

GCNTrack: A Pig-Tracking Method Based on Skeleton Feature Similarity

Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Pigsty Environment
2.2. Data Collection and Processing
2.3. Dataset Establishment
2.4. The Tracking Method Based on Skeleton Feature Similarity
2.4.1. Pig Skeleton Keypoint Detection
2.4.2. Dual-Tracking Strategy
| Algorithm 1: Detailed calculation steps of the tracking algorithm |
| Assume: now_keypoints stores the ID, bounding box, keypoint, and ID information of each pig in the fk; pre_keypoints stores the ID, bounding box, and keypoint information of the previous frame; the current set of lost pigs is referred to as lose_pig; now_pig_num is the total number of current pig IDs.; and max_pig_num is the maximum number of pigs. Input: now_keypoints, pre_keypoints, lose_pig, now_pig_num, max_pig_num 1: for frame fk in Video do 2: if first_frame then: 3: label.init(keypoints) 4: end 5: iou = calculate_iou_match(now_keypoints, pre_keypoints, cost_limit = 0.3) 6: if all pigs are successfully matched then: 7: lose_pig = update(now_keypoints, pre_keypoints) 8: update(label) 9: end 10: similarity=calculate_gcn _match(keypoints, lose_pig, cost_limit=0.2) 11: if all pigs are successfully matched then: 12: lose_pig = update(now_keypoints, pre_keypoints) 13: update(label) 14: end 15: if now_pig_num < max_pig_num then: 16: now_pig_num+1 17: lose_pig = update(now_keypoints, pre_keypoints) 18: update(label) 19: end 20: similarity=calculate_gcn_match(keypoints, lose_pig) 21: lose_pig = update(now_keypoints, pre_keypoints) 22: update(label) 23: end Output: label |
3. Results
3.1. Experimental Setup
3.1.1. Experimental Platform and Parameter Settings
3.1.2. Evaluation Metrics
3.2. Keypoint Detection Evaluation
3.3. Tracking Effect Evaluation
3.3.1. Comparison of Different Tracking Approaches
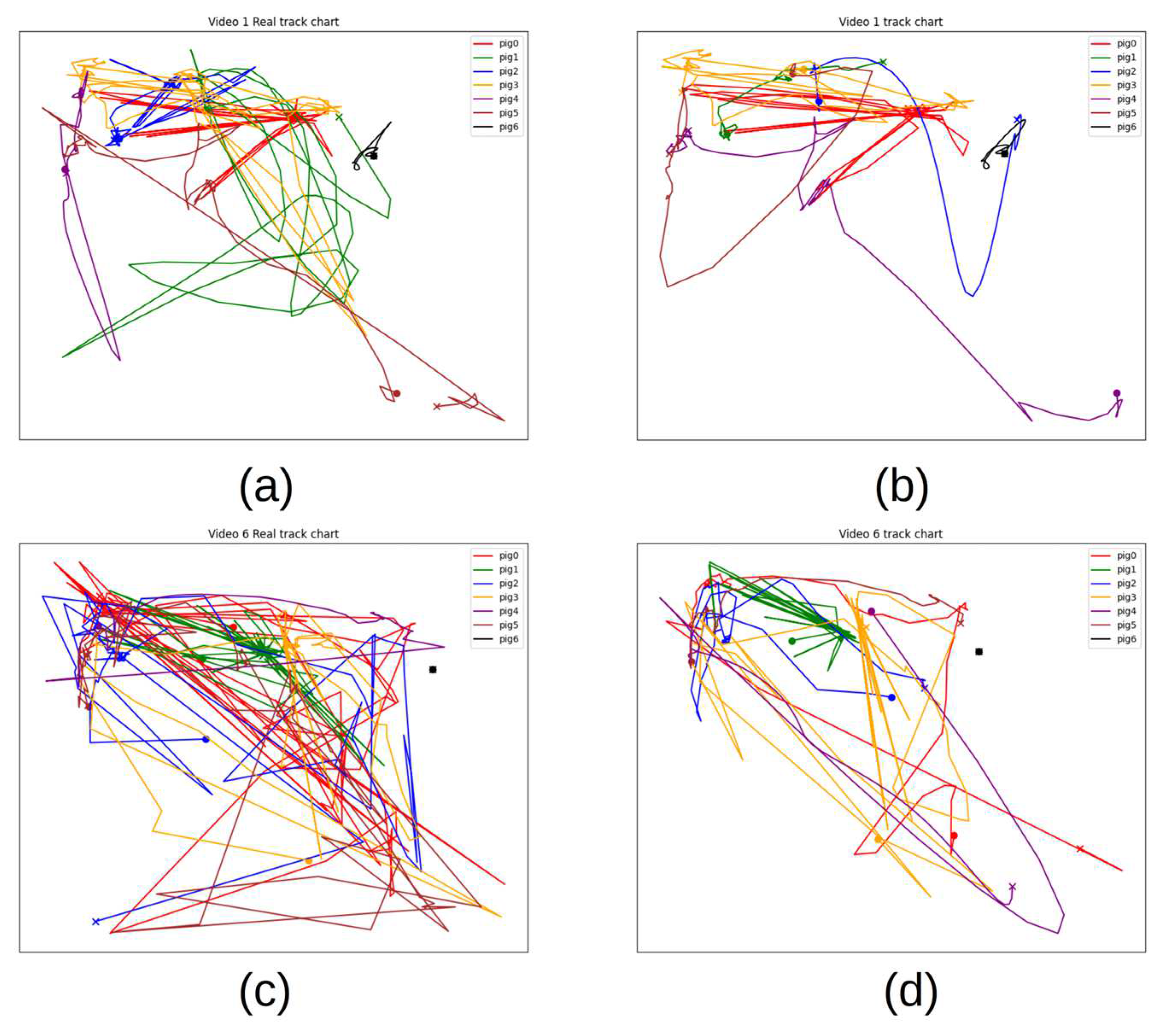
3.3.2. Validation of Tracking Results
3.4. Ablation Study
3.4.1. Ablation Study of Tracking Methods
3.4.2. Ablation Study of GCN Depth
3.4.3. Ablation Study of Keypoints
3.5. Tracking Test on a Long Video
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FOV | Field of view |
| OKS | Object keypoint similarity |
| CNN | Convolution neural network |
| GCN | Graph convolutional network |
| Re-ID | Reidentification |
| IDF1 | Identification F1 score |
| MOTA | Multiple object tracking accuracy |
| IOU | Intersection over union |
| IDS | Identity switch |
| MT | Mostly tracked |
| ML | Mostly lost |
| AP | Average precision |
| FPS | Frames per second |
| MOT | Multiple object tracking |
| Box | Bounding box |
References
- Iredale, S.K.; Nevill, C.H.; Lutz, C.K. The Influence of Observer Presence on Baboon (Papio Spp.) and Rhesus Macaque (Macaca mulatta) Behavior. Appl. Anim. Behav. Sci. 2010, 122, 53–57. [Google Scholar] [PubMed]
