
The Improved Deeplabv3plus Based Fast Lane Detection Method



Abstract
:1. Introduction
2. Related Work
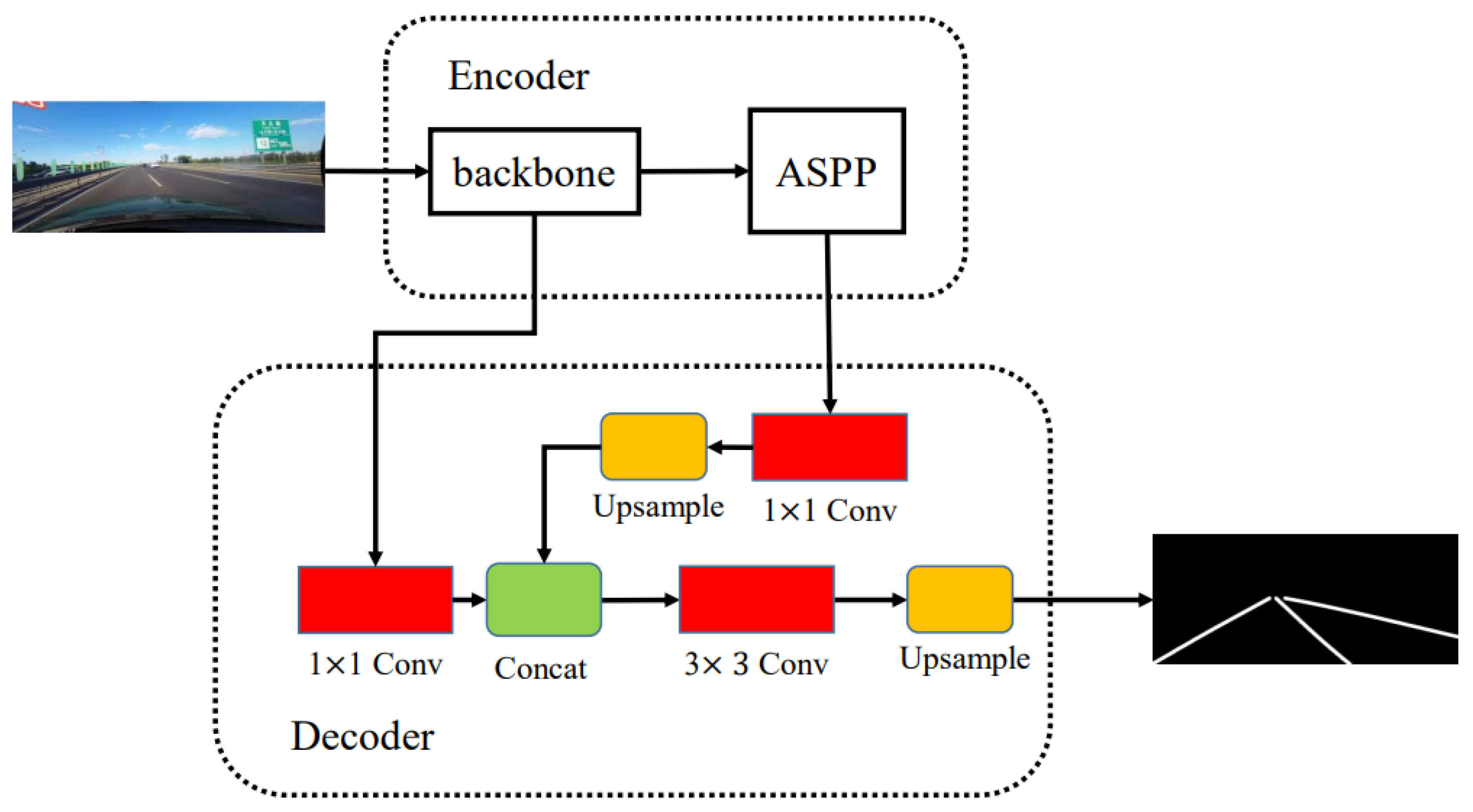
2.1. Deeplabv3plus
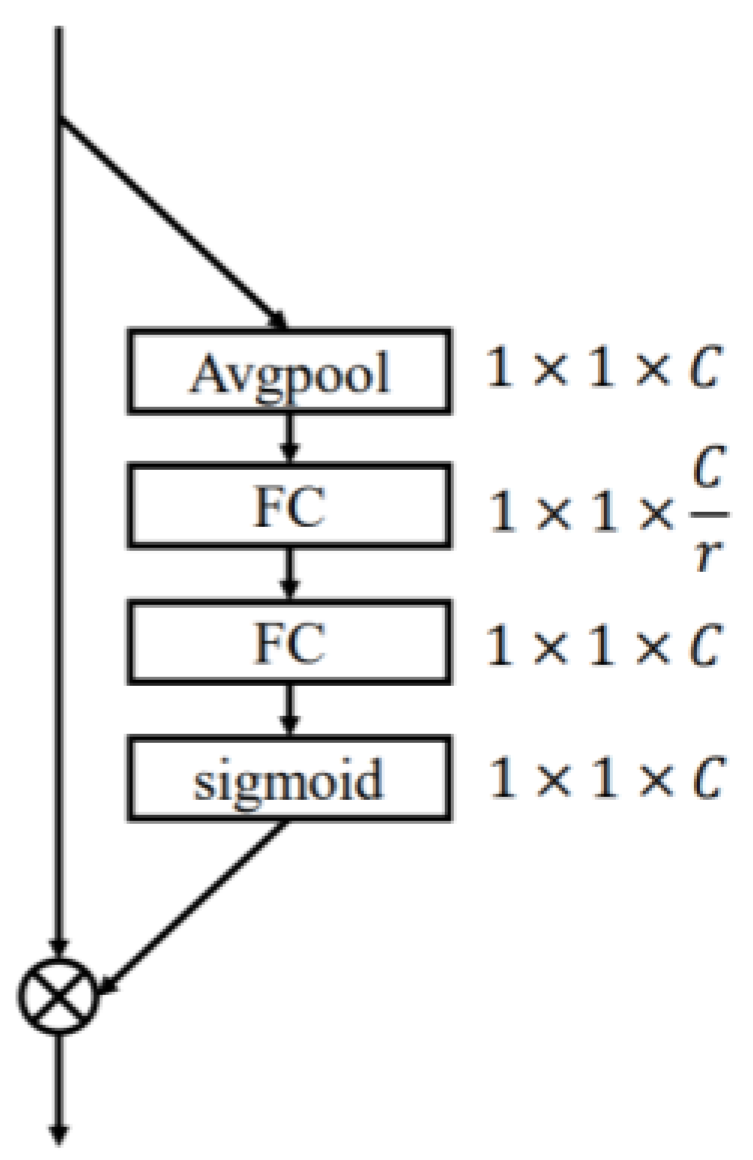
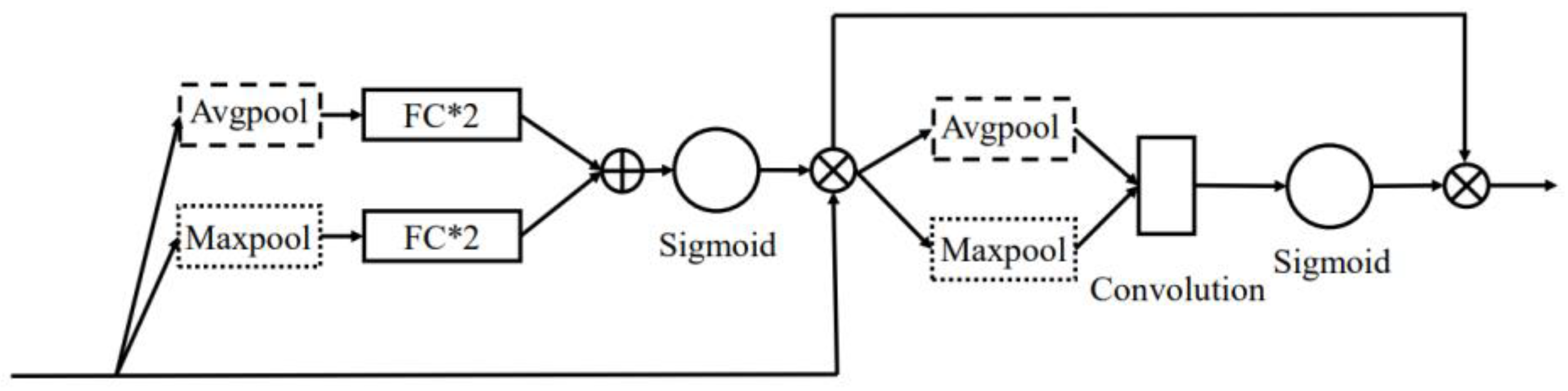
2.2. Attentional Mechanism
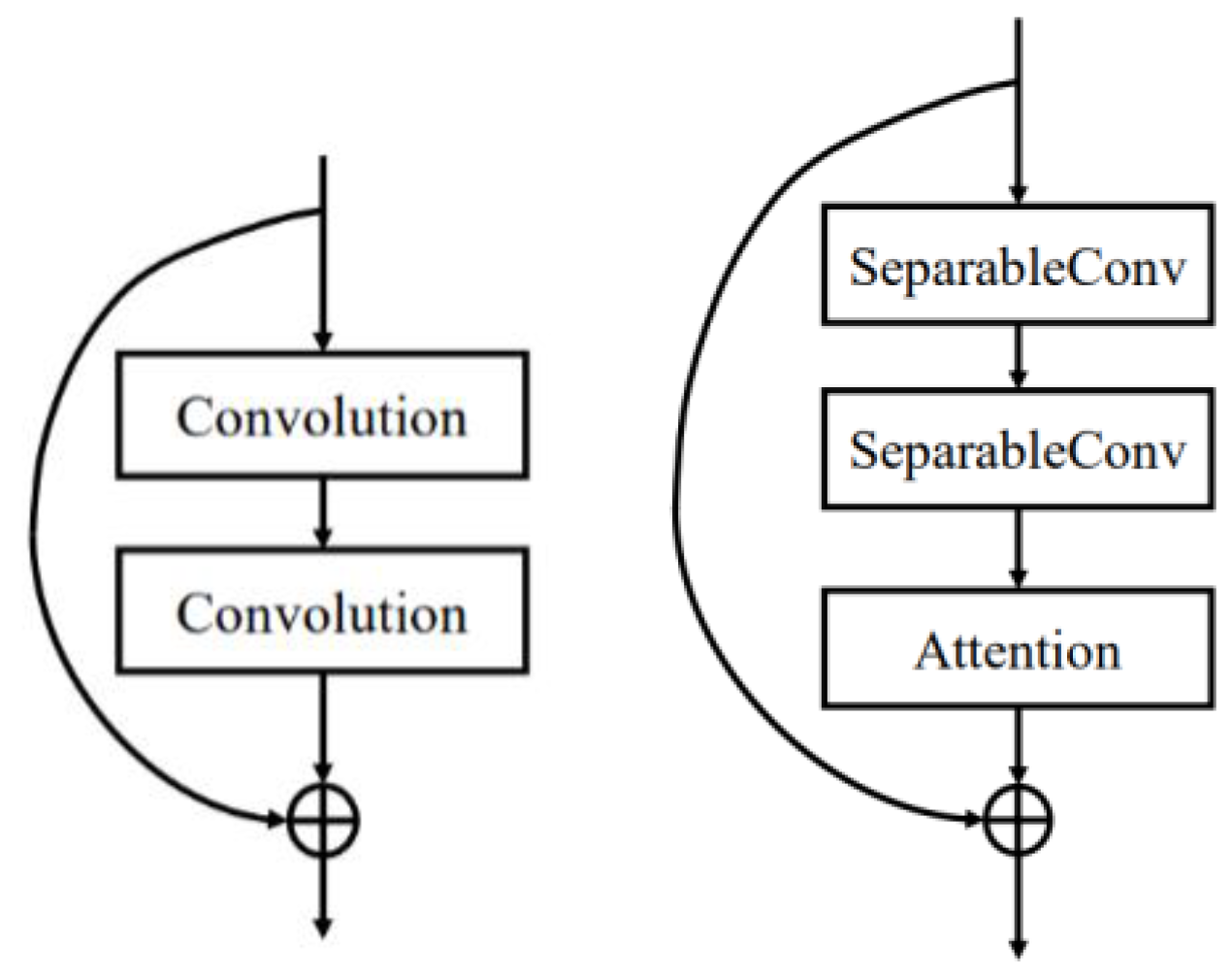
2.3. Attention Distillation
2.4. Depthwise Separable Convolution
3. Methodology
3.1. Backbone
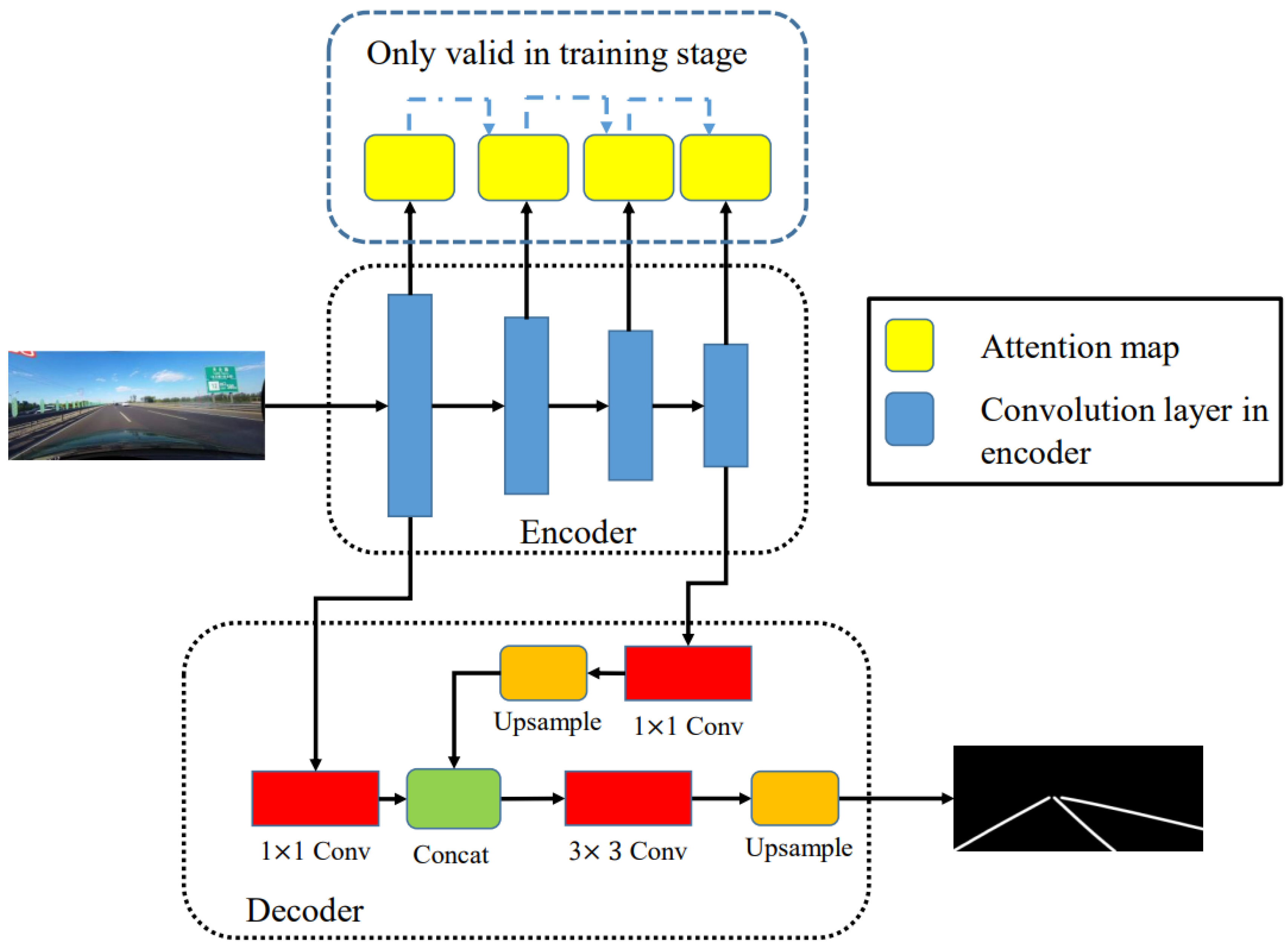
3.2. SAD
4. Experiments
4.1. Implementation Details
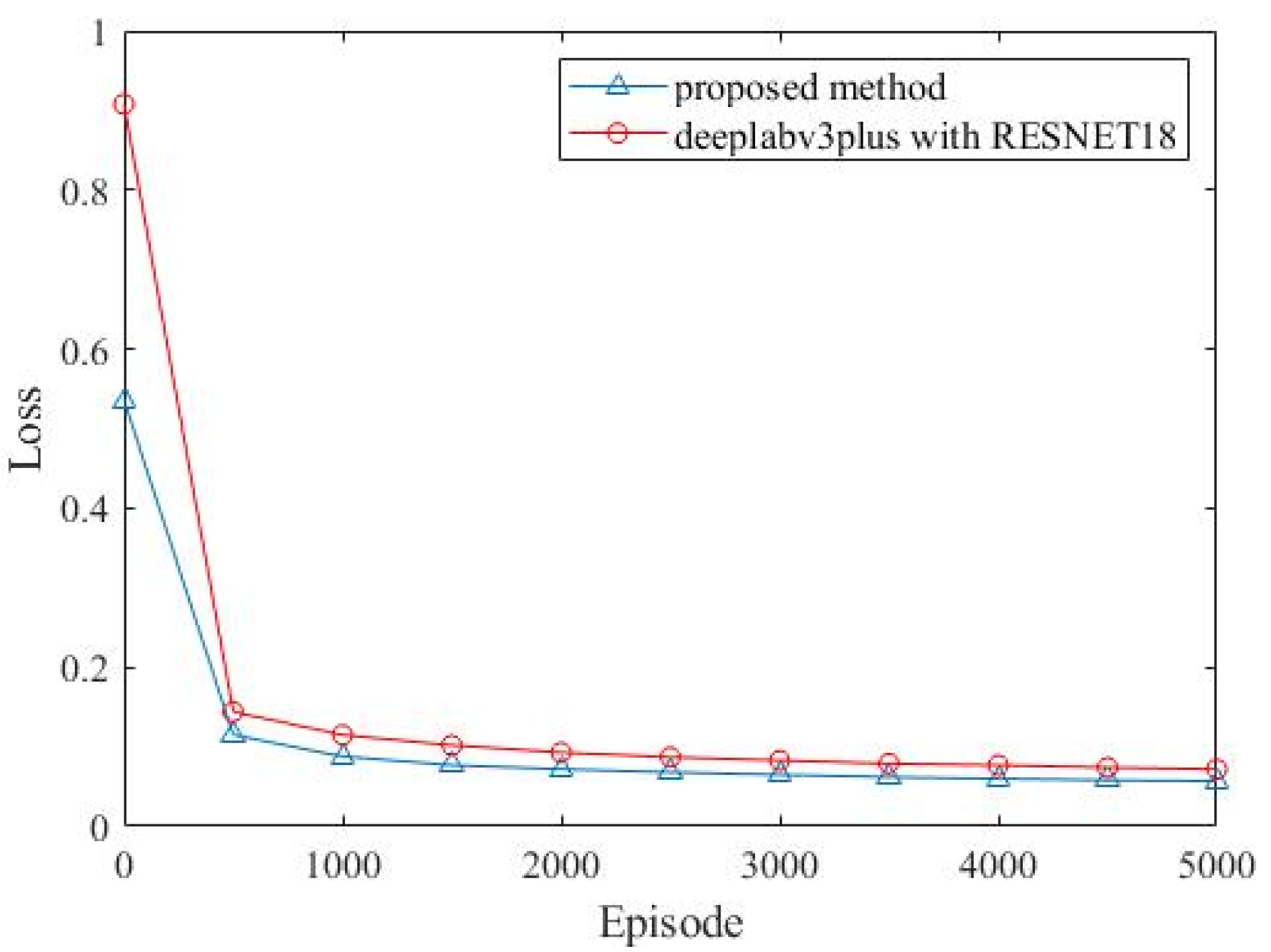
4.2. Ablation Experiments
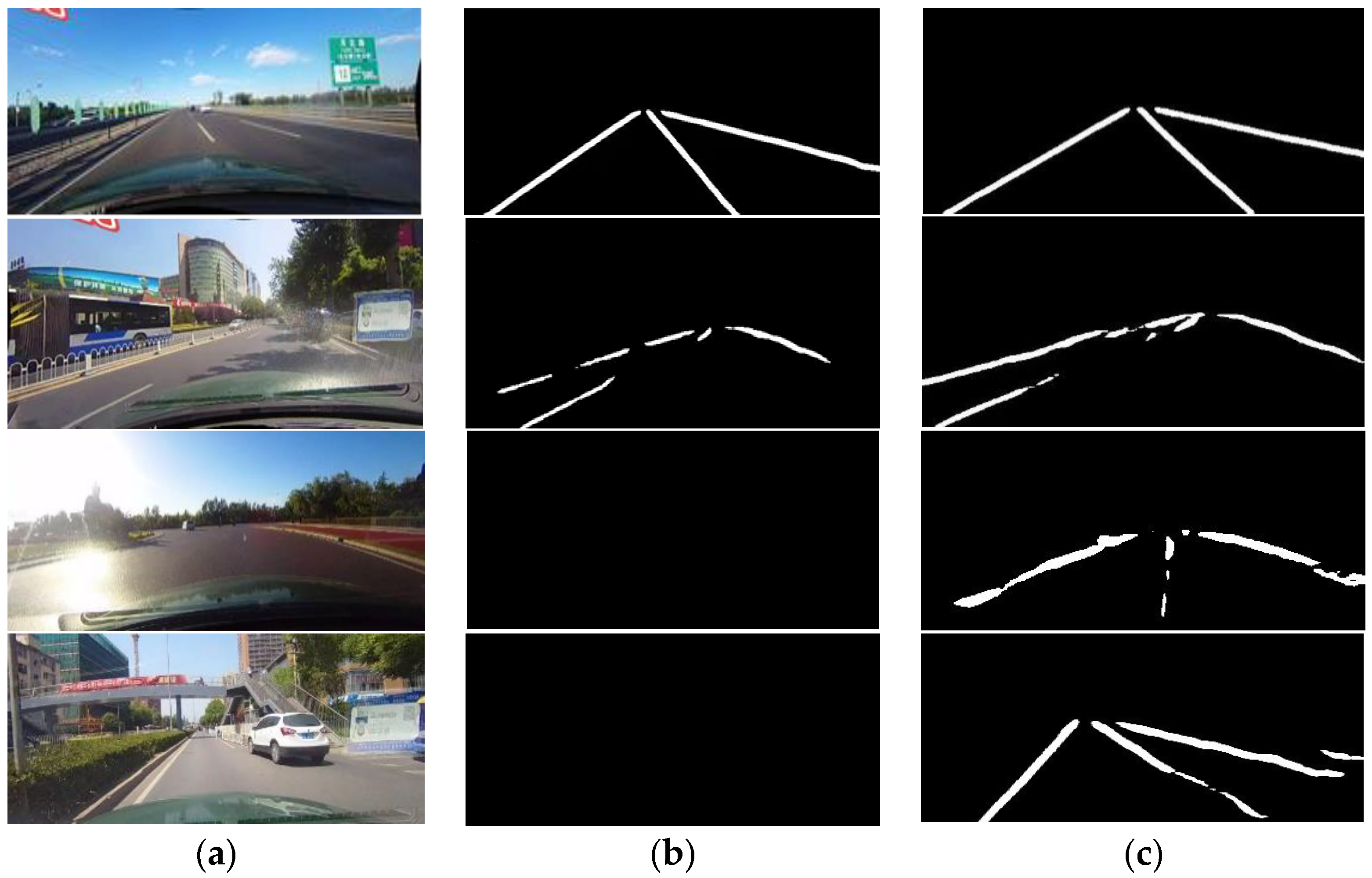
4.3. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Yousri, R.; Elattar, M.A.; Saeed Darweesh, M. A deep learning-based benchmarking framework for lane segmentation in the complex and dynamic road scenes. IEEE Access 2021, 9, 117565–117580. [Google Scholar] [CrossRef]
