
From Prediction to Precision: Explainable AI-Driven Insights for Targeted Treatment in Equine Colic

Simple Summary
Abstract
1. Introduction
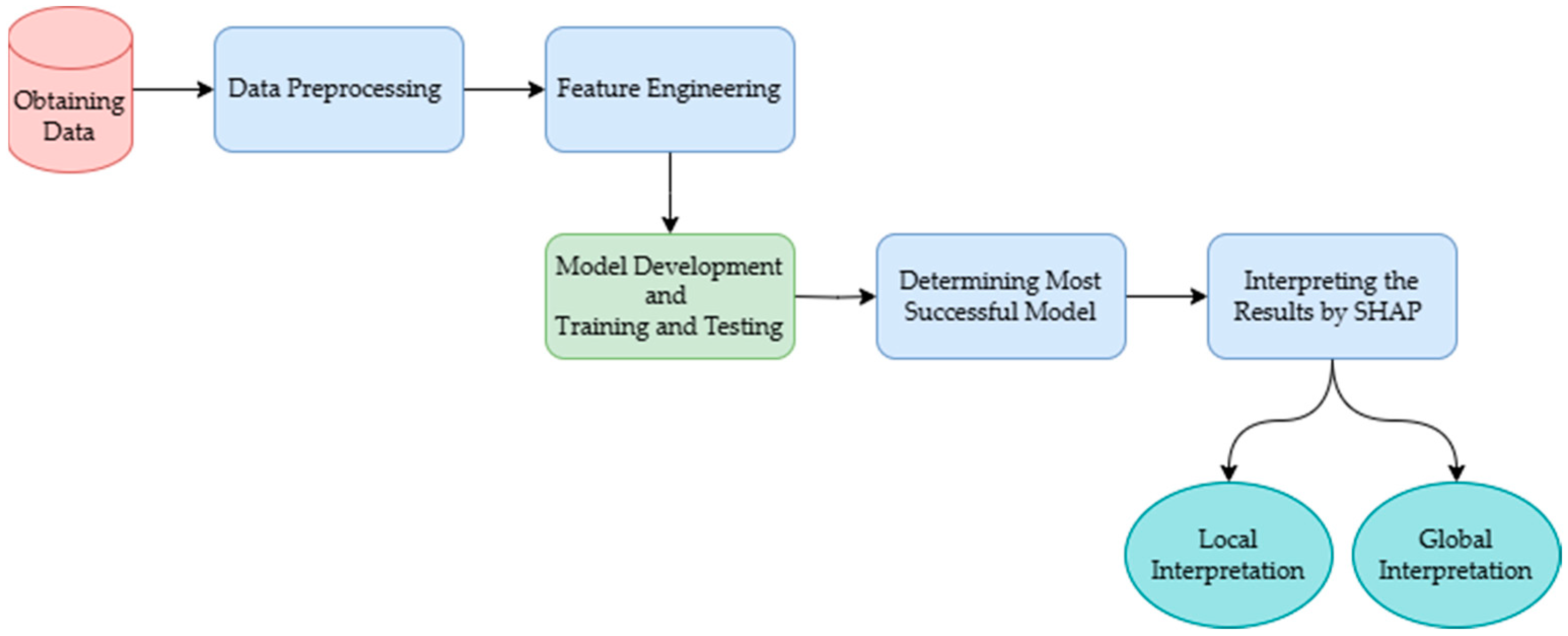
2. Materials and Methods
2.1. Data Collection and Preprocessing
2.2. Prediction Model Development and Evaluation
