
Evidence of Immune Modulators in the Secretome of the Equine Tapeworm Anoplocephala perfoliata

 , , ,
, , ,  , , , and
, , , and 
Abstract
1. Introduction
2. Results
2.1. De Novo Assembly of the A. perfoliata Transcriptome
2.2. Transcriptome Functional Annotation and Gene Ontology Terms Analysis
2.3. Transcripts Expression of A. perfoliata Transcriptome
2.4. Bioinformatics of Potential Immune Modulators
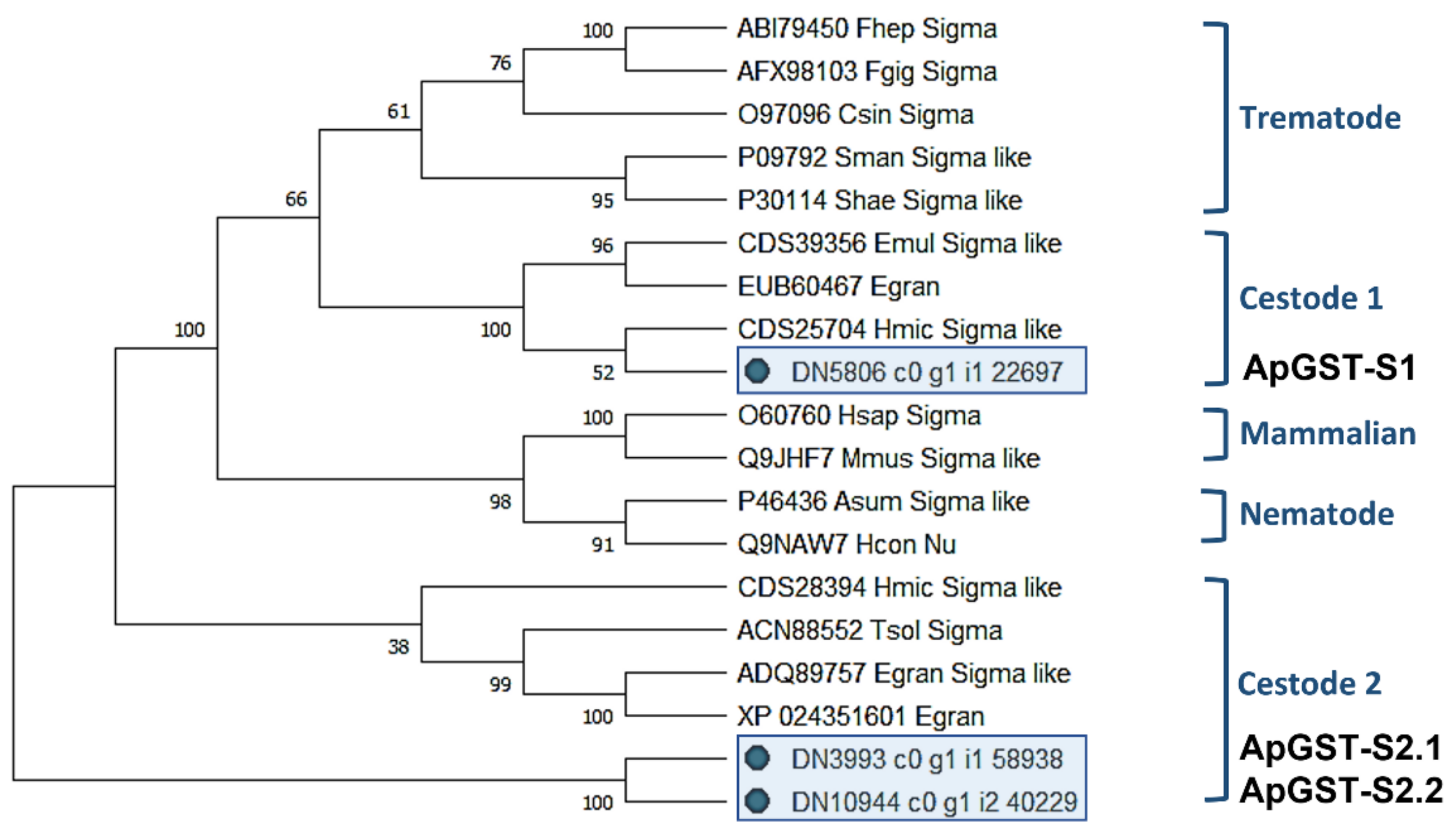
2.4.1. Characterisation of Novel A. perfoliata Sigma Class GSTs
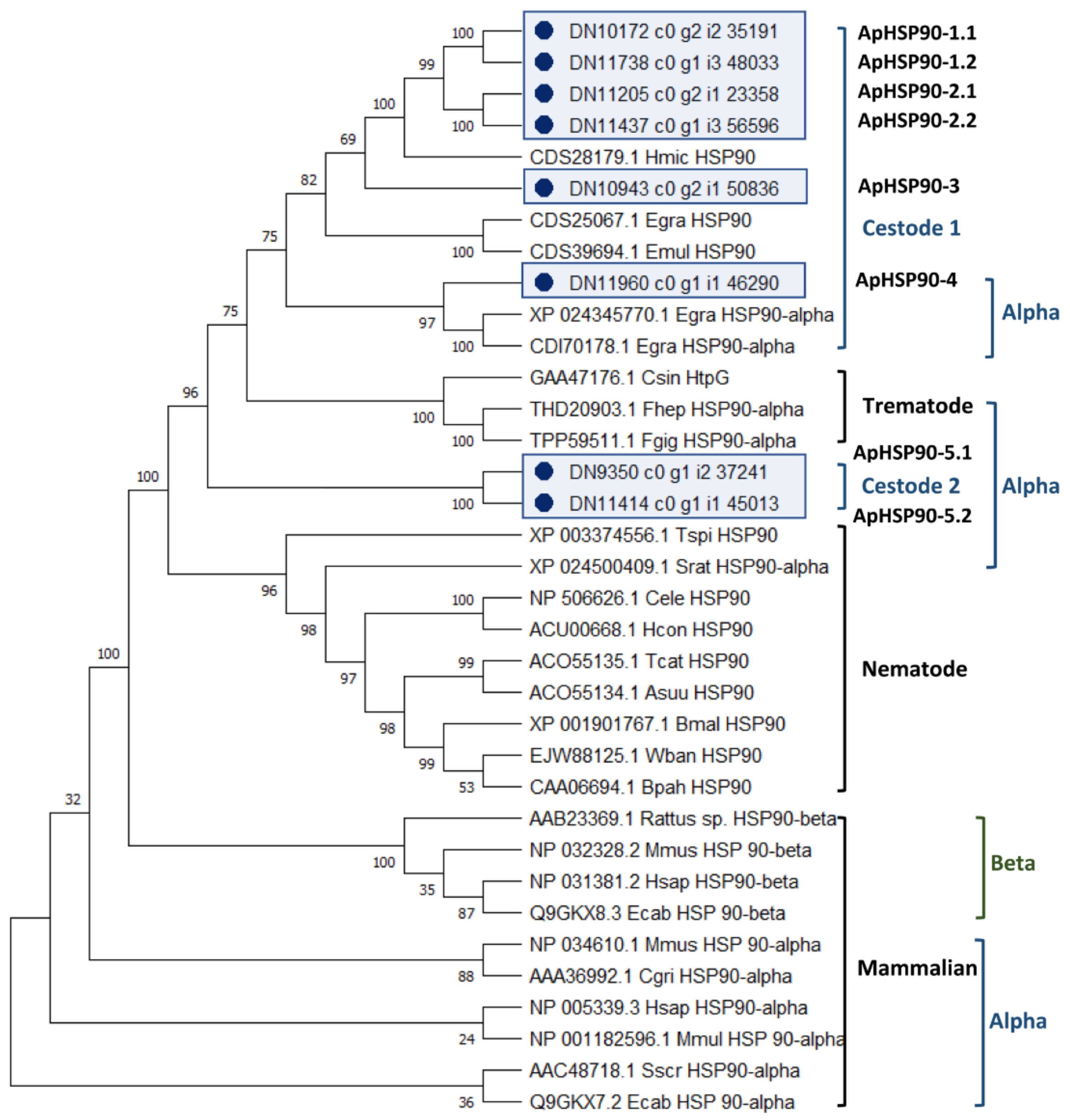
2.4.2. Characterisation of Novel A. perfoliata Heat Shock Protein 90
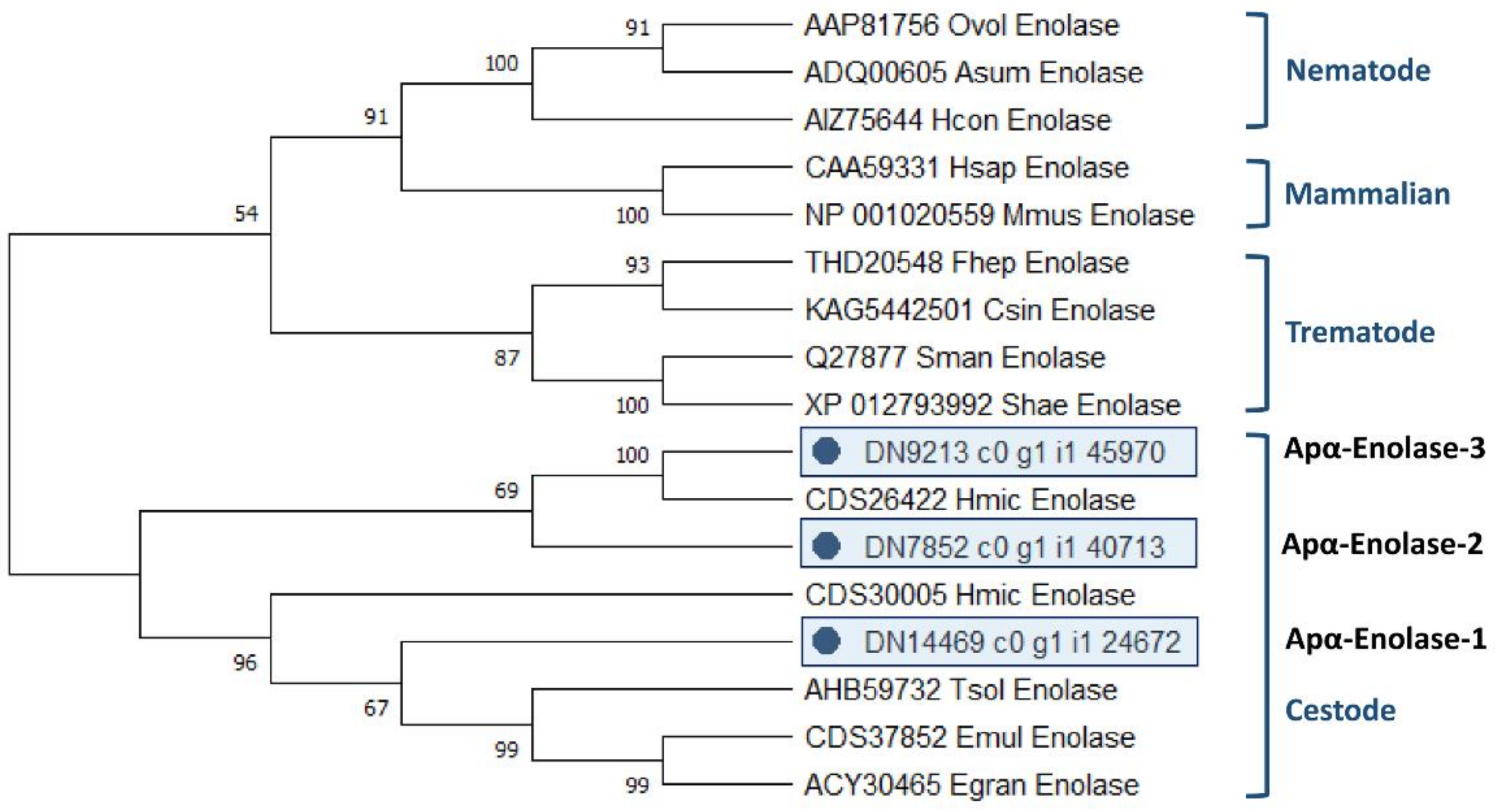
2.4.3. Characterisation of Novel A. perfoliata Alpha-Enolase
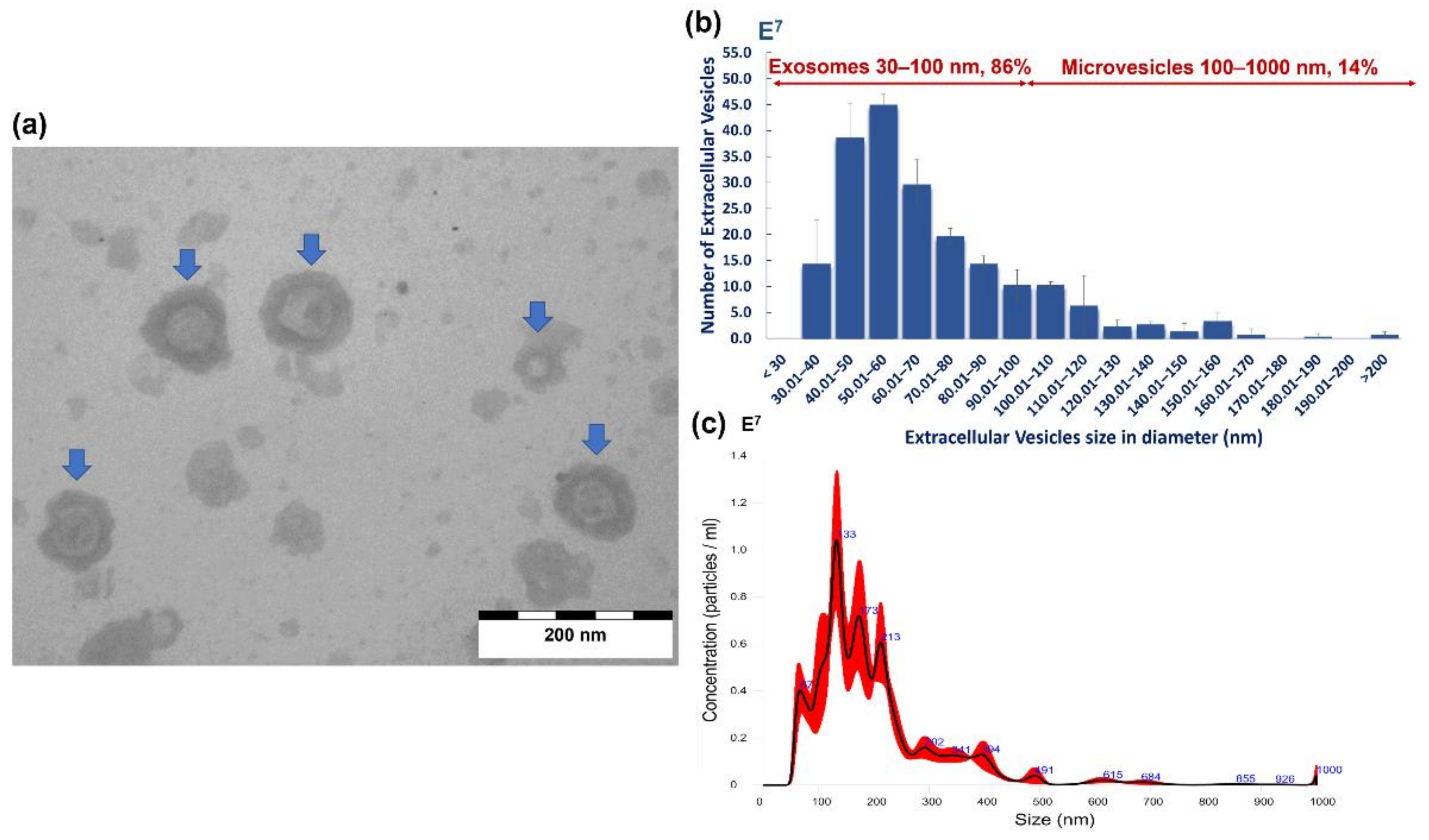
2.5. Morphological Characterisation and Size Distribution of A. perfoliata EVs
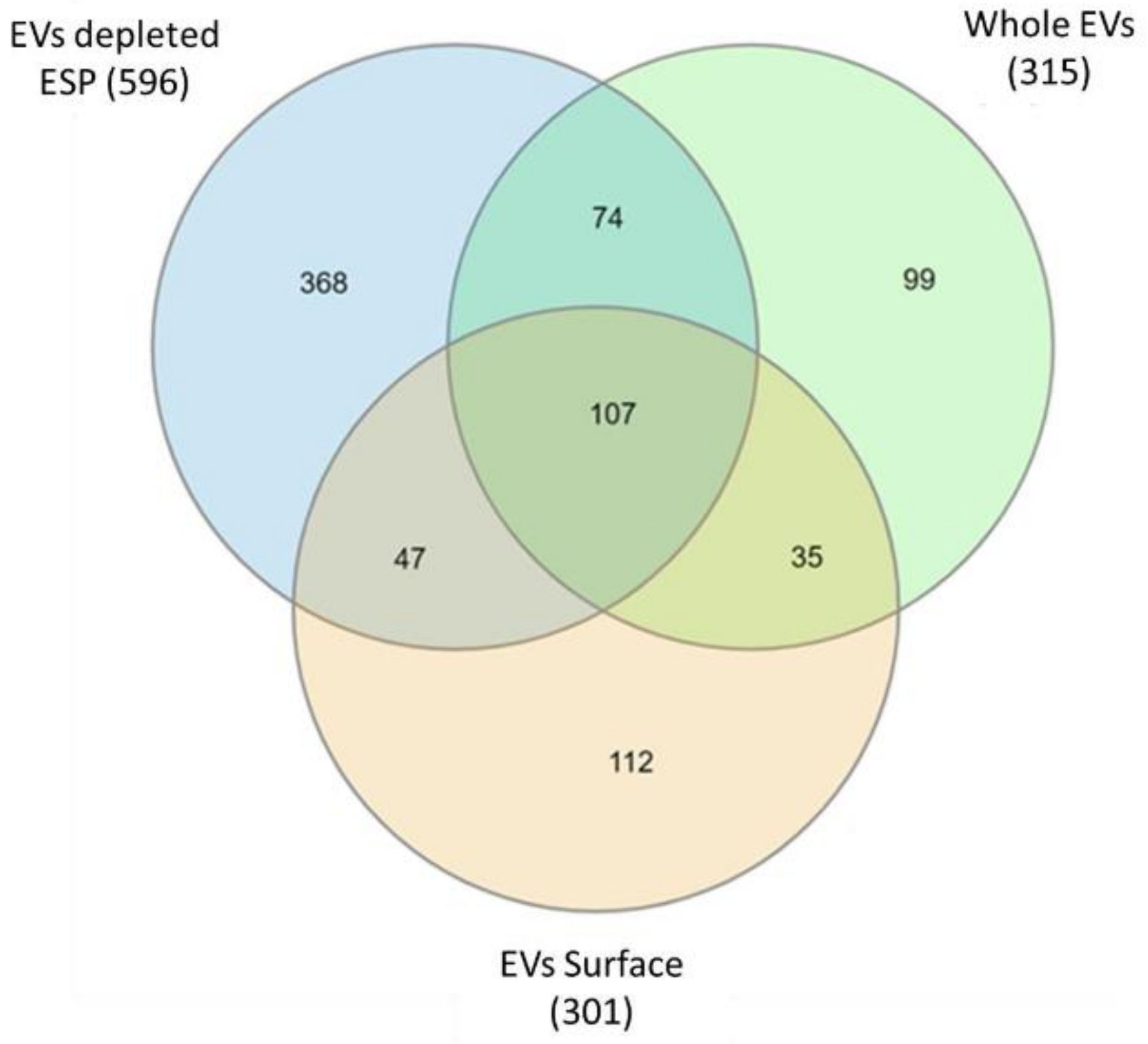
2.6. Protein Profiling of A. perfoliata Proteomics Datasets
2.7. Gene Ontology Enrichment Analysis
3. Discussion
4. Materials and Methods
4.1. Collection of Adult A. perfoliata and In Vitro Maintenance
4.2. Total RNA Extraction and Purification
4.3. RNA-Seq Library Construction and Next Generation Sequencing
4.4. De Novo Transcriptome Sequencing Analysis Pipeline
4.5. Functional Annotation and Gene Ontology (GO) Terms Analysis
4.6. Bioinformatic Analysis of Potential Immune Modulators
4.7. Sequence Alignment and Phylogenetic Analysis of Potential Immune Modulators
4.8. Extracellular Vesicles Purification by Size Exclusion Chromatography
4.9. Characterization of Extracellular Vesicles Released from A. perfoliata
4.9.1. Transmission Electron Microscopy (TEM) Analysis
4.9.2. Nanoparticle Tracking Analysis (NTA)
4.9.3. Extracellular Vesicle Surface Protein Hydrolysis
4.10. Secretome Proteomics Analysis
4.10.1. One Dimensional Sodium Dodecyl Sulfate Polyacrylamide Gel Electrophoresis
4.10.2. Trypsin In-Gel Digestion and Liquid Chromatography-Tandem Mass Spectrometry
4.10.3. Protein Identification and Gene Ontology Terms Enrichment Analysis
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gasser, R.B.; Williamson, R.M.C.; Beveridge, I. Anoplocephala perfoliata of horses—Significant scope for further research, improved diagnosis and control. Parasitology 2005, 131, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Lyons, E.T.; Bolin, D.C.; Bryant, U.K.; Cassone, L.M.; Jackson, C.B.; Janes, J.G.; Kennedy, L.A.; Loynachan, A.T.; Boll, K.R.; Burkhardt, A.S.; et al. Postmortem examination (2016–2017) of weanling and older horses for the presence of select species of endoparasites: Gasterophilus spp., Anoplocephala spp. and Strongylus spp. in specific anatomical sites. Vet. Parasitol. Reg. Stud. Rep. 2018, 13, 98–104. [Google Scholar] [CrossRef]
- Mathewos, M.; Girma, D.; Fesseha, H.; Yirgalem, M.; Eshetu, E. Prevalence of Gastrointestinal Helminthiasis in Horses and Donkeys of Hawassa District, Southern Ethiopia. Vet. Med. Int. 2021, 2021, 6686688. [Google Scholar] [CrossRef]
- Nielsen, M.K. Equine tapeworm infections: Disease, diagnosis and control. Equine Vet. Educ. 2016, 28, 388–395. [Google Scholar] [CrossRef]
- Rehbein, S.; Visser, M.; Winter, R. Prevalence, intensity and seasonality of gastrointestinal parasites in abattoir horses in Germany. Parasitol. Res. 2013, 112, 407–413. [Google Scholar] [CrossRef] [PubMed]
- Tomczuk, K.; Grzybek, M.; Szczepaniak, K.; Studzińska, M.; Demkowska-Kutrzepa, M.; Roczeń-Karczmarz, M.; Abbass, Z.A.; Kostro, K.; Junkuszew, A. Factors affecting prevalence and abundance of A. perfoliata infections in horses from south-eastern Poland. Vet. Parasitol. 2017, 246, 19–24. [Google Scholar] [CrossRef]
- Proudman, C.J.; French, N.P.; Trees, A.J. Tapeworm infection is a significant risk factor for spasmodic colic and ileal impaction colic in the horse. Equine Vet. J. 1998, 30, 194–199. [Google Scholar] [CrossRef]
- Owen, R.A.; Jagger, D.W.; Quan-Taylor, R. Caecal intussusceptions in horses and the significance of Anoplocephala perfoliata. Vet. Rec. 1989, 124, 34–37. [Google Scholar] [CrossRef]
- Barclay, W.P.; Phillips, T.N.; Foerner, J.J. Intussusception associated with Anoplocephala perfoliata infection in five horses. J. Am. Vet. Med. Assoc. 1982, 180, 752–753. [Google Scholar]
- Ryu, S.H.; Bak, U.B.; Kim, J.G.; Yoon, H.J.; Seo, H.S.; Kim, J.T.; Park, J.Y.; Lee, C.W. Cecal rupture by Anoplocephala perfoliata infection in a thoroughbred horse in Seoul Race Park, South Korea. J. Vet. Sci. 2001, 2, 189–193. [Google Scholar] [CrossRef]
- Proudman, C.; Trees, A. Tapeworms as a Cause of Intestinal Disease in Horses. Parasitol. Today 1999, 15, 156–159. [Google Scholar] [CrossRef]
- Fogarty, U.; Del Piero, F.; Purnell, R.E.; Mosurski, K.R. Incidence of Anoplocephala perfoliata in horses examined at an Irish abattoir. Vet. Rec. 1994, 134, 515–518. [Google Scholar] [CrossRef] [PubMed]
- Proudman, C.J.; Edwards, G.B. Are tapeworms associated with equine colic? A case control study. Equine Vet. J. 1993, 25, 224–226. [Google Scholar] [CrossRef]
- Sallé, G.; Guillot, J.; Tapprest, J.; Foucher, N.; Sevin, C.; Laugier, C. Compilation of 29 years of postmortem examinations identifies major shifts in equine parasite prevalence from 2000 onwards. Int. J. Parasitol. 2020, 50, 125–132. [Google Scholar] [CrossRef] [PubMed]
- Williamson, R.M.C.; Gasser, R.B.; Middleton, D.; Beveridge, I. The distribution of Anoplocephala perfoliata in the intestine of the horse and associated pathological changes. Vet. Parasitol. 1997, 73, 225–241. [Google Scholar] [CrossRef]
- Lawson, A.L.; Pittaway, C.E.; Sparrow, R.M.; Balkwill, E.C.; Coles, G.C.; Tilley, A.; Wilson, A.D. Analysis of caecal mucosal inflammation and immune modulation during Anoplocephala perfoliata infection of horses. Parasite Immunol. 2019, 41. [Google Scholar] [CrossRef]
- Pearson, G.R.; Davies, L.W.; White, A.L.; O’Brien, J.K. Pathological lesions associated with Anoplocephala perfoliata at the ileo-caecal junction of horses. Vet. Rec. 1993, 132, 179–182. [Google Scholar] [CrossRef]