- Haixia, L.; Xizhou, L. Flexible lane detection using CNNs. In Proceedings of the 2021 International Conference on Computer Technology and Media Convergence Design (CTMCD 2021), Sanya, China, 23–25 April 2021; pp. 235–238. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, Z.; Ma, D.; Xue, J.H.; Liao, Q. Ripple-GAN: Lane line detection with ripple lane line detection network and Wasserstein GAN. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1532–1542. [Google Scholar] [CrossRef]
- Narote, S.P.; Bhujbal, P.N.; Narote, A.S.; Dhane, D.M. A review of recent advances in lane detection and departure warning system. Pattern Recognit. 2018, 73, 216–234. [Google Scholar] [CrossRef]
- Borkar, A.; Hayes, M.; Smith, M.T. A novel lane detection system with efficient ground truth generation. IEEE Trans. Intell. Transp. Syst. 2012, 13, 365–374. [Google Scholar] [CrossRef]
- Chen, J.; Ruan, Y.; Chen, Q. A precise information extraction algorithm for lane lines. China Commun. 2018, 15, 210–219. [Google Scholar] [CrossRef]
- Liu, F.; Zhang, Z.; Zhou, R. Automatic modulation recognition based on CNN and GRU. Tsinghua Sci. Technol. 2022, 27, 422–431. [Google Scholar] [CrossRef]
- Cai, W.; Wang, Y.; Ma, J.; Jin, Q. CAN: Effective cross features by global attention mechanism and neural network for ad click prediction. Tsinghua Sci. Technol. 2022, 27, 186–195. [Google Scholar] [CrossRef]
- Le, T.N.; Ono, S.; Sugimoto, A.; Kawasaki, H. Attention R-CNN for accident detection. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 313–320. [Google Scholar] [CrossRef]
- Deng, H.; Zhang, Y.; Li, R.; Hu, C.; Feng, Z.; Li, H. Combining residual attention mechanisms and generative adversarial networks for hippocampus segmentation. Tsinghua Sci. Technol. 2022, 27, 68–78. [Google Scholar] [CrossRef]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial CNN for traffic scene understanding. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI 2018), New Orleans, LA, USA, 2–7 February 2018; pp. 7276–7283. [Google Scholar]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards end-to-end lane detection: An instance segmentation approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 286–291. