1. Introduction
In recent years, the tracking control problem of electromechanical servo systems has garnered significant attention in both theoretical research and practical applications, owing to their inherent uncertainties [
1,
2,
3,
4]. Servo systems are widely used in high-precision fields, such as autonomous driving, unmanned aerial vehicle (UAV) navigation, and robotic control. However, the complex dynamic characteristics and uncertainties of these systems pose substantial challenges for achieving precise control. Inadequate handling of uncertainties and external disturbances can lead to deviations from the desired trajectory or even system instability, thereby compromising both the performance and safety. To address these issues, various control strategies have been proposed, including adaptive robust control, sliding mode control (SMC), and disturbance rejection control [
5,
6,
7,
8]. However, these methods often rely on partial or full knowledge of system dynamics, limiting their applicability in scenarios where the dynamic parameters are entirely unknown, particularly in industrial and engineering contexts where practical constraints are significant.
Model-free control strategies have gained considerable interest in overcoming reliance on dynamic models. These approaches, including iterative learning control [
9], neural network control [
10], reinforcement learning (RL) control [
11], and optimal control [
12], reduce dependence on precise system models and expand the scope of control technologies. However, they still face challenges in managing uncertainties, external disturbances, and noise in complex dynamic environments where maintaining stable control remains difficult.
To cope with these complex environments, researchers have explored the potential of combining RL with classical control methods [
13,
14,
15]. The combination of RL’s adaptability and the stability of classical control techniques can effectively overcome the limitations of traditional methods in dynamic environments.
A previous study [
16] introduced a hybrid control strategy based on the actor-critic architecture, enabling the simultaneous estimation of multiple PID controller gains. This strategy does not rely on precise dynamic models and can adaptively adjust to dynamic behaviors and operating environments, although its theoretical stability proof remains incomplete. Other studies [
17,
18] employed Lyapunov methods to verify RL stability in complex systems, such as helicopters and robots, but found it to be less effective in handling external disturbances. In practical applications, servo systems often encounter uncertain disturbances that can significantly degrade control performance or even lead to instability [
19,
20].
To enhance disturbance rejection, some studies have combined RL with disturbance observers. For example, refs. [
21,
22] proposed integrating RL with fuzzy logic systems (FLS). In [
21], RL optimizes the virtual and actual control at each step of the backstepping control, whereas FLS approximates unknown functions and provides feedforward compensation. Similarly, ref. [
22] applied the FLS to approximate unknown functions in large-scale nonlinear systems by utilizing state observers to estimate unmeasured states. However, the performance of an FLS is highly dependent on fuzzy rule design, which often requires extensive experimental tuning, complicating practical implementation. In addition, ref. [
23] proposed combining RL with sliding mode control, offering a solution distinct from traditional integral sliding mode control. This sliding mode controller uses neural networks for approximation and disturbance estimation, while an actor-critic architecture continuously learns the optimal control strategy using adaptive dynamic programming (ADP). However, the inherent discontinuity in sliding mode control may lead to chattering, which negatively impacts performance. Another study [
24] integrated RL with the robust integral of the sign of the error (RISE) controller using an actor-critic architecture to approximate unknown dynamics for feedforward compensation. While this improved the control accuracy, the high sensitivity of the sign function to error variations weakened the robustness of the system to noise. In environments with significant measurement noise, the RISE controller may misinterpret the noise as an error, exacerbating fluctuations in the control inputs. Despite these advancements, further research is necessary to develop more flexible and precise control strategies for handling greater uncertainties and complex environments.
This study proposes a novel backstepping command filter controller based on reinforcement learning (BCF-RL) to address these challenges. The BCF-RL controller effectively tackles the challenge of obtaining accurate dynamic models and reduces sensitivity to noise in state measurements. Using an actor-critic framework, the adaptive RL control strategy estimates unknown disturbances in real time and provides feedforward compensation, significantly mitigating the impact of unmodeled dynamics and external perturbations. Traditional noise suppression methods, such as the extended Kalman filter (EKF) and low-pass filters, are effective and often face high computational complexity and reduced robustness in nonlinear systems. By avoiding excessive signal smoothing, command filters achieve better noise suppression and faster response times, making them a more suitable choice.
Compared with the method in [
16], the BCF-RL approach provides more rigorous theoretical stability guarantees. Unlike traditional sliding mode control, it reduces chattering and improves system performance. Furthermore, compared with the RISE control strategy in [
24], this method demonstrates greater robustness to sensor noise while achieving faster response times. One key advantage is its minimal reliance on prior system knowledge, which allows for asymptotic tracking and robust performance against both unknown dynamics and external disturbances. These features make the BCF-RL a promising solution for the precise control of complex dynamic systems with high uncertainty. The contributions of this study are as follows:
- (1)
Given the sensitivity of the system speed signal to the measurement noise, a command filter was developed to process this noise, thereby enhancing the robustness of the controller.
- (2)
A hybrid data-model-driven control method was designed. By employing the actor-critic structure of reinforcement learning, this method provides a more accurate estimation of unknown disturbances, resulting in a higher accuracy in position tracking.
- (3)
The stability of the controller in reinforcement learning and the weight convergence of the two networks are rigorously proven from a theoretical perspective, ensuring the robustness and effectiveness of the control strategy.
This article is organized as follows:
Section 2 introduces the problem formulation and system architecture.
Section 3 details the design process of the main controller.
Section 4 describes the design process of the auxiliary controller.
Section 5 provides stability analysis and proof.
Section 6 presents the experimental results. Finally,
Section 7 concludes the article.
