



Reinforcement Learning-Based Control of Single-Track Two-Wheeled Robots in Narrow Terrain


Abstract
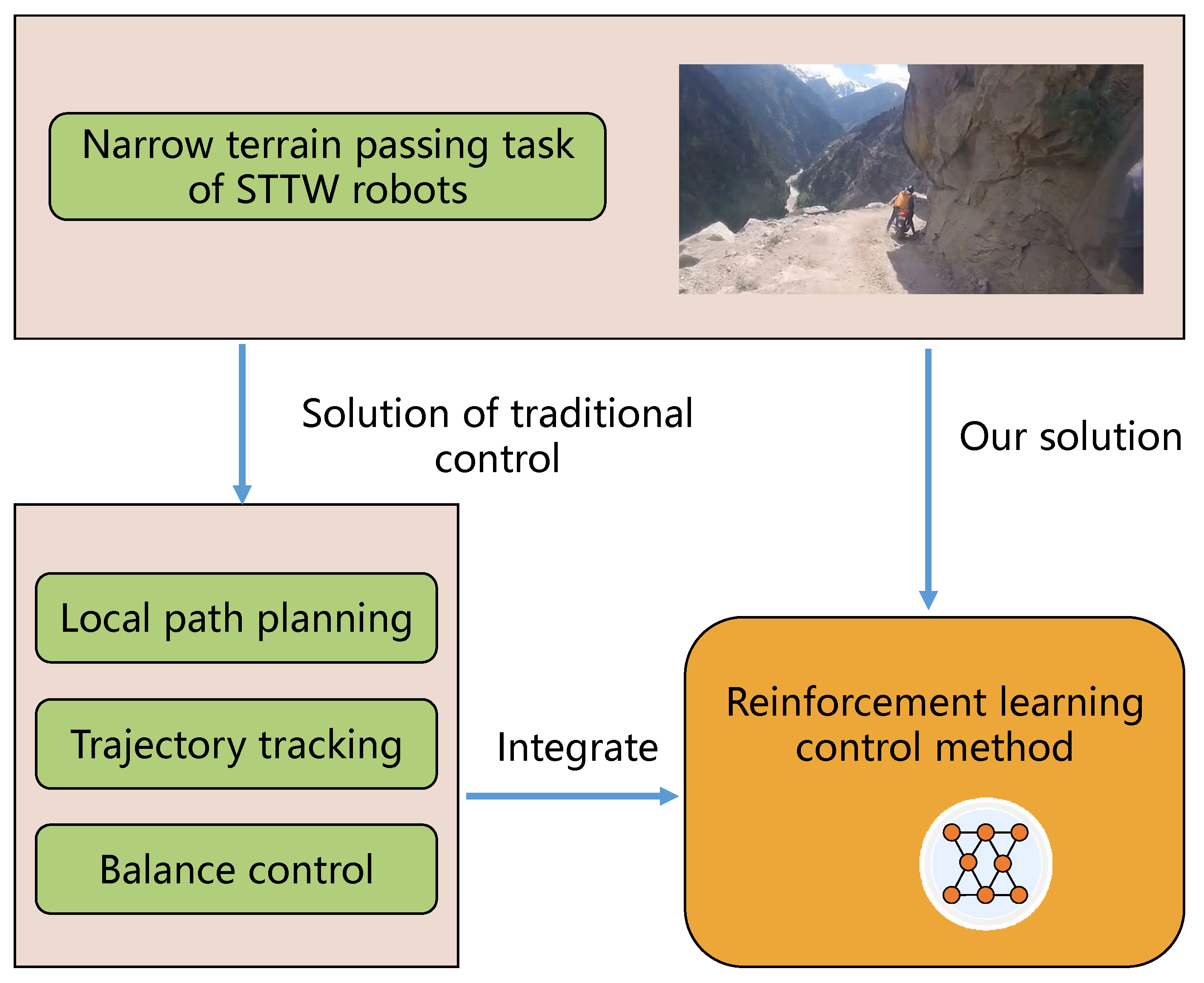
1. Introduction
- This article proposes a deep reinforcement learning-based STTW robot control method, which integrates local path planning, trajectory tracking, and balance control in a single framework.
- The proposed control method is applied to realize STTW robot driving in narrow terrain with line-of-sight occlusions and limited visibility. To the best of our knowledge, this paper is the first to study STTW robots in such an environment.
