
PigFRIS: A Three-Stage Pipeline for Fence Occlusion Segmentation, GAN-Based Pig Face Inpainting, and Efficient Pig Face Recognition



Simple Summary
Abstract
1. Introduction
- We propose an integrated three-stage system (PigFRIS) that systematically addresses fence occlusions in pig face recognition by unifying segmentation, GAN-based restoration, and lightweight classification rather than focusing solely on recognition or inpainting.
- We employ a customized YOLOv11L segmentation approach trained on pig faces with synthetic fence masks, enabling precise detection of real-farm obstructions such as metal bars that obscure critical facial cues.
- We apply inpainting technology specifically to pig face recognition for restoring occluded facial features. By targeting the challenge of fence-induced obstructions, our approach significantly enhances identification accuracy compared to baseline methods that ignore or inadequately handle such occlusions.
- We adopt EfficientNet-B2 as a resource-friendly recognition module, achieving strong identification accuracy under computational constraints. Empirical evaluations demonstrate a notable accuracy boost when occluded faces are repaired by the GAN before recognition.
- We present a newly collected and annotated dataset of pig faces frequently occluded by farm structures such as fences. This dataset captures realistic variations in lighting, pose, and environmental conditions, filling a gap in existing resources and enabling more accurate evaluations of occlusion-handling techniques in livestock identification.
- Contribution to Smart Farming and Animal Welfare. Our work provides a practical and scalable solution to the occlusion problem in pig face recognition, promoting non-invasive identification methods and supporting more efficient and ethical livestock management practices.
