
A 16S Next Generation Sequencing Based Molecular and Bioinformatics Pipeline to Identify Processed Meat Products Contamination and Mislabelling

 , , and
, , and
Abstract
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Collection of Pure Meat Samples to Confirm the Reliability of the Species Identification Pipeline
2.2. The Collection of Processed Meat Samples for Species Identification
2.3. DNA Extraction
2.4. PCR Amplification of the Mitochondrial 16S rRNA Gene
2.5. Library Preparation and Illumina MiSeq Sequencing
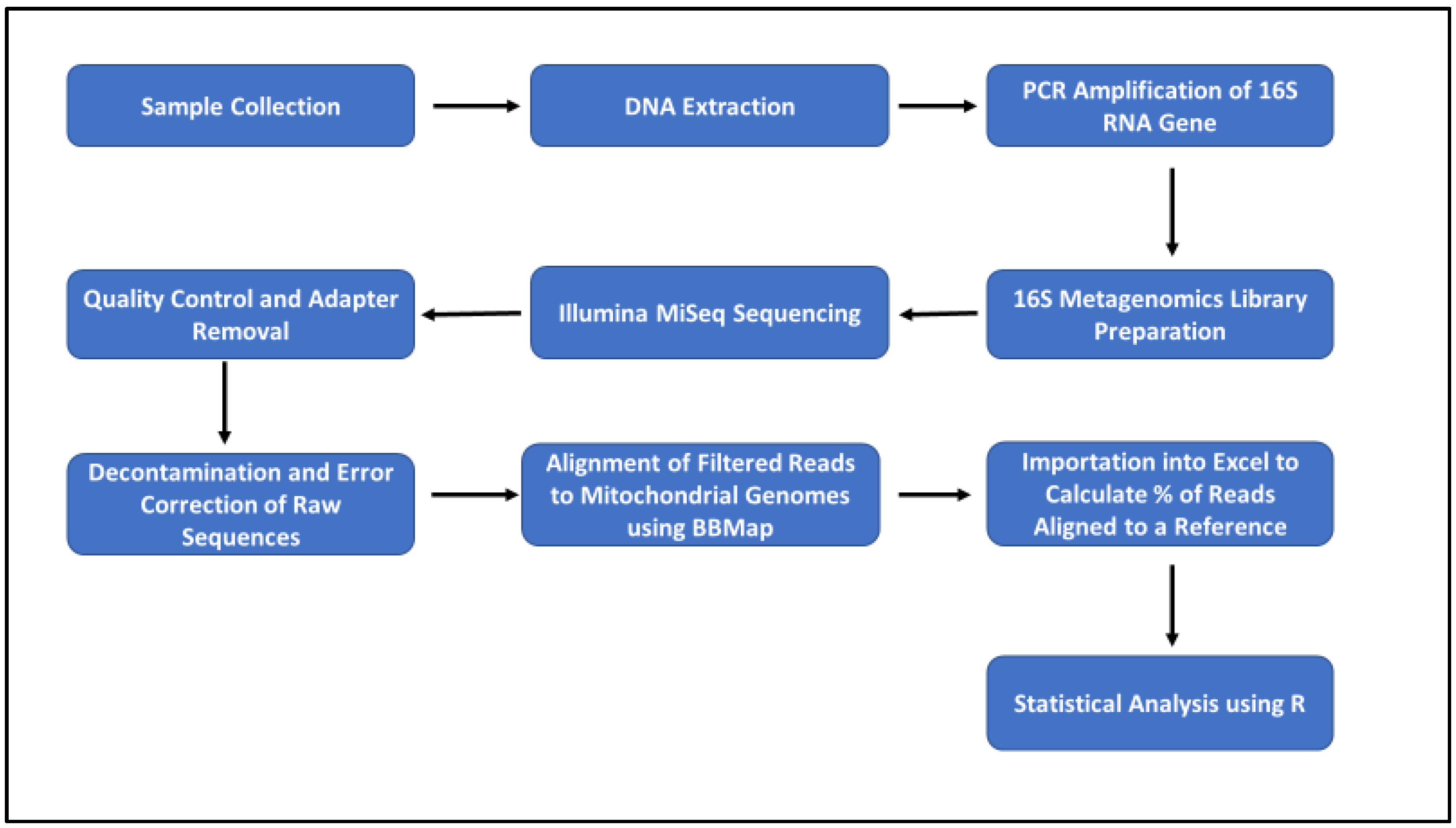
2.6. Bioinformatics and Data Analyses
3. Results
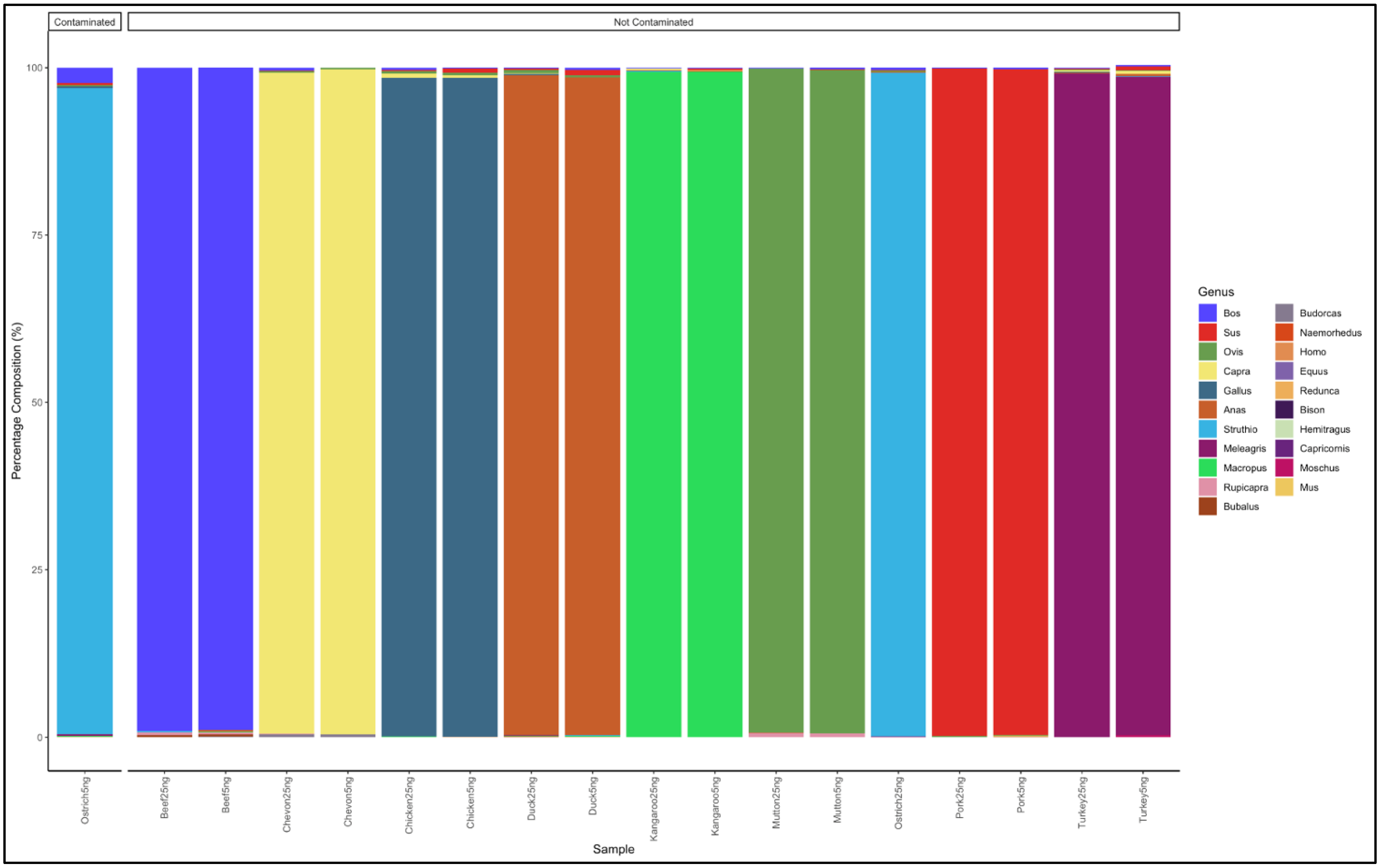
3.1. Identification of Meat Species Using Pure DNA from Known Meat Types
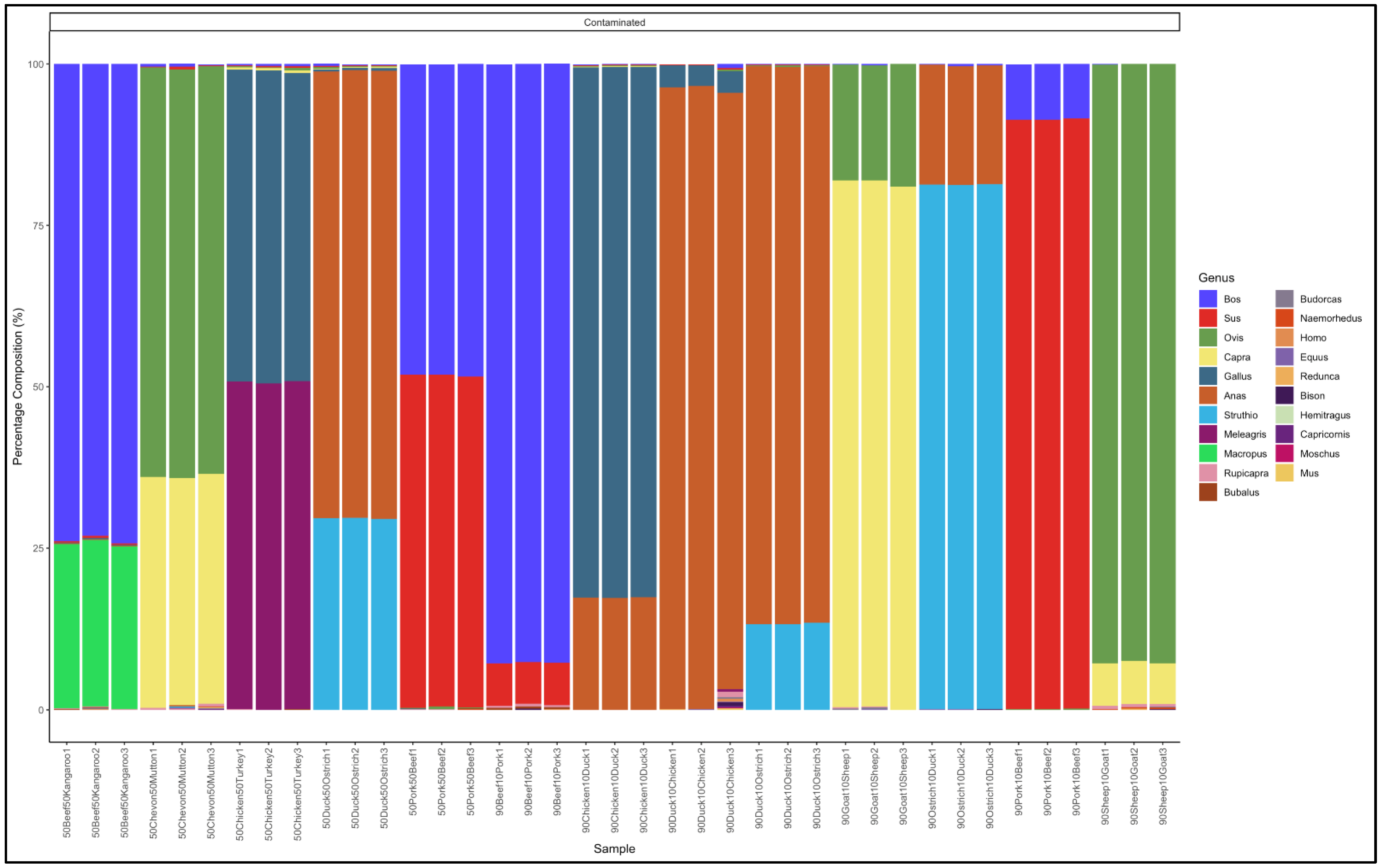
3.2. Identification of Meat Species Using Pure DNA from Known Meat Types Artificially Mixed at a Ratio of 1:1
3.3. Identification of Pure DNA from Known Meat Types Artificially Mixed at a Ratio of 9:1
3.4. Percentage Deviation from Expected Percentages in the Pure and Artificially Mixed Samples
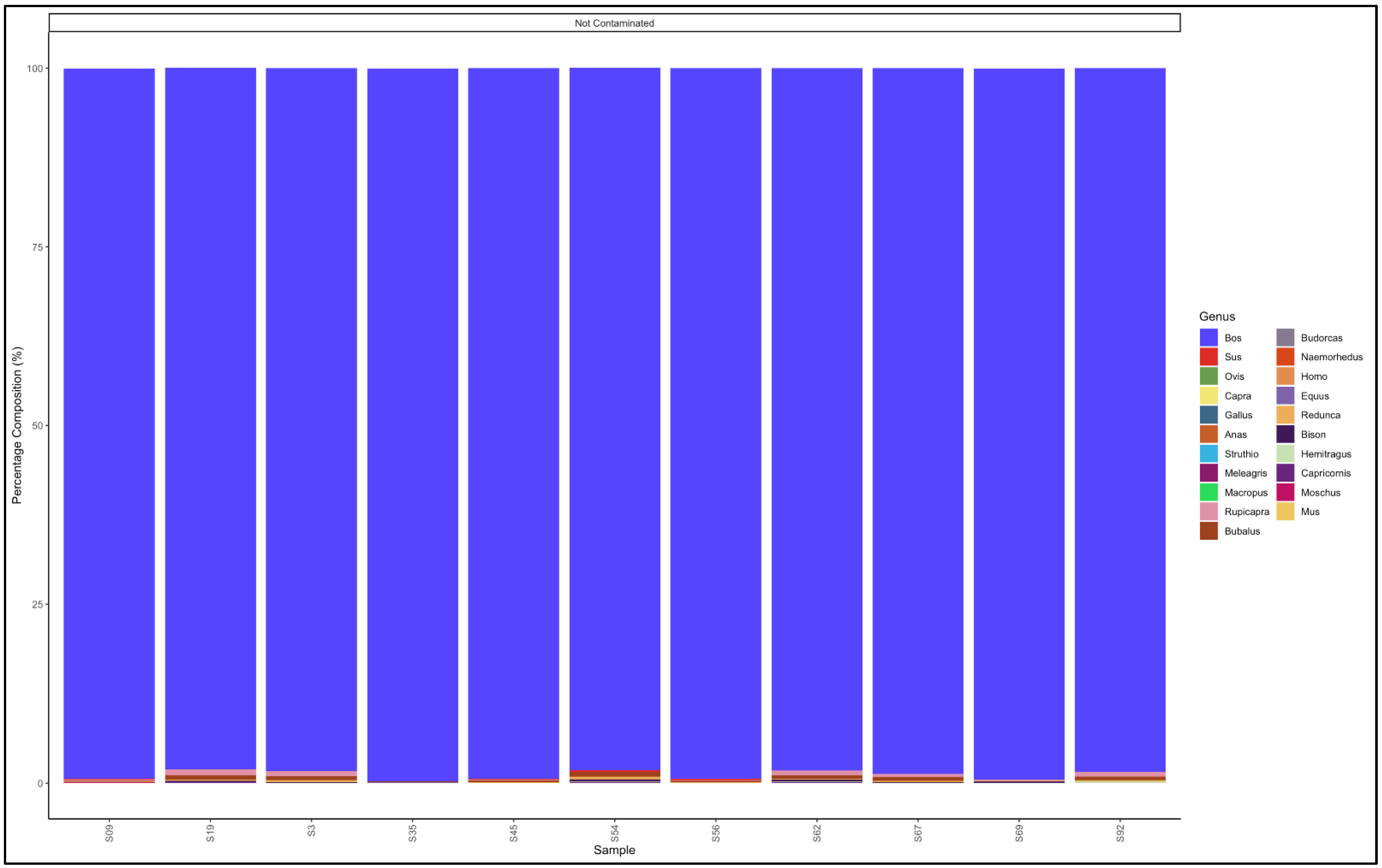
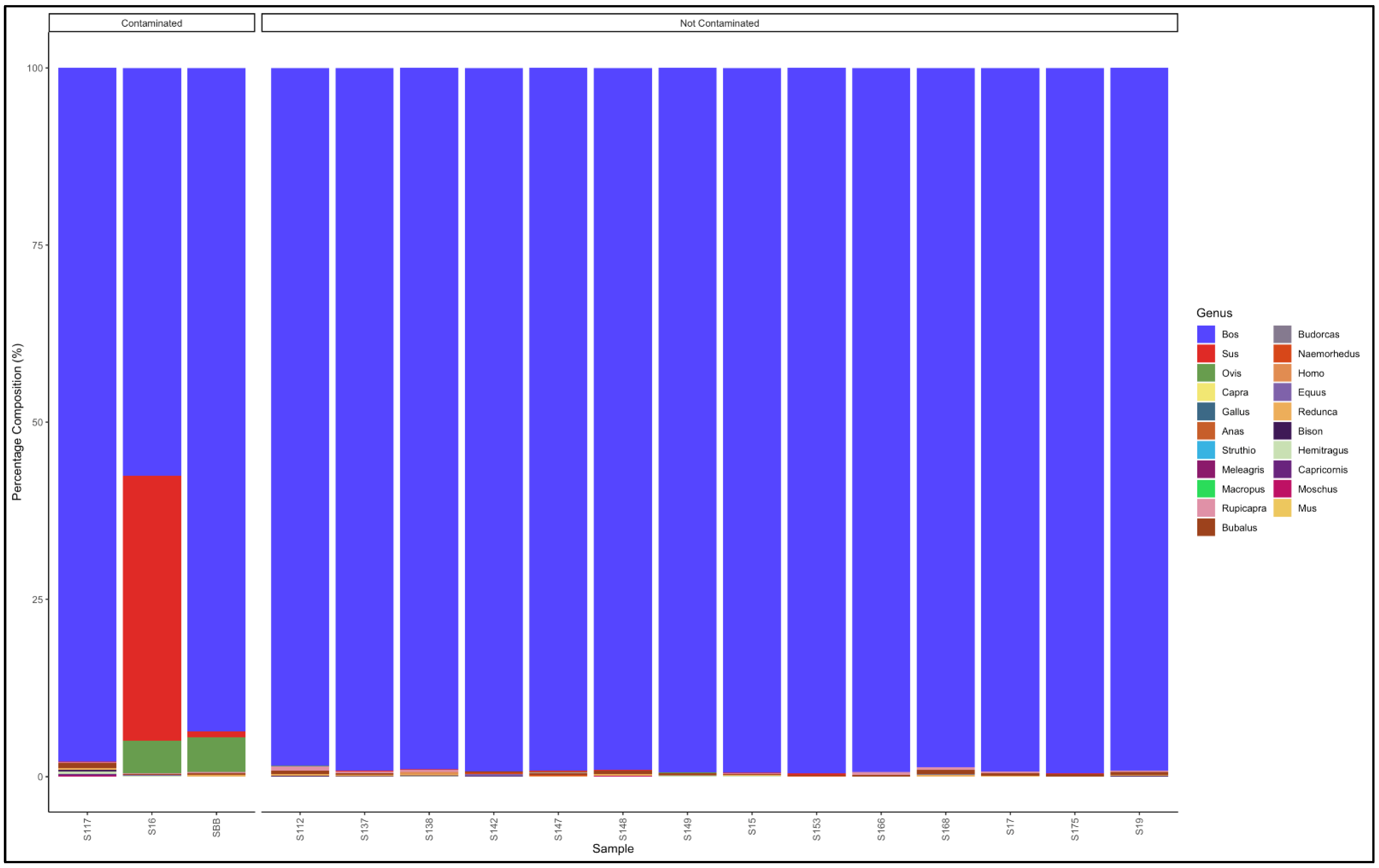
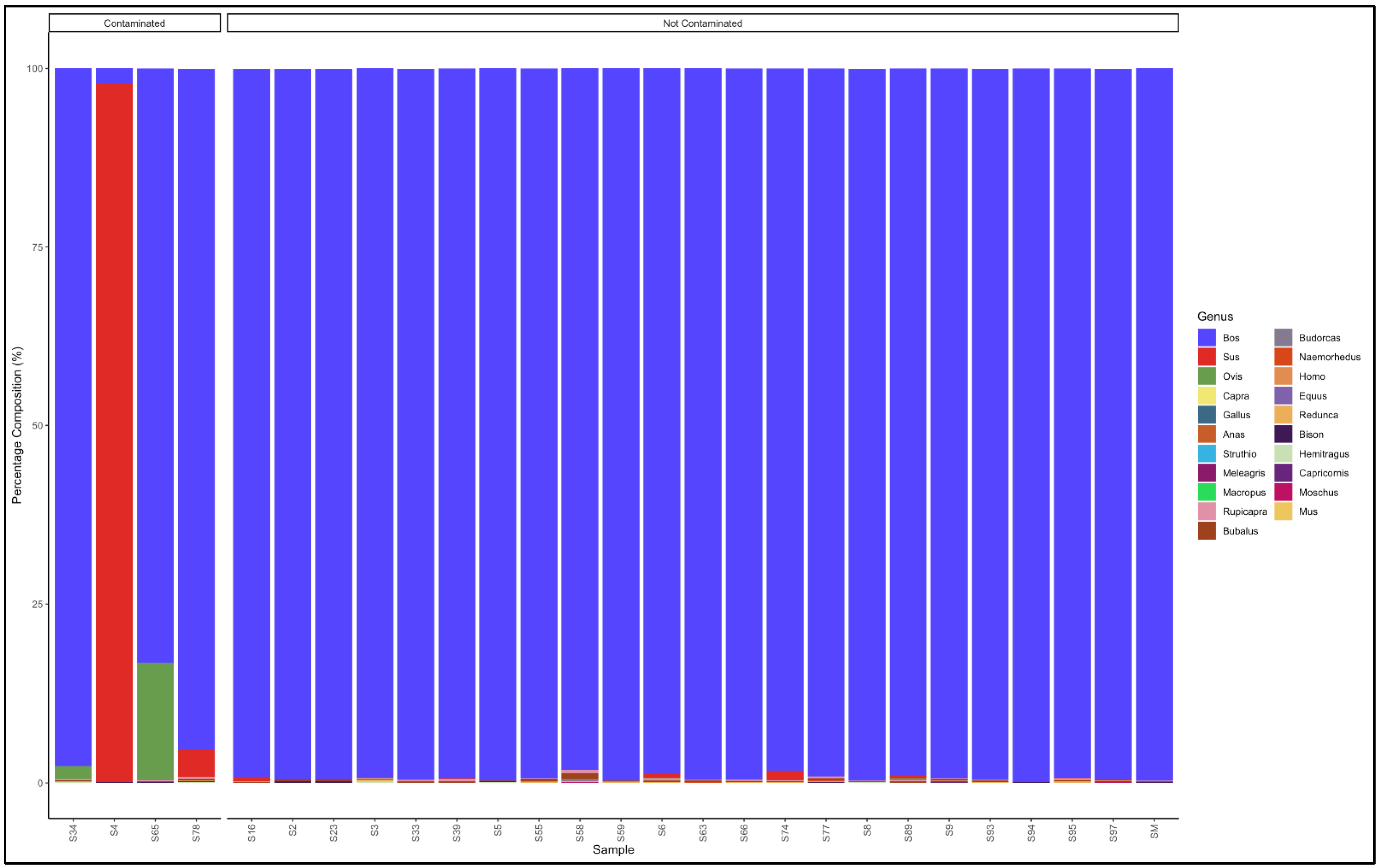
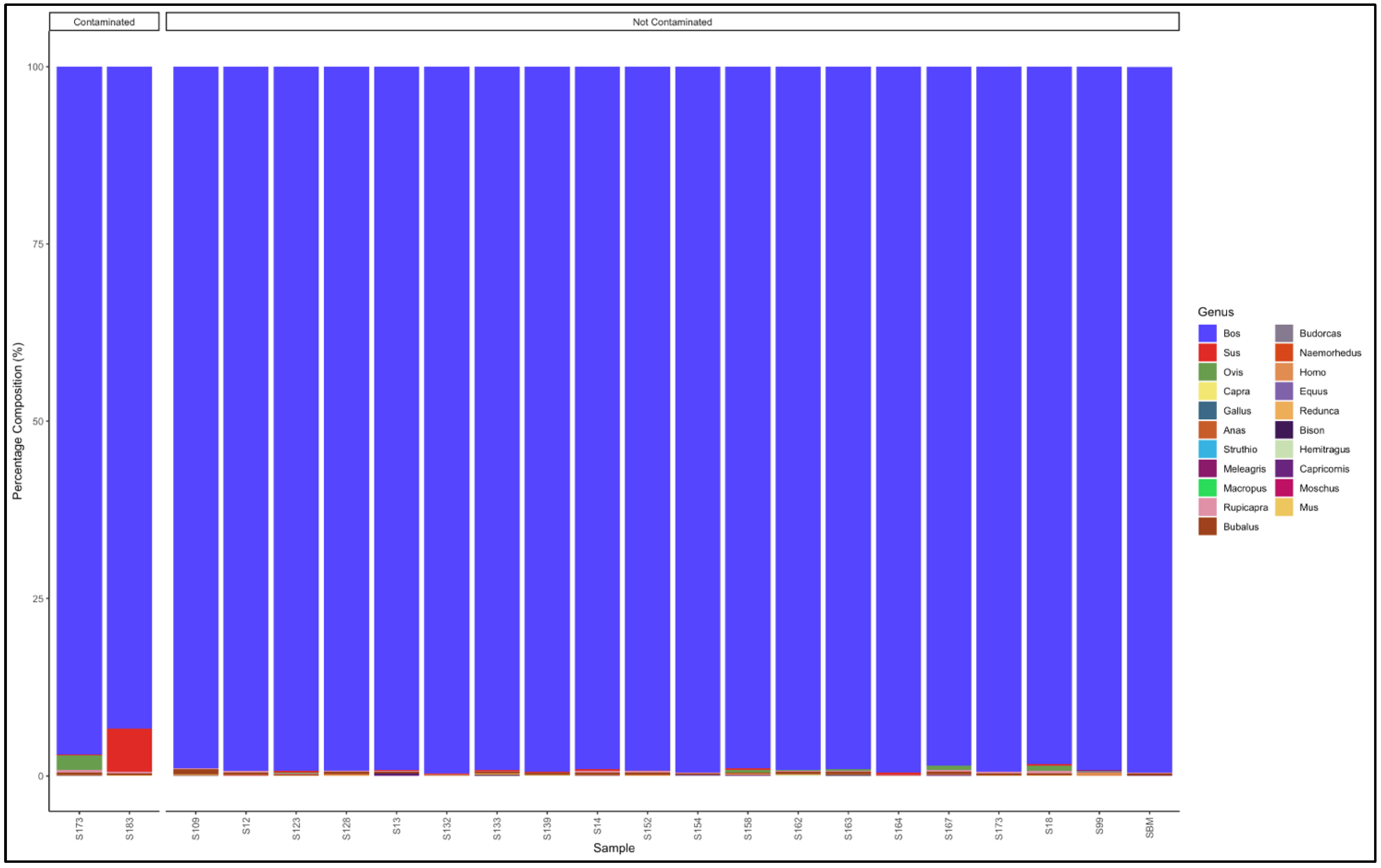
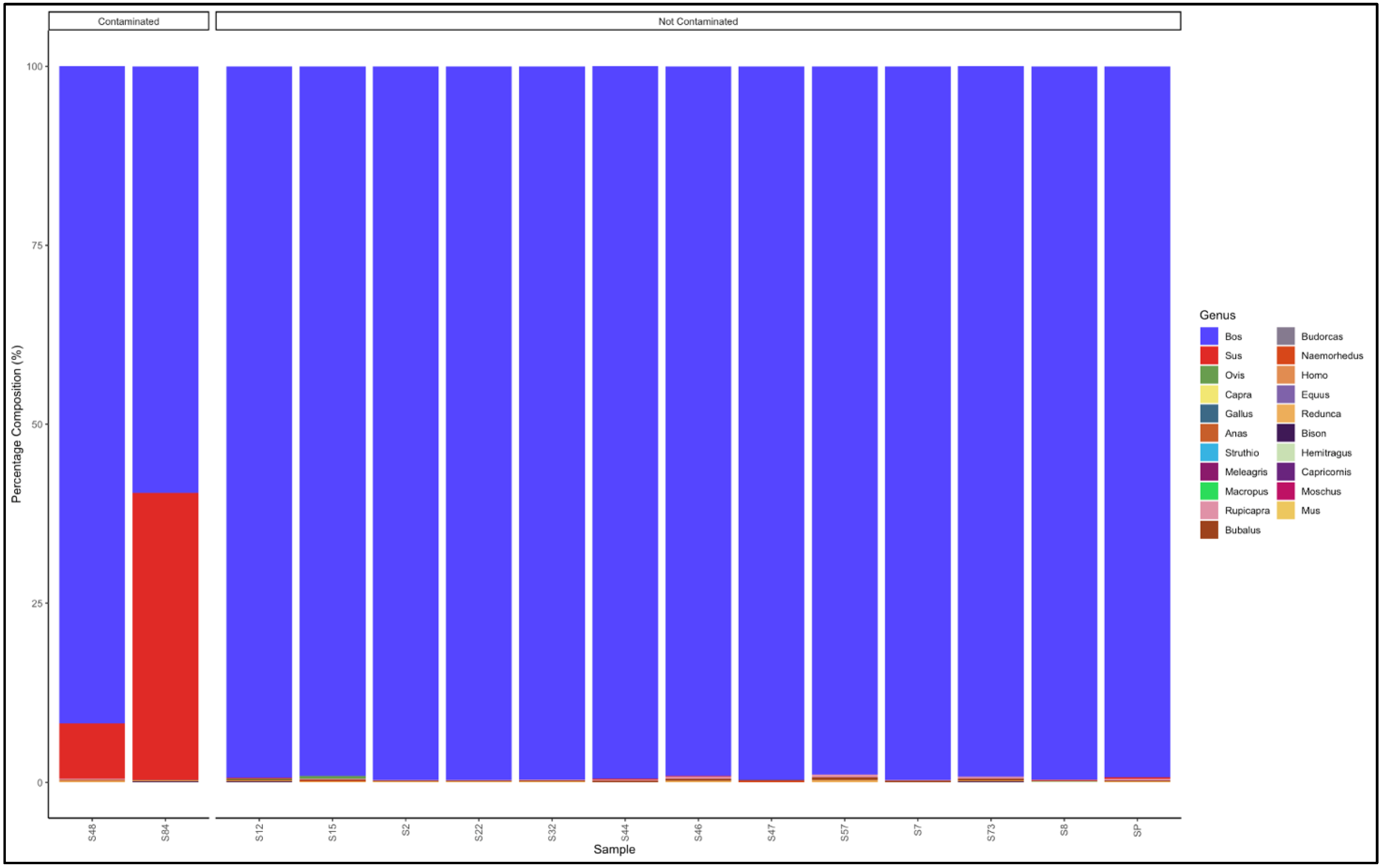
3.5. Identification of Species and Species Contamination of Processed Meat Collected from Processing Plants and Retail Outlets
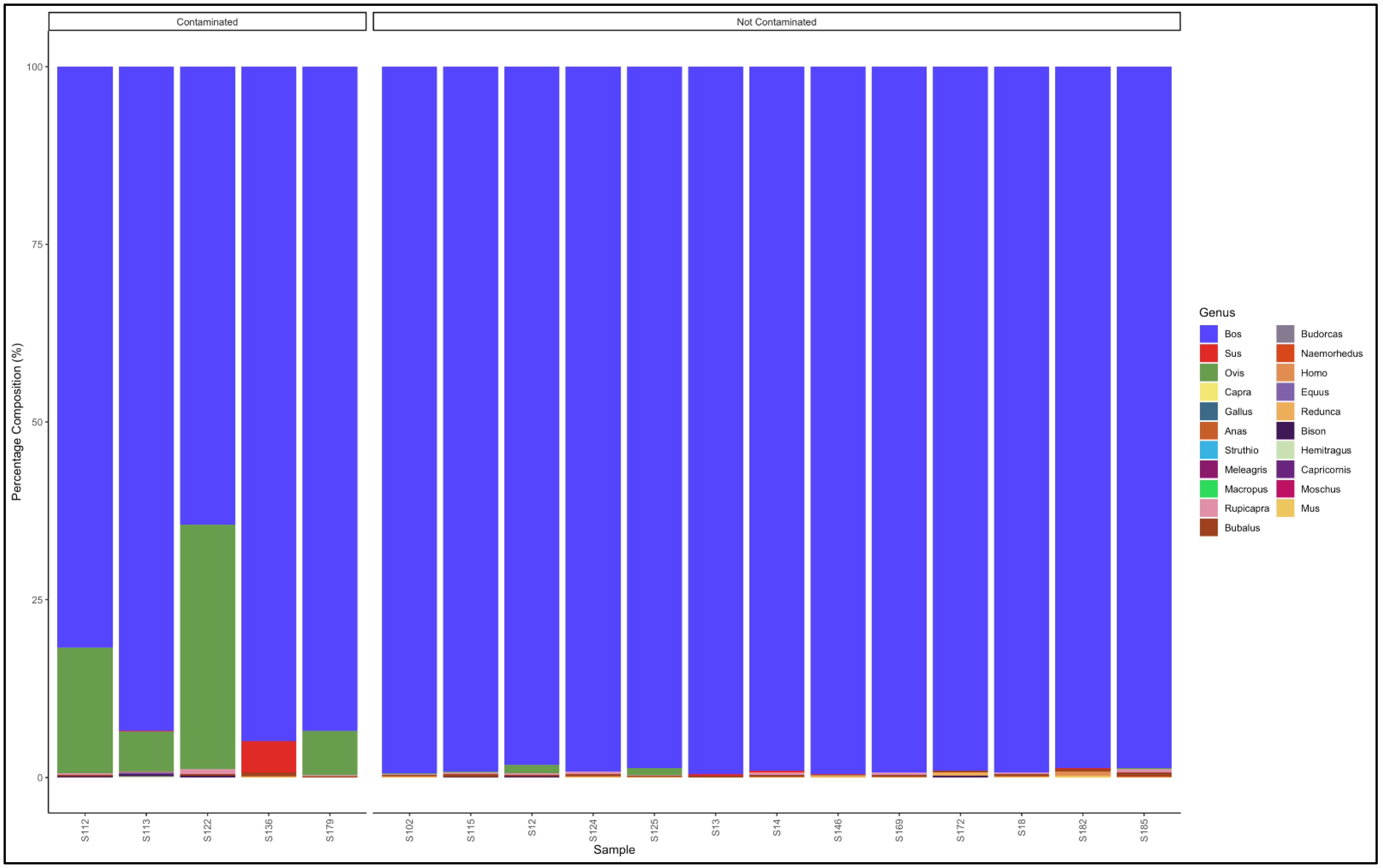
