1. Introduction
A significant challenge in image analysis for studying animal behavior is achieving precise object detection and tracking, particularly within dynamic and complex environments [
1,
2]. This involves identifying and following individual animals across scenes, including erratic movements, varying postures, and interactions with other animals or environmental elements. The complexity is further compounded by overlapping objects, occlusions, and visually cluttered backgrounds, which hinder the algorithm’s ability to consistently and accurately isolate and monitor the target animal or its particular feature [
3].
The rapid advancements in machine learning (ML) and computer vision have underscored the critical importance of precise image segmentation as a precursor to robust model training and reliable predictive performance. Object-based segmentation, emphasizing the identification of distinct objects instead of individual pixels, has become a critical research focus. This approach is particularly valuable in complex and dynamic visual settings, where traditional pixel-based methods often fail to maintain object-specific details, resulting in reduced classification accuracy and higher computational demands. While advancements in machine learning have significantly enhanced image analysis, ensuring reliable and efficient segmentation in these contexts remains a persistent challenge. Previous studies have explored various preprocessing and segmentation techniques to address these challenges. Convolutional neural networks (CNNs) and transfer learning models have proven their efficacy in structured environments. However, the process often demands extensive computational resources, limiting their scalability for real-time applications [
4,
5,
6]. On the other hand, unsupervised approaches, such as K-means clustering and principal component analysis (PCA), offer computational efficiency but lack the adaptability required for highly variable visual contexts [
7,
8,
9,
10]. While quantization and mathematical morphology have shown promise in simplifying image complexity and enhancing feature extraction, their integration into a cohesive preprocessing pipeline remains an open challenge [
11,
12].
In contrast to conventional methods that primarily depend on pixel-level modifications or computationally intensive processes, we propose an algorithm that combines convolutional operations, quantization strategies, and polynomial transformations to enhance segmentation accuracy while minimizing computational complexity. Such a move addresses a critical gap in literature by proposing an innovative preprocessing algorithm tailored for object-based image segmentation in complex visual environments. By generating metadata for each object, the framework enables enhanced interpretability and manageability of training datasets, providing a scalable solution for machine learning applications requiring precise object classification.
The current study aims to develop a systematic preprocessing pipeline that bridges the gap between computational efficiency and segmentation fidelity. The proposed approach aims to improve machine learning model performance in real-time and resource-constrained environments through adaptive object delineation and feature extraction. By addressing the limitations of existing methods, this research contributes a novel framework that paves the way for advancements in automated image processing and its application to high-stakes domains such as medical diagnostics, environmental monitoring, and autonomous systems.
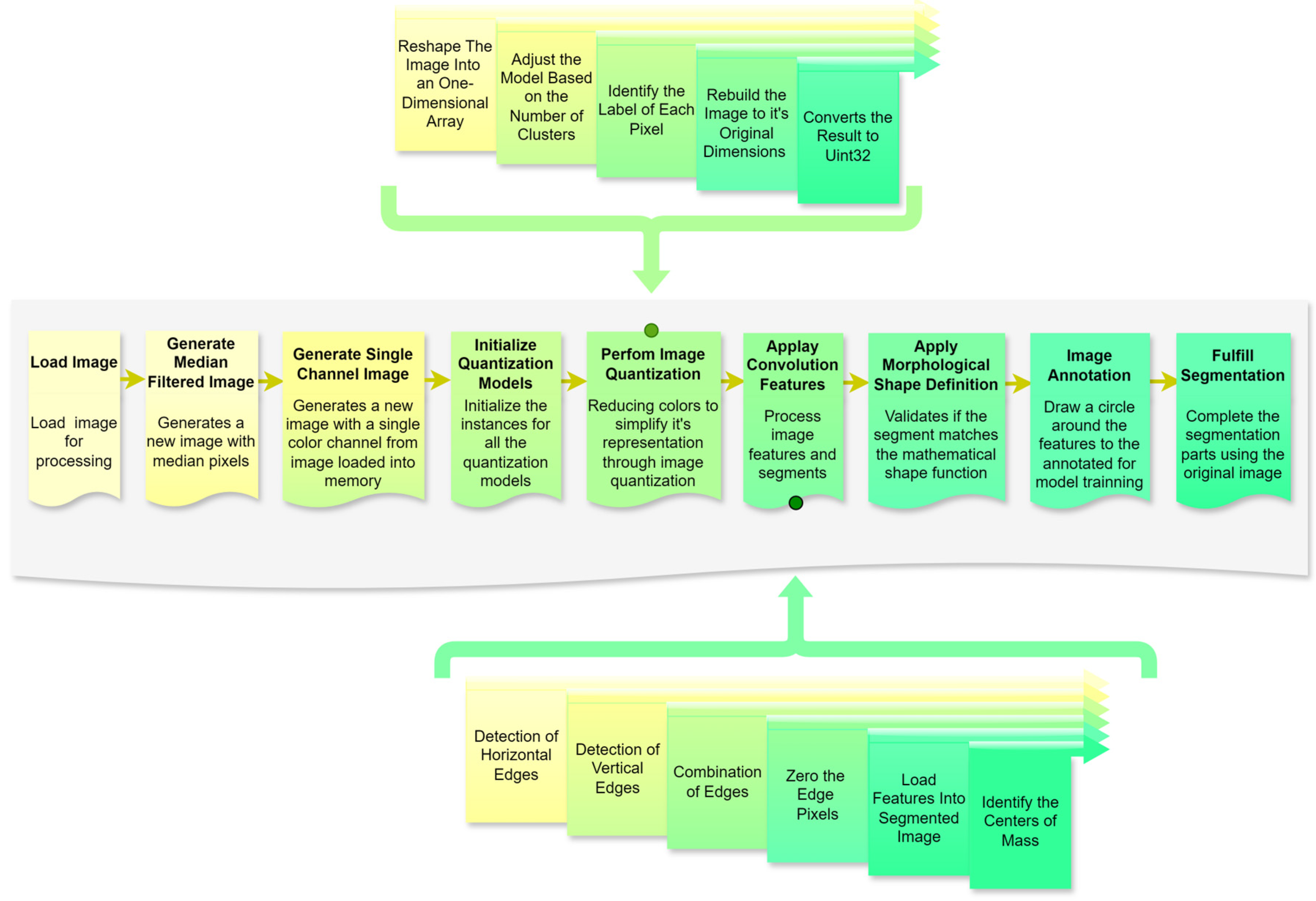
3. Methods
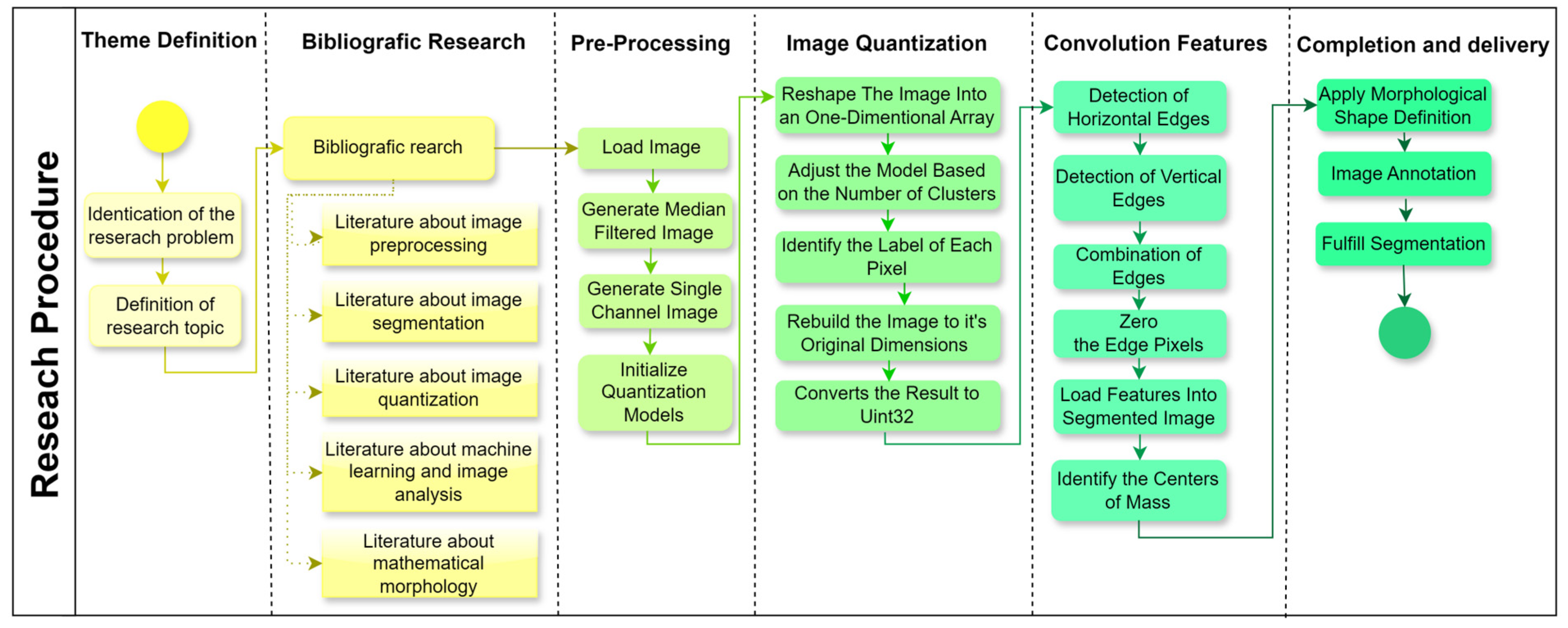
A structured research design was applied to the present study (
Figure 4), progressing through six stages to address the research objectives effectively. Each stage was designed to ensure a systematic approach to image preprocessing, segmentation, and feature extraction, which is critical for enhancing machine learning applications in image analysis. The following sections outline each phase in detail, making the methodology replicable and aligned with the research question.
