
Research on Calf Behavior Recognition Based on Improved Lightweight YOLOv8 in Farming Scenarios


Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Sources
2.2. Dataset Production
2.3. Test Platform and Model Test Index
2.3.1. Test Environment and Parameter Setting
2.3.2. Test Evaluation Indicators
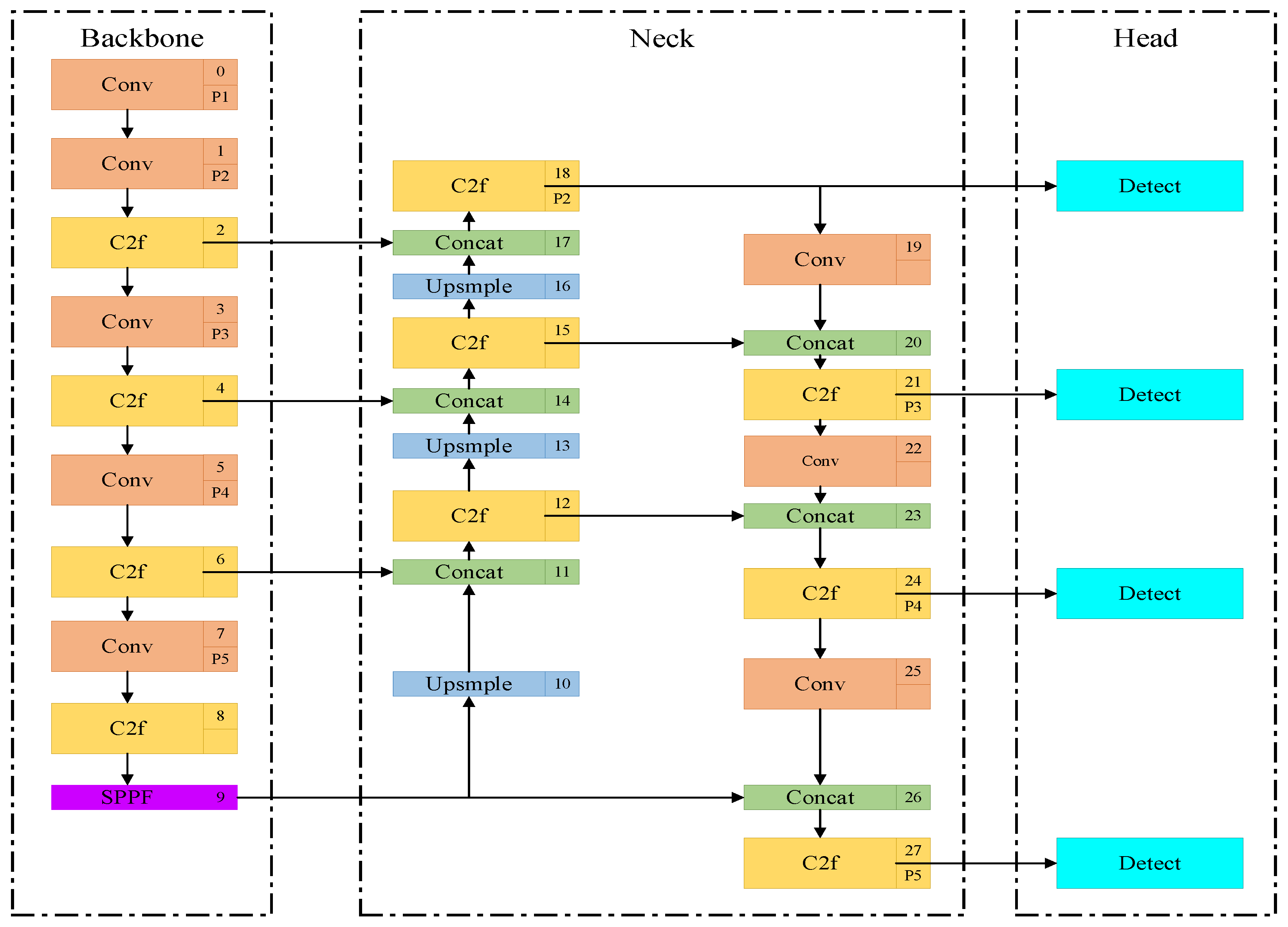
2.4. YOLOv8n-P2-Lamp Lightweight Calf Behavior Recognition Model
2.5. P2 Detection Layer
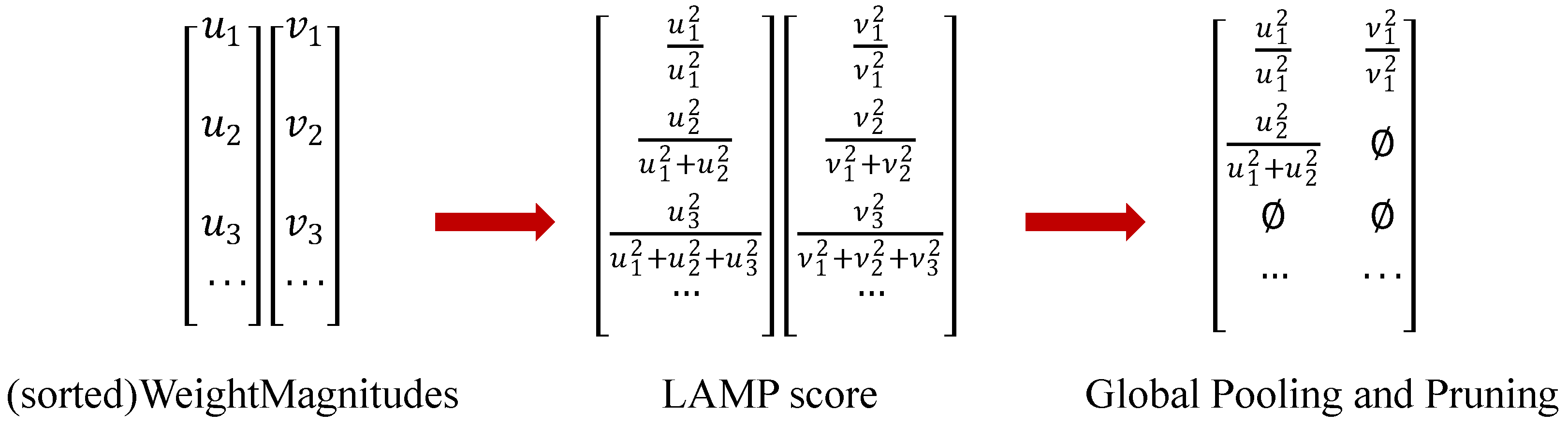
2.6. P2 Channel Pruning
3. Results
3.1. Training Results and Analysis of YOLOv8-P2 Model
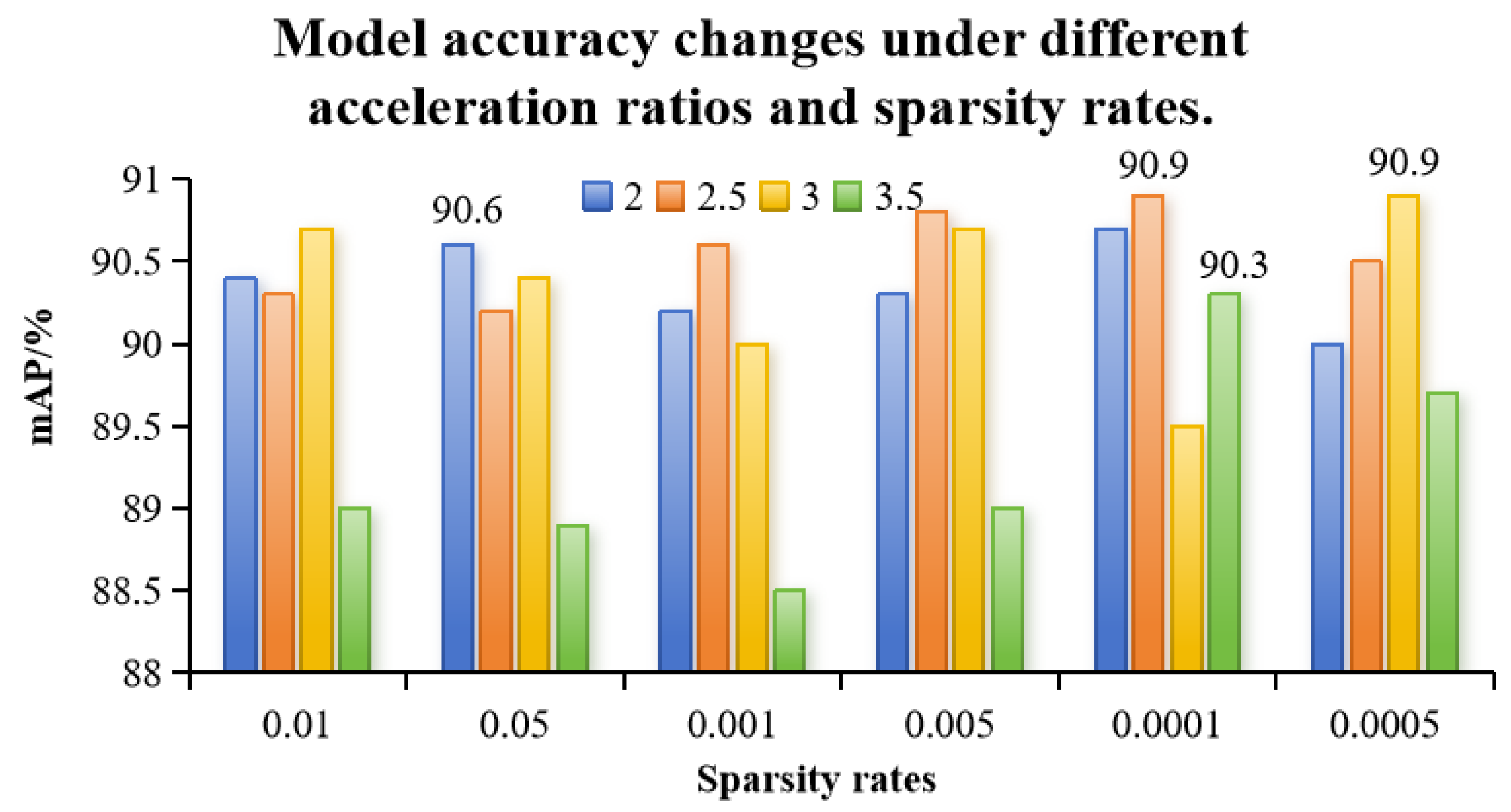
3.2. Pruning Strategy Comparison Experiment and Analysis
3.3. Comparison of Performance of Different Network Models
4. Discussion
