

Study Using Machine Learning Approach for Novel Prediction Model of Liquid Limit


 ,
,  , and
, and
Abstract
:1. Introduction
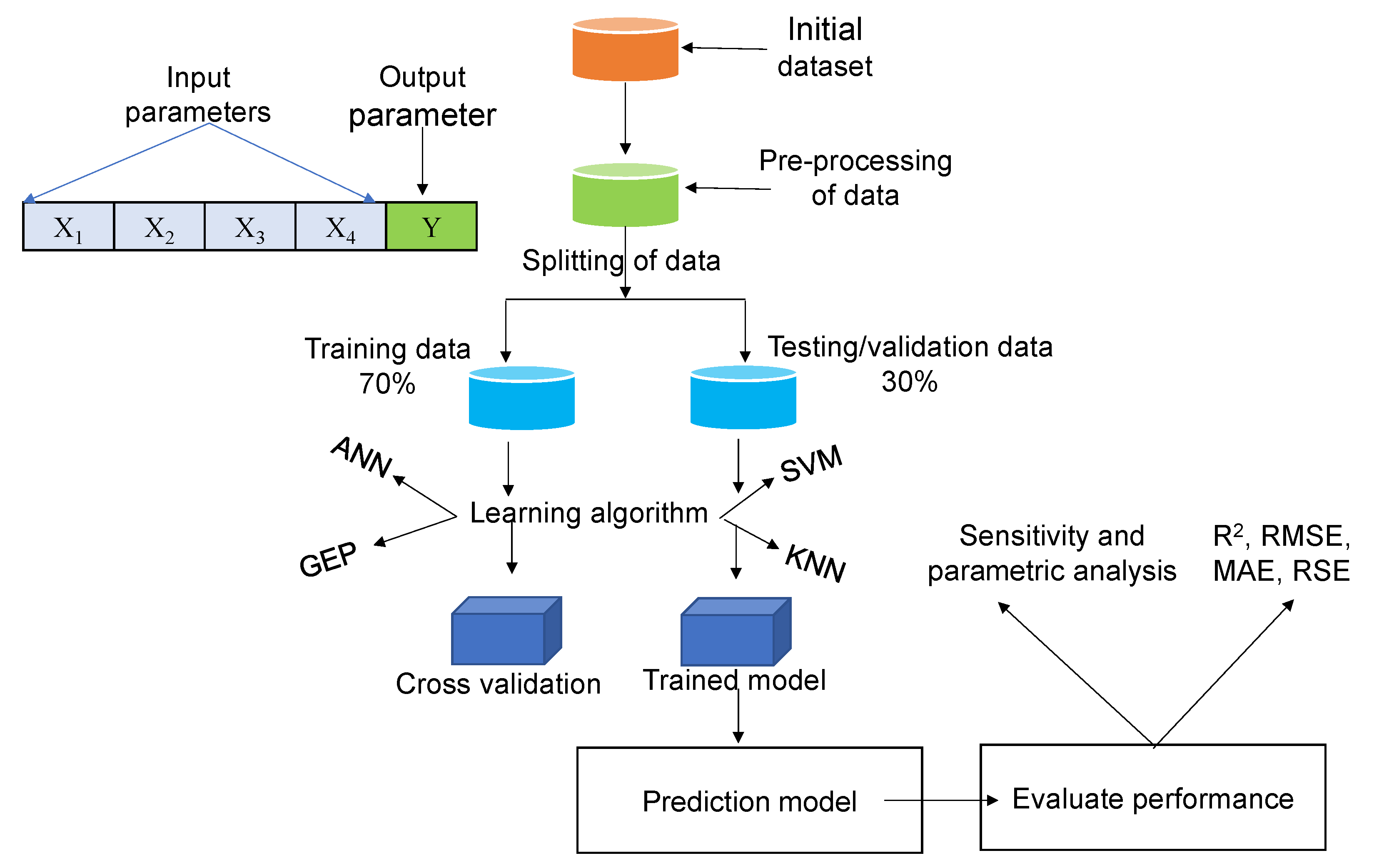
2. Research Methodology
2.1. Data Collection
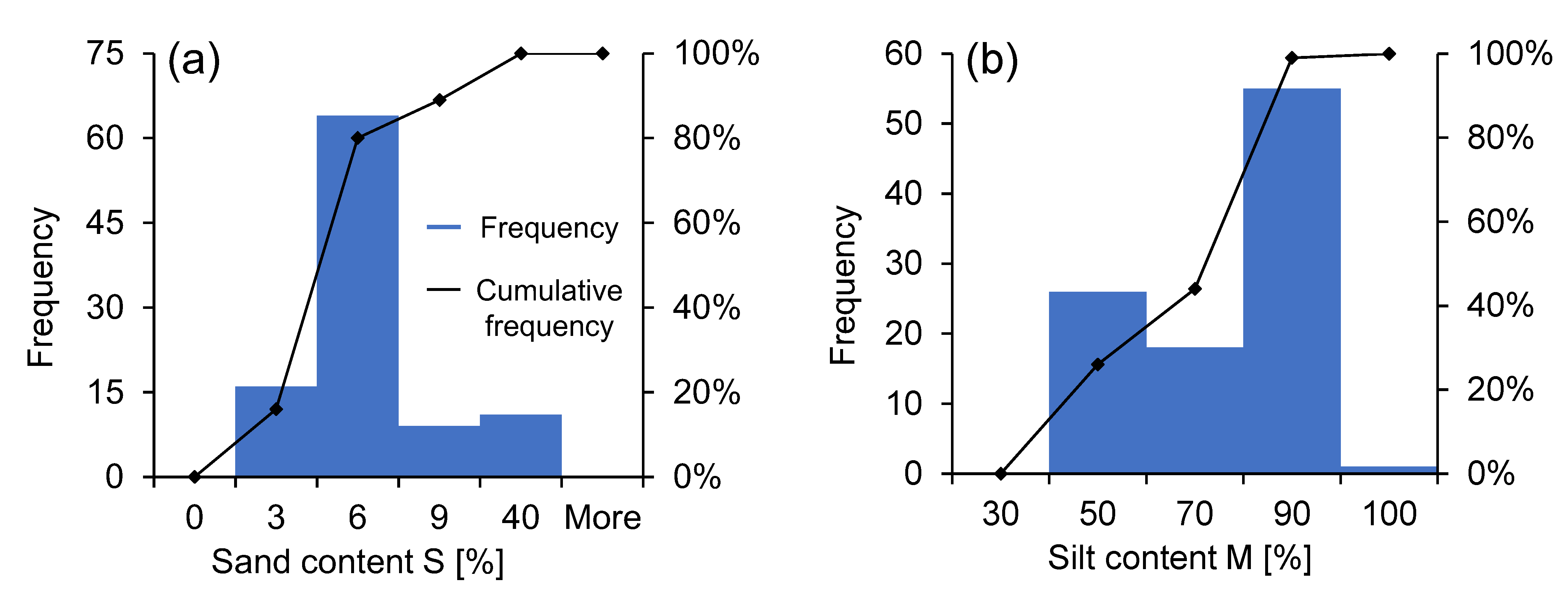
2.2. Laboratory Testing and Results
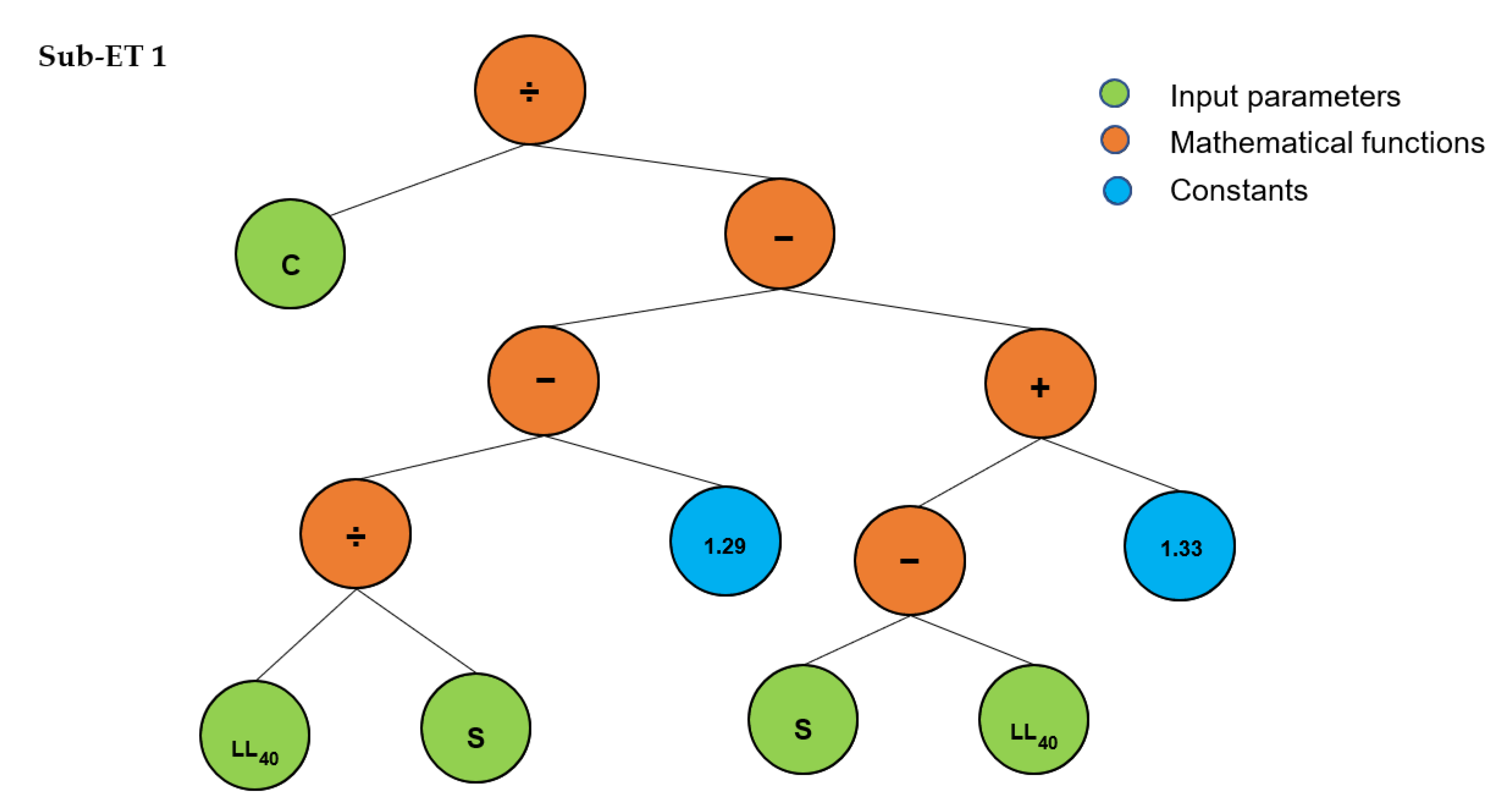
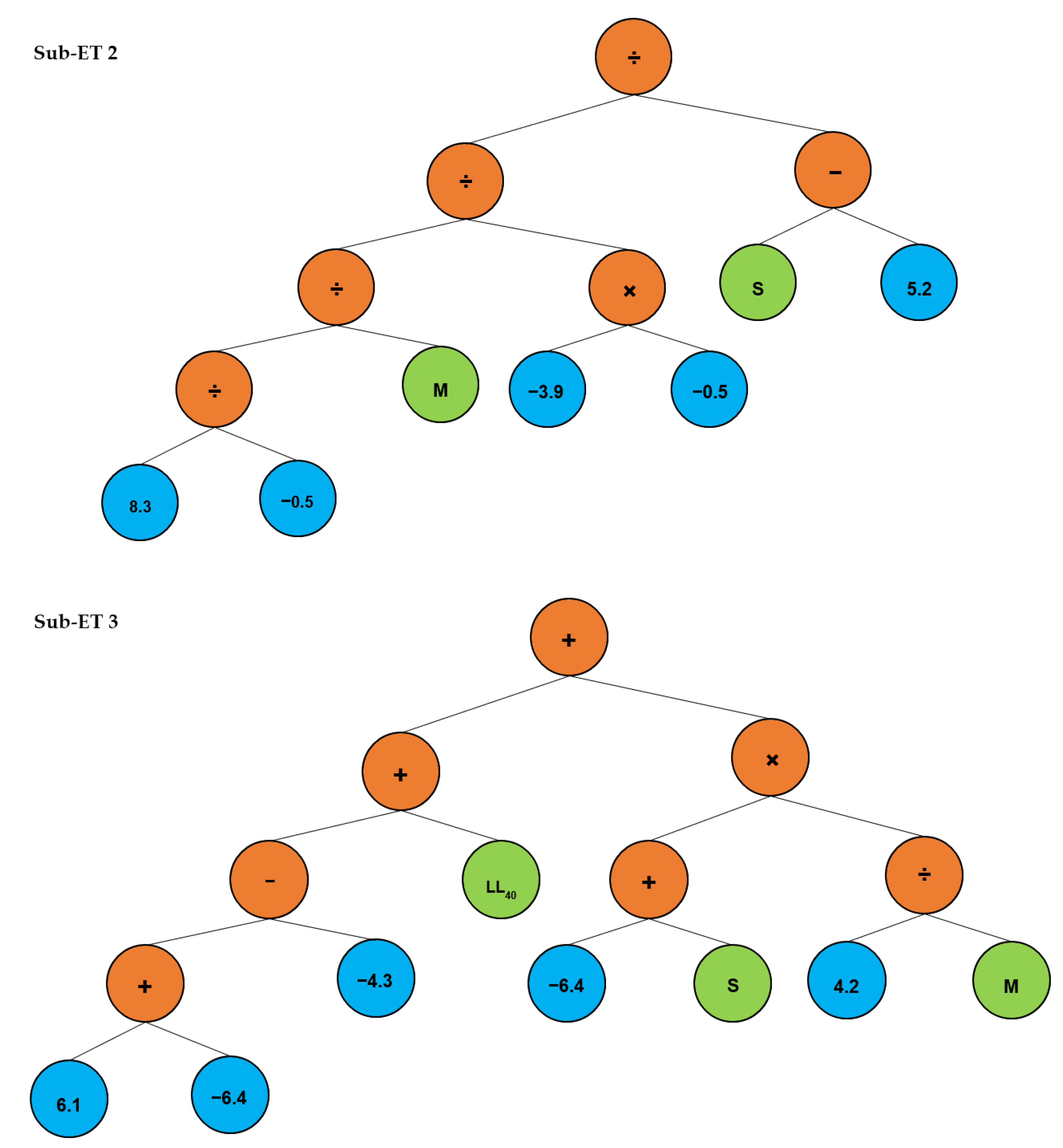
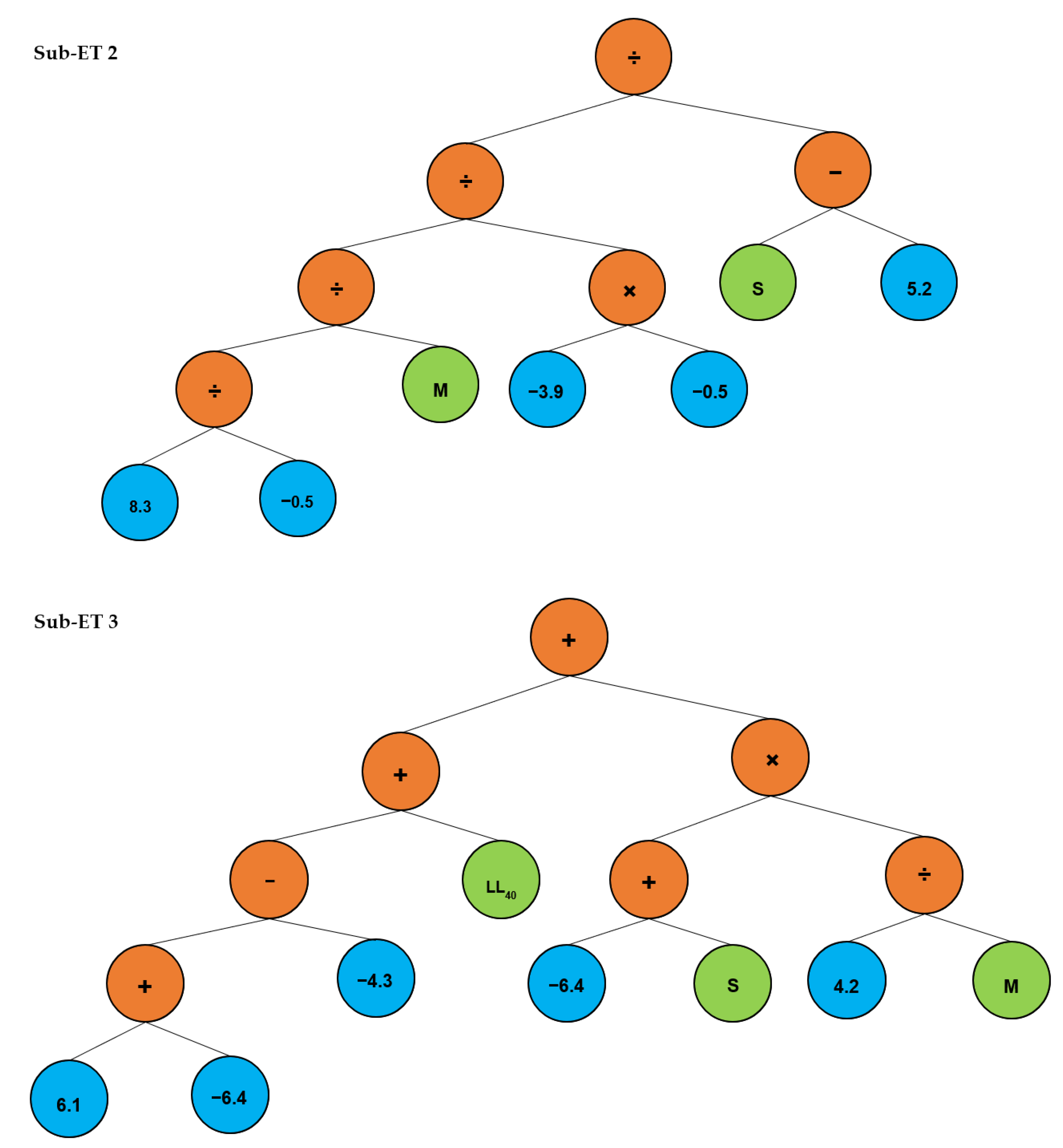
3. Development of Prediction Model Using Gene Expression Programming
3.1. General Settings
3.2. Prediction Model Evaluation Criteria
4. Results and Discussion
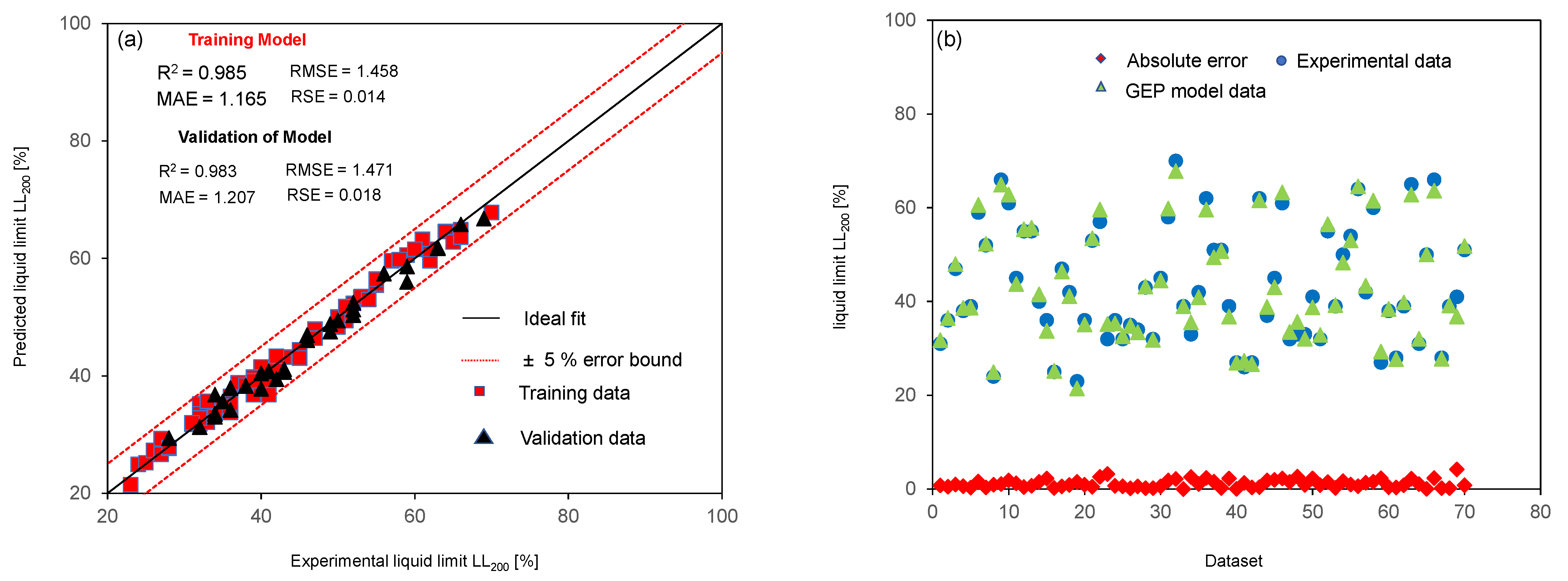
4.1. Performance Assessment of Model