- Kim, S.-H.; Kim, D.-H.; Park, H.-D. Animal Situation Tracking Service Using RFID, GPS, and Sensors. In Proceedings of the 2010 Second International Conference on Computer and Network Technology, Bangkok, Thailand, 23–25 April 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 153–156. [Google Scholar]
- Maselyne, J.; Adriaens, I.; Huybrechts, T.; De Ketelaere, B.; Millet, S.; Vangeyte, J.; Van Nuffel, A.; Saeys, W. Measuring the Drinking Behaviour of Individual Pigs Housed in Group Using Radio Frequency Identification (RFID). Animal 2016, 10, 1557–1566. [Google Scholar] [CrossRef] [PubMed]
- Mayer, K.; Ellis, K.; Taylor, K. Cattle Health Monitoring Using Wireless Sensor Networks; ACTA Press: Calgary, AB, Canada, 2004; pp. 8–10. [Google Scholar]
- Pandey, S.; Kalwa, U.; Kong, T.; Guo, B.; Gauger, P.C.; Peters, D.J.; Yoon, K.-J. Behavioral Monitoring Tool for Pig Farmers: Ear Tag Sensors, Machine Intelligence, and Technology Adoption Roadmap. Animals 2021, 11, 2665. [Google Scholar] [CrossRef]
- Cowton, J.; Kyriazakis, I.; Bacardit, J. Automated Individual Pig Localisation, Tracking and Behaviour Metric Extraction Using Deep Learning. IEEE Access 2019, 7, 108049–108060. [Google Scholar] [CrossRef]
- Zhang, L.; Gray, H.; Ye, X.; Collins, L.; Allinson, N. Automatic Individual Pig Detection and Tracking in Pig Farms. Sensors 2019, 19, 1188. [Google Scholar] [CrossRef]
- Lu, J.; Chen, Z.; Li, X.; Fu, Y.; Xiong, X.; Liu, X.; Wang, H. ORP-Byte: A Multi-Object Tracking Method of Pigs That Combines Oriented RepPoints and Improved Byte. Comput. Electron. Agric. 2024, 219, 108782. [Google Scholar] [CrossRef]
- Tu, S.; Ou, H.; Mao, L.; Du, J.; Cao, Y.; Chen, W. Behavior Tracking and Analyses of Group-Housed Pigs Based on Improved ByteTrack. Animals 2024, 14, 3299. [Google Scholar] [CrossRef]
- Liang, Z.; Xu, A.; Ye, J.; Zhou, S.; Weng, X.; Bao, S. An Automatic Movement Monitoring Method for Group-Housed Pigs. Animals 2024, 14, 2985. [Google Scholar] [CrossRef]
- Tu, S.; Cai, Y.; Liang, Y.; Lei, H.; Huang, Y.; Liu, H.; Xiao, D. Tracking and Monitoring of Individual Pig Behavior Based on YOLOv5-Byte. Comput. Electron. Agric. 2024, 221, 108997. [Google Scholar]
- Tzanidakis, C.; Simitzis, P.; Arvanitis, K.; Panagakis, P. An Overview of the Current Trends in Precision Pig Farming Technologies. Livest. Sci. 2021, 249, 104530. [Google Scholar] [CrossRef]
- Chen, G.; Rao, Y.; Lu, J.; Zhou, J. Temporal Coherence or Temporal Motion: Which Is More Critical for Video-Based Person Re-Identification? In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 660–676. [Google Scholar]
- Islam, K. Deep Learning for Video-Based Person Re-Identification: A Survey. arXiv 2023, arXiv:2303.11332. [Google Scholar]
- Song, W.; Wu, Y.; Zheng, J.; Chen, C.; Liu, F. Extended Global–Local Representation Learning for Video Person Re-Identification. IEEE Access 2019, 7, 122684–122696. [Google Scholar]
