
Multiomics Profiling Reveals Signatures of Dysmetabolism in Urban Populations in Central India

 , , , , , ,
, , , , , ,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
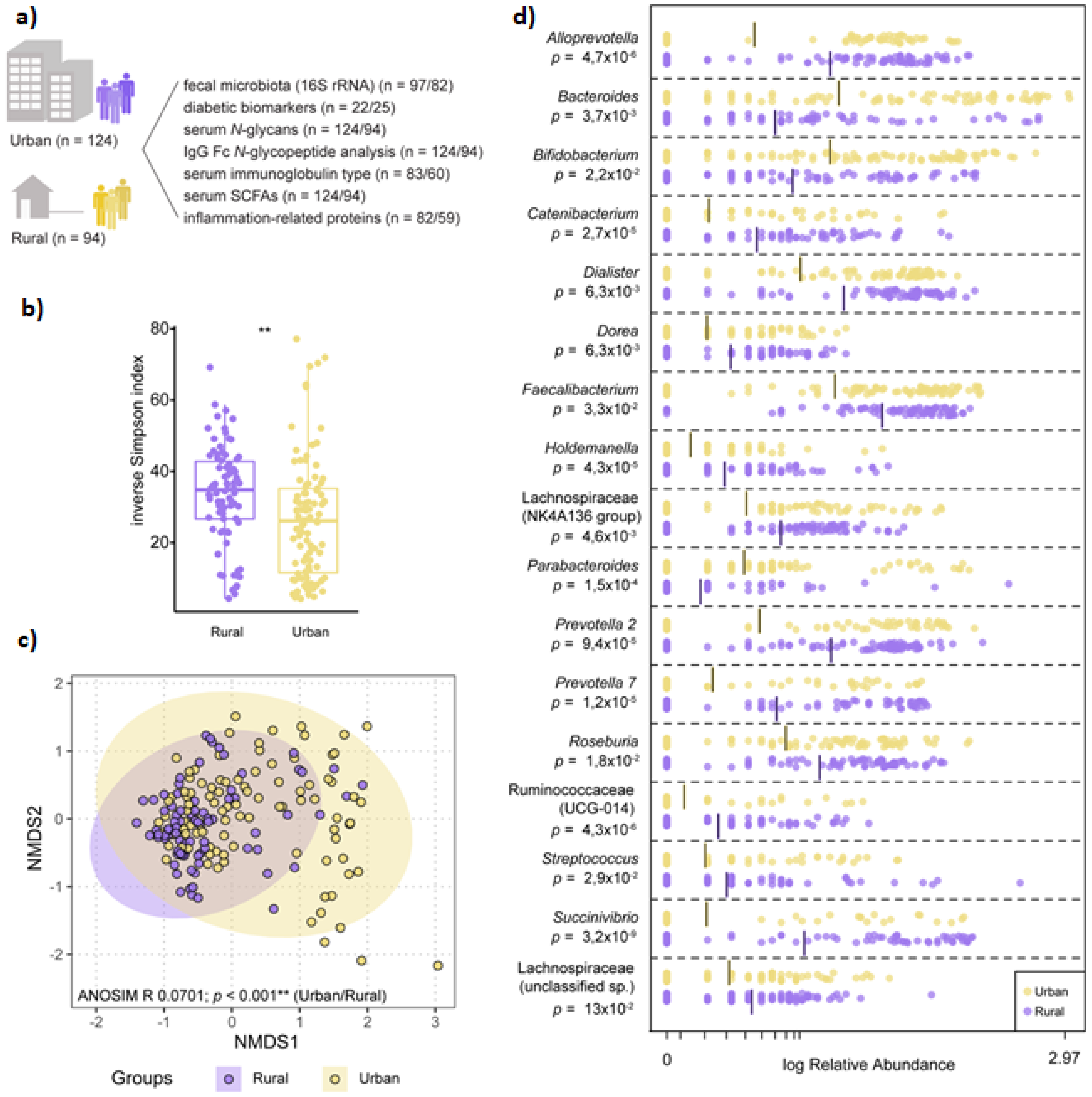
2.1. Participant Recruitment
2.2. Inclusion and Exclusion Criteria
2.3. Ethics Statement
2.4. Sample Preparation
2.5. Gut Bacterial Community Profiling by 16S rRNA Gene Sequencing
2.6. Serum Short Chain Fatty Acid Identification and Quantification
2.7. Serum N-Glycome Profiling
2.7.1. Experimental Design
2.7.2. Serum N-Glycome Analysis
2.7.3. IgG Fc N-Glycopeptides Analysis
2.8. Immune and Diabetic Protein Profiling of Sera
2.9. Statistical Analysis
Elastic Net Machine Learning Method
3. Results
