1. Introduction
With the continuous advancement of science and technology and the improvement of human living standards, cold storage warehouses, as buildings that can maintain a constant low temperature, are widely used in various fields such as food, chemistry, pharmaceuticals, vaccines, plasma, and scientific experiments [
1]. Due to reasons related to food, environmental protection, and biosafety, most cold storage warehouses have strict hygiene and protective requirements. However, the process of staff entering and exiting the warehouse involves multiple disinfections and wearing protective clothing, which is time-consuming and cumbersome. The frequent entry and exit of personnel also lead to drastic heat and moisture exchange between the interior of the cold storage warehouse and the external environment, resulting in temperature fluctuations, frost formation, and potential damage to stored items. Moreover, for the safety of workers and biological samples, it is inconvenient for personnel to enter the cold storage warehouse for cargo loading and unloading, handling, inspections, and equipment maintenance. Therefore, there is an urgent need for unmanned remote operation and human–machine interaction in cold storage warehouses [
2].
In a cold storage environment, low temperatures can pose a threat to the camera, motors, and controllers, leading to reduced operational lifespans. Therefore, it is essential to ensure precision while maximizing the real-time performance of the system. Consequently, rapid identification and grasping of cartons are key research areas [
3], as their intelligence and accuracy will impact the costs and overall competitiveness of cold storage enterprises. Thus, conducting research in this area holds significant importance.
Based on convolutional neural networks, object detection algorithms can be classified into two types based on the presence of region proposals: Two-Stage object detection algorithms and One-Stage object detection algorithms. Two-Stage object detection algorithms first generate a series of candidate boxes as examples and then classify these boxes using a convolutional neural network. Representative algorithms include RCNN [
4], Fast RCNN [
5], Faster RCNN [
6], SPPNet [
7], and others. One-Stage algorithms do not generate candidate boxes; instead, they directly input the image into the convolutional neural network, transforming the problem of object boundary localization into a regression problem. The YOLO series represents the One-Stage approach and stands out for its speed and real-time detection capabilities [
8]. YOLOv5 inherits the advantages of its predecessors and has significantly improved accuracy with model updates.
Many researchers have made improvements to the YOLOv5 algorithm for different scenarios. Chen et al. transformed various task requirements into a unified object localization task and proposed a self-template method to fill the image boundaries, improving the model’s generalization ability and speed [
9]. Chen integrated image feature classification and improved the algorithm’s output structure through model pruning and classification [
10]. Both of these algorithms have high complexity and low efficiency in single-class object recognition scenarios. Zhang et al. used intersection over union (IoU) as a distance function to improve detection speed. They also enhanced the accuracy of network detection regression through transfer learning and the CoordConv feature extraction method [
11]. Chen et al. performed Mosaic-9 augmentation on the dataset and replaced the ResNet feature extraction network with MobileNet V3 Small, improving the feature extraction speed for small target samples [
12]. Karoll et al. used a bidirectional feature pyramid network as an aggregation path and introduced the SimAM attention module for feature extraction, improving detection accuracy [
13]. However, these three improvements are more suitable for scenes with high background complexity and are not suitable for storage recognition. Li et al. extended and iterated the shallow cross-stage partial connection (CSP) module and introduced an improved attention module in the residual block [
14]. Zhou et al. introduced residual connections and weighted feature fusion to improve detection efficiency. They also combined Transformer modules to enhance information filtering rate [
15]. These two methods have significant advantages for specific datasets but lack universality. Mohammad et al. improved the algorithm’s ability to detect small objects by adding shallow high-resolution features and changing the size of the output feature maps [
16]. Zhou et al. added detection branches in the middle and head blocks of YOLOv5 to improve local feature acquisition. They also enhanced detection accuracy by adding CBAM and DA attention modules [
17]. Xiao et al. modified the network’s width and depth for detecting small objects in high-resolution images, improving detection speed [
18]. These three methods mainly focus on improving the detection of small-sized objects and do not fully meet the requirements of storage.
Although many studies have made improvements to the YOLOv5 algorithm, it is challenging to directly apply them to the recognition of stacked cartons in a cold storage warehouse environment. This article aims to address the need for high accuracy and real-time performance in cold storage logistics. The research content is as follows:
- (1)
By integrating the CA attention mechanism, meaningful features on the channel and spatial axes are extracted to enhance the correlation representation of target information between different channels in the feature map.
