
A Comparative Analysis of Slope Failure Prediction Using a Statistical and Machine Learning Approach on Displacement Data: Introducing a Tailored Performance Metric

 ,
,  ,
, 
Abstract
:1. Introduction
2. Materials and Method
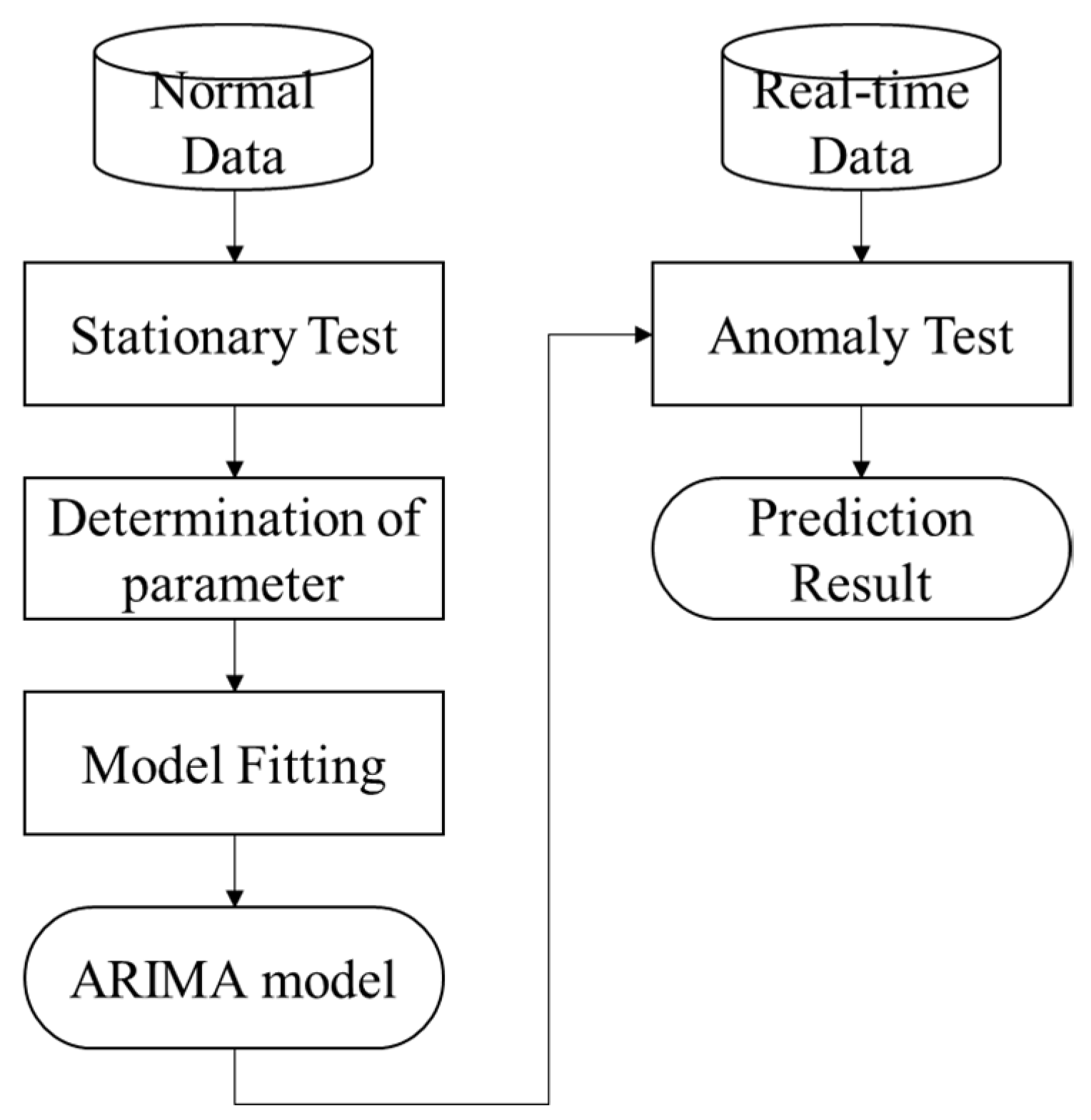
2.1. Statistical Approach
ARIMA
- Transform the time series to make it stationary, for example, by differentiation or applying a log transform.
- Assign p, d, and q appropriately. This task can be accomplished by inspecting autocorrelation and partial autocorrelation plots or by applying statistical tests [27].
- Fit the stationary time series to the ARIMA model and make predictions.
- Assess the effectiveness of the ARIMA model by using statistical measures like mean absolute error (MAE), mean square error (MSE), and root mean squared error (RMSE).
