
Analyzing the Emotions That News Agencies Express towards Candidates during Electoral Campaigns: 2018 Brazilian Presidential Election as a Case of Study



Abstract
:1. Introduction
2. Datasets
3. Methodology
3.1. A Framework to Measure Support and the Relation between News Media and Candidates
3.2. Analyzing Sentiment and Emotions
3.3. A Model to Measure News Agencies’ Support or Non-Support
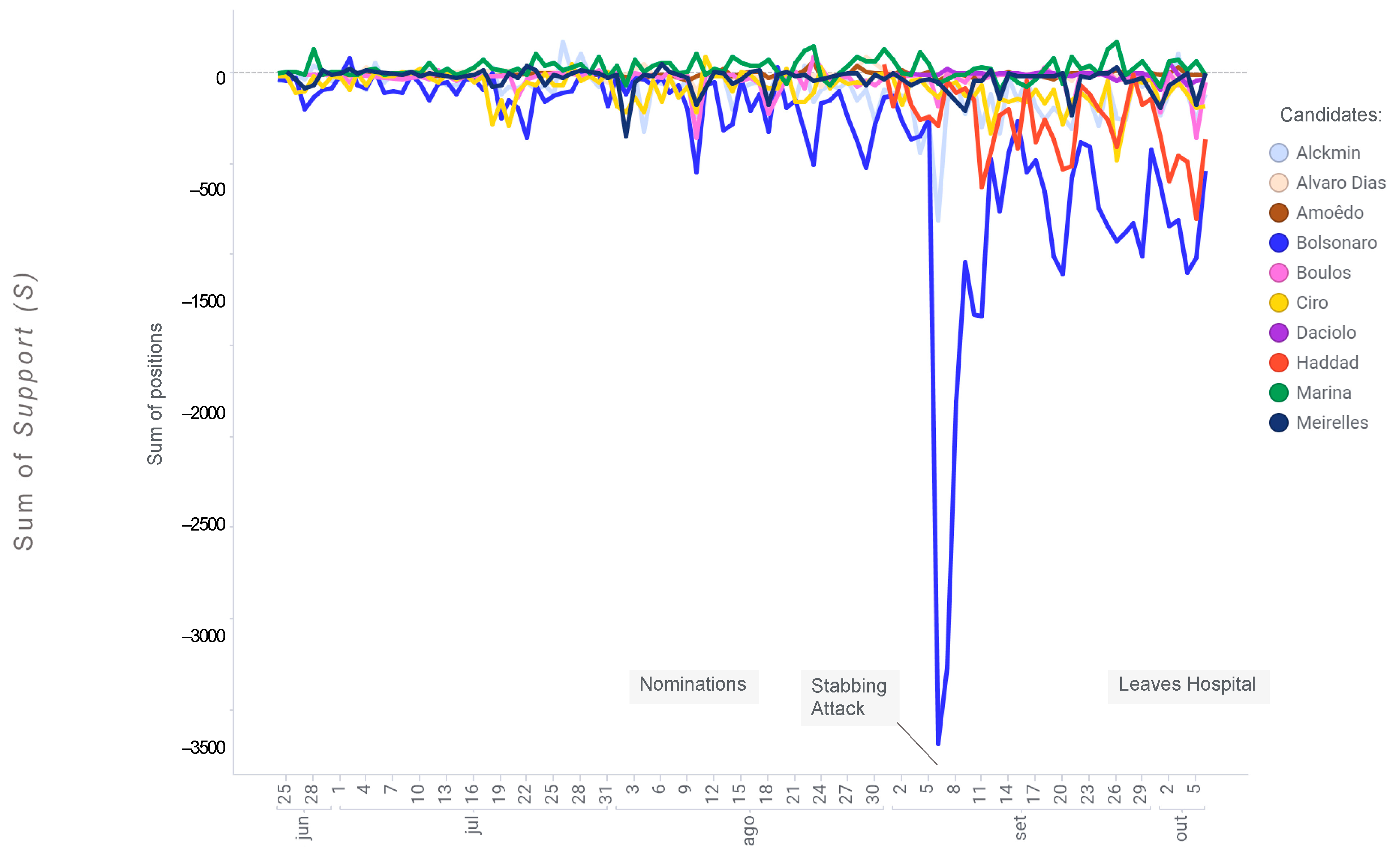
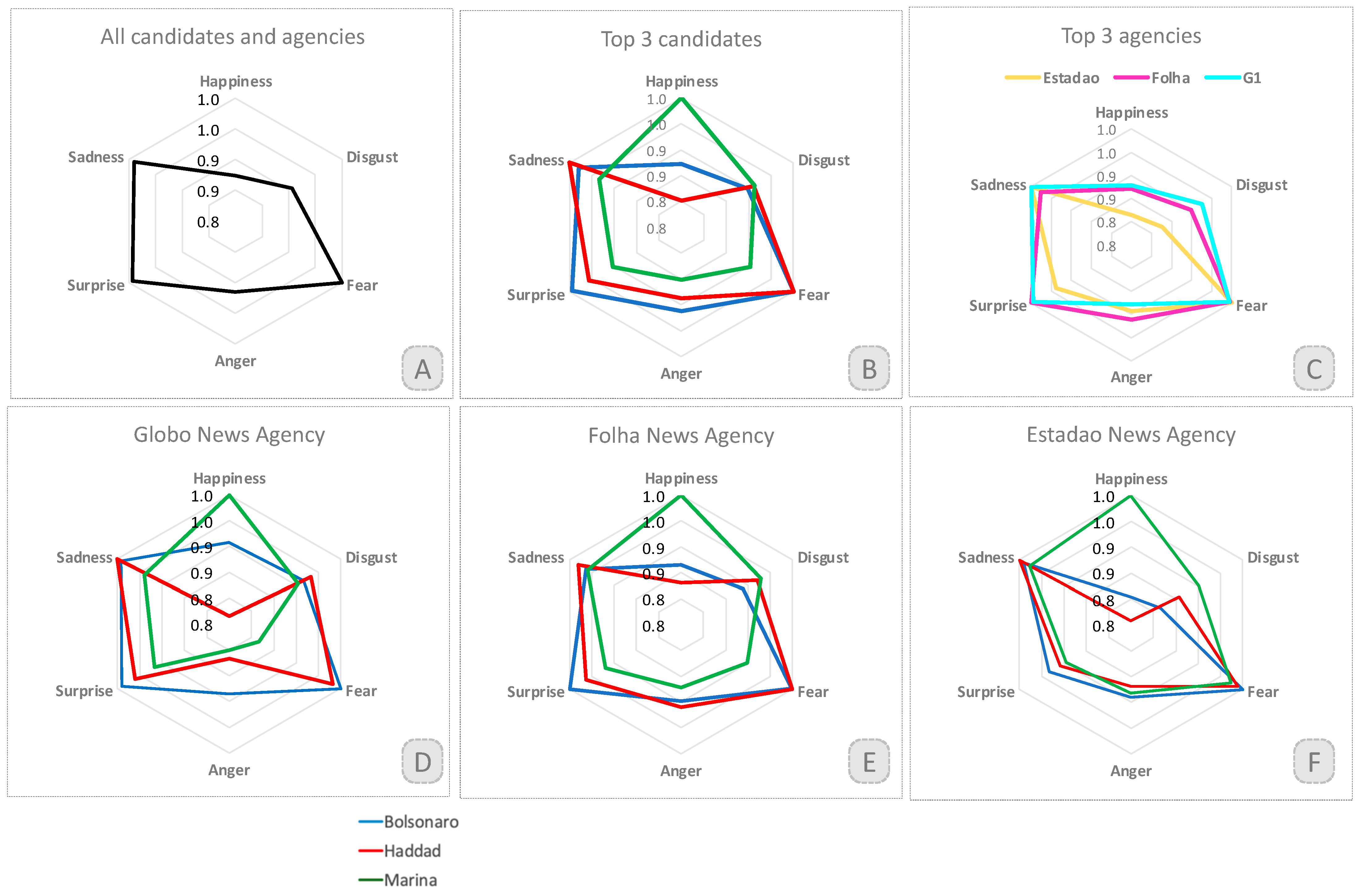
4. Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Political Scenario
Appendix B. The Selection of News Agencies
- Identify all national and state news agencies, including TV channels, radio stations, and newspapers.
- Evaluation of each agency based on the number of followers, the number of historical posts, and the frequency of daily posts.
- ▪
- Only agencies with more than 100 followers were included in the list.
- ▪
- Only agencies with recent posts were included in the list.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
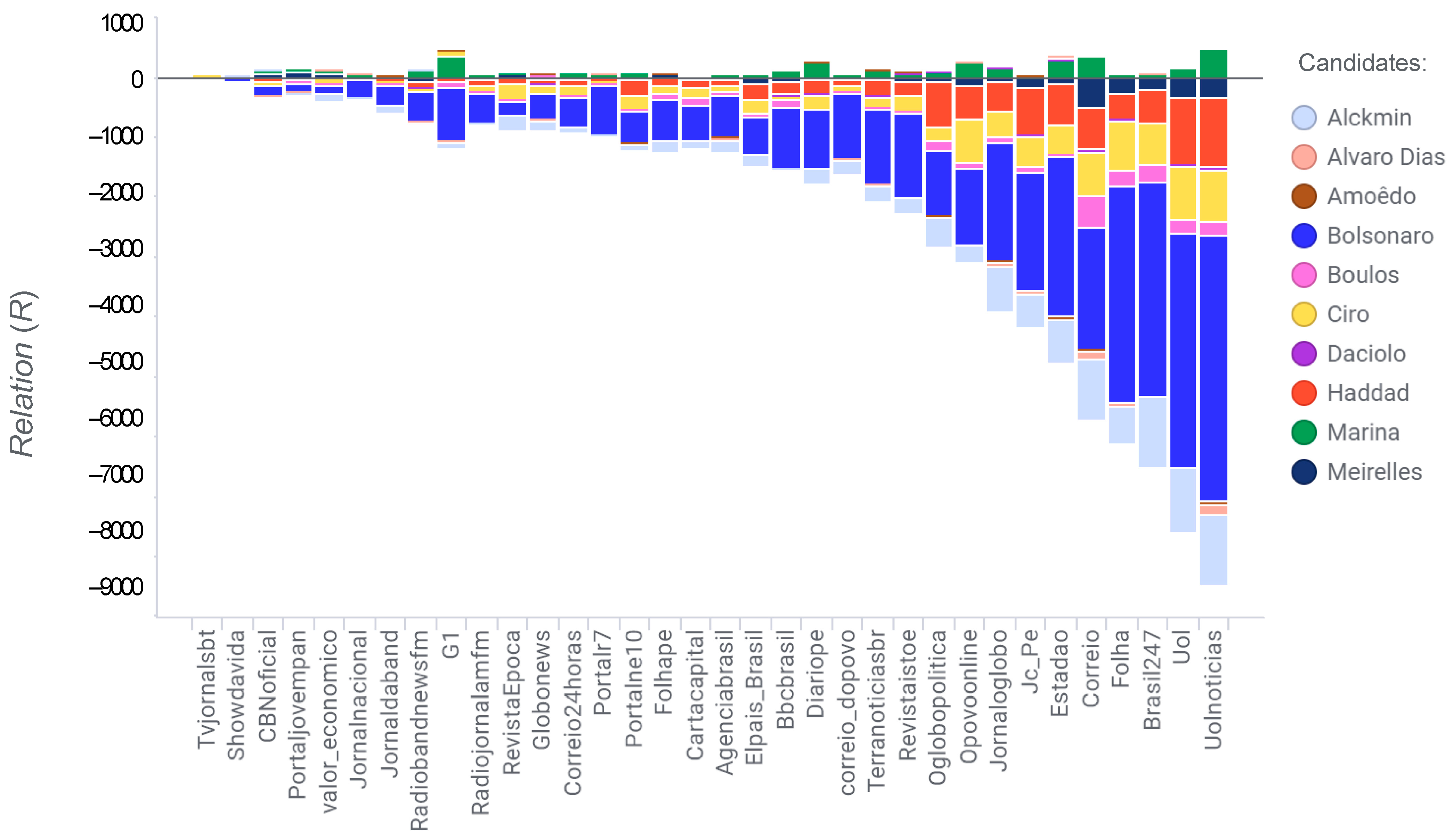
| Code | News Agency | Quantity of Posts | ∑ S | ∑ |S| |
|---|---|---|---|---|
| Ag_01 | Uolnoticias | 5865 | −15,198.50 | 45,021.50 |
| Ag_02 | Brasil247 | 5541 | −17,482.50 | 40,253.50 |
| Ag_03 | Uol | 4491 | −14,432.00 | 33,066.00 |
| Ag_04 | Folha | 4394 | −11,148.00 | 32,874.00 |
| Ag_05 | Estadao | 3266 | −7631.00 | 23,462.00 |
| Ag_06 | Correio | 2907 | −7268.00 | 21,000.00 |
| Ag_07 | Jornaloglobo | 2469 | −6332.50 | 18,190.50 |
| Ag_08 | Jc_Pe | 2132 | −7815.50 | 16,836.50 |
| Ag_09 | Opovoonline | 2081 | −5278.00 | 16,018.00 |
| Ag_10 | G1 | 1810 | −2799.50 | 13,242.50 |
| Ag_11 | Oglobopolitica | 1762 | −4514.00 | 13,222.00 |