4.1. Impact of Lighting Intensity on Model Performance
4.2. Impact of Occlusion Degree on Model Performance
4.3. Visualization Methods
4.4. Limitations and Future Directions
5. Conclusions
- (1)
- This study introduces a P2 small-object detection layer into the YOLO v8n network, proposing an improved YOLOv8-P2 network model. After the improvement, the network model achieved a precision of 89.1%, recall of 87.8%, and mean average precision (mAP) of 91.2%, with 2.92 M parameters, 12.2 G FLOPs, and a model size of 6.2 MB. The precision, recall, and mAP were all improved, and the parameter count was significantly decreased. This demonstrates that the introduced modifications effectively enhanced the model’s performance.
- (2)
- In this study exploring how model performance is affected by different sparsity rates and speed-up ratios, the experimental results show that the pruned model performed optimally when the sparsity rate was set to 0.0005 and the speed-up ratio was set to 3.0. Under these conditions, the model’s mean average precision (mAP) reached 90.9%, the parameter count was reduced to 0.949 M, the computational load decreased to 4.0 GFLOPs, and the model size was compressed to 2.3 MB. Compared to the original YOLO v8n network, the parameter count was reduced by 68.4%, the computational load decreased by 35.5%, and the model size was reduced by 62.9%, while the network’s mAP increased by 0.7%. This effectively reduced the model size and improved the network’s accuracy.