- Zhang, L.; Shi, Z.; Zhou, J.T.; Cheng, M.-M.; Liu, Y.; Bian, J.-W.; Zeng, Z.; Shen, C. Ordered or Orderless: A Revisit for Video Based Person Re-Identification. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1460–1466. [Google Scholar]
- Hou, R.; Ma, B.; Chang, H.; Gu, X.; Shan, S.; Chen, X. Vrstc: Occlusion-Free Video Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7183–7192. [Google Scholar]
- Kiran, M.; Bhuiyan, A.; Blais-Morin, L.-A.; Javan, M.; Ayed, I.B.; Granger, E. A Flow-Guided Mutual Attention Network for Video-Based Person Re-Identification. arXiv 2020, arXiv:2008.03788. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-Guided Contrastive Attention Model for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1179–1188. [Google Scholar]
- He, T.; Jin, X.; Shen, X.; Huang, J.; Chen, Z.; Hua, X.-S. Dense Interaction Learning for Video-Based Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 1490–1501. [Google Scholar]
- Cheng, D.; Gong, Y.; Chang, X.; Shi, W.; Hauptmann, A.; Zheng, N. Deep Feature Learning via Structured Graph Laplacian Embedding for Person Re-Identification. Pattern Recognit. 2018, 82, 94–104. [Google Scholar]
- Yan, Y.; Zhang, Q.; Ni, B.; Zhang, W.; Xu, M.; Yang, X. Learning Context Graph for Person Search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2158–2167. [Google Scholar]
- Pan, H.; Liu, Q.; Chen, Y.; He, Y.; Zheng, Y.; Zheng, F.; He, Z. Pose-Aided Video-Based Person Re-Identification via Recurrent Graph Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7183–7196. [Google Scholar]
- Hong, X.; Adam, T.; Ghazali, M. Tran-GCN: A Transformer-Enhanced Graph Convolutional Network for Person Re-Identification in Monitoring Videos. arXiv 2024, arXiv:2409.09391. [Google Scholar]
- Ning, G.; Pei, J.; Huang, H. Lighttrack: A Generic Framework for Online Top-down Human Pose Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1034–1035. [Google Scholar]
- Zhijun, H.E.; Hongbo, Z.; Jianrong, W.; Wenquan, F. Pose Matters: Pose Guided Graph Attention Network for Person Re-Identification. Chin. J. Aeronaut. 2023, 36, 447–464. [Google Scholar]
- Wang, M.; Larsen, M.L.; Liu, D.; Winters, J.F.; Rault, J.-L.; Norton, T. Towards Re-Identification for Long-Term Tracking of Group Housed Pigs. Biosyst. Eng. 2022, 222, 71–81. [Google Scholar]
- Guo, Q.; Sun, Y.; Orsini, C.; Bolhuis, J.E.; de Vlieg, J.; Bijma, P.; de With, P.H. Enhanced Camera-Based Individual Pig Detection and Tracking for Smart Pig Farms. Comput. Electron. Agric. 2023, 211, 108009. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, S.; Yin, P.; Xu, A.; Ye, J. GANPose: Pose Estimation of Grouped Pigs Using a Generative Adversarial Network. Comput. Electron. Agric. 2023, 212, 108119. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-based action recognition with shift graph convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 183–192. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality Reduction by Learning an Invariant Mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Mathis, A.; Mamidanna, P.; Cury, K.M.; Abe, T.; Murthy, V.N.; Mathis, M.W.; Bethge, M. DeepLabCut: Markerless Pose Estimation of User-Defined Body Parts with Deep Learning. Nat. Neurosci. 2018, 21, 1281–1289. [Google Scholar] [CrossRef]