| Ag_12 | Diariope | 1738 | −3843.00 | 12,552.00 |
| Ag_13 | Terranoticiasbr | 1576 | −4051.00 | 12,387.00 |
| Ag_14 | Revistaistoe | 1508 | −4147.50 | 11,863.50 |
| Ag_15 | Bbcbrasil | 1453 | −3623.50 | 10,308.50 |
| Ag_16 | correio_dopovo | 1293 | −3421.00 | 10,095.00 |
| Ag_17 | Agenciabrasil | 1222 | −3063.50 | 9253.50 |
| Ag_18 | Portalne10 | 927 | −1507.50 | 7550.50 |
| Ag_19 | Elpais_Brasil | 904 | −2392.00 | 6268.00 |
| Ag_20 | Folhape | 847 | −2325.50 | 6352.50 |
| Ag_21 | Cartacapital | 783 | −2429.00 | 5354.00 |
| Ag_22 | RevistaEpoca | 626 | −1212.50 | 4200.50 |
| Ag_23 | Radiobandnewsfm | 612 | −1569.50 | 4501.50 |
| Ag_24 | Correio24horas | 571 | −1962.00 | 4093.00 |
| Ag_25 | Globonews | 554 | −1809.50 | 3669.50 |
| Ag_26 | Portalr7 | 527 | −1478.50 | 3992.50 |
| Ag_27 | Radiojornalamfm | 479 | −1632.50 | 3602.50 |
| Ag_28 | CBNoficial | 419 | −1102.50 | 3064.50 |
| Ag_29 | Jornaldaband | 356 | −1064.00 | 2562.00 |
| Ag_30 | Portaljovempan | 283 | −236.00 | 1850.00 |
| Ag_31 | valor_economico | 246 | −302.00 | 1889.00 |
| Ag_32 | Jornalnacional | 212 | −672.50 | 1584.50 |
| Ag_33 | Showdavida | 36 | −103.00 | 233.00 |
| Ag_34 | Tvjornalsbt | 3 | 11.00 | 23.00 |
| Ag_35 | Stjnoticias | 2 | −14.00 | 14.00 |
| News Agency | Quantity of Posts | ∑ S | ∑ |S| |
|---|---|---|---|
| Folha | 4394 | −11,148.00 | 32,874.00 |
| Estadao | 3266 | −7631.00 | 23,462.00 |
| Cartacapital | 783 | −2429.00 | 5354.00 |
| Uolnoticias | 5865 | −15,198.50 | 45,021.50 |
| Jornaloglobo | 2469 | −6332.50 | 18,190.50 |
| RevistaEpoca | 626 | −1212.50 | 4200.50 |
| valor_economico | 246 | −302.00 | 1889.00 |
| Oglobopolitica | 1762 | −4514.00 | 13,222.00 |
