H.; Fischer, M.; Probst, C.; Gethmann, J.M.; Conraths, F.J.; Homeier-Bachmann, T. Automated Detection and Counting of Wild Boar in Camera Trap Images. Animals 2024, 14, 1408. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Wang, Z.; Wu, Y.; Qin, Y.; Cao, X.; Huang, Y. An improved faster R-CNN for UAV-based catenary support device inspection. Int. J. Softw. Eng. Knowl. Eng. 2020, 30, 941–959. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Bastidas, A.A.; Tang, H. Channel attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Jepkoech, J.; Mugo, D.M.; Kenduiywo, B.K.; Too, E.C. The effect of adaptive learning rate on the accuracy of neural networks. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 736–751. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A survey of transfer learning. J. Big data 2016, 3, 1–40. [Google Scholar] [CrossRef]
- Liang, T.; Glossner, J.; Wang, L.; Shi, S.; Zhang, X. Pruning and quantization for deep neural network acceleration: A survey. Neurocomputing 2021, 461, 370–403. [Google Scholar] [CrossRef]
- Gallagher, J.E.; Oughton, E.J. Surveying You Only Look Once (YOLO) Multispectral Object Detection Advancements, Applications and Challenges. IEEE Access 2025, 13, 7366–7395. [Google Scholar] [CrossRef]
- Wu, D.; Cao, L.; Zhou, P.; Li, N.; Li, Y.; Wang, D. Infrared small-target detection based on radiation characteristics with a multimodal feature fusion network. Remote Sens. 2022, 14, 3570. [Google Scholar] [CrossRef]
- Li, W.; Li, A.; Kong, X.; Zhang, Y.; Li, Z. MF-YOLO: Multimodal Fusion for Remote Sensing Object Detection Based on YOLOv5s. In Proceedings of the 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Tianjin, China, 8–10 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 897–903. [Google Scholar]
- Jiao, S.; Li, G.; Zhang, G.; Zhou, J.; Li, J. Multimodal fall detection for solitary individuals based on audio-video decision fusion processing. Heliyon 2024, 10, e29596. [Google Scholar] [CrossRef] [PubMed]
- Zohaib, M.; Asim, M.; ELAffendi, M. Enhancing emergency vehicle detection: A deep learning approach with multimodal fusion. Mathematics 2024, 12, 1514. [Google Scholar] [CrossRef]
- Kandylakis, Z.; Vasili, K.; Karantzalos, K. Fusing multimodal video data for detecting moving objects/targets in challenging indoor and outdoor scenes. Remote Sens. 2019, 11, 446. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, J.; Wu, S.; Li, H.; He, L.; Zhao, R.; Wu, C. An improved YOLOv7 network using RGB-D multi-modal feature fusion for tea shoots detection. Comput. Electron. Agric. 2024, 216, 108541. [Google Scholar] [CrossRef]
- Liu, C.; Feng, Q.; Sun, Y.; Li, Y.; Ru, M.; Xu, L. YOLACTFusion: An instance segmentation method for RGB-NIR multimodal image fusion based on an attention mechanism. Comput. Electron. Agric. 2023, 213, 108186. [Google Scholar] [CrossRef]
- Chai, S.; Wen, M.; Li, P.; Tian, Y. DCFA-YOLO: A Dual-Channel Cross-Feature-Fusion Attention YOLO Network for Cherry Tomato Bunch Detection. Agriculture 2025, 15, 271. [Google Scholar] [CrossRef]