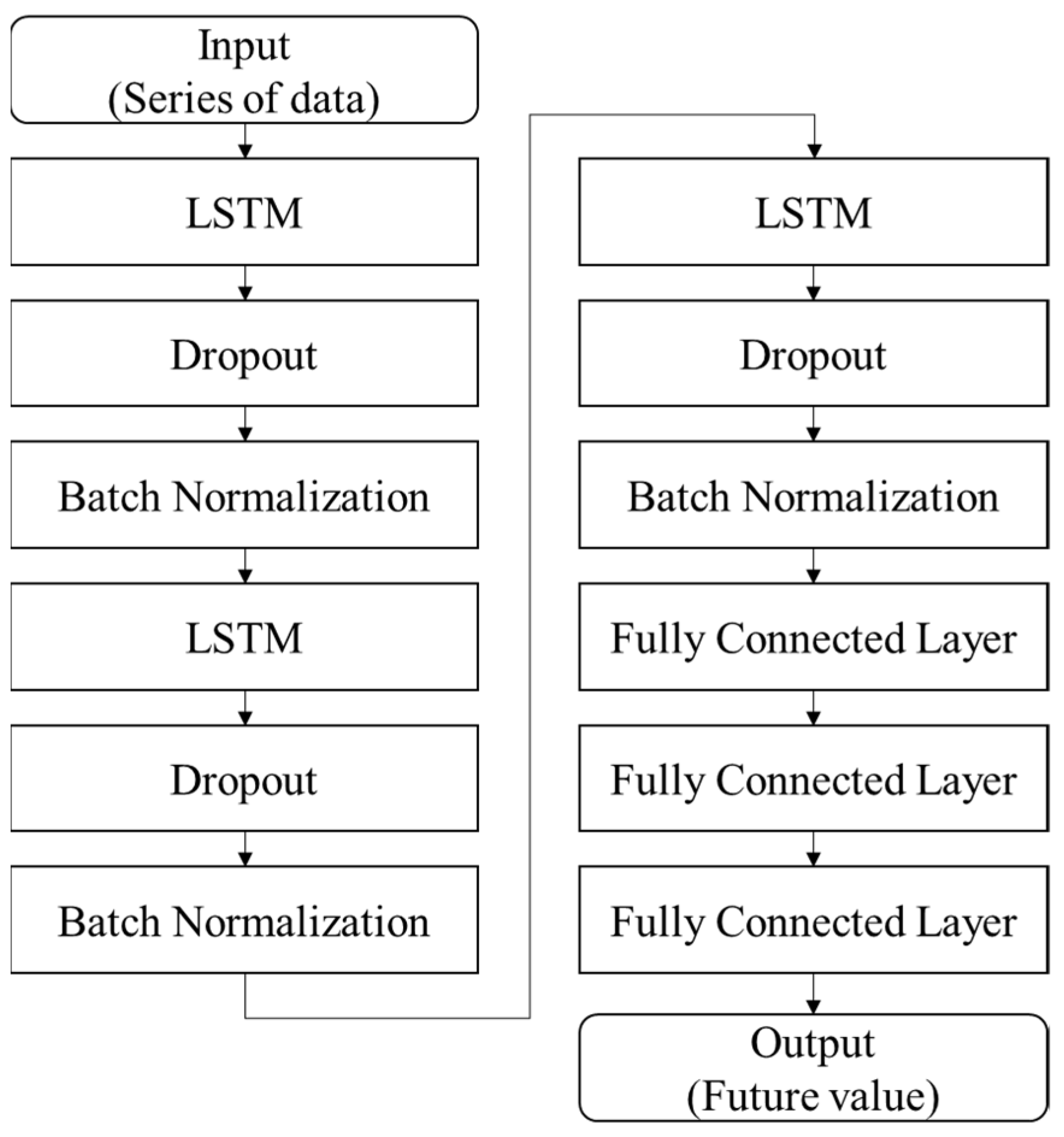
2.2. Machine Learning Approach
2.2.1. Long Short-Term Memory
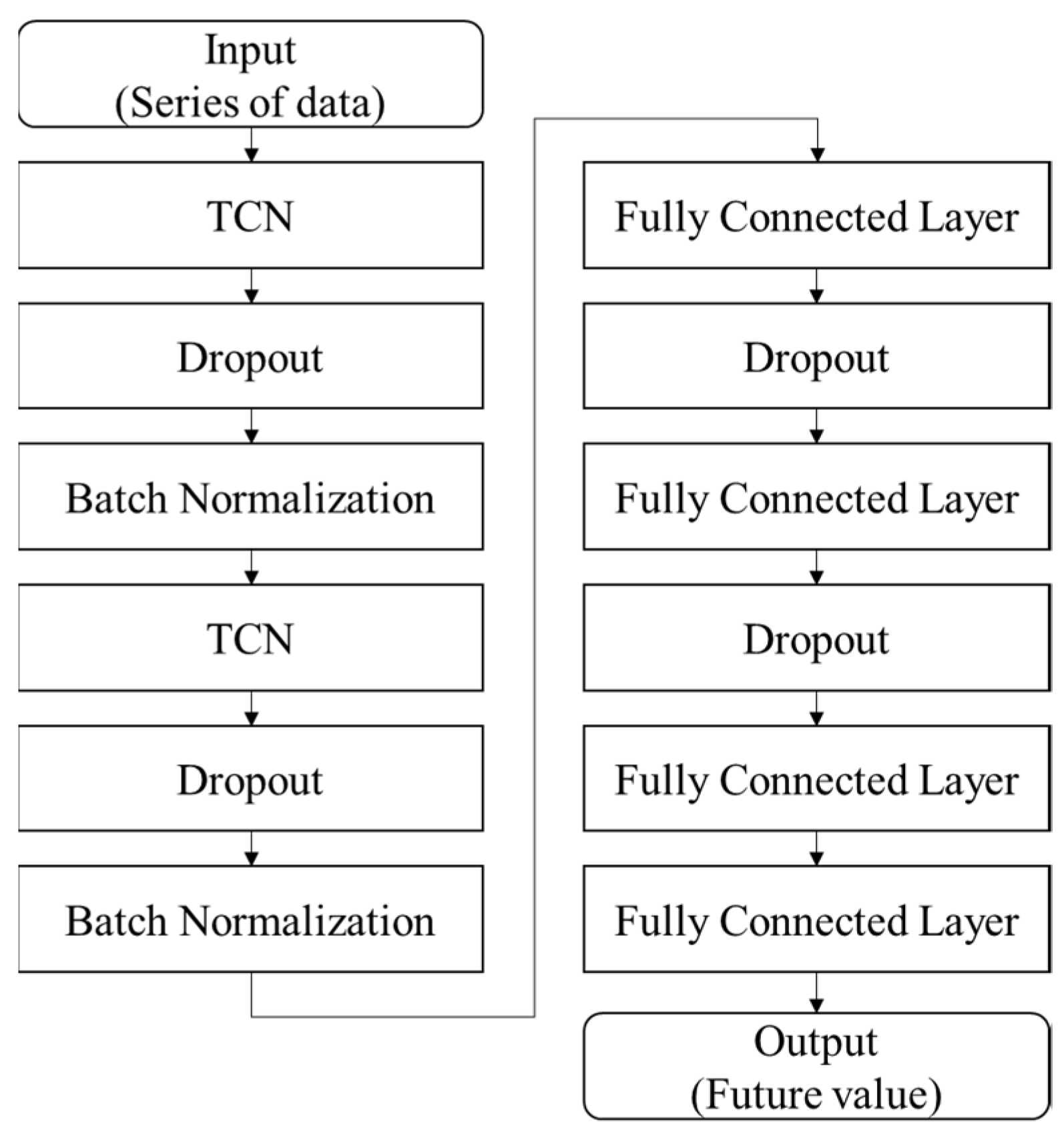
2.2.2. Temporal Convolutional Network (TCN)
2.3. Performance Assessment
- T: Ideal warning window preceding a slope failure.
