


Improved YOLOv8 Model for Lightweight Pigeon Egg Detection
 , ,
, ,
Abstract
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Acquisition and Processing
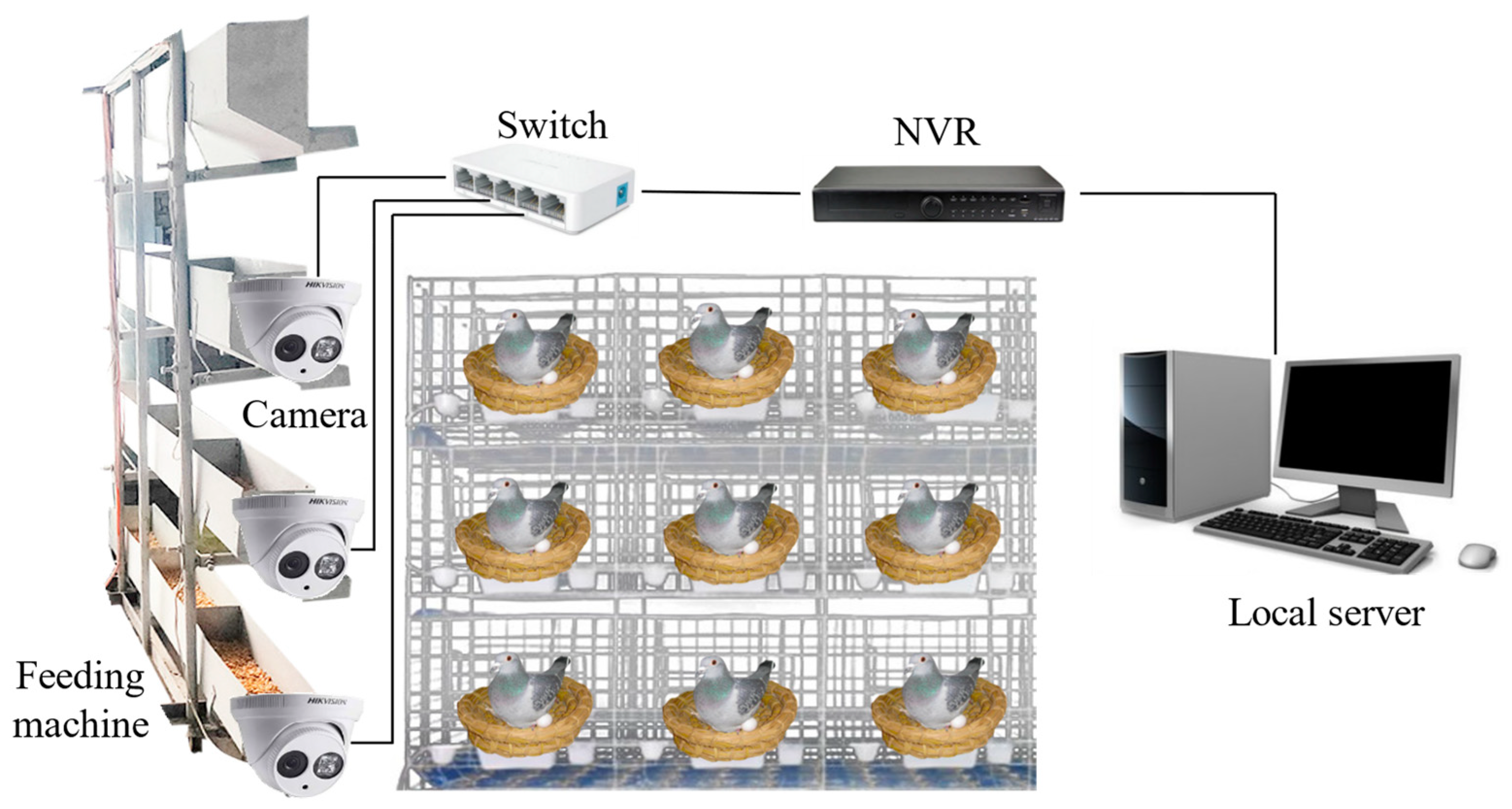
2.1.1. Data Acquisition
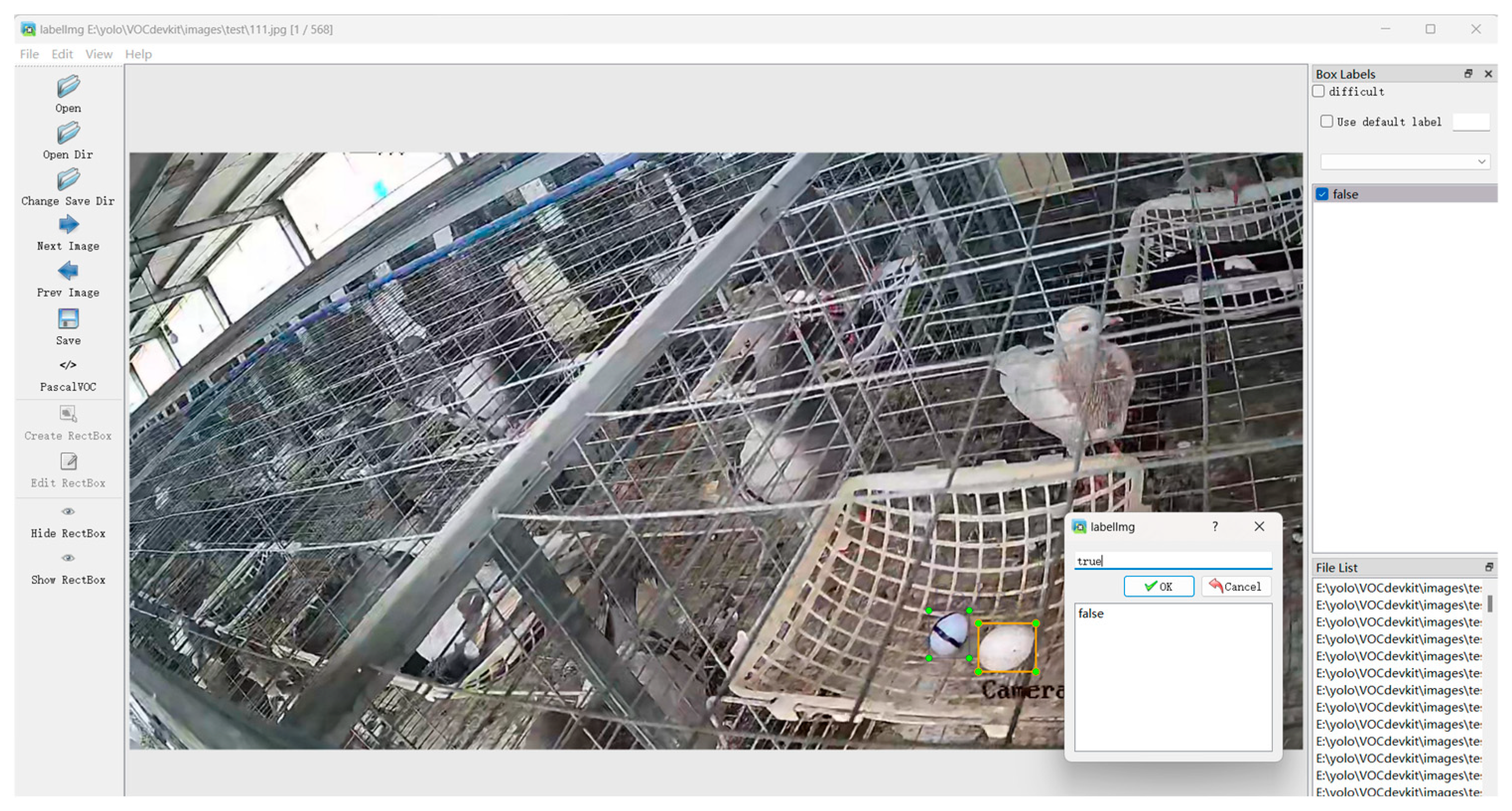
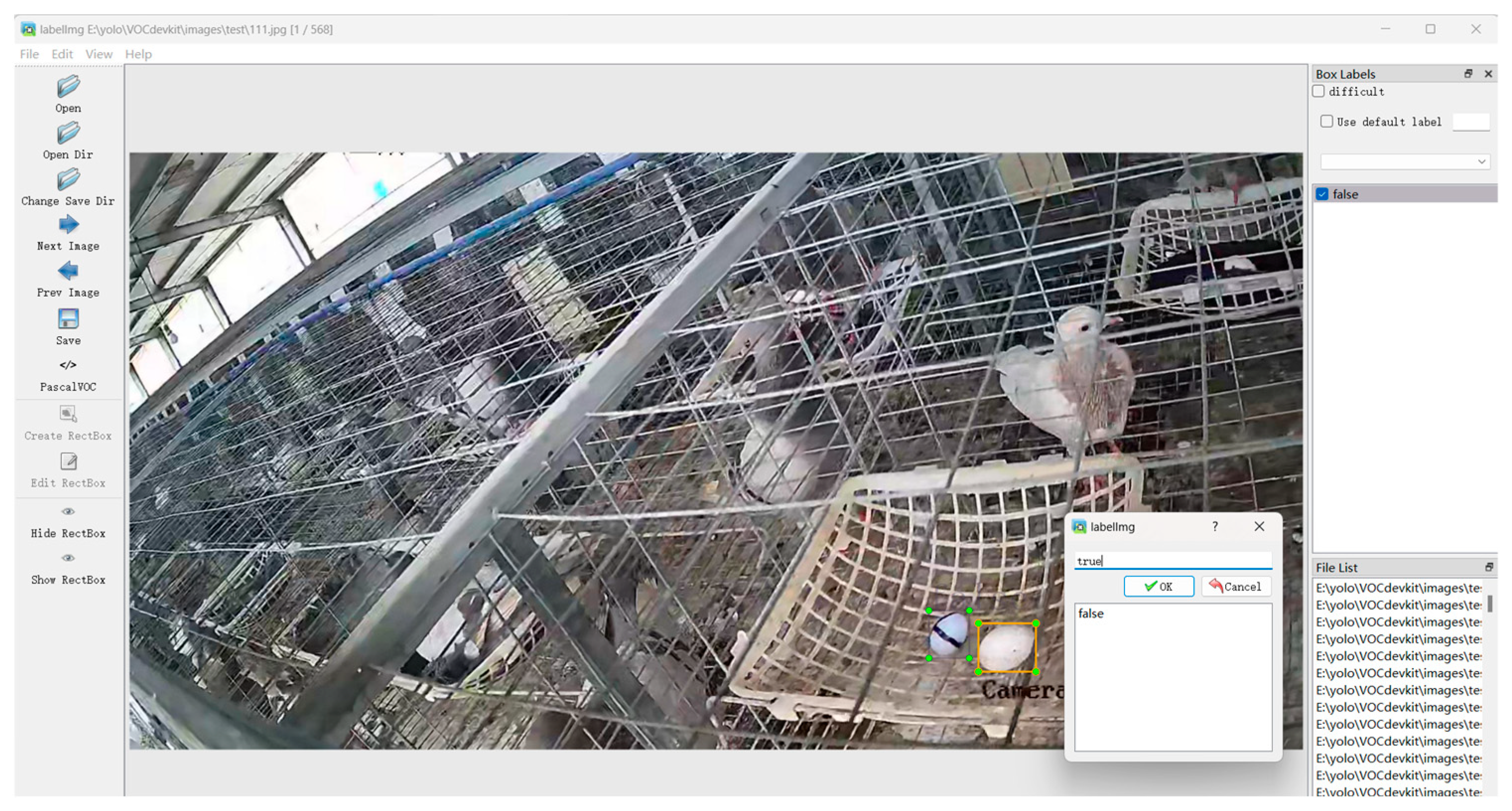
2.1.2. Dataset Annotation and Partition
- All annotated bounding boxes should accurately cover the target, closely fitting the target’s edges in a minimal rectangular box format [16]. They should not exclude any part of the real or fake pigeon eggs, while also avoiding the inclusion of excessive background information.
- Annotations for real and fake pigeon eggs should maintain consistency and strictly adhere to the requirements of the pigeon egg schema.
- For partially occluded pigeon egg targets, the annotation should include the occluding object along with the target, ensuring that no clearly identifiable pigeon egg targets are missed.
- If pigeon eggs are heavily obscured by pigeon cages, feathers, feces, or other breeding pigeons, making them difficult for the human eye to identify, then those targets should not be annotated.
