1. Introduction
With the advancement of agricultural informatization, the pig farming industry is undergoing a rapid transformation towards intensification, scale, and intelligence. The dynamic nature of pig farming necessitates accurate and efficient pig detection and counting methods.
However, the efficient and accurate detection and counting of pigs still pose significant challenges to the present day. There are several reasons for this. First, as the farming industry continues to expand, the number of pigs in pens has been increasing. Second, pigs can become dirty due to their various behaviors, and their tendency to cluster and nest can result in a large amount of occlusion, indistinct body features, and difficulty in distinguishing them from the environment [
1]. Additionally, changes in pig numbers occur due to factors such as deaths, sales, new pigs entering the herd, pen splitting or merging, and pigs growing into the next stage [
2]. Therefore, there is an urgent requirement for a pig counting method that can maintain a certain level of accuracy and efficiency in high-density dynamic farming environments, in order to truly achieve intensification and intelligence of the industry.
At present, pig counting in the industry relies heavily on manual inspections, which are known to be time-consuming, labor-intensive, and inefficient [
3]. Moreover, factors such as pigs moving back and forth can significantly reduce the accuracy of manual counting. Additionally, increased contact between caretakers and pigs during manual counting increases the risk of transmission of zoonotic diseases.
While electronic ear tags have been utilized for counting [
4,
5], they come with their own set of challenges. Pigs coming into contact with each other can lead to false reports, and there is a risk of ear tags falling off or getting damaged in environments where pigs scratch or in muddy conditions.
In the field of computer vision, Tian et al. [
6] have proposed an innovative method for pig counting on farms using deep learning techniques. Their approach combines a counting CNN and the ResNeXt model, achieving a high level of accuracy while maintaining a low computational cost. The results demonstrated a mean absolute error of 1.67 when applied to real-world data. Jensen et al. [
7] developed a novel approach for the automatic counting and positioning of slaughter pigs within a pen, utilizing a convolutional neural network (CNN) with a single linear regression output node. This model receives three partial images corresponding to different areas of the pen and estimates the number of pigs in each area. Furthermore, they obtained promising results, with a mean absolute error of less than one pig and a coefficient of determination between estimated and observed counts exceeding 0.9.
To enhance the automated piglet counting performance and address the challenge of partial occlusion, Huang et al. [
8] have proposed a two-stage center clustering network (CClusnet). In the initial stage, CClusnet predicts a semantic segmentation map and a center offset vector map for each image. In the subsequent stage, these maps are combined to generate scattered center points, and the piglet count is obtained using the mean-shift algorithm. This method achieved a mean absolute error of 0.43 per image for piglet counting. A bottom–up pig counting algorithm detected and associated three kinds of keypoints to count pigs [
9]; however, the use of this method can be challenging due to the possibility of occlusion and keypoints being invisible. The use of farrowing stalls exacerbates the difficulty of counting, as occlusion can cause a piglet to appear to be fragmented into multiple smaller parts within the scene, making it even more challenging to accurately count piglets.
Building upon traditional computer vision technology, Kashila et al. [
10] have utilized elliptical displacement calculation methods to achieve an impressive accuracy of 89.8% in detecting pig movement. In another study by Kashila et al. [
11], they employed an ellipse fitting technique to obtain a high accuracy of 88.7% in detecting and identifying individual pigs. Nasirahmadi et al. [
12,
13] have also utilized ellipse fitting and the Otus algorithm to successfully detect individual pigs and accurately determine their lying positions.
Tu et al. [
14] have proposed an innovative pig detection approach for grayscale video utilizing foreground object segmentation. Their method involves three stages. First, texture information is integrated to construct the background model. Next, pseudo-wavelet coefficients are computed, which are utilized in the final stage to estimate a probability map using a factor graph and a loopy belief propagation (BP) algorithm. However, it is important to note that this method suffers from high computational complexity due to the use of the BP algorithm and factor graphs. In a different study [
15], a background subtraction method based on a Gaussian Mixture Model (GMM) [
16] was utilized to detect moving pigs in scenarios with no windows and continuous lighting for 24 h. It is worth mentioning that the GMM background subtraction method can be computationally intensive and time-consuming. To address the limitations of the GMM approach, Li et al. [
17] have developed an enhanced pig detection algorithm based on an adaptive GMM. In this method, the Gaussian distribution is scanned periodically—typically once every m frames—in order to adapt the model. Redundant Gaussian distributions are detected and eliminated to enhance the convergence speed of the model. However, it is important to note that this method may face challenges in detecting pigs when sudden lighting changes occur. Traditional computer vision technology has the potential to improve animal welfare and achieve high recognition accuracy; however, it may not be suitable for industrial production requirements due to its slow detection speed. Additionally, the performance of the model may notably drop when the pigs are occluded or when there is significant variation in the size of the target pigs in the image.
To further enhance accuracy, numerous researchers have leveraged deep neural networks for pig detection and counting. Marsot et al. [
18] have employed a two-step approach for pig recognition. They first utilized two Haar feature-based cascade classifiers and a shallow convolutional neural network to automatically detect pig faces and eyes. Subsequently, a deep convolutional neural network was employed for recognition. Their approach achieved an accuracy of 83% on a test set consisting of 320 images containing 10 pigs.