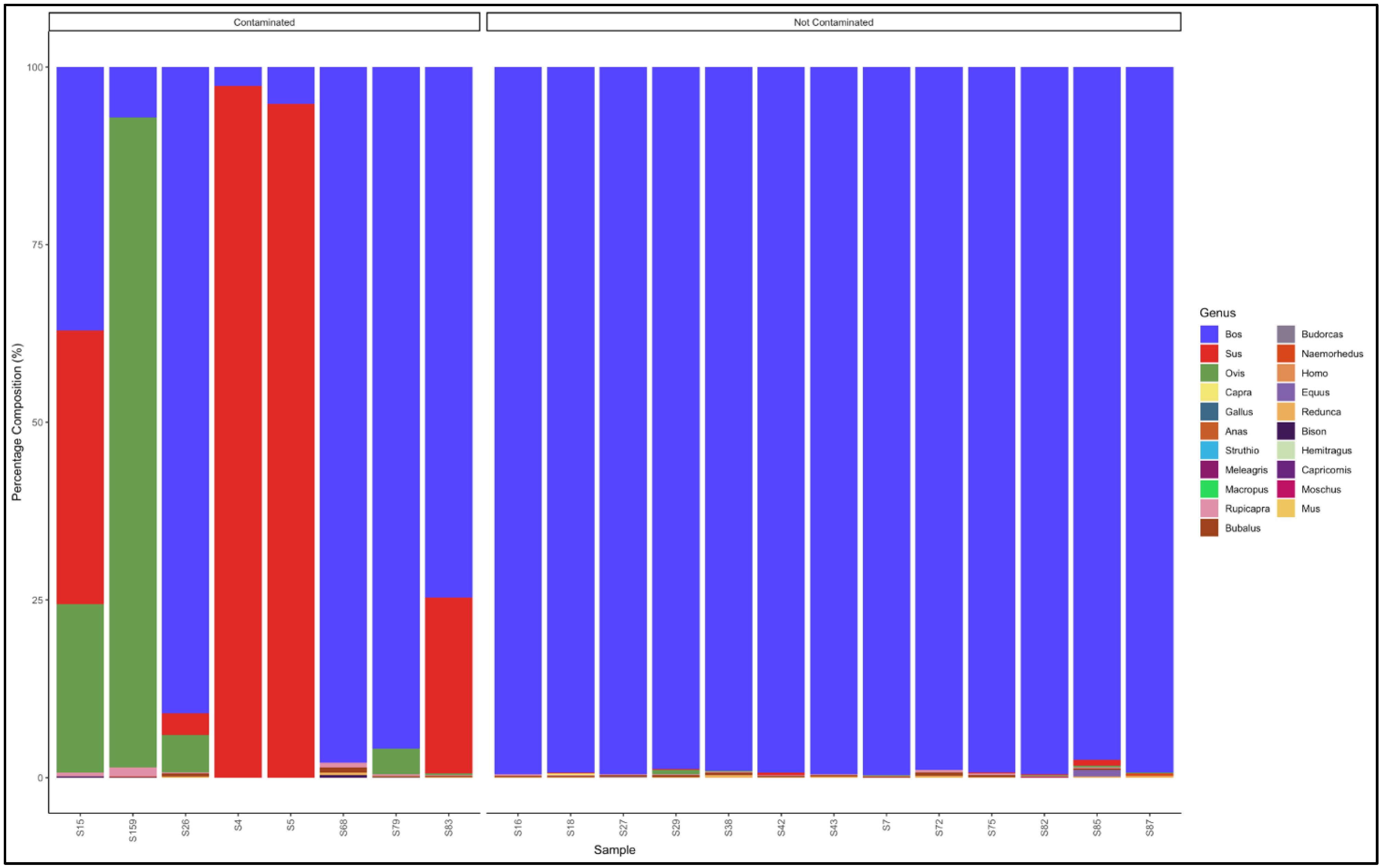
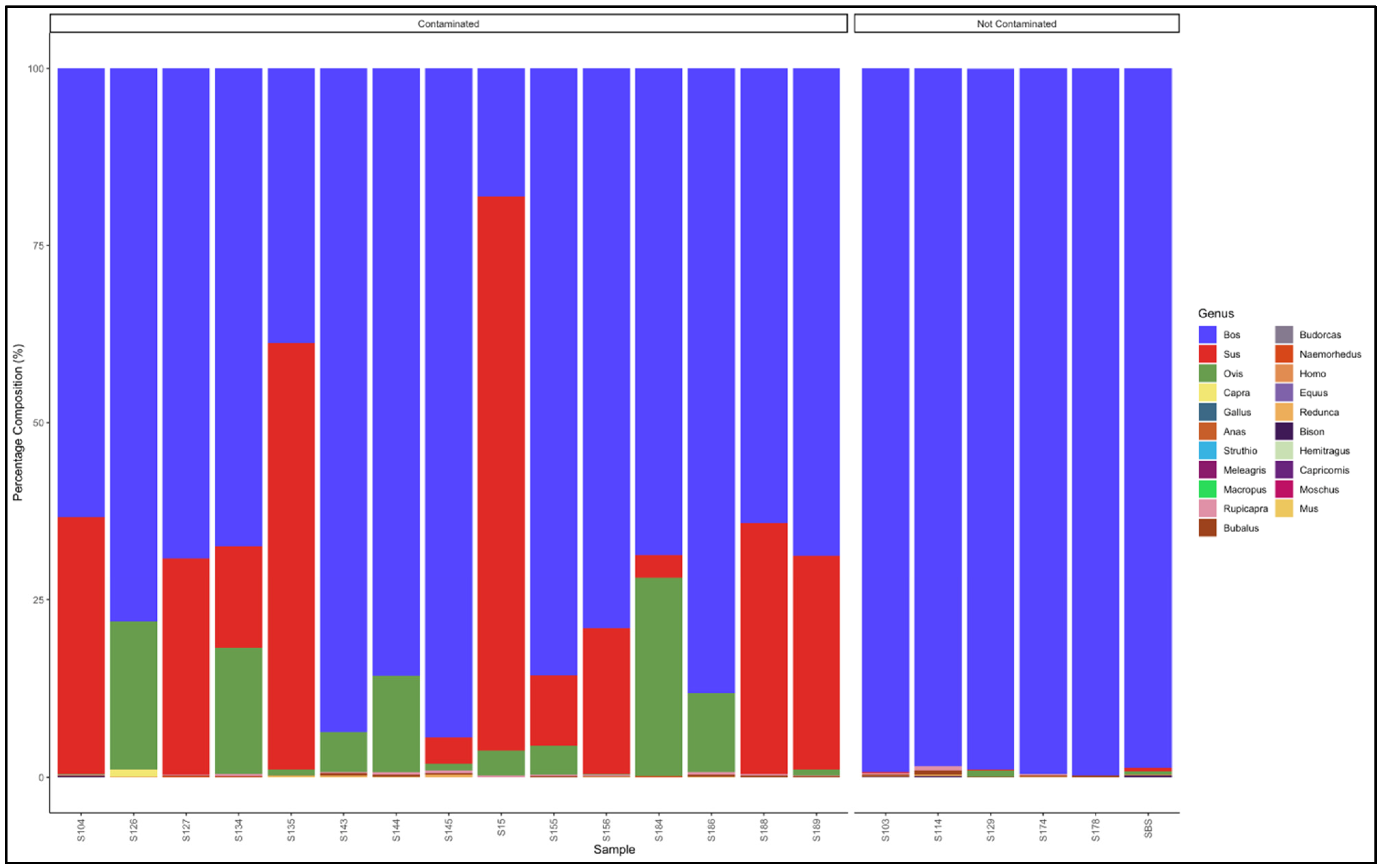
3.5.1. Biltong
3.5.2. Mince
3.5.3. Patties
3.5.4. Sausages
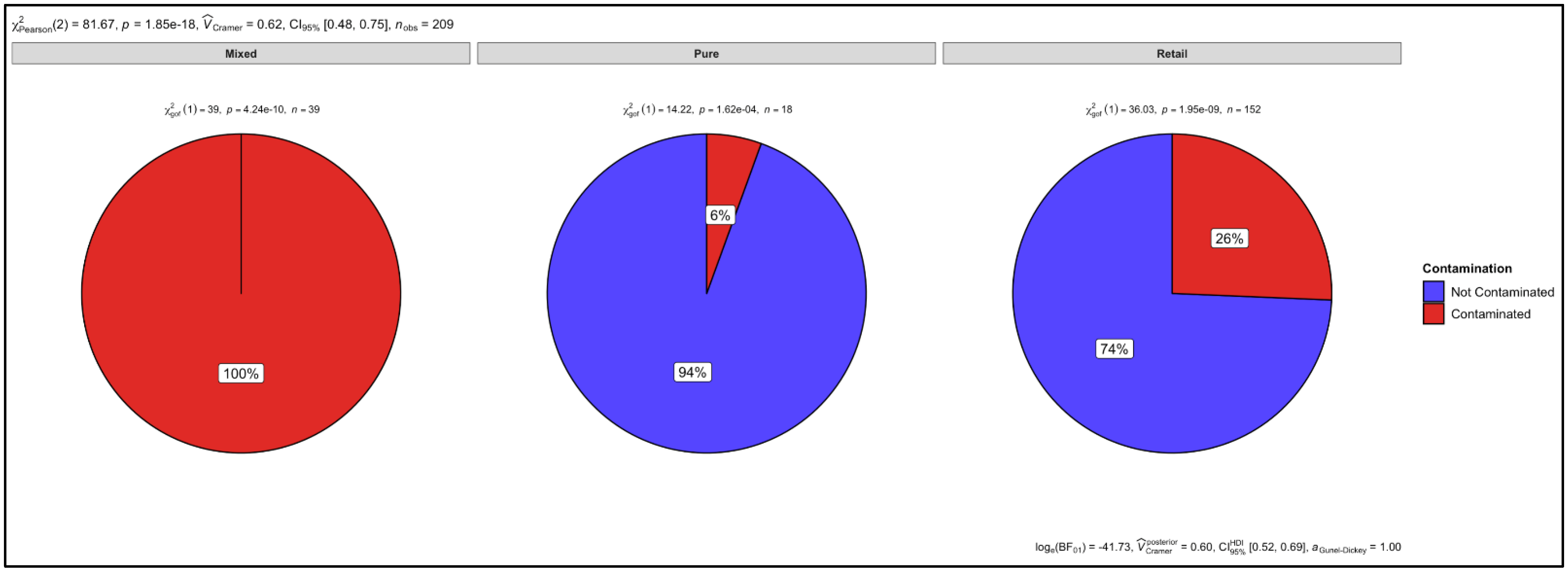
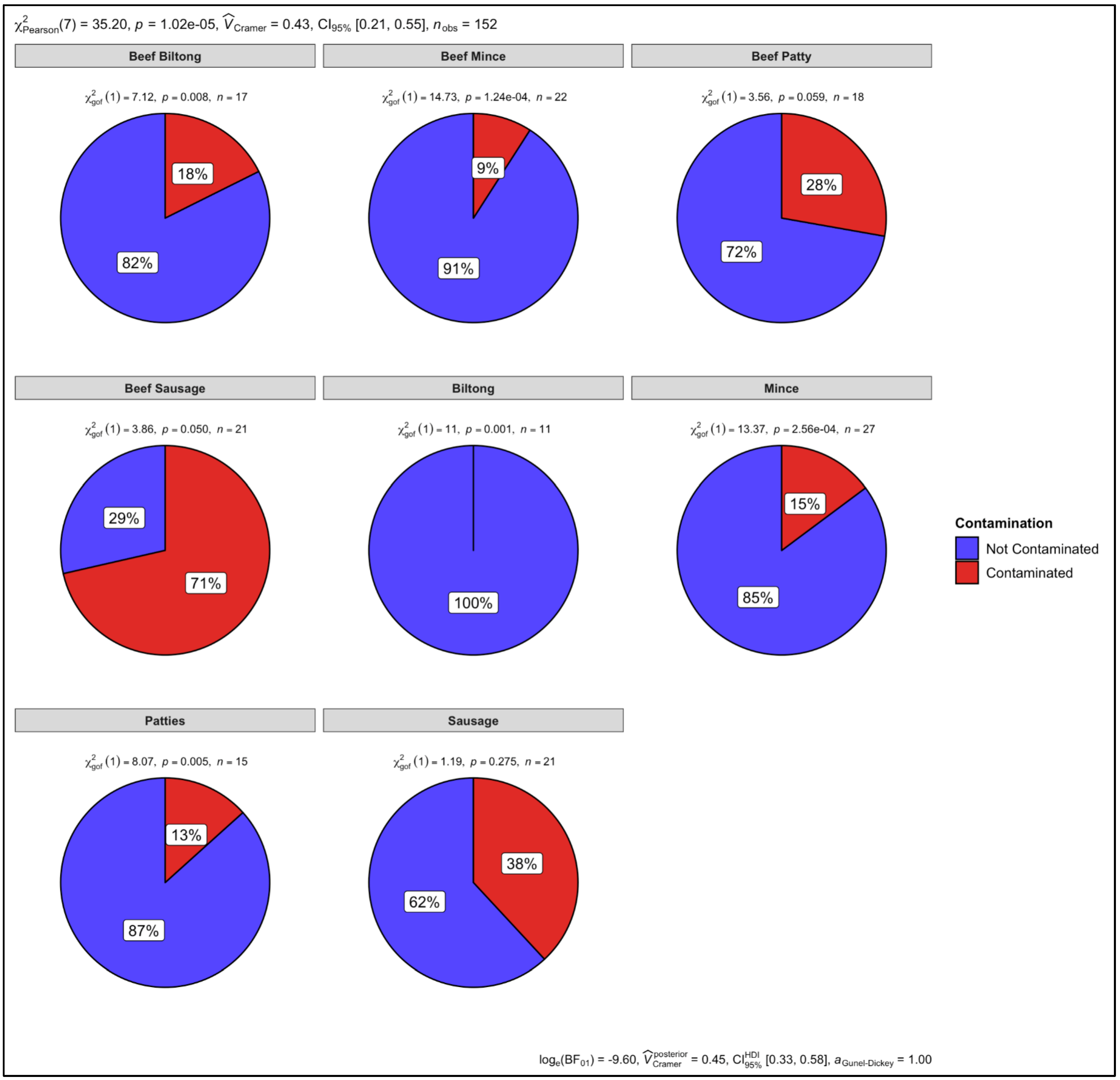
3.6. Proportion Test of Two Categories (Contaminated vs. Not Contaminated) Using a Chi-Square Test
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Disclaimer
References
- Cawthorn, D.M.; Steinman, H.A.; Hoffman, L.C. A High Incidence of Species Substitution and Mislabelling Detected in Meat Products Sold in South Africa. Food Control 2013, 32, 440–449. [Google Scholar] [CrossRef]
- D’Amato, M.E.; Alechine, E.; Cloete, K.W.; Davison, S.; Corach, D. Where Is the Game? Wild Meat Products Authentication in South Africa: A Case Study. Investig. Genet. 2013, 4, 6. [Google Scholar] [CrossRef]
- Walker, M.J.; Burns, M.; Burns, D.T. Horse Meat in Beef Products-Species Substitution 2013. J. Assoc. Public Anal. 2013, 41, 67–106. [Google Scholar]
- Cho, A.-R.; Dong, H.-J.; Cho, S. Meat Species Identification Using Loop-Mediated Isothermal Amplification Assay Targeting Species-Specific Mitochondrial DNA. Korean J. Food Sci. Anim. Resour. 2014, 34, 799. [Google Scholar] [CrossRef] [PubMed]
- Song, Q.; Chen, Y.; Zhao, L.; Ouyang, H.; Song, J. Monitoring of Sausage Products Sold in Sichuan Province, China: A First Comprehensive Report on Meat Species’ Authenticity Determination. Sci. Rep. 2019, 9, 19074. [Google Scholar] [CrossRef]
