
Research on Control Strategy of Heavy-Haul Train on Long and Steep Downgrades


Abstract
:1. Introduction
- On the railway lines which transport coal from west to east in China, the maximum load capacity of the train has reached 20,000 tons, with a total length of about 2.6 km, and the number of vehicles is more than 200.
- There are many sections with long and steep downgrades, and the value of the slope reaches 12‰. Since “long and steep downgrades” is a relative concept, a unified definition should be given for trains with different electric braking capacities [4], which is shown in Equation (1).
- When the HHT runs on long and steep downgrades, the speed will increase continuously. To avoid exceeding the speed limit, the electric braking and air braking should be used together, which is called “electric-air combined braking” [5,6]. However, if air braking is applied for a long period, the shortage of air-filled time may become a serious problem. This may lead to insufficient force to reduce the speed in the next braking. Therefore, the air braking must be applied intermittently for HHTs, and the driver must choose the timing of the braking application and release accurately until the train leaves the given sections [7]. At the same time, the use of electric braking prevents the train speed from increasing sharply, and makes the air-filled time of the train pipe more sufficient. This contributes to improving the release performance of the train.
- The heavy-haul railway line is long, represented by the Datong-Qinhuangdao railway and the Shuozhou-Huanghua railway, the lengths of which are about 653 km and 594 km, respectively. Importantly, HHTs barely stop in between stations, and thus drivers usually suffer from higher work intensities [8].