- Shankar, A.; Rizwan, P.; Mekala, M.S.; Elyan, E.; Gandomi, A.H.; Maple, C.; Rodrigues, J.J. A Multimodel-Based Screening Framework for C-19 Using Deep Learning-Inspired Data Fusion. IEEE J. Biomed. Health Inform. 2024, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Li, J.; Zhu, Z.; Zhao, L.; Wang, H.; Song, C.; Chen, Y.; Zhao, Q.; Yang, J.; Pei, Y. A comprehensive review on synergy of multi-modal data and ai technologies in medical diagnosis. Bioengineering 2024, 11, 219. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Wang, P.; Zheng, M.; Li, W.; Zhou, J.; Fu, L. One-stop multi-sensor fusion and multimodal precise quantified traditional Chinese medicine imaging health examination technology. J. Radiat. Res. Appl. Sci. 2024, 17, 101038. [Google Scholar] [CrossRef]
- Tang, J.; Ye, C.; Zhou, X.; Xu, L. YOLO-Fusion and Internet of Things: Advancing object detection in smart transportation. Alex. Eng. J. 2024, 107, 1–12. [Google Scholar] [CrossRef]
- Wu, Y. Fusion-based modeling of an intelligent algorithm for enhanced object detection using a Deep Learning Approach on radar and camera data. Inf. Fusion 2025, 113, 102647. [Google Scholar] [CrossRef]
- Tang, Q.; Liang, J.; Zhu, F. A comparative review on multi-modal sensors fusion based on deep learning. Signal Process. 2023, 213, 109165. [Google Scholar] [CrossRef]
- Wei, C.; Bai, L.; Chen, X.; Han, J. Cross-Modality Data Augmentation for Aerial Object Detection with Representation Learning. Remote Sens. 2024, 16, 4649. [Google Scholar] [CrossRef]
- Qing, J.; Deng, X.; Lan, Y.; Li, Z. GPT-aided diagnosis on agricultural image based on a new light YOLOPC. Comput. Electron. Agric. 2023, 213, 108168. [Google Scholar] [CrossRef]
- Hammami, M.; Friboulet, D.; Kechichian, R. Cycle GAN-based data augmentation for multi-organ detection in CT images via YOLO. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 390–393. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Machine-Processed | Superiority | Boundedness |
|---|---|---|---|
| YOLO v1 | First proposed a single-stage detection framework, dividing images into grids. Each grid predicts bounding boxes and class probabilities for objects of the same category, filtered by non-maximum suppression (NMS). | Detection speed with real-time capability; improved recall rate (reduced missed detections); strong generalization and ease of extension. | Limited detection and localization accuracy, especially for small objects. Grid-based division restricts precise object localization. |
| YOLO v2 | Introduced DarkNet-19 backbone, batch normalization, high-resolution input, anchor boxes, and K-Means clustering for bounding box optimization. | Improved detection accuracy while maintaining speed; enhanced generalization for diverse object types. | Limited adaptability in complex scenes; increased complexity in model tuning due to new parameters. |
| YOLO v3 | Utilized Darknet-53 backbone with Feature Pyramid Network (FPN) for multi-scale prediction. Split architecture into input, backbone, neck, and detection head. | Enhanced accuracy, small-object detection, and feature extraction capabilities. | High computational resource consumption; prone to missed or false detections in dense object overlaps. |
| YOLO v4 | Integrated Mosaic data augmentation, CBM (Convolution-BatchNorm-Mish), SAT (Self-Adversarial Training), CSPDarknet53 backbone, SPP module, and FPN + PAN for multi-scale feature fusion and receptive field expansion. | Balanced speed and accuracy with high detection performance across diverse objects. | Complex architecture; high training/deployment difficulty and computational demands. |