2.3. Post-Explainability Techniques
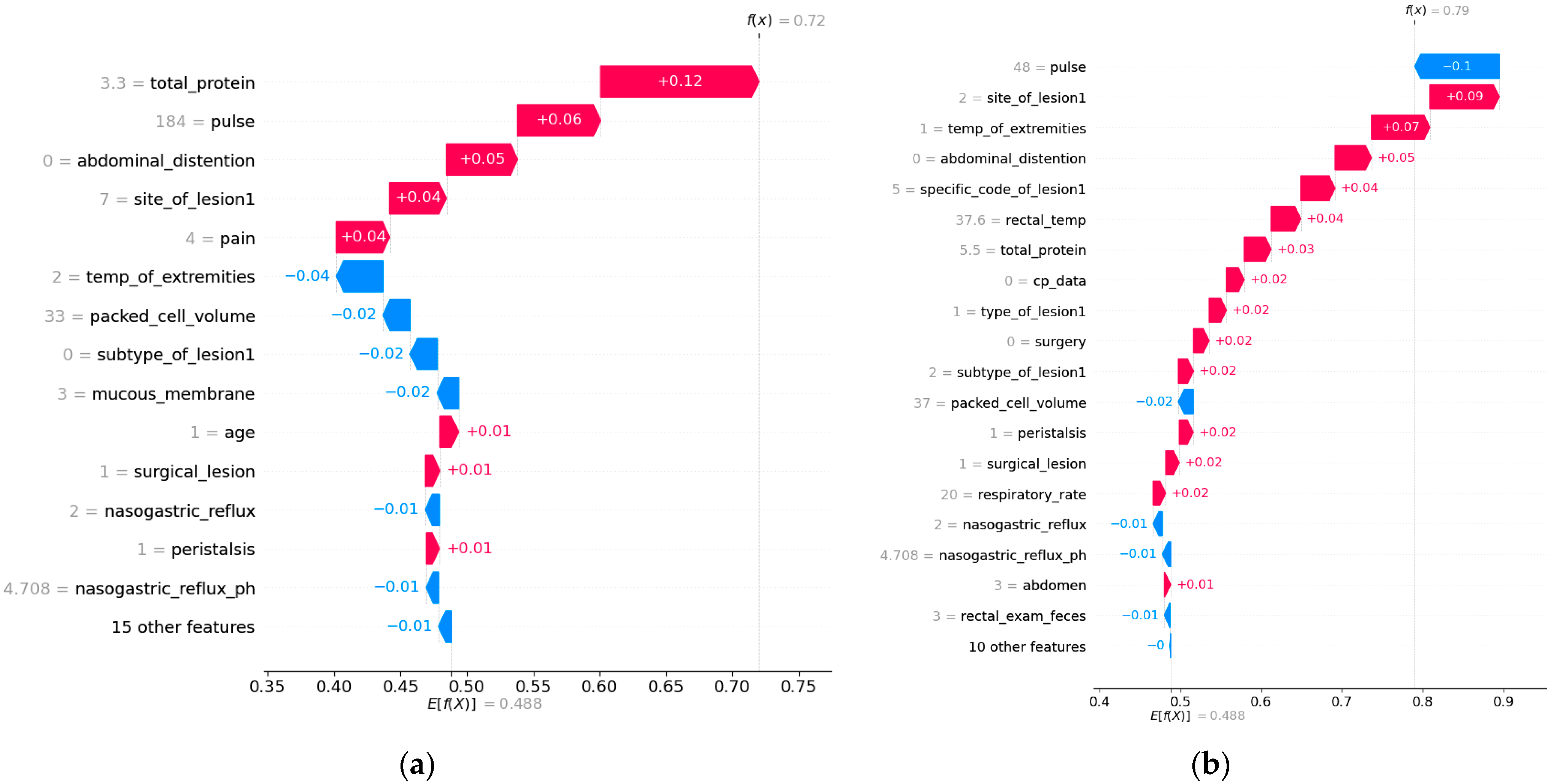
2.3.1. Local Explanation
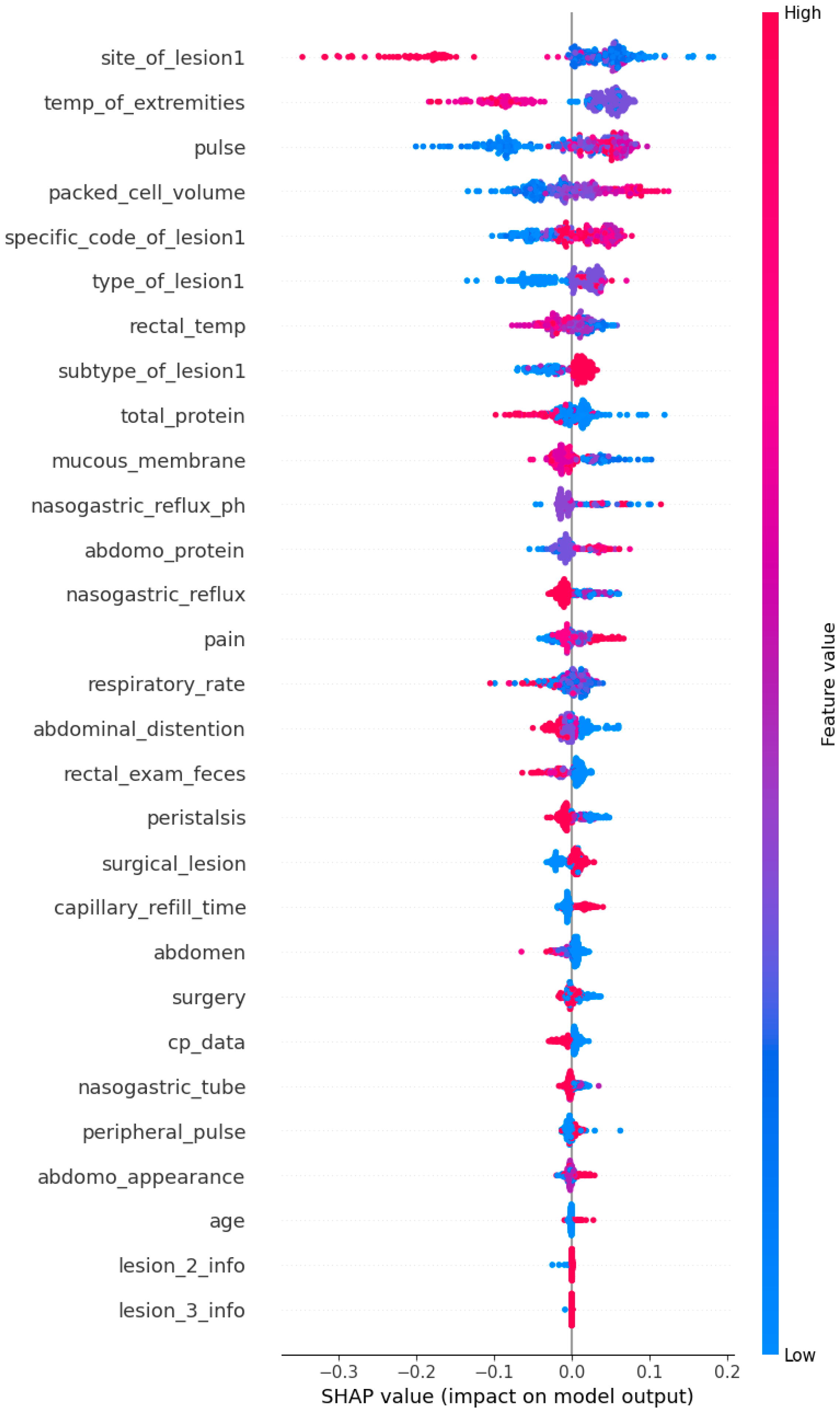
2.3.2. Global Explanation
- In Equation (2), is the number of iterations, is the sample of interest, is the attribute index and is the machine learning model. ‘’ is the prediction for , but with the exception of the corresponding value of attribute , a random number of attribute values were replaced with attribute values from random data points.
- The procedure must be repeated for each feature to obtain all Shapley values (Equations (1) and (2) are taken from the main study of [17]).