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Oğuz, E.; Küçükmanisa, A.; Duvar, R.; Urhan, O. A deep learning based fast lane detection approach. Chaos Solitons Fractals 2022, 155, 111722. [Google Scholar] [CrossRef]
- Zou, Q.; Jiang, H.; Dai, Q.; Yue, Y.; Chen, L.; Wang, Q. Robust lane detection from continuous driving scenes using deep neural networks. IEEE Trans. Veh. Technol. 2020, 69, 41–54. [Google Scholar] [CrossRef] [Green Version]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition. arXiv 2014, arXiv:1402.1128. [Google Scholar]
- Zhou, H.; Wang, H.; Zhang, H.; Hasith, K. LaCNet: Real-time end-to-end arbitrary-shaped lane and curb detection with instance segmentation network. In Proceedings of the 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; pp. 184–189. [Google Scholar] [CrossRef]
- Zhu, X.; Xiong, Y.; Dai, J.; Yuan, L.; Wei, Y. Deep feature flow for video recognition. In Proceedings of the 2017 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4141–4150. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Dai, J.; Yuan, L.; Wei, Y. Towards high performance video object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7210–7218. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Zhu, M.; White, M.; Li, Y.; Kalenichenko, D. Looking fast and slow: Memory-guided mobile video object detection. arXiv 2019, arXiv:1903.10172. [Google Scholar]
- Li, X.; Huang, Z.; Sun, X.; Liu, T. A fast detection method for polynomial fitting lane with self-attention module added. In Proceedings of the 2021 10th International Conference on Control, Automation and Information Sciences (ICCAIS), Xi’an, China, 14–17 October 2021; pp. 46–51. [Google Scholar] [CrossRef]
- Qin, Z.; Wang, H.; Li, X. Ultra fast structure-aware deep lane detection. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 276–291. [Google Scholar] [CrossRef]