3.1. Theme Definition and Background
The initial stage involves identifying the research problem and defining the research topic. This step narrows the study’s scope by pinpointing specific challenges in automated image processing for machine learning applications. Through thoroughly examining existing research gaps, this phase establishes the research objectives and justifies the necessity of further investigation into advanced preprocessing and segmentation techniques. The definition of the research problem is guided by preliminary observations and trends in image processing applications, ensuring a clear foundation for subsequent stages. Our hypothesis is that it is possible to create a framework able to apply quantization and segmentation processes on images with complex backgrounds, such as images of cattle in nature.
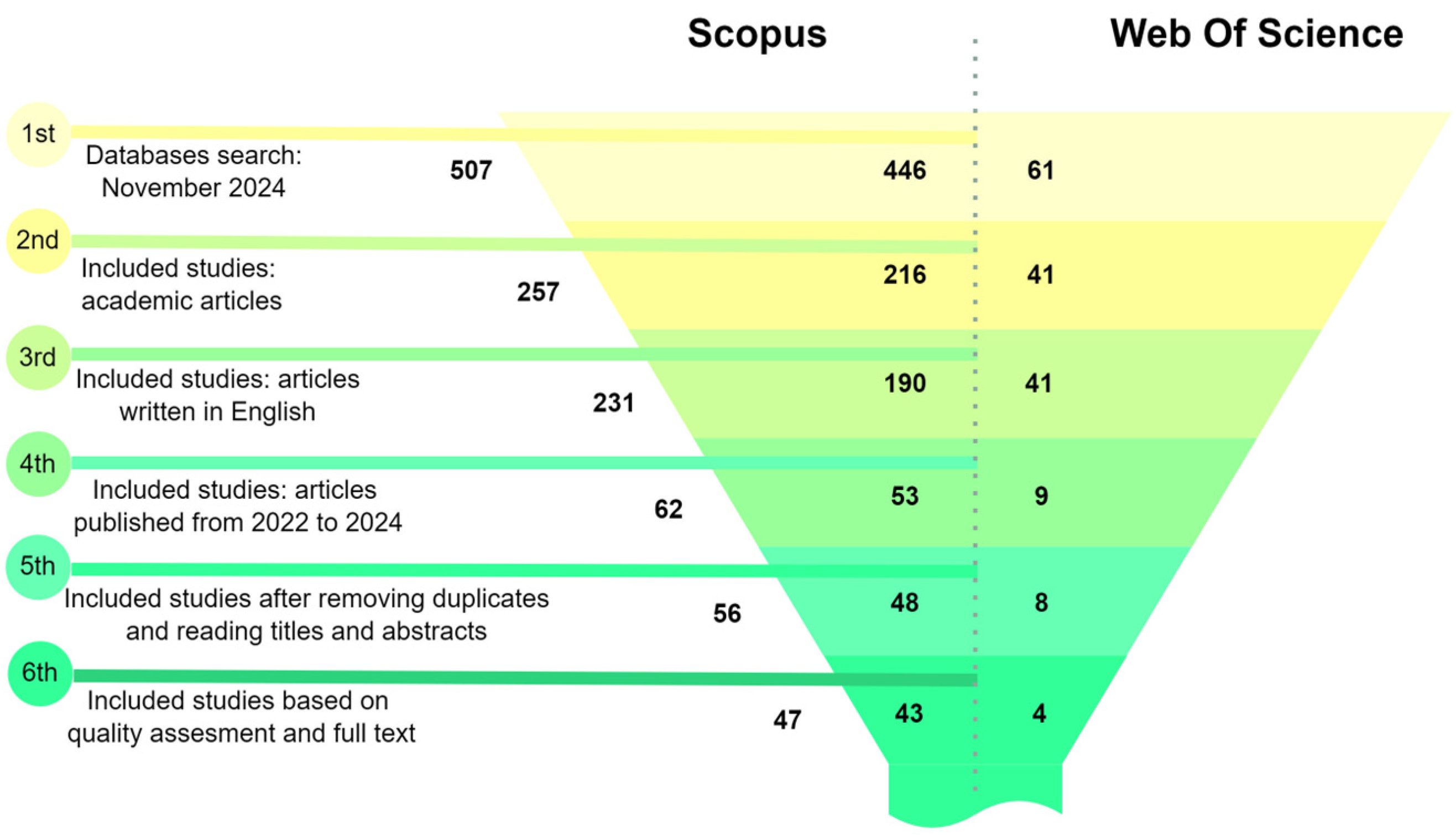
Following the theme definition, a comprehensive literature review involves gathering the relevant literature on crucial topics, including image preprocessing, segmentation, quantization, machine learning in image analysis, and mathematical morphology. Sources are selected based on their contributions to these subfields, providing theoretical grounding and identifying established methodologies, tools, and unresolved challenges. The findings from the literature review informed the design of processing stages and helped justify the choice of analytical tools and approaches (
Figure 5).
A systematic search of the Scopus and Web of Science databases was conducted using keywords related to image preprocessing and machine learning. An initial pool of 507 records, filtering by article type to include only peer-reviewed academic articles, was reduced to 257. Applying a language filter to select articles written in English further narrowed the selection to 231 articles. Restricting the publication date to the period between 2022 and 2024 yielded 62 articles, a timeline chosen to capture the most recent advancements in the field. After removing duplicates and conducting a detailed screening of titles and abstracts, 56 articles were subjected to a quality assessment. Ultimately, 47 articles were selected based on their relevance to the research topic. This systematic and rigorous selection process ensured a high-quality and focused dataset of studies, providing studies that met specific quality and relevance criteria in image preprocessing, segmentation, quantization, feature extraction, and mathematical morphology within the context of machine learning and image analysis.
3.2. Image Preprocessing
In the image preprocessing phase, contemporary methodologies often integrate convolutional operations to normalize pixel intensities, thereby enhancing segmentation accuracy and improving the reliability of downstream predictive tasks [
15,
16]. Furthermore, advanced adaptive preprocessing techniques have significantly improved segmentation performance, as highlighted by Zhou et al. [
20].
In this context, a series of raw images are provided and undergo initial processing of pixel median calculation to generate an image with less noise and reduce the number of cores in the original image. A new image with a single-color channel was generated through an initial convolution from the image transmitted in memory to unify the channels to ensure better results, preparing the images for more advanced processing in subsequent stages. The initialization of all models was also performed at this stage. This step is crucial to standardizing input data and reducing core variability. Preprocessing procedures minimize potential biases in the data, such as lighting or image quality inconsistencies, which can influence the protection of segmentation and feature extraction.