6. Experimental Verification
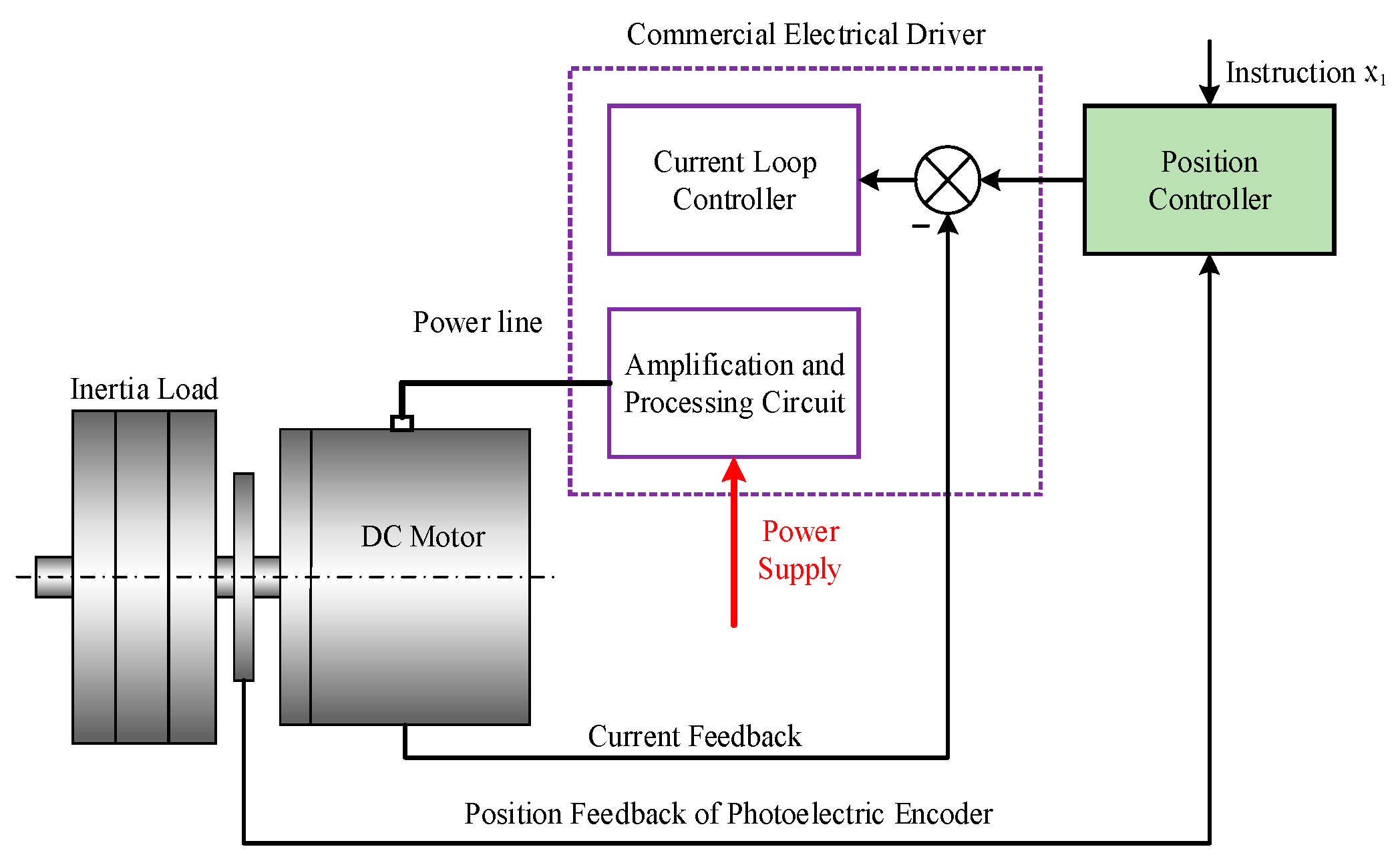
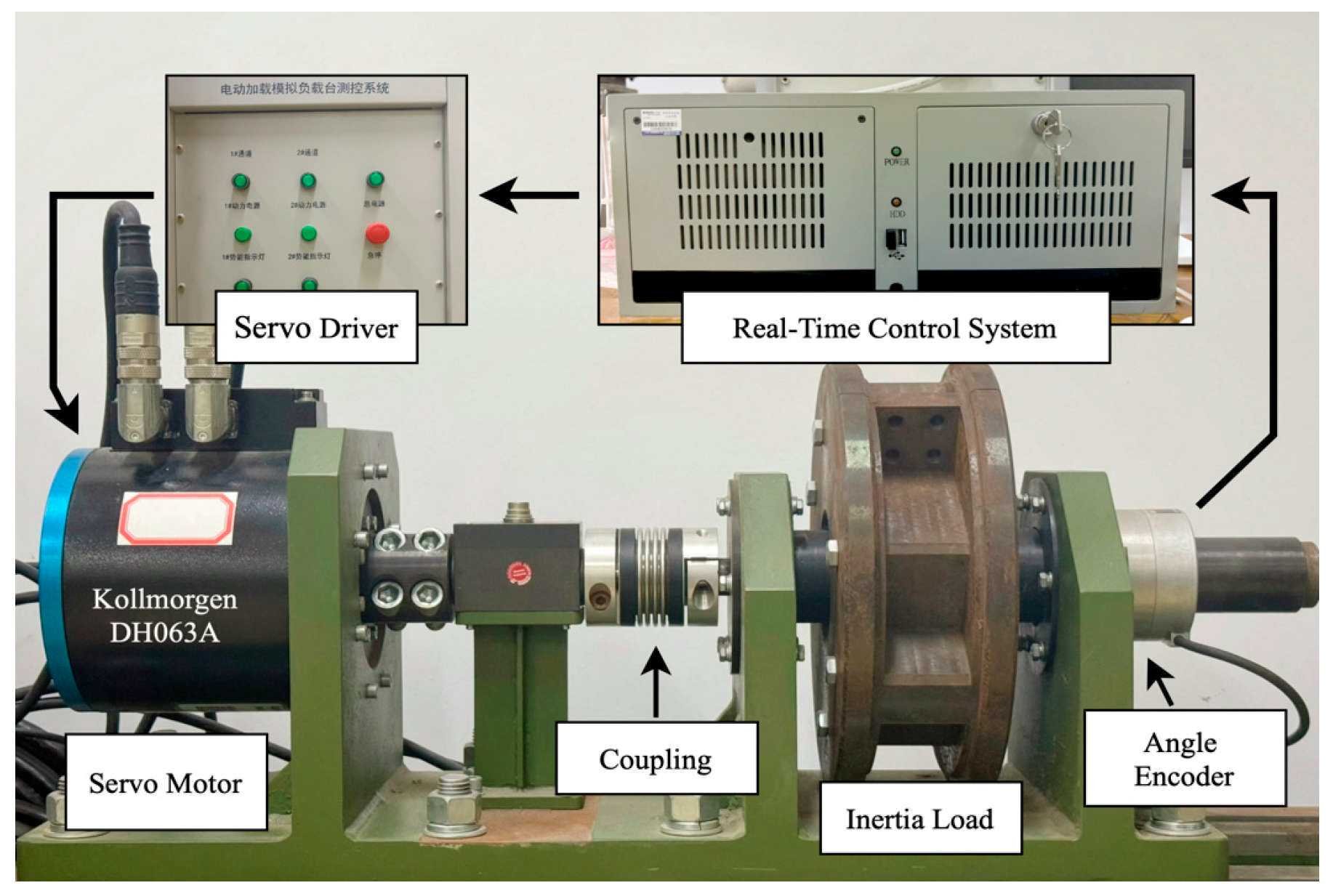
The overall assembly diagram and control system of the experimental platform are illustrated in
Figure 3, with the component list and motor specifications detailed in
Table 1. The platform comprises the following core components: a base unit, a PMSM drive system (including Kollmorgen D063M-13-1310 PMSM, Kollmorgen ServoStar 620 servo drive (Kollmorgen Corporation, Radford, VA, USA), Heidenhain ERN180 rotary encoder with ±13 arcsec accuracy (Heidenhain GmbH, Traunreut, Germany), inertia flywheel and coupling mechanism), power supply module, and measurement-control system. The measurement-control system integrates monitoring software with an industrial computer running real-time operating system RTU, which executes control programs developed in C language. Hardware interfaces include an Advantech PCI-1723 16-bit D/A conversion card for control command output and a Heidenhain IK-220 16-bit acquisition card for encoder signal collection. With a control cycle of 0.5 ms, the system velocity is calculated in real time through backward difference algorithm based on high-precision position signals.
