



Multi-Modality Sheep Face Recognition Based on Deep Learning
 , ,
, ,  , ,
, ,
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Acquisition and Processing
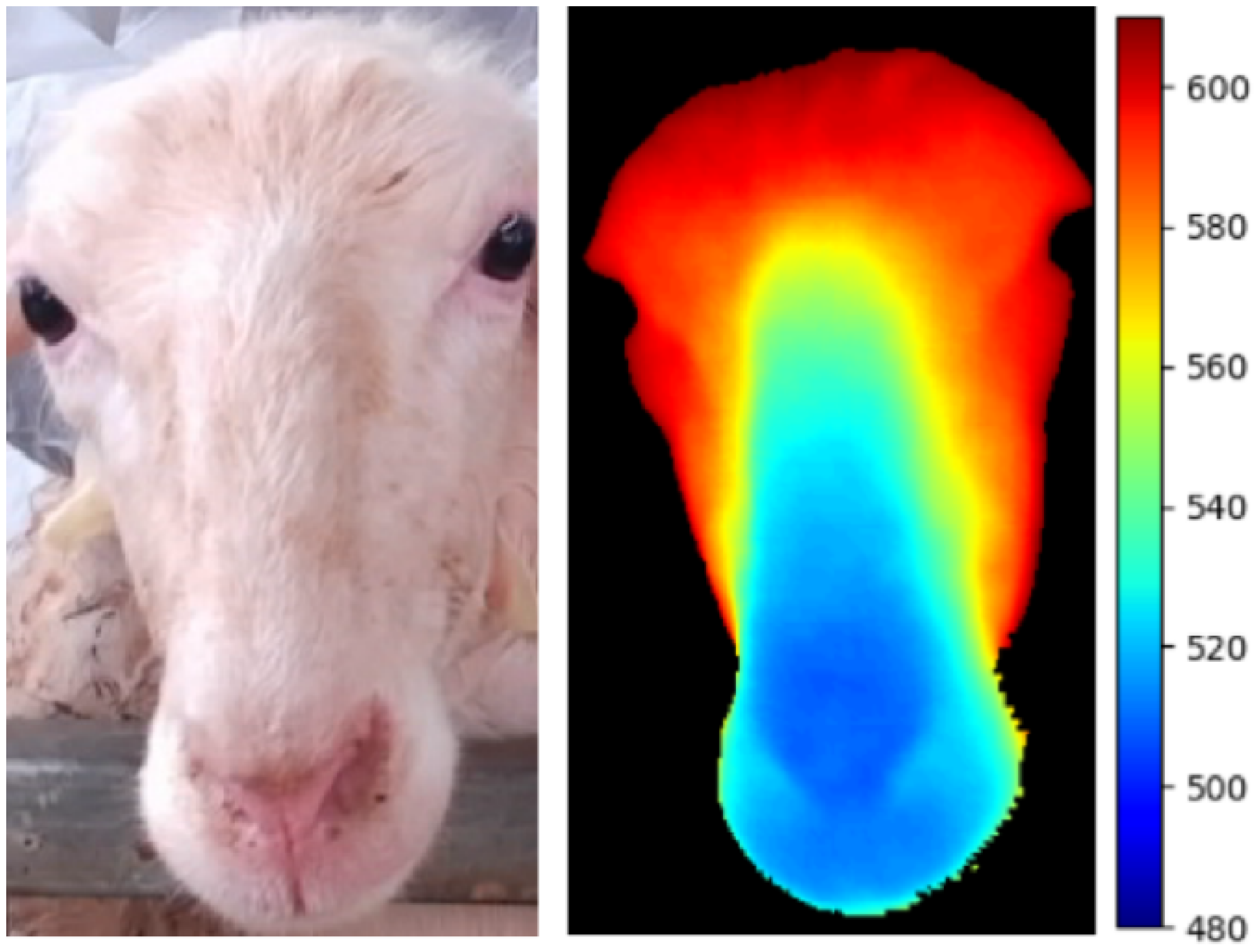
2.1.1. Multi-Modal Data Acquisition
2.1.2. Dataset Construction
2.2. Identification Methods
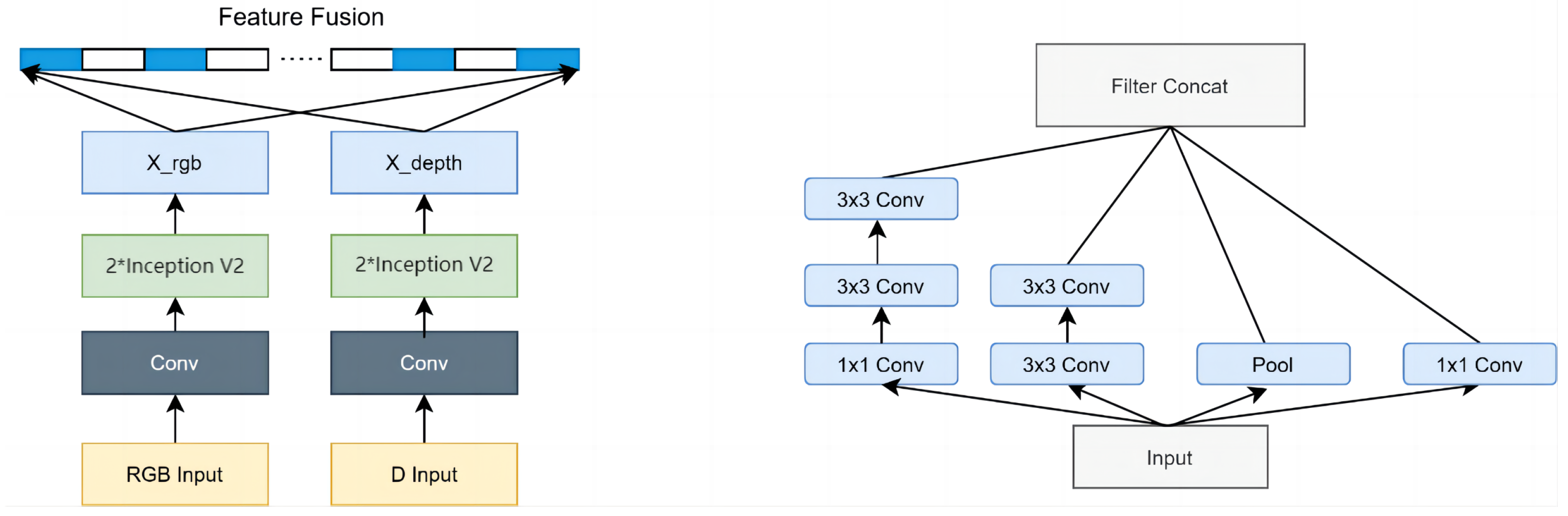
2.2.1. Two-Stream Convolutional Network Structure
2.2.2. ResNet18 Network
2.3. Attention Module
2.3.1. Convolutional Block Attention Module
2.3.2. Mamba Module
2.3.3. A Multimodal Sheep Face Recognition Network
3. Experiment and Results Analysis
3.1. Experimental Setup and Evaluation Metrics
3.1.1. Experimental Parameter Setting and Experimental Process
3.1.2. Evaluation Indicators
3.2. Performance Comparison of Different Models
3.3. Ablation Experiment
3.4. Comparative Experiments on Attention Mechanisms
4. Discussion
4.1. Optimal Shooting Distance for 3D Cameras
4.2. Selection and Compatibility Issues of 3D Cameras
4.3. Diversity of Sheep Breeds
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CBAM | Convolutional Block Attention Module |
| YOLOv5s | You Only Look Once version 5 small |
