
Data-Driven Decision Support for Equipment Selection and Maintenance Issues for Buildings

 , , , , and
, , , , and
Abstract
1. Introduction
2. Literature Review
2.1. Estimating Methods and Models
2.2. Multivariate Analysis and Machine Learning
2.3. Objectives
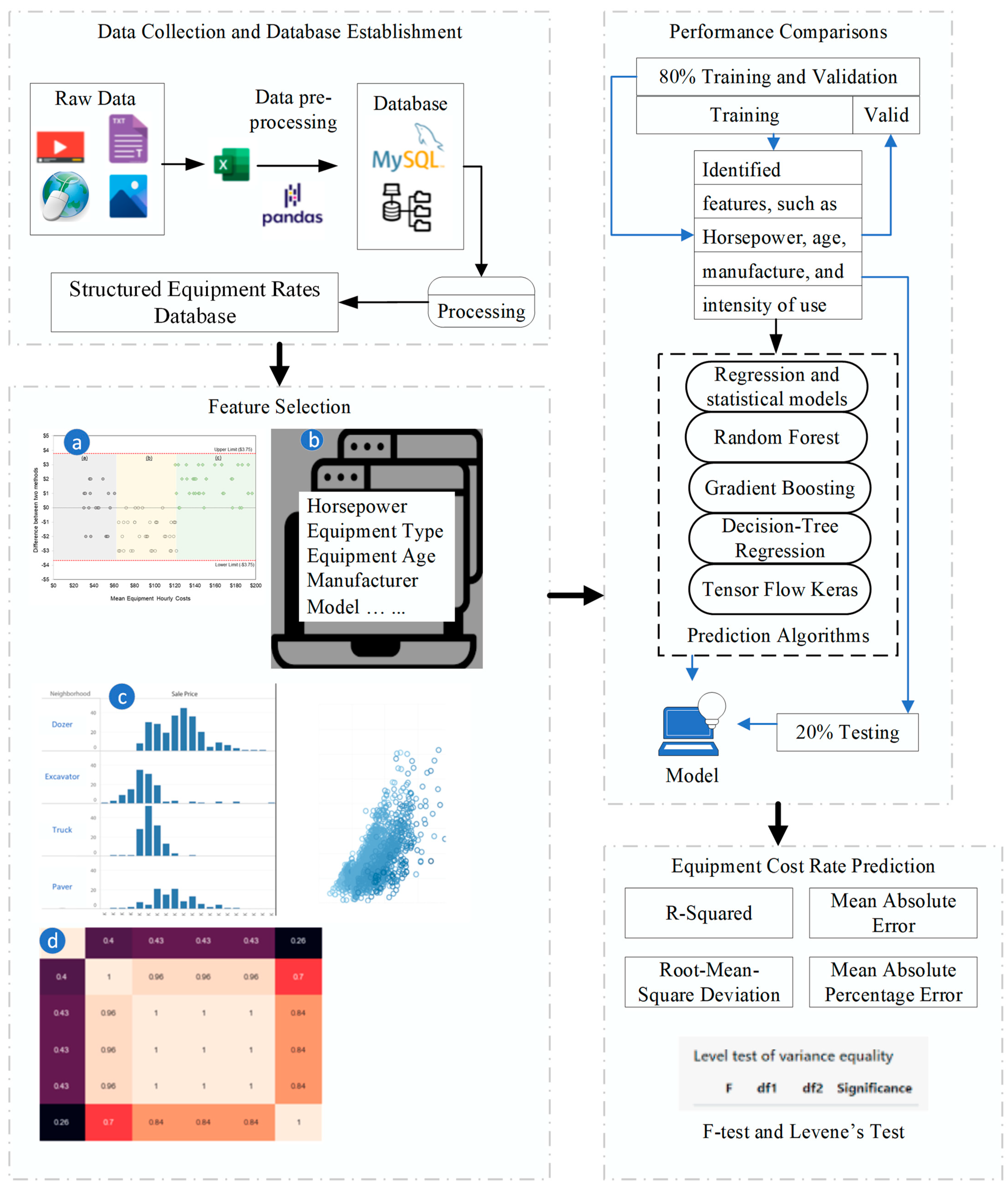
3. Research Methodology
3.1. Proposed Solution

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DS | Name | Data Source (DS) |
|---|---|---|
| 1 | CalTrans | California State Transportation Agency (400 Capitol Mall Suite 2340, Sacramento, CA, USA), Labor Surcharge and Equipment Rental Rates (Effective 1 April 2021, through 31 March 2022) |
| 2 | USDA Website | Equipment Rates: https://www.fs.usda.gov/Internet/FSE_DOCUMENTS/stelprdb5247321.pdf |
| 3 | Truck and Equipment | https://www.iltruck.com/ |
| 4 | Operator Salary | http://www.salary.com |
| 5 | Equipment Specs | https://www.constructionequipmentguide.com/equipment-specs-and-charts |
| 6 | AGC Equipment Cost | https://www.agc.org/sites/default/files/Files/Construction%20Markets/CM_GC_Guidelines.pdf |
| 7 | USACE Website | https://www.usace.army.mil/Cost-Engineering/EP1110-1-8/ |
| 8 | U.S. EIA Website | Energy Information Administration (1000 Independence Ave., SW, Washington, DC, USA): https://www.eia.gov/petroleum/gasdiesel/ and Electric Power Monthly: https://www.eia.gov/electricity/monthly/epm_table_grapher.php?t=epmt_5_6_a |
| 9 | Alibaba Website | Heavy Construction Equipment for Sale, Rent, and Lease: https://www.alibaba.com |
| 10 | Equipment Trader | Used Heavy Construction Equipment for Sale: https://www.equipmenttrader.com/ |
| 11 | Machinery Trader | (Construction) New and Used. https://www.machinerytrader.com/ |
| 12 | Machinery Zone | Classified Ads for Construction Equipment. https://www.machineryzone.com/ |
| 13 | U.S.A. Mascus | Used Construction and Farm Equipment. https://ar.mascus.com/ |
| 14 | Iron Planet | Used Heavy Construction Equipment and Trucks for Sale. https://eu.ironplanet.com/?iprefoh=www.ironplanet.com |
| 15 | Equipment Watch | Residual Value. https://equipmentwatch.com/values-guide/ |
| 16 | Bureau of Economic Analysis (BEA) | GDP estimations: https://www.bea.gov/data/gdp/gross-domestic-product |
| 17 | U.S. Census Bureau Website | https://www.census.gov/construction/c30/c30index.html |
