
Improved Data-Driven Building Daily Energy Consumption Prediction Models Based on Balance Point Temperature


Abstract
1. Introduction
- The balance point temperature is one of the factors that affect building energy consumption. How to use statistical methods to identify the balance point temperature scientifically and effectively?
- Currently, research on using balance point temperature as an input variable in data-driven models is relatively scarce. Can the addition of a balance point temperature label (BPT label) improve the prediction accuracy of data-driven models?
- Is there a difference in prediction accuracy of different data-driven model tools trained on the same dataset, and which data-driven model tool should be prioritized under different data conditions?
- What is the importance of each input variable, including the BPT label, in the prediction model?
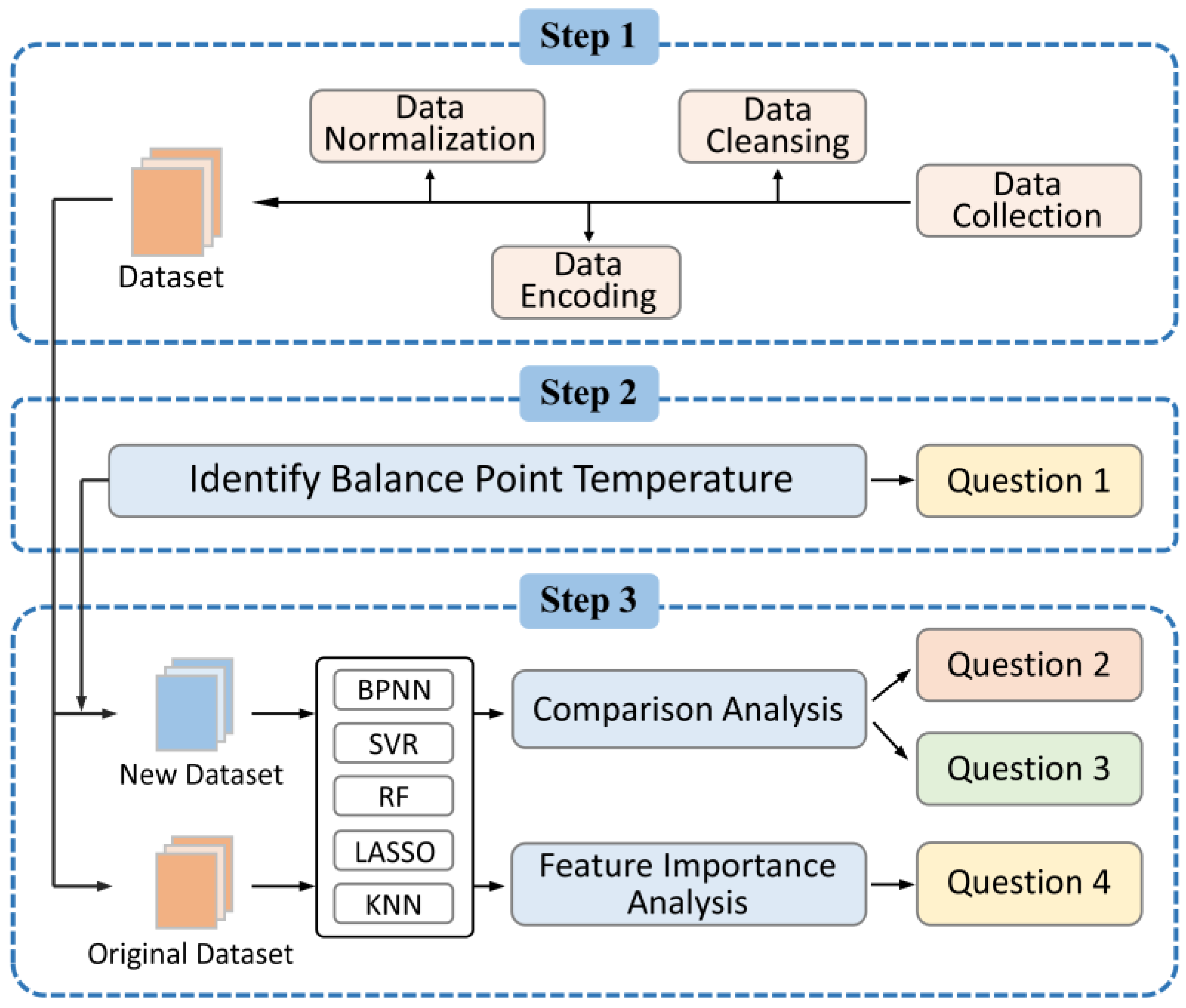
2. Methodology
2.1. Data Collection
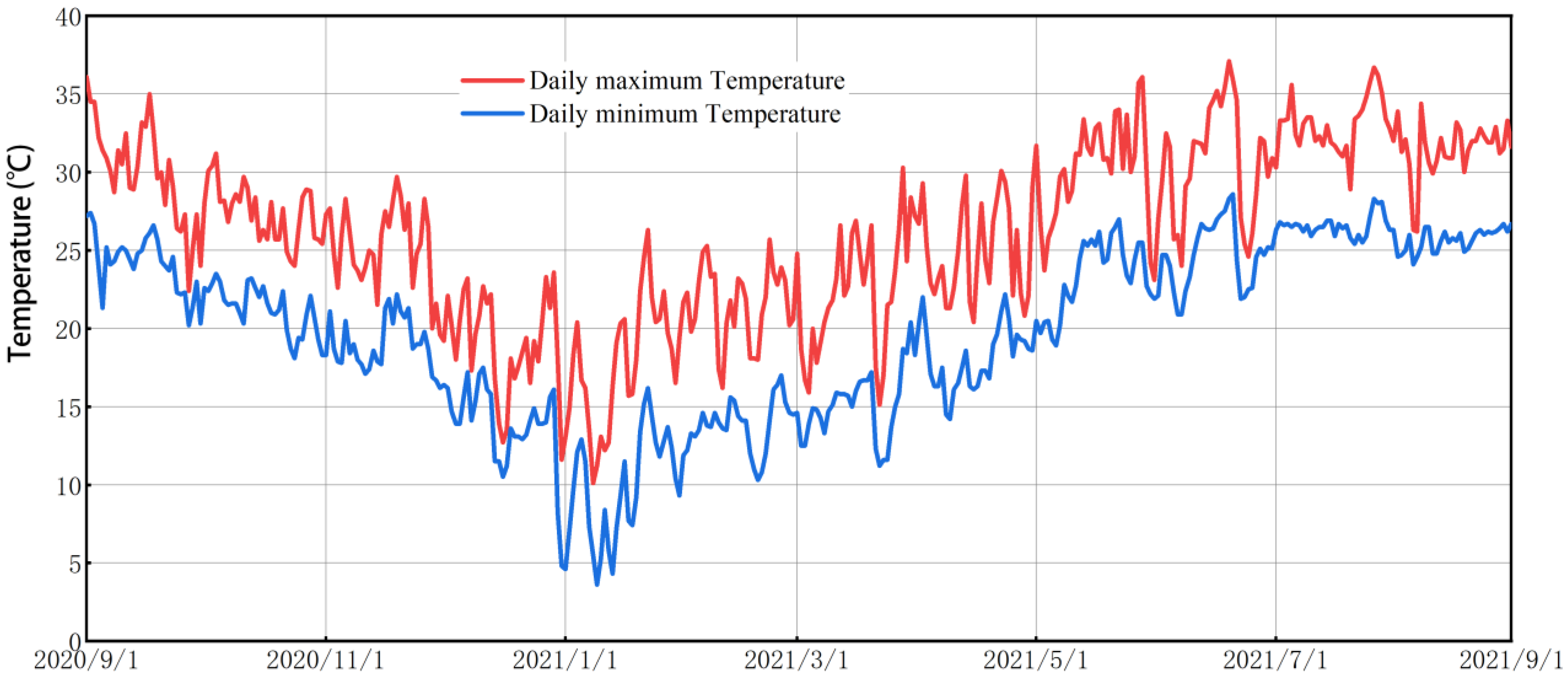
2.1.1. Electricity Consumption Data
2.1.2. Weather Data
2.1.3. Sunny Day Index
2.1.4. Holiday Index
2.2. Data Preparation
2.2.1. Data Cleansing
2.2.2. Data Encoding and Normalization
2.3. Data-Driven Models
2.3.1. Backpropagation Neural Network
2.3.2. Random Forest
- Select n samples from the dataset using a bootstrapped sampling approach to form a training set;
- Generate a decision tree using the sampled dataset.
