
A Decentralized LQR Output Feedback Control for Aero-Engines
Abstract
1. Introduction
- With the improvement of aero-engine performance, the function and complexity of control tasks have greatly increased, which has increased the workload of controller. The control system needs to use high-performance, multi-core processors as its controller, which in turn puts relatively high demands on the thermal management system of the aero-engine.
- The amount of software code in aero-engine control systems is increasing rapidly, which significantly impacts the software reliability.
- The core control tasks of the aero-engine, such as control-law calculation, are executed in the central controller. The central controller determines the performance of the entire aero-engine control system, and its failure or damage has significant impact on the aero-engine or even the aircraft.
2. Aero-Engine Model
2.1. Nonlinear Modeling
- (1)
- Intake
- (2)
- Fan
- (3)
- Compressor
- (4)
- Combustion chamber
- (5)
- High-pressure turbine
- (6)
- Low-pressure turbine
- (7)
- Bypass duct
- (8)
- Mixer
- (9)
- Nozzle
- (1)
- High-pressure rotor power balance
- (2)
- Low-pressure rotor power balance
- (3)
- Fan air flow balance
- (4)
- High-pressure turbine gas flow balance
- (5)
- Low-pressure turbine gas flow balance
- (6)
- Nozzle gas flow balance
2.2. Linear State Space Model
3. Output Feedback of Decentralized Control System
4. Q-Learning Based LQR Output Feedback Control
4.1. General LQR Problem Solving
4.2. Construction of the Output Feedback Control
4.3. Acquisition of the VCTs
5. Parameter Tuning Based on the Primal-Dual Method
- If is the optimal point of the primal problem, is the optimal point of the dual problem of the primal problem, then satisfies the KKT condition of :
- Define , then, if , , and is a symmetric positive semi-definite cone. A matrix norm makes a contractive mapping. There is a unique symmetric matrix that makes , that is, has a unique fixed point .
- The in the following algorithm converges to the optimal solution of the dual problem, that is, the optimal solution of the matrix required in Equation (58).