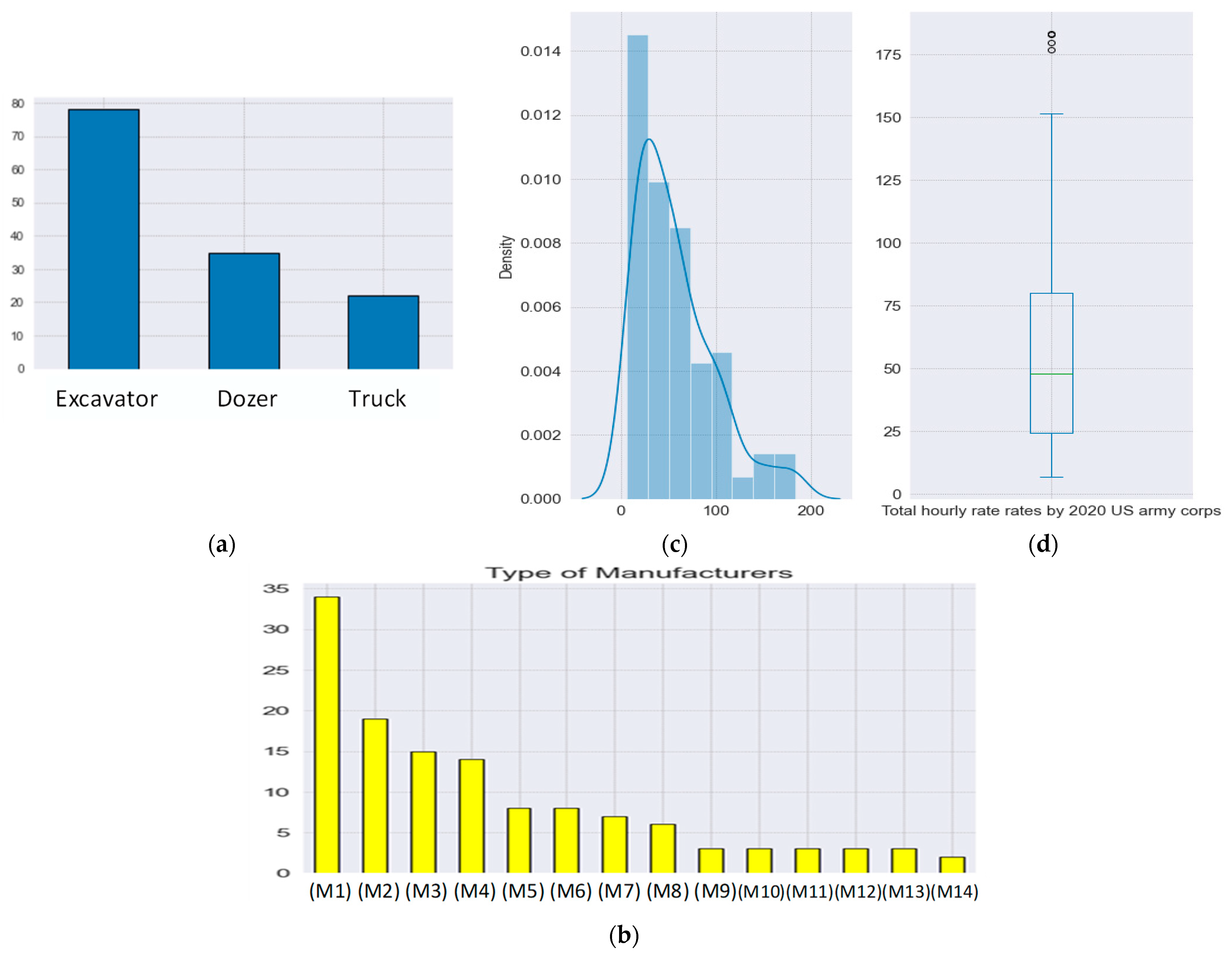
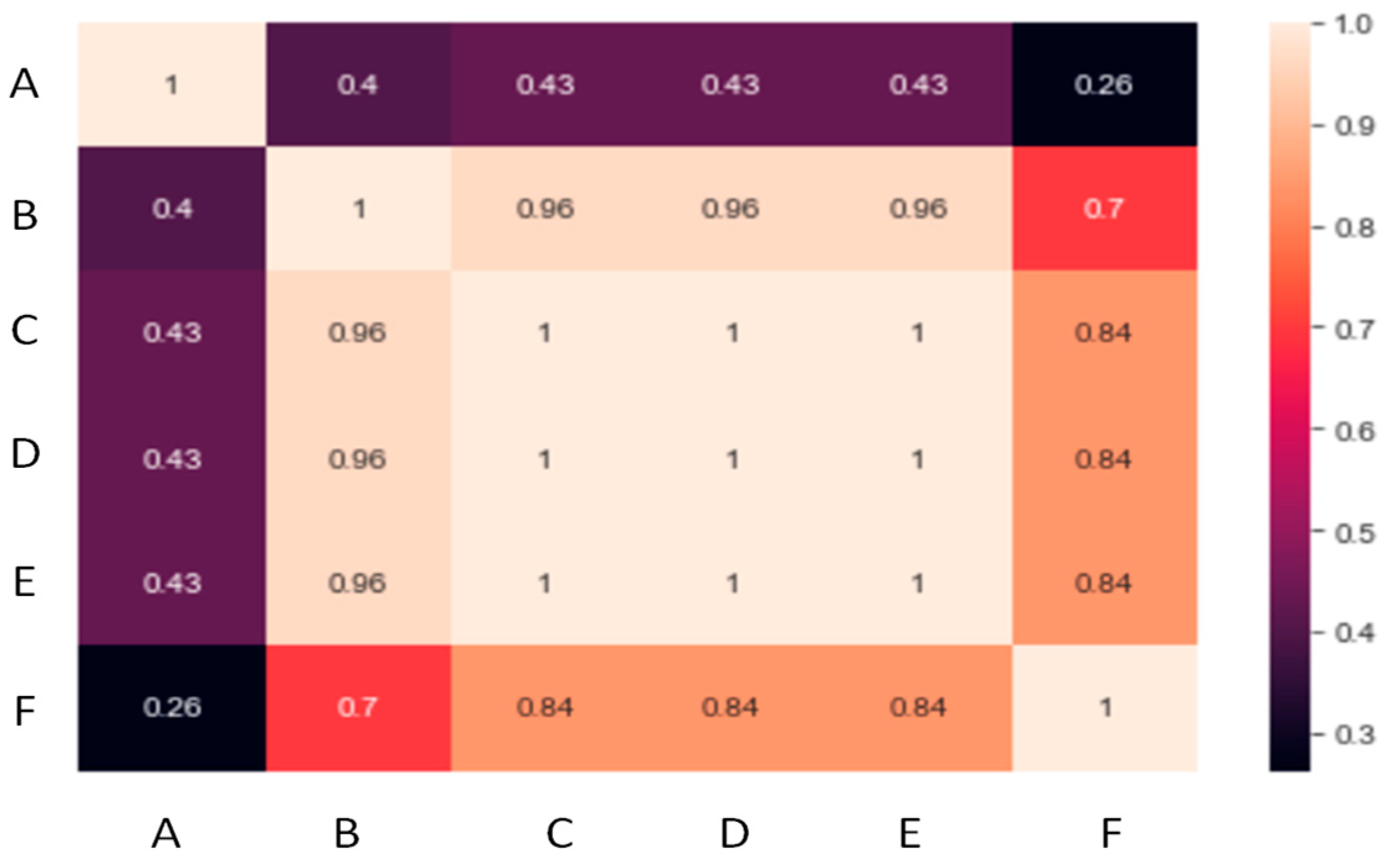
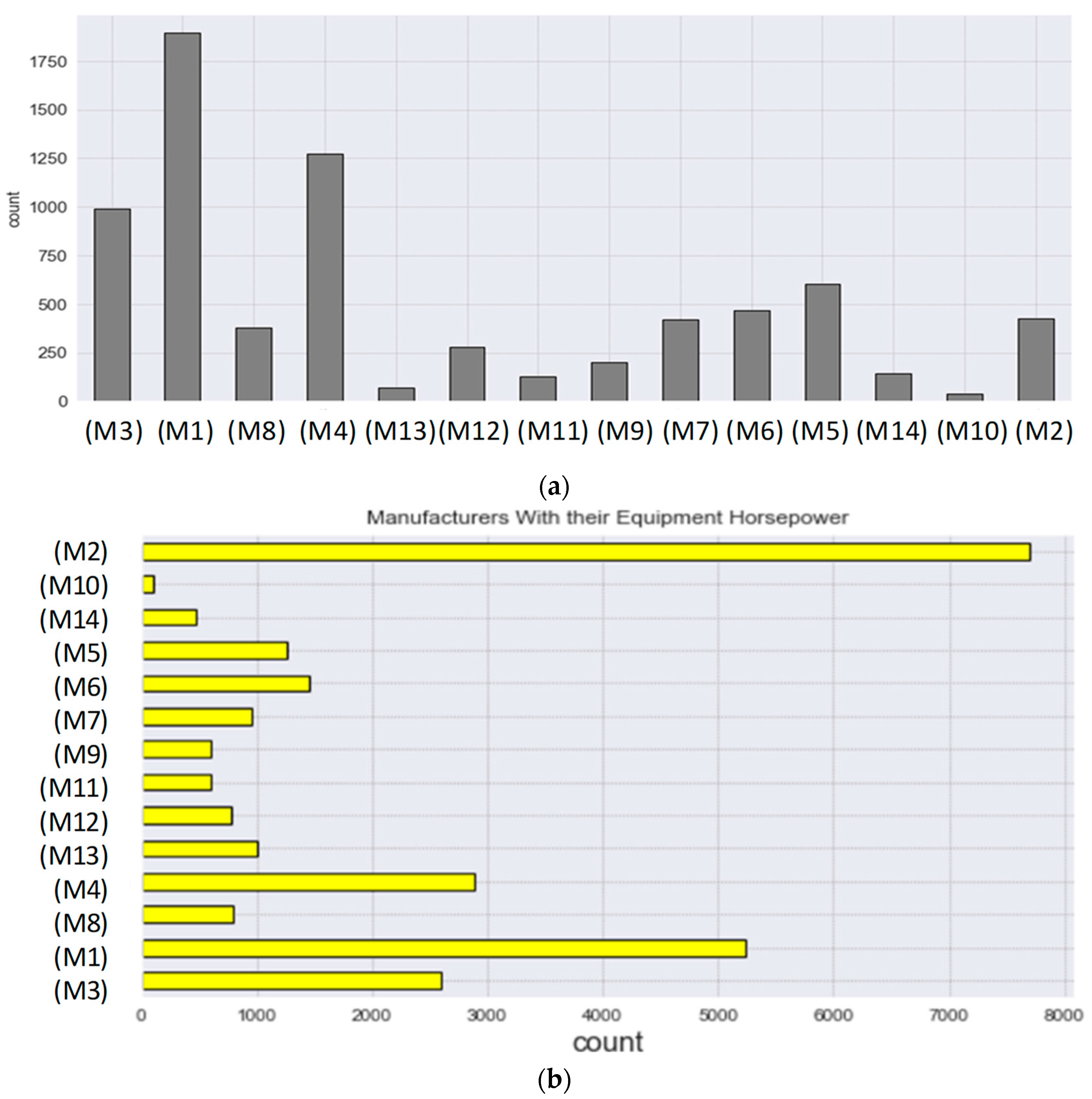
3.2. Data Collection and Model Development
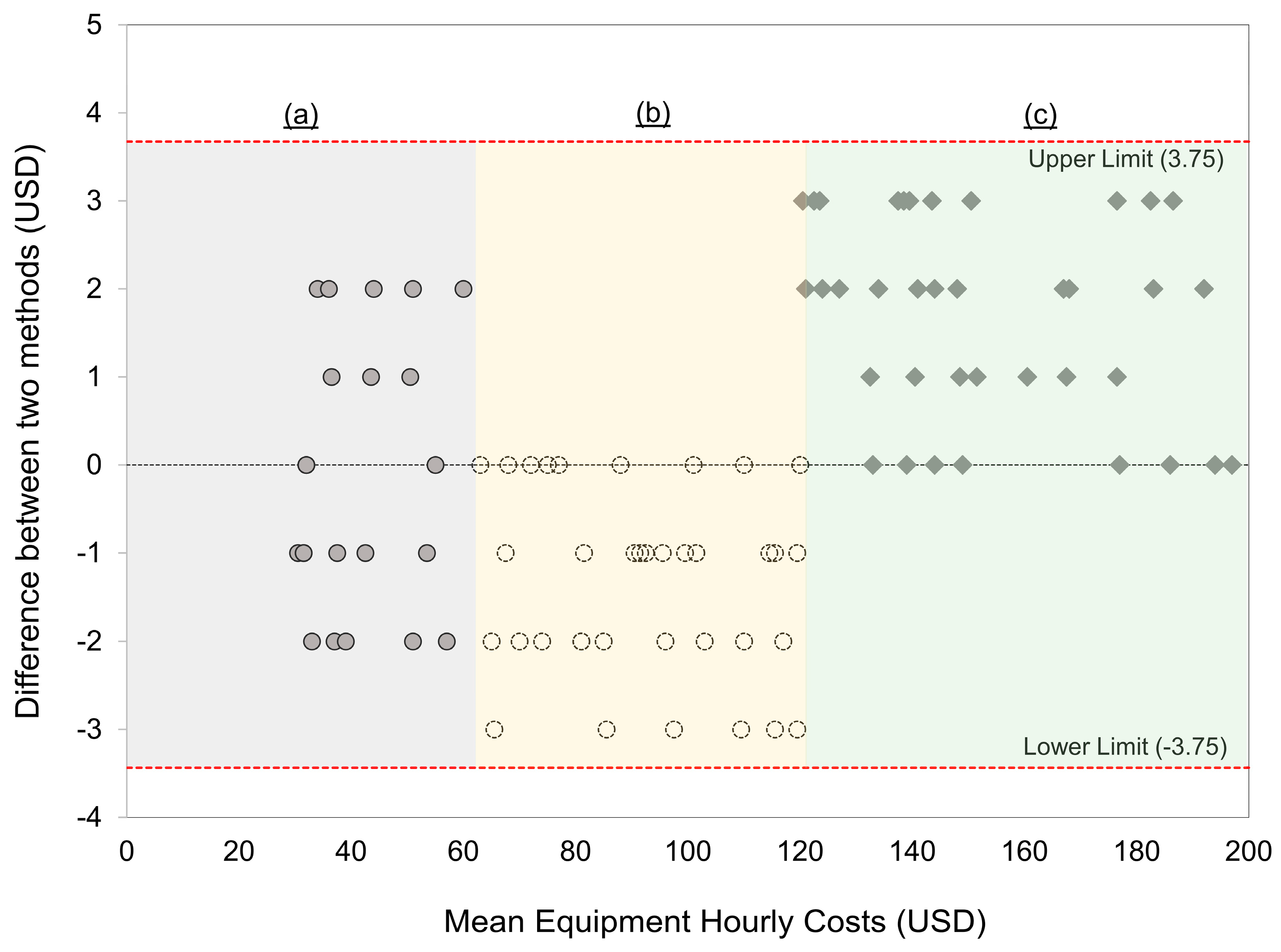
3.3. Comparison
3.4. Development of ECR Model
4. Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Ownership Cost | ||
| 1 | (a) Delivered Price | |
| (b) Tire Replacement Cost (If Wheeled) | ||
| (c) Delivered Price Less Tires (a–b) | ||
| 2 | Estimated Salvage Value | |
| 3 | Minimum Attractive Rate of Return (MARR) | |
| (a) Interest Rate | ||
| (b) Insurance Rate | ||
| (c) Tax Rate | ||
| (d) License and Storage Rate | ||
| (e) Total MARR (a + b + c + d) | ||
| 4 | Estimated Usage per Year (Hours/Year) | |
| 5 | Estimated Useful Life (Hours) | |
| 6 | Estimated Annual Ownership Cost | |
| Determine the present worth of salvage value. Subtract the result from the delivered cost and subtract tires (if wheeled) or from the delivered cost (if tracked). Convert the result to an equivalent series of equal annual payments. | ||
| 7 | Estimated Hourly Ownership Cost (6 ÷ 4) | |
| Operating Cost | ||
| 8 | Maintenance and Repair Cost | |
| 9 | Tire Cost | |
| 10 | Fuel Cost | |
| 11 | Service (Filters, Oil, and Grease) | |
| 12 | Special Wear Items (Cost ÷ Life) | |
| 13 | Estimated Hourly Operating Cost | |
| (Sum of Lines 8 Through 12) | ||
| 14 | Total Hourly Ownership and Operating Cost (7 + 13) | |
Appendix B
| EQUIPMENT INFORMATION | Cost | |
| A | Machine Designation | |
| B | Estimated Ownership Period (Years) | |
| C | Estimated Usage (Hours/Year) | |
| D | Ownership Usage (Total Hours) (B × C) | |
| OWNING COSTS | ||
| 1 | a. Delivered Price (P), to the customer (including attachments) | |
| b. Less Tire Replacement Cost if Desired | ||
| c. Delivered Price less Tires | ||
| 2 | Less Residual Value at Replacement (S) | |
| 3 | a. Net Value to be Recovered Through Work (Line 1c − Line 2) | |
| b. Cost Per Hour: Net Value/Total Hours | ||
| 4 | Interest Costs | |
| 5 | Insurance Costs | |
| 6 | Property Tax | |
| 7 | Total Hourly Owning Cost (Line 3b+ Line 4+ Line 5 and Line 6) | |
| OPERATING COSTS | ||
| 8 | Fuel Price: Unite Fuel Price × Consumption | |
| 9 | Planned Maintenance (PM) − Lube Oils, Filters, Grease, Labor | |