| CARAFE | Content-Aware ReAssembly of FEatures |
| ViT | Vision Transformer |
| T2T-Vit-SFR | Tokens-to-Token Vision Transforme - Sheep Face Recognition |
| CLM-Z | A Three-Dimensional Constrained Local Model |
| RGB-D | RGB-Depth |
| TOF | Time-of-Flight |
| YOLOv8n | You Only Look Once version 8 nano |
| ReLU | Rectified Linear Unit |
| MLP | Multi-layer Perceptron |
| AvgPool | Average Pooling |
| MaxPool | Maximum Pooling |
| Conv | Convolution |
| Cat | Concatenation |
| CBAM-DRESM | CBAM-DualRESnetMamba |
| FC | Full Connection |
| SGD | Stochastic Gradient Desent |
| AAM-Softmax | Angular Additive Margin Softmax |
| SDK | Software Development Kit |
| FRR | False Reject Rate |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
| SE | Squeeze-and-Excitation |
| ECA | Efficient Channel Attention |
| SA | Self-Attention |
| CA | Coordinate Attention |
References
- Zhang, C. Development and Application of Individual Recognition and Intelligent Measurement of Body Size Traits in Hu Sheep. Ph.D. Thesis, Huazhong Agricultural University, Wuhan, China, 2022. Available online: https://link.cnki.net/doi/10.27158/d.cnki.ghznu.2022.001786 (accessed on 8 February 2025).
