1. Introduction
Maintaining a safe working environment at construction sites is a major challenge for construction practitioners worldwide. Despite ongoing efforts by health and safety organizations, construction continues to exhibit high fatality rates, with 9.6 deaths per 100,000 full-time workers—2.5 times higher than the average across all industries [
1,
2,
3]. A significant portion of these fatalities results from falls from height (FFH), accounting for 34% of fall-related deaths [
4,
5,
6]. However, more than 350 deaths have been caused by falls from low heights [
7]. Among the contributing factors, mobile scaffolding poses particular risks due to its delicate structure and frequent misuse [
8]. In South Korea, 488 scaffolding-related deaths occurred from 2017–2021, including 45 directly involving mobile scaffolds [
9,
10]. These incidents are commonly attributed to improper safety measures, insufficient equipment, and non-compliance with protocols [
11]. Manual safety monitoring is labor-intensive and prone to error, necessitating the integration of automated systems for real-time oversight.
Traditional safety practices—such as toolbox talks, visual inspections, and PPE enforcement—are foundational, but limited by their subjective, time-consuming nature and inconsistency. Manual methods struggle to detect and respond promptly to dynamic site hazards. The rise of computer vision (CV) and deep learning offers promising alternatives for automated hazard detection, object recognition, and behavior analysis. Techniques such as CNNs, object detection, and instance segmentation are increasingly being applied in safety monitoring tasks [
12,
13]. Several studies have focused on detecting violations related to PPE, ladders, and worker positions [
14,
15,
16], but rarely do they address mobile scaffolds or employ depth-sensing data. For example, existing systems detect workers and objects using bounding box collisions without a contextual awareness of the depth, leading to false positives when workers are merely near but not on the scaffold [
17]. Moreover, most models operate on single-frame analysis and lack mechanisms to reassess or validate initial detections, resulting in misidentifications.
To address the critical gaps identified in current safety monitoring systems for mobile scaffolding, this study aims to develop a computer vision (CV)-based safety monitoring system with the following specific research objectives: (1) To develop an advanced detection system utilizing depth information to accurately assess the spatial context of workers in relation to the scaffold to reduce inaccurate detections. (2) To implement a status trigger module to minimize the false alarms. This dual-layer approach enables proactive safety management by monitoring a broad range of behaviors in real time. The proposed framework extends beyond specific safety checks to analyze a broad range of worker behaviors against established construction safety standards. This approach identifies unsafe conditions and informs risky behaviors before accidents occur, providing proactive safety management. Furthermore, this study contributes to the development of customized algorithms and specialized training datasets tailored to address the unique hazards associated with mobile scaffolding.
2. Related Work
Mobile scaffolding is extensively used at construction sites due to its portability and mobility. However, its complex design makes it one of the top three accident-prone elements in these environments. Despite its widespread use, research specifically addressing the safety of mobile scaffolding is limited. Several studies have explored methods for monitoring fixed scaffolding. For instance, Xu et al. proposed a three-dimensional (3D) local feature descriptor for detecting scaffolds in point clouds [
18], and Cho et al. leveraged image and building information management (BIM) data for automatic progress monitoring [
19]. Jung et al. [
20] investigated failure detection by applying image processing to small-scale scaffolds and identifying temporary structure changes. However, the literature on compliance monitoring and detecting the unsafe use of mobile scaffolds is scarce, highlighting the need for further exploration in this crucial area.
Despite these advancements, significant gaps persist in current research, particularly regarding the integration of depth information and comprehensive safety rule checking. For instance, studies such as fall protection for lone workers focus on ladders using SSD [
9] and mitigating falls by tracking objects using Mask R-CNN [
14], but both lack depth information, limiting their accuracy and scope. Similarly, the detection of the non-usage of hardhats [
21] and safety harnesses [
22] employ Faster R-CNN, targeting persons and harnesses without incorporating depth data, which can lead to misclassifications in complex environments. Additionally, while motion capturing data for unsafe actions utilizes depth information with CNN + LSTM, it is restricted to ladders, failing to address other critical construction elements. Action classification based on video segments with Bayesian networks also falls short by not using depth information, which could enhance the precision of recognizing unsafe behaviors [
16], as summarized in
Table 1.
The development of an artificial intelligence (AI)-driven system to enhance the monitoring of mobile scaffolding and enforce compliance with construction safety rules arises from critical needs and gaps in the safety practices followed in the construction industry. Khan et al. highlighted this issue and proposed an approach to the real-time automatic monitoring of workers for identifying mobile scaffolds based on their physical properties [
17]. For example, they demonstrated the potential of detecting the presence of outriggers along with personnel to effectively enforce safety rules. However, they covered only the basic safety conditions of mobile scaffolds, which are inadequate for ensuring overall safety during work. Moreover, they utilized Mask R-CNN, a two-stage detection process, for instance segmentation. This may lead to delays in real-time detection, posing a challenge for deployment at construction sites. Additionally, they employed a small dataset containing only 938 images, thereby raising concerns about the robustness of the object detection model in real-time monitoring. One of the key challenges in deploying such an object detection model at construction sites is minimizing misdetection and false positives to ensure the accurate identification of unsafe worker behaviors.
Our study bridges these gaps by integrating depth information with the YOLO model, specifically targeting mobile scaffolding and its components, such as guardrails and outriggers. This integration enables the precise detection of falls from height and other unsafe conditions, providing a more comprehensive and accurate safety monitoring solution. Additionally, our approach includes a status trigger module that evaluates behavior over a time window, significantly reducing false positives and missed detections. By leveraging advanced depth sensing technology and introducing the status trigger module, our approach ensures a step towards a reliable safety rule compliance and dynamic, real-time assessment of worker behavior in complex construction environments.
3. Methodology
This study adopts a deep learning-based computer vision (CV) framework to automatically detect unsafe worker behaviors associated with mobile scaffolding at construction sites. The methodology begins with dataset generation, followed by training a YOLO-based object detection model and applying rule-based classification aligned with OSHA regulations. Performance is evaluated using mean average precision (mAP), F1 score, confusion matrix, and ROC curve. The following subsections detail the dataset preparation, model training, and post-processing approach for regulatory compliance.
3.1. Analysis of OSHA and KOSHA Regulations for Mobile Scaffolding
In recent years, the number of accidents at construction sites caused by mobile scaffolding has risen to a concerning level [
24]. In response, both OSHA and KOSHA have implemented strict regulations to prevent such accidents. The KOSHA regulations comprise 13 chapters that address various sectors. These regulations focus significantly on the construction industry, covering approximately 277 related sectors. The summary of OSHA and KOSHA rules related to mobile scaffolding is shown in
Table 2.
According to Article 68 (1) and Article 68 (3) of KOSHA, scaffolding must be equipped with outriggers for stability and guardrails to ensure fall prevention must not be missing. Additionally, Article 68 (5) specifically addresses the weight limitations of mobile scaffolding, setting a maximum weight threshold of 240 kg. Moreover, the regulations stipulate that no more than two workers should be present at a time on a mobile scaffolding. Furthermore, as a general safety rule at construction sites, workers must wear helmets for personal protection. Therefore, workers should wear helmets while working on mobile scaffolding. This study evaluates safety behaviors by analyzing conditions related to mobile scaffolding use. Five typical scenarios are considered, involving helmet usage (workers with or without a helmet, denoted as
or
′), the presence or absence of guardrails and outriggers (
,
, or
), and the number of workers. Mobile scaffolding with a missing guardrail is represented as
, with an outrigger as
, and without an outrigger as
. Unsafe behavior is denoted as
. Based on these conditions, each scenario is classified as either safe or unsafe, as summarized in
Table 3.
3.2. Dataset Generation
To train the detection model, a comprehensive dataset of mobile scaffolds and construction workers was constructed using a combination of web scraping, real-world image capture, and video extraction. Videos recorded at the Construction Technology Innovation Laboratory (ConTI Lab) of Chung-Ang University, Seoul, South Korea, and a publicly available dataset from a previous study [
17] were also incorporated to enhance diversity.
Frames were extracted from the collected videos using Adobe Premiere Pro 2023 [
25] at a rate of 1 frame per second. In total, over 10,000 images were initially gathered, comprising web-scraped images, site captures, and frames from videos. To further increase diversity, additional images were captured in a controlled environment at ConTI Lab. Data preprocessing included duplicate removal using a similarity threshold of 60% [
26], resulting in a final dataset of 4868 unique images. The images were subsequently annotated using Roboflow [
27] and categorized into six classes: (1) missing guardrails (1860 instances), (2) mobile scaffolding without outriggers (1878 instances), (3) mobile scaffolding with outriggers (2234 instances), (4) workers with helmet (3333 instances), (5) workers without helmet (2829 instances), and (6) z-Tag (755 instances).
To ensure effective model training, the dataset was distributed into three subsets. Approximately 80% of the images were used to train the model, while 10% were used for validation. The remaining 10% was used to test the performance of the trained model. This distribution helped assess the model’s accuracy and generalizability on unseen data in the validation and testing stages. Data augmentation is a powerful method in deep learning that helps minimize the gap between the training and validation sets. By expanding the dataset with diverse variations, data augmentation creates a more comprehensive set of possible data points. This reduces the risk of overfitting and improves the model’s generalizability on unseen examples [
28]. The abovementioned dataset was processed using the horizontal flipping, random hue adjustment (−25 to +25), random saturation adjustment (−25 to +25), random brightness adjustment (−25 to +25), and random exposure adjustment (−25 to +25) features of Roboflow [
27]. These data augmentations expanded the dataset in terms of variations in object orientations, color tones, saturation levels, brightness levels, and exposure levels. This augmented dataset improved the model’s robustness, allowing it to handle different lighting conditions, and its generalizability to unseen examples. For evaluating classification performance, some random images from the test set were manually categorized into two classes: Safe (104 images) and Unsafe (158 images).
3.3. Object Detection Model
Object detection algorithms are broadly categorized into two types: two-stage and one-stage detectors. Two-stage methods, such as Region-based CNN (R-CNN) [
29], Fast R-CNN [
4], Faster R-CNN [
30], and Mask R-CNN [
31], first generate region proposals and then classify them. In contrast, one-stage methods, including the You Only Look Once (YOLO) series [
32] and Single-Shot MultiBox Detector (SSD) [
33], perform classification and localization simultaneously in a single pass through a convolutional neural network, eliminating the need for proposal generation.
One-stage detectors prioritize inference speed, making them suitable for real-time applications, although often at the cost of slightly reduced accuracy compared to two-stage approaches. Among one-stage detectors, the YOLO series has gained significant popularity due to its lightweight architecture, effective feature-fusion mechanisms, and strong detection performance. Notably, YOLOv5 and YOLOv7 have been widely adopted for their real-time capabilities and efficiency. However, YOLOv5 may face challenges in detecting small or densely packed objects, while YOLOv7’s performance can degrade under suboptimal training conditions or model configurations [
34,
35]. Subsequent advancements led to the development of YOLOv8 in 2023 [
36], which integrated improvements from earlier versions and achieved approximately 1% higher detection accuracy compared to YOLOv5.