| 10 | (a) Tires: Replacement Cost /Life In Hours | |
| (b) Undercarriage (Impact + Abrasiveness + Z Factor) X Basic Factor | ||
| 11 | Repair Cost (Per Hour) | |
| 12 | Special Wear Items (Cost/Life) | |
| 13 | Total Operating Costs (Add Lines 8, 9, 10a, 10b, 11, and 12) | |
| LABOR COSTS | ||
| 14 | Operator’s Hourly Wage (Including Fringes) | |
| UNIT OWNING AND OPERATING COSTS | ||
| 15 | Total Owning and Operating Cost (Add Lines 7, 13, and 14) | |
Appendix C
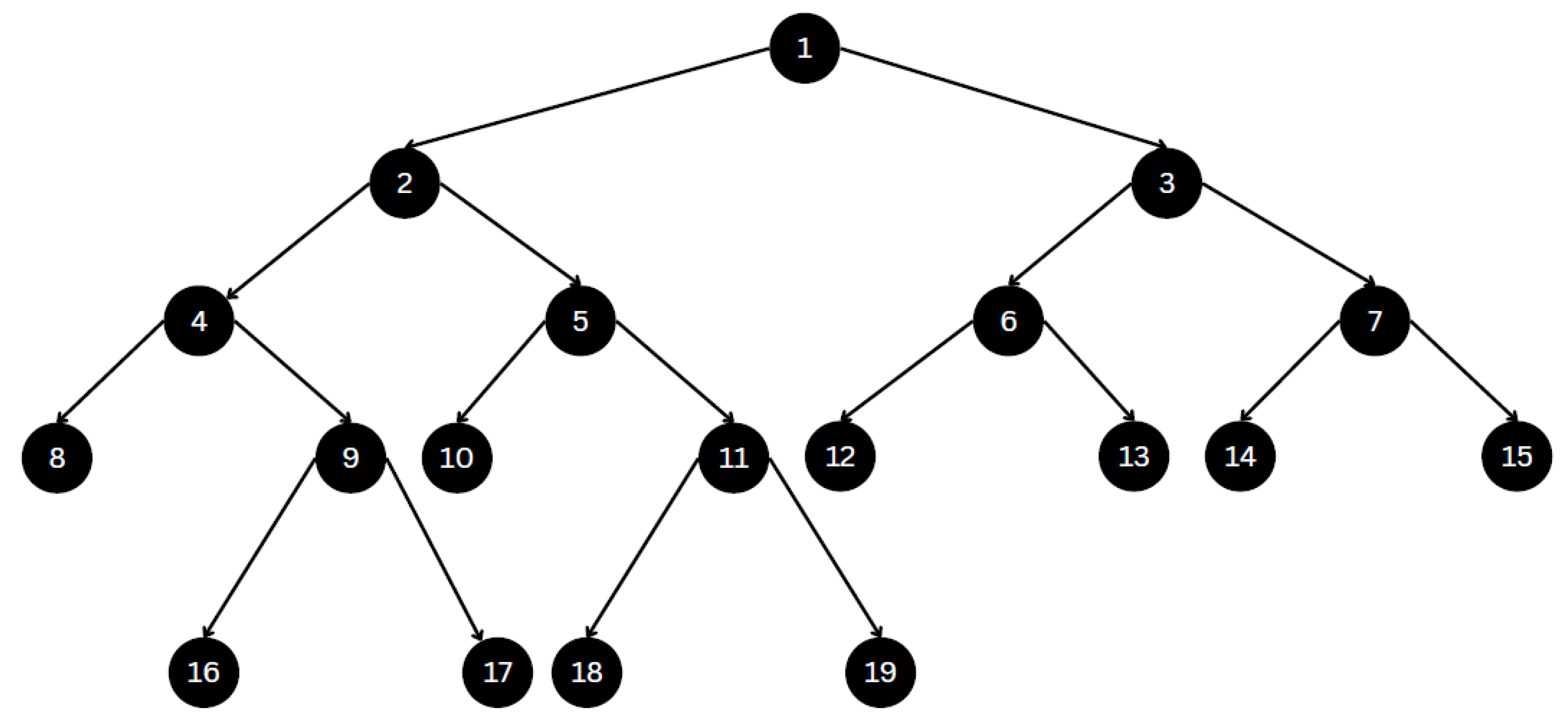
| 1 | Total hourly rate rates by 2015 U.S. Army corps ≤ 3.17, squared error =1676.545, samples = 115, value = 56.54 |
| 2 | Total hourly rate rates by 2020 IDOT procedure ≤ 40.883, squared error =349.46, samples = 55, value = 35.354 |
| 3 | Total hourly rate rates by 2020 IDOT procedure ≤ 133.22, squared error =1023.955, samples = 30, value = 113.65 |
| 4 | Total hourly rate rates by 2015 U.S. Army corps ≤ 20.065, squared error =76.965, samples = 50, value = 22.603 |
| 5 | Total hourly rate rates by 2015 U.S. Army corps ≤ 52.46, squared error =50.613, samples = 35, value = 56.061 |
| 6 | Total hourly rate rates by 2015 U.S. Army corps ≤ 59.695, squared error =119.632, samples = 23, value = 97.339 |
| 7 | Total hourly rate rates by 2015 U.S. Army corps ≤ 156.965 squared error =246.667, samples = 7, value = 167.265 |
| 8 | Squared error = 20.231, samples = 21, value = 14.176 |
| 9 | Total hourly rate rates by 2015 U.S. Army corps ≤ 25.915, squared error =29.352, samples = 29, value = 26.706 |
| 10 | Squared error = 13.152, samples = 17, value = 45.176 |
| 11 | Total hourly rate rates by 2020 IDOT procedure ≤ 65.597, squared error =39.235, samples = 15, value = 63.525 |
| 12 | Squared error = 14.155, samples = 10, value = 56.492 |
| 13 | Squared error = 40.652, samples = 13, value = 106.552 |
| 14 | Squared error = 7.134, samples = 3, value = 149.251 |
| 15 | Squared error = 6.092, samples = 4, value = 150.717 |
| 16 | Squared error = 2.196, samples = 17, value = 24.415 |
| 17 | Squared error = 4.965, samples = 12, value = 34.775 |
| 18 | Squared error = 6.59, samples = 11, value = 59.645 |
| 19 | Squared error = 6.509, samples = 7, value = 63.626 |
References