- Repeat steps 1 to 2 for k times, where k is the number of trees in the RF.
- Use the trained Random Forest to predict the test samples and decide the prediction result using the voting method, as shown in Figure 3.
- Construct N decision trees;
- When the current decision tree ktree = 1, the obtain the corresponding OOB data ;
- Calculate the prediction error of the current tree for ;
- Randomly perturb the i-th feature of as , calculate the prediction error of the current tree for ;
- For each decision tree, ktree = 2, …, N, repeat steps 2–4;
- Calculate the VIM of the target feature according to Equation (2).
2.3.3. Support Vector Regression
2.3.4. Least Absolute Shrinkage and Selection Operator
2.3.5. K-Nearest Neighbors
2.4. Model Performance Evaluation Metrics
3. Case Study
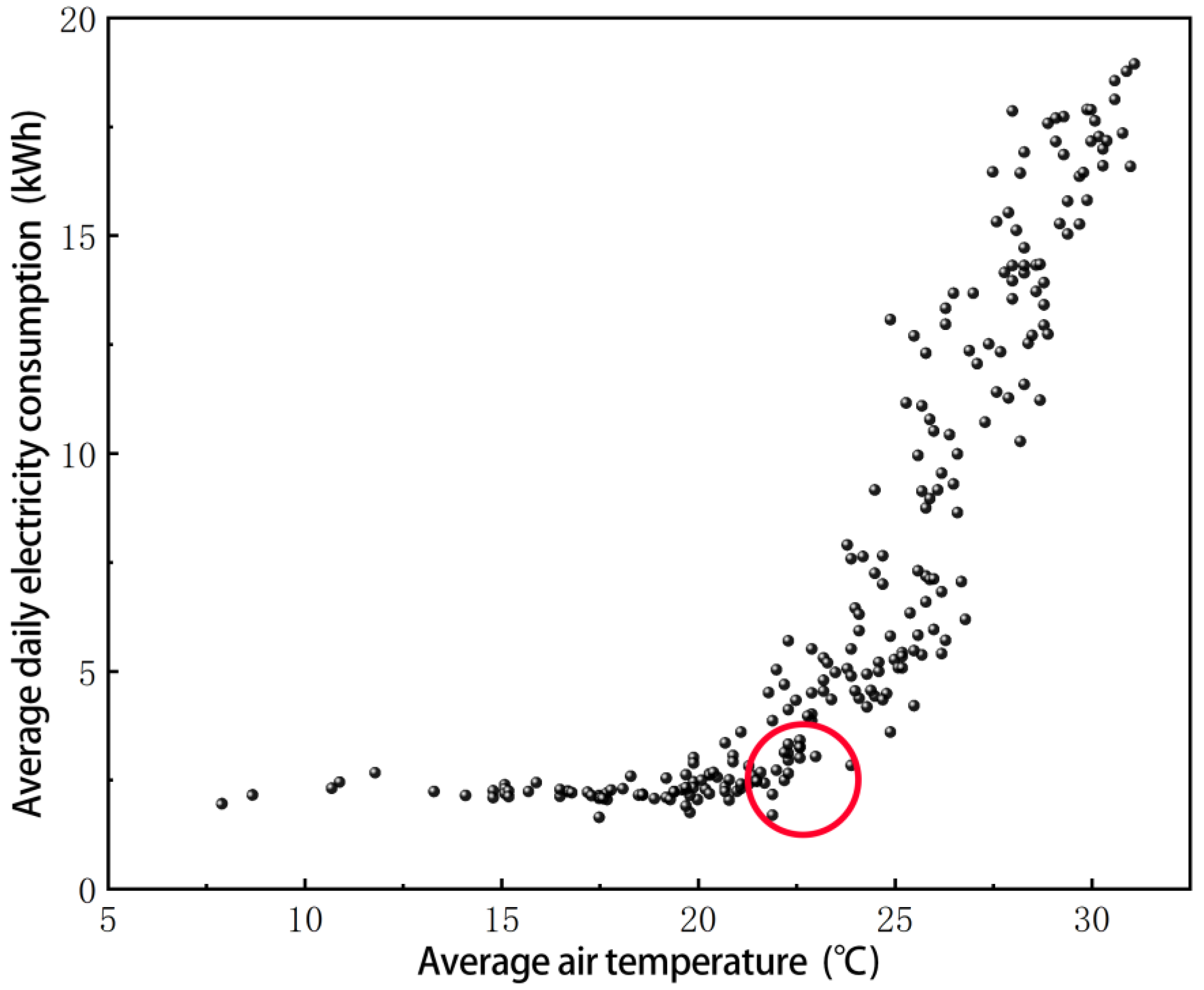
3.1. Identifying the Balance Point Temperature
| Algorithm 1. Identity balance point temperature. | |
| Input: | Daily average air temperature, Daily average electricity consumption |
| Output: | Balance point temperature |
| 1 Traversing all the points and dividing the data set into two parts. | |
| 2 Performing linear regression on each side. | |
| 3 Calculating the R2 values of the integrated model and the coordinates of the intersection points. | |
| 4 Plotting the change in R2 values. | |
| 5 Output the intersection point coordinate when the R2 value is maximum. | |
3.2. Prediction Model Implementation
4. Result and Analysis
4.1. Prediction Model Implementation
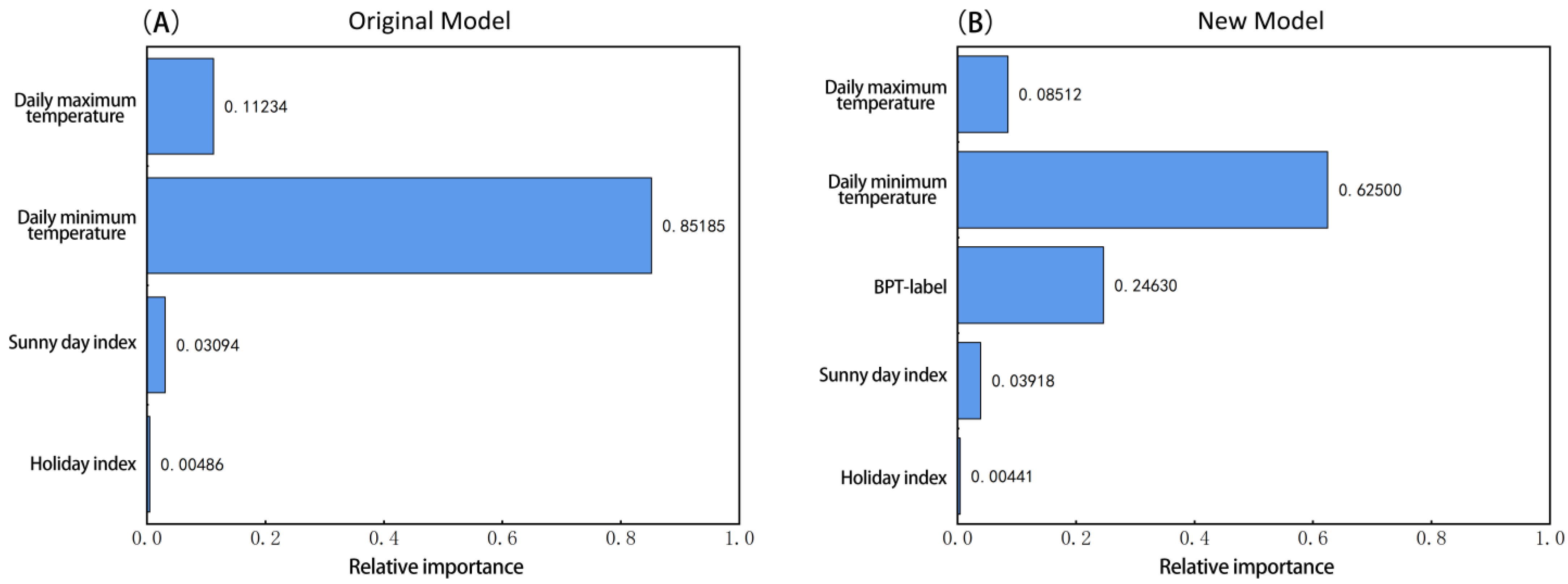
4.2. Importance Analysis of Input Variables
5. Discussion
- The current data-driven building energy consumption prediction models tend to focus on selecting input feature variables related to meteorological and building parameters. In order to discover more feature variables that influence building energy consumption, researchers have deployed