



An Automated Method for Extracting and Analyzing Railway Infrastructure Cost Data



Abstract
:1. Introduction
2. Related Work
2.1. Data Science and Machine Learning on Infrastructure Costs
2.2. Railway Infrastructure Studies
2.3. Strongly Related Studies
2.4. The Contribution of the Presented Method
- Integration of Data Mining, Statistics, and Machine Learning: The paper introduces an innovative approach that combines innovative techniques from data mining, statistics, and machine learning implemented in a very specific scenario, which is railway infrastructure costs.
- Automation and Efficiency: By leveraging data mining and machine learning, the paper aims to automate the process of extracting and analyzing data. This automation reduces the manual effort required for data inclusion and analysis, making the process more efficient.
- Cost Benchmarking: The paper focuses on the important task of cost benchmarking in the context of railway infrastructure projects. It employs machine learning and data analytics methods to identify the most relevant factors affecting project costs. This is valuable for comparing projects and understanding the drivers of cost differences.
- Real Historical Data: The paper validates its approach using real historical data from 23 projects within the client network rail. The usage of real data enhances the credibility and applicability of the proposed method.
- Deep Understanding of Cost Relationships: The approach presented in this paper not only enables cost benchmarking but also facilitates a deeper understanding of the relationships and relevant factors that impact infrastructure costs. This insight can be crucial for making informed decisions and optimizing future projects.
3. Materials and Methods
3.1. Materials
- Anaconda navigation version 2.2.
- The IDE (integrated development environment) Jupyter notebook version 6.4.5.
- Python language.
- Different open-source libraries were used, from which we highlighted: ‘xlrd’ for reading excel files or ‘os’ for accessing some operative system capabilities.
3.2. The Scenario
3.2.1. Versions 1.5 and 1.7
- Tier 1: Describes costs at project or subproject level for either ‘buildings’ or ‘Civil engineering’. The following categories can be found for this attribute: Buildings and property, civil engineering, electrical power plant, operational telecommunications, permanent way, railway control systems, and train power systems.
- Tier 2: Describes broad ‘cost categories’ such as Acquisition Costs; Construction Costs; Renewal Costs; Operation Costs; Maintenance Costs; End of Life Costs; and Lifecycle Cost. It takes a wider range of values: AC (OLE), AC Traction Power System, Buildings, Businesses, Canopies, Car parks and roads, DC, DC Traction Power System, Depot plant, Drainage, Earthworks, Electrical, Fencing, Level crossing, Lifts and escalators, Mechanical, Network, Operational telecoms, Plain line, Platforms, Signaling, Signaling power supplies, Station Information and Security Systems, Structures, Switches and crossings, Train sheds.
- Tier 3: Describes ‘cost groups’ covering the subdivision of cost category totals into a more detailed breakdown in each case. For instance, in the construction costs category, this includes key elements such as Substructure, Structure, Preliminaries, Services, and Equipment, and it can take the following values: Approaches, Auto (MSL), Auto (RTL), Auxiliary Transformer, Ballast, Business Voice, Cables, Cabling and Containments, Clocks, Closed Circuit, Television, Coastal and Estuarine Defenses, Concentrator, Conductor Rail System, Control, Control System Only, Controls and Interlocking, Culverts, Customer Information Systems, Disconnectors, DNO Supply, Driver Only Operation System Components, Embarkments, Footbridges, FSP Auto Reconfigurable, FSP Manual Reconfigurable, FSP Radial Feed, Generator, GSM-R, HV Cables, HV Switchgear, HV Transformers, Interlocking Only, Level Crossing Refurbishment Treatments, Lineside Telephone, LV dc Cables, LV Switchgear, Negative Short Circuit Device, Neutral Section, OLE system, Operational Voice, Over bridges, Phones only, Power, Principal Supply Point, Protection Relays, Protection System Upgrade, Public Address, Public Address/Voice Alarm, Public Emergency Telephone System, Radio, Rail, Rail Ballast, Rail Sleepers, Rail sleepers ballast, Retaining Walls, Rock Cuttings, RTU (SCADA), Signaling System, Sleepers, Soil cuttings, Station Help Points, Structures, TNO/DNO HV Supply, Trackside Equipment Only, Transformers/Rectifiers, Transmission FTN, Transmission IP, Transmission Legacy, Tunnels, Under bridges, Uninterruptable Power Supply, User Operated, Voice Recorders, Wire Run.