- (3)
- Compared with the SSD, YOLO v5n, YOLO v8n, YOLO v8-C2f-faster-EMA, and YOLO v8-P2 models, the model proposed in this study increased the average precision (mAP) by 0.7% while significantly reducing the number of parameters, the amount of computation, and the model size. This indicates that the pruning technology used can effectively enhance the performance of the model and provide solid technical support for real-time and accurate monitoring of the daily behavior of calves in breeding farms and deployment in mobile devices with less hardware and computational resources.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bakhshayeshi, I.; Erfani, E.; Taghikhah, F.R.; Elbourn, S.; Beheshti, A.; Asadnia, M. An Intelligence Cattle Reidentification System Over Transport by Siamese Neural Networks and YOLO. IEEE Internet Things J. 2024, 11, 2351–2363. [Google Scholar] [CrossRef]
- Han, S.; Fuentes, A.; Yoon, S.; Jeong, Y.; Kim, H.; Park, D.S. Deep learning-based multi-cattle tracking in crowded livestock farming using video. Comput. Electron. Agric. 2023, 212, 108044. [Google Scholar] [CrossRef]
- Wang, Z.; Song, H.; Wang, Y.; Hua, Z.; Li, R.; Xu, X. Research Progress and Technology Trend of Intelligent Morning of Dairy Cow Motion Behavior. Smart Agric. 2022, 4, 36–52. [Google Scholar] [CrossRef]
- Balasso, P.; Marchesini, G.; Ughelini, N.; Serva, L.; Andrighetto, I. Machine Learning to Detect Posture and Behavior in Dairy Cows: Information from an Accelerometer on the Animal’s Left Flank. Animals 2021, 11, 2972. [Google Scholar] [CrossRef]
- Taneja, M.; Byabazaire, J.; Jalodia, N.; Davy, A.; Olariu, C.; Malone, P. Machine learning based fog computing assisted data-driven approach for early lameness detection in dairy cattle. Comput. Electron. Agric. 2020, 171, 105286. [Google Scholar] [CrossRef]
- Umaña Sedó, S.G.; Winder, C.B.; Renaud, D.L. Graduate Student Literature review: The problem of calf mortality in dairy farms. J. Dairy Sci. 2023, 106, 7164–7176. [Google Scholar] [CrossRef]
- Li, Z.; Song, L.; Duan, Y.; Wang, Y.; Song, H. Basic motion behaviour recognition of dairy cows based on skeleton and hybrid convolution algorithms. Comput. Electron. Agric. 2022, 196, 106889. [Google Scholar] [CrossRef]
- Ban, Z.; Wang, C.; Zong, Z.; Lide, S.; Shuai, W.; Wenbo, Y.; Ze, Y.; Xiaodan, R. Research Progress in Bovine Mastitis Detection Methods: Traditional Techniques, Sensors, and Computer Vision. J. Inn. Mong. Agric. Univ. (Nat. Sci. Ed.) 2024, 1–20. Available online: https://link.oversea.cnki.net/doi/10.16853/j.cnki.1009-3575.2025.01.012.