- (2)
By introducing the lightweight Ghost module, the model parameters are compressed, maintaining detection accuracy and speed, and facilitating subsequent deployment on mobile embedded devices.
- (3)
By optimizing the loss function and replacing the original network’s GIoU with Alpha-DIoU, faster convergence can be achieved, and the predicted boxes can be closer to the ground truth, improving localization accuracy.
The writing process is as follows:
- (1)
Chapter 2 designs a human–machine interactive control system, reasonably arranges various modules, and explains the system modules and composition structure.
- (2)
Chapter 3 proposes an improved recognition algorithm and conducts testing and evaluation of the enhanced algorithm.
- (3)
Chapter 4 conducts practical tests on the control system and algorithm. An experimental platform is set up to analyze the system’s performance from fidelity, response time, and accuracy perspectives, demonstrating the overall improvement in the control system’s performance.
- (4)
Chapter 5 provides a reasonable summary of the work presented in this paper.
2. Human–Machine Interaction Control System
The system configuration is shown in
Figure 1. Firstly, an image acquisition is performed using a camera and transmitted to the PC. On the PC platform, using the Windows operating system, the YOLOv5 object detection model is run to detect and recognize objects in the images. After converting the coordinates of the target objects, they are transmitted to the lower-level machine using a serial communication protocol. Based on the received coordinate information, the gripper is accurately moved to the specified position by controlling the motor and air pump through instructions. The target localization and gripping are achieved by using a suction cup.
This paper’s control system consists of six subsystems: communication, capture, inference, electrical control, pneumatic control, and system. The framework diagram is shown in
Figure 2.
The communication subsystem is a key component of the system, responsible for data transmission and information exchange between the upper computer and other devices. Serial communication is used to exchange data and control instructions with each subsystem, enabling their collaborative work. The capture subsystem is responsible for invoking the camera device to capture images and obtain clear and accurate image data for subsequent analysis and processing. The inference subsystem refers to the use of deep learning models in the system for tasks such as object detection and recognition on the captured images or videos. The electrical control subsystem involves motor control and driving, responsible for controlling the operation of motors in the system. It enables automation control and precise motion execution. The pneumatic control subsystem involves gas control and driving, used to control and adjust the flow, pressure, and operation of gases. It performs the motion control of the suction cup and object gripping actions. The system subsystem includes the overall system switch and reset settings.
3. Control Algorithm Design
3.1. Introduction to YOLOv5
YOLOv5 divides an image into an S × S grid and generates several candidate boxes adaptively within each grid cell. The parameters of these boxes are then calculated to obtain information such as center point, width, height, and confidence. Finally, object prediction is performed to obtain the results. The network consists of four parts: the input, backbone, neck, and head.
The input module receives the image as input and employs the Mosaic data augmentation technique. It randomly crops, arranges, and concatenates four images to generate a new input image. Adaptive anchor box calculation and adaptive image scaling are used to adapt to anchor boxes and image sizes in different training datasets. Taking YOLOv5s as an example, each image is scaled to a size of 640 × 640. These improvements enrich the model, enhance its robustness, and improve training speed and detection capabilities. The backbone is a critical part of feature extraction, consisting of modules such as Focus, CBS, C3, and SPPF. The Focus module slices the image, expands the input channels by 4 times, and performs convolution operations to achieve feature extraction and downsampling. The CBS module is a convolutional layer that introduces non-linearity through BN batch normalization and SiLU activation function to avoid overfitting. The C3 module is used to further learn more features. The SPPF module, short for spatial pyramid pooling, is used to enlarge the receptive field and fuse information from feature maps of different scales to achieve feature fusion.
The neck module is mainly used for feature fusion and adopts the FPN-PAN network structure. It transmits localization features in a bottom-up manner, enabling the feature maps to contain both detailed and semantic information. The neck module is responsible for feature extraction and transfers these features to the output module, where the output layer generates object boxes and class confidences. To address the non-overlapping boundary issue, the GIOU (Generalized IOU) Loss is used as the regression box prediction loss function. The non-maximum suppression (NMS) method is applied to remove low-scored prediction boxes and select the best results. The output module generates feature maps at three scales, performing downsampling by a factor of 8, 16, and 32 on the original image. The output module includes classification loss, localization loss, and confidence loss, which are used to predict small, medium, and large objects.