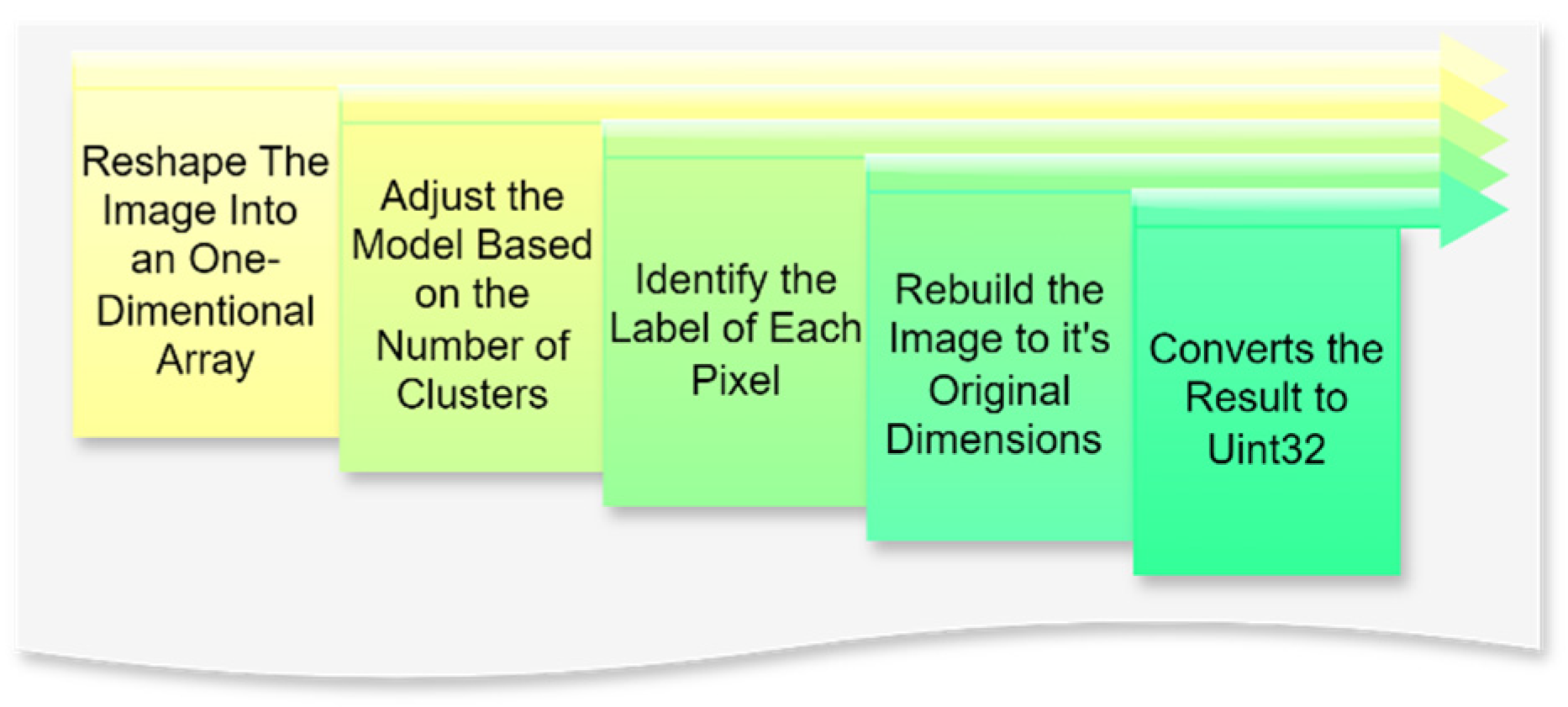
3.3. Image Quantization
The image quantization process, as highlighted in the literature, plays a critical role in reducing data volume while enhancing the visibility of salient features, a crucial aspect of classification tasks [
30]. K-means clustering, in particular, is widely acknowledged for its efficiency in simplifying image data by grouping similar pixels into clusters [
11]. Additionally, Kalake et al. [
32] demonstrate the integration of quantization with feature labeling as an effective strategy to optimize data preparation for segmentation, further improving the accuracy and efficiency of subsequent processing steps.
In this context, image quantization is a critical step in the preprocessing pipeline, aimed at reducing the complexity of visual data by limiting the number of unique colors while retaining the essential features required for subsequent machine learning tasks. The process begins with reshaping the image into a one-dimensional array, where the multidimensional pixel data are transformed into a single column with multiple rows. This adjustment standardizes the data structure, enabling efficient input into clustering models. The next step, fitting the model, involves defining the number of clusters that represent the desired palette of colors. The fitting process generates an array containing the selected colors or centroids, representing the image’s dominant tones.
Subsequently, each pixel is assigned a label corresponding to the nearest centroid through a prediction phase, effectively mapping the image to its reduced color space. The image is reconstructed to its original dimensions using these labels and centroids, ensuring that the spatial arrangement of pixels remains intact while adhering to the simplified color scheme. Finally, the processed image is converted into a positive integer format (Uint32), which optimizes computational storage and compatibility for downstream tasks.
3.4. Convolution Features
Convolutional neural networks effectively extract and filter image features, providing a robust foundation for advanced image analysis [
36]. Their demonstrated potential to enhance segmentation accuracy is particularly significant in complex image datasets characterized by high variability [
39,
40].
In this context, convolution feature extraction underpins the algorithm, enabling region segmentation through edge detection and feature localization. Horizontal edges are emphasized using convolutional kernels to detect vertical pixel intensity changes, while vertical edges are highlighted by detecting horizontal variations. Merging these outputs provides a comprehensive representation of the image’s structural features.
Edge pixels are zeroed to isolate contiguous regions, creating well-defined segments by distinctly separating adjacent areas. Detected features are loaded into the segmented image, preserving spatial and contextual relationships, with centers of mass calculated and included as precise reference points for analysis or classification. This standardized approach ensures replicability through consistent convolutional operations and parameter settings while enhancing machine learning training via structured feature extraction. Potential biases from specific kernel designs are mitigated by diverse feature detection strategies, ensuring robustness across visual contexts. Integrating edge detection, segmentation, and feature localization provides a solid framework for interpreting visual data in complex environments.
3.5. Completion and Delivery
The final stage of the preprocessing algorithm consolidates the segmented features and prepares the processed data for machine learning applications by applying mathematical validations, annotations, and segmentation refinement. This phase ensures that each segment is accurately defined, annotated, and primed for iterative or subsequent processing if required.
The process begins with applying a morphological shape definition, which validates that each segment aligns with the desired mathematical representation of its shape. This validation uses the object’s center of mass as the origin point and accepts as parameters two kernels—one for the X-axis and one for the Y-axis. These kernels define the transformation required to confirm the segment’s adherence to its expected geometrical properties. Following this, the image annotation step is executed. A square with a specified radius is drawn around the feature’s center of mass, serving as an automated bounding box. This annotation provides a visual marker for the machine learning model, acting as a consistent reference point for feature learning and classification. The model gains a precise spatial context by leveraging these bounding boxes, enhancing its capacity to generalize and interpret the features in diverse visual scenarios.
The final step extracts regions of interest from the original image based on the validated segments defined in the preceding stage. This method returns a tuple containing the segmented regions, ensuring that the extracted data aligns with the algorithm’s predefined structure. If the segmentation results require refinement, the process can be restarted seamlessly, providing an iterative framework for optimization. This structured approach ensures that the completion and delivery stage align with the overarching research objectives and facilitates replicability and robustness in handling complex image environments. Biases, such as errors in kernel selection or segmentation boundaries, are mitigated through parameter flexibility and iterative validation, ensuring reliable delivery of high-quality data to downstream machine learning processes.
Using libraries (SciPy, NumPy, OpenCV, Matplotlib, WebAgg, and Scikit-Learn), the stepwise methodology flow is shown in
Figure 6. The automated segmentation algorithm’s pipeline integrates structured and automated processes to enable efficient image preprocessing, feature extraction, and segmentation. This methodology ensures high replicability and alignment with the research objectives, delivering a robust foundation for object-based image analysis in complex visual environments.
4. Results
The proposed preprocessing algorithm improved object segmentation, feature extraction, and computational efficiency across complex image backgrounds. The implementation employed multiple computational tools to facilitate image segmentation and feature extraction in complex backgrounds.
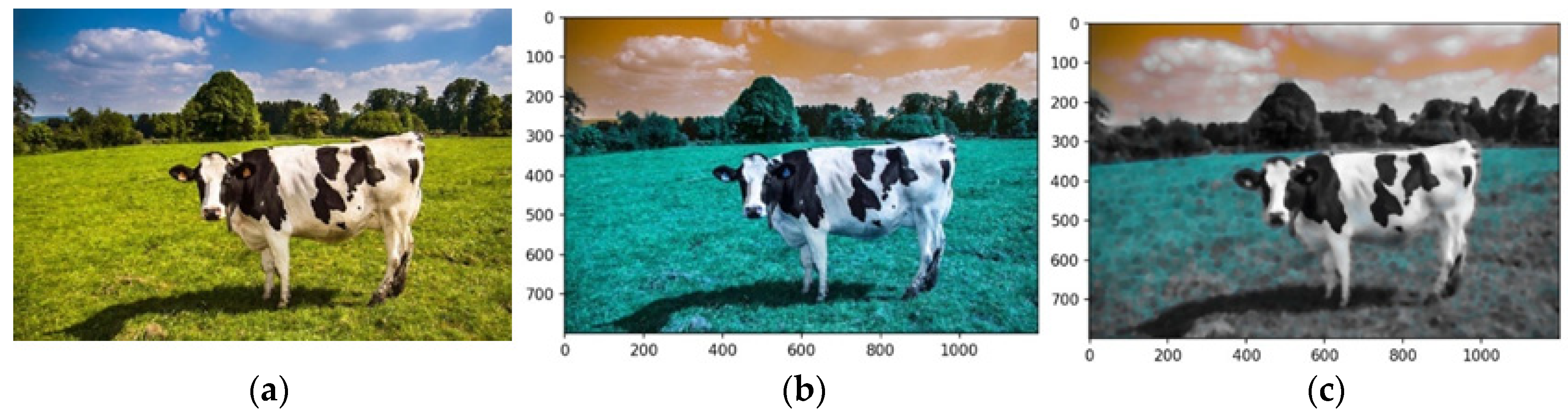
4.1. Load Image
Each pipeline component uses an image of a cow (
Figure 7a). The pipeline begins by loading the input image using robust image-handling libraries. This step ensures compatibility with downstream operations by standardizing input dimensions, resolution, and intensity distributions. Images are resized to a fixed resolution, and pixel intensity normalization is applied to create a consistent dataset for processing. These adjustments mitigate variability across input images, reducing preprocessing overhead.