- The control problem of HHT on long and steep downgrades is transformed into a multi-label learning process.
- The research method based on multi-label random forest (ML-RF) is proposed, in combination with line conditions, running speed, and other factors. Because ML-RF belongs to the category of machine learning, the control strategy can be obtained without the need of an accurate train model.
- With evaluation metrics of multi-label learning, a parameter optimization algorithm for ML-RF is designed. Tests are also conducted, considering the neutral zone.
2. Problem Description
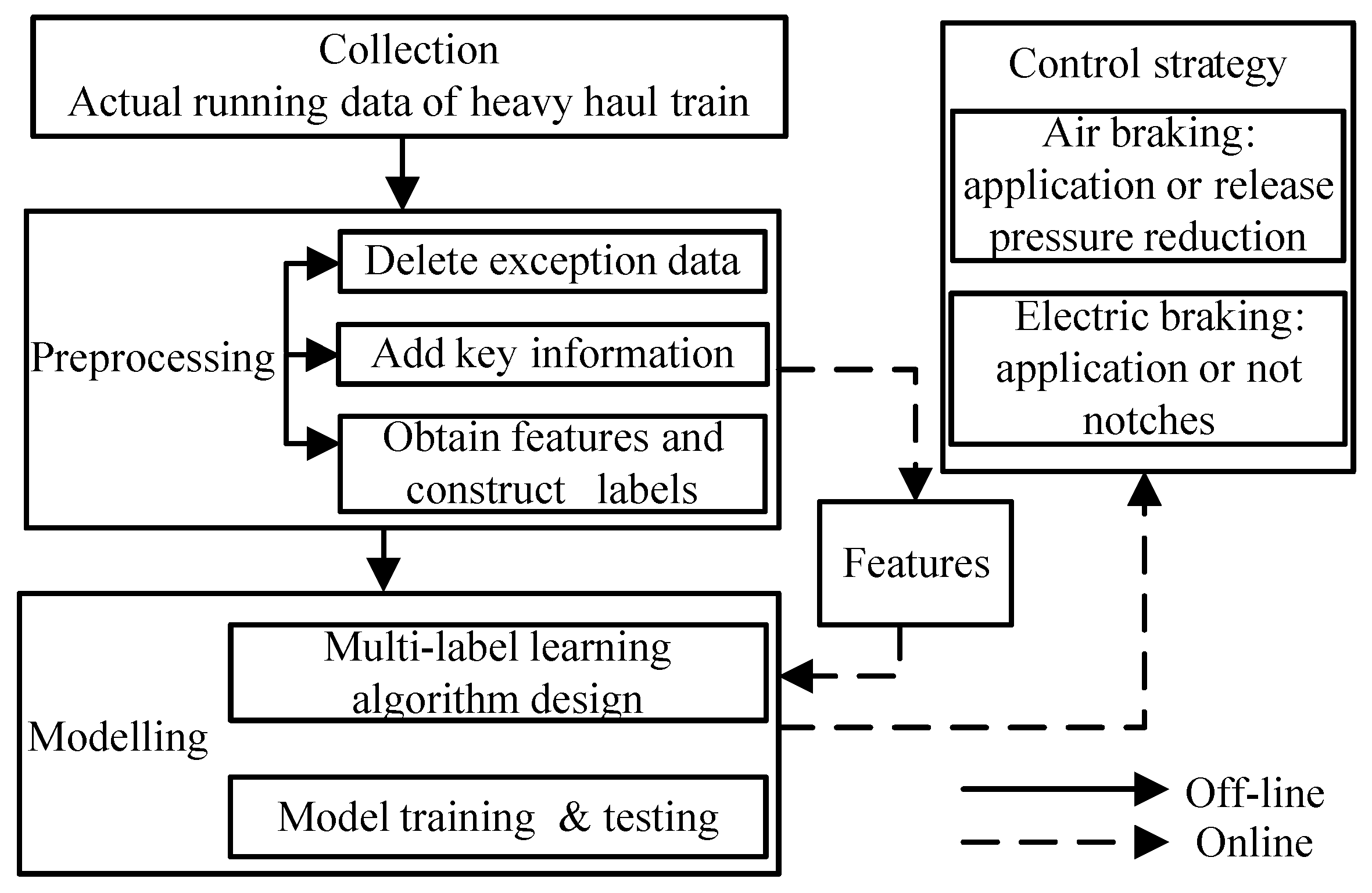
3. Prediction Model of Control Strategy
- The train operation status and the control process of the driver are reflected in the data.
- The train operation status is the result of forces acting on the real train. Here, the resistance forces and braking forces are included.
- For a driver, longitudinal train dynamics and braking system characteristics are considered during driving, such as the air-filled time.
3.1. Data Preprocessing
- le > 0, la = 0: electric braking is applied, while air braking is released;
- le > 0, la = 1: electric braking and air braking are applied together;
- le = 0, la = 1: only air braking is applied, especially when the train is running through a neutral zone.
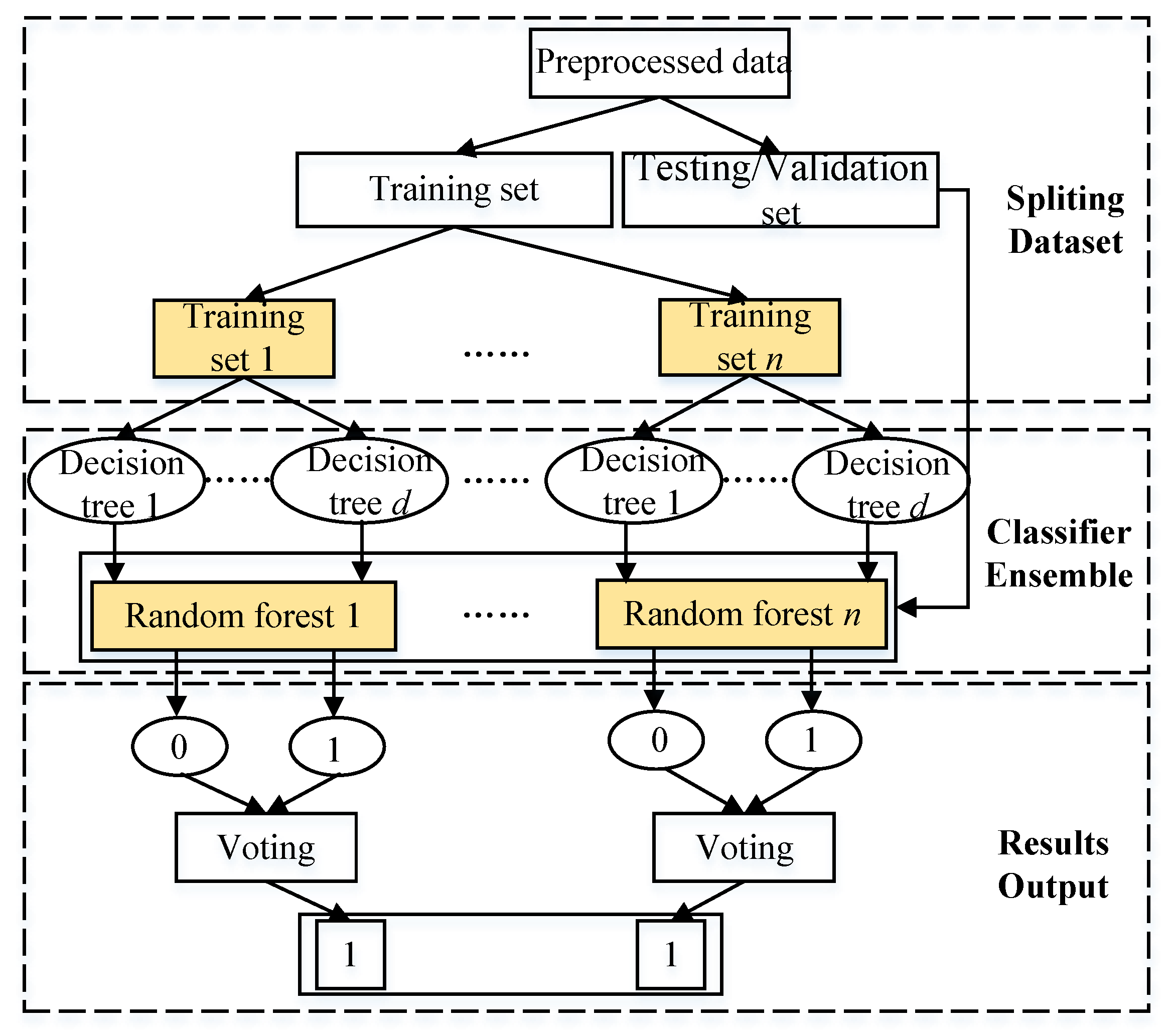
3.2. Multi-Label Learning Algorithm Based on Random Forest
- 1.
- Generate sub training data set (Training set 1, …, Training set n).For the training data set with m samples, k features, and n categories, the samples with same category are classified into one class and the rest are another class. Do this among all categories.