2.4. Used Technologies
3. Results
3.1. SHAP Local Interpretation
3.2. SHAP Global Interpretation
4. Discussion
Limitations and Future Works
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Features | Feature Information | Types |
|---|---|---|
| Age | Adult, young (<6 months) | Categoric |
| Temperature of extremities | Normal, warm, cool, cold | |
| Peripheral pulse | Normal, increased, reduced, absent | |
| Mucous membranes | Normal pink, bright pink, pale pink, pale cyanotic, bright red, dark cyanotic | |
| Capillary refill time | <3 s, ≥3 s | |
| Pain | No pain, depressed, mild pain, severe pain, extreme pain | |
| Peristalsis | Hypermotile, normal, hypomotile, absent | |
| Abdominal distension | None, slight, moderate, severe | |
| Nasogastric tube | None, slight, significant | |
| Nasogastric reflux | None, >1 L, <1 L | |
| Rectal examination-feces | Normal, increased, decreased, absent | |
| Abdomen | Normal, other, firm, small intestine, large intestine | |
| Abdominocentesis appearance | Clear, cloudy, serosanguinous | |
| Surgical lesion | No: non-surgical lesion/Yes: surgical lesion | |
| Cp data | No: pathology data not present/Yes: data present | |
| Surgery | No: horse had surgery/Yes: without surgery | |
| site_of_lesion1 | 1 = gastric, 2 = sm intestine, 3 = lg colon, 4 = lg colon and cecum, 5 = cecum, 6 = transverse colon, 7 = rectum/descending colon, 8 = uterus, 9 = bladder, 11 = all intestinal sites | |
| type_of_lesion1 | 1 = simple, 2 = strangulation, 3 = inflammation, 4 = other | |
| subtype_of_lesion1 | 1 = mechanical, 2 = paralytic | |
| specific_code_of_lesion1 | 1 = obturation, 2 = intrinsic, 3 = extrinsic, 4 = adynamic, 5 = volvulus/torsion, 6 = intussusception, 7 = thromboembolic, 8 = hernia, 9 = lipoma/splenic incarceration, 10 = displacement | |
| lesion_2_info | Presence, absence | |
| lesion_3_info | Presence, absence | |
| Rectal temperature | Min: 35.4–Max: 40.8 | Numeric |
| Nasogastric reflux pH | Min: 1–Max: 7.5 | |
| Pulse | Min: 30–Max: 184 | |
| Respiratory rate | Min: 8–Max: 96 | |
| Packed cell volume | Min: 23–Max: 75 | |
| Total protein | Min: 3.3–Max: 8.9 | |
| Abdominocentesis total protein | Min: 0.1–Max: 10.1 | |
| Outcome (Survive) | Lived, died (euthanized and died, merged as died) | Target (Categoric) |
Appendix B
Appendix B.1. Missing Data Handling
Appendix B.2. Label Encoding
Appendix B.3. Decoding of “Lesion” Features
| Site of Lesion | Type | Subtype | Specific Code |
|---|---|---|---|
| 1 = Gastric, 2 = Small Intestine, 3 = Large Colon, 4 = Large Colon and Cecum, 5 = Cecum, 6 = Transverse Colon, 7 = Rectum/Descending Colon, 8 = Uterus, 9 = Bladder, 11 = All Intestinal Sites, 00 = None, | 1 = Simple, 2 = Strangulation, 3 = Inflammation, 4 = Other | 1 = Mechanical, 2 = Paralytic, 0 = N/A | 1 = Obstruction, 2 = Intrinsic, 3 = Extrinsic, 4 = Adynamic, 5 = Volvulus/Torsion, 6 = Intussusception, 7 = Thromboembolic, 8 = Hernia, 9 = Lipoma/Splenic Incarceration 10 = Displacement, 0 = N/A |
Appendix B.4. Evaluation Metrics
| Metric | Formula |
|---|---|
| Accuracy: The ratio of correctly predicted observations to the total observations. It is useful when the dataset is balanced. | |
| Precision: The ratio of correctly predicted positive observations to the total predicted positive observations. Focuses on how many selected items are relevant. | |
| Recall: The ratio of correctly predicted positive observations to all actual positives. Also known as sensitivity. | |
| F1 Score: The harmonic mean of precision and recall. It is more suitable when the dataset has imbalanced classes, balancing precision and recall. |
References