- Δ: Time span to evaluate consecutive false alarms.
- : Time of the i-th slope failure.
- l (condition): Indicator function; 1 if the condition is true, 0 otherwise.
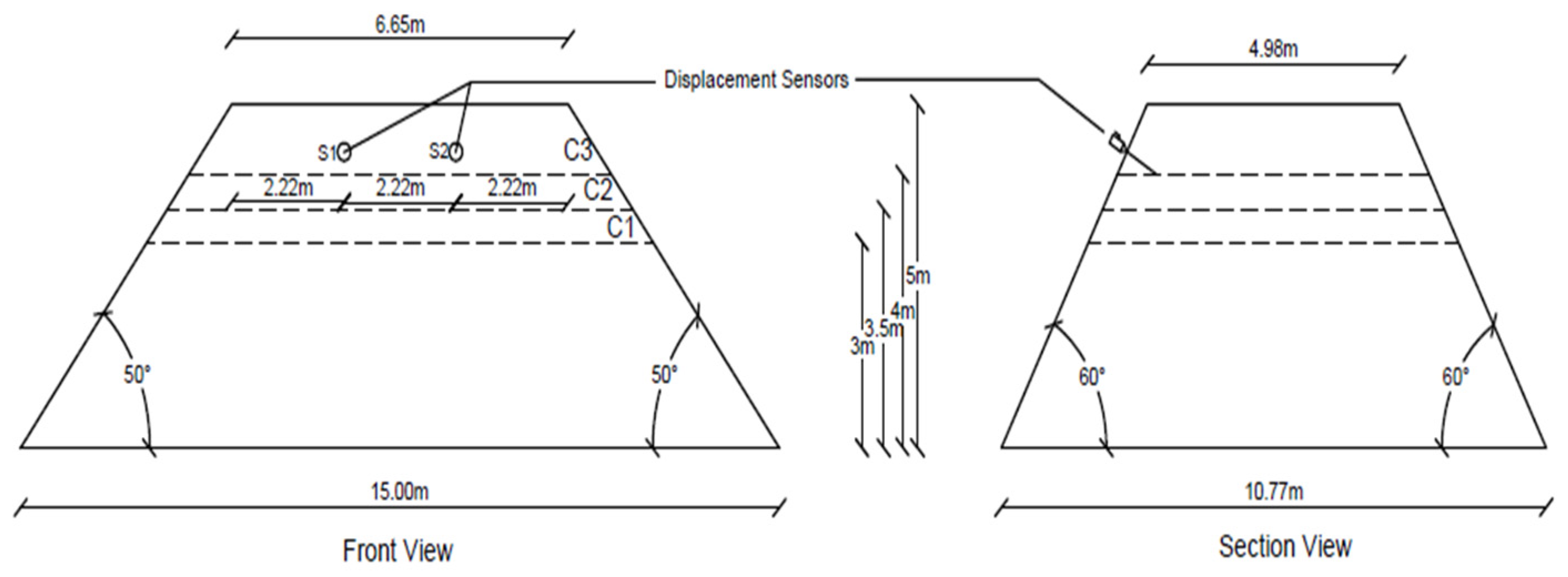
2.4. Design of Field Model Slope