Martin et al. [
19] have employed the Faster R-CNN [
20] object detection pipeline and the Neural Architecture Search (NAS) backbone network for feature extraction, achieving a mean average precision (mAP) of 80.2%. In another study conducted by the same authors [
21], Faster R-CNN was utilized to detect the positions and poses of pigs in all-weather videos captured from 10 pigsties. The detection performance yielded an mAP of 84% during the day and 58% during the night. Zhang et al. [
22] employed three CNN-based models—namely, the Faster-RCNN [
20], R-FCN [
23], and SSD models [
24]—for individual pig detection. Similarly, van der Zande et al. [
25] have utilized the YOLOv3 model for the same purpose. In another study, conducted by Guo et al. [
26], the YOLOv5s model was employed to achieve automated and continuous individual pig detection and tracking.
Although deep learning methods have achieved promising results in terms of pig detection, the use of attention mechanisms for feature extraction has not yet been fully explored. Additionally, the used loss functions may not effectively constrain the detection process to ensure precise results. To address these challenges and improve the pig detection and counting performance, we focused on exploring breakthroughs in the following areas.
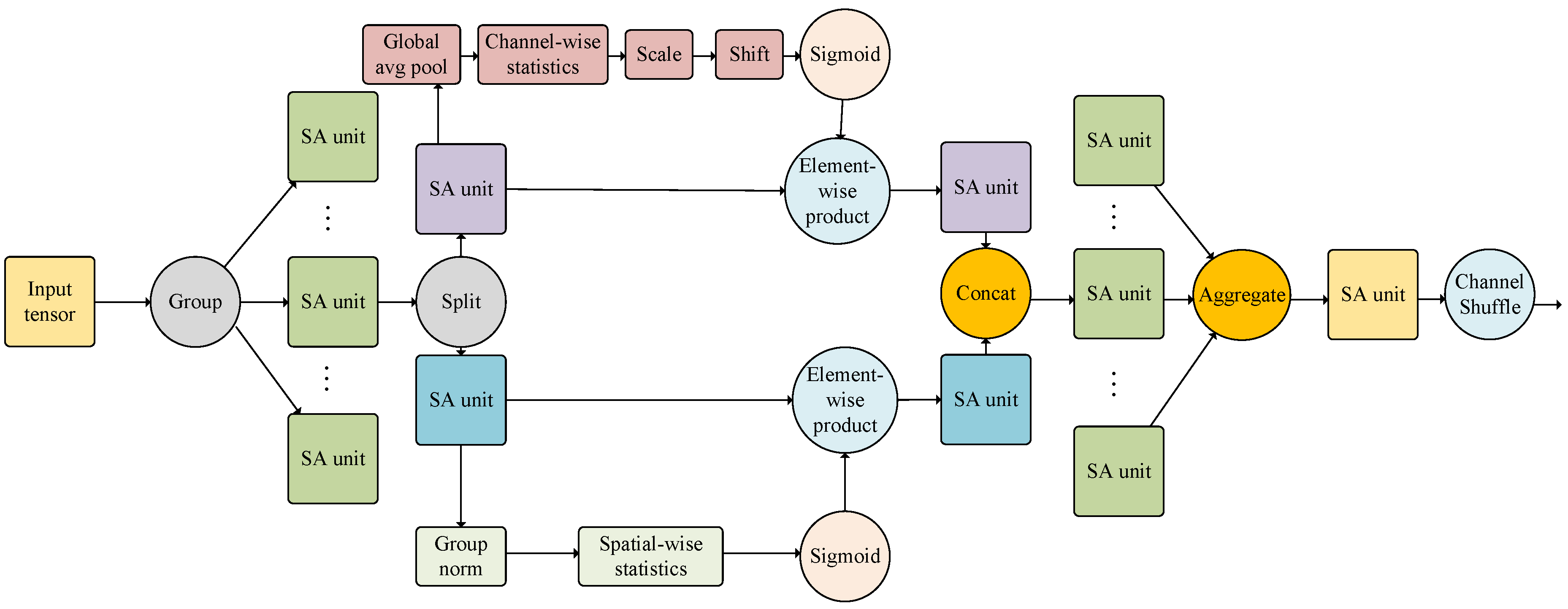
Shuffle attention [
27] is an attention mechanism that integrates group convolutions, spatial attention mechanisms, channel attention mechanisms, and the concepts of ShuffleNet. By introducing channel shuffle operations and block-wise parallel usage of spatial and channel attention mechanisms, shuffle attention achieves an efficient and tight integration of the two attention mechanisms while also possessing the characteristics of a low computational cost and plug-and-play capability. This means that shuffle attention can be quickly and seamlessly integrated into any CNN architecture for training while ignoring computational cost overheads.
Focal-CIoU is an advanced variant of CIoU, which aims to resolve the issue that CIoU may fail to accurately reflect the true differences in an object’s width, height, and confidence level. By introducing a focal term into the CIoU loss function, Focal-CIoU effectively improves upon the performance of CIoU and achieves more accurate results in object detection.
