
Output-Feedback Position Tracking Servo System with Feedback Gain Learning Mechanism via Order-Reduction Speed-Error-Stabilization Approach


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- an extended state observer (for the position reference derivative and controlled errors involving speed and its acceleration) equipped with a specially structured tuning factor yielding the first-order exponential convergent estimation error behavior; and
- the combination of an active damping injection pole-zero cancellation PI controller and nonlinear DOB for the first-order exponential convergent speed error stabilizer without dependence on the exact servo system parameter values.
2. Servo System Dynamics
3. Position-Tracking Control Law
3.1. Control Objective
3.2. Position Control with Feedback-Gain-Learning Algorithm
3.2.1. Position Reference Derivative Observer
3.2.2. Position-Tracking Control
3.3. Observer-Based Speed Error Stabilizer
3.3.1. Speed and Acceleration Error Observers
3.3.2. Speed Error Stabilizer
4. Closed Loop Analysis
4.1. Position Control Loop
4.2. Speed Error Stabilization Loop
4.3. Entire System Properties
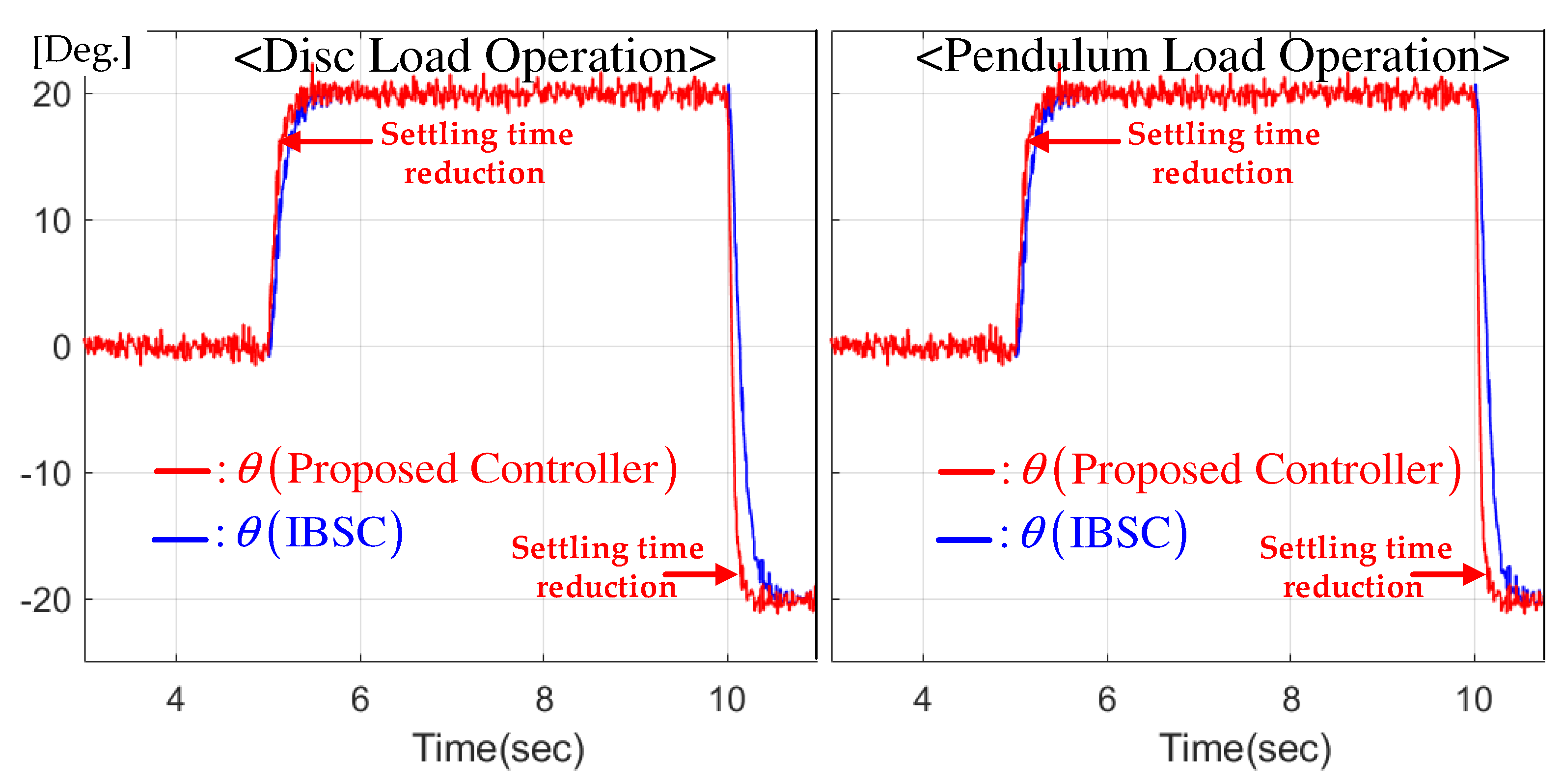
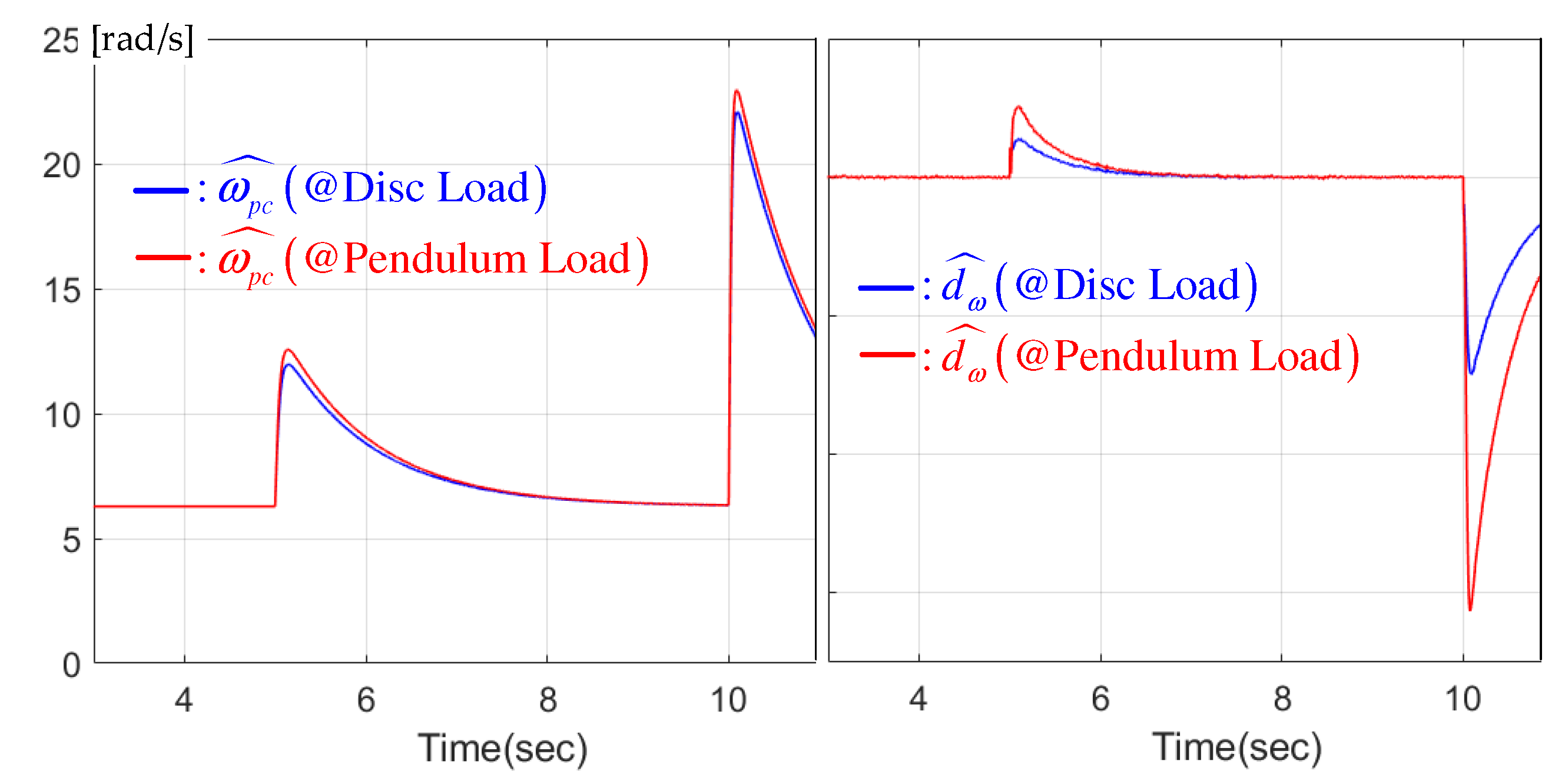
5. Experimental Results
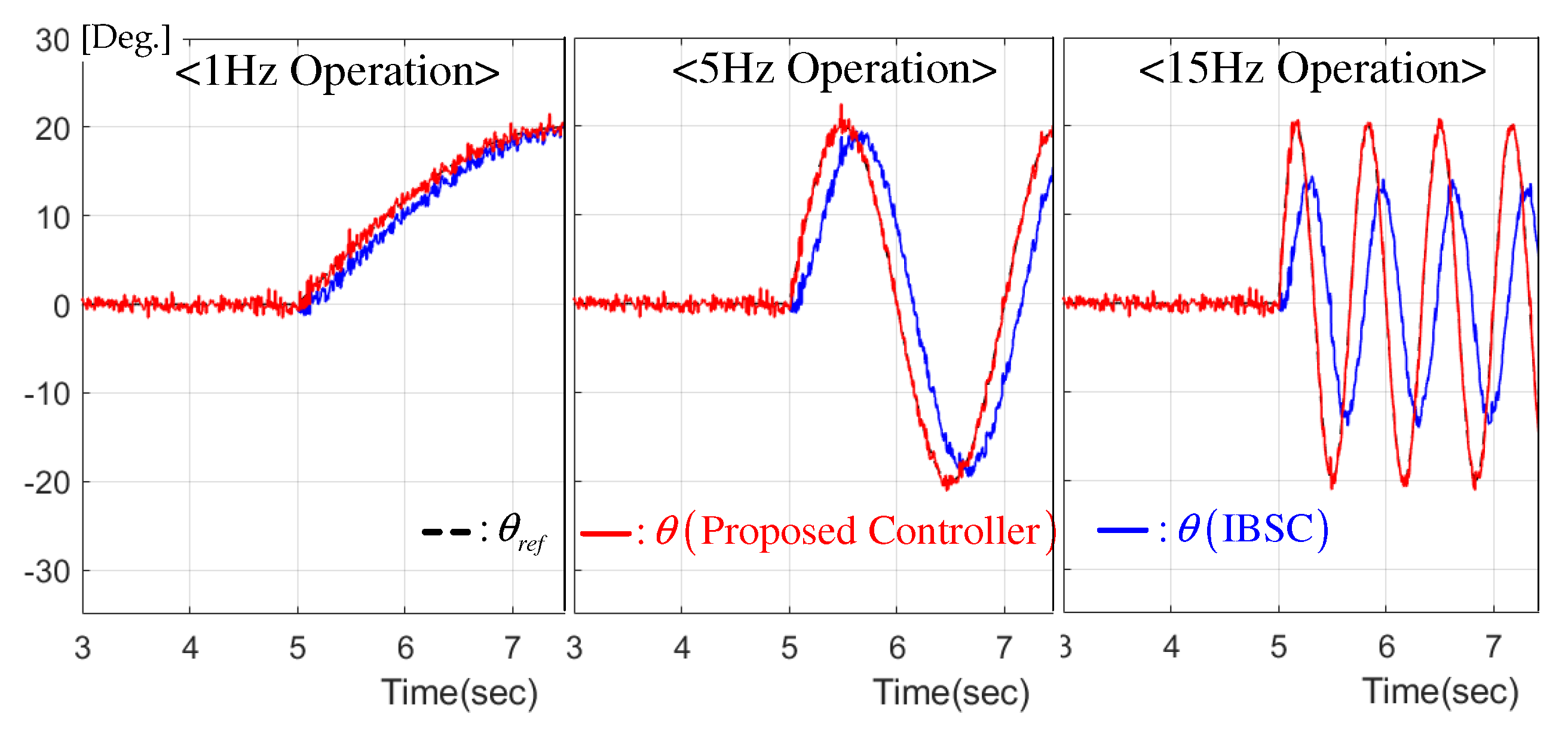
5.1. Reference Trajectory Tracking Performance
5.1.1. Case I: Stair Reference
5.1.2. Case II: Sinusoidal Reference
5.2. Constant Reference Regulation Performance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, P.; Zhu, L.; Zhang, C.; Wang, C.; Xiao, K. Prescribed Performance Control with Sliding-Mode Dynamic Surface for a Glue Pump Motor Based on Extended State Observers. Actuators 2021, 10, 282. [Google Scholar] [CrossRef]