3.1. Characteristics of the Study Participants
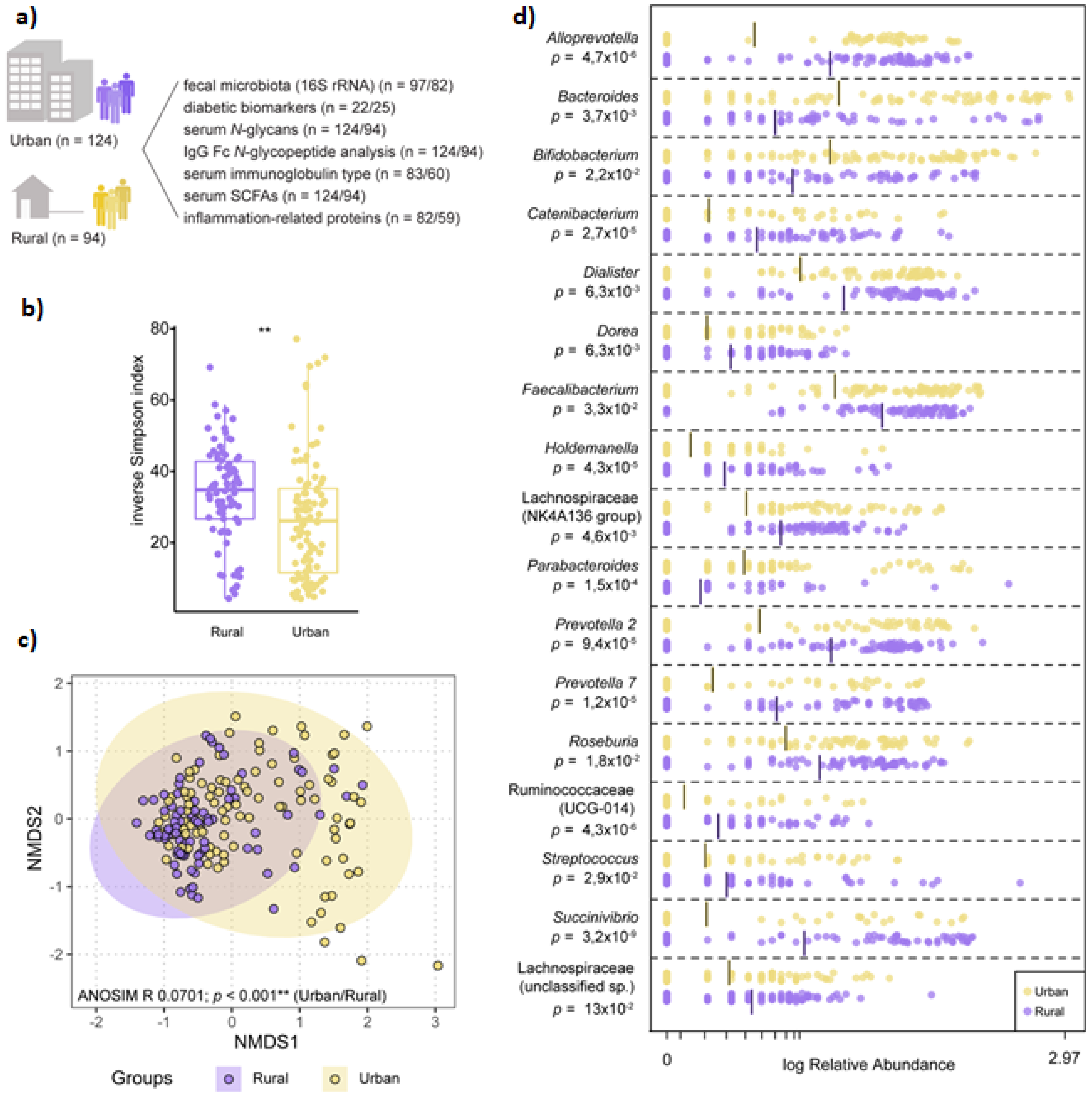
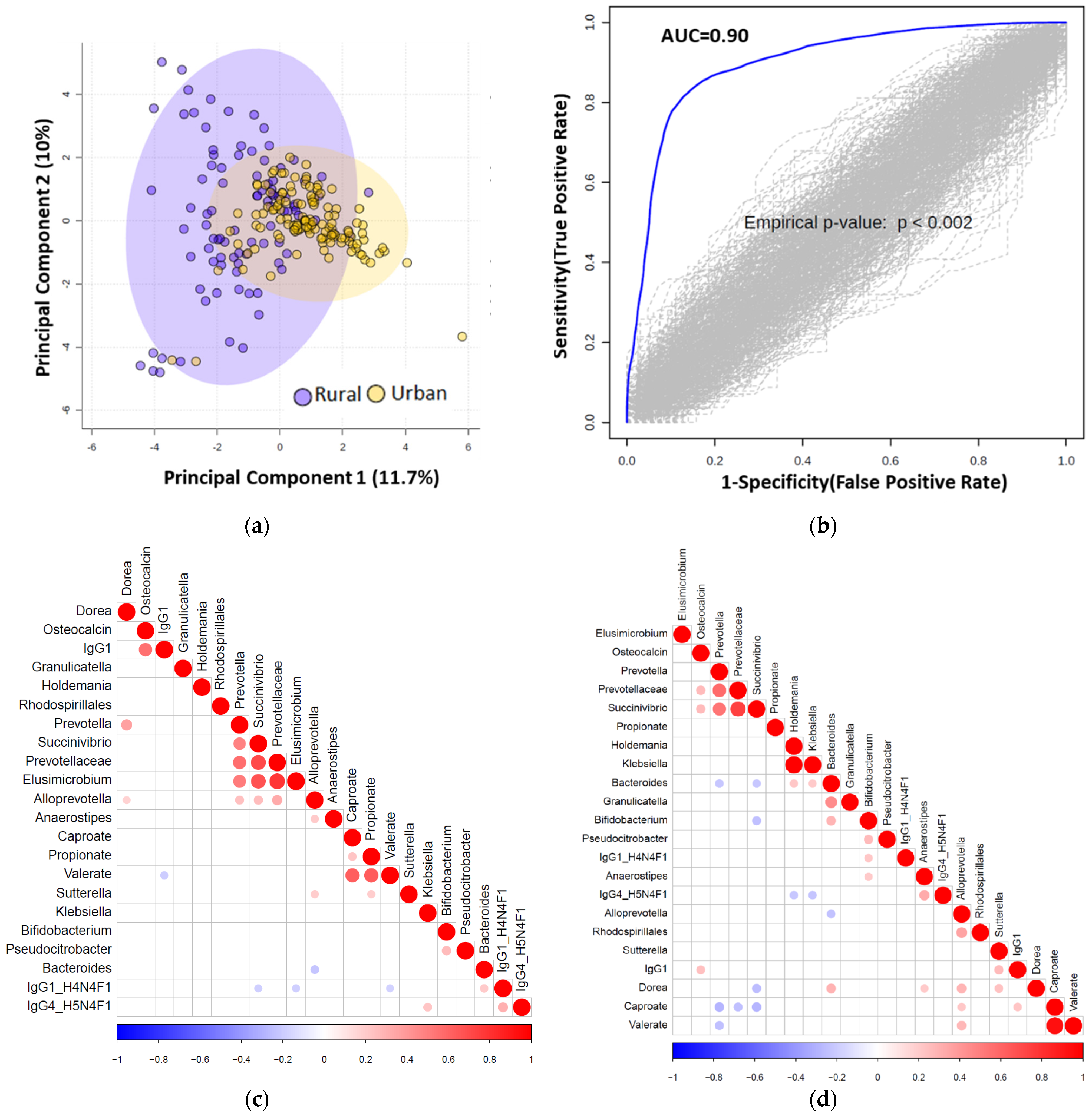
3.2. Microbiota Composition Varies by Geographic-Specific Factors
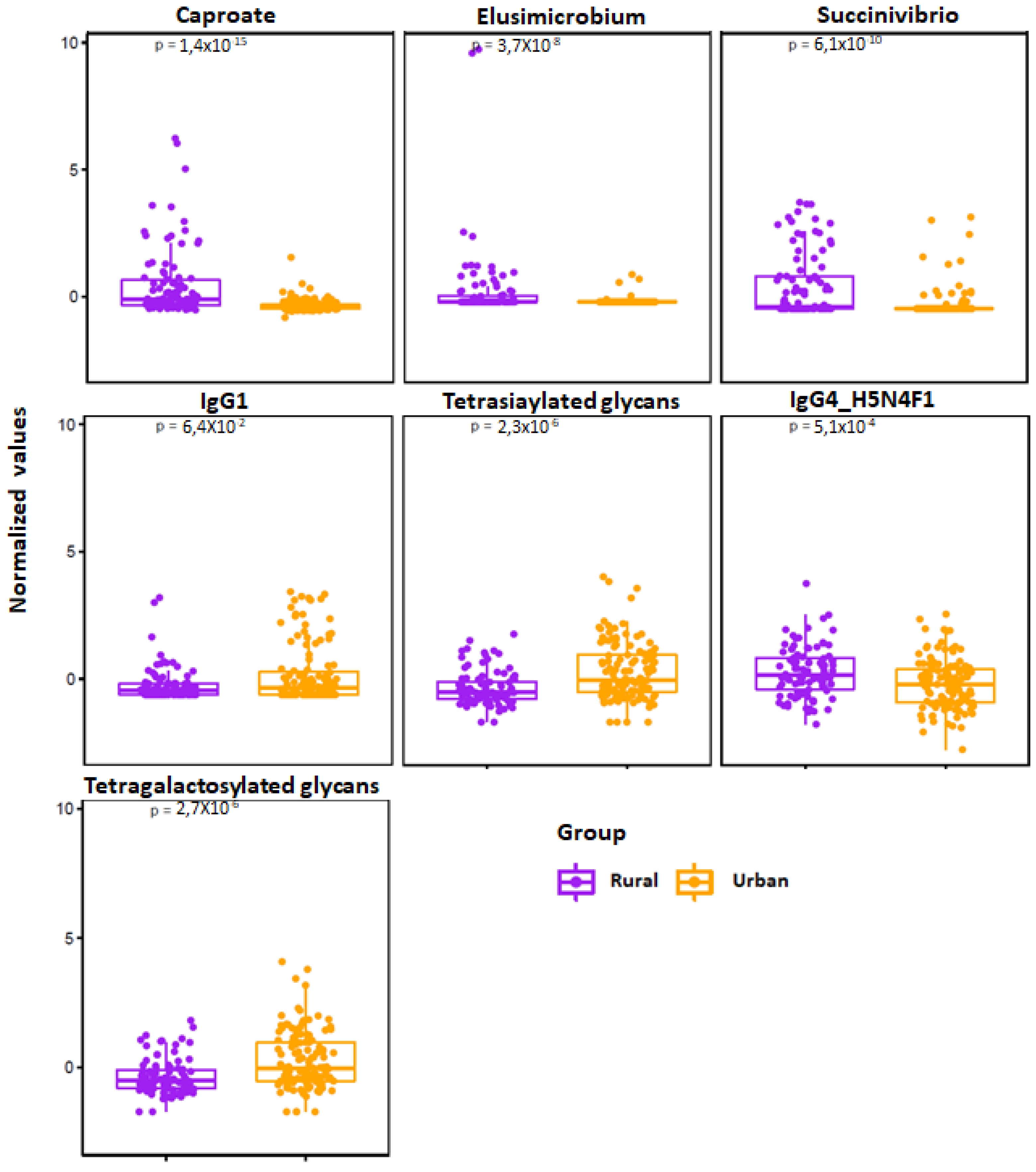
3.3. Dysmetabolic Hallmarks and Urban Living
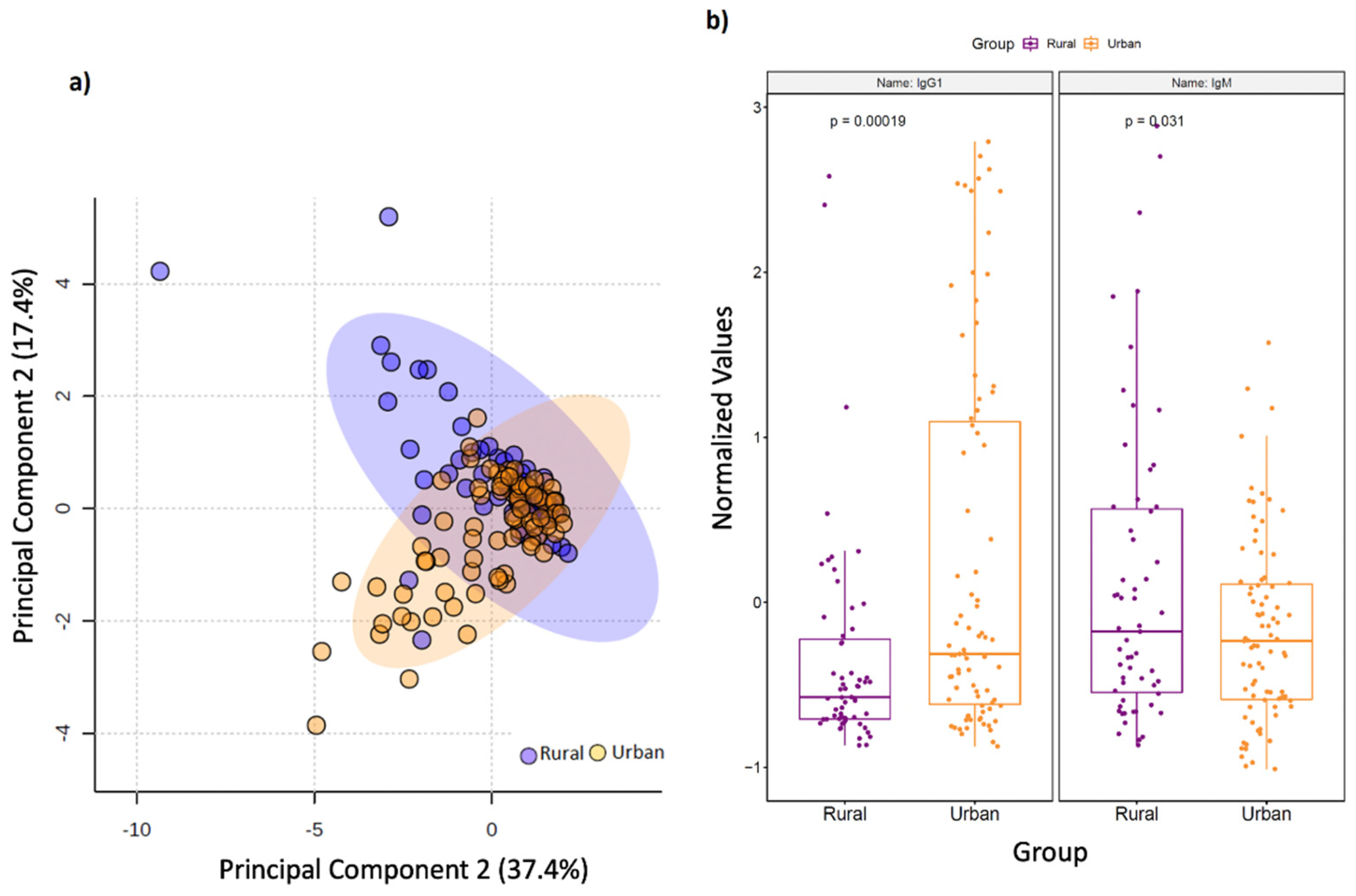
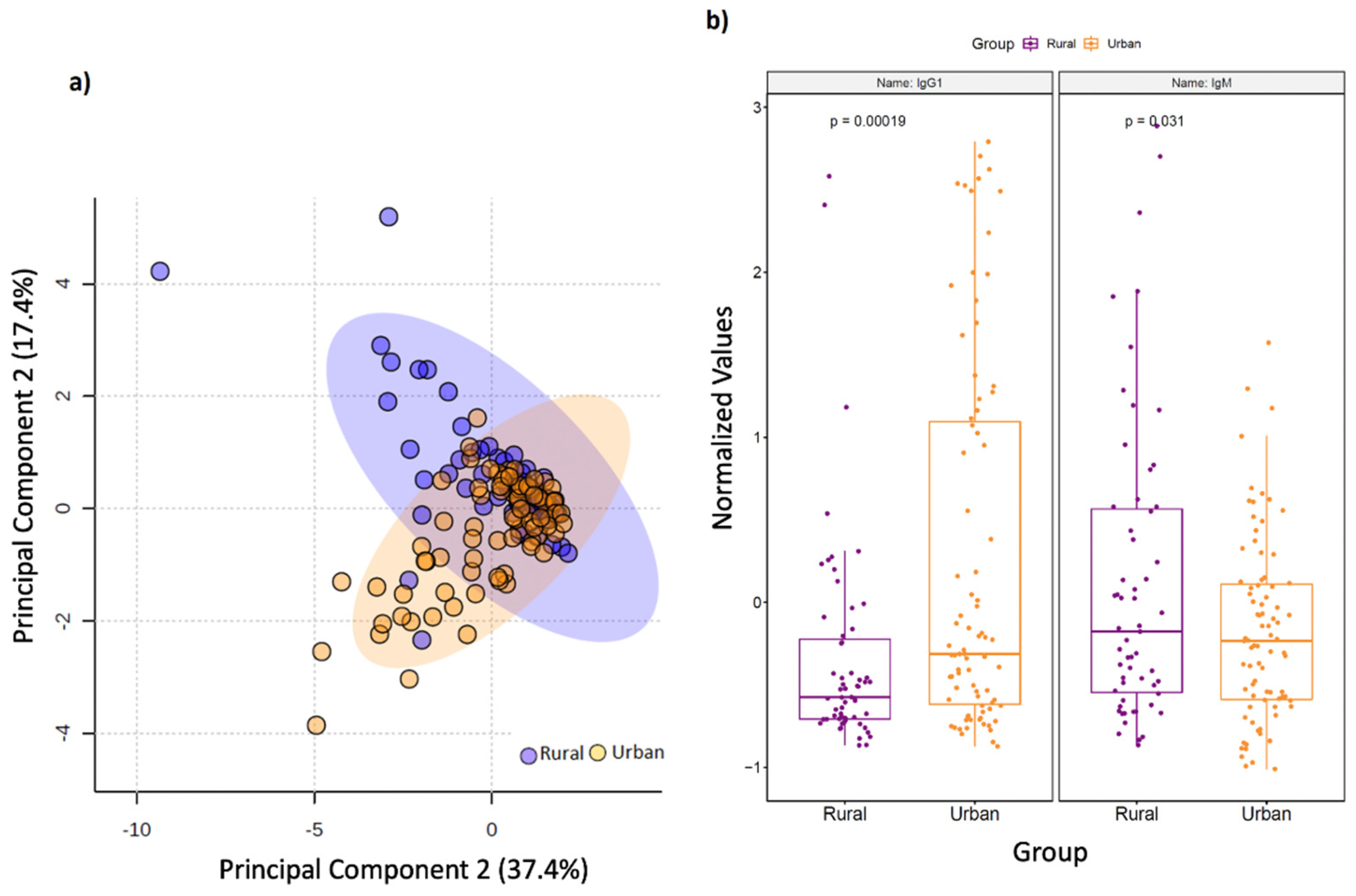
3.4. Rural Living Associates with Contrasting Serum Immunometabolic Features
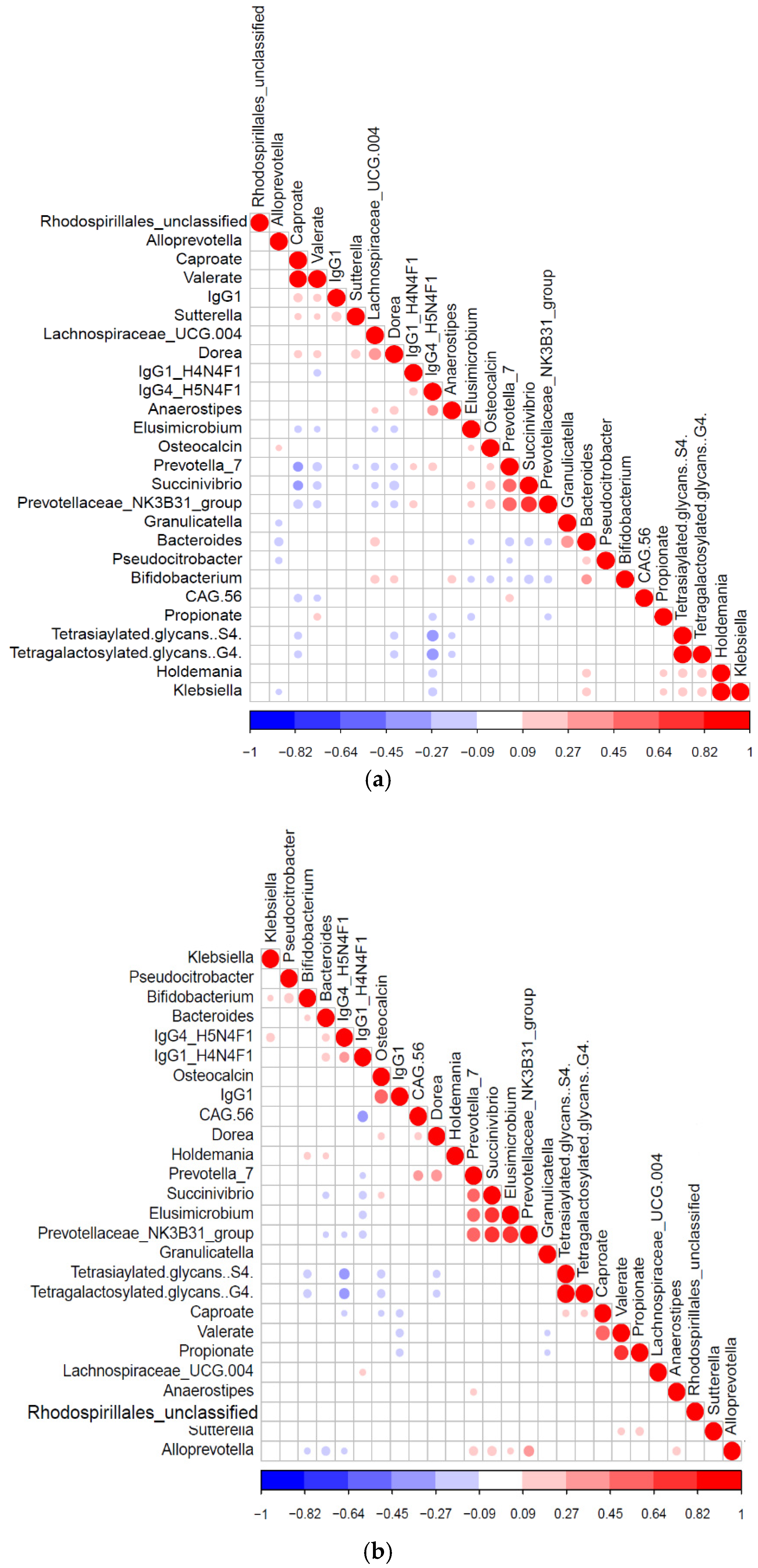
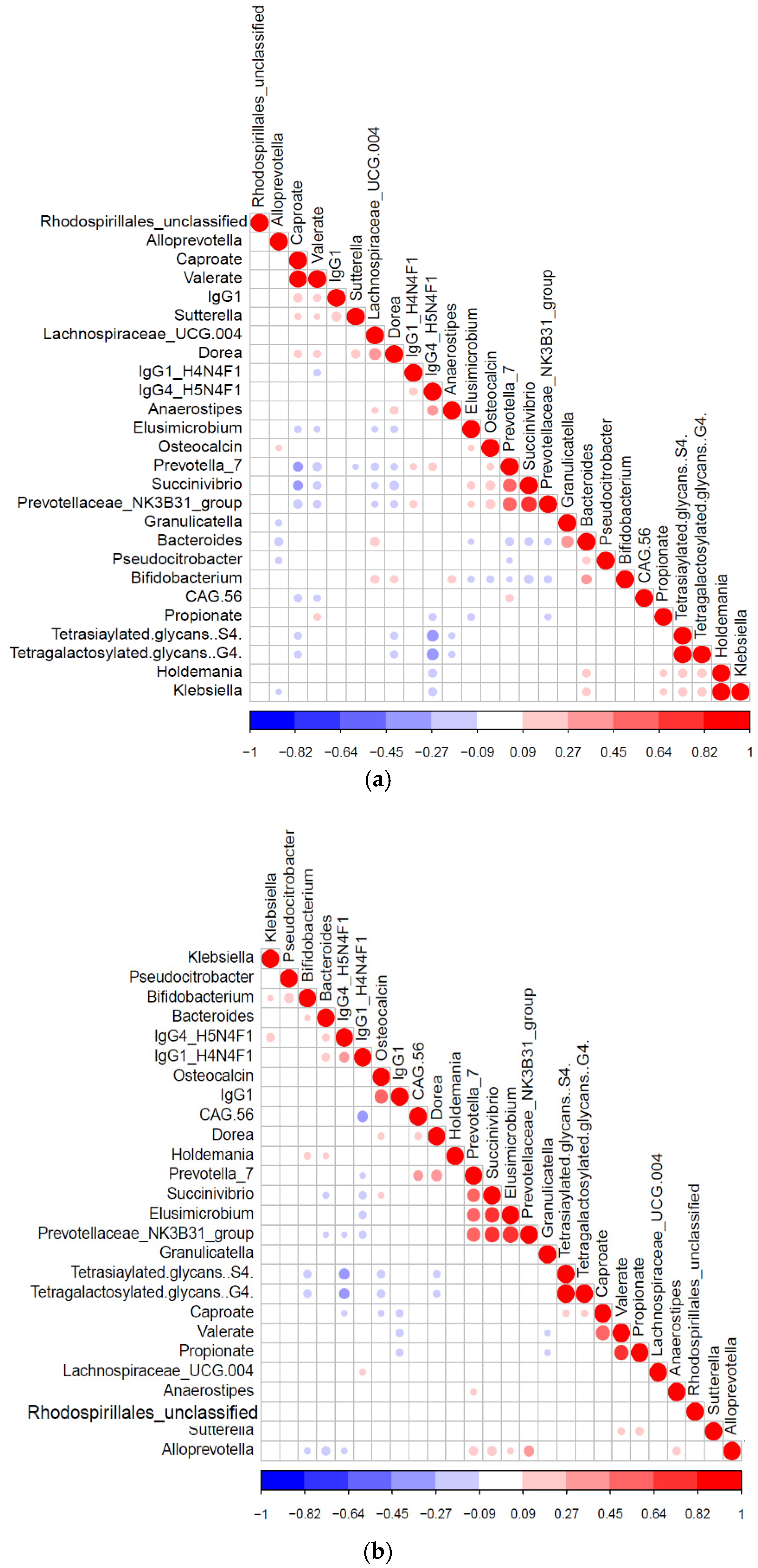
3.5. Diabetic Protein-Microbe Interactions Vary by Geography
3.6. Differential Impact of Glycated Serum Protein Levels on Immunometabolic and Gut Bacterial Features
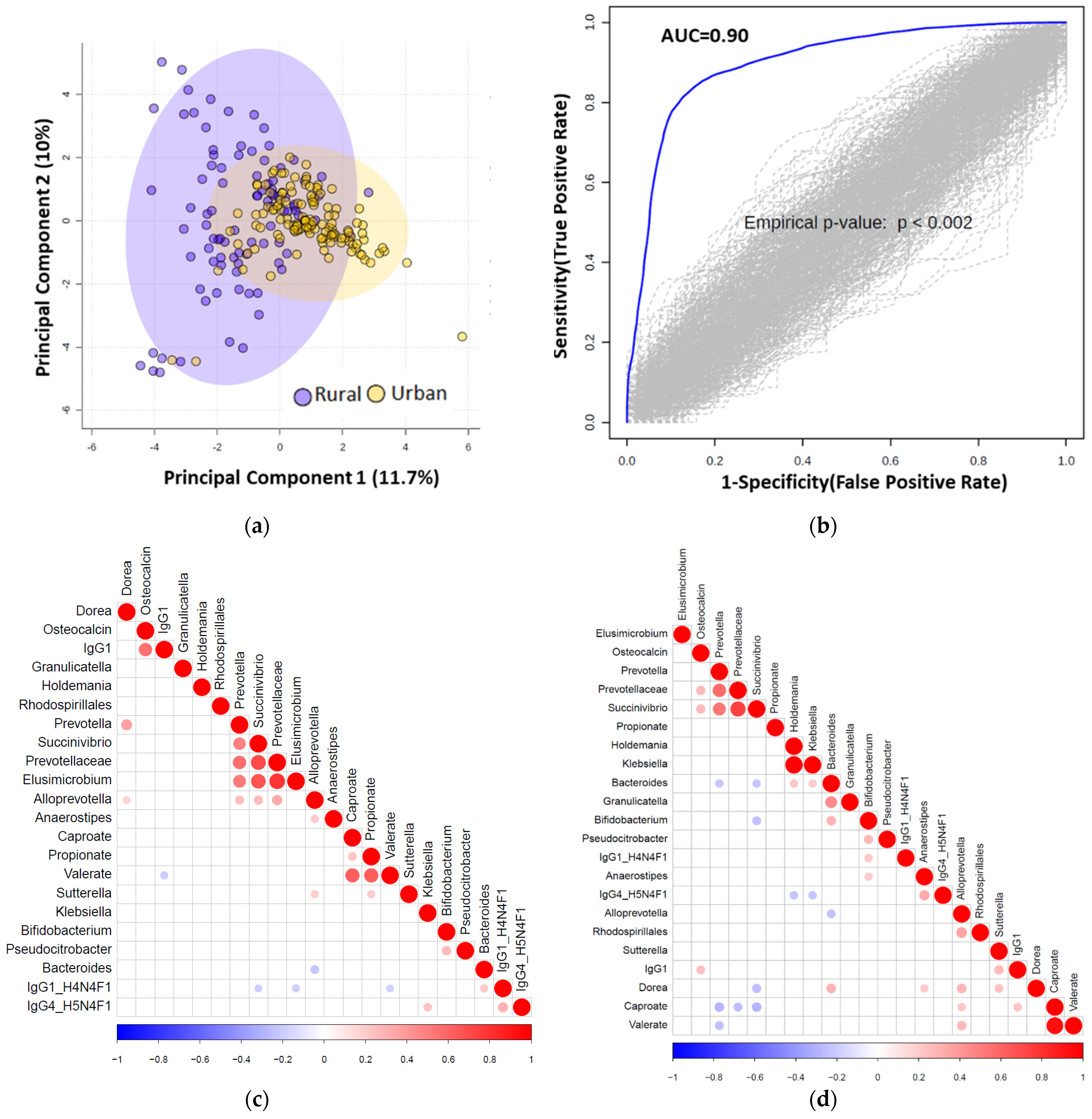