2. Materials and Methods
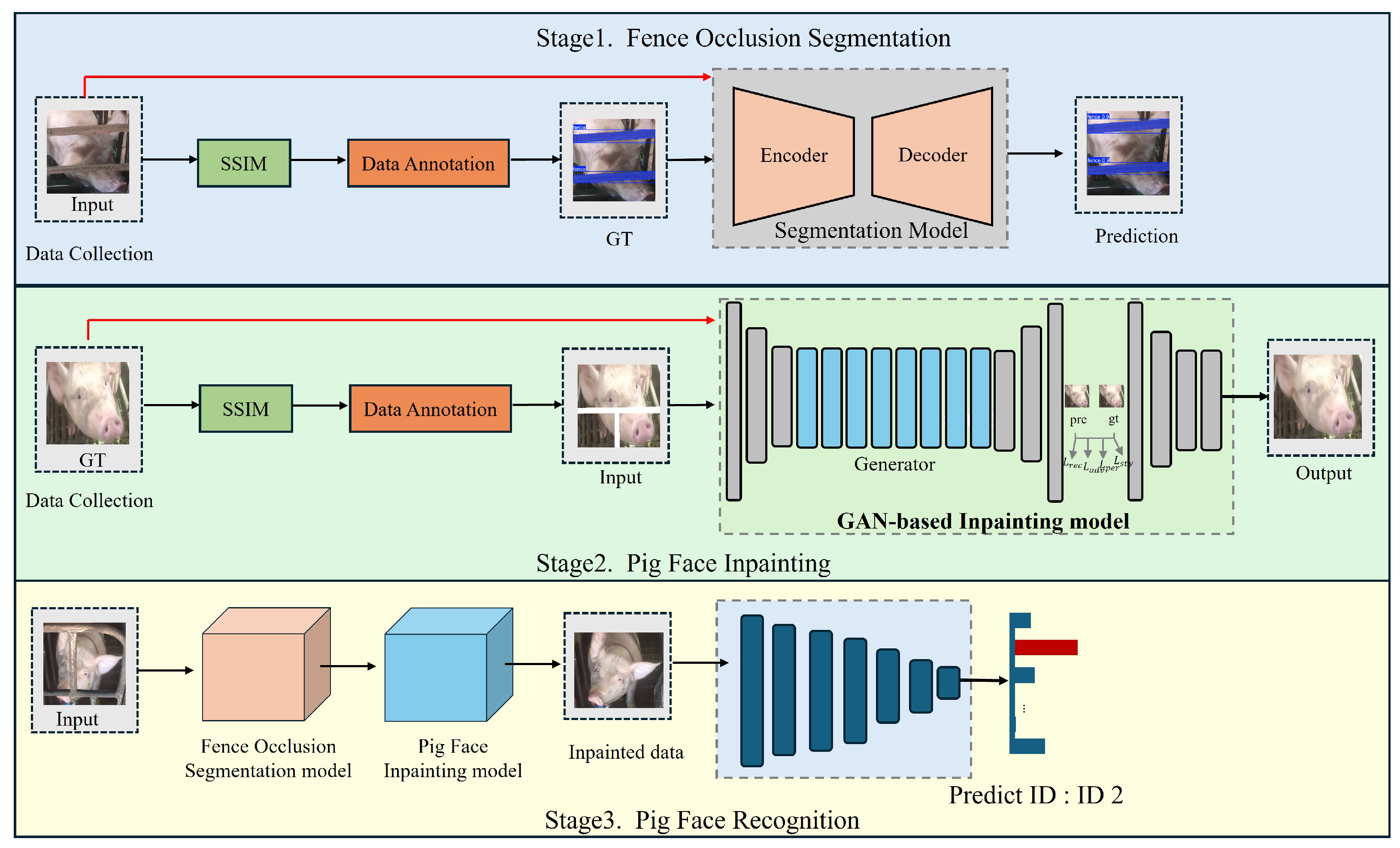
2.1. Overview of the Proposed PigFRIS System
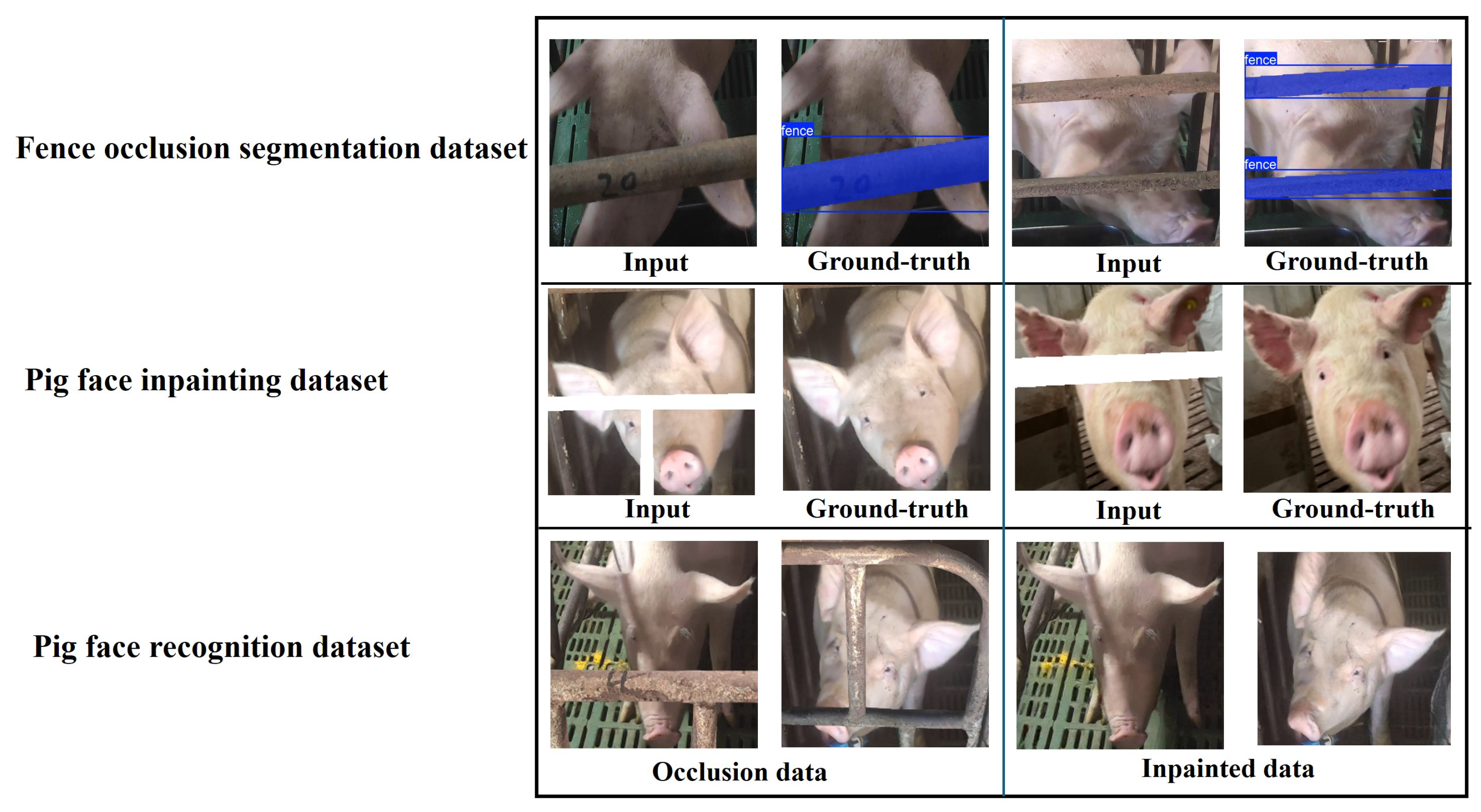
2.2. Dataset
2.2.1. Fence Occlusion Segmentation Dataset
2.2.2. Pig Face Inpainting Dataset
2.2.3. Pig Face Recognition Dataset
2.3. Architecture of the Proposed PigFRIS System
2.3.1. Occlusion Detection Module
2.3.2. Pig Face Inpainting Module
2.3.3. Pig Face Recognition Module
3. Evaluation Metrics
4. Experiments
4.1. Fence Occlusion Segmentation
4.1.1. Experimental Setup
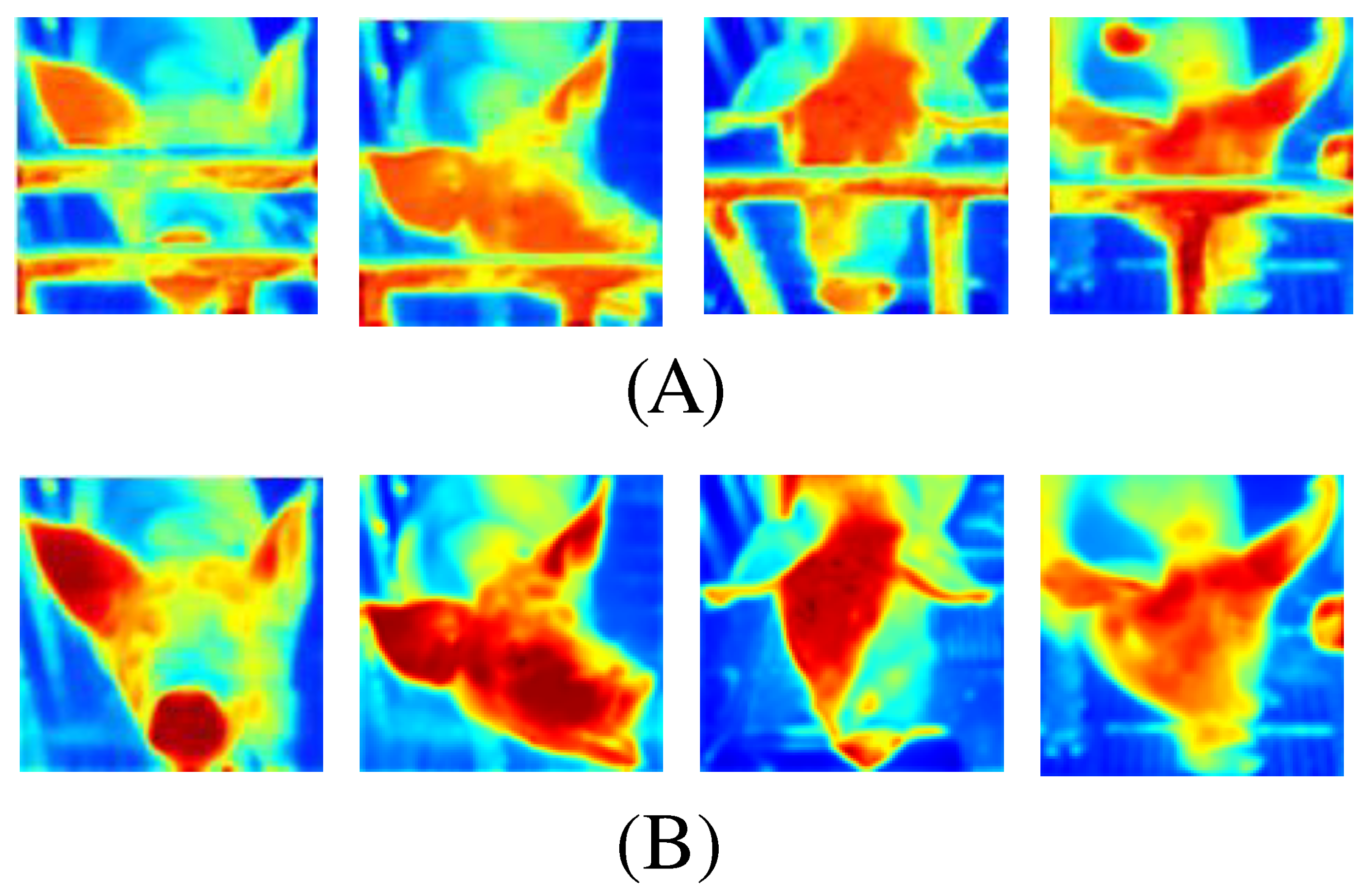
4.1.2. Experimental Results
4.2. Pig Fence Inpainting
4.2.1. Experimental Setup
4.2.2. Experimental Results
4.3. Pig Face Classification
4.3.1. Experimental Setup
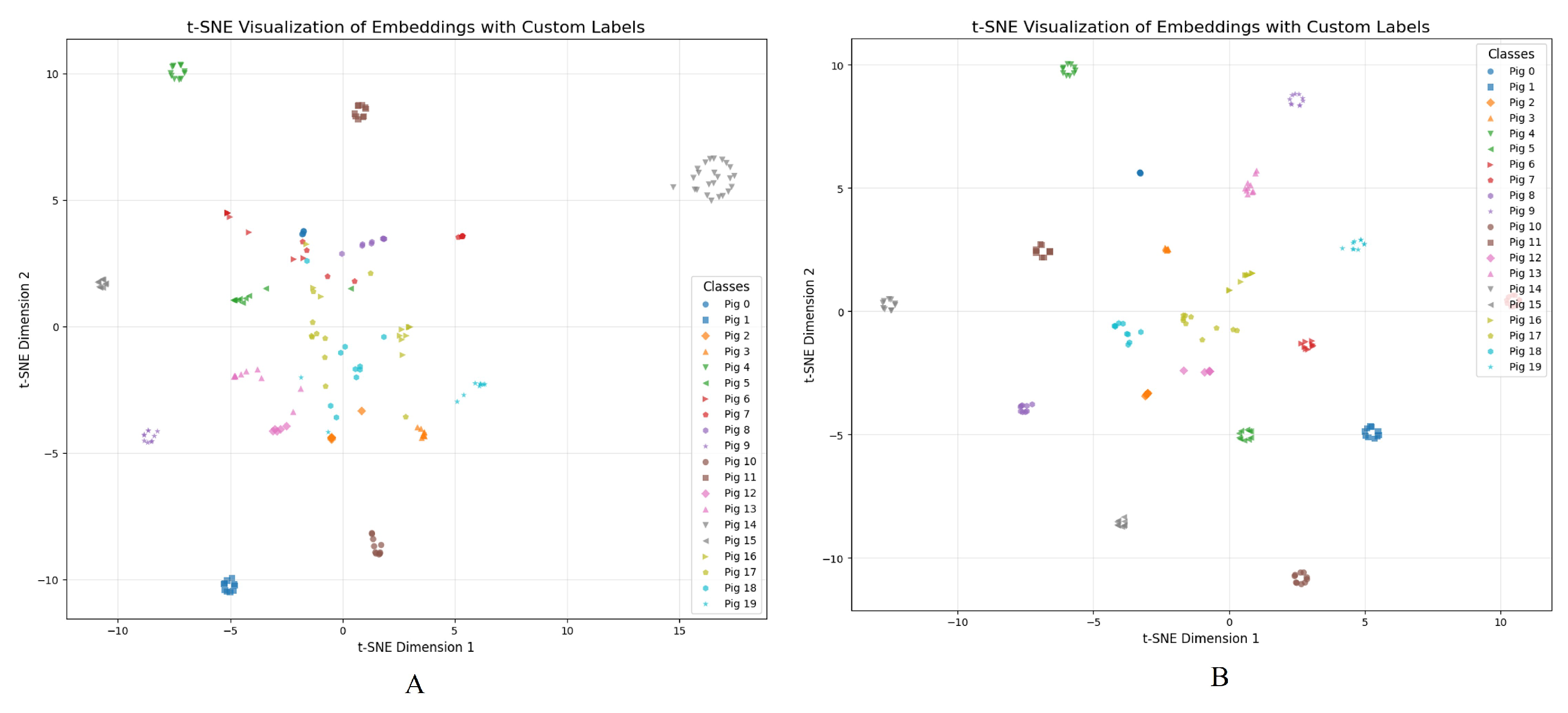
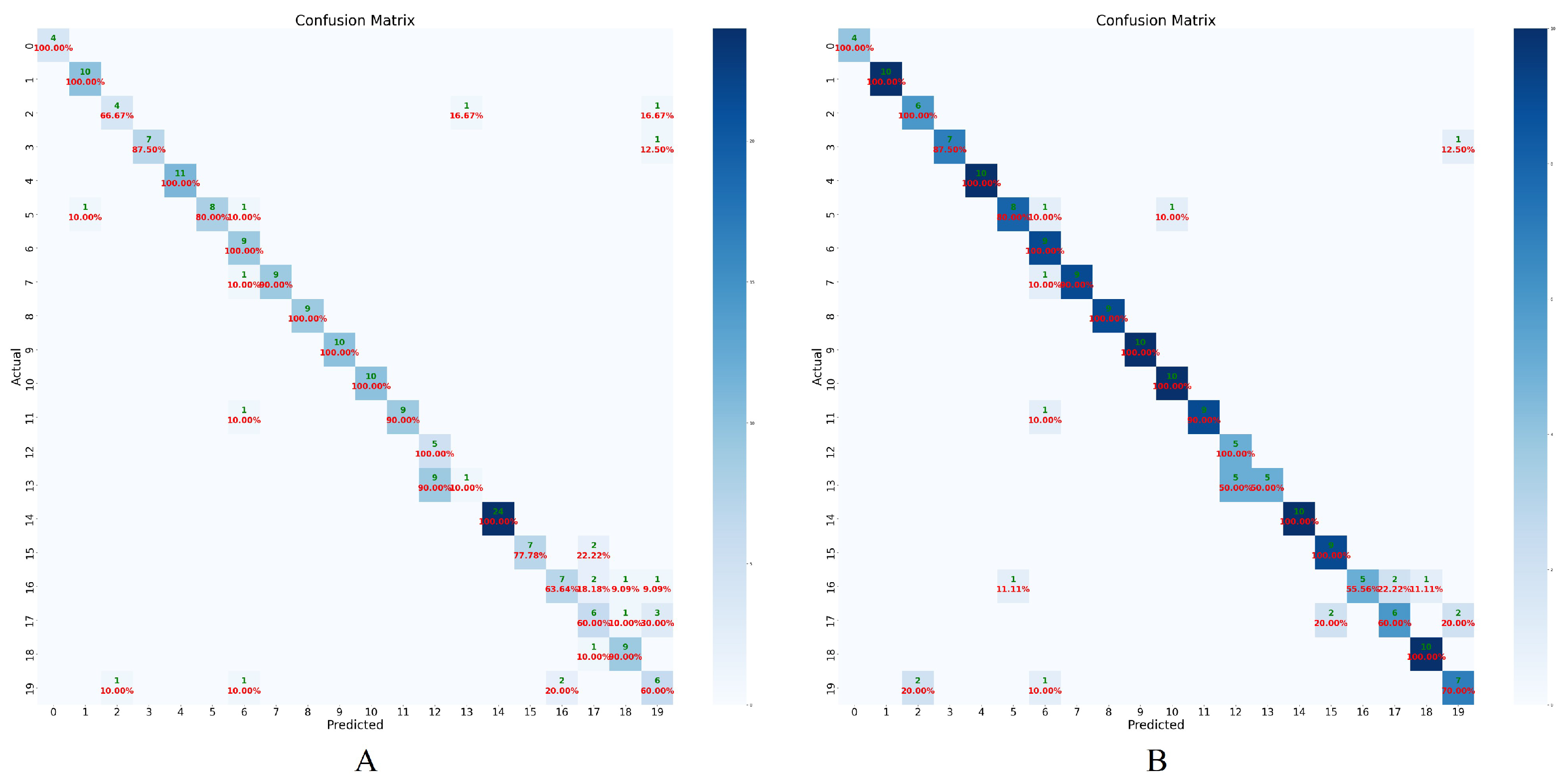
4.3.2. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, S.; He, Q.; Tao, S.; Chen, H.; Zhu, S.; Huang, Z. Pig Face Recognition Based on Trapezoid Normalized Pixel Difference Feature and Trimmed Mean Attention Mechanism. IEEE Trans. Instrum. Meas. 2022, 72, 1–13. [Google Scholar] [CrossRef]
- Jonna, S.; Nakka, K.K.; Sahay, R.R. Deep learning based fence segmentation and removal from an image using a video sequence. arXiv 2016, arXiv:1609.07727. [Google Scholar]
- Maselyne, J.; Saeys, W.; De Ketelaere, B.; Mertens, K.; Vangeyte, J.; Hessel, E.F.; Millet, S.; Van Nuffel, A. Validation of a High Frequency Radio Frequency Identification (HF RFID) system for registering feeding patterns of growing-finishing pigs. Comput. Electron. Agric. 2014, 102, 10–18. [Google Scholar]
- Pereira, E.; Araújo, Í.; Silva, L.F.V.; Batista, M.; Júnior, S.; Barboza, E.; Santos, E.; Gomes, F.; Fraga, I.T.; Davanso, R.; et al. RFID Technology for Animal Tracking: A Survey. IEEE J. Radio Freq. Identif. 2023, 7, 609–620. [Google Scholar] [CrossRef]
