
Animal Species Recognition with Deep Convolutional Neural Networks from Ecological Camera Trap Images
 ,
,  , ,
, ,
Abstract
Simple Summary
Abstract
1. Introduction
1.1. Deep Learning Solutions
1.2. Related Work
1.2.1. Camera Trap Dataset with Machine Learning
1.2.2. Target Species Recognition Using Machine Learning
1.2.3. Objective
2. Dataset
- The dataset was highly imbalanced within the three groups of species. Furthermore, the samples differed considerably with alternative day/night lighting conditions and seasonal weather, variation of animal body shape, color, texture, posture, and when partially obstructed with grass or another object or cropped out of the image.
- All the captured images had a resolution of 1920 × 1080 or 2048 × 1536 pixels, where snakes comprised a 5% to 15% pixelated area in the image background. With a dynamic body posture, lizards represented 0.025–0.35% of the whole image area, while toads comprised 0.7–0.16%, having uniform body shapes (Figure 1).
- Single target groups, especially toads and lizards, were often found in consecutive images, producing a serialized image of the same species within their background. In the dataset, toads and lizards appeared in 20–150 sequential images, and snakes could be detected in 3–15 sequential images (Figure 2).
- The infrared (IR) mode produced grayscale images with less lighting intensity variation in night-vision pictures. On the other hand, daytime images added complexity to the background due to an illumination brightness alteration (Figure 3).
3. Methodology
3.1. Deep Learning Networks
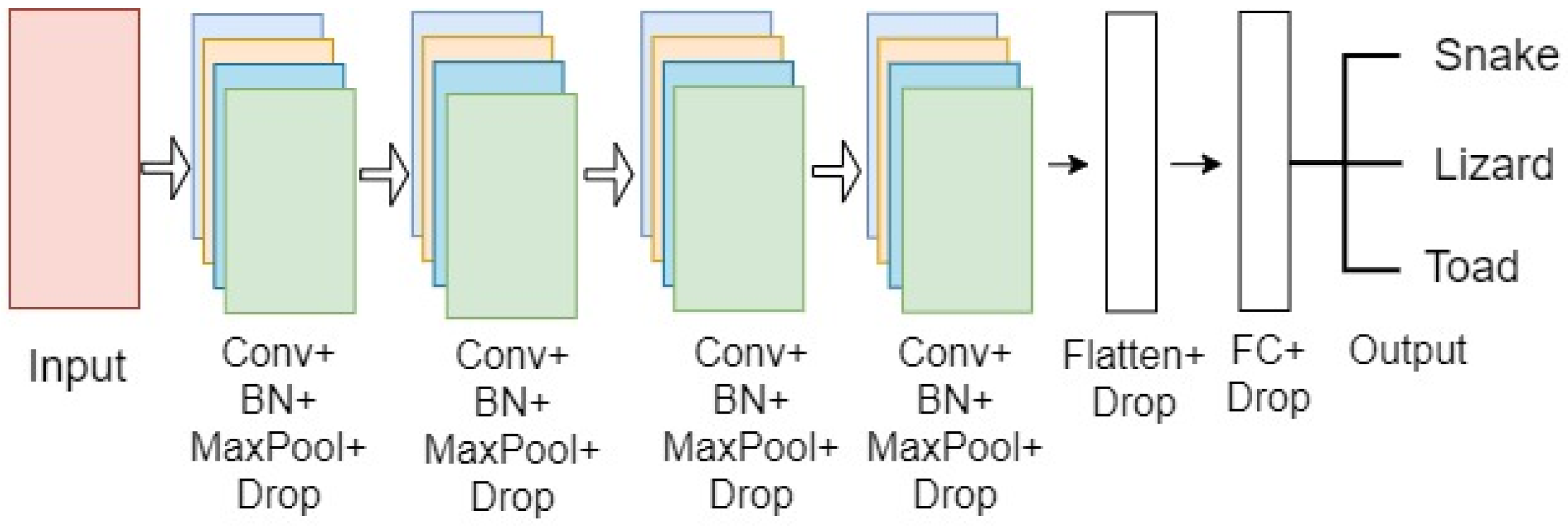
3.1.1. Self-Trained Model
3.1.2. VGG16 Model
3.1.3. ResNet50 Model
3.2. Image Classification Framework
3.3. Data Preprocessing
3.4. Augmentation
3.5. Evaluation Metrics
4. Experiment and Results
4.1. CNN-1
4.2. Pretrained Models
4.2.1. VGG16
4.2.2. ResNet50
4.3. Performance Summary
5. Discussion
5.1. Reflection of Performance
- 1.