| Brasil247 | 5541 | −17,482.50 | 40,253.50 |
| Revistaistoe | 1508 | −4147.50 | 11,863.50 |
| Radiojornalamfm | 479 | −1632.50 | 3602.50 |
| Portalne10 | 927 | −1507.50 | 7550.50 |
| Jc_Pe | 2132 | −7815.50 | 16,836.50 |
| Portaljovempan | 283 | −236.00 | 1850.00 |
| Opovoonline | 2081 | −5278.00 | 16,018.00 |
| Correio | 2907 | −7268.00 | 21,000.00 |
| correio_dopovo | 1293 | −3421.00 | 10,095.00 |
| Uol | 4491 | −14,432.00 | 33,066.00 |
| Folhape | 847 | −2325.50 | 6352.50 |
| Diariope | 1738 | −3843.00 | 12,552.00 |
| Jornaldaband | 356 | −1064.00 | 2562.00 |
| G1 | 1810 | −2799.50 | 13,242.50 |
| Agenciabrasil | 1222 | −3063.50 | 9253.50 |
| Correio24horas | 571 | −1962.00 | 4093.00 |
| Tvjornalsbt | 3 | 11.00 | 23.00 |
| CBNoficial | 419 | −1102.50 | 3064.50 |
| Terranoticiasbr | 1576 | −4051.00 | 12,387.00 |
| Bbcbrasil | 1453 | −3623.50 | 10,308.50 |
| Elpais_Brasil | 904 | −2392.00 | 6268.00 |
| Radiobandnewsfm | 612 | −1569.50 | 4501.50 |
| Portalr7 | 527 | −1478.50 | 3992.50 |
| Globonews | 554 | −1809.50 | 3669.50 |
| Jornalnacional | 212 | −672.50 | 1584.50 |
| Showdavida | 36 | −103.00 | 233.00 |
| Stjnoticias | 2 | −14.00 | 14.00 |
| Standard Deviation Sum (S) | 4429.30 | ||
| Standard Deviation Sum (|S|) | 11,486.10 | ||
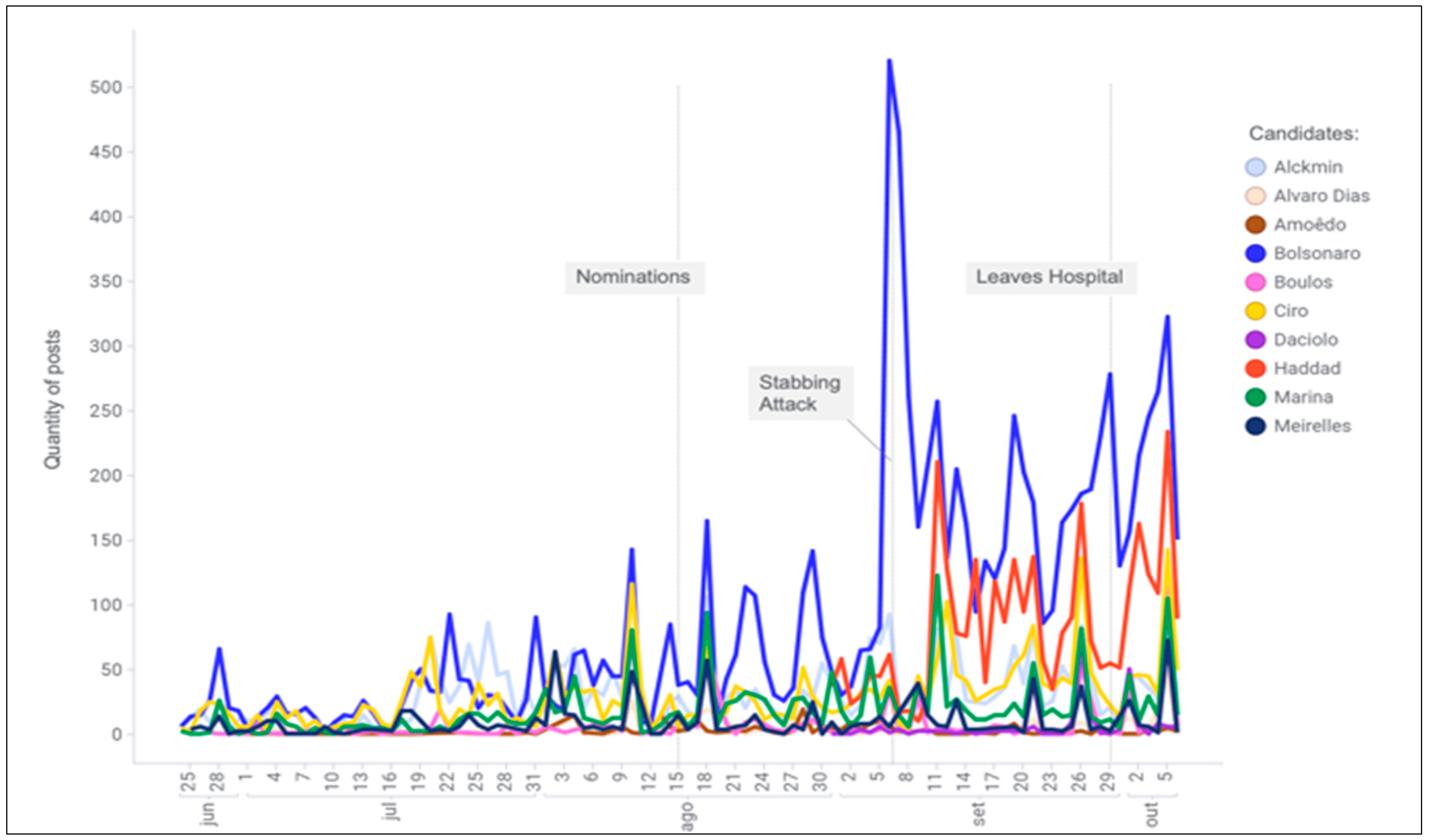
| Candidate | Quantity of Posts | ∑ S | ∑ |S| |
|---|---|---|---|
| Bolsonaro | 32,530 | −88,726.5 | 243,972.5 |
| Haddad | 7018 | −22,989.0 | 51,235.0 |
| Ciro | 3686 | −10,100.0 | 26,676.0 |
| Alckmin | 3614 | −10,553.0 | 26,930.0 |
| Marina | 2019 | 2782.0 | 15,901.0 |
| Lula | 1841 | −5459.5 | 13,310.5 |
| Meirelles | 1018 | −2988.5 | 7240.5 |
| Boulos | 835 | −3205.5 | 6078.5 |
| Alvaro Dias | 340 | −701.5 | 2398.5 |