- Schindler, F.; Steinhage, V. Identification of animals and recognition of their actions in wildlife videos using deep learning techniques. Ecol. Inform. 2021, 61, 101215. [Google Scholar] [CrossRef]
- Xu, B.; Wang, W.; Guo, L.; Chen, G.; Li, Y.; Cao, Z.; Wu, S. CattleFaceNet: A cattle face identification approach based on RetinaFace and ArcFace loss. Comput. Electron. Agric. 2022, 193, 106675. [Google Scholar] [CrossRef]
- Li, G.; Sun, J.; Guan, M.; Sun, S.; Shi, G.; Zhu, C. A New Method for non-destructive identification and Tracking of multi-object behaviors in beef cattle based on deep learning. Animals 2024, 14, 2464. [Google Scholar] [CrossRef]
- Wan, Z.; Tian, F.; Zhang, C. Sheep face recognition model based on deep learning and bilinear feature fusion. Animals 2023, 13, 1957. [Google Scholar] [CrossRef]
- Mougeot, G.; Li, D.; Jia, S. A deep learning approach for dog face verification and recognition. In Proceedings of the PRICAI 2019: Trends in Artificial Intelligence: 16th Pacific Rim International Conference on Artificial Intelligence, Cuvu, Yanuca Island, Fiji, 26–30 August 2019; Proceedings, Part III 16. Springer: Cham, Switzerland, 2019; pp. 418–430. [Google Scholar]
- Wang, K.; Yang, F.; Chen, Z.; Chen, Y.; Zhang, Y. A fine-grained bird classification method based on attention and decoupled knowledge distillation. Animals 2023, 13, 264. [Google Scholar] [CrossRef]
- Marsot, M.; Mei, J.; Shan, X.; Ye, L.; Feng, P.; Yan, X.; Li, C.; Zhao, Y. An adaptive pig face recognition approach using Convolutional Neural Networks. Comput. Electron. Agric. 2020, 173, 105386. [Google Scholar]
- Wang, Z.; Liu, T. Two-stage method based on triplet margin loss for pig face recognition. Comput. Electron. Agric. 2022, 194, 106737. [Google Scholar]