3.2. Model Comparison
After thorough comparison and consideration, we have decided to use YOLOv5 instead of YOLOv8 as the object detection model for this project. While YOLOv8 shows some performance improvements in certain aspects, YOLOv5 remains better suited for our current needs. Firstly, YOLOv5 exhibits faster inference speed, reaching up to 62.5 FPS under equivalent hardware conditions, whereas YOLOv8 achieves 54.4 FPS. Secondly, the average precision of both models on the COCO test set is quite close, with 47.0 and 47.2 mAP for YOLOv5 and YOLOv8, respectively, indicating minimal differences.
However, YOLOv5 has a parameter count of only 41M, making it more lightweight compared to YOLOv8’s 52M, which is more resource-friendly for our storage and computational resources. Moreover, YOLOv5 supports a wider range of input resolutions, ranging from 640 to 1280, for both training and inference. In contrast, YOLOv8 requires a minimum resolution of 1280, which places higher demands on the input images. Additionally, YOLOv5 offers various data augmentation techniques that can enhance model robustness, providing valuable assistance to us.
Furthermore, YOLOv5 boasts a more active developer community and a wealth of application cases, making it easier to obtain support and reference existing experiences. In summary, considering factors such as accuracy, speed, and resource requirements, we believe YOLOv5 is the superior choice. While YOLOv8 also has its merits, YOLOv5 can deliver the detection performance we need for the current project, while offering greater stability, flexibility, and ease of use.
3.3. Improvements to YOLOv5
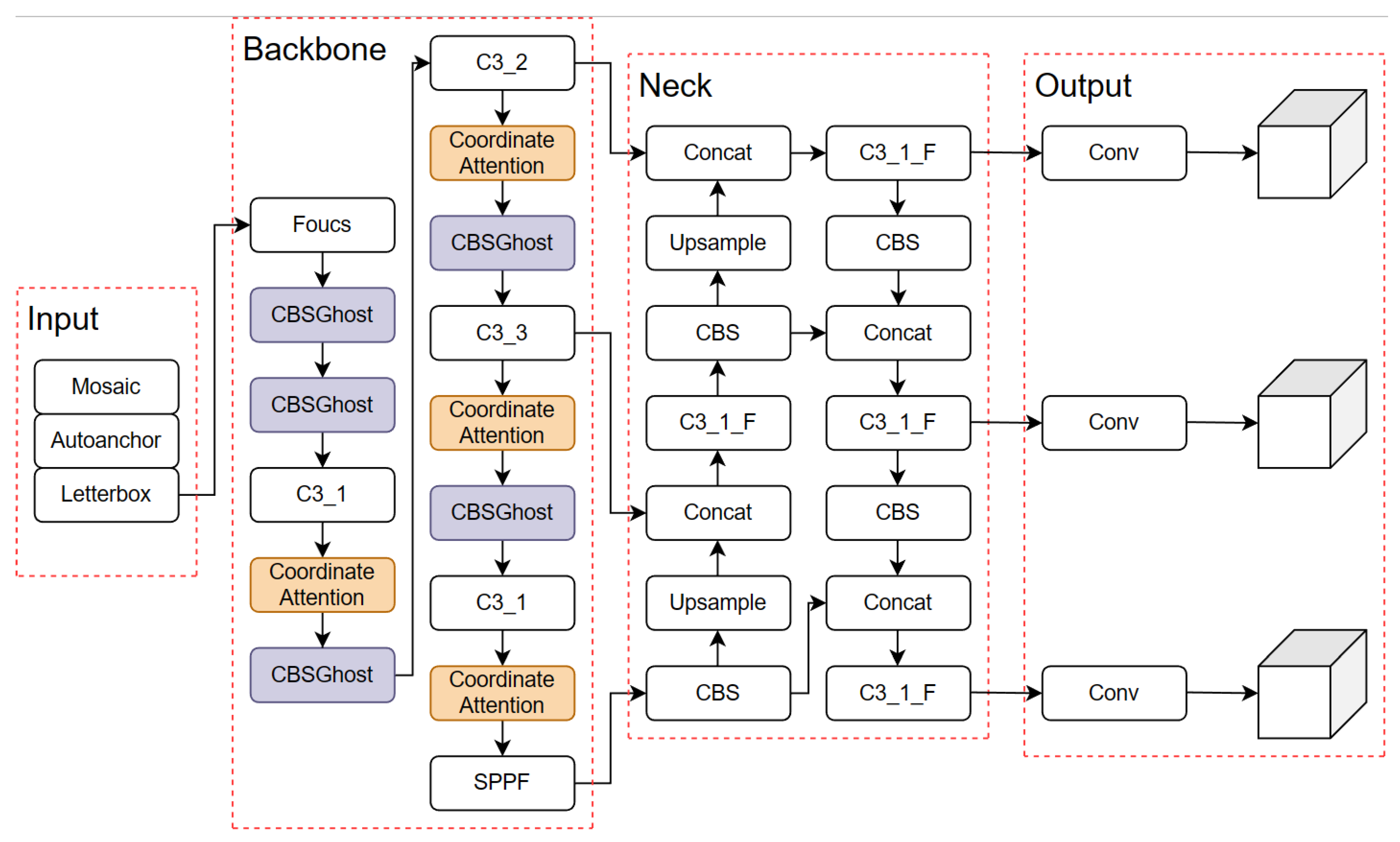
A series of improvements were made to the YOLOv5 base, and the improved network structure is shown in
Figure 3.