2.5. Installation of Subsurface Displacement Sensors and Simulation of Slope Failure
3. Experiment
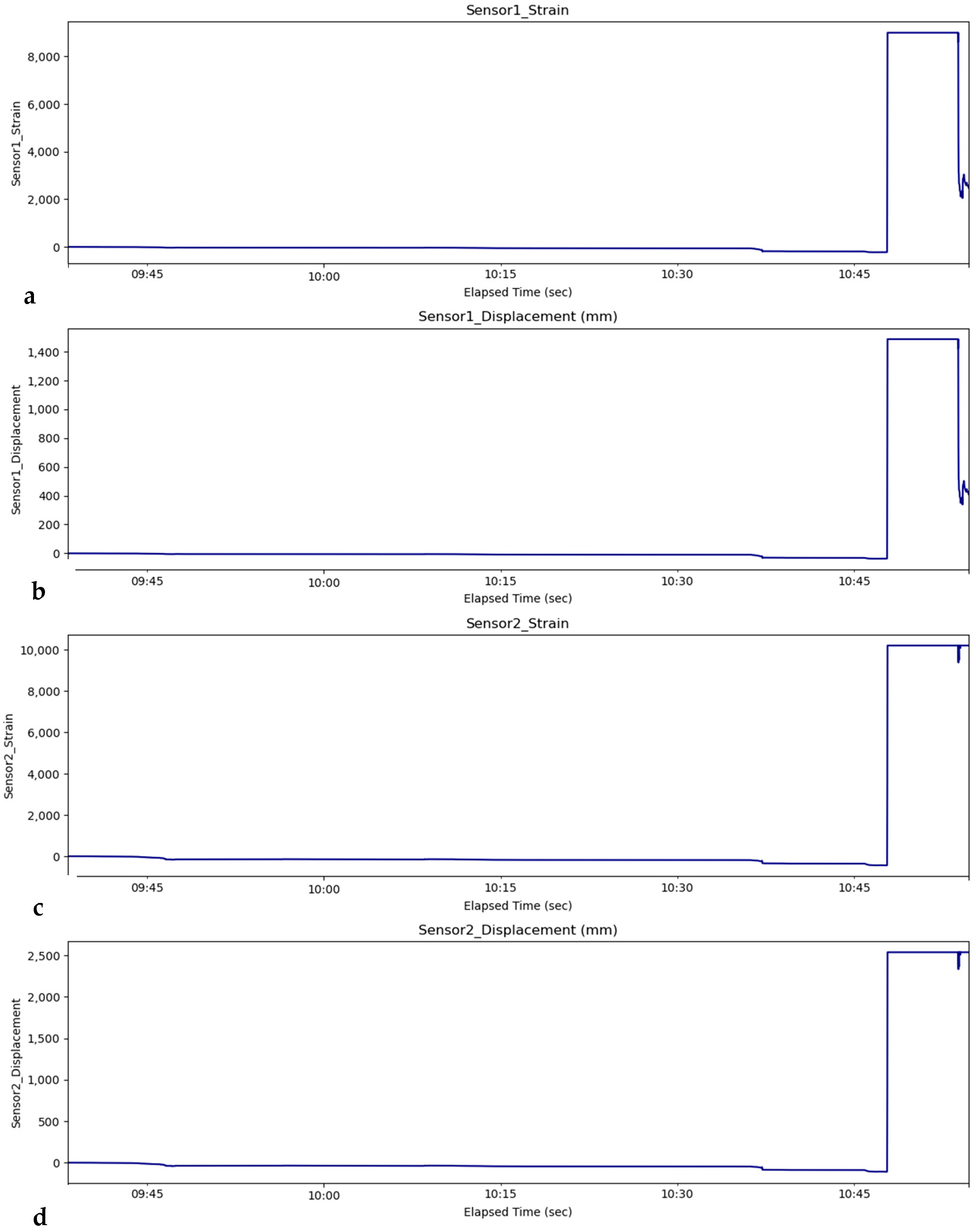
3.1. Data Description
3.2. Prediction Model Development
3.2.1. Statistical Approach
3.2.2. Machine Learning Approach
LSTM-Based Model
TCN-Based Model