- Pavone, S.; Veronesi, F.; Genchi, C.; Fioretti, D.P.; Brianti, E.; Mandara, M.T. Pathological changes caused by Anoplocephala perfoliata in the mucosa/submucosa and in the enteric nervous system of equine ileocecal junction. Vet. Parasitol. 2011, 176, 43–52. [Google Scholar] [CrossRef]
- Cantacessi, C.; Mulvenna, J.; Young, N.D.; Kasny, M.; Horak, P.; Aziz, A.; Hofmann, A.; Loukas, A.; Gasser, R.B. A deep exploration of the transcriptome and “excretory/secretory” proteome of adult Fascioloides magna. Mol. Cell. Proteom. 2012, 11, 1340–1353. [Google Scholar] [CrossRef]
- Choudhary, V.; Garg, S.; Chourasia, R.; Hasnani, J.J.; Patel, P.V.; Shah, T.M.; Bhatt, V.D.; Mohapatra, A.; Blake, D.P.; Joshi, C.G. Transcriptome analysis of the adult rumen fluke Paramphistomum cervi following next generation sequencing. Gene 2015, 570, 64–70. [Google Scholar] [CrossRef]
- Huson, K.M.; Morphew, R.M.; Allen, N.R.; Hegarty, M.J.; Worgan, H.J.; Girdwood, S.E.; Jones, E.L.; Phillips, H.C.; Vickers, M.; Swain, M.; et al. Polyomic tools for an emerging livestock parasite, the rumen fluke Calicophoron daubneyi; identifying shifts in rumen functionality. Parasit. Vectors 2018, 11, 617. [Google Scholar] [CrossRef]
- Liu, G.-H.; Xu, M.-J.; Song, H.-Q.; Wang, C.-R.; Zhu, X.-Q. De novo assembly and characterization of the transcriptome of the pancreatic fluke Eurytrema pancreaticum (trematoda: Dicrocoeliidae) using Illumina paired-end sequencing. Gene 2016, 576, 333–338. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.-X.; Cong, W.; Elsheikha, H.M.; Liu, G.-H.; Ma, J.-G.; Huang, W.-Y.; Zhao, Q.; Zhu, X.-Q. De novo transcriptome sequencing and analysis of the juvenile and adult stages of Fasciola gigantica. Infect. Genet. Evol. 2017, 51, 33–40. [Google Scholar] [CrossRef]
- Guo, A. The complete mitochondrial genome of Anoplocephala perfoliata, the first representative for the family Anoplocephalidae. Parasites Vectors 2015, 8, 549. [Google Scholar] [CrossRef] [PubMed]
- Victor, B.; Kanobana, K.; Gabriël, S.; Polman, K.; Deckers, N.; Dorny, P.; Deelder, A.M.; Palmblad, M. Proteomic analysis of Taenia solium metacestode excretion-secretion proteins. Proteomics 2012, 12, 1860–1869. [Google Scholar] [CrossRef] [PubMed]
- Wangchuk, P.; Kouremenos, K.; Eichenberger, R.M.; Pearson, M.; Susianto, A.; Wishart, D.S.; McConville, M.J.; Loukas, A. Metabolomic profiling of the excretory–secretory products of hookworm and whipworm. Metabolomics 2019, 15, 101. [Google Scholar] [CrossRef]
- Robinson, M.W.; Menon, R.; Donnelly, S.M.; Dalton, J.P.; Ranganathan, S. An integrated transcriptomics and proteomics analysis of the secretome of the helminth pathogen Fasciola hepatica: Proteins associated with invasion and infection of the mammalian host. Mol. Cell. Proteom. 2009, 8, 1891–1907. [Google Scholar] [CrossRef] [PubMed]
- Bień, J.; Sałamatin, R.; Sulima, A.; Savijoki, K.; Bruce Conn, D.; Näreaho, A.; Młocicki, D. Mass spectrometry analysis of the excretory-secretory (E-S) products of the model cestode Hymenolepis diminut a reveals their immunogenic properties and the presence of new E-S proteins in cestodes. Acta Parasitol. 2016, 61, 429–442. [Google Scholar] [CrossRef]
- Han, C.; Yu, J.; Zhang, Z.; Zhai, P.; Zhang, Y.; Meng, S.; Yu, Y.; Li, X.; Song, M. Immunomodulatory effects of Trichinella spiralis excretory-secretory antigens on macrophages. Exp. Parasitol. 2019, 196, 68–72. [Google Scholar] [CrossRef] [PubMed]
- Marcilla, A.; Trelis, M.; Cortés, A.; Sotillo, J.; Cantalapiedra, F.; Minguez, M.T.; Valero, M.L.; Sánchez del Pino, M.M.; Muñoz-Antoli, C.; Toledo, R.; et al. Extracellular Vesicles from Parasitic Helminths Contain Specific Excretory/Secretory Proteins and Are Internalized in Intestinal Host Cells. PLoS ONE 2012, 7, e45974. [Google Scholar] [CrossRef]
- Morphew, R.M.; Wright, H.A.; LaCourse, E.J.; Porter, J.; Barrett, J.; Woods, D.J.; Brophy, P.M. Towards Delineating Functions within the Fasciola Secreted Cathepsin L Protease Family by Integrating In Vivo Based Sub-Proteomics and Phylogenetics. PLoS Negl. Trop. Dis. 2011, 5, e937. [Google Scholar] [CrossRef]
- Pan, W.; Hao, W.T.; Shen, Y.J.; Li, X.Y.; Wang, Y.J.; Sun, F.F.; Yin, J.H.; Zhang, J.; Tang, R.X.; Cao, J.P.; et al. The excretory-secretory products of Echinococcus granulosus protoscoleces directly regulate the differentiation of B10, B17 and Th17 cells. Parasites Vectors 2017, 10, 1–11. [Google Scholar] [CrossRef]
- Vendelova, E.; Camargo de Lima, J.; Lorenzatto, K.R.; Monteiro, K.M.; Mueller, T.; Veepaschit, J.; Grimm, C.; Brehm, K.; Hrčková, G.; Lutz, M.B.; et al. Proteomic Analysis of Excretory-Secretory Products of Mesocestoides corti Metacestodes Reveals Potential Suppressors of Dendritic Cell Functions. PLoS Negl. Trop. Dis. 2016, 10, 5061. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Bai, X.; Zhu, H.; Wang, X.; Shi, H.; Tang, B.; Boireau, P.; Cai, X.; Luo, X.; Liu, M.; et al. Immunoproteomic analysis of the excretory-secretory products of Trichinella pseudospiralis adult worms and newborn larvae. Parasites Vectors 2017, 10, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Eichenberger, R.M.; Sotillo, J.; Loukas, A. Immunobiology of parasitic worm extracellular vesicles. Immunol. Cell Biol. 2018, 96, 704–713. [Google Scholar] [CrossRef] [PubMed]
- Zakeri, A.; Hansen, E.P.; Andersen, S.D.; Williams, A.R.; Nejsum, P. Immunomodulation by helminths: Intracellular pathways and extracellular vesicles. Front. Immunol. 2018, 9, 2349. [Google Scholar] [CrossRef]
- Maizels, R.M.; Smits, H.H.; McSorley, H.J. Modulation of Host Immunity by Helminths: The Expanding Repertoire of Parasite Effector Molecules. Immunity 2018, 49, 801–818. [Google Scholar] [CrossRef]
- Mazanec, H.; Koník, P.; Gardian, Z.; Kuchta, R. Extracellular vesicles secreted by model tapeworm Hymenolepis diminuta: Biogenesis, ultrastructure and protein composition. Int. J. Parasitol. 2021, 51, 327–332. [Google Scholar] [CrossRef] [PubMed]
- Liang, P.; Mao, L.; Zhang, S.; Guo, X.; Liu, G.; Wang, L.; Hou, J.; Zheng, Y.; Luo, X. Identification and molecular characterization of exosome-like vesicles derived from the Taenia asiatica adult worm. Acta Trop. 2019, 198, 105036. [Google Scholar] [CrossRef]