2.2. YOLOv8 Network Model
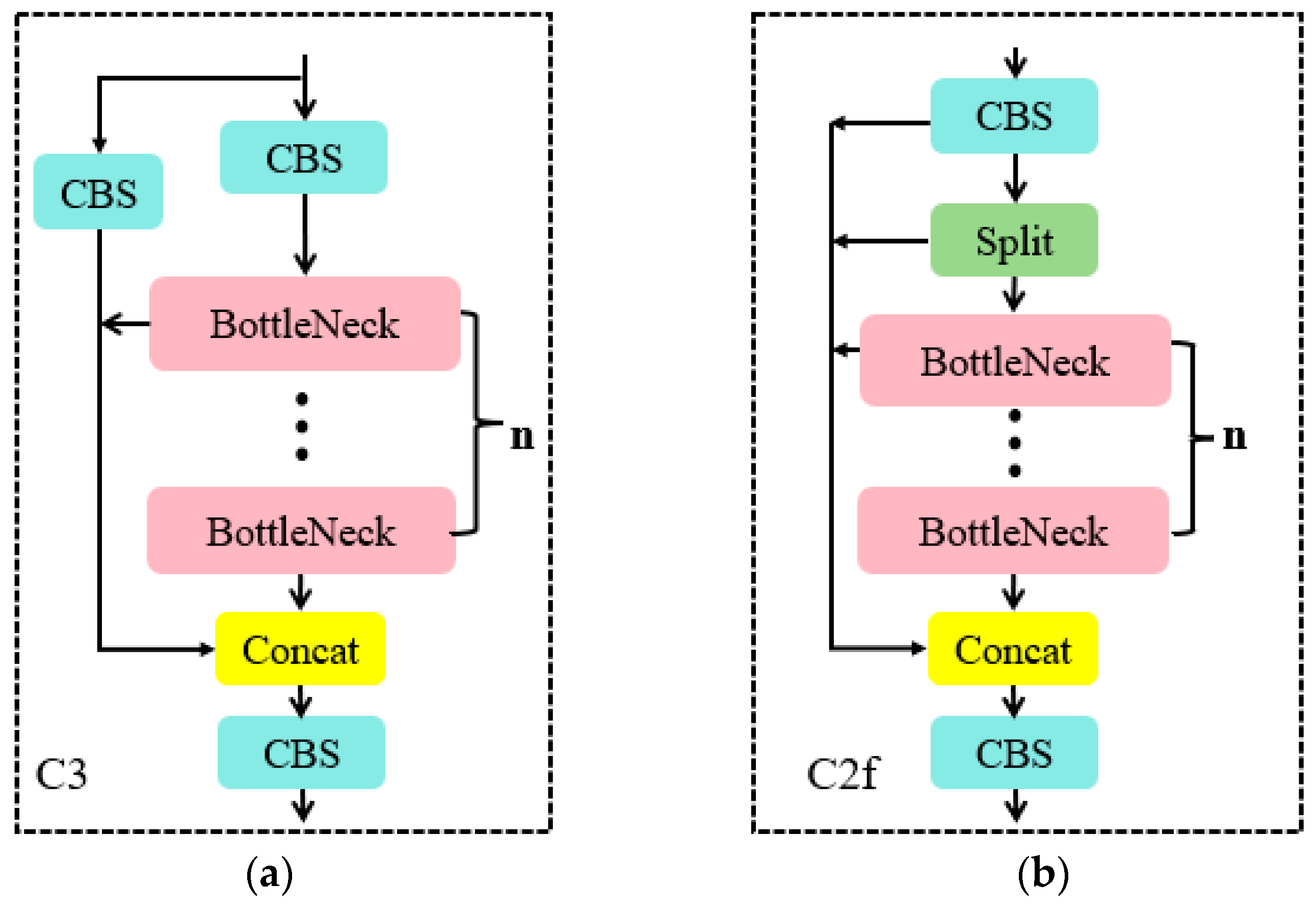
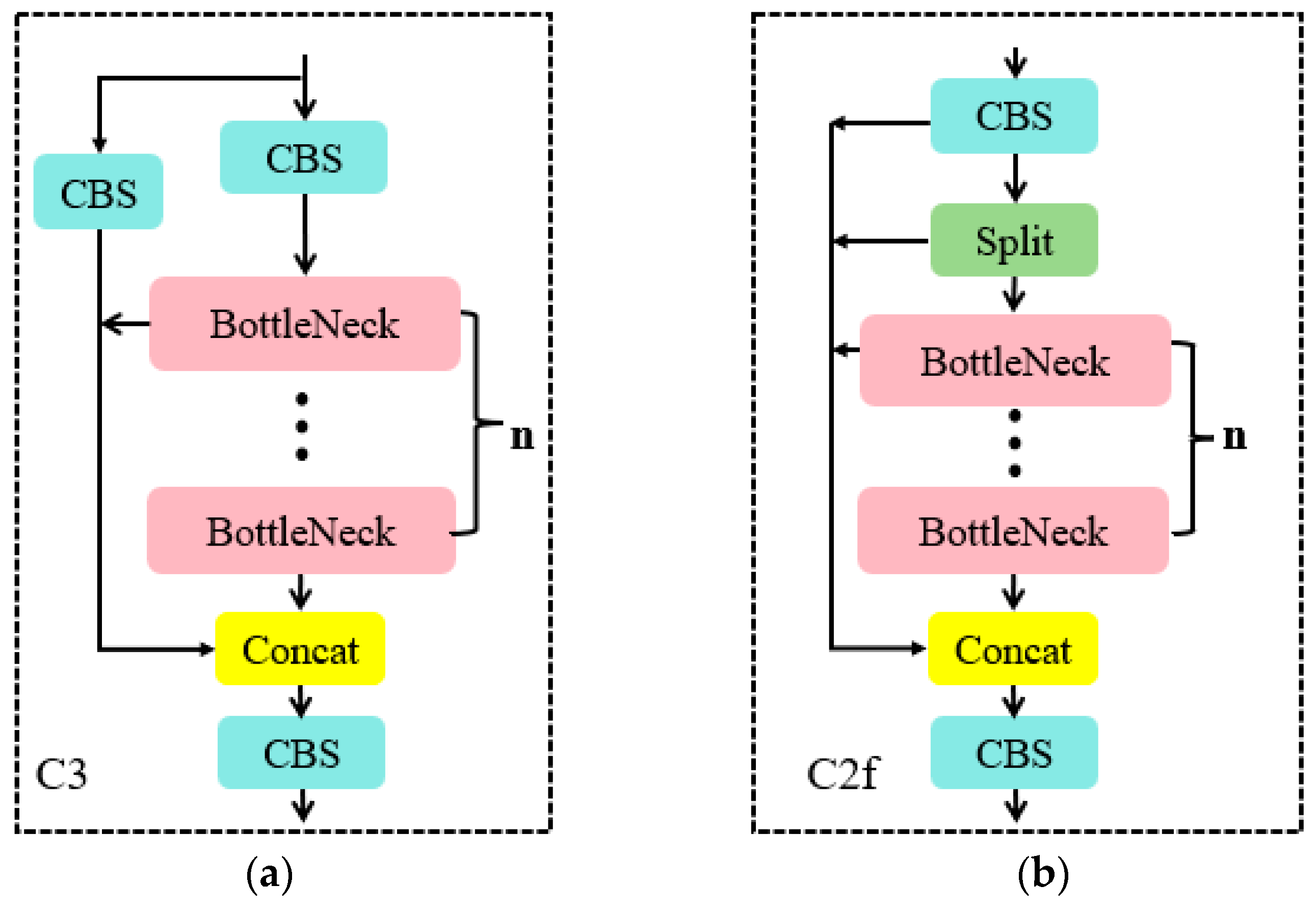
- In the backbone network and neck network, YOLOv8 incorporates the design concept of YOLOv7 ELAN [21]. It replaces the C3 structure of YOLOv5 with the C2f structure. The C2f module can combine advanced features with context information to enhance the gradient flow of the model and the feature representation capability of the network by adding additional jump connections, thus improving detection accuracy. The specific module structure is shown in Figure 4.