- 2.
- Construct decision trees in a forest (Decision tree 1, …, Decision tree d).
- New training data set Sd is randomly sampled from the sub training set n through the replacement method; usually, the new training data sets are the same size m as that of the original sub one, and there will be a repetition between them.
- Candidates at each split node are randomly sampled from k features.
- The set Sd is used and the selected features are considered to build a tree.
- Repeat until all decision trees are constructed.In this paper, the determination about the number of trees and number of selected features will be discussed in Section 3.4.
- 3.
- Construct a random forest.The decision trees built above are used to construct a random forest.
- 4.
- Repeat the process in steps 2–3 until n random forests are constructed.
- 5.
- Determine the classification result according to the voting selection of the decision trees.
3.3. Performance Metrics
- Hamming Loss evaluates the inconsistency between predicted labels and true labels for an object.
- Accuracy Score evaluates the objects whose predicted labels are exactly the same as the true labels.
- Jaccard Similarity is a method of similarity measure, and evaluates the coefficient of the size of the intersection and the union between the predicted labels and true labels.
- F1 Score is a comprehensive evaluation method that takes into account both the precision and recall of the model by the introduction of the harmonic means. Precision is the proportion of actual positives in all classified positives, and recall is the proportion of actual positives that are correctly classified. Macro-averaging is taken to calculate the average of them.