- Shaurette, M. Higher Hourly Cost Compensation for Heavy Equipment Used In Demolition Activity. Int. J. Constr. Educ. Res. 2015, 11, 280–291. [Google Scholar] [CrossRef]
- EquipmentWatch. Available online: https://equipmentwatch.com/ (accessed on 6 February 2023).
- Illinois Department of Transportation Annual Report. 2021. Available online: https://idot.illinois.gov/about-idot/our-story/performance/reports/annual-reports.html (accessed on 20 April 2022).
- Jorge, J.E.; Herbsman, Z. Determination of Construction Equipment Rental Rates in Force Account Operations for Federal and State Government Agencies. In Proceedings of the Transportation Research Record, Washington, DC, USA, 5–7 January 1989; Volume 1234, pp. 74–83. [Google Scholar]
- The Schedule of Average Annual Equipment Ownership Expense (SOAAEOE). Available online: https://idot.illinois.gov/transportation-system/local-transportation-partners/county-engineers-and-local-public-agencies/lpa-project-development-and-implementation/policy-and-procedures/schedule-avg.html (accessed on 20 April 2022).
- Slobodnyak, I.; Sidorov, A. Time Value of Money Application for the Asymmetric Distribution of Payments and Facts of Economic Life. J. Risk Financ. Manag. 2022, 15, 573. [Google Scholar] [CrossRef]
- AGC Contractors Equipment Cost Guide. Available online: https://www.agc.org/sites/default/files/Files/Construction%20Markets/CM_GC_Guidelines.pdf (accessed on 30 March 2022).
- Labor Surcharge and Equipment Rental Rates. Division of Construction, Department of Transportation, California State Transportation Agency, State of California. Available online: https://dot.ca.gov/programs/construction/equipment-rental-rates-and-labor-surcharge (accessed on 6 February 2023).
- CAT Rental: How Much Does It Cost to Rent Heavy Equipment? Available online: https://www.catrentalstore.com/en_US/blog/cost-to-rent-heavy-equipment.html (accessed on 13 April 2022).
- Shehadeh, A.; Alshboul, O.; Al Mamlook, R.E.; Hamedat, O. Machine Learning Models for Predicting the Residual Value of Heavy Construction Equipment: An Evaluation of Modified Decision Tree, LightGBM, and XGBoost regression. Autom. Constr. 2021, 129, 103827. [Google Scholar] [CrossRef]
- Xie, H.; Shi, W.; Issa, R.R.; Guo, X.; Shi, Y.; Liu, X. Machine Learning of Concrete Temperature Development for Quality Control of Field Curing. J. Comput. Civ. Eng. 2020, 34, 04020031. [Google Scholar] [CrossRef]