- Suti, A.; Di Rito, G.; Galatolo, R. Fault-Tolerant Control of a Three-Phase Permanent Magnet Synchronous Motor for Lightweight UAV Propellers via Central Point Drive. Actuators 2021, 10, 253. [Google Scholar] [CrossRef]
- Božek, P.; Nikitin, Y. The Development of an Optimally-Tuned PID Control for the Actuator of a Transport Robot. Actuators 2021, 10, 195. [Google Scholar] [CrossRef]
- Ismail, M.; Wiedemann, S.; Bosch, C.; Stuckmann, C. Design and Evaluation of Fault-Tolerant Electro-Mechanical Actuators for Flight Controls of Unmanned Aerial Vehicles. Actuators 2021, 10, 175. [Google Scholar] [CrossRef]
- Kim, S.K.; Ahn, C.K. Active-damping Speed Tracking Technique for Permanent Magnet Synchronous Motors with Transient Performance Boosting Mechanism. IEEE Trans. Ind. Inf. 2021, 1, 1–9. [Google Scholar] [CrossRef]
- Park, J.K.; Lee, J.H.; Kim, S.K.; Ahn, C.K. Output-Feedback Speed-Tracking Control Without Current Feedback for BLDCMs Based on Active-Damping and Invariant Surface Approach. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 2528–2532. [Google Scholar] [CrossRef]
- Lin, C.H.; Ho, C.W.; Hu, G.H.; Sreeramaneni, B.; Yan, J.J. Secure Data Transmission Based on Adaptive Chattering-Free Sliding Mode Synchronization of Unified Chaotic Systems. Mathematics 2021, 9, 2658. [Google Scholar] [CrossRef]
- Li, M.; Zhang, R.; Yang, S. Adaptive Synchronization of Fractional-Order Complex-Valued Chaotic Neural Networks with Time-Delay and Unknown Parameters. Physics 2021, 3, 924–939. [Google Scholar]
- Andeescu, G.D.; Pitic, C.; Blaabjerg, F.; Boldea, I. Combined flux observer with signal injection enhancement for wide speed range sensorless direct torque control of IPMSM drives. IEEE Trans. Energy Convers. 2008, 23, 393–402. [Google Scholar] [CrossRef]