Figure 7b shows the preprocessed image loaded via OpenCV’s function in the RGB color model. In contrast,
Figure 7c uses the BGR model, highlighting the impact of color channel ordering on visual interpretation. Scale invariance was maintained by standardizing all images to ensure consistent feature extraction and analysis. These were reshaped into a tabular format using NumPy’s ‘reshape’ function, converting the 2D image array into a 1D array, where each row represents a pixel’s RGB values.
4.2. Generate Median-Filtered Image
A median filter was applied to the input image to reduce high-frequency noise while preserving edge details, enhancing object boundaries crucial for segmentation. Replacing each pixel’s intensity with the median value of its neighborhood eliminated slight isolated noise without compromising boundary integrity, as shown in
Figure 7c.
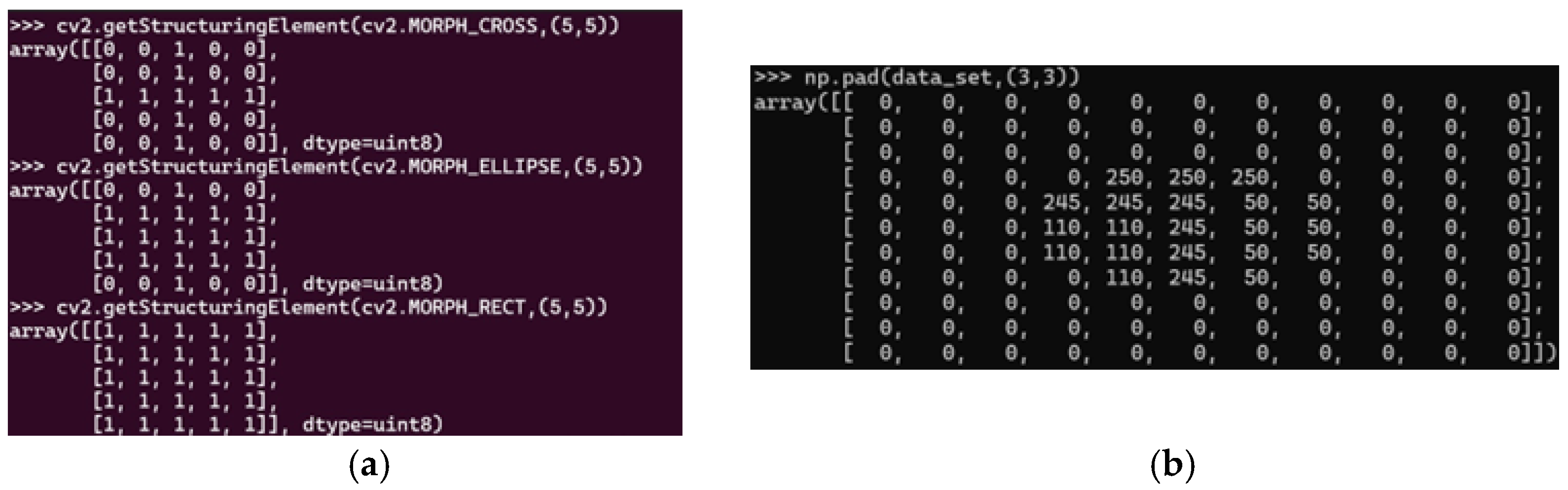
A 3D median filter with a kernel size of (5,5,5) was used to process RGB images, ensuring noise reduction across all channels while maintaining inter-channel consistency. Unlike traditional 2D filters applied separately to each channel, this method minimizes artifacts and preserved color data integrity. The kernel size (5,5,5) balanced effective noise suppression with edge preservation, which is critical for segmentation, feature extraction, and classification. This configuration ensured robust processing by maintaining object details and reducing noise interference.
In this study, the kernel size of 5 × 5 × 5 was selected to align with the desired size of the features to be extracted. This choice directly relates to the dimensions of the features we aim to preserve and analyze. If smaller features are of interest, a smaller kernel size should be configured. Conversely, to focus only on features larger than 5 × 5 × 5 pixels, a larger kernel size should be set.
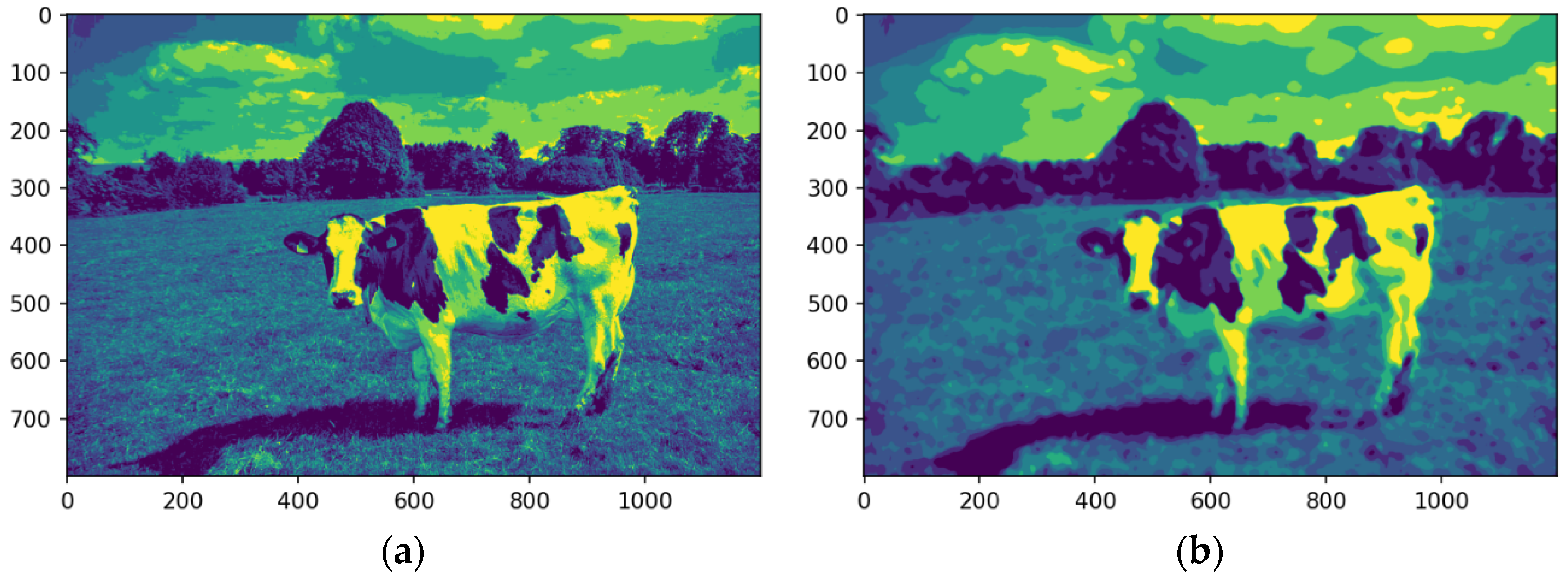
4.3. Generate Single-Channel Image
The image is converted into a single-channel representation to simplify computational requirements and streamline analysis. Selecting the most prominent or frequently occurring color channel shifts the focus to the features most pertinent to segmentation. This dimensionality reduction strategy enhances computational efficiency while preserving essential visual information.
Figure 8a shows the image after the conversion into a single-channel representation, while
Figure 8b illustrates the image using a median filter.
The analysis targets key visual features by isolating the dominant color channel. The image was linearized and reshaped into a two-dimensional array while maintaining the BGR channel structure, enabling the application of a computationally efficient single-channel convolution kernel. Dimensionality reduction preserves essential visual features while improving efficiency for segmentation.