- Wang, L.Q.; Liu, T.L.; Liang, P.H.; Zhang, S.H.; Li, T.S.; Li, Y.P.; Liu, G.X.; Mao, L.; Luo, X.N. Characterization of exosome-like vesicles derived from Taenia pisiformis cysticercus and their immunoregulatory role on macrophages. Parasites Vectors 2020, 13, 1–16. [Google Scholar] [CrossRef]
- Nicolao, M.C.; Rodriguez Rodrigues, C.; Cumino, A.C. Extracellular vesicles from Echinococcus granulosus larval stage: Isolation, characterization and uptake by dendritic cells. PLoS Negl. Trop. Dis. 2019, 13, e0007032. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, W.; Cui, F.; Shi, C.; Ma, Y.; Yu, Y.; Zhao, W.; Zhao, J. Extracellular vesicles derived from Echinococcus granulosus hydatid cyst fluid from patients: Isolation, characterization and evaluation of immunomodulatory functions on T cells. Int. J. Parasitol. 2019, 49, 1029–1037. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Cai, M.; Yang, J.; Li, Y.; Ding, J.; Kandil, O.M.; Kutyrev, I.; Ayaz, M.; Zheng, Y. Comparative analysis of different extracellular vesicles secreted by Echinococcus granulosus protoscoleces. Acta Trop. 2021, 213, 105756. [Google Scholar] [CrossRef] [PubMed]
- Ancarola, M.E.; Marcilla, A.; Herz, M.; Macchiaroli, N.; Pérez, M.; Asurmendi, S.; Brehm, K.; Poncini, C.; Rosenzvit, M.; Cucher, M. Cestode parasites release extracellular vesicles with microRNAs and immunodiagnostic protein cargo. Int. J. Parasitol. 2017, 47, 675–686. [Google Scholar] [CrossRef]
- Davis, C.N.; Phillips, H.; Tomes, J.J.; Swain, M.T.; Wilkinson, T.J.; Brophy, P.M.; Morphew, R.M. The importance of extracellular vesicle purification for downstream analysis: A comparison of differential centrifugation and size exclusion chromatography for helminth pathogens. PLoS Negl. Trop. Dis. 2019, 13, e0007191. [Google Scholar] [CrossRef] [PubMed]
- Cwiklinski, K.; De La Torre-Escudero, E.; Trelis, M.; Bernal, D.; Dufresne, P.J.; Brennan, G.P.; O’Neill, S.; Tort, J.; Paterson, S.; Marcilla, A.; et al. The extracellular vesicles of the helminth pathogen, Fasciola hepatica: Biogenesis pathways and cargo molecules involved in parasite pathogenesis. Mol. Cell. Proteom. 2015, 14, 3258–3273. [Google Scholar] [CrossRef] [PubMed]
- De la Torre-Escudero, E.; Gerlach, J.Q.; Bennett, A.P.S.; Cwiklinski, K.; Jewhurst, H.L.; Huson, K.M.; Joshi, L.; Kilcoyne, M.; O’Neill, S.; Dalton, J.P.; et al. Surface molecules of extracellular vesicles secreted by the helminth pathogen Fasciola hepatica direct their internalisation by host cells. PLoS Negl. Trop. Dis. 2019, 13, e0007087. [Google Scholar] [CrossRef]
- Bennett, A.P.S.; de la Torre-Escudero, E.; Oliver, N.A.M.; Huson, K.M.; Robinson, M.W. The cellular and molecular origins of extracellular vesicles released by the helminth pathogen, Fasciola hepatica. Int. J. Parasitol. 2020, 50, 671–683. [Google Scholar] [CrossRef]
- Allen, N.R.; Taylor-Mew, A.R.; Wilkinson, T.J.; Huws, S.; Phillips, H.; Morphew, R.M.; Brophy, P.M. Modulation of Rumen Microbes Through Extracellular Vesicle Released by the Rumen Fluke Calicophoron daubneyi. Front. Cell. Infect. Microbiol. 2021, 11, 263. [Google Scholar] [CrossRef]
- Liu, F.; Cui, S.J.; Hu, W.; Feng, Z.; Wang, Z.Q.; Han, Z.G. Excretory/secretory proteome of the adult developmental stage of human blood fluke, Schistosoma japonicum. Mol. Cell. Proteom. 2009, 8, 1236–1251. [Google Scholar] [CrossRef]
- Kifle, D.W.; Pearson, M.S.; Becker, L.; Pickering, D.; Loukas, A.; Sotillo, J. Proteomic analysis of two populations of Schistosoma mansoni-derived extracellular vesicles: 15k pellet and 120k pellet vesicles. Mol. Biochem. Parasitol. 2020, 236, 111264. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.A.; Bae, Y.A.; Lee, E.G.; Kim, S.H.; Diaz-Camacho, S.P.; Nawa, Y.; Kang, I.; Kong, Y. A novel sigma-like glutathione transferase of Taenia solium metacestode. Int. J. Parasitol. 2010, 40, 1097–1106. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Zhou, X.; Chen, L.; Zhang, Z.; Wang, C.; Gu, X.; Wang, T.; Peng, X.; Yang, G. Cloning and characterization of a novel sigma-like glutathione S-transferase from the giant panda parasitic nematode, Baylisascaris schroederi. Parasites Vectors 2015, 8, 44. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.C.; Yang, Y.J.; Ma, K.X.; Shi, C.Y.; Chen, G.W.; Liu, D.Z. A novel sigma class glutathione S-transferase gene in freshwater planarian Dugesia japonica: Cloning, characterization and protective effects in herbicide glyphosate stress. Ecotoxicology 2020, 29, 295–304. [Google Scholar] [CrossRef] [PubMed]
- Yamamoto, K.; Fujii, H.; Aso, Y.; Banno, Y.; Koga, K. Expression and characterization of a sigma-class glutathione S-transferase of the fall webworm, Hyphantria cunea. Biosci. Biotechnol. Biochem. 2007, 71, 553–560. [Google Scholar] [CrossRef] [PubMed]
- Skantar, A.M.; Carta, L.K. Molecular characterization and phylogenetic evaluation of the Hsp90 gene from selected nematodes. J. Nematol. 2004, 36, 466–480. [Google Scholar]
- Chen, B.; Zhong, D.; Monteiro, A. Comparative genomics and evolution of the HSP90 family of genes across all kingdoms of organisms. BMC Genom. 2006, 7, 156. [Google Scholar] [CrossRef]
- Pancholi, V. Multifunctional α-enolase: Its role in diseases. Cell. Mol. Life Sci. 2001, 58, 902–920. [Google Scholar] [CrossRef]
- Keerthikumar, S.; Chisanga, D.; Ariyaratne, D.; Al Saffar, H.; Anand, S.; Zhao, K.; Samuel, M.; Pathan, M.; Jois, M.; Chilamkurti, N.; et al. ExoCarta: A Web-Based Compendium of Exosomal Cargo. J. Mol. Biol. 2016, 428, 688–692. [Google Scholar] [CrossRef]
- Mathivanan, S.; Fahner, C.J.; Reid, G.E.; Simpson, R.J. ExoCarta 2012: Database of exosomal proteins, RNA and lipids. Nucleic Acids Res. 2012, 40, D1241–D1244. [Google Scholar] [CrossRef]
- Kalra, H.; Simpson, R.J.; Ji, H.; Aikawa, E.; Altevogt, P.; Askenase, P.; Bond, V.C.; Borràs, F.E.; Breakefield, X.; Budnik, V.; et al. Vesiclepedia: A Compendium for Extracellular Vesicles with Continuous Community Annotation. PLoS Biol. 2012, 10, e1001450. [Google Scholar] [CrossRef]