- Li, G.; Jiao, J.; Shi, G.; Ma, H.; Gu, L.; Tao, L. Fast recognition of pig faces based on improved Yolov3. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2022; Volume 2171, p. 012005. [Google Scholar]
- Li, G.; Shi, G.; Jiao, J. YOLOv5-KCB: A new method for individual pig detection using optimized K-means, CA attention mechanism and a bi-directional feature pyramid network. Sensors 2023, 23, 5242. [Google Scholar] [CrossRef]
- Ma, R.; Ali, H.; Chung, S.; Kim, S.C.; Kim, H. A lightweight pig face recognition method based on automatic detection and knowledge distillation. Appl. Sci. 2023, 14, 259. [Google Scholar] [CrossRef]
- Shigang, W.; Jian, W.; Meimei, C.; Jinyang, W. A pig face recognition method for distinguishing features. In Proceedings of the 2021 IEEE Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2021; pp. 972–976. [Google Scholar]
- Shi, C.; Liu, W.; Meng, J.; Jia, X.; Liu, J. Self-prior guided generative adversarial network for image inpainting. Vis. Comput. 2024, 1–13. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5505–5514. [Google Scholar]
- Zheng, C.; Cham, T.J.; Cai, J. Tfill: Image completion via a transformer-based architecture. arXiv 2021, arXiv:2104.00845. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Zeng, Y.; Fu, J.; Chao, H.; Guo, B. Aggregated contextual transformations for high-resolution image inpainting. IEEE Trans. Vis. Comput. Graph. 2022, 29, 3266–3280. [Google Scholar] [CrossRef]
- Dubey, S.R.; Singh, S.K.; Chaudhuri, B.B. Activation functions in deep learning: A comprehensive survey and benchmark. Neurocomputing 2022, 503, 92–108. [Google Scholar]
- Segu, M.; Tonioni, A.; Tombari, F. Batch normalization embeddings for deep domain generalization. Pattern Recognit. 2023, 135, 109115. [Google Scholar]