| Daciolo | 313 | −597.5 | 1961.5 |
| Amoêdo | 270 | −264.0 | 1590.0 |
| Kátia Abreu | 73 | −231.5 | 541.5 |
| Rodrigo Maia | 65 | −159.0 | 495.0 |
| Flávio Rocha | 53 | −38.5 | 389.5 |
| Eymael | 43 | −41.0 | 366.0 |
| Vera Lúcia | 41 | −163.0 | 295.0 |
| Paulo Rabello | 40 | −218.5 | 369.5 |
| Cristovam Buarque | 30 | −84.5 | 180.5 |
| Goulart Filho | 30 | −65.5 | 238.5 |
| Rebelo | 21 | 0.5 | 196.5 |
| Dávila | 13 | −47.0 | 76.0 |
| Standard Deviation Sum (S) | 19,604.5 | ||
| Standard Deviation Sum (|S|) | 53,141.9 | ||
| Alckmin | Bolsonaro | Haddad | Marina | Total | Standard Dev. | |
|---|---|---|---|---|---|---|
| Brasil247 | −1186.5 | −12,675.0 | −1638.5 | 43.5 | −15,456.5 | 5916.8 |
| Correio | −974.0 | −3338.0 | −1136.0 | 326.5 | −5121.5 | 1519.9 |
| Estadao | −757.5 | −4758.0 | −1207.5 | 285.0 | −6438.0 | 2190.1 |
| Folha | −692.0 | −7151.0 | −1311.0 | 32.0 | −9122.0 | 3293.1 |
| G1 | −87.0 | −1832.5 | −769.5 | 310.5 | −2378.5 | 938.1 |
| Jc_Pe | −575.5 | −4350.5 | −1687.0 | −21.0 | −6634.0 | 1923.7 |
| Jornaloglobo | −743.5 | −3785.5 | −858.0 | 124.5 | −5262.5 | 1704.0 |
| Opovoonline | −274.0 | −2594.5 | −220.0 | 211.0 | −3877.5 | 1235.7 |
| Uol | −1154.0 | −8749.5 | −2330.5 | 107.5 | −12,126.5 | 3939.8 |
| Uolnoticias | −1367.0 | −9487.5 | −2323.0 | 453.5 | −12,724.0 | 4359.2 |
| Total | −7811.0 | −58,722.0 | −14,481.0 | 1873.0 | ||
| Standard Dev. | 404.8 | 3506.5 | 544.9 | 154.2 |
Appendix C. Methods to Classify Tweets with Naïve Bayes and Stemming
- •
- Generate the database with support tables: The creation of the temporary staging database with support tables such as the list of candidates, the list of official news agencies, and the electoral events.