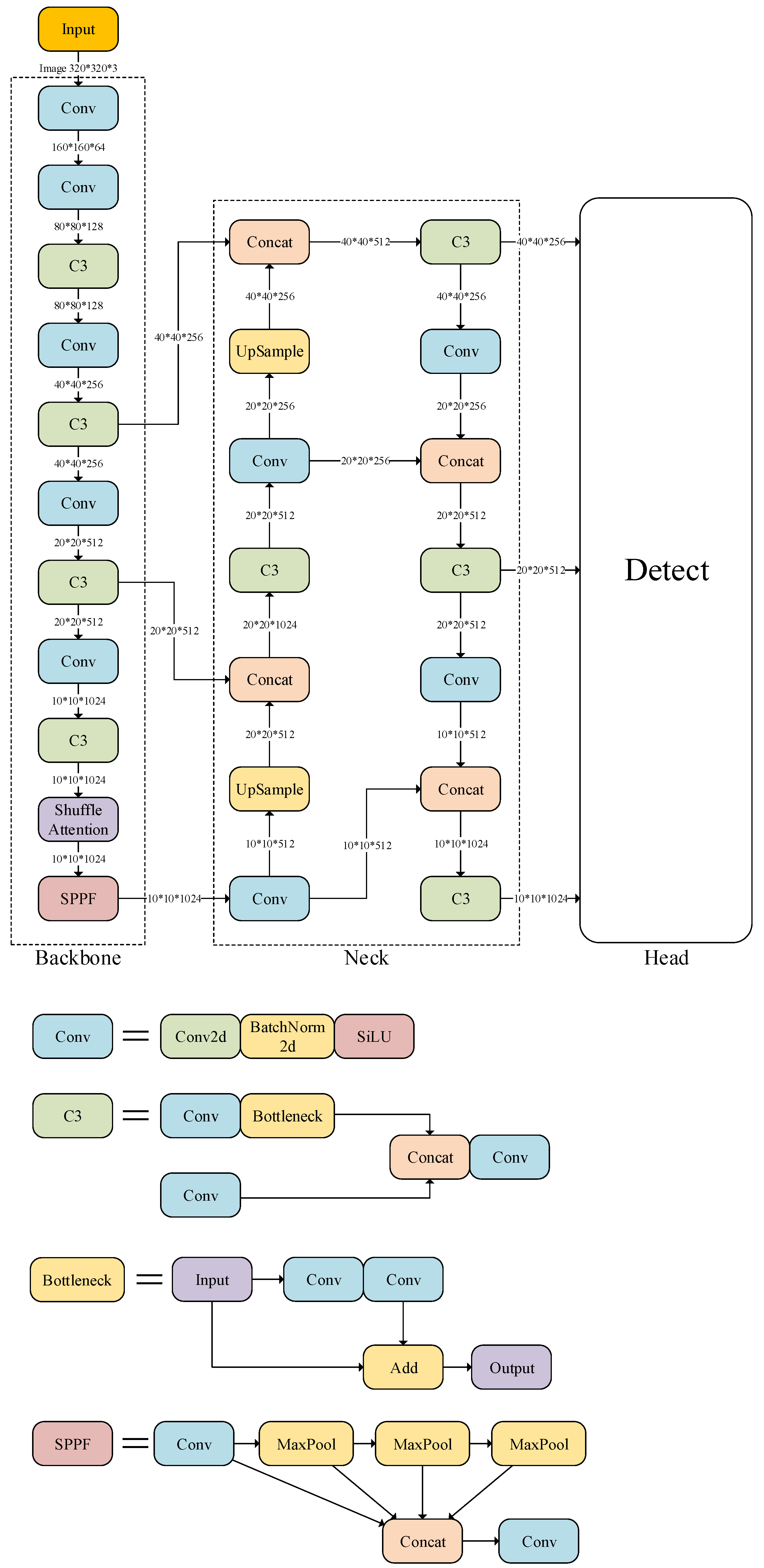
Leveraging the advantages of the various methods mentioned above, we propose a network model that integrates the shuffle attention mechanism and Focal-CIoU into YOLOv5, with the aim of achieving effective detection and counting of densely raised pigs. Specifically, in contrast to density map-based counting methods, YOLOv5-based counting directly detects the size and location of each target, allowing for accurate counting of pigs based on the identified targets. By utilizing YOLOv5-based counting, it becomes possible to directly annotate and visualize the pigs in the original image. This approach enhances our understanding of their behavior and simplifies the detection of movement patterns. To verify the effectiveness of the proposed model, several comparative experiments were designed to compare the performance differences between different models and YOLOv5-SA-FC. The main innovations of this paper can be summarized as follows:
We first establish a novel data set for pig detection and counting, which comprises 8070 images. The original videos were captured from six cameras installed on a farm over a period of two months. There are more than 200 pigs on the farm, with ages ranging from around 140 to 150 days. The aforementioned factors provide a more diverse data set, including variations in illumination, ages, angles, and other aspects.
We propose a novel pig detection and counting method called YOLOv5-SA-FC, which is based on the shuffle attention module and the Focal-CIoU loss function. The channel attention and spatial attention units in the shuffle attention module enable YOLOv5-SA-FC to focus on regions in the image that are crucial for detection, leading to the extraction of more rich, robust, and discriminative features. Meanwhile, the Focal-CIoU loss function ensures that the proposed YOLOv5-SA-FC model emphasizes prediction boxes having higher overlap with the target box, leading to an increased contribution of positive samples and improved model performance. Our model achieves the best performance for pig detection and counting tasks, with a 2.3% improvement over existing models.
We conducted several comparative and ablation experiments to validate the performance of our proposed model, including a comparison with different models, evaluations of the effectiveness of the shuffle attention module and the Focal-CIoU loss function, and an overall assessment of the superiority of YOLOv5-SA-FC.
The remainder of this paper is organized as follows. In
Section 2, we provide a detailed description of the materials and methods used in this study. In
Section 3, we present the results and discussions based on the conducted experiments.
