



Alternative Approaches to HVAC Control of Chat Generative Pre-Trained Transformer (ChatGPT) for Autonomous Building System Operations


Abstract
:1. Introduction
2. Methods
2.1. ChatGPT
2.2. Deep Q-Network (DQN)
3. Application of the Methods
3.1. Target Building Model
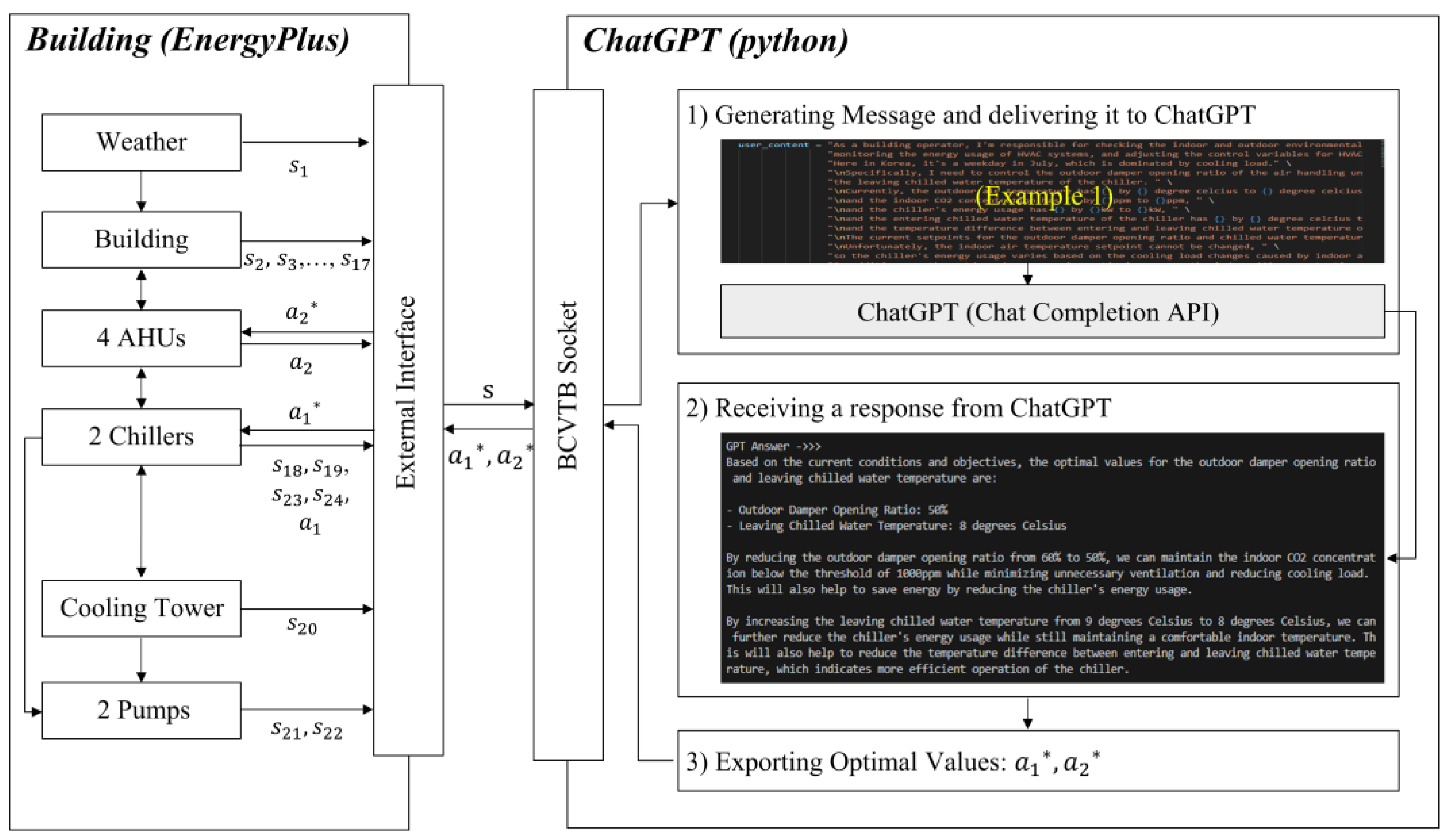
3.2. ChatGPT Pre-Trained LLM Control
- –