- The proposed method offers good generalization to terrain other than that used during training.
2. Related Work
2.1. Reinforcement Learning
2.2. STTW Robots
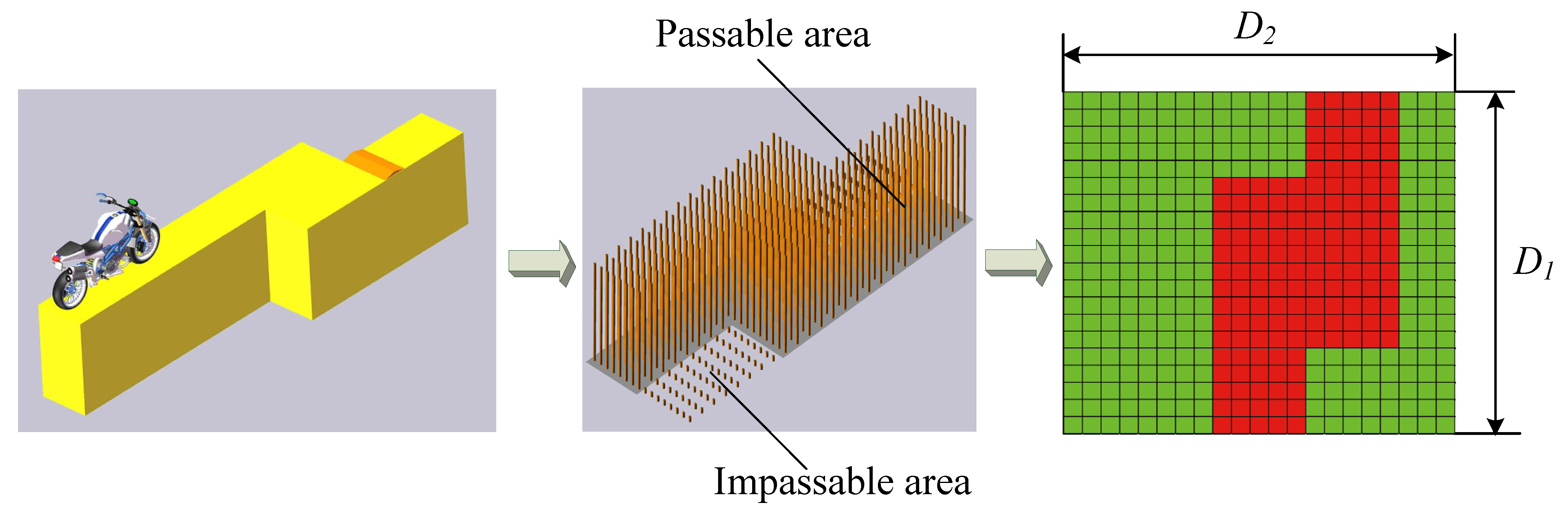
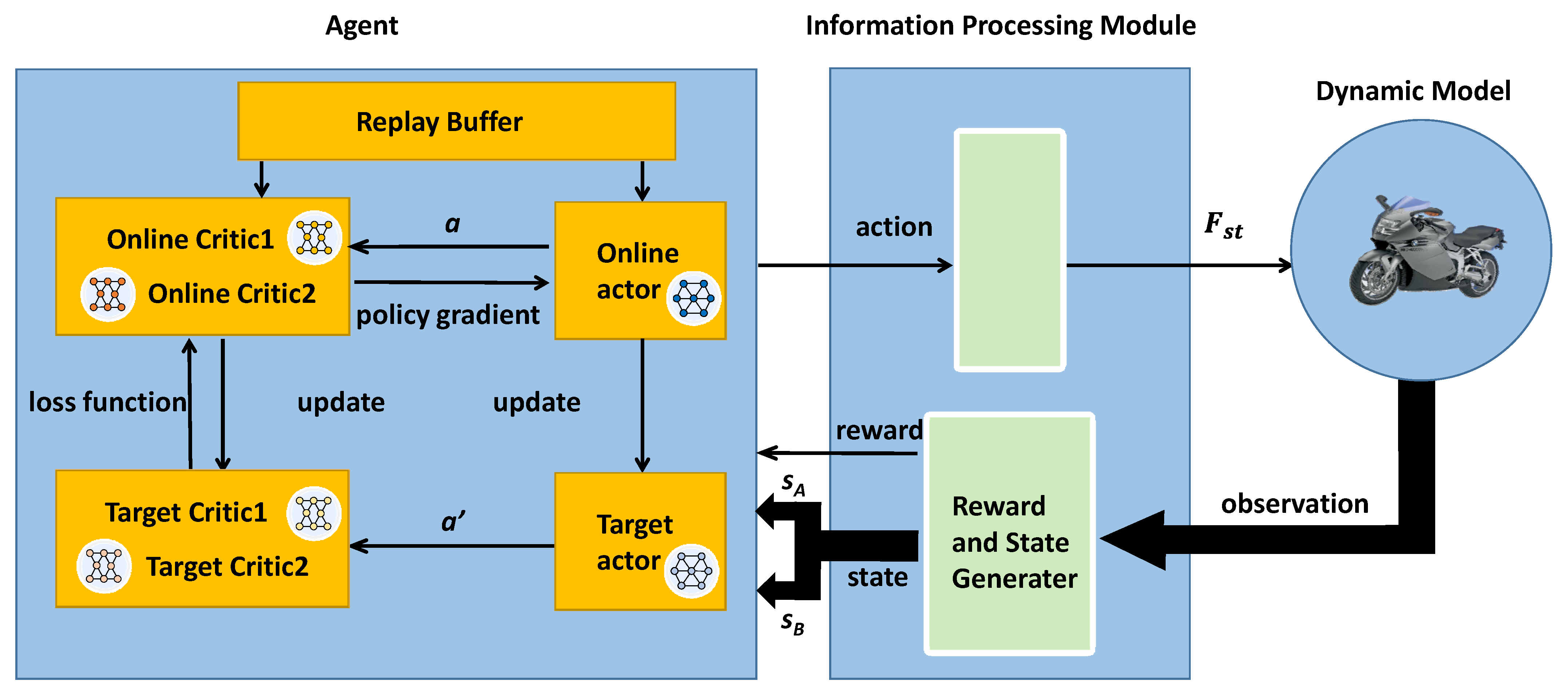
3. STTW Robots Control Method for Narrow Terrain
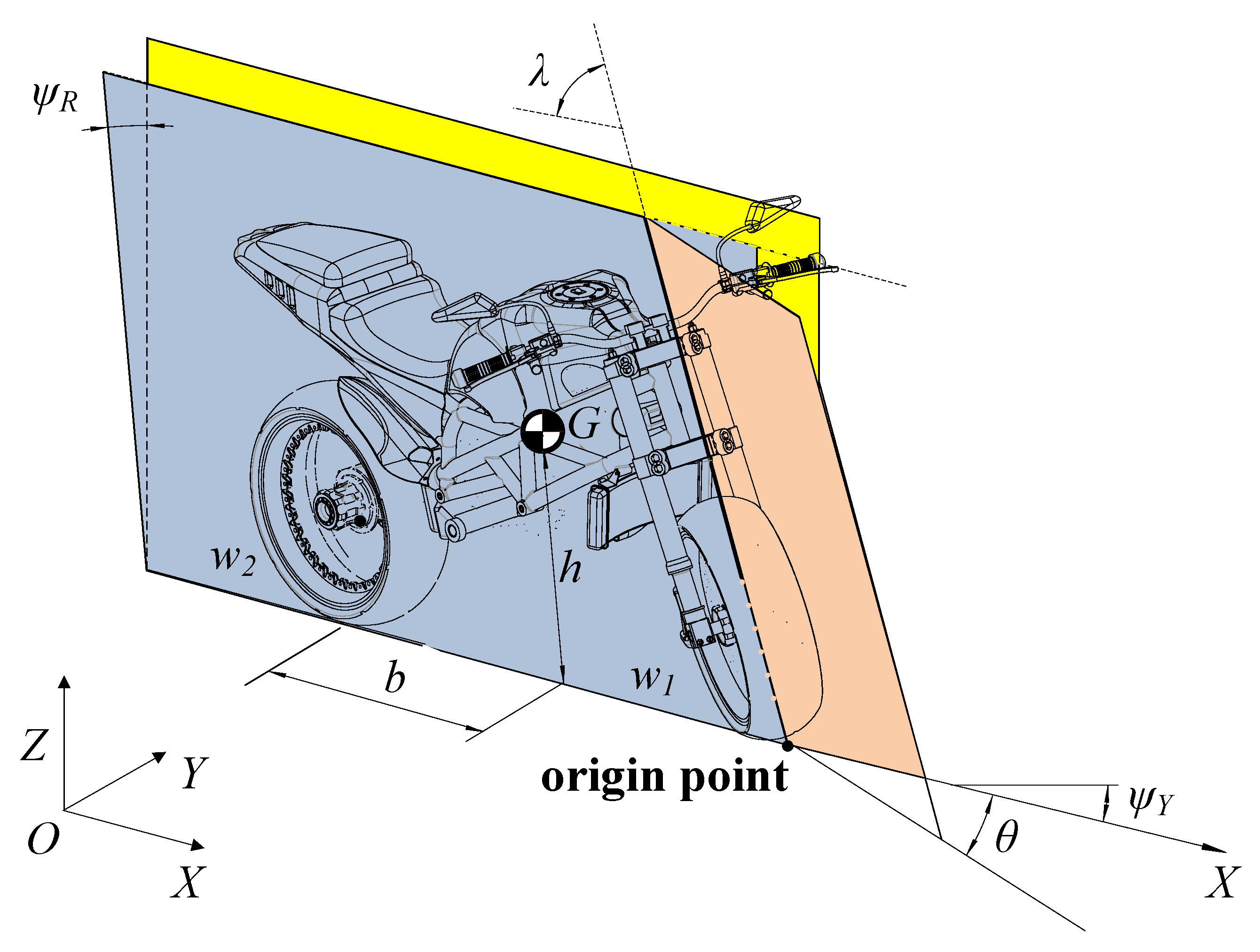
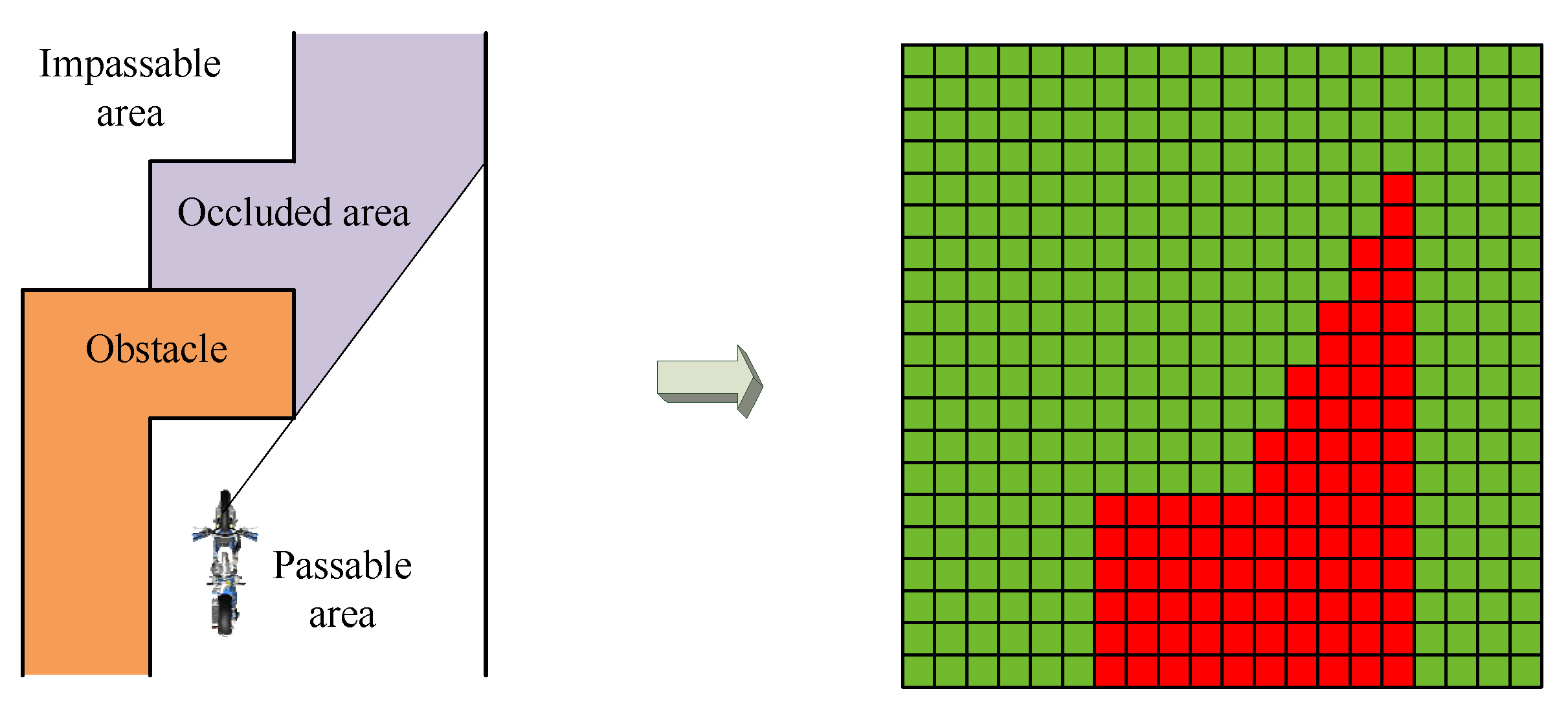
3.1. State
3.2. Action
3.3. Reward Shaping
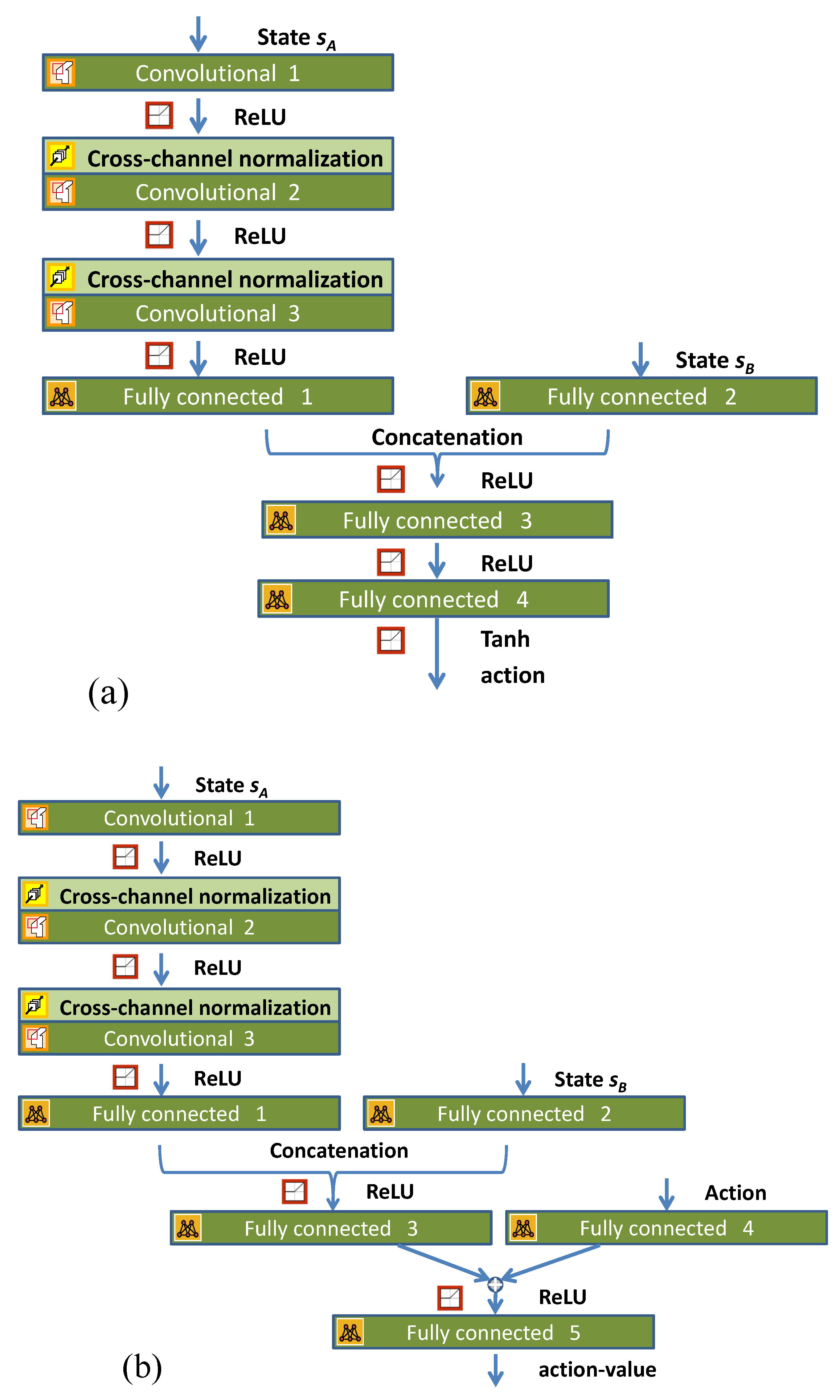
3.4. Network Structure
3.5. Training Algorithm
- According to the current observation s, select action where N is stochastic noise, using Gaussian noise with variance decay.