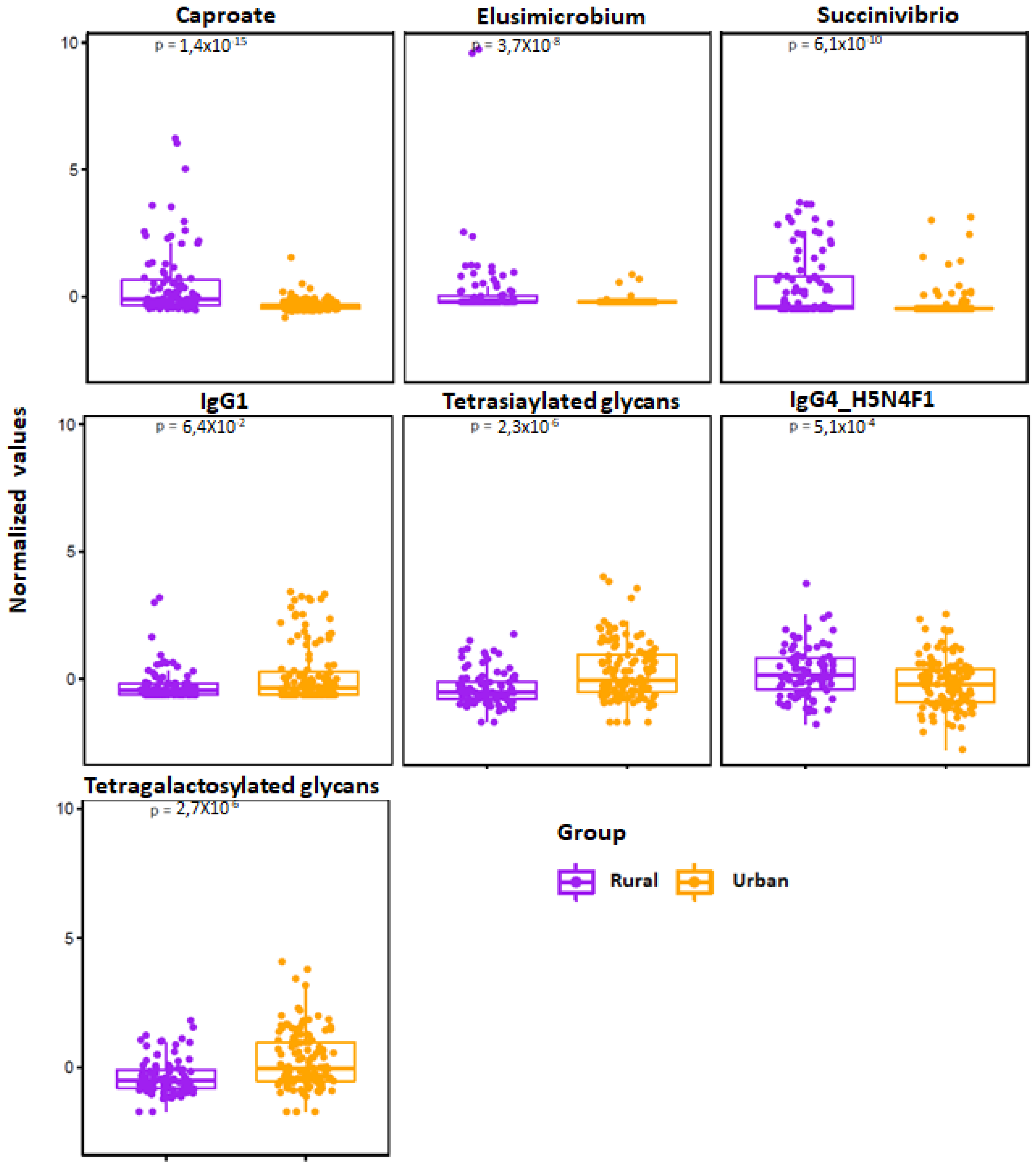
3.7. Multiomics Data Integration Identified Potential Biomarkers Distinguishing Urban vs. Rural Cohort
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mohan, P.; Mohan, S.B.; Dutta, M. Communicable or non-communicable diseases? Building strong primary health systems to address double burden of disease in India. J. Fam. Med. Prim. Care 2019, 8, 326–329. [Google Scholar] [CrossRef]
- Arokiasamy, P. India’s escalating burden of non-communicable diseases. Lancet Glob. Health 2018, 6, e1262–e1263. [Google Scholar] [CrossRef] [Green Version]
- GBD 2016 Disease and Injury Incidence and Prevalence Collaborators. Global, regional, and national