- Flores-Munguia, M.E.; Bermudez-Almada, M.C.; Vázquez-Moreno, L. A Research Note: Detection of Adulteration in Processed Traditional Meat Products. J. Muscle Foods 2000, 11, 319–325. [Google Scholar] [CrossRef]
- Doosti, A.; Ghasemi Dehkordi, P.; Rahimi, E. Molecular Assay to Fraud Identification of Meat Products. J. Food Sci. Technol. 2014, 51, 148–152. [Google Scholar] [CrossRef] [PubMed]
- Murugaiah, C.; Noor, Z.M.; Mastakim, M.; Bilung, L.M.; Selamat, J.; Radu, S. Meat Species Identification and Halal Authentication Analysis Using Mitochondrial DNA. Meat Sci. 2009, 83, 57–61. [Google Scholar] [CrossRef] [PubMed]
- Bottero, M.T.; Dalmasso, A. Animal Species Identification in Food Products: Evolution of Biomolecular Methods. Vet. J. 2011, 190, 34–38. [Google Scholar] [CrossRef] [PubMed]
- Department of Health (DoH). Foodstuffs, Cosmetics and Disinfectants Act, 1972 (Act 54 of 1972). The Regula Nons Relating to the Labelung and Advertising of Foodstuffs, R.146 of 1 March 2010: Amendment; Government Printing Offices: Pretoria, South Africa, 2012. [Google Scholar]
- Department of Trade and Industry (DTI). Consumer Protection Act (Act No. 68 of 2008) (R. 467/2009); Government Printing Office: Pretoria, South Africa, 2009. [Google Scholar]