- Hossain, E.; Kabir, M.A.; Zheng, L.; Swain, D.L.; McGrath, S.; Medway, J. A systematic review of machine learning techniques for cattle identification: Datasets, methods and future directions. Artif. Intell. Agric. 2022, 6, 138–155. [Google Scholar] [CrossRef]
- Godlee, F.; Waters, A. Healthy people, healthy animals, and a healthy environment: One Health. BMJ 2018, 362, k3020. [Google Scholar] [CrossRef]
- Van Engen, N.K.; Coetzee, J.F. Effects of transportation on cattle health and production: A review. Anim. Health Res. Rev. 2018, 19, 142–154. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Zhu, W.; Norton, T. Behaviour recognition of pigs and cattle: Journey from computer vision to deep learning. Comput. Electron. Agric. 2021, 187, 106255. [Google Scholar] [CrossRef]
- Cornou, C.; Lundbye-Christensen, S.; Kristensen, A.R. Modelling and monitoring sows’ activity types in farrowing house using acceleration data. Comput. Electron. Agric. 2011, 76, 316–324. [Google Scholar] [CrossRef]
- Tian, F.; Wang, R.; Liu, M.; Wang, Z.; Li, F.; Wang, Z. Oestrus detection and prediction in dairy cows based on neural networks(Article). Nongye Jixie Xuebao Trans. Chin. Soc. Agric. Mach. 2013, 44, 277–281. [Google Scholar] [CrossRef]
- Handcock, R.N.; Swain, D.L.; Bishop-Hurley, G.J.; Patison, K.P.; Wark, T.; Valencia, P.; Corke, P.; O’neill, C.J. Monitoring Animal Behaviour and Environmental Interactions Using Wireless Sensor Networks, GPS Collars and Satellite Remote Sensing. Sensors 2009, 9, 3586–3603. [Google Scholar] [CrossRef]
- Tsai, D.M.; Huang, C.Y. A motion and image analysis method for automatic detection of estrus and mating behavior in cattle. Comput. Electron. Agric. 2014, 104, 25–31. [Google Scholar] [CrossRef]
- Jiang, B.; Song, H.; Wang, H.; Li, C. Dairy cow lameness detection using a back curvature feature. Comput. Electron. Agric. 2022, 194, 106729. [Google Scholar] [CrossRef]
- Peng, Y.; Kondo, N.; Fujiura, T.; Suzuki, T.; Ouma, S.; Wulandari Yoshioka, H.; Itoyama, E. Dam behavior patterns in Japanese black beef cattle prior to calving: Automated detection using LSTM-RNN. Comput. Electron. Agric. 2020, 169, 105178. [Google Scholar] [CrossRef]
- Ma, S.; Zhang, Q.; Li, T.; Song, H. Basic motion behavior recognition of single dairy cow based on improved Rexnet 3D network. Comput. Electron. Agric. 2022, 194, 106772. [Google Scholar] [CrossRef]