- Aguilar-Lazcano, C.A.; Espinosa-Curiel, I.E.; Ríos-Martínez, J.A.; Madera-Ramírez, F.A.; Pérez-Espinosa, H. Machine Learning-Based Sensor Data Fusion for Animal Monitoring: Scoping Review. Sensors 2023, 23, 5732. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Huang, Y.; Chen, Z.; Chesser, G.D., Jr.; Purswell, J.L.; Linhoss, J.; Zhao, Y. Practices and Applications of Convolutional Neural Network-Based Computer Vision Systems in Animal Farming: A Review. Sensors 2021, 21, 1492. [Google Scholar] [CrossRef] [PubMed]
- Norouzzadeh, M.S.; Nguyen, A.; Kosmala, M.; Swanson, A.; Palmer, M.S.; Packer, C.; Clune, J. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proc. Natl. Acad. Sci. USA 2018, 115, E5716–E5725. [Google Scholar] [CrossRef] [PubMed]
- Binta Islam, S.; Valles, D.; Hibbitts, T.J.; Ryberg, W.A.; Walkup, D.K.; Forstner, M.R.J. Animal Species Recognition with Deep Convolutional Neural Networks from Ecological Camera Trap Images. Animals 2023, 13, 1526. [Google Scholar] [CrossRef]
- Kariri, E.; Louati, H.; Louati, A.; Masmoudi, F. Exploring the Advancements and Future Research Directions of Artificial Neural Networks: A Text Mining Approach. Appl. Sci. 2023, 13, 3186. [Google Scholar] [CrossRef]
- Delplanque, A.; Foucher, S.; Lejeune, P.; Linchant, J.; Théau, J. Multispecies detection and identification of African mammals in aerial imagery using convolutional neural networks. Remote. Sens. Ecol. Conserv. 2022, 8, 166–179. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, H.; Tian, F.; Zhou, Y.; Zhao, S.; Du, X. Research on sheep face recognition algorithm based on improved AlexNet model. Neural Comput. Appl. 2023, 35, 24971–24979. [Google Scholar] [CrossRef]
- Wan, Z.; Tian, F.; Zhang, C. Sheep Face Recognition Model Based on Deep Learning and Bilinear Feature Fusion. Animals 2023, 13, 1957. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, L.; Li, Y.; Hao, J.; Sun, Y.; Li, S. Sheep Face Recognition Method Based on Improved MobileFaceNet. Trans. Chin. Soc. Agric. Mach. 2022, 53, 267–274. Available online: https://link.cnki.net/urlid/11.1964.S.20220317.1251.014 (accessed on 8 February 2025).
- Zhang, S.; Han, D.; Tian, M.; Gong, C.; Wei, Y.; Wang, B. Sheep face recognition based on weak edge feature fusion. J. Comput. Appl. 2022, 42 (Suppl. S2), 224–229. [Google Scholar]
- Ning, J.; Lin, J.; Yang, S.; Wang, Y.; Lan, X. Face Recognition Method of Dairy Goat Based on Improved YOLO v5s. Trans. Chin. Soc. Agric. Mach. 2023, 54, 331–337. Available online: https://link.cnki.net/urlid/11.1964.S.20230306.1228.002 (accessed on 8 February 2025).
- Li, X.; Xiang, Y.; Li, S. Combining convolutional and vision transformer structures for sheep face recognition. Comput. Electron. Agric. 2023, 205, 107651. [Google Scholar] [CrossRef]
- Zhang, X.; Xuan, C.; Ma, Y.; Tang, Z.; Gao, X. An efficient method for multi-view sheep face recognition. Eng. Appl. Artif. Intell. 2024, 134, 108697. [Google Scholar] [CrossRef]
- Uppal, H.; Sepas-Moghaddam, A.; Greenspan, M.; Etemad, A. Depth as attention for face representation learning. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2461–2476. [Google Scholar] [CrossRef]
- Ma, M.; Ren, J.; Zhao, L.; Testuggine, D.; Peng, X. Are multimodal transformers robust to missing modality? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 18177–18186. [Google Scholar] [CrossRef]
- Tang, G.; Xie, Y.; Li, K.; Liang, R.; Zhao, L. Multimodal emotion recognition from facial expression and speech based on feature fusion. Multimed. Tools Appl. 2023, 82, 16359–16373. [Google Scholar] [CrossRef]
- Almabdy, S.; Elrefaei, L. Feature extraction and fusion for face recognition systems using pre-trained convolutional neural networks. Int. J. Comput. Digit. Syst. 2021, 9, 1–7. [Google Scholar] [CrossRef]