- Initialization of , , and .
- Calculate .
- Solve from .
- Repeat.
- .
- Dual update: .
- Primal update: .
- .
- Until .
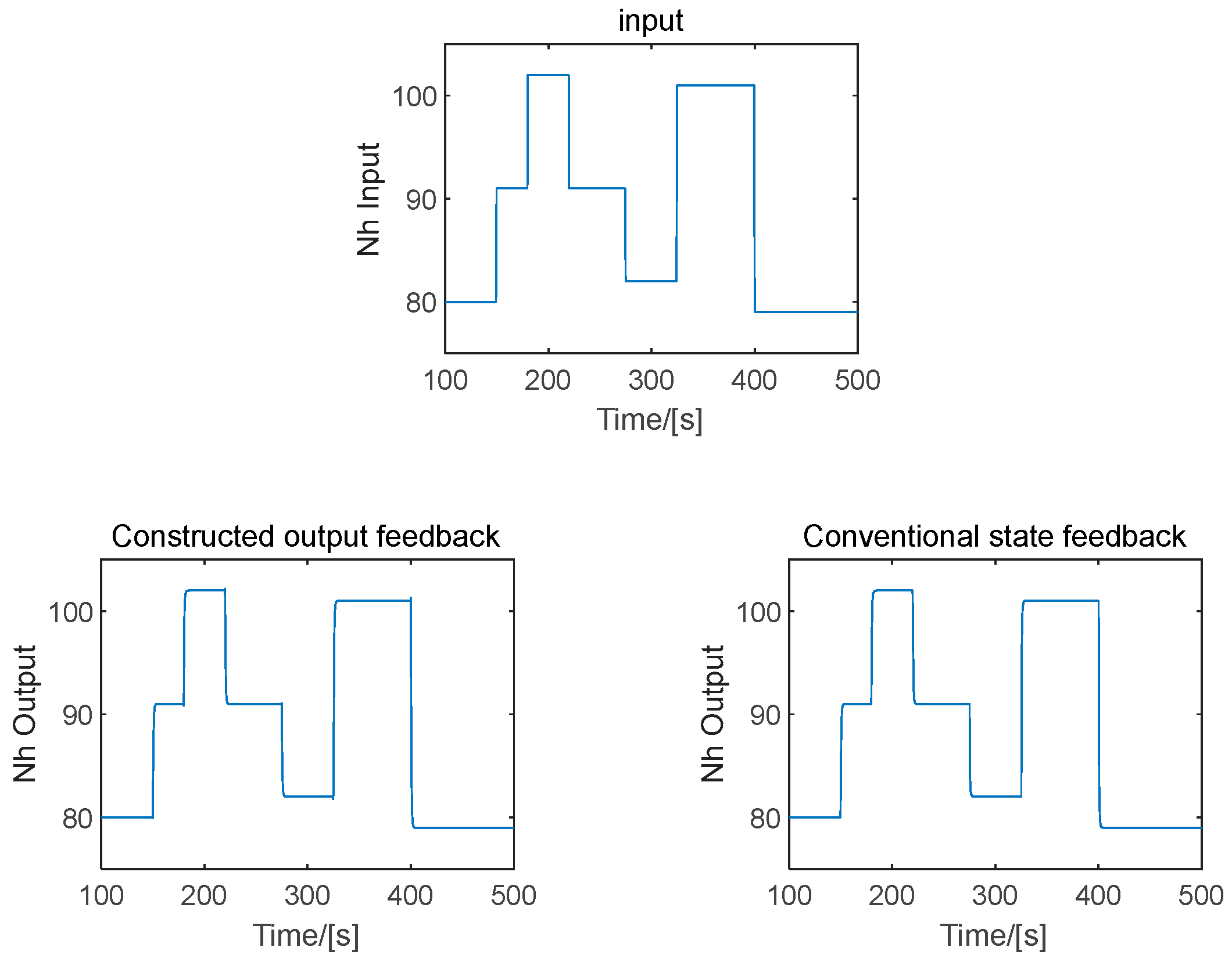
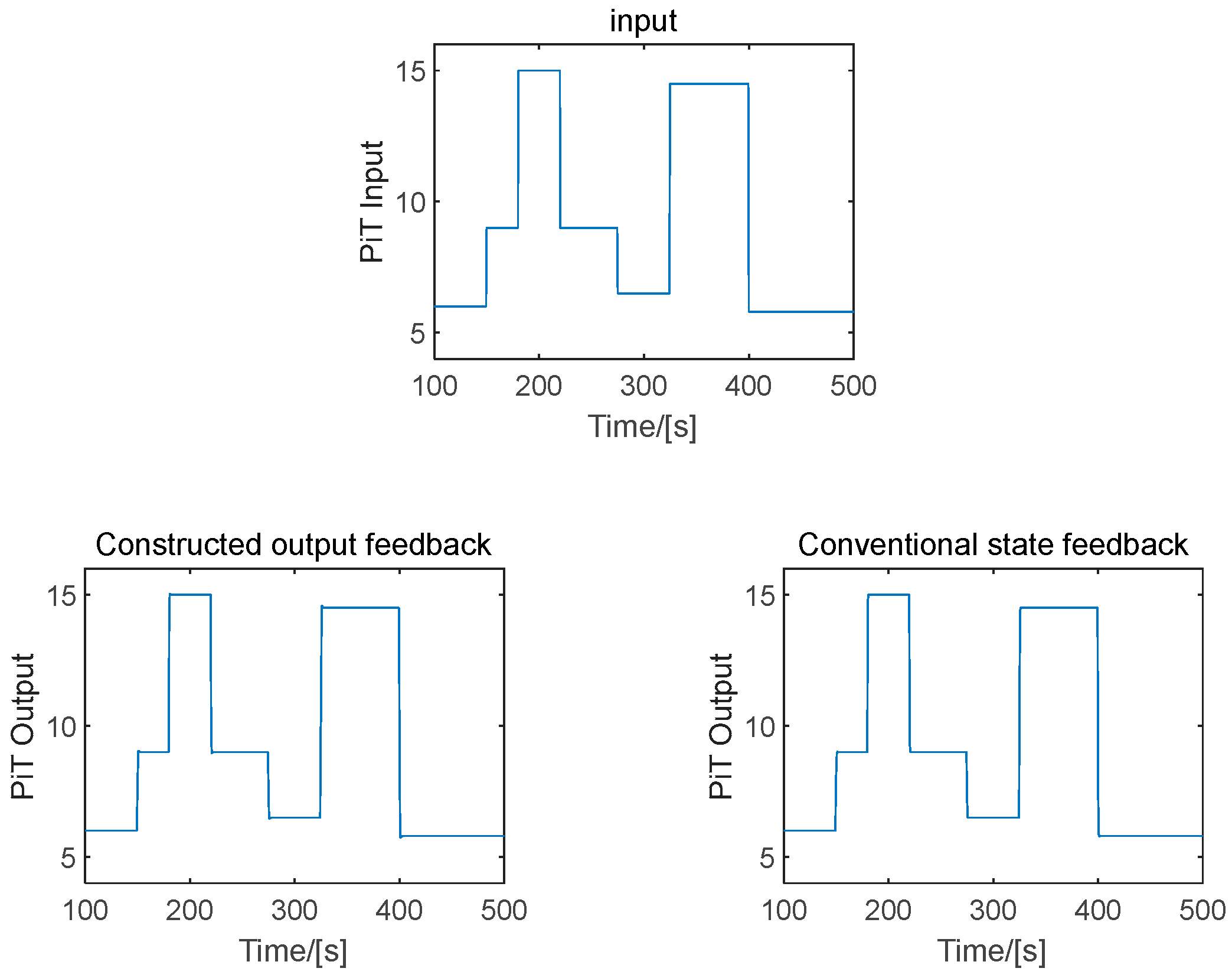
6. Simulation Analyses
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Thompson, H.; Fleming, P. Distributed Aero-Engine Control Systems Architecture Selection Using Multi-Objective Optimisation. In Proceedings of the 5th IFAC Workshop on Algorithms & Architecture for Real Time Control (AARTC’ 98), Cancun, Mexico, 15–17 April 1998. [Google Scholar]
- Skira, C.; Agnello, M. Control Systems for the Next Century’s Fighter Engines. J. Eng. Gas Turbines Power 1992, 114, 749–754. [Google Scholar] [CrossRef]
- Culley, D.; Thomas, R.; Saus, J. Concepts for Distributed Engine Control. In Proceedings of the 43rd AIAA/ASME/SAE/ASEE Joint Propulsion Conference & Exhibit, Cincinnati, OH, USA, 8–11 July 2007. [Google Scholar]
- Chen, T.; Shan, J. Distributed Tracking of Multiple Under-actuated Lagrangian Systems with Uncertain Parameters and Actuator Faults. In Proceedings of the 2019 American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019. [Google Scholar]
- Chen, T.; Shan, J. Distributed Tracking of a Class of Underactuated Lagrangian Systems with Uncertain Parameters and Actuator Faults. IEEE Trans. Ind. Electron. 2020, 67, 4244–4253. [Google Scholar] [CrossRef]
- Chen, T.; Shan, J. Distributed Fixed-time Control of Multi-agent Systems with Input Shaping. In Proceedings of the 2018 IEEE International Conference on Information and Automation (ICIA), Wuyishan, China, 11–13 August 2018. [Google Scholar]
- Chen, T.; Shan, J. Distributed Adaptive Attitude Control for Multiple Underactuated Flexible Spacecraft. In Proceedings of the 2018 Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018. [Google Scholar]
- Thompson, H.; Benitez-Perez, H.; Lee, D.; Ramos-Hernandez, D.; Fleming, P.; Legge, C. A CANbus-Based Safety-Critical Distributed Aeroengine Control Systems Architecture Demonstrator. Microprocess. Microsyst. 1999, 23, 345–355. [Google Scholar] [CrossRef]