- Yin, X.; Wu, D.; Shang, Y.; Jiang, B.; Song, H. Using an EfficientNet-LSTM for the recognition of single Cow’s motion behaviours in a complicated environment. Comput. Electron. Agric. 2020, 177, 105707. [Google Scholar] [CrossRef]
- Wang, F.; Li, D.; Xia, B. Research on Multi-Scale SE Attention Model for Multi-Target Detection Algorithm in Cattle. Heilongjiang Anim. Husb. Vet. 2025, 1–9. Available online: https://link.oversea.cnki.net/doi/10.13881/j.cnki.hljxmsy.2024.02.0085.
- Duan, Q.; Zhao, Z.; Jiang, T.; Gui, X.; Zhang, Y. Behavior Recognition Method of Beef Cattle Based on SNSS-YOLO v7. Nongye Jixie Xuebao Trans. Chin. Soc. Agric. Mach. 2023, 54, 266–274, 347. [Google Scholar] [CrossRef]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 464–472. [Google Scholar] [CrossRef]
- Masters, D.; Luschi, C. Revisiting small batch training for deep neural networks. arXiv 2018, arXiv:1804.07612. [Google Scholar]
- Guo, Z.N.; Guo, Z.Z. Lightweight recognition for the oestrus behavior of dairy cows combining YOLO v5n and channel pruning. Trans. Chin. Soc. Agric. Eng. 2022, 38, 130–140. [Google Scholar] [CrossRef]
- Xie, J.; Pang, Y.; Pan, J.; Nie, J.; Cao, J.; Han, J. Complementary Feature Pyramid Network for Object Detection. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–15. [Google Scholar] [CrossRef]
- Lee, J.; Park, S.; Mo, S.; Ahn, S.; Shin, J. Layer-adaptive sparsity for the Magnitude-based Pruning. arXiv 2021, arXiv:2010.07611. [Google Scholar]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming(Conference Paper). In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 2017, pp. 2755–2763. [Google Scholar] [CrossRef]
- Mittal, D.; Bhardwaj, S.; Khapra, M.M.; Ravindran, B. Recovering from Random Pruning: On the Plasticity of Deep Convolutional Neural Networks. arXiv 2018, arXiv:1801.10447. [Google Scholar]
- Fang, G.; Ma, X.; Song, M.; Mi, M.B.; Wang, X. DepGraph: Towards Any Structural Pruning. arXiv 2023, arXiv:2301.12900. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision-ECCV 2016, PT I, Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequences | Main Contributions |
|---|---|
| 1. | An improved model of YOLOv8 incorporating the P2 small-target detection layer is proposed, which significantly improves the recognition accuracy of small targets (e.g., calf leg bending). |
| 2. | The Lamp pruning strategy is introduced to reduce the number of model parameters and computational cost while maintaining a high mAP. |