Section 4 discusses the implications of the results obtained in our study. Finally, we conclude our findings and summarize the contributions of this paper in
Section 5.
3. Experimental Results and Analyses
In this section, we detail our experimental results and provide relevant discussions. The experiments are divided into several parts, including a comparison of different models, evaluations of the effectiveness of the shuffle attention module and the Focal-CIoU loss module, and an overall evaluation of the superiority of the YOLOv5-SA-FC model.
3.1. Comparison of Different Models
To verify the effectiveness of our proposed YOLOv5-SA-FC model, we compared it with several other models, including Faster-RCNN [
20], YOLOv2 [
35], YOLOv3 [
36], YOLOv4 [
37], and YOLOv5. The results are presented in
Table 2.
According to
Table 2, our proposed YOLOv5-SA-FC model achieved the best performance across all evaluation criteria. Specifically, YOLOv5-SA-FC achieved a counting accuracy of 95.6%, which is 36.96%, 19.80%, 15.46%, and 10.90% higher than the YOLOv2, YOLOv3, YOLOv4, and YOLOv5 models, respectively. In addition, YOLOv5-SA-FC achieved a precision of 92.7%, which is 12.9%, 47.14%, 6.67%, 10.36%, and 1.87% better than the Faster-RCNN, YOLOv2, YOLOv3, YOLOv4, and YOLOv5 models, and a recall of 88.1%, which is 7.70%, 29.37%, 24.08%, 16.84%, 6.14%, and 4.51% better than the Faster-RCNN, SSD, YOLOv2, YOLOv3, YOLOv4, and YOLOv5 models. Moreover, YOLOv5-SA-FC achieved a 0.90 F1 score, which is 0.11, 0.13, 0.34, 0.12, 0.80, and 0.30 higher than the Faster-RCNN, SSD, YOLOv2, YOLOv3, YOLOv4, and YOLOv5 models, and an mAP of 93.8%, which is 4.80%, 8.31%, 35.55%, 12.20%, 5.87%, and 3.08% superior to those of the aforementioned models, respectively. These results clearly demonstrate the effectiveness of our proposed YOLOv5-SA-FC model.
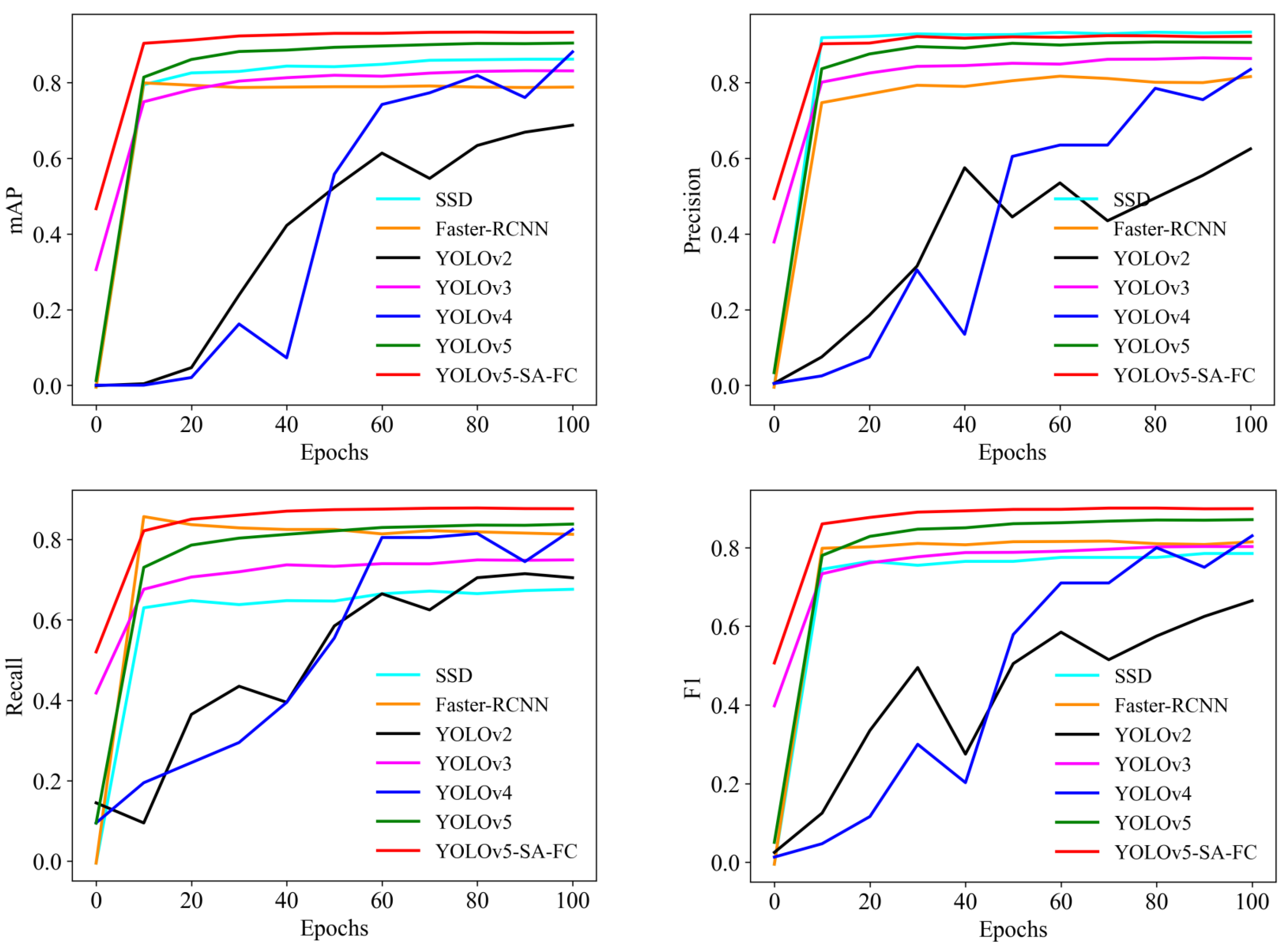
Figure 7 illustrates the comparison of different models across various iterations. The curves representing the mAP, recall, and F1 score of YOLOv5-SA-FC consistently outperform those of the Faster-RCNN, SSD, YOLOv2, YOLOv3, YOLOv4, and YOLOv5 models, indicating that YOLOv5-SA-FC had a superior performance, in terms of these metrics, when compared to the other models. We should note that the precision of the SSD was superior to that of our model, which was due to the more complex architecture of the SSD, specifically in terms of its feature extraction network. Additionally, the SSD utilizes a series of prior boxes (anchors) for object detection, which allows it to cover objects of different scales and aspect ratios. However, these factors also contribute to the slower speed of the SSD. Taking into account both speed and performance considerations, the obtained results validate the effectiveness of YOLOv5-SA-FC throughout the entire training phase.