- The experimental outcome reveals that augmentation parameters play a vital role in learning accuracy. The two kinds of models, self-trained (CNN-1) and transfer learning (VGG16 and ResNet50), react differently to augmented images, while pretrained models show more tolerance to transformed images. Without applying augmentation, CNN-1 provided remarkable training, validation, and testing accuracy for the given samples with no overfitting issues (Figure 9a). On the other hand, we observed a large generalization gap in the learning curve while training with a high augmentation threshold (Figure 9b).In ideal cases, augmentation is supposed to improve the model’s generalization ability and enhance the model’s performance. However, we noticed an opposite effect of the augmentation process, where a high augmentation parameter deteriorated the performance of CNN-1. The reason was likely that CNN-1 suffered from data deficiency. Due to the augmentation procedure, the model was trained with a new set of slightly modified data in each epoch. This made the model inefficient in learning the individual meaningful pattern of the target object. Another point that must be mentioned is that the self-trained model was not robust enough to train on the small challenging dataset. The high augmentation parameter added extra difficulty to the training process, negatively impacting the overall evaluation task of CNN-1. This obstacle can be overcome by training the model with a large amount of data, where the model will get sufficient information to learn salient features and improve the recognition ability. Moreover, there is always room for improvement in the deep learning architecture and tuning the model with the proper hyperparameters to optimize the performance.Nevertheless, a good learning curve with high training and validation accuracy (Figure 9, left) attained without applying augmentation can be misleading because the CNN model might memorize the data instead of learning the target features from the pixel value. Training a model with various image-augmented samples can aid the model in learning features invariant to transforms, such as left-to-right or top-to-bottom ordering [58]. The augmented data will thus represent a more comprehensive set of possible datapoints, eventually preventing the network from simply memorizing the samples. Keeping this in mind, the model was trained with considerably lower augmentation parameters than the value given in Table 2.As per the above analysis, deep learning networks require a large amount of training data for good accuracy, even if we apply the augmentation process [22]. Moreover, CNN-1 could identify target species from a similar location and background environment to those used while training the model. The accuracy might decrease drastically if we test the model with images taken from different locations. Even the VGG16 or ResNet50 models might need help recognizing classes if combined with different surroundings or were never introduced during training. That is why we suggest that all the automated ecological recognition outputs from the model should only be relied upon with human supervision, primarily for small-bodied species [59,60,61,62].
- 2.
- We also observed that the toad classification performed comparatively better, while many background samples were misclassified as lizards. The possible reason was that the original 600 toad samples were augmented by rotating 180 degrees and added to the existing dataset, producing repeated versions of the same image. Furthermore, most toad images consisted of night-vision samples that benefitted from blurred background features and provided a better view of the target object (Figure 3). Due to less complexity and disparity within the samples, the learning curve and test accuracy for toad classification showed optimum results. At the same time, lizards have a small body and a color that resembles the background properties, making feature extraction more complex during the training of models, which is likely why it was hard to distinguish the lizard images from the background images.The results also depict misclassifications between the snake and background images in all three models. Eleven snake species were in the snake group (Table A1), compared to a single lizard species and four frog/toad species. Thus, the snake dataset contained more body shape and size variations within the 700 sample images than the lizard and frog/toad groups. Most importantly, the complexity of background colors, vegetation, and shadows makes snakes harder to recognize through unique features and harder to differentiate from the background.
5.2. Limitations and Recommendations
- 1.