| YOLO v5 | Introduced adaptive anchor calculation, focus slicing, BottleneckCSP modules, Mosaic augmentation, and PANet neck for optimized feature transfer. | Improved training/inference speed; flexible deployment with multiple model sizes. | Structural complexity requiring computational resources; may need additional optimization for specific scenarios. |
| YOLOX | Introduced anchor-free design, decoupled heads, SimOTA dynamic label assignment, and simplified data augmentation/end-to-end optimization. | Excels in dense target scenarios and complex environments; reduces hyperparameter tuning complexity via anchor-free architecture; enables easy deployment. | Small target detection rates require improvement; high computational costs persist. |
| YOLO v6 | Designed an efficient decoupled-head, hybrid channel strategy to reduce redundancy and optimized loss functions and training strategies. | Enhanced efficiency with balanced speed and accuracy through architectural and training improvements. | Limited performance gains in highly complex scenes. |
| YOLO v7 | Combined Transformer attention mechanisms with path aggregation networks, optimized convolutional layers, and deeper feature extractors. | Improved accuracy in complex scenes with better speed–accuracy trade-off; supports multi-task extensions. | High model complexity and training costs. |
| YOLO v8 | Enhanced backbone, detection head (e.g., C2f structure for gradient flow), decoupled head, and channel adaptation for multi-scale tasks. | Versatile for detection, segmentation, and classification; easy deployment and modification (pip-installable). | Increased parameters and training costs; real-time performance needs optimization. |
| YOLO v9 | Built on YOLOv7 with programmable gradient information and Generalized Efficient Layer Aggregation Network (GELAN) for efficient gradient path planning. | High performance with reduced parameters and computations; suitable for resource-constrained scenarios. | Inaccurate small-object detection. |
| Basic Model | Model Variant | Input Size | mAP | FPS |
|---|---|---|---|---|
| YOLO v1 | Fast YOLO | 448 × 448 | 52.7 | 155 |
| YOLO v1 | 448 × 448 | 63.4 | 45 | |
| YOLO v2 | YOLO v2 | 288 × 288 | 69.0 | 91 |
| YOLO v2 | 352 × 352 | 73.7 | 81 | |
| YOLO v2 | 416 × 416 | 76.8 | 67 | |
| YOLO v2 | 480 × 480 | 77.8 | 59 | |
| YOLO v2 | 544 × 544 | 78.6 | 40 |
| Basic Model | Model Variant | Input Size | GPU | AP | AP50 (%) | AP75 (%) | APS (%) | APM (%) | APL (%) | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLO v3 | YOLO v3 | 320 × 320 | Tesla M40 GPU | 28.2 | 51.5 | 29.7 | 11.9 | 30.6 | 43.4 | 45 |
| YOLO v3 | 416 × 416 | 31.0 | 55.3 | 32.3 | 15.2 | 33.2 | 42.8 | 35 | ||
| YOLO v3 | 608 × 608 | 33.0 | 57.9 | 34.4 | 18.3 | 35.4 | 41.9 | 20 | ||
| YOLO v3-SPP | 608 × 608 | 36.2 | 60.6 | 38.2 | 20.6 | 37.4 | 46.1 | 20 | ||
| YOLO v4 | YOLO v4 | 416 × 416 | Tesla M40 GPU | 41.2 | 62.8 | 44.3 | 20.4 | 44.4 | 56.0 | 38 |
| YOLO v4 | 512 × 512 | 43.0 | 64.9 | 46.5 | 24.3 | 46.1 | 55.2 | 31 | ||
| YOLO v4 | 608 × 608 | 43.5 | 54.7 | 47.3 | 26.7 | 46.7 | 53.3 | 23 | ||