Furthermore, the qualitative comparison results for the different models, including the Faster-RCNN, SSD, YOLOv2, YOLOv3, YOLOv4, and YOLOv5 models, are depicted in
Figure 8. It is evident that YOLOv5-SA-FC outperformed the other models by obtaining more accurate predicted bounding boxes, especially in scenarios involving occlusion and other challenging situations.
The superiority of the YOLOv5-SA-FC model over other models can be attributed to the following points. The shuffle attention and Focal-CIoU loss used in YOLOv5-SA-FC enabled it to adaptively focus on more discriminative regions of the image for pig detection, allowing it to effectively fuse feature maps at various scales and extract more informative features, even in scenarios involving pig clustering or occlusion. As a result, YOLOv5-SA-FC was shown to be capable of achieving rapid and efficient pig detection and counting, with a remarkable 95.6% counting accuracy and 93.8% mAP—significantly better than those for the other models.
3.2. Evaluating the Effectiveness of the Shuffle Attention Module
To assess the effectiveness of the shuffle attention module, we conducted a comparison between YOLOv5 and YOLOv5-SA. YOLOv5-SA was formed by integrating the shuffle attention module into the YOLOv5 backbone. The results are given in
Table 3.
Table 3 shows that the YOLOv5-SA model outperforms the YOLOv5 model on all evaluation criteria. Specifically, YOLOv5-SA achieved a 94.4% counting accuracy, which is 9.51% higher than that of YOLOv5; 92.3% precision, which is 1.43% better than that of YOLOv5; 87.9% recall, which is 4.27% superior to that of YOLOv5; and a 0.89 F1 score, which is 2.30% better than that of YOLOv5. Additionally, YOLOv5-SA achieved an mAP of 93.6%, which is 2.86% higher than that of YOLOv5. These results demonstrate the effectiveness of the shuffle attention module.
Moreover,
Figure 9 illustrates the results obtained by the different models at various iterations. The curves representing the mAP, precision, recall, and F1 score for YOLOv5-SA consistently outperformed those of YOLOv5, indicating that YOLOv5-SA had a superior performance in terms of mAP, precision, recall, and F1 score, when compared to YOLOv5. These results validate the effectiveness of the shuffle attention module throughout the entire training phase.
The superiority of the YOLOv5-SA model over the YOLOv5 model can be attributed to several reasons. First, the inclusion of spatial and channel attention mechanisms in YOLOv5-SA enabled it to focus on both the informative parts and their spatial locations, leading to more accurate predictions. This attention mechanism allows the model to dynamically adapt its attention to different regions of the input, improving its ability to capture relevant features. Second, YOLOv5-SA employs feature fusion techniques and a channel shuffle operator to facilitate the integration of information across different groups, enabling the model to capture diverse features and, thus, enhancing its performance. The channel shuffle operation promotes a cross-group information flow, allowing for better communication and exchanges of information between different parts of the network. Overall, the combination of spatial attention, channel attention, feature fusion, and the channel shuffle operator in YOLOv5-SA led to improved accuracy and efficiency, making it the more effective and advanced model in the comparison.
3.3. Evaluating of the Effectiveness of the Focal-CIoU Loss Function
To confirm the superiority of our proposed YOLOv5-SA-FC model, we carried out a comparison with the other models mentioned above, including YOLOv5, YOLOv5-SA, and YOLOv5-FC, against YOLOv5-SA-FC, which combines the shuffle attention and Focal-CIoU modules into the YOLOv5 structure. The results are presented in
Table 4.
Table 5 clearly demonstrates that the YOLOv5-FC model outperforms the YOLOv5 model across all evaluation criteria. Specifically, YOLOv5-FC achieved an impressive counting accuracy of 88.8%, which is 3.02% higher than that of YOLOv5. Additionally, it achieved a precision of 92.2%, which is 1.32% better than that of YOLOv5, and a recall of 85.8%, which is 1.78% superior to that of YOLOv5. Moreover, YOLOv5-FC achieved an F1 score of 0.87, which is 2.29% better than that of YOLOv5. Finally, YOLOv5-SA achieved an mAP of 92.3%, which is 1.43% higher than that of YOLOv5. These results clearly demonstrate the effectiveness of the shuffle attention module.