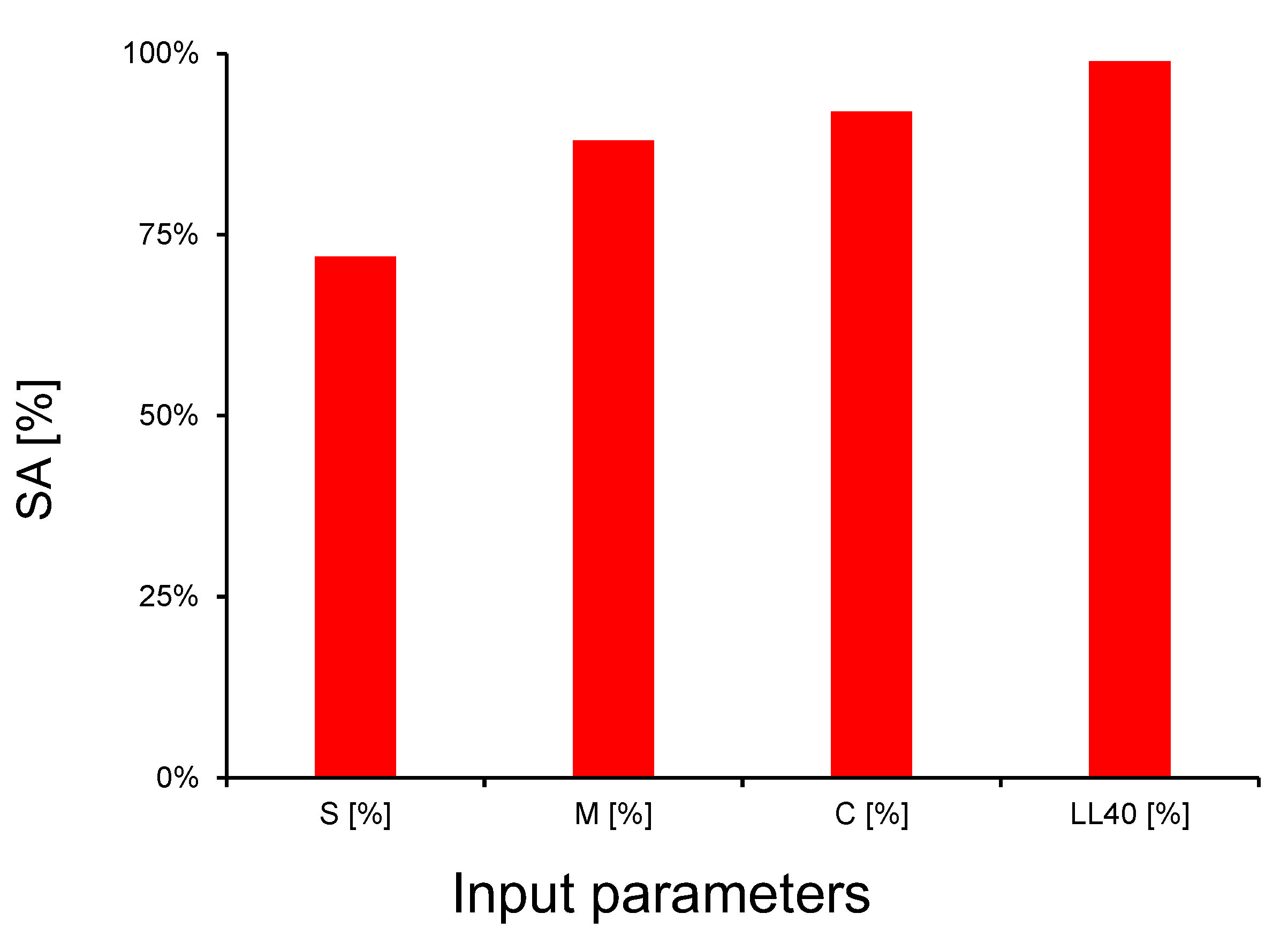
4.2. Sensitivity and Parametric Study
4.3. Practical Application and Future Prospects of Research
5. Conclusions
- The LL is governed by different particle sizes, which include S, C, and M. However, conventional methods do not incorporate the effect of S, C, and M explicitly. Therefore, the proposed model was developed to account for S, C, and M in order to better capture the behavior of the consistency of fine soils.
- The proposed prediction model is simple, robust, and justifies all the acceptance requirements in terms of high accuracy and low errors in prediction. The values of R2, RMSE, MAE, and RSE for