- Parkinson, J.; Wasmuth, J.D.; Salinas, G.; Bizarro, C.V.; Sanford, C.; Berriman, M.; Ferreira, H.B.; Zaha, A.; Blaxter, M.L.; Maizels, R.M.; et al. A Transcriptomic Analysis of Echinococcus granulosus Larval Stages: Implications for Parasite Biology and Host Adaptation. PLoS Negl. Trop. Dis. 2012, 6, e1897. [Google Scholar] [CrossRef]
- Debarba, J.A.; Sehabiague, M.P.C.; Monteiro, K.M.; Gerber, A.L.; Vasconcelos, A.T.R.; Ferreira, H.B.; Zaha, A. Transcriptomic analysis of the early strobilar development of echinococcus granulosus. Pathogens 2020, 9, 465. [Google Scholar] [CrossRef]
- Tsai, I.J.; Zarowiecki, M.; Holroyd, N.; Garciarrubio, A.; Sanchez-Flores, A.; Brooks, K.L.; Tracey, A.; Bobes, R.J.; Fragoso, G.; Sciutto, E.; et al. The genomes of four tapeworm species reveal adaptations to parasitism. Nature 2013, 496, 57–63. [Google Scholar] [CrossRef] [PubMed]
- Preza, M.; Calvelo, J.; Langleib, M.; Hoffmann, F.; Castillo, E.; Koziol, U.; Iriarte, A. Stage-specific transcriptomic analysis of the model cestode Hymenolepis microstoma. Genomics 2021, 113, 620–632. [Google Scholar] [CrossRef] [PubMed]
- Olson, P.D.; Zarowiecki, M.; James, K.; Baillie, A.; Bartl, G.; Burchell, P.; Chellappoo, A.; Jarero, F.; Tan, L.Y.; Holroyd, N.; et al. Genome-wide transcriptome profiling and spatial expression analyses identify signals and switches of development in tapeworms. Evodevo 2018, 9, 1–29. [Google Scholar] [CrossRef]
- Yang, D.; Fu, Y.; Wu, X.; Xie, Y.; Nie, H.; Chen, L.; Nong, X.; Gu, X.; Wang, S.; Peng, X.; et al. Annotation of the transcriptome from taenia pisiformis and its comparative analysis with three taeniidae species. PLoS ONE 2012, 7, e32283. [Google Scholar] [CrossRef]
- García-Montoya, G.M.; Mesa-Arango, J.A.; Isaza-Agudelo, J.P.; Agudelo-Lopez, S.P.; Cabarcas, F.; Barrera, L.F.; Alzate, J.F. Transcriptome profiling of the cysticercus stage of the laboratory model Taenia crassiceps, strain ORF. Acta Trop. 2016, 154, 50–62. [Google Scholar] [CrossRef]
- Pan, W.; Shen, Y.; Han, X.; Wang, Y.; Liu, H.; Jiang, Y.; Zhang, Y.; Wang, Y.; Xu, Y.; Cao, J. Transcriptome Profiles of the Protoscoleces of Echinococcus granulosus Reveal that Excretory-Secretory Products Are Essential to Metabolic Adaptation. PLoS Negl. Trop. Dis. 2014, 8, e3392. [Google Scholar] [CrossRef]
- Hewitson, J.P.; Grainger, J.R.; Maizels, R.M. Helminth immunoregulation: The role of parasite secreted proteins in modulating host immunity. Mol. Biochem. Parasitol. 2009, 167, 1–11. [Google Scholar] [CrossRef]
- Gazzinelli-Guimaraes, P.H.; Nutman, T.B. Helminth parasites and immune regulation. F1000Research 2018, 7. [Google Scholar] [CrossRef]
- Nono, J.K.; Pletinckx, K.; Lutz, M.B.; Brehm, K. Excretory/secretory-products of echinococcus multilocularis larvae induce apoptosis and tolerogenic properties in dendritic cells in vitro. PLoS Negl. Trop. Dis. 2012, 6, e1516. [Google Scholar] [CrossRef]
- Abels, E.R.; Breakefield, X.O. Introduction to Extracellular Vesicles: Biogenesis, RNA Cargo Selection, Content, Release, and Uptake. Cell. Mol. Neurobiol. 2016, 36, 301–312. [Google Scholar] [CrossRef] [PubMed]
- Savina, A.; Furlán, M.; Vidal, M.; Colombo, M.I. Exosome release is regulated by a calcium-dependent mechanism in K562 cells. J. Biol. Chem. 2003, 278, 20083–20090. [Google Scholar] [CrossRef] [PubMed]
- Taylor, J.; Azimi, I.; Monteith, G.; Bebawy, M. Ca2+ mediates extracellular vesicle biogenesis through alternate pathways in malignancy. J. Extracell. Vesicles 2020, 9. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Xiao, D.; Shen, Y.; Han, X.; Zhao, F.; Li, X.; Wu, W.; Zhou, H.; Zhang, J.; Cao, J. Proteomic analysis of the excretory/secretory products and antigenic proteins of Echinococcus granulosus adult worms from infected dogs. BMC Vet. Res. 2015, 11, 119. [Google Scholar] [CrossRef] [PubMed]
- Virginio, V.G.; Monteiro, K.M.; Drumond, F.; De Carvalho, M.O.; Vargas, D.M.; Zaha, A.; Ferreira, H.B. Excretory/secretory products from in vitro-cultured Echinococcus granulosus protoscoleces. Mol. Biochem. Parasitol. 2012, 183, 15–22. [Google Scholar] [CrossRef] [PubMed]
- Buzás, E.I.; Tóth, E.; Sódar, B.W.; Szabó-Taylor, K. Molecular interactions at the surface of extracellular vesicles. Semin. Immunopathol. 2018, 40, 453–464. [Google Scholar] [CrossRef]
- Murphy, A.; Cwiklinski, K.; Lalor, R.; O’Connell, B.; Robinson, M.W.; Gerlach, J.; Joshi, L.; Kilcoyne, M.; Dalton, J.P.; O’Neill, S.M. Fasciola hepatica extracellular vesicles isolated from excretory-secretory products using a gravity flow method modulate dendritic cell phenotype and activity. PLoS Negl. Trop. Dis. 2020, 14, e0008626. [Google Scholar] [CrossRef]
- Andreu, Z.; Yáñez-Mó, M. Tetraspanins in extracellular vesicle formation and function. Front. Immunol. 2014, 5, 442. [Google Scholar] [CrossRef]
- Margulis, L.; Chapman, M.J. Kingdoms and Domains: An Illustrated Guide to the Phyla of Life on Earth; Academic Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Mansour, T.E.; Mansour, J.M. Energy Metabolism in Parasitic Helminths: Targets for Antiparasitic Agents. In Chemotherapeutic Targets in Parasites: Contemporary Strategies; Mansour, T.E., Ed.; Cambridge University Press: Cambridge, UK, 2002; pp. 33–57. ISBN 9780521620659. [Google Scholar]
- Barrett, J. Forty years of helminth biochemistry. Parasitology 2009, 136, 1633–1642. [Google Scholar] [CrossRef]
- Chappell, L.H. The biology of the external surfaces of helminth parasites. Proc. R. Soc. Edinburgh. Sect. B Biol. Sci. 1980, 79, 145–172. [Google Scholar] [CrossRef]
- LaCourse, E.J.; Perally, S.; Morphew, R.M.; Moxon, J.V.; Prescott, M.; Dowling, D.J.; O’Neill, S.M.; Kipar, A.; Hetzel, U.; Hoey, E.; et al. The Sigma Class Glutathione Transferase from the Liver Fluke Fasciola hepatica. PLoS Negl. Trop. Dis. 2012, 6, e1666. [Google Scholar] [CrossRef] [PubMed]
- Dowling, D.J.; Hamilton, C.M.; Donnelly, S.; La Course, J.; Brophy, P.M.; Dalton, J.; O’Neill, S.M. Major secretory antigens of the Helminth Fasciola hepatica activate a suppressive dendritic cell phenotype that attenuates Th17 cells but fails to activate Th2 immune responses. Infect. Immun. 2010, 78, 793–801. [Google Scholar] [CrossRef]