- Kaur, R.; Singh, S. A comprehensive review of object detection with deep learning. Digit. Signal Process. 2023, 132, 103812. [Google Scholar]
- Ma, R.; Fuentes, A.; Yoon, S.; Lee, W.Y.; Kim, S.C.; Kim, H.; Park, D.S. Local refinement mechanism for improved plant leaf segmentation in cluttered backgrounds. Front. Plant Sci. 2023, 14, 1211075. [Google Scholar]
- Wang, X.; Song, J. ICIoU: Improved loss based on complete intersection over union for bounding box regression. IEEE Access 2021, 9, 105686–105695. [Google Scholar]
- Shang, S.; Liu, J.; Yang, Y. Multi-layer transformer aggregation encoder for answer generation. IEEE Access 2020, 8, 90410–90419. [Google Scholar]
- Feng, X.; Song, D.; Chen, Y.; Chen, Z.; Ni, J.; Chen, H. Convolutional transformer based dual discriminator generative adversarial networks for video anomaly detection. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 5546–5554. [Google Scholar]
- Koonce, B.; Koonce, B. EfficientNet. Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress: Berkeley, CA, USA, 2021; pp. 109–123. [Google Scholar]
- Naidu, G.; Zuva, T.; Sibanda, E.M. A review of evaluation metrics in machine learning algorithms. In Proceedings of the Computer Science On-Line Conference; Springer: Cham, Switzerland, 2023; pp. 15–25. [Google Scholar]
- Terven, J.; Cordova-Esparza, D.M.; Ramirez-Pedraza, A.; Chavez-Urbiola, E.A.; Romero-Gonzalez, J.A. Loss functions and metrics in deep learning. arXiv 2023, arXiv:2307.02694. [Google Scholar]
- Kynkäänniemi, T.; Karras, T.; Laine, S.; Lehtinen, J.; Aila, T. Improved precision and recall metric for assessing generative models. Adv. Neural Inf. Process. Syst. 2019, 32, 3929–3938. [Google Scholar]