- Ye, Z. Fast multi-direction lane detection. In Proceedings of the 2021 2nd International Conference on Computing and Data Science (CDS), Stanford, CA, USA, 28–29 January 2021; pp. 301–304. [Google Scholar] [CrossRef]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection CNNS by self attention distillation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 7 October–2 November 2019; pp. 1013–1021. [Google Scholar] [CrossRef] [Green Version]
- Guo, J.-M.; Markoni, H. Deep Learning Based Lane Line Detection and Segmentation Using Slice Image Feature. In Proceedings of the 2021 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Hualien City, Taiwan, 16–19 November 2021; pp. 1–2. [Google Scholar]
- Liu, W.; Yan, F.; Tang, K.; Zhang, J.; Deng, T. Lane detection in complex scenes based on end-to-end neural network. In Proceedings of the 2020 Chinese Automation Congress (CAC 2020), Shanghai, China, 6–8 November 2020; pp. 4300–4305. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar] [CrossRef] [Green Version]
- Chen, L. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Networks, R.S.; Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z. ResNeSt: Split-attention networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–13. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef] [Green Version]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | RESNET-101 | RESNET-18 | RESNET-18_sep | RESNET-18_sep (SE) |
|---|---|---|---|---|
| Parameters (m) | 13.22 | 11.18 | 1.46 | 1.55 |
| Frame | Train | Validation | Test | Resolution |
|---|---|---|---|---|
| 133,235 | 88,880 | 9675 | 34,680 | 1640 × 590 |
| Type | SE | CBAM |
|---|---|---|
| Accuracy (%) | 97.49 | 97.33 |
| Baseline | Depthwise Separable Conv | SE | SAD | ASPP | Accuracy (%) |
|---|---|---|---|---|---|
| √ | √ | 95.83 | |||
| √ | √ | √ | 96.86 (+1.03) | ||
| √ | √ | √ | 97.26 (+1.43) | ||
| √ | √ | √ | 97.31 (+1.48) | ||
| √ | √ | √ | √ | 97.35 (+1.52) | |
| √ | √ | √ | 97.49 (+1.66) |