training data were found to be 0.985, 1.458, 1.165, and 0.014, respectively, and were 0.983, 1.471, 1.207, and 0.018 for validation data. The results indicate the higher accuracy and generalization capability of the proposed prediction model.
- The proposed model predicted the responses with minimal error and the prediction data lie within ±5% error, which further confirms the reliability. The performance of the sensitivity analysis indicates that all the parameters involved in developing the model are sensitive to LL200, with S being the least significant parameter and having a sensitivity value of 0.78.
- The model can be used with the least possible error for low-plasticity clayey soils and reduces the risk of underestimation of the LL, eventually leading to the safe design and analysis of structures.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Das, B.M. Principles of Geotechnical Engineering; Cengage Learning: Belmont, CA, USA, 2021; ISBN 0357420667. [Google Scholar]
- Bowles, J.E. Foundation Engineering; McGraw Hills: Singapore, 1997. [Google Scholar]
- Sharma, B.; Bora, P.K. Plastic Limit, Liquid Limit and Undrained Shear Strength of Soil—Reappraisal. J. Geotech. Geoenvironment. Eng. 2003, 129, 774–777. [Google Scholar] [CrossRef]
- Haigh, S. Consistency of the Casagrande Liquid Limit Test. Geotech. Test. J. 2015, 39. [Google Scholar] [CrossRef]
- Budhu, M. Soil Mechanics and Foundations; John Wiley & Sons: Hoboken, NJ, USA, 2010; ISBN 0470556846. [Google Scholar]
- Casey, B.; Germaine, J.T. Stress Dependence of Shear Strength in Fine-Grained Soils and Correlations with Liquid Limit. J. Geotech. Geoenviron. Eng. 2013, 139, 1709–1717. [Google Scholar] [CrossRef]
- ASTM-D4318; Test Methods for Liquid Limit, Plastic Limit, and Plasticity Index of Soils. ASTM: West Conshohocken, PA, USA, 2017. [CrossRef]
- BS 1377-2:2022; Methods of Test for Soils for Civil Engineering Purpose. Part 2: Classification Tests. BSI: London, UK, 1990.