- YOLOv8 replaces the detection head with a decoupled-head structure, separating the classification head from the detection head. Additionally, it switches from Anchor-Based to Anchor-Free detection.
- Regarding the loss function, YOLOv8 separates the regression and classification tasks in object-detection prediction. For the regression task, it employs Distribution Focal Loss (DFL Loss) and Complete Intersection over Union Loss (CIoU Loss). For the classification task, it uses Binary Cross-Entropy Loss (BCE Loss).
2.3. YOLOv8-PG Model Improvement Strategy
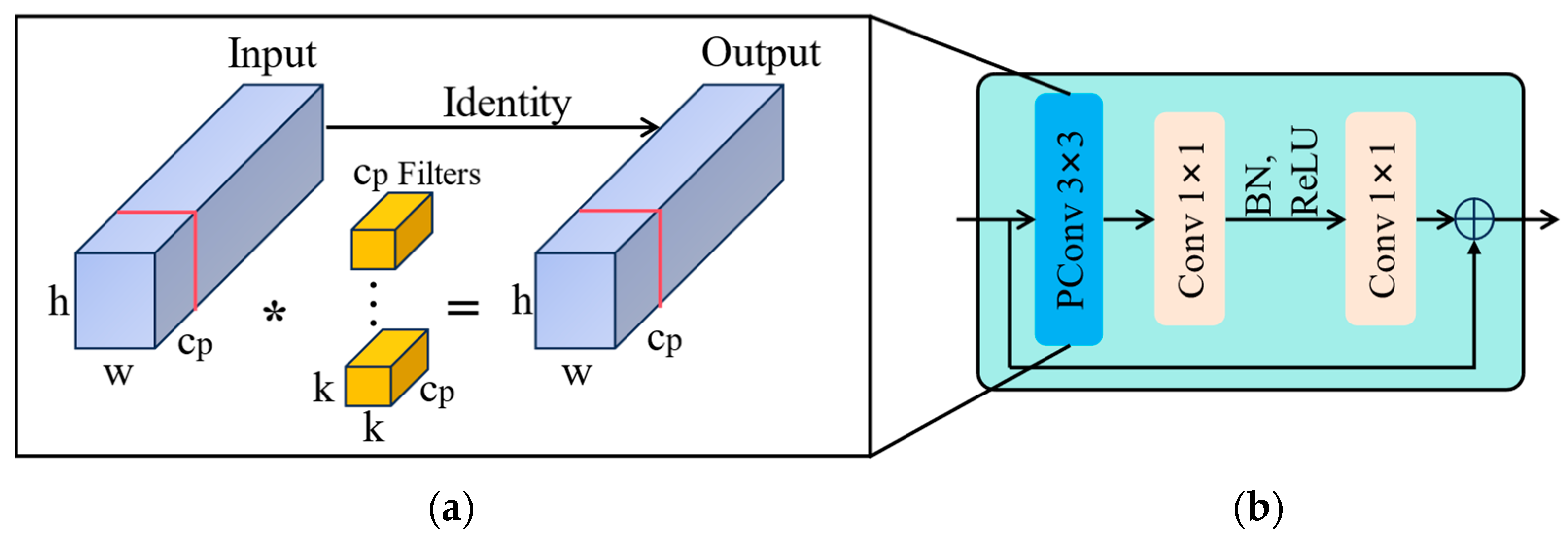
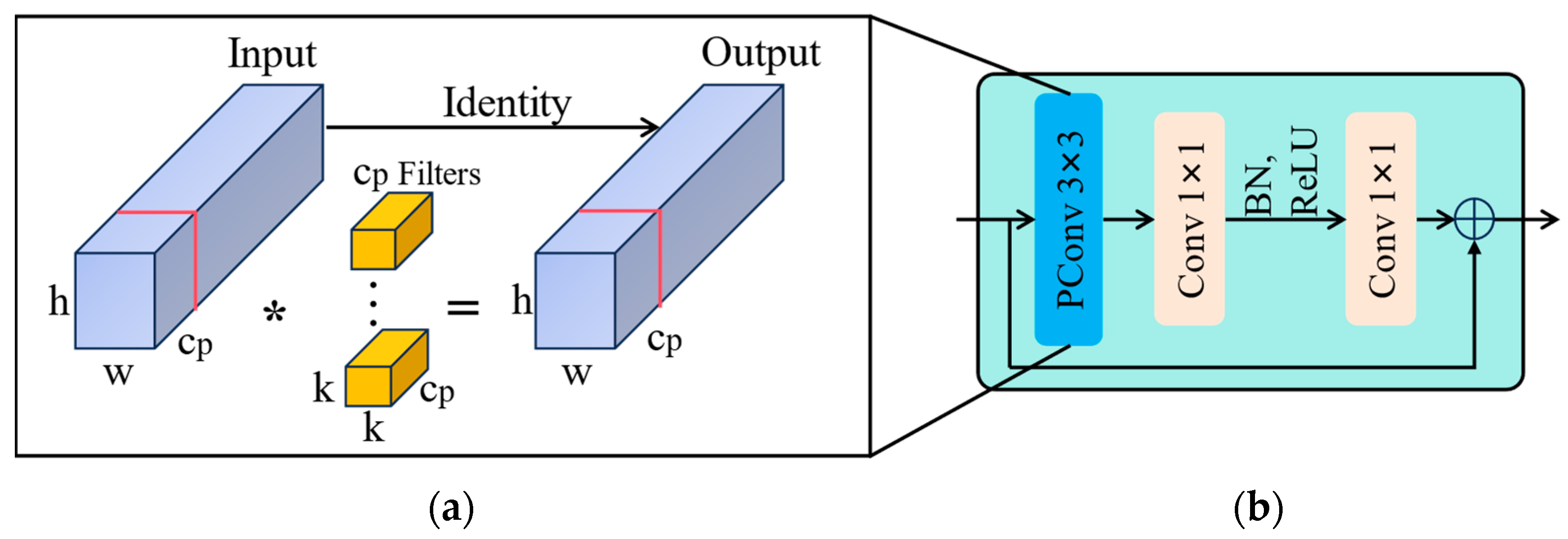
2.3.1. Fasternet Block
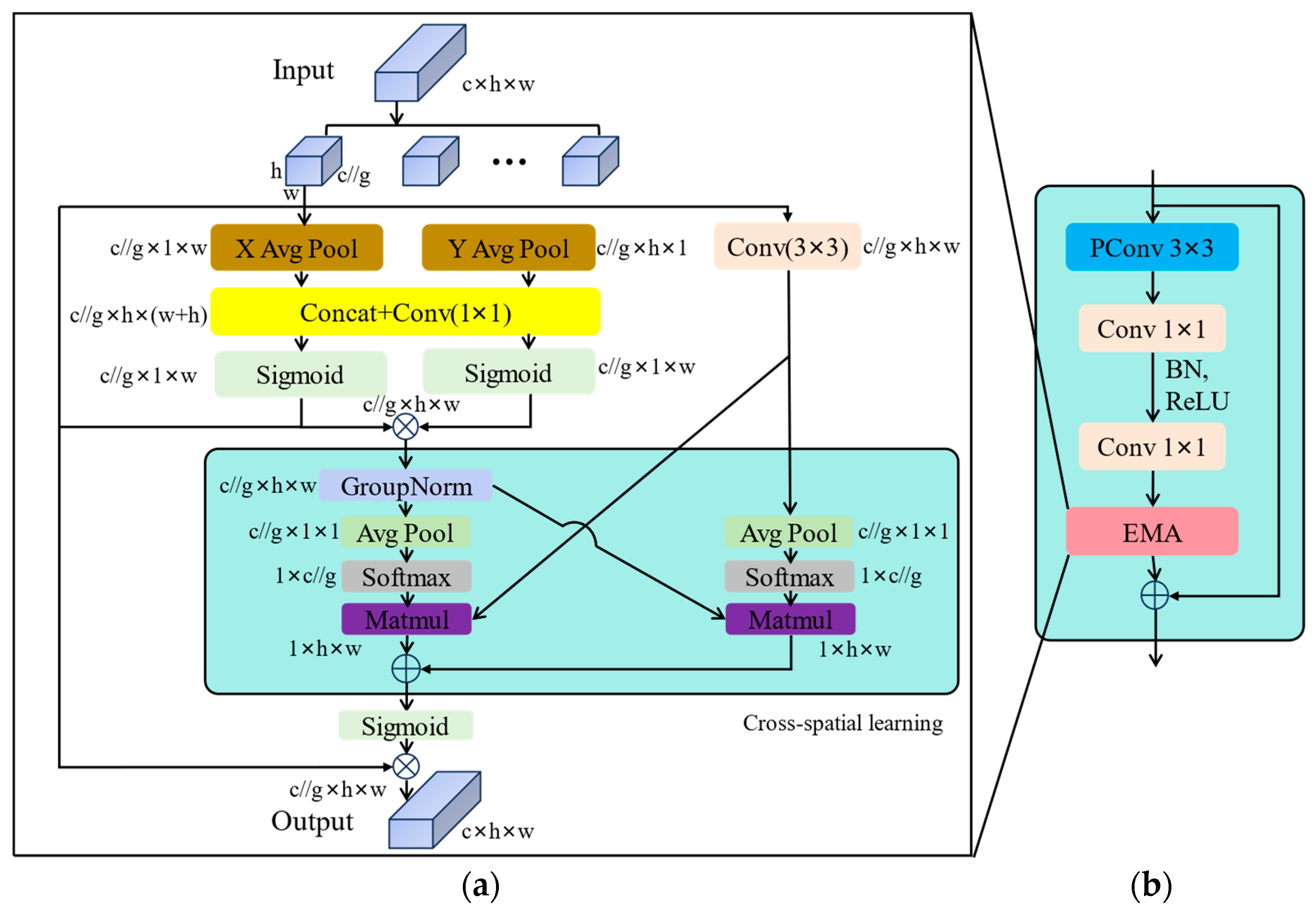
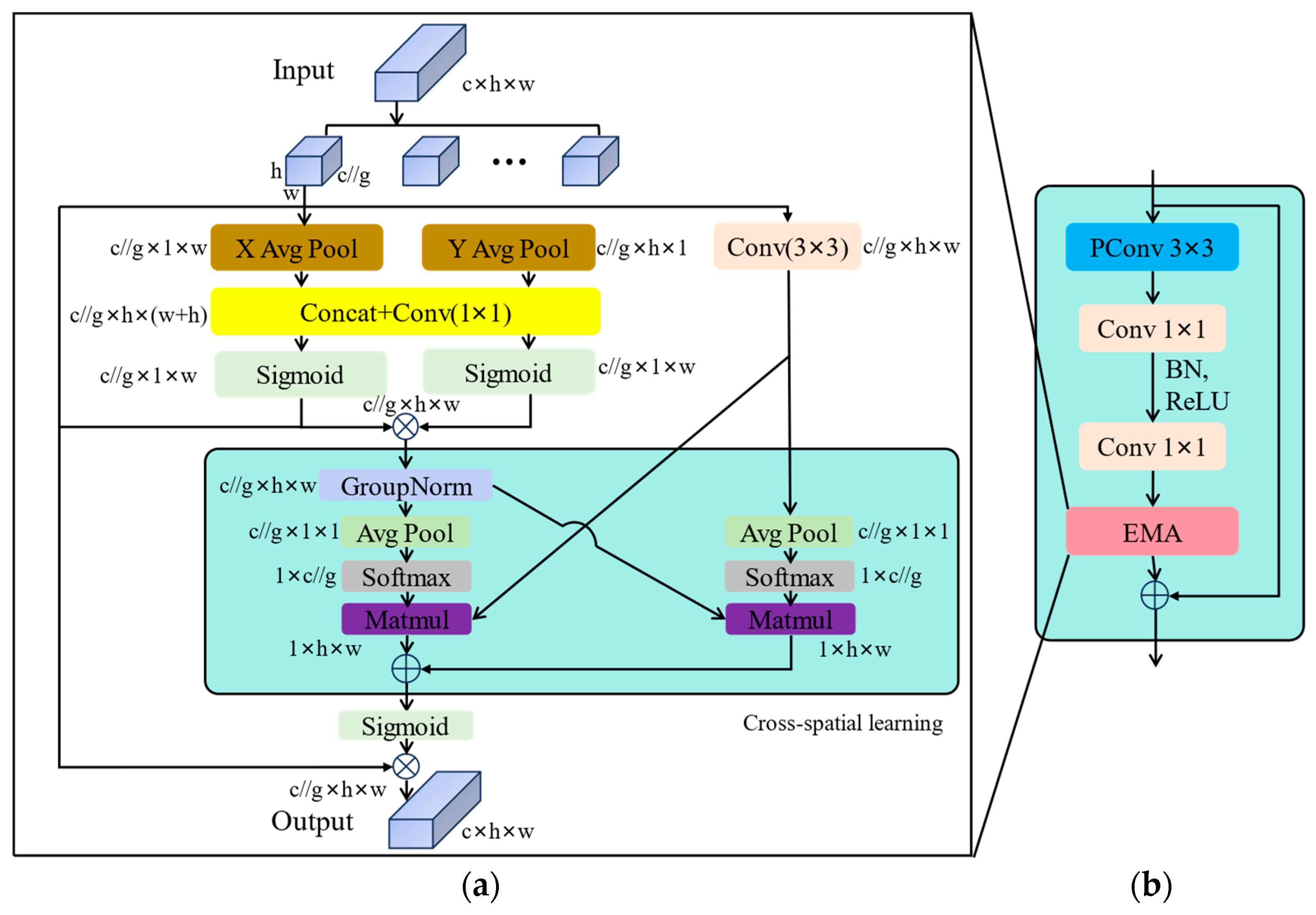
2.3.2. Efficient Multi-Scale Attention (EMA)
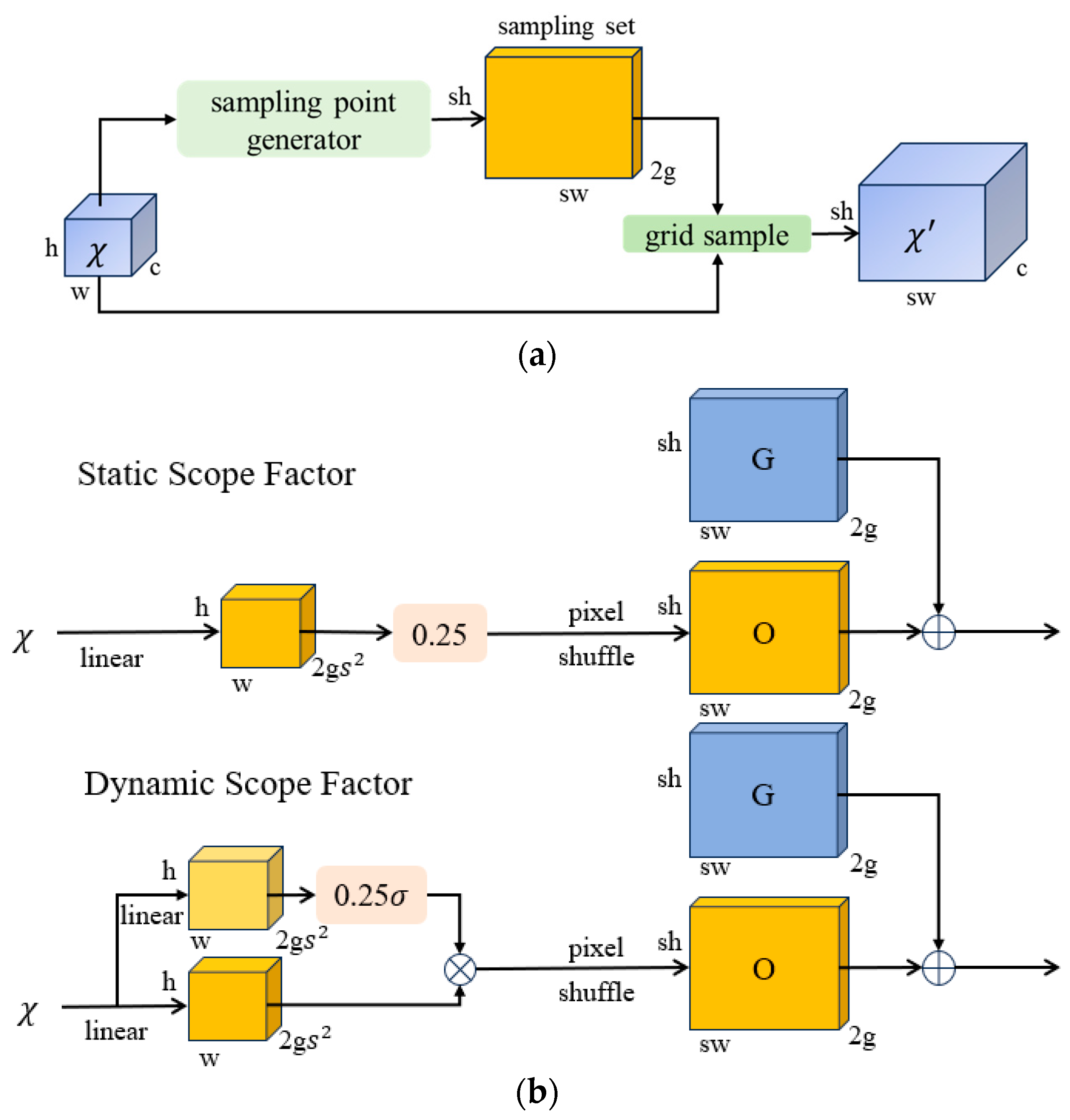
2.3.3. Dysample
2.3.4. EMASlideLoss
2.4. YOLOv8-PG Network Model
3. Experiments and Results