- Work Type: A label that describes the work that has been carried out such as refurbishment, replace full, or replace partial.
- Work Type code: The unique identifier code linking the work type that has been carried out.
3.2.2. Versions 2.0, 2.1, and 2.2
- Primary reference: A group of eight numbers and letters uniquely identifying each asset of each project.
- Asset: Is a generic classification attribute that replaces the older attribute Tier 1. It also describes the costs at a subproject level distinguishing between ‘buildings’ and ‘civil engineering’. However, this attribute is a bit more specific, indicating different subcategories inside civils such as earthworks, different types of drainage, and assets regarding the building of structures. The range of values that this attribute can take are the following: Buildings and property, civils (drainage—resilience), civils (drainage—earthworks), civils (drainage—track), civils (earthworks), civils (structures), electric power and plant, permanent way, railway control systems, telecommunications, train power systems.
- Structures: A more specific classification attribute slightly similar to the previous Tier 3 categories where a wider range of attributes can be distinguished: AC HV Cables, AC HV switchgear, AC HV transformer, AC overhead line equipment (OLE), AC protection Relay, AC remote terminal unit, AC transmission or distribution network operator HV supply, auxiliary transformer, bespoke color light signaling, buildings, canopies, car parks and roads, chamber, channel, coastal defenses, conductor rail heating, control system, controls and interlocking, culvert, DC conductor rail system, DC disconnectors, DC HV cables, DC HV