- Execute action to interact with the dynamic model and return the reward and the next observation to the agent.
- Store the obtained data in the replay buffer β.
- From the replay buffer, select a random mini-batch of K samples , .
- The critic network is updated by minimizing the loss L:whereand is a discount factor that determines the priority for short-term rewards. and represent the action’s minimum and maximum values. is stochastic noise, using Gaussian noise with variance decay; and the clip function is used to clip the action based on and , which keeps the target close to the original action.
- Every 2 steps, update the actor network using the deterministic policy gradient to maximize the expected discounted reward J, as follows:where
- and
- Every 2 steps, target actor network and target critic network are updated using a soft-updating technique with smoothing factor τ, as follows:
4. Simulation Settings
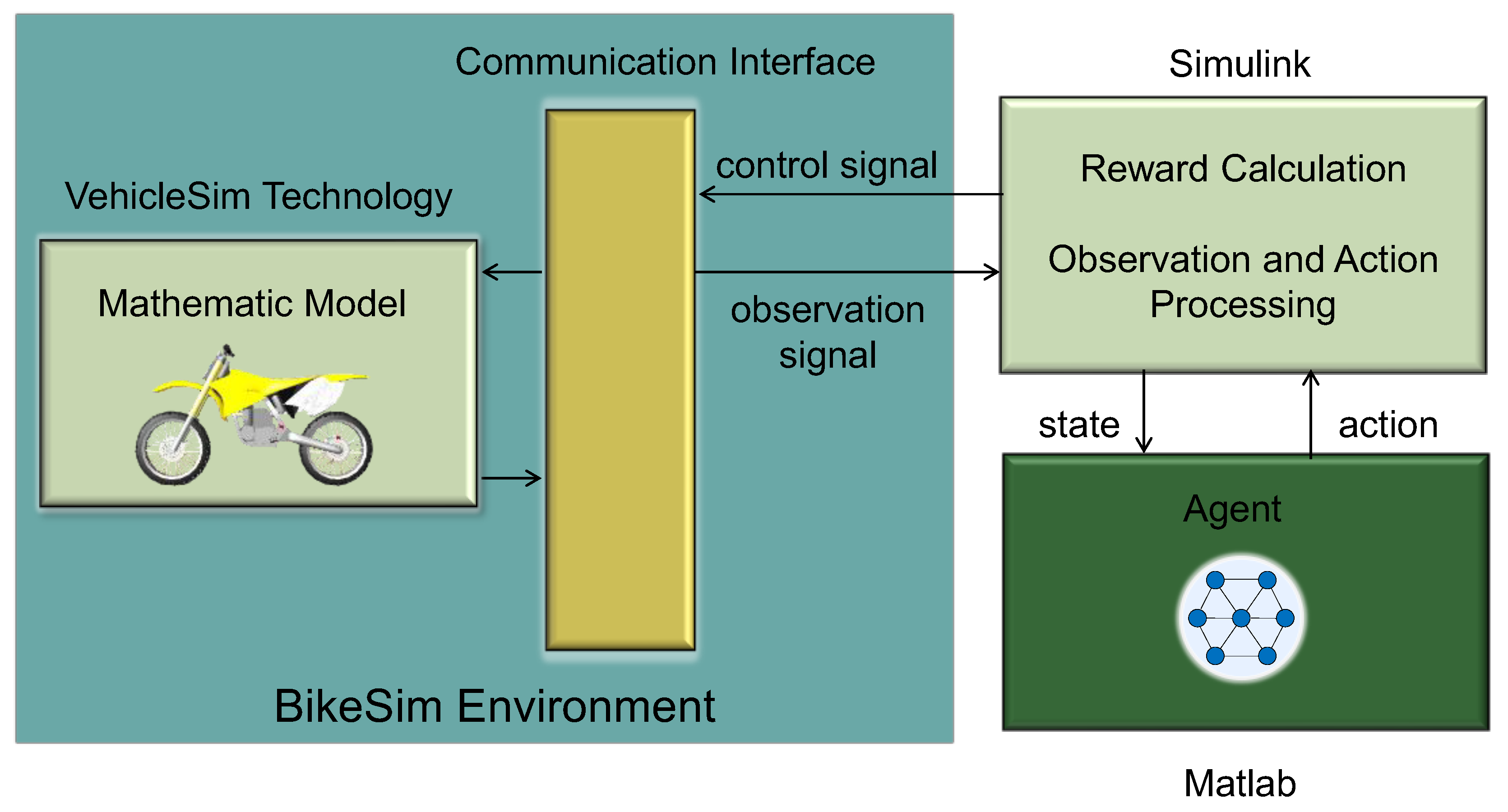
4.1. Simulation Platform
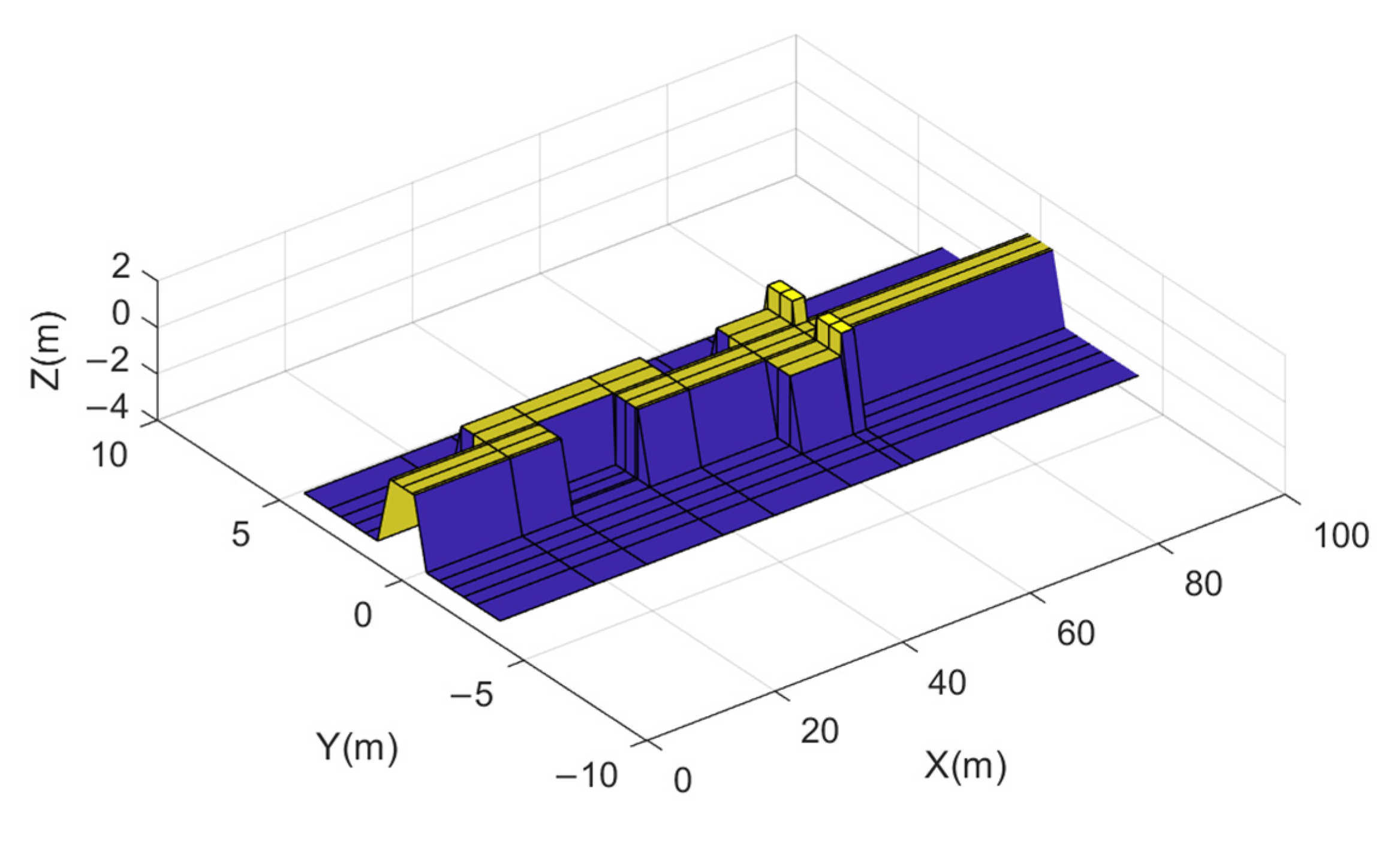
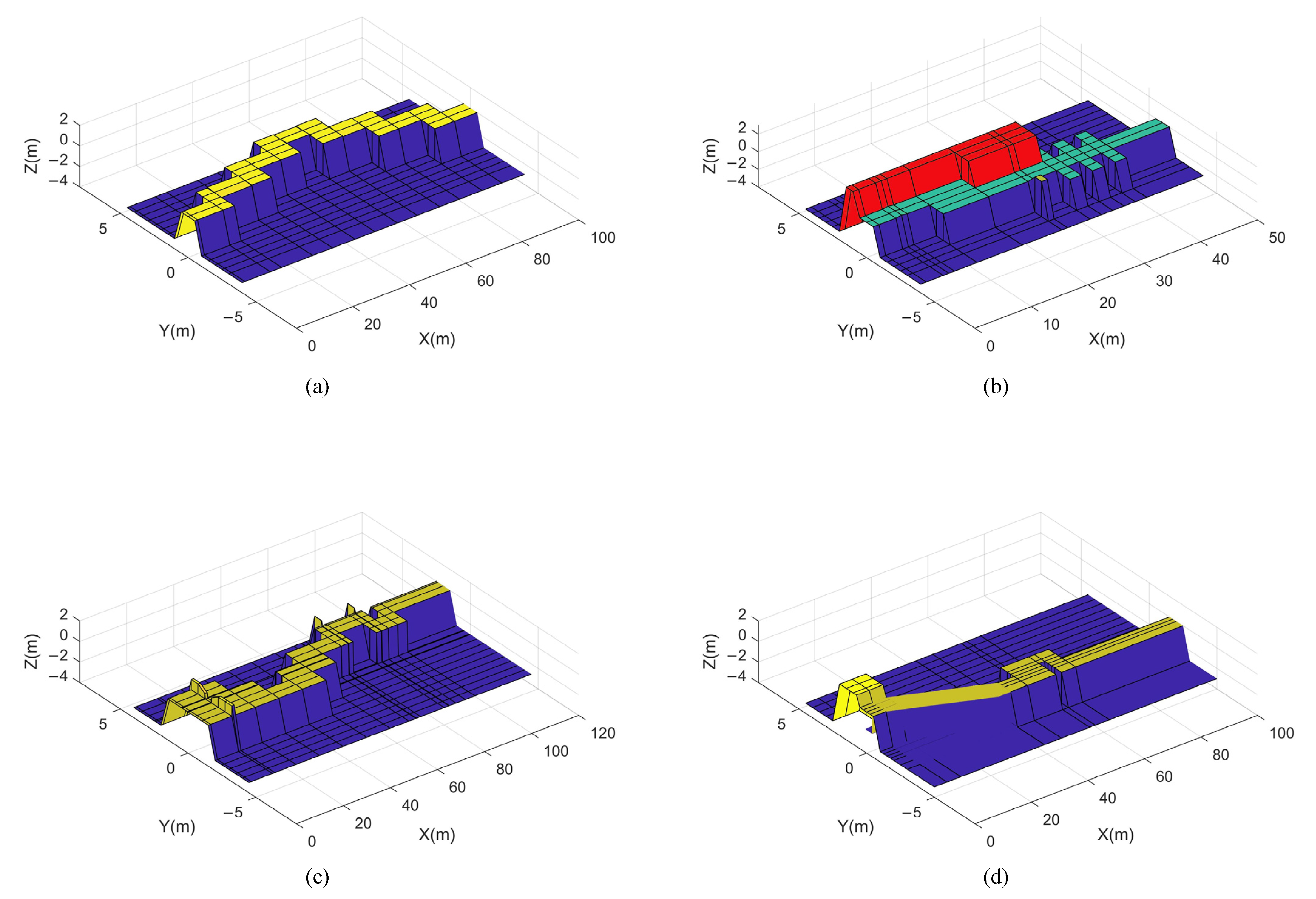
4.2. Training Terrain Structure