incidence, prevalence, and years lived with disability for 328 diseases and injuries for 195 countries, 1990–2016: A systematic analysis for the Global Burden of Disease Study 2016. Lancet 2017, 390, 1211–1259. [Google Scholar] [CrossRef] [Green Version]
- India State-level Disease Burden Initiative Collaborators. Nations within a nation: Variations in epidemiological transition across the states of India, 1990-2016 in the Global Burden of Disease Study. Lancet 2017, 390, 2427–2460. [Google Scholar]
- Lumeng, C.N.; Saltiel, A.R. Inflammatory links between obesity and metabolic disease. J. Clin. Investig. 2011, 121, 2111–2117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Furman, D.; Campisi, J.; Verdin, E.; Carrera-Bastos, P.; Targ, S.; Franceschi, C.; Ferrucci, L.; Gilroy, D.W.; Fasano, A.; Miller, G.W.; et al. Chronic inflammation in the etiology of disease across the life span. Nat. Med. 2019, 25, 1822–1832. [Google Scholar] [CrossRef] [PubMed]
- India State-Level Disease Burden Initiative Diabetes Collaborators. The increasing burden of diabetes and variations among the states of India: The Global Burden of Disease Study 1990–2016. Lancet Glob. Health 2018, 6, e1352–e1362. [Google Scholar] [CrossRef] [Green Version]
- International Diabetes Federation. 9th Edition. International Diabetes Federation; 2019. IDF Diabetes Atlas. Available online: https://www.diabetesatlas.org/en/ (accessed on 15 February 2021).