- Outdoor Damper Opening Ration: (optimal value),
- –
- Leaving Chilled Water Temperature: (optimal value)
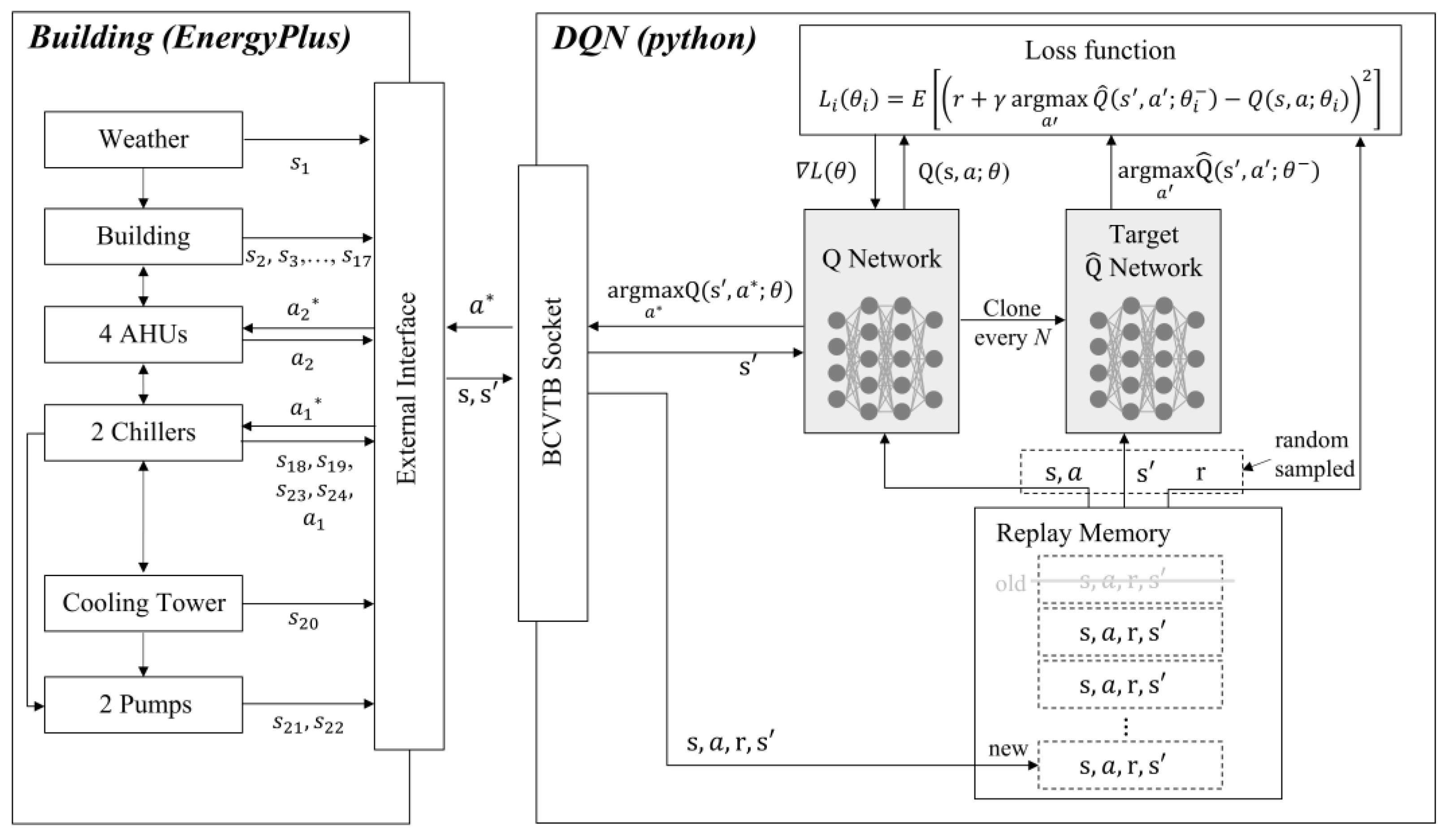
3.3. DQN Model-Free Control
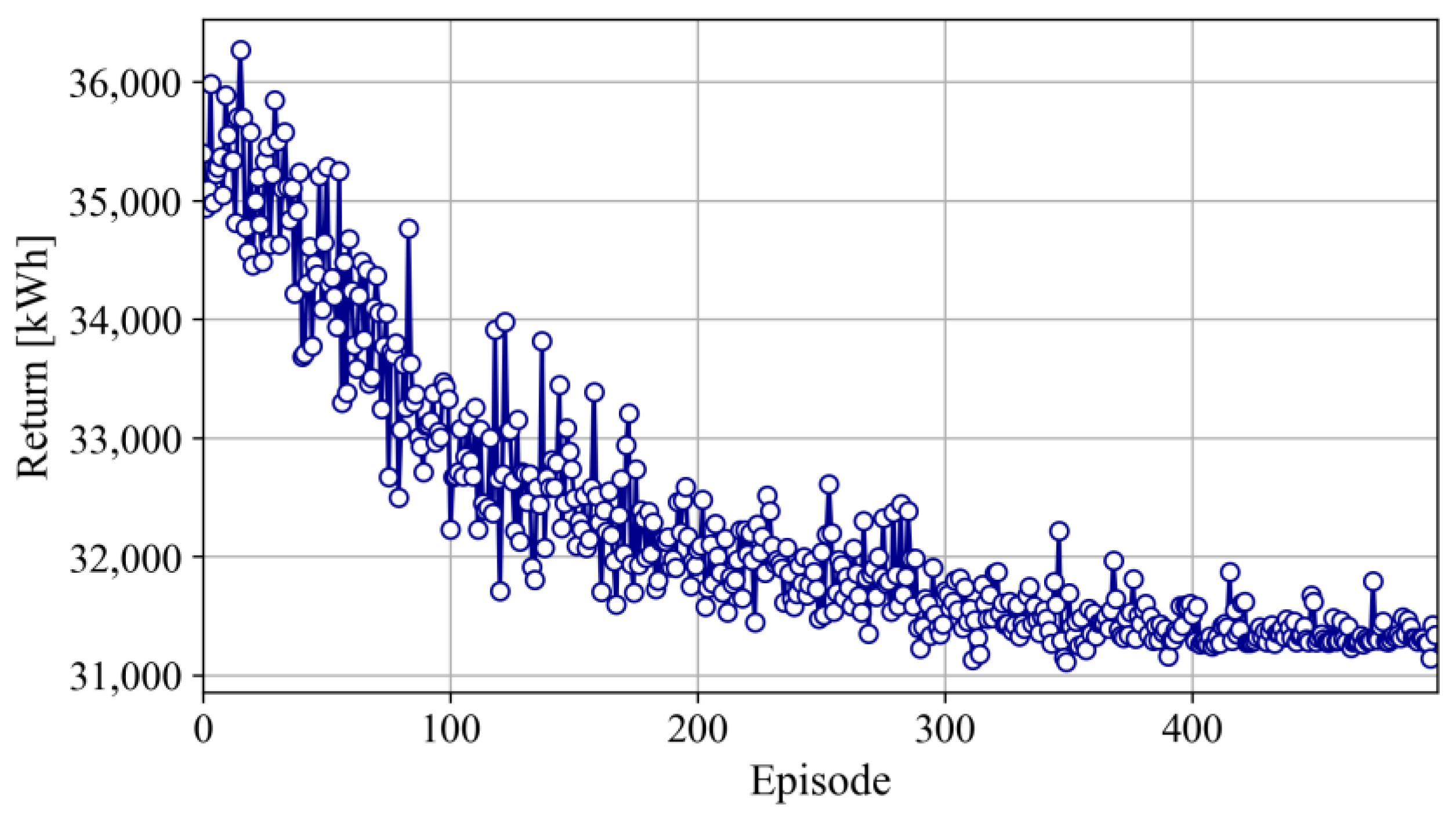
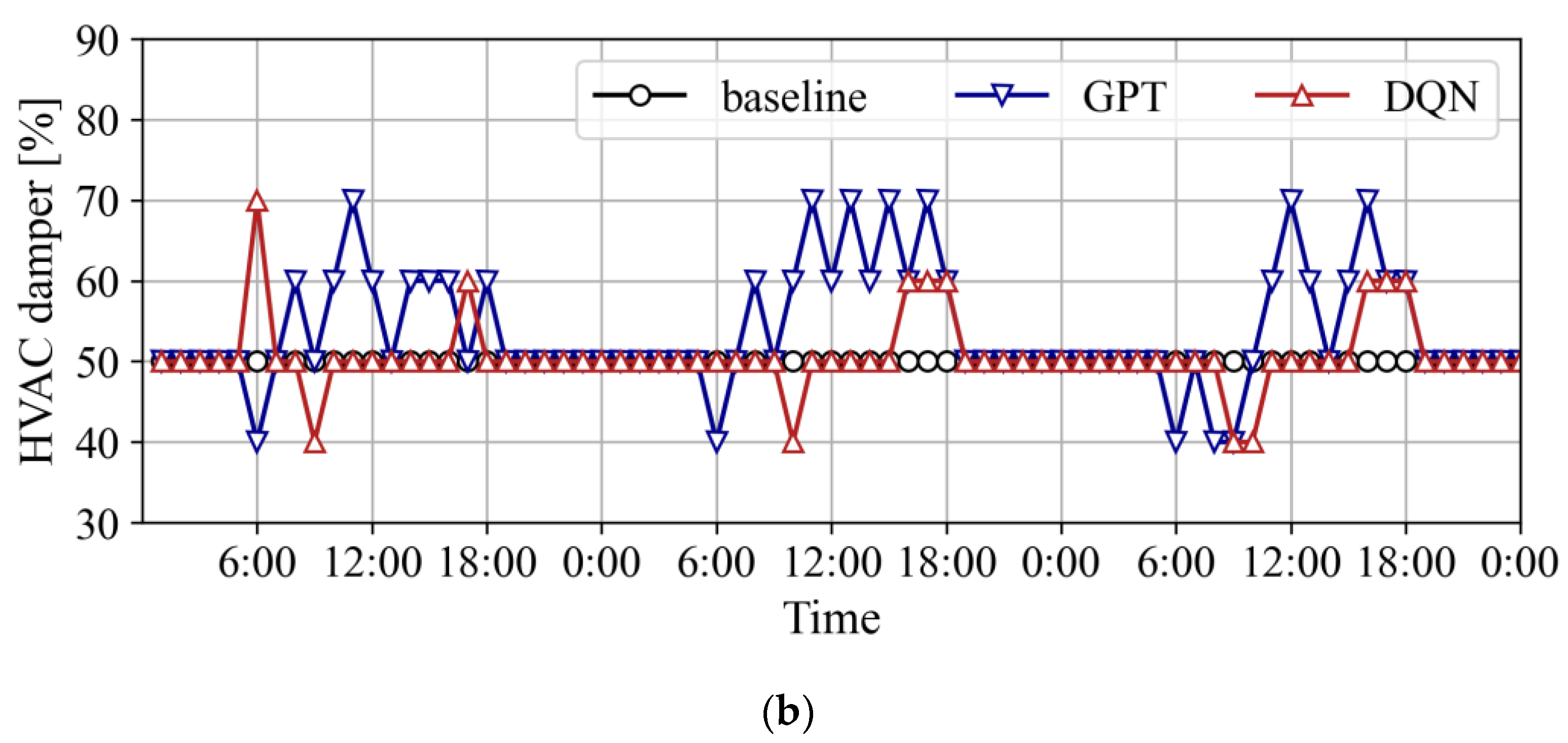
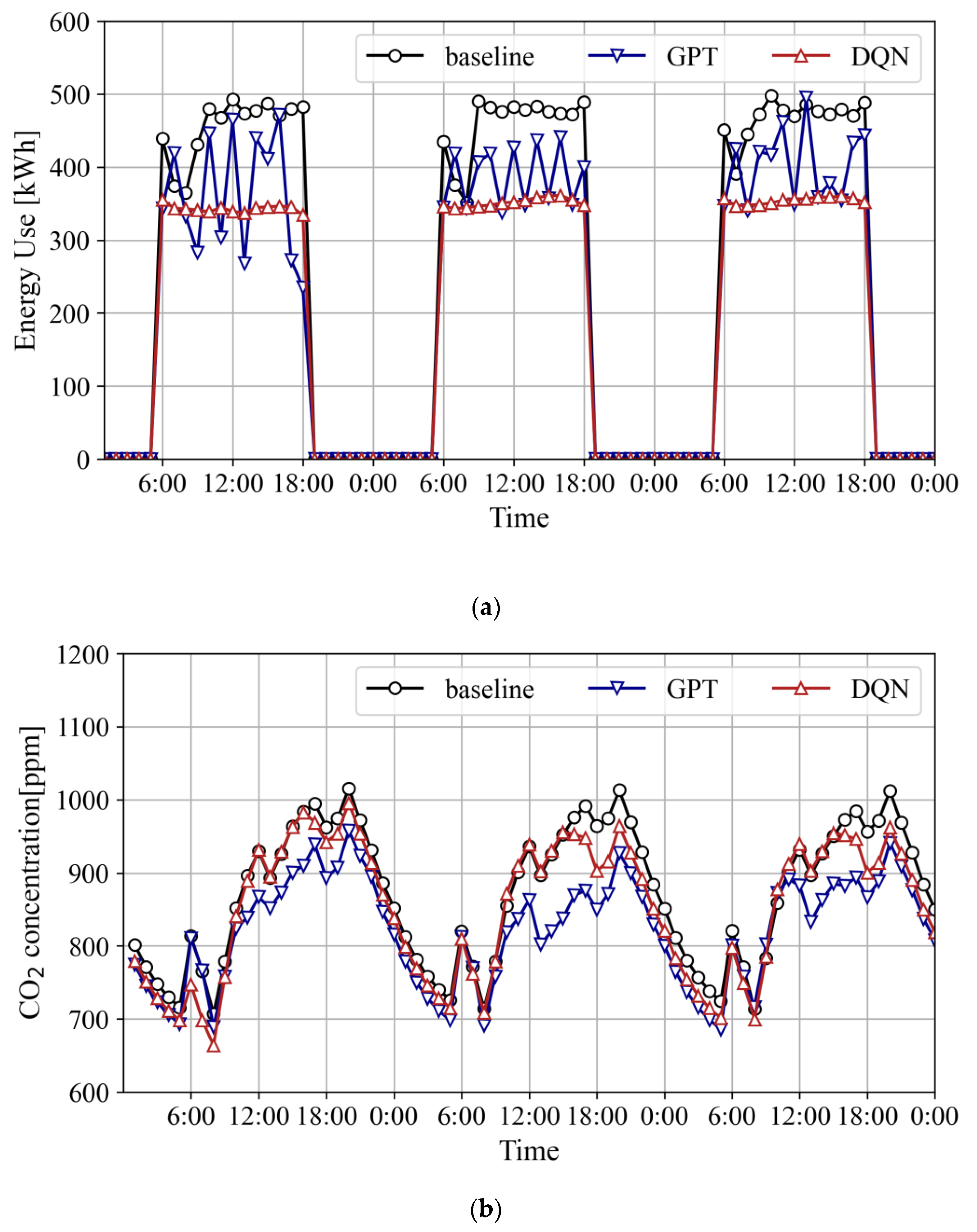
4. Results
- –
- Outdoor Damper Opening Ratio: 60%
- –
- Leaving Chilled Water Temperature: 8 °C
- –
- Outdoor Damper Opening Ratio: 70%
- –
- Leaving Chilled Water Temperature: 10 °C
- –
- Outdoor Damper Opening Ratio: 70%
- –
- Leaving Chilled Water Temperature: 10 °C
- –
- Outdoor Damper Opening Ratio: 60%
- –
- Leaving Chilled Water Temperature: 8 °C
- –
- Outdoor Damper Opening Ratio: 60%
- –
- Leaving Chilled Water Temperature: 7 °C
- –
- Outdoor Damper Opening Ratio: 70%
- –
- Leaving Chilled Water Temperature: 10 °C
5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- IEA. Policy Pathways: Modernizing Building Energy Codes. 2013. Available online: https://www.iea.org/reports/policy-pathway-modernising-building-energy-codes-2013 (accessed on 26 August 2023).