3.1. Experimental Details
3.2. Model Evaluation Index
3.3. Ablation Experiment Results
- (1)
- The first group presents the experimental results of the baseline YOLOv8n, serving as the benchmark for the following four groups of experiments. Its F1 is 97.54%, and mAP50, mAP75, and mAP50-95 are 99.19%, 85.01%, and 68.86%, respectively. The parameter count is 3.006 M, and the GFLOPs value is 8.1 G.
- (2)
- The experiments from the second group to the fifth group progressively incorporate one improvement point at a time. After replacing the Bottleneck of C2f with the Fasternet-EMA Block module in the backbone network of YOLOv8n, the model’s accuracy in various aspects improved, and both the computational complexity and parameter count decreased. Further introducing Fasternet Block into the neck network C2f results in a slight decrease in accuracy, but the model becomes more lightweight, with a reduction of 0.7 G in parameters and 0.344 M in computations. After introducing the ultra-lightweight and effective dynamic upsampler Dysample, F1, mAP50-95, and mAP75 all improved, with negligible impact on parameters and computations. Finally, replacing the EMASlideLoss classification loss function does not increase the model’s parameter count or computational complexity but improves the imbalance of samples, leading to a further improvement in model accuracy.
- (3)
- The fifth group shows the results of adding all improvement points. Compared to the baseline model, the YOLOv8-PG model increased F1 by 0.76%, and the mAP50, mAP75, and mAP50-95 metrics improved by 0.14%, 4.45%, and 1.56%, respectively. Additionally, the computational complexity significantly decreased, with GFLOPs reduced from 8.1 G to 6.1 G and parameters reduced from 3.006 M to 2.318 M, representing reductions of 24.69% and 22.89%, respectively.