3.4. Parameters Determination
| Algorithm 1: The algorithm of parameter determination |
| Input: data set T, the range of ntree: [nmin, nmax] |
| Output: the optimal ntree |
|
|
|
|
|
4. Simulation Results
4.1. Data Set
4.2. Results Analysis
4.2.1. Optimal Parameters
4.2.2. Performance for Test Data Set
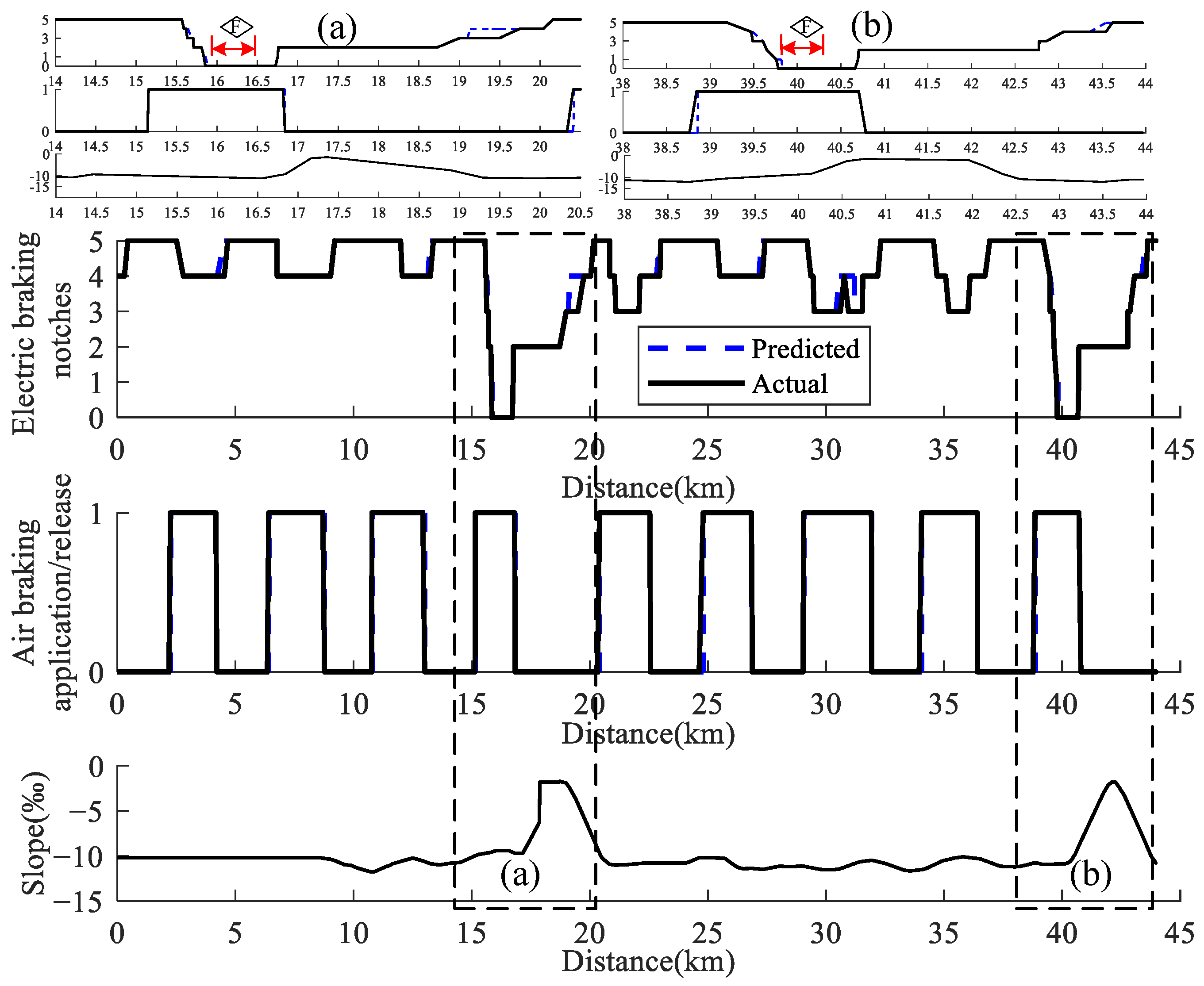
- From the perspective of evaluation metrics, the average values of Accuracy Score, Jaccard Similarity, F1 Score, and Hamming Loss reach up to 0.9016, 0.9332, 0.9228, and 0.0236, respectively. All of those show that the error rate of the prediction model for two kinds of braking is low, and the consistency of the predicted value and actual value is high.
- From the perspective of ensuring train operation safety, it can be seen from Figure 8 and Figure 9 that, for the HHTs running on long and steep downgrades, under the line conditions shown in the simulation, the reasonable electric braking force is used in the air braking release stage, which provides a guarantee for air-filled time. Figure 10 and Figure 11 show the HHT runs within the speed limit.
- When the train runs in the neutral zone, the electric braking force is zero. Before entering, the train is always in the release regime to prepare for the braking, because there are long and steep downgrades in this section. Through the discussion, it can be seen that the coordination of air braking and electric braking control is good.