numerous sensors within and around buildings and constructed energy management systems. However, the excessive monitoring data has instead increased the difficulty of analysis, as most input variables have minimal impact on building energy consumption, such as the holiday index in this study (which had a feature importance of only 0.4%). Therefore, improving feature variable selection can involve more comprehensive consideration of building attributes and environmental factors, using more advanced feature selection techniques, and exploring new feature variable methods. This article is the first study to use the balance point temperature label as a feature variable. Through the data analysis, it was found that the balance point temperature label can significantly improve the performance of the building energy consumption prediction model, with an importance of about 25%.
- Building energy consumption models can be modeled based on different machine learning algorithms, such as BPNN, RF, SVR, LASSO, KNN, etc., as used in this study. Different algorithms are suitable for different datasets and problems, so selecting the appropriate algorithm is crucial to improve predictive performance. This article suggests through the analysis of a case in Xiamen that when there are sufficient input features, BPNN is optimal, and when input features are insufficient, KNN is best. However, in actual situations, there is no quantitative standard for whether input feature data is sufficient, but rather a subjective judgment based on the researcher’s experience. Therefore, before conducting predictive analysis on a specific building case, potential models should be screened instead of using a single prediction model or method that the researcher is good at. In addition, model optimization can also improve predictive performance. Hyper-parameters should be optimized before model application.