- Zafra, R.; Pérez-écija, R.A.; Buffoni, L.; Pacheco, I.L.; Martínez-Moreno, A.; LaCourse, E.J.; Perally, S.; Brophy, P.M.; Pérez, J. Early hepatic and peritoneal changes and immune response in goats vaccinated with a recombinant glutathione transferase sigma class and challenged with Fasciola hepatica. Res. Vet. Sci. 2013, 94, 602–609. [Google Scholar] [CrossRef] [PubMed]
- Grezel, D.; Capron, M.; Grzych, J.-M.; Fontaine, J.; Lecocq, J.-P.; Capron, A. Protective immunity induced in rat schistosomiasis by a single dose of the Sm28GST recombinant antigen: Effector mechanisms involving IgE and IgA antibodies. Eur. J. Immunol. 1993, 23, 454–460. [Google Scholar] [CrossRef]
- Fonseca, C.T.; Oliveira, S.C.; Alves, C.C. Eliminating schistosomes through vaccination: What are the best immune weapons? Front. Immunol. 2015, 6, 95. [Google Scholar] [CrossRef] [PubMed]
- Ivanoff, N.; Phillips, N.; Schacht, A.M.; Heydari, C.; Capron, A.; Riveau, G. Mucosal vaccination against schistosomiasis using liposome-associated Sm 28 kDa glutathione S-transferase. Vaccine 1996, 14, 1123–1131. [Google Scholar] [CrossRef]
- Boulanger, D.; Reid, G.D.F.; Sturrock, R.F.; Wolowczuk, I.; Balloul, J.M.; Grezel, D.; Pierce, R.J.; Otieno, M.F.; Guerret, S.; Grimaud, A.; et al. Immunization of mice and baboons with the recombinant Sm28GST affects both worm viability and fecundity after experimental infection with Schistosoma mansoni. Parasite Immunol. 1991, 13, 473–490. [Google Scholar] [CrossRef]
- Riveau, G.; Schacht, A.M.; Dompnier, J.P.; Deplanque, D.; Seck, M.; Waucquier, N.; Senghor, S.; Delcroix-Genete, D.; Hermann, E.; Idris-Khodja, N.; et al. Safety and efficacy of the rSh28GST urinary schistosomiasis vaccine: A phase 3 randomized, controlled trial in Senegalese children. PLoS Negl. Trop. Dis. 2018, 12, e0006968. [Google Scholar] [CrossRef]
- Molehin, A.J. Schistosomiasis vaccine development: Update on human clinical trials. J. Biomed. Sci. 2020, 27, 1–7. [Google Scholar] [CrossRef]
- Al-Naseri, A.; Al-Absi, S.; El Ridi, R.; Mahana, N. A comprehensive and critical overview of schistosomiasis vaccine candidates. J. Parasit. Dis. 2021, 45, 557–580. [Google Scholar] [CrossRef] [PubMed]
- Fukano, K.; Kimura, K. Measurement of enolase activity in cell lysates. In Methods in Enzymology; Academic Press: Cambridge, MA, USA, 2014; Volume 542, pp. 115–124. ISBN 9780124166189. [Google Scholar]
- Díaz-Ramos, À.; Roig-Borrellas, A.; García-Melero, A.; López-Alemany, R. α-enolase, a multifunctional protein: Its role on pathophysiological situations. J. Biomed. Biotechnol. 2012, 2012, 156795. [Google Scholar] [CrossRef] [PubMed]
- Jolodar, A.; Fischer, P.; Bergmann, S.; Büttner, D.W.; Hammerschmidt, S.; Brattig, N.W. Molecular cloning of an α-enolase from the human filarial parasite Onchocerca volvulus that binds human plasminogen. Biochim. Biophys. Acta Gene Struct. Expr. 2003, 1627, 111–120. [Google Scholar] [CrossRef]
- Johnson, J.L. Evolution and function of diverse Hsp90 homologs and cochaperone proteins. Biochim. Biophys. Acta Mol. Cell Res. 2012, 1823, 607–613. [Google Scholar] [CrossRef]
- Hoter, A.; El-Sabban, M.; Naim, H. The HSP90 Family: Structure, Regulation, Function, and Implications in Health and Disease. Int. J. Mol. Sci. 2018, 19, 2560. [Google Scholar] [CrossRef] [PubMed]
- Backe, S.J.; Sager, R.A.; Woodford, M.R.; Makedon, A.M.; Mollapour, M. Post-translational modifications of Hsp90 and translating the chaperone code. J. Biol. Chem. 2020, 295, 11099–11117. [Google Scholar] [CrossRef] [PubMed]
- Biebl, M.M.; Buchner, J. Structure, function, and regulation of the hsp90 machinery. Cold Spring Harb. Perspect. Biol. 2019, 11, a034017. [Google Scholar] [CrossRef]
- Roy, N.; Nageshan, R.K.; Ranade, S.; Tatu, U. Heat shock protein 90 from neglected protozoan parasites. Biochim. Biophys. Acta Mol. Cell Res. 2012, 1823, 707–711. [Google Scholar] [CrossRef]
- Zininga, T.; Ramatsui, L.; Shonhai, A. Heat shock proteins as immunomodulants. Molecules 2018, 23, 2846. [Google Scholar] [CrossRef]
- Gillan, V.; Devaney, E. Nematode Hsp90: Highly conserved but functionally diverse. Parasitology 2014, 141, 1203–1215. [Google Scholar] [CrossRef]
- Xu, Z.; Ji, M.; Li, C.; Du, X.; Hu, W.; McManus, D.P.; You, H. A biological and immunological characterization of schistosoma japonicum heat shock proteins 40 and 90α. Int. J. Mol. Sci. 2020, 21, 4034. [Google Scholar] [CrossRef]
- Jayaprakash, P.; Dong, H.; Zou, M.; Bhatia, A.; O’Brien, K.; Chen, M.; Woodley, D.T.; Li, W. Hsp90α and Hsp90β together operate a hypoxia and nutrient paucity stress-response mechanism during wound healing. J. Cell Sci. 2015, 128, 1475–1480. [Google Scholar] [CrossRef]
- Morphew, R.M.; MacKintosh, N.; Hart, E.H.; Prescott, M.; LaCourse, E.J.; Brophy, P.M. In vitro biomarker discovery in the parasitic flatworm Fasciola hepatica for monitoring chemotherapeutic treatment. EuPA Open Proteom. 2014, 3, 85–99. [Google Scholar] [CrossRef]
- Goecks, J.; Nekrutenko, A.; Taylor, J.; Afgan, E.; Ananda, G.; Baker, D.; Blankenberg, D.; Chakrabarty, R.; Coraor, N.; Goecks, J.; et al. Galaxy: A comprehensive approach for supporting accessible, reproducible, and transparent computational research in the life sciences. Genome Biol. 2010, 11, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Afgan, E.; Baker, D.; Batut, B.; Van Den Beek, M.; Bouvier, D.; Ech, M.; Chilton, J.; Clements, D.; Coraor, N.; Grüning, B.A.; et al. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2018 update. Nucleic Acids Res. 2018, 46, W537–W544. [Google Scholar] [CrossRef] [PubMed]
- Jalili, V.; Afgan, E.; Gu, Q.; Clements, D.; Blankenberg, D.; Goecks, J.; Taylor, J.; Nekrutenko, A. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2020 update. Nucleic Acids Res. 2020, 48, W395–W402, Erratum in 2020, 48, 8205–8207. [Google Scholar] [CrossRef] [PubMed]
- Andrews, S. FastQC: A Quality Control Tool for High Throughput Sequence Data. Available online: http://www.bioinformatics.babraham.ac.uk/projects/fastqc/ (accessed on 5 August 2019).