- From the analysis of adaptability to different train operation status, although the slope of the line from 6.5 km to 29 km in scenario 1 is the same as the line from 0 km to 22.5 km in scenario 2, the control strategies for air braking and electric braking are different due to the different initial running speed of the train.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, J.; Ren, S.J.; Zhang, M.R. Model-based assessment of longitudinal dynamic performance and energy consumption of heavy haul train on long-steep downgrades. Transport 2019, 34, 250–259. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.X.; Sheng, W.P.; Liu, H.E. A Modeling Method for the Driving Process of Heavy-Haul Train Based on Multi-Mass Model. IEEE Access 2020, 8, 185548–185556. [Google Scholar] [CrossRef]
- Mcclanachan, M.; Cole, C. Current train control optimization methods with a view for application in heavy haul railways. Proc. Inst. Mech. Eng. F J. Rail Rapid Transit 2012, 226, 36–47. [Google Scholar] [CrossRef]
- Yang, Y.Q.; Mao, B.H.; Wang, M. Research on freight train operation control simulation on long steep down lines. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part A Civ. Eng. 2021, 7, 05021003. [Google Scholar] [CrossRef]
- Yang, X.G.; Wei, W. Comparative Study on Simulation and Experiment of Heavy Haul Train Operating Conditions. J. Transp. Technol. 2019, 8, 129–137. [Google Scholar]
- Yang, M.; Wang, K.Y.; Shi, Z.Y.; Ge, X.; Zhou, Y.C. Release performance of heavy-haul train based on electric-pneumatic blend braking. J. Chongqing Univ. Techno. (Nat. Sci). 2017, 31, 84–89. [Google Scholar]
- Sun, Z.Y.; Wang, C.M. Security problems of operation heavy haul trains on the long heavy down grade. Railw. Locomot. Car 2009, 29, 4–7. [Google Scholar]
- Du, K.B.; Zhang, Z.F.; Wen, Y.L. Research on autonomous driving control technology for heavy haul train. Control. Theory Appl. 2020, 31–35. [Google Scholar] [CrossRef]
- Spiryagin, M.; Wolfs, P.; Cole, C.; Spiryagin, V.; Sun, Y.Q.; McSweeney, T. Design and Simulation of Heavy Haul Locomotives and Trains; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Cole, C. Longitudinal train dynamics. In Handbook of Railway Vehicle Dynamics; Chapter 9; Taylor & Francis: London, UK, 2006; pp. 239–278. [Google Scholar]
- He, F.H.; Zhang, B. Study on Brake control strategies for 20 kt combined heavy haul train under special working condition. In Proceedings of the 9th International Heavy Haul Conference on Heavy Haul and Innovation Development, Shanghai, China, 22–25 June 2009; pp. 617–623. [Google Scholar]
- Dong, K.Y.; Wei, W. Optimizing of cycle braking of 10,000 t train on long heavy down grade of Shenshuo. J. Dalian Jiaotong Univ. 2017, 38, 17–20. [Google Scholar]
- Zhang, X.F.; Lin, H.Q.; Zheng, M.H.; Lu, X.H. Study on air brake application and energy-saving strategy for 30 t axle load in long heavy down grade of Shenchi-Huanghua Railway. J. China Railw. Soc. 2018, 40, 63–69. [Google Scholar]
- Yang, H.; Ma, H.P.; Fu, Y.T.; Li, Z.Q. Brake strategy for heavy-haul train based on multi-particle model. J. Beijing Univ. Technol. 2020, 46, 169–179. [Google Scholar]
- Lin, X.; Wang, Q.Y.; Wang, P.L.; Sun, P.F.; Feng, X.Y. The energy-efficient operation problem of a freight train considering long-distance steep downhill sections. Energies 2017, 10, 794. [Google Scholar] [CrossRef]
- Yu, H.Z.; Huang, Y.N.; Wang, M.Z. Research on operating strategy based on particle swarm optimization for heavy haul train on long down-slope. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2735–2740. [Google Scholar]
- Huang, Y.C.; Su, S.; Liu, W.T. Optimization on the driving curve of heavy haul trains based on artificial bee colony algorithm. In Proceedings of the 2020 23rd International Conference on Intelligent Transportation Systems (ITSC), ELECTR NETWORK, Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Su, S.; Huang, Y.; Liu, W.T.; Tang, T.; Cao, Y.; Liu, H.J. Optimization of the speed curve for heavy-haul trains considering cyclic air braking: An MILP approach. Eng. Optim. 2022, 1–15. [Google Scholar] [CrossRef]