- Stevens, J. Unified Soil Classification System. Civ. Eng. ASCE 1982, 52, 61–62. [Google Scholar]
- Polidori, E. Proposal for a New Classification of Common Inorganic Soils for Engineering Purposes. Geotech. Geol. Eng. 2015, 33, 1569–1579. [Google Scholar] [CrossRef]
- Polidori, E. Relationship between the Atterberg Limits and Clay Content. Soils Found. 2007, 47, 887–896. [Google Scholar] [CrossRef]
- Afolagboye, L.; Abdu-Raheem, Y.A.; Ajayi, D.E.; Talabi, A.O. A Comparison between the Consistency Limits of Lateritic Soil Fractions Passing through Sieve Numbers 40 and 200. Innov. Infrastruct. Solut. 2021, 6, 1–8. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Alavi, A.H.; Gandomi, A.H.; Mollahasani, A. Nonlinear Genetic-Based Simulation of Soil Shear Strength Parameters. J. Earth Syst. Sci. 2011, 120, 1001–1022. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Alavi, A.H.; Mollahasani, A.; Gandomi, A.H. A Hybrid Computational Approach to Formulate Soil Deformation Moduli Obtained from PLT. Eng. Geol. 2011, 123, 324–332. [Google Scholar] [CrossRef]
- Zheng, D.; Wu, R.; Sufian, M.; Kahla, N.B.; Atig, M.; Deifalla, A.F.; Accouche, O.; Azab, M. Flexural Strength Prediction of Steel Fiber-Reinforced Concrete Using Artificial Intelligence. Materials 2022, 15, 5194. [Google Scholar] [CrossRef]
- Shah, S.A.R.; Azab, M.; Seif ElDin, H.M.; Barakat, O.; Anwar, M.K.; Bashir, Y. Predicting Compressive Strength of Blast Furnace Slag and Fly Ash Based Sustainable Concrete Using Machine Learning Techniques: An Application of Advanced Decision-Making Approaches. Buildings 2022, 12, 914. [Google Scholar] [CrossRef]
- Seybold, C.A.; Elrashidi, M.A.; Engel, R.J. Linear Regression Models to Estimate Soil Liquid Limit and Plasticity Index from Basic Soil Properties. Soil Sci. 2008, 173, 25–34. [Google Scholar] [CrossRef]
- Díaz, E.; Pastor, J.L.; Rabat, Á.; Tomás, R. Machine Learning Techniques for Relating Liquid Limit Obtained by Casagrande Cup and Fall Cone Test in Low-Medium Plasticity Fine Grained Soils. Eng. Geol. 2021, 294, 106381. [Google Scholar] [CrossRef]
- Keller, T.; Dexter, A.R. Plastic Limits of Agricultural Soils as Functions of Soil Texture and Organic Matter Content. Soil Res. 2012, 50, 7–17. [Google Scholar] [CrossRef]
- Karakan, E.; Shimobe, S.; Sezer, A. Effect of Clay Fraction and Mineralogy on Fall Cone Results of Clay–Sand Mixtures. Eng. Geol. 2020, 279, 105887. [Google Scholar] [CrossRef]
- Wroth, C.P.; Wood, D.M. The Correlation of Index Properties with Some Basic Engineering Properties of Soils. Can. Geotech. J. 1978, 15, 137–145. [Google Scholar] [CrossRef]