- Tang, L.; Zhong, L.; Rahman, M.; Hu., Y. A novel direct torque control for interior permanent-magnet synchronous machine drive with low ripple in torque and flux—A speed-senseroless approach. IEEE Trans. Ind. Appl. 2003, 39, 1748–1756. [Google Scholar] [CrossRef]
- Olalla, C.; Leyva, R.; Queinnec, I.; Maksimovic, D. Robust Gain-Scheduled Control of Switched-Mode DC-DC Converters. IEEE Trans. Power Electron. 2012, 27, 3006–3019. [Google Scholar] [CrossRef]
- Sul, S.K. Control of Electric Machine Drive Systems; Wiley: Hoboken, NJ, USA, 2011; Volume 88. [Google Scholar]
- Sengupta, I.; Gupta, S.; Deb, D.; Ozana, S. Dynamic Stability of an Electric Monowheel System Using LQG-Based Adaptive Control. Appl. Sci. 2021, 11, 9766. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Z. Variational Bayesian Iteration-Based Invariant Kalman Filter for Attitude Estimation on Matrix Lie Groups. Aerospace 2021, 8, 246. [Google Scholar] [CrossRef]
- Huang, H.; Tang, J.; Zhang, B. Positioning Parameter Determination Based on Statistical Regression Applied to Autonomous Underwater Vehicle. Appl. Sci. 2021, 11, 7777. [Google Scholar] [CrossRef]
- Kim, S.K.; Lee, J.S.; Lee, K.B. Self-Tuning Adaptive Speed Controller for Permanent Magnet Synchronous Motor. IEEE Trans. Power Electron. 2017, 32, 1493–1506. [Google Scholar] [CrossRef]
- Kim, S.K. Robust adaptive speed regulator with self-tuning law for surfaced-mounted permanent magnet synchronous motor. Control Eng. Pract. 2017, 61, 55–71. [Google Scholar] [CrossRef]
- El-Sousy, F.F.M.; Abuhasel, K.A. Nonlinear Robust Optimal Control via Adaptive Dynamic Programming of Permanent-Magnet Linear Synchronous Motor Drive for Uncertain Two-Axis Motion Control System. IEEE Trans. Ind. Appl. 2020, 56, 1940–1952. [Google Scholar] [CrossRef]