More recently, YOLOv12 [
37] has been introduced by Ultralytics, offering further enhancements in both accuracy and robustness. YOLOv12 incorporates advanced feature extraction modules, improved anchor-free designs, and optimized backbone networks, enabling superior performance particularly in challenging detection scenarios such as construction sites [
37]. Its efficient single-pass architecture has consistently demonstrated its effectiveness in detecting objects under challenging conditions, including variations in illumination and occlusions. Given the requirements of this study, YOLOv12 was selected as the object detection model [
37]. Its efficient single-pass architecture, real-time processing capabilities, and robustness to variations in illumination, occlusions, and object scales make it an ideal choice for detecting workers and mobile scaffoldings at construction sites. Compared to earlier versions, YOLOv12 demonstrated improved accuracy and reliability, validating its effectiveness for the application scenarios considered in this research.
3.4. Post-Processing/OSHA Rules Compliance in 2D-Plane
The YOLOv12 model was trained to detect six construction safety-related classes. For helmet detection, the object detection model analyzes spatial and structural features in the head region of identified human figures. It distinguishes between “worker with helmet” and “worker without helmet” as separate classes by recognizing the presence or absence of helmet-like contours and textures. If these features are missing, the model classifies the instance as a “worker without helmet”, indicating a potential safety violation. Regarding guardrail detection, the model identifies geometric structures and contextual positioning characteristic of guardrails, particularly along the upper edges of mobile scaffolding. The training dataset includes two scaffold-related classes—mobile scaffold with outriggers and without outriggers—both of which are expected to include guardrails. Additionally, a separate class labeled “missing guardrails” was annotated for scaffolding lacking these safety components. This labeling strategy enables the model to distinguish compliant from non-compliant configurations, facilitating the accurate detection of guardrail absence as a critical hazard.
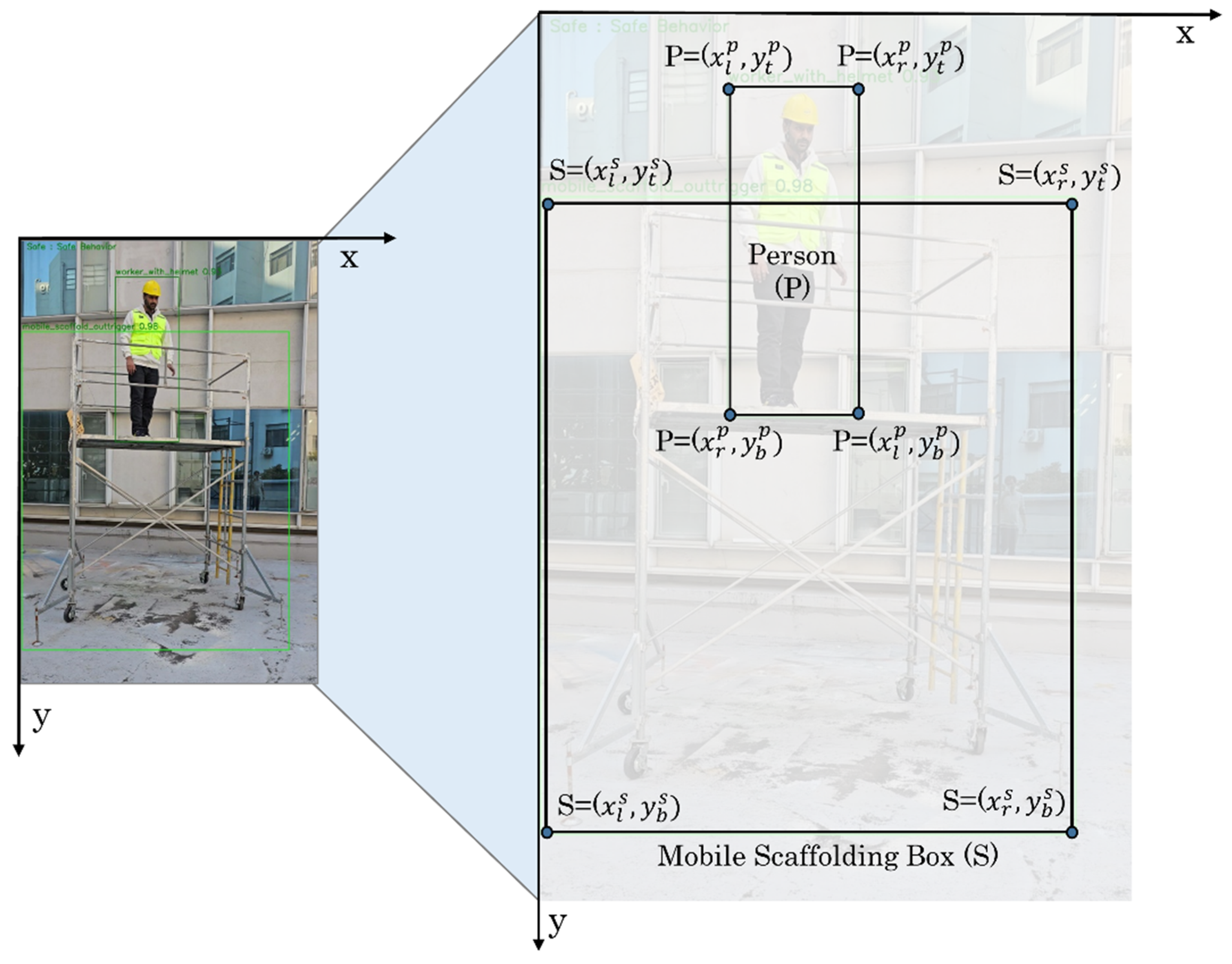
After object detection, post-processing is necessary to determine worker behaviors on mobile scaffoldings. Object detection provides the bounding box coordinates of the detected objects, but these coordinates are insufficient to assess whether a person is on mobile scaffolding or to determine the number of people on mobile scaffolding at any given time. To identify worker behavior on mobile scaffolding, a specific process must be followed to check the position of workers on the mobile scaffolding.
Figure 1 presents the relative position of the person and the mobile scaffolding with a bounding box, while
Figure 2 shows the possible cases of working scenarios.
If the detected object belongs to the “Mobile Scaffolding with Missing Guardrails” () subclass and there is a person () on the scaffolding, the behavior is considered unsafe. Similarly, if the mobile scaffolding belongs to the “Mobile Scaffolding without Outrigger” subclass and there is a person () on the scaffolding, the behavior is deemed unsafe. To determine whether a person is on a mobile scaffolding, we must examine the relationship between the bounding boxes of the mobile scaffolding and the person.
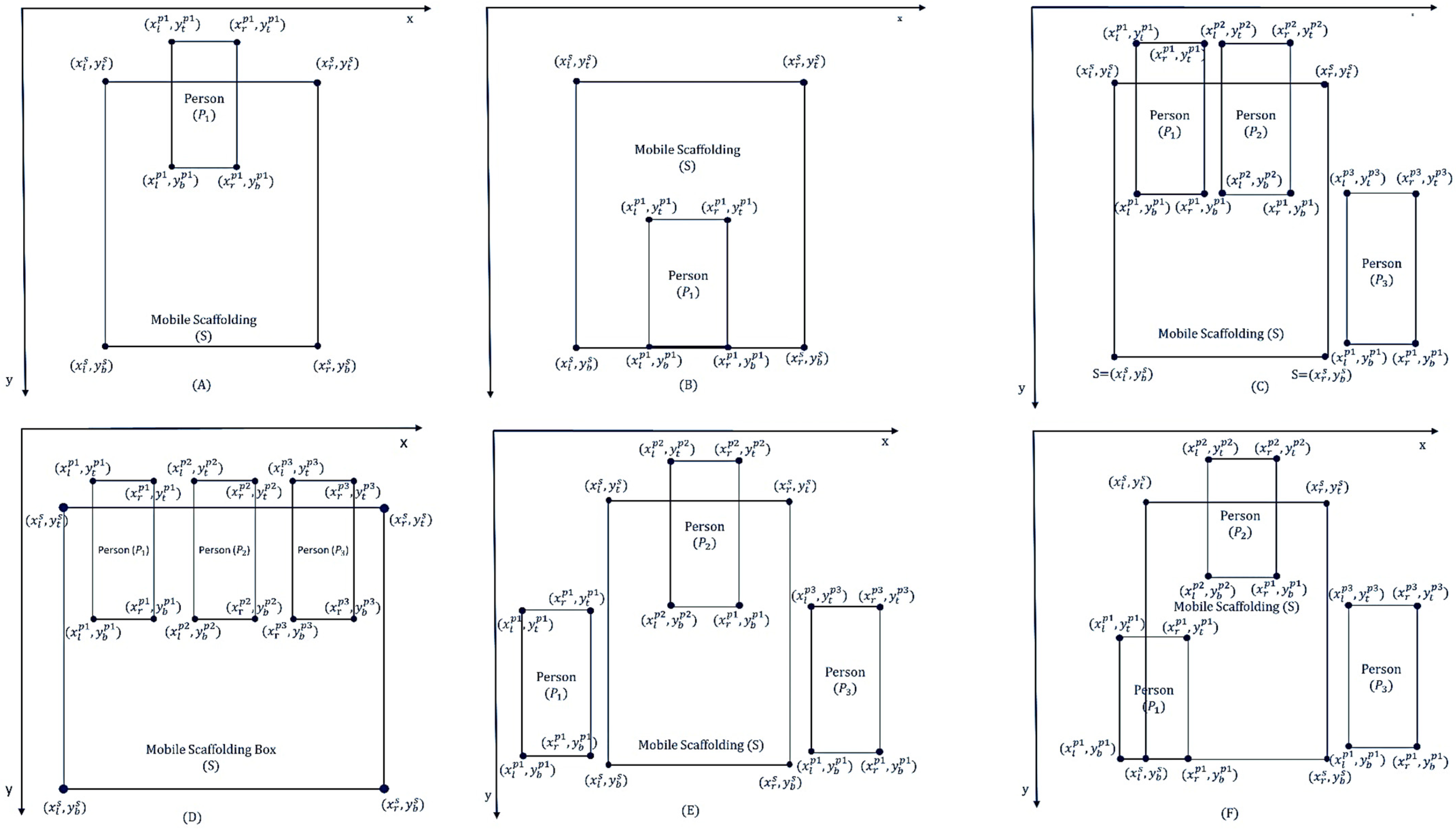
Figure 2 illustrates six different cases to discuss the relationship between the bounding box and mobile scaffolding. The x and y vertices originate from the top-left corner. The values of the x and y coordinates increase from top to bottom and left to right, respectively.
If left coordinate of a person
is greater than that of mobile scaffolding
, right coordinate of the person
is smaller than that of the mobile scaffolding
, and vertical center of the person
is less than that of the mobile scaffolding
, the following condition is satisfied:
If the left coordinate of a person
is greater than that of mobile scaffolding
, right coordinate of the person
is smaller than that of the mobile scaffolding
, and vertical center of the person
is higher than that of the mobile scaffolding
, the following condition is satisfied:
The left coordinate of the first person is greater than that of the mobile scaffolding right coordinate of the first person is smaller than that of the mobile scaffolding , and y value of the person’s centroid is greater than that of the mobile scaffolding’s centroid .
The left coordinate of the second person is smaller than that of the mobile scaffolding , right coordinate of the second person is smaller than that of the mobile scaffolding , and vertical center of the person is higher than that of the mobile scaffolding .
The left coordinate of the third person
is greater than that of the mobile scaffolding
, right coordinate of the third person
is greater than that of the mobile scaffolding
, and vertical center of the third person
is higher than that of the mobile scaffolding
Then, the conditions for case C are satisfied.
The left coordinate of a person is greater than that of the mobile scaffolding , right coordinate of the person is smaller than that of the mobile scaffolding , and vertical center of the person is higher than that of the mobile scaffolding .