3.4. Experimental Comparison with Other Models
3.5. Model Improvement Visualization
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| EMA | Efficient Multi-scale Attention |
| PConv | Partial Convolution |
| EXPMA | Exponential Moving Average |
| EMASlideLoss | Exponential Moving Average Slide Loss |
| Faster R-CNN | Faster Region-based Convolutional Neural Networks |
| Mask R-CNN | Mask Region-based Convolutional Neural Networks |
| YOLO | You Only Look Once |
| MATLAB | Matrix Laboratory |
| CA | Coordinate Attention |
| CBAM | Convolutional Block Attention Module |
| BiFPN | Bidirectional Feature Pyramid Network |
| SOTA | state-of-the-art |
| ELAN | Efficient Layer Attention Network |
| CIoU Loss | Complete Intersection over Union Loss |
| DFL Loss | Distribution Focal Loss |
| BCE Loss | Binary Cross-Entropy Loss |
| IoU | Intersection over Union |
| Conv | Convolution |
| SiLU | Sigmoid Linear Unit |
| BN | Batch Normalization |
| SPPF | Spatial Pyramid Pooling-Fast |
| FLOPs | floating point operations |
| GFLOPs | Giga Floating-point Operations Per Second |
| P | Precision |
| R | Recall |
| F1 | F1-score |
| AP | Average Precision |
| mAP50 | mean Average Precision at IoU threshold of 0.5 |
| mAP75 | mean Average Precision at IoU threshold of 0.75 |
| mAP50-95 | mean Average Precision at a range of IoU thresholds from 0.50 to 0.95 |
| FPS | Frame Per Second |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
References
- Ji, F.; Zhang, D.; Shao, Y.; Yu, X.; Liu, X.; Shan, D.; Wang, Z. Changes in the Diversity and Composition of Gut Microbiota in Pigeon Squabs Infected with Trichomonas Gallinae. Sci. Rep. 2020, 10, 19978. [Google Scholar] [CrossRef]
- Pomianowski, J.F.; Mikulski, D.; Pudyszak, K.; Cooper, R.G.; Angowski, M.; Jóźwik, A.; Horbańczuk, J.O. Chemical Composition, Cholesterol Content, and Fatty Acid Profile of Pigeon Meat as Influenced by Meat-Type Breeds. Poult. Sci. 2009, 88, 1306–1309. [Google Scholar] [CrossRef] [PubMed]
- Chang, L.; Zhang, R.; Fu, S.; Mu, C.; Tang, Q.; Bu, Z. Effects of Different Dietary Calcium Levels on the Performance, Egg Quality, and Albumen Transparency of Laying Pigeons. Animals 2019, 9, 110. [Google Scholar] [CrossRef] [PubMed]
- Adawy, A.M.G.; Abdel-Wareth, A.A.A. Productive Performance and Nutritional of Domesticated Pigeons. Present Status and Future Concerns. SVU-Int. J. Agric. Sci. 2023, 5, 160–167. [Google Scholar] [CrossRef]
- Pourreza, H.R.; Pourreza, H.R.; Pourreza, R.S.; Fazeli, S.; Taghizadeh, B. Automatic Detection of Eggshell Defects Based on Machine Vision. Artic. J. Anim. Vet. Adv. 2008, 7, 1200–1203. [Google Scholar]
- Deng, X.; Wang, Q.; Chen, H.; Xie, H. Eggshell Crack Detection Using a Wavelet-Based Support Vector Machine. Comput. Electron. Agric. 2010, 70, 135–143. [Google Scholar] [CrossRef]
- Lunadei, L.; Ruiz-Garcia, L.; Bodria, L.; Guidetti, R. Automatic Identification of Defects on Eggshell through a Multispectral Vision System. Food Bioprocess Technol. 2012, 5, 3042–3050. [Google Scholar] [CrossRef]
- Wang, Y. Research on the Computer Vision Cracked Eggs Detecting Method. Int. J. Comput. Appl. Technol. 2014, 50, 215–219. [Google Scholar] [CrossRef]
- Sunardi, S.; Yudhana, A.; Saifullah, S. Identity Analysis of Egg Based on Digital and Thermal Imaging: Image Processing and Counting Object Concept. Int. J. Electr. Comput. Eng. 2017, 7, 200–208. [Google Scholar] [CrossRef]
- Ying, A.L.; Nisar, H.; Voon, Y.V. Efficient Counting and Localizing Objects of Interest for Agricultural Automation. In Proceedings of the 2017 IEEE Region 10 Conference (TENCON), Penang, Malaysia, 5–8 November 2017; ISBN 9781509011346. [Google Scholar]
- Ab Nasir, A.F.; Sabarudin, S.S.; Abdul Majeed, A.P.P.; Abdul Ghani, A.S. Automated Egg Grading System Using Computer Vision: Investigation on Weight Measure versus Shape Parameters. IOP Conf. Ser. Mater. Sci. Eng. 2018, 342, 012003. [Google Scholar] [CrossRef]
- Li, Q.; Shao, Z.; Zhou, W.; Su, Q.; Wang, Q. MobileOne-YOLO: Improving the YOLOv7 Network for the Detection of Unfertilized Duck Eggs and Early Duck Embryo Development—A Novel Approach. Comput. Electron. Agric. 2023, 214, 108316. [Google Scholar] [CrossRef]
- Chen, J.; Ma, A.; Huang, L.; Li, H.; Zhang, H.; Huang, Y.; Zhu, T. Efficient and Lightweight Grape and Picking Point Synchronous Detection Model Based on Key Point Detection. Comput. Electron. Agric. 2024, 217, 108612. [Google Scholar] [CrossRef]
- Huang, Y.; Luo, Y.; Cao, Y.; Lin, X.; Wei, H.; Wu, M.; Yang, X.; Zhao, Z. Damage Detection of Unwashed Eggs through Video and Deep Learning. Foods 2023, 12, 2179. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Huang, Y.; Wang, Q.; Yuan, K.; Zhao, Z.; Li, Y. An Improved YOLOv5 Model: Application to Leaky Eggs Detection. LWT 2023, 187, 115313. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Terven, J.; Cordova-Esparza, D. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. arXiv 2023, arXiv:2303.03667. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. arXiv 2023, arXiv:2305.13563. [Google Scholar]
- Chen, S.; Li, Y.; Zhang, Y.; Yang, Y.; Zhang, X. Soft X-Ray Image Recognition and Classification of Maize Seed Cracks Based on Image Enhancement and Optimized YOLOv8 Model. Comput. Electron. Agric. 2024, 216, 108475. [Google Scholar] [CrossRef]