4.3. Simulation Parameter Settings
- and
- where d is the position of the robot in the X direction.
5. Results
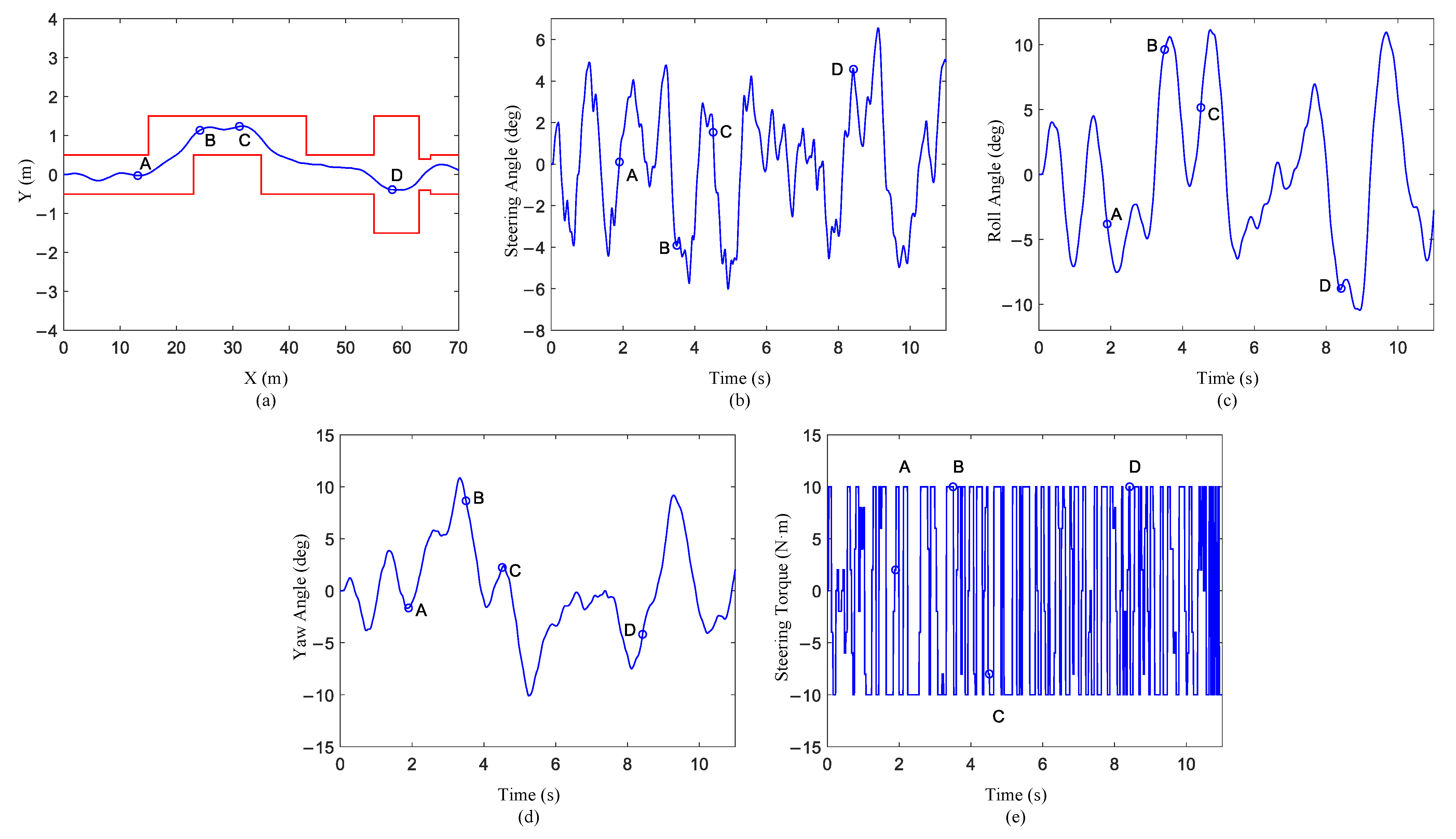
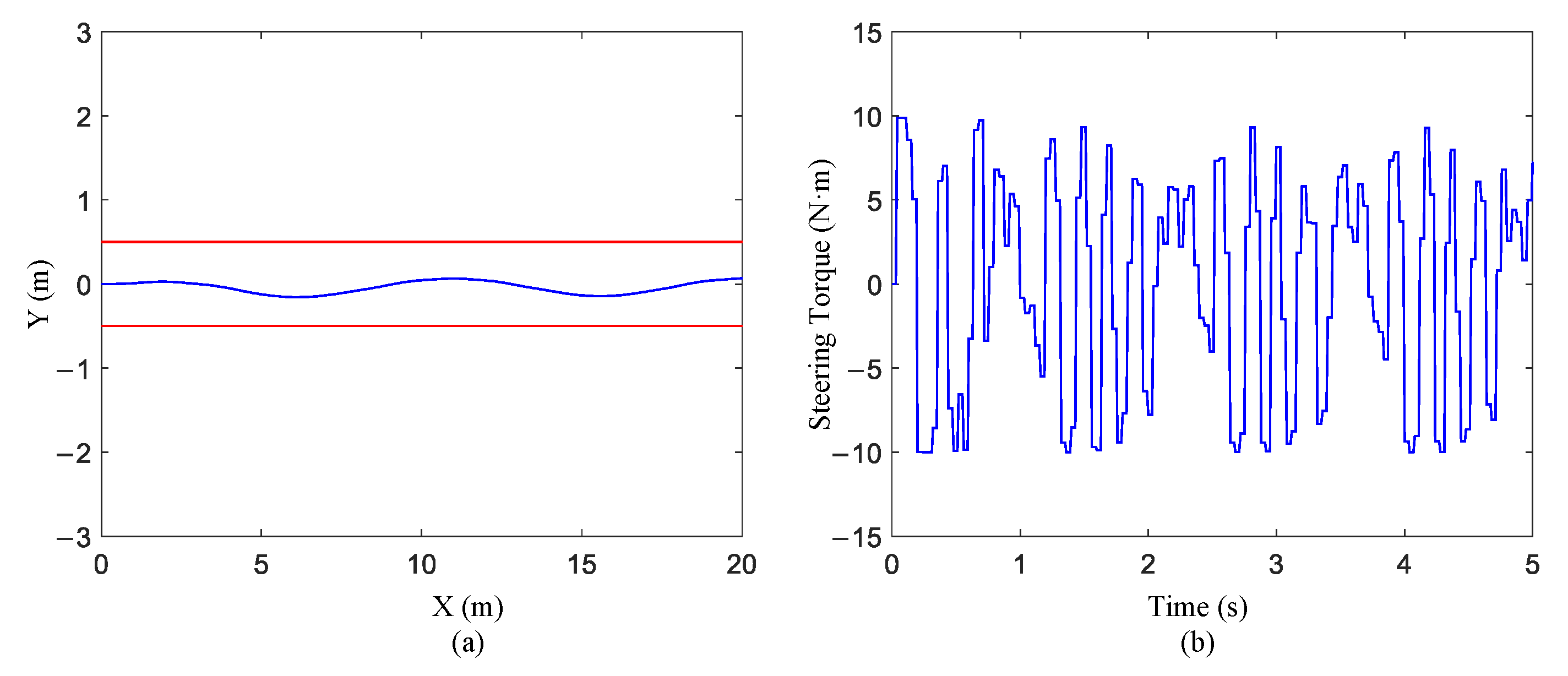
5.1. Results after Training
5.2. Robustness Test
- (1)
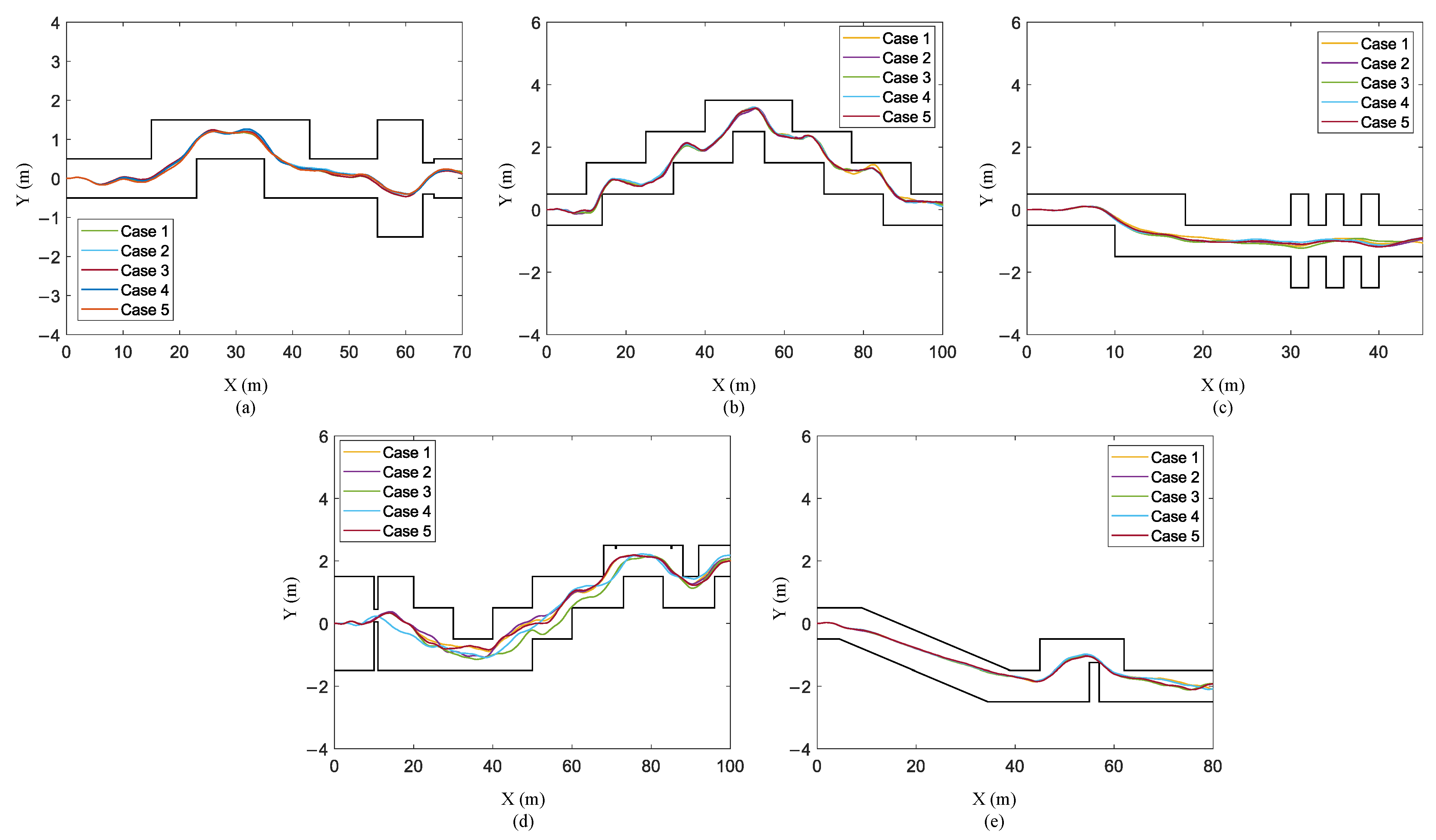
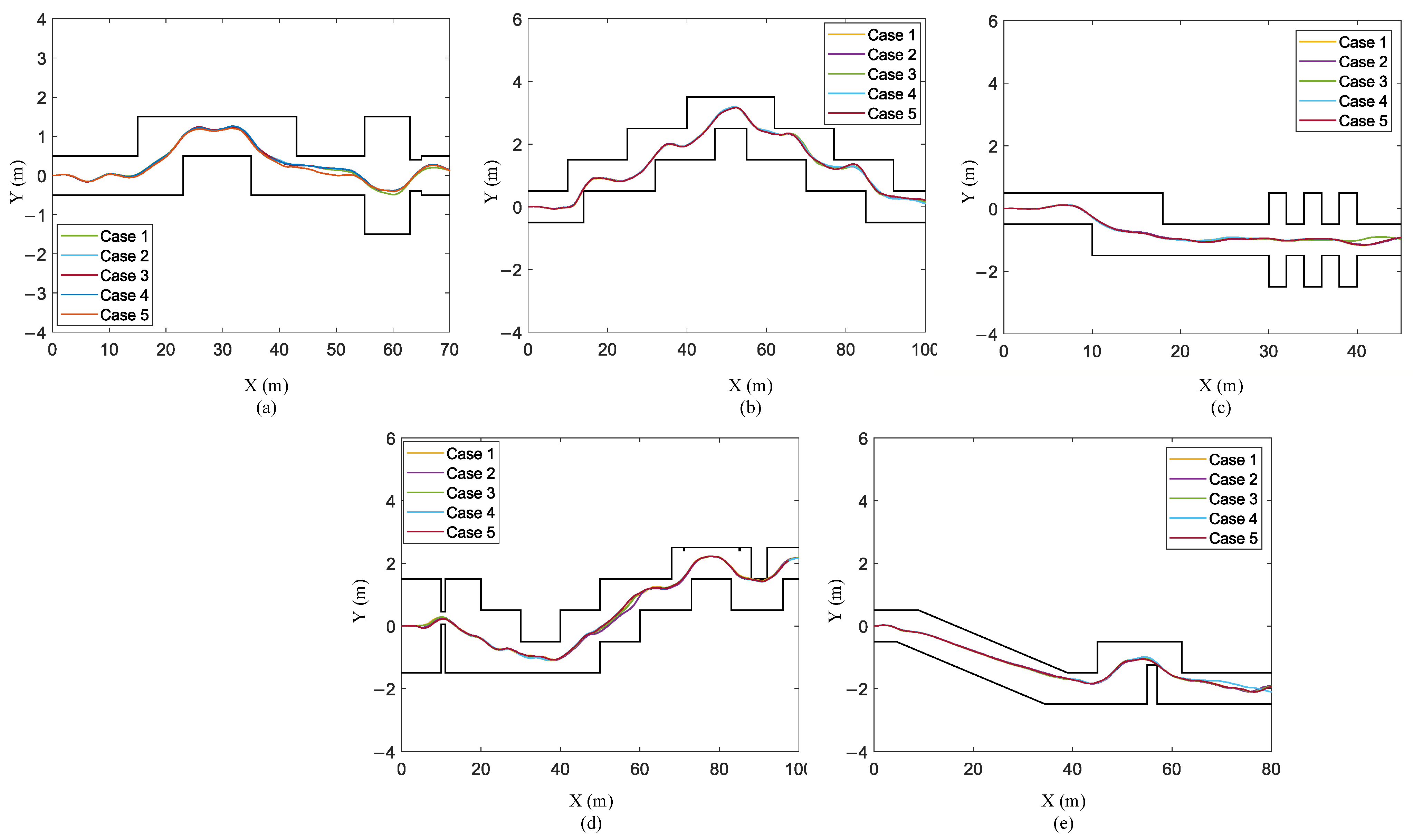
- Scenario I: The actuator is disturbed. We add Gaussian noise with a mean of zero and a variance 0.01 to the action signal. The trajectories of the STTW robot on the training terrain and four test terrains are shown in Figure 12.