switchgear, DC HV transformer, DC LV cables, DC LV switchgear, DC negative short circuit device, DC protection relay, DC remote terminal unit, depot plant, distribution network operator (DNO), electrical wiring and lighting system, embarkment, European train control system (ETCS), fencing, footbridges, FSP auto reconfiguration, FSO manual reconfiguration, FSP radial feed, generator, gravel drain, hot axle box detector (HABD), interlocking, level crossing, lifts and escalators, lighting, mechanical heating, mineworking’s–deep, mineworking’s–shallow, mineworking’s–surface, moving bridges, network, operational communications, over bridge, pantograph measuring system (PMS), pipe, plain line, platforms, points heating, principal supply point (PSP), pumps, ramp, remote condition monitoring (RCM), retaining wall, rock cutting, signaling cables, simple modular color light signaling, soil cutting, station information and surveillance system, switch and crossings, trackside equipment, train sheds, tunnel, under bridge, uninterruptible power supply, water tanking, wheel force measuring system.
- Work type: A label that uniquely identifies the work that has been carried out such as refurbishment or new building.
- Work solution: An attribute that briefly describes the work that has been carried out to accomplish the task.
3.3. The Output Structure
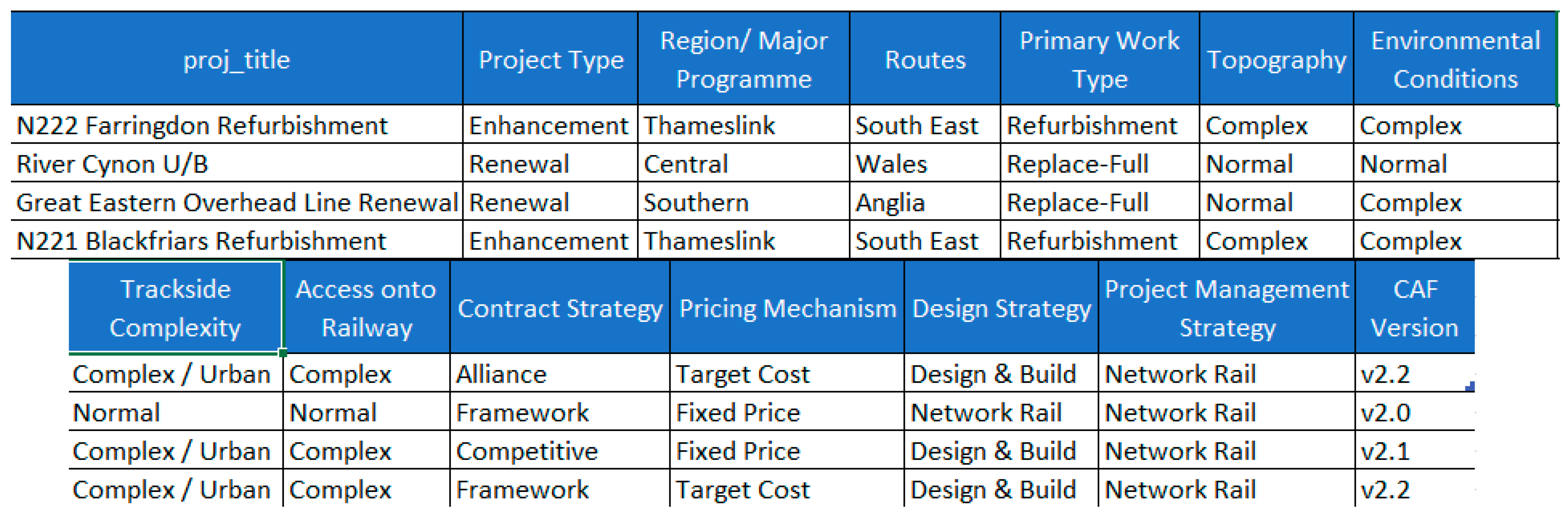
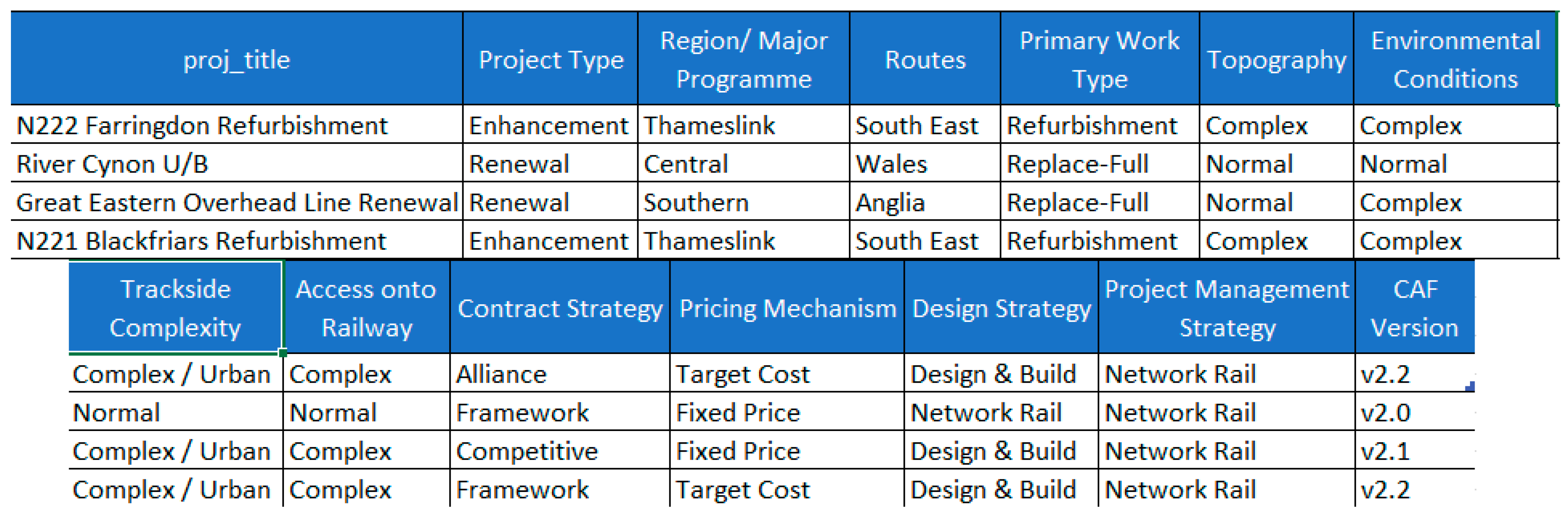
3.3.1. Project Details
3.3.2. Cost Details
3.3.3. GRIP Stage Details
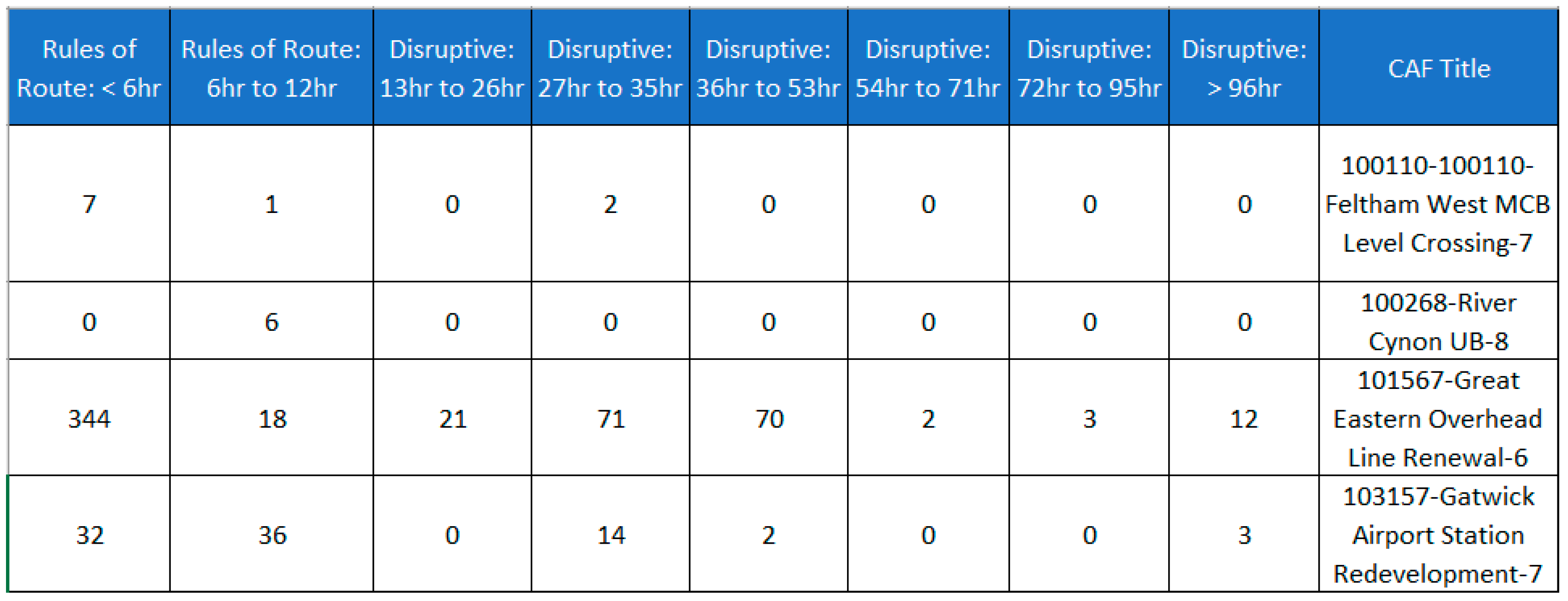
3.3.4. Possession Strategy
3.4. The Method Step by Step
3.4.1. Step 1: Data Extraction
- Description: During this step, the suggested method iteratively loads each of the CAF files taken as inputs to extract from them four different types of information: project details, cost details, stage GRIP details, and possession strategy.To perform this step, two data mining techniques are implemented. First, an association rule of mining is designed to support an automatic categorization of the raw data, which is based on the inner patterns of the input data and without the usage of machine learning algorithms. Additionally, an anomaly detection system is implemented that is also based on the manual analysis of the input data and without the usage of machine learning algorithms.
- Input: The input of this step consists of the information distributed into 23 CAF files coming from real historical projects with different structures depending on their version, which ranges from 1.5 to 2.3.
- Output: As a main result for this step, four different folders are created: one for storing the project information and the second for project details, whereas the last two are for the GRIP stage details and possession strategy, respectively. Each folder contains 299 different excel files with information extracted from the initial CAF files.
3.4.2. Step 2: Data Merging
- Description: During the process of data merging, the data generated in the previous step are gathered and combined, considering not only the fact that there are four types of information that will be merged into one file but also that that different versions of CAF files contain different attributes.
- Input: The input for this step is the same as the output for the previous step consisting of four different folders, each of them with 299 different files with their information extracted from each CAF.