- Though the models provided very good precision and accuracy, the question arises about the reliability of classification methods working with camera trap images [57,60,61], especially with small-bodied species (lizards and toads in our case). One of the limitations of the image classification technique is the process of labeling training samples, where the whole image is annotated as an object [20]. As this process does not provide the specific focus part of the image, the model learns the background information as a feature to represent the target species [20]. Therefore, whether the network considers the correct areas as a target while training remains uncertain; this problem worsens when we train the architecture with a small dataset where the model might become biased to any particular entity in the background and is erroneously considered an essential feature.Additionally, pretrained and self-trained architectures downsampled the raw data into 224 × 224 and 150 × 150 consecutive images, as training the models with the original images (1920 × 1080 and 2048 × 1536 pixels) was computationally expensive. Resolution reduction speeds up the data processing [63] and decreases the memory requirement while training a deep CNN [64]. However, the downsizing process can lose important details [63] for a smaller-bodied animal in a complex background [64].We suggest that automatic identification through a classification process with high accuracy should be considered with skepticism for small species in an ecological environment [57,60,61]. From a technical viewpoint, training a model with a large dataset will mitigate the problem. Furthermore, an alternative labeling method can be investigated to better teach models about the complex features of species within a challenging sample set.
- 2.
- While dividing the dataset, Norouzzadeh et al. [15] did not put similar images in their training and testing sets. The motivation was that overly similar images in the training and testing sets provide exemplary performance in the model’s evaluation but might have a poor generalization ability for unseen data as the model can memorize the samples in the training phase [15]. However, the researchers experimented with over 3 million images, where they trained the model with 284,000 samples and separated 3800 datapoints as a test set [15]. In our work, we did not have the luxury to put a sequence of toad or lizard samples only in the training or testing set due to the available data limitation. Though our model achieved high accuracy, it comprehended similar or somewhat repetitive images due to sequential attributes. Therefore, the trained model will likely have lower performance while predicting species from a captured event from a new location [57,62].
- 3.
- When reusing the trained models to identify diversified species or animals from a different territory, we have to consider the experimental and resource limitations. The models inherit some degree of bias as the dataset covers examples from specific taxa and geographic habitat. Additionally, as reported earlier, a big portion of the training and testing sets contain a series of similar toad and lizard images. Though the models delivered high performance with our data, it is impractical to assume that these models will act well with untrained images from a different ecological project. For future research, the study should extend by including species from different taxa and regions. Furthermore, we recommend that AI-based models be retrained with updated data and undergo continuous development.
- 4.
- New computer vision complex networks that can discriminate the background patterns and recurrent motions of “external” objects introduced in frames need to be investigated. Other deep learning models can be explored to seek better recognition solutions, such as MobileNet, EfficientNet, Ensemble learning [65], MetaFormer models, transformers with encoding layers, etc. The potential of object detection models such as you-only-look-once (YOLO) or region-based convolutional neural networks (RCNN) needs to be studied to facilitate identifying the location of a target object of interest in an image and then classify them with a label. A significant amount of image data, a better labeling procedure, and a robust network can minimize the misclassification by providing good recognition accuracy.