- Ramachandran, A.; Snehalatha, C.; Kapur, A.; Vijay, V.; Mohan, V.; Das, A.K.; Rao, P.V.; Yajnik, C.S.; Prasanna Kuman, K.M.; Nair, J.D.; et al. High prevalence of diabetes and impaired glucose tolerance in India: National Urban Diabetes Survey. Diabetologia 2001, 44, 1094–1101. [Google Scholar] [CrossRef]
- Deepa, M.; Grace, M.; Binukumar, B.; Pradeepa, R.; Roopa, S.; Khan, H.M.; Fatmi, Z.; Kadir, M.M.; Naeem, I.; Ajay, V.S.; et al. High burden of prediabetes in three large cities in South Asia: The Center for Cardio-metabolic Risk Reduction in South Asia (CARRS) Study. Diabetes Res. Clin. Pract. 2015, 110, 172–182. [Google Scholar] [CrossRef] [Green Version]
- Anjana, R.M.; Deep, M.; Pradeepa, R. Prevalence of diabetes and prediabetes in 15 states of India: Results from the ICMR-INDIAB population-based cross-sectional study. Lancet Diabetes Endocrinol. 2017, 5, 585–596. [Google Scholar] [CrossRef]
- Ahluwalia, T.S.; Kilpelainen, T.O.; Singh, S.; Rossing, P. Editorial: Novel Biomarkers for Type 2 Diabetes. Front. Endocrinol. 2019, 10, 649. [Google Scholar] [CrossRef] [Green Version]
- Yao, M.J.; Li, J.Y.; Li, J.Z.; Wu, T.F.; Xu, J.-H.; Huang, C.Z.; Cheng, D.; Chen, Q.K.; Yu, T. Diabetes mellitus increases the risk of enteric infections: A meta-analysis. Int. J. Clin. Exp. Med. 2018, 11, 5457–5468. [Google Scholar]
- Thaiss, C.A.; Levy, M.; Grosheva, I.; Zheng, D.; Soffer, E.; Blacher, E.; Braverman, S.; Tengeler, A.C.; Barak, O.; Elazer, M.; et al. Hyperglycemia drives intestinal barrier dysfunction and risk for enteric infection. Science 2018, 359, 1376–1383. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dotz, V.; Wuhrer, M. N-glycome signatures in human plasma: Associations with physiology and major diseases. FEBS Lett. 2019, 593, 2966–2976. [Google Scholar] [CrossRef] [Green Version]
- Lauc, G.; Pezer, M.; Rudan, I.; Campbell, H. Mechanisms of disease: The human N-glycome. Biochim. Biophys. Acta 2016, 1860, 1574–1582. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Keser, T.; Gornik, I.; Vuckovic, F.; Selek, N.; Pavic, T.; Lukic, E.; Gudelj, I.; Gasparovic, H.; Biocina, B.; Tilin, T.; et al. Increased plasma N-glycome complexity is associated with higher risk of type 2 diabetes. Diabetologia 2017, 60, 2352–2360. [Google Scholar] [CrossRef] [PubMed]
- Rudman, N.; Gornik, O.; Lauc, G. Altered N-glycosylation profiles as potential biomarkers and drug targets in diabetes. FEBS Lett. 2019, 593, 1598–1615. [Google Scholar] [CrossRef] [Green Version]
- Gudelj, I.; Lauc, G.; Pezer, M. Immunoglobulin G glycosylation in aging and diseases. Cell Immunol. 2018, 333, 65–79. [Google Scholar] [CrossRef] [PubMed]
- Gurung, M.; Li, Z.; You, H.; Rodrigues, R.; Jump, D.B.; Morgun, A.; Shulzhenko, N. Role of gut microbiota in type 2 diabetes pathophysiology. EBioMedicine 2020, 51, 102590. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guasch-Ferre, M.; Hruby, A.; Toledo, E.; Clish, C.B.; Martinez-Gonzalez, M.A.; Salas-Salvado, J.; Hu, F.B. Metabolomics in Prediabetes and Diabetes: A Systematic Review and Meta-analysis. Diabetes Care 2016, 39, 833–846. [Google Scholar] [CrossRef] [Green Version]
- Arneth, M.; Arneth, R.; Shams, M. Metabolomics of Type 1 and Type 2 Diabetes. Int. J. Mol. Sci. 2019, 20, 2467. [Google Scholar] [CrossRef] [Green Version]
- Zhou, W.; Sailani, M.R.; Contrepoi, K.; Zhou, Y.; Ahadi, S.; Leopold, S.R.; Zhang, M.J.; Rao, V.; Avina, M.; Mishra, T.; et al. Longitudinal multi-omics of host-microbe dynamics in prediabetes. Nature 2019, 569, 663–671. [Google Scholar] [CrossRef] [PubMed]
- Vallianou, N.; Stratigou, T.; Christodoulatos, G.S.; Dalamaga, M. Understanding the Role of the Gut Microbiome and Microbial Metabolites in Obesity and Obesity-Associated Metabolic Disorders: Current Evidence and Perspectives. Curr. Obes. Rep. 2019, 8, 317–332. [Google Scholar] [CrossRef] [PubMed]
- Mullish, B.J.; Pechlivanis, A.; Barker, G.F.; Thursz, M.R.; Marchesi, J.R.; McDonald, J.A.K. Functional Microbiomics: Evaluation of Gut Microbiota-Bile Acid Metabolism Interactions in Health and Disease. Methods 2018, 149, 49–58. [Google Scholar] [CrossRef] [Green Version]
- Callahan, B.J.; McMurdie, P.J.; Rosen, M.J.; Han, A.W.; Johnson, A.J.; Holmes, S.P. DADA2: High resolution samples inference from Illumina amplicon data. Nat. Methods 2016, 13, 581–583. [Google Scholar] [CrossRef] [Green Version]
- Oksanen, J.; Blanchett, F.G.; Kindt, R.; Legendre, P.; Minchin, P.R.; O’Hara, R.B.; Simpson, G.L.; Solymos, P.; Stevens, M.H.H.; Wagner, H. The vegan package. Community Ecol. Package 2014. R Package Version 2.2-0. Available online: http://CRAN.Rproject.org/package=vegan (accessed on 15 February 2021).
- Kaufman, L.; Rousseeuw, P.J. Partitioning around Medoids (Program PAM). In Finding Groups in Data: An Introduction to Cluster Analysis; Kaufman, L., Rousseeuw, P.J., Eds.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1990; pp. 68–125. [Google Scholar]
- Segata, N.; Izard, J.; Waldron, L.; Gevers, D.; Miropolsky, L.; Garrett, W.S.; Huttenhower, C. Metagenomic biomarker discovery and explanation. Genome Biol. 2011, 12, R60. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schloss, P.D.; Westcott, S.L. Assessing and Improving Methods Used in Operational Taxonomic Unit-Based Approaches for 16S rRNA Gene Sequence Analysis. Appl. Environ. Microbiol. 2011, 77, 3219–3226. [Google Scholar] [CrossRef] [Green Version]
- Moreau, N.M.; Goupry, S.M.; Antignac, J.P.; Monteau, F.J.; Le Bizec, B.J.; Champ, M.M.; Martin, L.J.; Dumon, H.J. Simultaneous measurement of plasma concentrations and 13C-enrichment of short-chain fatty acids, lactic acid and ketone bodies by gas chromatography coupled to mass spectrometry. J. Chromatogr. B Anal. Technol. Biomed. Life Sci. 2003, 784, 395–403. [Google Scholar] [CrossRef]
- Ugrina, I.; Campbell, H.; Vučković, F. Laboratory Experimental Design for a Glycomic Study. In High-Throughput Glycomics and Glycoproteomics; Lauc, G., Wuhrer, M., Eds.; Methods in Molecular Biology; Springer: New York, NY, USA, 2017; Volume 1503, pp. 13–19. [Google Scholar]
- Akmačić, I.T.; Ugrina, I.; Štambuk, J.; Gudelj, I.; Vučković, F.; Lauc, G.; Pučić-Baković, M. High-throughput glycomics: Optimization of sample preparation. Biochemistry 2015, 80, 934–942. [Google Scholar] [PubMed]
- Simurina, M.; de Haan, N.; Vuckovic, F.; Kennedy, N.A.; Štambuk, J.; Falck, D.; Trbojević-Akmačić, I.; Clerc, F.; Razdorov, G.; Khon, A.; et al. Glycosylation of Immunoglobulin G Associates with Clinical Features of Inflammatory Bowel Diseases. Gastroenterology 2018, 154, 1320–1333.e.10. [Google Scholar] [CrossRef]
- Balbin, M.; Grubb, A.; de Lange, G.G.; Grubb, R. DNA sequences specific for Caucasian G3m(b) and (g) allotypes: Allotyping at the genomic level. Immunogenetics 1994, 39, 187–193. [Google Scholar] [CrossRef] [PubMed]
- Johnson, M.P.; Keyho, R.; Blackburn, N.B.; Laston, S.; Kumar, S.; Peralta, J.; Thapa, S.S.; Towne, B.; Subedi, J.; Blangero, J.; et al. Glycated Serum Protein Genetics and Pleiotropy with Cardiometabolic Risk Factors. J. Diabetes Res. 2019, 2019, 2310235. [Google Scholar] [CrossRef] [PubMed]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Bravo-Merodio, L.; Williams, J.A.; Gkoutos, G.C.; Acharjee, A. Omics biomarker identification pipeline for translational medicine. J. Transl. Med. 2019, 17, 155. [Google Scholar] [CrossRef] [Green Version]
- Bravo-Merodio, L.; Acharjee, A.; Hazeldine, J.; Bentley, C.; Foster, M.; Gkoutos, G.V.; Lord, J.M. Machine Learning for the detection of early immunological markers as predictors of multi-organ dysfunction. Sci. Data 2019, 6, 328. [Google Scholar] [CrossRef] [Green Version]
- Stapleton, C.J.; Acharjee, A.; Irvine, H.J.; Wolcott, Z.C.; Patel, A.B.; Kinberly, W.T. High-throughput metabolite profiling: Identification of plasma taurine as a potential biomarker of functional outcome after aneurysmal subarachnoid hemorrhage. J. Neurosurg. 2020, 133, 1635–1978. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A language and environment for statistical computing. [Internet]. Vienna: R Foundation for Statistical Computing. 2013. Available online: http://www.R-project.org/ (accessed on 15 February 2021).