- Neloy, A.A.; Haque, H.S.; Ul Islam, M.M. Ensemble Learning Based Rental Apartment Price Prediction Model by Categorical Features Factoring. In Proceedings of the 2019 11th International Conference on Machine Learning and Computing, Zhuhai, China, 22–24 February 2019; pp. 350–356. [Google Scholar]
- Li, Y.; Wang, S.; Ma, Y.; Pan, Q.; Cambria, E. Popularity Prediction on Vacation Rental Websites. J. Neurocomputing 2020, 412, 372–380. [Google Scholar] [CrossRef]
- Abed, Y.G.; Hasan, T.M.; Zehawi, R.N. Cost Prediction for Roads Construction using Machine Learning Models. Int. J. Electr. Comput. Eng. Syst. 2022, 13, 927–936. [Google Scholar]
- Heidari, M.; Zad, S.; Rafatirad, S. Ensemble of Supervised and Unsupervised Learning Models to Predict a Profitable Business Decision. In Proceedings of the IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Toronto, ON, Canada, 21–24 April 2021; pp. 1–6. [Google Scholar]
- Wang, W.; Pan, C. Collectively Learned Multi-Level Spatial Embeddings for Residential Rental Price Prediction. In Proceedings of the IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 274–283. [Google Scholar]
- Heidari, M.; Rafatirad, S. Bidirectional Transformer Based on Online Text-Based Information to Implement Convolutional Neural Network Model for Secure Business Investment. In Proceedings of the IEEE International Symposium on Technology and Society (ISTAS), Tempe, AZ, USA, 12–15 November 2020; pp. 322–329. [Google Scholar]
- Feng, Y.; Wang, S. A Forecast for Bicycle Rental Demand Based on Random Forests and Multiple Linear Regression. In Proceedings of the IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 101–105. [Google Scholar]
- Alshboul, O.; Shehadeh, A.; Al-Kasasbeh, M.; Al Mamlook, R.E.; Halalsheh, N.; Alkasasbeh, M. Deep and Machine Learning Approaches for Forecasting the Residual Value of Heavy Construction Equipment: A Management Decision Support Model. J. Eng. Constr. Archit. Manag. 2021, 29, 4153–4176. [Google Scholar] [CrossRef]
- Supervised vs. Unsupervised Learning; What’s the Difference? IBM Blog. Available online: https://www.ibm.com/cloud/blog/supervised-vs-unsupervised-learning (accessed on 17 November 2022).