The left coordinate of the person is smaller than that of the mobile scaffolding , right coordinate of the person is smaller than that of the mobile scaffolding , and vertical center of the person is higher than that of the mobile scaffolding .
The left coordinate of the person
is greater than that of the mobile scaffolding
, right coordinate of the person
is greater than that of the mobile scaffolding
, and vertical center of the person
is greater than that of the mobile scaffolding
. Then, the following conditions for Case D are satisfied.
The left coordinate of a person is greater than that of the mobile scaffolding and the right coordinate of the person is smaller than that of the mobile scaffolding .
The left coordinate of the person is smaller than that of the mobile scaffolding , right coordinate of the person is smaller than that of the mobile scaffolding , and vertical center of the person is higher than that of the mobile scaffolding .
The left coordinate of the person
is greater than that of the mobile scaffolding
and the right coordinate of the person
is greater than that of the mobile scaffolding
. Then, the following conditions for Case E are satisfied.
The horizontal center of a person () is higher than the left coordinate of the mobile scaffolding and it is smaller than the right coordinate of the mobile scaffolding .
The left coordinate of the person is smaller than that of the mobile scaffolding right coordinate of the person is smaller than that of the mobile scaffolding , and vertical center of the person is higher than that of the mobile scaffolding .
The left coordinate of the person
is greater than that of the mobile scaffolding
and the right coordinate of the person
is greater than the right coordinate of the mobile scaffolding
Then, the following conditions for Case F are satisfied.
3.5. Post-Processing to Check Worker Position in 3D-Plane
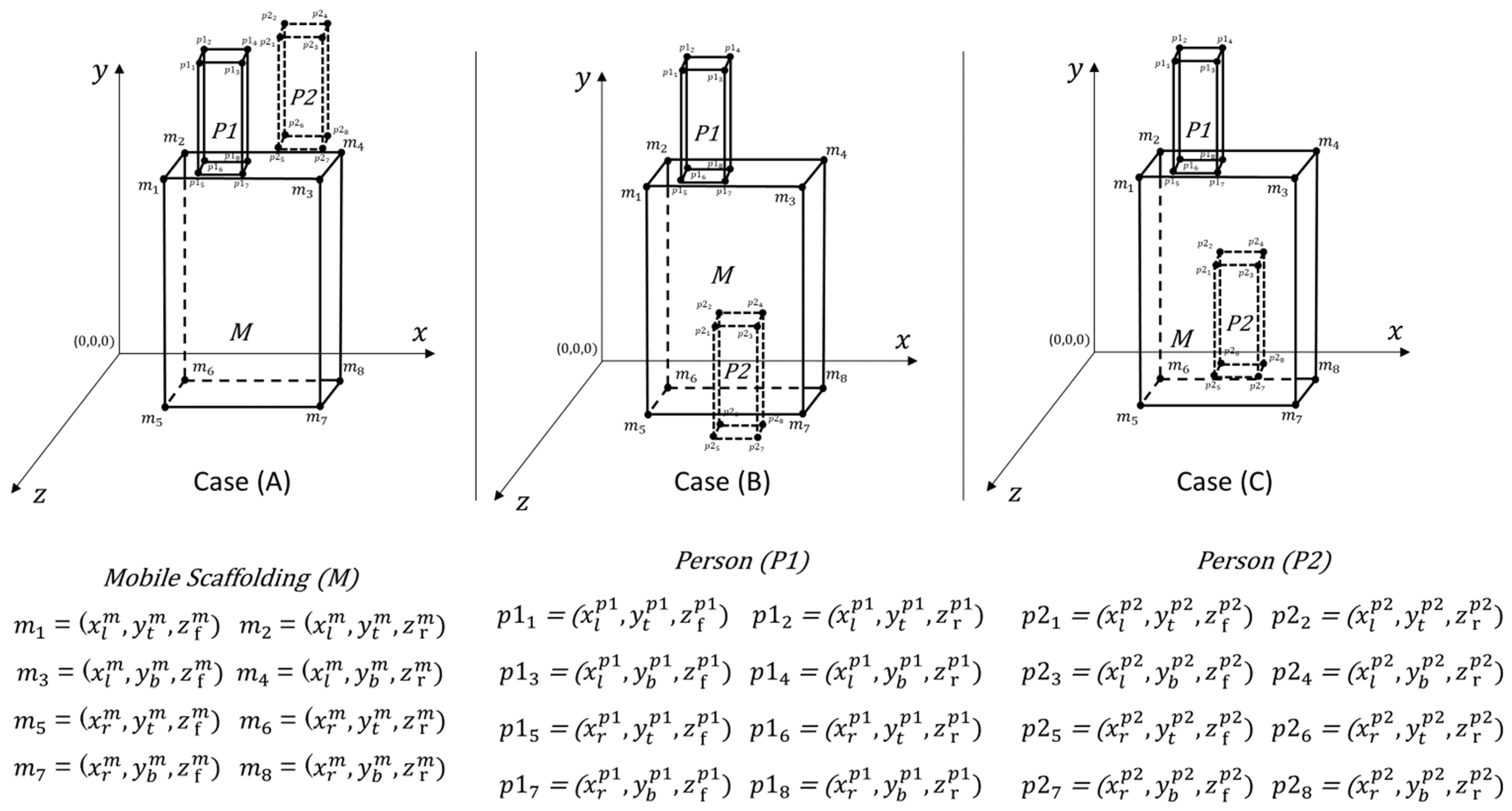
To check the worker’s accurate position, the depth information is considered to make a 3D-plane.
Figure 3 illustrates the various positions of individuals on mobile scaffolding in three different scenarios, depicted in a three-dimensional space (
). In each scenario, M represents the mobile scaffolding, while
and
denote Person 1 and Person 2, respectively.
Person
is on the mobile scaffold
while person
is standing behind the mobile scaffold at the same height level. The left coordinates of both persons
and
are greater than that of the mobile scaffold
. The right coordinates of the persons,
and
are smaller than that of the mobile scaffold
Additionally, the vertical center of the persons,
and
, is less than that of the mobile scaffold,
. To check the
position, the rear position of the mobile scaffold
is less than the front position of person
and the front position of the mobile scaffold
is greater than the rear position of the first person
. Since person
is behind the mobile scaffolding, the rear position of the mobile scaffold
is greater than the front position of the second person
The following condition is satisfied:
Person
is on the mobile scaffold
while person
is standing in front the mobile scaffold on the ground level. Like Case A, the left coordinates of both persons
and
are greater than that of the mobile scaffold
. The right coordinates of the persons,
and
, are smaller than that of the mobile scaffold
. Additionally, the vertical center of the persons,
, is less than that of the mobile scaffold,
, but
is greater than that of the mobile scaffold,
. This means that worker is on ground level. The rear position of the mobile scaffold
is less than the front position of person
, and the front position of the mobile scaffold
is greater than the rear position of person
. Person
is in front of the mobile scaffolding and the front position of the mobile scaffold
is less than the rear position of person
. The following condition is satisfied:
Person is on the mobile scaffold M while person is standing in behind the mobile scaffold on the ground level. As in Case A and Case B, the left coordinates of both persons and are greater than that of the mobile scaffold . The right coordinates of the persons, and , are smaller than that of the mobile scaffold . However, the vertical center of the persons, , is less than that of the mobile scaffold , but is greater than that of the mobile scaffold . This indicates that person is on ground level.
The rear position of the mobile scaffold
is less than the front position of person
and the front position of the mobile scaffold
is greater than the rear position of person
. Person
is in behind the mobile scaffolding and the front position of the mobile scaffold
is greater than the rear position of person
. The following condition is satisfied:
3.6. Algorithms for Rule Compliance and Status Trigger Module
In the behavior analysis phase, the system takes a proactive approach to minimize detection errors and accurately identify unsafe worker behaviors on mobile scaffoldings. For instance, when the system detects a worker without a helmet on a mobile scaffold, it initiates a monitoring process for 3 s. During this time, the system continuously observes the worker’s actions. If the worker puts the helmet back on their head within the 3 s window, the system corrects the detection and classifies the behavior as safe, attributing the temporary removal to external factors such as hot weather. Similarly, in cases where multiple workers are detected on mobile scaffolding, the system tracks their presence over a period of 3 s. If the number of workers exceeds two within this observation window, it classifies the situation as genuinely unsafe as opposed to a transient occurrence.
This extended monitoring period prevents false positives and enhances the accuracy of identifying potential hazards related to the number of workers on a mobile scaffold. The flowchart in
Figure 4 illustrates safe and unsafe behaviors, concluding in the initiation of the final status. The proposed method comprises two distinct stages: the initial stage involves the classification of safe and unsafe behaviors, and the subsequent stage entails monitoring status for 3 s and assigning the final status.
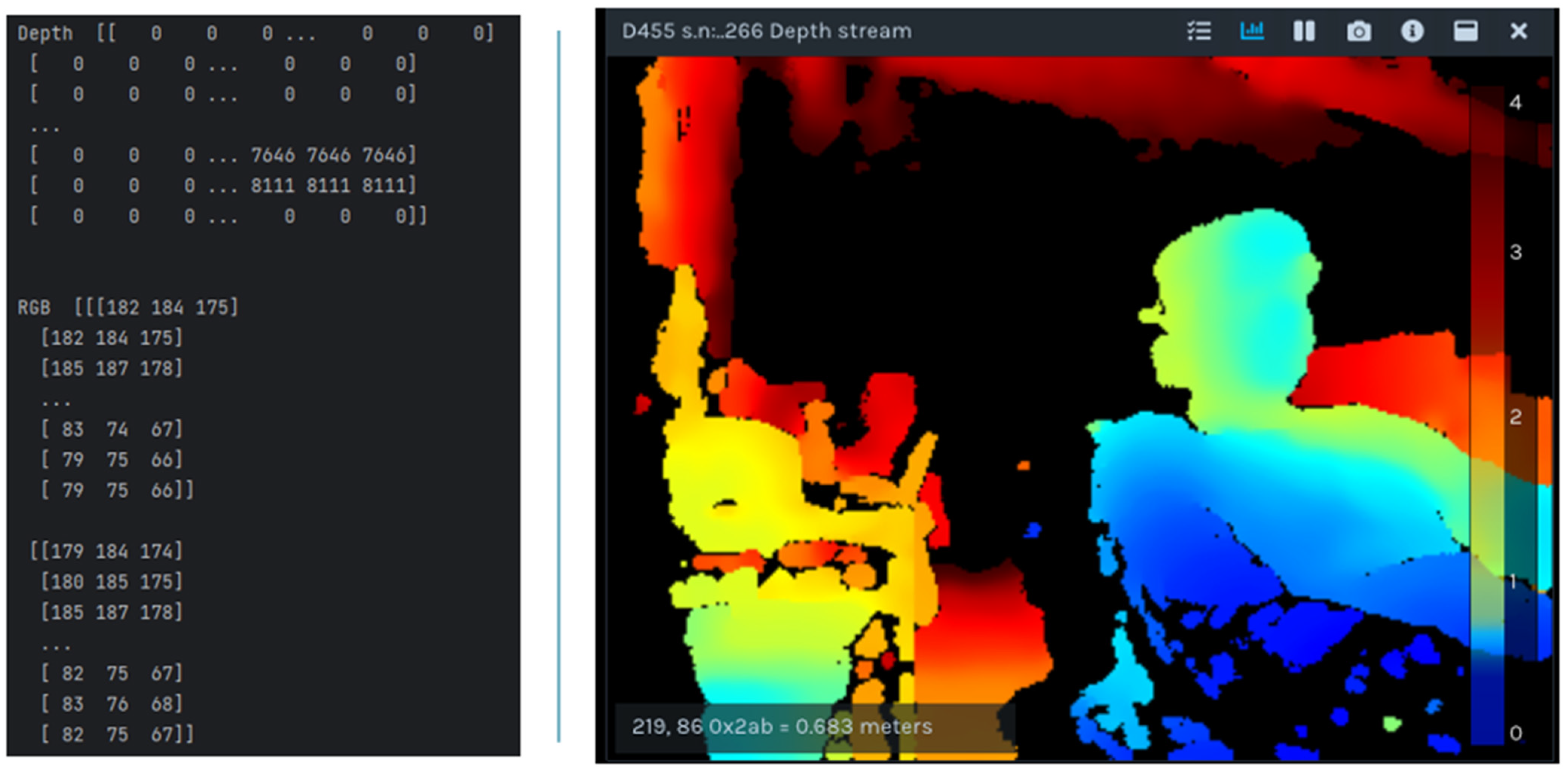
Appendix A shows the algorithms of both stages. Algorithm A1 describes the algorithm of detecting unsafe behaviors by using an image and the YOLO model. To incorporate third dimension, real sense camera is used that captures two images: an RGB image and a depth image. Both images are represented as two-dimensional arrays of the same size. To integrate depth information into the RGB image, the depth value from the corresponding index in the depth image is used, as shown in
Figure 5. It initializes a list, infers the image using the model, checks for safe or unsafe behavior, and returns the result to Algorithm A2.