Figure 8 illustrates the original image (a), its single-channel representation, and the median-filtered version (b). The median-filtered image (b) proves more effective for segmentation, particularly in distinguishing the cow from the background by homogenizing grass texture, thereby enhancing object differentiation.
4.4. Initialize Quantization Models
A K-means clustering algorithm was employed to segment the image into discrete clusters based on color or intensity values. This process involves identifying representative centroids that define the clusters to which pixels are assigned. The model adapts to various image types and lighting conditions by initializing the K-means algorithm. We created two separate K-means instances: one for the original image and another for the median-filtered image. This study employed K-means clustering using Scikit-learn to reduce the image’s color palette and simplify subsequent processing.
In this module, the number of clusters was initialized to eight, corresponding to the total number of colors that the algorithm applies to the image following the quantization process. The algorithm is configured to partition the image pixels into eight distinct clusters by defining this hyperparameter as eight. Each cluster encapsulates a unique color or a specific range of similar colors, effectively reducing the image’s color palette while preserving its essential visual information.
4.5. Perform Image Quantization
Image quantization is performed by mapping each pixel to the nearest cluster centroid using the initial model. This process reduces color or intensity variability across the image, simplifying the segmentation task while maintaining essential features. The resulting quantized image serves as a foundation for detecting meaningful object boundaries.
Figure 9 presents the subprocess, including the performed image quantization.
A K-means clustering-based quantization technique was applied to reduce the image’s color palette and simplify subsequent analysis, involving the following steps in
Table 2.
Figure 10 illustrates the image after the quantization stage was performed.
After K-means quantization (
Figure 10a,b), the original and median-filtered images were reduced to an eight-color palette. While both showed reduced color complexity, the median-filtered image exhibited a more explicit feature definition, notably enhancing the cow’s contours and its distinction from the background. This improvement was particularly evident in the sky and cloud regions, where quantization produced a more coherent representation. The process improved efficiency for subsequent tasks like segmentation and feature extraction by reducing the color palette while retaining key visual details.
4.6. Apply Convolution Features
The pipeline employs convolutional operations to extract spatial features from the quantized image, such as edges and textures. Horizontal and vertical edge detection filters are applied to capture directional patterns, which are then merged to form a comprehensive feature map. These operations enhance the differentiation of objects within the image, enabling robust segmentation.
Figure 11 presents the subprocess, including the applied convolution features.
A convolutional filter-based approach was employed to extract salient features from the image. As displayed, this technique involves applying filters to detect specific image patterns. A horizontal edge detection filter was applied to identify horizontal lines and edges within the image. This filter highlights areas of rapid intensity change in the horizontal direction (
Figure 12a,b). The median-filtered image significantly enhances the detectability of horizontal edges, which are crucial for defining the contours of features. By reducing noise and smoothing the image, the median filter improves the signal-to-noise ratio, making it easier to identify and extract relevant features. This enhanced edge information facilitates more accurate segmentation and analysis of the image content.
A vertical edge detection filter was applied to detect vertical lines and edges. This filter emphasizes areas of rapid intensity change in the vertical direction. As illustrated in
Figure 12c,d, the median-filtered image enhances the detectability of vertical edges, which are crucial for defining the contours of features.
The outputs of the horizontal and vertical filters were merged into a single feature map, representing the image’s overall edge and line structure. This combined map (
Figure 12e,f) comprehensively depicts structural features, enhancing edge and contour accuracy. Integrating these complementary edge maps enables the detection of complex shapes and patterns not evident in individual maps. Edge pixels were set to zero to isolate objects or regions of interest, creating clear segment boundaries. As shown in
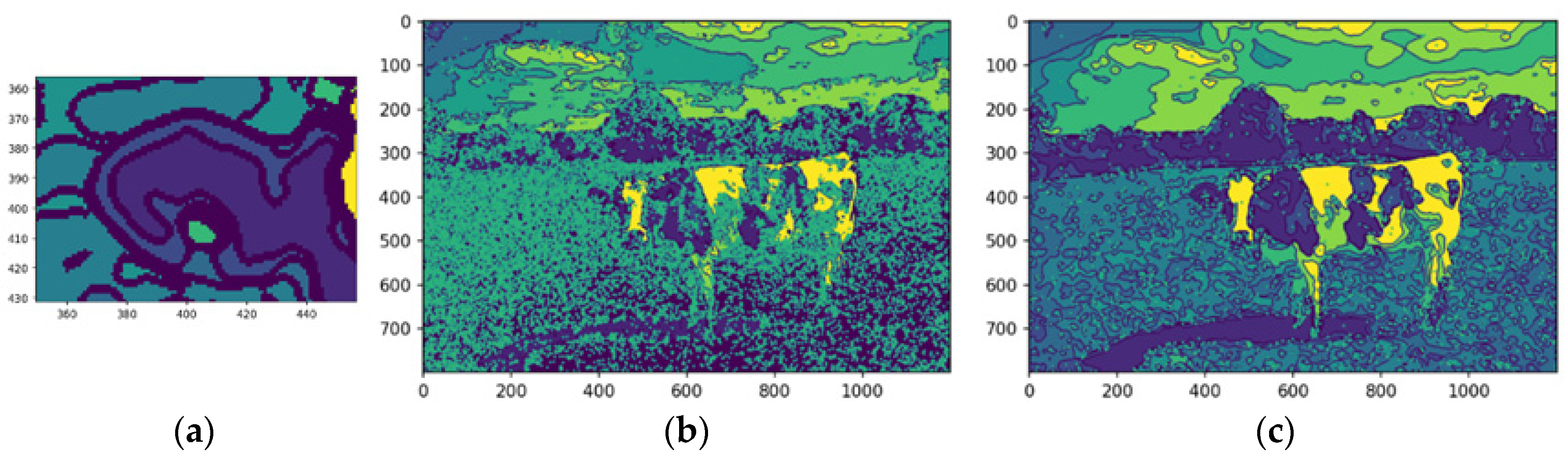
Figure 13a, this separation enhances segment distinction, minimizing interference from neighboring regions and improving the accuracy of tasks like segmentation and feature extraction.
Extracted features were integrated into the segmented image, creating a comprehensive representation for further analysis. Overlaying these features onto the original image highlights critical regions of interest, enabling tasks such as object recognition and scene understanding. The center of mass was calculated for each feature, providing a quantitative measure of spatial location for tasks like object tracking and shape analysis. The median-filtered image significantly enhanced the accuracy of these calculations (
Figure 13b,c).
By enhancing feature delineation and reducing noise, the median filter enabled more precise localization of the center of mass, particularly for objects with complex shapes or indistinct boundaries. This improvement is evident in the more accurate representation of the cow’s center of mass in the median-filtered image, as the enhanced feature definition allows for a more reliable calculation.
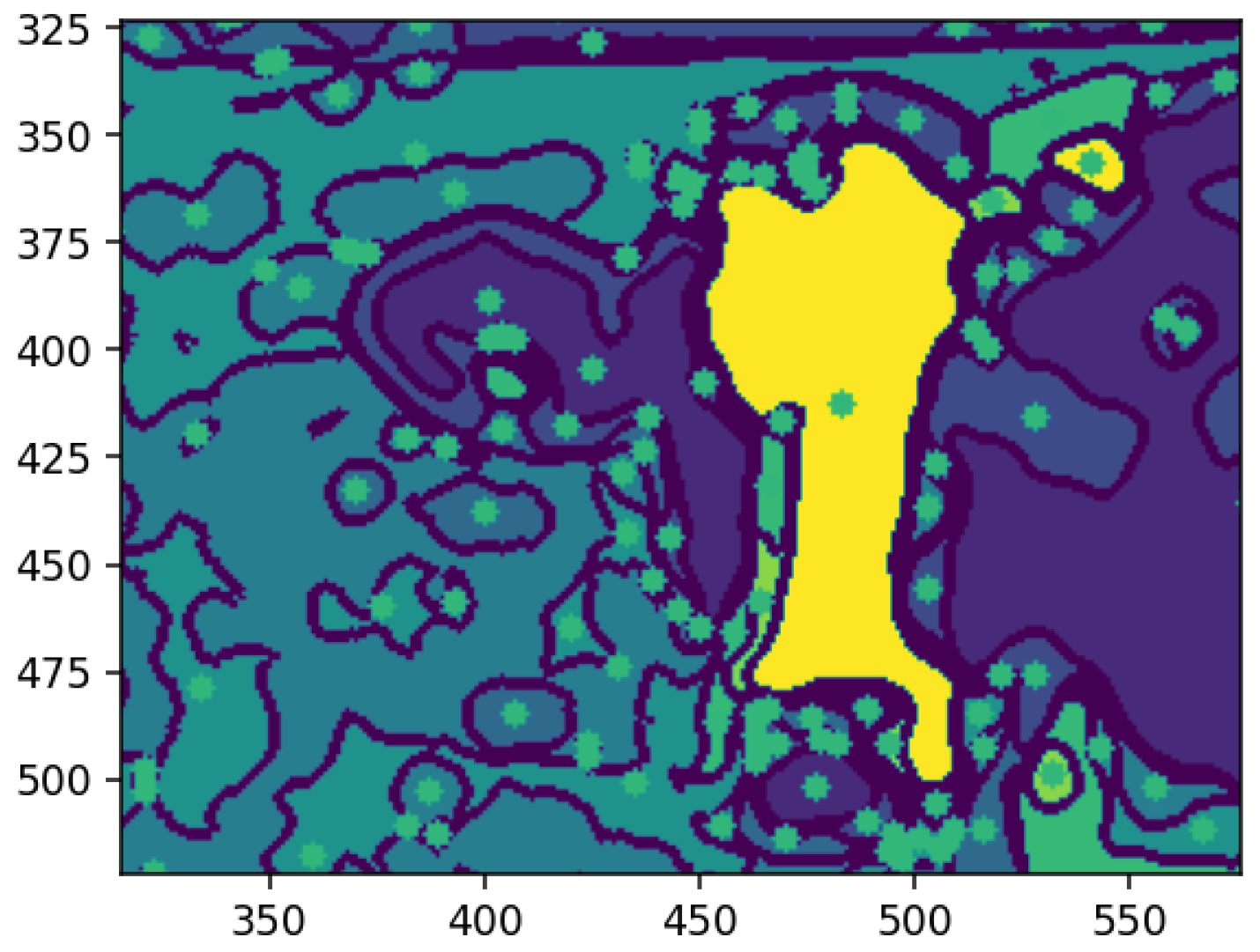
Figure 14 shows each feature annotated with a square marking its center of mass, the weighted average position of all pixels within the feature. This geometric representation clarifies spatial distribution, enabling the identification of relative positions and aiding tasks, like feature tracking, object recognition, and segmentation. Highlighting centers of mass provides a concise, computationally efficient representation for further analysis.