- The Commission of the European Communities. Commission Directive 2003/126/EC of 23 December 2003 on the Analytical Method for the Determination of Constituents of Animal Origin for the Official Control of Feedingstuffs. Off. J. Eur. Union 2003, 2003, 78–84. [Google Scholar]
- Koh, B.-R.-D.; Kim, J.-Y.; Na, H.-M.; Park, S.-D.; Kim, Y.-H. Development of Species-Specific Multiplex PCR Assays of Mitochondrial 12S RRNA and 16S RRNA for the Identification of Animal Species. Korean J. Vet. Serv. 2011, 34, 417–428. [Google Scholar] [CrossRef][Green Version]
- Alikord, M.; Momtaz, H.; Kadivar, M.; Rad, A.H. Species Identification and Animal Authentication in Meat Products: A Review. J. Food Meas. Charact. 2018, 12, 145–155. [Google Scholar] [CrossRef]
- Xing, R.-R.; Wang, N.; Hu, R.-R.; Zhang, J.-K.; Han, J.-X.; Chen, Y. Application of next Generation Sequencing for Species Identification in Meat and Poultry Products: A DNA Metabarcoding Approach. Food Control 2019, 101, 173–179. [Google Scholar] [CrossRef]
- Kesmen, Z.; Yetiman, A.E.; Şahin, F.; Yetim, H. Detection of Chicken and Turkey Meat in Meat Mixtures by Using Real-Time PCR Assays. J. Food Sci. 2012, 77, C167–C173. [Google Scholar] [CrossRef] [PubMed]
- Tillmar, A.O.; Dell’Amico, B.; Welander, J.; Holmlund, G. A Universal Method for Species Identification of Mammals Utilizing next Generation Sequencing for the Analysis of DNA Mixtures. PLoS ONE 2013, 8, e83761. [Google Scholar] [CrossRef]