Algorithm A2 monitors the status received from Algorithm A1, checks for consistency over 3 s, and triggers the final status if the status remains unchanged for 3 s. By using this behavioral analysis approach, the system can make more informed decisions about worker safety, avoiding misclassifications and providing a comprehensive understanding of worker behavior on mobile scaffolding. This sophisticated analysis improves the overall effectiveness of the system in terms of monitoring mobile scaffolding and promoting a safer environment.
4. Experiment, Result, and Evaluation
To seamlessly integrate the third dimension and improve the accuracy of the detection system, an experiment was conducted utilizing the object detection algorithm YOLOv12. Through transfer learning, pre-training weights from the COCO dataset were employed and fine-tuned for the custom dataset. The model underwent training over 300 epochs, with an initial learning rate of 0.01, a batch size of 96, and an image size of 640. The training process utilized a computer equipped with an Intel Core i9 10th-generation CPU (3.30 GHz across 28 CPU cores), 128 GB of RAM, and running Ubuntu 22.04.3 LTS. Additionally, three NVIDIA RTX 3090 GPUs were employed during training.
The Intel RealSense Depth Camera D455 (Intel Corporation, Santa Clara, CA, USA), renowned for its exceptional precision, was selected for its high-definition depth-sensing capabilities. Offering a resolution of up to 1280 × 720 pixels and a frame rate of up to 90 frames per second, the D455’s extended range of 6 m is ideal for various applications, including robotics and augmented reality. Leveraging advanced stereo vision technology, the D455 employs a pair of infrared cameras to detect depth disparities, ensuring accurate depth mapping. Despite its ability to measure distances beyond 6 m, the accuracy diminishes with distance. Notably, the D455’s increased baseline of 95 mm enhances the depth accuracy, with a margin of error below 2% at a distance of 4 m. Its components, including an RGB camera, Left Imager, IR projector, and Right Imager, collectively contribute to its robust depth-sensing capabilities. Operating based on stereo vision technology akin to human eyes, the D455 compares disparities between images captured by its two infrared cameras to calculate precise depth maps. This process involves emitting infrared light patterns onto the scene, capturing images with depth disparities, and subsequently triangulating these disparities to calculate accurate distances to objects in the scene.
4.1. Evaluation Metrics
To evaluate the efficiency of the trained model and usefulness of the algorithm, the precision Equation (10), recall Equation (11), F1-score Equation (12), and accuracy (13) were determined. Precision measures the ratio of correctly predicted true positives, while recall or the true positive rate (TPR) indicate the accurate identification of true positives. The false positive rate (FPR) highlights instances in which the model inaccurately classifies the positive class. The average precision serves as a crucial evaluation metric, providing a consolidated numerical representation of the algorithm’s overall utility.
In this context, true positive (), false negative (), false positive (), and true negative () represent specific outcomes in the evaluation this context, and true positive (), false negative (), false positive (), and true negative () represent specific outcomes in the evaluation process.
4.2. Results
Four well-known object detection models, YOLOv5, YOLOv8, YOLOv11, and YOLOv12, were trained on the curated dataset and their performances were evalauted on the validation and testing sets, as shown in
Table 4. YOLOv12 achieved the highest recall and mAP scores, indicating a better overall performance. While YOLOv5 had slightly higher precision, YOLOv12 showed the best balance across all metrics and was, therefore, selected for an evaluation performance of proposed mobile scaffolding safety and unsafe behavior classification.
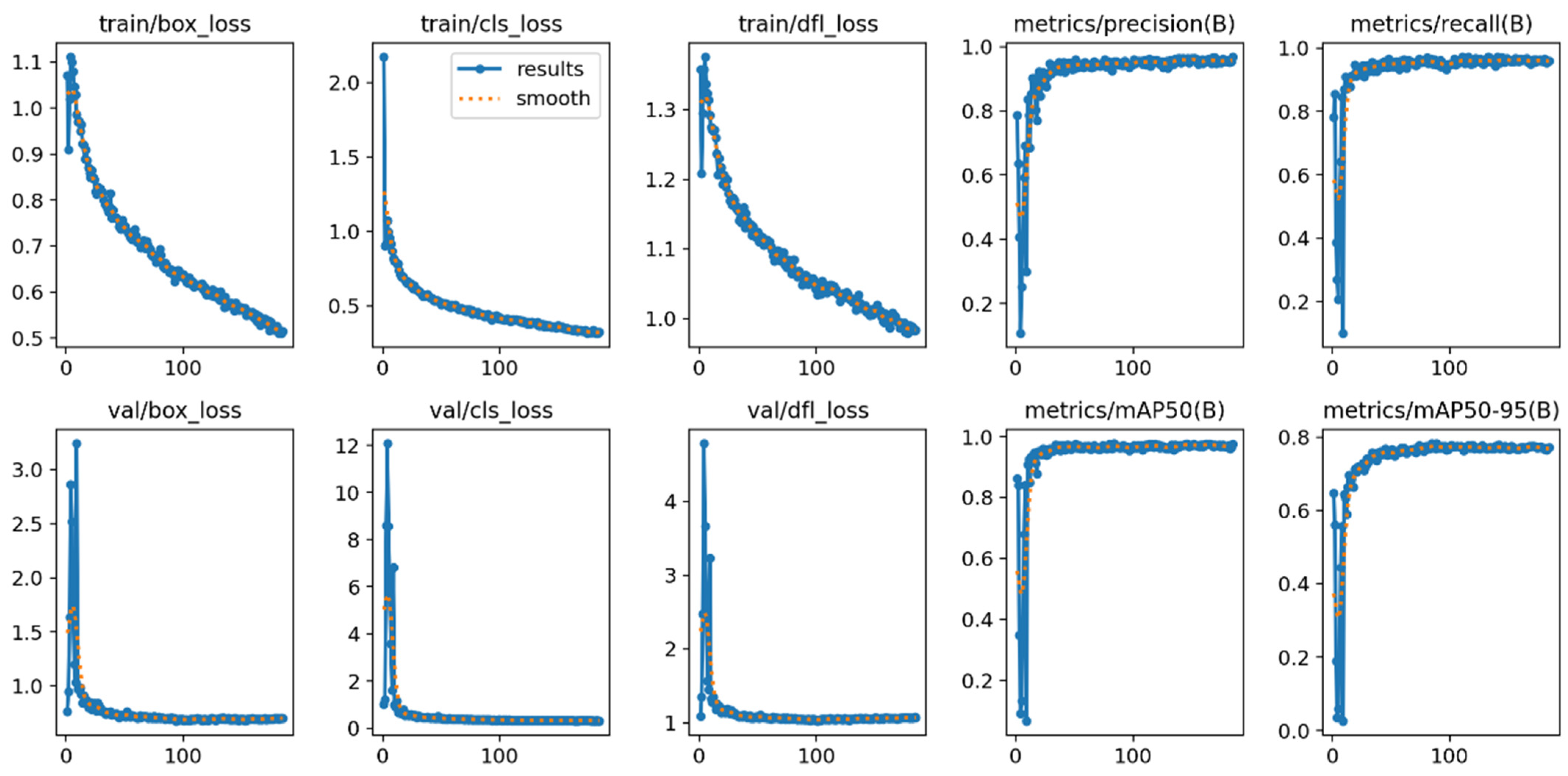
The training results of the object detection YOLOv12 model are shown in
Figure 6, which shows comprehensive results, including loss, precision, and recall. The accuracy values of the trained model for detecting instances of a “Missing Guardrail”, “Mobile Scaffold without outrigger”, “Mobile Scaffolding”, “Worker with helmet”, “Worker without helmet”, and “z-tag” were 99%, 99%, 99%, 96%, 88%, and 99% respectively. The overall mean average precision was 97% at a confidence level of 0.5 on the validation set, as illustrated in
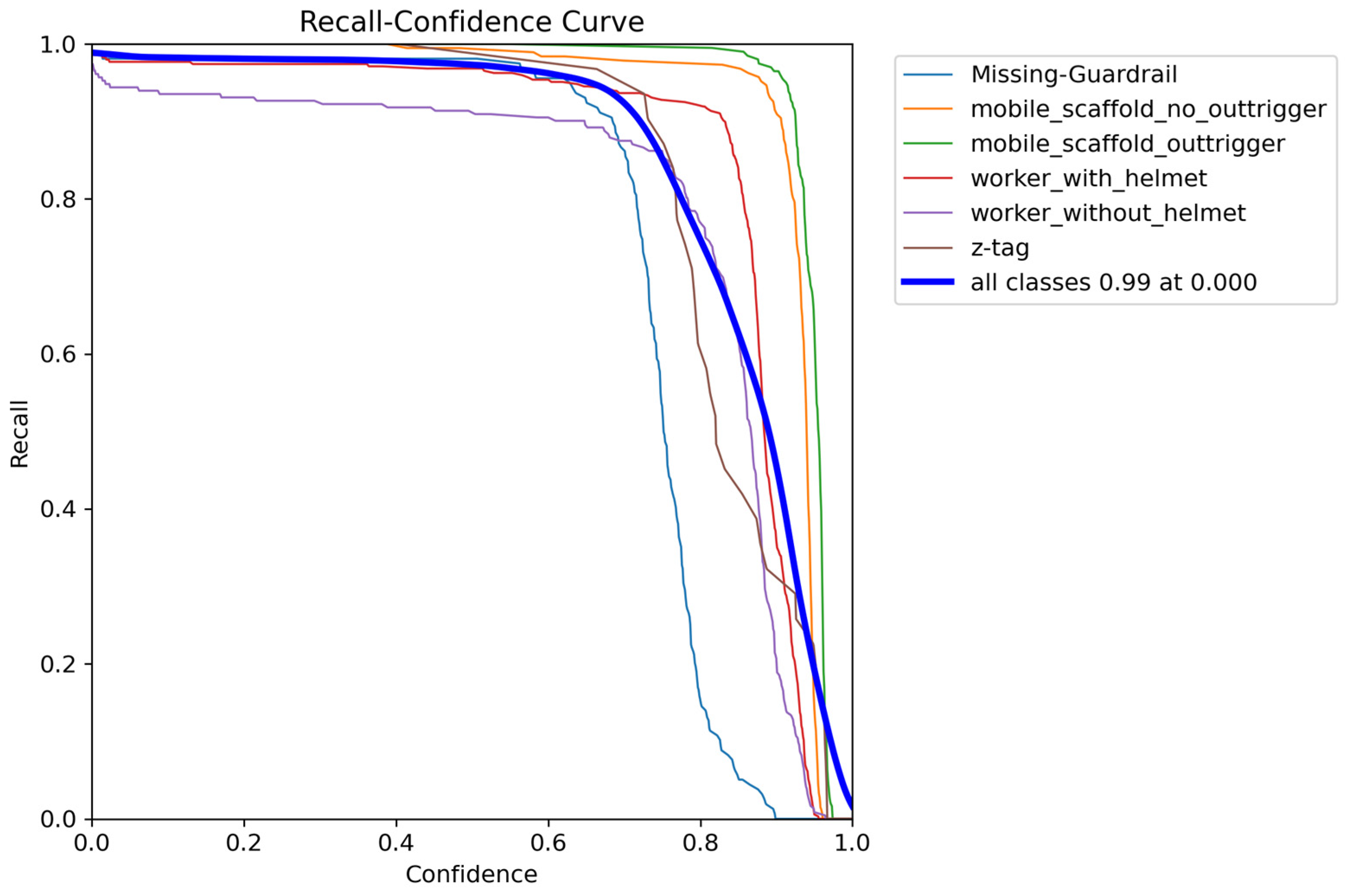
Figure 7. The recall score of the object detection model, along with its confidence scores, is shown in
Figure 8. This information helps to select the confidence score to be used during the classification task.