- •
- Ingestion of posts mentioning candidates from news agencies: As a recursive process, news agencies’ tweets were ingested daily in a stage table.
- •
- Generate main tables of selected posts: Processing the staging table with a data wrangling process, cleaning incorrect and duplicated records, removing incorrect records, and generating the main research tables.
- •
- Analyze the posts, calculating sentiments and emotions: All the posts were analyzed using different techniques to calculate sentiments and emotions.
- •
- According to the results for each scenario, rank the techniques and identify the most efficient method to calculate sentiments and emotions.
- •
- Calculate the position of each post, considering all the fields of polarity, sentiment, and emotion, suggesting the position of the news agency related to the candidate.
- •
- Generate graphs and insights: Business Intelligence graphs and advanced analytics insights were produced over the resultant data.
- •
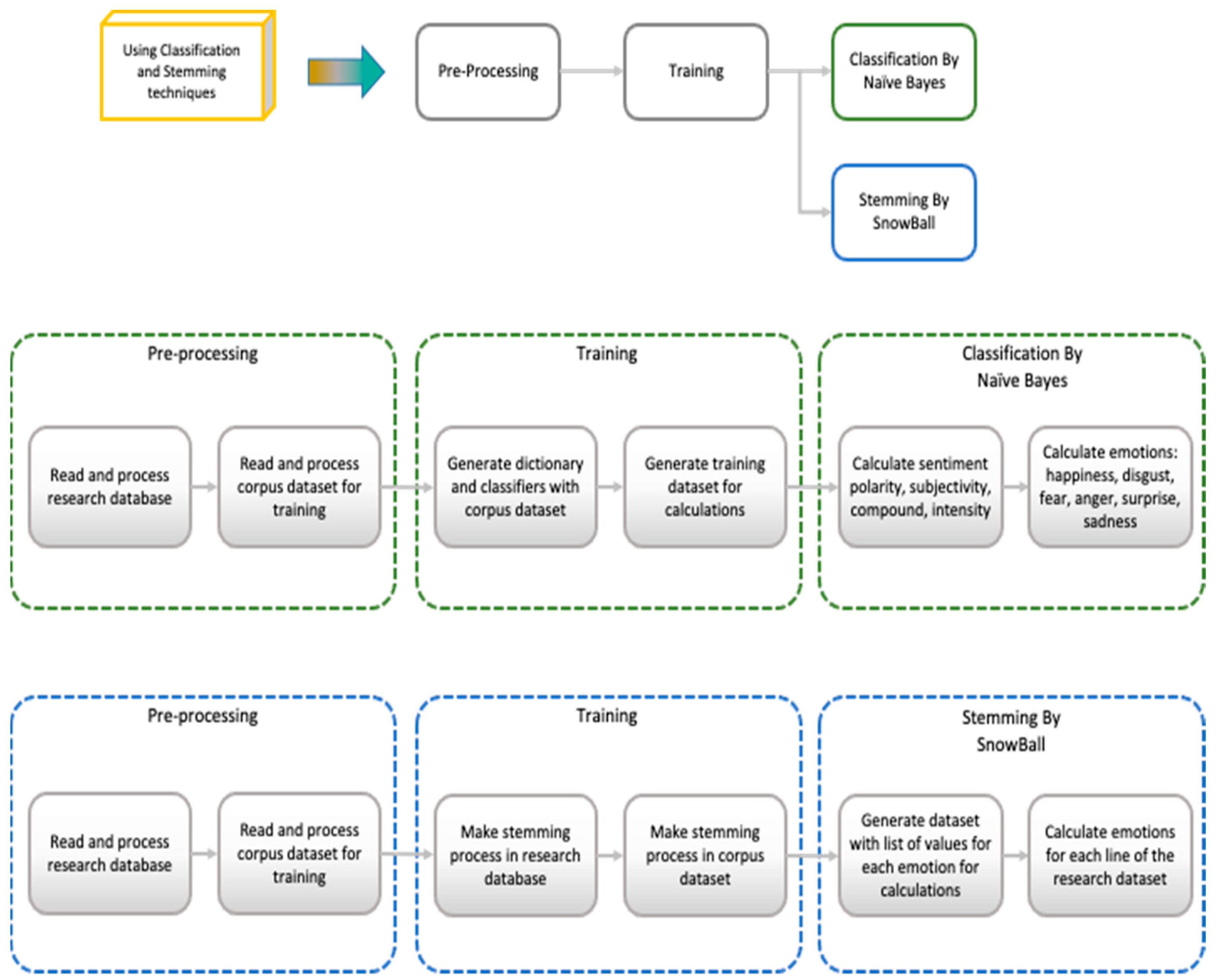
- The differences in the use of the Naïve Bayes classification and the Stemming calculation are explained in Figure 1.
- •
- Pre-processing: This phase comprehends the preparation of all data (the research work database and the training datasets) for the following stages. In this research, all data were obtained in the following steps:
- •
- Acquisition: All official news agency posts were extracted daily during the research period.
- •
- Cleaning and Enrichment: The resulting dataset was cleaned, and the remaining posts only about the candidates in the presidential election remained, removing any false cognates, and were enriched with calculated fields to facilitate the analysis and filtering.
- •
- Discovery and Text Mining: An exploratory analysis was made using text mining to understand the indicators and identify insights into the data and their derivatives.