- Fang, H.-S.; Li, J.; Tang, H.; Xu, C.; Zhu, H.; Xiu, Y.; Li, Y.-L.; Lu, C. Alphapose: Whole-Body Regional Multi-Person Pose Estimation and Tracking in Real-Time. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7157–7173. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-Object Tracking by Associating Every Detection Box. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- François, J.; Wang, S.; State, R.; Engel, T. BotTrack: Tracking Botnets Using NetFlow and PageRank. In Proceedings of the NETWORKING 2011: 10th International IFIP TC 6 Networking Conference, Valencia, Spain, 9–13 May 2011; Proceedings, Part I 10. Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–14. [Google Scholar]
- Parmiggiani, A.; Liu, D.; Psota, E.; Fitzgerald, R.; Norton, T. Don’t Get Lost in the Crowd: Graph Convolutional Network for Online Animal Tracking in Dense Groups. Comput. Electron. Agric. 2023, 212, 108038. [Google Scholar]
- Gan, H.; Ou, M.; Zhao, F.; Xu, C.; Li, S.; Chen, C.; Xue, Y. Automated Piglet Tracking Using a Single Convolutional Neural Network. Biosyst. Eng. 2021, 205, 48–63. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Number | Duration (s) | Number of Pigs | Number of Times that Pigs Left | Recording Date |
|---|---|---|---|---|
| Video 1 | 90 | 7 | 14 | 7.14 |
| Video 2 | 220 | 7 | 10 | 7.15 |
| Video 3 | 87 | 7 | 8 | 7.15 |
| Video 4 | 302 | 7 | 16 | 7.21 |
| Video 5 | 302 | 7 | 14 | 7.16 |
| Video 6 | 842 | 7 | 35 | 7.14 |
| Video 7 | 302 | 7 | 12 | 9.08 |
| Video 8 | 302 | 7 | 14 | 7.15 |
| Method | Backbone | AP50 | AP75 | AP90 |
|---|---|---|---|---|
| DeepLabCut [34] | ResNet | 0.84 | 0.49 | 0.36 |
| AlphaPose [35] | ResNet | 0.88 | 0.67 | 0.21 |
| YOLOv7-Pose | YOLO | 0.87 | 0.78 | 0.36 |
| Method | Videos | MOTA | IDF1 | MT | ML | Tracking Precision | Individual Detection Percentage | Individual Tracking Percentage | IDS |
|---|---|---|---|---|---|---|---|---|---|
| ByteTrack [36] | 1, 2, 3 | 25.87 | 24.70 | 0.30 | 0.16 | 0.23 | 0.87 | 0.19 | 22.57 |
| 4, 5 | 29.15 | 29.74 | 0.27 | 0.1 | 0.22 | 0.14 | 39.14 | ||
| BotTrack [37] | 1, 2, 3 | 26.06 | 28.70 | 0.36 | 0.09 | 0.21 | 0.87 | 0.21 | 24.65 |
| 4, 5 | 30.64 | 24.64 | 0.27 | 0.1 | 0.25 | 0.17 | 37.66 | ||
| BotTrack(Re-ID) [37] | 1, 2, 3 | 26.34 | 28.40 | 0.36 | 0.09 | 0.21 | 0.87 | 0.20 | 22.42 |
| 4, 5 | 29.91 | 25.64 | 0.27 | 0.1 | 0.26 | 0.19 | 34.65 | ||
| Dual-tracking strategy (ours) | 1, 2, 3 | 84.98 | 82.22 | 0.79 | 0 | 0.83 | 0.87 | 0.80 | 1.61 |
| 4, 5 | 82.36 | 76.00 | 0.85 | 0 | 0.74 | 0.73 | 2.35 | ||
| 7 | 59.65 | 70.15 | 0.57 | 0 | 0.65 | 0.72 | 0.60 | 4.76 | |
| 8 | 79.32 | 73.76 | 0.71 | 0 | 0.70 | 0.83 | 0.69 | 2.60 |