- Hong, J.; Wishart, D.S.; Xia, J. Using MetaboAnalyst 4.0 for Comprehensive and Integrative Metabolomics Data Analysis. Curr. Protoc. Bioinform. 2019, 68, e86. [Google Scholar]
- Barengolts, E. Gut microbiota, Prebiotics, Probiotics, and Synbiotics in Management of Obesity and Prediabetes: Review of Randomized controlled Trials. Endocr. Pract. 2016, 22, 1224–1234. [Google Scholar] [CrossRef] [Green Version]
- De Groot, P.; Nikolic, T.; Pellegrini, S.; Sordi, V.; Imangaliyev, S.; Rampanelli, E.; Hanssen, N.; Attaye, I.; Bakker, G.; Duinkerken, G.; et al. Faecal microbiota transplantation halts progression of human new-onset type 1 diabetes in a randomised controlled trial. Gut 2020, 70, 92–105. [Google Scholar] [CrossRef]
- Ganz, M.L.; Wintfeld, N.; Li, Q.; Ala, V.; Langer, J.; Hammer, M. The association of body mass index with the risk of type 2 diabetes: A case-control study nested in an electronic health records system in the United States. Diabetol. Metab. Syndr. 2014, 6, 50. [Google Scholar] [CrossRef] [Green Version]
- Eckel, R.H.; Kahn, S.E.; Ferrannini, E.; Goldfine, A.B.; Nathan, D.M.; Schwartz, M.W.; Smith, R.J.; Smith, S.R. Obesity and Type 2 Diabetes: What Can be Unified and What Needs to be Individualized? J Clin Endocrinol Metab. 2011, 96, 1654–1663. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al-Goblan, A.S.; Al-Alfi, M.; Khan, M.Z. Mechanisms linking diabetes mellitus and obesity. Diabetes Metab. Syndr. Obes. 2014, 7, 587–591. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martin, R.; Miquel, S.; Benevides, L.; Bridonneau, C.; Robert, V.; Hudault, S.; Chain, F.; Berteau, O.; Azevedo, V.; Chatel, J.M.; et al. Functional Characterization of Novel Faecalibacterium prausnitzii Strains Isolated from Healthy Volunteers: A Step Forward in the Use of F. prausnitzii as a Next Generation Probiotic. Front. Microbiol. 2017, 8, 1226. [Google Scholar] [CrossRef] [PubMed]
- Parada Venegas, D.; De la Funete, M.; Landskron, G.; Gonzalez, M.J.; Quera, R.; Dijstra, G.; Harmsen, H.J.M.; Faber, K.N.; Hermoso, M.A. Short Chain Fatty Acids (SCFAs)-Mediated Gut Epithelial and Immune Regulation and its Relevance for Inflammatory Bowel Diseases. Front. Immunol. 2019, 10, 277. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Monaghan, T.M.; Sloan, T.J.; Stockdale, S.R.; Blanchard, A.M.; Emes, R.D.; Wilcox, M.; Biswas, R.; Nashine, R.; Manke, S.; Gandhi, J.; et al. Metagenomics reveals impact of geography and acute diarrheal disease on the Central Indian human gut microbiome. Gut Microbes 2020, 12, 1752606. [Google Scholar] [CrossRef] [PubMed]
- Gronwall, C.; Vas, J.; Silverman, G.J. Protective roles of natural IgM antibodies. Front. Immunol. 2012, 3, 66. [Google Scholar] [CrossRef] [Green Version]
- Gronwall, C.; Silverman, G.J. Natural IgM: Beneficial autoantibodies for the control of inflammatory and autoimmune disease. J. Clin. Immunol. 2014, 34, S12–S21. [Google Scholar] [CrossRef] [Green Version]
- Tachang, G.K. Metabolic Syndrome May be a Sign of Rapid Aging. J. Diabetes Metab. 2016, 7, 5. [Google Scholar] [CrossRef]
- Cheema, A.; Adeloye, D.; Sidhu, S.; Sridhar, D.; Chan, K.Y. Urbanization and prevalence of type 2 diabetes in Southern Asia: A systematic analysis. J. Glob. Health 2014, 4, 010404. [Google Scholar] [CrossRef]
- Krishnamoorthy, Y.; Rajaa, S.; Murali, S.; Rehman, T.; Sahoo, J.; Kar, S.S. Prevalence of metabolic syndrome among adult population in India: A systematic review and meta-analysis. PLoS ONE 2020, 15, e0240971. [Google Scholar] [CrossRef] [PubMed]
- Monaghan, T.M.; Pucic-Bakovic, M.; Vuckovic, F.; Lee, C.; Kao, D. Human Glycome Project. Decreased Complexity of Serum N-glycan Structures Associates with successful Fecal Microbiota Transplantation for Recurrent Clostridioides difficile infection. Gastroenterology 2019, 157, 1676–1678. [Google Scholar] [CrossRef]
- Obregon-Tito, A.J.; Tito, R.Y.; Metcalf, J.; Sankaranarayan, K.; Clement, J.C.; Ursell, L.K.; Xu, Z.Z.; Van Treuren, W.; Knight, R.; Gaffney, P.M.; et al. Subsistence strategies in traditional societies distinguish gut microbiomes. Nat. Comm. 2015, 25, 6505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ou, J.; Carbonero, F.; Zoetendal, E.G.; Delany, J.P.; Wang, M.; Newton, K.; Gaskins, H.R.; O’Keefe, S.J. Diet, microbiota, and microbial metabolites on colon cancer in rural Africans and African Americans. Am. J. Clin. Nutr. 2013, 98, 111–120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schnorr, S.L. The diverse microbiome of the hunter-gatherer. Nature 2015, 518, S14–S15. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.; Qie, Y.; Park, J.; Kim, C.H. Gut Microbial Metabolites Fuel Antibody Responses. Cell Host Microbe 2016, 20, 202–214. [Google Scholar] [CrossRef] [PubMed] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Rural, n = 94 | Urban, n = 124 | p-Value |
|---|---|---|---|
| Age, yrs (median (IQR)) | 39 (27, 53) | 38 (30, 49) | >0.9 |
| Gender | 0.3 | ||
| Female | 47 (50%) | 52 (42%) | |
| Male | 47 (50%) | 72 (58%) | |
| BMI (median (IQR)) | 21.0 (19.2, 22.3) | 25.0 (23.5, 26.0) | <0.001 |
| BMI Class | <0.001 | ||
| Underweight | 10 (11%) | 0 (0%) | |
| Normal | 68 (72%) | 20 (16%) | |
| Overweight | 12 (13%) | 38 (31%) | |
| Pre-Obese | 2 (2.1%) | 62 (50%) | |
| Obese | 2 (2.1%) | 4 (3.2%) | |
| Smoker | 23 (24%) | 31 (25%) | >0.9 |
| Hospitalized | 13 (14%) | 45 (36%) | |
| Drugs | 0.017 | ||
| Antacid | 24 (26%) | 12 (9.7%) | |
| PPI | 1 (1.1%) | 1 (0.8%) | |
| Co-morbidities | <0.001 | ||
| Diabetes mellitus | 8 (8.5%) | 15 (12%) | |
| Epilepsy | 3 (3.2%) | 12 (9.7%) | |
| High cholesterol | 0 (0%) | 1 (0.8%) | |