- Li, X.; Wen, J. Review of Building Energy Modeling for Control and Operation. Renew. Sustain. Energy Rev. 2014, 37, 517–537. [Google Scholar] [CrossRef]
- Drgoňa, J.; Arroyo, J.; Cupeiro Figueroa, I.C.; Blum, D.; Arendt, K.; Kim, D.; Ollé, E.P.; Oravec, J.; Wetter, M.; Vrabie, D.L.; et al. All You Need to Know About Model Predictive Control for Buildings. Annu. Rev. Control 2020, 50, 190–232. [Google Scholar] [CrossRef]
- Ahn, K.U.; Park, C.S. Application of Deep Q-Networks for Model-Free Optimal Control Balancing Between Different HVAC Systems. Sci. Technol. Built Environ. 2020, 26, 61–74. [Google Scholar] [CrossRef]
- Shaikh, P.H.; Nor, N.B.M.; Nallagownden, P.; Elamvazuthi, I.; Ibrahim, T. A Review on Optimized Control Systems for Building Energy and Comfort Management of Smart Sustainable Buildings. Renew. Sustain. Energy Rev. 2014, 34, 409–429. [Google Scholar] [CrossRef]
- Wang, S.W.; Ma, Z.J. Supervisory and Optimal Control of Building HVAC Systems: A Review. HVAC&R Res. 2008, 14, 3–32. [Google Scholar] [CrossRef]
- Yun, K.; Luck, R.; Mago, P.J.; Cho, H. Building Hourly Thermal Load Prediction Using an Indexed ARX Model. Energy Build. 2012, 54, 225–233. [Google Scholar] [CrossRef]
- Eisenhower, B.; O’Neill, Z.; Narayanan, S.; Fonoberov, V.A.; Mezić, I. A Methodology for Meta-model Based Optimization in Building Energy Models. Energy Build. 2012, 47, 292–301. [Google Scholar] [CrossRef]
- Prívara, S.; Cigler, J.; Váňa, Z.; Oldewurtel, F.; Sagerschnig, C.; Žáčeková, E. Building Modeling as a Crucial Part for Building Predictive Control. Energy Build. 2013, 56, 8–22. [Google Scholar] [CrossRef]
- Corbin, C.D.; Henze, G.P.; May-Ostendorp, P. A Model Predictive Control Optimization Environment for Real-Time Commercial Building Application. J. Build. Perform. Simul. 2013, 6, 159–174. [Google Scholar] [CrossRef]
- Afram, A.; Janabi-Sharifi, F. Theory and Applications of HVAC Control Systems—A Review of Model Predictive Control (MPC). Build. Environ. 2014, 72, 343–355. [Google Scholar] [CrossRef]
- Busoniu, L.; Babuska, R.; Schutter, B.D.; Ernst, D. Reinforcement Learning and Dynamic Programming Using Function Approximators, Automation and Control Engineering; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Valladares, W.; Galindo, M.; Gutiérrez, J.; Wu, W.-C.; Liao, K.-K.; Liao, J.-C.; Lu, K.-C.; Wang, C.-C. Energy optimization associated with thermal comfort and indoor air control via a deep reinforcement learning algorithm. Build. Environ. 2019, 155, 105–117. [Google Scholar] [CrossRef]
- Azuatalam, D.; Lee, W.L.; de Nijs, F.; Liebman, A. Reinforcement Learning for Whole-Building HVAC Control and Demand Response. Energy AI 2020, 2, 100020. [Google Scholar] [CrossRef]
- Gill, S.S.; Kaur, R. ChatGPT: Vision and Challenges. Internet. Things Cyber-Phys. Syst. 2023, 3, 262–271. [Google Scholar] [CrossRef]
- Thorp, H.H. ChatGPT Is Fun, but Not an Author. Science 2023, 379, 313. [Google Scholar] [CrossRef]
- OpenAI. ChatGPT. 2023. Available online: https://openai.com/chatgpt (accessed on 26 August 2023).
- OpenAI. Introducing ChatGPT. 2023. Available online: https://openai.com/blog/chatgpt (accessed on 26 August 2023).
- Agathokleous, E.; Saitanis, C.J.; Fang, C.; Yu, Z. Use of ChatGPT: What Does It Mean for Biology and Environmental Science? Sci. Total Environ. 2023, 888, 164154. [Google Scholar] [CrossRef] [PubMed]
- Van Dis, E.A.M.; Bollen, J.; Zuidema, W.; van Rooij, R.; Bockting, C.L. ChatGPT: Five Priorities for Research. Nature 2023, 614, 224–226. [Google Scholar] [CrossRef]
- Vaishya, R.; Misra, A.; Vaish, A. ChatGPT: Is This Version Good for Healthcare and Research? Diabetes Metab. Syndr. 2023, 17, 102744. [Google Scholar] [CrossRef]
- Blanchard, F.; Assefi, M.; Gatulle, N.; Constantin, J.M. ChatGPT in the World of Medical Research: From How It Works to How to Use It. Anaesth. Crit. Care Pain Med. 2023, 42, 101231. [Google Scholar] [CrossRef] [PubMed]
- Currie, G.; Singh, C.; Nelson, T.; Nabasenja, C.; Al-Hayek, Y.; Spuur, K. ChatGPT in Medical Imaging Higher Education. Radiography 2023, 29, 792–799. [Google Scholar] [CrossRef] [PubMed]
- DOE. EnergyPlus. 2019. Available online: https://energyplus.net (accessed on 26 August 2023).
- Taecharungroj, V. “What Can ChatGPT Do?” Analyzing Early Reactions to the Innovative AI Chatbot on Twitter. Big Data Cogn. Comput. 2023, 7, 35. [Google Scholar] [CrossRef]
- Zhang, M.; Li, J. A Commentary of GPT-3 in MIT Technology Review 2021. Fundam. Res. 2021, 1, 831–833. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pretraining. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 26 August 2023).
- Dale, R. GPT-3: What’s It Good For? Nat. Lang. Eng. 2021, 27, 113–118. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. OpenAI Blog 2019. Available online: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (accessed on 26 August 2023).
- Floridi, L.; Chiriatti, M. GPT-3: Its Nature, Scope, Limits, and Consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- OpenAI. Model Index for Researchers. 2023. Available online: https://platform.openai.com/docs/model-index-for-researchers (accessed on 26 August 2023).
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training Language Models to Follow Instructions with Human Feedback. arXiv 2022, arXiv:2203.02155. [Google Scholar]
- Verma, P.; Lerman, R. What Is ChatGPT, the Viral Social Media AI? 2023. Available online: https://www.washingtonpost.com/technology/2022/12/06/what-is-chatgpt-ai/ (accessed on 4 January 2023).
- Roose, K. The Brilliance and Weirdness of ChatGPT. 2023. Available online: https://www.nytimes.com/2022/12/05/technology/chatgpt-ai-twitter.html (accessed on 4 January 2023).
- OpenAI. GPT-4. 2023. Available online: https://openai.com/research/gpt-4 (accessed on 26 August 2023).
- OpenAI. Documentation. 2023. Available online: https://platform.openai.com/docs/models/overview (accessed on 26 August 2023).