- Chen, L.; Guo, Y. Design of the Distributed Control System Based on CAN Bus. Comput. Inf. Sci. 2011, 4, 83–89. [Google Scholar] [CrossRef]
- Lv, C.; Chang, J.; Bao, W.; Yu, D. Recent Research Progress on Airbreathing Aero-engine Control Algorithm. Propuls. Power Res. 2022, 11, 1–57. [Google Scholar] [CrossRef]
- Xu, Y.; Pan, M.; Huang, J.; Zhou, W.; Qiu, X.; Chen, Y. Estimation-Based and Dropout-Dependent Control Design for Aeroengine Distributed Control System with Packet Dropout. Int. J. Aerosp. Eng. 2022, 2022, 8658704. [Google Scholar] [CrossRef]
- Fan, X.; Pan, M.; Huang, J. Response Time Analysis of TTCAN Bus for Aero-engine Distributed Control System. In Proceedings of the Asia-Pacific International Symposium on Aerospace Technology (APISAT 2015), Cairns, QLD, Australia, 25–27 November 2015. [Google Scholar]
- Schley, W. Distributed Flight Control and Propulsion Control Implementation Issues and Lessons Learned. In Proceedings of the ASME 1998 International Gas Turbine and Aeroengine Congress and Exhibition, Stockholm, Sweden, 2–5 June 1998. [Google Scholar]
- Zulkifli, N.; Ramli, M. State Feedback Controller Tuning for Liquid Slosh Suppression System Utilizing LQR-LMI Approach. In Proceedings of the 2021 IEEE International Conference on Automatic Control & Intelligent Systems (I2CACIS), Shah Alam, Malaysia, 26–26 June 2021. [Google Scholar]
- Zhou, Y.; Xu, G.; Wei, S.; Zhang, X.; Huang, Y. Experiment Study on the Control Method of Motor-Generator Pair System. IEEE Access 2017, 6, 925–936. [Google Scholar] [CrossRef]
- Wu, A.; Qian, Y.; Liu, W.; Sreeram, V. Linear Quadratic Regulation for Discrete-Time Antilinear Systems: An Anti-Riccati Matrix Equation Approach. J. Frankl. Inst. 2016, 353, 1041–1060. [Google Scholar] [CrossRef]
- Bhawal, C.; Qais, I.; Pal, D. Constrained Generalized Continuous Algebraic Riccati Equation (CGCAREs) Are Generically Unsolvable. IEEE Control Syst. Lett. 2019, 3, 192–197. [Google Scholar] [CrossRef]
- Rizvi, S.; Lin, Z. Output Feedback Optimal Tracking Control Using Reinforcement Q-Learning. In Proceedings of the 2018 Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018. [Google Scholar]