For mobile scaffolding safety and worker behavior classification, the object detection model based on YOLOv12 was extended by incorporating the safety rules extracted from OSHA and KOSHA. The model was trained to detect four specific conditions: (1) workers with/without a helmet on a mobile scaffold with a missing guardrail, (2) workers without a helmet on a mobile scaffold with an outrigger, (3) workers with/without a helmet on a mobile scaffold with an outrigger, and (4) more than two workers on a single mobile scaffold. By detecting these unsafe conditions, managers can promptly implement corrective actions to prevent potential accidents. The results and findings of this study are discussed in two sections: the first section is the classification of two-dimensional (2D) detection to validate OSHA/KOSHA rules compliance, and then qualitatively validating the result of three-dimensional (3D) detection by comparing the results with 2D detection.
4.2.1. OSHA Rules Validation with Two-Dimensional Detection
Four different scenarios are tested to validate rule compliance. In
Figure 9a, instances of safe behavior are depicted to validate all the scenarios that have been discussed earlier in the thesis. This figure effectively demonstrates that safety protocols were followed within each of these scenarios, emphasizing the correct utilization of safety equipment and adherence to established guidelines.
Figure 9b depicts unsafe behaviors resulting from the absence of a guardrail on a mobile scaffold, in line with the specified condition. This figure highlights the potential hazards resulting from such situations, emphasizing the significance of guardrails in preventing accidents and promoting a safer work environment.
Figure 10a presents an example of unsafe behavior resulting from the presence of more than two workers on a single mobile scaffold, as outlined in the designated condition. The figure illustrates the potential risks associated with overcrowded scaffolding, underscoring the need to enforce guidelines that limit the number of workers per scaffold to ensure their safety.
Figure 10b portrays an instance of unsafe behavior owing to the absence of outriggers on a mobile scaffold, which is consistent with the specified condition. This figure depicts the potential instability and dangers posed by such circumstances, reinforcing the essential role of outriggers in maintaining scaffold stability and averting potential accidents. These figures not only visually enhance our understanding of various scenarios, but also contribute to a deeper comprehension of the importance of adhering to safety protocols and guidelines in the construction environment.
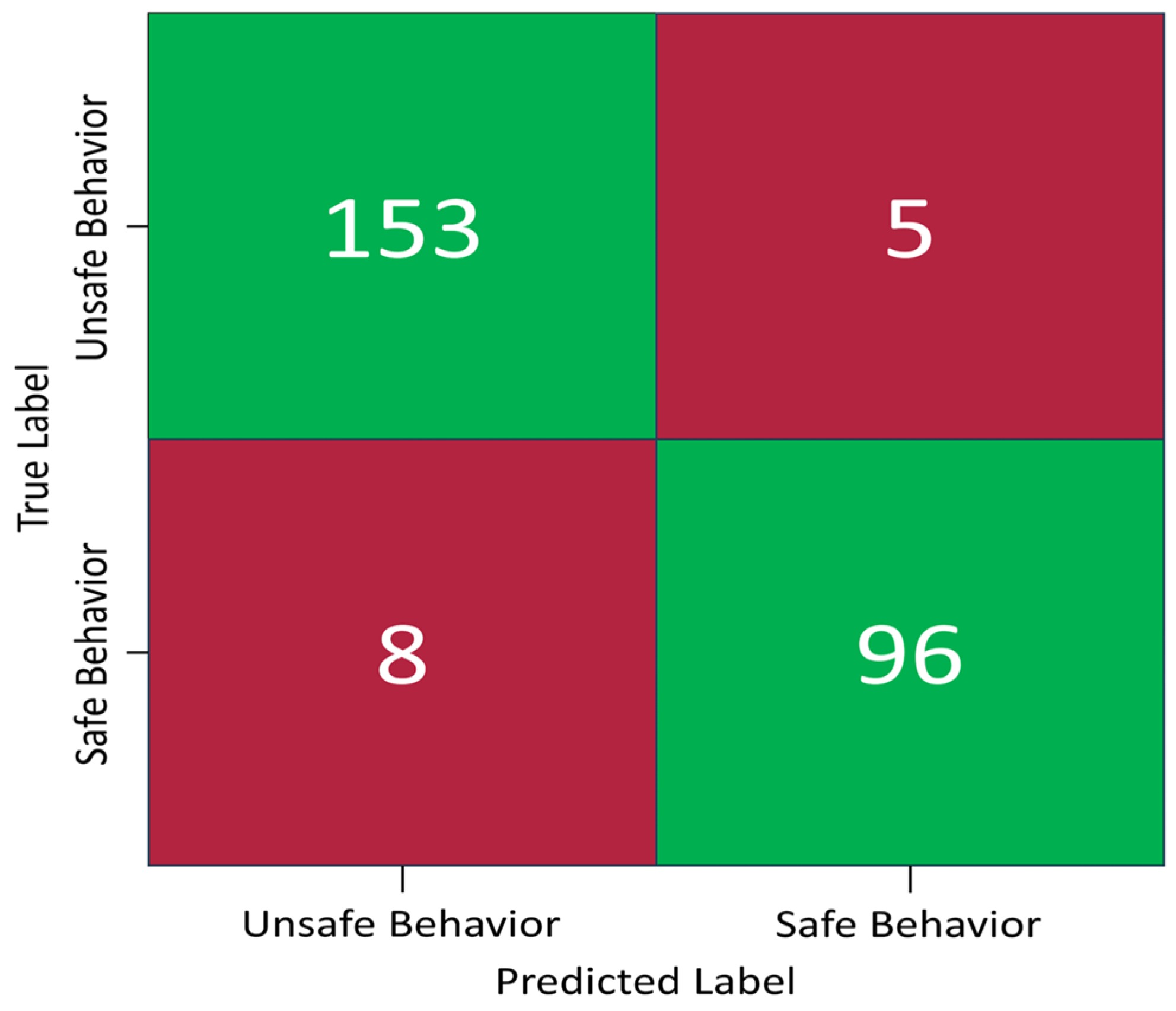
The model’s performance was assessed using a confusion matrix.
Figure 11 shows a (2 × 2) confusion matrix, where two is the number of classes, which are safe behavior and unsafe behavior. In this matrix, the top-left cell represents the instances that were classified correctly (153 TPs). Conversely, the top-right cell denotes inaccurately assigned instances (5 FPs). The bottom-left cell represents the instances that were predicted incorrectly (8 FNs). Finally, the bottom-right cell represents the instances that were classified accurately (96 TN). This detailed breakdown offers valuable insights into the classification accuracy of the model and the areas that require further attention for model refinement.
Table 5 lists the key performance indicators of the proposed approach. These performance indicators highlight the system’s effectiveness in differentiating between safe and unsafe behaviors. In terms of detecting safe behaviors, the system achieved a precision of 0.95, indicating a high degree of accuracy in identifying true safe actions. Moreover, the recall value of 0.97 indicates the system’s ability to capture instances of safe behavior. This combination resulted in a robust F1-Score of 0.96, showcasing the system’s balanced performance in this regard.
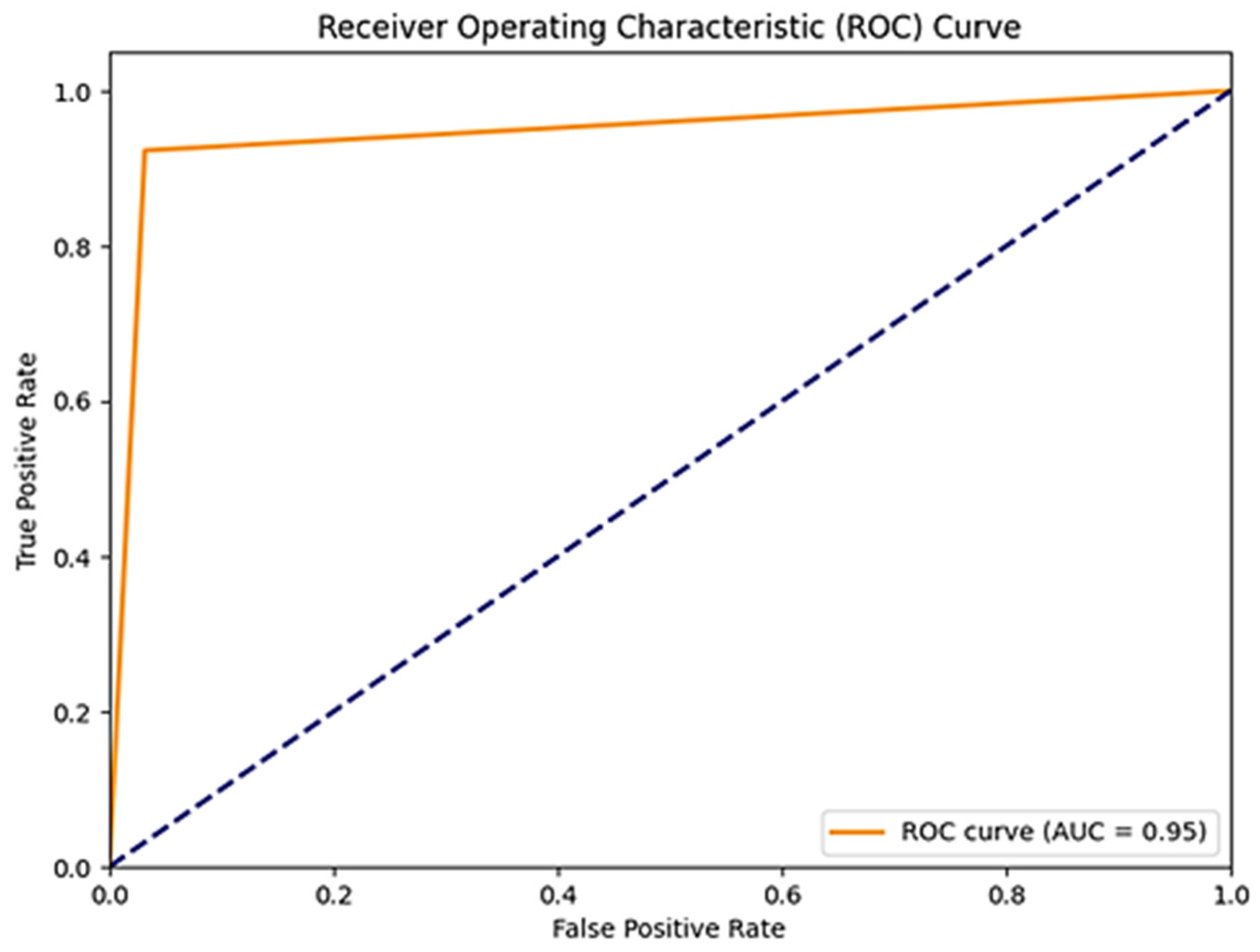
Meanwhile, in terms of detecting unsafe behavior, the system achieved a perfect precision value of 0.95, implying that 95% of the instances classified as unsafe were accurate. However, the recall of 0.92 suggested that the system failed to capture a few instances of actual unsafe behavior. This discrepancy in recall led to an F1-Score of 0.94, indicating the need for improved sensitivity in identifying unsafe actions. The ROC-AUC curve for binary classification behavior is shown in
Figure 12, which achieved 95% accuracy, demonstrating the reliability of the model in classifying unsafe behaviors. Overall, while the system achieved impressive accuracy in detecting safe behaviors, further refinement is needed to enhance its capability in identifying instances of unsafe behavior.