- Errouissi, R.; Ouhrouche, M.; Chen, W.H.; Trzynadlowski, A.M. Robust Cascaded Nonlinear Predictive Control of a Permanent Magnet Synchronous Motor With Antiwindup Compensator. IEEE Trans. Ind. Electron. 2012, 59, 3078–3088. [Google Scholar] [CrossRef]
- Son, Y.I.; Kim, I.H.; Choi, D.S.; Shim, H. Robust Cascade Control of Electric Motor Drives Using Dual Reduced-Order PI Observer. IEEE Trans. Ind. Electron. 2015, 62, 3672–3682. [Google Scholar] [CrossRef]
- Corradini, M.L.; Ippoliti, G.; Longhi, S.; Orlando, G. A Quasi-Sliding Mode Approach for Robust Control and Speed Estimation of PM Synchronous Motors. IEEE Trans. Ind. Electron. 2012, 59, 1096–1104. [Google Scholar] [CrossRef]
- Geyer, T.; Papafotieu, G.; Morari, M. Model predictive direct torque control-part I: Concept, algorithm and analysis. IEEE Trans. Ind. Electron. 2009, 56, 1894–1905. [Google Scholar] [CrossRef]
- Ahmed, A.A.; Koh, B.K.; Lee, Y.I. A Comparison of Finite Control Set and Continuous Control Set Model Predictive Control Schemes for Speed Control of Induction Motors. IEEE Trans. Ind. Inf. 2018, 14, 1334–1346. [Google Scholar] [CrossRef]
- Tao, T.; Zhao, W.; Du, Y.; Cheng, Y.; Zhu, J. Simplified Fault-Tolerant Model Predictive Control for a Five-Phase Permanent-Magnet Motor with Reduced Computation Burden. IEEE Trans. Power Electron. 2020, 35, 3850–3858. [Google Scholar] [CrossRef]
- Kim, S.K.; Kim, Y.; Ahn, C.K. Energy-Shaping Speed Controller with Time-Varying Damping Injection for Permanent-Magnet Synchronous Motors. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 381–385. [Google Scholar] [CrossRef]
- Kim, S.K.; Ahn, C.K. Position Regulator with Variable Cut-Off Frequency Mechanism for Hybrid-Type Stepper Motors. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 3533–3540. [Google Scholar] [CrossRef]