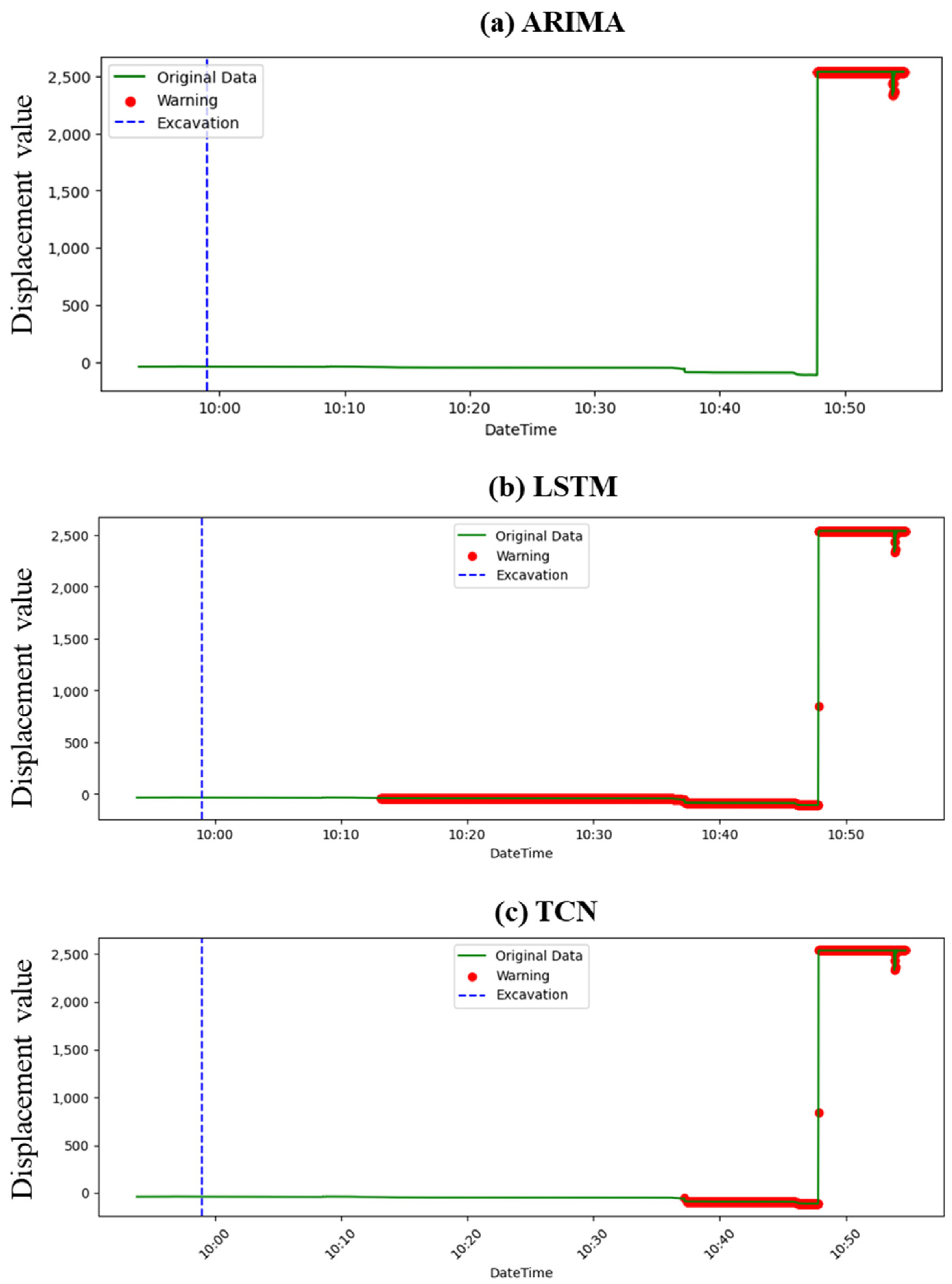
4. Result
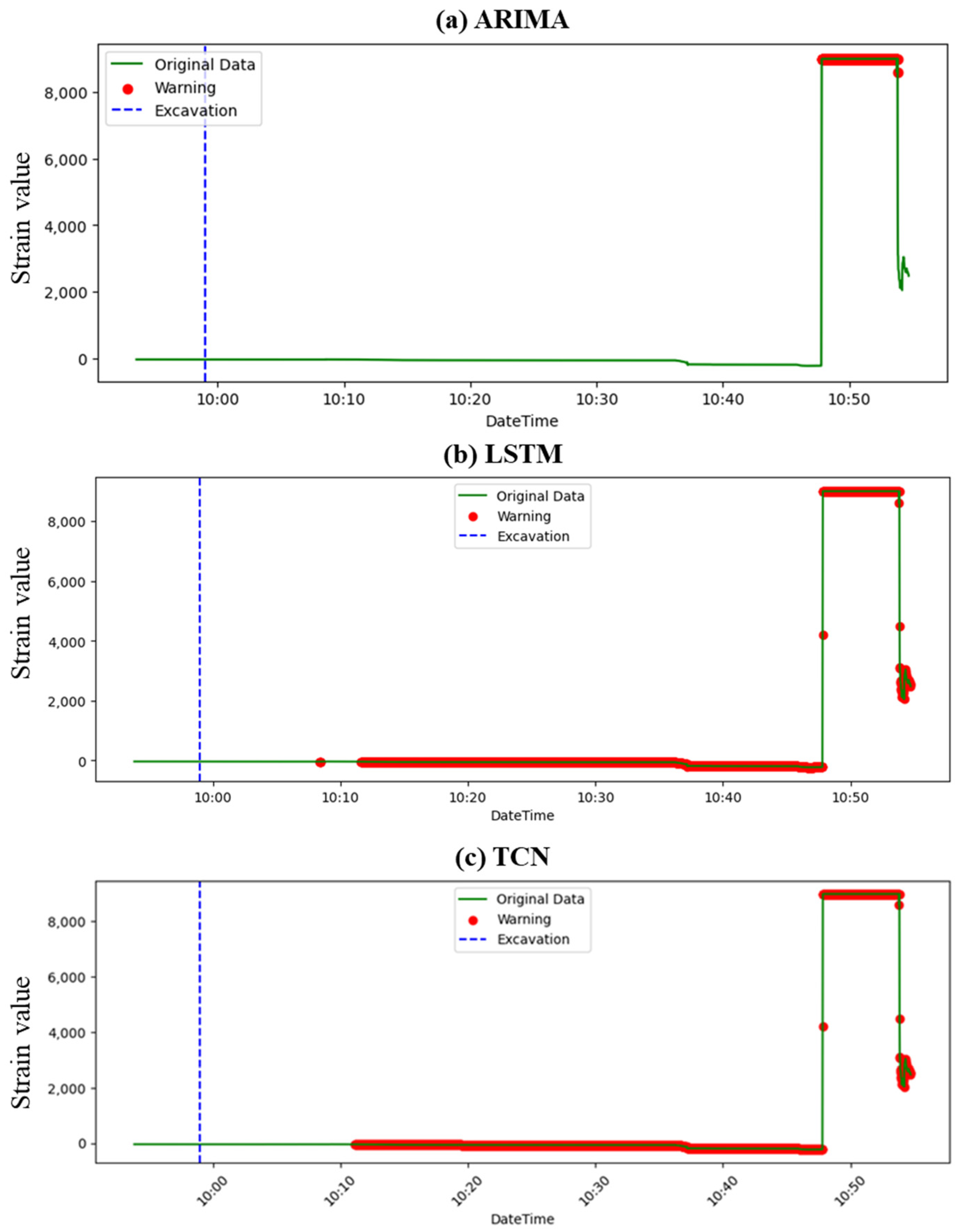
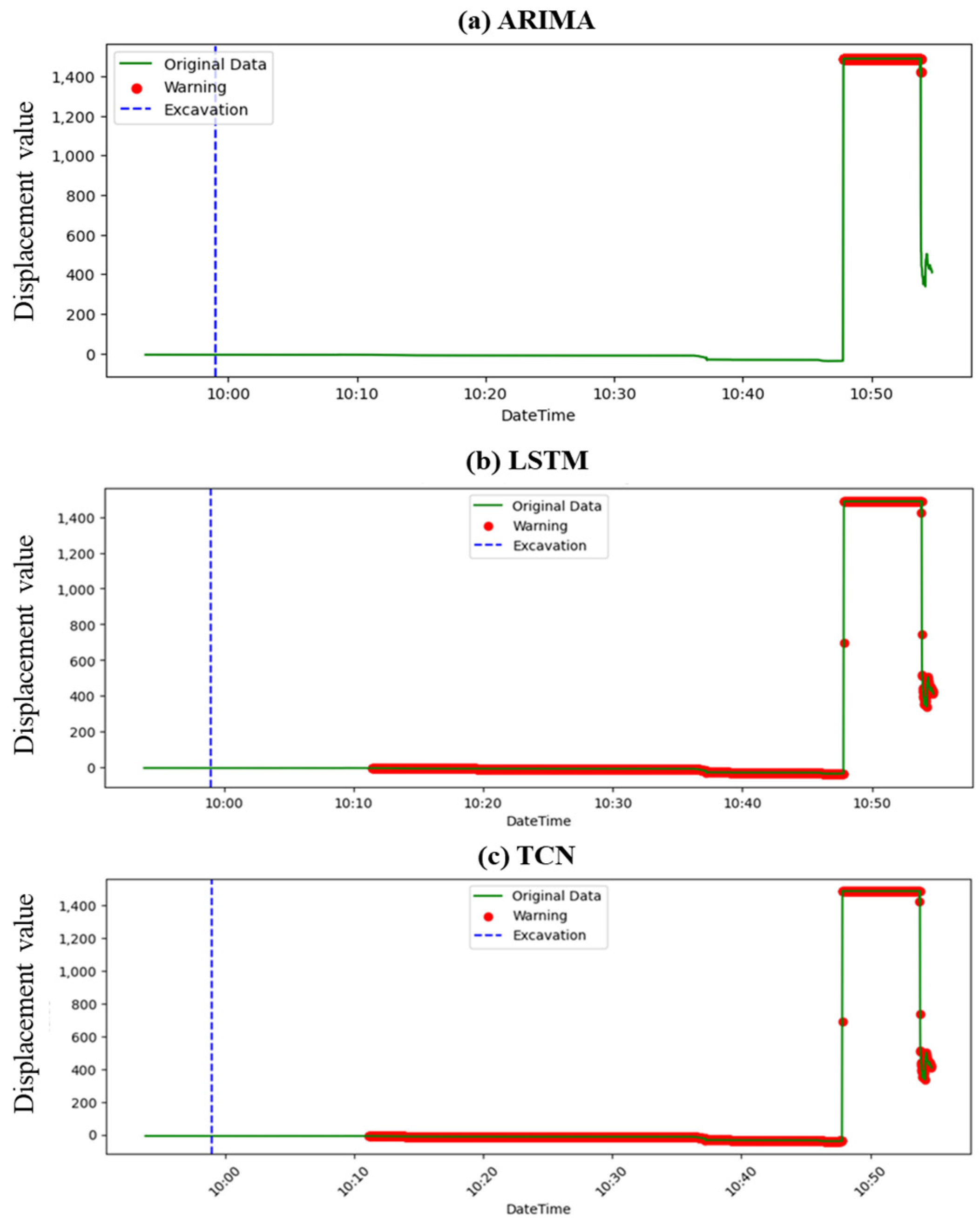
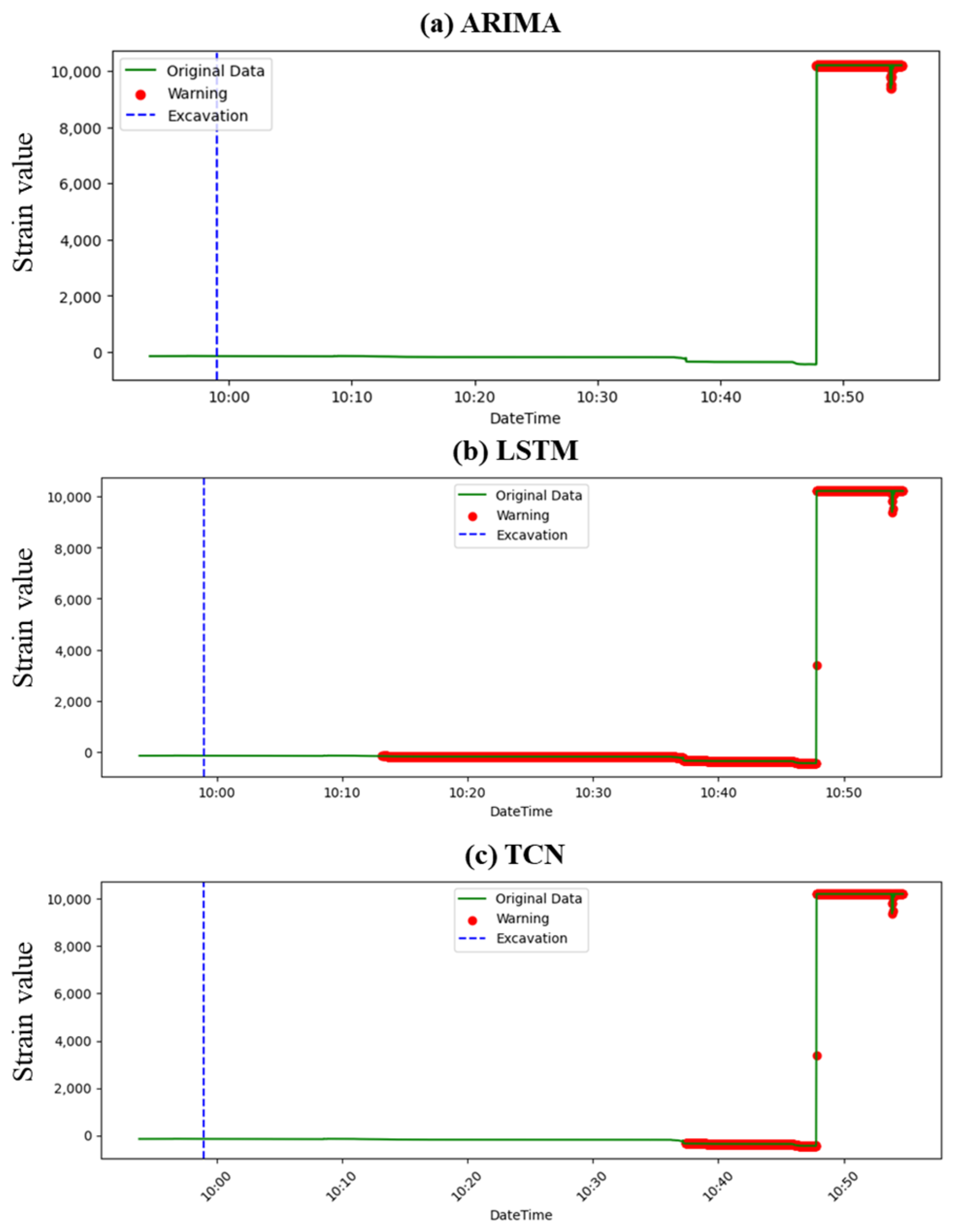
4.1. Prediction Result
4.2. Performance Assessment
5. Conclusions
- Comparative efficacy: Across the datasets, the ARIMA model consistently showed limitations in providing timely warnings prior to slope failures. In contrast, LSTM and TCN demonstrated more promising capabilities, with LSTM consistently outperforming the other models regarding the timeliness of its warnings.