- (2)
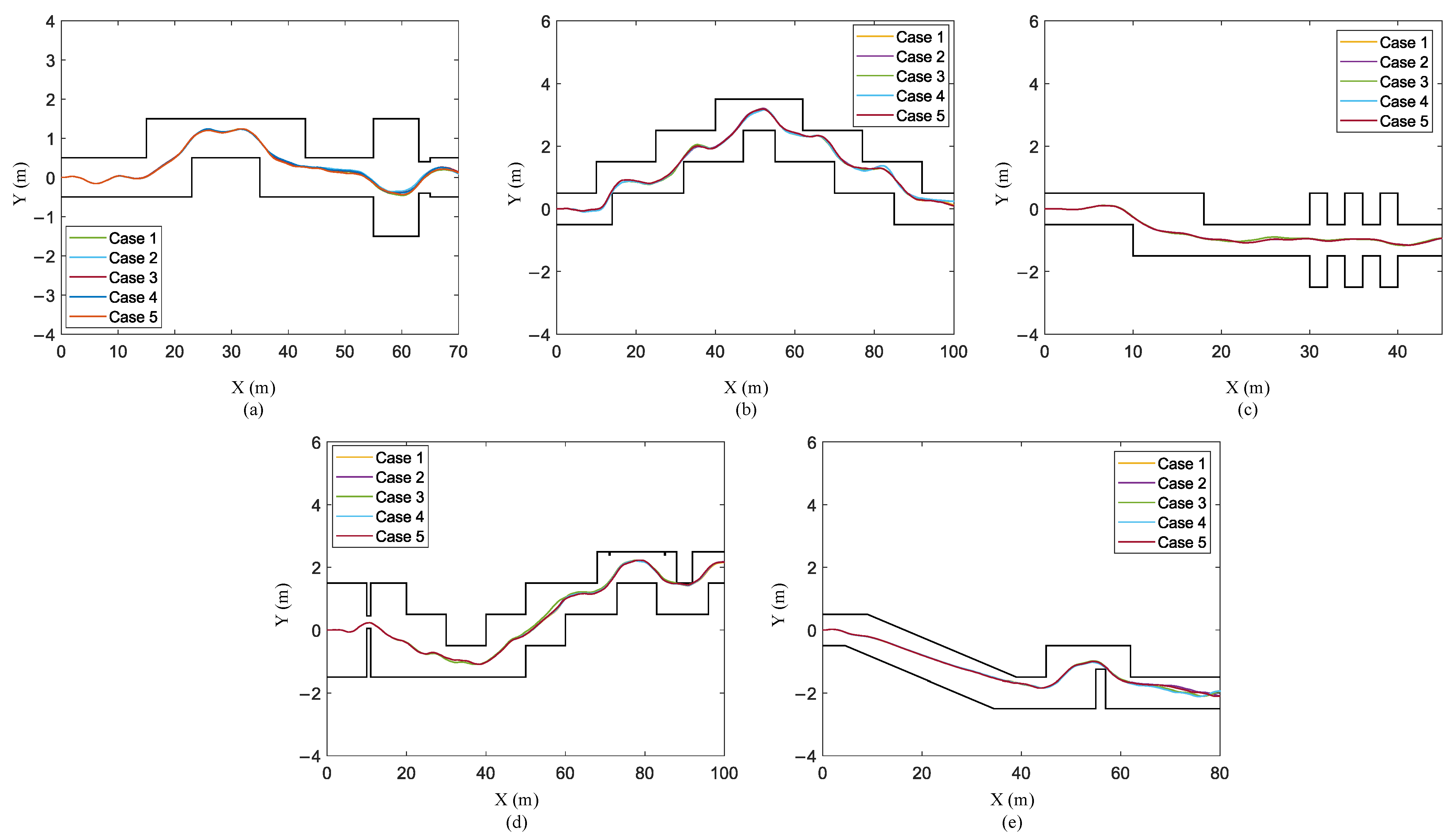
- Scenario II: The main frame is disturbed by force. We added a disturbing force in the robot center, and the disturbing force obeys Gaussian noise with a mean of zero and a variance 100. We have verified it five times in training terrain and testing terrain, and the results show that the robot can overcome these disturbances and successfully pass through narrow terrain. The trajectory of the robot is shown in Figure 13.
- (3)
- Scenario III: The perception system has errors. Considering that the perception system is not completely reliable, we assume that there is a certain error in the obtained geographic information. In the state sA matrix, there is a 2.5% probability that the value of any row or column is set to 1 or −1. Likewise, we conducted five verifications in training terrain and testing terrain. The simulation results are shown in Figure 14. As can be seen from the figure, the robot successfully passed through these narrow terrains.
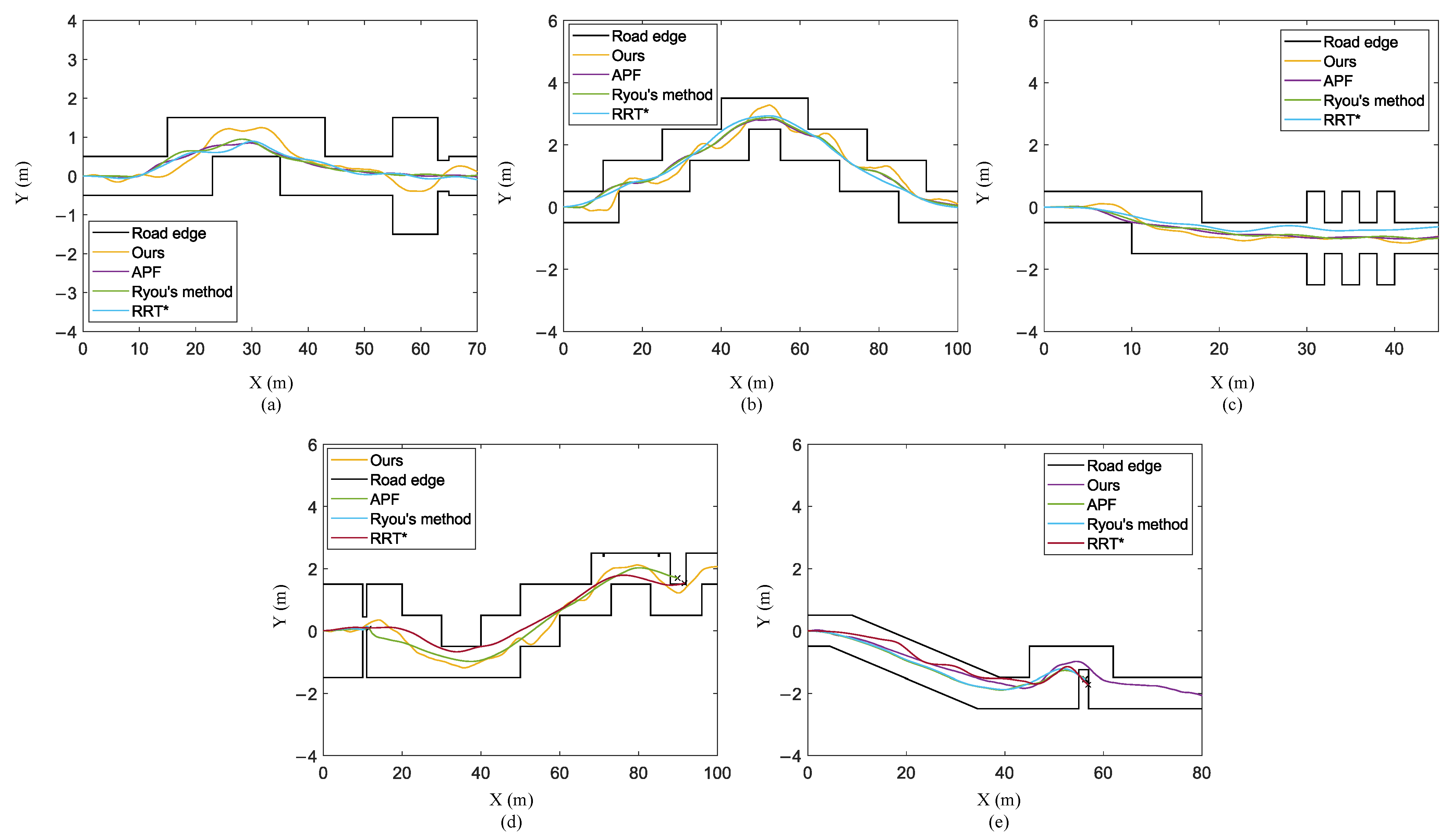
5.3. Comparison with Traditional Path Planning and Control Methods
- The artificial potential field (APF) [37]. The artificial potential field method is used to design an artificial potential field to guide the robot to move in an environment full of obstacles. In this method, the target point generates an attractive potential to the mobile robot, and the obstacles generate a repulsive potential to the mobile robot. Finally, the motion of the mobile robot is controlled by seeking the resultant force as follows:
- The path planning method for the intermediate step [46]. This method transforms terrain with obstacles into a simple polygon, and decomposes free space into polygons. According to the generated face graph, the method finds the sequence of polygons. Finally, this sequence is used for the planned path.
- Variation of rapidly exploring random trees (RRT*) [38]. The original RRT algorithm uses an initial point as the root node and increases leaf nodes through random sampling. A path composed of tree nodes from the initial point to the target point can be found in the random tree. Based on the RRT algorithm, the RRT* algorithm adds a search for the adjacent nodes of the newly generated node and the process of rerouting.