| YOLO v5 | YOLO v5-N | 640 × 640 | Tesla T4 GPU | 28.0 | 45.7 | - | - | - | - | 602 |
| YOLO v5-S | 640 × 640 | 37.4 | 56.8 | - | - | - | - | 376 | ||
| YOLO v5-M | 640 × 640 | 45.4 | 64.1 | - | - | - | - | 182 | ||
| YOLO v5-L | 640 × 640 | 49.0 | 67.3 | - | - | - | - | 113 | ||
| YOLO v6 | YOLO v6-N | 640 × 640 | Tesla T4 GPU | 35.9 | 51.2 | - | - | - | - | 802 |
| YOLO v6-T | 640 × 640 | 40.3 | 56.6 | - | - | - | - | 449 | ||
| YOLO v6-S | 640 × 640 | 43.5 | 60.4 | - | - | - | - | 358 | ||
| YOLO v6-M | 640 × 640 | 49.5 | 66.8 | - | - | - | - | 179 | ||
| YOLO v6-L-ReLU | 640 × 640 | 51.7 | 69.2 | - | - | - | - | 113 | ||
| YOLO v6-L | 640 × 640 | 52.5 | 70.0 | - | - | - | - | 98 | ||
| YOLO v7 | YOLOv7-tiny | 416 × 416 | V100 GPU | 35.2 | 52.8 | 37.3 | 15.7 | 38.0 | 53.4 | 273 |
| YOLO v7 | 640 × 640 | 51.2 | 69.7 | 55.5 | 35.2 | 56.0 | 66.7 | 118 | ||
| YOLO v7-X | 640 × 640 | 52.9 | 71.1 | 57.5 | 36.9 | 57.7 | 68.6 | 98 | ||
| YOLO v7-E6 | 1280 × 1280 | 55.9 | 73.5 | 61.1 | 40.6 | 60.3 | 70.0 | 54 | ||
| YOLO v7-D6 | 1280 × 1280 | 56.3 | 73.8 | 61.4 | 41.3 | 60.6 | 70.1 | 43 | ||
| YOLO v7-E6E | 1280 × 1280 | 56.8 | 74.4 | 62.1 | 40.8 | 62.1 | 70.6 | 35 | ||
| YOLO v8 | YOLO v8n | 640 × 640 | V100 GPU | 37.3 | 52.6 | - | - | - | - | - |
| YOLO v8s | 640 × 640 | 44.9 | 61.8 | - | - | - | - | - | ||
| YOLO v8m | 640 × 640 | 50.2 | 67.2 | - | - | - | - | - | ||
| YOLO v8l | 640 × 640 | 52.9 | 69.8 | 57.5 | 35.3 | 58.3 | 69.8 | |||
| YOLO v8x | 640 × 640 | 53.9 | 71.0 | 58.7 | 35.7 | 59.3 | 70.7 | |||
| YOLO v9 | YOLO v9-T | 640 × 640 | V100 GPU | 38.3 | 53.1 | 41.3 | - | - | - | - |
| YOLO v9-S | 640 × 640 | 46.8 | 63.4 | 50.7 | 26.6 | 56.0 | 64.5 | - | ||
| YOLO v9-M | 640 × 640 | 51.4 | 68.1 | 56.1 | 33.6 | 57.0 | 68.0 | - | ||
| YOLO v9-C | 640 × 640 | 53.0 | 70.2 | 57.8 | 36.2 | 58.5 | 69.3 | - | ||
| YOLO v9-E | 640 × 640 | 55.6 | 72.8 | 60.6 | 40.2 | 61.0 | 71.4 | - |
| Dataset | Categories | Image Size (Input Resolution) | Year Established | Key Features | Download Address | |
|---|---|---|---|---|---|---|
| Common Object Detection Datasets | Pascal VOC | 20 classes | Variable (resized to fixed resolution for model input) | 2005 | Foundational dataset for object detection with 20 common object categories. | http://host.robots.ox.ac.uk/pascal/VOC/voc2007/index.html (accessed on 20 January 2025) |
| ImageNet | 9000 classes | Variable | 2010 | Large-scale dataset with extensive image classification labels. | https://image-net.org/download.php (accessed on 20 January 2025) | |
| COCO | 80 classes | Typically resized to 608 × 608 or model-specific resolutions | 2014 | Rich contextual information; complex real-world scenes with precise annotations. | https://cocodataset.org/ (accessed on 20 January 2025) | |
| Google Open Images | 600 classes | Variable | 2017 | Large-scale dataset and multi-object scenes. | https://storage.googleapis.com/openimages/web/download_v7.html (accessed on 20 January 2025) | |
| Animal Phenotyping Datasets | AP-10 K Animal Pose Estimation [33] | 54 classes | Variable | 2021 | Benchmark for animal pose estimation with diverse animal postures. | https://github.com/AlexTheBad/AP10K (accessed on 20 January 2025) |