- Christophersen, M.T.; Dupont, N.; Berg-Sørensen, K.S.; Konnerup, C.; Pihl, T.H.; Andersen, P.H. Short-term survival and mortality rates in a retrospective study of colic in 1588 Danish horses. Acta Vet. Scand. 2014, 56, 20. [Google Scholar] [CrossRef]
- Spadari, A.; Gialletti, R.; Gandini, M.; Valle, E.; Cerullo, A.; Cavallini, D.; Giusto, G. Short-term survival and postoperative complications rates in horses undergoing colic surgery: A multicentre study. Animals 2023, 13, 1107. [Google Scholar] [CrossRef] [PubMed]
- Iglesias-García, M.; Rodríguez Hurtado, I.; Ortiz-Díez, G.; De la Calle del Barrio, J.; Fernández Pérez, C.; Gómez Lucas, R. Predictive models for equine emergency exploratory laparotomy in Spain: Pre-, intra-, and post-operative mortality-associated factors. Animals 2022, 12, 1375. [Google Scholar] [CrossRef]
- Morton, A.J.; Blikslager, A.T. Surgical and postoperative factors influencing short-term survival of horses following small intestinal resection: 92 cases (1994–2001). Equine Vet. J. 2010, 42, 450–454. [Google Scholar] [CrossRef] [PubMed]
- Dybkjær, E.; Steffensen, K.F.; Honoré, M.L.; Dinesen, M.A.; Christophersen, M.T.; Pihl, T.H. Short-term survival rates of 1397 horses referred for colic from 2010 to 2018. Acta Vet. Scand. 2022, 64, 11. [Google Scholar] [CrossRef] [PubMed]
- Freeman, D.E.; Hammock, P.; Baker, G.J.; Goetz, T.; Foreman, J.H.; Schaeffer, D.J.; Richter, H.-A.; Inoue, O.; Magid, J.H. Short- and long-term survival and prevalence of postoperative ileus after small intestinal surgery in the horse. Equine Vet. J. 2000, 32, 42–46. [Google Scholar] [CrossRef] [PubMed]
- Thomson, P.; Garrido, D.; Santibáñez, R.; Lara, F. Preliminary Functional Analysis of the Gut Microbiome in Colic Horses. Animals 2024, 14, 3222. [Google Scholar] [CrossRef] [PubMed]
- Fraiwan, M.A.; Abutarbush, S.M. Using Artificial Intelligence to Predict Survivability Likelihood and Need for Surgery in Horses Presented With Acute Abdomen (Colic). J. Equine Vet. Sci. 2020, 90, 102973. [Google Scholar] [CrossRef]
- Mahmoud, M. Towards Sustainable Equine Welfare: Comparative Analysis of Machine Learning Techniques in Predicting Horse Survival. Sustain. Mach. Intell. J. 2023, 5, 1–10. [Google Scholar] [CrossRef]
- Megahed, A.; Kandeel, S.; Alshaya, D.S.; Attia, K.A.; AlKahtani, M.D.; Albohairy, F.M.; Selim, A. A comparison of logistic regression and classification tree to assess brucellosis associated risk factors in dairy cattle. Prev. Vet. Med. 2022, 203, 105664. [Google Scholar] [CrossRef] [PubMed]
- Shahinfar, S.; Khansefid, M.; Haile-Mariam, M.; Pryce, J.E. Machine learning approaches for the prediction of lameness in dairy cows. Animal 2021, 15, 100391. [Google Scholar] [CrossRef]
- Guleria, P.; Naga Srinivasu, P.; Ahmed, S.; Almusallam, N.; Alarfaj, F.K. XAI Framework for Cardiovascular Disease Prediction Using Classification Techniques. Electronics 2022, 11, 4086. [Google Scholar] [CrossRef]
- Hernandez, M.; Ramon-Julvez, U.; Ferraz, F.; with the ADNI Consortium. Explainable AI toward understanding the performance of the top three TADPOLE Challenge methods in the forecast of Alzheimer’s disease diagnosis. PLoS ONE 2022, 17, e0264695. [Google Scholar] [CrossRef]
- Çetintav, B.; Yalçın, A. Targeting Vaccine Hesitancy A Data-Driven Approach Using AI and Public Health Data. Mehmet Akif Ersoy Univ. J. Health Sci. Inst. 2024, 12, 24–33. [Google Scholar] [CrossRef]
- McLeish, M.; Cecile, M. Horse Colic [Dataset]; UCI Machine Learning Repository; University of California: Irvine, CA, USA, 1989. [Google Scholar] [CrossRef]
- de Klerk, J.; Tildesley, M.; Labuschagne, K.; Gorsich, E. Modelling bluetongue and African horse sickness vector (Culicoides spp.) distribution in the Western Cape in South Africa using random forest machine learning. Parasites Vectors 2024, 17, 354. [Google Scholar] [CrossRef]