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Species | Scientific Name | Common Name | Approximate Number of Animal Images |
|---|---|---|---|
| Toads/frogs | Bufonidae | 600 | |
| Incilius nebulifer | Gulf Coast toad | ||
| Ranidae | |||
| Lithobates sphenocephala | Leopard frog | ||
| Lizards | Anolis carolinensis | Green anole | 1400 |
| Snakes | Virginia striatula | Rough earth snake | 700 |
| Micrurus tener | Coral snake | ||
| Masticophis flagellum | Coachwhip | ||
| Pantherophis obsoletus | Black rat snake | ||
| Storeria dekayi | DeKay’s ground snake | ||
| Thamnophis proximus | Western ribbon snake | ||
| Pantherophis slowinskii | Slowinski’s corn snake | ||
| Coluber constrictor | Eastern racer | ||
| Heterodon platirhinos | Eastern hognose snake | ||
| Lampropeltis calligaster | Prairie kingsnake | ||
| Agkistrodon piscivorus | Western cottonmouth |
References
- Swanson, A.; Kosmala, M.; Lintott, C.; Simpson, R.; Smith, A.; Packer, C. Snapshot Serengeti, high-frequency annotated camera trap images of 40 mammalian species in an African savanna. Sci. Data 2015, 2, 150026. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; Kays, R.; Zhang, Z.; Ning, G.; Huang, C.; Han, T.X.; Millspaugh, J.; Forrester, T.; McShea, W. Visual informatics tools for supporting large-scale collaborative wildlife monitoring with citizen scientists. IEEE Circuits Syst. Mag. 2016, 16, 73–86. [Google Scholar] [CrossRef]
- Kays, R.; Tilak, S.; Kranstauber, B.; Jansen, P.A.; Carbone, C.; Rowcliffe, M.J.; Fountain, T.; Eggert, J.; He, Z. Monitoring wild animal communities with arrays of motion sensitive camera traps. arXiv 2010, arXiv:1009.5718. [Google Scholar]
- Islam, S.B. Herpetofauna Species Classification from Camera Trap Images Using Deep Neural Network for Conservation Monitorin, Thesis, Texas State University, San Marcos, Texas, USA, 2020. Available online: https://digital.library.txstate.edu/handle/10877/13026 (accessed on 16 April 2023).
- Adams, C.S.; Ryberg, W.A.; Hibbitts, T.J.; Pierce, B.L.; Pierce, J.B.; Rudolph, D.C. Evaluating effectiveness and cost of time-lapse triggered camera trapping techniques to detect terrestrial squamate diversity. Herpetol. Rev. 2017, 48, 44–48. [Google Scholar]
- Gibbons, J.W.; Scott, D.E.; Ryan, T.J.; Buhlmann, K.A.; Tuberville, T.D.; Metts, B.S.; Greene, J.L.; Mills, T.; Leiden, Y.; Poppy, S. The Global Decline of Reptiles, Déjà Vu Amphibians: Reptile species are declining on a global scale. Six significant threats to reptile populations are habitat loss and degradation, introduced invasive species, environmental pollution, disease, unsustainable use, and global climate change. BioScience 2000, 50, 653–666. [Google Scholar]
- Böhm, M.; Collen, B.; Baillie, J.E.; Bowles, P.; Chanson, J.; Cox, N.; Hammerson, G.; Hoffmann, M.; Livingstone, S.R.; Ram, M. The conservation status of the world’s reptiles. Biol. Conserv. 2013, 157, 372–385. [Google Scholar] [CrossRef]
- Whitfield, S.M.; Bell, K.E.; Philippi, T.; Sasa, M.; Bolaños, F.; Chaves, G.; Savage, J.M.; Donnelly, M.A. Amphibian and reptile declines over 35 years at La Selva, Costa Rica. Proc. Natl. Acad. Sci. USA 2007, 104, 8352–8356. [Google Scholar] [CrossRef]
- Welbourne, D.; Claridge, A.; Paull, D.; Ford, F. Improving terrestrial squamate surveys with camera-trap programming and hardware modifications. Animals 2019, 9, 388. [Google Scholar] [CrossRef]
- Welbourne, D.J.; Paull, D.J.; Claridge, A.W.; Ford, F. A frontier in the use of camera traps: Surveying terrestrial squamate assemblages. Remote Sens. Ecol. Conserv. 2017, 3, 133–145. [Google Scholar] [CrossRef]
- Burton, A.C.; Neilson, E.; Moreira, D.; Ladle, A.; Steenweg, R.; Fisher, J.T.; Bayne, E.; Boutin, S. Wildlife camera trapping: A review and recommendations for linking surveys to ecological processes. J. Appl. Ecol. 2015, 52, 675–685. [Google Scholar] [CrossRef]