6.1. Overview of Proposed and Comparative Controllers
To compare the effectiveness of the proposed algorithm, the following five controllers were implemented for comparative experiments under the same conditions:
C1: To adjust the proposed BCF-RL controller, the parameters of the BCF main controller were first determined according to Theorem 1 to ensure fast response and stability. Then, the RL auxiliary controller was integrated, and its parameters were adjusted to achieve fast convergence of the neural network. Finally, we fine-tuned the parameters to optimize the overall control performance. After the calculation, the control parameters were determined as follows: , The number of hidden layers in the neural network was five. The initial weight value of the neural network was set to 0.1 for each element. Through friction fitting experiments, the parameters of the friction model are obtained as follows: The controller gains of C2–C4 are the same as those in C1.
C2: The BCF-SNN controller estimates unknown dynamics using a single-actor neural network (SNN). Unlike the proposed controller, it does not include a critic network for evaluating the actor network. The control law is shown in (65).
To ensure a fair comparison, the initial weight value of the BCF-SNN controller was set to be the same as that of the BCF-RL controller.
Remark 2. The neural networks used in this study feature a shallow architecture, resulting in lower computational complexity than deep neural networks. They are implemented in C language and executed on a real-time control system.
C3: Extended state observer (ESO) is a classic method for estimating states and system disturbances. To further compare the estimation performance of the disturbances, the neural network in C2 was replaced with an ESO for disturbance estimation. The specific design of the ESO can be found in [
19]. The ESO bandwidth was set to
.
C4: The BCF controller, which does not include a neural network compared with the BCF-RL, has the control law shown in (66).
C5: The traditional PID controller follows the control law expressed in (67).
The PID control parameters were set as and . These parameter values were determined using the typical Type-II system methodology for PID controller tuning and have been validated through simulation experiments.
6.2. Verification of Disturbance Estimation
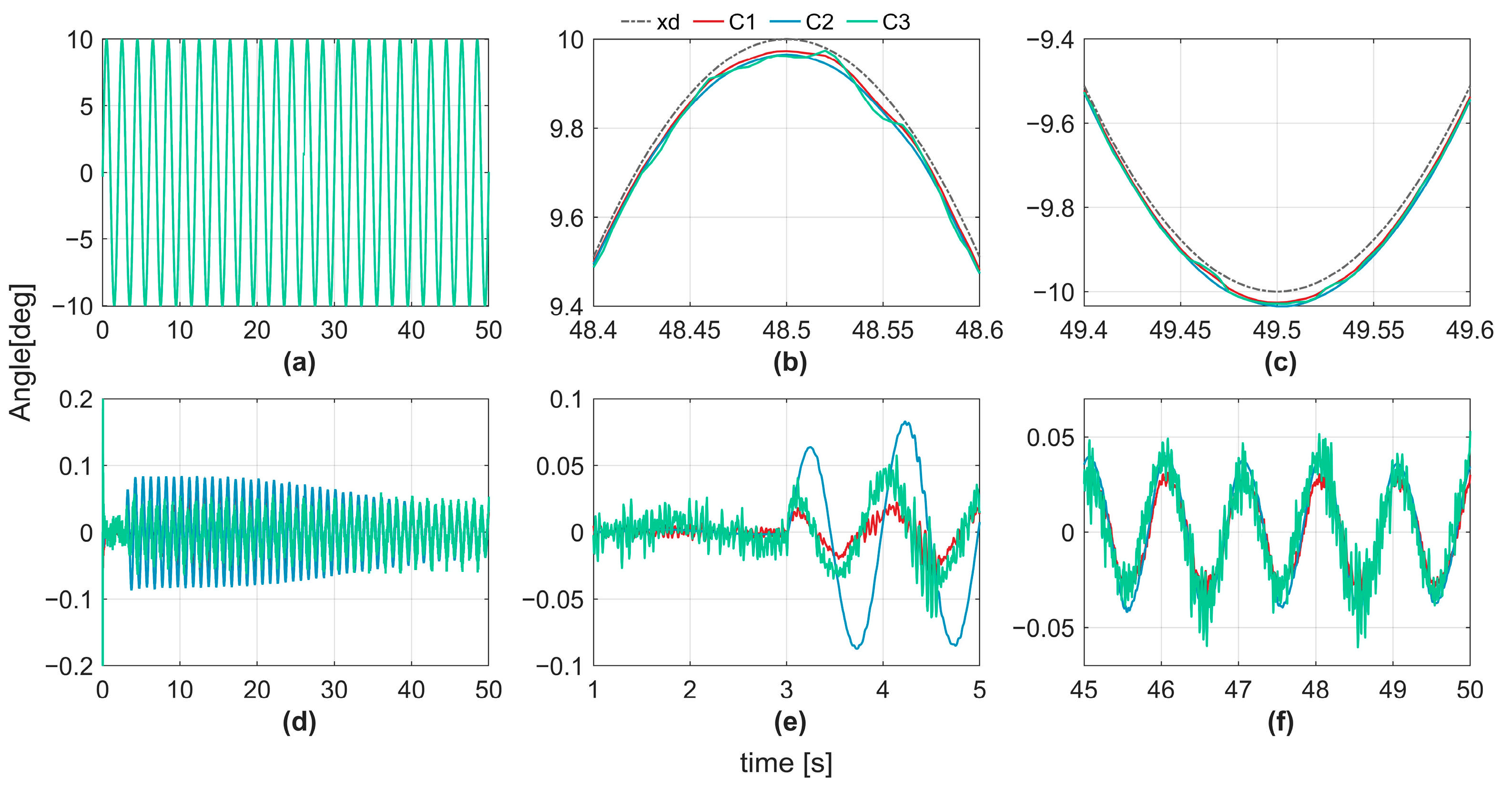
Simulations were conducted using the MATLAB/Simulink (2023b) software. Three controllers (C1, C2, C3) are compared in this study. The comparison between C1 and C2 evaluates the performance of the actor-critic mechanism implemented in C1. C3 employs a classical Extended state observer (ESO) for disturbance estimation. Because of the unmeasurable nature of unknown dynamics in real systems, the evaluation of disturbance estimation is conducted solely through simulations. In the simulation, the desired trajectory is defined as (deg), with the unknown disturbance set to zero during the first 3 s and introduced at as (Nm).
The tracking trajectories and errors of the three controllers are shown in
Figure 4.
Figure 4a shows the tracking curves of the four controllers.
Figure 4b and
Figure 4c show zoomed-in views of the last crest and trough regions in
Figure 4a, respectively.
Figure 4d presents the tracking error curves of the four controllers. To better observe the tracking performance immediately after the disturbance introduced at the 3 s mark,
Figure 4e displays a zoomed-in view of
Figure 4d over the 1–5 s interval. It can be observed that before the disturbance occurs, C3 exhibits the largest tracking error, followed by C3, whereas C1 achieves the smallest errors with minimal differences.