| Type | Run Time (ms) |
|---|---|
| RESNET-101 | 34.3 |
| SCNN [11] | 133.5 |
| SAD [19] | 13.4 |
| Proposed method | 8.7 |
| Type | MIOU (%) |
|---|---|
| Deeplabv3plus | 46.8 |
| Proposed method | 60.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Zhao, Y.; Tian, Y.; Zhang, Y.; Gao, L. The Improved Deeplabv3plus Based Fast Lane Detection Method. Actuators 2022, 11, 197. https://doi.org/10.3390/act11070197
Wang Z, Zhao Y, Tian Y, Zhang Y, Gao L. The Improved Deeplabv3plus Based Fast Lane Detection Method. Actuators. 2022; 11(7):197. https://doi.org/10.3390/act11070197
Chicago/Turabian StyleWang, Zhong, Yin Zhao, Yang Tian, Yahui Zhang, and Landa Gao. 2022. "The Improved Deeplabv3plus Based Fast Lane Detection Method" Actuators 11, no. 7: 197. https://doi.org/10.3390/act11070197
APA StyleWang, Z., Zhao, Y., Tian, Y., Zhang, Y., & Gao, L. (2022). The Improved Deeplabv3plus Based Fast Lane Detection Method. Actuators, 11(7), 197. https://doi.org/10.3390/act11070197