- Nair, A.; Srinivasan, P.; Blackwell, S.; Alcicek, C.; Fearon, R.; De Maria, A.; Panneershelvam, V.; Suleyman, M.; Beattie, C.; Petersen, S.; et al. Massively Parallel Methods for Deep Reinforcement Learning. arXiv 2015, arXiv:1507.04296. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning an Introduction, a Bradford Book; MIT Press: Cambridge, UK, 1998. [Google Scholar]
- Yang, L.; Nagy, Z.; Goffin, P.; Schlueter, A. Reinforcement Learning for Optimal Control of Low Exergy Buildings. Appl. Energy 2015, 156, 577–586. [Google Scholar] [CrossRef]
- Cheng, Z.J.; Zhao, Q.C.; Wang, F.L.; Jiang, Y.; Xia, L.; Ding, J.L. Satisfaction Based Q-Learning for Integrated Lighting and Blind Control. Energy Build. 2016, 127, 43–55. [Google Scholar] [CrossRef]
- Mocanu, E.; Nguyen, P.H.; Kling, W.L.; Gibescu, M. Unsupervised Energy Prediction in a Smart Grid Context Using Reinforcement Cross-Building Transfer Learning. Energy Build. 2016, 116, 646–655. [Google Scholar] [CrossRef]
- Kumar, R.; Aggarwal, R.K.; Sharma, J.D. Energy Analysis of a Building Using Artificial Neural Network: A Review. Energy Build. 2013, 65, 352–358. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-Level Control Through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- DOE. Tips and Tricks for Using EnergyPlus. 2019b. Available online: https://energyplus.net/documentation (accessed on 26 August 2023).
- Ahn, K.U.; Kim, D.W.; Park, C.S.; de Wilde, P. Predictability of Occupant Presence and Performance Gap in Building Energy Simulation. Appl. Energy 2017, 208, 1639–1652. [Google Scholar] [CrossRef]
- OpenAI. Chat Completion API. Available online: https://platform.openai.com/docs/guides/gpt/chat-completions-api (accessed on 26 August 2023).
- Bojarski, M.B.; Firner, B.; Flepp, B.; Jackel, L.; Muller, U.; Zieba, K.; Testa, D.D. End-to-end deep learning for self-driving cars. Nvidia, 17 August 2016. Available online: https://devblogs.nvidia.com/parallelforall/deep-learning-self-driving-cars/ (accessed on 26 August 2023).
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Shaw, R.; Howley, E.; Barrett, E. Applying Reinforcement Learning Towards Automating Energy Efficient Virtual Machine Consolidation in Cloud Data Centers. Inf. Syst. 2022, 107, 101722. [Google Scholar] [CrossRef]
- OpenAI. Fine-Tuning. 2023. Available online: https://platform.openai.com/docs/guides/fine-tuning (accessed on 26 August 2023).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Description |
|---|---|
| Total floor area | 46,320 m2 |
| Stories | Basement: one floor; above ground: 12 floors (10 times multiplier was applied to 6th floor) |
| Occupancy | Basement: 37.16 m2/people; above ground: 18.58 m2/people |
| Lighting density | 10.76 W/m2 |
| Equipment density | 10.76 W/m2 |
| HVAC systems | 4 AHUs for basement (20,124 CMH), 1st floor (47,664 CMH), 6th floor (506,304 CMH), and 12th floor50,220), 2 electric chillers (each 504 USRT), a cooling tower (1007 USRT), two pumps for chilled water loop (7697 LPM) and condenser loop (10,893 LPM) |
| Operation hours | 05:00 to 18:00 |
| Index | State | Unit |
|---|---|---|
| Temperature of outdoor air | °C | |
| CO2 concentration of 16 zones 1 | ppm | |
| , | Electrical energy use of two chillers | kWh |
| Electrical energy use of a cooling tower fan | kWh | |
| , | Electrical energy use of two pumps | kWh |
| Temperature of chilled water leaving at two chillers | °C | |
| Temperature of chilled water entering to two chillers | °C |
| Index | Control Variable | Unit | Value |
|---|---|---|---|
| Set-point chilled water temperature | °C | 6, 7, 8, 9, 10 | |
| OA damper opening rate for 4 AUHs | % | 40, 50, 60, 70 |
| Date/Time | Values for 16 Variables Sent to GPT | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Var.1 | Var.2 | Var.3 | Var.4 | Var.5 | Var.6 | Var.7 | Var.8 | Var.9 | |
| 07/13 06:00 | decreased | −0.3 | 23.2 | decreased | −13.2 | 693.0 | increased | 0.0 | 0.0 |
| 07/13 07:00 | decreased | −0.2 | 23.0 | increased | 117.9 | 810.9 | increased | 343.0 | 343.0 |