3.3.1. Addition of Coordinate Attention (CA) Mechanism
The Coordinate Attention (CA) mechanism incorporates position information into channel attention. It not only captures inter-channel information but also captures direction and position-aware information, which helps the model to locate and recognize the target of interest more accurately [
19]. The CA mechanism consists of two steps: coordinate information embedding and coordinate attention generation, encoding precise positional information for channel relationships and long-range dependencies. The structure of the CA mechanism is shown in
Figure 4.
For the input feature tensor,
, where C, H, and W represent the number of channels, height, and width of the input feature map, respectively. CA encodes each channel by pooling kernels of size (H, 1) and (1, W) along the horizontal and vertical coordinates, respectively. The output for the c-th channel at height h and width w is given by the following equation:
The two transformations mentioned above aggregate features along two spatial directions to obtain a pair of direction-aware feature maps, namely X Avg Pool and Y Avg Pool in
Figure 4. These feature maps are then concatenated and undergo a convolutional transformation F1 using a shared 1 × 1 convolutional kernel, as shown in the following equation:
In the equation, [·,·] represents the concatenation operation along the spatial dimension, δ is a non-linear activation function, and f refers to the intermediate feature map obtained from spatial information in the horizontal and vertical directions. The feature map f is split into two separate tensors,
and
, along the spatial dimension. These tensors are then transformed to have the same number of channels as the input tensor X using two 1 × 1 convolutions, denoted as
and
, as shown in the following equation:
In the equation,
represents the sigmoid function, which is applied to expand and scale the tensors
and
as attention weights. The final output feature tensor
of the CA module can be expressed as follows:
By introducing the attention mechanism into the detection network, this study focuses the model’s attention on the target objects, thereby improving accuracy. The CA attention mechanism is added to the C3 module of the YOLO backbone network, as shown in
Figure 5. The input feature map dimensions are set to 128, 256, 512, and 1024, according to the output size of the original position module. This structure allows the model to effectively utilize the CA attention mechanism and enhance the performance of the YOLO network.
3.3.2. Ghost Module Replacement
Replacing the C3 module in the YOLOv5 backbone network, which has a large number of parameters and slower detection speed, is necessary to achieve lightweight modeling for real-time object detection in embedded platforms for human–machine interaction. To address this, the Ghost module is introduced in this study, enabling a significant reduction in network parameters, model size, and computational speed improvement [
20].
The Ghost module aims to alleviate the redundancy issue in traditional convolutional neural networks, which increases computational complexity. By reducing the number of convolutions and using a small number of convolutions to linearly transform features, the Ghost module achieves an increased feature map with fewer parameters, as shown in
Figure 6. The process involves splitting the original convolutional layer into two steps; the first step performs convolutional computation using GhostNet, and the second step integrates the features to form the new output.
Given the input feature map
and output feature map
, with a convolutional kernel f of size k × k, the convolutional computation
is performed. Here, C, H, and W represent the channel number, height, and width of the input feature map, while n, h, and w represent the channel number, height, and width of the output feature map. Linear operations are applied to each original feature map to generate s feature maps, as follows:
In the equation,
represents the i-th original feature map in Y,
represents the linear operation, m represents the number of intrinsic feature maps, and
represents the number of feature maps obtained. The theoretical acceleration ratio can be calculated as follows:
The parameter compression rate is given by
In this paper, all three CBS (Convolution-BatchNorm-SiLU) structures in the YOLOv5 architecture are replaced with the CBSGhost module, achieving structural lightweighting, as shown in
Figure 7.