- •
- Training: Using the training datasets for Naïve Bayes classification, the dictionary and classifiers were created to provide referential information and a list of pre-trained terms to evaluate each post-classifying emotion.
- •
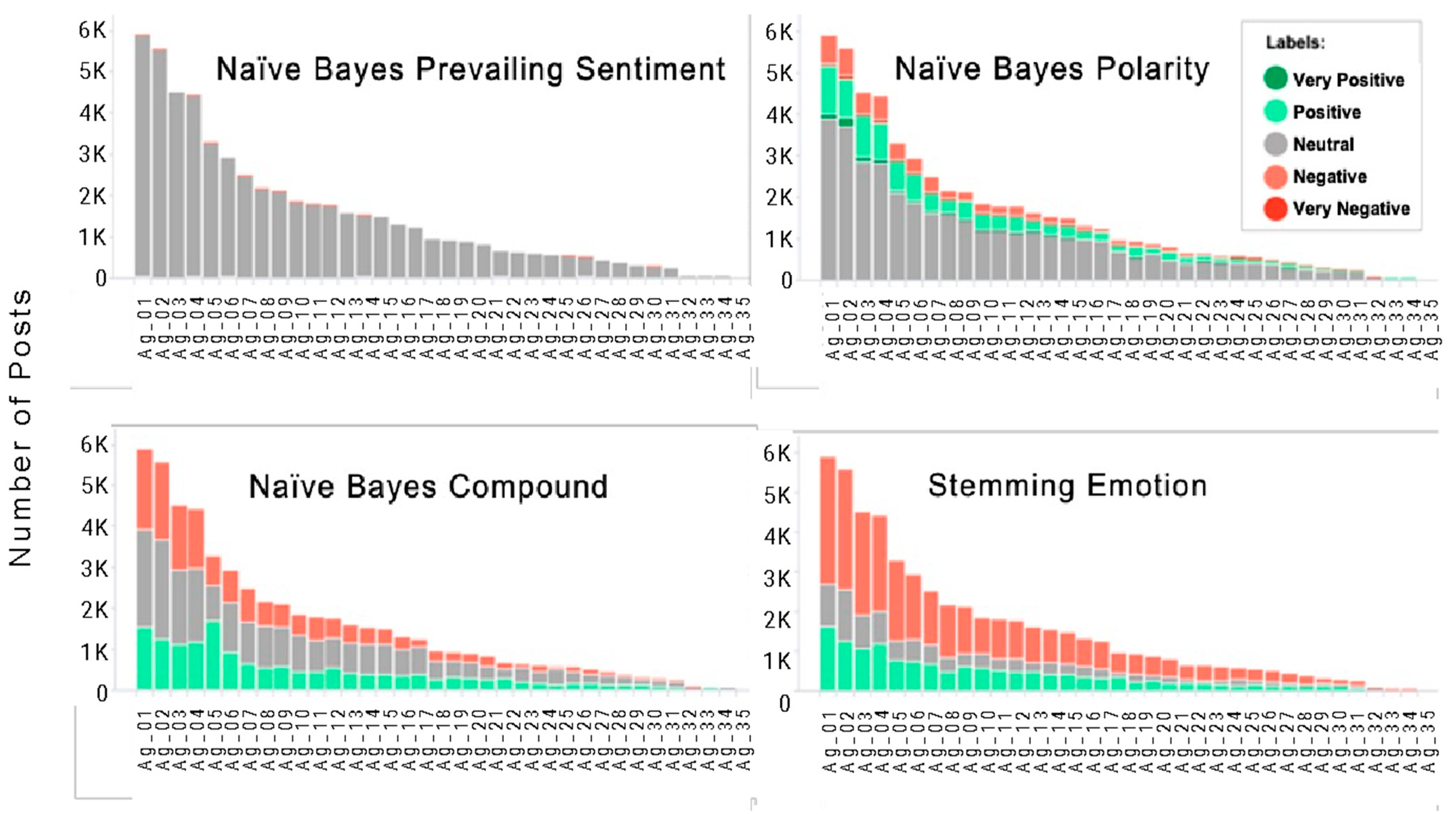
- Classification with Naïve Bayes: Using the list of trained terms, each line of the research work database was classified, calculating information as sentiment polarity, subjectivity, compound, and intensity, and was also classified for emotions as happiness, disgust, fear, anger, surprise, and sadness. Every single emotion has a value between 0 and 1 for each post.
- •
- Step 1: The Stemming process transformed each word into its root without prefixes and suffixes. As a result, we obtained a list of stems from each tweet. Each stem is associated with one or more emotions.
- •
- Step 2: The research worktable was analyzed line by line, adding the value of the emotions in the research worktable list for each post word. As a result, each research worktable received the total emotion score for each emotion normalized between 0 and 1.