- ASTM D6913/D6913M-17; Standard Test Method for Particle-Size Analysis of Soils. ANSI: Washington, DC, USA, 2007.
- Ferreira, C. Gene Expression Programming: Mathematical Modeling by an Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2006; Volume 21, ISBN 3540328491. [Google Scholar]
- Al Bodour, W.; Hanandeh, S.; Hajij, M.; Murad, Y. Development of Evaluation Framework for the Unconfined Compressive Strength of Soils Based on the Fundamental Soil Parameters Using Gene Expression Programming and Deep Learning Methods. J. Mater. Civ. Eng. 2022, 34, 4021452. [Google Scholar] [CrossRef]
- Mollahasani, A.; Alavi, A.H.; Gandomi, A.H. Empirical Modeling of Plate Load Test Moduli of Soil via Gene Expression Programming. Comput. Geotech. 2011, 38, 281–286. [Google Scholar] [CrossRef]
- Azim, I.; Yang, J.; Javed, M.F.; Iqbal, M.F.; Mahmood, Z.; Wang, F.; Liu, Q. Prediction Model for Compressive Arch Action Capacity of RC Frame Structures under Column Removal Scenario Using Gene Expression Programming. In Structures; Elsevier: Amsterdam, The Netherlands, 2020; Volume 25, pp. 212–228. [Google Scholar]
- Tarawneh, B. Gene Expression Programming Model to Predict Driven Pipe Piles Set-Up. Int. J. Geotech. Eng. 2018, 14, 538–544. [Google Scholar] [CrossRef]
- Pham, V.-N.; Oh, E.; Ong, D.E.L. Effects of Binder Types and Other Significant Variables on the Unconfined Compressive Strength of Chemical-Stabilized Clayey Soil Using Gene-Expression Programming. Neural Comput. Appl. 2022, 34, 9103–9121. [Google Scholar] [CrossRef]
- Ferreira, C. Gene Expression Programming in Problem Solving. In Soft Computing and Industry; Springer: Berlin/Heidelberg, Germany, 2002; pp. 635–653. [Google Scholar]
- Iqbal, M.F.; Liu, Q.; Azim, I.; Zhu, X.; Yang, J.; Javed, M.F.; Rauf, M. Prediction of Mechanical Properties of Green Concrete Incorporating Waste Foundry Sand Based on Gene Expression Programming. J. Hazard. Mater. 2020, 384, 121322. [Google Scholar] [CrossRef] [PubMed]
- Çanakcı, H.; Baykasoğlu, A.; Güllü, H. Prediction of Compressive and Tensile Strength of Gaziantep Basalts via Neural Networks and Gene Expression Programming. Neural Comput. Appl. 2009, 18, 1031–1041. [Google Scholar] [CrossRef]
- Goharzay, M.; Noorzad, A.; Ardakani, A.M.; Jalal, M. A Worldwide SPT-Based Soil Liquefaction Triggering Analysis Utilizing Gene Expression Programming and Bayesian Probabilistic Method. J. Rock Mech. Geotech. Eng. 2017, 9, 683–693. [Google Scholar] [CrossRef]
- Gholampour, A.; Gandomi, A.H.; Ozbakkaloglu, T. New Formulations for Mechanical Properties of Recycled Aggregate Concrete Using Gene Expression Programming. Constr. Build. Mater. 2017, 130, 122–145. [Google Scholar] [CrossRef]