Figure 4f illustrates the zoomed-in tracking errors during the steady-state phase (45–50 s), showing that C3 has similar maximum tracking errors. Benefiting from the neural network’s more accurate disturbance estimation, the tracking errors of C2 and C1 were significantly reduced. In particular, C1, with its actor-critic mechanism, achieves the smallest tracking error. The maximum steady-state tracking errors for C1, C2, and C3 are 0.038°, 0.043°, and 0.06°, respectively.
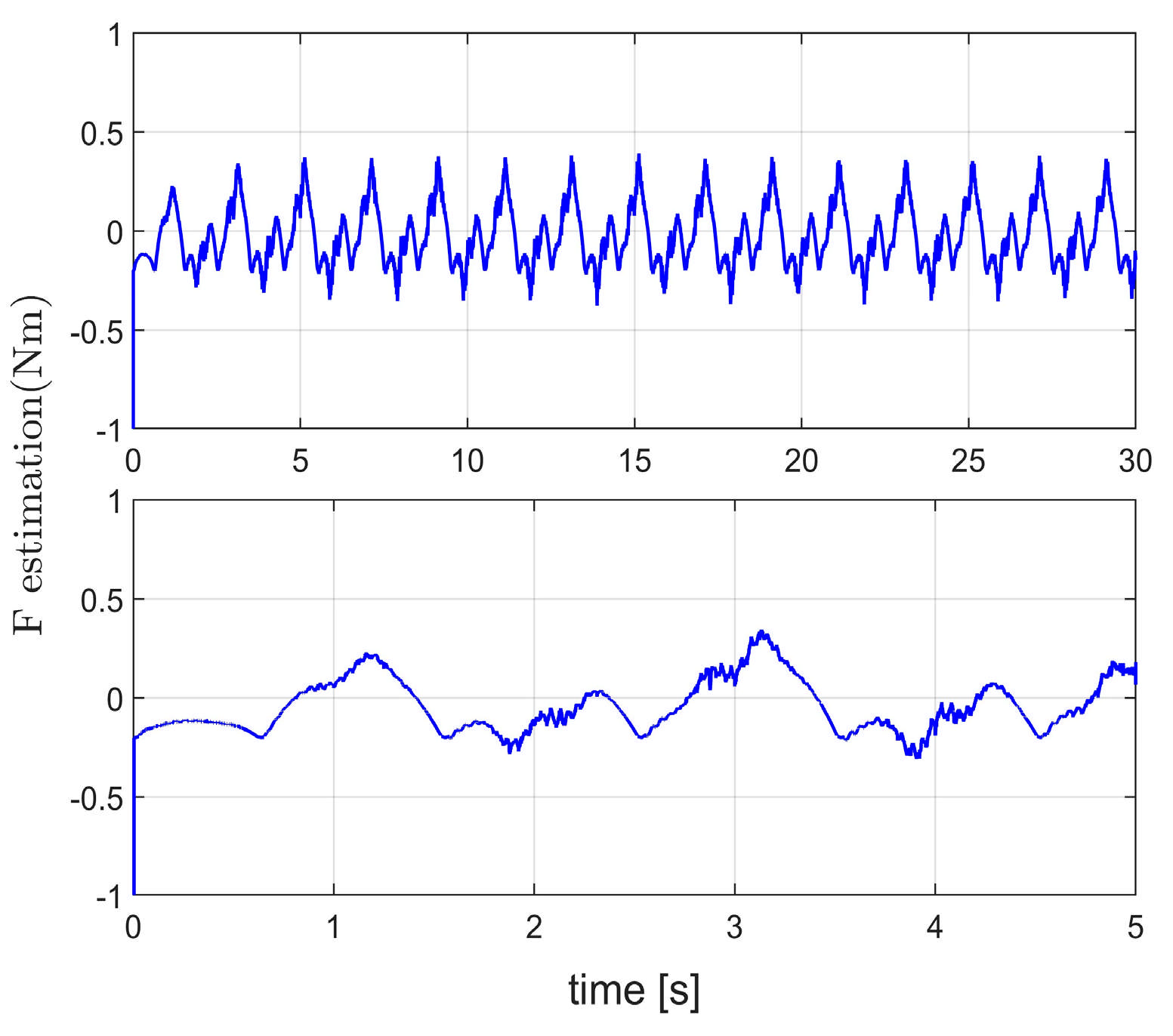
Figure 5 illustrates the estimation trajectories and errors of the unknown disturbances for the three controllers.
Figure 5b and
Figure 5c show zoomed-in views of the last crest and trough regions in
Figure 5a, respectively.
Figure 5d shows the tracking error curves of the unknown disturbances, while
Figure 5e presents a zoomed-in view of
Figure 5d over the 1–5 s interval. It can be observed that in the absence of disturbances, the disturbance estimation errors of the three controllers fluctuate around zero. After the disturbance is introduced at the 3 s mark, C1 achieves the smallest estimation error, followed by C3 and C2.
Figure 5f highlights the steady-state phase (45–50 s), where C1 still maintains the smallest estimation error, C2 ranks second, and C3 has the largest error. Although C3 initially converges faster when estimating unknown disturbances, its steady-state accuracy is inferior to that of C1 and C2. Additionally, C3’s estimation curve exhibits persistent oscillations, which are less smooth than those of C2 and C1, potentially imposing extra computational burdens on the system. The superior estimation accuracy of C1 over C2 further validates the effectiveness of the proposed actor-critic mechanism in C1.
Table 2 presents the results. The primary performance metrics include the maximum absolute tracking error (M), average tracking error (μ), and standard deviation of the tracking error (σ), as defined in [
19]. The subscript ‘o’ indicates the analysis term for an unknown dynamic estimation error.
Figure 6 shows a bar chart derived from the normalized data presented in
Table 2. Both
Table 2 and
Figure 6 indicate that all indicators of C1 surpassed those of C2 and C3.