- Bolger, A.M.; Lohse, M.; Usadel, B. Trimmomatic: A flexible trimmer for Illumina sequence data. Bioinformatics 2014, 30, 2114–2120. [Google Scholar] [CrossRef] [PubMed]
- Grabherr, M.G.; Haas, B.J.; Yassour, M.; Levin, J.Z.; Thompson, D.A.; Amit, I.; Adiconis, X.; Fan, L.; Raychowdhury, R.; Zeng, Q.; et al. Full-length transcriptome assembly from RNA-Seq data without a reference genome. Nat. Biotechnol. 2011, 29, 644–652. [Google Scholar] [CrossRef] [PubMed]
- Haas, B.J.; Papanicolaou, A.; Yassour, M.; Grabherr, M.; Blood, P.D.; Bowden, J.; Couger, M.B.; Eccles, D.; Li, B.; Lieber, M.; et al. De novo transcript sequence reconstruction from RNA-seq using the Trinity platform for reference generation and analysis. Nat. Protoc. 2013, 8, 1494–1512. [Google Scholar] [CrossRef]
- Fu, L.; Niu, B.; Zhu, Z.; Wu, S.; Li, W. CD-HIT: Accelerated for clustering the next-generation sequencing data. Bioinformatics 2012, 28, 3150–3152. [Google Scholar] [CrossRef]
- Li, W.; Jaroszewski, L.; Godzik, A. Clustering of highly homologous sequences to reduce the size of large protein databases. Bioinformatics 2001, 17, 282–283. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Jaroszewski, L.; Godzik, A. Tolerating some redundancy significantly speeds up clustering of large protein databases. Bioinformatics 2002, 18, 77–82. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Godzik, A. Cd-hit: A fast program for clustering and comparing large sets of protein or nucleotide sequences. Bioinformatics 2006, 22, 1658–1659. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Niu, B.; Gao, Y.; Fu, L.; Li, W. CD-HIT Suite: A web server for clustering and comparing biological sequences. Bioinformatics 2010, 26, 680–682. [Google Scholar] [CrossRef] [PubMed]
- Howe, K.L.; Achuthan, P.; Allen, J.; Allen, J.; Alvarez-Jarreta, J.; Amode, M.R.; Armean, I.M.; Azov, A.G.; Bennett, R.; Bhai, J.; et al. Ensembl 2021. Nucleic Acids Res. 2021, 49, D884–D891. [Google Scholar] [CrossRef] [PubMed]
- Götz, S.; García-Gómez, J.M.; Terol, J.; Williams, T.D.; Nagaraj, S.H.; Nueda, M.J.; Robles, M.; Talón, M.; Dopazo, J.; Conesa, A. High-throughput functional annotation and data mining with the Blast2GO suite. Nucleic Acids Res. 2008, 36, 3420–3435. [Google Scholar] [CrossRef]
- Patro, R.; Duggal, G.; Love, M.I.; Irizarry, R.A.; Kingsford, C. Salmon provides fast and bias-aware quantification of transcript expression. Nat. Methods 2017, 14, 417–419. [Google Scholar] [CrossRef]
- Gasteiger, E.; Gattiker, A.; Hoogland, C.; Ivanyi, I.; Appel, R.D.; Bairoch, A. ExPASy: The proteomics server for in-depth protein knowledge and analysis. Nucleic Acids Res. 2003, 31, 3784–3788. [Google Scholar] [CrossRef]
- Altschul, S.F.; Madden, T.L.; Schäffer, A.A.; Zhang, J.; Zhang, Z.; Miller, W.; Lipman, D.J. Gapped BLAST and PSI-BLAST: A new generation of protein database search programs. Nucleic Acids Res. 1997, 25, 3389–3402. [Google Scholar] [CrossRef]
- Hall, T.A. BioEdit: A user-friendly biological sequence alignment editor and analysis program for Windows 95/98/NT. Nucleic Acids Symp. Ser. 1999, 41, 95–98. [Google Scholar]
- Mistry, J.; Chuguransky, S.; Williams, L.; Qureshi, M.; Salazar, G.A.; Sonnhammer, E.L.L.; Tosatto, S.C.E.; Paladin, L.; Raj, S.; Richardson, L.J.; et al. Pfam: The protein families database in 2021. Nucleic Acids Res. 2021, 49, D412–D419. [Google Scholar] [CrossRef]
- Morphew, R.M.; Eccleston, N.; Wilkinson, T.J.; McGarry, J.; Perally, S.; Prescott, M.; Ward, D.; Williams, D.; Paterson, S.; Raman, M.; et al. Proteomics and in Silico Approaches To Extend Understanding of the Glutathione Transferase Superfamily of the Tropical Liver Fluke Fasciola gigantica. J. Proteome Res. 2012, 11, 5876–5889. [Google Scholar] [CrossRef]
- Trottein, F.; Godin, C.; Pierce, R.J.; Sellin, B.; Taylor, M.G.; Gorillot, I.; Silva, M.S.; Lecocq, J.P.; Capron, A. Inter-species variation of schistosome 28-kDa glutathione S-transferases. Mol. Biochem. Parasitol. 1992, 54, 63–72. [Google Scholar] [CrossRef]
- Balloul, J.M.; Sondermeyer, P.; Dreyer, D.; Capron, M.; Grzych, J.M.; Pierce, R.J.; Carvallo, D.; Lecocq, J.P.; Capron, A. Molecular cloning of a protective antigen of schistosomes. Nature 1987, 326, 149–153. [Google Scholar] [CrossRef]
- Faya, N.; Penkler, D.L.; Tastan Bishop, Ö. Human, vector and parasite Hsp90 proteins: A comparative bioinformatics analysis. FEBS Open Bio 2015, 5, 916–927. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Wang, Z.; Li, D.; Chen, Q. Identification and characterization of a Bursaphelenchus xylophilus (aphelenchida: Aphelenchoididae) thermotolerance-related gene: Bx-HSP90. Int. J. Mol. Sci. 2012, 13, 8819–8833. [Google Scholar] [CrossRef] [PubMed]
- Pantzartzi, C.N.; Drosopoulou, E.; Scouras, Z.G. Assessment and Reconstruction of Novel HSP90 Genes: Duplications, Gains and Losses in Fungal and Animal Lineages. PLoS ONE 2013, 8, 73217. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.Y.; Cheng, Y.S.; Shih, H.H. Expression patterns and structural modelling of Hsp70 and Hsp90 in a fish-borne zoonotic nematode Anisakis pegreffii. Vet. Parasitol. 2015, 212, 281–291. [Google Scholar] [CrossRef] [PubMed]
- Pepin, K.; Momose, F.; Ishida, N.; Nagata, K. Molecular Cloning of Horse Hsp90 cDNA and Its Comparative Analysis with Other Vertebrate Hsp90 Sequences. J. Vet. Med. Sci. 2001, 63, 115–124. [Google Scholar] [CrossRef] [PubMed]
- Feng, H.; Wang, L.; Liu, Y.; He, L.; Li, M.; Lu, W.; Xue, C. Molecular characterization and expression of a heat shock protein gene (HSP90) from the carmine spider mite, Tetranychus cinnabarinus (Boisduval). J. Insect Sci. 2010, 10, 1536–2442. [Google Scholar] [CrossRef] [PubMed]
- Zheng, H.; Zhang, W.; Zhang, L.; Zhang, Z.; Li, J.; Lu, G.; Zhu, Y.; Wang, Y.; Huang, Y.; Liu, J.; et al. The genome of the hydatid tapeworm Echinococcus granulosus. Nat. Genet. 2013, 45, 1168–1175. [Google Scholar] [CrossRef]
- Iriarte, A.; Arbildi, P.; La-Rocca, S.; Musto, H.; Fernández, V. Identification of novel glutathione transferases in Echinococcus granulosus. An evolutionary perspective. Acta Trop. 2012, 123, 208–216. [Google Scholar] [CrossRef]
- Kanaoka, Y.; Fujimori, K.; Kikuno, R.; Sakaguchi, Y.; Urade, Y.; Hayaishi, O. Structure and chromosomal localization of human and mouse genes for hematopoietic prostaglandin D synthase. Eur. J. Biochem. 2000, 267, 3315–3322. [Google Scholar] [CrossRef]
- Liebau, E.; Schönberger, Ö.L.; Walter, R.D.; Henkle-Dührsen, K.J. Molecular cloning and expression of a cDNA encoding glutathione S-transferase from Ascaris suum. Mol. Biochem. Parasitol. 1994, 63, 167–170. [Google Scholar] [CrossRef]
- Liebau, E.; Eckelt, V.H.O.; Wildenburg, G.; Teesdale-Spittle, P.; Brophy, P.M.; Walter, R.D.; Henkle-Dührsen, K. Structural and functional analysis of a glutathione S-transferase from Ascaris suum. Biochem. J. 1997, 324, 659–666. [Google Scholar] [CrossRef]
- Sharp, P.J.; Smith, D.R.J.; Bach, W.; Wagland, B.M.; Cobon, G.S. Purified glutathione s-transferases from parasites as candidate protective antigens. Int. J. Parasitol. 1991, 21, 839–846. [Google Scholar] [CrossRef]
- Kang, S.Y.; Ahn, I.Y.; Park, C.Y.; Chung, Y.B.; Hong, S.T.; Kong, Y.; Cho, S.Y.; Hong, S.J. Clonorchis sinensis: Molecular cloning and characterization of 28-kDa glutathione S-transferase. Exp. Parasitol. 2001, 97, 186–195. [Google Scholar] [CrossRef] [PubMed]
- Blum, M.; Chang, H.Y.; Chuguransky, S.; Grego, T.; Kandasaamy, S.; Mitchell, A.; Nuka, G.; Paysan-Lafosse, T.; Qureshi, M.; Raj, S.; et al. The InterPro protein families and domains database: 20 years on. Nucleic Acids Res. 2021, 49, D344–D354. [Google Scholar] [CrossRef] [PubMed]
- Jones, P.; Binns, D.; Chang, H.Y.; Fraser, M.; Li, W.; McAnulla, C.; McWilliam, H.; Maslen, J.; Mitchell, A.; Nuka, G.; et al. InterProScan 5: Genome-scale protein function classification. Bioinformatics 2014, 30, 1236–1240. [Google Scholar] [CrossRef]
- Jones, D.T. Protein secondary structure prediction based on position-specific scoring matrices. J. Mol. Biol. 1999, 292, 195–202. [Google Scholar] [CrossRef] [PubMed]
- Buchan, D.W.A.; Jones, D.T. The PSIPRED Protein Analysis Workbench: 20 years on. Nucleic Acids Res. 2019, 47, W402–W407. [Google Scholar] [CrossRef]
- Letunic, I.; Bork, P. 20 years of the SMART protein domain annotation resource. Nucleic Acids Res. 2018, 46, D493–D496. [Google Scholar] [CrossRef]
- Letunic, I.; Khedkar, S.; Bork, P. SMART: Recent updates, new developments and status in 2020. Nucleic Acids Res. 2021, 49, D458–D460. [Google Scholar] [CrossRef]
- Hall, B.G. Building phylogenetic trees from molecular data with MEGA. Mol. Biol. Evol. 2013, 30, 1229–1235. [Google Scholar] [CrossRef]
- Kumar, S.; Stecher, G.; Li, M.; Knyaz, C.; Tamura, K. MEGA X: Molecular Evolutionary Genetics Analysis across Computing Platforms. Mol. Biol. Evol. 2018, 35, 1547–1549. [Google Scholar] [CrossRef] [PubMed]
- Théry, C.; Amigorena, S.; Raposo, G.; Clayton, A. Isolation and Characterization of Exosomes from Cell Culture Supernatants and Biological Fluids. Curr. Protoc. Cell Biol. 2006, 30, 3–22. [Google Scholar] [CrossRef] [PubMed]
- Schneider, C.A.; Rasband, W.S.; Eliceiri, K.W. NIH Image to ImageJ: 25 years of image analysis. Nat. Methods 2012, 9, 671–675. [Google Scholar] [CrossRef] [PubMed]