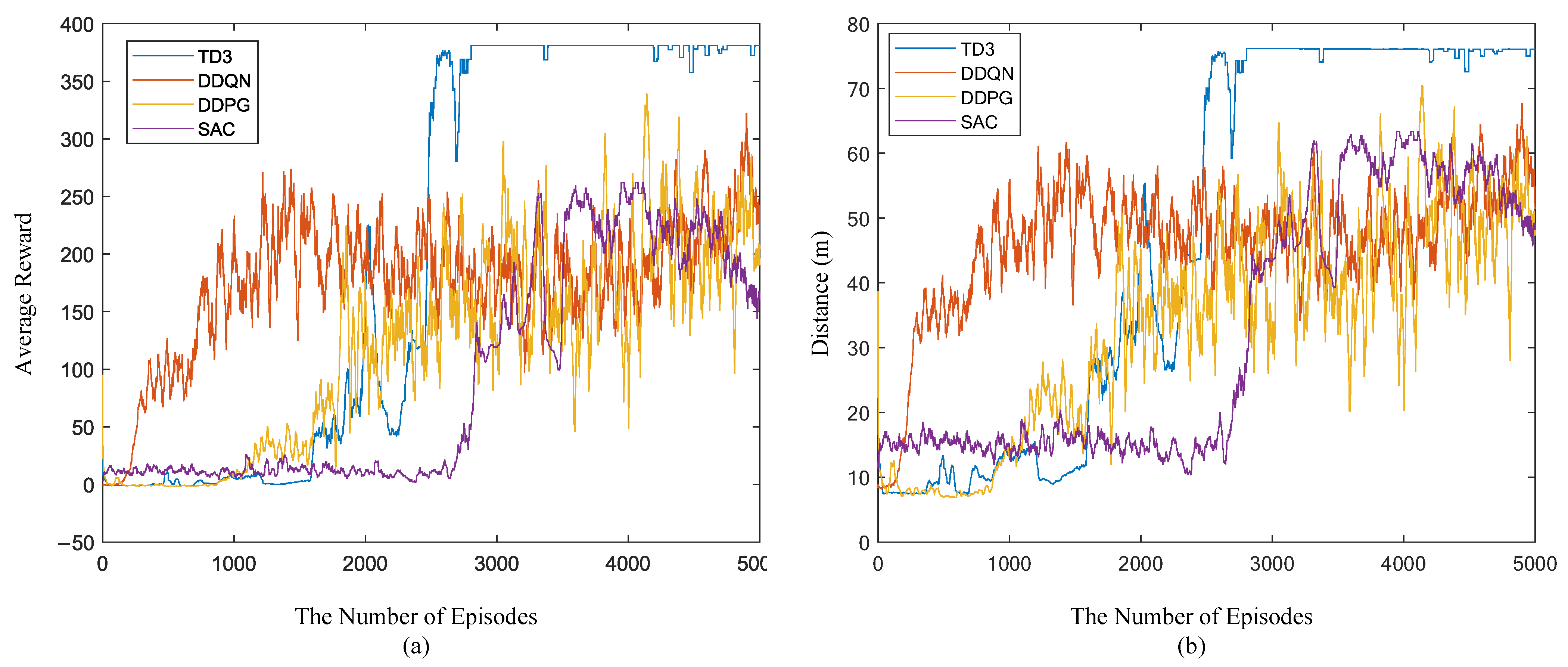
5.4. Comparison between Different Reinforcement Learning Algorithms
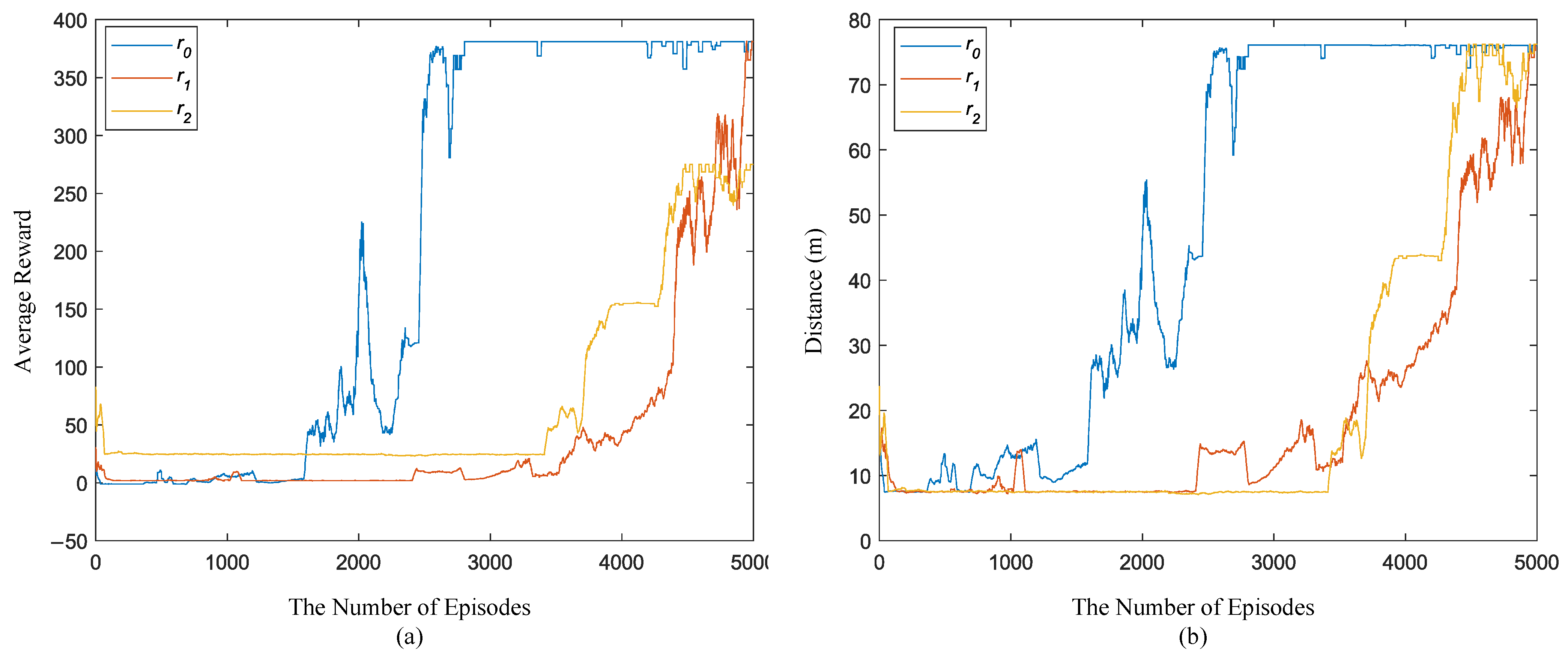
5.5. Comparison between Different Reward Functions
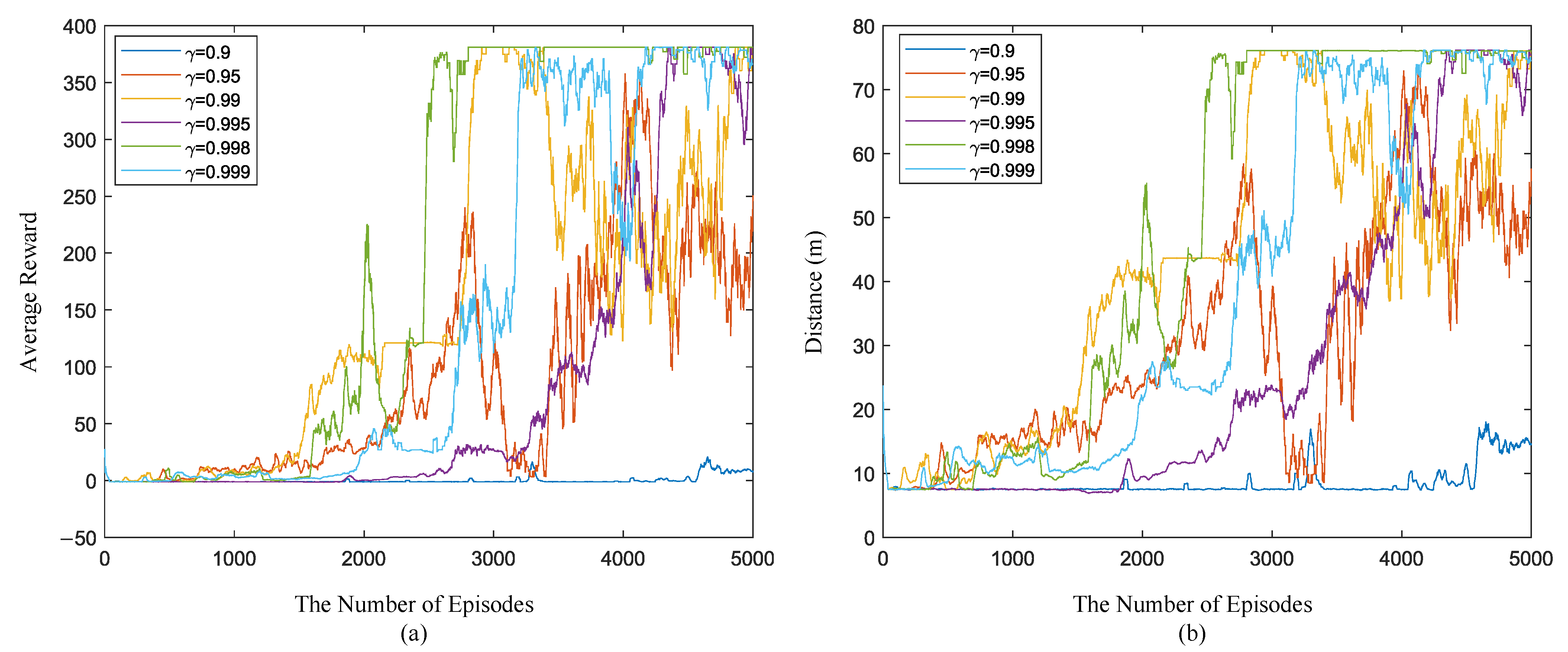
5.6. Comparison between Different Training Parameters
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Terrain | Completed | Simulation Time | Execution Time |
|---|---|---|---|
| Training Terrain | √ | 11 s | 17.26 s |
| Test Terrain 1 | √ | 20 s | 44.99 s |
| Test Terrain 2 | √ | 13 s | 26.71 s |
| Test Terrain 3 | √ | 16 s | 36.29 s |
| Test Terrain 4 | √ | 15 s | 29.38 s |
References
- Astrom, K.J.; Klein, R.E.; Lennartsson, A. Bicycle dynamics and control: Adapted bicycles for education and research. IEEE Control. Syst. Mag. 2005, 25, 26–47. [Google Scholar]
- Tanaka, Y.; Murakami, T. A study on straight-line tracking and posture control in electric bicycle. IEEE Trans. Ind. Electron. 2009, 56, 159–168. [Google Scholar] [CrossRef]
- Sun, Y.; Zhao, H.; Chen, Z.; Zheng, X.; Zhao, M.; Liang, B. Fuzzy model-based multi-objective dynamic programming with modified particle swarm optimization approach for the balance control of bicycle robot. IET Control. Theory Appl. 2022, 16, 7–19. [Google Scholar] [CrossRef]
- Suryanarayanan, S.; Tomizuka, M.; Weaver, M. System dynamics and control of bicycles at high speeds. In Proceedings of the 2002 American Control Conference, Anchorage, AK, USA, 8–10 May 2002. [Google Scholar]
- Yu, Y.; Zhao, M. Steering control for autonomously balancing bicycle at low speed. In Proceedings of the 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018. [Google Scholar]
- Zhang, Y.; Li, J.; Yi, J.; Song, D. Balance control and analysis of stationary riderless motorcycles. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Keo, L.; Yamakita, M. Control of an autonomous electric bicycle with both steering and balancer controls. Adv. Robot. 2011, 25, 1–22. [Google Scholar] [CrossRef]
- Yetkin, H.; Kalouche, S.; Vernier, M.; Colvin, G.; Redmill, K.; Ozguner, U. Gyroscopic stabilization of an unmanned bicycle. In Proceedings of the 2014 American Control Conference, Portland, OR, USA, 4–6 June 2014. [Google Scholar]
- Stasinopoulos, S.; Zhao, M.; Zhong, Y. Human behavior inspired obstacle avoidance & road surface quality detection for autonomous bicycles. In Proceedings of the 2015 IEEE International Conference on Robotics and Biomimetics (ROBIO), Zhuhai, China, 6–9 December 2015. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Lin, L.-J. Self-improving reactive agents based on reinforcement learning, planning and teaching. Mach. Learn. 1992, 8, 293–321. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Peters, J.; Schaal, S. Natural actor-critic. Neurocomputing 2008, 71, 1180–1190. [Google Scholar] [CrossRef]
- Bhatnagar, S.; Sutton, R.S.; Ghavamzadeh, M.; Lee, M. Incremental Natural-Gradient Actor-Critic Algorithms. In Proceedings of the 21st Annual Conference on Neural Information Processing Systems, Vancouver, Canada, 3–6 December 2007. [Google Scholar]
- Degris, T.; White, M.; Sutton, R. Off-Policy Actor-Critic. In Proceedings of the International Conference on Machine Learning, Edinburgh, Scotland, 26 June–1 July 2012. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Barth-Maron, G.; Hoffman, M.W.; Budden, D.; Dabney, W.; Horgan, D.; Dhruva, T.; Muldal, A.; Heess, N.; Lillicrap, T. Distributed Distributional Deterministic Policy Gradients. In Proceedings of the 2018 International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Vecerik, M.; Sushkov, O.; Barker, D.; Rothörl, T.; Hester, T.; Scholz, J. A practical approach to insertion with variable socket position using deep reinforcement learning. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Hausknecht, M.; Stone, P. Deep reinforcement learning in parameterized action space. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 June 2015. [Google Scholar]
- Vanvuchelen, N.; Gijsbrechts, J.; Boute, R. Use of proximal policy optimization for the joint replenishment problem. Comput. Ind. 2020, 119, 103239. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Choi, S.; Le, T.P.; Nguyen, Q.D.; Layek, M.A.; Lee, S.; Chung, T. Toward self-driving bicycles using state-of-the-art deep reinforcement learning algorithms. Symmetry 2019, 11, 290. [Google Scholar] [CrossRef]
- Zhu, X.; Deng, Y.; Zheng, X.; Zheng, Q.; Liang, B.; Liu, Y. Online Reinforcement-Learning-Based Adaptive Terminal Sliding Mode Control for Disturbed Bicycle Robots on a Curved Pavement. Electronics 2022, 11, 3495. [Google Scholar] [CrossRef]
- Guo, L.; Chen, Z.; Song, Y. Semi-empirical dynamics modeling of a bicycle robot based on feature selection and RHONN. Neurocomputing 2022, 511, 448–461. [Google Scholar] [CrossRef]
- Beznos, A.; Formal’Sky, A.; Gurfinkel, E.; Jicharev, D.; Lensky, A.; Savitsky, K.; Tchesalin, L. Control of autonomous motion of two-wheel bicycle with gyroscopic stabilisation. In Proceedings of the 1998 IEEE International Conference on Robotics and Automation, Leuven, Belgium, 20–20 May 1998. [Google Scholar]