- Data quality issues: The predictive performance of building energy consumption models is influenced by the quality and quantity of input data. If the data contains missing values, outliers, or noise, the predictive performance of the model will be affected.
- Transferability issues: The predictive performance of building energy consumption models may be influenced by transferability issues between datasets. This is because building characteristics and environmental factors may vary across different geographic locations and time periods, thus limiting the predictive performance of the model.
- Interpretability issues: Machine learning models are often considered “black box” models, making it difficult to explain the reasons for their predicted results. This may limit the practical application of the model.
6. Conclusions
- This article proposes a statistical algorithm for calculating the balance point temperature and identifies the balance point temperature of a residential building in Xiamen, China as 22.2 °C. Significant differences in the correlation between temperature and building energy consumption exist around this balance point temperature.
- Adding the balance point temperature label to the input variables can significantly improve the daily energy consumption prediction accuracy of data-driven models. The R2 values of the BPNN model increased by 0.3448, SVR increased by 0.2262, RF increased by 0.2165, LASSO increased by 0.3066, and KNN increased by 0.1440.
- In the task of daily energy consumption prediction, the prediction accuracy of data-driven models varies under different input data conditions. When the input variable data is insufficient, the prediction performance from high to low is KNN, RF, SVR, BPNN, and LASSO. When the input variable data is sufficient, the prediction performance is in the order of BPNN, SVR, KNN, RF, and LASSO.