- Bradford, M.M. A rapid and sensitive method for the quantitation of microgram quantities of protein utilizing the principle of protein-dye binding. Anal. Biochem. 1976, 72, 248–254. [Google Scholar] [CrossRef]
- Perkins, D.N.; Pappin, D.J.C.; Creasy, D.M.; Cottrell, J.S. Probability-based protein identification by searching sequence databases using mass spectrometry data. Electrophoresis 1999, 20, 3551–3567. [Google Scholar] [CrossRef]
- Heberle, H.; Meirelles, V.G.; da Silva, F.R.; Telles, G.P.; Minghim, R. InteractiVenn: A web-based tool for the analysis of sets through Venn diagrams. BMC Bioinform. 2015, 16, 169. [Google Scholar] [CrossRef]
- Klopfenstein, D.V.; Zhang, L.; Pedersen, B.S.; Ramírez, F.; Vesztrocy, A.W.; Naldi, A.; Mungall, C.J.; Yunes, J.M.; Botvinnik, O.; Weigel, M.; et al. GOATOOLS: A Python library for Gene Ontology analyses. Sci. Rep. 2018, 8, 1–17. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Illumina RNA Sequencing | Trimmed Reads |
| Total reads (bp) | 104,519,050 |
| Mean (SD) reads per sample (bp) | 2,903,307 (608,363) |
| Sequence length (bp) | 36–76 |
| GC percentage (%) | 46 |
| De Novo Trinity Assembly | Assembled Transcript |
| Total assembled length (bp) | 56,913,324 |
| Number of contigs | 74,607 |
| Number of contigs (without Isoforms) | 26,653 |
| Mean (SD) contig lengths per sample (bp) | 763 (762) |
| Max. contig lengths (bp) | 11,266 |
| Min. contig lengths (bp) | 201 |
| Contigs N50 | 1155 |
| TransDecoder | Peptide Dataset |
| Number of protein sequences | 34,341 |
| Rank | Gene ID | Length | Mean Effective Length | Mean Number Reads | Mean TPM | Description |
|---|---|---|---|---|---|---|
| 1 | DN10805_c3_g6_i1_11702 | 1036 | 858 | 407,936 | 46,601 | Uncharacterised |
| 2 | DN10805_c3_g2_i9_11698 | 1754 | 1591 | 264,055 | 16,600 | Uncharacterised |
| 3 | DN6887_c0_g1_i1_76818 | 384 | 212 | 34,703 | 16,001 | Uncharacterised |
| 4 | DN8498_c0_g2_i2_20529 | 333 | 162 | 17,101 | 10,383 | Uncharacterised |
| 5 | DN14755_c0_g1_i1_41815 | 314 | 148 | 10,387 | 6916 | Uncharacterised |
| 6 | DN8064_c0_g1_i1_68336 | 477 | 315 | 13,860 | 4289 | Uncharacterised |
| 7 | DN8427_c0_g1_i1_72770 | 410 | 234 | 10,236 | 4283 | Uncharacterised |
| 8 | DN7932_c0_g1_i1_6806 | 401 | 225 | 9709 | 4239 | Uncharacterised |
| 9 | DN12386_c1_g1_i9_39644 | 4006 | 3843 | 158,692 | 4199 | Transcript antisense to ribosomal rna protein |
| 10 | DN10805_c3_g2_i7_11692 | 3260 | 3097 | 133,004 | 4199 | Uncharacterised |
| 11 | DN3788_c0_g1_i1_50567 | 426 | 265 | 10,398 | 3869 | Uncharacterised |
| 12 | DN8606_c1_g1_i3_340 | 314 | 146 | 5533 | 3826 | Uncharacterised |
| 13 | DN12640_c1_g1_i8_71952 | 9547 | 9384 | 316,400 | 3293 | Uncharacterised |
| 14 | DN10987_c0_g1_i3_65072 | 874 | 711 | 23,587 | 3277 | Expressed conserved protein |
| 15 | DN5384_c0_g1_i1_75533 | 414 | 241 | 8058 | 3248 | Uncharacterised |
| 16 | DN8805_c0_g1_i1_60212 | 444 | 283 | 8962 | 3129 | Uncharacterised |
| 17 | DN12068_c0_g3_i1_63804 | 1028 | 851 | 25,275 | 2996 | Expressed conserved protein |
| 18 | DN13746_c0_g1_i1_26674 | 358 | 199 | 5871 | 2919 | Uncharacterised |
| 19 | DN10069_c0_g1_i3_2055 | 985 | 809 | 21,491 | 2662 | Expressed conserved protein |
| 20 | DN11085_c1_g1_i5_42186 | 381 | 221 | 5786 | 2641 | Uncharacterised |
| 21 | DN9799_c0_g1_i1_46050 | 508 | 346 | 9173 | 2617 | Dynein light chain 1, cytoplasmic |
| 22 | DN118_c0_g1_i1_52814 | 595 | 420 | 10,683 | 2540 | Tegumental protein |
| 23 | DN10418_c3_g5_i1_34715 | 483 | 311 | 8002 | 2501 | Immunogenic protein |
| 24 | DN6144_c0_g1_i1_49576 | 641 | 469 | 11,504 | 2425 | Dynein light chain type 1 2 |
| 25 | DN3712_c0_g1_i1_698 | 602 | 440 | 10,689 | 2400 | Dynein light chain 1, putative |
| 26 | DN10763_c1_g5_i1_22341 | 281 | 128 | 3136 | 2298 | Uncharacterised |
| 27 | DN7817_c0_g1_i1_51569 | 1013 | 850 | 19,568 | 2191 | Expressed conserved protein |
| 28 | DN9590_c0_g2_i1_51137 | 480 | 318 | 6844 | 2115 | Uncharacterised |
| 29 | DN10367_c0_g1_i3_29401 | 1522 | 1347 | 28,911 | 2057 | Expressed conserved protein |
| 30 | DN3791_c0_g1_i1_14014 | 632 | 470 | 9552 | 2007 | Uncharacterised |
| 31 | DN4055_c0_g1_i1_61482 | 518 | 346 | 7092 | 1989 | Dynein light chain type 1 2 |
| 32 | DN6146_c0_g1_i2_38481 | 514 | 352 | 6601 | 1906 | Uncharacterised |
| 33 | DN15763_c0_g1_i1_57495 | 831 | 668 | 12,973 | 1887 | Tegumental protein |
| 34 | DN10204_c0_g1_i2_51272 | 516 | 354 | 6655 | 1828 | Uncharacterised |
| 35 | DN12126_c0_g1_i9_41589 | 2283 | 2120 | 38,789 | 1826 | Uncharacterised |
| 36 | DN502_c0_g1_i1_32021 | 462 | 284 | 5326 | 1809 | Uncharacterised |
| 37 | DN10922_c1_g1_i5_14239 | 1292 | 1129 | 19,933 | 1778 | Deoxyhypusine hydroxylase |
| 38 | DN5442_c0_g1_i1_26423 | 439 | 261 | 4666 | 1728 | Uncharacterised |
| 39 | DN5954_c0_g1_i2_54752 | 370 | 201 | 3606 | 1703 | Uncharacterised |
| 40 | DN9433_c0_g1_i5_18544 | 424 | 251 | 4344 | 1674 | 8 kDa glycoprotein |
| 41 | DN12201_c0_g3_i1_43360 | 334 | 176 | 3135 | 1672 | No hit |
| 42 | DN11009_c0_g1_i1_3069 | 711 | 535 | 9247 | 1669 | Uncharacterised |
| 43 | DN11588_c0_g1_i4_75797 | 406 | 245 | 4072 | 1669 | Uncharacterised |
| 44 | DN10667_c1_g1_i2_72481 | 469 | 296 | 5181 | 1666 | Uncharacterised |
| 45 | DN5960_c0_g1_i2_30732 | 274 | 122 | 1928 | 1571 | Uncharacterised |
| 46 | DN7341_c0_g1_i1_31615 | 484 | 322 | 4974 | 1532 | Dynein light chain 1, cytoplasmic |
| 47 | DN1202_c0_g1_i1_62670 | 642 | 470 | 7386 | 1532 | Profilin allergen |
| 48 | DN10641_c0_g1_i1_57690 | 585 | 423 | 6391 | 1528 | Uncharacterised |
| 49 | DN15681_c0_g1_i1_62555 | 578 | 416 | 6427 | 1513 | Uncharacterised |
| 50 | DN9547_c0_g1_i1_1108 | 381 | 221 | 3260 | 1477 | Uncharacterised |
| Parameters | Mean EV ± SE |
|---|---|
| Mean (nm) | 199.1 ± 5.3 |
| Mode (nm) | 144.7 ± 7.5 |
| SD (nm) | 108.7 ± 8.5 |
| D10 (nm) | 105.9 ± 2.6 |
| D50 (nm) | 168.3 ± 4.6 |
| D90 (nm) | 337.9 ± 14.7 |
| Concentration (particles/mL) | 9.42 × 1011 ± 7.20 × 1011 |
| Concentration (particles/frame) 1:600 dilution | 81.2 ± 6.1 |
| Concentration (centres/frame) 1:600 dilution | 116.1 ± 7.1 |
| No. | Protein Description | Sequence ID | Number of Sequenced Peptides | MASCOT Score |
|---|---|---|---|---|
| 1 | WD repeat and FYVE domain-containing protein 3 | DN11838_c0_g1_i2_56054 | 78 | 1933 |
| 2 | Actin, cytoplasmic type 5 | DN10334_c0_g1_i3_17117 | 41 | 958 |
| 3 | Myosin XV | DN10026_c0_g1_i2_27828 | 36 | 346 |
| 4 | Myosin heavy chain 10 or non-muscle myosin IIB | DN10438_c0_g2_i2_34624 | 34 | 1235 |
| 5 | Leucine-rich repeat-containing protein | DN11834_c0_g1_i11_56034 | 30 | 611 |
| 6 | Otoferlin | DN10250_c0_g1_i1_26991 | 29 | 245 |
| 7 | Fascin 2 | DN10161_c0_g1_i1_59685 | 29 | 599 |
| 8 | Calpain A | DN9786_c0_g1_i1_72692 | 27 | 1113 |
| 9 | Annexin A7 | DN8700_c0_g1_i1_600 | 26 | 747 |
| 10 | Phosphoenolpyruvate carboxykinase | DN11364_c0_g2_i1_39228 | 25 | 691 |
| 11 | Actin, cytoplasmic type 5 | DN10334_c0_g1_i1_17115 | 24 | 865 |
| 12 | Heat shock 70 kDa protein 4 | DN12581_c0_g1_i2_73130 | 23 | 440 |
| 13 | Expressed conserved protein | DN11921_c1_g2_i1_46303 | 22 | 400 |
| 14 | Von Willebrand factor A domain containing protein | DN11931_c2_g1_i10_58523 | 22 | 396 |
| 15 | Expressed conserved protein | DN7822_c0_g2_i1_27391 | 22 | 131 |
| 16 | Annexin A7 | DN7793_c0_g1_i1_23754 | 21 | 321 |
| 17 | Aldo keto reductase family 1-member B4 | DN11165_c0_g1_i1_24177 | 21 | 416 |
| 18 | Expressed conserved protein | DN10367_c0_g1_i3_29401 | 21 | 473 |
| 19 | Solute carrier family 5 | DN12278_c0_g6_i1_68615 | 20 | 642 |
| 20 | Tegumental antigen | DN5781_c0_g1_i1_2927 | 20 | 674 |
| 21 | Programmed cell death 6- interacting protein | DN10491_c0_g3_i2_21343 | 19 | 303 |
| 22 | Peroxidasin | DN10163_c0_g1_i1_35077 | 18 | 419 |
| 23 | Enolase | DN14469_c0_g1_i1_24672 (Apα-Enolase-1) | 18 | 447 |
| 24 | Ubiquitin-60S ribosomal protein L40 | DN12547_c0_g1_i1_46361 | 18 | 335 |
| 25 | Annexin A13 (Annexin XIII) | DN9930_c0_g1_i1_67885 | 17 | 1023 |
| 26 | Tegumental protein | DN15763_c0_g1_i1_57495 | 17 | 260 |
| 27 | Molecular chaperone HtpG/Heat shock protein 90 alpha | DN11960_c0_g1_i1_46290 (ApHSP90-4) | 16 | 239 |
| 28 | Expressed conserved protein | DN8957_c0_g1_i1_66134 | 16 | 299 |
| 29 | Glycoprotein Antigen 5 | DN9013_c0_g1_i2_47406 | 16 | 476 |
| 30 | Annexin A13 (Annexin XIII) | DN12676_c0_g1_i9_72045 | 15 | 480 |
| 31 | Alpha 2 macroglobulin | DN12789_c0_g1_i5_70580 | 15 | 293 |
| 32 | Phosphoglycerate kinase | DN11218_c0_g1_i1_75075 | 14 | 338 |
| 33 | Annexin B9-like isoform X1 | DN11220_c0_g1_i12_22997 | 14 | 650 |
| 34 | Non-lysosomal glucosylceramidase | DN9975_c0_g1_i9_4448 | 14 | 274 |
| 35 | Solute carrier family 5 | DN10836_c0_g1_i4_11677 | 14 | 600 |
| 36 | Basement membrane-specific heparan sulfate proteoglycan core protein | DN9818_c0_g2_i1_37822 | 14 | 237 |
| 37 | Tegumental protein | DN118_c0_g1_i1_52814 | 14 | 417 |
| 38 | H17g protein tegumental antigen | DN11977_c0_g1_i2_72857 | 14 | 357 |
| 39 | Hypothetical transcript | DN9865_c0_g1_i1_63028 | 14 | 594 |
| 40 | Cytosolic malate dehydrogenase | DN10181_c0_g1_i1_47181 | 13 | 139 |
| 41 | Putative anoctamin | DN11493_c0_g1_i2_56859 | 13 | 145 |
| 42 | Plasma membrane calcium- transporting ATPase 3 | DN11817_c3_g5_i1_69816 | 13 | 234 |
| 43 | Uncharacterised | DN6547_c0_g1_i3_66219 | 13 | 250 |
| 44 | Annexin A13 (Annexin XIII) | DN12676_c0_g1_i5_72043 | 13 | 547 |