4.7. Applying the Morphological Shape Definition
A morphological validation step ensures that the detected segments represent valid objects by analyzing geometric properties, like shape, size, and center of mass, discarding non-conforming segments. The method uses the center of mass as the origin for mapping along the X and Y axes, guided by kernels defined as pixel ranges before and after the center. Morphological shape criteria determine whether a segment matches the expected characteristics, returning a Boolean value: valid if it aligns with the target feature’s morphology, otherwise invalid. This process filters noise and irrelevant regions, ensuring segmentation integrity.
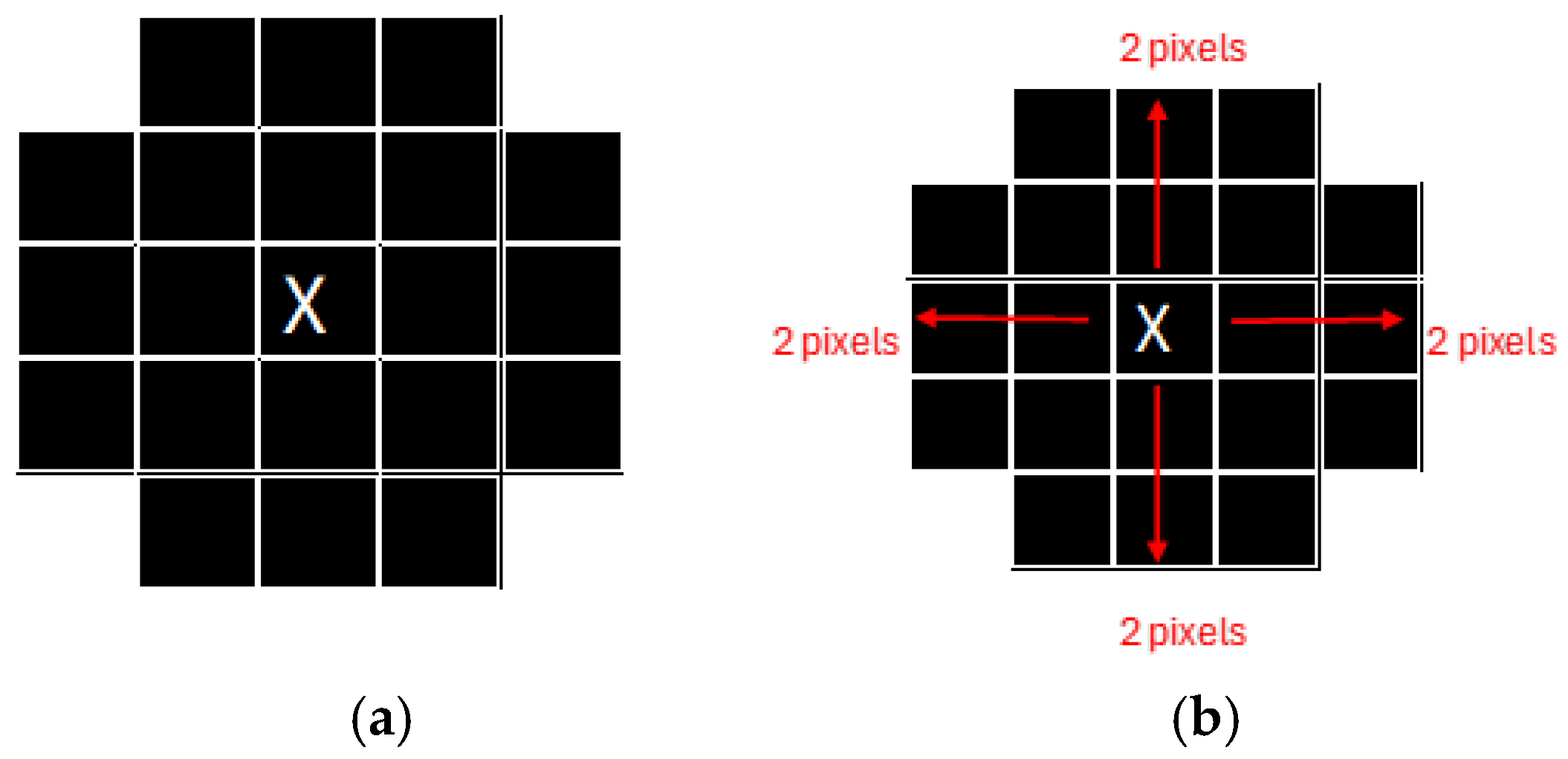
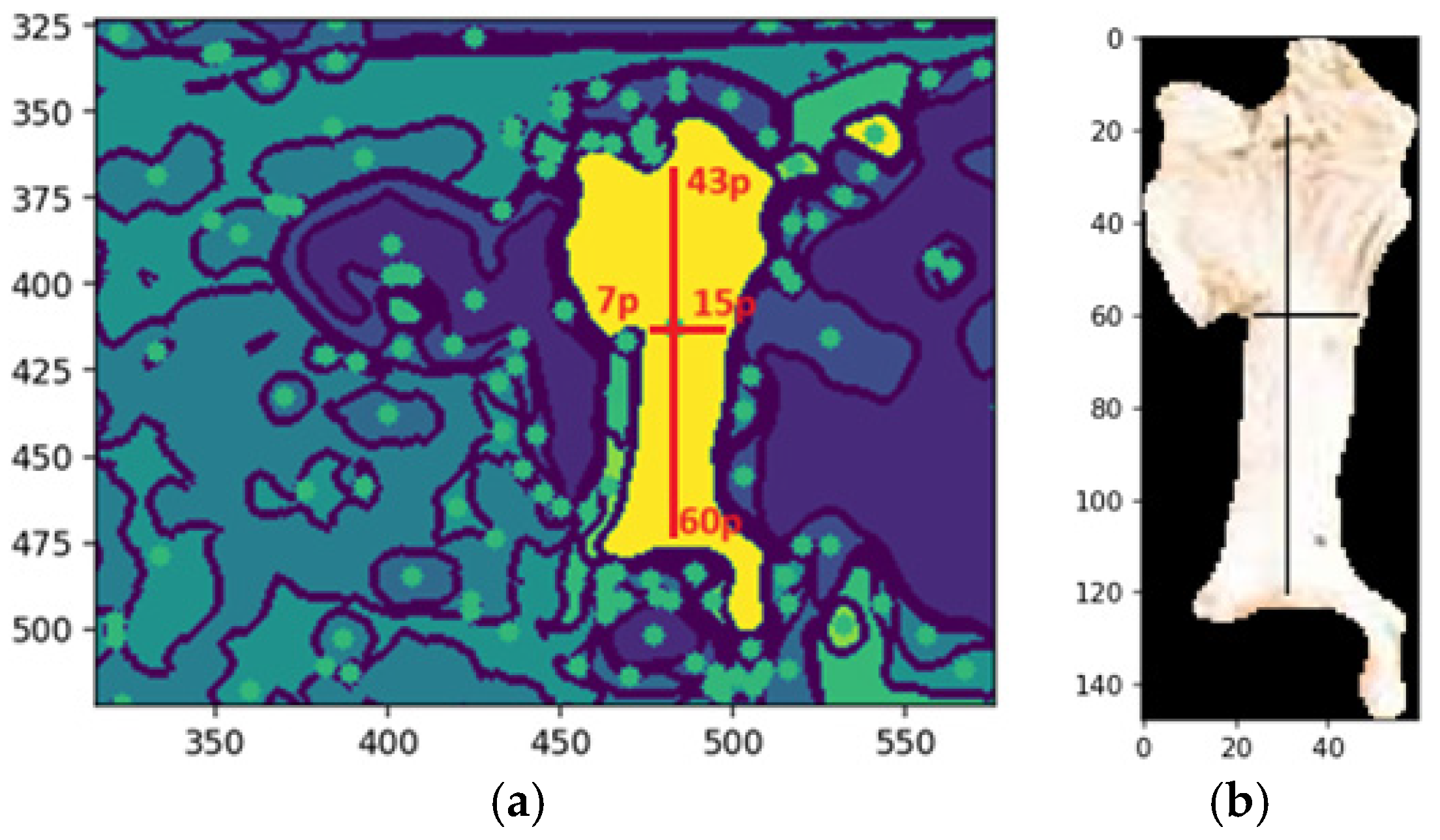
Figure 15a shows an example of the dimensions of the shape of the front head feature, and
Figure 15b shows the extraction of the feature with the same dimensions of shape.