6.3. Verification of Handling System Noise
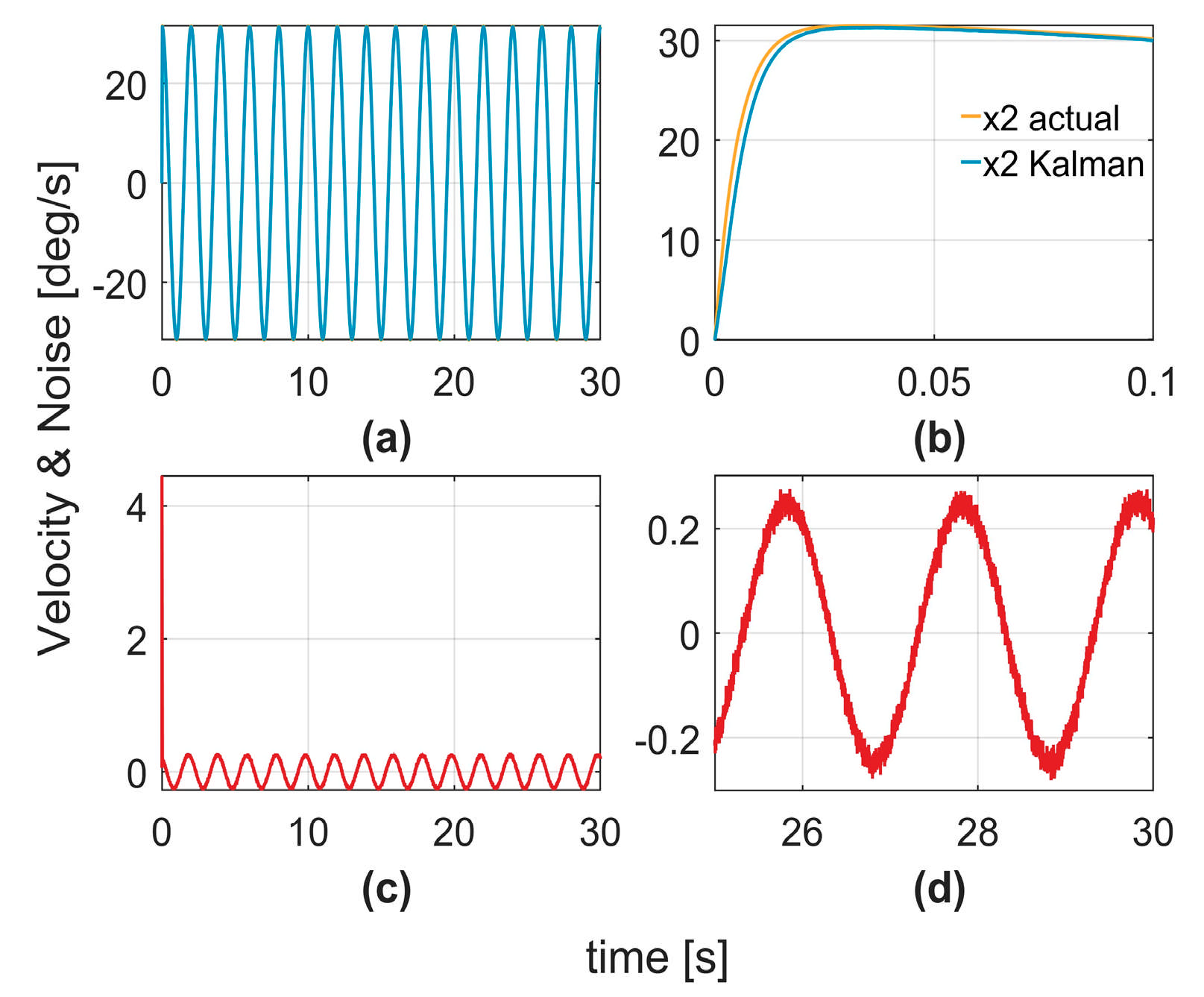
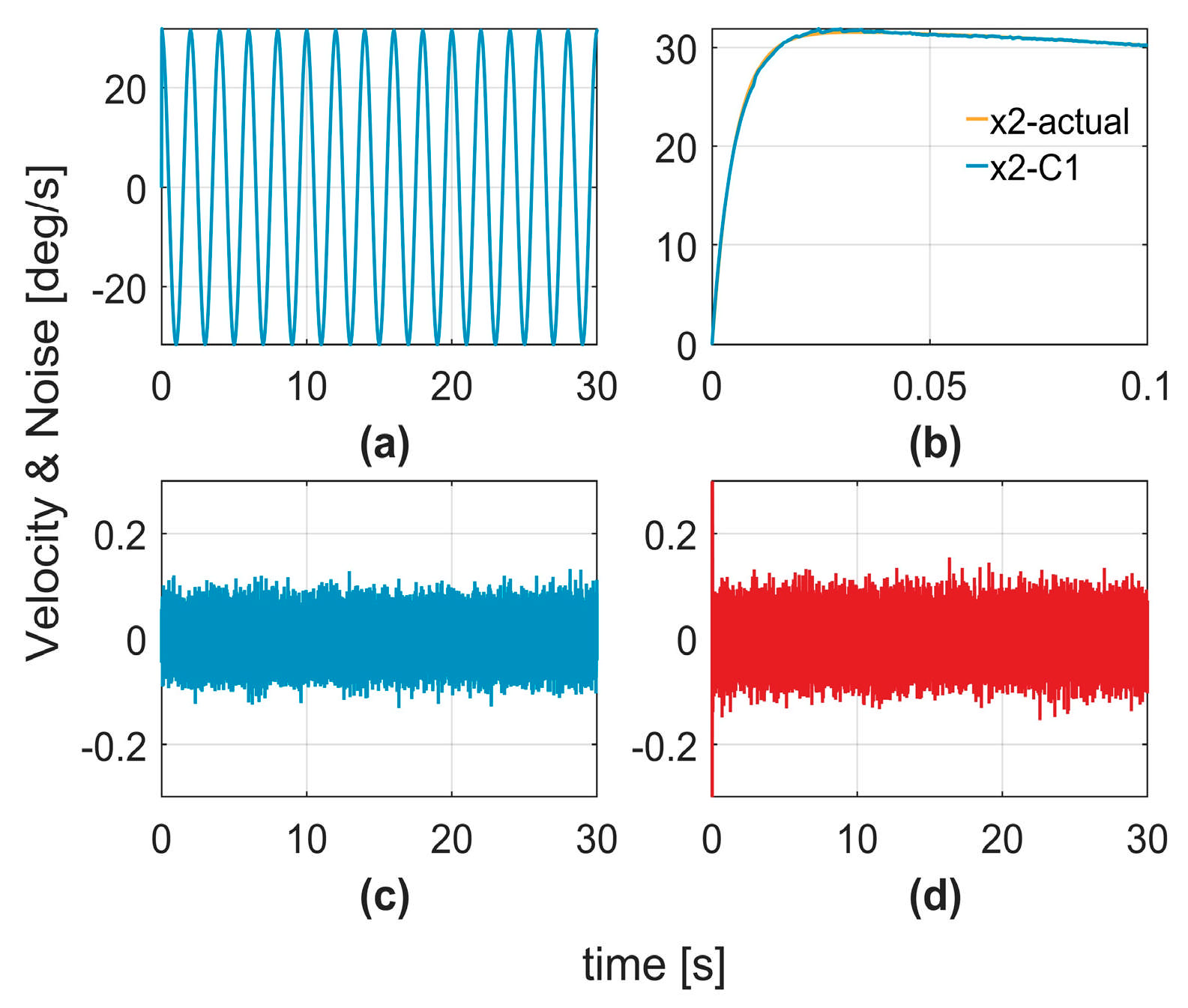
To verify the effectiveness of the controller in handling the system noise, a comparative analysis with a Kalman filter was conducted.