- Machado, G.; Mendoza, M.R.; Corbellini, L.G. What variables are important in predicting bovine viral diarrhea virus? A random forest approach. Vet. Res. 2015, 46, 85. [Google Scholar] [CrossRef]
- Edelman, D. Adapting support vector machine methods for horserace odds prediction. Ann. Oper. Res. 2007, 151, 325–336. [Google Scholar] [CrossRef]
- Taha, A.; Darwish, A.; Hassanien, A.E.; ElKholy, A. Arabian horse identification based on whale optimised multi-class support vector machine. Int. J. Comput. Appl. Technol. 2020, 63, 83–92. [Google Scholar] [CrossRef]
- Burócziová, M.; Říha, J. Horse breed discrimination using machine learning methods. J. Appl. Genet. 2009, 50, 375–377. [Google Scholar] [CrossRef]
- Sawitri, S.; Simanjuntak, M.; Pardede, A.M.H. Application of Naive Bayes Method to Diagnose FMD Disease in Goats. Matech 2024, 3, 140–148. Available online: https://journal.binainternusa.org/index.php/matech/article/view/171 (accessed on 23 November 2024).
- Bidder, O.R.; Campbell, H.A.; Gómez-Laich, A.; Urgé, P.; Walker, J.; Cai, Y.; Wilson, R.P. Love thy neighbour: Automatic animal behavioural classification of acceleration data using the k-nearest neighbour algorithm. PLoS ONE 2014, 9, e88609. [Google Scholar] [CrossRef] [PubMed]
- Jayalakshmi, N.; Sangeeta, V.; Muttipati, A.S. Taylor Horse Herd Optimized Deep Fuzzy clustering and Laplace based K-nearest neighbor for web page recommendation. Adv. Eng. Softw. 2023, 175, 103351. [Google Scholar] [CrossRef]
- Chunga, J.; Shina, D.; Hwanga, S.; Park, G. Horse race rank prediction using learning-to-rank approaches. Korean J. Appl. Stat. 2024, 37, 239–253. [Google Scholar] [CrossRef]
- Lu, Y.H.; Li, Z.Z.; Liu, Z.L.; Su, C.; Wang, H.J.; Zhang, B.; Hou, Y. Association analysis between common pesticide and veterinary drug exposure in humans and diabetes mellitus based on XGBoost. Chin. J. Food Hyg. 2023, 35, 3. [Google Scholar] [CrossRef]
- Chen, L. Prediction model of pet rescue outcome based on LightGBM and Bayesian optimisation. J. Phys. Conf. Ser. 2023, 2646, 012030. [Google Scholar] [CrossRef]
- Tran, V.Q.; Byeon, H. Predicting dementia in Parkinson’s disease on a small tabular dataset using hybrid LightGBM–TabPFN and SHAP. Digit. Health 2024, 10, 20552076241272585. [Google Scholar] [CrossRef]
- Chandraprabha, M.; Dhanaraj, R.K. Adaboost CNN with Horse Herd Optimization Algorithm to Forecast the Rice Crop Yield. Int. J. Recent Innov. Trends Comput. Commun. 2023, 11, 192–203. [Google Scholar] [CrossRef]
- Dissanayake, O.; McPherson, S.; Allyndree, J.; Kennedy, E.; Cunningham, P.; Riaboff, L. Personalized Weighted AdaBoost for Animal Behavior Recognition from Sensor Data. In Proceedings of the 31st Irish Conference on Artificial Intelligence and Cognitive Science (AICS), Letterkenny, Ireland, 7–8 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Nhat-Duc, H.; Van-Duc, T. Comparison of histogram-based gradient boosting classification machine, random forest, and deep convolutional neural network for pavement raveling severity classification. Autom. Constr. 2023, 148, 104767. [Google Scholar] [CrossRef]
- Piles, M.; Bergsma, R.; Gianola, D.; Gilbert, H.; Tusell, L. Feature selection stability and accuracy of prediction models for genomic prediction of residual feed intake in pigs using machine learning. Front. Genet. 2021, 12, 611506. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Molnar, C. Interpretable Machine Learning. 2020. Available online: https://christophm.github.io/interpretable-ml-book (accessed on 23 November 2024).