| Method | Videos | MOTA | IDF1 | MT | ML | Tracking Precision | Individual Detection Percentage | Individual Tracking Percentage | IDS |
|---|---|---|---|---|---|---|---|---|---|
| Only GCN strategy | 1, 2, 3 | 84.15 | 77.36 | 0.75 | 0 | 0.70 | 0.87 | 0.75 | 2.00 |
| 4, 5 | 81.34 | 69.78 | 0.85 | 0 | 0.61 | 0.67 | 2.36 | ||
| Dual-tracking strategy | 1, 2, 3 | 84.98 | 82.22 | 0.79 | 0 | 0.83 | 0.87 | 0.80 | 1.61 |
| 4, 5 | 82.36 | 76.00 | 0.85 | 0 | 0.74 | 0.73 | 2.35 |
| Gcn Depth | Videos | Model Accuracy | MOTA | IDF1 | MT | ML | Tracking Precision | Individual Tracking Percentage | IDS | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| One Layer | 1, 2, 3 | 88.72 | 84.67 | 81.53 | 0.80 | 0 | 0.79 | 0.74 | 1.62 | 23.51 |
| 4, 5 | 81.00 | 55.50 | 0.85 | 0 | 0.43 | 0.62 | 2.5 | |||
| Two Layers | 1, 2, 3 | 89.46 | 84.98 | 82.22 | 0.79 | 0 | 0.83 | 0.80 | 1.61 | 23.51 |
| 4, 5 | 82.36 | 76.00 | 0.85 | 0 | 0.74 | 0.73 | 2.35 | |||
| Three Layers | 1, 2, 3 | 88.88 | 81.79 | 81.25 | 0.93 | 0 | 0.76 | 0.77 | 2.04 | 23.50 |
| 4, 5 | 81.51 | 72.00 | 0.85 | 0 | 0.63 | 0.66 | 2.28 | |||
| Four Layers | 1, 2, 3 | 89.06 | 81.33 | 80.33 | 0.93 | 0 | 0.74 | 0.71 | 1.91 | 23.45 |
| 4, 5 | 81.56 | 71.47 | 0.92 | 0 | 0.64 | 0.69 | 2.35 |
| Keypoints | Accuracy | Accuracy Change |
|---|---|---|
| - | 89.46 | - |
| hoof joints (6, 8, 10, 12) | 87.14 | −2.32 |
| elbow joints (5, 7, 9, 11) | 87.83 | −1.63 |
| hoof joints (6, 10) | 88.81 | −0.65 |
| hoof joints (6, 8) | 88.99 | −0.47 |
| elbow joints (5, 9) | 89.12 | −0.34 |
| back keypoints (1, 2, 3, 4) | 89.25 | −0.21 |
| back keypoints (1, 4) | 89.30 | −0.16 |
| elbow joints (5, 11) | 89.33 | −0.13 |
| ID | Total Number of Frames 1 | Individual Tracking Percentage | IDS | Number of Times the Pig Disappears 2 | Detection Precision |
|---|---|---|---|---|---|
| 0 | 4134 | 55.35% | 14 | 28 | 92.44 |
| 1 | 10,946 | 11.86% | 9 | 23 | 82.39 |
| 2 | 11,258 | 73.44% | 2 | 17 | 99.08 |
| 3 | 7540 | 6.55% | 11 | 20 | 96.67 |
| 4 | 2106 | 98.77% | 0 | 5 | 98.78 |
| 5 | 4914 | 15.87% | 7 | 13 | 94.50 |
| 6 | 1092 | 76.19% | 1 | 1 | 93.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, Z.; Wang, Z.; Ye, J.; Zhou, S.; Xu, A. GCNTrack: A Pig-Tracking Method Based on Skeleton Feature Similarity. Animals 2025, 15, 1040. https://doi.org/10.3390/ani15071040
Yin Z, Wang Z, Ye J, Zhou S, Xu A. GCNTrack: A Pig-Tracking Method Based on Skeleton Feature Similarity. Animals. 2025; 15(7):1040. https://doi.org/10.3390/ani15071040
Chicago/Turabian StyleYin, Zhaoyang, Zehua Wang, Junhua Ye, Suyin Zhou, and Aijun Xu. 2025. "GCNTrack: A Pig-Tracking Method Based on Skeleton Feature Similarity" Animals 15, no. 7: 1040. https://doi.org/10.3390/ani15071040
APA StyleYin, Z., Wang, Z., Ye, J., Zhou, S., & Xu, A. (2025). GCNTrack: A Pig-Tracking Method Based on Skeleton Feature Similarity. Animals, 15(7), 1040. https://doi.org/10.3390/ani15071040