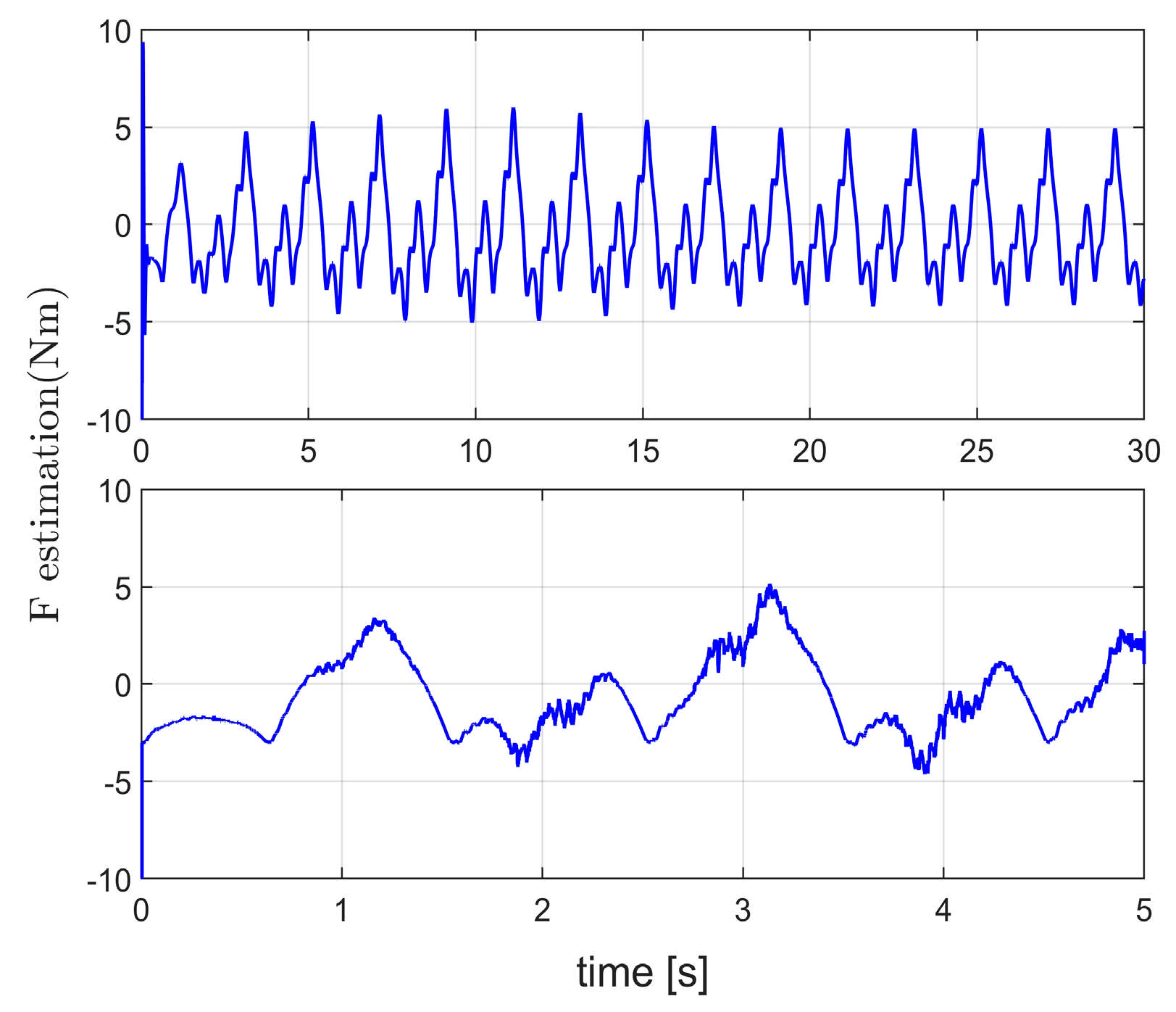
Figure 7a,b illustrates the velocity estimations generated by the Kalman filter.
Figure 7c,d depicts the estimation errors, representing the differences between the estimated and actual velocities, which correspond to the estimated noise signals.
Figure 8a,b shows the velocity estimations produced by the C1 controller, whereas
Figure 8d displays the noise signals estimated using Equation (11).
Figure 8c shows the artificially introduced noise signals added to the system. By comparing
Figure 7d and
Figure 8d, it is evident that the proposed method not only achieves more accurate noise signal estimation, but also generates smoother estimation curves, significantly mitigating the impact of noise on the system. This demonstrates that the proposed method outperformed the Kalman filter in terms of noise suppression and system robustness.
6.4. Verification of Tracking Performance
Five controllers were evaluated for tracking performance of the desired trajectory (deg).
6.4.1. Case 1: No Additive Disturbance
Figure 9 compares tracking errors in Case 1. Controller C5 exhibited the maximum steady-state error (0.074°), followed by C4 (0.062°). With reduced disturbance effects, C3 achieved a lower maximum steady-state error (0.056°) than the former two controllers. Through neural network-based estimation and compensation for unknown dynamics, C2 and C1 demonstrated higher precision. Particularly, C1 with critic neural network integration achieved optimal tracking performance (maximum steady-state error: 0.041°).
Figure 10 compares controller energy consumption.