| Sheep Grazing Dataset [34] | 5 classes | Variable | 2024 | Supports intelligent sheep grazing management with behavioral analysis. | https://zenodo.org/records/11313800 (accessed on 20 January 2025) | |
| Cow Body Condition Scoring [35] | 5 classes | 1297 × 720 | 2024 | Enables automated body condition assessment for cattle health monitoring. | https://www.scidb.cn/en/detail?dataSetId=16b8bdaf31ee4c8b9891fc7e9df6e41c (accessed on 20 January 2025) | |
| Salmon Health Assessment [36] | 2 classes | 1920 × 1080 | 2024 | Provides data for salmon growth status evaluation and health risk assessment. | https://data.mendeley.com/datasets/rvrt4zs969/1 (accessed on 20 January 2025) | |
| Custom Datasets | Total Samples | Data Augmentation Methods | Hardware | Application Scenarios |
|---|---|---|---|---|
| Sheep Face Dataset [37] | 4000 | Mosaic augmentation; random adjustments to hue, saturation, brightness; flipping, shearing, scaling, translation | Binocular cameras | Accurate detection and localization of goat faces in complex environments, supporting precision livestock farming with technical insights. |
| Dairy Cow Body Condition Dataset [38] | 8972 | Manual filtering | Hikvision network cameras | Commercial body condition scoring for dairy cows, providing theoretical foundations and intelligent solutions for modern dairy farming. |
| Meat Pigeon Behavior Dataset [39] | 10,320 | Fog simulation; random flipping; noise injection; blurring | Hikvision DS-2CD3T47EDWD-L (4 mm) cameras | Technical reference for intelligent meat pigeon breeding and scientific management, enhancing automation in poultry farming. |
| Annotation Method | Significance | Application Scenarios |
|---|---|---|
| Bounding Box Annotation | Provides rough location information of the target object, suitable for object detection tasks. | Animal detection, quantity statistics, target tracking. |
| Semantic Segmentation Annotation | Provides pixel-level fine annotation, suitable for tasks that require precise target boundaries. | Animal contour extraction, background separation, scene understanding. |
| Instance Segmentation Annotation | Provides pixel-level annotation while distinguishing different individuals. | Analysis of multi-animal scenes, individual behavior research, phenotypic feature quantification. |
| Keypoint Annotation | Provides the posture and structural information of the target animal, suitable for pose estimation and behavior analysis tasks. | Animal pose estimation, behavior recognition, phenotypic feature measurement. |
| Trajectory Annotation | Provides the movement information of the target animal, suitable for behavior analysis and tracking tasks. | Animal behavior analysis, target tracking, group behavior research. |
| Scenario | Animal | Algorithm | Improvement Method | Performance Indicator | Reference |
|---|---|---|---|---|---|
| Body Size Estimation | Cow | YOLOv5 | Combined with Siamese network | mAP50: 95.13% | [42] |
| Cow | YOLOv5 | Sparse BN layer, channel pruning | Model size reduced by 86.10%, parameter quantity decreased by 88.19%, and FLOPs reduced by 63.25%, respectively | [43] | |
| Cow | YOLOv5 | Attention mechanism of bilateral filtering, optimized pooling | mAP50: 90.74% | [44] | |
| Pig | YOLOv5 | Established a body weight prediction system | The prediction error meets the breeding requirements | [45] | |