References
- Ahuja, Ravinder, and S. C. Sharma. 2022. Sentiment Analysis on Different Domains Using Machine Learning Algorithms. In Advances in Data and Information Sciences: Proceedings of ICDIS 2021. Singapore: Springer, pp. 143–53. [Google Scholar]
- Ali, Farahat, Muhammad Awais, and Muhammad Faran. 2021. Social Media Use and Political Polarization: The Mediating Role of Political Engagement and Political Loyalty. International Journal of Media and Information Literacy 6: 17–33. [Google Scholar] [CrossRef]
- Allen, James. 1995. Natural Language Understanding. San Francisco: Benjamin-Cummings Publishing Co., Inc. [Google Scholar]
- Anderson, Brian D. O., and Mengbin Ye. 2019. Recent advances in the modeling and analysis of opinion dynamics on influence networks. International Journal of Automation and Computing 16: 129–49. [Google Scholar] [CrossRef]
- Bellovary, Andrea K., Nathaniel A. Young, and Amit Goldenberg. 2021. Left-and right-leaning news organizations use negative emotional content and elicit user engagement similarly. Affective Science 2: 391–96. [Google Scholar] [CrossRef]
- Borondo, Javier, Alfredo J. Morales, Juan-Carlos Losada, and Rosa M. Benito. 2012. Characterizing and modeling an electoral campaign in the context of Twitter: 2011 Spanish Presidential election as a case study. Chaos: An Interdisciplinary Journal of Nonlinear Science 22: 023138. [Google Scholar] [CrossRef] [PubMed]
- Borondo, Javier, Alfredo J. Morales, Rosa M. Benito, and Juan Carlos Losada. 2014. Mapping the online communication patterns of political conversations. Physica A: Statistical Mechanics and its Applications 414: 403–13. [Google Scholar] [CrossRef]
- Borondo, Javier, Alfredo J. Morales, Rosa M. Benito, and Juan Carlos Losada. 2015. Multiple leaders on a multilayer social media. Chaos, Solitons & Fractals 72: 90–98. [Google Scholar]
- Braha, Dan. 2012. Global civil unrest: Contagion, self-organization, and prediction. PLoS ONE 7: e48596. [Google Scholar] [CrossRef] [PubMed]
- Braha, Dan, and Marcus A. M. De Aguiar De Aguiar. 2017. Voting contagion: Modeling and analysis of a century of US presidential elections. PLoS ONE 12: e0177970. [Google Scholar] [CrossRef]
- Budiharto, Widodo, and Meiliana Meiliana. 2018. Prediction and analysis of Indonesia Presidential election from Twitter using sentiment analysis. Journal of Big Data 5: 51. [Google Scholar] [CrossRef]
- Buntoro, Buntoro, GHULAM ASROFI, Rizal Arifin, Gus Nanang Syaifuddiin, Ali Selamat, O. Krejcar, and F. Hamido. 2021. The Implementation of the machine learning algorithm for the sentiment analysis of Indonesia’s 2019 Presidential election. IIUM Engineering Journal 22: 78–92. [Google Scholar] [CrossRef]
- Ceron, Andrea, Luigi Curini, and Stefano M. Iacus. 2015. Using sentiment analysis to monitor electoral campaigns: Method matters—evidence from the United States and Italy. Social Science Computer Review 33: 3–20. [Google Scholar] [CrossRef]
- Chmiel, Anna, Pawel Sobkowicz, Julian Sienkiewicz, Georgios Paltoglou, Kevan Buckley, Mike Thelwall, and Janusz A. Hołyst. 2011. Negative emotions boost user activity at BBC forum. Physica A: Statistical Mechanics and Its Applications 390: 2936–44. [Google Scholar] [CrossRef]
- Chong, Wei Yen, Bhawani Selvaretnam, and Lay-Ki Soon. 2014. Natural language processing for sentiment analysis: An exploratory analysis on tweets. Paper presented at the 2014 4th International Conference on Artificial Intelligence with Applications in Engineering and Technology, Kota Kinabalu, Malaysia, December 3–5; pp. 212–17. [Google Scholar]
- Conover, Michael D., Bruno Gonçalves, Jacob Ratkiewicz, Alessandro Flammini, and Filippo Menczer. 2011. Predicting the political alignment of Twitter users. Paper presented at the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Boston, MA, USA, October 9–11; pp. 192–99. [Google Scholar]
- Conover, Michael, Jacob Ratkiewicz, Matthew Francisco, Bruno Gonçalves, Filippo Menczer, and Alessandro Flammini. 2011. Political Polarization on Twitter. Paper presented at the International AAAI Conference on Web and Social Media, Barcelona, Spain, July 17–21; vol. 5, pp. 89–96. [Google Scholar] [CrossRef]
- de León, Ernesto, and Damian Trilling. 2021. A sadness bias in political news sharing? The role of discrete emotions in the engagement and dissemination of political news on Facebook. Social Media+ Society 7: 20563051211059710. [Google Scholar] [CrossRef]
- de Oliveira, Douglas Nunes, and Luiz Henrique de Campos Merschmann. 2021. Joint evaluation of preprocessing tasks with classifiers for sentiment analysis in Brazilian Portuguese language. Multimedia Tools and Applications 80: 15391–412. [Google Scholar] [CrossRef]
- dos Santos Brito, Kellyton, Silvio Romero de Lemos Meira, and Paulo Jorge Leitão Adeodato. 2021. Correlations of social media performance and electoral results in Brazilian presidential elections. Information Polity 26: 417–39. [Google Scholar] [CrossRef]
- Ekman, Paul. 1999. Basic emotions. Handbook of Cognition and Emotion 98: 16. [Google Scholar]
- Folha. n.d. Available online: www1.folha.uol.com.br/fsp/brasil/fc1506200017.htm (accessed on 22 July 2023).
- Ghafariyan, S. 2019. Andbrain Dataset v5. Available online: www.kaggle.com/code/jibinjk/starter-emotions-sensor-data-set-5123fe52-6 (accessed on 22 July 2023).
- González-Bailón, Sandra, Javier Borge-Holthoefer, Alejandro Rivero, and Yamir Moreno. 2011. The dynamics of protest recruitment through an online network. Scientific Reports 1: 197. Available online: http://snowball.tartarus.org/algorithms/portuguese/stemmer.html (accessed on 22 July 2023).
- Kaur, Parneet. 2022. Sentiment analysis using web scraping for live news data with machine learning algorithms. Materials Today: Proceedings 65: 3333–41. [Google Scholar] [CrossRef]
- Kratzwald, Bernhard, Suzana Ilić, Mathias Kraus, Stefan Feuerriegel, and Helmut Prendinger. 2018. Deep learning for affective computing: Text-based emotion recognition in decision support. Decision Support Systems 115: 24–35. [Google Scholar] [CrossRef]
- Kumar, Akshi, and Teeja Mary Sebastian. 2012. Sentiment analysis: A perspective on its past, present and future. International Journal of Intelligent Systems and Applications 4: 1–14. [Google Scholar] [CrossRef]
- Kwak, Haewoon, Changhyun Lee, Hosung Park, and Sue Moon. 2010. What is Twitter, a social network or a news media? Paper presented at the 19th International Conference on World Wide Web, Raleigh, NC, USA, April 26–30; pp. 591–600. [Google Scholar]
- Leech, Geoffrey. 2014. The state of the art in corpus linguistics. English Corpus Linguistics, 8–29. [Google Scholar]
- Marketing4Ecommerce. n.d. Available online: https://marketing4ecommerce.net/en/social-media-in-brazil-this-is-how-social-media-works-in-the-largest-country-in-south-america (accessed on 22 July 2023).