Figure 15a illustrates an example of the morphological shape definition applied to identify a specific feature on the forehead of a cattle. In this case, the feature’s center of mass, determined by the central pixel, served as the reference point for defining its spatial dimensions. The region of interest was delineated by extending 43 pixels upward and 60 pixels downward along the y-axis, with 7 pixels to the left and 15 pixels to the right along the x-axis. This precise bounding allowed for accurate identification and isolation of the feature, demonstrating the effectiveness of the morphological shape definition technique in segmentation tasks, while
Figure 15b illustrates the segmented feature based on the shape definition.
The desired pattern is defined based on the feature’s center of mass to detect a specific feature, such as a cow’s forehead. From this central point, pixel extensions to the boundary are calculated in all cardinal directions—up, down, left, and right—to delineate the feature’s structure. The method scans the image for regions matching the defined morphology. If a segment, such as the belly instead of the forehead, does not align with the target pattern, it is deemed invalid. This validation step ensures that only features matching the defined shape advance to further processing (
Figure 15).
Morphological shape definition in segmentation enhances precision, efficiency, and feature extraction accuracy. Specifying the expected shape of the cow’s forehead ensures that only relevant segments are selected, reducing false positives by filtering out irrelevant regions like the neck or body. This approach provides an apparent geometric reference, improving robustness and enabling reliable distinction of the forehead from similar features. It also optimizes computational efficiency by focusing analysis on pertinent regions, reducing processing time and computational costs while supporting tasks like feature tracking and classification.
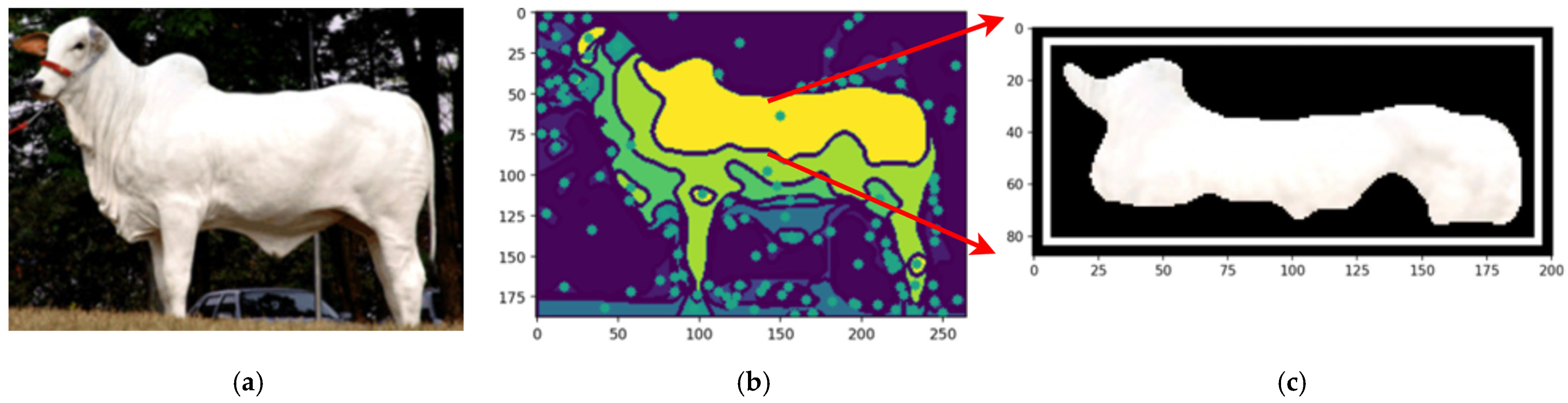
Validated segments were annotated with bounding boxes, using the center of mass as the reference point. These annotations delineate the feature’s boundaries, aiding machine learning models in interpreting the location and shape for object recognition and classification. They also provide visual feedback for validating segmentation accuracy and enhance model training by supplying labeled data, improving generalization to unseen images and optimizing pipeline performance.
Figure 16b shows the automated bounding box precisely delineating the cow’s forehead, streamlining object detection by consistently identifying and annotating the region of interest. This provides a clear spatial representation for tasks like classification or tracking. Automated bounding boxes reduce manual annotation, saving time and effort while enhancing pipeline efficiency. They ensure uniformity and reproducibility across datasets, supporting scalable and reliable machine learning training. In
Figure 15b, the bounding box serves as both a visual aid and a precise reference, improving the accuracy and effectiveness of subsequent processing steps.
The final stage refines the segmentation output, ensuring coherence and completeness through morphological operations that resolve overlaps and gaps, creating a comprehensive segmentation map for downstream tasks. This method returns a tuple of valid image regions defined by coherent, non-overlapping segments from the refinement process (
Figure 16c). Each tuple includes spatial boundaries and associated features, preserving segmentation integrity and compatibility with further steps. The process allows for iterative adjustments, enabling parameter refinement or addressing issues like over- or under-segmentation, improving accuracy and robustness for complex or application-specific data (
Figure 16d).
The fulfill segmentation method enhances segmentation adaptability and precision by returning a tuple of high-quality, coherent image regions, reducing noise and errors in subsequent analyses. Optional bounding boxes provide flexibility for spatial localization, or a generalized segmentation map based on task requirements. The method’s iterative capability allows for parameter adjustments and tailored refinements, addressing challenges like irregular boundaries or complex images. This flexibility improves segmentation accuracy, robustness, and scalability, making it suitable for diverse applications, such as object recognition, pattern analysis, and machine learning data preparation.
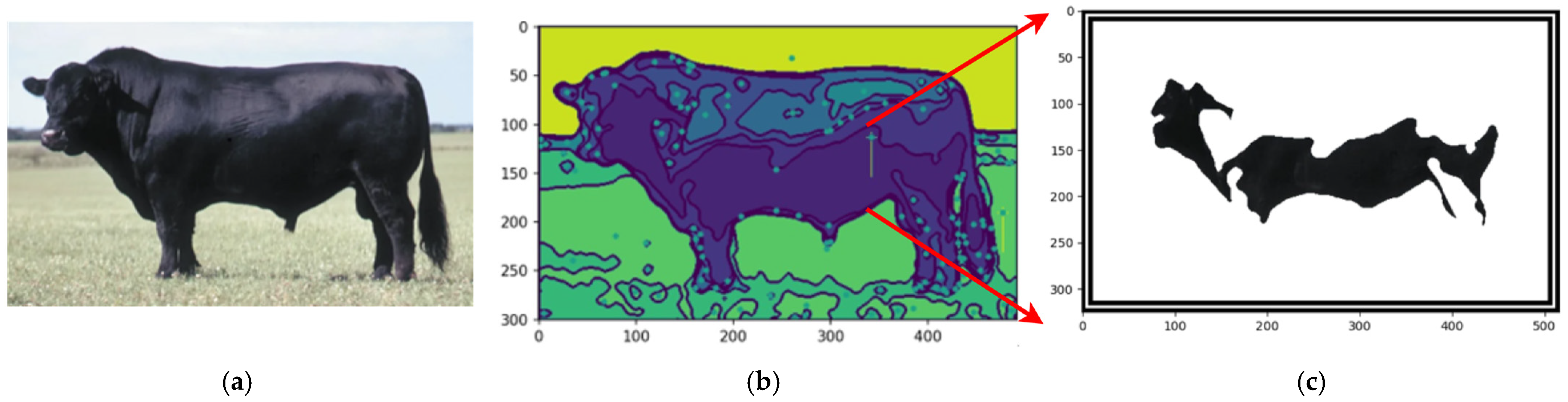
Figure 17 compares the original cow photograph (a) with the segmented feature (b), where the detected feature is highlighted in its original color, preserving detail. This segmentation isolates relevant features precisely, enabling accurate analysis while retaining critical information for further classification.