| 3. | A calf behavior dataset containing complex lighting and occlusion scenarios is constructed, and the robustness of the model is verified. |
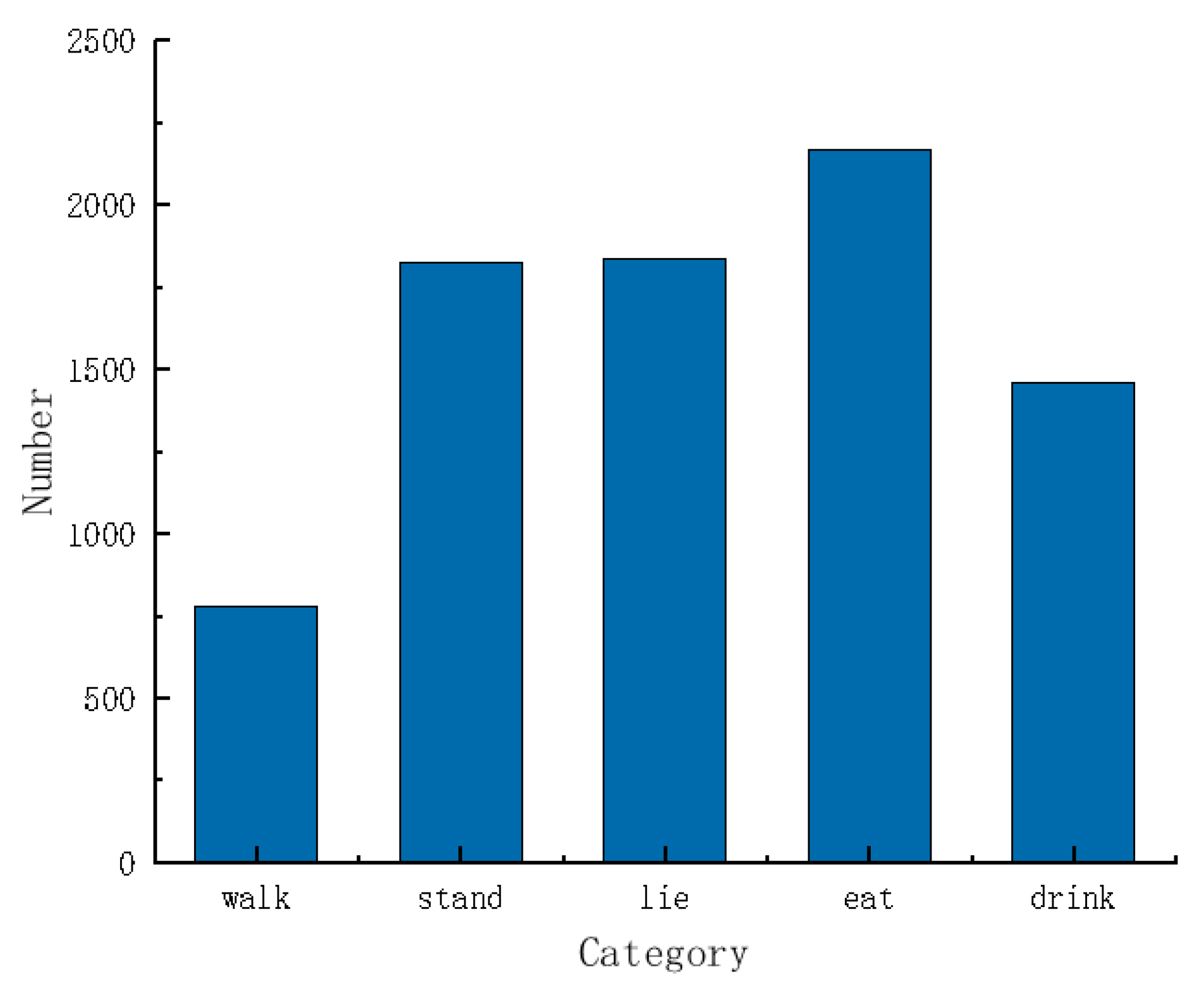
| Type | Behavioral Description | Labels |
|---|---|---|
| Walking | Alternated bending of limbs, trunk horizontal, head raised | Walking |
| Standing | Leg upright to support body | Standing |
| Lying Down | Abdominal contact with ground | Lying |
| Feeding | Feeding with head through railing | Eating |
| Drinking Water | Drinking with head over sink | Drink |
| Parameter | Values |
|---|---|
| Training batch size | 16 |
| Epochs | 250 |
| Image size | 640 × 640 |
| Batch | 128 |
| Initial learning rate | 0.01 |
| Momentum | 0.937 |
| Sparsity training epochs | 500 |
| Parameter | Values |
| Behavior | Precision (%) | Recall (%) | mAP50 (%) |
|---|---|---|---|
| Drinking | 79.2 | 78.3 | 78.7 |
| Lying | 76.0 | 77.3 | 79.0 |
| Eating | 89.3 | 89.3 | 91.5 |
| Standing | 93.1 | 90.0 | 94.0 |
| Walking | 93.8 | 96.7 | 97.7 |
| Index Algorithms | Params (M) | FLOPS (G) | Model Size (Mb) | Precision (%) | Recall (%) | mAP50 (%) |
|---|---|---|---|---|---|---|
| YOLO v8-C2f-faster-EMA | 2.310 | 6.5 | 4.9 | 88.5 | 85.6 | 89.5 |
| V8-P2-Lamp/2.5/0.0001 | 1.103 | 4.5 | 2.6 | 89.0 | 85.6 | 90.9 |
| V8-P2-Lamp/3.0/0.0005 | 0.949 | 4.0 | 2.3 | 88.1 | 87.6 | 90.9 |
| V8-P2-Slim/2.5/0.0001 | 2.431 | 4.9 | 5.2 | 85.4 | 84.9 | 87.5 |
| V8-P2-Slim/3.0/0.0005 | 2.320 | 4.0 | 5.0 | 85.7 | 85.9 | 87.9 |
| V8-P2-Random/2.5/0.0001 | 1.103 | 4.5 | 2.6 | 90.0 | 85.0 | 90.0 |
| V8-P2-Random/3.0/0.0005 | 0.949 | 4.0 | 2.3 | 86.1 | 88.6 | 90.4 |
| V8-P2-DepGraph/2.5/0.0001 | 1.103 | 4.5 | 2.6 | 89.1 | 86.5 | 89.8 |
| V8-P2-DepGraph/3.0/0.0005 | 0.949 | 4.0 | 2.3 | 89.9 | 85.8 | 90.3 |
| Index Algorithms | Params (M) | FLOPS (G) | Model Size (Mb) | Precision (%) | Recall (%) | mAP50 (%) |
|---|---|---|---|---|---|---|
| SSD | 52 | 26.2 | 92.6 | 87.1 | 69.2 | 84.5 |
| YOLO v5n | 3.2 | 4.6 | 27 | 86.8 | 68.7 | 80.9 |
| YOLO v8n | 3.007 | 8.1 | 6.2 | 88.7 | 87.6 | 90.2 |
| YOLO v8-C2f-faster-EMA | 2.310 | 6.5 | 4.9 | 88.5 | 85.6 | 89.5 |
| YOLO v11n | 2.583 | 6.3 | 5.5 | 87.4 | 86.0 | 89.2 |
| YOLO v12n | 2.569 | 6.5 | 5.3 | 87.9 | 84.8 | 89.0 |
| YOLO v8-P2 | 2.922 | 12.2 | 6.2 | 89.1 | 87.8 | 91.2 |
| YOLO v8-P2-Lamp | 0.949 | 4.0 | 2.3 | 88.1 | 87.6 | 90.9 |