- Lewis, F.; Vamvoudakis, K. Reinforcement Learning for Partially Observable Dynamic Processes: Adaptive Dynamic Programming Using Measured Output Data. IEEE Trans. Syst. Man Cybern. Part B 2011, 41, 14–25. [Google Scholar] [CrossRef] [PubMed]
- Salhi, S.; Salhi, S. LQR Control of a Grid Side Converter of a DFIG Based WECS: LMI Approach Based on Lyapunov Condition. In Proceedings of the 2019 16th International Multi-Conference on Systems, Signals & Devices (SSD), Istanbul, Turkey, 21–24 March 2019. [Google Scholar]
- Nguyen, T.; Gajic, Z. Solving the Matrix Differential Riccati Equation: A Lyapunov Equation Approach. IEEE Trans. Autom. Control 2010, 55, 191–194. [Google Scholar]
- Bi, H.; Chen, D. The Estimation of the Solutions Matrix of the Perturbed Discrete Time Algebraic Riccati Equation. In Proceedings of the 10th World Congress on Intelligent Control and Automation, Beijing, China, 6–8 July 2012. [Google Scholar]
- Vargas, F.; Gonzalez, R. On the Existence of a Stabilizing Solution of Modified Algebraic Riccati Equations in Terms of Standard Algebraic Riccati Equations and Linear Matrix Inequalities. IEEE Control Syst. Lett. 2020, 4, 91–96. [Google Scholar] [CrossRef]
- Chen, M.; Zhang, L.; Su, H.; Chen, G. Stabilizing Solution and Parameter Dependence of Modified Algebraic Riccati Equation with Application to Discrete-Time Network Synchronization. IEEE Trans. Autom. Control 2016, 61, 228–233. [Google Scholar] [CrossRef]
- Chapman, J.; Litt, J. Control Design for an Advanced Geared Turbofan Engine. In Proceedings of the 53rd AIAA/SAE/ASEE Joint Propulsion Conference, Atlanta, GA, USA, 10–12 July 2017. [Google Scholar]
- Mawid, M.; Park, T.; Sekar, B.; Arana, C. Application of Pulse Detonation Combustion to Turbofan Engines. J. Eng. Gas Turbines Power 2003, 125, 270–283. [Google Scholar] [CrossRef]
- Pavlenko, D.; Dvirnyk, Y.; Przysowa, R. Advanced Materials and Technologies for Compressor Blades of Small Turbofan Engine. Aerospace 2021, 8, 1. [Google Scholar] [CrossRef]
- Gharoun, H.; Keramati, A.; Nasiri, M. An Integrated Approach for Aircraft Turbofan Engine Fault Detection Based on Data Mining Techniques. Expert Syst. 2019, 36, e12370. [Google Scholar] [CrossRef]