- Data source insights: While the nature of data (strain or displacement) impacted prediction capabilities somewhat, the source of data (Sensor 1 or Sensor 2) seemed to have a more pronounced effect. Predictions were remarkably similar when models used strain and displacement data from the same sensor. This can be attributed to the fact that displacement values are derived from strain measurements, leading to inherent correlations between the two types of data.
- LSTM outperforms others: LSTM’s recurrent nature, enabling it to retain memory from prior data in sequences, likely contributed to its enhanced performance. Especially for events like slope failures where historical data play a crucial role in prediction, LSTM’s ability to capture long-term dependencies proved invaluable.
- Timeliness vs. consistency: While LSTM provided earlier warnings, TCN’s consistency in providing continuous alerts, even if slightly delayed, highlighted the potential trade-off between early prediction and sustained warning periods. This distinction is crucial for practical applications where consistent warnings might be preferred over sporadic early alerts.
- Implications for field applications: This study’s findings suggest that for real-world applications, employing LSTM models can significantly enhance the lead time for slope failure warnings, granting authorities a better window for preventive measures. However, the choice between LSTM and TCN would hinge on specific on-ground requirements—whether early warning or continuous alert consistency is more critical.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alfieri, L.; Salamon, P.; Pappenberger, F.; Wetterhall, F.; Thielen, J. Operational early warning systems for water-related hazards in Europe. Environ. Sci. Policy 2012, 21, 35–49. [Google Scholar] [CrossRef]
- Barredo, J.I. Normalised flood losses in Europe: 1970–2006. Nat. Hazards Earth Syst. Sci. 2009, 9, 97–104. [Google Scholar] [CrossRef]
- European Environment Agency. Mapping the impacts of natural hazards and technological accidents in Europe An overview of the last decade. In Technical Report No 132010; European Environment Agency: Copenhagen, Denmark, 2010; Issue 13. [Google Scholar] [CrossRef]
- Piciullo, L.; Calvello, M.; Cepeda, J.M. Territorial early warning systems for rainfall-induced landslides. Earth-Sci. Rev. 2018, 179, 228–247. [Google Scholar] [CrossRef]
- Kim, Y.S. Development of Slope Failure Forecasting and Warning System; Research Institute Report: Seoul, Republic of Korea, 2015. (In Korean) [Google Scholar]
- Froude, M.J.; Petley, D.N. Global fatal landslide occurrence from 2004 to 2016. Nat. Hazards Earth Syst. Sci. 2018, 18, 2161–2181. [Google Scholar] [CrossRef]
- Shanmugam, G.; Wang, Y. The landslide problem. J. Palaeogeogr. 2015, 4, 109–166. [Google Scholar] [CrossRef]
- Nepal, N.; Chen, J.; Chen, H.; Wang, X.; Pangali Sharma, T.P. Assessment of landslide susceptibility along the Araniko Highway in Poiqu/Bhote Koshi/Sun Koshi Watershed, Nepal Himalaya. Prog. Disaster Sci. 2019, 3, 100037. [Google Scholar] [CrossRef]
- Sassa, K.; Wang, G.; Fukuoka, H.; Wang, F.; Ochiai, T.; Sugiyama, M.; Sekiguchi, T. Landslide risk evaluation and hazard zoning for rapid and long-travel landslides in urban development areas. Landslides 2004, 1, 221–235. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Sharma, M.; Donaldson, K.A. Explainable boosting machines for slope failure spatial predictive modeling. Remote Sens. 2021, 13, 4991. [Google Scholar] [CrossRef]
- Zaker Esteghamati, M.; Kottke, A.R.; Rodriguez-Marek, A. A Data-Driven Approach to Evaluate Site Amplification of Ground-Motion Models Using Vector Proxies Derived from Horizontal-to-Vertical Spectral Ratios. Bull. Seismol. Soc. Am. 2022, 112, 3001–3015. [Google Scholar] [CrossRef]
- Bishop, A.W. The use of the Slip Circle in the Stability Analysis of Slopes. Géotechnique 1955, 5, 7–17. [Google Scholar] [CrossRef]
- Janbu, N. Application of composite slip surfaces for stability analysis. Eur. Conferr. Stab. Earth Slopes 1954, 3, 43–49. Available online: https://api.semanticscholar.org/CorpusID:131229483 (accessed on 12 June 2023).