- Output: There are two main outputs that can be distinguished for this step: On the one hand, a new folder is generated with 299 different files combining the four types of information. Alternatively, five breakdown documents are created summarizing all projects depending on the existing CAF version (1.5, 1.7, 2.0, 2.1, and 2.2).
3.4.3. Step 3: Data Analysis
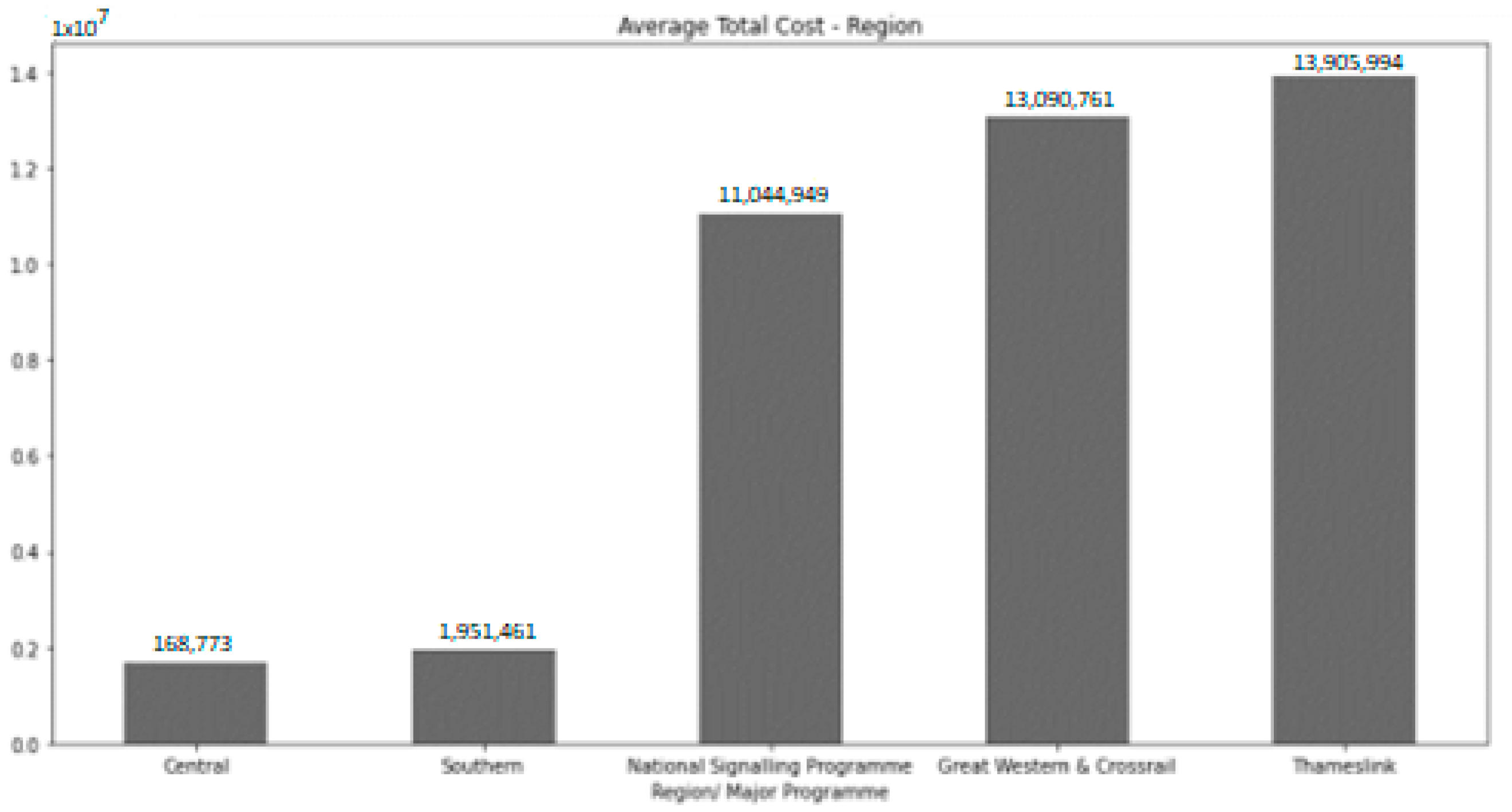
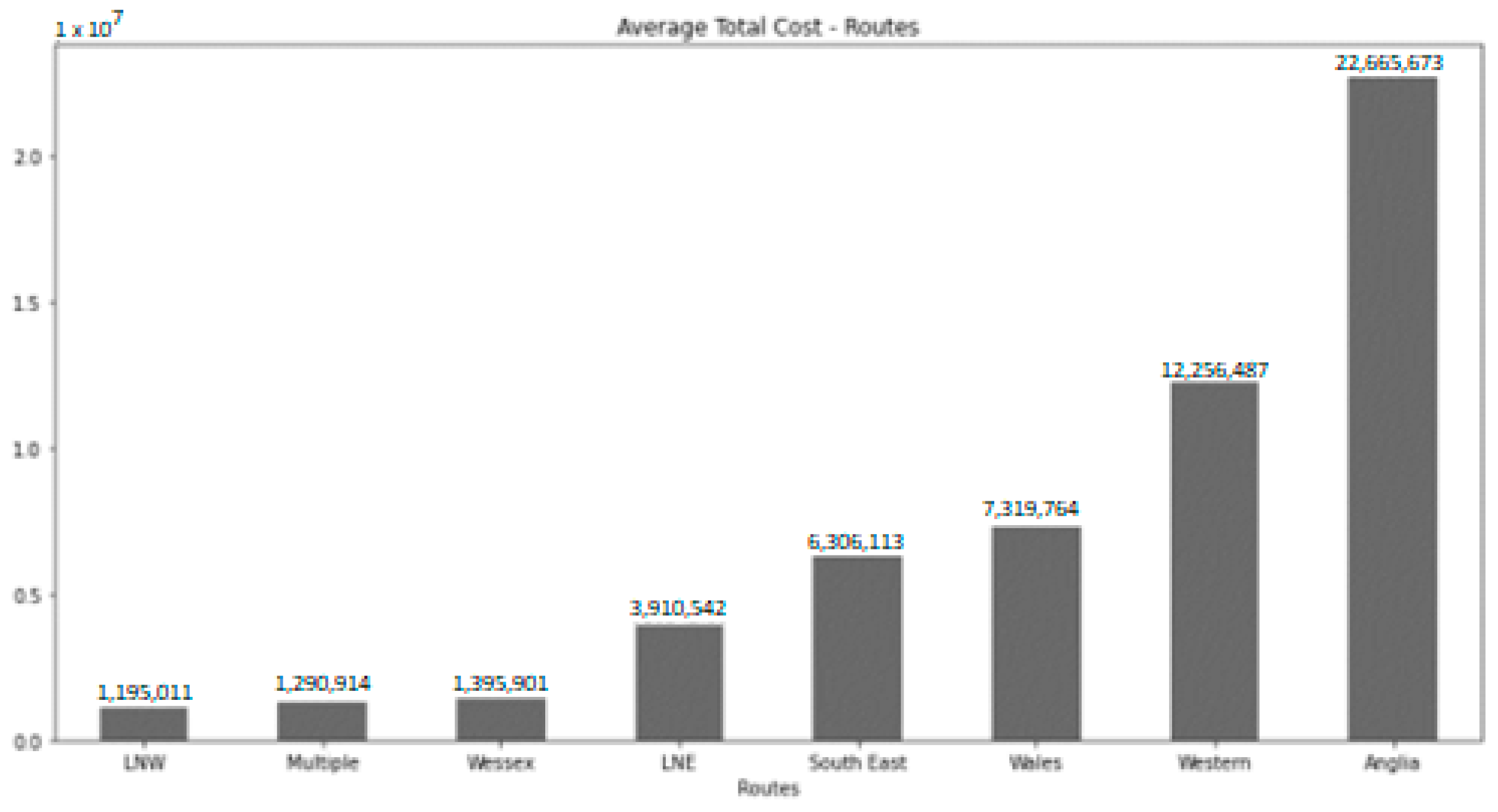
- Description: As a final step, some analysis techniques are implemented to demonstrate that converting data to a common format allows the whole picture to be seen and for the relationships between the different attributes to be found. Additionally, three different machine learning algorithms are implemented to predict future project costs: linear regression, lasso regression, and random forest. To perform an unbiased validation of the algorithms, two iterations are implemented, taking as the training set a random sample consisting of 85% of the total dataset and leaving as the test set the remaining 15%.Regarding the hyperparameter tuning, it is worth commenting that the random forest is configured using 800 trees in the forest and with a maximum depth of 6. Alternatively, the lasso regression algorithm is configured with an alpha value of 0.5, and finally, the linear regression is left with the default configuration.