- Li, J. Turbofan Engine H∞ Output Feedback Control and Delay Compensation Strategy. Master’s Thesis, Dalian University of Technology, Dalian, China, 2021. [Google Scholar]
- Belapurkar, R. Stability and Performance of Propulsion Control Systems with Distributed Control Architectures and Failures. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 2012. [Google Scholar]
- Balakrishnan, V.; Vandenberghe, L. Semidefinite Programming Duality and Linear Time-Invariant Systems. IEEE Trans. Autom. Control 2003, 48, 30–41. [Google Scholar] [CrossRef]
- Gattami, A. Generalized Linear Quadratic Control. IEEE Trans. Autom. Control 2010, 55, 131–136. [Google Scholar] [CrossRef]
- Lee, D.; Hu, J.H. Primal-Dual Q-Learning Framework for LQR Design. IEEE Trans. Autom. Control 2019, 64, 3756–3763. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Steps | ||||
|---|---|---|---|---|
| 0.1 | 3 | 0.0659 | 0.0274 | |
| 0.01 | 4 | 6.0304 × 10−4 | 0.0140 | |
| 0.001 | 4 | 6.0304 × 10−4 | 0.0140 | |
| 0.0007 | 4 | 6.0304 × 10−4 | 0.0140 | |
| 0.0006 | 8 | 3.5857 × 10−5 | 4.6999 × 10−5 |
| Steps | ||||
|---|---|---|---|---|
| 0.1 | 1 | 0.0041 | 0.0041 | |
| 0.01 | 1 | 0.0041 | 0.0042 | |
| 0.001 | 2 | 4.8053 × 10−9 | 6.9260 × 10−8 | |
| 0.0001 | 2 | 4.8053 × 10−9 | 4.1779 × 10−5 | |
| 4.0 × 10−9 | 5 | 3.8062 × 10−9 | 5.6807 × 10−8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, X.; Li, J.; Ren, J.; Wu, Y. A Decentralized LQR Output Feedback Control for Aero-Engines. Actuators 2023, 12, 164. https://doi.org/10.3390/act12040164
Ji X, Li J, Ren J, Wu Y. A Decentralized LQR Output Feedback Control for Aero-Engines. Actuators. 2023; 12(4):164. https://doi.org/10.3390/act12040164
Chicago/Turabian StyleJi, Xiaoxiang, Jianghong Li, Jiao Ren, and Yafeng Wu. 2023. "A Decentralized LQR Output Feedback Control for Aero-Engines" Actuators 12, no. 4: 164. https://doi.org/10.3390/act12040164
APA StyleJi, X., Li, J., Ren, J., & Wu, Y. (2023). A Decentralized LQR Output Feedback Control for Aero-Engines. Actuators, 12(4), 164. https://doi.org/10.3390/act12040164