- Morgenstern, N.R.; Price, V.E. The Analysis of the Stability of General Slip Surfaces. Géotechnique 1965, 15, 79–93. [Google Scholar] [CrossRef]
- Spencer, E. A Method of analysis of the Stability of Embankments Assuming Parallel Inter-Slice Forces. Géotechnique 1967, 17, 11–26. [Google Scholar] [CrossRef]
- Duncan, J.M. State of the Art: Limit Equilibrium and Finite-Element Analysis of Slopes. J. Geotech. Eng. 1996, 122, 577–596. [Google Scholar] [CrossRef]
- Chakraborty, A.; Goswami, D. Two Dimensional (2D) Slope-Stability Analysis—A review. Int. J. Res. Appl. Sci. Eng. Technol. 2018, 6, 2108–2112. [Google Scholar]
- Zienkiewicz, O.C.; Taylor, R.L. The Finite Element Method Volume 1: The Basis. Methods 2000, 1, 708. [Google Scholar]
- He, L.; Gomes, A.T.; Broggi, M.; Beer, M. Failure analysis of soil slopes with advanced Bayesian networks. Period. Polytech. Civ. Eng. 2019, 63, 763–774. [Google Scholar] [CrossRef]
- Sompolski, M.; Tympalski, M.; Kopeć, A.; Milczarek, W. Application of the Autoregressive Integrated Moving Average (ARIMA) Model in Prediction of Mining Ground Surface Displacement. In Proceedings of the EGU22, the 24th EGU General Assembly, Vienna, Austria, 23–27 May 2022; p. 12697. [Google Scholar]
- Makridakis, S.; Hibon, M.; Moser, C. Accuracy of Forecasting: An Empirical Investigation. J. R. Stat. Soc. Ser. A 1979, 142, 97. [Google Scholar] [CrossRef]
- Aggarwal, A.; Alshehri, M.; Kumar, M.; Alfarraj, O.; Sharma, P.; Pardasani, K.R. Landslide data analysis using various time-series forecasting models. Comput. Electr. Eng. 2020, 88, 106858. [Google Scholar] [CrossRef]
- Wang, Y.; Tang, H.; Huang, J.; Wen, T.; Ma, J.; Zhang, J. A comparative study of different machine learning methods for reservoir landslide displacement prediction. Eng. Geol. 2022, 298, 106544. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Holden-Day Series in Time Series Analysis and Digital Signal Processing; Holden-Day Inc.: San Francisco, CA, USA, 1976; 575p. [Google Scholar]
- Bianco, A.M.; García Ben, M.; Martínez, E.J.; Yohai, V.J. Outlier detection in regression models with ARIMA errors using robust estimates. J. Forecast. 2001, 20, 565–579. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Kwiatkowski, D.; Phillips, P.C.B.; Schmidt, P.; Shin, Y. Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series have a unit root? J. Econom. 1992, 54, 159–178. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Khandakar, Y. Automatic Time Series Forecasting: The forecast Package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef]
- Karim, A.A.; Pardede, E.; Mann, S. A Model Selection Approach for Time Series Forecasting: Incorporating Google Trends Data in Australian Macro Indicators. Entropy 2023, 25, 1144. [Google Scholar] [CrossRef]
- Duan, G.; Su, Y.; Fu, J. Landslide Displacement Prediction Based on Multivariate LSTM Model. Int. J. Environ. Res. Public Health 2023, 20, 1167. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Dasgupta, S., McAllester, D., Eds.; PMLR: London, UK, 2013; Volume 28, pp. 1310–1318. Available online: https://proceedings.mlr.press/v28/pascanu13.html (accessed on 4 July 2023).
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based Encoder-Decoder for Multi-sensor Anomaly Detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- Ning, C.; Xie, Y.; Sun, L. LSTM, WaveNet, and 2D CNN for nonlinear time history prediction of seismic responses. Eng. Struct. 2023, 286, 116083. [Google Scholar] [CrossRef]
- Soleimani-Babakamali, M.H.; Esteghamati, M.Z. Estimating seismic demand models of a building inventory from nonlinear static analysis using deep learning methods. Eng. Struct. 2022, 266, 114576. [Google Scholar] [CrossRef]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal convolutional networks for action segmentation and detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition 2017, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1003–1012. [Google Scholar] [CrossRef]
- Oord A van den Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Lemaire, Q.; Holzapfel, A. Temporal convolutional networks for speech and music detection in radio broadcast. In Proceedings of the 20th International Society for Music Information Retrieval Conference, ISMIR 2019, Delft, The Netherlands, 4–8 November 2019; pp. 229–236. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image Transformer. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; PMLR: London, UK, 2018; Volume 80, pp. 4055–4064. Available online: https://proceedings.mlr.press/v80/parmar18a.html (accessed on 23 July 2023).
- Kwon, H.J. Mountain ranges of Korea. J. Korean Geogr. Soc. 2000, 35, 389–400. [Google Scholar]
- Park, K. Development in geomorphology and soil geography: Focusing on the Journal of the Korean Geomorphological Association. J. Korean Geogr. Soc. 2012, 47, 474–489. [Google Scholar]
- Kim, M.-I.; Jeon, G.-C. Characterization of physical factor of unsaturated ground deformation induced by rainfall. J. Eng. Geol. 2008, 18, 127–136. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Physical Properties | Values |
|---|---|
| Density of soil | 17.9 kN/m3 |
| Sand | 57.5% |
| Clay | 1.5% |
| Silt | 10% |
| D50 | 0.85 mm |
| Maximum dry density | 19.3 kN/m3 |
| Optimum water content | 13% |
| Statistical | Machine Learning | ||
|---|---|---|---|
| ARIMA | LSTM | TCN | |
| Sensor1_strain | 0 | 0.81 | 0.78 |
| Sensor1_dispacement | 0.12 | 0.79 | 0.78 |
| Sensor2_strain | 0 | 0.76 | 0.69 |
| Sensor2_dispacement | 0.14 | 0.78 | 0.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chaulagain, S.; Choi, J.; Kim, Y.; Yeon, J.; Kim, Y.; Ji, B. A Comparative Analysis of Slope Failure Prediction Using a Statistical and Machine Learning Approach on Displacement Data: Introducing a Tailored Performance Metric. Buildings 2023, 13, 2691. https://doi.org/10.3390/buildings13112691
Chaulagain S, Choi J, Kim Y, Yeon J, Kim Y, Ji B. A Comparative Analysis of Slope Failure Prediction Using a Statistical and Machine Learning Approach on Displacement Data: Introducing a Tailored Performance Metric. Buildings. 2023; 13(11):2691. https://doi.org/10.3390/buildings13112691
Chicago/Turabian StyleChaulagain, Suresh, Junhyuk Choi, Yongjin Kim, Jaeheum Yeon, Yongseong Kim, and Bongjun Ji. 2023. "A Comparative Analysis of Slope Failure Prediction Using a Statistical and Machine Learning Approach on Displacement Data: Introducing a Tailored Performance Metric" Buildings 13, no. 11: 2691. https://doi.org/10.3390/buildings13112691
APA StyleChaulagain, S., Choi, J., Kim, Y., Yeon, J., Kim, Y., & Ji, B. (2023). A Comparative Analysis of Slope Failure Prediction Using a Statistical and Machine Learning Approach on Displacement Data: Introducing a Tailored Performance Metric. Buildings, 13(11), 2691. https://doi.org/10.3390/buildings13112691