- Wang, P.; Yi, J.; Liu, T. Stability and control of a rider–bicycle system: Analysis and experiments. IEEE Trans. Autom. Sci. Eng. 2019, 17, 348–360. [Google Scholar] [CrossRef]
- Seekhao, P.; Tungpimolrut, K.; Parnichkun, M. Development and control of a bicycle robot based on steering and pendulum balancing. Mechatronics 2020, 69, 102386. [Google Scholar] [CrossRef]
- Hwang, C.-L.; Wu, H.-M.; Shih, C.-L. Fuzzy sliding-mode underactuated control for autonomous dynamic balance of an electrical bicycle. IEEE Trans. Control. Syst. Technol. 2009, 17, 658–670. [Google Scholar] [CrossRef]
- Mu, J.; Yan, X.-G.; Spurgeon, S.K.; Mao, Z. Generalized regular form based SMC for nonlinear systems with application to a WMR. IEEE Trans. Ind. Electron. 2017, 64, 6714–6723. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, H.; Lee, J. Stable control of the bicycle robot on a curved path by using a reaction wheel. J. Mech. Sci. Technol. 2015, 29, 2219–2226. [Google Scholar] [CrossRef]
- Chen, L.; Liu, J.; Wang, H.; Hu, Y.; Zheng, X.; Ye, M.; Zhang, J. Robust control of reaction wheel bicycle robot via adaptive integral terminal sliding mode. Nonlinear Dyn. 2021, 104, 2291–2302. [Google Scholar] [CrossRef]
- Elbanhawi, M.; Simic, M. Sampling-based robot motion planning: A review. IEEE Access 2014, 2, 56–77. [Google Scholar] [CrossRef]
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef]
- Zhao, M.; Stasinopoulos, S.; Yu, Y. Obstacle detection and avoidance for autonomous bicycles. In Proceedings of the 2017 13th IEEE Conference on Automation Science and Engineering (CASE), Xi’an, China, 20–23 August 2017. [Google Scholar]
- Wang, P.; Yi, J.; Liu, T.; Zhang, Y. Trajectory tracking and balance control of an autonomous bikebot. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Persson, N.; Ekström, M.C.; Ekström, M.; Papadopoulos, A.V. Trajectory tracking and stabilisation of a riderless bicycle. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021. [Google Scholar]
- He, K.; Deng, Y.; Wang, G.; Sun, X.; Sun, Y.; Chen, Z. Learning-Based Trajectory Tracking and Balance Control for Bicycle Robots With a Pendulum: A Gaussian Process Approach. IEEE/ASME Trans. Mechatron. 2022, 27, 634–644. [Google Scholar] [CrossRef]
- Lee, T.-C.; Polak, J.W.; Bell, M.G. BikeSim User Manual Version 1.0; Working paper; Centre for Transport Studies: London, UK, 2008. [Google Scholar]
- Dabladji, M.E.-H.; Ichalal, D.; Arioui, H.; Mammar, S. Unknown-input observer design for motorcycle lateral dynamics: Ts approach. Control. Eng. Pract. 2016, 54, 12–26. [Google Scholar] [CrossRef]
- Damon, P.-M.; Ichalal, D.; Arioui, H. Steering and lateral motorcycle dynamics estimation: Validation of Luenberger LPV observer approach. IEEE Trans. Intell. Veh. 2019, 4, 277–286. [Google Scholar] [CrossRef]
- Ryou, G.; Tal, E.; Karaman, S. Multi-fidelity black-box optimization for time-optimal quadrotor maneuvers. Int. J. Robot. Res. 2021, 40, 1352–1369. [Google Scholar] [CrossRef]
- Sharp, R.; Evangelou, S.; Limebeer, D.J. Advances in the modelling of motorcycle dynamics. Multibody Syst. Dyn. 2004, 12, 251–283. [Google Scholar] [CrossRef]


















| Content | Literature | ||||
|---|---|---|---|---|---|
| Refs. [1,3,4,5,6,8,27,31,32,33,36] | Refs. [2,7,30,35,40,41,42] | Refs. [37,38] | Refs. [9,39] | Refs. [28,29] | |
| Path planning | × | × | √ | √ | × |
| Trajectory tracking | × | √ | × | √ | × |
| Balance control | √ | √ | × | √ | √ |
| Consider narrow roads? | × | × | √ | × | × |
| Consider uneven roads? | × | × | × | × | √ |
| Consider low visibility? | × | × | × | × | × |
| Consider line-of-sight occlusions? | × | × | × | √ | × |
| Terrain | Our Method | APF | The Method in [46] | RRT* | |||
|---|---|---|---|---|---|---|---|
| Completed | Completed | Completed | Completed | ||||
| Training Terrain | √ | 9 | √ | 9 | √ | 9 | √ |
| Test Terrain 1 | √ | 6 | √ | 5.5 | √ | 5.5 | √ |
| Test Terrain 2 | √ | 9 | √ | 9 | √ | 9 | √ |
| Test Terrain 3 | √ | 2.5 | × | 4.5 | × | 5 | × |
| Test Terrain 4 | √ | 7 | × | 7 | × | 7 | × |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Q.; Tian, Y.; Deng, Y.; Zhu, X.; Chen, Z.; Liang, B. Reinforcement Learning-Based Control of Single-Track Two-Wheeled Robots in Narrow Terrain. Actuators 2023, 12, 109. https://doi.org/10.3390/act12030109
Zheng Q, Tian Y, Deng Y, Zhu X, Chen Z, Liang B. Reinforcement Learning-Based Control of Single-Track Two-Wheeled Robots in Narrow Terrain. Actuators. 2023; 12(3):109. https://doi.org/10.3390/act12030109
Chicago/Turabian StyleZheng, Qingyuan, Yu Tian, Yang Deng, Xianjin Zhu, Zhang Chen, and Bing Liang. 2023. "Reinforcement Learning-Based Control of Single-Track Two-Wheeled Robots in Narrow Terrain" Actuators 12, no. 3: 109. https://doi.org/10.3390/act12030109
APA StyleZheng, Q., Tian, Y., Deng, Y., Zhu, X., Chen, Z., & Liang, B. (2023). Reinforcement Learning-Based Control of Single-Track Two-Wheeled Robots in Narrow Terrain. Actuators, 12(3), 109. https://doi.org/10.3390/act12030109