| 45 | Von Willebrand factor A domain containing protein | DN10879_c1_g1_i8_12057 | 13 | 381 |
| 46 | Annexin A4-like | DN12342_c0_g1_i2_39792 | 13 | 824 |
| 47 | Carbonic anhydrase | DN11803_c0_g3_i1_69783 | 13 | 255 |
| 48 | Annexin A7 | DN11263_c0_g1_i4_60744 | 12 | 320 |
| 49 | Calpain | DN4288_c0_g1_i1_31793 | 12 | 321 |
| 50 | Unnamed protein product, partial | DN11248_c0_g2_i1_22893 | 12 | 267 |
| No. | Protein Description | Sequence ID | Number of Sequenced Peptides | MASCOT Score |
|---|---|---|---|---|
| 1 | WD repeat and FYVE domain-containing protein 3 | DN11838_c0_g1_i2_56054 | 72 | 1302 |
| 2 | Expressed conserved protein | DN10367_c0_g1_i3_29401 | 50 | 1039 |
| 3 | Myosin heavy chain 10 or non-muscle myosin IIB | DN10438_c0_g2_i2_34624 | 50 | 1372 |
| 4 | P29 | DN11822_c0_g2_i2_55872 | 44 | 1617 |
| 5 | Basement membrane-specific heparan sulfate proteoglycan core protein | DN9818_c0_g2_i1_37822 | 44 | 470 |
| 6 | Spectrin alpha chain | DN11694_c0_g1_i1_54338 | 37 | 686 |
| 7 | Expressed conserved protein | DN11921_c1_g2_i1_46303 | 37 | 701 |
| 8 | Myosin XV | DN10026_c0_g1_i2_27828 | 34 | 296 |
| 9 | Collagen alpha-2(I) chain | DN6173_c0_g1_i4_63619 | 33 | 759 |
| 10 | Expressed conserved protein | DN7822_c0_g2_i1_27391 | 32 | 114 |
| 11 | Expressed conserved protein | DN10746_c0_g1_i6_22331 | 31 | 841 |
| 12 | Annexin A7 | DN8700_c0_g1_i1_600 | 30 | 1130 |
| 13 | Leucine-rich repeat-containing protein | DN11834_c0_g1_i3_56030 | 29 | 596 |
| 14 | Annexin A13 (Annexin XIII) | DN9930_c0_g1_i1_67885 | 29 | 1313 |
| 15 | Microtubule actin cross linking factor 1 | DN10747_c0_g1_i5_35870 | 28 | 231 |
| 16 | Peroxidasin | DN10163_c0_g1_i1_35077 | 28 | 393 |
| 17 | Spectrin alpha actinin | DN11195_c0_g3_i1_24267 | 28 | 231 |
| 18 | Myosin heavy chain | DN11757_c0_g1_i1_61366 | 28 | 613 |
| 19 | Heat shock 70 kDa protein 4 | DN12581_c0_g1_i2_73130 | 27 | 634 |
| 20 | Calpain A | DN9786_c0_g1_i1_72692 | 26 | 931 |
| 21 | Expressed conserved protein | DN11614_c0_g2_i3_53973 | 24 | 338 |
| 22 | Plasma membrane calcium-transporting ATPase 3 | DN10463_c3_g1_i2_34420 | 23 | 329 |
| 23 | Von Willebrand factor A domain containing protein | DN10879_c1_g1_i8_12057 | 23 | 310 |
| 24 | Enolase | DN14469_c0_g1_i1_24672 (Apα-Enolase-1) | 23 | 474 |
| 25 | Calpain | DN4288_c0_g1_i1_31793 | 23 | 333 |
| 26 | Galectin carbohydrate recognition domain | DN6894_c0_g1_i2_12735 | 21 | 631 |
| 27 | Tegumental antigen | DN5781_c0_g1_i1_2927 | 21 | 1112 |
| 28 | No hit | DN10801_c0_g1_i14_11633 | 20 | 594 |
| 29 | Phosphoenolpyruvate carboxykinase | DN11364_c0_g2_i1_39228 | 20 | 253 |
| 30 | Molecular chaperone HtpG/Heat shock protein 90 alpha | DN11960_c0_g1_i1_46290 (ApHSP90-4) | 20 | 372 |
| 31 | Annexin A7 | DN7793_c0_g1_i1_23754 | 20 | 336 |
| 32 | Glycoprotein Antigen 5 | DN9013_c0_g1_i2_47406 | 20 | 458 |
| 33 | Annexin A7 | DN11263_c0_g1_i4_60744 | 20 | 355 |
| 34 | H17g protein tegumental antigen | DN11977_c0_g1_i2_72857 | 19 | 470 |
| 35 | Programmed cell death 6-interacting protein | DN10491_c0_g3_i2_21343 | 19 | 645 |
| 36 | Expressed conserved protein | DN12262_c0_g1_i1_68587 | 18 | 203 |
| 37 | Actin modulator protein | DN8972_c0_g1_i1_2323 | 17 | 395 |
| 38 | Otoferlin | DN10250_c0_g1_i1_26991 | 17 | 527 |
| 39 | Ornithine aminotransferase | DN9481_c0_g1_i1_55273 | 17 | 289 |
| 40 | Unnamed protein product | DN12187_c0_g1_i1_66436 | 17 | 335 |
| 41 | Fascin 2 | DN10161_c0_g1_i1_59685 | 16 | 535 |
| 42 | Actin, cytoplasmic type 5 | DN10334_c0_g1_i3_17117 | 16 | 570 |
| 43 | Calmodulin | DN5211_c0_g1_i2_35332 | 16 | 381 |
| 44 | Expressed conserved protein | DN8957_c0_g1_i1_66134 | 16 | 681 |
| 45 | Paramyosin | DN10354_c0_g1_i1_3720 | 15 | 299 |
| 46 | Serine/threonine kinase | DN8156_c0_g1_i2_52113 | 15 | 212 |
| 47 | Protein kinase C and casein kinase substrate in neurons protein 1 | DN7152_c0_g1_i2_8970 | 15 | 456 |
| 48 | Tegumental protein | DN118_c0_g1_i1_52814 | 14 | 205 |
| 49 | Lysyl oxidase | DN7852_c0_g1_i1_1626 | 14 | 189 |
| 50 | Phosphoglycerate kinase | DN11218_c0_g1_i1_75075 | 14 | 123 |
| No. | Protein Description | Sequence ID | Number of Sequenced Peptides | MASCOT Score |
|---|---|---|---|---|
| 1 | WD repeat and FYVE domain-containing protein 3 | DN11838_c0_g1_i2_56054 | 292 | 6943 |
| 2 | Basement membrane-specific heparan sulfate proteoglycan core protein | DN9818_c0_g2_i1_37822 | 169 | 2575 |
| 3 | Enolase | DN14469_c0_g1_i1_24672 (Apα-Enolase-1) | 146 | 5177 |
| 4 | Alpha 2 macroglobulin | DN12789_c0_g1_i5_70580 | 118 | 2655 |
| 5 | Ornithine aminotransferase | DN9481_c0_g1_i1_55273 | 106 | 2044 |
| 6 | Aldo keto reductase family 1-member B4 | DN10754_c1_g2_i7_35857 | 96 | 3057 |
| 7 | Deoxyhypusine hydroxylase | DN10922_c1_g1_i5_14239 | 95 | 1993 |
| 8 | Protein disulfide-isomerase | DN9431_c0_g1_i1_5402 | 91 | 3042 |
| 9 | Peroxidasin | DN10163_c0_g1_i1_35077 | 89 | 2110 |
| 10 | Cytosolic malate dehydrogenase | DN10181_c0_g1_i1_47181 | 75 | 1053 |
| 11 | Heat shock 70 kDa protein 4 | DN12581_c0_g1_i2_73130 | 74 | 1512 |
| 12 | Actin, cytoplasmic type 5 | DN10334_c0_g1_i3_17117 | 68 | 1765 |
| 13 | Glycogen phosphorylase | DN9054_c0_g2_i1_35634 | 63 | 865 |
| 14 | Fascin 2 | DN10161_c0_g1_i1_59685 | 62 | 952 |
| 15 | Lysosomal alpha-glucosidase | DN10704_c0_g1_i4_9857 | 60 | 932 |
| 16 | Gynecophoral canal protein | DN2510_c0_g1_i1_41860 | 59 | 991 |
| 17 | Phosphoenolpyruvate carboxykinase | DN11364_c0_g2_i1_39228 | 57 | 1088 |
| 18 | Protein disulfide-isomerase A3 | DN6375_c0_g1_i1_15550 | 55 | 1134 |
| 19 | Von Willebrand factor A domain containing protein | DN10879_c1_g1_i8_12057 | 53 | 1406 |
| 20 | Calpain A | DN9786_c0_g1_i1_72692 | 52 | 1568 |
| 21 | Spectrin alpha chain | DN11694_c0_g1_i1_54338 | 50 | 513 |
| 22 | Putative zinc binding dehydrogenase | DN10593_c0_g1_i11_28936 | 50 | 1031 |
| 23 | Phosphoglycerate kinase | DN11218_c0_g1_i1_75075 | 50 | 958 |
| 24 | Fructose-bisphosphate aldolase | DN10221_c0_g1_i1_65390 | 46 | 909 |
| 25 | NADP-dependent malic enzyme | DN8932_c0_g1_i2_2337 | 45 | 1210 |
| 26 | Actin modulator protein | DN8953_c0_g1_i6_52210 | 45 | 977 |
| 27 | EF hand family protein | DN9944_c0_g2_i4_42845 | 42 | 1195 |
| 28 | Expressed conserved protein | DN11614_c0_g2_i3_53973 | 41 | 201 |
| 29 | Molecular chaperone HtpG/ Heat shock protein 90 alpha | DN11960_c0_g1_i1_46290 (ApHSP90-4) | 41 | 801 |
| 30 | Spectrin alpha actinin | DN11195_c0_g3_i1_24267 | 40 | 467 |
| 31 | Basement membrane-specific heparan sulfate proteoglycan core protein | DN9714_c0_g1_i3_20481 | 40 | 770 |
| 32 | Beta galactosidase | DN10618_c0_g1_i1_32785 | 39 | 752 |
| 33 | Transketolase | DN9107_c0_g1_i1_32351 | 39 | 985 |
| 34 | Glucose-6-phosphate isomerase | DN10660_c0_g1_i2_45795 | 38 | 709 |
| 35 | Puromycin sensitive aminopeptidase | DN10270_c0_g1_i2_26817 | 37 | 706 |
| 36 | Calsyntenin 1 | DN10458_c0_g1_i1_34309 | 37 | 638 |
| 37 | Gynecophoral canal protein | DN7995_c0_g1_i1_6847 | 37 | 653 |
| 38 | Glycerol kinase | DN8664_c0_g1_i1_13160 | 37 | 1104 |
| 39 | Peptidyl-glycine alpha-amidating monooxygenase A | DN8251_c0_g1_i1_16141 | 36 | 725 |
| 40 | Hypothetical transcript | DN9865_c0_g1_i1_63028 | 36 | 642 |
| 41 | Adenylosuccinate synthetase | DN10697_c0_g3_i1_6876 | 36 | 810 |
| 42 | Glucose-6-phosphate 1-dehydrogenase | DN11811_c2_g4_i1_55908 | 35 | 1378 |
| 43 | Myosin heavy chain 10 or non-muscle myosin IIB | DN12309_c0_g1_i3_64783 | 35 | 70 |
| 44 | Expressed conserved protein | DN11119_c0_g1_i2_24053 | 34 | 662 |
| 45 | Putative actin-interacting protein 1 | DN1602_c0_g1_i1_69974 | 34 | 218 |
| 46 | Expressed conserved protein | DN7822_c0_g2_i1_27391 | 34 | 595 |
| 47 | Puromycin sensitive aminopeptidase | DN10270_c0_g1_i1_26816 | 33 | 488 |
| 48 | Phosphoglucomutase | DN12341_c1_g3_i1_64791 | 33 | 449 |
| 49 | Ubiquitin modifier activating enzyme 1 | DN11247_c1_g1_i4_75101 | 33 | 784 |
| 50 | Peptidyl prolyl cis trans isomerase B | DN4872_c0_g1_i1_43079 | 32 | 202 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wititkornkul, B.; Hulme, B.J.; Tomes, J.J.; Allen, N.R.; Davis, C.N.; Davey, S.D.; Cookson, A.R.; Phillips, H.C.; Hegarty, M.J.; Swain, M.T.; et al. Evidence of Immune Modulators in the Secretome of the Equine Tapeworm Anoplocephala perfoliata. Pathogens 2021, 10, 912. https://doi.org/10.3390/pathogens10070912
Wititkornkul B, Hulme BJ, Tomes JJ, Allen NR, Davis CN, Davey SD, Cookson AR, Phillips HC, Hegarty MJ, Swain MT, et al. Evidence of Immune Modulators in the Secretome of the Equine Tapeworm Anoplocephala perfoliata. Pathogens. 2021; 10(7):912. https://doi.org/10.3390/pathogens10070912
Chicago/Turabian StyleWititkornkul, Boontarikaan, Benjamin J. Hulme, John J. Tomes, Nathan R. Allen, Chelsea N. Davis, Sarah D. Davey, Alan R. Cookson, Helen C. Phillips, Matthew J. Hegarty, Martin T. Swain, and et al. 2021. "Evidence of Immune Modulators in the Secretome of the Equine Tapeworm Anoplocephala perfoliata" Pathogens 10, no. 7: 912. https://doi.org/10.3390/pathogens10070912
APA StyleWititkornkul, B., Hulme, B. J., Tomes, J. J., Allen, N. R., Davis, C. N., Davey, S. D., Cookson, A. R., Phillips, H. C., Hegarty, M. J., Swain, M. T., Brophy, P. M., Wonfor, R. E., & Morphew, R. M. (2021). Evidence of Immune Modulators in the Secretome of the Equine Tapeworm Anoplocephala perfoliata. Pathogens, 10(7), 912. https://doi.org/10.3390/pathogens10070912