- Nguyen, H.; Maclagan, S.J.; Nguyen, T.D.; Nguyen, T.; Flemons, P.; Andrews, K.; Ritchie, E.G.; Phung, D. Animal Recognition and Identification with Deep Convolutional Neural Networks for Automated Wildlife Monitoring. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 40–49. [Google Scholar]
- Yu, X.; Wang, J.; Kays, R.; Jansen, P.A.; Wang, T.; Huang, T. Automated identification of animal species in camera trap images. EURASIP J. Image Video Process. 2013, 2013, 52. [Google Scholar] [CrossRef]
- Schneider, S.; Taylor, G.W.; Kremer, S. Deep Learning Object Detection Methods for Ecological Camera Trap Data. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018; pp. 321–328. [Google Scholar]
- Norouzzadeh, M.S.; Nguyen, A.; Kosmala, M.; Swanson, A.; Palmer, M.S.; Packer, C.; Clune, J. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proc. Natl. Acad. Sci. USA 2018, 115, E5716–E5725. [Google Scholar] [CrossRef]
- Rosebrock, A. Deep Learning for Computer Vision with Python: Starter Bundle, 3rd ed.; PyImageSearch: USA, 2019. [Google Scholar]
- Wäldchen, J.; Mäder, P. Machine learning for image based species identification. Methods Ecol. Evol. 2018, 9, 2216–2225. [Google Scholar]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. In Advances in Computer Vision: Proceedings of the 2019 Computer Vision Conference (CVC); Springer International Publishing: Singapore, 2019; pp. 128–144. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn and Tensorflow: Concepts. In Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: London, CA, USA, 2017. [Google Scholar]
- Norouzzadeh, M.S.; Morris, D.; Beery, S.; Joshi, N.; Jojic, N.; Clune, J. A deep active learning system for species identification and counting in camera trap images. Methods Ecol. Evol. 2021, 12, 150–161. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Chen, G.; Han, T.X.; He, Z.; Kays, R.; Forrester, T. Deep Convolutional Neural Network based species recognition for wild animal monitoring. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 858–862. [Google Scholar]
- Gomez, A.; Salazar, A.; Vargas, F. Towards automatic wild animal monitoring: Identification of animal species in camera-trap images using very deep convolutional neural networks. arXiv 2016, arXiv:1603.06169. [Google Scholar] [CrossRef]
- Schindler, F.; Steinhage, V. Identification of animals and recognition of their actions in wildlife videos using deep learning techniques. Ecol. Inform. 2021, 61, 101215. [Google Scholar] [CrossRef]
- Chen, R.; Little, R.; Mihaylova, L.; Delahay, R.; Cox, R. Wildlife surveillance using deep learning methods. Ecol. Evol. 2019, 9, 9453–9466. [Google Scholar] [CrossRef]
- Sahu, R. Detecting and Counting Small Animal Species Using Drone Imagery by Applying Deep Learning. In Visual Object Tracking with Deep Neural Networks; IntechOpen: London, UK, 2019. [Google Scholar]
- Aota, T.; Ashizawa, K.; Mori, H.; Toda, M.; Chiba, S. Detection of Anolis carolinensis using drone images and a deep neural network: An effective tool for controlling invasive species. Biol. Invasions 2021, 23, 1321–1327. [Google Scholar] [CrossRef]
- Abdurrazaq, I.S.; Suyanto, S.; Utama, D.Q. Image-Based Classification of Snake Species Using Convolutional Neural Network. In Proceedings of the 2019 International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 5–6 December 2019; pp. 97–102. [Google Scholar]
- Patel, A.; Cheung, L.; Khatod, N.; Matijosaitiene, I.; Arteaga, A.; Gilkey, J.W. Revealing the unknown: Real-time recognition of Galápagos snake species using deep learning. Animals 2020, 10, 806. [Google Scholar] [CrossRef]
- Rajabizadeh, M.; Rezghi, M. A comparative study on image-based snake identification using machine learning. Sci. Rep. 2021, 11, 19142. [Google Scholar] [CrossRef] [PubMed]
- Abayaratne, S.; Ilmini, W.; Fernando, T. Identification of Snake Species in Sri Lanka Using Convolutional Neural Networks. 2019. Available online: http://dr.lib.sjp.ac.lk/handle/123456789/12085 (accessed on 16 April 2023).