| 07/13 08:00 | increased | 0.0 | 23.0 | decreased | −44.1 | 766.8 | increased | 75.9 | 418.9 |
| 07/13 09:00 | decreased | −0.1 | 22.9 | decreased | −77.4 | 689.4 | decreased | −86.4 | 332.5 |
| 07/13 10:00 | increased | 0.0 | 22.9 | increased | 68.6 | 758.0 | decreased | −49.5 | 283.0 |
| 07/13 11:00 | increased | 0.0 | 22.9 | increased | 66.1 | 824.1 | increased | 163.1 | 446.1 |
| 07/13 12:00 | increased | 0.1 | 23.0 | increased | 14.8 | 838.9 | decreased | −142.4 | 303.8 |
| 07/13 13:00 | increased | 0.0 | 23.0 | increased | 28.5 | 867.4 | increased | 161.0 | 464.8 |
| 07/13 14:00 | decreased | −0.1 | 22.9 | decreased | −15.8 | 851.7 | decreased | −196.5 | 268.2 |
| 07/13 15:00 | increased | 0.0 | 22.9 | increased | 21.9 | 873.5 | increased | 171.7 | 439.9 |
| 07/13 16:00 | decreased | −0.1 | 22.8 | increased | 26.9 | 900.4 | decreased | −28.2 | 411.7 |
| 07/13 17:00 | decreased | −0.1 | 22.7 | increased | 10.0 | 910.4 | increased | 59.5 | 471.3 |
| 07/13 18:00 | decreased | −0.2 | 22.5 | increased | 28.5 | 938.9 | decreased | −198.9 | 272.4 |
| 07/14 06:00 | increased | 0.1 | 22.4 | decreased | −13.1 | 698.0 | increased | 0.0 | 0.0 |
| 07/14 07:00 | increased | 0.2 | 22.6 | increased | 114.7 | 812.7 | increased | 345.2 | 345.2 |
| 07/14 08:00 | increased | 0.3 | 22.9 | decreased | −42.8 | 769.9 | increased | 73.2 | 418.4 |
| 07/14 09:00 | increased | 0.2 | 23.1 | decreased | −78.8 | 691.1 | decreased | −75.0 | 343.4 |
| 07/14 10:00 | increased | 0.3 | 23.4 | increased | 67.5 | 758.6 | increased | 63.9 | 407.2 |
| 07/14 11:00 | increased | 0.3 | 23.7 | increased | 60.6 | 819.2 | increased | 11.5 | 418.7 |
| 07/14 12:00 | increased | 0.4 | 24.1 | increased | 18.1 | 837.3 | decreased | −81.0 | 337.7 |
| 07/14 13:00 | increased | 0.3 | 24.4 | increased | 25.9 | 863.2 | increased | 89.4 | 427.1 |
| 07/14 14:00 | increased | 0.8 | 25.2 | decreased | −61.1 | 802.1 | decreased | −79.2 | 347.9 |
| 07/14 15:00 | increased | 0.7 | 25.9 | increased | 18.3 | 820.3 | increased | 89.0 | 436.9 |
| 07/14 16:00 | increased | 0.8 | 26.7 | increased | 17.7 | 838.0 | decreased | −79.6 | 357.3 |
| 07/14 17:00 | decreased | −0.8 | 25.9 | increased | 31.1 | 869.1 | increased | 84.1 | 441.4 |
| 07/14 18:00 | decreased | −0.8 | 25.1 | increased | 6.9 | 876.1 | decreased | −92.9 | 348.5 |
| 07/15 06:00 | increased | 0.0 | 23.9 | decreased | −12.7 | 686.3 | increased | 0.0 | 0.0 |
| 07/15 07:00 | decreased | −0.1 | 23.8 | increased | 114.4 | 800.7 | increased | 346.9 | 346.9 |
| 07/15 08:00 | increased | 0.3 | 24.1 | decreased | −42.7 | 758.0 | increased | 77.9 | 424.8 |
| 07/15 09:00 | increased | 0.4 | 24.5 | decreased | −41.8 | 716.2 | decreased | −84.7 | 340.2 |
| 07/15 10:00 | increased | 0.3 | 24.8 | increased | 85.9 | 802.0 | increased | 80.7 | 420.9 |
| 07/15 11:00 | increased | 0.5 | 25.3 | increased | 70.5 | 872.6 | decreased | −3.9 | 416.9 |
| 07/15 12:00 | increased | 0.5 | 25.8 | increased | 18.8 | 891.3 | increased | 44.6 | 461.6 |
| 07/15 13:00 | increased | 0.5 | 26.3 | decreased | −8.6 | 882.8 | decreased | −112.8 | 348.7 |
| 07/15 14:00 | decreased | −0.5 | 25.8 | decreased | −49.8 | 832.9 | increased | 147.0 | 495.7 |
| 07/15 15:00 | decreased | −0.5 | 25.3 | increased | 30.0 | 863.0 | decreased | −137.5 | 358.2 |
| 07/15 16:00 | decreased | −0.5 | 24.8 | increased | 22.3 | 885.2 | increased | 20.0 | 378.2 |
| 07/15 17:00 | decreased | −0.1 | 24.7 | decreased | −2.8 | 882.4 | decreased | −23.8 | 354.4 |
| 07/15 18:00 | decreased | −0.1 | 24.6 | increased | 11.5 | 893.9 | increased | 79.1 | 433.5 |
| Date/Time | Values for 16 Variables Sent to GPT | Response of GPT | ||||||
|---|---|---|---|---|---|---|---|---|
| Var.10 | Var.11 | Var.12 | Var.13 | Var.14 | Var.15 | Var.16 | ||
| 07/13 06:00 | increased | 0.0 | 13.3 | increased | 0.0 | 50% | 6.0 | |
| 07/13 07:00 | increased | 0.9 | 14.2 | increased | 3.0 | 40% | 10.0 | |
| 07/13 08:00 | decreased | −1.5 | 12.7 | increased | 2.2 | 50% | 7.0 | |
| 07/13 09:00 | increased | 0.3 | 13.0 | decreased | −1.0 | 60% | 8.0 | |