| Pig | YOLOv5 | Introduced MobilenetV3 network and attention mechanism | The model is reduced to 10.2 M, and the error rate is lower than 2% | [29] | |
| Chicken | YOLOv8 | Introduced volume and mass calculation system | The prediction error rate is lower than 5% | [46] | |
| Cow | YOLOv8 | Established a method for estimating cow body weight | P: 97.8%, R: 96.4%, mAP50: 99.0% | [47] | |
| Cow | YOLOv3 | Mean filtering algorithm, custom FilterLayer layer | P: 99.18%, R: 97.51%, mAP50: 99.0%, frame rate: 21 FPS | [48] | |
| Sheep | YOLOv7 | Body length estimation based on distance | The error rate is low and meets the actual needs | [49] | |
| Sheep | YOLOv8 | Combined with Roboflow algorithm | mAP50: 88.2% | [50] | |
| Pig | YOLOv5 | Combined with U-Net network | mAP50: 92% | [51] | |
| Individual Recognition | Cow | YOLOv3 | Integrated individual recognition and detection system | mAP50: 96% | [27] |
| Cow | YOLOv8 | Introduced hash algorithm and sliding window for segmentation | mAP50: 98.6% | [52] | |
| Pig | YOLOv5 | Introduced attention mechanism, optimized neck feature fusion | mAP50: 98.4% | [53] | |
| Pig | YOLOv8 | LSKA attention mechanism, optimized downsampling, loss function | mAP50: 94.76%, frame rate: 79 FPS | [54] | |
| Pig | YOLOv7 | EMobileNet backbone network, Horizontal–Vertical Attention Mechanism (HVAM) | Model parameters are 0.97 M, mAP50: 99.34%, frame rate: 120 FPS | [31] | |
| Sheep | YOLOv4 | Introduced GhostNet module, improved feature fusion network | mAP50: 96.7%, frame rate: 28 FPS | [28] | |
| Sheep | YOLOv5 | CBAM attention mechanism | P: 97%, R: 89%, mAP50: 93.5%, frame rate: 140 FPS, model parameters are 14.68 M | [17] | |
| Sheep | YOLOv5 | ShuffleNetv2 module and Ghost module | mAP50: 97.8%, model parameters are 9.5 M. | [55] | |
| Fish | YOLOv2 | Continuous frame optimization classification method | The mAP50 of the two data sets was 93.94% and 97.06%, respectively | [26] | |
| Fish | YOLOv3 | Introduced MobileNet network | Both the parameter quantity and the mean average precision are improved compared with the baseline model | [56] | |
| Fish | YOLOv7 | Improved convolution kernel, detection head, network pruning | Average accuracy rate: 92.86%; the amount of calculation is reduced by about 35% | [57] | |
| Behavior Recognition and Monitoring | Dairy Cow | YOLOv5 | Introduced GCNet and Swin Transformer in the backbone network; introduced BiFPN in the neck; introduced CA (Coordinate Attention) attention mechanism in the head. | P: 99.7%, R: 99.5%, mAP50: 99.5%, frame rate: 156.3 FPS | [58] |
| Dairy Cow | YOLOv7 | Added self-attention and convolution hybrid module (ACmix), improved the downstream task of ByteTrack | P: 97.3%, R: 96%, mAP50: 97.3% | [59] | |
| Cow | YOLOv8 | Optimized the conv convolution layer, introduced the attention mechanism | P: 93.6%, R: 92.9%, mAP50: 96.5% | [40,41] | |
| Duck | YOLOv8 | Introduced SENet attention mechanism, WIoU v3 loss function | mAP50: 94.4%, the model is reduced by 2.8 MB, and the parameter quantity is reduced by 8.7% | [32] | |
| Fish | YOLOv5 | RFB module, CBAM attention mechanism, optimized FPN module | P: 99.8%, R: 99.5%, mAP50: 99.5% | [60] | |
| Chicken | YOLOv5 | Attention mechanism, optimized spatial pyramid pooling module | P: 93.6%, R: 99.5%, mAP50: 95.45% | [61] | |