- Input: The main input for this step is all the attributes extracted in the previous step coming from 23 CAF files that are combined for analysis and comparison.
- Output: As the main result, some inferences are made, and some knowledge of the current data is extracted to validate the suggested method.
4. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Soibelman, L.; Wu, J.; Caldas, C.; Brilakis, I.; Lin, K.Y. Management and analysis of unstructured construction data types. Adv. Eng. Inform. 2008, 22, 15–27. [Google Scholar] [CrossRef]
- Fereshtehnejad, E.; Shafieezadeh, A. A multi-type multi-occurrence hazard lifecycle cost analysis framework for infrastructure management decision making. Eng. Struct. 2018, 167, 504–517. [Google Scholar] [CrossRef]
- Schonlau, M.; Gweon, H.; Wenemark, M. Automatic Classification of Open-Ended Questions: Check-All-That-Apply Questions. Soc. Sci. Comput. Rev. 2019, 39, 562–572. [Google Scholar] [CrossRef]
- Wang, Y.; Kung, L.A.; Byrd, T.A. Big data analytics: Understanding its capabilities and potential benefits for healthcare organizations. Technol. Forecast. Soc. Chang. 2018, 126, 3–13. [Google Scholar] [CrossRef]
- Miller, C.; Meggers, F. Mining electrical meter data to predict principal building use, performance class, and operations strategy for hundreds of non-residential buildings. Energy Build. 2017, 156, 360–373. [Google Scholar] [CrossRef]
- Cerquitelli, T.; Meo, M.; Curado, M.; Skorin-Kapov, L.; Tsiropoulou, E. Machine learning empowered computer networks. Comput. Netw. 2023, 230, 109807. [Google Scholar] [CrossRef]
- Desai, V.S. Improved Decision Tree Methodology for the Attributes of Unknown or Uncertain Characteristics-Construction Project Prospective. Int. J. Appl. Manag. Technol. 2008, 6, 201. [Google Scholar]
- Zhong, Y. Research on Construction Engineering Project Management Optimization Based on C4.5 Improved Algorithm. IOP Conf. Ser. Mater. Sci. Eng. 2019, 688, 055036. [Google Scholar] [CrossRef]
- Chen, D.; Hajderanj, L.; Fiske, J. Towards automated cost analysis, benchmarking and estimating in construction: A machine learning approach. In Proceedings of the Multi Conference on Computer Science and Information Systems, MCCSIS 2019, Porto, Portugal, 16–18 July 2019; pp. 85–91. [Google Scholar] [CrossRef]
- Ji, C.; Xu, C. New method for allocating high-speed railway infrastructure costs among train types. E3S Web Conf. 2021, 233, 01137. [Google Scholar] [CrossRef]
- Caíno-Lores, S.; García, A.; García-Carballeira, F.; Carretero, J. Efficient design assessment in the railway electric infrastructure domain using cloud computing. Integr. Comput.-Aided Eng. 2017, 24, 57–72. [Google Scholar] [CrossRef]
- Durazo-Cardenas, I.; Starr, A.; Turner, C.J.; Tiwari, A.; Kirkwood, L.; Bevilacqua, M.; Tsourdos, A.; Shehab, E.; Baguley, P.; Xu, Y.; et al. An autonomous system for maintenance scheduling data-rich complex infrastructure: Fusing the railways’ condition, planning and cost. Transp. Res. Part C Emerg. Technol. 2018, 89, 234–253. [Google Scholar] [CrossRef]
- Andersson, M. Swedish Data for Railway Infrastructure Maintenance and Renewal Cost Modelling, 9th ed.; Allan, J.J., Brebbia, C.A., Hill, R.J., Sciutto, G., Sone, S., Eds.; WIT Transactions on The Built Environment; WIT Press: Billerica, MA, USA, 2004; Volume 74, p. 1015. [Google Scholar]
- Rama, D.; Andrews, J.D. Railway infrastructure asset management: The whole-system life cost analysis. IET Intell. Transp. Syst. 2016, 10, 58–64. [Google Scholar] [CrossRef]
- Kouris, I.N.; Makris, C.H.; Tsakalidis, A.K. Using Information Retrieval techniques for supporting data mining. Data Knowl. Eng. 2005, 52, 353–383. [Google Scholar] [CrossRef]
- Fan, M.; Fan, H.; Chen, N.; Chen, Z.; Du, W. Active on-demand service method based on event-driven architecture for geospatial data retrieval. Comput. Geosci. 2013, 56, 1–11. [Google Scholar] [CrossRef]