| Hypertension | 0 (0%) | 7 (5.6%) | |
| Hypothyroidism | 0 (0%) | 1 (0.8%) | |
| Seizure disorder | 0 (0%) | 1 (0.8%) | |
| Tuberculosis | 0 (0%) | 1 (0.8%) | |
| Toilet facilities | 80 (85%) | 124 (100%) | <0.001 |
| Hand soap | 80 (85%) | 124 (100%) | <0.001 |
| Domestic animals | 42 (45%) | 21 (17%) | <0.001 |
| Water supply | <0.001 | ||
| Borewell | 0 (0%) | 18 (15%) | |
| Corporation water connection | 6 (6.4%) | 101 (81%) | |
| Corporation water tank | 78 (83%) | 3 (2.4%) | |
| Well water | 10 (11%) | 2 (1.6%) |
| Feature | tstat | Rural | Urban | p-Value (FDR Corrected) |
|---|---|---|---|---|
| Serum Short-chain Fatty Acids | ||||
| Caproate | 6.679 | ↑ | ↓ | 0.000000 |
| Valerate | 5.5217 | ↑ | ↓ | 0.000001 |
| Acetate | 3.1602 | ↑ | ↓ | 0.006598 |
| Propionate | 3.0367 | ↑ | ↓ | 0.007375 |
| Serum Diabetic panel | ||||
| BMI | −3.9651 | ↓ | ↑ | 0.003120 |
| C-peptide | −3.4949 | ↓ | ↑ | 0.006466 |
| Insulin | −3.0994 | ↓ | ↑ | 0.013355 |
| Leptin | −2.9744 | ↓ | ↑ | 0.014119 |
| Serum IgG Fc N-Glycopeptides | ||||
| IgG1 H4N4F1: IgG1 glycopeptide with monogalactosylated glycan with core fucose | −3.6748 | ↓ | ↑ | 0.004191 |
| IgG4 H5N4F1: IgG4 glycopeptide with digalactosylated glycan with core fucose | 3.4585 | ↑ | ↓ | 0.004569 |
| IgG1 H3N4F1: IgG1 glycopeptide with agalactosylated glycan with core fucose | −2.9742 | ↓ | ↑ | 0.014886 |
| IgG4 H5N4F1S1: IgG4 glycopeptide with digalactosylated and monosialylated glycan with core fucose | 2.889 | ↑ | ↓ | 0.014886 |
| IgG1_H5N4F1S1: IgG1 glycopeptide with digalactosylated and monosialylated glycan with core fucose. | 2.5309 | ↑ | ↓ | 0.033823 |
| Serum Immunoglobulin isotype | ||||
| IgG1 | −3.5703 | ↓ | ↑ | 0.003905 |
| IgM | 2.5608 | ↑ | ↓ | 0.045976 |
| Inflammation-related Protein | ||||
| IFN-γ | 3.077 | ↑ | ↓ | 0.051323 |
| Osteocalcin | −3.063 | ↓ | ↑ | 0.051323 |
| Serum N-Glycans | ||||
| S4: Tetrasialylated glycans | −5.2077 | ↓ | ↑ | 0.000004 |
| G4: Tetragalactosylated glycans | −5.1823 | ↓ | ↑ | 0.000004 |
| AF: Antennary fucosylation | −4.7813 | ↓ | ↑ | 0.000019 |
| S1: Monosialylated glycans | 3.9387 | ↑ | ↓ | 0.000413 |
| HB: High branching glycans | −3.9283 | ↓ | ↑ | 0.000413 |
| LB: Low branching glycans | 3.8475 | ↑ | ↓ | 0.000470 |
| S3: Trisialylated glycans | −3.25 | ↓ | ↑ | 0.003435 |
| G2: Digalactosylated glycans | 2.9324 | ↑ | ↓ | 0.008372 |
| G3: Trigalctosylated glycans | −2.7838 | ↓ | ↑ | 0.011686 |
| B: Bisection (Glycans with bisecting GlcNAc) | 2.403 | ↑ | ↓ | 0.030770 |
| HM: High mannose glycans | 2.2316 | ↑ | ↓ | 0.043612 |
| Feature | tstat | Normal GSP (n = 30) | Low GSP (n = 54) | p-Value (FDR Corrected) |
|---|---|---|---|---|
| MMP-2 | −3.5975 | ↑ | ↓ | 0.000548 |
| HM: High mannose glycans | 2.8571 | ↓ | ↑ | 0.005416 |
| MMP-3 | 2.8315 | ↓ | ↑ | 0.005827 |
| sCD163 | −2.7054 | ↑ | ↓ | 0.008297 |
| sIL-6Rα | −2.6473 | ↑ | ↓ | 0.009727 |
| IFN-α2 | −2.4229 | ↑ | ↓ | 0.017598 |
| IgG4 H5N4F1S1: IgG4 glycopeptide with digalactosylated and monosialylated glycan with core fucose | 2.3389 | ↑ | ↓ | 0.021773 |
| Cyanobacteria | −2.2579 | ↑ | ↓ | 0.026608 |
| Melainabacteria | −2.2579 | ↑ | ↓ | 0.026608 |
| 2-methylbutyrate | −2.196 | ↑ | ↓ | 0.030914 |
| AF: Antennary Fucosylation | −2.1194 | ↑ | ↓ | 0.03708 |
| Gastranaerophilales_unclassified | −2.0844 | ↑ | ↓ | 0.040231 |
| Gastranaerophilales | −2.0666 | ↑ | ↓ | 0.041926 |
| sCD30/TNFRSF8 | −2.0552 | ↑ | ↓ | 0.043046 |
| Feature | tstat | Normal GSP (n = 30) | High GSP (n = 33) | p-Value (FDR Corrected) |
|---|---|---|---|---|
| IgG2 | −2.7269 | ↑ | ↓ | 0.008335 |
| Caproate | −2.6832 | ↑ | ↓ | 0.009373 |
| Roseburia | −2.4077 | ↑ | ↓ | 0.019095 |
| Valerate | −2.2378 | ↑ | ↓ | 0.028897 |
| Dorea | −2.2193 | ↑ | ↓ | 0.030193 |
| IgM | −2.1594 | ↑ | ↓ | 0.034761 |
| APRIL/TNFSF13 | 2.141 | ↓ | ↑ | 0.036276 |
| Feature | tstat | Normal GSP (n = 30) | Very High GSP (n = 18) | p-Value (FDR Corrected) |
|---|---|---|---|---|
| Caproate | 2.4758 | ↑ | ↓ | 0.017035 |
| Blautia | −2.0712 | ↓ | ↑ | 0.04398 |
| Osteopontin | 2.0162 | ↑ | ↓ | 0.049643 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Monaghan, T.M.; Biswas, R.N.; Nashine, R.R.; Joshi, S.S.; Mullish, B.H.; Seekatz, A.M.; Blanco, J.M.; McDonald, J.A.K.; Marchesi, J.R.; Yau, T.o.; et al. Multiomics Profiling Reveals Signatures of Dysmetabolism in Urban Populations in Central India. Microorganisms 2021, 9, 1485. https://doi.org/10.3390/microorganisms9071485
Monaghan TM, Biswas RN, Nashine RR, Joshi SS, Mullish BH, Seekatz AM, Blanco JM, McDonald JAK, Marchesi JR, Yau To, et al. Multiomics Profiling Reveals Signatures of Dysmetabolism in Urban Populations in Central India. Microorganisms. 2021; 9(7):1485. https://doi.org/10.3390/microorganisms9071485
Chicago/Turabian StyleMonaghan, Tanya M., Rima N. Biswas, Rupam R. Nashine, Samidha S. Joshi, Benjamin H. Mullish, Anna M. Seekatz, Jesus Miguens Blanco, Julie A. K. McDonald, Julian R. Marchesi, Tung on Yau, and et al. 2021. "Multiomics Profiling Reveals Signatures of Dysmetabolism in Urban Populations in Central India" Microorganisms 9, no. 7: 1485. https://doi.org/10.3390/microorganisms9071485
APA StyleMonaghan, T. M., Biswas, R. N., Nashine, R. R., Joshi, S. S., Mullish, B. H., Seekatz, A. M., Blanco, J. M., McDonald, J. A. K., Marchesi, J. R., Yau, T. o., Christodoulou, N., Hatziapostolou, M., Pucic-Bakovic, M., Vuckovic, F., Klicek, F., Lauc, G., Xue, N., Dottorini, T., Ambalkar, S., ... Kashyap, R. S. (2021). Multiomics Profiling Reveals Signatures of Dysmetabolism in Urban Populations in Central India. Microorganisms, 9(7), 1485. https://doi.org/10.3390/microorganisms9071485