| Chicken | YOLOv5 | Dataset and model optimization | P: 93.7%, R: 84.6%, mAP50: 90.9% | [62] | |
| Chicken | YOLOv5 | Loss function | P: 99.9%, R: 99.2%, mAP50: 99.6% | [63] | |
| Pigeon | YOLOv4 | Introduced GhostNet | mAP50: 97.06%, frame rate: 35.71 FPS | [64] | |
| Pig | YOLOv8 | Introduced Multi-Path Coordinate Attention (MPCA) mechanism, optimized C2f | P: 88.2%, R: 92.2%, mAP50: 95.3% | [65] | |
| Sheep | YOLOv8 | Model lightweight, introduced attention mechanism, loss function | mAP50: 98.11% | [66] | |
| Sheep | YOLOv4 | Introduced behavior reasoning strategy | mAP50: 96%, and the frame rate is 17 FPS. | [67] | |
| Sheep | YOLOv8 | CBAM attention mechanism, improved convolution module | The mAP50 is higher than 96%, the model volume is reduced by 13.3%, the computation amount is decreased by 12.1%, and the frame rate is 52.1 FPS. | [68] | |
| Biomass Estimation | Sheep | YOLOv5 | Bidirectional line-crossing counting method | High accuracy rate, in line with practical applications | [69] |
| Fish | YOLOv5 | Channel pruning, model lightweight | When pruning 15%, the average accuracy rate of the model is above 90%, and the frame rate is 13 FPS | [70] | |
| Shrimp | YOLOv5 | CBAM attention mechanism | P: 97.2%, R: 96.5%, mAP50: 96.3% | [71] | |
| Shrimp | YOLOv8 | Adaptive frame skipping | Counting rate: 82.57%, frame rate: 97.47 FPS | [72] | |
| Chicken | YOLOv7 | Introduced deep convolution, attention mechanism | The mAP50 is 96.9%, and the model volume is reduced to 5.6 MB | [73] | |
| Duck | YOLOv7 | CBAM attention mechanism | P: 96.84%, R: 94.57%, mAP50: 98.72% | [74] | |
| Cow | YOLOv5 | Introduced SPPFCSPC, GSConv, CA attention mechanism | P: 95.5%, mAP50: 95.2%, frame rate: 88 FPS | [75] | |
| Cow | YOLOv7 | Introduced PConv, DioU, DyHead | P: 98.8%, R: 99%, mAP50: 92.1% | [76] | |
| Cow | YOLOv8 | Transfer learning, data augmentation | P: 91%, R:83.4%, mAP50: 88.8% | [19] | |
| Pig | YOLOv7 | Introduced REPConv, CA attention mechanism | mAP50: 96.58%, frame rate: 22 FPS | [77] | |
| Pig | YOLOv4 | Proposed an automatic counting algorithm | mAP50: 98.11%, frame rate is approximately 10 FPS | [78] |
| Model | P | R | mAP50 | mAP50:95 |
|---|---|---|---|---|
| Faster R-CNN | 0.862 | 0.843 | 0.879 | 0.605 |
| YOLOX | 0.869 | 0.859 | 0.901 | 0.639 |
| YOLOv7 | 0.87 | 0.862 | 0.911 | 0.642 |
| YOLOv8n | 0.883 | 0.866 | 0.913 | 0.644 |
| YOLOv8n_BiF_DSC | 0.936 | 0.929 | 0.965 | 0.715 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Jian, R.; Jun, X.; Shi, G. A Review of You Only Look Once Algorithms in Animal Phenotyping Applications. Animals 2025, 15, 1126. https://doi.org/10.3390/ani15081126
Li G, Jian R, Jun X, Shi G. A Review of You Only Look Once Algorithms in Animal Phenotyping Applications. Animals. 2025; 15(8):1126. https://doi.org/10.3390/ani15081126
Chicago/Turabian StyleLi, Guangbo, Rui Jian, Xie Jun, and Guolong Shi. 2025. "A Review of You Only Look Once Algorithms in Animal Phenotyping Applications" Animals 15, no. 8: 1126. https://doi.org/10.3390/ani15081126
APA StyleLi, G., Jian, R., Jun, X., & Shi, G. (2025). A Review of You Only Look Once Algorithms in Animal Phenotyping Applications. Animals, 15(8), 1126. https://doi.org/10.3390/ani15081126