- Among the input variables of the daily energy consumption prediction model, the dominant variable is the daily minimum temperature, which is much more important than the daily maximum temperature. The balance point temperature label is crucial in the prediction model and accounts for 25% of the importance.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Anderson, J.E.; Wulfhorst, G.; Lang, W. Energy analysis of the built environment—A review and outlook. Renew. Sustain. Energy Rev. 2015, 44, 149–158. [Google Scholar] [CrossRef]
- Tam, V.W.; Le, K.N.; Tran, C.N.; Illankoon, I.C.S. A review on international ecological legislation on energy consumption: Greenhouse gas emission management. Int. J. Constr. Manag. 2021, 21, 631–647. [Google Scholar] [CrossRef]
- Du, K.; Xie, J.; Khandelwal, M.; Zhou, J. Utilization Methods and Practice of Abandoned Mines and Related Rock Mechanics under the Ecological and Double Carbon Strategy in China—A Comprehensive Review. Minerals 2022, 12, 1065. [Google Scholar] [CrossRef]
- Deng, H.; Xie, C. An improved particle swarm optimization algorithm for inverse kinematics solution of multi-DOF serial robotic manipulators. Soft Comput. 2021, 25, 13695–13708. [Google Scholar] [CrossRef]
- Zhang, J.-R.; Zhang, J.; Lok, T.-M.; Lyu, M.R. A hybrid particle swarm optimization–back-propagation algorithm for feedforward neural network training. Appl. Math. Comput. 2007, 185, 1026–1037. [Google Scholar] [CrossRef]
- Chu, Y.; Yuan, H.; Jiang, S.; Fu, C. Neural Network-Based Reference Block Quality Enhancement for Motion Compensation Prediction. Appl. Sci. 2023, 13, 2795. [Google Scholar] [CrossRef]
- Raza, A.; Ullah, N.; Khan, J.A.; Assam, M.; Guzzo, A.; Aljuaid, H. DeepBreastCancerNet: A Novel Deep Learning Model for Breast Cancer Detection Using Ultrasound Images. Appl. Sci. 2023, 13, 2082. [Google Scholar] [CrossRef]
- Amber, K.P.; Aslam, M.W.; Mahmood, A.; Kousar, A.; Younis, M.Y.; Akbar, B.; Chaudhary, G.Q.; Hussain, S.K. Energy consumption forecasting for university sector buildings. Energies 2017, 10, 1579. [Google Scholar] [CrossRef]
- Yang, H.; Ran, M.; Zhuang, C. Prediction of Building Electricity Consumption Based on Joinpoint–Multiple Linear Regression. Energies 2022, 15, 8543. [Google Scholar] [CrossRef]
- Yang, J.; Ning, C.; Deb, C.; Zhang, F.; Cheong, D.; Lee, S.E.; Sekhar, C.; Tham, K.W. k-Shape clustering algorithm for building energy usage patterns analysis and forecasting model accuracy improvement. Energy Build. 2017, 146, 27–37. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Multi-sequence LSTM-RNN deep learning and metaheuristics for electric load forecasting. Energies 2020, 13, 391. [Google Scholar] [CrossRef]
- Liang, Y.; Pan, Y.; Yuan, X.; Jia, W.; Huang, Z. Surrogate modeling for long-term and high-resolution prediction of building thermal load with a metric-optimized KNN algorithm. Energy Built Environ. 2022. [CrossRef]
- Ding, Z.; Wang, Z.; Hu, T.; Wang, H. A Comprehensive Study on Integrating Clustering with Regression for Short-Term Forecasting of Building Energy Consumption: Case Study of a Green Building. Buildings 2022, 12, 1701. [Google Scholar] [CrossRef]
- Javed, F.; Arshad, N.; Wallin, F.; Vassileva, I.; Dahlquist, E. Forecasting for demand response in smart grids: An analysis on use of anthropologic and structural data and short term multiple loads forecasting. Appl. Energy 2012, 96, 150–160. [Google Scholar] [CrossRef]
- Li, Q.; Meng, Q.; Cai, J.; Yoshino, H.; Mochida, A. Applying support vector machine to predict hourly cooling load in the building. Appl. Energy 2009, 86, 2249–2256. [Google Scholar] [CrossRef]