- Wang, X.; Tang, T.; He, H. Optimal control of heavy haul train based on approximate dynamic programming. Adv. Mech. Eng. 2017, 9, 1687814017698110. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Li, S.K.; Tang, T.; Xun, J. Intelligent operation of heavy haul train with data imbalance: A machine learning method. Knowl-Based Syst. 2019, 163, 36–50. [Google Scholar] [CrossRef]
- Huang, Y.N.; Tan, L.T.; Chen, L.; Tang, T. A neutral network driving curve generation method for the heavy-haul train. Adv. Mech. Eng. 2016, 8, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Wei, S.Y.; Zhu, L.; Chen, L.J.; Lin, Q.Q. An adaboost-based intelligent driving algorithm for heavy-haul trains. Actuators 2021, 10, 188. [Google Scholar] [CrossRef]
- Tang, H.Y.; Wang, Y.; Liu, X.; Feng, X.Y. Reinforcement learning approach for optimal control of multiple electric locomotives in a heavy-haul freight train: A Double-Switch-Q-network architecture. Knowl-Based Syst. 2020, 190, 105173. [Google Scholar] [CrossRef]
- Bai, Y.; Mao, B.H.; Ho, T.; Feng, Y.; Chen, S.K. Station Stopping of Freight Trains with Pneumatic Braking. Math. Probl. Eng. 2014, 2014, 1–7. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. A review on Multi-label Learning Algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Wu, Q.H.; Wang, H.H.; Yan, X.S.; Liu, X.B. MapReduce-based adaptive random forest algorithm for multi-label classification. Neural Comput. Appl. 2019, 31, 8239–8252. [Google Scholar] [CrossRef]
- Wang, Z.Y.; Wang, Y.R.; Zeng, R.C.; Srinivasan, R.S.; Ahrentzen, S. Random Forest based hourly building energy prediction. Energy Build. 2018, 171, 11–25. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Mining multi-label data. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2009; pp. 667–685. [Google Scholar]
- Szymański, P.; Kajdanowicz, T.; Kersting, K. How is a data-driven approach better than random choice in label space division for multi-label classification? Entropy 2016, 18, 282. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Meanings |
|---|---|
| the set of objects used for evaluation | |
| the set of labels that spans the output space y | |
| an object undergoing classification | |
| the label set assigned to object by the evaluated classifier h | |
| the set of true labels for | |
| tpj fpj fnj tnj | true positives, false positives, false negatives and true negatives of the label Lj, counted per label over the output of classifier h on the set of testing objects X, i.e., h(X) |
| the operator that converts logical value to a number, i.e., it yields 1 if p is true and 0 if p is false. | |
| denotes the logical exclusive or. |
| Method | Accuracy Score | Jaccard Similarity | F1 Score | Hamming Loss |
|---|---|---|---|---|
| ML-RF | 0.8661 | 0.9100 | 0.9330 | 0.0325 |
| ML-Adaboost | 0.7991 | 0.8735 | 0.9218 | 0.0434 |
| ML-SVM | 0.7723 | 0.8504 | 0.8142 | 0.0466 |
| ML-KNN | 0.5938 | 0.6786 | 0.6556 | 0.0982 |
| Method | Accuracy Score | Jaccard Similarity | F1 Score | Hamming Loss |
|---|---|---|---|---|
| ML-RF | 0.9370 | 0.9563 | 0.9125 | 0.0147 |
| ML-Adaboost | 0.8483 | 0.9120 | 0.9003 | 0.0274 |
| ML-SVM | 0.8946 | 0.9235 | 0.8021 | 0.0222 |
| ML-KNN | 0.7095 | 0.7931 | 0.6605 | 0.0652 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, H.; Tai, G.; Lin, Z.; Huang, Y. Research on Control Strategy of Heavy-Haul Train on Long and Steep Downgrades. Actuators 2022, 11, 145. https://doi.org/10.3390/act11060145
Yu H, Tai G, Lin Z, Huang Y. Research on Control Strategy of Heavy-Haul Train on Long and Steep Downgrades. Actuators. 2022; 11(6):145. https://doi.org/10.3390/act11060145
Chicago/Turabian StyleYu, Huazhen, Guoxuan Tai, Zhengnan Lin, and Youneng Huang. 2022. "Research on Control Strategy of Heavy-Haul Train on Long and Steep Downgrades" Actuators 11, no. 6: 145. https://doi.org/10.3390/act11060145
APA StyleYu, H., Tai, G., Lin, Z., & Huang, Y. (2022). Research on Control Strategy of Heavy-Haul Train on Long and Steep Downgrades. Actuators, 11(6), 145. https://doi.org/10.3390/act11060145