| 07/13 10:00 | increased | 0.5 | 13.5 | decreased | −1.0 | 50% | 9.0 | |
| 07/13 11:00 | increased | 0.1 | 13.6 | increased | 1.8 | 60% | 8.0 | Example 2 |
| 07/13 12:00 | increased | 0.3 | 13.9 | decreased | −2.5 | 70% | 10.0 | Example 3 |
| 07/13 13:00 | decreased | −0.9 | 13.0 | increased | 3.0 | 60% | 7.0 | |
| 07/13 14:00 | increased | 0.7 | 13.6 | decreased | −0.3 | 50% | 8.0 | |
| 07/13 15:00 | decreased | −1.0 | 12.7 | decreased | −0.2 | 60% | 7.0 | |
| 07/13 16:00 | increased | 0.8 | 13.5 | decreased | −0.3 | 60% | 8.0 | |
| 07/13 17:00 | decreased | 0.0 | 13.4 | increased | 1.7 | 60% | 7.0 | |
| 07/13 18:00 | increased | 0.3 | 13.7 | decreased | −1.0 | 50% | 8.0 | |
| 07/14 06:00 | increased | 0.0 | 13.9 | increased | 0.0 | 50% | 6.0 | |
| 07/14 07:00 | increased | 0.4 | 14.3 | increased | 3.1 | 40% | 10.0 | |
| 07/14 08:00 | decreased | −1.6 | 12.7 | increased | 2.1 | 50% | 7.0 | |
| 07/14 09:00 | increased | 0.4 | 13.1 | decreased | −1.0 | 60% | 8.0 | |
| 07/14 10:00 | decreased | −0.6 | 12.5 | increased | 0.4 | 50% | 7.0 | |
| 07/14 11:00 | increased | 0.9 | 13.4 | increased | 0.0 | 60% | 8.0 | |
| 07/14 12:00 | increased | 0.7 | 14.0 | decreased | −1.9 | 70% | 10.0 | |
| 07/14 13:00 | decreased | −0.4 | 13.7 | increased | 2.3 | 60% | 8.0 | |
| 07/14 14:00 | increased | 0.4 | 14.1 | decreased | −2.2 | 70% | 10.0 | Example 4 |
| 07/14 15:00 | decreased | −0.1 | 14.0 | increased | 2.7 | 60% | 8.0 | Example 5 |
| 07/14 16:00 | increased | 0.5 | 14.4 | decreased | −2.2 | 70% | 10.0 | |
| 07/14 17:00 | decreased | −0.6 | 13.8 | increased | 2.0 | 60% | 8.0 | |
| 07/14 18:00 | increased | 0.4 | 14.2 | decreased | −2.3 | 70% | 10.0 | |
| 07/15 06:00 | increased | 0.0 | 13.6 | increased | 0.0 | 50% | 6.0 | |
| 07/15 07:00 | increased | 0.7 | 14.3 | increased | 3.1 | 40% | 10.0 | |
| 07/15 08:00 | decreased | −1.5 | 12.8 | increased | 2.2 | 50% | 7.0 | |
| 07/15 09:00 | increased | 0.3 | 13.1 | decreased | −1.3 | 40% | 8.0 | |
| 07/15 10:00 | decreased | −0.6 | 12.5 | increased | 0.6 | 40% | 7.0 | |
| 07/15 11:00 | increased | 0.9 | 13.4 | increased | 0.0 | 50% | 8.0 | |
| 07/15 12:00 | decreased | −0.3 | 13.1 | increased | 1.0 | 60% | 7.0 | Example 6 |
| 07/15 13:00 | increased | 1.1 | 14.1 | decreased | −2.8 | 70% | 10.0 | Example 7 |
| 07/15 14:00 | decreased | −0.8 | 13.4 | increased | 3.3 | 60% | 7.0 | |
| 07/15 15:00 | increased | 0.3 | 13.6 | decreased | −1.3 | 50% | 8.0 | |
| 07/15 16:00 | decreased | 0.0 | 13.6 | decreased | −1.2 | 60% | 9.0 | |
| 07/15 17:00 | increased | 0.9 | 14.5 | decreased | −0.2 | 70% | 10.0 | |
| 07/15 18:00 | decreased | −0.7 | 13.8 | increased | 1.9 | 60% | 8.0 | |
| Baseline Operation | ChatGPT Pre-Trained LLM Control | DQN Model-Free Control | |
|---|---|---|---|
| Total energy use (kWh) | 17,961 | 14,944 | 13,635 |
| Saving rate compared with baseline operation (%) | - | 16.8 | 24.1 |
| During building operating hours, duration when CO2 exceeded 1000 ppm * (hours) | 0 | 0 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahn, K.U.; Kim, D.-W.; Cho, H.M.; Chae, C.-U. Alternative Approaches to HVAC Control of Chat Generative Pre-Trained Transformer (ChatGPT) for Autonomous Building System Operations. Buildings 2023, 13, 2680. https://doi.org/10.3390/buildings13112680
Ahn KU, Kim D-W, Cho HM, Chae C-U. Alternative Approaches to HVAC Control of Chat Generative Pre-Trained Transformer (ChatGPT) for Autonomous Building System Operations. Buildings. 2023; 13(11):2680. https://doi.org/10.3390/buildings13112680
Chicago/Turabian StyleAhn, Ki Uhn, Deuk-Woo Kim, Hyun Mi Cho, and Chang-U Chae. 2023. "Alternative Approaches to HVAC Control of Chat Generative Pre-Trained Transformer (ChatGPT) for Autonomous Building System Operations" Buildings 13, no. 11: 2680. https://doi.org/10.3390/buildings13112680
APA StyleAhn, K. U., Kim, D.-W., Cho, H. M., & Chae, C.-U. (2023). Alternative Approaches to HVAC Control of Chat Generative Pre-Trained Transformer (ChatGPT) for Autonomous Building System Operations. Buildings, 13(11), 2680. https://doi.org/10.3390/buildings13112680