- Li, Y.; Ma, C.; Li, L.; Wang, R.; Liu, Z.; Sun, Z. Lightweight Tunnel Obstacle Detection Based on Improved YOLOv5. Sensors 2024, 24, 395. [Google Scholar] [CrossRef]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE: Content-Aware ReAssembly of FEatures. arXiv 2019, arXiv:1905.02188. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to Upsample by Learning to Sample. arXiv 2023, arXiv:2308.15085. [Google Scholar]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X. YOLO-FaceV2: A Scale and Occlusion Aware Face Detector. arXiv 2022, arXiv:2208.02019. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean Teachers Are Better Role Models: Weight-Averaged Consistency Targets Improve Semi-Supervised Deep Learning Results. arXiv 2017, arXiv:1703.01780. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury Google, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. arXiv 2016, arXiv:1610.02391. [Google Scholar] [CrossRef]
- Xu, Z.; Fan, M.; Zhang, Y. Visual Detection of Eggs Based on Deep Learning for Egg Picking Robot. J. Phys. Conf. Ser. 2021, 1976, 012013. [Google Scholar] [CrossRef]
- Qi, J.; Liu, X.; Liu, K.; Xu, F.; Guo, H.; Tian, X.; Li, M.; Bao, Z.; Li, Y. An Improved YOLOv5 Model Based on Visual Attention Mechanism: Application to Recognition of Tomato Virus Disease. Comput. Electron. Agric. 2022, 194, 106780. [Google Scholar] [CrossRef]
- Xie, X.; Qin, Y.; Zhang, Z.; Yan, Z.; Jin, H.; Xu, M.; Zhang, C. GY-SLAM: A Dense Semantic SLAM System for Plant Factory Transport Robots. Sensors 2024, 24, 1374. [Google Scholar] [CrossRef]
- Huang, D.; Tu, Y.; Zhang, Z.; Ye, Z. A Lightweight Vehicle Detection Method Fusing GSConv and Coordinate Attention Mechanism. Sensors 2024, 24, 2394. [Google Scholar] [CrossRef]
- Jia, Y.; Fu, K.; Lan, H.; Wang, X.; Su, Z. Maize Tassel Detection with CA-YOLO for UAV Images in Complex Field Environments. Comput. Electron. Agric. 2024, 217, 108562. [Google Scholar] [CrossRef]
- Zeng, Q.; Zhou, G.; Wan, L.; Wang, L.; Xuan, G.; Shao, Y. Detection of Coal and Gangue Based on Improved YOLOv8. Sensors 2024, 24, 1246. [Google Scholar] [CrossRef]
- Li, T.; Sun, M.; He, Q.; Zhang, G.; Shi, G.; Ding, X.; Lin, S. Tomato Recognition and Location Algorithm Based on Improved YOLOv5. Comput. Electron. Agric. 2023, 208, 107759. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, X.; Shi, Y.; Qi, H.; Jia, M.; Wang, W. Lightweight Detection Method for X-Ray Security Inspection with Occlusion. Sensors 2024, 24, 1002. [Google Scholar] [CrossRef] [PubMed]
- Ju, J.; Chen, G.; Lv, Z.; Zhao, M.; Sun, L.; Wang, Z.; Wang, J. Design and Experiment of an Adaptive Cruise Weeding Robot for Paddy Fields Based on Improved YOLOv5. Comput. Electron. Agric. 2024, 219, 108824. [Google Scholar] [CrossRef]
- Yu, C.; Feng, J.; Zheng, Z.; Guo, J.; Hu, Y. A Lightweight SOD-YOLOv5n Model-Based Winter Jujube Detection and Counting Method Deployed on Android. Comput. Electron. Agric. 2024, 218, 108701. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Software Environment | Hardware Environment |
|---|---|
| Operating system: Ubuntu 20.04 | CPU: 15 vCPU AMD EPYC 7742 64-Core |
| Programming language: Python 3.8 | GPU: RTX 3090 (24 GB) × 1 |
| Deep learning framework: PyTorch 2.0.0 | |
| Accelerated environment: CUDA 11.8 |
| Parameters | Values |
|---|---|
| lr0 | 0.01 |
| lrf | 0.01 |
| Momentum | 0.937 |
| Weight decay | 0.0005 |
| Warmup epochs | 3 |
| Warmup momentum | 0.8 |
| Batch size | 16 |
| Epochs | 300 |
| Workers | 8 |
| A | B | C | D | F1 | mAP50-95 | mAP75 | mAP50 | Params | GFLOPs | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | 97.54 | 68.86 | 85.01 | 99.19 | 3.006 M | 8.1 G |
| 2 | √ | × | × | × | 97.81 | 69.45 | 86.67 | 99.01 | 2.649 M | 7.1 G |
| 3 | √ | √ | × | × | 98.07 | 69.10 | 85.97 | 99.23 | 2.305 M | 6.4 G |
| 4 | √ | √ | √ | × | 98.17 | 69.94 | 88.57 | 99.27 | 2.318 M | 6.4 G |
| 5 | √ | √ | √ | √ | 98.30 | 70.42 | 89.46 | 99.33 | 2.318 M | 6.4 G |
| Model | F1 | mAP50-95 | mAP75 | mAP50 | Params | GFLOPs |
|---|---|---|---|---|---|---|
| Faster R-CNN | 68.98 | 42.70 | 32.35 | 89.47 | 136.710 M | 369.7 G |
| YOLOv5s | 98.80 | 69.15 | 88.24 | 99.47 | 7.057 M | 16.3 G |
| YOLOv7 | 98.83 | 70.68 | 90.07 | 99.63 | 36.487 M | 103.2 G |
| YOLOv8n | 97.54 | 68.86 | 85.01 | 99.19 | 3.006 M | 8.1 G |
| YOLOv8s | 97.63 | 69.2 | 87.41 | 99.25 | 11.136 M | 28.4 G |
| YOLOv8-PG | 98.3 | 70.42 | 89.46 | 99.33 | 2.318 M | 6.4 G |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, T.; Zhou, J.; Xie, B.; Liu, L.; Ji, C.; Liu, Y.; Liu, B.; Zhang, B. Improved YOLOv8 Model for Lightweight Pigeon Egg Detection. Animals 2024, 14, 1226. https://doi.org/10.3390/ani14081226
Jiang T, Zhou J, Xie B, Liu L, Ji C, Liu Y, Liu B, Zhang B. Improved YOLOv8 Model for Lightweight Pigeon Egg Detection. Animals. 2024; 14(8):1226. https://doi.org/10.3390/ani14081226
Chicago/Turabian StyleJiang, Tao, Jie Zhou, Binbin Xie, Longshen Liu, Chengyue Ji, Yao Liu, Binghan Liu, and Bo Zhang. 2024. "Improved YOLOv8 Model for Lightweight Pigeon Egg Detection" Animals 14, no. 8: 1226. https://doi.org/10.3390/ani14081226
APA StyleJiang, T., Zhou, J., Xie, B., Liu, L., Ji, C., Liu, Y., Liu, B., & Zhang, B. (2024). Improved YOLOv8 Model for Lightweight Pigeon Egg Detection. Animals, 14(8), 1226. https://doi.org/10.3390/ani14081226