- Yacouby, R.; Axman, D. Probabilistic extension of precision, recall, and f1 score for more thorough evaluation of classification models. In Proceedings of the First Workshop on Evaluation and Comparison of NLP Systems, Online, 20 November 2020; pp. 79–91. [Google Scholar]
- Soloveitchik, M.; Diskin, T.; Morin, E.; Wiesel, A. Conditional frechet inception distance. arXiv 2021, arXiv:2103.11521. [Google Scholar]
- Snell, J.; Ridgeway, K.; Liao, R.; Roads, B.D.; Mozer, M.C.; Zemel, R.S. Learning to generate images with perceptual similarity metrics. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 4277–4281. [Google Scholar]
- Helmrich, C.R.; Bosse, S.; Schwarz, H.; Marpe, D.; Wiegand, T. A study of the extended perceptually weighted peak signal-to-noise ratio (XPSNR) for video compression with different resolutions and bit depths. ITU J. ICT Discov. 2020, 3, 65–72. [Google Scholar]
- Boursalie, O.; Samavi, R.; Doyle, T.E. Evaluation metrics for deep learning imputation models. In Proceedings of the International Workshop on Health Intelligence; Springer: Cham, Switzerland, 2021; pp. 309–322. [Google Scholar]
- Hodson, T.O. Root mean square error (RMSE) or mean absolute error (MAE): When to use them or not. Geosci. Model Dev. Discuss. 2022, 2022, 1–10. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 19 February 2025).
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2025; pp. 1–21. [Google Scholar]
- Patwardhan, K.A.; Sapiro, G.; Bertalmio, M. Video inpainting of occluding and occluded objects. In Proceedings of the IEEE International Conference on Image Processing 2005, Genova, Italy, 14 September 2005; Volume 2, p. II-69. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Augmentation Strategy | Original Images | Augmented Dataset Size | Usage |
|---|---|---|---|---|
| Occlusion segmentation dataset | zoom + cut-out | 186 | 558 | Fence Segmentation |