- Sholahudin, S.; Han, H. Simplified dynamic neural network model to predict heating load of a building using Taguchi method. Energy 2016, 115, 1672–1678. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Q.; Yuan, T. Research on short-term and ultra-short-term cooling load prediction models for office buildings. Energy Build. 2017, 154, 254–267. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Q.; Yuan, T.; Yang, K. Model input selection for building heating load prediction: A case study for an office building in Tianjin. Energy Build. 2018, 159, 254–270. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Zhao, Y. A short-term building cooling load prediction method using deep learning algorithms. Appl. Energy 2017, 195, 222–233. [Google Scholar] [CrossRef]
- Bracale, A.; Carpinelli, G.; De Falco, P.; Hong, T. Short-term industrial reactive power forecasting. Int. J. Electr. Power Energy Syst. 2019, 107, 177–185. [Google Scholar] [CrossRef]
- Krese, G.; Lampret, Ž.; Butala, V.; Prek, M. Determination of a Building’s balance point temperature as an energy characteristic. Energy 2018, 165, 1034–1049. [Google Scholar] [CrossRef]
- Hao, Z.; Xie, J.; Zhang, X.; Liu, J. Simplified Model of Heat Load Prediction and Its Application in Estimation of Building Envelope Thermal Performance. Buildings 2023, 13, 1076. [Google Scholar] [CrossRef]
- Aranda, A.; Ferreira, G.; Mainar-Toledo, M.; Scarpellini, S.; Sastresa, E.L. Multiple regression models to predict the annual energy consumption in the Spanish banking sector. Energy Build. 2012, 49, 380–387. [Google Scholar] [CrossRef]
- Historical Weather in Xiamen. Available online: https://q-weather.info/weather/59134/history/ (accessed on 21 September 2022).
- General Office of the State Council. Notice of the General Office of the State Council on the Arrangement of Some Holidays in 2023. Available online: http://www.gov.cn/zhengce/content/2022-12/08/content_5730844.htm (accessed on 21 September 2022).
- Bourdeau, M.; Zhai, X.Q.; Nefzaoui, E.; Guo, X.; Chatellier, P. Modeling and forecasting building energy consumption: A review of data-driven techniques. Sustain. Cities Soc. 2019, 48, 101533. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, Y.; Xiao, T.; Wang, H.; Hou, P. A novel short-term load forecasting framework based on time-series clustering and early classification algorithm. Energy Build. 2021, 251, 111375. [Google Scholar] [CrossRef]
- Cheadle, C.; Vawter, M.P.; Freed, W.J.; Becker, K.G. Analysis of microarray data using Z score transformation. J. Mol. Diagn. 2003, 5, 73–81. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Neural Networks for Perception; Elsevier: Amsterdam, The Netherlands, 1992; pp. 65–93. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Deb, S.; Gao, X.-Z. Prediction of Charging Demand of Electric City Buses of Helsinki, Finland by Random Forest. Energies 2022, 15, 3679. [Google Scholar] [CrossRef]
- Janitza, S.; Strobl, C.; Boulesteix, A.-L. An AUC-based permutation variable importance measure for random forests. BMC Bioinform. 2013, 14, 119. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.-L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Kukreja, S.L.; Löfberg, J.; Brenner, M.J. A least absolute shrinkage and selection operator (LASSO) for nonlinear system identification. IFAC Proc. Vol. 2006, 39, 814–819. [Google Scholar] [CrossRef]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- ASHRAE Guideline 14: Measurement of Energy, Demand, and Water Savings; ASHRAE: Atlanta, GA, USA, 2014.