- Progga, N.I.; Rezoana, N.; Hossain, M.S.; Islam, R.U.; Andersson, K. A CNN Based Model for Venomous and Non-venomous Snake Classification. In Proceedings of the International Conference on Applied Intelligence and Informatics, Nottingham, UK, 30–31 July 2021; pp. 216–231. [Google Scholar]
- Picek, L.; Bolon, I.; Durso, A.; De Castañeda, R.L.R. Overview of the SnakeCLEF 2020: AutomaticSnake Species Identification Challenge. In Proceedings of the CLEF (Working Notes), Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Bloch, L.; Boketta, A.; Keibel, C.; Mense, E.; Michailutschenko, A.; Pelka, O.; Rückert, J.; Willemeit, L.; Friedrich, C.M. Combination of Image and Location Information for Snake Species Identification using Object Detection and EfficientNets. In Proceedings of the CLEF (Working Notes), Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Yu, J.; Chang, H.; Cai, Z.; Xie, G.; Zhang, L.; Lu, K.; Du, S.; Wei, Z.; Liu, Z.; Gao, F. Efficient Model Integration for Snake Classification. In Proceedings of the CLEF 2022: Conference and Labs of the Evaluation Forum, Bologna, Italy, 5–8 September 2022. [Google Scholar]
- Zou, C.; Xu, F.; Wang, M.; Li, W.; Cheng, Y. Solutions for Fine-grained and Long-tailed Snake Species Recognition in SnakeCLEF 2022. arXiv 2022, arXiv:2207.01216. [Google Scholar]
- Neuharth, D.B.; Ryberg, W.A.; Adams, C.S.; Hibbitts, T.J.; Walkup, D.K.; Frizzell, S.L.; Johnson, T.E.; Pierce, B.L.; Pierce, J.B.; Rudolph, D.C. Searching for rare and secretive snakes: Are camera-trap and box-trap methods interchangeable? Wildl. Res. 2020, 47, 476–484. [Google Scholar] [CrossRef]
- Raschka, S.; Mirjalili, V. Python Machine Learning: Machine Learning and Deep Learning with Python, Scikit-Learn, and TensorFlow, 2nd ed.; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hijazi, S.L.; Kumar, R.; Rowen, C. Using Convolutional Neural Networks for Image Recognition; Cadence Design Systems Inc.: San Jose, CA, USA, 2015. [Google Scholar]
- Liu, D. A Practical Guide to ReLU. 2017. Available online: https://medium.com/@danqing/a-practical-guide-to-relu-b83ca804f1f7 (accessed on 19 January 2022).
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y. Convolutional Networks for Images, Speech, and Time Series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Tabak, M.A.; Norouzzadeh, M.S.; Wolfson, D.W.; Sweeney, S.J.; VerCauteren, K.C.; Snow, N.P.; Halseth, J.M.; Di Salvo, P.A.; Lewis, J.S.; White, M.D. Machine learning to classify animal species in camera trap images: Applications in ecology. Methods Ecol. Evol. 2019, 10, 585–590. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 630–645. [Google Scholar]
- Gaasedelen, E. ResNet, Torchvision, Bottlenecks, and Layers Not as They Seem. 2018. Available online: https://erikgaas.medium.com/resnet-torchvision-bottlenecks-and-layers-not-as-they-seem-145620f93096 (accessed on 16 April 2023).
- Rosebrock, A. Fine-Tuning ResNet with Keras, TensorFlow, and Deep Learning. 2020. Available online: https://www.pyimagesearch.com/2020/04/27/fine-tuning-resnet-with-keras-tensorflow-and-deep-learning/ (accessed on 16 April 2023).
- Chollet, F. Building Powerful Image Classification Models Using Very Little Data. Available online: https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html (accessed on 8 February 2022).
- Rosebrock, A. Keras ImageDataGenerator and Data Augmentation. 2019. Available online: https://www.pyimagesearch.com/2019/07/08/keras-imagedatagenerator-and-data-augmentation/ (accessed on 8 February 2022).