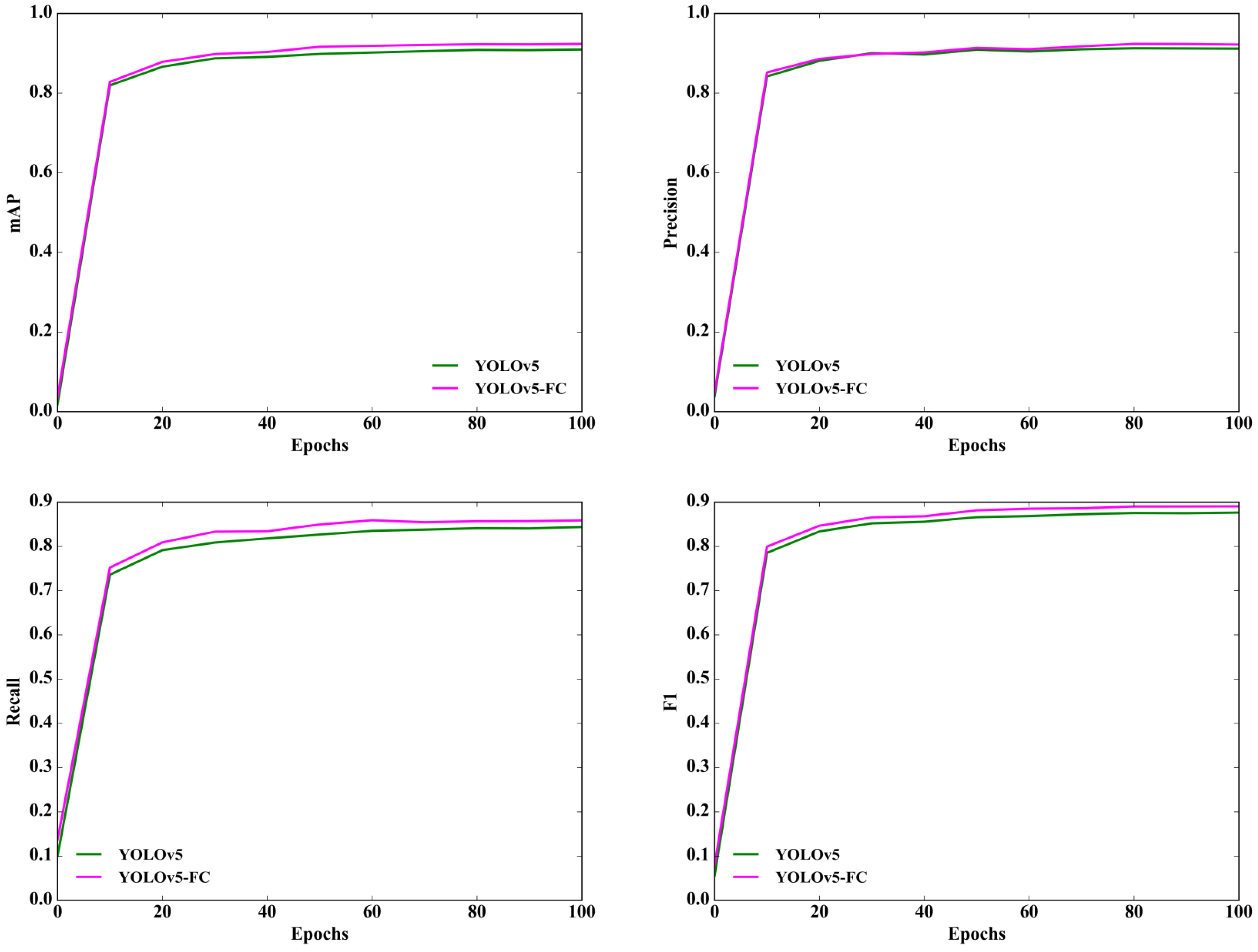
Additionally,
Figure 10 presents the comparison results of different models at various iterations. The curves depicting mAP, precision, recall, and F1 scores consistently outperform for YOLOv5-FC in comparison to YOLOv5. This clearly indicates that YOLOv5-FC exhibits a superior performance across mAP, precision, recall, and F1 score metrics when compared to YOLOv5. These results serve as validation for the effectiveness of the Focal-CIoU loss throughout the entire training phase.
The YOLOv5-FC model has been shown to outperform YOLOv5 due to several key factors. One of the main advantages of the Focal-CIoU loss function is that it addresses the issue of class imbalance while also improving the localization accuracy of the object detection model. Additionally, this loss function can effectively reduce the impact of easy negative samples, which are samples that are clearly not objects of interest. By doing so, the model can better focus on the more challenging samples that are critical for accurate object detection. Overall, the YOLOv5-FC model offers significant improvements over its predecessor, making it a powerful tool for object detection tasks.
3.4. Evaluating the Superiority of YOLOv5-SA-FC
To confirm the superiority of our proposed YOLOv5-SA-FC model, we conduct a comparison with other models mentioned in the previous section, such as YOLOv5, YOLOv5-SA, and YOLOv5-FC. We also introduce YOLOv5-SA-FC, which combines the shuffle attention and Focal-IoU modules into the YOLOv5 structure. The comparison results are presented in
Table 4.