The F1-score was 95% on the test set, underscoring the robustness and reliability of the approach, even when applied to unseen data curated within the same environmental context as the training dataset. The efficacy of the proposed Algorithm A1 relied on the object detection model’s ability to generalize and accurately detect objects.
4.2.2. Three-Dimensional Detection and Comparison with Two-Dimensional Detection
In the evaluation of 3D detection, a comprehensive array of scenarios was examined to ensure thorough validation. These scenarios included assessing workers’ positions both behind and on mobile scaffolding with missing guardrails or outriggers, as well as scenarios involving more than two workers in varying positions. Additionally, the analysis considered workers without helmets, indicative of unsafe behavior, and instances of mobile scaffolding lacking guardrails or outriggers. Both setups—with and without the Intel RealSense camera—were utilized to provide a comparative perspective on spatial detection capabilities. While the core detection framework is based on a 2D object detection model (YOLOv12), depth information captured from the RealSense camera was integrated to introduce a third dimension (z-axis) to the data. The term “3D detection” is thus used to reflect this augmentation. The depth data were employed not to improve the detection accuracy directly, but rather to enhance spatial reasoning, specifically, to determine whether a detected worker is on the scaffold platform or behind it. This distinction is crucial for the safety assessment, but is not possible with standard 2D RGB cameras. Furthermore, a quantitative analysis—such as a confusion matrix—could not be performed for this evaluation, as it requires real-time ground truth verification, which was not feasible in the current offline setting.
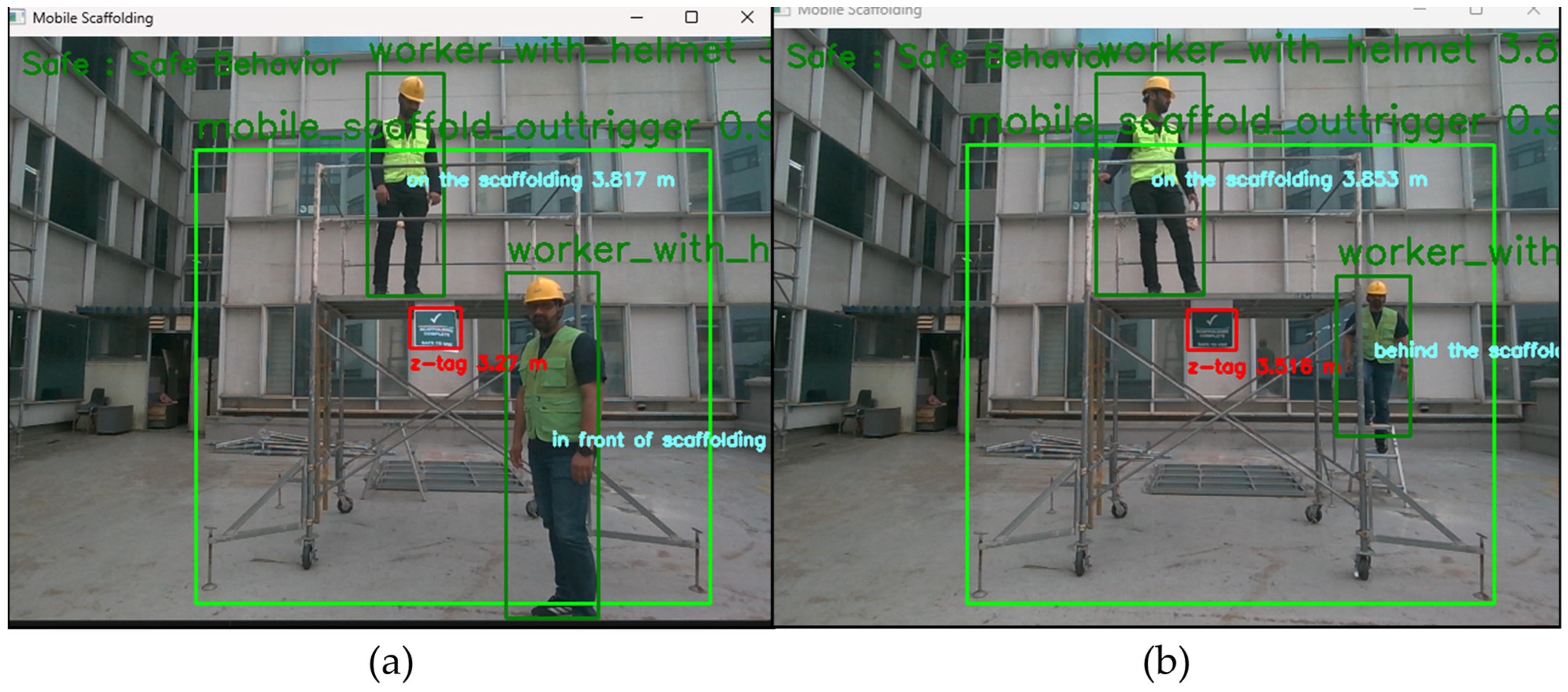
For instance,
Figure 13a portrays one worker positioned in front of the mobile scaffolding and another worker on the scaffolding, while
Figure 13b depicts a worker positioned behind the scaffolding with another worker on it. Notably, in
Figure 14a, the detection identifies a worker on mobile scaffolding lacking guardrails, categorizing the behavior as unsafe. Conversely, in
Figure 14b, despite the absence of both guardrails and workers, the behavior is classified as safe. Therefore, if an unsafe scenario is detected but no workers are present, it will be classified as safe, as the 3D system can accurately determine the position of workers. In
Figure 15 and
Figure 16, the efficacy of 2D and 3D detection methods is compared. In
Figure 15a, 2D detection erroneously identifies the behavior as unsafe due to the absence of a guardrail on the mobile scaffolding. However,
Figure 15b demonstrates the precision of 3D detection, accurately classifying the behavior as safe. This correct classification is attributed to the fact that there is no worker interaction with the mobile scaffolding at the moment, despite the absence of a guardrail. Similarly, in
Figure 16a,b, 2D detection inaccurately identifies the behavior as unsafe due to the lack of outriggers on the mobile scaffolding, whereas 3D detection precisely categorizes the behavior as safe.
Moreover,
Figure 17 demonstrates the consistency of 3D detection in accurately classifying behavior, even in the absence of outriggers.
Figure 17a illustrates a safe behavior with the worker positioned behind the mobile scaffolding, while
Figure 17b showcases an unsafe behavior with the worker on the scaffolding.
Furthermore, when considering a scenario where two workers are on the mobile scaffolding and one is behind it,
Figure 18a highlights the incorrect classification by 2D detection, whereas 3D detection accurately identifies the presence of two workers on the scaffolding and one behind it, providing a more precise assessment of the situation.
The comparative analysis between 3D and 2D detection methods in scaffolding safety assessments reveals substantial discrepancies in their efficacy and accuracy in identifying various safety hazards. Notably, while 2D detection often misclassifies unsafe scenarios, including workers positioned behind mobile scaffolding without guardrails, lacking outriggers, or incorrect counts of workers, 3D detection consistently delivers more precise results across these diverse conditions.
4.2.3. Status Trigger Module
A performance evaluation of the status trigger module (Algorithm A2) involved an analysis of a 15 s video captured within the controlled environment of ConTI Lab, featuring a spectrum of both safe and unsafe behaviors. Initially, our assessment focused on the post-processing module’s adherence to OSHA regulations, serving as a foundational benchmark for evaluating the subsequent system performance.
Subsequently, the status trigger module was deployed for evaluation, functioning within a narrow temporal window of 3 s to examine the evolving status. Upon the detection of unsafe behavior in an initial frame, typically occurring at the onset of an event, the module meticulously assessed subsequent frames to dynamically classify the behavior as safe or unsafe. For instance, as depicted in
Figure 19a–c, capturing frames at time intervals t = 0, 3, and 6 s, respectively, the initial frame did not exhibit immediate status results. However, through continuous analysis over the subsequent three-second intervals, the system dynamically updated the status, ultimately flagging the behavior as unsafe in
Figure 19b. Similarly, the status of the next three seconds was recorded and updated at the 6th second, as depicted in
Figure 19c. This iterative process of real-time evaluation and status updates showcases the system’s adaptive capabilities in discerning evolving scenarios.
In contrast to conventional methods, the proposed system demonstrated a superior performance, effectively mitigating instances of misdetections and false positives (FPs). Despite encountering challenges such as misclassifications and FPs, the status trigger module adeptly managed these complexities, thereby averting erroneous status triggers. A well-optimized model facilitated the precise identification of unsafe behaviors, whereas inadequacies could lead to false positives (FPs) and false negatives (FNs), thereby affecting the overall accuracy of the image analysis algorithm. This resilience in accurately identifying and flagging unsafe behaviors underscores the robustness and reliability of the system in real-world applications. Furthermore, the system’s ability to dynamically adapt and refine its assessments in response to evolving scenarios highlights its effectiveness in ensuring workplace safety.
5. Limitations
Despite the significant advancements achieved in this study, several limitations require to be highlighted. The model’s mathematical framework enhances bounding box analysis, but may not encompass all safety scenarios, such as verifying the proper installation of mobile scaffolding, which necessitates additional contextual checks beyond visual detection. While the training dataset is extensive, comprising a diverse range of scenarios, its representation of real-world construction site variations may still be limited. This potential lack of comprehensive diversity could restrict the generalizability of the model across varied construction environments. Utilizing synthetic images could mitigate this limitation by augmenting the dataset with additional diverse scenarios. The operational capabilities of the Intel RealSense camera (D455), which effectively detects the depth within the range of 0.6 m to 6 m, pose constraints on its suitability for scenarios requiring detection beyond this distance. This limitation restricts the application of depth sensing technology in larger construction sites or environments with extensive spatial requirements. Furthermore, the algorithm developed for this study is optimized for real-time 3D detection. While advantageous for immediate hazard identification and response, its real-time processing constraint may limit its utility in environments necessitating post-event analysis or where continuous monitoring with delayed processing is preferred.