- Vecvanags, A.; Aktas, K.; Pavlovs, I.; Avots, E.; Filipovs, J.; Brauns, A.; Done, G.; Jakovels, D.; Anbarjafari, G. Ungulate Detection and Species Classification from Camera Trap Images Using RetinaNet and Faster R-CNN. Entropy 2022, 24, 353. [Google Scholar] [CrossRef]
- Brownlee, J. How to Configure Image Data Augmentation in Keras. Available online: https://machinelearningmastery.com/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/ (accessed on 8 February 2022).
- Saeed, F.S.; Bashit, A.A.; Viswanathan, V.; Valles, D. An Initial Machine Learning-Based Victim’s Scream Detection Analysis for Burning Sites. Appl. Sci. 2021, 11, 8425. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Islam, S.B.; Valles, D.; Forstner, M.R. Herpetofauna Species Classification from Images with Deep Neural Network. In Proceedings of the 2020 Intermountain Engineering, Technology and Computing (IETC), Orem, UT, USA, 2–3 October 2020; pp. 1–6. [Google Scholar]
- Willi, M.; Pitman, R.T.; Cardoso, A.W.; Locke, C.; Swanson, A.; Boyer, A.; Veldthuis, M.; Fortson, L. Identifying animal species in camera trap images using deep learning and citizen science. Methods Ecol. Evol. 2019, 10, 80–91. [Google Scholar] [CrossRef]
- Lau, S. Image Augmentation for Deep Learning. Available online: https://towardsdatascience.com/image-augmentation-for-deep-learning-histogram-equalization-a71387f609b2 (accessed on 11 February 2022).
- Vélez, J.; Castiblanco-Camacho, P.J.; Tabak, M.A.; Chalmers, C.; Fergus, P.; Fieberg, J. Choosing an Appropriate Platform and Workflow for Processing Camera Trap Data Using Artificial Intelligence. arXiv 2022, arXiv:2202.02283. [Google Scholar]
- Leorna, S.; Brinkman, T. Human vs. machine: Detecting wildlife in camera trap images. Ecol. Inform. 2022, 72, 101876. [Google Scholar] [CrossRef]
- Tuia, D.; Kellenberger, B.; Beery, S.; Costelloe, B.R.; Zuffi, S.; Risse, B.; Mathis, A.; Mathis, M.W.; van Langevelde, F.; Burghardt, T. Perspectives in machine learning for wildlife conservation. Nat. Commun. 2022, 13, 792. [Google Scholar] [CrossRef]
- Schneider, S.; Greenberg, S.; Taylor, G.W.; Kremer, S.C. Three critical factors affecting automated image species recognition performance for camera traps. Ecol. Evol. 2020, 10, 3503–3517. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Wu, R.; Yan, S.; Shan, Y.; Dang, Q.; Sun, G. Deep image: Scaling up image recognition. arXiv 2015, arXiv:1501.02876. [Google Scholar]
- Sefat, M.S.; Shahjahan, M.; Rahman, M.; Valles, D. Ensemble Training with Classifiers Selection Mechanism. In Proceedings of the 2021 IEEE 12th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 1–4 December 2021; pp. 0131–0136. [Google Scholar]













| Camera Trap Data Subsets for Model Testing | ||||
|---|---|---|---|---|
| Snakes | Lizards | Toads | Background | |
| Training | 1250 | 1250 | 1250 | 1250 |
| Validation | 250 | 250 | 250 | 250 |
| Test | 100 | 100 | 100 | 100 |
| Augmentation Techniques | Parameters and Range for CNN-1 | Parameters and Range for VGG16 and ResNet50 |
|---|---|---|
| Rotation | 10% | 30% |
| Flipping | 0.1 | 0.2 |
| Shearing | 0.1 | 0.2 |