- Deng, W.; Yao, J.; Ma, D. Time-varying input delay compensation for nonlinear systems with additive disturbance: An output feedback approach. Int. J. Robust Nonlinear Control 2017, 28, 31–52. [Google Scholar] [CrossRef]
- Deng, W.; Yao, J. Extended-State-Observer-Based Adaptive Control of Electrohydraulic Servomechanisms without Velocity Measurement. IEEE/ASME Trans. Mechatron. 2020, 25, 1151–1161. [Google Scholar] [CrossRef]
- Deng, W.; Yao, J.; Wang, Y.; Yang, X.; Chen, J. Output feedback backstepping control of hydraulic actuators with valve dynamics compensation. Mech. Syst. Sig. Process. 2021, 158, 107769. [Google Scholar] [CrossRef]
- Khalil, H.K. Nonlinear Systems; Prentice Hall: Englewood Cliffs, NJ, USA, 2002. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, S.H.; Kim, S.-K.; Choi, H.D. Output-Feedback Position Tracking Servo System with Feedback Gain Learning Mechanism via Order-Reduction Speed-Error-Stabilization Approach. Actuators 2021, 10, 324. https://doi.org/10.3390/act10120324
You SH, Kim S-K, Choi HD. Output-Feedback Position Tracking Servo System with Feedback Gain Learning Mechanism via Order-Reduction Speed-Error-Stabilization Approach. Actuators. 2021; 10(12):324. https://doi.org/10.3390/act10120324
Chicago/Turabian StyleYou, Sung Hyun, Seok-Kyoon Kim, and Hyun Duck Choi. 2021. "Output-Feedback Position Tracking Servo System with Feedback Gain Learning Mechanism via Order-Reduction Speed-Error-Stabilization Approach" Actuators 10, no. 12: 324. https://doi.org/10.3390/act10120324
APA StyleYou, S. H., Kim, S.-K., & Choi, H. D. (2021). Output-Feedback Position Tracking Servo System with Feedback Gain Learning Mechanism via Order-Reduction Speed-Error-Stabilization Approach. Actuators, 10(12), 324. https://doi.org/10.3390/act10120324