- Seresht, N.G.; Fayek, A.R. Dynamic Modeling of Multifactor Construction Productivity for Equipment-Intensive Activities. J. Constr. Eng. Manag. 2018, 144, 04018091. [Google Scholar] [CrossRef]
- Milošević, I.; Kovačević, M.; Petronijević, P. Estimating Residual Value of Heavy Construction Equipment Using Ensemble Learning. J. Constr. Eng. Manag. 2021, 147, 04021073. [Google Scholar] [CrossRef]
- Baduge, S.K.; Thilakarathna, S.; Perera, J.S.; Arashpour, M.; Sharafi, P.; Teodosio, B.; Shringi, A.; Mendis, P. Artificial Intelligence and Smart Vision for Building and Construction 4.0: Machine and Deep Learning Methods and Applications. Autom. Constr. 2022, 141, 104440. [Google Scholar] [CrossRef]
- Khalaf, T.Z.; Çağlar, H.; Çağlar, A.; Hanoon, A.N. Particle Swarm Optimization Based Approach for Estimation of Costs and Duration of Construction Projects. J. Civ. Eng. 2020, 6, 384–401. [Google Scholar] [CrossRef]
- Lee, J.; Matsumura, K.; Yamakoshi, K.I.; Rolfe, P.; Tanaka, S.; Yamakoshi, T. Comparison between red, green and blue light reflection photoplethysmography for heart rate monitoring during motion. In Proceedings of the 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 1724–1727. [Google Scholar]
- Chicco, D.; Warrens, M.J.; Jurman, G. The Coefficient of Determination R-squared Is more Informative than SMAPE, MAE, MAPE, MSE and RMSE in Regression Analysis Evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef] [PubMed]
- Akinosho, T.D.; Oyedele, L.O.; Bilal, M.; Ajayi, A.O.; Delgado, M.D.; Akinade, O.O.; Ahmed, A.A. Deep learning in the construction industry: A review of present status and future innovations. J. Build. Eng. 2020, 32, 101827. [Google Scholar] [CrossRef]
- Sayed, M.; Abdel-Hamid, M.; El-Dash, K. Improving cost estimation in construction projects. Int. J. Constr. Manag. 2023, 23, 135–143. [Google Scholar] [CrossRef]
- USACE. EP1110-1-8 Construction Equipment Ownership and Operating Expense Schedule. Available online: https://www.usace.army.mil/Cost-Engineering/EP1110-1-8/ (accessed on 30 March 2022).
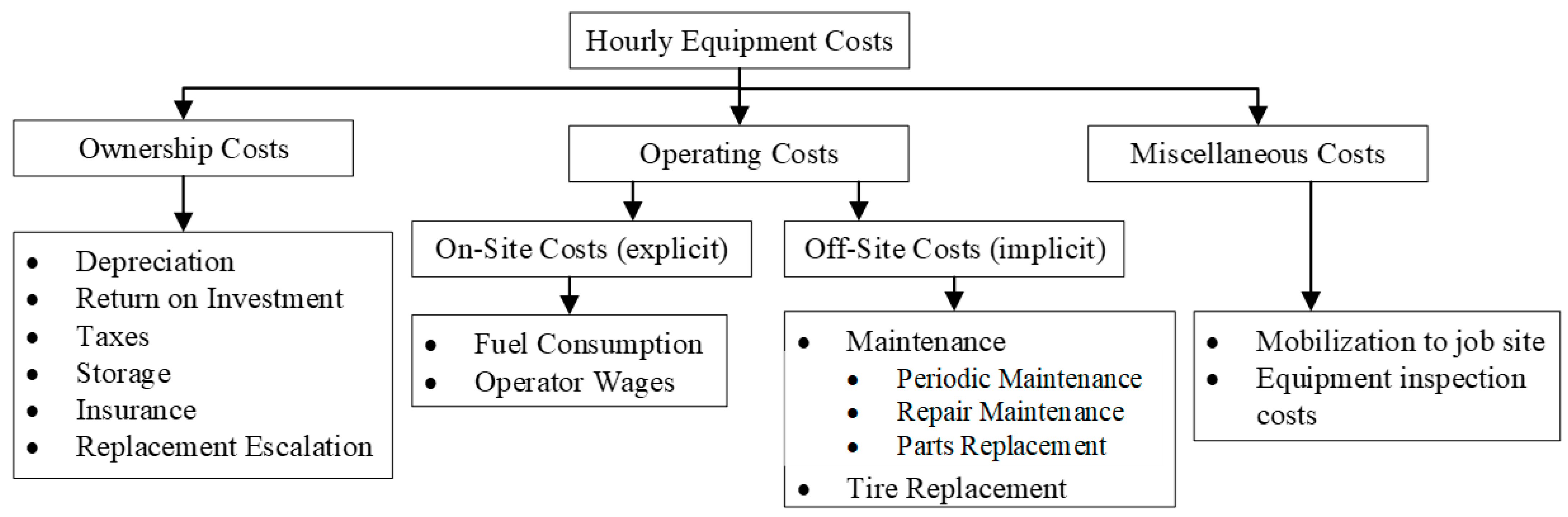


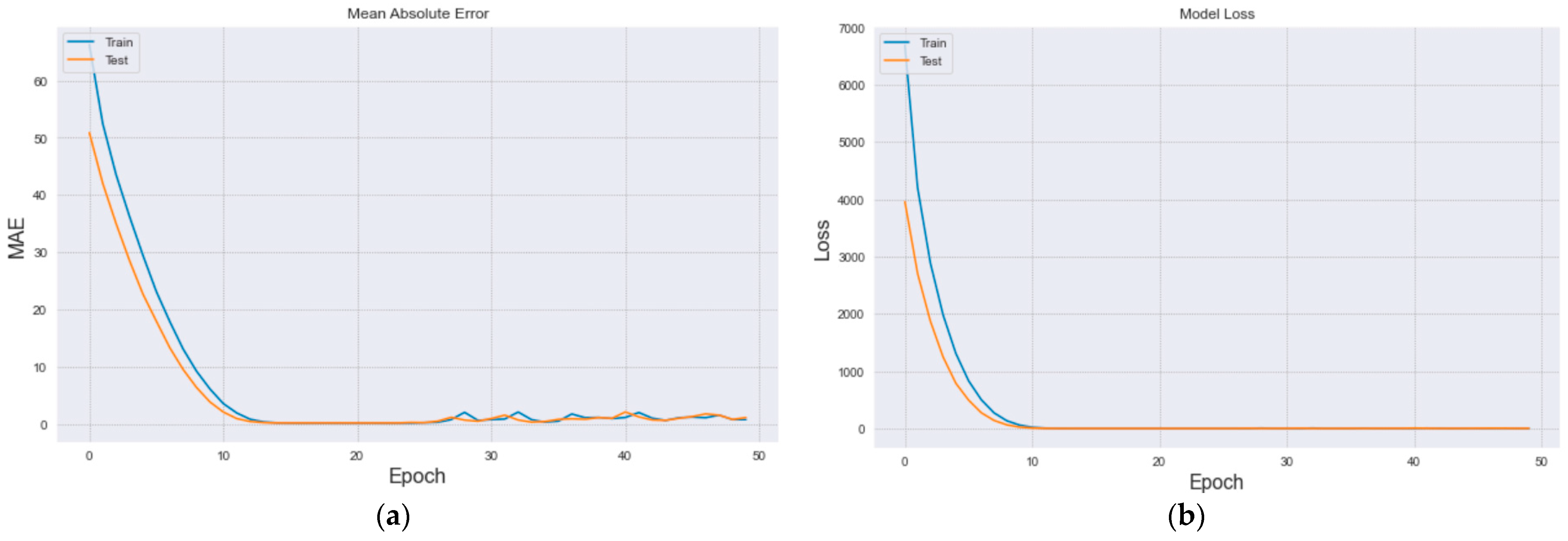
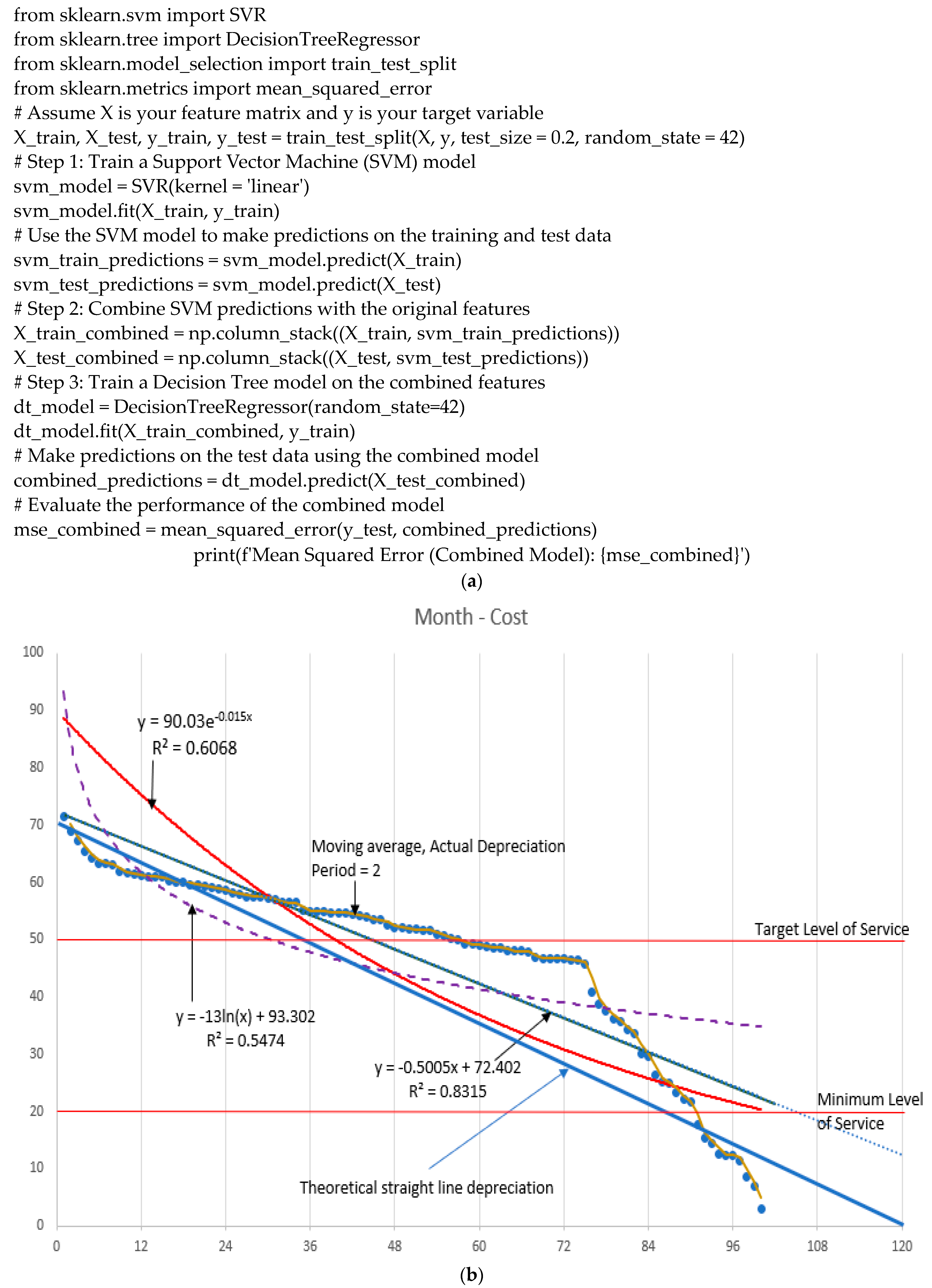
| Tools | Description | Advantages | Disadvantages |
|---|---|---|---|
| Cost Indexes | The indexes track changes in costs over time based on industry-specific factors and adjust historical cost data to current values. | (1) Adaptability based on industry-specific factors. (2) Widely accepted. | (1) Generalization: some project-specific factors are not considered. (2) Time lag leading to inaccuracies. |
| Expert Judgment (i.e., Delphi Method) | Expert opinions and judgment are valuable, especially when dealing with unique or specialized equipment. A Delphi method starts with obtaining input from a panel of experts through a structured and iterative process to reach a consensus on equipment costs. | (1) Expert insight. (2) Flexibility: applicable when data is limited or for unique projects. | (1) Subjectivity. (2) Resource intensive: the Delphi method has multiple rounds of expert input and is time-consuming. |
| Historical Data Analysis | This is considered analogous estimating, which uses historical data from similar scenarios to estimate equipment costs for a new scenario. It relies on the assumption that similar scenarios have similar cost structures. | (1) Practical with real-world data. (2) Context sensitivity: considers the specific characteristics of similar projects. | (1) Limited applicability for unique projects with significant differences. (2) Data quality relies on the availability and quality of historical data. |
| Monte Carlo Simulation | By simulating a large number of possible outcomes to account for uncertainty and variability in equipment costs, this method can handle high uncertainty. | (1) Risk assessment. (2) Comprehensive: various input distributions and scenarios. | (1) Complex and computationally intensive. (2) Requires accurate data and assumptions about probability distributions. |