The strong performance seen in the confusion matrix (
Figure 11) and evaluation metrics on the test set reflects this careful dataset design. However, it is important to note that if the model is deployed on entirely new construction sites with different environmental characteristics, equipment types, or camera configurations, the performance may degrade due to a domain shift. Real-world variability can introduce unseen visual patterns not covered in the training distribution. Therefore, ongoing model refinement with site-specific data or domain adaptation techniques would be necessary for reliable deployment across diverse construction environments. This highlights the importance of both dataset diversity and continuous evaluation in practical computer vision applications for safety monitoring.
These identified limitations highlight the need for further research and technological refinement to enhance the robustness and applicability of computer vision-based safety monitoring systems in complex construction settings.
6. Conclusions
This study presents a computer vision-based system for the real-time monitoring of unsafe behaviors on mobile scaffolds, targeting four critical safety violations: the absence of helmets, missing outriggers, a lack of guardrails, and overcrowding. A diverse dataset was compiled from construction sites and benchmark sources to train a YOLO-based object detection model integrated with a temporal status module. The results demonstrate the system’s accuracy and generalizability across various construction scenarios, enhanced by the use of depth information for spatial awareness. The inclusion of a status module improves real-time behavior classification, enabling the proactive enforcement of safety protocols. This dual-layered approach strengthens the system’s adaptability and positions it as a scalable solution for industrial safety monitoring.
Future research may focus on integrating more advanced hardware such as advanced depth cameras capable of providing extended range depth information, facilitating the more precise localization of construction workers and mitigating occlusion challenges. Additionally, the integration of blockchain technology holds promises for enhancing privacy and security, potentially incentivizing safety compliance through reward mechanisms aligned with adherence to safety protocols. Expanding the dataset with real-life examples from diverse construction sites remains a priority to enhance the system’s accuracy in detecting various construction-related hazards, further advancing the application of computer vision in construction safety practices. These advancements represent a significant step forward in leveraging computer vision technology to enhance safety practices in industries reliant on scaffolding and other complex structures. By enhancing the detection accuracy, operational efficiency, and safety compliance, our approach aims to mitigate risks, improve workplace conditions, and ultimately contribute to the overarching goal of ensuring safer working environments globally.
Author Contributions
Conceptualization, M.S.A., S.F.A.Z. and D.L.; methodology, M.S.A., S.F.A.Z. and R.H.; software, M.S.A. and S.F.A.Z.; validation, S.F.A.Z. and R.H.; formal analysis, M.S.A. and R.H.; investigation, M.S.A. and D.L.; resources, C.P.; data curation, M.S.A., S.F.A.Z. and R.H.; writing—original draft preparation, M.S.A. and R.H.; writing—review and editing, S.F.A.Z., D.L. and C.P.; supervision, C.P. and D.L.; project administration, C.P.; funding acquisition, C.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Chung-Ang University Young Scientist Scholarship (CAYSS) in 2022 and in part by the Technology development Program (RS2024-00446202) funded by the Ministry of SMEs and Startups (MSS, Korea).
Data Availability Statement
Data will be made available on request to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
| Algorithm A1. Image analysis using YOLOv12 model. |
| 1: | Input: {2Dimage, depth}, width_MS {The image to be analyzed and width of the MS.} |
| 2: | Input: model {The YOLO model to be used for detection.} |
| 3: | Output: Status, Recognitions |
| 4: | Function Scenario_Classification(model, 2Dimage, depth) |
| 5: | Initialize Status as “Safe”. |
| 6: | Initialize empty lists: Person, MobileScaffoldWithoutOutrigger, MobileScaffoldWithOutrigger. |
| 7: | Pass the frame to the YOLOv12-trained model for inference. |
| 8: | results ← model(image) {Inference the model} |
| 9: | Retrieve the detection results, including bounding box coordinates , class id, and scores. |
| 10: | foreach result in results do |
| 11: | class_id ← class id of the detection result. |
| 12: | if class_id == 0 then |
| 13: | Status ← “Unsafe”. |
| 14: | else if class_id == 1 then |
| 15: | MobileScaffoldWithoutOutrigger.add(result). |
| 16: | else if class_id == 2 then |
| 17: | MobileScaffoldWithOutrigger.add(result). |
| 18: | else if class_id == 3 then |
| 19: | Person.add(result) |
| 20: | else if class_id == 4 then |
| 21: | Status ← “Unsafe” |
| 22: | Person.add(result) |
| 23: | else if class_id == 5 then |
| 24: | z_tag = result |
| 25: | end if |
| 26: | end for |
| 27: | foreach per in Person do |
| 28: | if (per[(+)/2][(+)/2]) ≥ z-tag[()][ ()/2] ≥ (per[()/2][ ())/2])+ width_MS then |
| 29: | foreach MobileScaffoldWithoutOutrigger do |
| 30: | If then |
| 31: | Status ← “Unsafe”. |
| 32: | end if |
| 33: | end for |
| 34: | foreach MobileScaffoldWithOutrigger do |
| 35: | If then |
| 36: | Status ← “Unsafe”. |
| 37: | end if |
| 38: | end for |
| 39: | end if |
| 40: | end for |
| 41 | if number_of_persons > 2 then |
| 42: | Status ← “Unsafe”. |
| 43: | end if |
| 44: | return Status, results |
| Algorithm A2. Status trigger module. |
| 1: | Input: |
| 2: | status: safe/unsafe return from the detector module |
| 3: | timestamp: current time |
| 4: | Output: Video, |
| 5: | Steps: |
| 6: | Initialize previous_status as “Safe”. |
| 7: | Initialize status_start_time as “None” |
| 8: | Load the trained YOLOv12 model. |
| 9: | Set up the real-time video stream or access the video file. |
| 10: | foreach frame in Real Time Video do: |
| 11: | status = Scenario_Classification(model, frame) {Algorithm A1} |
| 12: | if status != previous_status then |
| 13: | Set status_start_time to current_time() |
| 14: | else if status = previous_status then |
| 15: | if status_start_time is None then |
| 16: | Set status_start_time to current_time() |
| 17: | end if |
| 18: | else if current_time() - status_start_time ≥ 3 seconds then |
| 19: | generate_alarm() {function that will generate alarm} |
| 20: | save_video() {function that will save video} |
| 21: | send_logs_to_database() {send logs to the database for records} |
| 22: | end if |
| 23: | end for |
References
- Hussain, R.; Zaidi, S.F.A.; Pedro, A.; Lee, H.; Park, C. Exploring construction workers’ attention and awareness in diverse virtual hazard scenarios to prevent struck-by accidents. Saf. Sci. 2024, 175, 106526. [Google Scholar] [CrossRef]
- Pedro, A.; Hussain, R.; Pham-Hang, A.T.; Pham, H.C. Visualization technologies in construction education: A comprehensive review of recent advances. In Engineering Education for Sustainability; River Publishers: Aalborg, Denmark, 2019; pp. 67–101. [Google Scholar] [CrossRef]
- Newaz, M.T.; Jefferies, M.; Ershadi, M. A critical analysis of construction incident trends and strategic interventions for enhancing safety. Saf. Sci. 2025, 187, 106865. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; Volume 2015, pp. 1440–1448. [Google Scholar] [CrossRef]
- Hussain, R.; Sabir, A.; Lee, D.Y.; Zaidi, S.F.A.; Pedro, A.; Abbas, M.S.; Park, C. Conversational AI-based VR system to improve construction safety training of migrant workers. Autom. Constr. 2024, 160, 105315. [Google Scholar] [CrossRef]
- Khan, M.; Nnaji, C.; Khan, M.S.; Ibrahim, A.; Lee, D.; Park, C. Risk factors and emerging technologies for preventing falls from heights at construction sites. Autom. Constr. 2023, 153, 104955. [Google Scholar] [CrossRef]
- OSHA. OSHA’s Fall Prevention Campaign. Available online: https://www.osha.gov/stop-falls (accessed on 28 January 2025).
- Khan, N.; Anjum, S.; Khalid, R.; Park, J.S.; Park, C. A Deep Learning-based Predication of Fall Portents for Lone Construction Worker. Proc. Int. Symp. Autom. Robot. Constr. 2021, 2021, 419–426. [Google Scholar] [CrossRef]
- KOSHA. 2022 Industrial Accident Status Analysis Booklet. Available online: https://www.moel.go.kr/policy/policydata/view.do?bbs_seq=20231201612 (accessed on 29 January 2025).
- Kim, H.; Lim, J.; Won, J.H.; Kwon, J.H.; Kim, S. Suggestion of safety certification standards and performance evaluation methods for fabricated mobile scaffold in South Korea. Int. J. Environ. Res. Public. Health 2022, 19, 133. [Google Scholar] [CrossRef]
- WS Safety. Scaffold Hazards and Control Measures. Available online: https://wssafety.com/scaffold-hazards-and-control-measures/ (accessed on 27 April 2025).
- Khan, N.; Zaidi, S.F.A.; Abbas, M.S.; Lee, D.; Lee, D. Tracking multiple construction workers using pose estimation and feature-assisted re-identification model. Autom. Constr. 2024, 168, 105771. [Google Scholar] [CrossRef]
- Ul Amin, S.; Sibtain Abbas, M.; Kim, B.; Jung, Y.; Seo, S. Enhanced Anomaly Detection in Pandemic Surveillance Videos: An Attention Approach with EfficientNet-B0 and CBAM Integration. IEEE Access 2024, 12, 162697–162712. [Google Scholar] [CrossRef]
- Anjum, S.; Khan, N.; Khalid, R.; Khan, M.; Lee, D.; Park, C. Fall Prevention from Ladders Utilizing a Deep Learning-Based Height Assessment Method. IEEE Access 2022, 10, 36725–36742. [Google Scholar] [CrossRef]
- Zaidi, S.F.A.; Yang, J.; Abbas, M.S.; Hussain, R.; Lee, D.; Park, C. Vision-Based Construction Safety Monitoring Utilizing Temporal Analysis to Reduce False Alarms. Buildings 2024, 14, 1878. [Google Scholar] [CrossRef]
- Gong, J.; Caldas, C.H.; Gordon, C. Learning and classifying actions of construction workers and equipment using Bag-of-Video-Feature-Words and Bayesian network models. Adv. Eng. Inform. 2011, 25, 771–782. [Google Scholar] [CrossRef]
- Khan, N.; Saleem, M.R.; Lee, D.; Park, M.W.; Park, C. Utilizing safety rule correlation for mobile scaffolds monitoring leveraging deep convolution neural networks. Comput. Ind. 2021, 129, 103448. [Google Scholar] [CrossRef]
- Xu, Y.; Tuttas, S.; Hoegner, L.; Stilla, U. Reconstruction of scaffolds from a photogrammetric point cloud of construction sites using a novel 3D local feature descriptor. Autom. Constr. 2018, 85, 76–95. [Google Scholar] [CrossRef]
- Cho, C.Y.; Liu, X. An automated reconstruction approach of mechanical systems in building information modeling (BIM) using 2D drawings. In Proceedings of the Congress on Computing in Civil Engineering, Seattle, WA, USA, 25–27 June 2017; pp. 236–244. [Google Scholar] [CrossRef]
- Jung, Y.; Lee, S. An approach to automated detection of failure in temporary structures supported by concrete shoring. In Proceedings of the 28th International Symposium on Automation and Robotics in Construction, ISARC 2011, Seoul, Republic of Korea, 29 June–2 July 2011; pp. 807–812. [Google Scholar] [CrossRef]
- Fang, W.; Ding, L.; Love, P.E.D.; Luo, H.; Li, H.; Peña-Mora, F.; Zhong, B.; Zhou, C. Computer vision applications in construction safety assurance. Autom. Constr. 2020, 110, 103013. [Google Scholar] [CrossRef]
- Fang, W.; Zhong, B.; Zhao, N.; Love, P.E.D.; Luo, H.; Xue, J.; Xu, S. A deep learning-based approach for mitigating falls from height with computer vision: Convolutional neural network. Adv. Eng. Inform. 2019, 39, 170–177. [Google Scholar] [CrossRef]
- Fang, Q.; Li, H.; Luo, X.; Ding, L.; Luo, H.; Rose, T.M.; An, W. Detecting non-hardhat-use by a deep learning method from far-field surveillance videos. Autom. Constr. 2018, 85, 1–9. [Google Scholar] [CrossRef]
- OSHA. Number of Accidents Due to Mobile Scaffolding. Available online: https://www.osha.gov/ords/imis/AccidentSearch.search?acc_keyword=%22Mobile Scaffold%22 (accessed on 18 March 2025).