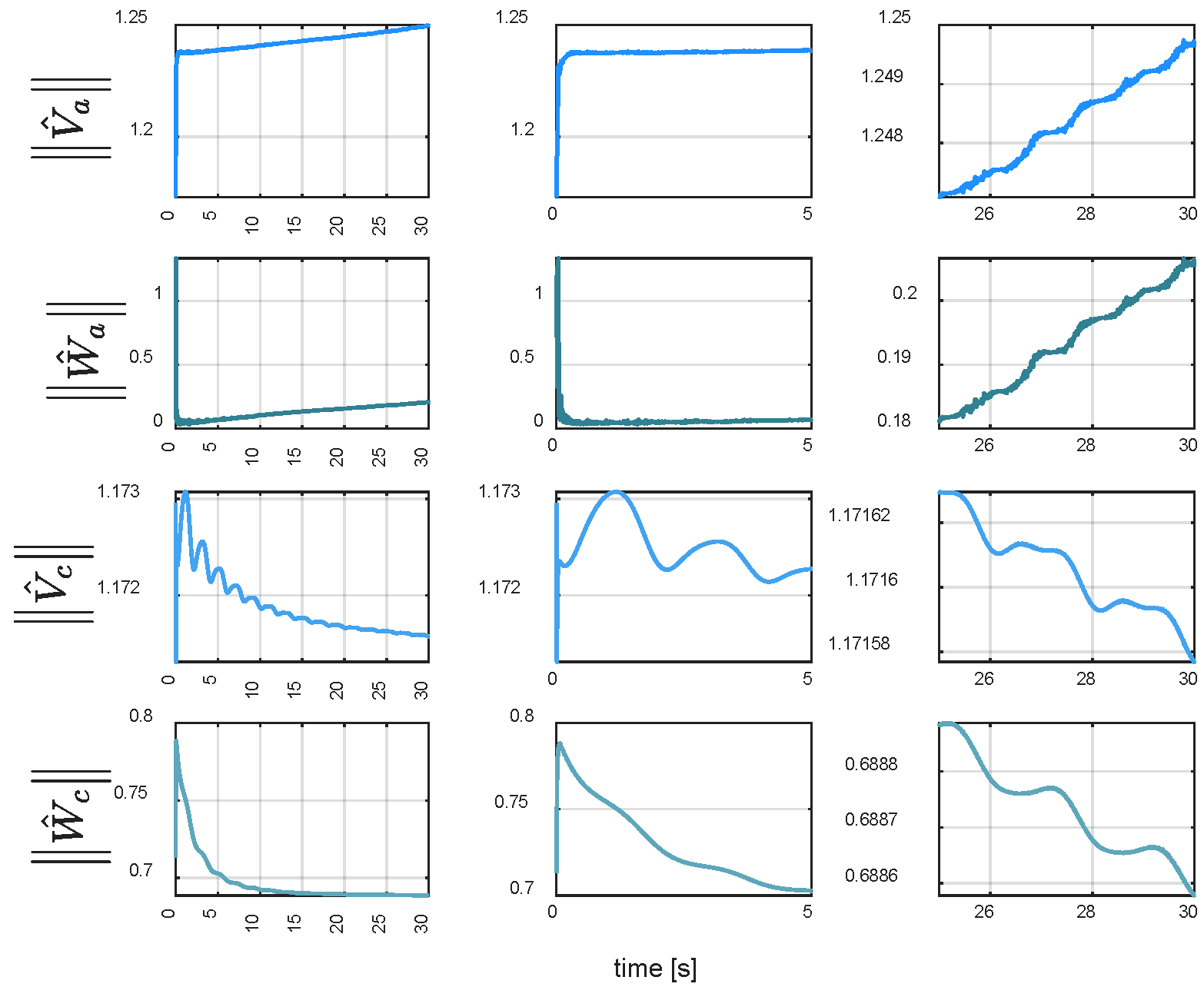
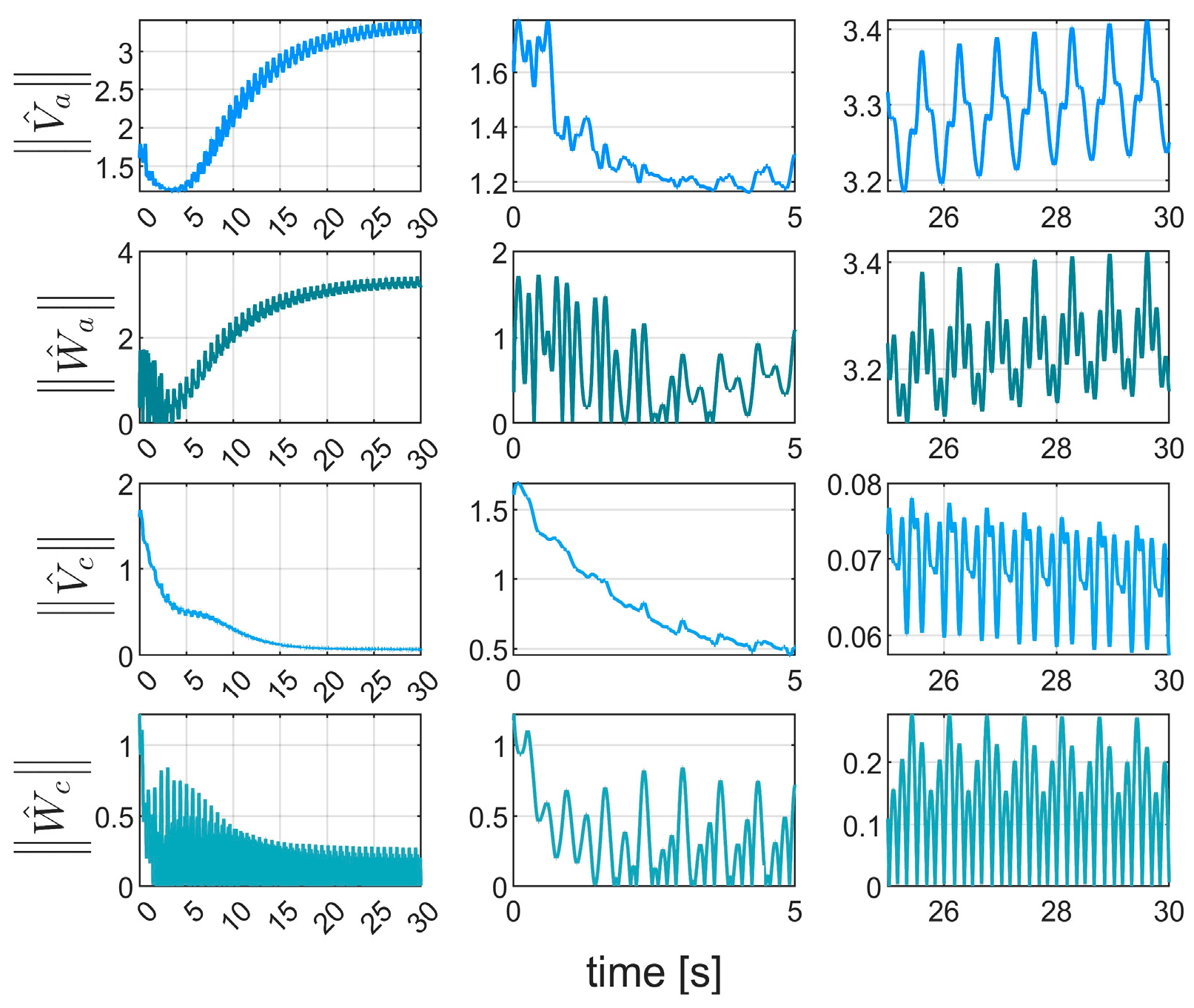
Figure 11 verifies real-time implementation of the RL-augmented controller.
Figure 12 shows rapid convergence of actor network weights under disturbance-free conditions.
Table 3 demonstrates the superiority of the proposed C1 controller across all key performance indicators (M is maximum steady-state error; μ is mean error; σ is the standard deviation of error). The root mean square of control input (Eu) reflects energy consumption. Comparative analysis reveals that C4 exhibits greater robustness than C5. However, because C4 lacks disturbance estimation compensation, its control precision is lower than that of C1–C3. Due to critic-actor structure, C1 achieves higher tracking accuracy compared to C2, which relies solely on a single neural network for disturbance estimation. While C2 demonstrates slightly lower energy consumption than C1, C1 outperforms C2 significantly with a 9% lower M value for critical performance metrics.
6.4.2. Case 2: Position–Velocity–Input Disturbance
Considering the diversity and complexity of actual working conditions, position–velocity–input interference is used to test the control effect of the controller, that is, the actual input of the plant is 0.5u − 0.2x1 + 0.05x2. Compared with Case 1, there are significant changes in the structural and unstructured uncertainties in this situation.