| Horizontal shift | True | True |
| Zooming | 10% | 30% |
| Fill mode | Nearest | Nearest |
| Multiclassification | Binary Classification | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| All Four Classes | Snakes vs. Background | Toads vs. Background | Lizards vs. Background | |||||||
| Snakes | Toads | Lizards | Background | Snakes | Background | Toads | Background | Lizards | Background | |
| F1-score | 0.80 | 0.82 | 0.76 | 0.53 | 0.82 | 0.84 | 0.96 | 0.96 | 0.72 | 0.80 |
| Accuracy | 72% | 83% | 96% | 77% | ||||||
| Multiclassification Experiment | ||||||
|---|---|---|---|---|---|---|
| Type 1 | Type 2 | Type 3 | ||||
| F1-score | Accuracy | F1-score | Accuracy | F1-score | Accuracy | |
| Snakes | 0.82 | 85% | 0.81 | 87% | 0.82 | 87% |
| Lizards | 0.92 | 0.94 | 0.90 | |||
| Toads | 0.96 | 0.98 | 0.95 | |||
| Background | 0.72 | 0.75 | 0.80 | |||
| Binary Classification Experiment | ||||||
|---|---|---|---|---|---|---|
| Type 1 | Type 2 | Type 3 | ||||
| F1-score | Accuracy | F1-score | Accuracy | F1-score | Accuracy | |
| Snakes | 0.85 | 85% | 0.95 | 95% | 0.99 | 96% |
| Background | 0.85 | 0.95 | 0.94 | |||
| Toads | 0.94 | 94% | 0.99 | 98% | 0.99 | 99% |
| Background | 0.94 | 0.98 | 0.99 | |||
| Lizards | 0.82 | 81% | 0.83 | 82% | 0.79 | 81% |
| Background | 0.78 | 0.81 | 0.83 | |||
| Multiclassification Experiment | ||||||
|---|---|---|---|---|---|---|
| Type 1 | Type 2 | Type 3 | ||||
| F1-score | Accuracy | F1-score | Accuracy | F1-score | Accuracy | |
| Snakes | 89 | 83% | 94 | 85% | 95 | 86% |
| Lizards | 78 | 80 | 79 | |||
| Toads | 96 | 95 | 99 | |||
| Background | 66 | 71 | 70 | |||
| Binary Classification Experiment | ||||||
|---|---|---|---|---|---|---|
| Type 1 | Type 2 | Type 3 | ||||
| F1-score | Accuracy | F1-score | Accuracy | F1-score | Accuracy | |
| Snakes | 88 | 87% | 96 | 95% | 97 | 96% |
| Background | 86 | 95 | 96 | |||
| Toads | 91 | 92% | 1 | 99% | 99 | 99% |
| Background | 92 | 99 | 99 | |||
| Lizards | 60 | 66% | 78 | 78% | 80 | 78% |
| Background | 70 | 78 | 76 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Binta Islam, S.; Valles, D.; Hibbitts, T.J.; Ryberg, W.A.; Walkup, D.K.; Forstner, M.R.J. Animal Species Recognition with Deep Convolutional Neural Networks from Ecological Camera Trap Images. Animals 2023, 13, 1526. https://doi.org/10.3390/ani13091526
Binta Islam S, Valles D, Hibbitts TJ, Ryberg WA, Walkup DK, Forstner MRJ. Animal Species Recognition with Deep Convolutional Neural Networks from Ecological Camera Trap Images. Animals. 2023; 13(9):1526. https://doi.org/10.3390/ani13091526
Chicago/Turabian StyleBinta Islam, Sazida, Damian Valles, Toby J. Hibbitts, Wade A. Ryberg, Danielle K. Walkup, and Michael R. J. Forstner. 2023. "Animal Species Recognition with Deep Convolutional Neural Networks from Ecological Camera Trap Images" Animals 13, no. 9: 1526. https://doi.org/10.3390/ani13091526
APA StyleBinta Islam, S., Valles, D., Hibbitts, T. J., Ryberg, W. A., Walkup, D. K., & Forstner, M. R. J. (2023). Animal Species Recognition with Deep Convolutional Neural Networks from Ecological Camera Trap Images. Animals, 13(9), 1526. https://doi.org/10.3390/ani13091526