- Martín-Gutiérrez, Samuel, Juan Carlos Losada, and Rosa M. Benito. 2018. Recurrent patterns of user behavior in different electoral campaigns: A twitter analysis of the Spanish general elections of 2015 and 2016. Complexity 2018: 2413481. [Google Scholar] [CrossRef]
- Morales, Alfredo Jose, Javier Borondo, Juan Carlos Losada, and Rosa M. Benito. 2015. Measuring political polarization: Twitter shows the two sides of Venezuela. Chaos: An Interdisciplinary Journal of Nonlinear Science 25: 033114. [Google Scholar] [CrossRef]
- Morales, A. J., J. C. Losada, and R. M. Benito. 2012. Users structure and behavior on an online social network during a political protest. Physica A: Statistical Mechanics and Its Applications 391: 5244–53. [Google Scholar] [CrossRef]
- Murphy, Kevin P. 2006. Naive Bayes classifiers. University of British Columbia 18: 1–8. [Google Scholar]
- Olimpio da Silva, Rogerio. 2017. Estudo da propagação de postagens de notícias no Twitter. Master dissertation, Univer-sidade de São Paulo, São Paulo, Brazil. [Google Scholar]
- Olivares, Gastón, Juan Pablo Cárdenas, Juan Carlos Losada, and Javier Borondo. 2019. Opinion polarization during a dichotomous electoral process. Complexity 2019: 5854037. [Google Scholar] [CrossRef]
- Perakakis, Emmanouil, George Mastorakis, and Ioannis Kopanakis. 2019. Social media monitoring: An innovative intelligent ap-proach. Designs 3: 24. [Google Scholar] [CrossRef]
- Purcell, Kristen, Lee Rainie, Amy Mitchell, Tom Rosenstiel, and Kenny Olmstead. 2010. Understanding the participatory news consumer. Pew Internet and American Life Project 1: 19–21. [Google Scholar]
- Recuero, Raquel, Felipe Bonow Soares, and Anatoliy Gruzd. 2020. Hyperpartisanship, disinformation and political conversations on Twitter: The Brazilian presidential election of 2018. Paper presented at the International AAAI Conference on Web and Social Media, Atlanta, GA, USA, June 8–11; vol. 14, pp. 569–78. [Google Scholar] [CrossRef]
- Rish, Irina. 2001. An empirical study of the naive Bayes classifier. Paper presented at IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, August 4–10; vol. 3, pp. 41–46. [Google Scholar]
- Roberts, Kirk, Michael A. Roach, Joseph Johnson, Josh Guthrie, and Sanda M. Harabagiu. 2012. Empatweet: Annotating and detecting emotions on Twitter. Paper presented at Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, May 23–25; pp. 3806–13. [Google Scholar]
- Ruby, J. 2013. Mineração de Sentimentos Aplicada em Textos em Português do Brasil. dissertation, Universidade do Contestado, Mafra, Brazil. Available online: https://drive.google.com/file/d/1SGjh9opctV0JXuwJuFolaBiM_j4GBUf9 (accessed on 22 July 2023).
- Saxena, Akrati, Harita Reddy, and Pratishtha Saxena. 2022. Recent developments in sentiment analysis on social networks: Techniques, datasets, and open issues. Principles of Social Networking: The New Horizon and Emerging Challenges, 279–306. [Google Scholar]
- Search Engine Journal. n.d. Available online: https://www.searchenginejournal.com/social-media-statistics/480507 (accessed on 22 July 2023).
- Sinclair, John. 2005. Corpus and Text-Basic Principles. In Developing Linguistic Corpora: A Guide to Good Practice. Edited by Martin Wynne. Oxford: Oxbow Books, pp. 1–16. [Google Scholar]
- Soares, Felipe Bonow, Raquel Recuero, and Gabriela Zago. 2019. Asymmetric polarization on Twitter and the 2018 Brazilian presidential elections. Paper presented at the 10th International Conference on Social Media and Society, Toronto, ON, Canada, July 19–21; pp. 67–76. [Google Scholar]
- Souza, Frederico Dias, and João Baptista de Oliveira e Souza. 2021. Sentiment analysis on Brazilian Portuguese user reviews. Paper presented at the 2021 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Temuco, Chile, November 2–4; pp. 1–6. [Google Scholar]
- Sufi, Fahim K., and Ibrahim Khalil. 2022. Automated Disaster Monitoring from Social Media Posts Using AI-Based Location Intelligence and Sentiment Analysis. IEEE Transactions on Computational Social Systems, 1–11. [Google Scholar] [CrossRef]
- Udemy. n.d. Available online: https://www.udemy.com/course/mineracao-de-emocao-em-textos-com-python-e-nltk (accessed on 22 July 2023).
- Yadamsuren, Borchuluun, and Sanda Erdelez. 2011. Online news reading behavior: From habitual reading to stumbling upon news. Proceedings of the American Society for Information Science and Technology 48: 1–10. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions, and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions, or products referred to in the content. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Olimpio da Silva, R.; Losada, J.C.; Borondo, J. Analyzing the Emotions That News Agencies Express towards Candidates during Electoral Campaigns: 2018 Brazilian Presidential Election as a Case of Study. Soc. Sci. 2023, 12, 458. https://doi.org/10.3390/socsci12080458
Olimpio da Silva R, Losada JC, Borondo J. Analyzing the Emotions That News Agencies Express towards Candidates during Electoral Campaigns: 2018 Brazilian Presidential Election as a Case of Study. Social Sciences. 2023; 12(8):458. https://doi.org/10.3390/socsci12080458
Chicago/Turabian StyleOlimpio da Silva, Rogerio, Juan Carlos Losada, and Javier Borondo. 2023. "Analyzing the Emotions That News Agencies Express towards Candidates during Electoral Campaigns: 2018 Brazilian Presidential Election as a Case of Study" Social Sciences 12, no. 8: 458. https://doi.org/10.3390/socsci12080458
APA StyleOlimpio da Silva, R., Losada, J. C., & Borondo, J. (2023). Analyzing the Emotions That News Agencies Express towards Candidates during Electoral Campaigns: 2018 Brazilian Presidential Election as a Case of Study. Social Sciences, 12(8), 458. https://doi.org/10.3390/socsci12080458