| Category | Number | Index Algorithms | F1 Score (%) | mAP50 (%) |
|---|---|---|---|---|
| Daytime | 2525 | SSD | 83 | 85.6 |
| YOLO v5n | 85 | 87.0 | ||
| YOLO v8n | 88 | 91.4 | ||
| YOLO v8-C2f-faster-EMA | 86 | 89.8 | ||
| YOLO v8-P2 | 89 | 91.1 | ||
| YOLO v8-P2-Lamp | 87 | 90.8 | ||
| Daytime (exposure) | 2526 | SSD | 83 | 82.1 |
| YOLO v5n | 85 | 85.4 | ||
| YOLO v8n | 87 | 88.0 | ||
| YOLO v8-C2f-faster-EMA | 84 | 87.2 | ||
| YOLO v8-P2 | 87 | 88.7 | ||
| YOLO v8-P2-Lamp | 81 | 85.1 | ||
| Nighttime | 3007 | SSD | 79 | 82.4 |
| YOLO v5n | 81 | 83.0 | ||
| YOLO v8n | 86 | 85.4 | ||
| YOLO v8-C2f-faster-EMA | 85 | 83.1 | ||
| YOLO v8-P2 | 84 | 84.5 | ||
| YOLO v8-P2-Lamp | 80 | 84.8 |
| Category | Number | Index Algorithms | F1 Score (%) | mAP50 (%) |
|---|---|---|---|---|
| Light masking | 2589 | SSD | 83 | 81.3 |
| YOLO v5n | 85 | 83.5 | ||
| YOLO v8n | 87 | 88.5 | ||
| YOLO v8-C2f-faster-EMA | 84 | 87.7 | ||
| YOLO v8-P2 | 87 | 88.6 | ||
| YOLO v8-P2-Lamp | 83 | 86.0 | ||
| Medium masking | 2413 | SSD | 82 | 80.3 |
| YOLO v5n | 86 | 82.3 | ||
| YOLO v8n | 91 | 92.3 | ||
| YOLO v8-C2f-faster-EMA | 92 | 92.9 | ||
| YOLO v8-P2 | 91 | 92.7 | ||
| YOLO v8-P2-Lamp | 89 | 92.3 | ||
| Heavy masking | 2379 | SSD | 73 | 82.1 |
| YOLO v5n | 79 | 83.6 | ||
| YOLO v8n | 81 | 82.9 | ||
| YOLO v8-C2f-faster-EMA | 75 | 77.7 | ||
| YOLO v8-P2 | 83 | 82.9 | ||
| YOLO v8-P2-Lamp | 80 | 83.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Z.; Wang, S.; Wang, C.; Zong, Z.; Zhang, C.; Su, L.; Ban, Z. Research on Calf Behavior Recognition Based on Improved Lightweight YOLOv8 in Farming Scenarios. Animals 2025, 15, 898. https://doi.org/10.3390/ani15060898
Yuan Z, Wang S, Wang C, Zong Z, Zhang C, Su L, Ban Z. Research on Calf Behavior Recognition Based on Improved Lightweight YOLOv8 in Farming Scenarios. Animals. 2025; 15(6):898. https://doi.org/10.3390/ani15060898
Chicago/Turabian StyleYuan, Ze, Shuai Wang, Chunguang Wang, Zheying Zong, Chunhui Zhang, Lide Su, and Zeyu Ban. 2025. "Research on Calf Behavior Recognition Based on Improved Lightweight YOLOv8 in Farming Scenarios" Animals 15, no. 6: 898. https://doi.org/10.3390/ani15060898
APA StyleYuan, Z., Wang, S., Wang, C., Zong, Z., Zhang, C., Su, L., & Ban, Z. (2025). Research on Calf Behavior Recognition Based on Improved Lightweight YOLOv8 in Farming Scenarios. Animals, 15(6), 898. https://doi.org/10.3390/ani15060898