3.3.3. Improved Loss Function
During the training process of convolutional neural networks, the network parameters are continuously updated by calculating the error using a loss function. The loss function of YOLOv5 consists of three parts. The BECLogits loss function is used to calculate the confidence
, the cross-entropy loss function is used to calculate the classification target
, and the GIoU Loss loss function is used to calculate the regression box prediction
. The total loss is defined as follows:
But the GIoU Loss still has some issues in certain situations. For example, when two bounding boxes are very close or overlap significantly, the IoU tends to approach 1, but they may not be well-aligned spatially. In such cases, GIoU can be highly misleading and lead to a decrease in detection performance. Therefore, when replacing the GIoU Loss function with the DIoU Loss function, as shown in
Figure 8, the problem of GIoU producing larger loss values when the distance between two boxes is large and results in a larger enclosing region is solved. This leads to faster convergence [
21]. The calculation formula for GIoU Loss is as follows:
Among them,
and
represent the center points of the predicted box and the ground truth box,
represents the Euclidean distance, the calculation result is
,
represents the diagonal length of the minimum enclosing box, and
represents the intersection over union between the predicted box and the ground truth box. Alpha-IoU Loss is a powerIoU loss function proposed by He et al. which can be used for accurate bbox regression and object detection [
22]. By extending GIoU Loss using Alpha-IoU, the predictive loss function Alpha-DIoU Loss is obtained, and the calculation formula is as follows:
By utilizing the hyperparameter , this predictive loss function can achieve different levels of bounding box regression accuracy more flexibly, and it exhibits greater stability for large datasets and noisy data. In this experiment, we set .
3.4. Performance Evaluation
3.4.1. Evaluation Metrics
The results of this model divide the data into true positives (TPs), false positives (FPs), true negatives (TNs), and false negatives (FNs) based on the annotated ground truth class and predicted class. TP represents the detection of a box that is actually a box, FP represents the detection of a box that is not actually a box, TN represents the detection of a non-box that is actually not a box, and FN represents the detection of a non-box that is actually a box. Precision (P) is the ratio of correctly identified boxes to the total number of predicted boxes, and recall (R) is the ratio of correctly identified boxes to the total number of ground truth positive samples.
Average Precision (AP) and mean Average Precision (mAP) can be used to evaluate the recognition performance of the model.
3.4.2. Evaluation Results
In this study, the Stack Carton Dataset (SCD) publicly released by Huazhong University of Science and Technology was used, consisting of a total of 8399 images and 151,679 instances. The dataset contains only one category: “Carton”. The training set and test set were divided in an 8:2 ratio. Conducting ablation experiments, the results are shown in
Table 1 and
Table 2, and
Figure 9.
By comparing the above tables and figures, it can be observed that the three improvements have different aspects of enhancing the model’s performance. Additionally, the models incorporating these three improvements have achieved a balance between speed and accuracy. It is evident that the improved algorithms have increased the confidence scores for stack cartons and further strengthened the detection capability, aligning with the requirements of embedded devices.
5. Conclusions
This paper presents a carton recognition and grasping control system based on YOLOv5.
By introducing the CA attention mechanism, incorporating Ghost lightweight modules, and modifying the loss function to Alpha-IoU, the system’s operational speed and prediction accuracy have been improved. Simulated experimental results on a PC platform demonstrate certain enhancements in carton stacking detection. The comprehensive algorithm improvements in this paper have led to a 0.711% increase in mean average precision (mAP) and a 0.7% increase in frames per second (FPS), all while maintaining precision.
An end-to-end human–machine interaction control system has been constructed, encompassing functions such as interface design, camera invocation, image transmission, and more, establishing a stable and reliable data interaction. Moreover, with the utilization of the enhanced model, algorithm response time has decreased by 2.16% and localization accuracy has improved by 4.67% in a simulated environment, facilitating future deployment on embedded systems.
This study combines principles from deep learning theory and, through preliminary experimental tests, presents an innovative solution for human–machine interaction applications of warehouse robots in the cold storage industry. It effectively enhances the overall efficiency of cold chain logistics, saves labor resources, and ensures personnel safety. Future work could focus on further optimizing system performance and enhancing algorithm efficiency and accuracy. The study holds significant potential for wide application and dissemination.



 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}