By employing the proposed automated segmentation algorithm, as illustrated in
Figure 3, the segmentation process yielded significantly enhanced results, even for cattle breeds with uniform coat colors. Texture-less breeds, such as Nelore (
Figure 17) and Black Angus (
Figure 18), present inherent challenges due to the lack of distinct patterns or markings. Despite these difficulties, the framework demonstrated its robustness by effectively identifying features through variations in color pigmentation. Even in texture-less breeds, subtle pigmentation differences enabled accurate detection of features, as evidenced by the calculated centers of mass. This performance underscores the framework’s adaptability to a wide range of visual complexities.
Figure 18 shows an example using a texture-less breed Nelore to capture the segmentations.
Figure 19 shows an example using a texture-less breed Black Angus to capture the segmentations.
The proposed automated segmentation algorithm offers several notable benefits, particularly in the context of livestock monitoring and management. Its ability to effectively handle texture-less breeds, such as Nelore and Black Angus, addresses a critical challenge in image analysis, where uniform coat colors typically hinder feature extraction. By leveraging subtle differences in pigmentation, the framework ensures precise and automated segmentation, enabling accurate identification of key features like the centers of mass.
Additionally, the algorithm’s robustness across diverse visual conditions highlights its potential for scalability and integration into broader applications, such as drone-based livestock monitoring and precision agriculture initiatives.
5. Discussion
The findings of this study underscore the significant advancements achieved by the proposed preprocessing algorithm in addressing the challenges of object-based segmentation in complex visual environments. The algorithm effectively delineates objects while maintaining computational efficiency by integrating convolution operations, quantization techniques, and polynomial transformations. The results demonstrate that this approach enhances segmentation accuracy and reduces computational overhead, paving the way for broader adoption of machine learning (ML) models in resource-constrained and real-time applications. Such an approach represents a significant step in bridging the gap between computational feasibility and the demand for high-fidelity object segmentation, a persistent challenge in computer vision.
The proposed algorithm demonstrates superior performance in several key areas compared with the existing literature. Traditional methods, such as CNN-based segmentation or transfer learning, often rely heavily on pixel-level adjustments, which, while effective in controlled scenarios, become computationally prohibitive in real-time or large-scale applications [
6]. Similarly, while computationally efficient, unsupervised methods like K-means clustering fail to adapt to dynamic backgrounds and object variability [
8]. The innovation of the current study lies in its ability to synergize these approaches, employing quantization to simplify image complexity and convolutional operations to enhance feature extraction, thereby offering a balanced solution that is both scalable and accurate. This improvement aligns with recent findings, emphasizing the need for preprocessing pipelines capable of handling diverse and intricate visual datasets [
11].
Another contribution of this research is its capacity to generate structured metadata alongside segmented images. Unlike traditional methods focusing solely on segmentation, the proposed framework produces metadata that enhances the interpretability and reusability of the segmented objects. This advancement is particularly beneficial for applications requiring dynamic object classification, such as autonomous systems and medical diagnostics, where interpretability and accuracy are paramount. The algorithm improves classification performance by treating each object as an independent training unit. It supports iterative model refinement, aligning with calls in the literature for more modular and adaptive preprocessing techniques [
2].
Despite its advancements, the algorithm has certain limitations. It relies on the initial calibration of convolutional and quantization parameters, which vary based on dataset complexity and application and require manual intervention. The future integration of adaptive parameter optimization, such as reinforcement learning or dynamic kernel adjustments, could address this challenge. Furthermore, while this study focused on static image datasets, extending the framework to video or temporal datasets remains an area for further research. Another limitation of these algorithms lies in their initiation of processing static images.
Overcoming this constraint could significantly enhance the algorithm’s versatility and scalability, paving the way for its application in dynamic contexts such as video analytics and real-time monitoring systems. A potential solution to address this limitation involves upgrading the process to automate the segmentation of video frames, thereby expanding the framework’s applicability to more complex and real-time scenarios.
Overall, the findings highlight the practical and theoretical contributions of the proposed preprocessing pipeline. By combining computational efficiency with high segmentation fidelity, this research provides a scalable and effective solution for object-based segmentation in machine learning. The implications of this work extend to various fields, including environmental monitoring, autonomous vehicles, and quality control in manufacturing, offering a robust foundation for future innovations in image preprocessing and analysis. Its practical implications are vast, spanning domains, such as autonomous systems, medical diagnostics, environmental monitoring, and manufacturing quality control.
As shown in
Figure 13, the developed approach is essential in complex image processing tasks, where the ability to retain fine details can significantly enhance the performance of machine learning models, leading to improved accuracy and robustness in subsequent analyses. Such high-fidelity feature detection is crucial to advancing automated systems for object recognition and analysis, particularly in Precision Livestock Farming.
To implement the framework illustrated in
Figure 6 using the Python programming language, the process involves a sequence of structured steps, each employing specific libraries and methodologies to achieve robust image processing and segmentation.
The first step involves loading the input image for processing. This can be achieved using widely adopted Python libraries such as OpenCV or PIL, which provide versatile functions for reading and handling image data. Once the image is loaded, the next step applies a median filter to reduce noise while preserving edge details. This operation is crucial for enhancing object boundaries and can be efficiently executed using the OpenCV library through its medianBlur function.
Subsequently, the multi-channel RGB image is converted into a single-channel image to simplify subsequent processing steps. This can be performed using the OpenCV cvtColor function, which transforms the image representation while retaining essential structural information.
To prepare the image for quantization, clustering algorithms such as k-means are utilized to categorize pixel values into distinct clusters. This step requires specifying the number of clusters, which determines the quantization level. For instance, in this study, the number of clusters was set to eight, effectively reducing the image to a palette of eight colors. The quantization process itself involves replacing each pixel’s value with the corresponding cluster centroid, thereby simplifying the image while maintaining critical features. This can be implemented using the KMeans module from the scikit-learn library.
Feature extraction is a pivotal step for identifying patterns and objects within the image. This can be achieved using convolutional operations, such as edge detection filters, available in OpenCV through functions like Sobel or Canny. These filters highlight the transitions in intensity, delineating object boundaries and facilitating segmentation.
Mathematical morphology is then applied to validate segments and refine identified features or patterns. This involves the use of morphological operations, such as closing or opening, to enhance or suppress specific structures within the image. The OpenCV morphologyEx function is particularly suited for this purpose, allowing for the precise manipulation of shapes based on structural elements.
Annotations are added around identified features or regions of interest to facilitate visualization and further analysis. Circles or bounding boxes can be drawn using functions such as circles or rectangles from the OpenCV library. Finally, segmentation is completed by mapping the processed features back onto the original image. This is achieved through bitwise operations, such as OpenCV’s bitwise_and, which merge segmented masks with the input image to produce the final segmented output.
By leveraging Python libraries such as OpenCV and scikit-learn, the implementation of this framework ensures a systematic and reproducible workflow. Each step is designed to enhance the quality and interpretability of the processed image, providing a robust foundation for feature extraction, segmentation, and subsequent analyses.
To conclude this manuscript, the implementation of the proposed framework integrates advanced Python libraries and tools to streamline image preprocessing, segmentation, and feature extraction for machine learning applications. The implementation leverages key libraries and their respective modules to create a modular, scalable, and efficient system. For instance, numpy handles array management, while scipy provides robust statistical, convolutional, and optimization functions. Machine learning functionalities are integrated using sklearn, and data visualization is facilitated through matplotlib.pyplot.
Image processing is managed with OpenCV (cv2), while dynamic module handling and asynchronous execution are supported by importlib and asyncio, respectively. The clustering and quantization processes are built on KMeans from sklearn, ensuring robust and adaptable data segmentation capabilities. By combining these tools, the framework achieves efficient preprocessing, accurate segmentation, and reliable feature extraction, laying a strong foundation for applications in complex datasets, such as animal behavior analysis and precision livestock farming. This implementation demonstrates the versatility of the framework and its potential to address a wide range of challenges in image-based machine learning workflows.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}