- Deb, S.; Zhang, Y. An overview of content-based image retrieval techniques. In Proceedings of the International Conference on Advanced Information Networking and Application (AINA), Fukuoka, Japan, 29–31 March 2004; Volume 1, pp. 59–64. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Main Aim | Approach |
|---|---|---|
| [7] | To enhance the data classification in construction projects | The creation of a method implementing machine learning and the knowledge for variable correlation |
| [8] | To optimize the management in construction engineering projects | The creation of a method that performs a risk assessment, an evaluation using rough set theory and the implementation of machine learning for optimization |
| [1] | To identify and analyze a large variety of data structures in construction projects | A study that encompasses the search and extraction of different data structures used in a wide-ranging project. |
| [9] | To analyze and estimate costs in construction projects | The development of a method that combines surveyors’ knowledge with machine learning to effectively assess and predict costs |
| Reference | Main Aim | Approach |
|---|---|---|
| [10] | To perform a deeper analysis of high-speed railway infrastructure costs | To develop a framework considering the type of train to perform a better cost estimation |
| [11] | To perform a massive number of simulations to produce an efficient design in railway electric infrastructures | A simulation model to perform a massive number of simulations efficiently in a cloud environment |
| [12] | Automatic and efficient job scheduling for maintenance on railway infrastructure | The fusion of technical and business drivers scheduling and optimizing the intervention plans that impact on costs. |
| [13] | To perform an analysis of infrastructure, costs, and traffic on Swedish railway infrastructure | The study incorporates data gathering and data recovering techniques to conclude with some data analysis |
| [13] | Railway infrastructure asset management | A proposed framework to assess the lifecycle cost analysis |
| Reference | Main Aim | Approach |
|---|---|---|
| [15] | The usage of information retrieval techniques to support data mining | To develop a two-step algorithm acting as a search engine for making recommendations to customers using data mining. |
| [16] | A service for geospatial data retrieval on-demand | The development of a prototype based on sensor web technologies |
| [17] | To review the extraction of information using content-based image retrieval techniques | A systematic review analyzing a group of selected papers with content-based image retrieval systems. |
| [5] | To predict the building use, performance, and operations strategies of non-residential buildings | To use data mining and machine learning for analyzing and predicting data. |
| First Fold | Second Fold | Average | |
|---|---|---|---|
| Linear regression | 0.845 | 0.832 | 0.839 |
| Lasso regression | 0.844 | 0.833 | 0.838 |
| Random forest | 0.939 | 0.928 | 0.934 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dopazo, D.A.; Mahdjoubi, L.; Gething, B. An Automated Method for Extracting and Analyzing Railway Infrastructure Cost Data. Buildings 2023, 13, 2405. https://doi.org/10.3390/buildings13102405
Dopazo DA, Mahdjoubi L, Gething B. An Automated Method for Extracting and Analyzing Railway Infrastructure Cost Data. Buildings. 2023; 13(10):2405. https://doi.org/10.3390/buildings13102405
Chicago/Turabian StyleDopazo, Daniel Adanza, Lamine Mahdjoubi, and Bill Gething. 2023. "An Automated Method for Extracting and Analyzing Railway Infrastructure Cost Data" Buildings 13, no. 10: 2405. https://doi.org/10.3390/buildings13102405
APA StyleDopazo, D. A., Mahdjoubi, L., & Gething, B. (2023). An Automated Method for Extracting and Analyzing Railway Infrastructure Cost Data. Buildings, 13(10), 2405. https://doi.org/10.3390/buildings13102405