- Punyapornwithaya, V.; Klaharn, K.; Arjkumpa, O.; Sansamur, C. Exploring the predictive capability of machine learning models in identifying foot and mouth disease outbreak occurrences in cattle farms in an endemic setting of Thailand. Prev. Vet. Med. 2022, 207, 105706. [Google Scholar] [CrossRef] [PubMed]
- Costa, M.C.; Arroyo, L.G.; Allen-Vercoe, E.; Stämpfli, H.R.; Kim, P.T.; Sturgeon, A.; Weese, J.S. Comparison of the fecal microbiota of healthy horses and horses with colitis by high throughput sequencing of the V3–V5 region of the 16S rRNA gene. PLoS ONE 2012, 7, e41484. [Google Scholar] [CrossRef] [PubMed]
| Models | Categories | Descriptions |
|---|---|---|
| Random Forest (RF) | Bagging, Decision Trees | Combines decision trees using the bagging method [16,17]. |
| Support Vector Machine (SVM) | Kernel Functions, Hyperplanes | Separates data using linear or non-linear hyperplanes [18,19]. |
| Gaussian Naive Bayes | Bayes Theorem, Gaussian Distribution | A classifier based on Bayes’ theorem and Gaussian distribution [20,21]. |
| K-Nearest Neighbors (KNN) | Distance Measurements | Classifies or regresses based on distances between data points [22,23]. |
| XGBoost | Gradient Boosting, Quadratic Derivatives | A fast and powerful boosting algorithm that reduces errors iteratively [24,25]. |
| LightGBM (LGBM) | Gradient Boosting, Histogram Algorithm | Uses histogram-based data splitting for speed and memory efficiency [26,27]. |
| AdaBoost | Weighted Error Minimization | Combines weak learners with weighted boosting [28,29]. |
| HistGradientBoost | Gradient Boosting, Histogram Algorithm | Employs histogram-based gradient boosting for improved performance [30,31]. |
| Models | Accuracy | Recall | Precision | F1 Score | |
|---|---|---|---|---|---|
| 1 | Random Forest | 0.861 | 0.859 | 0.860 | 0.859 |
| 2 | XGBoost | 0.860 | 0.860 | 0.862 | 0.861 |
| 3 | HistGradientBoost | 0.847 | 0.846 | 0.848 | 0.847 |
| 4 | LGBM | 0.834 | 0.832 | 0.833 | 0.832 |
| 5 | AdaBoost | 0.833 | 0.834 | 0.836 | 0.835 |
| 6 | KNN | 0.820 | 0.819 | 0.822 | 0.820 |
| 7 | SVM | 0.736 | 0.735 | 0.752 | 0.743 |
| 8 | Gaussian Naive Bayes | 0.735 | 0.733 | 0.783 | 0.717 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cetintav, B.; Yalcin, A. From Prediction to Precision: Explainable AI-Driven Insights for Targeted Treatment in Equine Colic. Animals 2025, 15, 126. https://doi.org/10.3390/ani15020126
Cetintav B, Yalcin A. From Prediction to Precision: Explainable AI-Driven Insights for Targeted Treatment in Equine Colic. Animals. 2025; 15(2):126. https://doi.org/10.3390/ani15020126
Chicago/Turabian StyleCetintav, Bekir, and Ahmet Yalcin. 2025. "From Prediction to Precision: Explainable AI-Driven Insights for Targeted Treatment in Equine Colic" Animals 15, no. 2: 126. https://doi.org/10.3390/ani15020126
APA StyleCetintav, B., & Yalcin, A. (2025). From Prediction to Precision: Explainable AI-Driven Insights for Targeted Treatment in Equine Colic. Animals, 15(2), 126. https://doi.org/10.3390/ani15020126