- Garreta, R.; Moncecchi, G. Learning Scikit-Learn: Machine Learning In Python; Packt Publishing Ltd.: Birmingham, UK, 2013. [Google Scholar]
- Said, S.A.M.; Habib, M.A.; Iqbal, M.O. Database for building energy prediction in Saudi Arabia. Energy Convers. Manag. 2003, 44, 191–201. [Google Scholar] [CrossRef]
- Verbai, Z.; Lakatos, Á.; Kalmár, F. Prediction of energy demand for heating of residential buildings using variable degree day. Energy 2014, 76, 780–787. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Detail | |
|---|---|---|
| Building | Building type | Apartment |
| Location | Xiamen, China | |
| Build time | 2014s | |
| Floors | 9 | |
| Room | Room area | 25.33 m2 |
| Height | 3.10 m | |
| Led tube | Model: TSZJD2-T5-28W | |
| Fan | Model: FSLD-40 | |
| Air conditioner | Model: KF-35 GW/S (35355) A1-N1 | |
| Socket | Maximum load: 2 kW |
| Variables | Symbol | Content | Type |
|---|---|---|---|
| Dependent variable | Y | Daily average electricity consumption | Continuous variable |
| Explanatory variable 1 | x1 | Holiday index | Proxy variable |
| Explanatory variable 2 | x2 | Sunny day index | Proxy variable |
| Explanatory variable 3 | x3 | Daily minimum temperature | Continuous variable |
| Explanatory variable 4 | x4 | Daily maximum temperature | Continuous variable |
| Model | Parameters | Optimal Value | Best Cross-Validation Score (R2) |
|---|---|---|---|
| BP | Activation | relu | 0.8484 |
| Learning rate | 0.01 | ||
| Hidden Layers | 3 | ||
| Hidden Nodes | 50 | ||
| SVR | Kernel function | RBF | 0.7436 |
| C | 0.8 | ||
| gamma | 0.23 | ||
| RF | Max depth | 5 | 0.8350 |
| Number of trees | 20 | ||
| LASSO | alpha | 0.001 | 0.6558 |
| KNN | K | 3 | 0.8233 |
| P | 3 | ||
| weights | distance |
| Model | R2 | CV−RMSE (%) | NMBE (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Original | New | Original | New | Original | New | |||||||
| Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | |
| BPNN | 0.8351 | 0.4946 | 0.9204 | 0.8393 | 54.03 | 56.38 | 37.54 | 37.18 | 18.81 | 10.00 | 2.68 | 0.94 |
| SVR | 0.7641 | 0.5151 | 0.8279 | 0.7413 | 48.77 | 64.59 | 41.65 | 47.18 | 10.71 | 74.18 | 8.68 | 54.51 |
| RF | 0.8733 | 0.5214 | 0.9171 | 0.7379 | 35.74 | 64.16 | 28.91 | 47.48 | 46.17 | 59.25 | 17.88 | 38.55 |
| LASSO | 0.6134 | 0.2167 | 0.6759 | 0.5232 | 62.42 | 82.09 | 57.16 | 64.04 | 24.00 | 84.76 | 26.00 | 38.23 |
| KNN | 0.9997 | 0.5942 | 0.9999 | 0.7382 | 1.84 | 59.08 | 0.95 | 47.46 | 0.00 | 58.64 | 0.00 | 60.92 |
| BP | SVR | RF | LASSO | KNN | |
|---|---|---|---|---|---|
| p-value | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Ran, M.; Feng, H. Improved Data-Driven Building Daily Energy Consumption Prediction Models Based on Balance Point Temperature. Buildings 2023, 13, 1423. https://doi.org/10.3390/buildings13061423
Yang H, Ran M, Feng H. Improved Data-Driven Building Daily Energy Consumption Prediction Models Based on Balance Point Temperature. Buildings. 2023; 13(6):1423. https://doi.org/10.3390/buildings13061423
Chicago/Turabian StyleYang, Hao, Maoyu Ran, and Haibo Feng. 2023. "Improved Data-Driven Building Daily Energy Consumption Prediction Models Based on Balance Point Temperature" Buildings 13, no. 6: 1423. https://doi.org/10.3390/buildings13061423
APA StyleYang, H., Ran, M., & Feng, H. (2023). Improved Data-Driven Building Daily Energy Consumption Prediction Models Based on Balance Point Temperature. Buildings, 13(6), 1423. https://doi.org/10.3390/buildings13061423