| Cost Estimation Software like 2024 CostWorks Estimator® and Parametric Estimation Tools | These tools use historical data and mathematical relationships (see Figure 1) to estimate costs based on key parameters. Parametric models for equipment cost prediction are industry-specific and customizable for different types of equipment. | (1) Efficiency: rapid cost estimates based on key parameters. (2) Easiness: user-friendly. | (1) Sensitivity to assumptions: accuracy of the assumptions and input parameters. (2) Limited flexibility: no complex relationships between variables. |
| Regression Analysis | (1) Linear regression: This statistical method models the relationship between independent variables (equipment features) and the dependent variable (cost). (2) Multiple regression: multiple independent variables and allows for complex modeling of cost factors. | (1) Interpretability. (2) Versatility: applicable to various types of data and well-suited to linear relationships. | (1) Assumption of linearity. (2) Limited complexity. |
| Machine-Learning (ML) Algorithms | Commonly used ML algorithms include: (1) Decision trees for both categorical and numerical data, versatile for different types of input features. (2) Random forest combining multiple decision trees, providing improved accuracy and robustness. (3) Gradient-boosting algorithms for regression tasks and complex relationships. (4) Deep-learning models (e.g., neural networks) for large and complex datasets, intricate patterns, and relationships. | (1) Capturing complex relationships and complex patterns. (2) High accuracy, especially with large and diverse datasets. | (1) Black-box nature: challenging to interpret. (2) Data intensiveness: substantial amounts of data for training. (3) Overfitting: providing accurate predictions for training data but not for newly added data. |
| References | Contents | Dataset |
|---|---|---|
| [12] | This study used an Advanced Regression Techniques (ART) method and categorical features as factors to predict rental apartment prices. The selected algorithms were (1) advanced linear regression, neural network, random forest, support vector machine (SVM), and decision-tree regressor for predictors; (2) Ensemble AdaBoosting Regressor, Ensemble Gradient Boosting Regressor, and Ensemble eXtreme Gradient Boosting (XGBoost) for ensemble learning; and (3) Ridge Regression, Lasso Regression, and Elastic Net Regression to combine the advance regression techniques. | The dataset was from bProperty.com about the apartments in the city of Dhaka, Bangladesh. |
| [13] | An encoder–decoder framework and a dual-gated recurrent unit (GRU) were used to calculate a house popularity feature through inter-event time, which was the gap between two successive reviews. The comparison between Long-Short-Term Memory (LSTM) and GRU algorithms showed that GRU algorithms had better time efficiency and less computation complexity. The dual-state gates allowed the gates to ignore irrelevant information. The TensorFlow library was used to develop the model. | The datasets of review comments were from vacation rental websites. The parameters were limited. |
| [14] | This study summarized the knowledge body on machine-learning algorithms and deep-learning approaches for construction cost prediction. But it only considered building, bridge, tower, dam, road, highway, railroad, airport, and tunnel costs. The selected algorithms of unsupervised learning detected unlabeled instances of data using the clustering learning method, such as Expectation-Maximization (EM) clustering, K-means clustering, and Self Organizing Map (SOM). The selected supervised learning implemented the detection (or classification) depending on the labeled instances of data in a training stage, which includes SVM, decision tree, random forest, naive Bayes (NB), K-nearest neighbors (K-NN), ANN, deep neural network, conventional neural network, and RNN. The evaluation metrics include error, accuracy, and R2. SVM and ANN produced the best outcomes in building and road projects. | Bibliographic records were retrieved from the Scopus database. The findings were incoherent. The research limitations include a lack of a quantitative dataset, impractical tasks, and invalidation. |