| Pig Face Inpainting Dataset | zoom + horizontal flipping | 500 | 1000 | Occlusion Removal |
| Pig Face Recognition Dataset | zoom horizontal, dropout | 1000 | 2000 | Pig Face Recognition |
| Model | Precision | Recall | |||
|---|---|---|---|---|---|
| YOLO8n [39] | 94.97± 0.7 | 89.83 ± 1.2 | 95.48 ± 0.4 | 90.17 ± 0.1 | 88.62 ± 0.5 |
| YOLO8s | 87.46 ± 0.4 | 94.58 ± 0.2 | 94.87 ± 1.1 | 90.60 ± 0.6 | 84.97 ± 0.8 |
| YOLO8m | 88.71 ± 0.1 | 93.22 ± 0.4 | 96.22 ± 0.1 | 92.35 ± 0.9 | 86.86 ± 0.5 |
| YOLO8l | 90.66 ± 0.2 | 86.44 ± 0.4 | 95.78 ± 1.6 | 93.29 ± 0.6 | 84.88 ± 1.7 |
| YOLO9c [40] | 90.15 ± 1.1 | 93.05 ± 0.5 | 91.98 ± 0.1 | 88.82 ± 1.2 | 85.43 ± 0.6 |
| YOLO11n [20] | 89.49 ± 0.4 | 91.53 ± 1.2 | 93.68 ± 0.8 | 88.28 ± 1.3 | 84.21 ± 0.4 |
| YOLO11s | 88.66 ± 0.6 | 88.14 ± 0.2 | 92.41 ± 1.7 | 89.01 ± 0.6 | 85.37 ± 0.8 |
| YOLO11m | 92.04 ± 1.1 | 89.83 ± 0.3 | 92.12 ± 0.6 | 89.47 ± 0.4 | 85.01 ± 1.6 |
| YOLO11l | 87.05 ± 0.4 | 94.92± 0.7 | 96.28± 1.4 | 91.90 ± 1.1 | 89.48± 1.1 |
| Model | FID ↓ | SSIM ↑ | PSNR ↑ | MAE ↓ |
|---|---|---|---|---|
| Deepfillv2 [41] | 72.5 ± 0.6 | 90.2 ± 0.2 | 29.3 ± 0.2 | 7.2 ± 0.4 |
| RFR [39] | 80.87 ± 0.4 | 15.14 ± 0.9 | 14.21 ± 0.3 | 76.5 ± 1.1 |
| TFill [19] | 53.98 ± 0.4 | 90.9 ± 0.5 | 30.34 ± 0.7 | 6.3 ± 0.2 |
| AOTGAN [21] | 51.48 ± 0.8 | 91.5 ± 0.1 | 30.25 ± 0.5 | 6.6 ± 0.1 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| MobileNet-V2 (w/ inpainting) | 87.71± 0.8 | 87.66± 1.1 | 87.71± 0.7 | 86.27± 0.9 |
| MobileNet-V2 (w/o inpainting) | 78.51 ± 1.0 | 76.96 ± 0.5 | 75.51 ± 1.2 | 73.01 ± 0.8 |
| MobileNet-V3 (w/ inpainting) | 89.94 ± 0.6 | 92.21 ± 1.3 | 89.94 ± 0.8 | 89.02 ± 1.2 |
| MobileNet-V3 (w/o inpainting) | 72.45 ± 0.8 | 83.06 ± 1.0 | 72.45 ± 0.9 | 72.86 ± 1.3 |
| EfficientNet-B0 (w/ inpainting) | 89.39 ± 1.0 | 86.52 ± 0.9 | 89.39 ± 1.2 | 87.11 ± 0.7 |