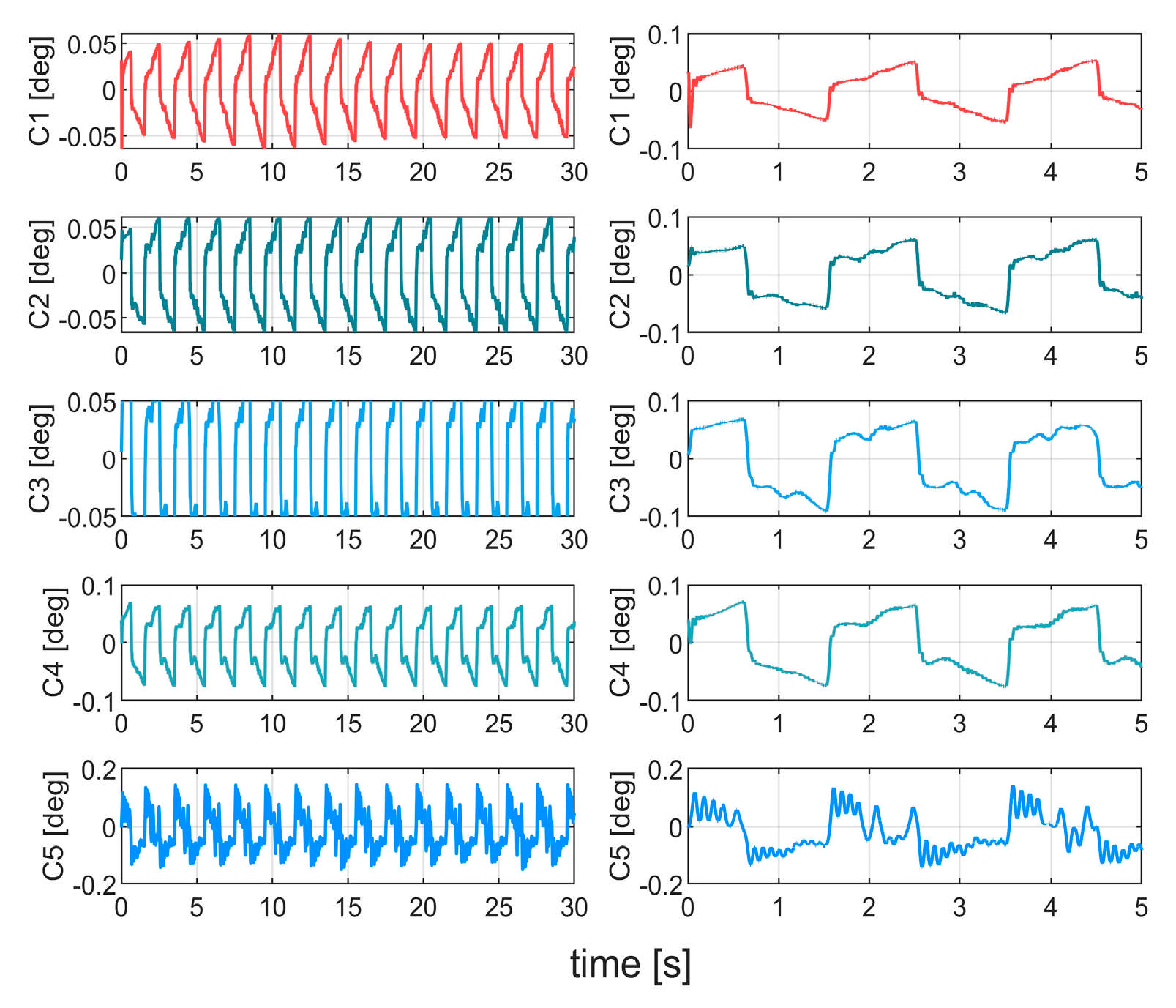
As shown in
Figure 13 and
Table 4, under complex conditions, C5 exhibits the largest steady-state tracking error of 0.12°, while the improvement of C4 is limited. Compared with C5 and C4, C3 achieves a 37% and 11% reduction in error, respectively. By employing neural network-based disturbance estimation and compensation, C2 further reduces the error to 0.064°. C1 achieves the lowest tracking error of 0.05°. The comparison of control inputs in
Figure 14 confirms that C1 achieves the best tracking while maintaining low energy consumption. The disturbance estimation in
Figure 15 and the variation of weight norms in
Figure 16 reveal that, despite the increased complexity, the actor-critic network remains convergent, and the reinforcement learning-assisted controller ensures stable operation under adverse conditions.
6.4.3. Confidence Interval and t-Test Analysis
To ensure the reliability of the experimental results, this study conducted repeated experiments on five controllers (C1–C5) under Case 2, collecting 20 trajectory tracking error samples for each controller. At a 95% confidence level (α = 0.05), the confidence interval was calculated based on the t-distribution using the following formula:
where
represents the mean tracking error of the
i-th controller,
denotes the standard deviation of the corresponding controller’s tracking error, and the sample size n = 20. Consulting the t-distribution table, with degrees of freedom n − 1 = 19, the critical value
= 2.093.
The confidence interval analysis presented in
Table 5 indicates that C1 exhibits the lowest mean tracking error (0.0418 deg) and the narrowest confidence interval ([0.0329, 0.0507]), demonstrating the smallest error and highest stability. In comparison, C2 has a slightly higher mean (0.0474 deg) and a marginally wider interval ([0.0375, 0.0573]); the confidence intervals of C3, C4, and C5 progressively increase in both mean and width, with C5 showing the highest mean (0.0835 deg) and the widest interval ([0.0671, 0.0999]), indicating the greatest variability. Overall, C1 outperforms C2, C3, C4, and C5 in terms of both mean error and stability, making it the optimal controller among the five.
To further quantify the performance advantage of the C1 controller, this study employed an independent samples Welch’s
t-test (two-sample
t-test assuming unequal variances) for inter-group difference analysis. As shown in
Table 6, using C1 as the baseline, one-tailed tests (α = 0.05) were conducted against C2–C5. The null hypothesis
was defined as
, indicating no difference in mean error between C1 and the i-th controller; the alternative hypothesis
was
, suggesting that C1’s mean error is less than that of the iii-th controller. The one-tailed critical t-value, based on degrees of freedom
, was approximately −1.686 from the t-distribution table. The t-value was calculated using the following formula:
The statistical results in
Table 6 indicate that, at a 95% confidence level, the mean error difference between C1 and C2 did not reach statistical significance (t = −0.881), failing to reject
. However, C1 demonstrated a significant advantage over C3, C4, and C5, with t-values of −2.128, −2.916, and −4.675, respectively, all below the critical value of −1.686–1.686−1.686. The negative mean differences (−0.016, −0.0226, and −0.0417) further confirm that C1’s tracking error is significantly lower than that of these controllers. Based on the hypothesis testing results, C1 exhibits statistically significant superiority in trajectory tracking performance, establishing it as the optimal controller.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}