- Hassan, J.; Alshameri, B.; Iqbal, F. Prediction of California Bearing Ratio (CBR) Using Index Soil Properties and Compaction Parameters of Low Plastic Fine-Grained Soil. Transp. Infrastruct. Geotechnol. 2021, 1–13. [Google Scholar] [CrossRef]
- Wang, H.-L.; Yin, Z.-Y. High Performance Prediction of Soil Compaction Parameters Using Multi Expression Programming. Eng. Geol. 2020, 276, 105758. [Google Scholar] [CrossRef]
- Ardakani, A.; Kordnaeij, A. Soil Compaction Parameters Prediction Using GMDH-Type Neural Network and Genetic Algorithm. Eur. J. Environ. Civ. Eng. 2019, 23, 449–462. [Google Scholar] [CrossRef]
- Zolfaghari, Z.; Mosaddeghi, M.R.; Ayoubi, S. ANN-based Pedotransfer and Soil Spatial Prediction Functions for Predicting Atterberg Consistency Limits and Indices from Easily Available Properties at the Watershed Scale in Western Iran. Soil Use Manag. 2015, 31, 142–154. [Google Scholar] [CrossRef]
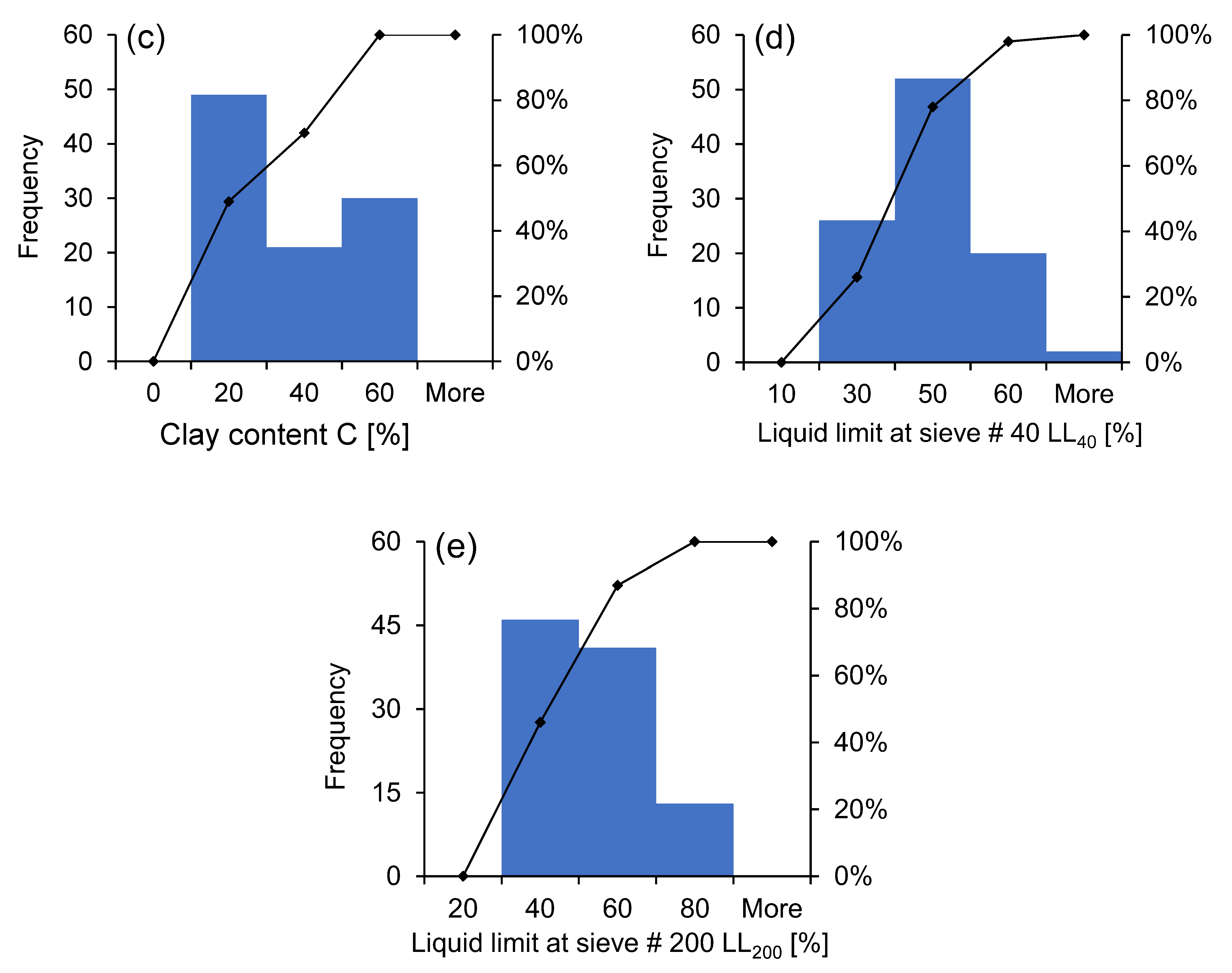

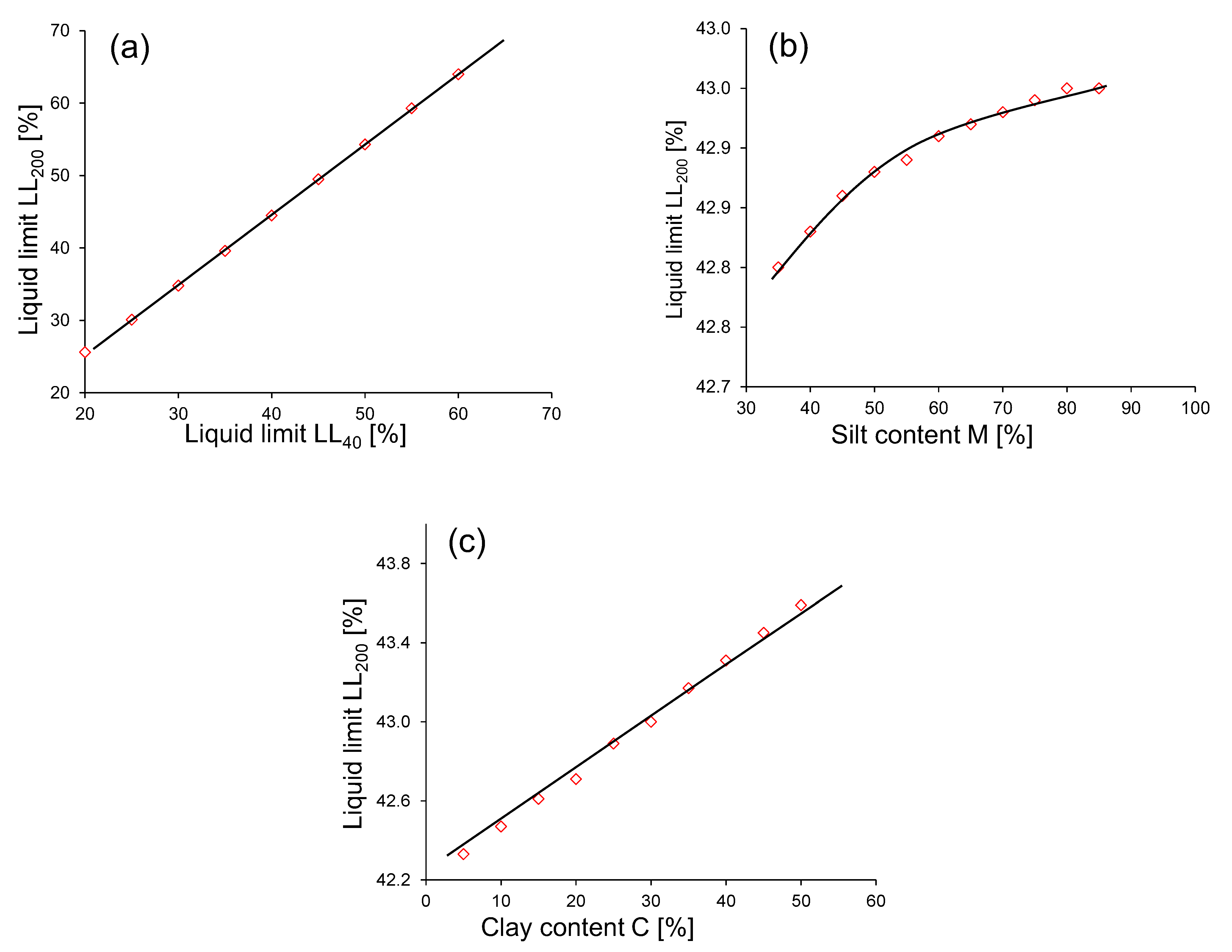

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predictors | Minimum | Maximum | Mean | Std. Deviation |
|---|---|---|---|---|
| S [%] | 2 | 36.2 | 5.95 | 4.39 |
| C [%] | 5 | 60 | 27.52 | 18.6 |
| M [%] | 34 | 93 | 66.45 | 17.68 |
| LL40 [%] | 16 | 62 | 39.1 | 11.75 |
| Output Data | ||||
| LL200 [%] | 23 | 70 | 44.1 | 11.97 |
| General | Model Setting |
|---|---|
| LL200 [%] | |
| Genes | 3 |
| Chromosomes | 30 |
| Head size | 7 |
| Set of functions | +, −, ×, ÷ |
| Linking function | + |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nawaz, M.N.; Qamar, S.U.; Alshameri, B.; Karam, S.; Çodur, M.K.; Nawaz, M.M.; Riaz, M.S.; Azab, M. Study Using Machine Learning Approach for Novel Prediction Model of Liquid Limit. Buildings 2022, 12, 1551. https://doi.org/10.3390/buildings12101551
Nawaz MN, Qamar SU, Alshameri B, Karam S, Çodur MK, Nawaz MM, Riaz MS, Azab M. Study Using Machine Learning Approach for Novel Prediction Model of Liquid Limit. Buildings. 2022; 12(10):1551. https://doi.org/10.3390/buildings12101551
Chicago/Turabian StyleNawaz, Muhammad Naqeeb, Sana Ullah Qamar, Badee Alshameri, Steve Karam, Merve Kayacı Çodur, Muhammad Muneeb Nawaz, Malik Sarmad Riaz, and Marc Azab. 2022. "Study Using Machine Learning Approach for Novel Prediction Model of Liquid Limit" Buildings 12, no. 10: 1551. https://doi.org/10.3390/buildings12101551
APA StyleNawaz, M. N., Qamar, S. U., Alshameri, B., Karam, S., Çodur, M. K., Nawaz, M. M., Riaz, M. S., & Azab, M. (2022). Study Using Machine Learning Approach for Novel Prediction Model of Liquid Limit. Buildings, 12(10), 1551. https://doi.org/10.3390/buildings12101551