Table 4 displays a comparison of the performance metrics for different models, highlighting the effectiveness of our proposed YOLOv5-SA-FC model. Our model outperforms others across all evaluation criteria, as demonstrated by
Table 4. Specifically, YOLOv5-SA-FC showcases significant advantages over YOLOv5, YOLOv5-FC, and YOLOv5-SA models. In terms of counting accuracy, it achieves an impressive 95.6%, surpassing YOLOv5 by 10.90%, YOLOv5-FC by 7.66%, and YOLOv5-SA by 1.27%. Additionally, in precision our model achieves 92.7%, outperforming YOLOv5 by 1.87%, YOLOv5-FC by 0.54%, and YOLOv5-SA by 0.43%. Moreover, in recall YOLOv5-SA-FC achieves 88.1%, which is 4.51%, 2.68%, and 0.23% higher than YOLOv5, YOLOv5-FC, and YOLOv5-SA, respectively. Further emphasizing its superiority, YOLOv5-SA-FC attains a 0.90 F1 score, showcasing improvements of 3.44%, 1.12%, and 1.12% over YOLOv5, YOLOv5-FC, and YOLOv5-SA, respectively. Additionally, its mean average precision (mAP) of 93.8% surpasses the corresponding values for the aforementioned models by 3.08%, 1.62%, and 0.21%.
Furthermore,
Figure 11 showcases the comparison results of different models at various iterations. The curves representing mAP, precision, recall, and F1 scores show YOLOv5-SA-FC consistently outperforms those of other models. This clearly indicates that YOLOv5-SA-FC exhibits a superior performance across all metrics when compared to the other models. These results serve as strong validation for the effectiveness of YOLOv5-SA-FC throughout the entire training phase.
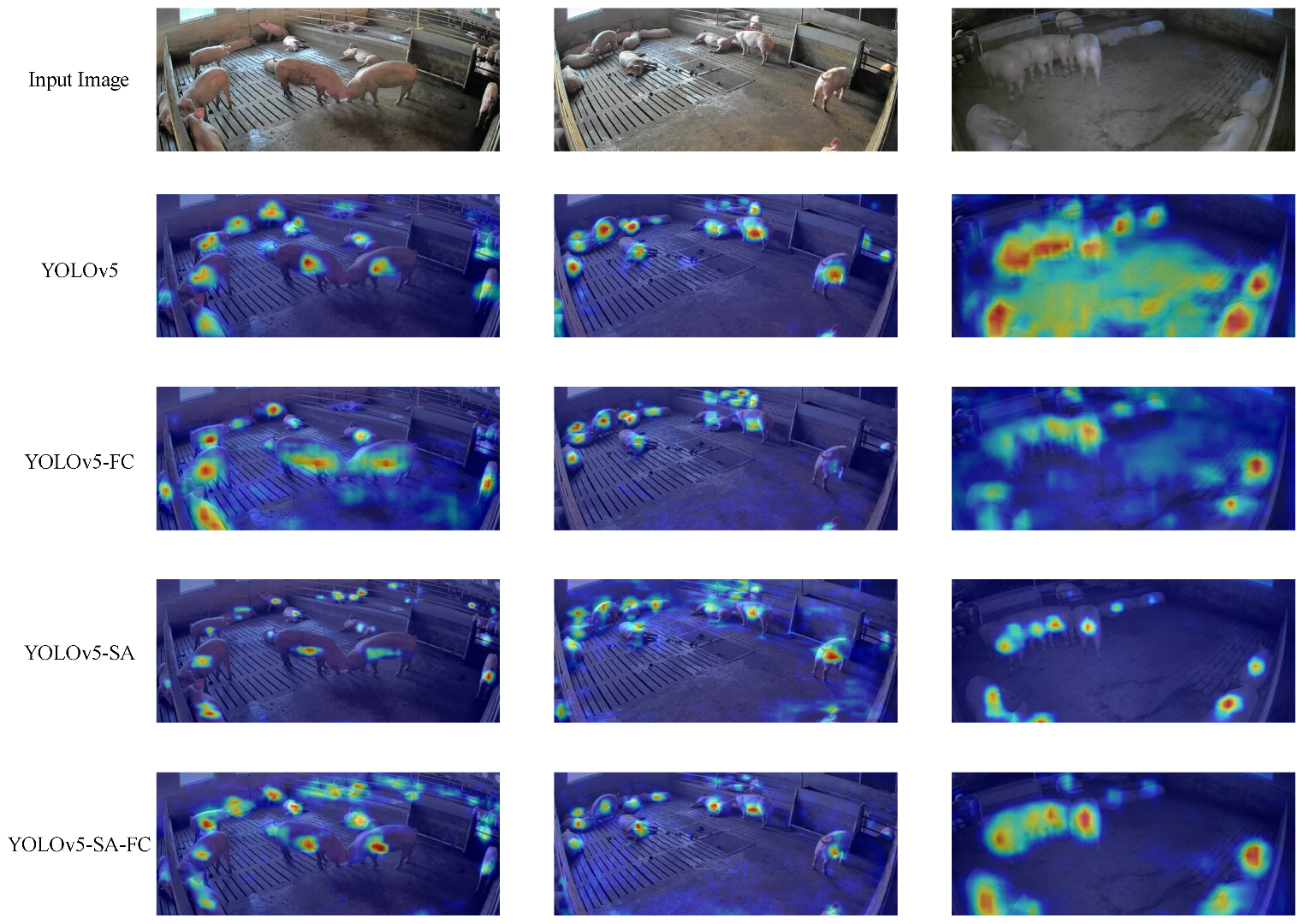
A heatmap comparison of the different models is provided in
Figure 12. The heatmaps illustrate the differences in the activation patterns and highlight the areas of focus for each model. The heatmap of YOLOv5-SA-FC presents more precise and concentrated activations, indicating its ability to accurately identify and localize objects. In contrast, the heatmaps of other models show scattered, less distinct activations. Additionally, the other models were prone to missing detections in the case of occlusion, as can be observed from the YOLOv5 heatmap. This comparison intuitively demonstrates the superior performance of YOLOv5-SA-FC in terms of capturing relevant features and making accurate predictions.