- Dai, Z.; Qiao, J.; Yang, S.; Hu, S.; Zuo, J.; Zhu, W.; Huang, C. Species Authentication of Common Meat Based on PCR Analysis of the Mitochondrial COI Gene. Appl. Biochem. Biotechnol. 2015, 176, 1770–1780. [Google Scholar] [CrossRef]
- Kumar, A.; Kumar, R.R.; Sharma, B.D.; Gokulakrishnan, P.; Mendiratta, S.K.; Sharma, D. Identification of Species Origin of Meat and Meat Products on the DNA Basis: A Review. Crit. Rev. Food Sci. Nutr. 2015, 55, 1340–1351. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.-Y.; Liu, Y.-P.; Yao, Y.-G. Species Authentication of Commercial Beef Jerky Based on PCR-RFLP Analysis of the Mitochondrial 12S RRNA Gene. J. Genet. Genom. 2010, 37, 763–769. [Google Scholar] [CrossRef]
- Di Pinto, A.; Bottaro, M.; Bonerba, E.; Bozzo, G.; Ceci, E.; Marchetti, P.; Mottola, A.; Tantillo, G. Occurrence of Mislabeling in Meat Products Using DNA-Based Assay. J. Food Sci. Technol. 2015, 52, 2479–2484. [Google Scholar] [CrossRef] [PubMed]
- Ballin, N.Z. Authentication of Meat and Meat Products. Meat Sci. 2010, 86, 577–587. [Google Scholar] [CrossRef] [PubMed]
- Dalmasso, A.; Fontanella, E.; Piatti, P.; Civera, T.; Rosati, S.; Bottero, M.T. A Multiplex PCR Assay for the Identification of Animal Species in Feedstuffs. Mol. Cell. Probes 2004, 18, 81–87. [Google Scholar] [CrossRef] [PubMed]
- Kane, D.E.; Hellberg, R.S. Identification of Species in Ground Meat Products Sold on the US Commercial Market Using DNA-Based Methods. Food Control 2016, 59, 158–163. [Google Scholar] [CrossRef]