| [15] | This real-estate rent-prediction study used the comparison of seven machine-learning algorithms, including linear regression, multilayer perceptron, random forest, KNN, locally weighted learning, sequential minimal optimization, and KStar algorithms. It focused on three house types—single-family, townhouse, and condo—and considered 21 data attributes (e.g., area space, price, number of beds/bathrooms, rent, school rating, etc.). Then, it used a hierarchical clustering approach based on house type and average rent estimate, and lazy learning algorithms were found to have higher accuracy and lower prediction errors compared to eager learning methods. | Using the Zillow API to collect a dataset of residential housing data for Virginia, US. |
| [16] | Locality-aware heterogeneous data was converted to linked latent spaces to learn their attributes for a final decision. A data-fusion model was implemented with four modules, including multi-granularity spatial context embedding, item set embedding, text encoder, and numerical feature. | GeoSpatial data from Airbnb. |
| [17] | A natural language processing approach was implemented based on the semantics of online information from Airbnb, Zillow, schools, public transportation, and crime rate websites for rent prediction. Eager and lazy machine-learning models were implemented, together with a transfer learning model for rent prediction. | Detection of a profitable rental property; online textual resources. |
| [18] | Due to the inaccuracy of the results of multiple linear regressions, a random forest model and a Generalized Boosted Regression (GBM) packet were used to improve the decision tree. The random forest model generated trees for classification and regression analysis. The GBM models improved the capacity of the decision tree by establishing a loss function in the previous model of gradient descent direction. | Strong model-generalization ability. The prediction accuracy was maintained when situations changed. |
| [10,19] | A decision-support model was developed based on the comparison results of deep- and machine-learning regression networks. It considered data mining, random forest (RF), decision tree (DT), deep neural network (DNN), and linear regression (LR) based modeling. Four performance metrics (i.e., mean absolute error (MAE), mean squared error (MSE), mean absolute percentage error (MAPE), and coefficient of determination (R2)) were used to measure and compare the developed algorithms’ accuracy. The DT model demonstrated the highest accuracy for the heavy construction equipment-related data that was recorded from public equipment auctions available online. The equipment types were grader, excavator, loader, compactor, asphalt paver, and truck. | The data resources included Mascus USA *, 2018; Machinery Zone, 2019; Machinery Trader, 2020; Iron Planet, 2020; Equipment Trader, 2020; Alibaba, 2020. |
| Linear Regression | Random Forest | Gradient Boosting | Decision-Tree Regression | Modified Decision Tree (MDT) with SVM | |
|---|---|---|---|---|---|
| R2 | 1.00 | 0.99 | 1.00 | 0.97 | 1.00 |
| RMSE | 0.00 | 3.37 | 2.62 | 2.62 | 1.73 |
| MAE | 0.00 | 1.95 | 1.32 | 1.32 | 1.38 |
| MAPE | 0.00 | 0.0300 | 0.0200 | 0.0200 | 0.0198 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, F.; Xie, H.; Inti, S.; Issa, R.R.A.; Vanka, V.S.V.; Yu, Y.; Huang, T. Data-Driven Decision Support for Equipment Selection and Maintenance Issues for Buildings. Buildings 2024, 14, 436. https://doi.org/10.3390/buildings14020436
Jiang F, Xie H, Inti S, Issa RRA, Vanka VSV, Yu Y, Huang T. Data-Driven Decision Support for Equipment Selection and Maintenance Issues for Buildings. Buildings. 2024; 14(2):436. https://doi.org/10.3390/buildings14020436
Chicago/Turabian StyleJiang, Fengchang, Haiyan Xie, Sundeep Inti, Raja R. A. Issa, Venkata Sai Vikas Vanka, Ye Yu, and Tianyi Huang. 2024. "Data-Driven Decision Support for Equipment Selection and Maintenance Issues for Buildings" Buildings 14, no. 2: 436. https://doi.org/10.3390/buildings14020436
APA StyleJiang, F., Xie, H., Inti, S., Issa, R. R. A., Vanka, V. S. V., Yu, Y., & Huang, T. (2024). Data-Driven Decision Support for Equipment Selection and Maintenance Issues for Buildings. Buildings, 14(2), 436. https://doi.org/10.3390/buildings14020436