The YOLOv5-SA-FC model was found to outperform the other models for several reasons. The shuffle attention mechanism allows the model to selectively focus on informative features while suppressing irrelevant ones, thus reducing the impact of noisy or irrelevant information and improving the robustness of the model. The Focal-CIoU loss function addresses the issue of class imbalance in object detection, which is common in real-world scenarios as certain classes tend to be rare or under-represented. It assigns higher weights to hard examples and reduces the influence of easy ones, improving the model’s accuracy and localization performance. Through the combination of these two techniques, the YOLOv5-SA-FC model achieved a better performance than the original YOLOv5 model. In particular, the proposed model detected objects with higher precision and recall while also being more efficient and robust with respect to variations in lighting, scale, and orientation.
4. Discussion
This paper introduces a more advanced version of the YOLOv5 model, called YOLOv5-SA-FC, which is specifically designed for the efficient detection of individual pigs. To demonstrate the effectiveness of our proposed model, we carried out a comparative study against several popular models, as well as ablating our model to obtain four different models: YOLOv5, YOLOv5-SA, YOLOv5-FC, and YOLOv5-SA-FC. Our experimental results indicated that both the YOLOv5-SA and YOLOv5-FC models outperform the original YOLOv5 model, thereby validating the effectiveness of both the Focal-CIoU and shuffle attention modules.
We also found some existing research used in the detection of pigs with YOLOv5 (e.g., Lai [
38], Li [
39], and Zhou [
40]) and compared them with our method. The specific results are shown in
Table 6 and were assessed using the mAP@0.5 metric:
From
Table 6, it can be seen that our YOLOv5-SA performs the best. The shuffle attention uses dual-channel fusion technology and a channel shuffling operation, making the model more sensitive to capturing target features, which enables the model to adaptively extract valuable information in critical areas of the image, reduce irrelevant interference (such as overlapping pigs), and improve accuracy. Moreover, the YOLOv5-SA-FC model achieved the best performance in all comparisons, further demonstrating the superiority of our proposed model. By leveraging the shuffle attention module, our model could dynamically focus on the most relevant features for pig detection and counting while reducing the weights of non-essential features. Additionally, the Focal-CIoU loss mechanism gave a higher priority to predicted boxes having higher overlap with the target box, thus significantly improving the detection performance.
In addition, to translate our research findings into practical productivity, we require several essential practical steps. Firstly, it is necessary to ensure that the farm has a computing center with sufficient performance capabilities to efficiently handle the computational tasks required by the models. Secondly, real-time video feeds from each pigpen need to be transmitted to the computing center, which may involve laying a substantial amount of wiring on the farm or establishing a wireless network hub to ensure the timeliness of data received by the computing center. Finally, personnel training is essential for the farm to operate smoothly, maintain the system, and provide technical support when necessary. In summary, deploying the model into practical production requires consideration of numerous factors, such as software, hardware, personnel, etc., and their effective integration to ensure the system’s proper functioning.
In conclusion, our proposed YOLOv5-SA-FC model outperformed existing models in terms of accuracy and efficiency, making it a promising solution for pig detection and counting applications.
5. Conclusions
In this paper, we proposed a new pig detection and counting model called YOLOv5-SA-FC, which integrates shuffle attention and Focal-CIoU loss into the YOLOv5 framework backbone. The channel attention and spatial attention units in the shuffle attention module enable YOLOv5-SA-FC to effectively focus on the critical regions of the image with a high detection capability, thereby enhancing the feature extraction performance with more discriminative, robust, and rich feature maps. The Focal-CIoU loss mechanism forces the model to prioritize the predicted boxes having higher overlap with the target box, thereby increasing the contribution of positive samples and improving the detection performance. Furthermore, we conducted ablation studies, the results of which indicated the performance enhancements brought by both the shuffle attention and Focal-CIoU modules. Moreover, the experimental results indicated that the proposed YOLOv5-SA-FC model presents a promising pig detection and counting performance, with a 93.8% mAP and 95.6% accuracy, thus significantly outperforming other state-of-the-art models.
In future work, we plan to develop more sophisticated and advanced models to further enhance the pig detection and counting performance. We intend to explore various data augmentation methods to improve the robustness of the model and experiment with other attention mechanisms to capture crucial features for pig detection with better accuracy. Additionally, we hope to extend our work to more complex scenarios, including pig tracking and behavior analysis, in order to better understand their habits. Finally, we will investigate the potential of applying our proposed model to various animal detection and counting tasks aside from pig detection, thus expanding the scope of our research.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}