- Drummond, L.; Álvarez, C.; Mullen, A.M. Proteins Recovery From Meat Processing Coproducts. Sustain. Meat Prod. Process. 2019, 69–83. [Google Scholar] [CrossRef]
- Horreo, J.L.; Ardura, A.; Pola, I.G.; Martinez, J.L.; Garcia-Vazquez, E. Universal Primers for Species Authentication of Animal Foodstuff in a Single Polymerase Chain Reaction. J. Sci. Food Agric. 2013, 93, 354–361. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Wu, T.; Liu, Y.; Zou, J.; Huang, Y.; Babu, S.V.; Lin, L. Rapid Identification of Pork Adulterated in the Beef and Mutton by Infrared Spectroscopy. J. Spectrosc. 2018, 2018, 2413874. [Google Scholar] [CrossRef]
- Wadapurkar, R.M.; Vyas, R. Computational Analysis of next Generation Sequencing Data and Its Applications in Clinical Oncology. Inform. Med. Unlocked 2018, 11, 75–82. [Google Scholar] [CrossRef]
- Tembe, D.; Mukaratirwa, S.; Zishiri, O.T. Undeclared Meat Species in Processed Meat Products from Retail Franchises in the Durban Metropole, KwaZulu-Natal Province, South Africa, Using Species-Specific DNA Primers. Food Prot. Trends 2018, 38, 440–449. [Google Scholar]
- O’Leary, N.A.; Wright, M.W.; Brister, J.R.; Ciufo, S.; Haddad, D.; McVeigh, R.; Rajput, B.; Robbertse, B.; Smith-White, B.; Ako-Adjei, D. Reference Sequence (RefSeq) Database at NCBI: Current Status, Taxonomic Expansion, and Functional Annotation. Nucleic Acids Res. 2016, 44, D733–D745. [Google Scholar] [CrossRef]