| EfficientNet-B0 (w/o inpainting) | 80.61 ± 1.3 | 86.27 ± 0.8 | 80.61 ± 0.6 | 79.80 ± 1.4 |
| EfficientNet-B1 (w/ inpainting) | 74.30 ± 1.5 | 78.90 ± 0.9 | 78.90 ± 1.1 | 69.03 ± 1.0 |
| EfficientNet-B1 (w/o inpainting) | 71.43 ± 1.2 | 81.68 ± 0.7 | 71.43 ± 0.8 | 68.38 ± 1.2 |
| EfficientNet-B2 (w/ inpainting) | 91.62 ± 0.9 | 93.22 ± 0.6 | 91.62 ± 0.8 | 91.44 ± 1.1 |
| EfficientNet-B2 (w/o inpainting) | 86.22 ± 1.3 | 87.93 ± 1.2 | 86.22 ± 1.0 | 85.88 ± 0.7 |
| ResNet50 (w/ inpainting) | 89.39 ± 0.8 | 90.83 ± 1.3 | 89.39 ± 1.2 | 89.05 ± 0.9 |
| ResNet50 (w/o inpainting) | 78.06 ± 1.1 | 83.81 ± 1.0 | 78.06 ± 0.7 | 78.03 ± 1.4 |
| ResNet101 (w/ inpainting) | 87.15 ± 0.9 | 89.52 ± 1.1 | 87.15 ± 0.6 | 86.14 ± 1.0 |
| ResNet101 (w/o inpainting) | 77.55 ± 1.2 | 80.05 ± 0.9 | 77.55 ± 1.3 | 76.46 ± 1.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, R.; Chung, S.; Kim, S.; Kim, H. PigFRIS: A Three-Stage Pipeline for Fence Occlusion Segmentation, GAN-Based Pig Face Inpainting, and Efficient Pig Face Recognition. Animals 2025, 15, 978. https://doi.org/10.3390/ani15070978
Ma R, Chung S, Kim S, Kim H. PigFRIS: A Three-Stage Pipeline for Fence Occlusion Segmentation, GAN-Based Pig Face Inpainting, and Efficient Pig Face Recognition. Animals. 2025; 15(7):978. https://doi.org/10.3390/ani15070978
Chicago/Turabian StyleMa, Ruihan, Seyeon Chung, Sangcheol Kim, and Hyongsuk Kim. 2025. "PigFRIS: A Three-Stage Pipeline for Fence Occlusion Segmentation, GAN-Based Pig Face Inpainting, and Efficient Pig Face Recognition" Animals 15, no. 7: 978. https://doi.org/10.3390/ani15070978
APA StyleMa, R., Chung, S., Kim, S., & Kim, H. (2025). PigFRIS: A Three-Stage Pipeline for Fence Occlusion Segmentation, GAN-Based Pig Face Inpainting, and Efficient Pig Face Recognition. Animals, 15(7), 978. https://doi.org/10.3390/ani15070978