- Kaashki, N.N.; Safabakhsh, R. RGB-D face recognition under various conditions via 3D constrained local model. J. Vis. Commun. Image Represent. 2018, 52, 66–85. [Google Scholar] [CrossRef]
- Uppal, H.; Sepas-Moghaddam, A.; Greenspan, M.; Etemad, A. Two-level attention-based fusion learning for rgb-d face recognition. In Proceedings of the IEEE/2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 13–18 September 2020; pp. 10120–10127. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, M.; Deng, W.; Shi, H.; Wen, D.; Zhang, Y.; Cui, X.; Zhao, J. Confidence-Aware RGB-D Face Recognition via Virtual Depth Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 1481–1489. [Google Scholar] [CrossRef]
- Grati, N.; Ben-Hamadou, A.; Hammami, M. Learning local representations for scalable RGB-D face recognition. Expert Syst. Appl. 2020, 150, 113319. [Google Scholar] [CrossRef]
- Zhang, H.; Han, H.; Cui, J.; Shan, S.; Chen, X. RGB-D face recognition via deep complementary and common feature learning. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 8–15. [Google Scholar] [CrossRef]
- Schelling, M.; Hermosilla, P.; Ropinski, T. Weakly-supervised optical flow estimation for time-of-flight. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 2135–2144. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Zhu, D.; Du, B.; Zhang, L. Two-stream convolutional networks for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6907–6921. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 42, 2011–2023. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Sheep | Number of Training Sets | Number of Validation Sets |
|---|---|---|
| 99 | 10,003 | 2501 |
| Models | RGB | Depth | Fusion |
|---|---|---|---|
| MobileNetV2 | 93.57% | 89.55% | 93.36% |
| ResNet18 | 96.32% | 90.38% | 96.03% |
| VGG-16 | 94.75% | 88.58% | 94.27% |
| EfficientNetV2-S | 95.73% | 91.69% | 95.85% |
| ConvNeXt-T | 95.20% | 85.02% | 94.32% |
| ViT-B | 91.24% | 84.45% | 90.76% |
| CBAM-DRESM | - | - | 98.49% |
| Models | Identification Accuracy | F1-Score | FRR |
|---|---|---|---|
| Resnet18 | 96.32% | 96.21% | 3.66% |
| DualResnet18 | 96.75% | 96.63% | 3.25% |
| DualResnet18+CBAM | 98.13% | 98.01% | 1.89% |
| DualResnet18+CBAM+Mamba | 98.49% | 98.39% | 1.50% |
| Models | Identification Accuracy | F1-Score | FRR |
|---|---|---|---|
| DualResnet18+SE | 97.12% | 97.05% | 2.86% |
| DualResnet18+ECA | 97.34% | 97.28% | 2.65% |
| DualResnet18+SA | 96.93% | 96.92% | 3.07% |
| DualResnet18+CA | 97.88% | 97.79% | 2.11% |
| DualResnet18+CBAM | 98.13% | 98.01% | 1.89% |
| Models | Identification Accuracy | F1-Score | FRR |
|---|---|---|---|
| DualResnet18+CBAM+SE | 98.05% | 97.93% | 1.92% |
| DualResnet18+CBAM+ECA | 98.21% | 98.10% | 1.79% |
| DualResnet18+CBAM+SA | 97.82% | 97.70% | 2.17% |
| DualResnet18+CBAM+CA | 98.35% | 98.24% | 1.65% |
| DualResnet18+CBAM+Mamba | 98.49% | 98.39% | 1.50% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, S.; Shu, Y.; Tian, F.; Zhou, Y.; Li, G.; Zhang, C.; Yao, C.; Wang, Z.; Che, L. Multi-Modality Sheep Face Recognition Based on Deep Learning. Animals 2025, 15, 1111. https://doi.org/10.3390/ani15081111
Liao S, Shu Y, Tian F, Zhou Y, Li G, Zhang C, Yao C, Wang Z, Che L. Multi-Modality Sheep Face Recognition Based on Deep Learning. Animals. 2025; 15(8):1111. https://doi.org/10.3390/ani15081111
Chicago/Turabian StyleLiao, Sheng, Yan Shu, Fang Tian, Yong Zhou, Guoliang Li, Cheng Zhang, Chao Yao, Zike Wang, and Longjie Che. 2025. "Multi-Modality Sheep Face Recognition Based on Deep Learning" Animals 15, no. 8: 1111. https://doi.org/10.3390/ani15081111
APA StyleLiao, S., Shu, Y., Tian, F., Zhou, Y., Li, G., Zhang, C., Yao, C., Wang, Z., & Che, L. (2025). Multi-Modality Sheep Face Recognition Based on Deep Learning. Animals, 15(8), 1111. https://doi.org/10.3390/ani15081111