- Adobe Premiere Pro. Available online: https://www.adobe.com/kr/products/premiere.html (accessed on 18 March 2025).
- Duplicate Photos Fixer Duplicate Photos Fixer. Available online: https://www.duplicatephotosfixer.com (accessed on 18 March 2025).
- Dwyer, B.; Nelson, J.; Hansen, T. Roboflow. Available online: https://roboflow.com (accessed on 29 January 2025.).
- Scantlebury, J.; Brown, N.; Von Delft, F.; Deane, C.M. Data Set Augmentation Allows Deep Learning-Based Virtual Screening to Better Generalize to Unseen Target Classes and Highlight Important Binding Interactions. J. Chem. Inf. Model. 2020, 60, 3722–3730. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2021, 199, 1066–1073. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- GitHub—Ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite. Available online: https://github.com/ultralytics/yolov5 (accessed on 29 January 2025).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
Figure 1.
Visual representation of bounding boxes.
Figure 1.
Visual representation of bounding boxes.
Figure 2.
Six cases (A–F) of workers on mobile scaffolding in a frame.
Figure 2.
Six cases (A–F) of workers on mobile scaffolding in a frame.
Figure 3.
Representation of different cases in 3D-plane.
Figure 3.
Representation of different cases in 3D-plane.
Figure 4.
Flowchart of proposed system for enhancing mobile scaffolding safety through object detection and behavioral analysis.
Figure 4.
Flowchart of proposed system for enhancing mobile scaffolding safety through object detection and behavioral analysis.
Figure 5.
Sample image extracted from RealSense camera.
Figure 5.
Sample image extracted from RealSense camera.
Figure 6.
Trained model result.
Figure 6.
Trained model result.
Figure 7.
Precision and recall curve of the best-fit model.
Figure 7.
Precision and recall curve of the best-fit model.
Figure 8.
Recall curve of the best-fit model.
Figure 8.
Recall curve of the best-fit model.
Figure 9.
Example of predicted worker behavior on mobile scaffolding in 2D: (a) Safe behavior validating the four scenarios cited. (b) Unsafe behavior due to missing guardrail.
Figure 9.
Example of predicted worker behavior on mobile scaffolding in 2D: (a) Safe behavior validating the four scenarios cited. (b) Unsafe behavior due to missing guardrail.
Figure 10.
Example of predicted unsafe worker behavior on mobile scaffolding in 2D: (a) Unsafe behavior resulting from the presence of more than two workers on a mobile scaffold. (b) Unsafe behavior owing to lack of outriggers on mobile scaffold.
Figure 10.
Example of predicted unsafe worker behavior on mobile scaffolding in 2D: (a) Unsafe behavior resulting from the presence of more than two workers on a mobile scaffold. (b) Unsafe behavior owing to lack of outriggers on mobile scaffold.
Figure 11.
Confusion matrix for classifying behavior using binary classification.
Figure 11.
Confusion matrix for classifying behavior using binary classification.
Figure 12.
ROC and AUC for classifying behavior using binary classification.
Figure 12.
ROC and AUC for classifying behavior using binary classification.
Figure 13.
Example of predicted safe worker behavior on mobile scaffolding in 3D: (a) A worker is on the mobile scaffolding, while another worker is positioned in front of the mobile scaffolding. (b) A worker is on the mobile scaffolding, while another worker is positioned behind the mobile scaffolding.
Figure 13.
Example of predicted safe worker behavior on mobile scaffolding in 3D: (a) A worker is on the mobile scaffolding, while another worker is positioned in front of the mobile scaffolding. (b) A worker is on the mobile scaffolding, while another worker is positioned behind the mobile scaffolding.
Figure 14.
Example of predicted behavior when guardrails are missing on mobile in 3D: (a) Worker is on mobile scaffolding without guardrail. (b) Only mobile scaffolding without guardrail scaffolding.
Figure 14.
Example of predicted behavior when guardrails are missing on mobile in 3D: (a) Worker is on mobile scaffolding without guardrail. (b) Only mobile scaffolding without guardrail scaffolding.
Figure 15.
Example of predicting behavior when guardrails are missing on mobile scaffolding in 2D and 3D: (a) Two-dimensional detection for worker behind the mobile scaffolding without guardrail. (b) Three-dimensional detection for worker behind the mobile scaffolding without guardrail.
Figure 15.
Example of predicting behavior when guardrails are missing on mobile scaffolding in 2D and 3D: (a) Two-dimensional detection for worker behind the mobile scaffolding without guardrail. (b) Three-dimensional detection for worker behind the mobile scaffolding without guardrail.
Figure 16.
Example of predicting behavior when outriggers are missing from mobile scaffolding in 2D and 3D: (a) Two-dimensional detection for worker behind the mobile scaffolding without outrigger. (b) Three-dimensional detection for worker behind the mobile scaffolding without outrigger.
Figure 16.
Example of predicting behavior when outriggers are missing from mobile scaffolding in 2D and 3D: (a) Two-dimensional detection for worker behind the mobile scaffolding without outrigger. (b) Three-dimensional detection for worker behind the mobile scaffolding without outrigger.
Figure 17.
Example of predicting behavior when outriggers are missing from mobile scaffolding in 3D: (a) Three-dimensional detection for worker behind the mobile scaffolding without outrigger. (b) Three-dimensional detection for worker on the mobile scaffolding without outrigger.
Figure 17.
Example of predicting behavior when outriggers are missing from mobile scaffolding in 3D: (a) Three-dimensional detection for worker behind the mobile scaffolding without outrigger. (b) Three-dimensional detection for worker on the mobile scaffolding without outrigger.
Figure 18.
Example of predicting behavior when more than 2 workers are on mobile scaffolding in 2D and 3D: (a) Three workers detected on mobile scaffolding in 2D detection. (b) Two workers detected on mobile scaffolding in 3D detection.
Figure 18.
Example of predicting behavior when more than 2 workers are on mobile scaffolding in 2D and 3D: (a) Three workers detected on mobile scaffolding in 2D detection. (b) Two workers detected on mobile scaffolding in 3D detection.
Figure 19.
Sequential frames from a video at (a) t = 0 s, (b) t = 3 s, and (c) t = 6 s.
Figure 19.
Sequential frames from a video at (a) t = 0 s, (b) t = 3 s, and (c) t = 6 s.
Table 1.
Summary of case conditions and behaviors.
Table 1.
Summary of case conditions and behaviors.
| Author | Objective | Safety Rules Checking | Targeted Objects | Depth Information | Technique | Model |
|---|
| [9] | Fall protection for lone worker | Fall | Ladder | No | Object detection | SSD |
| [14] | Mitigating falls by tracking objects | Fall | Person
Steel support
Concrete support | No | Tracking | Mask R-CNN |
| [21] | Detecting non-usage of hardhats from far-field surveillance videos | Hardhats | Person | No | Object detection | Faster R-CNN |
| [22] | Detection of safety harness | Falls from height | Person
Harness | No | Object detection | Faster R-CNN |
| [23] | Motion capturing data for unsafe actions | No | Ladder | Yes | Pose estimation | CNN + LSTM |
| [16] | Action classification based on a set of video segments | No | Workers and equipment | No | Action Recognition | Bayesian networks |
| Proposed Study | Computer Vision-Based Safety Monitoring of Mobile Scaffolding Integrating Depth Camera | Fall from height | Mobile scaffold with components, guardrails, and outriggers | Yes | Object detection | YOLO |
Table 2.
Comparison of OSHA and KOSHA regulations for mobile scaffoldings.
Table 2.
Comparison of OSHA and KOSHA regulations for mobile scaffoldings.
| Construction Entity | Construction Entity Status | OSHA | KOSHA |
|---|
| Mobile Scaffold | Outriggers Guardrail
No more than two workers | OSHA 1926.452(w)(6)(iii)
With outriggers
OSHA 29 CFR 1926.451(g)(4)(i)
With guardrail | Article 68 (1) Without outriggers Article 68 (3)
Without guardrail
[1] Article [C-28-2018] |
| Worker | Worker on scaffold | OSHA 1926.100 General Requirements
With helmet
Without helmet | Without helmet |
Table 3.
Summary of case conditions and behaviors on mobile scaffoldings.
Table 3.
Summary of case conditions and behaviors on mobile scaffoldings.
| Case | Statement | Mathematical Logic | Behavior |
|---|
| 1 | A worker with/without a helmet on mobile scaffolding with a missing guardrail | | Unsafe |
| 2 | A worker without a helmet on mobile scaffolding with an outrigger | | Unsafe |
| 3 | A worker with/without a helmet on mobile scaffolding without outrigger | | Unsafe |
| 4 | More than two workers working on mobile scaffolding | | Unsafe |
| 5 | Fewer than or equal to two workers with helmets working on mobile scaffolding | |W| ≤ 2 ∩ M ⊆ B | Safe |
Table 4.
Performance comparison of YOLO models on validation and test sets.
Table 4.
Performance comparison of YOLO models on validation and test sets.
| Dataset | Models | Precison | Recall | mAP-50 | mAP50-95 |
|---|
| Validation Set | Yolov5 | 0.959 | 0.965 | 0.969 | 0.741 |
| Yolov8 | 0.955 | 0.958 | 0.970 | 0.783 |
| Yolov11 | 0.966 | 0.952 | 0.979 | 0.785 |
| Yolov12 | 0.966 | 0.974 | 0.979 | 0.786 |
| Test Set | Yolov5 | 0.948 | 0.938 | 0.957 | 0.703 |
| Yolov8 | 0.931 | 0.921 | 0.948 | 0.716 |
| Yolov11 | 0.940 | 0.918 | 0.948 | 0.721 |
| Yolov12 | 0.952 | 0.927 | 0.957 | 0.736 |
Table 5.
Performance indicators for the detection of safe and unsafe behaviors.
Table 5.
Performance indicators for the detection of safe and unsafe behaviors.
| Actions | Precision | Recall | F1-Score | Accuracy |
|---|
| Safe Behavior | 0.95 | 0.97 | 0.96 | 0.95 |
| Unsafe Behavior | 0.95 | 0.92 | 0.94 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}