- Bushnell, B. BBMap: A Fast, Accurate, Splice-Aware Aligner; Lawrence Berkeley National Lab (LBNL): Berkeley, CA, USA, 2014. [Google Scholar]
- Zhang, Y.; Qu, Q.; Rao, M.; Zhang, N.; Zhao, Y.; Tao, F. Simultaneous Identification of Animal-Derived Components in Meats Using High-Throughput Sequencing in Combination with a Custom-Built Mitochondrial Genome Database. Sci. Rep. 2020, 10, 8965. [Google Scholar] [CrossRef] [PubMed]
- Martuscelli, M.; Serio, A.; Capezio, O.; Mastrocola, D. Safety, Quality and Analytical Authentication of Ḥalāl Meat Products, with Particular Emphasis on Salami: A Review. Foods 2020, 9, 1111. [Google Scholar] [CrossRef]
- Sun, W.; Chang, H.; Ren, Z.J.; Yang, Z.P.; Geng, R.Q.; Lu, S.X.; Du, L.; Tsunoda, K. Genetic Differentiation between Sheep and Goats Based on Microsatellite DNA. Asian Australas. J. Anim. Sci. 2004, 17, 583–587. [Google Scholar] [CrossRef]
- Nanda, I.; Schlegelmilch, K.; Haaf, T.; Schartl, M.; Schmid, M. Synteny Conservation of the Z Chromosome in 14 Avian Species (11 Families) Supports a Role for Z Dosage in Avian Sex Determination. Cytogenet. Genome Res. 2008, 122, 150–156. [Google Scholar] [CrossRef] [PubMed]
- Gibbs, R.; Weinstock, G.; Kappes, S.; Schook, L.; Skow, L.; Womack, J. Bovine Genomic Sequencing Initiative. 2002. Available online: https://www.genome.gov/Pages/Research/Sequencing/SeqProposals/BovineSEQ.pdf (accessed on 7 June 2021).
- Zimin, A.V.; Delcher, A.L.; Florea, L.; Kelley, D.R.; Schatz, M.C.; Puiu, D.; Hanrahan, F.; Pertea, G.; Van Tassell, C.P.; Sonstegard, T.S. A Whole-Genome Assembly of the Domestic Cow, Bos Taurus. Genome Biol. 2009, 10, R42. [Google Scholar] [CrossRef]
- Elsik, C.G.; Tellam, R.L.; Worley, K.C. The Genome Sequence of Taurine Cattle: A Window to Ruminant Biology and Evolution. Science 2009, 324, 522–528. [Google Scholar] [PubMed]
- Liao, X.; Peng, F.; Forni, S.; McLaren, D.; Plastow, G.; Stothard, P. Whole Genome Sequencing of Gir Cattle for Identifying Polymorphisms and Loci under Selection. Genome 2013, 56, 592–598. [Google Scholar] [CrossRef] [PubMed]
- Weldenegodguad, M.; Popov, R.; Pokharel, K.; Ammosov, I.; Ming, Y.; Ivanova, Z.; Kantanen, J. Whole-Genome Sequencing of Three Native Cattle Breeds Originating from the Northernmost Cattle Farming Regions. Front. Genet. 2019, 9, 728. [Google Scholar] [CrossRef]
- Rosen, B.D.; Bickhart, D.M.; Schnabel, R.D.; Koren, S.; Elsik, C.G.; Tseng, E.; Rowan, T.N.; Low, W.Y.; Zimin, A.; Couldrey, C. De Novo Assembly of the Cattle Reference Genome with Single-Molecule Sequencing. Gigascience 2020, 9, giaa021. [Google Scholar] [CrossRef]
- Renfree, M.B.; Papenfuss, A.T.; Deakin, J.E.; Lindsay, J.; Heider, T.; Belov, K.; Rens, W.; Waters, P.D.; Pharo, E.A.; Shaw, G. Genome Sequence of an Australian Kangaroo, Macropus Eugenii, Provides Insight into the Evolution of Mammalian Reproduction and Development. Genome Biol. 2011, 12, R81. [Google Scholar] [CrossRef] [PubMed]
- Murchison, E.P.; Adams, D.J. Sequencing Skippy: The Genome Sequence of an Australian Kangaroo, Macropus Eugenii. Genome Biol. 2011, 12, 123. [Google Scholar] [CrossRef] [PubMed]
- Wakefield, M.J.; Graves, J.A.M. The Kangaroo Genome: Leaps and Bounds in Comparative Genomics. EMBO Rep. 2003, 4, 143–147. [Google Scholar] [CrossRef]
- Deakin, J.E. Genome Sequence of an Australian Kangaroo, Macropus Eugenii. eLS 2013, 12, r81. [Google Scholar] [CrossRef]
- Nilsson, M.A.; Zheng, Y.; Kumar, V.; Phillips, M.J.; Janke, A. Speciation Generates Mosaic Genomes in Kangaroos. Genome Biol. Evol. 2018, 10, 33–44. [Google Scholar] [CrossRef] [PubMed]
- Itoh, A.; Ohkubo, T.; Nanami, S.; Tan, S.; Yamakura, T. Comparison of Statistical Tests for Habitat Associations in Tropical Forests: A Case Study of Sympatric Dipterocarp Trees in a Bornean Forest. For. Ecol. Manag. 2010, 259, 323–332. [Google Scholar] [CrossRef]
- Yang, L.; Tan, Z.; Wang, D.; Xue, L.; Guan, M.X.; Huang, T.; Li, R. Species Identification through Mitochondrial RRNA Genetic Analysis. Sci. Rep. 2014, 4, 4089. [Google Scholar] [CrossRef]
- Bottaro, M.; Marchetti, P.; Mottola, A.; Shehu, F.; Di Pinto, A. Detection of Mislabeling in Packaged Chicken Sausages by PCR. Albanian J. Agric. Sci. 2014, 455. [Google Scholar]
- Fajardo, V.; González, I.; Martín, I.; Hernández, P.E.; Garcı, T.; Martín, R. Differentiation of European Wild Boar (Sus Scrofa Scrofa) and Domestic Swine (Sus Scrofa Domestica) Meats by PCR Analysis Targeting the Mitochondrial D-Loop and the Nuclear Melanocortin Receptor 1 (MC1R) Genes. Meat Sci. 2008, 78, 314–322. [Google Scholar] [CrossRef]
- Maralit, B.A.; Aguila, R.D.; Ventolero, M.F.H.; Perez, S.K.L.; Willette, D.A.; Santos, M.D. Detection of Mislabeled Commercial Fishery By-Products in the Philippines Using DNA Barcodes and Its Implications to Food Traceability and Safety. Food Control 2013, 33, 119–125. [Google Scholar] [CrossRef]
- Ayuso, R.; Lehrer, S.B.; Tanaka, L.; Ibanez, M.D.; Pascual, C.; Burks, A.W.; Sussman, G.L.; Goldberg, B.; Lopez, M.; Reese, G. IgE Antibody Response to Vertebrate Meat Proteins Including Tropomyosin. Ann. Allergy Asthma Immunol. 1999, 83, 399–405. [Google Scholar] [CrossRef]
- Surowiec, I.; Fraser, P.D.; Patel, R.; Halket, J.; Bramley, P.M. Metabolomic Approach for the Detection of Mechanically Recovered Meat in Food Products. Food Chem. 2011, 125, 1468–1475. [Google Scholar] [CrossRef]
- DAFF. A Profile of the South African Beef Market Value Chain; DAFF: Pretoria, South Africa, 2018. [Google Scholar]
- DAFF. The Profile of the South African Mutton Value Chain; DAFF: Pretoria, South Africa, 2017. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mixture Ratio | Species 1: Species 2 |
|---|---|
| 1:1 | pork ‖ beef, mutton ‖ chevon, chicken ‖ turkey, ostrich ‖ duck and beef ‖ kangaroo |
| 9:1 | pork ‖ beef, pork ‖ beef, mutton ‖ chevon, chevon ‖ mutton, chicken ‖ duck, duck ‖ chicken, ostrich ‖ duck and duck ‖ ostrich |
| 16S Forward | 5′tcgtcggcagcgtcagatgtgtataagagacagGACGAGAAGACCCTATTGGAGC 3′ |
| 16S Reverse | 5′gtctcgtgggctcggagatgtgtataagagacagTCCGAGGTCRCCCCAACC 3′ |
| Artificially Mixed % Deviation | |||||
|---|---|---|---|---|---|
| Min. | Max. | Median | Mean | Standard Deviation | Variance |
| 1.0 | 24.59 | 9.08 | 13.76 | 6.98 | 48.66 |
| Pure % Deviation | |||||
| Min. | Max. | Median | Mean | Standard Deviation | Variance |
| 0.30 | 3.49 | 1.184 | 1.56 | 0.716 | 0.513 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chaora, N.S.; Khanyile, K.S.; Magwedere, K.; Pierneef, R.; Tabit, F.T.; Muchadeyi, F.C. A 16S Next Generation Sequencing Based Molecular and Bioinformatics Pipeline to Identify Processed Meat Products Contamination and Mislabelling. Animals 2022, 12, 416. https://doi.org/10.3390/ani12040416
Chaora NS, Khanyile KS, Magwedere K, Pierneef R, Tabit FT, Muchadeyi FC. A 16S Next Generation Sequencing Based Molecular and Bioinformatics Pipeline to Identify Processed Meat Products Contamination and Mislabelling. Animals. 2022; 12(4):416. https://doi.org/10.3390/ani12040416
Chicago/Turabian StyleChaora, Nyaradzo Stella, Khulekani Sedwell Khanyile, Kudakwashe Magwedere, Rian Pierneef, Frederick Tawi Tabit, and Farai Catherine Muchadeyi. 2022. "A 16S Next Generation Sequencing Based Molecular and Bioinformatics Pipeline to Identify Processed Meat Products Contamination and Mislabelling" Animals 12, no. 4: 416. https://doi.org/10.3390/ani12040416
APA StyleChaora, N. S., Khanyile, K. S., Magwedere, K., Pierneef, R., Tabit, F. T., & Muchadeyi, F. C. (2022). A 16S Next Generation Sequencing Based Molecular and Bioinformatics Pipeline to Identify Processed Meat Products Contamination and Mislabelling. Animals, 12(4), 416. https://doi.org/10.3390/ani12040416